python处理脚本收集
将字幕文件转为json
spaCy自然语言处理
上面那个脚本转化的文本并没有标点符号断句等内容,所以还需要用NLP来优化。 这里的核心还在于使用spaCy对文本进行自然语言处理。
- 自然语言处理就这么简单有趣 - 知乎
- spacy Can't find model 'en_core_web_sm' on windows 10 and Python 3.5.3 :: Anaconda custom (64-bit) - Stack Overflow
- spaCy · Industrial-strength Natural Language Processing in Python
- Prodigy · An annotation tool for AI, Machine Learning & NLP
源码
import re
import json
import spacy
import sys
def parse_time(time_string):
hours = int(re.findall(r'(\d+):\d+:\d+,\d+', time_string)[0])
minutes = int(re.findall(r'\d+:(\d+):\d+,\d+', time_string)[0])
seconds = int(re.findall(r'\d+:\d+:(\d+),\d+', time_string)[0])
milliseconds = int(re.findall(r'\d+:\d+:\d+,(\d+)', time_string)[0])
return (hours * 3600 + minutes * 60 + seconds) * 1000 + milliseconds
def parse_srt(srt_string):
srt_list = []
for line in srt_string.split('\n\n'):
if line != '':
index = int(re.match(r'\d+', line).group())
pos = re.search(r'\d+:\d+:\d+,\d+ --> \d+:\d+:\d+,\d+',
line).end() + 1
content = line[pos:]
start_time_string = re.findall(
r'(\d+:\d+:\d+,\d+) --> \d+:\d+:\d+,\d+', line)[0]
end_time_string = re.findall(
r'\d+:\d+:\d+,\d+ --> (\d+:\d+:\d+,\d+)', line)[0]
start_time = parse_time(start_time_string)
end_time = parse_time(end_time_string)
srt_list.append({
'index': index,
'content': content,
'start': start_time,
'end': end_time
})
return srt_list
def remove_modals(total_words: list):
modal_words = ['Yeah', 'yeah', 'Yep', 'yep', 'Uh', 'uh', 'okay', 'oh', 'Um', 'um', 'right']
# 替换为删除线
for index, word in enumerate(total_words):
if word in modal_words:
total_words[index] = f"~~{word}~~"
# 从当前位置开始,前/后找到一个有效位置
def find_valid_index(words_list: list, index, direction):
if direction == 'pre':
while index >= 0 and words_list[index].startswith("~~"):
index -= 1
if index >= 0:
return index
else:
return None
elif direction == 'after':
while index < len(words_list) - 1 and words_list[index].startswith("~~"):
index += 1
if index < len(words_list):
return index
else:
return None
else:
sys.exit('方向不对')
# 去除三个以内的重复词
def delete_duplicate(words_list: list):
for index, word in enumerate(words_list):
if word.startswith('~~'):
continue
# 以index为中心点向两边找
pre_word_third, pre_word_secondary, pre_word, word_secondary, word_third = '', '', '', '', ''
pre_index = find_valid_index(words_list, index - 1, 'pre')
if pre_index:
pre_word = words_list[pre_index]
if pre_word:
pre_index = find_valid_index(words_list, pre_index - 1, 'pre')
if pre_index:
pre_word_secondary = words_list[pre_index]
if pre_word_secondary:
pre_index = find_valid_index(words_list, pre_index - 1, 'pre')
if pre_index:
pre_word_third = words_list[pre_index]
after_index = find_valid_index(words_list, index + 1, 'after')
if after_index:
word_secondary = words_list[after_index]
if word_secondary:
after_index = find_valid_index(words_list, after_index + 1, 'after')
if after_index:
word_third = words_list[after_index]
# 先判断三个词的情况:
if [pre_word_third, pre_word_secondary, pre_word] == [word, word_secondary, word_third]:
print([pre_word_third, pre_word_secondary, pre_word])
words_list[index], words_list[index + 1], words_list[index + 2] = \
f"~~{words_list[index]}~~", f'~~{words_list[index + 1]}~~', f'~~{words_list[index + 2]}~~'
elif [pre_word_secondary, pre_word] == [word, word_secondary]:
print([pre_word_secondary, pre_word])
words_list[index], words_list[index + 1] = \
f"~~{words_list[index]}~~", f'~~{words_list[index + 1]}~~'
elif pre_word == word:
print(pre_word)
words_list[index] = f"~~{words_list[index]}~~"
# print(pre_word_third, pre_word_secondary, pre_word, word, word_secondary, word_third)
return words_list
def parse_sentence(srt_strings: list):
raw_total_words = ' '.join([item['content'] for item in srt_strings]).split(' ')
total_words = [item.strip() for item in raw_total_words]
# 借助python的默认用法:容器类型(列表、字典、对象等)在函数参数是传地址,原生类型(字符串、数字等)在函数参数是传值。
remove_modals(total_words)
delete_duplicate(total_words)
# python -m spacy download en_core_web_sm
nlp = spacy.load('en_core_web_sm')
doc = nlp(' '.join(total_words))
# for sent in doc.sents:
# print(sent.text_with_ws.replace(' ', ' '))
# print('\n')
# print('#' * 50)
sents = [sent.text_with_ws.replace(' ', ' ') for sent in doc.sents]
return sents
if __name__ == "__main__":
# srt_filename = 'Substrate Execute Block Code Walkthrough with Joe Petrowski and Shawn Tabrizi.srt'
srt_filename = "Intro to Substrate codebase and FRAME pallet deep-dive with Joe Petrowski and Shawn Tabrizi.srt"
title = srt_filename.split('.')[0]
json_out_filename = srt_filename.replace('.srt', '.json')
md_out_filename = srt_filename.replace('.srt', '.md')
srt = open(srt_filename, 'r', encoding="utf-8").read()
parsed_srt = parse_srt(srt)
# parse_txt(parsed_srt)
sentences = parse_sentence(parsed_srt)
# open(json_out_filename, 'w', encoding="utf-8").write(
# json.dumps(parsed_srt, indent=2, sort_keys=True))
# open(txt_out_filename, 'w', encoding='utf-8').write(
# '\n'.join([item['content'] for item in parsed_srt])
# )
content = f"# {title}\n" + '\n\n'.join(sentences)
open(md_out_filename, 'w', encoding='utf-8').write(content)
ffmpeg合并视频文件
import os
import re
import sys
import subprocess
from subprocess import CalledProcessError
# brew install ffmpeg
def supported_merge(files, target_dir, merged_name):
"""
ffmpeg只支持默认格式合并:
Unsupported audio codec. Must be one of mp1, mp2, mp3, 16-bit pcm_dvd, pcm_s16be, ac3 or dts.
:param files:
:param target_dir:
:return:
"""
merge_cmd = " ffmpeg -i 'concat:%s' -c copy %s/%s.mpg"
files_arg = '|'.join(files)
# 合并mpg
merge_status = os.system(merge_cmd % (files_arg, target_dir, merged_name))
# 转为mp4
if merge_status == 0:
convert_status = os.system(
f"ffmpeg -i {target_dir}/{merged_name}.mpg -y -qscale 0 -vcodec libx264 {target_dir}/{merged_name}.mp4")
else:
sys.exit('合并视频出错')
if convert_status != 0:
sys.exit('转化视频出错')
os.system(f"rm -rf {target_dir}/*.mpg")
# os.system(f"ffmpeg -i {target_file}.mpg {target_file}.MP4")
def mp4_to_mpg(file_list):
"""
文件名问题:
1. 空格
2. 括号: 英文括号需要加'\'
2. 竖线:需要替换
:param file_list:
:return:
"""
for index, mp4 in enumerate(file_list):
file_name = mp4.replace('.mp4', '')
status = os.system(f'ffmpeg -i {mp4} -qscale 4 {file_name}.mpg')
print(f"{index + 1}/{len(file_list)}: {status} {file_name}.mpg")
def subprocess_run(cmd: str):
try:
subprocess.run(cmd, shell=True, check=True, capture_output=True)
except CalledProcessError as e:
sys.exit(f'执行{cmd} 失败: {e}')
except Exception as e:
sys.exit(e)
def get_title_pic(title, pic_path):
"""ffmpeg加文字水印
drawtext:绘制文本,也就是文字水印,相关参数第一个似乎要写=,其它参数写:。默认字体 Sans
fontfile:字体文件
> [Mac 电脑查看字体文件位置 | 温欣爸比的博客](https://wxnacy.com/2019/04/03/mac-fonts-path/)
text:文字水印内容
fontsize:水印字体大小,直接填数字
box --是否使用背景框,默认为0
boxcolor --背景框的颜色
borderw --背景框的阴影,默认为0
bordercolor --背景框阴影的颜色
"""
target_pic_path = pic_path
if not pic_path.endswith('.jpg'):
pic_format = pic_path.split('.')[-1]
jpg_pic_path = pic_path.replace(pic_format, 'jpg')
convert_cmd = f"ffmpeg -i {pic_path} {jpg_pic_path}"
subprocess_run(convert_cmd)
print(convert_cmd)
target_pic_path = jpg_pic_path
rm_convert_jpg_cmd = f"rm {target_pic_path}"
else:
rm_convert_jpg_cmd = None
output_path = f"{'/'.join(pic_path.split('/')[:-1])}/{title}_video_cover.jpg"
# x=w-tw-th:y=h-th, 文本的位置,放置图片右下方位置;w、h 表示原图的宽、高;tw、th 表示文本宽高;在减去th 作为间距
drawtext_config = {
# "fontfile": "MiSans-Normal.ttf",
"fontfile": "/System/Library/Fonts/PingFang.ttc",
"text": title,
"x": "110",
"y": "250",
"fontsize": "38",
"fontcolor": "black",
"shadowy": "0"
}
drawtext = ':'.join([f"{key}={value}" for key, value in drawtext_config.items()])
insert_cmd = f'ffmpeg -i {target_pic_path} -vf drawtext={drawtext} -y {output_path}'
subprocess_run(insert_cmd)
print(insert_cmd)
if rm_convert_jpg_cmd:
subprocess_run(rm_convert_jpg_cmd)
return output_path
def get_cover_video(video_path):
mp3_path = video_path.replace('.mp4', '.mp3')
extract_mp3_cmd = f"ffmpeg -i {video_path} -f mp3 -vn {mp3_path}"
subprocess_run(extract_mp3_cmd)
video_name = video_path.split('/')[-1]
video_dir = '/'.join(video_path.split('/')[:-1])
title = '-'.join(video_name.split('.')[:-1])
pic_path = video_path.replace(".mp4", ".jpg")
cover_path = get_title_pic(title, pic_path)
cover_video = f"{video_dir}/{video_name}_covered.mp4"
convered_mp4_cmd = f"ffmpeg -loop 1 -i {cover_path} -i {mp3_path} -c:a copy -c:v libx264 -shortest {cover_video}"
subprocess_run(convered_mp4_cmd)
print(convered_mp4_cmd)
subprocess_run(f"rm {mp3_path}")
subprocess_run(f"rm {cover_path}")
return cover_video
def merge(target_dir, covered=False):
print('*' * 20, target_dir)
os.popen(f"rm -rf {target_dir}/*.mpg")
cmd_res = os.popen(f'ls {target_dir}/*.mp4').read()
output_file = target_dir.split("/")[-1]
file_list = [file for file in cmd_res.split('\n') if file]
if covered:
file_list = [get_cover_video(file) for file in file_list]
pattern = re.compile(r'(\d+)')
file_list.sort(key=lambda x: int(pattern.findall(x)[-2]))
try:
mp4_to_mpg(file_list)
except Exception:
sys.exit('转化分视频出错!')
mpg_cmd_res = os.popen(f'ls {target_dir}/*.mpg').read()
mpg_file_list = [mpg_file for mpg_file in mpg_cmd_res.split('\n') if mpg_file]
mpg_file_list.sort(key=lambda x: int(pattern.findall(x)[0]))
try:
supported_merge(mpg_file_list, target_dir, output_file)
if covered:
subprocess_run(f"rm {target_dir}/*_covered.mp4")
except Exception:
print("使用前记得调整一下文件名: 空格、括号等")
def main():
# if len(sys.argv) == 1:
# sys.exit("请传入待合并视频文件夹📁目录")
# else:
# target_dir = sys.argv[1]
# target_dirs = [target_dir]
target_dirs = ['']
for item in target_dirs:
merge(item, covered=True)
if __name__ == "__main__":
main()
IINA与ffmpeg给视频添加章节
ffmpeg
ffmpeg -i part1.mp4 -f ffmetadata part1.txt
ffmpeg -i part1.mp4 -i part1.txt -map_metadata 1 -codec copy part1_insert.mp4
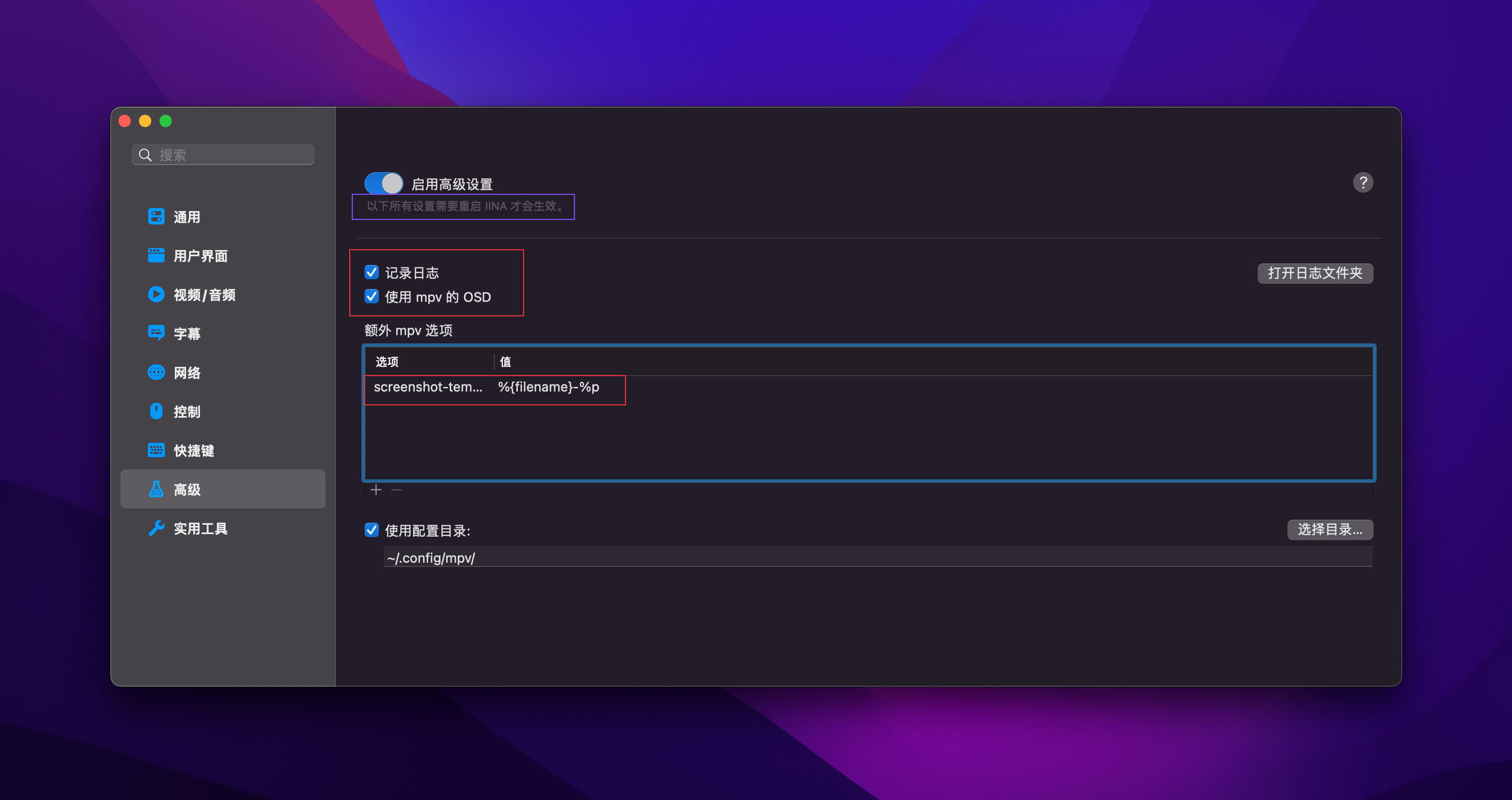
mpv screenshot template
screenshot-template: %{filename}-%p
- 按照视频文件名先分段,方便统一存放
本来打算用screenshot-directory参数,但是要报错,就算了
- %p: 截屏的时间,可以排序。这样方便后续按时间插入新章节。
思路
@startuml
title
视频教材化
主要结合IINA、MPV和FFMPEG给视频文件添加章节
end title
participant mpv[
=MPV内核
]
actor 手工操作 as mannual
participant iina[
=IINA播放器
]
participant ffmpeg[
=ffmpeg工具
----
python脚本
主要处理视频
添加章节书签
]
mpv -> iina: mpv内核指令
iina -> iina: 修改截图格式
note left
偏好设置
高级
启用高级设置
勾选记录日志、使用mpv的OSD
额外mpv选项:screenshot-template %n%f-%p
注意每次修改格式都要重启
end note
mannual-> iina: 使用快捷键截图1
mannual-> iina: 使用快捷键截图2
mannual-> iina: ...
mannual-> iina: 使用快捷键截图n
mannual-> mannual: 手动添加章节名称
iina -> ffmpeg: 开始处理截图文件夹
note right
1. 遍历文件夹,获取文件列表
2. 将文件名依次处理,提取出时间,生成时间表
3. 手动给时间表添加标题
end note
ffmpeg -> ffmpeg: 处理文件夹的文件,生成对应视频文件的章节时间表
note left
0:23:20 Start
0:40:30 First Performance
0:40:56 Break
1:04:44 Second Performance
1:24:45 Crowd Shots
1:27:45 Credit
end note
ffmpeg -> ffmpeg: 根据时间表生成视频章节文件
note left
;FFMETADATA1
major_brand=isom
minor_version=512
compatible_brands=isomiso2avc1mp41
encoder=Lavf59.16.100
[CHAPTER]
TIMEBASE=1/1000
START=1
END=448000
title=The Pledge
end note
ffmpeg -> ffmpeg: 将章节文件压入视频文件,生成新视频文件
note left
ffmpeg -i part1.mp4 -i part1.txt -map_metadata 1 -codec copy part1_insert.mp4
end note
@enduml
源码
"""
给视频文件添加章节书签
"""
import re
import os
import sys
import subprocess
from subprocess import CalledProcessError
def times_chapters(time_path: str, save_path: str):
"""
1. save_path: 保存在视频文件目录中。
:param time_path:
:param save_path:
:return:
"""
chapters = list()
with open(time_path, 'r') as f:
line_pattern = re.compile(r"(\d):(\d{2}):(\d{2}) (.*)")
for line in f:
if line.strip():
hrs, mins, secs, title = line_pattern.findall(line.strip())[0]
hrs, mins, secs = int(hrs), int(mins), int(secs)
minutes = (hrs * 60) + mins
seconds = secs + (minutes * 60)
timestamp = (seconds * 1000)
chap = {
"title": title,
"startTime": timestamp
}
chapters.append(chap)
text = """;FFMETADATA1
major_brand=isom
minor_version=512
compatible_brands=isomiso2avc1mp41
encoder=Lavf59.16.100
"""
for index, chap in enumerate(chapters):
title = chap['title']
start = chap['startTime']
if index + 1 < len(chapters):
end = chapters[index + 1]['startTime'] - 1
else:
end = start + 10000
"""
[CHAPTER]
TIMEBASE=1/1000
START={start}
END={end}
title={title}
"""
chapter = ["[CHAPTER]", "TIMEBASE=1/1000", f"START={start}", f"END={end}", f"title={title}", "\n"]
text += '\n'.join(chapter)
file_name = re.findall(r'(\d.*?\.mp4)', time_path)[0]
file_name = file_name.split('/')[-1]
chapters_path = f"{save_path}/{file_name}.txt"
if os.path.exists(chapters_path):
with open(chapters_path, 'r') as f:
raw_text = f.read()
else:
raw_text = ''
if text != raw_text:
with open(chapters_path, "w") as f:
f.write(text)
return chapters_path
else:
return None
def gen_timetable(screenshots_path: str):
"""
配合IINA的截图格式:
screenshot-template: %{filename}-%p-
0:23:20 Start
0:40:30 First Performance
0:40:56 Break
1:04:44 Second Performance
1:24:45 Crowd Shots
1:27:45 Credits
:param screenshots_path:
:return:
"""
info_pattern = re.compile(r'(\d.*?\.mp4)-(\d+:\d{2}:\d{2})-(.*?).png')
ls_png_cmd = f"ls {screenshots_path}/*.png"
try:
png_cmd_res = subprocess.run(ls_png_cmd, shell=True, check=True, capture_output=True)
except CalledProcessError as e:
png_cmd_res = e
if png_cmd_res.returncode == 0:
png_list = png_cmd_res.stdout.decode().split('\n')
png_infos = {}
for png in png_list:
png_info = info_pattern.findall(png)
if png_info:
video, timestamp, title = png_info[0]
# 去掉截图归类目录
# 例如:130-139.tokio-runtime/130-139.tokio-runtime.mp4-00:00:13-第一节-概要介绍.png
video = video.split('/')[-1]
if not title:
title = '未命名章节'
if not png_infos.get(video):
png_infos[video] = []
png_infos[video].append([timestamp, title])
# 按照第二个时间点元素排序
files = []
for video, chapters in png_infos.items():
file_path = f"{screenshots_path}/{video}.txt"
chapters.sort(key=lambda item: item[0].split(':'))
with open(file_path, 'w') as f:
for timestamp, chapter_name in chapters:
f.writelines(f"{timestamp} {chapter_name}\n ")
files.append(file_path)
return files
else:
sys.exit(f"执行指令{ls_png_cmd}出错:{png_cmd_res.stderr.decode()}")
def categorized_screenshots(root_screen_directory):
info_pattern = re.compile(r'(\d.*?)\.mp4-(\d+:\d{2}:\d{2})-(.*?).png')
ls_png_cmd = f"ls {root_screen_directory}/*.png"
try:
png_cmd_res = subprocess.run(ls_png_cmd, shell=True, check=True, capture_output=True)
except CalledProcessError as e:
png_cmd_res = e
if png_cmd_res.returncode == 0:
png_list = png_cmd_res.stdout.decode().split('\n')
file_titles = []
for png in png_list:
png_info = info_pattern.findall(png)
if png_info:
video_title, timestamp, title = png_info[0]
if video_title and video_title not in file_titles:
file_titles.append(video_title)
# 新建文件夹并整合截图
for title in file_titles:
dir_path = f"{root_screen_directory}/{title}"
if not os.path.exists(dir_path):
os.popen(f"mkdir {dir_path}")
os.popen(f"mv {root_screen_directory}/{title}.*.png {dir_path}/")
dir_res = os.popen(f"ls -d {root_screen_directory}/*/")
dirs = dir_res.read().split('\n')
return [item[:-1] for item in dirs]
def main(s_dir):
timetables = gen_timetable(s_dir)
chapter_files = []
for timetable in timetables:
chapter_path = times_chapters(timetable, video_path)
if chapter_path:
chapter_files.append(chapter_path)
for chapter_file in chapter_files:
video_name = re.findall(r'(\d.*?)\.mp4', chapter_file)[0]
edit_video_path = f"{video_path}/{video_name}.mp4"
inserted_video_path = f"{video_path}/{video_name}-chapters.mp4"
"""
-y: 默认覆盖, 但是这里载入章节文件不可以in-place修改。
-i: input
-codec: 编解码
-map_metadata 1: 只匹配头部内容,只能在第一次添加时生效
-map_chapters 1: 匹配章节,在后续修改章节时需要加上
"""
merge_command = f"ffmpeg -y -i {edit_video_path} -i {chapter_file} -map_metadata 1 -map_chapters 1 -codec copy {inserted_video_path}"
delete_command = f"rm {edit_video_path}"
mv_command = f"mv {inserted_video_path} {edit_video_path}"
os.system(merge_command)
os.system(delete_command)
os.system(mv_command)
if __name__ == "__main__":
timefile = ''
chapter_file = ''
if len(sys.argv) != 3:
sys.exit('请按顺序加入截图文件夹路径和视频文件路径')
else:
ss_path, video_path = sys.argv[1], sys.argv[2]
# times_chapters(timefile, chapter_file)
screenshot_dirs = categorized_screenshots(ss_path)
for screenshot_dir in screenshot_dirs:
if screenshot_dir:
main(screenshot_dir)