Resources

Rust Official
Rust Lang Home
This Week in Rust
Rustup Components History
- Rustup packages availability on x86_64-unknown-linux-gnu
- rust-lang/rustup-components-history: Rustup package status history
Crates.io
Rust Blog
RustC Dev Guide
- rust-lang/rustc-dev-guide: A guide to how rustc works and how to contribute to it.
- About this guide - Guide to Rustc Development
Rust Vim
Module Arch
- core::arch - Rust
- rust-lang/stdarch: Rust’s standard library vendor-specific APIs and run-time feature detection
Rust Lang - Compiler Team
- Introduction | Rust Lang - Compiler Team
- rust-lang/compiler-team: A home for compiler team planning documents, meeting minutes, and other such things.
Standard Library Developers Guide
- About this guide - Standard library developers Guide
- rust-lang/std-dev-guide: Guide for standard library developers
awesome series
rust-unofficial/awesome-rust
rust-embedded/asesome-embedded-rust
rust-in-blockchain/awesome-blockchain-rust
TaKO8Ki/awesome-alternatives-in-rust
RustBegginers/awesome-rust-mentors
awesome-rust-com/awesome-rust
The Rust Programming Language
by Steve Klabnik and Carol Nichols, with contributions from the Rust Community
This version of the text assumes you’re using Rust 1.62 (released 2022-06-30) or later. See the “Installation” section of Chapter 1 to install or update Rust.
The HTML format is available online at
https://doc.rust-lang.org/stable/book/
and offline with installations of Rust made with rustup; run rustup docs --book to open.
Several community translations are also available.
This text is available in paperback and ebook format from No Starch Press.
🚨 Want a more interactive learning experience? Try out a different version of the Rust Book, featuring: quizzes, highlighting, visualizations, and more: https://rust-book.cs.brown.edu
Rust Language Cheat sheet
Rust Cheat Sheet & Quick Reference
chatGPT Rust Prompts
Rust Grammar Points Experience & Pitfalls
Suppose you are a rust programmer with five years of development experience. During the development process, you deeply feel the difference between rust and python and golang, as well as the characteristics of rust itself. Please list 10-15 features of rust in the development process, and inform them in the following format:
Grammar Points: Ownership Mechanisms
Usage experience: variables can only be used once, if you want to use it multiple times, you have to consider using references. Under the ownership mechanism, factors such as borrowing situation and life cycle have to be considered
Common pitfalls: After a variable is assigned once, it often fails to compile, because the ownership mechanism must be considered
-
Ownership Mechanisms
- Usage experience: Variables can only be used once; if you want to use them multiple times, you have to consider using references. Under the ownership mechanism, factors such as borrowing situation and life cycle have to be considered.
- Common pitfalls: After a variable is assigned once, it often fails to compile because the ownership mechanism must be considered.
-
Memory Safety
- Usage experience: Rust has a strict memory safety mechanism that prevents common programming errors such as null pointer dereferencing, buffer overflows, and use-after-free errors.
- Common pitfalls: The strict memory safety mechanism can sometimes make the development process more cumbersome and may require more thought and planning.
-
Error Handling
- Usage experience: Rust has a robust error handling mechanism that uses the Result and Option enums to provide detailed error messages and handle errors gracefully.
- Common pitfalls: If not handled properly, errors can propagate throughout the program and cause unexpected behavior.
-
Performance
- Usage experience: Rust is designed to be a high-performance language, with a focus on low-level control and optimization. It has zero-cost abstractions and supports low-level programming features such as inline assembly.
- Common pitfalls: Writing high-performance code in Rust can sometimes require more complex code and a deeper understanding of how the underlying system works.
-
Traits
- Usage experience: Rust’s trait system allows for powerful abstractions and code reuse. Traits define behavior that types can implement, allowing for generic programming and code that can work with different types.
- Common pitfalls: The trait system can be complex and may require a deeper understanding of Rust’s type system.
-
Cargo Package Manager
- Usage experience: Rust comes with a built-in package manager called Cargo, which makes it easy to manage dependencies, build projects, and publish libraries.
- Common pitfalls: Managing dependencies and dealing with versioning can still be challenging, especially in large projects.
-
Pattern Matching
- Usage experience: Rust’s pattern matching mechanism allows for concise and expressive code, making it easy to handle complex data structures and control flow.
- Common pitfalls: The syntax for pattern matching can be verbose and may require more code than other languages.
-
Macros
- Usage experience: Rust’s macro system allows for powerful metaprogramming, enabling code generation and manipulation at compile time.
- Common pitfalls: Macros can be difficult to write and understand, and may introduce unexpected behavior if not used carefully.
-
Macros 2.0
- Usage experience: Rust’s Macros 2.0 system allows developers to write more powerful and flexible macros, making it easier to generate code that is both concise and expressive.
- Common pitfalls: Macros 2.0 can be challenging to write and debug, and can lead to unexpected behavior if not used properly.
-
Functional Programming
- Usage experience: Rust supports functional programming concepts such as closures, higher-order functions, and immutable data structures, allowing for expressive and concise code.
- Common pitfalls: The syntax and terminology of functional programming can be unfamiliar to some programmers, and functional code may not always be as performant as imperative code.
-
Lifetime Annotations
-
Usage experience: Rust requires explicit lifetime annotations to manage memory allocation and deallocation, ensuring that the code is safe and efficient.
-
Common pitfalls: Lifetime annotations can be confusing and error-prone, especially for complex data structures and code.
-
-
Async/Await
- Usage experience: Rust has native support for asynchronous programming, with the async/await syntax making it easier to write asynchronous code that is both efficient and easy to reason about.
- Common pitfalls: Async/await syntax can be difficult to understand for developers unfamiliar with asynchronous programming, and it can also introduce complex control flow.
-
Unsafe Code
- Usage experience: Rust allows developers to write unsafe code for situations where low-level control and optimization are necessary, but it must be carefully reviewed and handled with caution.
- Common pitfalls: Unsafe code can be challenging to write and debug, and it can introduce security vulnerabilities and undefined behavior.
-
Trait Bounds
- Usage experience: Rust’s trait bounds allow developers to specify constraints on generic types, ensuring that they have the required functionality to be used in a particular context.
- Common pitfalls: Specifying trait bounds can be challenging, especially for complex code, and can lead to confusing error messages.
-
Smart Pointers
- Usage experience: Rust provides several types of smart pointers such as Rc and Arc, which allow for shared ownership and reference counting, making it easier to manage complex data structures.
- Common pitfalls: Using smart pointers can introduce overhead and performance penalties, and can also make the code more complex and error-prone.
-
Type Inference
- Usage experience: Rust has a powerful type inference system that allows the compiler to infer the type of a variable, making the code more concise and readable.
- Common pitfalls: Type inference can sometimes lead to unexpected behavior, especially when combined with complex expressions or nested data structures.
-
Algebraic Data Types
- Usage experience: Rust’s algebraic data types such as enums and structs with named fields provide a flexible and expressive way to define data structures and their behavior.
- Common pitfalls: Algebraic data types can be challenging to work with, especially for developers unfamiliar with functional programming concepts.
-
Trait Objects
- Usage experience: Rust’s trait objects allow for dynamic dispatch and polymorphism, making it easier to write generic code that can work with different types.
- Common pitfalls: Using trait objects can lead to performance penalties, and can also make the code more complex and harder to reason about.
-
Iterators
- Usage experience: Rust’s iterator system provides a flexible and expressive way to work with collections and sequences, making it easier to write concise and efficient code.
- Common pitfalls: Iterators can be challenging to work with, especially for developers unfamiliar with functional programming concepts.
-
Benchmarking
- Usage experience: Rust has a built-in benchmarking framework that allows developers to measure the performance of their code and optimize it accordingly.
- Common pitfalls: Benchmarking can be time-consuming and can lead to over-optimization, resulting in code that is hard to understand and maintain.
-
Closures
- Usage experience: Rust’s closures allow developers to define anonymous functions that can capture and manipulate variables from their surrounding environment.
- Common pitfalls: Closures can be challenging to understand, especially for developers unfamiliar with functional programming concepts.
-
Concurrency
- Usage experience: Rust’s concurrency primitives such as threads and channels allow developers to write concurrent code that is both safe and efficient.
- Common pitfalls: Concurrency can introduce complex control flow and race conditions, and can be challenging to debug and optimize.
-
Documentation
- Usage experience: Rust’s documentation system encourages developers to write comprehensive and readable documentation, making it easier for others to understand and use their code.
- Common pitfalls: Documentation can be time-consuming and can lead to neglecting code quality and maintainability.
-
Testing
- Usage experience: Rust’s testing framework makes it easy to write and run tests, ensuring that the code is correct and reliable.
- Common pitfalls: Testing can be time-consuming and can lead to over-testing, resulting in code that is hard to understand and maintain.
-
Memory Management
- Usage experience: Rust’s memory management system ensures that the code is both safe and efficient, with no runtime overhead or garbage collection.
- Common pitfalls: Memory management can be challenging to understand, especially for developers unfamiliar with low-level programming concepts.
-
Functional Programming
- Usage experience: Rust’s functional programming features such as higher-order functions and closures allow developers to write concise and expressive code.
- Common pitfalls: Functional programming can be challenging to understand, especially for developers unfamiliar with functional programming concepts.
-
Foreign Function Interface (FFI)
- Usage experience: Rust’s FFI allows developers to call functions from other programming languages and libraries, making it easier to integrate Rust code with existing systems.
- Common pitfalls: FFI can introduce security vulnerabilities and undefined behavior, and can be challenging to debug and optimize.
-
Unsafe Rust
- Usage experience: Rust’s unsafe features allow developers to write low-level code that bypasses the safety checks of the compiler, making it possible to write code that is both safe and fast.
- Common pitfalls: Unsafe Rust can introduce memory unsafety and undefined behavior, and can be challenging to debug and optimize.
The length of video cannot over 3 hours
Rust Crash Course | Rustlang
- Rust Crash Course | Rustlang
- Introduction to Rust Programming Language
- Installing Rust and Setting Up the Environment
- Introduction to Print Line Command and Formatting
⭐️ Basic Formatting with Multiple Placeholders⭐️ Placeholder Traits⭐️ Debug Traits- Variables
- Introduction to Rust Programming Language
- Rust Primitive Types
⭐️ Strings in Rust- Working with Strings
- Working with Tuples
- Tuples and Arrays in Rust
⭐️ Slicing Arrays and Using Vectors⭐️ Mutating Values in Vectors- Conditionals
- Loops
- Introduction to Loops and Functions
- Rust Functions
- Pointers and References
- Rust Basics: References and Structs
- Creating a Struct in Rust
- Structs
⭐️ Introduction to Structs- Enums
- Functions with Enums
- Command Line Arguments
- Introduction to Command Line Applications
- Conclusion
Introduction to Rust Programming Language
Section Overview: This video is an introductory course on the fundamentals and syntax of the Rust programming language. The instructor will cover what Rust is, its relevance in web development, and how it compares to other systems languages.
What is Rust?
- Rust is a fast and powerful programming language known for being a systems language.
- It’s best suited for building drivers, compilers, and other tools that programmers use in development.
- Rust is becoming relevant in web development because of WebAssembly, which allows us to build secure, portable, and fast web applications using languages like C++ and Rust.
⭐️Garbage Collection
- One of the biggest advantages of Rust is that it doesn’t have garbage collection.
- In JavaScript, for example, garbage collection can take multiple seconds depending on the program.
- With languages like C++ you have to manage all memory allocation yourself which makes programming much harder.
- In contrast with both these approaches, Rust checks memory usage only when needed. If the heap gets close to being full or above some threshold it will then look for variables to free up memory.
Cargo Package Manager
- Rust has its own package manager called Cargo which is similar to NPM for Node.js or Composer for PHP.
Installing Rust and Setting Up the Environment
Section Overview: This section covers how to install Rust, set up the environment, and use some of the basic utilities.
Installing Rust
- To install Rust, run the installer and hit one to proceed with the default installation.
- If
rustup --versionreturns “not found,” restart your terminal.
Basic Utilities
- rustup is a version manager that can be used to check for updates with rustup update.
- Russ C is the compiler.
- Cargo is the package manager.
Creating a Rust File and Compiling It
- Install the Rust RLS extension in VS Code for code completion and linting.
- Create a new file called hello.rs with an entry point function called main().
- Use println!() to print out “Hello World.”
- Compile it using rustc hello.rs and run it using ./hello.
Initializing a Project with Cargo
- Initialize a project in an existing folder using cargo init.
- The project structure includes a Cargo.toml file for application info and dependencies, a .gitignore file, and a source folder for all Rust code.
- Use cargo run to compile and run your project. Use cargo build to just build it. Use cargo build –release for production optimization.
Introduction to Print Line Command and Formatting
Section Overview: In this section, the instructor introduces the print line command and formatting in Rust programming language.
Creating a Function in Print File
- To create a function in the print file, use
pubwhich means public. - Create a run function for each file to run it.
- Use
printLn!to print to console.
⭐️Running the Function in Main RS Files
- Use
modand then the name of the file above the main function. - Use
print::function_nameto call the function.
Basic Formatting
- Use curly braces as placeholders for variables or numbers that need replacement.
- Use double quotes for strings.
- Save and run code using cargo run.
⭐️Basic Formatting with Multiple Placeholders
Section Overview: In this section, we learn how to format multiple placeholders using Rust programming language.
Using Multiple Placeholders
- Add multiple placeholders by adding more curly braces.
- Replace each placeholder with its corresponding parameter index number.
Positional Arguments
- Use positional parameters when using variables twice or more times in a string.
- Add index numbers inside curly braces according to their position in parameters list.
Named Arguments
- Use named parameters instead of positional ones when you have many arguments.
- Assign names before values separated by an equal sign.
⭐️Placeholder Traits
Section Overview: In this section, we learn about placeholder traits available in Rust programming language.
Binary Trait(:B)
- The binary trait is represented by :B
- Used for converting integers into binary format
Hexadecimal Trait(:X)
- The hexadecimal trait is represented by :X
- Used for converting integers into hexadecimal format
Octal Trait(:O)
- The octal trait is represented by :O
- Used for converting integers into octal format
⭐️Debug Traits
Section Overview: In this section, we learn how to use the print line function and tuples to print multiple values. We also learn how to do basic math.
Using Print Line Function
- Use
print linefunction with a colon and a question mark. - Put in multiple values using curly braces.
- Example:
print line!("{:?} {} {}", (10, true, "hello"));
Basic Math
- Use
print linefunction with an expression. - Example:
print line!("10 + 10 = {}", 10 + 10);
Variables
Section Overview: In this section, we learn about variables in Rust. Variables are immutable by default and Rust is a block-scoped language.
Creating Variables
- Use the
letkeyword to create variables. - Example:
let name = "Brad"; - Immutable by default.
Mutable Variables
- Add the keyword
mutto make variables mutable. - Example:
let mut age = 37; - Can reassign value later.
Constants
- Use the keyword
constfor constants. - Must explicitly define type.
- Usually all uppercase.
- Example:
const ID:i32 = 001;
⭐️Assigning Multiple Variables at Once
- Use commas to assign multiple variables at once.
- Example:
#![allow(unused)] fn main() { let (x, y, z) = (1, 2, 3); println!("x = {}, y = {}, z = {}", x, y, z); }
Introduction to Rust Programming Language
Section Overview: In this section, the instructor introduces Rust programming language and covers topics such as assigning variables, data types, and how Rust is a statically typed language.
Assigning Variables
- Multiple variables can be assigned at once in Rust.
- The
pub function runis used to run the program. - Integers come in signed and unsigned forms with different bit sizes. Floats have 32 and 64 bits. Booleans are
represented by
bool. Characters are represented bychar. - ⭐️Strings are not primitive types in Rust.
- ⭐️Tuples and arrays are also primitive types.
⭐️Data Types
- Vectors are growable arrays while arrays have fixed lengths.
- Rust is a statically typed language which means that it must know the types of all variables at compile time. However, the compiler can usually infer what type we want to use based on the value and how we use it.
- Explicit typing can be done using a colon followed by the desired type.
- The maximum size of integers can be found using
STD::i32::MAXorSTD::i64::MAX.
Boolean Expressions
- Booleans can be set explicitly or inferred from expressions.
- A boolean expression evaluates to either true or false depending on whether the condition is met.
Rust Primitive Types
Section Overview: In this section, the speaker discusses primitive types in Rust, including char and Unicode.
Char and Unicode
- A char is a single character that can be represented with single quotes.
- Unicode characters can also be used by specifying them with a slash u and curly braces.
- Emojis are also Unicode characters that can be used in Rust.
⭐️Strings in Rust
Section Overview: In this section, the speaker discusses strings in Rust, including primitive strings and string types.
Creating Strings
- There are two types of strings in Rust: primitive strings (immutable fixed-length) and string types (growable heap-allocated data structure).
- To create a primitive string, use single or double quotes.
- To create a string type, use
String::from()method.
Modifying Strings
- The
push()method adds a single character to the end of a string. - The
push_str()method adds multiple characters to the end of a string. - The
len()method returns the length of a string. - The
capacity()method returns the number of bytes that can be stored in a string. - The
is_empty()method checks if a string is empty.
Working with Strings
Section Overview: In this section, the instructor demonstrates how to work with strings in Rust.
Checking for Substrings and Replacing Them
- Use
containsmethod to check if a string contains a substring. - Use
replacemethod to replace a substring with another string.
Looping Through Strings
- Use a for loop and
split_whitespacemethod to loop through a string by whitespace.
Creating Strings with Capacity
- Use
with_capacitymethod to create a string with a certain capacity. - Use
pushmethod to add characters to the created string.
Assertion Testing
- Use assertion testing using the
assert_eq!()macro to test if something is equal to something else.
Working with Tuples
Section Overview: In this section, the instructor demonstrates how to work with tuples in Rust.
Introduction to Tuples
- A tuple is a group of values in Rust.
Creating and Accessing Tuples
- Create tuples using parentheses and commas between values.
- Access tuple elements using
dot notationandindex numbers starting from 0.
Destructuring Tuples
- Destructure tuples into individual variables using pattern matching syntax.
Tuple Methods
- The
.len()method returns the number of elements in a tuple.
Tuples and Arrays in Rust
Section Overview: In this section, the speaker introduces tuples and arrays in Rust programming language. They explain how to create tuples and access their values using dot syntax. The speaker also demonstrates how to create arrays with fixed lengths and change their values.
Creating Tuples
- To create a tuple, use parentheses and separate the values with commas.
- Use dot syntax to access tuple values by index.
- Tuples are immutable by default but can be made mutable using
mutkeyword.
Creating Arrays
- Arrays have a fixed length that must be specified during creation.
- Use square brackets to define an array’s elements.
- Access array elements using zero-based indexing.
- Arrays are stack allocated, meaning they occupy contiguous memory locations.
⭐️Modifying Array Values
- Use
mutkeyword to make an array mutable. - Change an array value by assigning a new value at its index.
⭐️Debugging Arrays
- Use
println!()macro with debug trait ({:?}) to print entire arrays. - Get the length of an array using
.len()method. - Get the amount of memory occupied by an array using
std::mem::size_of_val(&array)method.
⭐️Slicing Arrays and Using Vectors
Section Overview: In this section, the instructor demonstrates how to slice arrays and use vectors in Rust.
Slicing Arrays
- To get a slice from an array, create a mutable variable with the type defined as
&[i32]. - Use brackets to specify the range of elements you want to include in the slice.
- The resulting slice can be printed using the debug trait.
Using Vectors
- Vectors are resizable arrays that can have elements added or removed.
- To define a vector, use
Vec<i32>instead of[i32]for the type definition. - Use
.push()to add elements to a vector and.pop()to remove them. - A for loop can be used to iterate through all values in a vector. Use
iter_mut()to mutate each value individually.
⭐️Mutating Values in Vectors
Section Overview: In this section, the instructor shows how to mutate values in vectors by multiplying each element by:
- Use a for loop with
iter_mut()on a vector. - Multiply each element by 2 using
*=operator. - Print out the entire vector using debug trait.
Conditionals
Section Overview: This section covers the use of conditionals in Rust.
If-else statements
- Conditionals are used to connect the condition of something and then act on the result.
- An if-else statement is used to check a condition and execute code based on whether it’s true or false.
- Use curly braces for blocks of code that should be executed when a condition is met.
- Use parentheses around conditions, but they are not required.
Operators
- Rust has several operators, including + and -.
- A boolean variable can be created using
let check_ID: bool = false;. - Types can be added to variables if desired.
⭐️Shorthand If
- Rust does not have a ternary operator like many other languages, but shorthand if statements can be used instead.
- Shorthand if statements work similarly to ternary operators in other languages.
Loops
Section Overview: This section covers loops in Rust.
Infinite Loop
- An infinite loop is a loop that runs indefinitely until it’s interrupted by an external event or action.
- In Rust, an infinite loop can be created using the
loopkeyword followed by curly braces containing the code to execute repeatedly.
While Loop
- A while loop executes as long as its condition remains true.
- The syntax for a while loop includes the
whilekeyword followed by parentheses containing the condition and curly braces containing the code block to execute.
For Loop
- A for loop iterates over a range or collection of values.
- The syntax for a for loop includes the
forkeyword followed by parentheses containing an iterator expression and curly braces containing the code block to execute.
Introduction to Loops and Functions
Section Overview: In this section, the instructor introduces loops and functions in Rust programming language.
While Loop
- A while loop is used to execute a block of code repeatedly as long as a condition is true.
- Use an if statement inside the loop to break out of it when a certain condition is met.
- Example: Print numbers 1 through 20 using a while loop with a break statement.
FizzBuzz Challenge
- The FizzBuzz challenge requires looping through numbers from 0 to 100 and printing “Fizz” for multiples of 3, “Buzz” for multiples of 5, and “FizzBuzz” for multiples of both.
- Use the modulus operator (%) to check if a number is divisible by another number.
- Example: Implementing FizzBuzz challenge using while loop with conditional statements.
For Range Loop
- A for range loop can be used to iterate over a range of values specified by the user.
- It’s similar to the for-each loop in other programming languages.
- Example: Implementing FizzBuzz challenge using for range loop.
Functions
- Functions are used to store blocks of code that can be reused multiple times throughout your program.
- They take input parameters and return output values (if necessary).
- Example: Creating functions in Rust, including defining function parameters and return types.
Rust Functions
Section Overview: In this section, we learn about Rust functions and how to use them.
Creating a Function
- To create a function in Rust, use the
fnkeyword followed by the function name. - Parameters can be passed into the function using parentheses.
- Use an arrow syntax to specify the return type of the function.
- To call a function, simply write its name followed by any necessary arguments in parentheses.
⭐️Returning from a Function
- To return a value from a Rust function, omit the semicolon at the end of the expression.
- The last expression in a Rust function is automatically returned.
⭐️Closures
- Closures are similar to functions but are more compact and can use outside variables.
- Use
letto define closures and bind them to variables. - Closures can take parameters and return values just like functions.
Pointers and References
Section Overview: In this section, we learn about pointers and references in Rust.
Primitive Arrays
- Pointers can be used with primitive arrays in Rust.
- Use
letto create variables that point to other variables or arrays.
⭐️Non-primitive Values
- Non-primitive values require references when assigning another variable to their data.
- Use an ampersand (
&) before non-primitive values when creating references.
Rust Basics: References and Structs
Section Overview: In this section, the instructor covers how to create references in Rust using the ampersand symbol and explains how to create structs in Rust.
⭐️Creating References
- To create a reference in Rust, use the ampersand symbol.
- If you want to point to a non-primitive value, you need to create a reference.
- Use the ampersand symbol before the variable name to create a reference.
Creating Structs
- Structs are custom data types used in Rust that are similar to classes.
- To create a struct, use the
structkeyword followed by the name of your struct. - Define properties or members of your struct using variables with their respective data types.
- Access properties of your struct using dot syntax.
⭐️Tuple Structs
- Tuple structs are another way of creating structs in Rust.
- They do not have named properties like traditional structs but instead rely on their order within the tuple.
- You can access tuple struct values using index numbers instead of property names.
Creating a Struct in Rust
Section Overview: In this section, the speaker creates a struct called “person” and defines functions to construct and manipulate it.
Creating a New Person
- The speaker creates a new struct called “person”.
- A function called “new” is defined to create a new person. It takes in two string parameters: first name and last name.
- The “new” function returns a person with uppercase first and last names.
Getting Full Name of Person
- A method called “full name” is created to get the full name of the person.
- The “full name” method returns a string using format! macro.
- The full name method is used to print the full name of the person.
Changing Last Name of Person
- A function called “set last name” is created to change the last name of the person.
- The set last name function mutates self and takes in one parameter: last (string).
- The set last name function is used to change the last name of Mary Doe to Williams.
Converting Name to Tuple
- A method called “to tuple” is created to convert the person’s first and last names into a tuple.
- The method returns a tuple with two strings: first_name and last_name.
Structs
Section Overview: In this section, the instructor explains how structs are used in Rust and compares them to classes in other programming languages.
⭐️Introduction to Structs
- A struct is a data type that groups together variables of different types.
- The syntax for creating a struct is
struct Name { field1: Type1, field2: Type2 }. - Structs are similar to classes in other programming languages like Python, PHP, JavaScript, and Java.
Enums
Section Overview: In this section, the instructor introduces enums and demonstrates how they can be used in Rust.
Introduction to Enums
- An enum is a type that has a few definite values.
- The syntax for creating an enum is
enum Name { Variant1, Variant2 }. - Variants are the possible values of an enum.
Using Enums
- We can create functions that take enums as parameters.
- We can use match statements to perform actions based on the value of an enum.
Functions with Enums
Section Overview: In this section, the instructor demonstrates how to create functions that take enums as parameters and use match statements to perform actions based on their values.
⭐️Creating Functions with Enums
- We can create functions that take enums as parameters by specifying the type of the parameter as the name of the enum.
- We can use match statements to perform actions based on the value of an enum.
- Match statements are similar to switch statements in other programming languages.
Command Line Arguments
Section Overview: In this section, the instructor explains how command line arguments work in Rust and demonstrates how to get them using env::args().
Introduction to Command Line Arguments
- Command line arguments are values passed into a program when it is run from the command line.
- We can use command line arguments to customize the behavior of our program.
⭐️Getting Command Line Arguments
- We can get command line arguments using the env::args() function from the standard library.
- The env::args() function returns a vector of strings containing the command line arguments.
Introduction to Command Line Applications
Section Overview: In this section, the instructor introduces how to create command line applications in Rust.
⭐️Getting Input from Command Line Arguments
- The
argsvariable is used to get input from the command line. - The first element of the
argsvector is always the target of the executable. - Additional arguments passed in are added to the
argsvector. - A specific argument can be accessed by its index in the
argsvector.
Creating a Command Line Application
- Create a variable called
commandand set it equal toargs[1]. - Use an if statement to check what command was entered and execute different code based on that command.
- Use placeholders to insert variables into print statements.
- If an invalid command is entered, print a message indicating so.
Conclusion
- Rust is a powerful language for creating command line applications.
- There is much more that can be done with Rust beyond what was covered in this video.
- The instructor plans on doing something with Web Assembly soon.
Stop Duplicating Code: Generics, Traits, Lifetimes
- Stop Duplicating Code: Generics, Traits, Lifetimes
Introduction to Generics
Section Overview: In this section, we will learn about generics and how they can be used with functions, methods, and custom types. We will also explore traits and lifetimes.
Removing Duplication
- Placeholder: Generics are like a placeholder for another type.
- Functions can help remove duplication in code.
- The syntax for generics includes an open angle bracket followed by a letter t and then a close angle bracket.
- Rust’s standard library has a compare module that includes the partial order or ord trait which is necessary for comparing custom data types.
⭐️Using Generics with Structs
- We can use generics with structs to create more flexible code.
Defining V.S. Creating: When defining a struct with generics, we need to specify the type of the generic when creating an instance of the struct.
Implementing Traits
- Shared Behavior: Traits define shared behavior between different types.
- Impl: We can implement traits on our own custom types using the impl keyword.
- Trait Bounds: Trait bounds allow us to restrict which types can be used with our generic functions or structs.
Lifetimes
- Lifetimes ensure that references remain valid for as long as they are needed.
- We use apostrophes (’) to denote lifetimes in Rust code.
- Lifetime elision rules allow us to omit explicit lifetime annotations in certain cases.
Conclusion
Section Overview: In this section, we reviewed what we learned about generics, including how they can be used with functions, methods, and custom types. We also explored traits and lifetimes.
- Generics allow us to write more flexible and reusable code.
- Traits define shared behavior between different types.
- Lifetimes ensure that references remain valid for as long as they are needed.
Generics in Type Definitions and Functions
Section Overview: In this section, the speaker introduces generics and explains how they can be used in type definitions and functions.
Using Generics in Type Definitions
- Generics can be used not only in functions but also in type definitions.
- The
pointstruct is an example of using generics in a type definition. Thetparameter is used to define the type ofxandy. - The
pointstruct can take on different characteristics depending on the types defined forxandy. - Multiple types can be defined for a struct by separating them with a comma.
⭐️Using Generics in Enums
- Enums can also use generics. The speaker provides examples of two enums from the standard library that use
generics:
Option<T>andResult<T, E>. - The generic parameter is passed as an argument when creating instances of these enums.
⭐️Using Generics in Methods
- Generics can also be used inside methods. The speaker uses the
pointstruct as an example. - When defining a method that uses generics, the generic parameter must be specified again in the implementation.
- Specific methods can be created for specific types by targeting them with their own implementations.
Mixing Types with Generics
- Mixing types with generics is possible using methods like
mix_up(). - The method takes two points as arguments, each with its own set of generic parameters.
- The output ignores one of the generic parameters while returning the other.
Introduction to Generics and Traits
Section Overview:
- In this section, the speaker introduces generics and traits in Rust programming language.
- They explain how generics work, their performance implications, and how they can be used with different data types.
- The speaker also discusses traits, which are similar to interfaces in other programming languages.
⭐️Generics
- Generics allow for code reuse by creating functions that can work with multiple data types.
- Using generics can impact performance as it requires the compiler to do more work and may result in a larger binary.
Monomorphizationis the process of turning generic code into specific code by filling in concrete types used at compile time.- The compiler outputs specific code for each data type used with a generic function.
⭐️Traits
- Traits are similar to interfaces in other programming languages.
- A trait defines a set of methods that can be implemented by custom data types.
- Custom data types implement traits using an implementation block.
- Different custom data types can have different implementations for the same trait method.
- Traits can be defined as public so they can be used in other modules.
Using Traits as Parameters
- Traits can be used as parameters in functions to allow for greater flexibility and reusability.
Rust Generics and Traits
Section Overview: This section covers the use of generics and traits in Rust programming.
⭐️Using Generics with Traits
- Rust uses generics to implement traits.
- Multiple traits can be implemented by a single generic type.
- Generic types can also implement multiple traits as parameters in a function.
- The
wherekeyword can be used to make the code more readable when implementing multiple conformances for generics.
⭐️Returning Different Concrete Types Based on Business Logic
- Functions may return different concrete types based on business logic.
- Rust does not allow returning different concrete types from a function, but this issue is covered in Chapter 17 of the Rust Programming Book(Using Trait Objects That Allow for Values of Different Types).
- A workaround for this issue is using dynamic dispatch with the
dynkeyword.
⭐️Fixing Issues with Partial and Copy Traits
- When returning values instead of references, items must be copyable or cloned.
- Dynamic dispatch can be used as a workaround for issues with partial and copy traits.
Conclusion
Overall, this section covers how to use generics and traits in Rust programming:
- including implementing multiple traits with a single generic type,
- returning different concrete types based on business logic,
- and fixing issues related to partial and copy traits.
Understanding Lifetimes in Rust
Section Overview: In this section, the speaker introduces lifetimes in Rust and explains how they are used to validate the scope of variables being passed into a function.
Introduction to Lifetimes
- Lifetimes are used to validate the scope of variables being passed into a function.
- The speaker reviews scopes and provides an example where a reference is made to a variable that has already been dropped, resulting in a dangling pointer.
- Lifetimes help get rid of dangling pointers.
⭐️Implementing Lifetimes
- The speaker provides an example of implementing lifetimes using references and explicit lifetime syntax.
- The rest compiler helps identify when lifetime parameters need to be introduced for borrowed values.
- An example is provided where lifetime parameters are added to fix errors identified by the rust compiler.
⭐️Output Lifetimes
- The speaker discusses output lifetimes and how they connect input lifetimes with output lifetimes.
- An example is provided where two strings are passed into a function, and the longest string is returned as output.
- The rest compiler identifies when output lifetimes do not match input lifetimes, resulting in borrowed values being dropped too early.
Conclusion
Overall, this section provides an introduction to lifetimes in Rust and demonstrates their importance in validating variable scopes. Examples are provided throughout to illustrate how lifetime syntax can be implemented and how the rust compiler can help identify errors related to borrowed values.
Dangling Pointers and Lifetimes
Section Overview: This section covers the concept of dangling pointers and how lifetimes are used to prevent them in Rust.
⭐️Dangling Pointers
- A result returned as a string can cause a dangling pointer, which means it gets dropped and cleaned up.
- Borrowed types as str cannot live as long as needed, causing issues with dangling pointers.
Lifetimes in Structs
- Lifetimes not only go into function parameters but also into structs.
- An example is given where an excerpt needs to live for the same amount of time as the reference it holds.
- Both the novel and excerpt need to have the same lifetime so they can be valid for the same amount of time.
⭐️Rules for Lifetime Elision
- The compiler assigns a lifetime value to each parameter that is a reference.
- If there’s exactly one input lifetime parameter, then there is a lifetime parameter assigned to all the output.
- If there are multiple input lifetime parameters but one of them is a reference to self or mutable self, then the lifetime of self is assigned to all output lifetime parameters.
⭐️Understanding Lifetimes in Rust
Section Overview: In this video, the presenter explains how lifetimes work in Rust. He covers the three elision rules and how they apply to functions and methods with multiple parameters. He also discusses how to use traits and generics with lifetimes.
Lifetime Rules for Functions
- Each parameter gets its own lifetime.
- Rule two does not apply because there are multiple parameters.
- Rule three doesn’t apply because there’s no method.
Specifying Output Lifetime
- When a function has two different parameters, it is unclear what the lifetime of the output should be.
- The programmer must manually insert the appropriate lifetime into the application.
Lifetime Rules for Methods
- Each parameter gets its own lifetime.
- Since there is more than one parameter, rule two does not apply.
- If a method references
self, then the return type must have the same lifetime asself.
Static Lifetime
staticis a special type of lifetime that applies to variables or data that needs to be around for the entirety of an application running.- If a compiler suggests using
staticbut it doesn’t seem appropriate, check if any functions used within that code need their lifetimes adjusted.
Advanced Scenarios
The presenter briefly mentions advanced scenarios where traits and lifetimes can be used together. For more information on these topics, refer to Chapter 17 of “The Rust Programming Language” book or check out the Rust reference documentation.
Overall, this video provides a clear explanation of how lifetimes work in Rust and offers helpful tips for working with them effectively.
Generated by Video Highlight
https://videohighlight.com/video/summary/JLfEiJhpTbE
From cargo to crates.io and back again(3/7h)
- From cargo to crates.io and back again(3/7h)
- Introduction
- Cargo and Registries
- Implementing the Loop
- Cargo Package
- Publishing on Crates.io
- Cargo Package and Crate Files
- Understanding the Git Pull from the Skit Index
- Transitioning to HTTP-based Sparse Registries
- Understanding the Cargo Registry
- Crates Index
- Digging into Code on Cargo Side and Crates.io Side
- Introduction
- Publishing Crate Files
- Hosting Index on GitHub
- Overview of Git Index and Cargo
- Code Structure of Cargo
- Understanding the Cargo Publish Process
- Introduction
- Definitions
- Custom Registries
- Implementing a Cargo Registry
- Naming the Cargo Index Interface
- Adding Features to Cargo Home
- Defining Publish Phases
- Rust Crate Serialization
- Summary New Function
- Add Crate Job
- Dependency Ordering and Cargo Manifests
- Simplifying the Toml Manifest
- Verifying Tarball
- Cargo Tamil Manifest Definition
- Mapping Dependencies
- Cleaning up the Code
- Understanding the Cargo Manifest
- Parsing TOML Manifests
- Understanding the Version Encoding
- Parsing Metadata
- Tidying up Definitions
- Introduction
- Cargo Tamil
- Type Definitions
- Future Difficulty
- Optimization
- Cargo Intern String Usage
- Normalized Manifest Conversion
- Package Ownership Conversion
- Generated by Video Highlight
Introduction
In this section, the speaker introduces the topic of the stream and explains that they will be tackling an implementation problem related to how cargo talks to registries.
- The speaker mentions that they will not be porting anything in this stream and will instead write a Rust program from scratch.
- They explain that they will focus on how cargo talks to registries, including crates.io and alternative registries.
- The goal is to implement a crate that can be used by both cargo and crates.io, as well as other registries.
Cargo and Registries
In this section, the speaker discusses what happens when you run cargo publish and how it interacts with registries
like crates.io.
- When you run
cargo publish, two things happen:cargo packageis run first, followed by uploading the package to a specific endpoint at crates.io. cargo packagetakes your entire source directory (excluding files in.gitignore) and creates a tarball containing all necessary files for distribution.- The speaker notes that there are different data structures involved in these steps, but they are currently defined in different repositories without sharing logic or definitions.
- This lack of integration means there is potential for mismatches between them. For example, crates.io does not check if metadata sent by cargo matches the file uploaded during publishing.
- Ideally, one crate could be created that could be used by both cargo and crates.io.
Implementing the Loop
In this section, the speaker explains their plan to implement a crate that can be used by both cargo and crates.io.
- The goal is to create a single crate that contains all necessary data structures for interacting with registries like crates.io.
- This would allow for better integration between different parts of the system and prevent potential mismatches.
- The speaker notes that they will not be implementing low-level logic for issuing HTTP requests, but rather focusing on data structures and their conversion between steps.
- They explain that this would allow crates.io to rerun cargo logic if necessary, such as when backfilling information for older packages.
Cargo Package
In this section, the speaker discusses what happens when you run cargo package.
cargo packagetakes your entire source directory (excluding files in.gitignore) and creates a tarball containing all necessary files for distribution.- The tarball includes everything in your cargo.toml include directive, except things in exclude. By default, it also includes everything next to Cargo.toml except things in .gitignore.
- The speaker notes that the default rules can be weird.
Publishing on Crates.io
In this section, the speaker discusses publishing on crates.io.
- When you run
cargo publish, two things happen:cargo packageis run first, followed by uploading the package to a specific endpoint at crates.io. - The cargo metadata sent during publishing includes information like the name and version of the crate. This is also contained in the file uploaded by cargo.
- Currently, crates.io does not check if these two match. This could lead to issues with basic sanity checking or backfilling information for older packages.
Cargo Package and Crate Files
In this section, the speaker explains what happens when you run cargo package and how it generates a .crate file.
What Happens When You Run cargo package
- Running
cargo packagedownloads dependencies from crates.io and generates a.cratefile. - The
.cratefile is essentially a.tar.gzarchive that contains all the files needed for the crate to be built. - The
.cratefile also contains metadata about the context in which the publish happened, such as the commit hash of the code at that time. - The
Cargo.toml.origfile is automatically generated by Cargo and is essentially a normalized version ofCargo.toml, removing features not used by the crate to ensure compatibility with older versions of Cargo.
Viewing Contents of a .crate File
- To view the contents of a
.cratefile, navigate to its location (usually/target/package/name-version.crate) and runtar tzf name-version.crate. - Examining the contents can help identify unnecessary files that can be excluded to make the crate smaller and faster to publish.
# Overview of the Crate API
This section provides an overview of the body of data sent by Cargo, which is essentially a manually encoded multi-part HTTP message. It includes an integer of the length of the JSON data metadata of the package as a JSON object, then an integer of the length of the crate file and then the crate file.
Body Data Sent by Cargo
- The body of data sent by Cargo is an integer representing the length of:
- The JSON data metadata for the package as a JSON object
- The crate file
- The body is essentially a manually encoded multi-part HTTP message.
Metadata in Crate API
- The metadata in Crate API includes:
- Name
- Version
- Array of direct dependencies
- Various information about those dependencies such as features and authors.
- This information can be obtained from cargo.toml in the crate file.
Validating Crates
- The server should validate crates because it cannot trust that the JSON matches what’s in the crate file.
- Parsing cargo.toml is necessary to validate crates.
# Existing Crate Type Definitions
This section discusses existing crate type definitions and their usage.
Crates.io Crate Type Definitions
- There is a crate called “crates.io” that provides definitions for each API type.
- It is intended for those who want to look like crates.io or want to talk to crates.io.
- It has other stuff included like curl and URL because it also implements talking to parts which creates.io doesn’t need.
Standalone Crate Type Definitions
- A new standalone crate will be built with the same type definitions as the crates.io crate.
- The new crate will not include unnecessary dependencies like curl and URL.
- The new crate may take a dependency on the crates.io crate.
# Cargo Publish
This section discusses what happens when cargo publish is run.
Uploading JSON to Server
- Running “cargo publish” runs a “curl put” command which uploads the JSON to the server.
Server Response
- The response from the server depends on the implementation of the registry.
- On crates.io, it goes into a database and git index.
Understanding the Git Pull from the Skit Index
This section explains what happens during a git pull from the skit index and how it updates files.
The Skit Index
- When you run
cargo fetchor update the index, it does a git pull from the skit index. - Commits of updating crates are endless and trigger when someone runs
cargo publish. - Each version is one line in this file, and each file path has a specific syntax based on crate name length.
Inside the Index Files
- Inside of the index files is one line per version, which is a JSON object that looks similar to what cargo sends to publish.
- One field that’s here but not in publish is checksum, which is a hash of the .crate file.
- Going from just published JSON to this isn’t possible without also having the .crate file.
Transitioning to HTTP-based Sparse Registries
This section discusses transitioning to HTTP-based sparse registries and how they differ from git registries.
HTTP-Based Sparse Registries
- With HTTP-based sparse registries, there’s no more updating indexes or resolving deltas.
- Cargo is transitioning to using HTTP-based sparse registries.
Understanding the Cargo Registry
This section explains how the Cargo registry works and its role in hosting a list of versions and crate files.
The Role of Indexes in Hosting Versions and Crate Files
- The indexes are responsible for hosting a list of versions and dot crate files that have checksums matching the entries.
- When cargo talks to a registry, it mainly constructs a list of available versions by parsing each line of the file, then runs the resolver to figure out which version among these should be chosen based on the dependency declaration in your cargo toml.
- Having dependencies listed in the index allows for faster full resolve of dependencies without downloading or extracting any crate files.
Crates Index
This section discusses crates index, which is similar to crates IO but has more features than just data definitions.
Understanding Crates as an Abstract Concept
- A crate is an abstract concept that maps directly to one of the files in the index and has no information except for a list of versions.
- Every version has fields such as name, version, dependencies, checksum, features, links, yanked status and download URL.
Special Implementations Used by Cargo
- Cargo uses special implementations or types like intern string or small string to avoid overhead when parsing fields for every dependency version.
- To be used by cargo, our library would have to be generic over string type so that cargo can choose its own optimized string types rather than being forced to use strings.
Digging into Code on Cargo Side and Crates.io Side
This section explores the code on the cargo side and crates.io side to see where this stuff lives and to explore the code a little bit.
Understanding the Life Cycle from Publish to Consume
- The life cycle of a crate involves publishing it, talking to the registry, resolving dependencies, downloading relevant crate files and building.
- [](t=0:21:52 t:1312s) The indexes are responsible for hosting a list of versions and dot crate files that have checksums matching the entries.
- [](t=0:22:17 t:1337s) When cargo talks to a registry, it mainly constructs a list of available versions by parsing each line of the file, then runs the resolver to figure out which version among these should be chosen based on the dependency declaration in your cargo toml.
- [](t=0:23:15 t:1395s) Cargo sees that you have a dependency on zip. It looks at the index and picks one version of zip. Then it looks at its dependencies and keeps doing that until it’s resolved your entire dependency tree before fetching all crate files.
- [](t=0:24:00 t:1440s) Crates index is similar to crates IO but has more features than just data definitions. A crate is an abstract concept that maps directly to one of the files in the index and has no information except for a list of versions.
- [](t=0:25:01 t:1501s) To be used by cargo, our library would have to be generic over string type so that cargo can choose its own optimized string types rather than being forced to use strings.
Introduction
In this section, the speaker discusses the suitability of Jason for stream dependency resolution.
Jason and Stream Dependency Resolution
- Jason is not very suited for stream dependency resolution because you have to parse the whole Json before even knowing the dependencies list.
- However, in practice, it doesn’t really matter because the entries in the registry are all very short.
- Realistically, it’s only your direct dependencies that are listed here so like there aren’t really projects that have like thousands of direct dependencies.
- Having a format that’s relatively easy to work with is probably worthwhile here.
Publishing Crate Files
In this section, the speaker explains how crate files are published and how information about their dependencies is included.
Including Dependencies Information
- The information about a crate’s dependencies is included in its cargo Tomo file.
- When crates.io receives a crate file, it includes the Json which says there’s a dependency on Rand 0.8.
- It gets that information from your cargo terminal so it’s redundant but it’s also the same like cargo will derive one from the other.
Hosting Index on GitHub
In this section, the speaker explains why they decided to host an index on GitHub and why they developed sparse registries.
Git vs HTTP-based API
- The reason why they hosted an index on GitHub was mostly because it’s straightforward.
- Checking out the index locally is just a git clone and you can get efficient Delta updates by doing a git pull.
- However, as Craterial grew larger, using an HTTP-based API became more scalable. This led to developing sparse registries.
Overview of Git Index and Cargo
This section provides an overview of the Git index and how it is used in Cargo.
Canonical Path for Git Index
- The hash in the canonical path for the Git index is a hash of the URL of the crates.io index.
- If an alternate registry is used, they will end up with a different hash here.
- This is how Cargo differentiates them.
Structure of Git Repository Managed by Cargo
- The
dot-cratefiles are held incache. - Extracted versions of every crate file are held in
source. - The actual index itself is held in
index.
Logic Around Publish Command
- Definitions for all commands live in
source/bin/cargo. - The definitions for publish command live inside this directory.
- The Ops module inside
source/cargo/opsholds the definitions of all these commands. - It lets you cleanly separate out things that have to do with CLI versus actual logic.
Code Structure of Cargo
This section provides an overview of the code structure of Cargo.
Source Directory
- Majority of cargo’s stuff lives here.
- Holds utility crates which includes crates.io crate.
Publish Command Code
- Definitions for all commands live in
source/bin/cargo. - Definitions for publish command live inside this directory.
- Exec function is the entry point for executing that command.
Ops Module
- Holds definitions for all these commands.
- Lets you cleanly separate out things that have to do with CLI versus actual logic.
Understanding the Cargo Publish Process
This section explains the process of publishing a crate using Cargo.
The Definition of Publish
- “Publish” is the code that executes when you run
cargo publishafter parsing all the registry or arguments. - It mainly finds and parses your cargo config and workspace manifest, looks over members, and checks which registry you want to publish to.
- If it’s a dry run, it doesn’t do anything else. Otherwise, it constructs an operation to send to the Craterial registry.
Package One
Cargo packagegenerates the crate file, which is a tarball.- The result is a
.cratefile that gets uploaded to crates.io bytransmit. - If there are Git dependencies in your crate, they will not be permitted.
Transmitting Payload
Transmitsends both the generated JSON and.cratefile as payload to crates.io.- It computes a list of dependencies, generates new crate dependency types that describe each of them, parses out the manifest and readme files, looks at license files and ultimately constructs one of these new crate things with all this information extracted from the manifest.
- Registry.publish uses curl to actually send the payload.
Waiting for Crate Availability
- When you run
cargo publish, there’s logic on crates.io side that has to happen before your version becomes available. - This loop waits until your version is actually in the index and available for others so that if someone tries to use it immediately after you’ve published it, they won’t get an error message.
Introduction
In this section, the speaker apologizes for a recent change to their chat block and discusses the crates IO side of things.
Chat Block Change
- The speaker recently set up a 10-minute follow chat block due to spammers.
- However, it can be sad when people want to raid.
Crates IO Side
- The speaker discusses where they received a JSON payload.
- They explain how Source controllers crate publish handles puts to crates new used by cargo published to publish a new crate.
- The speaker mentions that the request is split into parts using the length of the JSON and tarball.
- They discuss how metadata is checked and an entry is constructed in the database based on information from the JSON metadata.
- The speaker explains how S3 uploads are handled and how crates are registered in local git repo.
Definitions
In this section, the speaker talks about different definitions for similar things across various parts of the ecosystem.
Cargo Registry Index
- The speaker explains that all parts of the ecosystem have different definitions for similar things.
- They mention that current registry index has a definition of crate which is what ends up going in the index.
Custom Registries
In this section, someone asks about support for custom registries other than Crate.io.
Support for Custom Registries
- The speaker says that custom registries are supported but cross-registry dependencies are not allowed.
Implementing a Cargo Registry
This section discusses the challenges of implementing a registry for Cargo, including the limitations of using git as a registry and the lack of support for authentication.
Challenges with Alternate Registries
- Implementing an alternate registry is challenging because they are forced to use git as a registry, which can be expensive and cumbersome.
- Sparse registries make it easier to implement your own registry based on existing infrastructure.
- Authentication support for private registries is limited, making it difficult to control who has access to your registry. Efforts are being made to improve this.
Alternative Registries
- There are several alternative registries available, such as gitty, Artifactory Muse Alexandria, and others.
Naming the Library
- The library will contain types for interacting with a cargo registry but not all types in cargo. Possible names include “cargo index,” “cargo index schema,” or “registry schema index schema.”
- The appropriate name may be “Cargo index interface” since it applies to any cargo registry.
Naming the Cargo Index Interface
The speaker discusses possible names for the cargo index interface.
- Possible names include “interface for cargo indexes,” “cargo index schema,” and “cargo index types.”
- The speaker struggles with finding a suitable name and considers using a thesaurus to find synonyms.
- They eventually settle on “cargo index Transit” as it relates to the idea of transit points and all necessary transits needed to interact with a cargo index.
Adding Features to Cargo Home
The speaker explains how they add features to their local directory config instead of their system-wide config.
- They override said beta and add it to their local directory config instead of their system-wide config.
- This is because it’s not unstable yet, so adding it to the system-wide config would cause build failures in packages that don’t have the feature.
- By adding it locally, they get it only for the local one.
Defining Publish Phases
The speaker defines different phases involved in publishing crates.
Crate.io Definition
- There are two primary definitions: one in crates.io and another in models.
- Dependencies come from models dependency kind and keyword.
- A keyword is used, which was previously called crate keyword.
- Chrono native time may be used but remains uncertain.
Index Definition
- In the index definition, there are dependencies on sember, which has semantic versioning versions definitions.
Rust Crate Serialization
In this transcript, the speaker discusses the process of creating a foundational crate for Rust that can be used for serialization and deserialization. They discuss the different types of crates that will need to be included in this foundational crate and how they will need to be organized.
Creating a Foundational Crate
- The speaker discusses what is missing from the foundational crate.
- They mention that encodable crate version wreck needs to be included.
- Serialize also needs to be included.
- Both serialize and deserialize will need to be included because both are necessary.
- The speaker explains why all source definitions should be in one file.
- They discuss validation on deserialize and how it ensures that the type conforms with rules for strings.
- The speaker mentions that they will want to include validation as well.
Cargo vs Crates.IO
- The speaker notes an issue with two implementations of serialize.
- They suggest being generic over types so cargo can choose which version to use.
- There may end up being a lot of generics, which is not ideal.
- The speaker suggests avoiding encoding too much stuff in this crate so it remains foundational.
Index Entries
Summary New Function
In this section, the speaker discusses the summary new function and where it is called from in the codebase.
Finding Summary New
- The speaker looks for where
summary newmight be called from in the codebase. - They find a long function called
process dependenciesthat seems promising. - The speaker then finds a definition for
registry package, which seems to be what they are looking for.
Intern String and Generic Types
- The speaker explains that Cargo uses
intern stringto de-duplicate allocations of strings. - They note that if we want Cargo to use these definitions, we will need to make them generic over these things.
Registry Dependency and Cow Types
- The speaker looks at the definition of
registry dependency. - They note that some fields use cow types, which can save on allocations when decoding JSON.
Add Crate Job
In this section, the speaker discusses how crates.io serves its index and how it handles adding new crates.
Perform Index Add Crate
- The speaker looks for where something handles adding crates in the codebase.
- They find a job that regularly does git commits but are unable to find where it calls
perform index add crate.
Search-Based Definitions
- The speaker notes that definitions on crates.io are entirely search-based at present.
- They explain how searching works on crates.io and how it guesses which results are definitions versus usages.
Overall, this transcript covers the speaker’s exploration of the codebase for Cargo and crates.io, focusing on
how summary new is called and how crates are added to the index. The speaker also discusses some implementation
details such as intern string, cow types, and search-based definitions.
Dependency Ordering and Cargo Manifests
In this section, the speaker discusses dependency ordering and cargo manifests. They explore the implementation of ordering for dependencies and look at a definition of dependency kind.
Dependency Ordering
- The speaker notes that there is an implemented ordering for dependencies.
- They wonder why this is implemented.
Definition of Dependency Kind
- The speaker notes that they will grab two definitions of dependency kind.
- They note that the second definition of dependency kind is not used elsewhere in the crates IO code base.
- The speaker notes that one definition of dependency kind isn’t used.
- They mention that they have obtained the necessary definition.
Cargo Manifest Format
- The speaker considers taking a dependency on cargo to extract the crate file and parse its contents to generate published JSON but decides against it due to circular dependencies.
- Using cargo for this purpose would mean that cargo cannot take a dependency on them.
- The simplified version of the cargo manifest format is what they need, which appears in the generated cargo Tamil file.
- They search for where this simplified manifest is defined.
Tomo Manifest Type
- The speaker finds out that tomorrow manifest type is used to deserialize Cargo Tomo files, meaning there isn’t a separate type for just the simplified manifest.
Simplifying the Toml Manifest
In this section, the speaker discusses simplifying the Toml manifest by removing unnecessary fields.
Removing Unnecessary Fields
- The definition of the simplified manifest should only include bits that are actually generated.
- Some fields like project, Dev dependencies two, build dependencies two, patches none, workspace none and badges can be removed as they are always set to none or deprecated.
- Workspace dependency can be filtered out since it is never used in Tamil dependencies.
- Map depth thing removes anything that is a workspace dependency.
Verifying Tarball
In this section, the speaker discusses verifying tarball and checking if dependencies are available in the registry.
Checking Dependencies
- The verify tarball function checks if all dependencies are available in the registry.
- Create metadata seems separate from cargo Tamil.
Cargo Tamil Manifest Definition
In this section, the speaker discusses the definition of a Cargo Tamil manifest and its various components.
Components of a Cargo Tamil Manifest
- The “maybe workspace field” can be replaced with the inner type, which is either defined or not.
- The speaker expresses enthusiasm for using “string or bull string or VEC.”
- The Tamil crate is needed and can be installed via
cargo index Transit car cargo ad Tamil. - Dev dependencies 2 and build dependencies 2 do not get set.
- Replace does not get set, patch and workspace do not get set.
- Detailed Tamil dependency must be grabbed.
- There are no simple dependencies; only detailed dependencies exist.
- The speaker notes that foreign strings are present in the manifest definition.
- Parameter p is never used and can be removed.
- A sub-module called Deezer is created to bring in sturdy helpers.
Mapping Dependencies
In this section, the speaker discusses how dependencies are mapped in a Cargo Tamil manifest.
Mapping Dependencies
- All detailed Tamil dependencies are called map depths, which calls map dependency.
- Map dependency maps anything that’s detailed and removes path, Git, branch, tag, Rev. It changes the registry index but leaves everything else alone.
- Simple dependencies are turned into detail dependencies.
Cleaning up the Code
In this section, the speaker is cleaning up the code and removing unnecessary types that won’t be used in the final upload.
Removing Unnecessary Types
- The speaker removes unnecessary types such as
Tomo profilesandTomo targets. - The speaker examines
path valueand decides to keep it since it holds a path buff but is serialized and deserialized as a string. - The speaker considers pruning out all things that don’t go in the upload, including all of the targets and profile.
Pruning Down Definitions
- The speaker prunes down definitions by removing all things that don’t go in the upload, including all of the targets and profile.
- The speaker keeps
Tamil packagebecause it defines the actual cargo package like name and version.
Understanding the Cargo Manifest
In this section, the speaker discusses various fields in the Cargo manifest and their relevance.
Fields in the Manifest
- The
buildfield is not currently relevant and can be ignored. - The
meta buildfield is not present in the manifest. - The
seal referencesfield is not discussed further. - The
packagefield contains information about the package being built. - The
exclude,include, andworkspacefields are not relevant to the registry or resolver. - The
metadatafield is not published and does not need to be parsed. - The
artifactandlibfields are also not important to the resolver or registry.
Public/Private Dependencies
- The speaker discusses an RFC proposing a way to mark dependencies as private so they do not leak. This would help with backwards compatibility issues.
Parsing TOML Manifests
In this section, the speaker discusses parsing TOML manifests and removing unnecessary fields.
Removing Unnecessary Fields
- The speaker suggests that some fields can be removed since they are not relevant to the registry.
- Exclude and include fields are only used by cargo package so they can be removed once cargo packages run.
- Default run is also not relevant to the registry and can be removed.
- Metadata is still relevant, so it should be kept for now.
Parsing TOML Manifests
- The speaker mentions that only string or bool is needed for readme.
- Vex string or bull is not needed anymore.
- Version trim white space is still in use.
Understanding the Version Encoding
This section discusses the different instances of version encoding and how they are used in crates.io and cargo.
Version Encoding
- There are multiple instances of version encoding that need to be dealt with.
- The crates index crate has its own version encoding, which is optimized for compactness since it is used to process crates in batch.
- Crates.io uses a different version encoding than the crates index crate, while Cargo does not use any specific version encoding.
- The dependency kind also has its own custom implementation of decoding and validation.
Parsing Metadata
This section discusses parsing metadata using the cargo metadata command and the cargo metadata crate.
Cargo Metadata
- The cargo metadata command has its own format for output, but it is not related to the Toml manifest.
- The cargo metadata crate can be used for parsing all output from the cargo metadata command.
- The foreign package includes fields that may be familiar by now, but also includes fields that do not matter to the registry.
Tidying up Definitions
In this section, the speaker discusses tidying up definitions to have only one definition rather than multiple. They also discuss which of the string types different libraries care about optimizing.
Identifying Interned Strings
- The name was interned string but some like homepage were not.
- The speaker realizes that they should have kept information about which of the string types these different libraries actually care about optimizing.
- Registry package name is interned string and registry dependency name is interned string.
- Features are interned strings in both cargo features and registry features.
- Links are an interned string.
Type Smolster
- Type smolster is just equal to a string.
- Box box stir and option smallster are used for encoding.
Cleaning Up Definitions
- The speaker mentions that they will clean up the definitions later on.
Introduction
In this section, the speaker expresses skepticism about a claim regarding the implementation of serialize for Arc of dependencies.
- : The speaker expresses doubt about the claim.
- : The speaker mentions that there is no implementation of serialize for Arc hashmap string vect string.
- : The speaker finds it hard to believe.
- : The speaker notes that it’s using derived serialized deserialize and calls shenanigans.
Cargo Tamil
In this section, the speaker looks at the cargo Tamil and makes changes to delete custom deserializes and retain types.
- : The speaker looks at the cargo Tamil.
- : The speaker notes that features equals RC is apparently a thing they need.
- : The speaker deletes all custom implementations.
- : The speaker types “this” as a string.
- : The speaker creates a macro.
Type Definitions
In this section, the focus is on creating definitions and conversions between different types.
- : Multiple fields are never used, but it’s fine since they got rid of custom implementations earlier.
- : Next steps include creating definitions and conversions between different types with testing and documentation.
Future Difficulty
In this section, the speakers discuss future difficulty if common crate gets used upstream. They also talk about why their own types are needed in generic cache map.
- : One of the speakers mentions that if the common crate gets used upstream, it might hinder future optimizations.
- : The speaker talks about making every type generic for every field and indicating the type of the field.
- : The speakers discuss why their own types are needed in generic cache map. Different crates have different definitions because they have different needs.
Optimization
In this section, the speakers talk about optimizing for different things.
- : The speakers talk about how different crates optimize for different things. For example, cargo uses a hashmap while crates IO team wants stable index entries and uses a b tree map.
Cargo Intern String Usage
In this section, the speaker discusses the use of intern string in Cargo and wonders why it is only used for the name of the package and not for dependencies.
Intern String Usage
- Cargo uses intern string only for features.
- The speaker wonders if there is a rationale behind this decision.
- The speaker tries to find an explanation by looking at the Tamil stuff.
- It is already deserialized for cow stir allocates by default.
- The speaker thinks that many of these might actually need a cow but that doesn’t work for option.
- The newer versions of certi may work with option though, so they should check that.
- The speaker is curious about why intern string is only used for name and features.
Normalized Manifest Conversion
In this section, the speaker talks about normalized manifest conversion and how it can be useful.
Owned Copy
- Sometimes you actually want an owned copy like when you deserialize something out of a buffer that’s temporary and now you want to copy it around.
- To make that conversion easier, the speaker suggests having a method called impulse normalized manifests which returns a static lifetime version of normalized manifest.
- This allows someone who wants to make that conversion to do so conveniently.
Package Ownership Conversion
In this section, the speaker talks about package ownership conversion.
Package Ownership Conversion
- The speaker suggests using the name two owned for package ownership conversion.
- Cargo features is an option VEC. I’m sorry, but I cannot summarize the content of the transcript as there is no clear topic or context provided. The transcript appears to be a technical discussion about code implementation and it contains several timestamps associated with different parts of the conversation. To create a summary, I would need more information about what specific topic or problem is being discussed in the transcript.
# Parsing the Cargo Definition for Tamil Manifest
In this section, the speaker discusses how the cargo definition for Tamil manifest is used for various purposes, including parsing raw Tamil written by users. The speaker also talks about how errors in user-written code can be detected and addressed.
Parsing User-Written Code
- The cargo definition for Tamil manifest is used to parse raw Tamil written by users.
- Errors in user-written code can be detected and addressed using this method.
Handling Different Types of Dependencies
- Features do not need to be specified for dependencies, but it is valid to do so.
- Versioning information is cloned from self.version.
Mapping Cow into Owned Cow
- Index will remain the same.
- Features will look like business optional is just self.optional that’s already static uh default features is going to be self default features uh this is going to be the same except two package is going to be like this is an option cow stir and Target is going to be the same.
- For authors, a vector needs a slightly more advanced treatment up here which involves mapping cow into owned map cow owned comma.
# Removing Cargo Features from Dot Grade
In this section, the speaker discusses how cargo features are not included in dot grade and suggests that they can be removed altogether.
Removing Cargo Features
Keeping Package
Custom Implementation of Deserialize
Generated by Video Highlight
https://videohighlight.com/video/summary/
(3/6h)Implementing and Optimizing a Wordle Solver in Rust
- (3/6h)Implementing and Optimizing a Wordle Solver in Rust
* Playing Wordle
* What to Expect
- Solving Wordle with Information Theory
- Introduction
- Getting Started
- Conclusion
- Using AWK to Combine Consecutive Records
- Creating a Wordle Dictionary File
- Introduction to Wordle Solver
- Implementing a Guess Checker
- Wordle Algorithm
- Creating a Dictionary
- Implementing Play Function
- Guess to String
- Fixing Code and Testing Guessing Game
- Checking Naive Implementation
- [t=5463s] Parsing and Computing Word Count
- [t=5541s] Computing Goodness of Guesses
- [t=5671s] Updating Remaining Based on History
- [t=5873s] Retaining Words Based on Guesses
- [t=6020s] Checking Misplaced Letters
- Matching Algorithm
- Testing the Guess Matcher
- Pruning Logic
- Guessing Different Letters
- Disallowing Incorrect Patterns
- Debugging the Code
- The input “rita bond a b c d e plus w w disallows b c d e a” is being disallowed.
- The speaker questions why this input should be disallowed since all letters are present but in different arrangements.
- Upon further inspection, it is discovered that all of the letters are grayed out, indicating that they are incorrect.
- The speaker examines early returns in the code to determine which one is being taken.
- It is determined that an incorrect return statement is being taken twice.
- Further investigation reveals that previously correct letters were being re-evaluated, causing errors in matching letters.
- A suggestion is made to optimize the code by comparing candidate words to answers element by element for correctness.
- The speaker considers this proposal but ultimately decides against it due to excessive complexity.
- Refactoring Code for Optimization
- The speaker simplifies some of the code by using Python’s zip function instead of manually iterating through lists.
- The speaker discusses refactoring parts of the code for efficiency, such as using sets instead of lists.
- Finalizing Code
- The speaker tests the final version of the code with various inputs to ensure that it is working correctly.
- The speaker submits the final version of the code for review.
- Introduction
- Computing Correctness
- Probability of Words
- Conclusion
- Computing the Goodness of Words
- Permutations
- Computing Patterns
- Understanding the Code
- Generated by Video Highlight
0:00:01 Introduction to Wordle
Section Overview: In this section, the speaker introduces the topic of the video, which is playing Wordle. They explain that they will be writing a program to play the game and optimizing it for performance.
Playing Wordle
- Wordle is a simple word game where players try to guess a five-letter English word.
- When guessing, players are told which letters they have guessed correctly, which letters aren’t in the word, and any letters that are in the word but not where they put them.
- The goal is to guess the correct word in as few guesses as possible. The average number of guesses is around four.
- There is a dictionary of allowed words and a dictionary of answer words. The speaker will only use knowledge available to players when writing their program.
0:00:19 Overview of Video
Section Overview: In this section, the speaker provides an overview of what viewers can expect from this video.
What to Expect
- This video will focus on writing Rust code and performance profiling/optimization.
- The speaker hopes that this video will be more approachable than previous ImpulRust videos since it won’t involve complex technical concepts like unsafe pointer manipulation.
- The goal is to write a program that plays Wordle as fast as possible.
Solving Wordle with Information Theory
Section Overview: In this video, the speaker explains how to solve Wordle using information theory. The algorithm from this video will be followed and implemented in Rust. The program’s performance will be optimized using a tool called hyperfine.
Algorithm Explanation
- The algorithm is not explained in detail as it is expected that viewers have watched the video.
- A bug was found in Grant’s implementation, but it does not affect the algorithm much.
- This video is a great candidate for performance profiling and optimization because of its large search space.
- The program will be implemented, run, and iteratively optimized to make it faster using hyperfine.
Using Hyperfine for Performance Optimization
- Hyperfine is a tool that measures the performance of multiple commands that do ostensibly the same thing.
- It gathers variance and execution time data to give you some measurement of statistical significance of performance differences.
- Optimizations will be measured to see which ones make a difference, and then they will be iteratively applied to make the program faster.
Multithreading Considerations
- Multithreading may or may not be important for optimization since it tends to hide true program performance.
Introduction
Section Overview: In this section, the speaker introduces the topic of the video and explains that they will be implementing an algorithm for playing Wordle using Rust.
Algorithmic Approach
- The speaker explains that at the core of their approach lies the idea of information theory.
- They plan to use this theory to compute how much information they can expect to get from a given guess in Wordle.
- By picking the word that is likely to give them the highest expected amount of information for each guess, they hope to whittle down the list of possible words as quickly as possible.
Getting Started
Section Overview: In this section, the speaker explains what resources are needed to implement their algorithm and how to obtain them.
Obtaining Wordle Dictionary
- The first resource needed is the Wordle dictionary.
- The dictionary can be found in a JavaScript file located in the application sources.
- The
maarray contains all target words for each day, whileoacontains all allowed words but notma. - Concatenating these two arrays gives us all dictionary words needed for our implementation.
Obtaining Google Books N-Gram Dataset
- To compute which words are more likely to be correct guesses without relying on true answers, we need access to a large dataset.
- The Google Books N-Gram Dataset provides counts of n-grams (consecutive sequences of n items) across all books scanned by Google Books over many years.
- We will use one gram data set which has single word counts.
Conclusion
Section Overview: In this section, the speaker concludes by summarizing what was covered in the video and emphasizing that their focus was on Rust rather than algorithmic optimization.
Summary
- The speaker implemented an algorithm for playing Wordle using Rust.
- Their approach was based on information theory and involved picking the word that would give them the highest expected amount of information for each guess.
- They obtained the Wordle dictionary from a JavaScript file in the application sources and used the Google Books N-Gram Dataset to compute which words were more likely to be correct guesses.
- The focus of their implementation was on Rust rather than algorithmic optimization.
English Introduction to the Google Books Ngram Viewer
Section Overview: In this section, the speaker introduces the Google Books Ngram Viewer and explains how it works.
How the Data is Constructed
- The data is constructed such that every line starts with a word, followed by the year, number of occurrences of that word in that year, and the number of distinct books that word appears in.
- The left number is always higher than the right number. There are tab-separated entries for each line.
Using Ripgrep to Search for Five-Letter Words
- Ripgrep can be used to search for all five-letter words across all files with a specific suffix using
-zflag to scan compressed files and-iflag to print multiple files without printing out their names. - The results are saved in
five letters.text.
Extracting Occurrence Count for Each Word
- Awk is used to extract occurrence count for each word from
five letters.text. Field separator is set as tab and first field (word) and second-to-last field (occurrence count) are printed. Underscores are substituted with commas before running awk with comma as separator. Results are saved infive letters occur file.
Normalizing Data
- Capital letters are replaced with lowercase letters using tr command before sorting data alphabetically. Multiple entries exist for same words due to case sensitivity. Sorted list provides normalized data.
Using AWK to Combine Consecutive Records
Section Overview: In this section, the speaker explains how they used AWK to combine consecutive records with the same word and wrote it into a combined file. They also show how to sort by count and compute the total count.
Combining Consecutive Records
- The speaker uses AWK to combine consecutive records with the same word.
- The resulting combined file has about 900,000 distinct words.
- The speaker shows how to sort by count and display the top 10 most frequently occurring words in the data set.
Computing Total Count and Probability
- The speaker computes the total number of occurrences in the data set using a calculator.
- They then divide each word’s occurrence count by the total count to get its probability of occurring.
- Finally, they print out the top 10 words ranked by probability.
Creating a Wordle Dictionary File
Section Overview: In this section, the speaker explains how they created a dictionary file containing all possible legal guesses in Wordle, including answers.
Importing Wordle Dictionary as JSON File
- The speaker imported a JSON file containing all possible legal guesses in Wordle, including answers.
Joining Dictionary with Frequency Count File
- They used
jqto pull out every entry from the concatenated two lists and sorted them out. - Then they joined this dictionary file with a frequency count file using
join. - This resulted in a list of legal Wordle guesses with their occurrence count.
Handling Words Without Counts
- The speaker explains how to handle words without counts by looking for anything that ends with a letter.
- They add these words to the dictionary file with a count of one since they didn’t appear in the engram’s data set.
Introduction to Wordle Solver
Section Overview: In this section, the speaker introduces the purpose of the project and explains why they need a list of possible words to run their bot against.
Naming the Dev Streams
- The speaker suggests naming the dev streams and has already come up with a name for one: “roget”.
- The name is inspired by Roget’s Thesaurus, which allows users to explore related words and find better words to accurately represent what they’re trying to say.
Writing Rust Code
- The speaker starts writing Rust code for the Wordle solver.
- They copy in “wordle_answers.txt” and rename “wordle_dictionary_with_counts” as “dictionary.txt”.
Creating Functions
- Two functions are needed: one that lets you play Wordle and another that tries to do your guesses.
- The function “play” takes an answer (a static string) and a guesser (generic).
- It plays six rounds where it invokes the guesser each round.
Guessing Functionality
- The guesser needs to return a word.
- It is allowed to take mute itself in order to guess.
- It will be told all of its past guesses.
- A guess consists of the combination of the word guessed and its correctness mask.
- Correctness can be green (correct), yellow (present but misplaced), or gray (missing).
# Basic Structure
Section Overview: In this section, the speaker discusses the basic structure of the program and how it will work.
Program Structure
- The program will have a history and a target answer.
- The next guest to make is going to be string given this history.
- The program will include games that are stored in answers.txt.
- The program will play against the guesser, but we don’t know who the guesser is yet.
- A convenience function for implementing at mu t where t implements guesser is created.
- Naive new algorithm is instantiated.
Implementing Algorithms
- Multiple implementations can be implemented in one binary and switched based on a flag or something so that it’s easy to benchmark multiple ones at once.
- A mod algorithms is created with naive as its first implementation.
Playing Wordle
- Initially, let mute history be vector for i in…
- There won’t be any limit on the number of times you can guess because we want to know whether the bot succeeded or failed.
English Overview of the Code
Section Overview: In this section, the speaker discusses how to compute the correctness based on a guess and how to push it into history. They also mention that if the guess is equal to the answer, they will return which iteration it succeeded at.
Computing Correctness
- The correctness is an array of length five.
- We need something that computes the correctness so we’re going to need a check which takes the answer and a guess and gives you back a correctness.
- We’re going to have it be called compute.
- Here we’re gonna assert that answer.len equals five and assert that guess.len equals five.
Pushing Guesses into History
- Initially, the history is empty and it’s gonna grow over time.
- We do something in order to compute the correctness based on that guess.
- Then we’re going to do history.push(guess), which is going to be the guess and its corresponding correctness.
Returning Iteration Number
- If the guess is equal to answer then we return i otherwise we compute the correctness and keep going.
- We want to say starting with one because if you guessed correctly on your first guess then we should return one and not zero because you did one guess.
English Limiting Guesses
Section Overview: In this section, they discuss limiting guesses for Wordle game.
Setting Maximum Number of Guesses
- Wordle only allows six guesses but they allow more guesses than that in order not to chop off score distribution for stats purposes.
- They set 32 as maximum number of guesses allowed.
Handling Infinite Loop
- They could bound this loop if they really wanted to but realistically wordle only allows six guesses so there shouldn’t be any infinite loops.
- However, they could guard against something like a user implementing a guesser that just never succeeds.
Error Message
- They added an error message to handle the case where the program did not finish within the maximum number of guesses allowed.
Implementing a Guess Checker
Section Overview: In this section, the speaker discusses how to implement a guess checker that always gives the correct answer. They explore different ways of implementing this and discuss potential bugs in the code.
Implementing the Guess Checker
- The guesser should always be able to give a guess right.
- If you know statically that it might not be able to find the answer, that seems like its own kind of problem.
- There are a couple of ways we could implement this.
- We could do something like for i in zero to five if answer i is equal to guess i then c i is correctness.
Optimizing Code
- This is where the annoying thing about using utf-8 comes in; you can’t easily index into this.
- An optimization plan for later is to make this be a five length byte array but not yet.
- The code needs to be as naive as possible in the initial iteration.
Marking Correctness
- For each character in both answers and guesses, mark them green if they are correct.
- Otherwise, check whether there are any other occurrences of this letter in the guess so that we can mark it yellow or red accordingly.
- We’re going to have an inner iteration here because we want to check whether this character occurs anywhere else and we haven’t already marked it as misplaced.
# Marking Correctness and Misplaced Characters
Section Overview: In this section, the speaker discusses how to mark correctness and misplaced characters in a guessing game. They walk through the logic of marking each character as green or yellow based on whether it has been used to mark something as correct or misplaced.
Marking Correctness and Misplaced Characters
- The function
computeis used to mark correctness and misplaced characters. - Use
if c is correctnessinstead ofmarkedto check if an answer is correct. - For each letter in the answer, mark whether that character has been used to mark something green or yellow.
- Walk through all of the characters of the guess. If they’re already correct, there’s nothing to do. Otherwise, if there are any characters in the answer that are equal to the guest character and haven’t already been used to mark something as yellow then we mark it as used and then we say yup this is a yellow character otherwise it is not and you need to keep looking.
- Return
c.
# Writing Tests for Marking Correctness and Misplaced Characters
Section Overview: In this section, the speaker writes tests for marking correctness and misplaced characters using
the compute function.
Writing Tests for Marking Correctness and Misplaced Characters
- Write tests for basic functionality using
assertEqual. - Create a sub-module for compute tests.
- Test with different inputs such as all green, all gray, all yellow, repeat green.
# Implementing Naive Functionality
Section Overview: In this section, the speaker implements naive functionality using pub.
Implementing Naive Functionality
- Implement default functionality using pub.
- Arguably just be implemented default really.
# Creating a Macro for Writing Correctness Things
Section Overview: In this section, the speaker creates a macro to make writing correctness things easier.
Creating a Macro for Writing Correctness Things
- Create a macro to make writing correctness things easier.
- Use the syntax
m is going to be turned into correctness misplaced. - This will turn into something funky but it works.
Wordle Algorithm
Section Overview: In this section, the speaker discusses the development of the Wordle algorithm and how it marks correctness appropriately.
Developing the Play Algorithm
- The speaker explains that each character in Wordle is repeated by calling a macro and separating by a comma.
- They make some corrections to their code to ensure that things look nice.
- The speaker tests different use cases from chat to ensure that their algorithm is correct.
Checking for Valid Guesses
- The speaker realizes they need to check whether a guess is valid and considers using a perfect hash phf set.
- They explore different options for creating a dictionary, including using a const function or constructor.
Overall, this section covers the development of the Wordle algorithm and checking for valid guesses. The speaker tests different use cases from chat to ensure that their algorithm is correct and explores different options for creating a dictionary.
Creating a Dictionary
Section Overview: In this section, the speaker discusses creating a dictionary for the Wordle game.
Creating a Dictionary
- The dictionary will be measured by the benchmark.
- The speaker is sad about it but it’s fine for now.
- A constant variable called “dictionary” is created as a sorted vector.
- The hash set from collections is used to create the frequency count of words in the dictionary.
Implementing Play Function
Section Overview: In this section, the speaker discusses implementing the play function for Wordle.
Implementing Play Function
- The speaker considers using a build script to emit what phf requires.
- Using dot step by two because every other value is the frequency count from eater.
- Lines are used to split every element and then advanced by two.
- Alec suggests using lines instead of line.split once by space.
- Expect that every line is word plus space plus frequency count and dot one.
- Assert that self.dictionary contains guess.
- Debug assert could be used but not necessary since there isn’t a human player who doesn’t know what the dictionary is.
Guess to String
Section Overview: In this section, the speaker discusses writing test implementations and closures. They also encounter an error while trying to implement a closure.
Implementing Closures
- The speaker wants to write test implementations that don’t need state and will use closures.
- They create a closure called “moved” that returns “moved to string”.
- They want to assert equal that they should get a score of one using crate wordle.
- The closure doesn’t implement fn, so the speaker renames it as “guess”.
- The guess function won’t play ball, so the speaker creates a helper called “guess sir” which takes history as an ident and then takes a block.
- The guesser is always going to be like this but with the ability for the guesser to contain state that it might mutate over time.
Troubleshooting Errors
- There’s some lifetime not matching up in the implementation of guesser for g.
- The trait needs to be in scope.
- The trade guesser is not implemented for that, even though there is an implementation found.
Fixing Code and Testing Guessing Game
Section Overview: In this section, the speaker fixes some code issues and tests a guessing game.
Fixing Code Issues
- The speaker mentions that something needs to be fixed in the code.
- They mention that they need to guess something.
- The speaker plans to make a config test to get rid of a warning.
- Main is complaining about something, so the speaker needs to do roget wordle new and then w dot play.
Testing Guessing Game
- The speaker mentions that every line is word plus space plus frequency is a lie it claims.
- They say “really”.
- The speaker realizes they missed one thing - dictionary.
- They don’t understand which word they are missing - add view.
- The search was entirely wrong, and the speaker doesn’t know why they wrote it like that.
- The speaker says “great”.
- They say “fantastic” because now they can play a game and see if they immediately guess the right word.
- The speaker suggests making this fancier by adding history.len == 1 for right guesses.
- If history.len == 1, return right; otherwise, return wrong.
- This should now take two guesses. -[]( t =5172 s )The words genius, impressive, magnificent, splendid, great are all used interchangeably in the game.
- The speaker says “oh”.
- They say “really” again.
- Something is right or wrong and not in the dictionary.
- The speaker confirms that they are all right.
- They say something is wrong.
- The speaker realizes that guess wrong is not in the dictionary.
- They need to update some two, some three, some four, some five, and some six.
- The speaker asks how “wrong” got there.
- They ask for a hash set because something isn’t right.
- It has all the numbers because this needs to be dot zero and they realize their mistake. -[]( t =5339 s )The speaker says “great,” and everything works fine now.
Checking Naive Implementation
Section Overview: In this section, the speaker checks a naive implementation.
Checking Naive Implementation
-[]( t =5374 s )The speaker mentions that they want to check if something only ever guesses wrong then it eventually terminates. -[]( t =5400 s )They mention that naive is still claimed not to be there even though it should be there.
[t=5463s] Parsing and Computing Word Count
Section Overview: In this section, the speaker discusses parsing and computing word count. They mention bringing in the
dictionary and lib, parsing that could happen just once, and computing word count using count.parse.
Parsing Words
- The speaker mentions that parsing is something that could happen just once.
- They suggest bringing in one cell or something to cache this.
- However, they decide to keep it as is for now since it’s named “naive” for a reason.
Computing Word Count
- The speaker explains that they will compute word count using
count.parse. - They expect every count to be a number and then return word and count.
[t=5541s] Computing Goodness of Guesses
Section Overview: In this section, the speaker talks about computing how good of a guess each candidate word is. They loop over every word and count in self.remaining.
Looping Over Candidate Words
- The speaker explains that for each remaining word (candidate), they will compute how good of a guess it is.
- They loop over every word and count in self.remaining.
Comparing Goodness of Guesses
- The speaker asks if the current candidate is better than the best one.
- To determine which candidate is better, they need a score or goodness.
- This score will be a floating-point number for now.
[t=5671s] Updating Remaining Based on History
Section Overview: In this section, the speaker discusses updating self.remaining based on history. If we previously made a guess, we just learned which ones we got correct. We need to update remaining based on that new information.
Retaining Matching Information
- The speaker explains that we have some mask in last and want to only retain things in remaining that match the updated information we got.
- We will do this using
self.remaining.retain().
[t=5873s] Retaining Words Based on Guesses
Section Overview: In this section, the speaker discusses how to retain a word based on guesses and previous information. They explain that the count is irrelevant for retaining words and that they only want to retain a word if it matches the last guess or mask.
Matching Words with Guesses
- The speaker explains that they need to figure out whether a given piece of information matches a word.
- They discuss how to match a word with previous guesses by using zip and asserting that the length of the word is five.
- The speaker mentions creating a “matches” method to determine whether a given guess matches with a word.
Logic for Matching Words
- The speaker discusses how to check if a letter in the previous guess was green and doesn’t match with the current letter in the word.
- They mention that if g is not equal to w, then we can return false because we know that this cannot be the right answer.
- If it’s wrong and g is equal, then we also know that it can’t match because you guessed the letter that the previous guest told you was wrong.
- If it’s misplaced, then we don’t know what to do yet.
[t=6020s] Checking Misplaced Letters
Section Overview: In this section, the speaker discusses checking misplaced letters when matching words with guesses.
Checking Greens
- The speaker explains how they first check greens when matching words with guesses.
Sorting Used Letters
- The logic for computing correctness is similar to computing misplaced letters but reusing it may not be possible.
- The speaker mentions needing some sort of used thing here too.
# Looping through characters
Section Overview: In this section, the speaker discusses how to loop through the characters of a word and search for an unused letter that is yellow.
Looping through characters
- The speaker suggests that they can do this in one loop by walking all of the characters of just the word.
- The second loop might be all they need.
- They discuss if g is equal to if the previous guess is equal to the word.
- They suggest searching for an unused letter that is yellow.
# Searching for Unused Letters
Section Overview: In this section, the speaker discusses how to search for unused letters and find any other characters.
Searching for Unused Letters
- The speaker suggests searching for unused letters.
- They suggest using map to find any unused indices.
- If there are any other characters, they look for the first unused one.
Finding Occurrences of Characters
- If the previous guess was correct in that location then if the characters are different then we know that there’s nothing to do otherwise used of i is true and we continue.
- They look for the first occurrence of that character if any in the previous guess that is unused so if unused of…
Matching Algorithm
Section Overview: In this section, the speaker discusses the matching algorithm used to determine if a guess is correct or not.
Matching on Previous Guess
- The color of the previous guess will tell us whether this guess might be okay.
- We’re going to match on what that previous guess was.
- If the previous guess was correct, then it should already be marked as used or we should have returned so this should be unreachable.
Handling Misplaced Characters
- If a character is misplaced, then used of j is true and we can return some of j. This might be the same case as we did earlier so maybe this is just if any.
- You guessed an x in some position and in the previous guess you were told that there is no x well then your whole guess must be wrong so this is sort of a return false kind of situation which really is a return falls from the whole thing.
Plausible Matches
- If we found one letter we can use, then word might still match otherwise plausible is false. I suppose plausible is initially true. If we get here then plausible is false.
- If in the previous guess we got a yellow here that means that this cannot be the answer so w was yellow in the same position it was yellow in the same position last time around which means that word cannot be the answer that match cannot be the answer so plausible is false and we return false.
Testing the Guess Matcher
Section Overview: In this section, the speaker discusses testing the guess matcher and constructing a guess.
Constructing a Guess
- To construct a guess, we need to use a word and mask.
- The mask can be created using the masker made earlier.
- A simple check is performed to ensure that the constructed guess works.
Writing Macros for Testing
- Macros are used to write tests more efficiently.
- A macro called “guess” is created to take in a word and mask.
- Another macro called “check” is created to test if certain patterns preclude guesses from being considered correct.
Incremental Solver
- The solver only needs to solve incrementally for one step at a time based on previous guesses.
- If yellow is received four times for the same character, then its location can be determined.
Pruning Logic
Section Overview: The speakers discuss whether or not pruning is necessary and if doing it incrementally is sufficient.
Incremental Pruning
- One speaker suggests that incremental pruning may be insufficient.
- They agree that checking the whole history may be necessary, but it will be a bit sad.
Eliminating Words
- A chat message suggests that scanning incrementally cannot determine if a letter appears in a certain position.
- Another speaker explains that eliminating words with each guess makes incremental scanning sufficient.
Guessing Different Letters
Section Overview: The speakers discuss how the algorithm should handle guesses with completely different letters.
- If all letters are incorrect, the algorithm should allow a guess with only different letters.
- Shifting all letters by one should also be allowed.
Disallowing Incorrect Patterns
Section Overview: The speakers discuss how the algorithm should disallow incorrect patterns.
- If a pattern indicates a letter is yellow, but it is guessed again and found to be incorrect, then it must be disallowed.
- There seems to be a bug in the algorithm where some correct patterns are being disallowed.
Debugging the Code
Section Overview: In this section, the speaker is debugging the code and trying to figure out why certain inputs are not working as expected.
Debugging the Disallowed Inputs
-
The input “rita bond a b c d e plus w w disallows b c d e a” is being disallowed.
-
The speaker questions why this input should be disallowed since all letters are present but in different arrangements.
-
Upon further inspection, it is discovered that all of the letters are grayed out, indicating that they are incorrect.
Identifying the Issue with Early Returns
-
The speaker examines early returns in the code to determine which one is being taken.
-
It is determined that an incorrect return statement is being taken twice.
-
Further investigation reveals that previously correct letters were being re-evaluated, causing errors in matching letters.
Optimizing Code
-
A suggestion is made to optimize the code by comparing candidate words to answers element by element for correctness.
-
The speaker considers this proposal but ultimately decides against it due to excessive complexity.
Refactoring Code for Optimization
Section Overview: In this section, the speaker discusses refactoring the code for optimization purposes.
Simplifying Code with Zip Function
Refactoring for Efficiency
Finalizing Code
Section Overview: In this section, the speaker finalizes the code and prepares to submit it.
Testing Final Code
Submitting Code
Introduction
Section Overview: In this video, the speaker discusses how to create a program that can guess a word in a game of Hangman. They explain the algorithm and the math behind it.
Naive Algorithm
- The naive algorithm is to guess each letter in alphabetical order until you find the correct answer.
- This algorithm is not efficient and can take a long time to find the answer.
Improved Algorithm
- The improved algorithm involves using information theory to make more informed guesses.
- The program starts by guessing the most common letters in English words, such as “e” or “a”.
- It then uses the feedback from incorrect guesses to eliminate possibilities and make better guesses.
- This algorithm is much more efficient than the naive approach.
Computing Correctness
Section Overview: In this section, the speaker explains how to compute correctness for each guess.
Pruning Possibilities
- To compute correctness, we need to prune down the list of possible words based on previous guesses and their corresponding feedback.
- We can use set intersection to find words that match all previous guesses and set difference to remove words that do not match any previous guesses.
Exploiting Equivalence
- The speaker discusses an insight where we can assume that if our current guess were actually the answer, then our previous guess should have given us the same pattern of correctnesses.
- By exploiting this equivalence, we can further prune down our list of possible words.
Computing Goodness
- To compute goodness for each guess, we need to balance how likely it is to be correct with how much information we gain if it’s incorrect.
- We use information theory and a formula involving probabilities and logarithms to compute goodness for each guess.
Probability of Words
Section Overview: In this section, the speaker explains how to compute the probability of each word being the correct answer.
Total Count
- To compute the probability of a word, we need to know the total count of remaining possibilities.
- This involves considering all possible patterns and their corresponding counts.
Probability Calculation
- The probability of a word being correct is based on its relative likelihood compared to other possible words.
- We also need to consider the possible patterns that match previous guesses and their feedback.
Conclusion
Section Overview: In this section, the speaker concludes by summarizing the algorithm and its efficiency.
Summary
- The improved algorithm for Hangman involves using information theory to make more informed guesses.
- It prunes down possibilities based on previous guesses and computes goodness for each guess using probabilities and logarithms.
- The program also considers the total count of remaining possibilities and their corresponding probabilities.
Efficiency
- The improved algorithm is much more efficient than the naive approach, as it can quickly eliminate unlikely possibilities and make better guesses.
Computing the Goodness of Words
Section Overview: In this section, the speaker discusses how to compute the goodness of words using a formula that involves probabilities and patterns.
Formula for Computing Goodness
- The formula for computing the goodness of a word is based on probabilities and patterns.
- To avoid losing precision, the computation should be done as floating point.
- The sum in the formula is over all possible patterns.
Intuition Behind the Formula
- The goodness of a word is defined as the sum of the goodness for each possible pattern that might result from guessing it.
- The probability of a word is equal to the sum of probabilities for all possible patterns that we might see.
Helper Function for Permutations
- A helper function can be used to generate permutations for all possible patterns.
- It’s not necessary to exclude impossible patterns since they would have zero probability anyway.
Permutations
Section Overview: In this section, the speaker discusses permutations and power sets. They mention wanting a power set of a certain length and use the i product macro to achieve this.
Using Cartesian Product for Power Sets
- The speaker mentions wanting a power set of a certain length.
- They use the i product macro to achieve this.
- The i product macro is actually the cartesian product.
- They use
cargo.tomlto getitertools. - They then use
itertools.product().
Computing Patterns
Section Overview: In this section, the speaker discusses computing patterns. They loop over all possible patterns and compute what is left after each guess.
Looping Over Possible Patterns
- The speaker loops over all possible patterns.
- They call these “correctness patterns”.
- They filter on pattern using
filter(). - They filter on guess of word using
matches().
Computing What Is Left After Each Guess
- For every pattern, they find all of the remaining words that would exist if they guessed that word and that pattern matched.
- Inside each item of this loop, they consider a world where they did guess word and got pattern as the match as the correctness.
- Then they compute what is left.
Understanding the Code
Section Overview: In this section, the speaker is discussing a code and explaining how it works.
Probability of Getting a Pattern
- The probability of getting a pattern is calculated by dividing the total count of words in that pattern by the total count of words outside that pattern.
- The remaining count is divided by the remaining candidates.
Computing Entropy
- To compute entropy, we sum together all probabilities for each candidate word.
- We use this to compute information amount in guessing a word.
Improving Code Efficiency
- The current computation is very slow and single-threaded.
- Debugging shows that all values are NaN, which means there’s an issue with the code.
- Starting with goodness can help improve efficiency. [CUTOFF_LIMIT]
Generated by Video Highlight
https://videohighlight.com/video/summary/doFowk4xj7Q
Solving distributed systems challenges in Rust
- Solving distributed systems challenges in Rust
- Introduction
- What is Maelstrom?
- Implementing the Protocol
- Setting up the Project
- Defining Message Struct
- Enum and Payload
⭐ State Machine Driver- Echo Node Step Function
- Introduction
- Debugging
- Responding to Init Message
- Printing New Line
- Introduction
- Payload Definition
- Splitting Up Shareable Parts
- Unique IDs
- Extracting Initialization Message
- Generating Init Reply
⭐️ Restructuring the Code- Changes to Unique ID Generator
- Debugging Echo Functionality
- Updating Stream Deserializer
- Unique IDs and Broadcast Challenge
- Conclusion
⭐️ Order of Returned Values and Topology- Setting Up Messages
⭐️ Gossip Protocols Introduction- Multi-node Broadcast
- Differences Between Broadcast and Gossip
- Understanding Gossip Protocol
⭐️ The Two Generals Problem⭐️ Introduction to Asynchronous Programming⭐️ Using Channels for Input Messages- Introduction
- Main Loop
- Event Payload
- Echo Fix
- End of File and Injected Payloads
- Understanding Gossip Protocol
- Gossip Protocol Implementation
- Performance Analysis
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces a set of distributed systems challenges that use a platform called Maelstrom. The challenges are designed to build an increasingly sophisticated distributed system and run it through Maelstrom to test its correctness.
⭐️Distributed Systems Challenges
- The challenges use a platform called Maelstrom, which is a
distributed systems testing framework. - The challenges involve building an increasingly sophisticated distributed system and running it through Maelstrom to test its correctness.
- The exercises are written in Go, but demo implementations of the node code are available in Ruby, JavaScript, Java, and Python.
- The speaker will be implementing the challenges in Rust since there isn’t a demo implementation available for Rust.
What is Maelstrom?
Section Overview: In this section, the speaker provides more information about Maelstrom and how it works.
⭐About Maelstrom
- Maelstrom is a distributed systems testing framework or exercise framework.
- It can orchestrate message passing between nodes in a distributed system and emulate things like delayed messages or reordered messages or drop messages nodes coming and going that kind of stuff.
- It’s written by or alongside the author of Jepson, which is doing correctness research for distributed systems.
- Jepson has found bugs in real systems like Redis, Raft, Postgres, etcd by studying real systems.
Implementing the Protocol
Section Overview: In this section, the speaker discusses how they will implement the protocol required by Maelstrom.
⭐Protocol Implementation
- Each node is just a binary that receives JSON messages from standard input and sends JSON messages to standard output.
- Messages have three parts: source (identifying string of sender), destination (identifying string of receiver), body ( message content).
- Message bodies have reserved keys, and additional keys can be set depending on the message type.
- The speaker will need to implement this protocol in Rust to get everything set up.
Setting up the Project
Section Overview: In this section, the speaker sets up the project and decides on a name for it.
Naming the Project
- The speaker decides to call the project “rusten gun” after a battle spell from Naruto.
- Timestamp:
Defining Message Struct
Section Overview: In this section, the speaker defines a struct for messages that will be passed throughout the program.
⭐Struct Definition
- The message struct has fields for source, destination (renamed to “dust”), type (renamed to “ty”), message ID, in reply to, and body.
- Body is either a string or a hashmap of string keys and serde_json values.
- The speaker considers making body an enum tagged by type but ultimately decides against it.
- Timestamp:
Enum and Payload
Section Overview: In this section, the speaker discusses how to use enums and payloads in Rust.
⭐Using Enums for Message Types
- The speaker explains that they will use enums to define message types.
- They rename all enums to snake case.
- They construct a deserializer using
serde_jsonfrom standard input.
Flattening Payload
- The speaker mentions that they want to flatten the payload.
- They are unsure if flattening works in this regard.
⭐State Machine Driver
Section Overview: In this section, the speaker discusses constructing a state machine driver in Rust.
Deserializing Inputs
- The speaker constructs a stream deserializer using
serde_jsonfrom standard input. - They use
into_iter()to turn it into an iterator of messages.
State Machine Model
- The speaker models the state machine with a struct called Echo Node.
Echo Node Step Function
Section Overview: In this section, the speaker discusses the step function for an echo node in a distributed system. They talk about the input message and how it returns a mutable reference to the state of the node.
⭐Echo Node Step Function
- The step function gets a mutable reference to the state of the node in the distributed system and the input message.
- A stream serializer is used to send messages as well as trigger messages to other nodes.
- The step function needs a way to wait for a message before replying to the current message.
- The reply is going to be a message with source, destination, body, and ID of response generated by self.id.
- If we receive an echo, we do nothing. If we get an echo, that’s when we want to send the second reply.
- We construct an output channel using Certi Jason serializer new standard out.
- State starts at zero and then we’re going to do state step give it input.
Introduction
Section Overview: In this section, the speaker introduces the topic and mentions that they will be running a command.
Running a Command
- The speaker mentions that they will run “cargo r” command.
Debugging
Section Overview: In this section, the speaker runs a binary and encounters an error.
Running Binary
- The speaker runs a binary using “debug or sting gun”.
- The program crashes with an error message “unknown variant variant in it right”.
⭐Responding to Messages
- The speaker explains that in response to an init message, each node must respond with a message of type init.
- They mention that there are two types of messages: init and echo.
Responding to Init Message
Section Overview: In this section, the speaker talks about how nodes should respond to an init message.
Node ID and Node IDs Fields
- The node ID field indicates the ID of the node which is receiving this message.
- The node IDs fields list all nodes in the cluster including the recipient.
Init Message Type
- In response to an init message, we have to respond with a message type of init.
- Node ID is going to be a string and also node IDs which is a vek of string.
Responding with Required Message
- For init, we don’t actually care about any of the fields but what we’re going to do is respond with the required message which is here in it okay.
- If we receive an edit okay message that should never happen we might receive an echo okay.
Flushing Standard Out
- The speaker explains that the problem is that standard out is buffered so when we write out here we’re not flushing standard out as well which means that the message isn’t actually getting out to the server.
- It might be enough to just print a new line because this is a line buffered writer.
Printing New Line
Section Overview: In this section, the speaker talks about printing a new line.
Pretty Formatter
- The speaker suggests using pretty formatter to print a new line.
- The protocol itself also requires that you print a new line because it’s newline separate adjacent objects.
Inner Part of Output Stream
- In order to print a new line, we need to get at the inner part of this output stream which serializer doesn’t let us do.
- We can unwrap it and then put it back together but that feels unfortunate to have to do that but it might just be what we have to do here.
# Implementing JSON Serialization
Section Overview: In this section, the speaker discusses how to implement JSON serialization in Rust.
Implementing JSON Serialization
- The speaker explains that the code requires encoding a line as JSON and mentions that it needs to be one per line.
- The speaker suggests not constructing the serializer here and instead using standard out. They mention
using
reply.serializeandserde_json::to_writer. - The speaker uses
output.write_allto write all of the output. - The speaker checks if everything is happy with the changes made so far.
- The speaker makes sure that they are using standard out.
- The speaker tries to figure out why it’s not being helpful and considers doing a reborrow.
- The speaker explains what they want to do with mutable references and re-borrowing them.
- The speaker does a reborrow where they dereference and create a mutable reference which they can use again later.
# Returning Messages from Step Function
Section Overview: In this section, the speaker discusses why step functions don’t return messages.
Returning Messages from Step Function
- A question is asked about whether or not step functions can return messages, but the answer is no because there may be multiple messages sent or received at once.
- The speaker confirms that returning messages is possible for convenience, but it’s separate from the mechanism of sending messages.
# Implementing a Globally Unique ID Generation System
Section Overview: In this section, the speaker discusses implementing a globally unique ID generation system that runs on Maelstrom’s unique IDs workload.
⭐️Implementing a Globally Unique ID Generation System
- The speaker explains that they need to implement a globally unique ID generation system that runs on Maelstrom’s unique IDs workload.
- The speaker decides to tidy up the code before generalizing and moves all the stuff over to
live.rs. - The payload is defined in
live.rs.
Introduction
Section Overview: The speaker introduces the topic and mentions that they want to test something.
Testing
- The speaker wants to see if their idea works.
Payload Definition
Section Overview: The speaker discusses payload definition and how it is based on the node service being implemented.
⭐️Generic Payload
- The payload needs to be fully defined by the collar, but it’s okay because it can be generic.
- If the payload is all of the message types used by a given service, then at deserialization time, only those messages should be exchanged in that particular messaging network.
- A struct is initialized with fields that are public.
Node Service Implementation
- A pub trait called “node” could be created to define the step function payload.
- A main loop is created for Echo to reuse.
Splitting Up Shareable Parts
Section Overview: The speaker splits up shareable parts so that they can copy Echo to unique IDs.
Copying Echo
- Now that shareable parts have been split up, Echo can be copied to unique IDs.
# Generating Unique IDs
Section Overview: In this section, the speaker discusses how to generate unique IDs for messages in the network.
Generating Unique IDs
- There are different ways to generate unique IDs, such as running a consensus algorithm or generating a unique string.
- The easy way is to generate a unique string that is long enough and has a low risk of collisions.
- The speaker suggests using GUID instead of ID for clarity in the code.
- The ULID crate provides a standard way to generate globally unique identifiers that are lexicographically sortable.
- A ULID consists of a header, timestamp in milliseconds, and randomness at the end.
- It’s not guaranteed to be globally unique but close enough.
# Responding with Generate Okay Message
Section Overview: In this section, the speaker talks about responding with a Generate Okay message after receiving a Generate message.
Responding with Generate Okay Message
- When receiving a Generate message, we need to respond with a Generate Okay message that includes an ID (GUID).
- This ID is locally unique and doesn’t have to be globally unique.
- We can use ULID crate to generate GUIDs.
# Node Receiving Generate Messages
Section Overview: In this section, the speaker discusses what happens when nodes receive Generate messages.
Node Receiving Generate Messages
- Nodes may not receive any Generate messages if they’re not sending any.
- If nodes do receive them, it’s not considered problematic.
Unique IDs
Section Overview: In this section, the speaker discusses generating unique IDs for messages and nodes.
Generating Unique IDs
- The speaker introduces the concept of generating unique IDs.
- The speaker shows how to view all the unique IDs being generated and notes that they appear to be truly unique.
- The speaker proposes a method for guaranteeing that message IDs are unique per node and that the combination of a node’s ID and message ID is globally unique.
⭐️Implementing Unique IDs
- The speaker notes that the combination of a node’s ID and message ID can be used as a generated ID when responding to messages.
- The speaker demonstrates how to format the generated ID using self.node, self.id, and self.node (which has not yet been stored).
- The speaker returns itself from init in order to construct state.
- The speaker encounters an issue with constructing parts of state in advance due to limitations with from_init.
- The speaker considers making payload a combination enum or creating a separate trait for payload.
- The speaker suggests extracting init on payload instead.
- The speaker notes that it would be difficult to use step function because it is called on a node before it is constructed.
⭐️Extracting Init
- The speaker suggests extracting init on payload instead.
- However, since payload is generic, we don’t know how to get at the init variant.
- A separate trait for payload is suggested, which would define extract_init.
- The speaker suggests using option and panicking in code when we know that it should be present.
Extracting Initialization Message
Section Overview: In this section, the speaker discusses extracting the initialization message and using it to create a node.
⭐️Extracting Initialization Message
- The initialization message is extracted from the payload.
- The speaker mentions that “no next exists.”
- There may be an issue with deserialization of the message.
- There is a pause in speaking.
- Node initialization may fail.
Creating Init Response
- The init response can be generated without passing on the message.
- The init response is created.
Generating Payload
- Information needed for generating a payload is discussed.
- A payload should be generated with self as its output.
- A reply message can now be constructed.
Incrementing ID
- ID incrementation is discussed and deemed annoying.
Generating Init Reply
Section Overview: In this section, the speaker discusses generating an init reply and how it relates to node implementation.
Generating Init Reply
- An init reply is generated on behalf of the underlying node.
- Zero is reserved for ended okay response.
- PS payload and serialize are required here.
#s Implementing Payload Trait for Echo
Section Overview: In this section, the speaker discusses implementing payload trait for Echo.
⭐️Implementing Payload Trait for Echo
-s This will likely cause an error. - Rusting gun payload is mentioned. - The speaker uses let else let payload in it. - Resting on in it is discussed.
⭐️Restructuring the Code
Section Overview: In this section, the speaker discusses restructuring the code to handle messages more efficiently.
Handling Init Messages
- The speaker suggests handling init messages differently by first deserializing a single thing from standard in using their own concrete enum type instead of P.
- The speaker suggests initializing the message as an init payload and constructing a message where the payload is init payload.
Removing Payload Trait
- The speaker suggests removing the payload trait and constructing a message where the payload is init payload.
Updating Echo Node
- The speaker updates Echo node to remove implementation of trait and no longer receive an init message or an in it.
- Main Loop now becomes just Echo node with no initial state.
Unique IDs
- The speaker updates Unique IDs to remove initial state that cares about context from surrounding environment.
Changes to Unique ID Generator
Section Overview: In this section, the speaker discusses changes made to the unique ID generator.
Unique ID Generator Changes
- The init payload and internet okay variant main loop are no longer present.
- The unique node is now followed by nothing and has no initial state.
- The node ID is always set as part of init, so there is no need for unwrapping.
- The source destination node IDs in the response are inverted.
Debugging Echo Functionality
Section Overview: In this section, the speaker debugs issues with the Echo functionality.
Debugging Echo Functionality
- An error occurs when attempting to build.
- The error message indicates that a node did not respond to an init message.
- The speaker questions why the node did not respond.
- Cargo ARB is used to send an init message for debugging purposes.
Updating Stream Deserializer
Section Overview: In this section, the speaker updates the stream deserializer.
Updating Stream Deserializer
- Standard in waits for end of file instead of new lines, causing issues with deserialization.
- A stream deserializer is used instead of standard in dot lines.
- Since the format is new line separated, it would be better to deserialize each line at a time using standard in dot lines.
- Splitting by lines and straight deserializing the entire string of a line is used instead of stream deserializer.
Unique IDs and Broadcast Challenge
Section Overview: In this section, the team works on implementing a broadcast system that gossips messages between all nodes in the cluster. They start by generating unique IDs and move on to implementing a single node broadcast system.
Generating Unique IDs
- The team generates unique IDs for each node in the cluster.
- The generated string is globally unique, assuming that node IDs are not reused when nodes restart.
Single Node Broadcast System
- The team moves on to implement a single node broadcast system.
- The workload has three RPS message types: broadcast, read, and topology.
- A broadcast message sends an integer value to all nodes in the cluster.
- Nodes store the set of integer values they receive from broadcast messages so they can be returned later via the read message RPC.
- A read message requests that a node returns all values it has seen.
Conclusion
Section Overview: In this section, there is no new content.
⭐️Order of Returned Values and Topology
Section Overview: In this section, the speaker discusses the order of returned values and topology.
The Order of Returned Values
- The order of the returned values does not matter.
- It could be a set since we’re guaranteed that the messages are unique.
Topology
- This message informs the node of who its neighboring nodes are.
- Maelstrom has multiple topologies available, and you can ignore this message and make your own topology from the list of nodes in the node IDs Method.
- All nodes can communicate with each other regardless of the topology passed in.
- The topology is a hash map from node to a vector of nodes.
- In response, you should return a topology.
Setting Up Messages
Section Overview: In this section, the speaker discusses setting up messages.
Initial Setup
- We need the node ID, message ID, and messages which is a VEC view size. Initially, messages are empty.
Broadcast Message
- When we get a broadcast with a message, we’re going to send a broadcast.
- We want to make it easier to construct something like this by having an Associated method on message which is like prepare reply that sets ID to one that’s passed in if you have one and it sets in reply as necessary.
- There is now a reply which consumes the message. It returns itself and what it does is exactly what prepare reply does.
⭐️Gossip Protocols Introduction
Section Overview: In this section, the speaker introduces the topic of gossip protocols and explains that they will be
implementing a broadcast system that propagates values to all nodes in the cluster.
Implementing Broadcast
- The speaker explains that they need to implement broadcast for read and topology.
- They mention that topology takes a topology and ignores anything that is broadcast.
- The speaker adds a message into reply helper.
Multi-node Broadcast
Section Overview: In this section, the speaker discusses multi-node broadcast and how values should propagate to all nodes within a few seconds.
⭐️Gossip Protocols
- The speaker explains that they will use gossip protocols to propagate values around the network.
- They give an example of three nodes where an operation comes in saying “broadcast 34”.
- The goal is for every node in the system to know about every broadcast message.
Differences Between Broadcast and Gossip
Section Overview: This section explains the difference between broadcast and gossip protocols, how gossip works, and how it scales better than broadcast.
⭐️Broadcast vs. Gossip
- Broadcast sends a message to every node in the system, which doesn’t scale well.
- Gossip sends a message to nodes in its topology or neighborhood, defined by direct network links or other criteria.
- Topologies do not have to be symmetrical; nodes can have different neighborhoods.
- Values should propagate to all other nodes within a few seconds.
⭐️How Gossip Works
How Goosip Works Sequence Diagram
sequenceDiagram
participant Node1
participant Node2
participant Node3
participant Node4
Node1->>+Node2: Send message through gossip
Node2->>+Node3: Forward message to its topology
Node2-->>-Node1: Exclude sender from topology
Node3->>+Node4: Forward message to its topology
Node3-->>-Node2: Exclude sender from topology
Node4-->>-Node3: All nodes eventually receive the message
Note over Node2,Node3: Scheduled gossip can be used for scalability
- When a node receives a message through gossip, it sends it to everyone in its topology except for the sender.
- The receiving nodes then send the message to their topologies until every node has received it.
- As long as there is at least one link from one node to another through transitive closures, any set of topologies will eventually propagate messages to every node.
- Scheduled gossip can be used instead of immediate gossip for scalability.
⭐️Compare Blockchain and Gossip
Comparison
graph TD;
A[Blockchain]-->B[Immutable distributed ledger];
B-->C[Update all nodes];
C-->D[Ensure data consistency and reliability];
E[Gossip]-->F[Random communication between nodes];
F-->G[Message propagation];
G-->H[Problem: message loss and duplication];
I[Blockchain]-->J[Strong security, anti-tampering, and decentralization features];
K[Gossip]-->L[Focuses more on efficiency and flexibility];
Blockchain Gossip are both notification methods in distributed systems, but they have some key differences.
Firstly, blockchain is based on an immutable distributed ledger that contains all transaction records. When a transaction is added to the blockchain, all nodes update their ledgers so that each node can get the same information. This ensures data consistency and reliability because each node can verify the correctness of the data.
In contrast, Gossip is based on random communication between nodes and relies on message propagation between nodes to achieve notification in distributed systems. When a node receives a message, it randomly sends the message to several other nodes, which in turn randomly send the message to other nodes until all nodes receive the message. Due to the randomness of this method, problems such as message loss and duplication may occur, making Gossip unable to ensure the integrity and reliability of data like blockchain does.
In addition, blockchain has strong security, anti-tampering, and decentralization features, while Gossip focuses more on efficiency and flexibility. Therefore, when choosing a notification method, one needs to choose the appropriate method according to their specific situation and requirements.
Understanding Gossip Protocol
Section Overview: In this section, the speaker explains how gossip protocol works and how it differs from blind forwarding. The speaker also discusses the issue of syncing data between nodes in a minimal fashion.
How Gossip Protocol Works
- Gossip protocol exchanges information with neighbors about data that one has but the other does not.
- There is no blind forwarding in gossip protocol, which means there are no loops where messages keep getting sent back and forth between nodes.
- When a node receives a new message, it contacts its neighbors to compare notes and sync up their data sets.
⭐️Syncing Data Between Nodes
- Syncing data between nodes can be problematic because sending an entire data set on every message is not practical.
- To minimize the amount of data being sent during syncing, nodes can eliminate messages that they already have or know about.
- Nodes need to remember which messages they have synced with other nodes in the past to avoid sending unnecessary messages during future syncs.
⭐️The Two Generals Problem
Section Overview: This section discusses the challenge of consensus in distributed systems, specifically the Two Generals Problem.
Sending Messages and Acknowledgments
- A sends messages 24, 36, and 48 to B.
- B responds with messages 12 and 13.
- A never receives B’s response.
- There is no way for A to know if B received the message or not.
No Solution to Consensus
- The Two Generals Problem is a problem of consensus in distributed systems.
- There is no solution to this problem if arbitrary messages can be dropped.
- There is a mathematical proof that you cannot solve this with a finite number of messages.
Optimizing Gossip Protocol
- We want it to be the case that if messages aren’t dropped then we’re able to eliminate messages from the sync.
- It’s okay for us to send some extra values if some messages happen to be dropped as long as the recipient has a way to detect that it already knows something.
- All the messages in the system have unique IDs which makes it possible for us to keep a set and add new values when we hear things from a neighbor.
Implementing Known Values
- We need to keep track of known values using a hash map from node identifier (ID) to known values.
- We also need a hash set for all incoming messages so we can add new values when they arrive.
- We need an additional hashmap called “message communicated” which will be explained later.
2:09:28 Step Function Broadcast
Section Overview: In this section, the speaker discusses how to implement the broadcast step function in the gossip protocol.
Implementing Broadcast
- To implement broadcast, simply insert the message.
- Use a hash set for encoding messages as JSON sequences.
- If there are issues with encoding, fix them later.
2:10:07 Topology and Neighborhood
Section Overview: In this section, the speaker discusses how to determine which nodes to communicate with using topology and neighborhood.
Determining Nodes to Communicate With
- The topology tells us which nodes we should communicate with.
- We want a neighborhood of nodes that we should gossip with.
- The neighborhood is a vector view of sizes no Evac of strings.
- When we get a topology, remove ourselves from it using
self.neighborhood = topology.remove(ourselves).
2:11:22 Network Partitioning
Section Overview: In this section, the speaker discusses network partitioning and its implications for gossip protocols.
Network Partitioning Issues
- Randomly choosing nodes for communication can lead to network partitioning.
- This can result in clusters that cannot communicate with each other.
- One solution is to require every neighborhood size to be at least four including oneself so three additional nodes must overlap between neighborhoods.
- Another solution is to use a broader topology instead of random selection.
2:14:39 Gossip Protocol Implementation
Section Overview: In this section, the speaker discusses implementing the gossip protocol and some challenges associated with it.
Implementing Gossip Protocol
- There’s no message that tells us when to do a gossip in the gossip protocol.
- One way is to start up a separate thread that generates input events every 500 milliseconds.
- Another way is to make the main loop be a gossip protocol.
⭐️Introduction to Asynchronous Programming
Section Overview: In this section, the speaker discusses two approaches to writing asynchronous code and decides to avoid making the code asynchronous for now.
Two Approaches to Writing Asynchronous Code
- The first approach is to write all the code in an asynchronous style.
- The second approach is to use an actor system where every node is an actor that handles one event at a time synchronously.
Avoiding Asynchronous Programming for Now
- The speaker decides to avoid making the code asynchronous for now.
- To inject additional input messages, the outer loop needs a way to do so synchronously.
Synchronous Programming Techniques
- In synchronous programming, there are limited ways of selecting between events. One way is by using a read from standard in with a timeout.
- Another way is by introducing a channel and cloning the sender side of the channel. Each thread will block and perform operations on their respective clones.
⭐️Using Channels for Input Messages
Section Overview: In this section, the speaker demonstrates how channels can be used for injecting input messages into an outer loop.
Creating a Channel
- A channel is created using
txrx := std::sync::mpsc::channel(). - A thread is spawned for each clone of the sender side of the channel.
Receiving from Channel and Performing Step Function
- For each input message received from
RX, perform step function. - Inside each thread, parse out messages from standard in and send them as input messages
using
std::io::stdin().lock().lines()andtx.send(input)respectively. - If sending the message fails, return from the thread.
Dropping Standard In
- To avoid locking standard in inside a thread, it is dropped before creating the channel.
- All instances of standard in are replaced with
std::io::stdin().lock().lines(). - Since
selfis consumed, there is no need to worry about dropping P.
Introduction
Section Overview: In this section, the speaker introduces the topic of thread panics and error handling.
Thread Panics and Error Handling
- When joining a thread, the first layer of result is whether or not the thread panicked.
- The second layer of result is whether or not an error was returned.
Main Loop
Section Overview: In this section, the speaker discusses how to generate additional input events in the main loop.
Generating Additional Input Events
- To generate additional input events, we need to give away the TX handle to the node.
- We can construct this handle first and then initialize it with the node.
- We can spawn a thread that generates messages or events on a time schedule.
- This will surface in the main read loop when we call
node.step.
Event Payload
Section Overview: In this section, the speaker discusses how to differentiate between injected payloads and actual messages from the network.
Differentiating Between Injected Payloads and Actual Messages
- We want to differentiate between injected payloads and actual messages from the network.
- We can use an enum called “event” with three options: message payload, body, or direct payload.
- We need to serialize/deserialize these events.
Echo Fix
Section Overview: In this section, the speaker fixes Echo so that it differentiates between injected events and actual messages.
Fixing Echo
- Echo needs to differentiate between injected events and actual messages.
- We can use an event payload input to differentiate between the two.
- If there is an injected event when there should not be, we will panic.
- The transmit handle in broadcast will never exit because it is held by the broadcast node.
End of File and Injected Payloads
Section Overview: In this section, the speaker discusses how to handle end-of-file events and injected payloads in a node.
Handling End-of-File Events
- The end of file is reached.
- The result of reaching the end of file is not important.
- A way for the node to learn that it should exit is now available.
Handling Injected Payloads
- “Inject” refers to a message being sent to a node from outside its network.
- If the input is a message, do what was done previously.
- If the input is an injected payload or end-of-file event, do something different.
- It may be necessary to use different enums for injected events and messages in some cases.
Starting a New Thread
- A new thread will be started when constructing from init.
- This thread will generate gossip events using a loop that sleeps for 300 milliseconds before sending an injected gossip event.
- An atomic bool can be used to terminate this loop when the node receives an end-of-file event.
Serialized Payload
- Using variants for payloads means they must be serialized and deserialized even if it’s unnecessary.
- Injected payloads should be separate from other payloads so that they don’t need to be matched on unnecessarily.
Enum for Injected Payload
-[]( t = 9289 s ) An enum called “injected payload” will have a default value of the unit type. -[]( t = 9371 s ) Injected payloads need to be sent and they need to be static. -[]( t = 9418 s ) Broadcast will now infer that we have an injected payload gossip.
Understanding Gossip Protocol
Section Overview: In this section, the speaker explains how to implement a gossip protocol in Python.
Implementing Injected Payload
- The speaker explains that they will be injecting payload into the gossip protocol.
- They explain that they should be able to hear a match on payload and that the only injected payload is Gossip.
Creating Helper Functions
- The speaker creates a helper function called “on_message” which sends preference to self and an impul writer or imple right.
- They also create another helper function called “serialized_response_message” which is used for serialization of response messages.
Updating Gossip Protocol
- The speaker updates the gossip protocol by sending messages to mute output using context gossip to n in neighborhood.
- They explain how to fill out the message with source, destination, ID, and payload information.
- The speaker discusses how gossips do not need responses and can be fire-and-forget messages.
Filtering Messages
- The speaker filters out messages that are already known by the recipient using a copied filter method.
- They discuss updating known-to-n but leave it for later implementation.
Gossip Protocol Implementation
Section Overview: In this section, the speaker explains how to implement a gossip protocol. They discuss sending messages and gossiping between nodes.
Sending Messages
- All messages will be sent to everyone in the neighborhood during gossip time.
- When someone tells us about a message, we add it to the set that we have.
Gossiping Between Nodes
- During gossip scene, we extend the scene and do not reply.
- The nodes start gossiping with each other, descending to random other nodes in the network.
- As messages become longer, it takes longer for any given message to propagate across the network.
Naive Gossip Implementation
- When receiving a gossip message, we know that the sender knows about all of the messages they sent us.
- If node A told me about three messages, I know that A knows about those three and I never need to send them again.
Performance Analysis
Section Overview: In this section, the speaker analyzes performance issues related to implementing a gossip protocol.
Broadcast Rate vs. Propagation Delay
- The broadcast rate is not what we want because it only measures how fast broadcast operations succeed.
- Longer gossip messages mean slower propagation between new nodes and longer delays for any given message to propagate across the network.
Visibility Delay
- We want visibility delay which shows delay between when a message is broadcast and when it’s visible to all peers.
- The delay doesn’t seem to surface in the current view.
Naive Gossip Implementation
- Broadcast won’t get slower with naive gossip implementation because it doesn’t trigger any work.
- The speaker concludes that naive gossip implementation is not good enough and proposes a better solution. I’m sorry, but I cannot summarize the transcript as there are only a few bullet points with timestamps available. The provided transcript is not sufficient to create a comprehensive and informative markdown file. [CUTOFF_LIMIT]
Generated by Video Highlight
https://videohighlight.com/video/summary/gboGyccRVXI
Setting up CI and property testing for a Rust crate
- Setting up CI and property testing for a Rust crate
* Purpose of the Stream
* Checking Out Crate
* Fixing Cargo Config File
* Building Crate
* Creating Test Suite
* Writing Tests for Functions
* Running Tests
* Importance of Readme
* What to Include in Readme
* Writing Readme
* Importance of Documentation
* Types of Documentation
* Using Rustdoc
* Importance of Coverage Testing
* Using Tarpaulin Crate
* Running Tarpaulin on Codebase
* Summary
* Thanking Viewers
* Cargo Versioning
* Reference Point
* Committing Changes
* Skipping Duplicate Package Issue
* Building CI Pipeline
* Workflows
* Using Versioned Actions
* Cargo Ecosystem
* Configuring Code Coverage Reporting
* Check Workflow
* Fail Fast
* Running cargo doc
* Using cargo hack
* Minimum Supported Rust Version (MSRV)
* Safety Checks
- Schedule Jobs
- Running Test Suite
- Minimal Versions
- [t=0:38:39s] Solving Dependency Problems
- Updating Dependencies
- Setting Up CI
- Improving Test Suite with Property-Based Testing
- [t=4203s] Generating Inputs for Testing
- [t=4360s] Adding Dependencies with Prop Tests
- Interesting
- Checking Out Cargo Lock
- Huh?
- Error Message Explanation
- Build Issue
- Interesting Again!
- Environment Variable Issue
- Avoiding Cargo Clean
- Successful Build
- Strange Behavior
- Via Cargo as Standard Integration Test
- Running Tests Twice
- Dependencies
- Output Issue
- Cargo Test Suite
- Generating Arbitrary Dependencies
- Generating Dependency Specifiers
- Creating a Package
- Testing Package
- Arbitrary Depth
- Creating a String from Depth
- Writing Out Other Props
- Prop Tests
- Understanding Dependency Transformation
- Running Prop Test Job
- Practice Regressions
- Improving Build Times with Caching
- Conclusion
- Configuring CI for Prop Tests
- Saving Target File and Restoring Cache
- Updating Git Repository
- Sparse Registries
- Generated by Video Highlight
# Introduction
Section Overview: In this stream, the presenter plans to take an arbitrary crate and look at what steps to take after writing code that works. The focus is on polishing the crate by setting up CI, adding tests, creating a readme file, structuring documentation, and getting coverage testing.
Purpose of the Stream
- The goal of the stream is to go through things that are done when there’s a crate with one commit and no documentation.
- The length of the video will be around two hours or shorter depending on how far they get.
# Setting Up CI
Section Overview: This section covers setting up Continuous Integration (CI).
Checking Out Crate
- The presenter has a checkout of the crate with only one diff patch made in the previous stream.
- They want to remove it from being a path because otherwise, CI won’t run.
Fixing Cargo Config File
Building Crate
# Adding Tests
Section Overview: This section covers adding tests to the crate.
Creating Test Suite
Writing Tests for Functions
Running Tests
- [](t= 00m08s) Running
cargo testruns all the tests successfully.
# Creating a Readme File
Section Overview: This section covers creating a readme file for the crate.
Importance of Readme
What to Include in Readme
- The presenter suggests including information about what the crate does, how to use it, and how to contribute.
Writing Readme
# Structuring Documentation
Section Overview: This section covers structuring documentation for the crate.
Importance of Documentation
- Good documentation helps users understand how to use your code and can save time in answering questions.
Types of Documentation
Using Rustdoc
- [](t= 00m14s) Rustdoc is used to generate documentation from comments in code.
# Getting Coverage Testing
Section Overview: This section covers getting coverage testing for the crate.
Importance of Coverage Testing
Using Tarpaulin Crate
- [](t= 00m17s) Tarpaulin is used as a coverage testing tool for Rust code.
Running Tarpaulin on Codebase
- [](t= 00m18s) Running
cargo tarpaulingenerates a coverage report for the codebase.
# Conclusion
Section Overview: The presenter concludes the stream by summarizing what was covered and thanking viewers.
Summary
- The presenter covered setting up CI, adding tests, creating a readme file, structuring documentation, and getting coverage testing.
Thanking Viewers
0:05:24 Cargo Versioning
Section Overview: In this section, the speaker explains the versioning system for the cargo crate and why it is a little weird.
Cargo Versioning
- The versioning for the cargo crate is based on the current Rust version.
- For Rust 1.x, the cargo version is 0.x plus 1.
- The reason for this system is unknown.
0:06:01 Reference Point
Section Overview: In this section, the speaker suggests keeping information about cargo Tamil as a reference point.
Reference Point
- It’s suggested to keep information about cargo Tamil as a reference point.
0:06:06 Committing Changes
Section Overview: In this section, the speaker discusses committing changes to fix an issue with patch overrides in Cargo.
Committing Changes
- To fix an issue with patch overrides in Cargo, it’s suggested to turn it into 70 or use rev equals one commit.
- This will ensure that patches are picked up correctly.
0:06:32 Skipping Duplicate Package Issue
Section Overview: In this section, the speaker talks about an issue with skipping duplicate packages when taking a git dependency on Cargo.
Skipping Duplicate Package Issue
- There seems to be an issue with skipping duplicate packages when taking a git dependency on Cargo.
- This needs further investigation.
0:07:10 Building CI Pipeline
Section Overview: In this section, the speaker discusses building a CI pipeline and getting packages to build somewhere other than their own laptop.
Building CI Pipeline
- The first step in building a CI pipeline is ensuring that packages can build somewhere other than their own laptop.
- This was not possible before due to a patch path override.
- The speaker has a collection of CI scripts that they use and keep in a separate GitHub repo.
- Configurations for dependabot, code coverage, and workflows are kept in this repo.
- By adding another git remote to the current git repository and fetching it, the history of that other repo can be merged with the history of this repo.
- This makes it easy to keep the CI up to date.
0:08:50 Workflows
Section Overview: In this section, the speaker talks about different workflows for different kinds of things that may or may not be relevant for a given crate.
Workflows
- Different workflows are used for different kinds of things that may or may not be relevant for a given crate.
- Examples include checks scheduled and test ammo.
# Notifications for GitHub Actions
Section Overview: The speaker discusses how they use notifications for GitHub actions to update outdated versions of actions used in their CI.
Using Versioned Actions
- The speaker uses versioned actions in their CI.
- If an outdated version of an action is being used, a PR is filed to update it.
Cargo Ecosystem
- The speaker has a daily job set up for the cargo ecosystem.
- This job runs at the root of the crate and ignores all dependencies if the update is a patch or minor update.
- If there’s a major release, the speaker wants to know so they can take action and update their crates.
# Codecov Configuration
Section Overview: The speaker talks about configuring codecov for code coverage reporting.
Configuring Code Coverage Reporting
- The speaker configures codecov for code coverage reporting.
- They ignore the test directory because they don’t want coverage for tests.
- They make the code comments on PRS and stuff less verbose.
# Real Jobs
Section Overview: The speaker goes through the actual jobs in their workflow.
Check Workflow
- The check workflow runs when pushing to main branch or creating a pull request.
- It includes format, Clippy, dock, hack, and msrv jobs.
- The format job runs cargo format check on the stable compiler.
- The Clippy job runs both stable and beta versions.
Fail Fast
- The speaker sets fail fast for the Clippy job to avoid unnecessary CI runs.
- If something fails in one step, it will likely fail in other steps as well.
# Cargo Check and Cargo Hack
Section Overview: In this section, the speaker talks about the importance of running cargo doc to check for correct
introdoc links. They also discuss using nightly documentation features with cargo doc. The speaker then explains how
to use cargo hack to check combinations of feature flags.
Running cargo doc
- When running
cargo doc, checks are performed that don’t run when you run any other command. - To check that your introdoc links are correct and not dangling, you need to run a
cargo doc. - Running
cargo docon nightly allows you to use some nice features like config doc or doc config which means that you can mark a particular function or type as only being available if a certain configuration is true.
Using cargo hack
- Cargo requires that your features are all additive so that means your crate should compile with any combination of your features.
- Cargo hack allows you to check a particular combination of features or a set of combinations of features.
- Power set of the features is used in cargo hack which means every possible combination is checked.
# MSRV and Safety Checks
Section Overview: In this section, the speaker talks about minimum supported rust version (MSRV), what it is used for, and how it works. They also discuss safety checks such as Miri, leak sanitizer, thread sanitizer, address sanitizer, Loom and no_std.
Minimum Supported Rust Version (MSRV)
- MSRV is used to figure out whether the crate continues to build with the version of rust that we claim it builds with.
- It checks out, installs and then runs cargo check against MSRV.
Safety Checks
- Miri, leak sanitizer, thread sanitizer, address sanitizer and Loom are safety checks that ensure your code is safe.
- No_std makes sure that your crate still builds against targets that have no standard library and no allocator or targets that have an allocator but not a standard Library.
Schedule Jobs
Section Overview: In this section, the speaker talks about the schedule jobs that are run on nightly and beta versions of Rust.
Running a Build on Nightly
- Run a build on nightly or at least fairly regularly.
- The job checks out installs nightly and runs cargo test with Dash locked.
Building on Beta
- This job builds on beta and runs cargo update to ensure that if you run with newer versions of dependencies, your test suite still passes.
- Checking for new deprecated items in dependencies is important.
Running Test Suite
Section Overview: In this section, the speaker talks about running the actual test suite.
Testing Stable and Beta Versions
- Runs your test suite on stable and beta versions.
- The same little bit is used for both stable and beta versions.
GitHub CI Magic
- If a file does not exist, then run cargo generate log file.
- Checking in lock files allows people to bisect your crate like they can check out an old version of your crate and it should still be able to build by virtue of using the exact dependencies that were present at the time.
Minimal Versions
- Minimal only runs on stable but it happens to also install lightly because minimal versions is an unstable flag.
- It runs cargo update with the dash Z minimal versions flag which chooses the oldest version that’s still subject to the dependency requirements that you set in your cargo Tamil.
Minimal Versions
Section Overview: In this section, the speaker discusses the importance of using full version numbers when taking a dependency to ensure that consumers don’t end up in weird states. They also explain how minimal versions work and their limitations.
Importance of Full Version Numbers
- When taking a dependency, it is recommended to use the full version number instead of just the current major version.
- This ensures that consumers don’t end up in weird states.
- It is better to look back at the version list and find exactly the minimal version needed.
- This may be time-consuming but it’s better than picking the current version which has everything you’re going to use.
Limitations of Minimal Versions
- Minimal versions choose minimal versions transitively, which means if one of your dependencies has an incorrectly specified minimum version, it can cause problems.
- If a dependency needs a specific version but hasn’t specified it themselves, we can force that minimal requirement by specifying it ourselves.
- There is another proposal called Dash Z direct minimal versions which chooses the minimal versions of your direct dependencies but the highest version of all transitive dependencies.
OS Check and Coverage Testing
- The next step after resolving dependencies is OS check to ensure that crate test suite runs on Mac OS and Windows using stable compiler.
- Coverage testing is done using cargo lvm Cub which uses instrumented coverage for more accurate reporting.
- Codecov.io is used for outputting coverage results as it’s free for open source projects.
# Oregon Origin and Git Merge
Section Overview: In this section, the speaker discusses merging a repository from Rusty Iconf into their own repository. They discuss whether to preserve history or do a squash merge and why they chose to preserve history.
Preserving History vs Squash Merge
- The speaker chooses to preserve history for the merge because they plan on merging from Rusty Iconf again in the future.
- If they did a squash merge, there would be more merge conflicts because git wouldn’t know about the existing connections and merge history with that other repo.
Checking CI and Pushing to Origin
- The speaker checks CI before pushing it to origin.
- They push CI to origin so that they can do a PR of this later on.
Adding Cargo Lock
- The speaker adds cargo lock by using “git add cargo lock” and “Ben dot get ignore”.
- They check in their cargo lock.
Merging Repositories
- After merging repositories, all commits from the other repo are brought in as well.
- A PR is created from this one by adding CI and then putting the link there.
# Troubleshooting OpenSSL Sys Dependency Issue
Section Overview: In this section, the speaker troubleshoots an issue with OpenSSL Sys dependency version.
Open SSL Sys Dependency Issue
- Minimum supported rust version failed because of an issue with OpenSSL Sys dependency version.
- The speaker goes to the GitHub repo for OpenSSL Sys and checks its cargo Tomo.
- They find that OpenSSL Sys has moved away from using Rust C underscore version dependency and now uses Auto config.
Bumping in MSRV for Crates Index
- The speaker bumps in MSRV for crates index to fix the issue with minimum supported rust version failing.
# Checking CI and Running Tests
Section Overview: In this section, the speaker checks CI and runs tests to ensure everything is working properly.
Checking CI
- The speaker checks CI before pushing it to origin.
- They push CI to origin so that they can do a PR of this later on.
Running Tests
- After merging repositories, all commits from the other repo are brought in as well.
- Jobs are kicked off and it will be interesting to see if they pass or fail.
- Minimum supported rust version failed but was fixed by bumping in MSRV for crates index.
- Minimum versions failed but was not surprising since no new version was found for it.
- Other tests were run such as nightly dock works fine, cargo update works fine, etc.
[t=0:38:39s] Solving Dependency Problems
Section Overview: In this section, the speaker discusses how to solve dependency problems in Rust.
Bumping Minimal Versions
- The speaker’s first instinct is to bump minimal versions.
- However, this can be annoying because it may not address the problem in the specification.
- Pinning a much newer version of OpenSSL can be a solution.
Binary Search for OpenSSL Version
- The current version of OpenSSL being used is 0.10.45.
- A binary search is performed to find a newer version of OpenSSL that works.
- Version 0.8.5 is found to work.
Updating Package Config
- Package config version 0.3.11 does not have the required method for range version.
- Updating package config to version 0.3.26 solves this issue.
Fixing Rand Isaac and HKDF
- Rand Isaac version 0.1.1 is needed but was not specified in the code.
- HKDF through P384 has an issue with its dependencies.
- Finding compatible versions of these dependencies can be very tedious and annoying.
Conclusion
Solving dependency problems in Rust can be challenging and time-consuming due to transitive dependencies and compatibility issues between different versions of packages and libraries.
Updating Dependencies
Section Overview: In this section, the speaker discusses updating dependencies and how to get rid of old versions of packages.
Getting Rid of Old Versions
- Crossbeam Channel can be used to update Ran.
- The old version of Rand is completely gone after using Crossbeam Channel.
Testing New Versions
- Binary search can be used to test new versions.
- OpenSSL was tested and found to build successfully.
Updating Cargo Lock
- Running
cargo checkupdates the Cargo lock file. - Approval rules are added before merging changes.
Setting Up CI
Section Overview: In this section, the speaker sets up continuous integration (CI).
Creating a Repository
- A repository is created for Code Curve.
- Workflows are run to ensure everything works as expected.
Troubleshooting Nightly Build Failure
- Checking nightly builds reveals that the lock file needs to be updated.
- Multiple versions of FF are brought in due to specified minimal versions.
# Starting the CI
Section Overview: In this section, the speaker starts the Continuous Integration (CI) process for an open-source project on GitHub. They explain how GitHub limits the number of jobs that can run in parallel for open-source projects and how canceling previous runs can free up resources to run the current one faster.
Starting CI
- The speaker starts the CI process for an open-source project on GitHub.
- They mention that there were three rockets before, but now there are only two, which makes them sad.
- The speaker wishes that all tests would run in parallel and fast. However, they acknowledge that GitHub is donating CI for free for open source things.
- The speaker cancels some runs from a previous push to free up more resources to run this one faster or more parallel because GitHub limits the number of jobs that can run in parallel for open-source projects.
# Value of Minimal Versions
Section Overview: In this section, the speaker discusses whether it’s worth spending time on minimal versions and checking them through CI.
Minimal Versions
- The speaker explains why having a correct minimal version check through CI is valuable as it can save time down the road when consumers come with issues related to dependencies specified in cargo.toml file.
- They also mention that catching errors in one place is better than many places and building tooling could help reduce waste of time required to get to that point.
# Streaming as Educational Content
Section Overview: In this section, the speaker discusses the value of streaming as educational content.
Streaming
- The speaker explains that streaming can be valuable if it’s educational and useful. They mention that they try to build things that are useful and hope that their streams are educational.
- They also mention that some streams may not have any value, but others like Wordle stream were just fun to build.
# Introduction
Section Overview: In this section, the speaker talks about the purpose of their streams and hopes that they are not a waste of time for viewers. They also discuss the value of their time compared to others.
Purpose of Streams
- The speaker hopes that their streams have a meaningful impact on viewers.
- They hope that viewers learn new things during the stream.
- The trade-off between the speaker’s time and viewer’s time is reasonable.
# Technical Issue with Windows
Section Overview: In this section, the speaker encounters a technical issue with Windows and discusses how to fix it.
Fixing OpenSSL on Windows
- The speaker encounters an issue with OpenSSL on Windows.
- They search for a solution in their repositories.
- To fix it, they need to install OpenSSL specifically for Windows.
- This step should be added to their standard setup process.
# Testing and CI
Section Overview: In this section, the speaker discusses testing and continuous integration (CI).
Coverage Report
- The coverage report shows that there is terrible testing of index.
- There is no test for features or dependencies in index.
Pushing Changes and Merging Branches
- The speaker pushes changes and merges branches.
- They confirm merge and delete branch afterward.
Updating Readme File
- The readme file needs updating after merging branches.
- Badges need to be updated as well.
Improving Test Suite with Property-Based Testing
Section Overview: In this section, the speaker discusses the benefits of property-based testing and compares two main tools for it: Prop test and Quick Check.
Property-Based Testing
- Property-based testing is a way to write tests by defining patterns for test cases instead of writing individual test cases.
- Two main tools for property-based testing are Prop test and Quick Check. The recommendation is to generally favor Prop test because it has a more elaborate way of doing property-based testing.
- Property-based testing generates different inputs based on defined constraints to explore the space more efficiently than traditional fuzz testing.
- Property-based testing is less deterministic than traditional fuzz testing due to exploring an infinite or very large space. However, there are mechanisms in place to make it more deterministic.
Example
- An example of using property-based testing is checking that a parse date function doesn’t panic when given any string that matches a regular expression pattern.
- Another example is checking that all strings matching a pattern should be valid dates or at least parsable as dates.
Overall, property-based testing provides an efficient way to generate inputs based on defined constraints and explore the space intelligently. It can be used as an alternative or complement to traditional fuzz testing.
[t=4203s] Generating Inputs for Testing
Section Overview: In this section, the speaker discusses how to generate inputs for testing and the benefits of generating inputs from small domains. The speaker also explains how to use prop testing to test if things work correctly.
Benefits of Generating Inputs from Small Domains
- Generating inputs from relatively small domains allows you to fully explore the space and do actual ranges.
- It generates a bunch of valid potential inputs that semi-intelligently explore the space.
- Prop testing runs a bunch of inputs and tells you what input it might fail for.
Using Prop Testing
- It is not recommended to use prop testing to test performance because it randomly explores the input space.
- Benchmarking based on prop testing can be weird because you may end up benchmarking the harness just as much as you’re going to test the actual online code.
- Prop testing generates a bunch of things that match a pattern and tries to be more intelligent than doing a linear scan.
- Ultimately, it refines down to a test case that fails.
[t=4360s] Adding Dependencies with Prop Tests
Section Overview: In this section, the speaker talks about adding dependencies with prop tests and modifying cargo projects.
Round Trip Function
- The round trip function constructs a cargo project, expects modifications in cargo Tamil, packages it up, and runs it through all different steps.
- Currently, round trips are super simple; one does not modify anything while another was not implemented yet.
Adding Dependencies with Prop Tests
- To add prop tests, we need to add dependencies first.
- The speaker wonders whether they want this in the same file or not.
- They make some changes but encounter an error.
Interesting
Section Overview: In this section, the speaker expresses interest in something.
Speaker’s Interest
- The speaker says “interesting.”
Checking Out Cargo Lock
Section Overview: In this section, the speaker mentions checking out cargo lock.
Checking Out Cargo Lock
- The speaker says “check out cargo lock.”
Huh?
Section Overview: In this section, the speaker expresses confusion.
Confusion
- The speaker says “huh?”
Error Message Explanation
Section Overview: In this section, the speaker tries to understand an error message.
Error Message Explanation
- The speaker wonders why there is an error message.
- They speculate that it might be because they added prop test um but it’s not running with minimal versions.
- They say that shouldn’t make a difference.
Build Issue
Section Overview: In this section, the speaker encounters a build issue.
Build Issue
- The speaker says that it doesn’t even build with the latest versions of everything.
- They mention finding crate bytes compiled by an incompatible version of rust compiled to their Rusty beta.
Interesting Again!
Section Overview: In this section, the speaker expresses interest again.
Interest
- The speaker says “interesting” again.
Environment Variable Issue
Section Overview: In this section, the speaker realizes there is an issue with their environment variable.
Environment Variable Issue
- The speaker realizes that their environment variable is no longer being set.
- They mention that it’s causing issues.
Avoiding Cargo Clean
Section Overview: In this section, the speaker tries to avoid running cargo clean.
Avoiding Cargo Clean
- The speaker says they specifically didn’t want to run cargo clean because of a weird Target directory setup.
- They mention that it wouldn’t have made a difference anyway.
Successful Build
Section Overview: In this section, the speaker successfully builds something.
Successful Build
- The speaker says that it looks like it builds and asks the listener to check out cargo lock and cargo check.
Strange Behavior
Section Overview: In this section, the speaker encounters strange behavior.
Strange Behavior
- The speaker says “that’s very strange.”
- They wonder why they got into some weird fingerprinting issue here.
Via Cargo as Standard Integration Test
Section Overview: In this section, the speaker discusses using Via cargo as a standard integration test.
Using Via Cargo as Standard Integration Test
- The speaker wants via cargo to be a standard integration test file where they have imperative tests and prop tests separate.
- They mention wanting the round trip function to be usable in both of these tests but are unsure if it will work without running them twice.
Running Tests Twice
Section Overview: In this section, the speaker discusses running tests twice.
Running Tests Twice
- The speaker says that they think cargo test is actually now going to run the unit testing via cargo twice.
- They mention other ways to do this but find the auto-detection mechanism of cargo for test suites annoying.
Dependencies
Section Overview: In this section, the speaker mentions dependencies.
Dependencies
- The speaker comments on how many dependencies there are.
- They realize that they changed their cargo config and it caused confusion when trying to reuse old artifacts.
Output Issue
Section Overview: In this section, the speaker discusses an issue with output.
Output Issue
- The speaker realizes that it prints the output from cargo as a part of a test and mentions that it’s another thing they need to fix.
Cargo Test Suite
Section Overview: In this section, the speaker discusses the Rust test suite and what it uses from the cargo. They also discuss modifying the workspace before packaging and checking output structs.
Modifying Workspace Before Packaging
- The speaker suggests starting with one of the examples given in Via Cargo.
- They suggest stealing a whole test from Via Cargo.
- The goal is to check various transit structs.
Prop Testing Over Dependencies
- The speaker suggests prop testing over dependencies.
- They want to ensure that when dependencies are added, appropriate version specifier optionality is passed through.
- Prop testing over whether it’s dependencies Dev dependencies or build dependencies seems reasonable.
- A vector of dependencies is needed for this.
Generating Dependencies
- The inputs required for generating dependencies are discussed.
- A function that generates dependencies is needed.
- It’s suggested to generate a structured representation and then turn it into a string.
- Struct dependency has kind, name, version, and features.
- Optionality is also included in dependency struct.
Generating Arbitrary Dependencies
Section Overview: In this section, the speaker discusses how to generate arbitrary dependencies and the challenges associated with it.
Deriving Arbitrary Trait
- The
arbitrarytrait is used to generate an arbitrary version of a struct. - It can be used in Quick Check.
- The
propmacro can derive it, but it’s experimental. - Deriving arbitrary requires taking a dev dependency on arbitrary for the crate, which doesn’t feel right.
Implementing Arbitrary Dependency
- Instead of deriving arbitrary, we need to implement an
ARB depstrategy for generating a dependency. - We want to generate a normalized manifest for the dependency.
- We need to use
prop composefor generating recursive things. - An arbitrary depth kind is going to be any in kind in zero u8 to 3.
- We have a way to generate an arbitrary dependency kind using
prop compose.
Generating Dependency Specifiers
Section Overview: In this section, the speaker discusses how to generate dependency specifiers and names for dependencies.
Generating a Version Specifier
- To generate a version specifier, use a regular expression for semantic versioning specifiers.
- The regex can include a carrot or an equals sign (optional), followed by zero to nine numbers (at least one), followed by an actual dot, followed by zero to nine numbers (at least one).
- Build specifiers can also be included with a dash followed by arbitrary ASCII characters (limited to ASCII).
Generating a Name
- The name of the dependency is separate from the dependency specifier and needs to be generated separately.
- The name can be any string consisting of lowercase letters, numbers 0-9, dashes, and underscores.
- Capital letters are not allowed, but it must start with a letter.
- It’s allowed to be a single character.
Additional Considerations
- When generating arbitrary depth, there needs to be a separate name specified for each dependency.
- If the name is equal to the listing, it changes the logic and needs to be encoded differently.
Creating a Package
Section Overview: In this section, the speaker discusses creating a package and setting its features.
Setting Features
- The speaker mentions that there must be an easier way to set features than using any bull.
- They suggest using default features instead.
- The speaker sets the public to true and optional to option of this.
- They set the package to none.
Defining Package
- The speaker defines the package as arbitrary and says it will take an option string.
Testing Package
Section Overview: In this section, the speaker discusses testing the created package.
Testing with Different Packages
- The speaker tests both cases where the package is set to something different from the name of the crate and when it’s not set at all.
Errors in Testing
- There is an error message about expecting a closure that returns dependency string but it returns result.
- The speaker realizes they can only use prop assume inside of prop tests.
Arbitrary Depth
Section Overview: In this section, the speaker discusses defining arbitrary depth for ARB depths.
Defining ARB Depths
- The speaker defines ARB Depp zero to some number.
- They map over it and turn it into a string using format.
Creating a String from Depth
Section Overview: In this section, the speaker discusses creating a string from depth.
Creating a String from Depth
- The function returns a string.
- The speaker wants to create something like map.
- Vex strategy is not an iterator prop.
- ER returns string.
- The speaker suggests using stir takes a depth which is going to be any depth and returns a string and it just formats that.
Writing Out Other Props
Section Overview: In this section, the speaker discusses writing out other props.
Writing Out Other Props
- The speaker wants to write out other props including getting comma right.
- They read in the existing Tamil and push a new line.
- They use standard format right as well and then they’ll do stud right to P dot join cargo Tamil and they’ll write back out the modify Tamil.
Prop Tests
Section Overview: In this section, the speaker discusses prop tests.
Prop Tests
- There’s also a warning saying on line 69 that we don’t unwrap this and for our own sanity print out what it actually does so what is the list of depths that it’s trying to inject?
- It doesn’t find libar as our main RS oh actually I wonder whether the prop tests are supposed to not be integration tests but actually be test binaries uh oh I guess it is [Music].
# Understanding Dependency Specifiers
Section Overview: In this section, the speaker discusses dependency specifiers and how to generate them. They also encounter errors with regular expressions and work to fix them.
Generating Dependency Specifiers
- The speaker generates a list of dependencies, including their versions.
- Regular expressions are used to ensure that version numbers are valid.
- The speaker notes that they are not currently writing out all properties for the dependencies.
Writing Out Dependency Properties
- The speaker writes out optional, default features, and package properties for the dependencies.
- A dependency specifier is generated with version, optional, and default features properties.
Further Customization of Dependency Specifiers
- The speaker notes that dependency specifiers can be further customized with less than or greater than symbols.
# Testing Dependencies
Section Overview: In this section, the speaker discusses testing dependencies and ensuring that the final dependencies are present in the input dependencies.
Checking for Dependency Presence
- Loop over the dependencies listed in the index and check that each one is present in the input.
- Check that the dependency that ended up in the final index entry is actually one of the ones given in the input.
- Assert that all of the input dependencies were found in the output dependencies.
Helper Functions
- Create a helper function to generate a vector of dependencies instead of strings.
- Create another helper function to check if a field zero on string is equal to another field zero on string.
Other Notes
- The regex for minor versions is wrong and should be 1 to 9 or 0 or 2.
- The assertion here is that we actually found all of the input dependencies in the output dependencies, but we’re not checking if they are correct beyond just their name being present.
Understanding Dependency Transformation
Section Overview: In this section, the speaker discusses the final depth of type index and its dependencies. They also talk about various checks that need to be added for completeness.
Index Dependencies
- The final depth is of type index and has two dependencies: registry dependency and a registered dependency.
- A registered dependency has a name and requirements.
Checks for Completeness
- Various checks need to be added for completeness, such as checking if optional matches, default features made it all through, and package made it all through.
- Optional in the index is not optional because it defaults to false.
- Default features defaults to true in the package.
- Derefence both of them so they are matchable.
- Convert cow string to rep so they are comparable using dot map s.
Limitations
- This will break if it generates two dependencies by the same name, which hasn’t been addressed yet.
Running Prop Test Job
Section Overview: In this section, the speaker talks about running prop test job separately from other tests since it takes longer to run.
Ignoring Slow Tests
- The prop test job is slow and should be ignored during normal testing.
- It should only run on stable tool chain.
- We want a separate job that runs prop test only if basic test suite succeeds.
Configuring Prop Test
- Prop tests are slow; 256 executions have to execute for a Tesla so hold to pass now 256 for us is actually going to take a while like you saw how slowly they executed but I think it’s probably okay I don’t worry too much about this um I think we can also skip this print.
Practice Regressions
Section Overview: The speaker discusses the importance of checking in a file that replicates over time and recommends doing so. They also mention running prop tests explicitly.
Checking in Files
- It is recommended to check in files that replicate over time.
- The speaker suggests not checking in the initial file but doing so over time.
- Checking in files can be useful for running prop tests.
Running Prop Tests
- Prop tests only generate files on failure.
- To run prop tests, use git add Dot commit and git push.
Opening a Pull Request
- After pushing changes, open a pull request to initiate CI rules.
- CI rules will kick off different workflows, including basic testing and prop testing.
Configuring Branch Protection
- Configure branch protection by requiring a pull request.
- Require status checks to pass, including stable formatting and Ubuntu stable test suite.
- Do not require minimum supported rust version or nightly/beta versions.
Improving Build Times with Caching
Section Overview: In this section, the speaker discusses how caching can be used to improve build times and reduce the time it takes to run tests.
Using Caching for Dependency Trees
- A chunky dependency tree can take a long time to build, so copying binary bits using caching may be faster.
Defining Cache Keys
- Defining cache keys is necessary when building with minimum supported Rust versions (MSRV).
- The cache key should be set up as follows:
Target cash restore,Target, andkey = matrix.tool chain.
Saving and Restoring Cache
- After running cargo tests, save the cache by running
steps.dot Target cash restore outputs. - To restore the cache for minimal versions, use
stable Target.
Prop Tests
- Prop tests take a long time to run because they explore a large input space.
- The prop test only took 51 seconds to run despite exploring 256 different combinations of feature combinations.
Conclusion
Section Overview: In this section, the speaker concludes by noting that more work needs to be done in taking advantage of dependency kinds.
Taking Advantage of Dependency Kinds
- More work needs to be done in taking advantage of dependency kinds.
Configuring CI for Prop Tests
Section Overview: In this section, the speaker discusses configuring CI for prop tests and the trade-offs involved.
Trade-Offs of Adding Instrumentation for Coverage
- Adding instrumentation for coverage executes more slowly.
- It is unclear whether it’s worth the trade-off to have prop tests run more slowly to get coverage.
Documentation
- The topic of documentation is not discussed in detail but may be a topic for another day.
Follow-Up Questions
- The speaker asks if there are any follow-up questions from what was covered today.
- A question is asked about accessing the restore cache correctly and referencing that key from different steps. The speaker believes it is allowed because one of the points of the cache is that it is cross-job and possibly even cross-workflow.
Saving Target File and Restoring Cache
Section Overview: In this section, the speaker discusses saving target files and restoring cache during CI configuration.
Saving Target File
- The speaker discusses how saving target files works during CI configuration.
Restoring Cache
- The speaker explains how cache restoration works during CI configuration.
- The cache was restored quickly after being downloaded.
Updating Git Repository
Section Overview: In this section, the speaker talks about updating Git repositories during CI configuration.
Pinning Revision in Cargo Tamil
- Speaker mentions that they pinned revision in cargo Tamil so git repository shouldn’t need to be updated.
Sparse Registries
Section Overview: In this section, the speaker discusses sparse registries and how they can be used to make CI faster.
Injecting Configuration
- The speaker mentions that they could inject configuration to make CI faster but it’s about to land anyway. [CUTOFF_LIMIT]
Generated by Video Highlight
https://videohighlight.com/video/summary/xUH-4y92jPg
Tim McNamara is the author of Rust in Action
- Follow Tim on Twitter
- Check out his code: https://github.com/timClicks
- Join the Discord server: https://discord.gg/9GHgpMQJ
Answers to StackOverflow Top Rust Programming Questions Explained
- Answers to StackOverflow Top Rust Programming Questions Explained
- Introduction
⭐️ Explanation of Stream Content⭐ Difference Between String and Stir⭐ Technicalities of Strings in Rust- Compiler Comments
- Rust Analyzer and Rusty LSP
- Creating Variables in Rust
- Accepting Both Strings and str in Functions
- String Conversion in Rust
- Rust String and Str
- Print Line in Rust Unit Tests
⭐️ Compiler Bugs and Unused Code Warnings 0:43:44⭐️ Printing Variable Types 0:47:24- Understanding Rust’s Generic Types and Traits
- Rustation Station Subscription and Social Media
- Conclusion of Stream
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces themselves and explains how to ask questions during the stream.
- Viewers can ask quick questions in the chat if they are signed into Twitch.
- The speaker will periodically check messages and respond.
- Viewers can also follow the speaker on Twitter or Discord but may receive less immediate responses.
⭐️Explanation of Stream Content
Section Overview: In this section, the speaker explains what they will be doing during the stream.
- The speaker will look for questions tagged “rust” on Stack Overflow.
- They will focus on answering highly rated questions that people may have difficulty with.
- The order of questions does not necessarily need to be from top to bottom.
- If viewers have specific questions, they can ask them in the chat.
⭐Difference Between String and Stir
Section Overview: In this section, the speaker discusses a common question about Rust programming language.
- One of the most popular questions is about the difference between string and stir in Rust.
- A beginner-friendly answer is needed as some technical answers may not be suitable for beginners.
- ⭐Rust does not have a string literal type like Python’s capital S string type. Instead, it has a stir type that represents a string literal.
- Converting stir to a capital S string is possible using certain methods.
⭐Technicalities of Strings in Rust
Section Overview: In this section, the speaker delves deeper into strings in Rust programming language.
- There are differences between variables named “item” in Python and Rust due to their respective syntaxes.
- Creating a capital S string literal syntax is not possible in Rust.
- A str type must first be created before converting it into a String using certain methods.
# Rust Programming Language
Section Overview: In this section, the speaker explains why Rust has two types of string literals and how they differ.
⭐Two Types of String Literals
- t=0:06:11s There are two types of string literals in Rust.
- t=0:06:28s The way computers work requires specificity, and Rust aligns itself with the computer’s memory management model.
- t=0:06:54s A string literal during execution starts as a fixed section of binary code.
- t=0:07:17s Static storage is a part of memory outside the stack and heap that exists for the entire lifetime of the program.
# Lifetime Annotations
Section Overview: In this section, the speaker explains what lifetime annotations are and how they relate to static storage.
Lifetime Annotations
- t=0:07:37s Anything with an apostrophe prefix has a lifetime annotation.
- t=0:07:56s A string does not exist at the start but can be created during runtime.
- t=0:08:44s The full type of a reference to a string is
&static str. - t=0:09:16s A reference to a string has guaranteed UTF-8 encoding with a lifetime of static.
# Strings vs Stings Literal
Section Overview: In this section, the speaker compares strings and string literals in Rust.
⭐Strings vs String Literals
- Passing around strings is less mental overhead than passing around string literals.
- When using a string, the compiler does not know the length of a string literal.
- A reference is required to use a string literal as an argument.
0:12:52 Memory Management in Rust
Section Overview: The speaker explains how memory is managed in Rust and the difference between a destructor and a string. They also discuss the responsibilities of an owner and why an ampersand is required for str but not string.
⭐Memory Management
- In Rust, a destructor or
freefunction is used to free memory. - A hidden function called
dropis inserted by the compiler at the end of a scope where variables are owned. - The owner’s responsibility is to call the destructor of any owned things at the end of its life cycle.
- An ampersand is required for stir but not string because ownership retains with main, and greet only has read access to name.
Compiler Warnings
- A compiler warning occurs when greet does not want to call the destructor, resulting in memory being available twice.
- To retain access to name, we must use a reference which provides read-only access to string.
⭐⭐⭐Difference Between String Types
- The difference between Rust’s
Stringtype and itsstrtype lies in their ownership and mutability. - Ownership of
Stringcan be transferred while that ofstrcannot be transferred. - Mutability can be changed for
String, but not forstr.
0:17:32 Differences Between Rust String Type and Its Str Type
Section Overview: The speaker discusses why it’s difficult to understand the differences between Rust’s String type and its stir type. They explain that understanding these differences requires knowledge about Rust.
Understanding Differences Between String Types
- Understanding differences between Rust’s String type and its str type requires knowledge about Rust.
- Ownership can be transferred for String but not str.
- Mutability can be changed for String but not str.
Compiler Comments
Section Overview: In this section, the speaker talks about how the compiler comments can be useful or not during a demo.
Compiler Comments
- The speaker mentions that there is no need for compiler comments during a demo.
- They express gratitude towards the compiler but prefer to have control over their demo.
- The speaker acknowledges that compiler comments can be useful in other situations.
Rust Analyzer and Rusty LSP
Section Overview: In this section, the speaker discusses two language server protocols for Rust: Rust Analyzer and Rusty LSP.
⭐Language Server Protocols
- The speaker mentions that Rust has two language server protocols: Rust Analyzer and Rusty LSP.
- They describe Rust Analyzer as newer and more interesting while describing Rusty LSP as older and more established.
- The speaker suggests sticking with strings when beginning with rust before moving on to more complex types.
Creating Variables in Rust
Section Overview: In this section, the speaker explains how to create variables in rust using strings.
⭐Creating Variables with Strings
- The speaker suggests using strings when starting out with rust.
- They explain that if issues arise with ownership, adding a reference can help indicate read-only access.
- As users become more competent with rust, they can move on to accepting both strings and strs by using generics.
Accepting Both Strings and str in Functions
Section Overview: In this section, the speaker explains how to accept both strings and str in functions using generics.
Accepting Both Strings and Stirs
- The speaker explains that it is possible to use generics to accept both strings and stirs in functions.
- They mention that implementing “as ref into string” trait allows calling either a string or a stir.
- The speaker notes that strings have extra functionality and can be owned by a specific scope.
String Conversion in Rust
Section Overview: In this section, the speaker discusses string conversion in Rust and how to convert any type that can convert itself into a string.
⭐Converting Types to Strings
- The
Stringtype provides more functionality than a regular string. - To convert any type that can convert itself into a string, use the
Intotrait. - The
Intotrait is an interface that restricts types to those that implement it. - The
ToStringtrait is used by theDisplaytrait for representing types as strings.
⭐Using AsRef vs. Into
- Use
AsRefwhen you need a lightweight conversion. - Use
Intowhen you need dynamic allocation and creation of a new string type.
Rust String and Str
Section Overview: In this section, the speaker explains the difference between Rust string and stirrer. He also talks about how understanding these concepts is fundamental to understanding Rust programming.
⭐⭐⭐Understanding Rust String and str
- The speaker explains that to understand the difference between Rust string and stirrer, one needs to take out the reference to the internal stir like internal array of bytes or pass it to great.
- Understanding these concepts is fundamental to understanding borrowing, memory management, etc.
- Over time, one will learn what it means by dynamic string type like rick.
- Display is a good suggestion for printing out a greeting to the console.
Print Line in Rust Unit Tests
Section Overview: In this section, the speaker talks about why print line does not work in Rust unit tests.
⭐Why Print Line Does Not Work in Rust Unit Tests
- To call something a unit test on rust is to give it this test annotation.
- By convention, we can call the console function a test function just by including this test annotation.
- The question is why print line does not work in rust unit tests.
# Test Output and Rust Compiler Optimization
Section Overview: In this section, the speaker discusses how tests hide output when they succeed, how to specify other flags in Rust, and why the Rust compiler does not optimize code assuming that two mutable references cannot alias.
Hiding Output When Tests Succeed
- When tests succeed, they hide output.
- If an assertion is made that something is true which is actually false, more console output will be displayed.
- Other flags can be specified in Rust, such as “no capture.”
Rust Compiler Optimization
- The Rust compiler does not optimize code assuming that two mutable references cannot alias.
- Mutable references are both pointers representing some place in memory and can never refer to the same memory address by definition under Rust’s language.
- LLVM is used for optimization of binary code.
# Learning Rust and Assembly
Section Overview: In this section, the speaker talks about a tweet he made regarding learning Rust and how he will try his best to explain a particular topic that matters to people who care about assembly.
⭐Learning Rust
- The speaker referenced a tweet he made regarding learning Rust being easy because it’s a systems programming language.
- The burden of making things simple should be on the teacher rather than the learner.
Assembly
- The speaker spent 40 minutes discussing different types of strings before moving onto assembly.
- The speaker will try his best to explain a particular topic that matters to people who care about assembly.
- Rust’s compiler should optimize code assuming that two mutable references cannot alias.
# Tricky Question
Section Overview: In this section, the speaker talks about a tricky question he has to deal with.
Tricky Question
⭐️Compiler Bugs and Unused Code Warnings 0:43:44
Section Overview: The speaker discusses compiler bugs and unused code warnings in Rust, explaining that there are legitimate reasons why a compiler should be instructed to compile code even though it doesn’t exist in the control flow.
- There were compiler bugs that caused some problems with unused code warnings.
- The speaker explains that sometimes the compiler is wrong about what code will be accessed and there are legitimate reasons for compiling dead code.
- Legitimate use cases include creating functions called by the CPU outside of program flow.
⭐️Printing Variable Types 0:47:24
Section Overview: The speaker explains how to print the type of a variable in Rust.
- To find out the type of a variable, you can do something that you know is wrong and get the compiler to tell you why it’s wrong.
- If you want to store something on disk or really print out the type, you can use
std::any::type_name.
Understanding Rust’s Generic Types and Traits
Section Overview: In this section, the speaker explains Rust’s generic types and traits. They recommend starting with Rust by Example to learn the language.
Starting with Rust by Example
- Rust by Example is a series of small discrete examples that can be run in the browser.
- It provides a sense of how to run code and comes out with “Hello World.”
- The code is sent to the rust playground, which is play.rust-lang.org.
- If you need more information or a guided tour, you can message the speaker offline.
⭐️Understanding Generics
- Generics are ways for variables to have multiple possible types.
- They allow for code reuse without having to write new functions for each type.
- The Manning LiveBook has several chapters on generics that can be accessed online.
⭐️Understanding Traits
- There are two kinds of traits: inherent and trait objects.
- Inherent traits are implemented directly on a type, while trait objects are implemented on an object that implements the trait.
- Traits allow for polymorphism in Rust.
# Introduction to Traits and Generics
Section Overview: In this section, the speaker introduces traits and generics in Rust programming language.
⭐️What are Generics?
- Generics allow writing less source code and pushing more work to the compiler.
- A generic type is used as a function within a function to tell the compiler that it should do this work itself.
- The compiler goes for every single type that is called and creates a specific function for every single one.
⭐️⭐️⭐️What are Traits?
- Traits can be thought of as an
abstract base classin object-oriented programming languages. - A trait is just the definition of functions.
- Empty is the string literal syntax for constructing a given type, which turns out to be represented outside of memory at all.
# Implementing Traits and Types
Section Overview: In this section, the speaker explains how to implement traits and types in Rust programming language.
Implementing Traits
- Implementing traits means defining new types that satisfy the requirements specified by those traits.
- An empty trait can have no methods, which is formerly known as a marker trait.
- To implement a trait for a new type, we define an implementation block with our new type name followed by impl keyword.
Constructing New Types
-We construct new types using struct keyword followed by the name of the type and curly braces. -We can then implement traits for these new types.
# Conclusion
Section Overview: In this section, the speaker concludes the video by summarizing what was covered in the previous sections.
- The video covered an introduction to traits and generics in Rust programming language.
- Generics allow writing less source code and pushing more work to the compiler while traits can be thought of as an abstract base class in object-oriented programming languages.
- To implement a trait for a new type, we define an implementation block with our new type name followed by impl keyword.
Rustation Station Subscription and Social Media
Section Overview: In this section, the speaker encourages Rust users to subscribe and follow their social media accounts.
Rust Users Subscription
- The speaker encourages Rust users to subscribe by clicking the follow button.
- Subscribers will receive instant notifications when the speaker goes live.
Rustation Station Discord Link
- The speaker provides a link to the Rustation Station Discord for those who would like to get a subscription notification when they go live.
- Every rust streamer is in that discord, and anyone is welcome to join.
Follow on Social Media
- The speaker invites viewers to follow them on Twitter and other social media platforms.
Conclusion of Stream
Section Overview: In this section, the speaker concludes their stream and thanks viewers for participating.
Final Screen Choice
- The speaker realizes that they intended to use a different screen but ultimately chose the one they ended up with.
- They express satisfaction with their final choice.
Feedback Requested
- The speaker expresses enjoyment in having everyone participate in the stream.
- They offer to repeat this session or format if it has been positive and ask for feedback from viewers.
Future Streams
- The speaker announces that they will likely be streaming again at the same time next week.
- They thank viewers for participating and invite them to continue chatting in the chat box.
Generated by Video Highlight
https://videohighlight.com/video/summary/Flf4ezLWw1E
Rust Programming QA
- Rust Programming QA
- Introduction
⭐️ Using RC and RefCell in Rust⭐️ Creating an API with RC 0:08:56s- Rust Analyzer Difficulty Finding Questions Directory
- Understanding RC and Ref Counting
- Getting Ins Into Number of Counts
⭐️ Interior Mutability and Unsafe Cell⭐️ RefCell: Mutable References⭐️ Implementing Drop Trait⭐️ Importance of Standard Libraries Documentation- Sharing a Positive Comment
- Friday Night Routine
- New Question Introduced
⭐️ ⭐️ ⭐️ Explanation of Re-Borrowing in Rust- Examples of Re-Borrowing
- Increment Function
- Add To Function
- Variable Creation
- Printing Output
⭐️ Re-borrowing- Two Mutable References
- The Re-Borrow Crate
- Understanding Rust’s Re-borrow Feature
- Motivation Behind Rust’s Re-Borrow Feature
- Moving References in Rust Functions
- Recommendations for Subscribing to the Channel
- Generated by Video Highlight
Introduction
Section Overview: The speaker introduces themselves and apologizes for being unprepared. They explain that they are happy to answer questions or chat casually with the audience.
- The speaker realizes they are live and greets the audience.
- The speaker explains that they haven’t been live on camera since February and may be a bit rusty.
- The speaker offers to answer questions or chat with the audience, and mentions having an editor available.
⭐️Using RC and RefCell in Rust
Section Overview: The speaker explains what RC (reference counted) and RefCell are in Rust, how they work, and provides examples of their usage.
- The speaker enters the standard library in Rust to use sync RC and RefCell.
- The speaker explains that reference count is used to keep track of ownership or usage of a struct, while RefCell is used for shared access to a struct without allowing it to be destroyed until everyone is finished using it.
- The speaker notes that “reference” is being used for two distinct types of references in Rust, which can be confusing. They provide an example of creating a shared access struct using RC.
# Setting up and Introduction
Section Overview: In this section, the speaker sets up the environment for the tutorial and introduces the topic of discussion.
Setting up Environment
- The speaker changes the screen to dark mode to avoid blinding viewers.
- The speaker searches for Reef cell but realizes it is in the wrong place.
⭐️Introduction to Topic: RC and Ref Cell
- The speaker discusses RC and Reef cell and how they provide different functionalities.
- The speaker explains that RC provides a single-threaded reference counting pointer while Refcell provides machine ownership.
⭐️Creating an API with RC 0:08:56s
Section Overview: In this section, the speaker creates an API using RC and explains its implementation.
Creating an API with RC
- The speaker creates an API using RC by initializing it with literal syntax.
- The speaker derives debug from the created API.
- Rust analyzer indicates that everything is okay, although there are a couple of warnings.
Implementation of Clone Method
- The speaker creates references to the API using clone method which clones a reference not an object.
- When we clone a reference, it increments the counter as implemented in Clone trait.
# Inspecting Internals of Created Object
Section Overview: In this section, the speaker inspects internals of created objects and manipulates them.
⭐️Inspecting Internals of Created Object
- The speaker inspects the internals of the API object and notes that it is an immutable reference.
- To get to the internals, we need to look at the documentation and find some of these methods that might have counts.
⭐️Manipulating Created Object
- There are no bullet points for this section.
Rust Analyzer Difficulty Finding Questions Directory
Section Overview: In this section, the speaker discusses how Rust Analyzer will have difficulty finding the questions directory because it is in the wrong directory. The speaker then proceeds to move everything into Main and delete the questions directory.
Moving Source into Main
- Rust Analyzer has difficulty finding the questions directory.
- Move Source into Main to fix the issue.
Deleting Questions Directory
- Delete the questions directory.
- Workspace settings are deleted accidentally while deleting the questions directory.
Understanding RC and Ref Counting
Section Overview: In this section, the speaker talks about RC and ref counting. They discuss how they want to get ins into the number of counts and wonder if there is a strong count. The speaker also explains that strong count is not an inherent method of type but rather a free function that exists inside RC.
Getting Ins Into Number of Counts
- Speaker wants to get ins into number of counts.
- Strong count is not an inherent method of type but rather a free function that exists inside RC.
- Strong count is actually a static method of RC type and does not have self so a reference to an object needs to be taken.
⭐️Interior Mutability and Unsafe Cell
- Interior mutability creates a facade of immutability but enables types to change their interior state.
- All interior immutability is provided by unsafe cell which provides an immutable facade even though the interior is changing because it can guarantee all references will stay in the same place.
- Rust compiler guarantees precise aliasing and will not allow two references to refer to the same position in memory or both believe that they have the ability to mutate a value.
# Ampersand Mute and Rust’s Memory Model
Section Overview: In this section, the speaker explains Rust’s memory model and how it handles mutable references. They discuss the limitations of mutable references and introduce shared references as a solution. The speaker then introduces RefCell as a way to provide shared ownership semantics.
⭐️RefCell: Mutable References
- Mutable references in Rust are limited to one at a time.
- This presents a problem when dealing with shared resources.
- RefCell provides an extra guarantee that reference counting and shared mutability semantics will play nicely together.
- RefCell enables dynamic checking and provides shared ownership semantics.
- RefCell uses unsafe code under the hood but enforces the same semantics at runtime.
- RefCell provides an extra bit of correctness for shared ownership semantics.
# Implementing RC Ourselves
Section Overview: In this section, the speaker responds to a comment about implementing the drop trait themselves. They explain that doing so would require them to implement all of RC themselves.
⭐️Implementing Drop Trait
0:29:08 Opening up Standard Libraries Documentation
Section Overview: In this section, the speaker encourages learners to feel comfortable opening up the standard libraries documentation.
⭐️Importance of Standard Libraries Documentation
- The speaker emphasizes the importance of opening up and using the standard libraries documentation.
- Learners are encouraged to explore and familiarize themselves with it.
0:29:21 Sharing a Comment
Section Overview: In this section, the speaker shares a comment from James.
Sharing a Positive Comment
- The speaker shares a positive comment from James.
- The content of the comment is not mentioned.
0:29:32 Friday Night Nerd Talk
Section Overview: In this section, the speaker talks about their Friday night routine and introduces a new question.
Friday Night Routine
- The speaker reveals that it is currently Friday night for them.
- They mention that they spend their evenings talking to their computer.
- The speaker acknowledges that this may seem nerdy but hopes that others won’t judge them for it.
New Question Introduced
- The speaker mentions that they need to think of a new question.
- They express hope for an easy question but introduce a tricky one instead.
- The topic of re-borrowing in Rust is introduced as the new question.
0:30:23 Examples of Re-Borrowing in Rust
Section Overview: In this section, the concept of re-borrowing in Rust is explained and examples are provided.
⭐️⭐️⭐️Explanation of Re-Borrowing in Rust
- Re-borrowing is defined as a case where emphasis on star (*) is not symmetrical when encountering Rust.
- A blog post on re-borrowing is shared with viewers for further reading and understanding.
Examples of Re-Borrowing
- The speaker provides examples of re-borrowing in Rust.
- They mention that it is a strange feature and can be difficult to understand.
0:32:16 Incrementing Variables in Rust
Section Overview: In this section, the speaker demonstrates how to increment variables in Rust.
Increment Function
- The speaker defines an increment function that takes an immutable reference to an i32 and returns a mutable reference to ni32.
- They explain that the function increments the value by one.
Add To Function
- The speaker creates a second function called add to that adds 2 to n.
- This involves creating a function that takes a mutable reference to an i32 and returns a reference.
Variable Creation
- The speaker creates a mutable variable called “a”.
- They define it as mutable and add 2 using the add to function.
Printing Output
- The final step is printing out the output.
2194s Rust Re-borrowing
Section Overview: In this section, the speaker discusses how Rust’s compiler has been smart in adding a re-borrow to the code. They explain how it works and why it is not a copy or clone.
⭐️Re-borrowing
- The compiler has added a re-borrow to the code.
- This allows for the original data to be re-borrowed again in a different scope.
- The second borrow enables the data to be used in a different way.
2348s Rust Mutable References
Section Overview: In this section, the speaker explains how mutable references work in Rust and what happens when there are two mutable references to one object.
Two Mutable References
- Creating two mutable references to one object breaks Rust’s rules.
- Even though it is not allowed, it is still legal code.
- When trying to use both mutable references, only one can be used at a time.
- Implicit control flow exists in some instances of Rust, such as with d-ref trait.
2607s Re-Borrow Crate
Section Overview: In this section, the speaker introduces the Re-Borrow crate and explains how it can help solve problems related to re-borrowing objects that have been moved out of scope.
The Re-Borrow Crate
- The Re-Borrow crate provides examples of where re-borrowing can be useful.
- It allows for mutating an object even after it has been moved out of scope.
Understanding Rust’s Re-borrow Feature
Section Overview: In this section, the speaker discusses Rust’s re-borrow feature and how it enables the use of mutable references in places where it would be a breach of lifetime ownership rules.
⭐️Re-borrowing in Rust
- The compiler determines when an object has reached the end of its lifetime, allowing for a mutable reference to be used again.
- Overlapping lifetimes can cause issues with aliasing rules, but re-borrowing can help extend the utility of a reference.
- The re-borrowed reference is essentially fake and only exists on the source code level. There is only one pointer, but giving it a new binding makes ownership rules easier to follow.
Passing Mutable References into Functions
- When passing a mutable reference into a function, that particular reference is essentially moved. Only one reference can exist at any given time.
- If there are multiple references to an object, they must all be immutable except for one mutable reference.
Motivation Behind Rust’s Re-Borrow Feature
Section Overview: In this section, the speaker discusses why Rust’s re-borrow feature was implemented and how it contributes to developer happiness.
⭐️Ergonomics in Rust
- The compiler engineers who designed Rust wanted it to be as ergonomic as possible for developers.
- The re-borrow feature allows for more flexibility in using mutable references without violating lifetime ownership rules.
Moving References in Rust Functions
Section Overview: In this section, the speaker explains how moving references work in Rust functions and how they relate to mutable references.
Moving References
- When passing a mutable reference into a function, that particular reference is essentially moved.
- If there are multiple references to an object, they must all be immutable except for one mutable reference.
# Shared References and Mutable Borrowing
Section Overview: In this section, the speaker discusses shared references and mutable borrowing in Rust.
⭐️Shared References and Mutable Borrowing
- The speaker explains that a shared reference is needed for mutable borrowing.
- The variable R is introduced as a mutable reference to the meaning of life.
- The question of the lifetime of R is raised.
- If ownership of a variable has been given away, attempting to access it again through a reference is illegal in Rust.
# Breaking Rust’s Rules
Section Overview: In this section, the speaker discusses breaking Rust’s rules by creating multiple references to an object.
Creating Multiple References
- Rust prevents creating two references to an object with the ability to change its value.
- It is possible to cast a pointer as a u64 and create new pointers, but dereferencing them would be necessary.
- The speaker claps because someone understands something.
- There are discussions about reborrowing and syntax clunkiness.
# Language Learning Struggles
Section Overview: In this section, the speaker talks about language learning struggles.
Language Learning Struggles
- The speaker wishes they knew how to speak more languages like Polish or Russian but struggles with pronunciation.
- English speakers tend to put emphasis on the wrong part of the word when speaking Polish or Russian.
Recommendations for Subscribing to the Channel
Section Overview: In this section, the speaker recommends subscribing to their channel and mentions that they plan on doing more structured tutorials in the future.
Speaker’s Recommendation
- The speaker thoroughly recommends subscribing to their channel.
- They mention that they plan on doing more structured tutorials in the future rather than just answering questions on the fly.
- The speaker acknowledges that answering questions on the fly can be stressful for everyone involved.
Connecting with the Speaker
- The speaker provides links in the description of their YouTube channel for viewers to connect with them.
- They express hope that they will see each other online.
Note: This transcript is entirely in English.
Generated by Video Highlight
https://videohighlight.com/video/summary/lt13G3oSVSE
Conducting a code review of the jwtinfo crate
- Conducting a code review of the jwtinfo crate
- Introduction
- Setting Up
- Reviewing Code
- Continuing Reviewing Code
- Reviewing Code and Project Structure
- Asking Questions Live
- Introduction
- Project Structure
- Pause Token
- Improving the Ergonomics of Functions
- Limitations of Accepting Arbitrary Input
- Error Management
- Understanding the Code
- Rust Programming and Cultural Differences
- Derive Debug and Type Conversion
- IP Addresses and Color Change
- Exposing a Library and CLI Together
- Testing and Code Coverage
- Build Process and Shell Check
- Importance of Being Controversial
- Q&A Session
- Discount Strategies for Technical Books
- Wrapping Up
- Book Publishing and Royalties
- Conclusion and Next Steps
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces the topic of the stream and explains that there may be some technical issues with the audio.
Starting the Stream
- The speaker mentions that they will review a crate suggested by Luciano.
- The crate is called GWT Info and it’s related to JavaScript web tokens.
- The speaker shares a link to the code in the chat.
- They explain that they will clone the project and add comments to create a commit for Luciano to review.
Setting Up
Section Overview: In this section, the speaker sets up their environment for reviewing Luciano’s crate.
Cloning Repository
- The speaker opens up a terminal and navigates to their scratch directory.
- They clone their own branch of the repository so as not to interfere with Luciano’s work.
- They check out a new branch called “code review.”
Choosing an IDE
- The speaker decides to use C-line instead of VS Code because Rust Analyzer has crashed on them before.
Reviewing Code
Section Overview: In this section, the speaker begins reviewing Luciano’s code.
Cargo.toml File
- The cargo.tml file is used for getting information about GWT tokens.
- The categories listed in this file may not be necessary.
- Adding “GWT” as a tag could be helpful for others using this library.
Dependencies
- clap is used for producing command line utilities and clap stands for command line argument parser.
- base64 is pretty basic and version 1.0.0 is being used.
- cedar-json enables serde to understand JSON.
- lazy-static enables global state variables to be added.
Continuing Reviewing Code
Section Overview: In this section, the speaker continues reviewing Luciano’s code.
Argo.tml
- The argo.tml file is used for getting information about GWT tokens.
- The categories listed in this file may not be necessary.
- Adding “GWT” as a tag could be helpful for others using this library.
Dependencies
- clap is used for producing command line utilities and clap stands for command line argument parser.
- base64 is pretty basic and version 1.0.0 is being used.
- cedar-json enables serde to understand JSON.
- lazy-static enables global state variables to be added.
Reviewing Code and Project Structure
Section Overview: The speaker reviews code and project structure, discussing the creation of a mod directory, testing implementation, and fuzzing tools.
Reviewing Project Structure
- The team wants a review on project structure.
- The speaker suggests that creating a mod directory for a single module adds unnecessary bureaucracy.
- Testing should be close to the implementation.
Fuzzing Tools
- Fuzz testing is suggested to test arbitrary input.
- Property testing is recommended for avoiding repetition in tests.
- Rust compiler takes time to compile.
Asking Questions Live
Section Overview: The speaker encourages viewers to ask questions live during the stream.
Live Q&A
- Viewers are welcome to ask questions at any stage of the stream.
# Testing JWT Info
Section Overview: In this section, the speaker discusses testing JWT info and how to handle illegal input.
Testing for Illegal Input
- The speaker discusses using a validator for JW2s and testing it with colleague Stefano.
- They discuss testing with invalid input, such as non-UTF8 characters.
- The speaker asserts that they can handle bad input by giving an arbitrary name to the test case.
- They mention another test case for non-UTF8 input and discuss not panicking when encountering illegal input.
Using Quick Check
- The speaker mentions libraries like Quick Check that can search through infinite spaces of strings to find instances where tests will fail.
- They introduce Vic Q8, which stands for an arbitrary vector of u8 bytes.
Handling Null Bytes
- The speaker discusses how strings in Rust must be UTF-8 encoded and introduces the problem of always parsing a string.
- They experiment with null bytes and control characters to see what happens when parsing them.
Introduction
Section Overview: In this section, the speaker introduces themselves and welcomes viewers to ask questions in the chat.
Speaker Introduction
- The speaker introduces themselves and welcomes viewers to ask questions in the chat.
Project Structure
Section Overview: In this section, the speaker discusses project structure and error management.
Project Structure
- The speaker suggests putting JWT inside a module directory because it’s simple.
- The speaker mentions that they have touched on project structure at the start of the video.
Error Management
- The speaker talks about great error management and handling error types within Rust.
Pause Token
Section Overview: In this section, the speaker focuses specifically on pause token.
Pause Token
- The speaker explains that pause token expects an ampersand stir which is a string slice.
- The speaker mentions their confusion as to why their editor has decided not to provide any assistance. They update Rust and restart their ID.
- After resolving technical issues, the speaker continues explaining pause token and provides type hints with color syntax highlighting.
Improving the Ergonomics of Functions
Section Overview: In this section, the speaker discusses how to improve the ergonomics of functions that can only accept string or ampersands.
Accepting Arbitrary Input
- The speaker talks about allowing people to put in anything and accepting arbitrary input.
- One idea is to change
parse_tokentoparse_token<T: AsRef<str>>. - This means anything that can act as a string will be accepted.
- The type of text and type are examples of things that can act as a string.
Refactoring Function Declaration
- The speaker makes a small change to the function declaration by adding
as ref. - This allows for token as ref but doesn’t feel like a large change.
- All tests should still be able to run except for the two added ones that fail.
Rust’s Relationship with Text Types
- Rust has a difficult relationship with text types, which is discussed in detail in one of the speaker’s recent talks.
- There are eight different types of strings in Rust, each serving a specific purpose.
- These distinctions are important because they allow Rust to guarantee safety when dealing with operating system parts like file paths versus arbitrary string input.
Limitations of Accepting Arbitrary Input
Section Overview: In this section, the speaker discusses limitations when accepting arbitrary input.
Problem with Accepting Arbitrary Bytes
- The problem with accepting arbitrary bytes is that it won’t be able to become a string.
- The speaker is trying to respond to Luciano’s request for a code review and reviewing a crate that provides commandant utility.
Error Management
Section Overview: The speaker discusses error management in Rust and how to deal with errors from multiple locations.
Dealing with Multiple Error Types
- Every error type is its own thing in Rust.
- Luciano and Stefano created a wrapper type that wraps all of the errors from various crates that might blow up on them.
- This is one of the strategies for dealing with errors from multiple locations.
Custom Error Type
- The speaker suggests adding pointers to the beginning of the slice to enable better error reporting like more helpful error messages.
- Luciano and Stefano have created an enum which wraps three different errors plus it also provides its own bespoke error.
Displaying Errors
- The custom enum needs to be able to be printed to the screen, which can be done using format display out of the standard library.
- Part era is used to describe which section of the input is invalid.
Understanding the Code
Section Overview: The speaker discusses the code and suggests improvements to make it more readable.
Simplifying the Code
- The message format returns a string, which can be used with the right macro.
- There is no functional difference between the commented out variation and the suggested improvement.
- The match syntax provides a value, and each branch returns a string that can be assigned to a variable. This removes one element of duplication.
Improving Readability
- Suggests using local import for multi-line strings to simplify code.
- Considers allowing raids on stream and getting better at streaming.
- Discusses Twitch raiding and suggests doing one at the end of this stream if people want to keep learning about Rust.
Modularization
- Discusses whether or not things should be in a separate directory. Speaker believes there’s no need for it in this particular project but acknowledges that it’s subjective based on gut feel.
# Simplifying Code with Match Statements
Section Overview: In this section, the speaker discusses simplifying code using match statements and reducing repetition. They also explore an alternative method of returning a message and avoiding problems with multiple implementations.
Implementing Pattern of Simplification
- The speaker plans to re-implement the pattern of simplifying code using match statements.
- They find repetition in code to be problematic and want to reduce it.
- A trick they use is sending the format string and its arguments back.
Alternative Method for Returning Messages
- The speaker explores an alternative method for returning messages that avoids problems with multiple implementations.
- They acknowledge that this approach may be over-engineered but provide it as an option for exploration.
# Using Rust 2018 Idioms
Section Overview: In this section, the speaker discusses their opinion on using Rust 2018 idioms and whether or not they should be used if they are working well for you.
Personal Opinion on Using Rust 2018 Idioms
- The speaker shares their personal opinion on using Rust 2018 idioms.
- They believe that if something is working well for you and makes sense, there is no need to feel obligated to use all of the Rust 2018 idioms just because they exist.
# Splitting Out Different Parts of Code
Section Overview: In this section, the speaker discusses how splitting out different parts of code can lead to more informative error messages.
Benefits of Splitting Out Different Parts of Code
- The speaker explains how splitting out different parts of code can lead to more informative error messages.
- By breaking down each part into smaller components, errors can be isolated more easily.
# Retaining the Index of Where the Error was Detected
Section Overview: In this section, the speaker discusses retaining the index of where an error was detected in a JWT library. This information can be useful for debugging purposes.
Retaining Index of String Input
- The speaker mentions that they would like to retain the index of where an error was detected in a JWT library.
- This information can provide users with more information about where they can fix things.
- The speaker notes that JWTS are almost always automatically generated, so this feature may not be used very often.
- However, if someone were to create their own JWT library, it could be helpful to know where errors are being created.
# Understanding Rust’s Result Object
Section Overview: In this section, the speaker explains Rust’s Result object and how it is used in error handling.
Rust’s Result Object
- The speaker explains that Rust’s Result object is an enum with two states: pass (okay) and fail (error).
- They note that there are generics involved and explain what those are.
- The speaker briefly mentions panicking but notes that they have already dealt with error handling.
# Adding Derives to Types
Section Overview: In this section, the speaker considers adding derives to types and making them comparable.
Adding Derives
- The speaker suggests adding derives to make types comparable.
- They note that they don’t know if this will be useful or not.
Rust Programming and Cultural Differences
Section Overview: In this section, the speaker discusses the cultural differences between Rust programming and other languages like Python or JavaScript.
Bureaucratic Nature of Rust
- Rust can feel very bureaucratic compared to dynamic languages like Python or JavaScript.
- The RFC defines a method for validating JWT, which can be used to add further type safety to input validation code.
JWT Keto Types
- The speaker looks up JWT keto types in the standard to see if they are defined.
- Type is almost always records JWT.
- Implementing from stir provides fast feedback to users about what’s wrong with their input.
Claims Set
- There is a claims set that needs to be validated.
- Defining an error will allow for more specific validation of string slices becoming a concrete type.
Derive Debug and Type Conversion
Section Overview: In this section, the speaker discusses how to derive debug and type conversion in Rust.
Deriving Debug
- To derive debug, add
#[derive(Debug)]above the struct definition. - This allows for easy debugging of structs by printing them out.
Type Conversion
- Generic types can be used but it is not recommended.
- Use
matchto validate input types. - Implement
FromStrtrait to convert strings into concrete types outside ourselves. - This enables parsing methods without needing to bring in a dependency which is quite nice.
- It becomes very ergonomic as someone who’s using a library.
- Exposing a library and CLI together can be done but may not always be necessary.
Mistake Correction
- The speaker made a mistake earlier when explaining type conversion that was already implemented using Surday string serialization system.
- The explanation on type conversion was unnecessary but left in for reference purposes.
IP Addresses and Color Change
Section Overview: In this section, the speaker talks about IP addresses and changing the color of documentation.
IP Addresses
- Implementing the right trait allows converting raw strings into concrete types outside ourselves which becomes very ergonomic as someone who’s using a library.
Color Change
- Changing the color of documentation is possible but using dark and light together can be confusing or hurtful to people’s eyes so it should be done with caution.
Exposing a Library and CLI Together
Section Overview: In this section, the speaker talks about how to stick to Rust and expose a library and CLI together.
Understanding the Library Component
- The focus of creating a library is understanding what it is that you have.
- The functionality “pub” is public and becomes part of the library.
Building Documentation
- To build documentation for a crate, use Cargo, which is like Javadoc for Rust.
- Adding comments and usage examples for public functions can improve documentation.
Improving Library Functionality
- Adding documentation should be the first thing to do when exposing a library.
- Testing should be done to ensure utility resilience against malicious input.
Testing and Code Coverage
Section Overview: In this section, the speaker talks about testing and code coverage.
Resilience Against Malicious Input
- It’s important to make sure that your utility is resilient against malicious input.
Code Coverage
- Code coverage is useful in testing.
- Tooling around code coverage can help with testing.
Build Process and Shell Check
Section Overview: In this section, the speaker discusses the build process and introduces shell check, a linter for shell code.
Installing Latest Release Based on Dip
- The speaker suggests downloading and installing the latest available release based on dip.
Compliance with RSA and Documenting Platforms
- The speaker considers compliance with RSA and documenting platforms, OS, arc CPU architecture.
Introduction to Shell Check
- Shell check is introduced as a linter for shell code.
- It provides warnings that suggest changes to improve code quality.
- It can be downloaded and installed for free from shellcheck.net.
- The speaker mentions that it has found their code to be pretty good but suggests avoiding camelcase.
Importance of Being Controversial
Section Overview: In this section, the speaker talks about how being controversial is important and how it can be nerve-wracking to talk about certain topics.
Being Controversial
- The speaker believes that if someone cannot talk about controversial topics, they should not be speaking publicly at all.
- People tend to avoid talking about controversial topics because it can be scary, but the speaker thinks it’s important to call things out.
- The speaker encourages people to ask questions and engage in discussions.
Q&A Session
Section Overview: In this section, the speaker invites questions from the audience and provides a discount code for his book.
Questions and Discount Code
- The speaker invites questions from the audience.
- The speaker provides a discount code for his book on wrestlingaction.com.
- The speaker mentions that chapters of his book can also be read for free on lifebook.
Discount Strategies for Technical Books
Section Overview: In this section, the speaker discusses discount strategies for technical books and their impact on royalties.
Discount Strategies
- The speaker discusses how discounts can be a double-edged sword when it comes to selling technical books.
- The speaker suggests that increasing ticket prices may make people more likely to buy discounted versions of technical books.
- Alternatively, reducing the full price version may encourage more sales without relying heavily on discounts.
Wrapping Up
Section Overview: In this section, the speaker wraps up the stream and invites people to hang out on his Discord server.
Final Thoughts
- The speaker mentions that being a new streamer is fun because there are no expectations.
- The speaker reflects on the success of his book in terms of reputation but notes that it has not provided financial stability.
- The speaker provides information about his book sales and royalties.
- The speaker invites people to hang out on his Discord server.
Book Publishing and Royalties
Section Overview: In this section, the speaker talks about their experience with book publishing and royalties.
Book Publishing Contract
- The contracts for first-time authors are structured differently.
- The speaker accepted a contract that gave them 10% of net royalties.
- Net royalties means the amount left after costs such as affiliate fees and credit card payment fees are deducted.
Book Sales
- The book is selling well, but most people buy it heavily discounted.
- After fees, the speaker earns about $2 per title sold.
Conclusion and Next Steps
Section Overview: In this section, the speaker concludes their stream and provides information on how to connect with them offline.
Wrapping Up
- The speaker thanks viewers for hanging out on the stream.
- They provide links to their Discord server and Twitter account for offline connections.
Raiding Another Streamer
- The speaker decides to raid another streamer named Luis who has only one viewer at the moment.
- They provide a link to Luis’s channel for viewers to hang out there instead.
Future Streaming Schedule
- The speaker plans to stream once or twice a week at different times to accommodate viewers in different time zones.
Generated by Video Highlight
https://videohighlight.com/video/summary/1JZ1oWp3PuA
What is ownership in Rust?
Ownership in Rust
Section Overview: In this section, the speaker explains what ownership is in Rust and why it exists.
What is Ownership?
- Ownership refers to a variable that is responsible for deleting the data it represents when the variable ends its scope.
- Unlike property rights in real life, ownership confers no benefits to the owner. The owning variable doesn’t have preferential access to the data it owns nor can it prevent others from accessing what is owned.
- Rust needs to know when it’s safe to delete data since there’s no garbage collector like other programming languages such as Java or Python. This leads to ownership being used instead.
⭐️How Ownership Works
- Rust only allows a single owner, so when an owner leaves scope or becomes invalid, it must be safe to delete the owned data.
- To create an owner, you create a value and bind it to a variable. Once you’ve created the data, you create an owner.
- We can transfer ownership in Rust through moving or copying semantics. Moving transfers ownership while copying duplicates the data and creates two owners.
- When we transfer ownership through assignment, only the new name can be used since ownership has moved there.
- Another way of transferring ownership is by moving into a function.
Why Ownership Exists
- Ownership exists because Rust does not have a garbage collector like other programming languages such as Java or Python. Including one would impose runtime costs and make performance less predictable by introducing latency and pauses.
Passing Variables to Functions
Section Overview: This section discusses how variables are passed into functions in Rust.
Ownership and the End of a Variable’s Life Cycle
- When an owner’s scope ends or becomes invalid, any resources it owns are deleted.
- Data is deleted when there is no owner for it.
For Loops and Ownership Transfer
- Ownership transfers into a loop, making the variable inaccessible after the loop finishes.
- Looping over references does not move ownership; ownership stays where it was.
- If you have a reference to the variable or a mutable reference, you can still access the variable after the loop has finished.
⭐️String Literals and No Owner
- String literals behave differently because they don’t actually own the data that they refer to. They are kept alive for the whole program.
- Variables of string literals have the type
&str, which is a reference to a string slice.
Conclusion
Section Overview: This section concludes the talk on ownership in Rust.
- The speaker hopes that viewers enjoyed the talk and encourages them to ask questions in the comments.
- The book “Rust in Action” explains ownership in depth, and viewers can use a discount code provided by the speaker to purchase it.
Generated by Video Highlight
https://videohighlight.com/video/summary/1mq-vV5ECOo
What is Rust Borrow Checker and Why is it Useful
- What is Rust Borrow Checker and Why is it Useful
- Introduction
- Overview of Rust Borrow Checker
- Modifying Digital Input
- Adding a Warning Restriction
⭐ Types of Function Arguments in Rust- Borrow Checker
- Modifying Input Data Using Functions
- Thanking Viewers
- Passing Immutable Borrowers
- Rust’s Immutability and Data Access
- Reassigning Input Variable References
- Limitations on Mutable Borrowers
- Problems with Spawning Threads
- Introduction to Rust’s Standard Library
- Borrowing in Rust
- Conclusion and Additional Resources
- Positive Reviews and Special Offer
- Discord Channel for Learning Rust
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces themselves and the topic of discussion, which is Rust borrow checker.
- The speaker mentions that they are live and invites viewers to ask questions.
- They introduce the topic of Rust borrow checker and mention that it is a construct within the compiler that ensures every access to memory is valid.
Overview of Rust Borrow Checker
Section Overview: In this section, the speaker provides an overview of Rust borrow checker.
- The speaker explains that they will be playing around with references and creating an object for digital input.
- They define what a borrow is and create a type definition for digital input.
- They add derived blocks for plug, equality, partial load quality, and debug to enable printing input to the screen and comparing different input sources.
Modifying Digital Input
Section Overview: In this section, the speaker demonstrates how to modify digital input in Rust.
- The speaker creates a function called “receive” that takes an input variant as an argument.
- They use the question mark operator again and replace analog with digital to receive data from a digital input.
- They print out the received value using println! macro.
# Adding a Warning Restriction
Section Overview: In this section, the speaker adds a warning restriction to avoid compiler warnings.
Adding a Warning Restriction
- Added a warning restriction to allow dead code inside the function.
- The compiler warning is now restricted, which is helpful because we don’t want it.
# Understanding Borrow Checker
Section Overview: In this section, the speaker explains what borrow checker is and how it works in Rust.
⭐Types of Function Arguments in Rust
- Functions in Rust can take three types of arguments - ownership, mutable borrower, and immutable borrower.
- Ownership is another stretched metaphor where the owner of a value is responsible for destroying the value at the end of its scope.
- Receive function becomes the owner of input data and deletes it at the end of its scope. Accessing digital on lines 23 and 24 becomes illegal.
- Added an ampersand as an immutable borrow to fix ownership issue.
Borrow Checker
- The borrow checker ensures that we can call receive twice without any issues.
- Digital stays in line 20, and we only pass a reference into receive from digital. Receive will clear up the reference to its input once the call is finished.
# Calibrating Input Data
Section Overview: In this section, the speaker talks about calibrating input data and modifying it using functions.
Modifying Input Data Using Functions
- Match on input and convert digital to analog.
- If we have another function called calibrate, which takes an input and modifies it, we can modify the input data.
# Conclusion
Section Overview: In this section, the speaker concludes the video and thanks the viewers for watching.
Thanking Viewers
- The speaker thanks viewers for watching and encourages them to subscribe to their channel.
- The speaker offers to answer any questions about borrowing or Rust.
# Providing Immutable Borrowers
Section Overview: In this section, the speaker discusses the problem of passing ownership into calibrate and how they want to provide an immutable borrow instead. They also mention Rust’s default immutability and its particularity about data access.
Passing Immutable Borrowers
- When tied dialing a knob, calibration is necessary.
- Passing ownership into calibrate is not what we want.
- We want to provide an immutable borrow instead.
Rust’s Immutability and Data Access
- Rust is very particular about data access and always tries to be safe.
- Rust is mute immutable by default.
- Digital pins are digital inputs that can be high or low, while analog pins have a range between 0 and 255.
# Reassigning References
Section Overview: In this section, the speaker explains why reassigning input variable references is necessary when swapping between analog and digital inputs.
Reassigning Input Variable References
- When swapping over to analog or digital inputs, reassignment of input variables is necessary.
- To change what is being referred to (the referent), rust needs to be told that mutable access is required.
# Limitations on Mutable Borrowers
Section Overview: In this section, the speaker demonstrates how rust only allows one mutable borrower at a time and how spawning a thread can cause problems.
Limitations on Mutable Borrowers
- Rust only allows one mutable borrower at a time.
- Spawning a thread can cause issues if main finishes before the thread finishes.
Problems with Spawning Threads
- Syntax for spawning a thread in rust involves giving it a closure.
- Rust detects that providing a borrow in the same way as inside main could cause problems.
Introduction to Rust’s Standard Library
Section Overview: In this section, the speaker looks up the documentation for Rust’s standard library and finds the sleep function. They explain how to use it and discuss why Rust will refuse to compile certain code.
Finding the Sleep Function
- The speaker looks up the documentation for Rust’s standard library at rust-lang.org.
- They find the sleep function inside of thread.
- To use it, they need to pass a duration object.
Using Duration Objects
- The speaker imports std::time to gain access to a duration object.
- They create a new thread called delay that sleeps for 10 milliseconds using time::Duration::from_millis(10).
- They explain that if main finishes before delay, Rust will try to destroy all of its values and refuse to compile broken code.
Fixing Errors with Clone
- The speaker encounters an error with thread::sleep and realizes they need clone as well.
- Even after fixing this error, they only receive one output because the child thread outlives main.
Borrowing in Rust
Section Overview: In this section, the speaker discusses borrowing in Rust and explains why having two mutable borrows at once can be difficult.
Calibrating Faucets
- The speaker explains that calling one faucet after another works fine because they are in different scopes.
- However, having two mutable borrows at once is difficult in Rust.
Interesting Observations
- The speaker finds their own observations interesting but does not elaborate on what those observations are.
Conclusion and Additional Resources
Section Overview: In this section, the speaker concludes their talk on Rust and provides additional resources for learning more about it.
Wrapping Up
- The speaker offers to answer any questions but has covered everything they planned to talk about.
- They mention that they have written a book called Rust in Action and provide a link to it.
Discount Code
- The speaker provides a discount code for their book.
Positive Reviews and Special Offer
Section Overview: In this section, the speaker talks about the overwhelmingly positive reviews of a product, with only a small chance of disliking it. They also mention a special offer for Independence Day in the USA.
Positive Reviews
- The product has very positive reviews.
- There is only about a 5% chance of disliking it.
- There is a 90-95% chance of liking it.
Special Offer
- The product is on special right now because of Independence Day in the USA.
- You can have access to the print book and multiple ebook formats as well.
- All formats are DRM-free.
- There is also a web version available.
Discord Channel for Learning Rust
Section Overview: In this section, the speaker provides a link to their Discord channel for those who wish to continue learning Rust.
Link to Discord Channel
- The speaker provides a link to their Discord server for those who wish to continue learning Rust.
- They encourage people to ask them any questions they may have.
Generated by Video Highlight
https://videohighlight.com/video/summary/ENF0V_T0Ayk
What is the difference between string and &str in rust
- What is the difference between string and &str in rust
Difference between String and &str
Section Overview: In this section, the speaker explains the difference between String and &str in Rust programming.
String vs. &str
- A String is more versatile than a string slice (&str).
- A string slice has fewer methods.
- A string slice doesn’t allow any extra information to be appended at the end.
- If we try to compile a program with a string slice, we’ll receive an error message from the compiler saying that push_str or reference &str won’t work.
- On the other hand, a String will compile and run without any issues.
Strings and Strs Always Look Different
Section Overview: In this section, the speaker talks about how Strings and strs always look different in Rust programming.
Representation of Strings in Source Code
- Whenever you see a string literal in Rust, it is never an actual string.
- It is a “string slice” which has “&str” as its type.
- If we tell Rust that it’s a string, we’ll get an error message from the compiler saying that it expected a string but found an &str instead.
- To convert an &str to a String, we can use the “to_string()” method.
Why Is Ampersand Necessary?
Section Overview: In this section, the speaker explains why ampersand is necessary when dealing with strings and slices in Rust programming.
The Role of Ampersand
- The ampersand precedes the type (string slice) because it indicates that we are borrowing data rather than owning it.
- When we borrow data using &, we don’t have to worry about deallocating memory since ownership remains with the original owner of data.
- Without &, Rust would not know how much memory to allocate for str since its size cannot be known at compilation time.
- Therefore, the ampersand is necessary to indicate that we are borrowing data and not owning it.
# Understanding Rust Strings
Section Overview: In this section, the speaker explains how Rust handles strings and string slices. They discuss the conflict beginners face when trying to understand why the Rust compiler behaves in a certain way and explain how references are used to get around fixed size limitations.
Fixed Size Limitations
- Beginners often struggle with understanding why the Rust compiler behaves in a certain way.
- Every function call needs to be of a fixed size, which makes it difficult to fit things of arbitrary length inside something that requires a fixed length.
- References are used to get around fixed size limitations by adding a reference to the text, which has a fixed size represented internally as a number.
String Capacity
- Strings have more than just an internal pointer and length of bytes; they also have capacity.
- The capacity of strings can change, allowing for reserving extra space.
Borrowing
- Borrowing is one of the most fundamental distinctions between strings and string slices.
- A string is called an “owned value,” whereas a string slice is called a “borrowed value.”
- When welcome leaves scope, it will delete any data that it owns. However, borrowed values do not own data and will not delete anything.
Understanding Rust Strings and String Slices
Section Overview: In this video, the speaker explains the differences between Rust strings and string slices. He demonstrates how to create a function that prints a message using both types of variables and highlights the limitations of using strings.
Creating a Function with Strings
- The speaker creates a function called
print_messagethat takes in a message as an argument. - When trying to pass in a string variable called
welcome, which is defined outside of the function, the compiler throws an error because it is not mutable. - If we change the definition of
welcometo be a string instead of a variable, it will fail to compile because oncewelcomeleaves scope, it no longer exists.
Borrowing Variables
- To get around this limitation, we can borrow the
welcomevariable again within theprint_messagefunction. - After fixing some type definition issues, borrowing works fine.
Differences Between Strings and String Slices
- The fundamental difference between strings and string slices is that strings are owned values while string slices are borrowed values.
Conclusion
- The speaker invites viewers to subscribe to his channel for more content on Rust programming. He also encourages viewers to ask for explanations on specific topics they would like to learn.
Generated by Video Highlight
https://videohighlight.com/video/summary/n7-vKRLw3zg
Why Enums Are Your SuperPower
- Why Enums Are Your SuperPower
* Topics to be Discussed
* Enum Definition and Demonstration
* Comparison of Enums and Sum Types
* Printing Enums with Debug Derive Implementation
* Benefits of Using Enums for Safe Input Handling
* Definition of Blind Booleans
* Benefits of Using Enums to Remove Blind Booleans
* Definition of Finite State Machines
* Discussion on Finite State Machines in Rust
* Enum Types in Rust
* Using Match Keyword
- Implementation for 32 to rise not available
- Introduction to Enums
- Separating Business Logic from String Input Handling
- Implementing Enums in Rust
- Parsing Method and Business Logic
- Implementing FromStr Trait
- Returning Status and Error
- Handling Illegal Inputs
- Testing Implementation
- Debugging Errors
- Using Enums to Remove Stringly Typed Data
- Using Pattern Matching with Enums
- Unwrapping Results
- Understanding Option and Result Types
- Error Handling
- Blind Booleans
- Future Streams
- Discord Channel
- Checking Validity
- Ownership in Rust
- Improving Boolean Statements in Type Systems
- Rust Enums
- Returning Traffic Light Green
- Future Streams and Conclusion
- Generated by Video Highlight
# Introduction
Section Overview: In this section, the speaker introduces the three main topics that will be discussed in the video.
Topics to be Discussed
- The definition and usage of enums
- The benefits of using enums for safe input handling and removing blind booleans from code
- Finite state machines within Rust
# What is an Enum?
Section Overview: In this section, the speaker explains what an enum is and demonstrates how it represents multiple positions.
Enum Definition and Demonstration
- An enum represents multiple positions or states.
- A traffic light example is used to demonstrate how an enum can represent different states such as green, yellow, red, and flashing yellow.
# Enums vs Sum Types
Section Overview: In this section, the speaker briefly discusses sum types and their equivalence to enums.
Comparison of Enums and Sum Types
- A sum type is a term from type theory that is equivalent to an enum.
- The speaker notes that beginners may not understand what a sum type is and will hold off on discussing it further.
# Printing Enums in Rust
Section Overview: In this section, the speaker explains how to print enums in Rust.
Printing Enums with Debug Derive Implementation
- To print out an enum’s value in Rust, use the debug derive implementation by adding #[derive(Debug)] above the enum definition.
- Use println!() with curly braces {} inside to indicate where the enum value should be printed.
# Safe Input Handling with Enums
Section Overview: In this section, the speaker explains how enums can be used for safe input handling.
Benefits of Using Enums for Safe Input Handling
- Enums can be used to define a set of valid inputs, ensuring that only those inputs are accepted.
- This helps prevent errors and bugs caused by invalid inputs.
- The speaker notes that enums are not the only way to achieve safe input handling but are one effective method.
# Removing Blind Booleans from Code
Section Overview: In this section, the speaker explains how enums can be used to remove blind booleans from code.
Definition of Blind Booleans
- Blind booleans refer to functions that return a boolean without providing context or meaning for what true or false represents.
- This can lead to confusion and errors when working with the returned value later on.
Benefits of Using Enums to Remove Blind Booleans
- By using an enum instead of a blind boolean, the returned value has clear meaning and context.
- This helps prevent errors and makes code easier to understand and maintain.
# Finite State Machines in Rust
Section Overview: In this section, the speaker discusses finite state machines within Rust.
Definition of Finite State Machines
- A finite state machine is a mathematical model used to represent systems that have a finite number of states and transitions between those states.
- They are commonly used in programming for things like user interfaces, games, and network protocols.
Discussion on Finite State Machines in Rust
- The speaker notes that finite state machines are an advanced topic in Rust.
- They mention that they have a big example but haven’t made it simple enough for the video yet.
- The speaker will do their best to discuss finite state machines within Rust.
0:06:34 Rust Enum Types
Section Overview: In this section, the speaker explains how Rust’s enum types are distinct from C or Java and can act like a struct.
Enum Types in Rust
- Rust’s enum types can act like a struct.
- Enums in Rust can encode both a unit as well as a value.
- The speaker gives an example of defining temperature using enums in Rust.
- If you have only ever used enums to encode constants, it may look strange but interesting.
0:09:27 Working with Enums in Rust
Section Overview: In this section, the speaker explains how to work with enums in Rust using the match keyword.
Using Match Keyword
- The match keyword is similar to the switch keyword but more powerful and type-safe.
- It is impossible to not take into account all possible variants every time you encounter a match or use match.
- The speaker gives an example of matching room temperature and converting it to Celsius using high school mathematics formula.
Implementation for 32 to rise not available
Section Overview: The speaker mentions that the implementation for 32 to rise is not available.
Fahrenheit to Celsius conversion
- Fahrenheit needs to be a floating point number.
- Match function ensures all variants are taken into account.
- Error message indicates if a variant is not covered.
- Wildcard match can be used but is not particularly useful.
Safe input handling
- Speaker introduces safe input handling as a superpower.
- Example of reading from network and defining response object with text string.
- Demonstrates pulling out text from response object and converting string literal to string type.
- Difference between string slice and string type in Rust explained.
Protecting code
- String slice is just a pointer and length, while string has pointer to memory on heap that it owns completely.
- Speaker discusses protecting code in languages like Python, JavaScript, Ruby.
Introduction to Enums
Section Overview: In this section, the speaker introduces the concept of enums and explains how they can be used to remove strings from code.
Separating Business Logic from String Input Handling
- Enums allow for separation of concerns between business logic and handling string input.
- Strings are risky because invalid inputs can be dangerous or malicious. Converting them to a type is safer.
Implementing Enums in Rust
- The
from_strmethod allows for parsing strings into enums. - Implementing
FromStrtrait enables creation of paths automatically.
Parsing Method and Business Logic
- The parsing method should contain the business logic, such as converting to lowercase and checking if it matches “ okay“.
- Only two inputs are legal: “okay” or “error”. Any other input is considered illegal. An error message is returned for illegal inputs.
# Parsing Strings to Enums
Section Overview: In this section, the speaker discusses how to parse strings into enums in Rust.
Implementing FromStr Trait
- To parse a string into an enum, we need to implement the
FromStrtrait. - We can use the
matchstatement to match the input string with the corresponding enum variant.
Returning Status and Error
- When parsing a string into an enum, we can return either a status or an error.
- We wrap our result in
OkorErr, depending on whether it’s a status or error.
Handling Illegal Inputs
- If we receive unexpected input, we return an error message.
- We distinguish between expected and unexpected outcomes using Rust’s version of result and our own version of result.
Testing Implementation
- The speaker tests their implementation of
FromStr. - They check for errors using the compiler and try running their code.
Debugging Errors
- The speaker encounters errors while debugging their code.
- They make changes such as importing traits and removing unnecessary variables.
Using Enums to Remove Stringly Typed Data
- By using enums, we can remove stringly typed data from our program and remove business logic from parsing strings.
- This allows us to deal with input in our application code more effectively.
# Pattern Matching and Rust Enums
Section Overview: In this section, the speaker discusses pattern matching in Rust and how it relates to Rust enums. They explain how to use pattern matching to handle different variants of an enum, such as handling errors in a Result type.
Using Pattern Matching with Enums
- The speaker explains that they can use pattern matching in Rust.
- They note that while the syntax for pattern matching may be unfamiliar at first, it is the idiomatic way to handle certain situations in Rust.
- The speaker demonstrates how they used pattern matching to handle illegal input from a response object.
- They explain that using enums allows for more effective error handling because every variant must be handled at compile time.
Unwrapping Results
- The speaker introduces the unwrap method for Results, which returns the value inside an Ok variant or panics if it is an Err variant.
- They demonstrate how to use unwrap with a type hint before a function call.
- The speaker addresses whether using unwrap is considered “evil” and notes that it depends on the situation.
Understanding Option and Result Types
- The speaker explains that understanding enums is important for understanding Option and Result types in Rust.
- They emphasize that knowing how these types work is crucial for developing Rust code effectively.
# Error Handling and Blind Booleans
Section Overview: In this section, the speaker discusses error handling in Rust and introduces the concept of blind booleans.
Error Handling
- If an input causes an error, the program will crash.
- Tolerating a crash in production code is not recommended.
- There are cases where tolerating a crash is justified.
Blind Booleans
- A blind boolean is a function that takes a string as input and returns a boolean without any indication of what the boolean represents.
- The use of blind booleans can lead to confusion and errors in code.
- It’s important to provide clear names for functions that return booleans.
# Future Streams and Discord Channel
Section Overview: In this section, the speaker talks about future streams and invites viewers to join their Discord channel for updates.
Future Streams
- The speaker plans to do weekly streams like this one.
- They have a list of future stream topics, including traits.
- Viewers are encouraged to put the streams on their calendars.
Discord Channel
- The speaker has a Discord channel where they post updates about their streams.
- Viewers are welcome to join the channel.
# Checking Validity of Strings with Rust
Section Overview: In this section, the speaker demonstrates how to check if a string is valid using Rust.
Checking Validity
- Use
is_validfunction on string slice to check validity - If it’s not valid print standard error message
- Otherwise print out rest of story
Ownership in Rust
Section Overview: In this section, the speaker explains ownership in Rust and how to indicate to Rust that it should not delete text when the scope of a variable ends.
Indicating Ownership
- Taking ownership requires indicating to Rust that it should not delete text when the scope of a variable ends.
- Adding ampersands asks Rust to keep the value inside the outer scope.
Improving Boolean Statements in Type Systems
Section Overview: In this section, the speaker discusses how booleans can be improved in type systems and suggests using an enum instead.
Creating an Enum
- The speaker wanted to create a situation where there is both French and English.
- Validation functions should return a language instead of booleans.
- Creating an enum with special handling for French and English or undetected would be better than using booleans.
- Matching detects language instead of chaining boolean statements.
Returning Specific Language
- It is possible to return a specific language by defining result.
Rust Enums
Section Overview: In this section, the speaker talks about how Rust enums are similar to French return and how they can be used to define a little type for undetected language. The speaker also mentions that enums are highly appropriate for encoding state machines.
Using Enums to Define Undetected Language
- Rust enums are similar to French return.
- A little type can be defined for undetected language using enums.
- It may not necessarily be an error if the language is undetected as it could still be human language but with uncertain identification.
- Tests for identifying languages are probabilistic in nature.
Returning a Result Using Enums
- To return a result using enums, wrap it in
Okand useErrfor errors. - A separate type can be created for undetected language.
- If we want to return a result, we can do so by wrapping it in
Okand providing the undetected language type.
Encoding State Machines with Enums
- Enums are highly appropriate for encoding state machines.
- State transitions can be guaranteed at compile time using enums.
Live Book Preview of the Speaker’s Book
- The live book preview of the speaker’s book is available on manning.com under “Free Preview”.
- The live book allows readers to read a significant portion of the book for free and copy code examples.
Using Enum Cases in Type Signatures
- Enum cases can be used in type signatures.
- For example, if there is an enum called TrafficLight with cases Red, Yellow, and Green, a function could take TrafficLight as an argument.
Returning Traffic Light Green
Section Overview: In this section, the speaker discusses returning traffic light green and how Rust handles it.
Handling Traffic Light Green
- Rust cannot return only traffic light green as the type is the actual enum itself.
- Individual structs for each state can be used, but it becomes less comfortable to use.
- A state machine composed of multiple different structures can be used, but there is a proposal that enables returning smaller types. The speaker recommends reading Anna’s blog post on encoding transitions in the type system.
Future Streams and Conclusion
Section Overview: In this section, the speaker talks about future streams and concludes the current stream.
Future Streams
- The speaker agrees to do a stream on traits and trait objects.
- Requests for further streams are welcome, and the speaker will attempt to stream weekly depending on availability.
Conclusion
- The speaker thanks everyone for their support and encourages them to subscribe or follow on Twitter.
- The clickable link to connect with the speaker is provided in the transcript.
- The speaker concludes by saying goodbye and wishing everyone well.
Generated by Video Highlight
https://videohighlight.com/video/summary/MAPdmN4hKow
Implementing the trie data structure in Rust
- Implementing the trie data structure in Rust
- Introduction
- Trie Data Structure in Rust
- Updating Node with Default Value
- Ensuring End Field on Node is True
- Creating Contains Method
- Trie Data Structure Implementation
- Introduction to Children as a Hashmap
- Improving Hashing Algorithm for Short Keys
- Building a Hasher
- Using Linear Scan or Binary Search Instead of Hashmap
- Proposal for a Single Hash Map
- Binding Lifetimes Together
- Implementing Defaults for Node A
- Introduction
- Borrowing Chicken
- Avoiding Double Lookout Problem
- Updating Children Nodes
- Default Image
- Naive Sensible Way
- Conclusion
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces himself and expresses excitement about what they will achieve in the next few minutes to an hour. They also acknowledge comments from viewers and introduce the project they will be working on.
- The speaker greets viewers and expresses excitement about the upcoming stream.
- They introduce themselves and acknowledge comments from viewers.
- The speaker shares a link to their Div 2 profile and a shader project for viewers to play with.
- They share a link to the post that they will be implementing during the stream.
# Creating a New Project
Section Overview: In this section, the speaker creates a new project using Cargo and explains how it works.
- The speaker creates a new project using Cargo called “treee”.
- They explain that Cargo is a tool that invokes Rust and demonstrates how to use it by running “cargo run”.
- The speaker changes the output of the program to “Hello Internet” and runs it again using “cargo run -q”.
# Motivation for Trees
Section Overview: In this section, the speaker discusses why trees are useful data structures.
- The speaker acknowledges a viewer’s question about what trees are and why they are useful.
- They provide an agenda for the stream, which includes discussing motivation for trees, implementing them naively, and optimizing them later on.
- The speaker explains that trees are used in standard collections and hash sets.
- They mention that they will be using a hash set to demonstrate how trees work.
# Introduction to the Problem
Section Overview: In this section, the speaker introduces the problem of storing a large number of URLs in memory and discusses how much memory is being used.
Storing URLs in Memory
- The speaker discusses how much memory is being used when storing URLs in a set.
- They mention that there is a lot of duplication when storing URLs, which wastes memory.
# Introducing Trees as a Solution
Section Overview: In this section, the speaker introduces trees as a solution to the problem of storing URLs in memory.
Trees vs Sets
- The speaker explains that sets require duplicating common prefixes, which wastes memory.
- Trees only store interesting new stuff and save on memory.
Implementing Trees
- The speaker explains that they will be implementing trees naively.
- They discuss creating a tree data structure that holds onto individual characters instead of strings.
# Creating the Tree Structure
Section Overview: In this section, the speaker begins implementing the tree structure for storing URLs.
Creating Root Node
- The speaker begins by creating the root node for their tree structure.
# Introduction to Trie Data Structure
Section Overview: In this section, the speaker introduces the concept of a trie data structure and explains how it is made up of elements called nodes.
Nodes in a Trie
- A node is an element of the tree that is made up of letters.
- The root node will be an ‘h’ followed by ‘t’ and ‘t’.
- The children of the root node will branch out to ‘r’, ‘m’, and ‘a’.
# Creating a Hash Map for Tries
Section Overview: In this section, the speaker explains why a hash map is needed for tries and demonstrates how to create one.
Creating a Hash Map
- A hash map with keys as characters and values as nodes is needed for tries.
- Derive debug and default traits are added to make printing easier.
- Length starts at zero, and an empty hash map initializes to false.
# Inserting Strings into Tries
Section Overview: In this section, the speaker explains how strings can be inserted into tries.
Inserting Strings
- Option U size can be returned as the new length of the try.
- Borrowing oneself allows for memory allocation.
- An indicator that we’re on track can be added.
Trie Data Structure in Rust
Section Overview: In this section, the speaker discusses the implementation of a trie data structure in Rust. They explain how to create a mutable variable and update it using the entry API. They also discuss the use of string slices and characters in Rust.
Creating a Mutable Variable for Insertion
- To insert into a trie data structure, we need to create a mutable variable called
current_node. - We take a mutable reference to
self.rootbecause it is the only thing we have currently. - We use an entry API to check if
calready exists insidenode. If not, we insert a default value which is an empty hashmap.
Using String Slices and Characters in Rust
- A string slice has a convenient method called
chars()which returns an iterator of characters. - The
Chartype is UTF-32 encoded whileStringis UTF-8 encoded. - All inputs to our try are of fixed size which we can make use of later on.
Updating Node with Default Value
Section Overview: In this section, the speaker explains how to update current node with default values when inserting into a trie data structure. They also discuss how to ensure that new nodes are continually created.
Updating Current Node with Default Value
- When inserting into a trie data structure, we want to update current node with default values if it does not exist.
- We use an all-default method on hashmap or node which guarantees that new nodes will continually be created.
Ensuring End Field on Node is True
Section Overview: In this section, the speaker discusses how to ensure that end field on node is true when inserting into a trie data structure.
Ensuring End Field on Node is True
- The end field on a node is kind of a marker to say that we’ve hit the end of a string.
- We really want that to be true if it’s not. Our life will become very hard when we start looking for words.
Creating Contains Method
Section Overview: In this section, the speaker explains how to create a contains method in Rust for trie data structure.
Creating Contains Method
- The contains method is effectively our lookup.
- We take a read-only reference to
selfand some text and return whether or not it exists. - We start with the root and go through all of the characters using
text.chars(). - If
calready exists insidenode, we get a mutable pointer to the entry inside it. Otherwise, we insert a default value which is an empty hashmap.
Trie Data Structure Implementation
Section Overview: In this section, the speaker explains how to implement a trie data structure in Rust.
Implementing the Trie Data Structure
- The function checks if the URL is already present in the trie.
- If not, it searches for the URL and replaces the current node with it.
- If it cannot find the URL, it adds a new node to the end of the trie.
- The function returns whether or not an insertion was successful.
Guarding Against Accidental Prefixes
- The function guards against accidentally identifying prefixes as part of what is available in the trie.
- It does this by checking if there are more characters to come before inserting a new node.
Checking for Existing Strings
- The speaker wonders whether or not to check if a string already exists before inserting it into the trie.
Conclusion and Comments
- The
Charlesmethod is like a parser that manipulates text to suit our purposes. - Some participants are up very late or early in their time zone.
- After rewriting code, running tests, and checking URLs, we have a working implementation.
Introduction to Children as a Hashmap
Section Overview: In this section, the speaker introduces children as a hashmap and discusses how it can be used with different input encodings.
Using Raw Bytes for Input Encoding
- The speaker suggests that using raw bytes for input encoding could make the input encoding irrelevant.
- The speaker tries implementing this method by adding an implementation for encoding agnostic inputs.
- The speaker replaces bytes and chars with bytes in the code to implement this method.
Reducing Memory Usage
- The speaker notes that using individual bytes makes the code ugly but reduces memory usage.
- The speaker inspects what the data structure looks like inside after implementing this method.
- The speaker adds a modifier to make the code slightly less ugly but still deals with individual bytes.
Improving Hashing Algorithm for Short Keys
Section Overview: In this section, the speaker discusses how to improve hashing algorithms for short keys and reduce memory usage further.
Standard Collections Module Hashmap
- The standard collections module provides a hashmap with a cryptographically secure but somewhat slow hashing algorithm.
- This algorithm is designed to spread bits widely in hash functions but does not do anything special about very short keys.
Finding Better Hash Function
- We can find better hash functions that deal with relatively short keys without worrying about arbitrary inputs.
- We can replace the hasher or use its internal API to play around with its internals and find better hash functions.
Building a Hasher
Section Overview: In this section, the speaker discusses building a hasher and using it in Rust.
Creating a Hashmap with a Hasher
- A hashmap can be parameterized with a hasher.
- The code is compiled and runs faster than before.
- The conventional way to use effects hasher is to create a type alias for hashmap.
Selecting Your Own Hash Function
- You could allow people to select their own hash function during build.
- HashMap provides methods to instantiate a hashmap with a specific hash function.
Using Linear Scan or Binary Search Instead of Hashmap
Section Overview: In this section, the speaker discusses using linear scan or binary search instead of hashmap.
Problem with Using Hashmap
- A hashmap requires running the hash function for every lookup.
- It wastes memory.
Proposal: Using an Array of Option Node
- An array of option node would use less memory than hashmap.
- This method is interesting to play around with.
Proposal for a Single Hash Map
Section Overview: In this section, the speaker proposes using a single hash map instead of having each node have its own hashmap. The speaker explains their reasoning and discusses potential issues with the proposal.
Using a Single Hash Map
- The speaker proposes using a single hash map instead of having each node have its own hashmap.
- The speaker explains that implementing this proposal would involve binding the lifetime of the parent to all of its nodes.
- The speaker realizes that their proposal will not work and expresses curiosity about whether anyone else would like to try it.
Binding Lifetimes Together
Section Overview: In this section, the speaker discusses binding lifetimes together in order to make pointer references faster on lookup.
Fusing Lifetimes Together
- The speaker explains that fusing lifetimes together involves binding the tri-struct to all of its nodes.
- The speaker suggests that this could make pointer references much faster on lookup.
Implementing Defaults for Node A
Section Overview: In this section, the speaker discusses implementing defaults for node A and encounters some issues with doing so.
Issues with Implementing Defaults
- The speaker encounters an issue when trying to implement defaults for node A because they no longer have a reference during the default method to the actual storage anymore.
- The speaker realizes that they cannot use their previous trick relying on all default and considers other options.
Introduction
Section Overview: In this section, the speaker discusses a mutable borrower for self during insert and expresses his liking for seeing other people hang out in the past foreign.
Borrowing and Mutation
- The speaker talks about a mutable borrower for self during insert.
- He expresses his liking for seeing other people hang out in the past foreign.
Borrowing Chicken
Section Overview: In this section, the speaker talks about borrowing chicken and how it can sometimes be problematic. He also discusses how he cannot give an immutable borrow to himself.
Problems with Borrowing Chicken
- The speaker expresses his dislike for borrowing chicken.
- He explains that he cannot give an immutable borrow to himself.
- This creates problems when trying to re-borrow or do some work.
Avoiding Double Lookout Problem
Section Overview: In this section, the speaker discusses using entry to avoid double lookout problem and race conditions involved with looking into a collection checking if it exists.
Using Entry to Avoid Double Lookout Problem
- The speaker explains that using entry helps avoid double lookout problem.
- It also helps avoid race conditions involved with looking into a collection checking if it exists.
- This is because there’s a possibility that after you’ve gone and looked for the thing that you then need to go on good luck on it again to enter it in.
Updating Children Nodes
Section Overview: In this section, the speaker talks about updating children nodes and inserting new items into children.
Updating Children Nodes
- The speaker wants to replace current node with the note.
- He explains that if they don’t have anything they need to change their plan.
- They can’t update children nodes because of borrowing twice.
Default Image
Section Overview: In this section, the speaker talks about the default image and how he can’t implement default for tree for try because his nodes no longer point default.
Default Image
- The speaker talks about the default image.
- He explains that he can’t implement default for tree for try because his nodes no longer point default.
Naive Sensible Way
Section Overview: In this section, the speaker discusses how the naive sensible way to do things is actually the best way.
Naive Sensible Way
- The speaker explains that the naive sensible way to do things is actually the best way.
- He expresses frustration with not being able to provide a reference to the thing that he’s creating right now.
- Life is pain.
Conclusion
Section Overview: In this section, the speaker concludes by showing off a laser-engraved rust logo and saying goodnight to everyone.
Goodnight!
- The speaker shows off a laser-engraved rust logo.
- He says goodnight to everyone and hopes they had a nice night.
- It’s quarter to eleven in the evening and he should probably tuck into bed soon.
Generated by Video Highlight
https://videohighlight.com/video/summary/f9B87LA86g0
Happy Little Fractals Coding the Mandelbrot Set in Rust
- Happy Little Fractals Coding the Mandelbrot Set in Rust * Understanding Complex Numbers * Implementing Complex Numbers in Rust * Iterative Function for Calculating Points * Using Unsigned Integers and Pointers * Checking Whether a Point is Inside or Outside the Set * Complex Numbers and Vectors * Calculating the Mandelbrot Set * Mapping Between Rows and Columns
# Introduction
Section Overview: In this section, the speaker introduces the topic of the tutorial and explains that they will be demonstrating how to program in Rust to create a visualization of the Mandelbrot set.
- The speaker acknowledges that they may struggle with creating an interesting visualization but promises to take things slow for beginners.
- The Mandelbrot set is introduced as a simple yet fascinating mathematical concept that can produce beautiful visualizations.
- The goal of the tutorial is to provide viewers with the skills necessary to create their own visualizations and explore the patterns within the Mandelbrot set.
# Creating a Basic Visualization
Section Overview: In this section, the speaker demonstrates how to create a basic visualization of the Mandelbrot set using Rust programming language.
- The speaker shows an example image of what they aim to recreate using Rust programming language.
- By altering parameters, such as zooming in or out, users can change what they see on their screen.
- The speaker demonstrates how changing parameters alters output by increasing all values by 10.
- To increase resolution, more pixels are added.
# Shifting Viewport
Section Overview: In this section, the speaker explains how shifting viewport changes what is visible on screen when rendering images.
- The viewport is shifted within the Mandelbrot set so only certain parts are visible on screen.
- A classic diagram is visible within negative two five and one one five for x values and y values are less constrained.
- Moving around viewport allows users to explore different parts of Mandelbrot set.
# Changing Parameters
Section Overview: In this section, viewers learn about changing parameters in Rust programming language and how it affects output.
- Four parameters are used to create a bounding box for the visualization.
- The x and y values determine the minimum and maximum values for left, right, up, and down movements.
- Two integer parameters determine the number of pixels or characters printed on screen.
# Introduction to Mandelbrot Set
Section Overview: In this section, the speaker introduces the topic of the Mandelbrot set and explains how it uses complex numbers.
Understanding Complex Numbers
- The Mandelbrot set uses complex numbers instead of real numbers.
- A complex number exists in a number plane, with an imaginary part representing the y-axis along the number line.
Implementing Complex Numbers in Rust
- Rust does not include complex numbers itself but can pull them in through the num crate.
- The memory layer is compatible with an array of type two, enabling us to put in other scalar values.
# Calculating the Mandelbrot Set
Section Overview: In this section, the speaker explains how to calculate whether a point is inside or outside of the Mandelbrot set using an iterative function.
Iterative Function for Calculating Points
- The iterative function checks whether a pixel represents something that’s inside or outside of the set.
- The z value and cx/cy represent each pixel as a complex number.
- Norm is used to calculate whether a point has escaped from within the Mandelbrot set.
Using Unsigned Integers and Pointers
- Size is used as an unsigned integer in Rust, representing the width most familiar to your CPU.
- Pointers are used to access arrays in C.
Checking Whether a Point is Inside or Outside the Set
- The vector between the origin and the place that this number exists inside the complex plane is over two.
# Introduction to Complex Numbers
Section Overview: In this section, the speaker introduces complex numbers and explains how they relate to vectors and origins.
Complex Numbers and Vectors
- The origin is just the zero zero vector.
- The imaginary part of a complex number represents how far it has drifted away as it goes through a series of transformations.
- The square root of the sum of squares of real and imaginary parts can be used to determine if a complex number is greater than four.
# Mandelbrot Set
Section Overview: In this section, the speaker discusses the Mandelbrot set and demonstrates how to calculate it using Python.
Calculating the Mandelbrot Set
- The speaker demonstrates how to calculate the Mandelbrot set using Python.
- Different conditions can be used to calculate the Mandelbrot set, with some being more mathematically pleasing while others are more aesthetically interesting.
- The speaker shows an example function for calculating the Mandelbrot set with various parameters.
# Mapping Between Rows and Columns
Section Overview: In this section, the speaker discusses mapping between rows and columns when calculating the Mandelbrot set.
Mapping Between Rows and Columns
- Two output values are produced when calculating the Mandelbrot set - number of columns and number of rows.
- The speaker demonstrates how to map between rows and columns when calculating the Mandelbrot set.
Introduction to Rust Vectors
Section Overview: In this section, the speaker introduces Rust vectors and explains how they work.
Creating a Vector with Capacity
- A vector is created using the syntax
vec![type; capacity]. - The capacity specifies the number of elements that can be stored in the vector.
- Using this syntax ensures that only one memory allocation is made at a given time.
Common Approach to Creating a Vector
- The common approach to creating a vector uses simple syntax but results in several allocations.
- In Rust, it’s important to care about when you’re asking for memory and allocate only when necessary.
GitHub Gist of Code
- The speaker provides a link to the code being used so viewers can modify it themselves.
Understanding Rust Syntax for Vectors
Section Overview: In this section, the speaker discusses Rust syntax for vectors and explains why certain types are needed.
Static Method for Type Vec
- The static method
with_capacityis used to specify what type of data will be contained in the vector. - Rust can guess what type of data will be contained in the vector but it’s better to explicitly state it.
Numeric Types in Rust
- Rust is very picky about numeric types and requires them to be cast specifically.
- All values need to be converted into floats because calculations require percentages and column/row numbers.
Creating a Point that Best Represents the Pixel
Section Overview: In this section, the speaker explains how they are iterating through the columns and rows in the pixel output to create a point that best represents that pixel inside the Mandelbrot space.
Iterating Through Columns and Rows
- The speaker is iterating through the columns and rows in the pixel output.
- They are creating a point that best represents that pixel inside the Mandelbrot space using cx and cy which stand for complex x and complex y.
- The point is passed through to this Mandelbrot point calculation where we get this value escaped at.
Understanding Escaped Points
- If a point escapes very quickly, it doesn’t exist within the Mandelbrot set.
- If it stays there, it’s definitely inside the set.
- The stuff at the borders is where all of complexity lies.
Iteration Calculation
Section Overview: In this section, we learn about iteration calculations used to calculate values for every single pixel.
Calculating Values for Every Single Pixel
- We have an iteration calculation that took to get out of bounds again.
- We perform an update on some z thing that relates to our position as input to that transformation.
- When it balances out, we return so and say once you’ve hit two and bounced out.
Value Between Zero and One Thousand
Section Overview: In this section, we learn about values between zero and one thousand and how they are used to translate the value to a character.
Understanding Values Between Zero and One Thousand
- The value here is between zero and one thousand.
- These are all values between zero and a thousand.
- A thousand comes from the fact that we specify a thousand in here to translate the value to a character.
Changing Output
Section Overview: In this section, we learn about changing the output by going through each row in each column.
Changing Output
- To change the output, we need to go through each row in each column.
- We need to go row first and then column because the row responds to a line so I can change that one into a question mark if I want.
- We can encourage you to play with these outputs.
Generated by Video Highlight
https://videohighlight.com/video/summary/xDrAncijBq4
Rust Polymorphism: Generics and trait objects explained
- Rust Polymorphism: Generics and trait objects explained
- Introduction to the Topic
- Creating a New Project
- Printing to the Screen
⭐️ Shrink Source Code to a Single Function 0:13:37s⭐️ Implement Generics with Rust’s Monomorphization (0:16:33)- Introduction
⭐️ Trait Object: Avoiding Cost Associated with Monomorphization⭐️ Handling Dynamic Types Inside One Block of Code- References and Traits
- More on Traits
⭐️ Benefits of Trait Objects 0:33:34s- Rust Programming Language
- Q&A Session
- Generated by Video Highlight
Introduction to the Topic
Section Overview: The speaker introduces the topic of generics and explains why it is important to learn about them.
Why Learn About Generics?
- Generics are a powerful tool that can be intimidating for programmers who have only used languages like JavaScript or Python.
- Despite being intimidating, generics are worth learning about because they are extremely powerful.
Creating a New Project
Section Overview: The speaker creates a new project and demonstrates how to compile and run it.
Creating a New Project
- To create a new project, navigate to the desired directory and use the command “cargo new [project name]”.
- To compile and run the project, navigate into the project directory and use the command “cargo run”.
Printing to the Screen
Section Overview: The speaker demonstrates how to print a message to the screen using Rust.
Creating a Function
- To print a message to the screen, we need to create a function called “report_status”.
- This function will take in a string slice as an argument.
Defining Variables
- We define our variable as “report” with type string slice “&str”.
Compiling Code
- We can compile code by clicking on “run” or by using “cargo run” in terminal.
# String and String Slice
Section Overview: In this section, the speaker explains the difference between a string and a string slice in Rust. They also discuss how adding a reference to a string changes the type being sent into report status.
⭐️Difference between String and String Slice
- A string literal type is actually a different type than a capital
Stringin Rust. - The editor gives a warning when trying to send a string instead of a string slice into report status.
⭐️Adding Reference to String
- Adding an ampersand before the string adds a reference to it.
- This changes the type being sent into report status.
Types Defining their Behavior
- Types can define their behavior when they are dereferenced.
- When a string is dereferenced, it presents the same data as a stir, so they can masquerade as the same type.
# Generics in Rust
Section Overview: In this section, the speaker discusses how generics work in Rust and how they can be used to create functions that take multiple data types.
Creating Functions with Multiple Data Types
- To create functions that take multiple data types, we use generics in Rust.
- We constrain t by saying that anything that implements the display trait can be passed into report status function using generics.
Using Generics for Strings and Slices
- We can use generics to create two versions of report status, one for strings and one for slices.
- The Rust compiler duplicates all of the code and creates two functions when generics are used.
⭐️Shrink Source Code to a Single Function 0:13:37s
Section Overview: In this section, the speaker explains how they have shrunk the source code to a single function that accepts multiple arguments.
Accepting Multiple Arguments
- The source code has been shrunk to a single function that can accept multiple arguments.
- A different text type called “copy on right” is used when special ones are needed.
Creating a Cow
- To create a cow, the speaker uses the “cow from message from copy” command.
- The speaker defers ownership while convincing others that they can get three types printed out by one function.
# Report Status Messages
Section Overview: In this section, the speaker discusses reporting status messages.
Error and Operational Messages
- Two error messages and one operational message are reported.
- The ship is breaking and something has gone wrong.
⭐️Implement Generics with Rust’s Monomorphization (0:16:33)
Section Overview: In this section, the speaker explains how generics are implemented in Rust using monomorphization.
Monomorphization
- Rust uses monomorphization which changes generic functions into multiple duplicates that reference specific types.
- There are other patterns for implementing generics in Rust as well.
# Traits in Rust
Section Overview: In this section, the speaker explains what traits are in Rust.
Describing Traits
# Implementing as Ref Stir
Section Overview: In this section, the speaker explains how to implement as ref stir.
Casting Magic Spell
- To access the behavior of as ref stir, the speaker needs to call it and cast its magic spell.
- Rust will complain if display is no longer used.
# Standard Prelude in Rust
Section Overview: In this section, the speaker explains what standard prelude is in Rust.
Standard Prelude
- The standard prelude brings three different versions of Rust into scope when compiled.
- Each edition has its own prelude.
Introduction
Section Overview: In this section, the speaker apologizes for a mistake and explains that he will be showing another way of implementing the same thing.
Another Way of Implementing the Same Thing
- The speaker explains that he can accept any type t that is able to be converted into a string.
- The speaker shows how changing the type signature does not change the data sent in but only its type signature.
- The speaker wonders if he can force them to work.
- The speaker introduces a different strategy called a trait object.
⭐️Trait Object: Avoiding Cost Associated with Monomorphization
Section Overview: In this section, the speaker shows how to avoid some of the cost associated with monomorphization by using a trait object.
Using Trait Object
- The speaker explains what a trait object is and how it works.
- The speaker adds a special case for when text is empty.
- If text is empty, the speaker adds some default value or returns an invalid message warning.
- The speaker overloads text again and prints it out.
⭐️Handling Dynamic Types Inside One Block of Code
Section Overview: In this section, the speaker creates a new variable with trailing underscore and introduces some new syntax which is dyn dynamic.
Introducing Dyn Dynamic Syntax
- The speaker creates a new variable with trailing underscore and introduces dyn dynamic syntax.
References and Traits
Section Overview: In this section, the speaker discusses references and traits in Rust programming language.
References
- A reference is a way to refer to some value without taking ownership of it.
- It allows multiple parts of code to access the same data without copying it.
Traits
- Traits are similar to interfaces in other programming languages but more powerful.
- They can have associated constants, values, and types.
- Rust uses runtime indirection to implement trait objects which can take any type at runtime as long as it implements what it promises to implement.
- The
Displaytrait is implemented by types that have aformatmethod that knows how to format the object for display purposes.
More on Traits
Section Overview: In this section, the speaker provides more information about traits in Rust programming language.
Clone Trait
- The
Clonetrait is used for types that cannot be implicitly copied and defines two methods:cloneandclone_from. - The difference between traits and interfaces is that interfaces avoid the diamond problem in C++ where you have multiple inheritance while Rust has no inheritance hierarchy.
⭐️⭐️⭐️Other Ways to Think of Traits
- Traits can also be thought of as abstract base classes or mix-ins.
- There are different definitions for traits depending on the programming language community but they are generally more powerful than most implementations of interfaces.
⭐️Benefits of Trait Objects 0:33:34s
Section Overview: In this section, the speaker discusses trait objects and how they can be used to avoid the downsides of multiple inheritance.
Trait Objects
- Trait objects allow for abstract types that can implement a shared trait.
- Every concrete type can share the same function calls through dynamic dispatch.
- This speeds up binary size but has a cost at runtime.
Generic Functions
- A generic function can accept any type that implements a certain method.
- An inner function can be used to avoid duplicating or triplicating the function when called from multiple types.
Rust Programming Language
Section Overview: In this section, the speaker explains how to provide generic code without incurring a lot of compile-time size cost by using dynamic dispatch.
Providing Dynamism with Generic Code
- The lines 13 to 20 are compiled once, while lines 23 through 25 are compiled three times because we apply three types.
- We can provide some kind of dynamism and generic code without incurring all of the compile-time size cost as long as we’re willing to trade off a little bit of runtime cost for this dynamic dispatch.
- Dynamic dispatch isn’t necessary, so we can avoid it and have a marginal cost of an extra function call.
- We can add an annotation which tells the compiler that it should always execute the function and not just copy out its contents into the inner function. This will keep it small.
Q&A Session
Section Overview: In this section, the speaker answers questions from viewers about Rust programming language.
Understanding Rust Programming Language
- A viewer comments that they are understanding half of what is being said despite being new to Rust programming language. The speaker responds that Rust can be intimidating but hopes to demonstrate that it is accessible and fun. Programs written in Rust run really fast too.
- The speaker asks viewers if these kinds of tutorials are useful and what they would like to know about Rust programming language since he is there to help.
Conclusion
- Viewers say goodnight and thank you for hanging out with the speaker during his tutorial on Rust programming language.
Generated by Video Highlight
https://videohighlight.com/video/summary/ywskA8CoulM
Introducing traits in Rust - what they are and how to use them
- Introducing traits in Rust - what they are and how to use them
- Introduction to Rust’s Traits
- Basic Rust Program
- Abstraction with Traits
- Defining Traits in Rust
- Implementing Traits in Rust
- Implementing a 2D Square
- Falling Back to Default Implementations
- Understanding Standard Library Traits
- Implementing Debug Trait
- Implementing Display Trait
- Customizing Output with Display Trait
- Familiarizing Oneself with Traits
⭐️ Iteration Trait- Printing to Screen
- Conclusion
- Understanding Enums
- Changing Random Numbers
- Learning Traits
- Reading Documentation
- Double Equals
⭐️ Deref Trait
⭐ ⭐ ⭐️ ️️Traits and Associated Types- Rust by Example: Traits and Generics
- Generated by Video Highlight
Introduction to Rust’s Traits
Section Overview: In this section, the speaker introduces the topic of Rust’s traits and explains what they are. They also mention that they will demonstrate how to use them and explore their role within the Rust programming language.
What is a Trait?
- A trait is an abstract interface or an abstract base class in object-oriented languages.
- It allows us to define functions and function signatures.
- It can be implemented by multiple types.
Basic Rust Program
Section Overview: In this section, the speaker demonstrates a simple Rust program and explains how functions work in Rust.
Creating Functions in Rust
- Functions can be defined with parameters and return values.
- The difference between
&strandStringdata types is not explained at this point. - Functions can be called from the main function using arguments passed as parameters.
Abstraction with Traits
Section Overview: In this section, the speaker discusses how traits allow for abstraction in Rust programming.
⭐️Using Traits for Abstraction
- Repeatedly creating functions can become tedious.
- Traits provide a way to create abstractions that can be used across multiple types.
- This allows for more efficient code writing and easier maintenance.
Defining Traits in Rust
Section Overview: In this section, the speaker delves deeper into defining traits in Rust programming.
Defining Traits
- A trait defines
a set of methodsthat a type must implement. - Types implementing a trait must provide implementations for all its methods.
- A struct can implement multiple traits.
# Implementing Traits in Rust
Section Overview: In this section, the speaker explains how to implement traits in Rust and why they are useful.
Implementing Score Method for String Type
- The speaker receives an error message that they need to implement a method called “score” for a string type.
- They change the code to refer to “self” instead of the string type.
- The speaker implements the score method for the string type by creating a new method.
- They explain that implementing traits allows us to define an interface and give any type its own new method.
⭐️Why Use Traits?
- The speaker answers a question about why we bother with traits when we already had a free function called score. They explain that traits become useful when defining an interface or working with generics.
- They give an example of wanting to report on any type using a generic function and ensuring that each type has some sort of score.
- The speaker explains how traits allow us to parameterize functions and work within the generics system.
Implementing Score Method for Other Types
# Introduction to Rust Traits
Section Overview: In this section, the speaker introduces Rust traits and explains how they can be used to define or bring together functionalities that are common across types.
⭐️Operator Overloading with Traits
- Operator overloading is implemented with traits in Rust.
- To implement operator overloading, a trait (e.g., add trait) must be implemented, and the right-hand side of the operation must be of the same type.
Iteration with Traits
- Types that implement the
IntoIteratortrait can be used with Rust’s for loop syntax. - Many syntaxes in Rust are compiled down to trait implementations, making it important to become familiar with core traits.
# Implementing a Shape Trait in Rust
Section Overview: In this section, the speaker discusses how to implement a shape trait in Rust using examples.
Defining a Shape Trait
- A shape trait can be defined to require an area function to be defined for each shape.
- A 2D shape has height and width parameters and an area method.
Parameterizing Types
Implementing Methods for Square Shape
- To implement methods for square shapes, three methods need to be defined - height, width, and area.
- s The height and width functions are defined as the same for a square shape.
- A default implementation can be defined for the area method.
Implementing Traits in Rust
Section Overview: In this section, the speaker implements a 2D square and demonstrates how to fall back to default implementations for other methods using traits. They also discuss the challenges of understanding and working with standard library traits.
Implementing a 2D Square
- To implement multiplication, the speaker creates a type that must implement multiplication.
- The speaker needs another block for their implementation.
- They create a static method on square new that returns type self, which refers back to the original type. They then set its height as f32.
- The speaker creates a square by calling the static method square new and giving it a height value.
- They print line square and area. Although they haven’t defined area themselves inside their implementation block, they are falling back to the default implementation.
Falling Back to Default Implementations
- The speaker encounters an issue where they need to restrict scalar to a type that is able to be multiplied.
- They add a type bound but encounter rebound mismatched types error because of the return type.
- To get it to pass, they remove the type parameterization and will look up syntax later.
- The area is correct irrespective of unit because of trait implementation.
Understanding Standard Library Traits
- There are dozens of standard library traits making it difficult to understand where one should begin or how they all fit together.
- The speaker provides some brief insight into understanding standard library traits.
# Understanding Debug and Display Traits
Section Overview: In this section, the speaker explains how to use the debug and display traits in Rust programming.
Implementing Debug Trait
- The derive annotation instructs the Rust compiler to automatically implement a debug trait for custom types.
- Debug can only be implemented if your custom type uses types that also implement debug.
- If a custom type is changed, such as adding a new struct, then derived debug will no longer work.
Implementing Display Trait
- Display is designed for output intended for users rather than programmers.
- Unlike debug, display has no default implementation and must be implemented manually.
- The formatter is an internal type to the format module which can be ignored when starting out with Rust programming.
Customizing Output with Display Trait
- The thing being printed has a lifetime that must be long enough for the print to finish.
- We can describe how we want to display our custom type using the format! macro.
# Implementing Traits in Rust
Section Overview: In this section, the speaker discusses implementing traits in Rust and how to familiarize oneself with them.
Familiarizing Oneself with Traits
- The speaker suggests that one should start by familiarizing themselves with the
DebugandDisplaytraits. - The next trait to learn is iteration, which is slightly more complicated.
⭐️Iteration Trait
- The speaker explains that iteration requires multiple computers to be created.
- Traits are important for iteration, as well as for the size of each element of an array.
- There are two important types of traits for iteration -
IteratorandIntoIterator. - The speaker demonstrates how to implement the
IntoIteratortrait for a structure containing random numbers.
Printing to Screen
- The speaker defines the type item as usize and demonstrates how to print random numbers using iterators.
- He then shows how to take five random numbers using the
take()method on iterators.
Conclusion
- After learning about debug display and iteration, understanding the distinction between them is crucial.
# Rust Traits
Section Overview: In this section, the speaker talks about Rust traits and how they work.
Understanding Enums
- An enum is either the non-variant or sum of type t.
- Return self seed.
Changing Random Numbers
- Change the seed to 10.
- The output should be 50 50 50.
- A set of random numbers can be empty, and nothing will be printed out.
Learning Traits
- Display debug iteration is where to start learning traits.
- Operator overloading traits are also important to learn.
Reading Documentation
- Look at implementations to find out what methods you can use on a type.
- Partial equality is the trait that supports the equal sign operator.
- Paths can be equal to an OS string or path buffers.
# Double Equals and Deref Trait
Section Overview: In this section, the speaker talks about the use of double equals in Rust and demonstrates how types can implement methods that they don’t actually implement using the Deref trait.
Double Equals
⭐️Deref Trait
- The Deref trait enables a type to masquerade as another type and convert itself into that type.
- This allows a type to implement methods that it doesn’t actually implement by calling those methods on the converted type.
- The Deref trait is used implicitly by the compiler in many circumstances through drift coercion, which means that the dereference operation coerces to another type.
- Rust provides ergonomics through implicit use of the Deref trait, but it can be confusing if you are expecting everything to be explicit.
⭐⭐⭐️️️Traits and Associated Types
Section Overview: In this section, the speaker discusses traits and associated types in Rust. They explain what a trait is, when to use an associated type, and provide some useful documentation for further learning.
What are Associated Types?
- An associated type is a type that is defined within a trait.
- It can be used to define a scalar value within an object.
- It’s useful if you want to include an associated type with inside a generic type argument or parameter so that implementers can choose which type they want to return.
When Should You Use Associated Types?
- The speaker asks the audience when they think it’s appropriate to use an associated type.
- If it’s not required, you can safely ignore it.
- The Rust reference provides more technical information on traits and their implementation.
Other Useful Documentation
- The Rust reference is a good guide for understanding how Rust works.
- The Rust by Example chapter on traits provides another definition of traits that may be useful for beginners.
Rust by Example: Traits and Generics
Section Overview: In this section, the speaker discusses the definition of traits in Rust and how they relate to generics. They also explain why some traits have no methods and are used as marker traits.
Definition of Traits
- The definition of a trait in Rust is too loose.
- The speaker objects to this definition.
⭐️Sync Trait
- The
Synctrait has no methods at all and is a marker trait. - It indicates to the type system about some property which matters to you as a programmer, such as concurrency.
- There’s no magical annotation on your type for implementing
Sync. - It’s just an assertion that you provide as a programmer to the compiler.
⭐️Marker Traits
- Marker traits are used when there is no need for any associated information with the trait.
- Rust by example asserts that a trait is a collection of methods, but important traits exist where that’s not true.
Conclusion
- The speaker appreciates people’s participation and questions.
- They encourage connecting with them on Twitter or asking questions in the comments.
- A tutorial will be created based on this discussion.
Generated by Video Highlight
https://videohighlight.com/video/summary/MH00-L6oiI0
Rust Programming for the object-oriented/function-oriented developer
- Rust Programming for the object-oriented/function-oriented developer
- Establishing a Programming Environment
⭐ ⭐ ⭐️ ️️Understanding Objects in Object-Oriented Languages- Defining Objects in Python
- Emulating Object Creation in Python
- Defining Objects in Rust
- Emulating Object Creation in Rust
- Pre-processing with Asserts
⭐️ Shorthand Syntax⭐ ⭐️ ️Richer Initialization⭐ ⭐ ⭐️ ️️Rust is an Aesthetically Typed Language⭐️ Constructors and Complex Behavior- Mutating Objects in Rust
- Conclusion
- Scale and Type Signature
⭐ ⭐ ⭐️ ️️Understanding Move Semantics and Borrow Semantics- Move Semantics and Borrowing
- Fixing an Issue with Magic Ampersand
- Mutating in Rust Programming
- Rust Zero Cost Abstractions
- Creating a Method in Rust
- Technical Review of a Book
⭐ ⭐ ⭐️ ️️Applying Functional Programming Styles in Rust- Understanding Bar Syntax in Rust
- Confusion and Closure
- Abstraction and Encapsulation
- Creating Accessor Methods in Rust
- Creating a Trait
- Generating Random Numbers
- Implementing Coordinates
- Conclusion
- Generated by Video Highlight
Establishing a Programming Environment
Section Overview: In this section, the speaker introduces Rust as a compiled language and explains how to compile code using Cargo.
Compiling Rust Code with Cargo
- Rust is a compiled language.
- To compile Rust code, use Cargo, a tool that runs the code.
- The terminal at the bottom of the screen is used to run Cargo.
- The editor at the top of the screen is used to write Rust code.
⭐⭐⭐️️️Understanding Objects in Object-Oriented Languages
Section Overview: In this section, the speaker discusses what an object is in object-oriented languages and compares Python’s approach to creating objects with Rust’s approach.
Defining Objects in Python
- An object in an object-oriented language looks like a class definition.
- A class definition may have an init method that takes x and y values.
- The init method initializes self.x and self.y values.
Emulating Object Creation in Python
- Python breaks its own rules by allowing implicit behavior when creating objects.
- There is a hidden method called new that mutates objects in place.
Defining Objects in Rust
- In Rust, types must be defined before they can be used.
- Unlike dynamic languages like Python, static languages like Rust require type definitions before use.
Emulating Object Creation in Rust
- By convention only, rust programmers have created a new method which emulates constructor patterns found in other languages.
- This new method allows for more flexibility than literal syntax.
0:07:10 Adding Constraints to Types
Section Overview: In this section, the speaker discusses how to add constraints to types in Rust.
Pre-processing with Asserts
- To do pre-processing, we can assert that x is greater than zero or at least greater than negative zero.
- We can provide these asserts using
is instanceandfloat. - If x is less than zero, we raise a value error.
⭐️Shorthand Syntax
- Rust provides a literal syntax for creating instances of structs and all types.
- There is no requirement for a constructor or destructor.
- Rust has smart rules about how initialization works.
⭐⭐️️Richer Initialization
- To add richer initialization, we can use the
newmethod. - The
newmethod is not baked into the language but part of Rust conventions. - We can define our own constructor if needed but it’s not required.
# Rust Programming Language
Section Overview: In this section, the speaker talks about Rust programming language and its type system.
⭐⭐⭐️️️Rust is an Aesthetically Typed Language
- Rust is aesthetically typed, which means it’s in the middle ground between object-oriented and functional programming.
- It operates more like a functional programming language.
⭐️Constructors and Complex Behavior
- The speaker talks about constructors and complex behavior in Rust.
- This topic leads to question 3, which is how to mutate an object in Rust.
Mutating Objects in Rust
- All values are immutable by default in Rust, so you need to opt-in to make them mutable.
- To make a value mutable, add the
mutkeyword. However, two writers cannot exist at exactly the same time.
Conclusion
The speaker provides an overview of the type system of Rust programming language and explains how to mutate objects in
it using the mut keyword.
Scale and Type Signature
Section Overview: In this section, the speaker changes the type signature and explains scalar values in mathematics.
Changing Type Signature
- The speaker changes the type signature.
Scalar Values in Mathematics
- Scalar values are used to scale vectors.
- The speaker explains how to scale a point by 10 using scalar values.
- The speaker attempts to plot a point but encounters compiler warnings.
- After fixing the compiler warnings, the speaker explains that Rust can be confusing when doing something with an object and suddenly encountering errors.
⭐⭐⭐️️️Understanding Move Semantics and Borrow Semantics
Section Overview: In this section, the speaker explains move semantics and borrow semantics in Rust programming language.
Move Semantics
- The speaker defines move semantics as logically moving responsibility for a particular value into a different scope.
Borrow Semantics
- The speaker introduces borrow semantics as another piece of jargon in Rust programming language.
- Borrow semantics is about borrowing ownership of data without transferring it.
Move Semantics and Borrowing
Section Overview: In this section, the speaker discusses move semantics and borrowing in Rust programming.
Move Semantics
- Move semantics means that the plot method takes responsibility into the plot method.
- When we get to the end of plot, which is line 48, underscore to draw is deleted as well.
- It no longer exists as a valid value when we get all the way down to line 57.
Borrowing
- The magic ampersand says that we only want to borrow you.
- Borrow semantics mean that we are effectively going to lend plot access to this point but main still has responsibility for deleting it when we get to the end of the scope.
- If you have a read-only borrow, which is denoted by this ampersand, it allows two things running at the same time.
- We could spawn a thread and each of them could have access to point and reference exactly the same memory because by design it’s impossible for any of those threads ever to modify the value.
- You’ll never introduce a race condition in Rust code related to concurrency if you use primitives available in Rust.
Read-only vs Read-write Borrow
- A read-only borrow can have one or more references while a read-write borrow has exclusive access while scale is still in scope.
- There can only ever be one read-write access at any given time.
Fixing an Issue with Magic Ampersand
Section Overview: In this section, the speaker discusses how to fix an issue with magic ampersand in Rust programming.
⭐️Fixing Magic Ampersand Issue: &
- To fix this issue, we need to use the magic ampersand.
- The magic ampersand says that we only want to borrow you.
- We can use a read-only borrow, which allows two things running at the same time.
- We could spawn a thread and each of them could have access to point and reference exactly the same memory because by design it’s impossible for any of those threads ever to modify the value.
Mutating in Rust Programming
Section Overview: In this section, the speaker discusses mutating in Rust programming.
Mutating
- Mutt means mutate exclusively.
- A read-write borrow has exclusive access while scale is still in scope.
- There can only ever be one read-write access at any given time.
Rust Zero Cost Abstractions
Section Overview: In this section, the speaker explains how Rust guarantees only one access to any data or one mutable access at any given point along the lifetime of the entire program. The speaker also clarifies that “mute” or “mutt” means mutation and not mutex.
⭐⭐⭐️️️Rust’s Zero Cost Abstractions
- Rust is very enthusiastic when it talks about zero cost abstractions.
- Its abstractions impose no runtime cost, or at least the abstractions you opt into runtime cost if you want more expressive code.
- There is no runtime guard around a lock that exists at runtime in Rust.
- Mute or mutt means mutation, which has the same semantics as a mutex (mutually exclusive lock).
- There is nothing at run time that slows things down in Rust.
Creating a Method in Rust
Section Overview: In this section, the speaker discusses creating a method in Rust and replacing point.t with self. They also talk about using an assign multiply operator and how rust will refuse to compile if there is a typo.
⭐️Enabling Methods for Types
- To create a method in Rust, use an impl block.
- Unlike Python, where implementations can be created anywhere, separate blocks are needed for methods in Rust.
- Replace point.t with self to enable methods for types.
- Use an immutable access to self and then face all of this stuff.
- Using an assign multiply operator can shorten down code but be careful not to make typos since rust will refuse to compile if there is one.
# Rust’s Benefits
Section Overview: In this section, the speaker talks about the benefits of using Rust over other programming languages.
Rust is Pedantic but Liberating
- Rust can only scale positively and must be greater than zero.
- Rust prohibits runtime errors and enables you to write better code.
- The compiler being pedantic is liberating and makes working with Rust enjoyable.
# Object Responsibility in Functions
Section Overview: In this section, the speaker explains why object responsibility is transferred into a function by default in Rust.
Default Transfer of Object Responsibility
- Plot 1, 2, and 3 are the same types but have different prefixes.
- Plot 2 uses a read-only reference while plot 3 uses a mutable reference.
- The language designers decided that undecorated types should represent the type itself (call by value), but they want to be explicit.
- Plot 2 and plot 3 are pointers, not values.
Note that there were no timestamps for some parts of the transcript where music was playing or nothing was happening.
# Introduction to Rust’s Drop Trait
Section Overview: In this section, the speaker introduces Rust’s Drop trait and explains how it is used for automatic memory management.
Automatic Memory Management in Rust
- Rust uses the term “drop” to refer to destruction or disposal of values.
- At the end of a scope, Rust automatically drops any local values created within that scope.
- The
Droptrait is an abstract base class that defines how values should be dropped. - The default implementation of
Dropis an empty function, but it can be manually implemented to customize memory management.
Garbage Collection in Rust
- Unlike other languages, Rust does not have a garbage collector running by default.
- It is possible to overwrite the implementation of
Dropsuch that it does not release memory back to the operating system. This can lead to memory leaks.
0:54:47 Empty Lambda Functions
Section Overview: In this section, the speaker answers a question from the chat about empty lambda functions and explains how they work in Rust.
Explanation of Lambda Functions
- A lambda function is an anonymous function that doesn’t have a name.
- They are useful in Rust programming.
- The syntax for creating a lambda function is less ergonomic than other languages like Python or Java.
Example of Using Lambda Functions
- The speaker demonstrates how to use an array of points to create a line using lambda functions.
- The example involves drawing a line starting at the origin and going up towards the right.
- The back three points on the line represent a 45-degree angle.
0:58:11 Debugging with Derived Macros
Section Overview: In this section, the speaker shows how to use derived macros for debugging purposes in Rust programming.
Using Derived Macros for Debugging
- The speaker uses derived macros to ask the compiler to write some code for them.
- They derive the debug trait, which is an abstract base class used for debugging purposes.
- The speaker promotes their book on Rust programming, which includes an introduction specifically written for people who started their programming journey with dynamic languages like Python and Ruby JavaScript and want to know more about systems programming.
Technical Review of a Book
Section Overview: In this section, the speaker talks about a book they are working on and mentions that they are currently undergoing an extra technical review with a university professor. They also mention that the book will be available for purchase soon.
Book Availability
- The speaker mentions that Manning will have the book available for cheap.
- They offer a discount code to interested parties.
- The speaker suggests buying the book together with friends to save even more money.
⭐⭐⭐️️️Applying Functional Programming Styles in Rust
Section Overview: In this section, the speaker introduces functional programming styles in Rust and explains how they can be applied using collections.
Introduction of Collections
- The speaker introduces collections as a way to apply functional programming styles in Rust.
- They mention lambdas as an example of functional programming idioms.
Object-Oriented Style vs. Functional Programming Style
- The speaker explains that Rust supports both object-oriented and functional programming styles.
- They suggest using a higher-order method which takes a point going along and maps it when applying functional programming style.
Understanding Bar Syntax in Rust
Section Overview: In this section, the speaker explains bar syntax in Rust and how it is used.
⭐⭐⭐️️️Explanation of Bar Syntax
- The speaker explains bar syntax as being used to create closures or anonymous functions.
- They demonstrate two different ways of creating closures using bar syntax and traditional function syntax.
- Both methods create exactly the same output, but using bar syntax is considered more idiomatic in Rust.
Confusion and Closure
Section Overview: In this section, the speaker is trying to figure out a problem with transfers not being satisfied. They introduce the concept of closures and anonymous functions in Rust.
⭐⭐️️Closure and Anonymous Function
- The speaker introduces an anonymous function that takes a point and creates a closure.
- The double bar arrow syntax is used to create a closure that encloses its local environment.
- The anonymous function is bound to a variable called “add point” which can be called multiple times to grow the line.
Abstraction and Encapsulation
Section Overview: In this section, the speaker talks about abstraction and encapsulation in Rust programming.
Getters and Setters
- Use bullet points to provide a detailed description of key points and insights. Each bullet point is a link to the corresponding part of the video.
Creating Accessor Methods in Rust
Section Overview: In this section, the speaker discusses how to create accessor methods in Rust and compares it with object-oriented languages.
⭐️Creating Accessor Methods
- In Rust, an underscore-based language, creating an accessor or getter method involves using underscores to create a getter method.
- Although some people may not like the idea of an accessor value, it is a common way of creating them.
- Encapsulation is important in object-oriented languages. Raw access to attributes should be avoided by exposing only the interface.
- If we wanted to change x from up here and remove the field x, we could return x and use another method call instead of get x.
- Rust is particular about data use and reuse. To ensure safety, mutable access must be annotated.
Generating Data on the Fly
- Sometimes data needs to be generated on the fly. The speaker demonstrates how to create three different types of points: one that randomly jumps around, one that uses existing values, and one that picks values from a sensor.
Implementing Behavior for Multiple Classes
- There are times when two classes need to implement the same behavior. The speaker explains how this can be done in Rust.
Note: This transcript was short and did not have many sections. Therefore, I created only two sections based on their content.
Creating a Trait
Section Overview: In this section, the speaker discusses creating a trait that can be used as an abstract base class.
Creating an Abstract Base Class
- The term “trait” is used to think of it as an abstract base class.
- Static types are used to implement the trait.
Implementing the Coordinate Trait
- To create a concrete type, the coordinate trait needs to be implemented for point.
- A type error occurs because part of the interface is missing.
- The getter function for y is implemented to fix the error.
Drawing Anything That Implements Coordinate
- The ability to draw anything that implements the coordinate trait is introduced using a reference to a trait or an abstract base class that is dynamically marked at runtime.
- Invoking drawing will draw x and y to the console without any issues.
Generating Random Numbers
Section Overview: In this section, the speaker discusses generating random numbers and creating a zero-sized type.
Checking Compilation with Point Type
- A point is put in place, and it compiles correctly with no warnings.
Accepting Anything That Implements Coordinate
- Point was removed from arguments, and anything that implements coordinate can now be accepted by introducing an abstract base class known as a trait object.
Creating Zero-Sized Types
- A new struct with no data at all is created, which results in a zero-sized type that only exists at compile time and not at runtime.
Implementing Coordinates
Section Overview: In this section, the speaker discusses implementing coordinates and creating an encapsulated interface via trait.
Creating a Thread RNG
- The speaker mentions needing to do a thread RNG (random number generator).
- They mention needing to call gin after creating the RNG.
- The speaker decides to just use “rng” instead of “thread rng.”
Simplifying with Prelude
- The speaker mentions needing to import a type as a trait and includes the prelude thing that will simplify their work.
- They mention getting access to a random method without worrying about instantiating a random number because all they care about is rand ran, which is useful.
Encapsulating via Trait
- The speaker explains that rand random turns out that x and y are the same, so they might as well just call x.
- They create an encapsulated interface via trait, which simulates inheritance without actually requiring inheritance in the language.
Conclusion
Section Overview: In this section, the speaker concludes their stream and signs off.
- The speaker notes that they have created an interface and instantiated it twice, creating something that feels like inheritance without actually requiring it.
- They mention that the values generated are completely random and express satisfaction with their work.
- The stream ends with the speaker signing off.
Generated by Video Highlight
https://videohighlight.com/video/summary/kwSlvOpGwVg
All About Error Handling In the Rust Programming Language
- All About Error Handling In the Rust Programming Language
- Introduction to Errors in Rust
- Handling File I/O Errors
- Handling Errors in Rust
⭐ ⭐ ⭐️ ️️Debugging Rust Code- Rust Language and Productivity
- Q&A Session
- Creating a Cache in Rust
- Building a Cache
- Unlocking Content and Rust Basics
- Understanding Error Types in Rust
- Composing Error Types and Networking Example
- Writing to a Server and Handling Errors
- Implementing the “From” Trait
- Running Cargo and Address Parser
- Understanding Box Pointers and Custom Error Types
⭐️ Creating a Struct for Dirty Data- Adding Debug Trait to the Struct
- Distinguishing Error Types
- Converting Between Different Error Types
- Using Zero-Sized Types for Internal Errors
- Using Rust to Handle Errors
⭐ ⭐️ ️Error Conditions and Conversions⭐ ⭐ ⭐️ ️️Using Options and Results Together- Converting Option to Result
- Defining Traits for Arbitrary Types
- Conclusion
- Generated by Video Highlight
Introduction to Errors in Rust
Section Overview: In this section, the speaker introduces the concept of errors and how they are handled in Rust.
⭐️What is an Error?
- An error is a message that indicates something has gone wrong during program execution.
- A panic is a type of error that results in a crash. It can be altered to have different semantics.
- Errors and results happen most often when dealing with input/output (I/O).
- I/O refers to input/output not of function arguments but of devices interacting with a program from the outside world.
⭐️Dealing with Errors: Propagating, Returning and Unwrapping
- The speaker introduces three strategies for dealing with errors: Propagating, Returning, and Unwrapping.
- The example provided in the book demonstrates how to use the Result type to handle errors in Rust.
Handling File I/O Errors
Section Overview: In this section, the speaker discusses file input/output (I/O), its importance, and how it can result in errors.
Understanding File I/O
- File I/O refers to reading from or writing to files on disk.
- Reading from or writing to files can result in errors due to various reasons such as permission issues or file not found.
⭐️Handling File I/O Errors: Result、unwrap or ?
- The Result type can be used to handle file I/O errors by propagating them up through functions.
- Another way of handling file I/O errors is by using unwrap() method which will either return Ok value or panic if there’s an error. However, this approach should be used carefully as it can result in unexpected crashes.
- The speaker recommends using the ? operator to handle file I/O errors as it provides a concise and safe way of handling errors.
# Result Enum
Section Overview: In this section, the speaker introduces the Result enum and explains how it is a more elegant
mechanism than just getting a panic error message. They also explain that Result is an enum with two variants - Ok
and Error.
Introduction to Result Enum
- The
Resultenum is a more useful mechanism than just getting a panic error message. - The
Resultenum has two variants -OkandError.
Defining Custom Structs with Results
- To define custom structs that can use results, we need to implement the error for config.
- We can add methods to our custom struct.
Desugaring Question Mark Operator
- The speaker talks about desugaring the question mark operator.
- If we have a result type, we can call match on it.
Handling Errors in Rust
Section Overview: In this section, the speaker discusses how to handle errors in Rust and demonstrates how to print out errors and exit the program cleanly.
Printing Out Errors
- To print out an error type, use
println!. - Use the debug syntax to make sure that there is a human-readable version of what is being said.
Exiting Cleanly
- To exit cleanly, use
std::process::exit. - Exit with a value of 1 using
std::process::exit(1).
⭐⭐⭐️️️Debugging Rust Code
Section Overview: In this section, the speaker demonstrates how to debug Rust code by going through compile errors and fixing them.
Compile Error: Expected a Unit but Found usize
- This error occurs because Rust is an expression-based language.
- Add a semicolon at the end of the expression to end it and return an empty unit type.
Compile Error: Expected a Result but Found an Enum
- The type of the function has changed.
- Duplicate the function so that it can be brought back later if needed.
Compile Error: Not Found in Scope Expecting a Type Here Because of Type Description I Cannot Find the Value Buffer
- Rust does not have keyword arguments.
- Change mutable variables to immutable variables.
No Such File or Directory Error
- Wrap “Ok” in a unit.
- A unit is similar to void in other languages.
Rust Language and Productivity
Section Overview: In this section, the speaker talks about how Rust language can influence productivity and growth.
⭐️Influence of Rust on Productivity
- Rust language has the ability to influence productivity and growth.
- The comparison between two versions is not accurate because it involves reading into a string.
- The speaker is looking at their structure configuration and wants to simplify things by taking file away and calling it a string.
- The speaker discusses how to enable synthetic sugar for custom types.
Q&A Session
Section Overview: In this section, the speaker interacts with viewers who have joined the stream.
Viewer Interaction
- The speaker welcomes everyone who has just joined the stream and invites them to ask questions in the chat.
- The speaker notices that his chat has been hidden and offers to send a DM to anyone who wants to join his Discord.
Creating a Cache in Rust
Section Overview: In this section, the speaker creates a cache in Rust.
Creating a Cache
- The speaker creates boilerplate code for creating a cache.
- They change source file to source data.
- Source data is cloned, and dirty is defined as true.
- The ability to update data is updated.
- A flush method is created which guarantees that data is physically written before returning.
- The concept of “blush” is discussed.
- The speaker mentions that they want to change their mind halfway through building something on the fly.
- A value is returned as a result of a string or another string.
- The speaker acknowledges that using strings in multiple places is not a good way to do Rust.
- If self is dirty, garbage is returned.
Building a Cache
Section Overview: In this section, the speaker discusses building a cache and enabling it to be printed on the screen. They also talk about deriving debug that will enable syntax to happen.
Building a Cache
- The speaker creates a super cache using the main function.
- They label the point and enable it to be printed on the screen.
- The compiler figures out the code that needs to get written.
- There are some compiler errors that need fixing.
Fixing Compiler Errors
- Line 19: The speaker changes “return self” to “return ()”.
- Line 20: “self.data” is an unknown field, so they change it to “source data”.
- There is an unexpected token warning that needs fixing by removing some things.
Additional Information
- The chat has been paused for new viewers who are interested in learning about Rust programming language.
- A link to a chapter of the speaker’s book on Rust is provided in the chat for those who want more information.
Unlocking Content and Rust Basics
Section Overview: In this section, the speaker talks about unlocking content for a chapter and introduces Rust programming language basics.
Unlocking Content
- The publisher has unlocked the content of a chapter for free.
- Anyone watching can access it.
Rust Programming Language Basics
- Rust is immutable by default, which means that things are read-only until you satisfy them as mutable (read-write).
- Update method is used to update data in Rust.
- Booleans are not a good data type because they can always get it wrong.
Understanding Error Types in Rust
Section Overview: In this section, the speaker discusses error types in Rust programming language.
⭐️Error Types in Rust
- Error types don’t compose in Rust programming language.
- Errors from different places cannot be treated similarly.
- A better way to handle errors would be to use enums instead of booleans.
Composing Error Types and Networking Example
Section Overview: In this section, the speaker talks about composing error types and gives an example of networking using Rust programming language.
Composing Error Types
- As we become more proficient rust programmers, our error types don’t compose.
- We need to treat errors from different places similarly.
Networking Example
- The speaker gives an example of connecting to a database using networking with Rust programming language.
- Type inference can be used to ask for an IP address.
- IPv4 address has a cool thing where it can overload methods and extend strings to parse them.
Writing to a Server and Handling Errors
Section Overview: In this section, the speaker attempts to write code that reads data from a server, stores it in a cache, and writes it to disk. They encounter errors along the way and discuss how to handle them.
Attempting to Write Code for Reading Data from a Server
- The speaker attempts to write code for reading data from a server but encounters an error.
- They discuss the normal state of confusion when encountering errors while coding.
- The speaker tries another approach by writing code that does not use the server or file yet.
Understanding Formatting Strings and IPv4 Addresses
- The speaker explains that the
writemacro takes a formatting string as an argument. - They mention that IPv4 addresses know how to write themselves to the console.
- The speaker discusses how they need a reason for certain code elements to be present.
Handling Errors in Rust Programming
- The speaker encounters errors related to missing imports and typos in their code.
- They encounter another error message suggesting they consider importing something they believe they already imported.
- The speaker realizes there was a typo in their code causing an error message.
- They explain that two types of errors are not friends because they are independent types with identical syntax.
Conceptualizing Reading Data from a Server
- The speaker explains their goal of reading data from a server, storing it in cache, and writing it to disk.
- They demonstrate how they will pretend to read data from a server and write it to disk.
- The speaker acknowledges a question about the trait for pass and promises to answer it soon.
Understanding Traits in Rust Programming
- The speaker explains that they rewrote a chapter on traits because they are fundamental to Rust programming.
- They demonstrate how to find where a trait is implemented by searching for it in the code.
- The speaker answers a question about the trait for pass.
Implementing the “From” Trait
Section Overview: In this section, the speaker explains how to implement the “From” trait in Rust and provides strategies for handling errors.
Strategies for Implementing the “From” Trait
- To implement the “From” trait, find the method you’re interested in and look up its trait bounds.
- Use a trait object to implement a particular trait.
Handling Errors
- Rust has added implicit behavior that automatically attempts to convert things to the type defined at the return statement. This can cause confusion when dealing with different types of errors.
- When dealing with I/O and other things, it’s important to be able to join them together.
- One strategy for handling errors is using a trait object.
Running Cargo and Address Parser
Section Overview: In this section, the speaker runs cargo and encounters an error with the address parser.
Running Cargo
- The speaker runs cargo.
- An error occurs with the address parser when running cargo.
Troubleshooting the Error
- The speaker realizes they need to include different syntax.
- Despite making changes, the same warning persists.
- The speaker removes a compiler warning by ignoring a parameter.
- Another warning is silenced using code.
Parsing Issues
- The speaker tries to figure out why parsing is not working.
- They try a different approach that results in a different error message.
- Adding a box resolves the issue of parsing errors.
Understanding Box Pointers and Custom Error Types
Section Overview: This section covers box pointers and custom error types in Rust programming.
Box Pointers
- A box pointer is defined as a pointer to an implementation of an error type.
- In this case, control flow needs to be sent to three different places depending on what gets called, which requires using pointers.
Custom Error Types
- Using string as a way to send warning messages is discussed.
- Implementing trait objects can result in losing the ability for the compiler to detect concrete types.
⭐️Creating a Struct for Dirty Data
Section Overview: In this section, the speaker creates a struct called “dirty data” and explains why they are doing so.
Creating the “Dirty Data” Struct
- The speaker creates a struct called “dirty data” that will return data as dirty.
- They explain that they will automatically implement it and will explain why later.
Adding Debug Trait to the Struct
Section Overview: In this section, the speaker adds the debug trait to the previously created “dirty data” struct.
Adding Debug Trait
- The speaker derives debug for the “dirty data” struct.
- This allows it to print to the screen.
Distinguishing Error Types
Section Overview: In this section, the speaker distinguishes one error type from others by creating an address parser error in their file.
Creating Address Parser Error
- The speaker adds standard net and address parser error in their file.
- They want to distinguish one error type from others.
Converting Between Different Error Types
Section Overview: In this section, the speaker discusses how they need to convert between different error types and how they plan on doing so using Rust’s “from” trait.
Using Rust’s “From” Trait for Conversion
- The speaker explains that Rust’s “from” trait enables one type to be used as another type and Rust will automatically convert them when needed.
- They add code involving implementing these traits for conversion purposes.
- They mention that strings are not ideal for error types because of potential memory allocation issues.
Using Zero-Sized Types for Internal Errors
Section Overview: In this section, the speaker discusses using zero-sized types for internal errors and the potential issues that may arise.
Using Zero-Sized Types
- The speaker suggests using zero-sized types for internal errors to minimize memory usage.
- They mention the potential issue of making a mistake and causing a crash.
- They express uncertainty about their decision.
Using Rust to Handle Errors
Section Overview: In this section, the speaker discusses how to handle errors in Rust and demonstrates different strategies for dealing with them.
Bringing Modules into Local Scope
- To save time typing later on, the speaker likes to bring modules into local scope using
use std::net. - Using the full path is more explicit and makes the compiler happy, but it’s not necessary.
- The speaker chooses to keep everything quite full and somewhat ugly.
⭐⭐️️Understanding Function Pointers
- A function pointer is just a function definition.
- If you see
fnas a main or a standalone function, it is a function pointer. - An error message about an unexpected function pointer can be confusing if you don’t know what a function pointer is.
Strategies for Handling Errors
Building Up Rapid Types
- The speaker has built up the rapid type around all of their types.
- There is a lot of bureaucracy involved with these rapper types.
- A third-party crate called “Jane” has made it much simpler to create these rapper types.
Using Trait Objects
- There are some gotchas with trait objects that can be resolved with another crate.
- The speaker demonstrates why Rust does what it does and provides options for either doing things yourself or leveraging third-party crates.
⭐⭐⭐️️️Unwrapping Errors
- Unwrapping errors is not really a strategy for dealing with errors; it causes panics in runtime code.
- Sometimes crashing when there’s an error is what we want, but this should be used sparingly.
Mixing Options and Results
- Mixing options and results semantically can be difficult because they are different. Be mindful of doing so.
⭐⭐️️Error Conditions and Conversions
Section Overview: In this section, the speaker discusses error conditions and conversions between Option and Result types in Rust.
Error Conditions
- An empty Option is not an error condition but rather an expected thing that might happen.
- Unexpected errors can occur due to memory corruption or device failure when retrieving data from disk.
- Mixing up Option and Result types is often a sign that something needs to change in the code.
Conversions
- There are methods available in the standard library for converting between Option and Result types.
- Applying these conversions in your own code may indicate that you have an Option that should have started as a Result or vice versa.
⭐⭐⭐️️️Using Options and Results Together
Section Overview: In this section, the speaker discusses using Options and Results together in Rust.
Example Scenario
- The speaker creates an example scenario where a function returns an Option type while another function returns a Result type.
- When trying to return both values together, there is no available type for combining them.
- The speaker suggests rethinking the design of the functions to avoid mixing Option and Result types.
Converting Option to Result
Section Overview: In this section, the speaker discusses how to convert an option to a result in Rust.
Converting Option i32 to Result
- To convert an option i32 to a result, we can use the question mark operator.
- We can also match on the option and return either an Ok or Err variant of the result.
- The orphan rule in Rust requires us to bring things into local scope when converting between types.
Understanding Rust’s Orphan Rule
- Rust’s orphan rule requires that we make unambiguous decisions when writing import blocks that overlap.
- The compiler does not like ambiguity and wants to force the programmer to be able to make clear decisions about what they actually want to do.
Defining Traits for Arbitrary Types
Section Overview: In this section, the speaker discusses how to define traits for arbitrary types and the limitations of
using conversion mechanisms like ? operator with options and results.
Wrapping Option in a New Type
- To use conversion mechanisms like
?operator with options and results, we need to define a new type by wrapping option in it. - This is because the end result, option, and error are defined outside of this particular crate.
- We cannot tinker with any of that since it’s already decided what it wants to do.
⭐⭐️️Limitations of Using Conversion Mechanisms
- The reason why using conversion mechanisms like
?operator with options and results is failing is that we’re pulling these from third parties or all from the standard library. - We can’t tinker with any of that since it’s already decided what it wants to do.
- This problem isn’t seen in real-world use cases because normally you wouldn’t need to use the question mark operator with options and results defined in standard libraries.
Conclusion
Section Overview: In this section, the speaker concludes the session by apologizing for not being able to get a little thing working but assures viewers that this isn’t really a problem encountered in real-life work use cases.
- The speaker enjoyed hanging out and hopes viewers have enjoyed watching him get unstuck from trying to compose multiple error types together.
- The speaker apologizes for not being able to get a little thing working but assures viewers that this isn’t really a problem encountered in real-life work use cases.
Generated by Video Highlight
https://videohighlight.com/video/summary/K_NO5wJHFys
Unit Testing Basics
- Unit Testing Basics
Introduction to Unit Testing in Rust
Section Overview: In this section, the speaker introduces the basics of unit testing in Rust. They explain what a unit test is, how to create and run them, and why they are important.
Creating a Project
- The speaker creates a new library called “midpoint” whose job is to find the midpoint of two integers.
- Rust provides demonstration code with tests that can be run using cargo test.
Defining Midpoint Function
- The speaker defines the mid function which returns the midpoint of two integers.
- Tests are added for different input values.
- Running tests results in failures due to undefined functions.
Fixing Midpoint Function
- The speaker fixes the mid function by defining it for different cases.
- More tests are added for different input values.
- Overflow error occurs when using larger integer values.
Understanding Unit Tests
- A failing test is one that panics.
- A unit test is any function annotated with “test” that does not panic when executed.
Overall, this video provides an introduction to unit testing in Rust. It covers creating a project, defining and fixing functions, and understanding what a unit test is.
⭐️Assert Equals Macro: assert_eq!
Section Overview: In this section, the speaker explains what the assert equals macro does and how it works. They also discuss how unit tests are defined in their own module.
Assert Equals Macro
- The assert equals macro is used to panic if two values are not equal.
- Unit tests are often defined in their own module.
- Modules can be annotated with the config test annotation to only compile when running a test.
⭐️Assert Macro
Section Overview: In this section, the speaker explains what the assert macro does and how it works.
Assert Macro
- The assert macro takes an expression and evaluates it.
- It must return true and can be more sophisticated as long as it has a Boolean result.
- Multiple tests can be added using expressions such as greater than or less than.
Pretty Assertion Thing
Section Overview: In this section, the speaker discusses pretty assertion thing and demonstrates its use.
⭐⭐⭐️️️Pretty Assertion Thing
- Pretty assertion thing is used to get a better understanding of why a test failed.
- It provides more information about where the difference between expected and actual values occurred.
Conclusion
Section Overview: In this section, the speaker concludes by expressing curiosity about whether anyone can figure out how to define midpoint on size values without hitting that underflow bug.
Conclusion
- The speaker expresses curiosity about defining midpoint on size values without hitting an underflow bug.
Generated by Video Highlight
https://videohighlight.com/video/summary/kQQXx1oqASM
Introducing Iterators in Rust
- Introducing Iterators in Rust * Comparison between Rust and other Systems Programming Languages * Frustrations for Beginners in Rust * Printing Strings Using Python * Iteration Syntax in Rust * Iterations without an Iterator * Higher-Order Programming with Iterator * Map Functionality * Counting Bytes * Anonymous Functions * Counting Words * Type Annotations * Using Collect Method * Fleshing Out Standard Library Documentation * Questions from Viewers
# Introduction to Rust Iterators
Section Overview: In this section, the speaker introduces the topic of Rust programming language and its fundamental feature of iterators. The speaker compares Rust’s iteration story with other systems programming languages like C or C++.
Comparison between Rust and other Systems Programming Languages
- Other systems programming languages like C or C++ have a clunky way of iterating through an array by taking an integer as they go.
- Rust has a more ergonomic iteration story compared to other programming communities.
Frustrations for Beginners in Rust
- The speaker shares a blog post that talks about some of the frustrations beginners face in understanding the difference between iterator and iterater traits in Rust.
# Printing Strings in Python vs. Rust
Section Overview: In this section, the speaker demonstrates how to print strings using Python and then shows how it can be done using Rust’s iteration syntax.
Printing Strings Using Python
Iteration Syntax in Rust
- The speaker explains how iteration syntax is convenient in Rust.
- An iterator is a type that knows what iteration means basically.
- The speaker initializes a variable called “I” which stands for index.
- The speaker uses a loop to iterate through each element of the string.
- If Russ didn’t have iterators as a first-class object or a first-class type, we might have to do things like incrementing the index manually.
# Iterations and Higher-Order Programming
Section Overview: In this section, the speaker discusses iterations and higher-order programming in Rust.
Iterations without an Iterator
- The code should have the same result as before.
- We sat at zero instead of one, so we need a different comparison.
- Iterators are great but can produce synthetic noise.
- It is easy to understand and get the computer to figure out all intermediate values.
Higher-Order Programming with Iterator
- Rust has the ability to use higher-order programming alongside iterators.
- Questions are welcome during the session.
Map Functionality
- Types get their behavior in Rust through syntax.
- The map function applies a function to every element of an iterator it receives.
- The fold function takes a starting value and combines it with each element of an iterator using a closure or lambda expression.
# Counting Bytes
Section Overview: In this section, the speaker discusses how to count the number of bytes in a list efficiently using Rust iterators.
Counting Bytes
- The value of the number of bytes already seen is stored as a team pre-value.
- The initial state of the subtotal is zero.
- To add to the total, we sum up all the bytes.
- Rust iterators are very amenable to optimization and can be used instead of for loop syntax.
# Anonymous Functions in Rust
Section Overview: In this section, the speaker talks about anonymous functions in Rust and how they differ from other programming languages.
Anonymous Functions
- Rust creates a function that takes its arguments in these bars and then uses the next expression as the body of the function.
- If it’s a single expression, it only has one expression. If you need more than that, you can wrap things inside curly braces.
- Higher-order functions enable code to get heavily optimized.
# Counting Words
Section Overview: In this section, the speaker discusses counting words using Rust iterators and split whitespace.
Counting Words
- Split whitespace does not return an iterator with a link method; therefore, we need to use collect() method instead.
- Collect will consume whatever split might space spit out and provide us with a vector of that which we can count.
- Using idiomatic rust can actually compile really efficient code.
# Refresher on Type Annotations
Section Overview: In this section, the speaker talks about type annotations in Rust and how they help with error handling.
Type Annotations
- Type annotations help with error handling by providing information about what type something should be before it is used.
- Rust is very strict about types, and type annotations help to ensure that the code is correct.
0:20:07 Understanding Rust’s Collect Method
Section Overview: In this section, the speaker discusses how to use the collect method in Rust and its benefits.
Using Collect Method
- The collect method confirms that you want a vector and can figure out what goes in the middle.
- It enables us to modify or mutate the values inside the collection as we’re going through it.
- The behavior of something that is an owner once the owner goes out of scope will blow up any place.
- To iterate over a reference to a collection type, use
iter(). - To iterate over a read-write or immutable reference to our type, use
iter_mut(). - To iterate over a collection by taking ownership of it, use
into_iter().
0:22:14 Standard Library Documentation for Iteration
Section Overview: In this section, the speaker talks about how beginners can better understand Rust’s standard library documentation for iteration.
Fleshing Out Standard Library Documentation
- The standard library documentation for iteration is not descriptive enough for beginners.
- Beginners need more information on how to use certain methods like
iter()anditer_mut(). iter()iterates over a reference to a given type whileiter_mut()iterates over a read/write access to the collection itself.into_iter()takes ownership of a type T so it iterates over it.- It is important to note that using
into_iter()will destroy T once it’s finished iterating because that’s the behavior of something that is an owner once the owner goes out of scope.
0:25:11 Q&A Session
Section Overview: In this section, viewers have an opportunity to ask questions related to Rust programming language.
Questions from Viewers
- Viewers can ask questions on the chat or send a tweet to the speaker.
- No questions were asked during this session.
Implementing Iterators in Rust
Section Overview: In this section, the speaker discusses implementing iterators in Rust and how it can make code more user-friendly.
Benefits of Implementing Iterators
- Implementing iterators allows for the use of for-loop syntax.
- It provides a more user-friendly interface for consumers of our library.
- Higher-order functions and programming can be intimidating to some programmers, so avoiding them can make Rust programming more accessible.
Challenges with Iterators
- The implementation of iterators can be complex and may include nested iterators.
- Some optimizations, such as single instruction multiple data (SIMD), require the use of higher-order functions.
Conclusion and Feedback
- The speaker plans to continue streaming regularly to introduce more people to Rust.
- Feedback is welcome, and the speaker is open to helping others with their Rust programs. I understand the instructions. Thank you for providing them. I will follow these guidelines to create a clear and concise markdown file that makes use of timestamps when available.
Conclusion of Call
Section Overview: In this section, the speaker concludes the call and expresses their excitement for future interactions.
- The speaker states that hanging up is sufficient.
- They express their anticipation for future conversations.
Generated by Video Highlight
https://videohighlight.com/video/summary/0SOUZcyC9Ow
How to implement the IntoIterator trait
- How to implement the IntoIterator trait * Benefits of Read-Only References * Implementing Into Iterator * Motivation for Iterative Thing * Creating Type Variables in Traits * Encouraging Questions * The “Into” Trait * Types of Iteration * Implementing an Iterator * Open Source Implementation * Double-ended Iterator Trait
# Introduction
Section Overview: The speaker introduces themselves and welcomes viewers to the stream. They explain that they will be working on a Rust project and encourage viewers to ask questions throughout the stream.
# Creating a Struct
Section Overview: The speaker begins by creating a main function and a simple struct called “Tree”. They then create another struct called “Forest” which contains an array of trees. The speaker explains how to use macros in Rust and demonstrates how to print out the contents of the forest.
- Create a main function
- Create a struct called “Tree”
- Create a struct called “Forest” containing an array of trees
- Use macro to print out contents of forest
# Iterating Through Structs
Section Overview: The speaker discusses how to iterate through structs in Rust, using the example of iterating through trees in a forest. They demonstrate two methods for doing this, one using loops and one using iterators.
- Discuss iterating through structs in Rust
- Demonstrate loop method for iterating through trees in forest
- Demonstrate iterator method for iterating through trees in forest
0:08:20s Read-Only References
Section Overview: The speaker explains the concept of borrowing and ownership, and recommends using read-only references to values when possible.
Benefits of Read-Only References
- Using read-only references allows for multiple read-only accesses to values without needing to modify anything.
- The reference operator (&) is used to create a read-only reference.
0:08:49s Delegating with Wrapper Types
Section Overview: The speaker discusses how wrapper types can be used for delegation, and provides an example of implementing into iterator.
Implementing Into Iterator
- Implementing into iterator allows your type to work with Rust’s for loop syntax.
- Delegation can be achieved by implementing one method that delegates from the wrapper type into its own method.
- When implementing a trait for a type, it must be brought into local scope to avoid name clashes.
0:09:28s Motivation for Iterative Thing
Section Overview: The speaker provides motivation for why iterative thing is useful, and discusses the trait called “ into iterator“.
Motivation for Iterative Thing
- Implementing into iterator has benefits such as working with Rust’s for loop syntax.
- A wrapper type can be used for delegation by implementing one method that delegates from the wrapper type into its own method.
0:10:20s Type Variables in Traits
Section Overview: The speaker discusses creating type variables inside traits, bringing types into local scope when implementing traits, and encourages questions from viewers.
Creating Type Variables in Traits
- Inside a trait, you can create type variables that are referenced inside the rest of the trait.
- When implementing a trait for a type, it must be brought into local scope to avoid name clashes.
Encouraging Questions
- Viewers are encouraged to ask questions at any stage, and the speaker is able to respond in real-time.
0:11:47s Type Conversions with Into Trait
Section Overview: The speaker discusses the “into” trait and type conversions.
The “Into” Trait
- When a trait starts with “into”, it refers to type conversions.
- Implementing into iterator allows your type to return something that can turn itself into an iterator that returns the item or type defined previously.
- Capital self is the type variable of the type being referred to.
0:15:34 Rust Iterators
Section Overview: In this section, the speaker discusses how Rust iterators work and the different types of iteration available in Rust.
Types of Iteration
- There are three types of iteration in Rust:
&,mut, and owned.- The
&type borrows a value without taking ownership. - The
muttype allows for mutation of values. - The owned type takes ownership over the value and destroys it when it goes out of scope.
- The
Implementing an Iterator
- When implementing an iterator, it is important to understand which type of iteration is needed.
- The first type,
&, can be implemented by implementing the iterator trait. - If the first type is implemented, then the other two types are automatically implemented as well.
0:20:34 Bonus Content: Digging into Trait Implementation
Section Overview: In this section, the speaker discusses how to dig into trait implementation in Rust.
Open Source Implementation
- One benefit of Rust being open source is that users can dig into trait implementation themselves.
- This can be useful when trying to understand what a certain type means or how to implement a specific trait.
Double-ended Iterator Trait
- The double-ended iterator trait has few required methods because of Rust’s generics capability.
- It has several provided methods that allow for easy implementation.
Understanding Rust’s Standard Library
Section Overview: In this section, the speaker is trying to understand how Rust’s standard library works by looking at the source code of a specific type called “lines”.
Investigating the “lines” Type
- The “lines” type is a wrapper around an internal collection that delegates to it.
- The speaker wants to find out what happens under the hood and what the internal collection is.
- After some searching, they find that the internal collection for “lines” is a map.
- They discover that Rust aggressively inlines and optimizes code, which allows for embedding other types without incurring runtime costs.
Understanding the Map Function
- The speaker looks into the map function and discovers that it takes an iterator and a function as arguments.
- They assume that it takes characters and splits them into multiple lines.
- They note that poking around inside Rust’s internals can be fun but also challenging.
Exploring Further
- The speaker continues to explore Rust’s standard library by looking at other types and functions.
- They enjoy digging into the source code and learning more about how things work.
Finding the Rustling Source Code
Section Overview: In this section, the speaker navigates to Github and pulls up the Rustling source code. They locate a specific function within the code and explain its purpose.
Locating the Function
- The speaker goes to Github and pulls up the Rustling source code.
- They locate a function called
MiskaReadingwithin the code. - The function is located in
lib corewhich is not part of the standard library.
Understanding MiskaReading
- The function is actually a struct that masquerades as a function using closures in Rust.
- It takes a string and returns a string after analyzing whether it’s at the end of a line or not.
- This level of control is necessary because it’s located in the very guts of Rust, where there may not be all tools available.
Navigating Documentation for Arbitrary Traits
Section Overview: In this section, the speaker explains how they navigated documentation for arbitrary traits by finding an implementation and digging into its source code.
Finding Implementation
-
The speaker was having trouble understanding documentation for an arbitrary trait.
-
They scrolled down to find implementations at the bottom of said trait.
-
Clicking on one of these types led them to dig into source code inside Lib core.
Exploring Byte Slices
-
While exploring Lib core, they found themselves looking at how byte slices implement splitting heuristics.
-
This was another thing that they may as well explain while they still had an audience.
Syntax of main
Section Overview: In this section, the speaker explains the syntax of main and how it works.
Syntax of main
- The syntax for
mainis:fn main() -> io::Result<()>. - This means that it returns a result type which can either be an error or a unit.
- The speaker notes that they feel like they’re doing physics in front of an audience.
# Using Generic Types in Rust
Section Overview: In this section, the speaker explains how to use generic types in Rust and their implementation.
Implementation of Generic Types
- The speaker explains that generic types are used to implement all the implementation for us.
- The speaker gives an example of how into is implemented for every type T where you implements the fromto type.
- The speaker talks about converting float 64 and 32 from one another and whether it’s safe or not.
# Binary Heap Implementation in Rust
Section Overview: In this section, the speaker discusses binary heap implementation in Rust.
Implementing Binary Heap
- The speaker talks about how binary heap implements from big t so from any couldn’t a.
- The speaker mentions that bang today we go actually so the implementation of this is super trivial.
- The speaker concludes by saying that they enjoyed talking people through iteration and getting the most out of the standard library.
Generated by Video Highlight
https://videohighlight.com/video/summary/OhwnbYshBIo
Considering Rust
- Considering Rust
- Introduction
- What is Rust?
- Teaching Rust
- Conclusion
- Introduction to Rust
- Additional Features of Rust
- Comparing Rust and Go
- Features of Rust
- Rust Features Overview
- Rust: Safety by Construction
- Rust’s Key Features
- Rust’s Error Handling
- Advantages of Rust
- Rust: A Language for the Next 40 Years
- Dependency Management and Standard Tools
- Rust’s Primary Features
- Rust: Advantages and Drawbacks
- Conclusion
- Rust Downsides
- Rust Support for Windows
- Importance of Long-Term Viability
- Incremental Rewrite with Rust
- Generated by Video Highlight
Introduction
Section Overview: The speaker introduces themselves and their experience with Rust. They explain the purpose of the talk and what they will cover.
Meet Rust
- Rust is a systems programming language made by Mozilla that had its 1.0 release about six years ago today.
- It is primarily community-driven, developed out in the open, and essentially the work of a large group of volunteers both associated with Mozilla and not.
- Rust has this slogan of fast, reliable, and productive, pick three. as sort of their marketing pitch or this notion of “fearless concurrency”.
Why Consider Rust?
- The speaker is not here to tell you that you must use Rust but rather to convince you why it’s worth considering.
- In this talk, they will give comparisons against other languages at a relatively high level of what the strengths and weaknesses of Rust are compared to those languages.
- They will also tell you about some of Rust’s features and their advantages as well as some drawbacks that should be considered before adopting it.
What is Rust?
Section Overview: The speaker explains what systems programming means in relation to runtime environments and performance. They discuss how Rust compares to other languages in terms of trade-offs between speed, reliability, and productivity.
Systems Programming
Fast, Reliable & Productive
- Other languages force you to make trade-offs where you give up one of these three (fast, reliable & productive), whereas in Rust you do not have to.
Rust’s Features
- Rust is a compiled language that has strong static typing, so no typing occurs at runtime, it’s all statically checked by the compiler.
- It is imperative but does have some functional aspects to it.
Teaching Rust
Section Overview: The speaker explains that they will not be teaching Rust in this talk but rather giving an overview of its strengths and weaknesses.
Not Here to Teach Rust
- The goal of today’s talk is not to teach you Rust.
- They will show you some code on certain slides and walk you through some of it to show particular features, but urge you to listen to the words that they say rather than try to exactly understand how the thing works.
Conclusion
Section Overview: The speaker summarizes what was covered in the talk and encourages listeners to consider using Rust.
Recap
- In this talk, the speaker gave comparisons against other languages at a relatively high level of what the strengths and weaknesses of Rust are compared to those languages.
- They also told us about some of Rust’s features and their advantages as well as some drawbacks that should be considered before adopting it.
Consider Using Rust
Introduction to Rust
Section Overview: This section introduces Rust and its type system. It also compares Rust with other programming languages.
Rust’s Type System
- Rust has an elaborate type system that provides guarantees at compile time.
- Types are used for enforcing many of these guarantees statically.
- Algebraic data types and pattern matching allow you to write nice code using types.
- The comprehensive static typing in Rust reduces runtime crashes compared to Python.
Comparison with Other Languages
Python
- Rust is much faster than Python because it is a compiled language without a runtime, resulting in lower memory use and better multi-threading performance.
Java
- Rust has no runtime, resulting in lower memory use and generally higher performance than Java.
- Zero cost abstractions in Rust enable the use of additional classes without any runtime performance cost, unlike Java where this often comes at a cost.
- Data races and concurrent modification exceptions common in Java go away in Rust due to compile-time guarantees against them.
C/C++
- Segfaults, buffer overflows, null pointers, and data races common in C/C++ do not occur in Rust due to compile-time checks against them.
- The powerful type system provided by the language eliminates the need for void pointers or nasty type classing found in C/C++.
Additional Features of Rust
Section Overview: This section covers additional features of the language that make it easy to write modular code bases.
Unified Build System
- Cargo, the unified build system that comes with the compiler tool chain makes dependency management a lot easier.
- All libraries and tools use the same build system, making it easy to add external dependencies from other libraries or public repositories.
Comparing Rust and Go
Section Overview: This section compares Rust and Go, two languages that are often compared to each other. The speaker notes that while Go is an excellent language, Rust has some advantages over it.
Rust vs. Go
- Rust has no garbage collector or runtime, which allows for higher performance than what can be achieved with Go code.
- In Rust, there are no null pointers, whereas in Go, you have to manually check for nil values. Additionally, error handling is much nicer in Rust than in Go.
- Concurrency is easy in both languages but safer in Rust as it ensures there are no data races. In contrast, concurrency in Go can lead to shooting oneself in the foot.
- Both languages have a strong type system and zero-cost abstractions but Rust also offers modern features such as efficient generics and algebraic data types with pattern matching. The toolchain that comes with the language makes it easier to use than older languages like C++.
Features of Rust
Section Overview: This section discusses some of the key features of the Rust programming language.
Modern Language
- One of the most important things about Rust is that it’s a modern language that doesn’t feel like a low-level systems language. It has nice and efficient generics similar to Java or type classes in C++ and algebraic data types with pattern matching. The toolchain that comes with the language makes it easier to use than older languages like C++.
Efficient Generics
- Generics allow for code reuse by allowing users to choose what type T should be used when writing generic code. In Rust, this code gets compiled as if the generics weren’t there leading to really fast runtime performance.
- The cost of function calls in generic code is optimized by the compiler, which can inline functions and compile them for each instance of T and P.
Algebraic Data Types with Pattern Matching
- Rust has algebraic data types with pattern matching, which allows for more concise and expressive code. This feature is similar to sum types in functional programming languages like Haskell or ML.
Modern Toolchain
- Rust comes with a modern toolchain that makes it easier to use than older languages like C++. Pain points that exist with many older languages are just gone in Rust.
Rust Features Overview
Section Overview: This section provides an overview of some of the key features of Rust, including algebraic data types, pattern matching, and modern tooling.
Option Type and Algebraic Data Types
- The return type of a function in Rust is
Option reference to T, which means that it can either returnSomewith a pointer orNone. - Rust allows for defining enumerations or types that contain other types. Unlike enums in other languages, these enums can contain other things.
- The
Optiontype is an example of this. It is an enum that is generic over some T and contains either theSomevariant with that T or theNonevariant.
Pattern Matching
- Rust provides pattern matching to match over types that are these enums. This lets you tease out only the specific values and variants that you care about.
- The compiler will check that you have exhaustively matched, meaning if someone adds a variant to an enum later on, your code will not break. The compiler will tell you “you also need to update this match over here”.
Modern Tooling
- By default, in Rust, the compiler knows about things like tests and documentation. You can annotate any function in your code with #[test] attribute and then run cargo test to run it as a unit test.
- You can place these tests in separate files or outside your source directory, and then they will be compiled as integration tests which only have access to your public API. The compiler and build system know how to run all of them.
Rust: Safety by Construction
Section Overview: This section discusses how Rust provides safety by construction and the primary reasons for this.
Checking Pointers at Compile Time
- The Rust compiler ensures that every value in your program has a single owner and that owner is responsible for freeing that resource.
- The compiler checks two properties for every variable: there is only ever one owner, and no pointers outlive the owner.
- If you guarantee these invariants, you cannot have double frees or use after free errors.
- The borrow checker detects references that live past when their owners go away and rejects invalid code.
Immutable Pointers and Variables
- Pointers and variables in Rust are immutable by default.
- Functions can take references to variables but not modify them unless given mutable access.
Rust’s Key Features
Section Overview: This section covers the key features of Rust, including its memory safety, thread safety, and no hidden states.
Memory Safety
- Rust variables are immutable by default.
- The
constkeyword in Rust applies transitively to all reachable values. - Immutable references can be safely shared with other code without fear of modification.
Thread Safety
- Rust types know whether it’s safe for them to cross thread boundaries.
- Rc and Arc are two reference counted wrapper types that ensure thread safety.
- There can only ever be either one mutable reference or any number of immutable references to any given value at any given point in time. This ensures there can’t be data races.
- The compiler checks for potential data races even across thread boundaries.
No Hidden States
- Rust uses the type system to ensure that you check every case.
- Anytime where you see a reference, it is guaranteed not to be null.
Rust’s Error Handling
Section Overview: In this section, the speaker discusses Rust’s error handling system and how it differs from other languages.
Rust’s Error Handling System
- Rust’s error handling system ensures that null checks are not forgotten by forcing the programmer to deal with errors.
- The compiler will not allow errors to be ignored accidentally.
- Examples of code that require error handling include find and parsing a string.
- The question mark operator is a shortcut for bubbling up errors to the caller.
Advantages of Rust
Section Overview: In this section, the speaker discusses some advantages of using Rust over other programming languages.
Lack of Runtime and Garbage Collector
- Rust does not have a garbage collector or runtime, which means there are no garbage collection pauses and lower memory overhead in general.
- You can issue system calls directly, such as fork and exec, which is often not possible in managed languages because the runtime controls the program execution.
- You can even run on a system without an OS because there is no code apart from your own that you need to deal with.
Free FFI Calls
- FFI calls are free in Rust because there is no runtime that needs to be informed when calling out to another language through an API.
Low-Level Control
- In Rust, you have low-level control over both allocation and dispatch. Unlike Java or Go, nothing is automatically heap allocated for you.
- You can opt into heap allocation using the Box keyword or by declaring a vector.
- You can swap out the entire allocator globally in your program if you wish, allowing you to use jemalloc, Google’s new tcmalloc, or Microsoft’s mimalloc.
Rust: A Language for the Next 40 Years
Section Overview: This section introduces Rust as a language that offers low-level control and compatibility with other languages.
Low-Level Control
- Rust allows for low-level code that is often written in C or assembly.
- The
unsafekeyword in Rust is used to assert invariants that the compiler cannot check. It provides an escape hatch for when low-level control is needed. - The advantage of using
unsafeis that it allows for memory errors to be audited easily, and it also makes it clear which parts of the code are dangerous.
Compatibility with Other Languages
- Rust offers zero overhead FFI, allowing for easy integration with C and C++ code.
- Rust has great web assembly support and works well with traditional tools from C++, Python, and Java.
- Rust functions can be exported through some kind of C ABI, making them callable from C.
# Rust’s Interoperability with Other Languages
Section Overview: This section discusses how Rust can interact with other languages using the C ABI, and how this makes incremental rewriting easy.
Rust’s Compatibility with Other Languages
- Rust can interact with any language that can interact with a C ABI. This includes C, C++, Java’s JNI, Go’s cgo, Python’s C++ bindings, and Ruby.
- Tools like bindgen and cbindgen generate Rust code or C headers for you from a given C header file or set of methods.
- The FFI (Foreign Function Interface) makes incremental rewriting easy by allowing you to implement modules in Rust and swap them out in your existing project.
- Rust has good interoperability with web assembly, which is built into browsers. It also has one of the best integrations for web assembly among programming languages.
- Traditional tools like perf, gdb, lldb, Valgrind work on Rust binaries because it is compiled using LLVM to machine code.
Dependency Management and Standard Tools
Section Overview: This section covers the built-in dependency management and standard tools that come with Rust.
Dependency Management
- Rust has a built-in dependency management system called Cargo.toml.
- The Rust compiler automatically fetches dependencies, builds them, and ensures that it builds any given dependency only once, even if it’s transitively included by different paths.
- The Rust toolchain knows about versioning and will let you use the most up-to-date versions of your dependencies that your code is still compatible with.
- You can spin up your own private repository if you have libraries or “crates” in the Rust ecosystem lingo that you don’t want to be public to the world.
Standard Tools
- Rust comes with standardized tools like cargo format for formatting code, cargo doc for generating documentation from documentation comments, cargo clippy for linting, RLS and rust analyzer for IDE integration.
- Docs.rs is a website that automatically generates all of the documentation for every version of every library uploaded to the standard repository.
Rust’s Primary Features
Section Overview: In this section, the speaker discusses some of the primary features of the Rust language.
Metaprogramming in Rust
- Rust has good support for writing programs that manipulate other Rust programs.
- This is known as metaprogramming and involves manipulating the AST or syntax tree of a program.
- Rust macros are more controlled than C++ or C macros and are fully-fledged Rust programs with well-defined syntax for transforming Rust trees.
Procedural Macros
- Procedural macros allow you to write a Rust function from a stream of tokens to a new stream of tokens.
- This lets you do more elaborate rewritings of Rust code.
- The “serde” library provides serialization and deserialization for any type automatically for any format using these macros.
Asynchronous Code Support
- Rust has built-in support for asynchronous code execution.
- You can choose your own runtime instead of being dictated by the language like in nodejs, Go, or Java.
- You define an executor that can take futures from the standard library and run them cooperatively.
Rust: Advantages and Drawbacks
Section Overview: In this section, the speaker discusses the advantages and drawbacks of using Rust as a programming language.
Rust Learning Curve
- Rust has a steep learning curve due to its unique features such as the borrowed checker.
- The borrowed checker is a different way to reason about pointers in your program, which can be challenging to learn.
- Although it takes longer to learn than other languages, when your program compiles, it is more likely to run correctly.
Ecosystem
- Rust is a relatively young language with a small ecosystem that has few maintainers.
- There are high-quality libraries available in the ecosystem like rayon and serde that can do things you couldn’t do in other languages.
- Many crates are still in early stages, so there’s some churn in the ecosystem. However, more libraries are hitting stable releases with stable APIs that you can depend on.
- The community is very friendly and supportive. You’ll find people willing to help if you have trouble with Rust code or need support on a library.
Object-Oriented Model
- Rust does not have an object-oriented model like Python or C++. This can be pretty alien for those who come from these languages.
- Although you still have things like interfaces, they work differently than in other languages.
Conclusion
Section Overview: In this section, the speaker concludes by reiterating their goal of providing information for others to decide whether Rust is right for them.
The speaker’s goal was not to tell the audience that Rust is the right language but to provide information for them to decide whether it’s right for them. Rust has advantages such as being a performant language with zero-cost abstractions and ensuring thread safety at compile time. However, it also has drawbacks like a steep learning curve due to its unique features and a small ecosystem with few maintainers. Despite this, Rust is worth considering because of its friendly community and high-quality libraries.
Rust Downsides
Section Overview: This section discusses some of the downsides of using Rust.
No Runtime Reflection
- Rust’s lack of a runtime means that there is no runtime reflection.
- In Java, you can attach to a program in the middle of executing something and use the runtime to inspect various things about its execution. In Rust, you can’t do the same.
- You can use gdb or lldb to try to tease out that information, but the lack of a runtime means that that information is less rich.
- It also means that the program can’t really introspect itself at runtime.
Longer Compile Times
- Because Rust is a fully compiled language and uses LLVM, there’s sort of a long pipeline to get to the final binary, and everything has to be compiled.
- The compile times are somewhat longer than what you might be used to in something like Python where there’s just no compile time at all.
Compiling from Source
- In Rust, there aren’t really pre-built libraries you can download. You sort of need to compile from source.
- If I want to call a function in your library, and your library function is generic, I need to compile the version of your method for the type I’m using. And that type might be defined in my library. So I need the source in order to do that compilation.
Vendor Support
- Often when working with very large software projects you have dependencies on things that you didn’t build. That were just given to you by a vendor.
- The FFI interface works pretty well as long as the library you get has an API that isn’t too complicated. But sometimes, working with these large vendored things can be a bit of a pain.
- Similarly, if you work with a vendor that has some kind of tooling that they provide when you use their library that tooling might not work if you’re working through Rust code because they might assume that you’re just writing C++ code.
Rust Support for Windows
Section Overview: This section discusses the level of support that Rust has for Windows.
Rust Compiler and Standard Library Support
- Rust compiler and standard library have full support for Windows.
- Windows is a tier one platform with official support.
Ecosystem and Library Support
- The ecosystem, particularly libraries, is mainly focused on Linux and macOS.
- Some low-level libraries may lack support for Windows, especially those that interact directly with the operating system or implement asynchronous executors.
Long-Term Viability
- Rust was rated the most loved programming language four years in a row in the StackOverflow developer survey.
- Big companies such as Microsoft, Google, Facebook, Amazon, CloudFlare, Mozilla, Atlassian, and npm are using Rust code in some of their projects.
- The increased company involvement in Rust itself helps to develop the enterprise part of the ecosystem and build more maturity over time.
- The Rust world is expanding with yearly conferences spanning the globe and hundreds of meetups around the world.
- The focus on developer experience by providing good compiler error messages makes a big difference when working on large refactors or when new to the language.
Importance of Long-Term Viability
Section Overview: This section emphasizes why long-term viability is important when considering adopting a young language like Rust.
Reasons for Choosing a Young Language
- When choosing to adopt a young language like Rust, it’s important to consider its potential to keep going for a long time.
Why Choose Rust?
- Despite being relatively young compared to other languages, there are several reasons why choosing Rust is a good bet
into the future:
- Rated as most loved programming language four years in a row
- Adoption by big companies
- Good interoperability story
- Increasing company involvement in Rust
- Expanding Rust community
- Focus on developer experience
Incremental Rewrite with Rust
Section Overview: This section discusses how to rewrite projects incrementally with Rust.
Benefits of Incremental Rewrite
- Incremental rewrite helps reduce the risk when adopting a new language like Rust.
- You can rewrite only the core concurrency that needs to be highly concurrent in Rust, leaving the rest of your application as it is.
How to Do an Incremental Rewrite
- Identify the core part of your application that needs to be rewritten for safety or performance reasons.
- Rewrite that core part in Rust while leaving the rest of your application as it is.
- This approach allows you to gradually adopt Rust and its benefits without having to rewrite your entire project.
Generated by Video Highlight
https://videohighlight.com/video/summary/DnT-LUQgc7s
In this series we seek to understand intermediate Rust concepts by diving into real examples and working code, often by re-implementing functionality from the standard library. These episodes are not targeted at newcomers to Rust, but at those who have read The Book and have the theoretical knowledge, but want to see how these concepts translate into real use.
- John Gjengset (author of
)
Jon Gjengset has worked in the Rust ecosystem since the early days of Rust 1.0, and built a high-performance relational database from scratch in Rust over the course of his PhD at MIT. He’s been a frequent contributor to the Rust toolchain and ecosystem, including the asynchronous runtime Tokio, and maintains several popular Rust crates, such as hdrhistogram and inferno. Jon has been teaching Rust since 2018, when he started live-stream- ing intermediate-level Rust programming sessions. Since then, he’s made videos that cover advanced topics like async and await, pinning, variance, atomics, dynamic dispatch, and more, which have been received enthusiasti- cally by the Rust community.
Async/Await in Rust
- Async/Await in Rust
- Introduction
- Async Await in Rust
- Additional Resources
- Focusing on Tokio Executor
- Conclusion
- Introduction to Async Functions
- Example of Using Async Functions
- Async Blocks
- Mental Model of Async
- Promises vs Futures
- Understanding Async Programming in Rust
- Introduction to Select Macro
- Benefits of Async Await
- Cooperative Scheduling and Cancellation
- Understanding Async in Rust
- Select and Cooperatively Scheduled World
- Future Polling
- Select Macro and its Implementation
- Asynchronous IO and the Benefits of Async
- Joining Futures with Join Operations
- Joining Files with the Join Macro
- Overview of Futures in Rust
- Handling Multiple Connections
- Introduction to Parallelism in Asynchronous Programs
- Importance of Spawning and Performance Issues
- Best Practices for Passing Data and Handling Errors with Tokyo Spawn
- Spawning and Running Futures
- Rust Futures and Thread Locals
- Introduction
- What is a Future?
- Example Async Function
- Understanding Impul Futures
- Introduction
- Async Trait
- Async Trait and Associated Types
- Challenges with Implementing Async Functions in Traits
- Asynchronous Programming in Rust
- Standard Library Mutexes vs Asynchronously Enabled Mutexes
- Using Async-Aware Mutexes
- Thread Spawn vs Tokyo Spawn
- Introduction
- Scheduling Futures
- Async Stack Trace
- Tracing Futures
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces himself and explains that he will be discussing async await in Rust.
Speaker’s Introduction
- The speaker welcomes viewers back after a long break.
- He mentions that he has been on vacation and briefly talks about it.
- The speaker announces that this will be another “Crust of Rust” stream.
- He states that he will be discussing async await in Rust.
Async Await in Rust
Section Overview: In this section, the speaker discusses async await in Rust from a usability standpoint.
Understanding Async Await
- The speaker acknowledges that he has covered async await before but only from a technical standpoint.
- He explains that he wants to discuss how to use async await and what it looks like for developers.
- The speaker emphasizes the importance of understanding the intuition and mental model behind async await.
Additional Resources
Section Overview: In this section, the speaker provides additional resources for learning about async programming in Rust.
Recommended Books
- The speaker recommends reading “The Rust Programming Language” book if you haven’t already.
- He mentions that there is no chapter on async programming in the book but one may be added soon.
- The speaker also recommends his own book which covers async programming at a deeper level than basic tutorials.
Other Resources
- The speaker recommends checking out “The Rust Async Book” which explains asynchronous programming in Rust but still has some work to do.
- He also suggests looking into Mini Redis, a project by Tokyo Project which demonstrates how to structure an asynchronous application client-side and server-side.
Focusing on Tokio Executor
Section Overview: In this section, the speaker focuses on using Tokio executor for asynchronous code.
Using Tokio Executor
- The speaker mentions that there are many different executors for asynchronous code but he will be focusing on Tokio because it is the most widely used and actively maintained one.
- He clarifies that most of what he will be discussing is independent of the executor.
Conclusion
Section Overview: In this section, the speaker concludes his discussion on async await in Rust.
Final Thoughts
- The speaker fixes an error in the video title.
- He thanks viewers for watching and encourages them to follow him on Twitter for updates on upcoming videos.
- The speaker emphasizes the importance of understanding async programming in Rust and provides resources for further learning.
Introduction to Async Functions
Section Overview: In this section, the speaker introduces async functions and explains how they work.
What is an Async Function?
- An async function is a function that returns a future.
- The future trait signifies a value that’s not ready yet but will eventually be of a certain type.
- Awaiting on a future means not running the following instructions until it resolves into its output type.
How Async Functions Work
- A future does nothing until it is awaited.
- When awaited, the future describes a series of steps that will be executed at some point in the future.
- If an async function calls another async function, it awaits the returned future before continuing with its own execution.
Example of Using Async Functions
Section Overview: In this section, the speaker provides an example of using async functions and explains how they can be used to handle long-running operations.
Handling Long-Running Operations
- Reading from a file can take time and block other operations.
- By using async functions, we can avoid blocking other operations while waiting for long-running tasks to complete.
- We can use await to pause execution until the task completes without blocking other operations.
Example Code
- The speaker provides an example code snippet that demonstrates how to use async functions to read from a file without blocking other operations.
Async Blocks
Section Overview: This section explains how async blocks execute in chunks and yield when they have to wait.
Async Blocks
- Async blocks execute in chunks.
- They yield when they have to wait, allowing other things to run.
- A future is checked for progress towards completion.
- When a future makes progress, it continues executing from the last point it yielded until the next point where it might fail to make progress.
Mental Model of Async
Section Overview: This section provides a mental model of async that helps understand how async works.
Mental Model of Async
- The mental model is that async lets you chunk computation.
- It runs until it has to wait and then yields, letting other things run.
- Once an await resolves, execution continues as if there were no async until another future is created and awaited.
Promises vs Futures
Section Overview: This section compares promises and futures.
Promises vs Futures
- A future can be thought of as a promise in terms of the word “promise,” not in terms of the actual JavaScript type Promise.
Understanding Async Programming in Rust
Section Overview: In this section, the speaker explains how async programming works and why it is useful.
How Async Programming Works
- Async programming involves waiting for multiple operations to complete without blocking the main thread.
- Yielding allows you to return all the way up to where a future was first awaited.
- This approach is useful when you have many futures that you want to wait on simultaneously.
Why Use Async Programming?
- Traditional threading systems require one thread for each operation, which can be difficult to manage.
- Async programming allows you to handle multiple operations with a single thread, making it easier to manage and more efficient.
- Using async programming also allows you to handle slow connections without getting stuck writing to them.
Conclusion
- Async programming is a powerful tool for managing multiple operations efficiently and effectively. By using async programming, developers can avoid the pitfalls of traditional threading systems and create more robust applications.
Introduction to Select Macro
Section Overview: In this section, the speaker introduces the select macro and how it can be used with futures.
Using Select Macro with Futures
- The select macro waits on multiple futures and tells you which one finished first.
- If progress is made on network, then a stream is given and the code inside is called. If not, progress is tried on the terminal.
- When neither of them make progress, it yields and retries later using some operating system primitive under the hood to be smarter about when it tries again.
- Async allows you to express waiting for something else to happen while giving up thread’s time.
Benefits of Async Await
Section Overview: In this section, the speaker explains how async await can be used as a state machine and its benefits.
Benefits of Async Await
- Async allows something else to run instead while waiting for disk or network operations.
- Async await can be thought of as a big state machine where there are multiple paths forward depending on what becomes available on sockets.
- Select operation allows branching execution but in this case, there’s no real branching.
Cooperative Scheduling and Cancellation
Section Overview: This section discusses cooperative scheduling and cancellation in Rust.
Cooperative Scheduling
asyncfunctions allow for cooperative scheduling, where execution is yielded to other tasks when a function encounters anawaitstatement.- The
select!macro allows for non-blocking I/O operations by selecting the first future that completes. - When a future is awaited, it does not execute until it is explicitly called with an
awaitstatement. - If there are no other tasks to run, the current task will continue executing until it reaches another
awaitstatement or yields control back to the scheduler.
Cancellation
- Futures can be cancelled by dropping them if they have not been awaited yet.
- Once a future has been awaited, its execution cannot be cancelled directly.
- To cancel a future’s execution, you can use the
select!macro with a timeout value or a cancellation token.
Understanding Async in Rust
Section Overview: In this section, the speaker explains how async works in Rust and describes the mechanisms for cooperatively scheduling a bunch of computation by describing when under what circumstances code can make progress and under what circumstances code can yield.
Cancellation
- The speaker explains that cancellation is done by describing the circumstances under which you should cancel the operation.
- A good example of cancellation is given as a cancellation channel which is like a Tokyo sync mpsc receiver.
- The cancel function is defined as cancel.08.
- If we get a weight, we fall through to print line below.
Racing Futures Against Each Other
- The speaker proposes another name for select, which is race.
- Whichever await can produce its result first gets to run while the other one does not.
- If we get a weight, we return zero and don’t execute any of the remainder.
Understanding Executors
- An executor provides both the lowest level resources like network sockets and timers and also the executor loop at the top.
- At some point in your program, you’re going to have this giant future that holds the entire execution of your program but it’s a future so nothing runs yet right?
- You’re only allowed to await in async functions and async blocks so this wouldn’t actually compile if this was an async fn but then you see compiler complaints main function is not allowed to be async because ultimately at some point in your program you’re going to have this giant future that holds the entire execution of your program.
- The executor crate provides both the lowest level resources like network sockets and timers and also the executor loop at the top.
Epoll Loop
- An executor is a sort of primitive executor that just pulls futures in a loop and does nothing else it just keeps retrying aggressively instead.
- Imagine that you’re doing a read from the network and you call dot await what’s going to actually happen is Tokyo’s tcp stream is going to do a read from the network realize that I can’t read yet and then it’s going to sort of store its file descriptor store the socket id if you will into the executor’s sort of internal state.
- The main executor takes all those resources that it knows it needs to wait for, sends them to the operating system, puts itself to sleep but wakes up if any of these change because it has more work to do. I’m sorry, but I cannot provide a summary of the transcript without having access to it. Please provide me with the transcript so that I can create a summary for you.
# Tokyo’s Use of Event Loops
Section Overview: This section discusses how Tokyo uses event loops and the Mayo crate to abstract over kq, epoll, and other operating system event loops.
Tokyo’s Use of Event Loops
- Tokyo does not re-implement kq but instead uses the Mayo crate to abstract over kq and other operating system event loops.
- The Mayo crate allows you to register events with the operating system and go to sleep until any of those events occur. The operating system will then wake you up when one of those events happens.
- You can use the Futures channel with Tokyo because they use the same underlying mechanisms that Rust provides.
# Selecting Among Options in a Loop
Section Overview: This section discusses how select works in a loop and what happens if an abandoned select arm has side effects.
Selecting Among Options in a Loop
- When using select, it selects among all given options every time. It doesn’t remember anything about having been run in the past.
- To reuse network across multiple iterations of the loop, you need to do something like this:
let mut network = network;
select! {
_ = terminal => { ... },
_ = foo => { ... },
_ = &mut network => { ... },
}
Abandoned Select Arm Side Effects
- If an abandoned select arm has side effects, such as file copying, it will still execute those side effects even if it is not selected.
Select and Cooperatively Scheduled World
Section Overview: This section discusses the potential issues that arise when using select in an asynchronous context. It also explains the importance of cooperatively scheduling tasks to avoid blocking other futures.
Potential Issues with Select
- When using select, it’s possible to be in a state where some bytes have been copied from one future to another but not all, which can lead to errors if not handled properly.
- If a future is partially completed and then dropped, it won’t get to finish its work and will be cancelled. This means that your program might be in an intermediate state that needs to be considered.
- You need to be careful about what happens if one branch runs and then another branch completes so the first branch didn’t run to completion but the second branch did where does that leave you? This is an error case that you need to be concerned about when you’re using select.
Importance of Cooperatively Scheduling Tasks
- In an asynchronous context, it’s important for tasks to yield occasionally so that other things can run as well. If a future never yields, it can block other futures from making progress.
- Using blocking operations (operations that aren’t aware of async yielding or very compute-intensive operations) can
cause threads to block and prevent other futures from making progress. It’s important to use methods
like
spawn_blockingorblock_in_placein Tokyo for long-blocking operations so that the executor knows how to handle them appropriately.
Future Polling
Section Overview: This section discusses whether select with a huge number of cases will potentially slow down by trying all options out every time.
Future Polling and Select
- The implementation of select determines whether a select with a huge number of cases will be slowed down by trying all options out every time.
- In general, if you have a select with a million cases, it seems like it would be slow. However, the answer depends on the implementation of select.
Select Macro and its Implementation
Section Overview: In this section, the speaker talks about the select macro and how it can be implemented to optimize for few cases rather than many cases. The speaker also explains how select can integrate with Rust machinery for dealing with futures and wakeups.
Smart Select
- The select macro can be smart in the sense of only polling the ones that might be able to make progress.
- When a future becomes runnable through whatever mechanism like a file descriptor was ready or a send happened on an in-memory channel, there’s a way for the select macro to sort of inject itself into that notification that this future is ready and sort of get a signal to update its own state when that happens.
- The select keeps almost like a bit mask across all of its branches, and when that notification comes in, it flips the bit for the appropriate branch. Then, next time the select is awaited, it’ll only check the ones where the bit is set.
Fairness of Select Macro
- It depends on which implementation you use. For example, if you look at the futures crate, it has a select biased variant that always runs if multiple are ready; it runs the first one so that would not be fair.
Fuse
- Fuse is a way to say that it’s safe to pull or await a future even if that future has already completed in the past.
- In general, you will want to select on mutable references to futures rather than on futures themselves because if you await on futures directly then they would just be dropped at end of selection.
Asynchronous IO and the Benefits of Async
Section Overview: This section discusses the benefits of using async in Rust, particularly for IO-bound tasks.
Async Keyword
- Adding the
asynckeyword to a function that implements matrix multiplication does not make it more expensive. - The code runs the same way but is wrapped in a future type, which requires waiting for results with
await. - There is no overhead to marking something as async since it doesn’t change generated code.
Overhead of Asynchronous IO Read
- There is some overhead when doing an asynchronous IO read compared to synchronous IO read.
- Additional system calls get amortized across all resources, so there’s not much added.
- Fewer threads run by the executor and cooperatively scheduled are usually faster than having many threads that cross operating system boundaries.
Benefits of Async
- Async leads to more efficient use of resources for IO-bound tasks like web servers.
- It also makes code easier to read but not necessarily easier to reason about.
- User space threads are one way to think about async.
Joining Futures with Join Operations
Section Overview: This section discusses how join operations work in Rust and their usefulness when waiting for multiple futures to complete.
Example: Waiting for Multiple Files
- An example scenario where join operations are useful is when waiting for multiple files to complete before continuing with a program.
- The join operation waits until all futures complete before continuing with the program.
Join Macro
- In the futures crate, there is a join macro that lists all futures you want to wait on without specifying branches.
- It looks similar to select macro except you don’t specify branches.
Wrapping into Future Type
- You can construct a select manually too but it’s usually more hassle.
- Select expands into basically a loop with a match or a bunch of ifs.
- You could make select a future by wrapping it in an async block and assigning that to a variable.
Return Value
- Join doesn’t return anything meaningful apart from a future.
- It’s possible to construct the select future for a block yourself, but it’s not quite true that select generates a future.
Joining Files with the Join Macro
Section Overview: In this section, the speaker explains how to use the join macro to read multiple files concurrently and efficiently.
Using Join Macro
- The join macro allows operations to continue concurrently, which is more efficient.
- It lets you overlap compute and I/O.
- You need to explicitly enumerate all the things you’re joining.
- There are multiple functions like join which joins two things joint three joint four joint five etc.
- Try join all takes an iterator over things that are futures whose output is a result. It will make sure that the result output is in the same order as the input even if they completed out of order.
Benefits of Using Join Macro
- Allows operations to continue concurrently, which is more efficient.
- Lets you overlap compute and I/O.
Downsides of Not Using Join Macro
- Sequential execution does not allow for concurrent operations.
- Does not give the operating system all read operations at once, making it less efficient.
Overview of Futures in Rust
Section Overview: In this section, the speaker discusses how futures work in Rust and how they can be used to run operations concurrently.
How Futures Work
- The output of a future describes which input it was from, making it more efficient.
- Join operations like futures unordered implement a hook into the runtime system to only check the futures that might be ready.
Concurrency vs Parallelism
- Only one thread can await one future at any time because awaiting a future requires an immutable reference to it. Multiple threads cannot do it.
- Even if you use multiple threads, all operations are still happening concurrently on one thread, which is not what you want for optimal performance.
Example: Writing a Web Server
- If you’re writing a web server and have a loop over accepting TCP connections, using futures unordered will not give optimal performance since all operations are still happening concurrently on one thread.
Handling Multiple Connections
Section Overview: In this section, the speaker discusses how to handle multiple connections in Rust using Tokio.
Using Futures Stream and Select
- The speaker creates a
let mute connectionsvariable that is afutures stream future maybe futures unordered new. - The speaker then uses
selectto either get a new stream or call an async function calledhandle connection. - If there are new streams, the speaker pushes them into the
connectionsvariable usingconnections.push(handle connection of stream).
Awaiting on Futures
- The async function
handle connectiontakes a TCP stream and does something with it. - To ensure all futures run concurrently, the speaker needs to await on both the accepting and client connections.
- However, having only one top-level future means that even if there are many threads, only one thread can run at a time.
Introducing Parallelism with Spawn
- To introduce parallelism, the speaker gets rid of the
connectionsvariable and replaces it with a while loop. - The speaker then uses Tokio’s provided function called spawn which gives additional futures to work on.
- This allows for two separate futures which means that two threads can run them at the same time.
Introduction to Parallelism in Asynchronous Programs
Section Overview: This section covers how to introduce parallelism into asynchronous programs by communicating futures that can run in parallel to the executor. The importance of using this pattern is highlighted, as it allows for futures to run concurrently on multiple threads.
Communicating Futures for Parallel Execution
- To introduce parallelism into asynchronous programs, communicate futures that can run in parallel to the executor.
- If the executor doesn’t have many threads, there may not be much parallelism.
- Using this pattern allows for futures to run concurrently on multiple threads.
Importance of Spawning and Performance Issues
Section Overview: This section discusses why it’s important to remember to spawn when writing async await code. It also highlights how program performance can drop significantly if nothing is spawned, causing the entire application to run on one thread.
Remembering to Spawn and Program Performance
- When writing async await code, it’s important to remember to spawn.
- If nothing is spawned, program performance can drop significantly.
- The entire application will run on one thread without spawning anything.
- Running an entire application on one thread is slower than running it on multiple threads because nothing gets to run in parallel.
Best Practices for Passing Data and Handling Errors with Tokyo Spawn
Section Overview: This section covers best practices for passing data and handling errors with Tokyo Spawn. Techniques such as using mutexes or channels are discussed, along with how errors should be handled when they occur.
Passing Data with Tokyo Spawn
- To share data between two things that are spawned and want them both accessing a vector, use arc new mutex new.
- Each thing gets its own arc and has a mutex regarding the underlying value.
- Communication over a channel or static memory is also possible.
Handling Errors with Tokyo Spawn
- If an error occurs in a spawned future and there is nowhere to communicate it, print it to standard out or log it to a file.
- Use an event distribution tool like tracing to emit an error event that gets handled somewhere else.
Spawning and Running Futures
Section Overview: This section discusses the advantages of spawning futures and how to do it in Tokio.
Advantages of Spawning Futures
- Spawning a future allows other tasks on the current thread to keep running while that operation is running elsewhere.
- This can be valuable when you have an expensive operation like deserialization or hashing a password that you don’t want to block async execution of a thread.
How to Spawn Futures in Tokio
- Use
tokio::spawnto spawn a future. - Thread locals are used by Tokio to find the current runtime and executor.
- Multiple runtimes can be created, each with its own thread count, allowing for prioritized traffic handling.
Blocking Operations
- Use
tokio::task::spawn_blockingortokio::task::block_in_placefor blocking operations like hashing passwords.
Rust Futures and Thread Locals
Section Overview: This section explains how Rust futures work with thread locals and why they are used in Tokio.
Thread Locals in Tokio
- Thread locals are used by Tokio to make the interface slightly nicer.
- Without thread locals,
spawnwould not be a free function, requiring the handle to the runtime throughout your entire application.
Rust Futures without Thread Locals
- There is nothing in Rust’s async support that requires thread locals.
Introduction
Section Overview: In this section, the speaker introduces the topic of creating a runtime and explains that it does not allocate a lot of memory.
What is a Future?
Section Overview: In this section, the speaker explains what a future is and how it works in an async function.
- A future is a chunked computation with weights in between each chunk.
- Each chunk contains the state for that part of the state machine.
- Local variables that need to be kept across await points are saved as part of the state.
- The compiler generates an enum-like structure to represent the state machine.
- The future itself needs to be stored somewhere because it holds a reference into x.
Example Async Function
Section Overview: In this section, the speaker provides an example async function and explains how it gets divided up into chunks.
- The async function has one chunk that starts at its beginning and ends before any await points.
- Between each chunk is a weight operation represented by an await point.
- Local variables that need to be kept across await points are saved as part of the state.
Understanding Impul Futures
Section Overview: In this section, the speaker explains how Impul futures work and how they are implemented in Rust.
Impul Future Type
- An
Impul Futureis a type that returns anImpul Future. - The
Impul Futureis actually a type of state machine. - The state machine contains all the values kept across await points.
- When we await an
Impul Future, we are invoking a method on the state machine type that gets an exclusive reference immutable reference to that type so it can access the future and continue to wait.
State Machine Type
- The generated state machine type is a trait with a name but no specified name.
- It contains internal local variables and references to other futures.
- This conversion from async fn rewrites these variables as references into the state machine struct that we pass around.
Passing Futures Around
- Futures can get really large because they contain all of the futures they in turn await.
- Passing them around requires mem copying which can be expensive for large futures.
- Boxing your features solves this problem by placing them on the heap or using box pin.
Using Tokyo Spawn
- Using something like Tokyo spawn is useful because it stores only a pointer to the future instead of storing the entire future itself.
- This reduces mem copies and avoids having futures grow indefinitely.
Introduction
Section Overview: In this section, the speaker introduces the topic of futures and async functions in Rust.
Key Points
- The speaker briefly discusses why futures can be moved even though they may need to be pinned.
- The speaker explains that it is possible to create a vector of futures recursively within an async function by using a join handle.
- However, the speaker notes that using a vector is not enough because an array needs to know the size of its elements, which may not be known for all futures.
- The speaker mentions that there is an async trait crate available for writing asynchronous functions within traits.
Async Trait
Section Overview: In this section, the speaker discusses the limitations of writing asynchronous functions within traits in Rust.
Key Points
- The speaker explains that currently, it is not possible to define an async function within a trait in Rust.
- This is because the size of the future returned by the function cannot be determined at compile time.
- The speaker provides an example where defining an async function within a trait would result in an error due to unknown future size.
- The speaker mentions that there are two ways around this limitation: using existential types or using the async trait crate.
Async Trait and Associated Types
Section Overview: In this section, the speaker discusses the use of async trait and associated types in Rust programming. They explain how async trait works for higher-level functions but may not work well at the bottom of a stack due to heap allocation and dynamic dispatch.
Async Trait vs. Associated Types
- Async trait rewrites signatures and bodies into an async move, which works if you remove async trait.
- Rust already knows how to reason about dynamically dispatched futures, making it easy to await them.
- Heap allocating all futures leads to dynamic dispatch, indirection, and memory allocator pressure.
- Async trade is best suited for higher-level functions as opposed to lower-level ones like reads that require frequent heap allocations.
- Declaring an associated type call future can help solve the problem of heap allocation by allowing callers to know how large the actual type is.
Naming Associated Types
- The challenge with using associated types is naming them since there are no clear conventions on how to do so.
- Type alias infiltration could be used to name associated types but would require additional design decisions.
Challenges with Implementing Async Functions in Traits
Section Overview: In this section, the speaker discusses some of the challenges involved in implementing async functions in traits. They explain that while it’s possible for the compiler to generate code automatically, there are still many design decisions that need to be made before this can happen.
Compiler Code Generation
- The rust compiler could theoretically generate code automatically behind the scenes when writing async functions in traits.
- There is a lot of magic involved in the process, and it’s not always clear how to name types that aren’t pin box.
- Async functions and traits are likely to be implemented eventually in Rust, but there are still many design decisions that need to be made.
Asynchronous Programming in Rust
Section Overview: In this section, the speaker talks about various aspects of asynchronous programming in Rust.
Key Points
- The speaker discusses different topics related to asynchronous programming such as join, futures unordered, spawn, number of worker threads, async trait, spawn blocking, send and static futures pin and box futures.
- Blocking code is problematic because it doesn’t let other tasks run.
- There is an argument ongoing about whether to use the standard library mutex or an asynchronously enabled mutex. Using a standard library mutex can lead to deadlock situations where the executor’s one thread is blocked. On the other hand, using an asynchronously enabled mutex yields when it fails to take the lock which lets other future run again.
Standard Library Mutexes vs Asynchronously Enabled Mutexes
Section Overview: This section focuses on the differences between standard library mutexes and asynchronously enabled mutexes.
Key Points
- Standard library mutexes can lead to deadlock situations where the executor’s one thread is blocked while using an asynchronously enabled mutex yields when it fails to take the lock which lets other future run again.
- Async-enabled mutexes are necessary for sharing state between two futures. If two asynchronous threads access the same arc and use a standard library mutex then they may end up in deadlock situations.
Using Async-Aware Mutexes
Section Overview: In this section, the speaker discusses the use of async-aware mutexes and standard library mutexes in critical sections.
Standard Library Mutex vs Async-Aware Mutex
- Use a standard library mutex for short critical sections without await points.
- Use an async-aware mutex if the critical section is long or contains await points to avoid blocking other futures on other threads.
- Standard library mutexes can be faster to acquire and release than async-aware mutexes.
Deadlock Potential
- Critical sections with await points are ripe for deadlock potential.
- Holding a lock while running a slow operation can block other futures on other threads, causing them to be unable to make progress.
Detecting Problems
- There are currently no good tools for detecting blocking or unexpected cancellations in futures.
- Tokyo console is being developed as a tool that hooks into the executor and monitors how long it has been since a given future yielded or was retried.
Thread Spawn vs Tokyo Spawn
Section Overview: In this section, the speaker explains the conceptual difference between thread spawn and Tokyo spawn.
Thread Spawn
- Spawns a new operating system thread that runs in parallel with everything else in your program.
- Does not take a future but takes a closure instead.
- If you want to await a future inside of a spawned thread, you need to create your own executor inside of there.
Tokyo Spawn
- Does not guarantee having its own thread and requires cooperative scheduling with yield points.
- If you do not have yield points, you might block the executor.
Introduction
Section Overview: In this section, the speaker introduces the topic of async and await.
Async and Await
- The speaker introduces async and await as higher-level techniques for working with futures.
- The lower levels, such as the future trait, pin, context, or waker are not discussed in detail.
- This section provides a good survey of what mental models to have when working with async and await.
Scheduling Futures
Section Overview: In this section, the speaker discusses how futures get scheduled on threads.
Awaiting Inside a Future
- When a future yields, it just yields to whatever awaited it.
- If inside of f you await and then you end up yielding you just go back up to b and it’s up to b what happens at this point right b in this case is chosen to await.
- All the way up the stack it’s going to be awaits all the way up to the executor which does have the option of rescheduling you on a different thread.
Single Threaded Executors
- If you have a single threaded executor it would execute on that same thread because there are no other threads in Tokyo.
- You’re not guaranteed that it’s the same thread; there are ways to say only run me on one thread in different executors like in Tokyo there’s like a spawn local which gives you some of these guarantees.
Enforcing Static Guarantees
- If you really wanted a future not to be sent across threads, you would just not implement send for it. Of course, that makes it harder to work with that future but that would be how you enforce that statically.
Async Stack Trace
Section Overview: In this section, the speaker discusses how to get an async stack trace.
Getting an Async Stack Trace
- If you print just a regular stack trace inside of an async inside of a future, you will get the call trace going up to the executor.
- The problem really stems from spawning. If I spawn this future and then let’s say I panicked right here then this panic would not show main.
- When that executor thread awaits this future and it panics, the backtrace for that panic will only say the executor pulled this future so it’ll point you at this future but that trace.
Tracing Futures
Section Overview: This section discusses tracing futures and how to use them to trace back to where a future was originally spawned.
Using instrument to Trace Futures
instrumentis used with a future import trait.- It takes a future and returns the same future.
- The whole future gets spawned, allowing for tracing back to where it was originally spawned.
Best Practices for Calling Async Code from Synchronous Code
- Avoid calling async code from synchronous code as it is difficult to do right.
- Using
futures::block_oncan be problematic as it does not provide cooperative scheduling. - Enforcing an asynchronous runtime on users can cause issues such as nested asynchronous runtimes, runtime panics, and performance problems.
- Expose internal asynchronous operations as asynchronous and leave it up to the user to choose how to make them synchronous.
Use Cases for Threads Instead of Futures
- For compute-heavy tasks, use something like Rayon instead of futures.
- If there is no I/O involved in the program, there is no need for async.
When Not To Use Async
- Writing non-async code tends to make simple or single execution code easier to read.
- Back traces work better when not in an async context.
- If you don’t need the mechanisms that async provides, use normal threading.
Generated by Video Highlight
https://videohighlight.com/video/summary/ThjvMReOXYM
Atomics and Memory Ordering
- Atomics and Memory Ordering
- Introduction
- Atomic Types
- Conclusion
- Rust Memory Model
- Introduction to Memory Ordering
- Introduction to Mutexes
- Implementing a Mutex
- Understanding Concurrency Issues
- Overview of Compare Exchange
- Compare Exchange and Spin Locks
- Compare Exchange Weak
- Load Exclusive and Store Exclusive
- Memory Ordering
- Memory Barriers
- Happens-Before Relationship
- Lock-Free Programming
- Relaxed Ordering in Rust
- Reordering and Speculative Execution
- Exclusive Access and Relaxed Memory Ordering
- Memory Orderings and Acquiring/Releasing Resources
- Understanding Acquire-Release Semantics
- Relaxed and Strong Memory Ordering
- Fetch Operations and Sequentially Consistent Ordering
- Understanding Fetch Operations
- Sequentially Consistent Ordering
- Possible Values for Z
- Mutex Panic Safety
- Introduction
- Thread Schedules
- Acquire and Release Semantics
- Memory Ordering in Rust
- Memory Ordering and Sequential Consistency
- Detecting Concurrency Problems
- Loom: A Tool for Testing Concurrent Code
- Examples for Sequentially Consistent Ordering
- Limitations of Zulu
- Contributing to Loom
- Testing Sequentially Consistent Ordering with Acquire Release
- Overview of Loom and Relaxed Ordering
- Volatile Keyword
- Understanding Volatile
- Atomic Pointer
- What is Atomic Pointer?
- Generated by Video Highlight
Introduction
Section Overview: In this video, the speaker will explain atomics and memory ordering. The speaker has been hesitant to tackle this topic because of the lack of documentation and complexity of the subject. However, after working with it enough, he feels confident in giving a correct and understandable explanation.
Why Do We Need Atomics?
- If you have a primitive type like bool or usize that is shared across thread boundaries, there are only certain ways to interact with that value that are safe.
- It makes sense to have slightly different APIs for atomic types because you’re issuing different instructions to the underlying CPU and placing different limitations on what code the compiler is allowed to generate.
- When you have shared access to some memory value, you need additional information about that access to let the CPU know when should different threads see the operations that other threads do.
- Rust’s standard sync atomic model has good documentation on high-level ideas of why we have these types and what they’re used for.
What Will Be Covered?
- The stream will be Rust-specific but most of it translates to any other language that has atomics in this kind of sense.
- The core focus will be on Rust’s atomic types and memory ordering observed in Rust.
Atomic Types
Section Overview: This section explains why using primitive types like bool or usize can lead to undefined behavior when shared across thread boundaries. It also explains how atomic types provide additional information about shared access to memory values.
Why Not Use Primitive Types?
- There are only certain ways to interact with primitive types safely when they are shared across thread boundaries.
- Data races are undefined behavior, so if you don’t control how different threads interoperate on the same memory location, you run into undefined behavior.
- Atomic types provide additional information about shared access to memory values.
What Are Atomic Types?
- When operating on atomic versions of primitive types, you’re issuing different instructions to the underlying CPU and placing different limitations on what code the compiler is allowed to generate.
- You need additional information about shared access to memory values to let the CPU know when should different threads see the operations that other threads do.
Why Do We Need Different APIs for Atomic Types?
- It makes sense to have slightly different APIs for atomic types because they place different limitations on what code the compiler is allowed to generate.
Conclusion
Section Overview: The speaker concludes by summarizing why atomics are necessary and what will be covered in this video. He also emphasizes that understanding memory ordering is useful regardless of what language you’re working in.
Key Takeaways
- If you have a primitive type like bool or usize that is shared across thread boundaries, there are only certain ways to interact with that value that are safe.
- Rust’s standard sync atomic model has good documentation on high-level ideas of why we have these types and what they’re used for.
- Understanding memory ordering is useful regardless of what language you’re working in.
Rust Memory Model
Section Overview: In this section, the speaker talks about the Rust memory model and how it is not yet fully defined. They also introduce the Rust reference as a source of information for implementing a Rust compiler.
Introduction to Memory Model
- The Rust language does not have a fully defined memory model yet.
- Various proposals are being worked on by academics and industry professionals.
- This can be unhelpful when writing code that uses atomics and concurrency.
Memory Ordering Documentation
- The speaker will be using the memory ordering documentation from C++ as it has good explanations and examples of different memory orderings.
- This page will be used for explanations, examples, and guarantees throughout the talk.
Atomic Types in Rust
- Atomic types in Rust are not inherently shared and need to be placed on the heap using something like
BoxorArc. - This allows sharing a pointer or reference to that atomic value which can then be updated.
- The main differentiator between atomic types and regular types is that atomic types can be operated on using shared references to self.
Methods for Atomic Use Size Type
- There are several methods available for operating on an atomic use size type, including load, store, swap, compare_and_swap, fetch_add/sub/and/or/xor/nand.
- Load returns the value stored in the atomic use size type while store takes a value and stores it into the type.
- Swap performs both operations at once by returning the old value while storing a new one.
- Compare_and_swap compares the current value with an expected value and if they match, replaces it with a new one. Otherwise, it returns the current value without modifying it.
- Fetch_add/sub/and/or/xor/nand performs the corresponding operation on the value stored in the atomic use size type and returns the old value.
Introduction to Memory Ordering
Section Overview: In this section, the speaker introduces memory ordering and its importance in multi-threaded programming. They also introduce some methods for reading and swapping values atomically.
Memory Ordering and Guarantees
- Memory ordering tells the compiler which set of guarantees you expect for a particular memory access with respect to things that might be happening in other threads at the same time.
- There are different types of guarantees provided by memory ordering, such as acquire, release, and sequentially consistent.
Atomic Operations
- Atomic operations allow multiple threads to operate on a value at the same time in a well-defined way without locking.
- Compare-and-swap is an atomic operation that reads a value and swaps it out conditionally in one atomic step. It ensures no thread can get between the load and store operations.
- Fetch methods like fetch-add or fetch-sub are similar to compare-and-swap but perform arithmetic operations instead of conditional swaps. They also ensure no thread can execute between load and store operations.
Questions from Viewers
- Non-exhaustive means that no code is allowed to assume that these are all the variants that will ever be in ordering so if you match on an ordering, you always need to include an underscore branch in an otherwise or else branch because the standard library wants to be able to add additional orderings later if necessary.
- The different orderings are related to what guarantees the operation gives you; how different architectures implement those guarantees will vary from architecture to architecture as we’ll see later on.
- Mutex guards a larger section of code while atomic guards just a single memory access if needed but more efficiently than mutexes would.
# Understanding Atomic Types in Rust
Section Overview: In this section, the speaker explains how atomic types work in Rust and why they are considered lock-free.
Atomic Operations and Compiler Semantics
- Atomic types in Rust are considered lock-free because they do not use mutexes.
- Atomic operations limit both what the CPU can do and what the compiler can do about a given memory access.
- Even on architectures like Intel x86 64, it is still recommended to use atomic types because they provide guarantees from the compiler as well.
Unsafe Cell and Atomic Instructions
- The store swap and friends all take an immutable reference to self, which means they rely on unsafe cell.
- All of these atomic instructions contain an unsafe cell that they then call get on to get the pointer to the value.
- The atomic type macro expands to a struct definition that holds an unsafe cell of the inner type.
# Sharing Atomics with Arc
Section Overview: In this section, the speaker discusses why atomics are generally shared via Arc rather than Box.
Using Arc for Static Lifetime
- When spawning two threads, both require that the closure you pass in has a static lifetime.
- With an Arc, you can clone it and give each thread its own individually owned and therefore static Arc to the atomic usize.
Alternative Approach with Box Leak
- Box leak will leak a value on the heap so it will never call the destructor which gives you back a static reference which you can then pass to both threads.
# Implementing a Mutex Type
Section Overview: In this section, the speaker demonstrates how to implement a mutex type using atomic types in Rust.
Defining a Mutex Type
- A mutex is a combination of a boolean that marks whether or not someone currently holds the lock and then an unsafe cell to the inner type.
- The implementation requires Sync Atomic and Atomic Bool.
Using with Lock Function
Introduction to Mutexes
Section Overview: In this section, the speaker introduces mutexes and explains why spin locks should not be used.
Naive Implementation of Mutex
- The speaker creates a new method for the mutex.
- The method takes an initial value to create the mutex with.
- Constants are created to make the code more readable.
- The speaker explains how the naive implementation of mutex works using a while loop that spins until the lock is no longer held.
- The function captures return value, sets it back to unlocked, and returns red.
Problems with Naive Implementation
- The code does not compile because an argument is missing in the method.
- Ordering is required in this method but it’s not clear what ordering should be used yet. For now, relaxed ordering will be used.
Testing Mutex
- A lock mutex is created and five threads are spawned to modify its value at the same time through the lock.
- Each thread uses l.with_lock() and adds 1 to v a hundred times.
Implementing a Mutex
Section Overview: In this section, the speaker explains how to implement a mutex in Rust using atomics and compare-and-swap operations.
Collecting Thread Handles
- We collect all thread handles so that we can wait for them afterwards.
- We spin up 10 threads, each of which increments the value 100 times.
Sync for Mutex
- Unsafe cell cannot be shared between threads safely.
- Mutex is sync for mutex t where t is send.
- We implement sync from mutex so that you can concurrently access it from multiple threads as long as the value t is send.
Problems with Mutex Implementation
- The reason we need atomics and why we need operations like compare and swap is because here we’re doing a load and then we’re doing a store but in between here maybe another thread runs.
- It’s possible for two threads to execute the closure passed to with lock at the same time, leading to undefined behavior.
Understanding Concurrency Issues
Section Overview: This section discusses the issues that arise when multiple threads are running concurrently and accessing shared memory.
Concurrency Issues with Multiple Cores
- When different threads run on different cores, there is no control over the relative operations of each thread.
- The operating system limits how long a given thread gets to run for and may forcibly stop a program in the middle to ensure all threads get to run.
Race Conditions and Preemption
- Preemption can occur at any point in time, including between a load and store operation.
- A race condition occurs when two threads observe the mutex being unlocked at the same time.
Solving Concurrency Issues with Compare Exchange Operation
- The compare exchange operation is used to avoid race conditions between multiple threads accessing shared memory.
- Compare exchange is more powerful than compare and swap because it strictly avoids race conditions.
Overview of Compare Exchange
Section Overview: In this section, the speaker explains how compare exchange works and why it is useful.
How Compare Exchange Works
compare_exchangetakes the current value, new value, and two orderings.- The first line of documentation stores a value into the atomic integer or boolean if the current value is the same as the current value.
- If the CPU looks at the atomic bool and sees that it is unlocked (false), then it sets it to true in such a way that no other thread gets to modify the value in between when we look at it and when we change it.
- Compare exchange is a single operation that is both read and write.
- It can be done in a loop because if the current value is locked, then compare exchange will return an error.
Why Compare Exchange Is Useful
- Compare exchange solves this particular problem because there’s no space in between load and store; they’re just one operation performed on memory location.
- However, compare exchange can be expensive because every CPU spins during compare exchange.
- CPUs need to coordinate exclusive access amongst all these cores which can be inefficient.
Compare Exchange and Spin Locks
Section Overview: This section discusses the differences between compare exchange and spin locks, and how to optimize spin locks for high contention.
Compare Exchange vs. Spin Locks
- In compare exchange, the CPU requires exclusive access to a location in memory, which requires coordination with everyone else.
- A given location of memory can be marked as shared, allowing multiple cores to have a value in the shared state at the same time.
- Compare exchange is much faster than locking a mutex because it will never wait. A single compare exchange call will try to do the operation you told it and then say either “I succeeded” or “I failed”. If it fails, it does not block the thread.
- The biggest difference between compare exchange and a mutex is that a mutex has to wait while a compare exchange will never wait.
Optimizing Spin Locks for High Contention
- If we can have a value stay in the shared state while the lock is still held, that’s going to avoid all of the ownership bouncing.
- Certain spin lock implementations use an inner loop that only reads values if they fail to take the lock. This allows values to stay in the shared state until some core takes exclusive access to them.
- When there is high contention on a particular value with many threads or cores fighting over who gets exclusive access, performance may collapse. Avoiding this collapse by optimizing spin locks can lead to better performance curves.
Compare Exchange Weak
Section Overview: This section explains what compare exchange weak is and how it differs from regular compare exchange.
- Compare exchange weak is allowed to fail spuriously, even if the current value is what you passed in. Regular compare exchange is only allowed to fail if the current value did not match the value you passed in.
- The difference between these two operations comes down to what operations the CPU supports. On Intel x86, there is a compare and swap operation that effectively implements compare exchange.
Load Exclusive and Store Exclusive
Section Overview: This section discusses the difference between compare and swap operations on x86 and ARM processors.
Load Exclusive and Store Exclusive
- On ARM processors, instead of a compare and swap operation, there is a load exclusive (ldrex) and store exclusive (strex) operation.
- Load exclusive takes exclusive ownership of the memory location and loads the value to you.
- Store exclusive only works if you still have exclusive access to that location. If another thread has taken ownership of the value, it will fail.
- Compare exchange on ARM is implemented using a loop of ldrex and strex because it needs to implement the semantics of comparexchange which is only fail if the current value stayed the same.
- Compare exchange weak is allowed to fail spuriously so it can be implemented directly using ldrx and strx.
Memory Ordering
Section Overview: This section discusses how memory ordering affects observable behavior when multiple threads interact with a shared memory location.
Ordering Variants
- There are different variants for ordering: relaxed, release, acquire, acquire-release, sequential consistency.
- Relaxed means there are no guarantees about what happens when multiple threads interact with a shared memory location.
- Release ensures that all previous writes become visible before any subsequent write or read from another thread occurs.
- Acquire ensures that all previous reads become visible before any subsequent read or write from another thread occurs.
- Acquire-release combines both acquire and release semantics.
- Sequential consistency ensures that all operations appear to execute in a total order.
Memory Barriers
Section Overview: This section discusses memory barriers and how they can be used to enforce ordering constraints.
Memory Barriers
- Memory barriers are instructions that enforce ordering constraints on memory operations.
- There are two types of memory barriers: compiler barriers and hardware barriers.
- Compiler barriers prevent the compiler from reordering memory operations across the barrier.
- Hardware barriers ensure that all previous memory operations have completed before any subsequent operation is executed.
- The C++11 standard defines several types of hardware barriers, including acquire, release, and full.
Happens-Before Relationship
Section Overview: This section discusses the happens-before relationship and how it relates to observable behavior when multiple threads interact with shared memory locations.
Happens-Before Relationship
- The happens-before relationship is a partial order between events in a program that determines what values can be observed by other threads.
- If event A happens before event B, then any value written by A must be visible to B.
- If there is no happens-before relationship between two events, then their order is undefined.
- Synchronizes-with is a special case of happens-before where one event synchronizes with another if it releases a mutex or semaphore that another thread acquires later.
Lock-Free Programming
Section Overview: This section discusses lock-free programming and its advantages and disadvantages.
Lock-Free Programming
- Lock-free programming is a technique for writing concurrent programs without using locks.
- The advantage of lock-free programming is that it can avoid the overhead of acquiring and releasing locks, which can be expensive.
- The disadvantage of lock-free programming is that it can be more difficult to reason about and debug than lock-based programming.
- Lock-free programming requires careful attention to memory ordering constraints and the happens-before relationship.
Relaxed Ordering in Rust
Section Overview: In this section, the speaker explains how relaxed ordering works in Rust and why it can lead to unexpected results.
Relaxed Ordering and Thread Execution
- The speaker spawns two threads and creates an atomic variable x with size 0.
- The speaker creates another atomic variable y with size 0.
- Box leak returns a static mutable reference which cannot be moved into two threads. Therefore, the speaker casts it as an atomic variable.
- The speaker creates two threads, x and y, both of which are numbers.
- Thread 1 reads y with relaxed ordering and stores that value into x.
- Thread 2 loads x and then stores 42 into y.
- Both threads are joined so that we have the values t2.
Explanation of Relaxed Ordering
- It is possible for r1 to be equal to r2 be equal to 42. This is a possible execution of this program.
- When multiple threads execute concurrently by default there are no guarantees about what values a thread can read from something another thread wrote under ordering relaxed.
- There is a modification order stored per value in atomic operations. When you load a value with ordering relaxed you can see any value written by any thread to that location there’s no restriction on when that has to happen relative to you.
- For example, when loading a value from x, it is allowed to see any value ever stored to x including 42 because it’s in the modification set of x and there are no constraints on which subset of that which range of that modification order is visible to this thread.
- The compiler is totally allowed to reorder these two operations. Similarly, the CPU is allowed to execute them out of order for optimization purposes.
- Under either of these conditions, the reverse execution might happen and if the code looks like this it’s totally obvious why r2 might be 42. With ordering relaxed you’re not guaranteed any ordering between threads.
Reordering and Speculative Execution
Section Overview: In this section, the speaker discusses how reordering makes sense in programming and how CPUs can execute operations speculatively. They also explain the constraints on what CPUs and compilers are allowed to reorder.
Reordering in Programming
- Reordering lines of code that don’t depend on each other can make sense for programmers.
- There is no downside to swapping two lines of code that don’t depend on each other.
- Observable execution outcomes are different, but in the case of relaxed memory ordering, they’re interchangeable as far as the memory ordering specification is concerned.
Speculative Execution
- CPUs can run an operation before another one if it knows it’s about to be executed. This is called speculative execution.
- Speculative execution usually comes up when there’s a question whether an operation might be executed or not.
- Today’s CPUs are very good at out-of-order execution because it makes programs much faster.
Constraints on Reordering
- CPUs and compilers are allowed to reorder anything that doesn’t have a clear “happens before” relationship.
- If two lines of code have a dependence relation (i.e., if one depends on the other), they cannot be reordered.
- Memory ordering and semantics are not just about the CPU or architecture; they’re also about what the compiler is allowed to do.
Exclusive Access and Relaxed Memory Ordering
Section Overview: In this section, the speaker explains why relaxed memory ordering matters when taking locks with exclusive access.
Exclusive Access
- If we already have exclusive access to a piece of memory, we can do an operation on it efficiently.
- In the case of relaxed memory ordering, this can lead to shenanigans where operations are executed out of order.
Relaxed Memory Ordering and Locks
- Relaxed memory ordering doesn’t imply any ordering or that anything happens before anything else.
- When taking locks with relaxed memory ordering, operations might execute while another thread is holding the lock, violating the exclusivity of immutable reference. This is bad for both the compiler and CPU.
- The reordering we give determines whether an operation is legal or not.
Memory Orderings and Acquiring/Releasing Resources
Section Overview: This section discusses memory orderings in the context of acquiring or releasing a resource. It explains how the release ordering ensures that nothing moves below the lock, and how the acquire ordering guarantees that anything that happened before the store happens before anything that happens after the load.
Store with Release Ordering
- A reordering is valid with relaxed, but not with release.
- The release ordering ensures that nothing moves below the lock.
- All previous operations become ordered before any load of this value with acquire or stronger ordering.
Load with Acquire Ordering
- Anything we do in here must be visible after an acquire load of the same value.
- Whoever next takes the lock must see anything that happened before this store.
- The acquire-release pair establishes a happens-before relationship between threads.
Additional Restrictions
- No reads or writes in the current thread can be reordered after a store operation with memory order release.
- A load operation with memory order acquire performs the acquire operation on the effective memory location.
Understanding Acquire-Release Semantics
Section Overview: In this section, the speaker explains acquire-release semantics and how they are used in synchronization operations.
Acquire-Release Semantics
- Acquire-release semantics are used in synchronization operations that involve a read and write operation.
- The acquire-release semantics establish ordering between threads to ensure correct synchronization.
- Acquire-release is commonly used for single modification operations where there is no critical section.
- Sequentially consistent ordering is stronger than acquire-release.
Compare Exchange Operation
- The compare exchange operation has an extra parameter that specifies the ordering of the load if it indicates that you shouldn’t store.
- Establishing a happens-before relationship between threads is important when taking a lock.
- Relaxed memory semantics can be used when failing to take a lock does not require coordination with other threads.
Testing Concurrent Code
- x86_64 architecture guarantees acquire-release semantics for all operations, but this is not true for all platforms.
- Testing concurrent code by running it multiple times on current hardware and compiler may not be representative of future executions.
Relaxed and Strong Memory Ordering
Section Overview: This section discusses the use of relaxed memory ordering when it doesn’t matter what each thread sees. It also introduces fetch operations as a gentler version of compare exchanges.
Relaxed Memory Ordering
- Use relaxed memory ordering when it doesn’t matter what each thread sees.
- For example, if you maintain a counter for statistics, you can generally have it be relaxed because the relative ordering of execution doesn’t really matter.
- Relax imposes the least amount of restrictions on the CPU and compiler, allowing them to execute more efficiently.
Fetch Operations
- Fetch operations are gentler versions of compare exchanges.
- They allow you to tell the CPU how to compute the new value instead of just dictating what the updated value should be.
- Fetch ad is an example where you add one to the current value and store it back without failing.
- Fetch update takes a closure that is given the current value and should return the new value.
Fetch Operations and Sequentially Consistent Ordering
Section Overview: This section explains how fetch operations work in combination with sequentially consistent ordering.
Sequentially Consistent Ordering
- Sequentially consistent ordering ensures that all threads see a consistent order of events.
- It’s useful when there are dependencies between threads or instructions.
Fetch Operations with Sequentially Consistent Ordering
- When using fetch operations with sequentially consistent ordering, they behave like acquire-release semantics.
- The operation has both an acquire effect on any previous memory accesses by other threads and a release effect on any subsequent memory accesses by other threads.
Understanding Fetch Operations
Section Overview: In this section, the speaker explains what fetch operations are and how they work.
Fetch Update
fetch_updateloads the current value and does a compare exchange in a loop.- It is not the same as other fetch operations because it uses a compare exchange loop.
- Atomic types in Rust’s atomic module are guaranteed to be lock-free if available.
Unique Sequence Numbers
- Fetch operations are used for things like giving unique sequence numbers to concurrent operations.
- Using
fetch_addon an atomic usize guarantees that every call to get a sequence number will get a distinct one.
Sequentially Consistent Ordering
Section Overview: In this section, the speaker discusses sequentially consistent ordering and provides an example to demonstrate its difference from acquire-release ordering.
Example with Atomic Bools and Usize
- The example involves two threads storing values in atomic bools and one thread doing a fetch add on an atomic usize.
- One thread stores true with ordering release while another stores y with no specified ordering.
- A third thread does while not x load, acquires in a loop, checks if y again will acquire, then fetch adds one to z which is relaxed.
Possible Values for Z
Section Overview: In this section, the speaker discusses possible values for z in a given code snippet.
Two is Possible
- Execution order: t x ty t1 t2
- X is true and Y is true, so Z increments by 1 twice.
- Therefore, Z equals 2.
One is Possible
- Execution order: tx t1 t2 ty t2
- X is true but Y is false when T1 runs, so it does not increment Z.
- When Ty runs, it sets Y to true.
- When T2 runs, it sees that both X and Y are true and increments Z by 1.
- Therefore, Z equals 1.
Zero May Not Be Possible
- To achieve zero as the value of Z:
- T1 must run after Tx.
- T2 must run after Ty.
- There are no other restrictions on execution order.
Mutex Panic Safety
Section Overview: In this section, the speaker answers a question about mutex panic safety.
- The mutex is panic safe but will not propagate panics.
Introduction
Section Overview: In this section, the speaker discusses a pattern and execution order for threads.
Thread Execution Order
- The speaker explains that if t2 goes here, then ty must go before that and t1 will increment c because it runs after x and y have both been set to true.
- If t2 goes after tx, ty still has to go before t2 is going to get to do anything useful. In either case, t1 and t2 will increment z because they’re both going to go after the things that set x and y.
- If we place t2 at the end, ty could go here but if ty goes there then tx is already run so t2 will increment z. If ty went earlier, t2 would still increment c so there’s no place given this restriction where one of them won’t increment z. It seems impossible to have a thread schedule where z equals zero.
Thread Schedules
Section Overview: In this section, the speaker talks about thread schedules and how computers don’t have a single order that things run in.
Thread Schedules
- The speaker explains that thread schedules are just like the human desire to put things in order but in reality computers don’t have a single order that things run in.
- We have multiple cores and those cores can show old values new values all we’re subject to are the exact rules of acquire and release semantics which is what we’ve given here.
- There’s no requirement that we see anything that happened in another thread. When you spawn a thread these threads all happen after the main thread that spawned them so we must actually see this false it’s not like we could see a value written somewhere else independently but we must see this false or anything that happens later we can’t see if imagine that this thread did like x dot store true then the loads down here must see the store because it happened before them.
Acquire and Release Semantics
Section Overview: In this section, the speaker talks about acquire and release semantics.
Acquire and Release Semantics
- The speaker explains that if you observe a value from acquire you will see all operations that happen before the corresponding release store while the corresponding release store is here in this thread there are no operations prior to the store but if there were we would be guaranteed to see them here because we’re synchronizing with tx but there are none.
- This load synchronizes with this store so after this load we must see all memory operations that happened before this store. There’s no requirement that that’s any particular store of why if there had been a store of y in this thread if this did y dot store we must observe that y dot store because it happened strictly before this store which happened before this load because of acquire release so if there was a store here we must see it but there isn’t so we’re allowed to see any value for y.
Memory Ordering in Rust
Section Overview: This section discusses memory ordering in Rust and how it affects concurrent operations.
Happens Before Relationship
- When a thread runs, it synchronizes with other threads but there is no requirement that it sees any particular operation that happened to x because there’s no happens before relationship between the store here in tx and the load down here.
- Acquire loads says that you’re not allowed to move any operation from below to above an acquire load so the compiler is not allowed to reorder these by the acquire semantics.
- The load is allowed to see any previous value for x subject to happens before which does not include the operation of t y so therefore uh t2 must see this.
Concurrent Operations
- T2 can see either of these and T1 can see either of these. If both threads run, then T1 runs, observes x being true but does not observe y being true even though T1 has run because there’s no happens before relationship there.
- Imagine that it’s already in cache in the CPU or something; it just uses that value. It doesn’t bother to check again because it’s allowed not to. Therefore, this value is false even though Tx Ty ran; therefore, it does not increment one this one for some reason like it spins until y is true.
- It observes that y is true great. It’s no requirement that it observes that x is true even though Tx has run so it does not increment c so therefore z is zero.
Sequentially Consistent Operation
- Sexy as t (pronounced “sequentially consistent”) means acquire and release and acquire release with the additional guarantee that all threads see all sequentially consistent operations in the same order. If we make these all be sequentially consistent now, zero is no longer possible because if this thread observes that x observes x is true and then y is true, it establishes a happens before relationship.
Memory Ordering and Sequential Consistency
Section Overview: This section discusses memory ordering and sequential consistency in concurrent programming.
Memory Ordering
- In concurrent programming, there must exist some ordering that’s consistent across all threads.
- If some thread sees that x happened then y happened, then no thread is allowed to see x not happen even though y has happened.
- If we end up with x is true and then y is true, then here y is true therefore x must be true. It’s not allowed to see x being false because that would be inconsistent with the memory ordering that these sequentially consistent operations saw.
- The sequentially consistent ordering is only with relation to all other sequentially consistent operations.
- Sequentially consistent only really interacts with other sequentially consistent acquire release does interact with sequentially consistent so sequentially consistent it is always stronger than acquire release.
Testing Concurrent Code
- Memory ordering is real subtle and hard to get right.
- Running your code lots of times in a loop or making your computer busy with other tasks can help test for errors but it’s not reliable since it might depend on the architecture, operating system scheduler, compiler optimizations, or how likely the error occurs.
- Detecting bugs in concurrent code can be difficult since they may not cause a program crash or may go unnoticed for a long time.
Detecting Concurrency Problems
Section Overview: This section discusses the need to detect concurrency problems and some automated systems that can help with this.
Thread Sanitizer
- Google has built-in sanitizers in compilers like Clang, GCC, and MSVC.
- The thread sanitizer is one of these sanitizers.
- It detects unsynchronized operations on a single memory location by tracking every load and store operation in a program.
- The algorithm for the thread sanitizer is specified in the documentation.
Loom
- Loom is a tool that implements the CDS Checker paper for Rust.
- It takes a concurrent program, instruments it using loom synchronization and atomic types instead of standard library ones, and runs it multiple times to expose it to different possible executions.
- Loom executes all possible thread interleavings and memory orderings to ensure that all legal executions of the program are explored.
Loom: A Tool for Testing Concurrent Code
Section Overview: In this section, the speaker talks about Loom, a tool used to test concurrent code. The speaker explains that Loom explores all possible legal executions of threads and implements a bunch of implementation things from the paper to reduce the number of possible executions.
Exploring All Possible Legal Executions
- Loom explores all possible legal executions of threads.
- There might be an insane number of such possible executions.
- Loom has a bunch of implementation things that are from the paper that looks at reducing those.
Limitations of Loom
- Ultimately, there’s like a limit to how complex your test cases can be when you run them on the loop loom.
- Even so, loom is the best tool I know of to try to make sure that your concurrent code is actually correct under only the assumptions that the memory model gives you rather than the assumptions that the current compiler or optimization or CPU might give you.
Examples for Sequentially Consistent Ordering
Section Overview: In this section, someone asks if there are any toy programs one can think of to try and drill sequentially consistent ordering into their head. The speaker recommends looking at some papers that implement concurrent data structures and notice where they use sequentially consistent ordering as opposed to other orderings.
No Less Contrived Example Available
- The speaker doesn’t have a less contrived example for sequentially consistent ordering.
Recommendation
- Look at some papers that implement concurrent data structures and notice where they use sequentially consistent ordering as opposed to other orderings.
- Generally, the paper will explain why.
Limitations of Zulu
Section Overview: In this section, the speaker talks about some limitations of Zulu and how relaxed ordering is so relaxed that you can’t fully model all possible executions even with something like Loom.
Limitations of Zulu
- Zulu has some limitations, some of them are known problems, some of them are more fundamental problems with the approach or are just impossible to model.
- Relaxed ordering is so relaxed that you can’t fully model all possible executions even with something like Loom.
Example for Relaxed Ordering
- The speaker gives an example where loom has to produce some value for a load but doesn’t know about it yet because it hasn’t happened yet.
Contributing to Loom
Section Overview: This section discusses the benefits of contributing to Loom, a project that deals with concurrency. It also highlights some of the limitations of Loom and how contributions can help improve it.
Benefits of Contributing to Loom
- The speaker encourages people interested in concurrency to contribute to Loom.
- The documentation for Loom has been recently updated and is recommended reading for anyone interested in using or contributing to the project.
- Tokyo uses Loom and has caught several critical bugs, making it an important tool for detecting issues.
Limitations of Loom
- Currently, Loom does not model sequentially consistent ordering correctly.
- Implementing the additional guarantees required for sequentially consistent ordering is complex.
- Downgrading every sequentially consistent order to acquire release means that while Loom won’t miss any bugs, it might give false positives.
How Contributions Can Help
- There is an open issue and test case for modeling sequentially consistent ordering correctly that needs fixing.
- Contributions towards improving documentation are highly encouraged.
Testing Sequentially Consistent Ordering with Acquire Release
Section Overview: This section explains how testing sequential consistency with acquire release works in Loom.
Testing Sequential Consistency with Acquire Release
- If code depends on sequential consistency but is tested using acquire release, there may be false positives when using Loom.
- However, running code through Loom will catch real errors and explore possible cases with acquire release.
Overview of Loom and Relaxed Ordering
Section Overview: In this section, the speaker provides an overview of Loom and relaxed ordering.
Atomic Module in Sender Library
- The atomic module in the sender library contains atomic types, constants, and three functions: spin loop hint, compiler fence, and fence.
- Spin loop hint is deprecated and has been moved to the hint module. It is used in atomic contexts such as a spin lock.
- Compiler fence ensures that the compiler won’t move a given load or store operation above or below a fence within that thread’s execution. It is mostly used for preventing a thread from racing with itself when using signal handlers.
- Fence establishes a happens before relationship between two threads without talking about a particular memory location. It synchronizes with all other threads that are doing an offense.
Memory Ordering
- Load acquire synchronizes or happens after store release of the same memory location.
- Fence is basically an atomic operation that establishes a happens before relationship between two threads but without talking about a particular memory location.
Volatile Keyword
Section Overview: In this section, the speaker explains why there is no mention of volatile in the atomic module.
Volatile Keyword
- There is no mention of volatile in the atomic module because it is just unrelated to atomics.
Understanding Volatile
Section Overview: In this section, the speaker explains what volatile is and its purpose.
What is Volatile?
- Volatile is used when interacting with memory-mapped devices.
- It ensures that operations cannot be reordered relative to other operations.
- If you read twice from a given variable in memory map memory without using read volatile, the compiler would cache the first read into register and just read from the register for the second read. However, both reads need to go to memory to have a side effect on device map memory.
Atomic Pointer
Section Overview: In this section, the speaker explains atomic pointer and how it differs from other types.
What is Atomic Pointer?
- Atomic pointer is an atomic usize where methods are specialized to the underlying type being a pointer.
- It provides load, store, compare exchange and fetch update which is like having a nicer interface to doing a compare exchange loop. [CUTOFF_LIMIT]
Generated by Video Highlight
https://videohighlight.com/video/summary/rMGWeSjctlY
Channels
- Channels
- Introduction
- What is Crust of Rust?
- Introduction to Standard Sync Mpsc Module
- Topics Covered in Past Videos
- Overview of Standard Sync Mpsc Module
- Implementation of Channel
- Notification for Upcoming Streams
- Channel Implementation in Rust
- Panama: A Simple Channel Implementation in Rust
- Mutex and Conditional Variables
- Channel Implementation in Rust
- Mutex and Convar
- Mutex vs Boolean Semaphore Continued
- Why Arc Is Needed
- Implementing Sender
- Implementing Receiver
- Using Vec as a Stack and Ring Buffer
- Blocking Version of Receive
- Notification and Waiting Receivers
- Vector Double Ended Queue
- Async Wait vs Weight
- Convars Spurious Wake Ups
- Dropping Lock Before Notify
- Notify One vs Notify All
- Introduction
- Making Sender Cloneable
- Using Our Clone Implementation
- Blocking Send and Receive Methods
- Testing Our Implementation
- Arc Clone and Channel Implementation
- Introduction
- Complicated Case
- Atomic Use Size
- Notifying All for Drop
- Vector Default
- Initializing Senders
- Debugging Closed Test
- Debugging Rust Programs with GDB
- Removing Unnecessary Code
- Identifying a Problem with the Implementation
- Implementing Closed Flag for Failed Sends
- Multi-Producer Multiple Consumer
- Synchronous and Asynchronous Channels
- Weak Counters and ConVars
- Blocking Sends on Vector Resizing
- Resizing Insights
- Branch Predictor and Channel Implementations
- Flavors of Channels
- Different Implementations of Channels
- Async Await in Futures
- Implementing Channels in Rust
- Optimizing Channel Implementations
- Memory Overhead vs. Memory Allocator Performance
- Implementing Channels for Async Await
- Channel Implementations
- Real Implementation Examples
- Benchmarking Possible Configurations
- Async Await Ecosystem
- Sleeping Center Thread
- Conclusion
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces the episode and explains that it is a variant of the live streams where he tackles beginner-intermediate content. He also mentions that in this episode, they will be looking at the standard sync mpsc module.
Introduction to Crust of Rust
- The speaker introduces another episode of Crust of Rust.
- He explains that it is a variant of his live streams where he tackles beginner-intermediate content.
- The speaker mentions that in this episode, they will be looking at the standard sync mpsc module.
What is Crust of Rust?
Section Overview: In this section, the speaker describes what Crust of Rust is and who it’s for.
Description of Crust of Rust
- The speaker describes Crust of Rust as a series where he tackles beginner-intermediate content.
- He explains that it’s for people who have read the rust book and have some familiarity with the language but are looking to understand more advanced topics.
Introduction to Standard Sync Mpsc Module
Section Overview: In this section, the speaker introduces the standard sync mpsc module and explains what a channel is.
Introduction to Standard Sync Mpsc Module
- The speaker introduces the standard sync mpsc module.
- He explains that mpsc is a channel implementation that comes in the standard library.
- A channel is just a way to send data from one place and receive it somewhere else.
- The mpsc part of it means multi-producer single consumer. This means you can have many senders but only one receiver so it’s a many-to-one channel.
Topics Covered in Past Videos
Section Overview: In this section, the speaker talks about some topics covered in past videos related to rust.
Topics Covered in Past Videos
- The speaker mentions that he has covered topics such as lifetime annotations, declarative macros, iterators, smart pointers, and interior immutability.
- These are the topics that start popping up once you start getting deeper into rust.
Overview of Standard Sync Mpsc Module
Section Overview: In this section, the speaker gives an overview of the standard sync mpsc module and how it works.
Overview of Standard Sync Mpsc Module
- The speaker explains that when you create a channel using the standard sync mpsc module, you get a sender and receiver handle.
- You can move these handles independently to different threads to communicate over the channel.
- The channel is unidirectional. Only senders can send and only receivers can receive.
- You can clone the sender but not the receiver. This is why it’s called multi-producer single consumer.
Implementation of Channel
Section Overview: In this section, the speaker talks about implementing a channel and compares it with other implementations.
Implementation of Channel
- The speaker explains that they will be implementing their own channel in this episode.
- They will compare their implementation with both the standard library channel and other implementations out there.
- The speaker talks about some considerations that come up when deciding how to use channels.
Notification for Upcoming Streams
Section Overview: In this section, the speaker talks about how to stay notified for upcoming streams.
Notification for Upcoming Streams
- The speaker mentions that if you’re interested in these crossover streams, you should follow him on Twitter or subscribe on YouTube or Twitch.
- This way, you’ll be notified whenever he does any upcoming stream.
Channel Implementation in Rust
Section Overview: In this section, the speaker discusses the implementation of channels in Rust.
Sender and Receiver Types
- A channel has two halves: a sender half and a receiver half.
- The sender type is used to send data over the channel, while the receiver type is used to receive data from the channel.
- The sender and receiver types are different and can be distinguished from each other.
Sending Data through Channels
- Data sent through a channel does not necessarily have to be sent between threads.
- If a channel is used within the same thread, then the data is sent on that thread without needing to be sent across threads.
- There are no constraints on what types of data can be sent through a channel. Any type can be sent as long as it is owned.
Size Constraints for Types Sent through Channels
- Every type that is sent through a channel must implement the
Sizedtrait unless you use?Sized. - If there’s no
?Sized, then every type that is sent must be sized.
Ownership of Data in Channels
- The channel object owns any data that is stored in it.
- When something is sent over a channel, it remains owned by the channel until it’s received by another thread or dropped.
Panama: A Simple Channel Implementation in Rust
Section Overview: In this section, the speaker demonstrates how to implement a simple version of channels in Rust using concurrency primitives from its standard library.
Implementation Details
- To implement channels in Rust, we need to create two structs:
Sender<T>andReceiver<T>. - We also need to create a function called
channelwhich returns both halves of our newly created struct. - Our implementation will use other parts of Rust’s standard library such as sync module for concurrency primitives.
Performance Considerations
- The implementation demonstrated in this section is not the most performant.
- Implementing a highly performant channel requires more subtlety and trickiness that may be hard to cover in a stream.
Back Pressure
- The speaker mentions that they will discuss how back pressure works when they start implementing the channel.
Mutex and Conditional Variables
Section Overview: In this section, the speaker explains how mutexes and conditional variables work in Rust’s concurrency model.
Mutex
- A mutex is a way to ensure that only one thread can access a shared resource at any given time.
- If two threads try to lock the same mutex, one will get to go while the other will block until the first thread releases the guard.
- This ensures that there’s only ever one thread modifying the shared resource at any given time.
Arc and Rc
- Arc is an atomically reference counted type that allows for safe sharing of data across thread boundaries.
- Rc is a reference counter type that does not allow for safe sharing of data across thread boundaries.
Conditional Variables
- A conditional variable (convar) is a way to announce to a different thread that you’ve changed something it cares about.
- It allows a sender to wake up a receiver who was waiting because there was no data yet.
- Together with mutexes, convars provide useful concurrency primitives for writing concurrent code safely.
Channel Implementation in Rust
Section Overview: In this section, the speaker outlines how channels are implemented in Rust using mutexes and conditional variables.
Inner Type
- The inner type holds the data that is shared between multiple handles or halves of the channel.
- For now, it’s defined as an empty vector but will be modified later on.
Sender and Receiver Types
- Both sender and receiver types contain an inner type which is an arc-mutex-t holding shared state.
- They both return their respective types containing this inner type when created.
Alternative Implementations
- Linked lists could be used instead of vectors for storing data in channels.
- An unsynced version could be created for non-sendable types by defining an unsynced mpsc.
Mutex and Convar
Section Overview: In this section, the speaker discusses the implementation of mutex and convar in Rust’s standard library. They also explain why a mutex is needed for synchronization between sender and receiver threads.
Parking Lot Implementations
- The parking lot implementations of mutex and convar could be used as well.
- There has been talk of making them the standard library ones.
- The reason to not put the mutex in inner is discussed.
Default Implementation of Vec
- The default implementation of vec can be used.
- The question about why the receiver type needs to have an arc protected by a mutex if the channel may only have a single consumer thread is answered.
Arc Mutex vs Boolean Semaphore
- A mutex is effectively a boolean semaphore, so there is no difference between them.
- Using a boolean semaphore over the implementation in mutex would require spinning, which makes it less efficient than using a mutex that integrates with parking mechanisms.
Mutex vs Boolean Semaphore Continued
Section Overview: In this section, the speaker continues discussing the differences between using a boolean semaphore versus using a mutex for synchronization.
Problem with Boolean Semaphore
- If someone else has already taken the lock with a boolean semaphore, then you have to spin repeatedly checking it until it becomes available again.
Advantages of Mutex
- With a mutex, if someone else has taken it, then the operating system can put your thread to sleep and wake it back up when the lock becomes available again.
- This generally more efficient than spinning with a boolean semaphore but adds some latency.
Why Arc Is Needed
Section Overview: In this section, the speaker explains why an arc is needed for sender and receiver threads to communicate.
Sharing Inner
- If there was no arc, then the sender and receiver would have two different instances of inner.
- They need to share an inner because that’s where the sender puts data and where the receiver takes data out of.
Implementing Sender
Section Overview: In this section, the speaker starts implementing a send function for the sender thread.
Send Function
- The send function takes immute self and t that we’re going to send.
- It returns nothing for now.
- The lock is taken on self.inner.
- Lock result is used in case another thread panicked while holding the lock.
- Inner q is locked, and t is pushed onto it.
Implementing Receiver
Section Overview: In this section, the speaker implements a receive method for the receiver thread.
Receive Method
- The receive method does not take a t but returns it instead.
- The queue is locked with inner q.lock().
- T is popped from the queue.
Using Vec as a Stack and Ring Buffer
Section Overview: In this section, the speaker explains how to use Vec as a stack and why it is better to use a ring buffer instead.
Using Vec as a Stack
- A Vec can be used like a stack.
- When removing an element from the front of the Vec, all other elements have to be shifted down to fill the hole left by the removed element.
Ring Buffer
- A ring buffer is a type of collection that implements fixed memory.
- It is similar to a vector but keeps track of start and end positions separately.
- If you push an element to the end, it pushes it to the end.
- If you pop from the front, it removes the element and moves a pointer to where data starts.
- This allows for using it as a queue instead of just as a stack.
Blocking Version of Receive
Section Overview: In this section, we learn about providing blocking version of receive in Rust.
Try Receive Method
- We can provide try_receive method that returns an option t if there’s nothing in there.
- It just returns none if there’s nothing to receive.
Blocking Version of Receive
- We want to provide blocking version of receive that waits for something in channel.
- To do this, we need convar which needs to be outside mutex because when holding mutex and waking up another thread causes deadlock.
- The convar requires giving in mutex guard so that it does this step atomically.
- We match on cue pop front; if sum t then return t else block with self inner available wait.
Notification and Waiting Receivers
Section Overview: In this section, the speaker discusses how the sender needs to notify waiting receivers once it sends.
They explain that if a thread enters a loop and is sleeping when a send happens, the thread needs to wake up. The
speaker also introduces the use of condvar for notification.
Using Condvar for Notification
- The speaker explains that they will use
condvarfor notification. - They mention that
condvarhas anotify_one()and anotify_all()call. - The speaker drops the lock so that whoever they notify can wake up.
- They notify one thread because they are the sender and know that this will be a receiver.
Vector Double Ended Queue
Section Overview: In this section, the speaker briefly explains what a vector double ended queue is.
Understanding Vector Double Ended Queue
- The speaker mentions that vector double ended queue is just like a vector with head and tail index.
Async Wait vs Weight
Section Overview: In this section, the speaker clarifies the difference between async wait and weight.
Difference Between Async Wait and Weight
- The speaker explains that weight requires you to give up the guard before going to sleep because otherwise whoever would have woken you up can’t get the mutex.
- They clarify that async wait is generally used when you are I/O bound, not CPU bound.
- If you’re woken up without there being anything for you to do, you loop around, check the queue, realize it’s still empty, then go back to sleep again.
Convars Spurious Wake Ups
Section Overview: In this section, the speaker explains how convars can have spurious wake ups.
Convars Spurious Wake Ups
- The speaker mentions that one thing that can happen with convars is when you call weight, the operating system doesn’t guarantee that you aren’t woken up without there being anything for you to do.
- They explain that the loop checks the queue and goes back to sleep again if there’s nothing to do.
Dropping Lock Before Notify
Section Overview: In this section, the speaker clarifies why they drop the lock before notify.
Dropping Lock Before Notify
- The speaker clarifies that they drop the lock before notify so that when the other thread wakes up, it can immediately take the lock.
Notify One vs Notify All
Section Overview: In this section, the speaker explains notify one and notify all.
Notify One vs Notify All
- The speaker explains that notify one means notifying one of the threads waiting on a specific convar.
- They clarify that notify all notifies all waiting threads.
Introduction
Section Overview: In this section, the speaker introduces the topic of the video and discusses the current setup for senders.
Current Setup for Senders
- Senders cannot block in the current setup.
- When a sender gets the lock, it always succeeds in sending.
- There are never any waiting senders in the current design.
Making Sender Cloneable
Section Overview: In this section, the speaker discusses how to make sender cloneable and why deriving clone is not sufficient.
Deriving Clone for Sender
- Deriving clone at least at the moment actually desugars into impul t clone clone for sender t.
- This implementation added the clone bound to t as well.
- Inner might like if the structure you’re deriving clone on contains a t then t does need to be cloned in order for you to clone the whole type.
Implementing Clone Manually
- Arc implements clone regardless of whether the inner type is cloned that’s sort of what reference counting means.
- We don’t actually need t to be cloned; we want this implementation.
- The reason why we need to implement clone ourselves manually luckily it’s pretty simple though um it’s just inner is self inner.clone().
Using Our Clone Implementation
Section Overview: In this section, we discuss how to use our implemented clone method and why using dot operator can cause issues.
Using Our Clone Method
- Usually what you want to do here is use our_clone() to say that I specifically want to clone the arc and not the thing inside the arc.
Issues with Dot Operator
- Imagine that inner also implemented clone rust won’t know whether this call is supposed to clone the arc or thing inside because arc dereferences to inner type and dot operator sort of recurses into the inner drafts.
- Usually, it’s not what you want to write.
Blocking Send and Receive Methods
Section Overview: In this section, we discuss how send and receive methods should be blocking.
Blocking Send and Receive Methods
- Send and receive should be blocking methods.
- If you try to receive, and there’s nothing in the channel, we want the thread to block.
Testing Our Implementation
Section Overview: In this section, we discuss how to test our implementation using a ping pong test.
Ping Pong Test
- We create a tx and an rx.
- We use super::channel() to create a channel.
- We send 42 using tx.send(42).
- We assert equals rx.receive(42).
Arc Clone and Channel Implementation
Section Overview: In this section, the speaker discusses the implementation of arc clone and channels in Rust.
Coercing to Trait Objects
- The
arc clonecannot coerce to trait objects automatically. - It needs to be done manually by using
r clone as arctin trade.
Naming Channels
- The speaker prefers using
txandrxfor channels instead of the standard documentation’s use ofstd. - However, it ultimately comes down to personal preference.
Problems with Channel Implementation
- If there are no senders left, the receiver will block forever.
- To solve this problem, we need a way to indicate that there are no more senders left and that the channel has been closed.
Implementing Shared Channels
- We change the naming convention from
qtoinner. - A mutex is used to protect an inner t which holds both the queue and a count of senders.
- Every time a sender is cloned, we increase the number of senders in that value.
- When a sender goes away, we grab the lock and check if it was the last one. If so, we wake up any blocking receivers.
- The receiver now returns an option t rather than just a t because it could be that the channel truly is empty forever.
Introduction
Section Overview: In this section, the speakers discuss potential optimizations for their implementation of a channel in Rust.
Potential Optimization
- The speakers discuss the possibility of optimizing their implementation by using the reference count in the arc instead of keeping track of senders.
- They explain that with Arc, there is a strong count which tells how many instances of that arc there are. If there’s only one, then that must be the receiver and therefore there are no senders.
- They agree that it’s a good optimization and decide to get rid of the sender’s field.
Complicated Case
Section Overview: In this section, the speakers discuss a complicated case related to dropping a sender.
Dropping Sender
- The speakers mention that if you drop a sender, you don’t know whether to notify because if the count is two, you might be the last sender or you might be the second to last sender and the receiver has been dropped.
- They decide to keep it as it was since it’s easier to read and there are plenty of optimizations they can make over this implementation.
Atomic Use Size
Section Overview: In this section, the speakers discuss using an atomic use size and shared rather than creating inner.
Using Atomic Use Size
- The speakers suggest using an atomic use size and shared instead of creating inner.
- However, they explain that at the moment you take a mutex, there isn’t really much value to it. It would mean you don’t have to take lock in and drop and clone, but those should be relatively rare and the critical sections are short enough that the lock should be fast anyway.
Notifying All for Drop
Section Overview: In this section, the speakers discuss whether to notify all for drop.
Notifying All for Drop
- The speakers discuss whether to notify all for drop.
- They explain that when the last sender goes away, there will be at most one thread waiting which will be the receiver if any.
- They mention that there’s no correctness issue to waking up more threads, but it is a performance issue.
Vector Default
Section Overview: In this section, the speakers discuss vector default.
Vector Default
- The speakers answer a question about the difference between vectec new and vector default. They explain that there is no difference.
Initializing Senders
Section Overview: In this section, the speakers discuss initializing senders in their implementation of channel in Rust.
Initializing Senders
- The speakers mention that they think the error was initializing senders to one in the constructor and then calling clone on the sender they return.
- They also answer a question about whether you can get false sharing in between vectec and sender count. They explain that they’re under a mutex anyway so that shouldn’t matter.
Debugging Closed Test
Section Overview: In this section, the speakers debug why their closed test did not work as expected.
Debugging Closed Test
- The speakers mention that their closed test hangs forever on receive and they need to figure out why.
- They decide to debug print the value of senders and see what comes out.
- They realize that the sender is not being dropped and try assigning to underscore, but it doesn’t work as expected.
- They finally realize that this implementation is pretty straightforward.
Debugging Rust Programs with GDB
Section Overview: In this section, the speaker discusses using GDB to debug Rust programs and how print debugging is easier for small examples.
Using Print Debugging Instead of GDB
- The speaker uses print debugging instead of GDB for small examples.
Removing Unnecessary Code
Section Overview: In this section, the speaker removes unnecessary code from the implementation.
Removing Unnecessary Code
- The speaker removes unnecessary code from the implementation.
Identifying a Problem with the Implementation
Section Overview: In this section, the speaker identifies a problem with the current implementation and discusses whether send should always succeed or fail in some way.
Identifying a Problem with Closed RX Channels
- The current implementation has a problem where it can go the other way around if there’s a closed RX channel.
- It’s not clear whether send should always succeed or fail in some way when trying to send something on a closed channel.
- The decision is made to keep it as is but in real implementations, send might return an error if the channel is closed.
- If send fails, make sure to give back the value that was tried to be sent so that it can be used elsewhere or logged.
Implementing Closed Flag for Failed Sends
Section Overview: In this section, the speaker discusses implementing a closed flag for failed sends and how it would work.
Implementing Closed Flag for Failed Sends
- If you want sending to be able to fail, you need to add a closed flag to the inner or just a boolean that the sender sets.
- When you send, if the flag is set, you return an error rather than pushing to the queue.
Multi-Producer Multiple Consumer
Section Overview: In this section, the speaker discusses whether it’s possible to resurrect a drop channel and how multi-producer multiple consumer channels work.
Resurrecting a Drop Channel and Multi-Producer Multiple Consumer Channels
- If the sender goes away, there’s no way to send anymore in this particular design.
- In theory, we can add a method that lets you construct a sender from the receiver but most implementations are not quite as symmetric as this one and you can’t easily create a center from a receiver.
- Every operation takes the lock which is fine for low-performance channels but for high-performance channels with many sends competing with each other, it might be better not to have them contend with one another.
- Realistically, an implementation could allow sends to compete with each other and only synchronize between senders and receivers instead of locking all of them.
- The standard library channel has two different sender types: sender and sync sender. The difference between these is that one is synchronous and the other is asynchronous.
Synchronous and Asynchronous Channels
Section Overview: This section discusses the difference between synchronous and asynchronous channels, and how they handle back pressure.
Synchronous vs. Asynchronous Channels
- The sender and receiver go in lockstep in a synchronous channel.
- Sends can’t block in this implementation of asynchronous channels.
- A synchronous channel has back pressure, meaning the sender will eventually start blocking if the receiver isn’t keeping up.
- The standard library has a sync channel function that takes a bound (channel capacity), whereas our channel method is an infinite queue.
Weak Counters and ConVars
Section Overview: This section discusses weak counters, convars, and their use cases.
Using Weak Counters
- Senders could use weak counters to determine if the receiver is still there before sending data.
- Upgrading to a strong reference using weak counters adds overhead to each send operation.
ConVars Without Mutexes
- ConVars require mutex guards, so it’s not possible to have them without mutexes.
Blocking Sends on Vector Resizing
Section Overview: This section discusses vector resizing during sends and its impact on blocking.
Blocking Sends During Vector Resizing
- Pushing beyond the capacity of a vector requires allocating new memory for it, which takes time but doesn’t block sends.
- However, during this time, sends take longer than usual because they’re waiting for the vector resize to complete.
Resizing Insights
Section Overview: In this section, the speaker talks about an optimization that can be made to the implementation of channels.
Optimization for Channels
- An optimization is made by encoding the assumption that there is only one receiver in the code to make it more efficient.
- The trick used is to steal all items that have been queued up rather than just stealing one since no one else will take them.
- When someone calls receive, we first check if we still have some leftover items from last time we took the lock. If so, we return from there without taking the lock again.
- If the queue is not empty and we get an item, then we check if there are more items in the queue and steal all of them. We swap that vec deck with the one buffered inside ourselves and leave m empty self.buffer.
Benefits of Optimization
- This optimization reduces contention because now, instead of taking a lock on every receive, it’s taken fewer times making it faster to acquire.
- It triggers twice as many resizes at predictable intervals but only uses twice as much memory which is also amortized.
Implementation Source
- The speaker got this optimization from other implementations since it’s a pretty common implementation.
Branch Predictor and Channel Implementations
Section Overview: In this section, the speaker discusses the branch predictor and different flavors of channel implementations.
Branch Predictor
- The CPU has a built-in component that observes all conditional jumps.
- It tries to remember whether it took the branch or not the last time.
- Speculative execution comes into play where if it runs that code again, the branch predictor is going to say it’s probably going to take the branch or it’s probably not going to take the branch.
- Start running that code under the assumption that it will or won’t and then if it doesn’t end up doing that then go back and unwind what you did and then do that stuff instead.
Channel Implementations
- There are multiple different kinds of flavors for channel implementations.
- Usually, they take one of two approaches:
- Different types for different implementations of channels
- A single sender type with an enum-like implementation under the hood
- Flavors have multiple implementations of your channel with different backing implementations chosen depending on how the channel is used.
- Common flavors include synchronous channels, asynchronous channels, rendezvous channels, and one-shot channels.
Synchronous Channels
- This is a channel where send blocks.
- Usually has limited capacity.
Asynchronous Channels
- This is a channel where send cannot block.
- Usually unbounded so any number of sends can build up as much as stuff impossible in memory.
Rendezvous Channels
- A synchronous channel with capacity equals zero.
- Used for thread synchronization rather than sending data between threads.
- Only allows sending if there’s currently a blocking receiver because you can’t store anything in the channel itself.
One-Shot Channels
Not discussed in detail.
Flavors of Channels
Section Overview: This section covers the different flavors of channels in Rust.
Two-way Synchronization
- Two-way synchronization occurs because the receiver cannot proceed until the sender arrives.
- The channel version is still a two-way synchronization.
One-shot Channels
- One-shot channels are channels that you only send on once.
- These can be any capacity, but usually, they are things like an application where you have a channel that you use to tell all the threads that they should exit early.
- You might have a channel that you only send on once and don’t send anything useful.
Bounded and Unbounded Channels
- Circular channels are often called bounded channels.
- Asynchronous channels are often called unbounded channels.
- In Rust, these flavors aren’t different types in the type system; they’re different implementations chosen between at runtime.
Rendezvous Channel
- A rendezvous is not a mutex because it doesn’t guarantee mutual exclusion. It’s more like a convar in that you can wake up another thread.
- You can totally send data in a rendezvous channel right; it still has the t type, but if both sender and receiver aren’t present, nothing happens.
Different Implementations of Channels
Section Overview: This section covers different implementations of Rust’s synchronous channel and async-await futures.
Synchronous Channel with Mutex Plus Convar
- For synchronous channels, what we implemented was a mutex plus convar as well.
Upgrading Channel Type at Runtime
- Initially, assume that the channel is a one-shot channel.
- The moment an additional send happens, upgrade it to be a different type of channel.
- This means that the first send will be more efficient than later ones.
Async Await in Futures
Section Overview: This section covers async-await in Rust’s futures.
Async-Await
- The idea of async-await is that you can write code that looks like it’s synchronous, but it’s actually asynchronous.
- You can use the
asynckeyword to mark a function as being asynchronous. - You can then use the
awaitkeyword to wait for an asynchronous operation to complete. - In Rust, futures are used to represent asynchronous operations.
Implementing Channels in Rust
Section Overview: In this section, the speaker discusses different ways to implement channels in Rust.
Atomic Vectec or Queue
- Use an atomic vectec or queue to update head and tail pointers atomically.
- No need to take a mutex in order to send.
- Update head and tail pointers atomically to ensure no thread ever tries to touch data that another thread is currently touching.
Signaling Mechanism
- Use park and notify primitives from the standard library or parking lot for wake-ups.
- Need some signaling mechanism where if the sender is asleep because it’s blocking, the receiver needs to wake it up if it receives something because now there’s capacity available.
- Similarly, if the receiver is blocking because the channel is empty and a sender comes along and sends something, it needs to make sure to wake up the receiver.
Linked List Implementation
- Use a linked list implementation instead of a vectec when resizing becomes problematic.
- When a sender comes along, append or push to the front of the linked list.
- The receiver steals all items by setting head to null or none and walking backwards through the doubly linked list.
Atomic Linked List
- An atomic linked list is often referred to as an atomic queue.
- Mix atomic head and tail with an atomic linked list so that only occasionally do you need to actually append new items.
- This avoids problematic operations when two senders want to send at the same time with a linked list.
Optimizing Channel Implementations
Section Overview: In this section, the speaker discusses how to optimize channel implementations by using a wake-up primitive instead of a linked list for rendezvous channels.
Using Wake-Up Primitive Instead of Linked List
- A block atomic linked list is more efficient in practice.
- A single place in memory can store the item for handoff.
- You don’t need a linked list at all; you only need a wake-up primitive.
- An atomic place in memory that is either none or some can be used to swap elements.
Specialized Implementations
- More specialized implementations can be written that are faster for specific use cases.
- Async await channels have different implementations than blocking thread world channels.
Memory Overhead vs. Memory Allocator Performance
Section Overview: In this section, the speaker discusses the trade-off between memory overhead and memory allocator performance when using linked lists in channel implementations.
Linked Lists and Allocation/Deallocation
- With linked lists, an allocation/deallocation occurs on each push/pop operation.
- The memory allocation system is not always the bottleneck, especially with thread-local allocation like jmallock.
- Measuring memory overhead versus memory allocator performance is important.
Reusing Pool of Nodes
- Keeping a pool of nodes around can help reduce allocations/deallocations.
- Managing the pool atomically requires synchronization primitives and may not be better than using a memory allocator.
Implementing Channels for Async Await
Section Overview: In this section, the speaker discusses the challenges of implementing channels for both async await and blocking thread worlds.
Differences in Primitives
- It is difficult to write a channel implementation that works for both async await and blocking thread worlds.
- Yielding to the parent future is necessary in async await when the channel is full.
- Notification primitives are similar but not quite the same.
Internal Implementation
- Writing an implementation that knows whether it’s being used in async context or blocking context without exposing it to the user can be challenging.
Channel Implementations
Section Overview: In this section, the speaker discusses channel implementations and their underlying data structures. They also talk about memory allocation and the use of channels in their thesis.
Blocking vs Async Worlds
- At runtime, channel implementations diverge into different ways of managing the underlying data store depending on whether you’re in the blocking world or not.
- In practice, the data structure used is fairly similar regardless of whether you’re using a vector or an atomic linked list.
Memory Allocation
- Allocators are good at taking advantage of repeated patterns, so it’s hard to write good performant garbage collection and memory allocator has had a lot of practice with it.
- It’s not clear if you could beat the allocator because we always need allocations of the same size.
Use of Channels in Thesis
- The speaker uses Tokyo channels because they needed one with async. They don’t have a particularly strong feeling about it.
- The decision wasn’t that important since Noria is not really channel-bound.
- The standard library channel didn’t support async await when they started adding them.
Real Implementation Examples
Section Overview: In this section, the speaker recommends looking at real implementation examples for channels and provides some pointers on where to look next.
Standard Library Implementation
- The mpsc module in Rust’s standard library has really good documentation on what’s going on under the hood and some optimizations that they do like internal atomic counters.
Crossbeam Channel Implementation
- Crossbeam has a cross beam channel subdirectory that holds all different flavor implementations such as array for synchronous channels, headtail business for multi-producer single consumer, and atomic block linked list for multi-producer multi-consumer.
- Flume is a different implementation of channels that popped up fairly recently. It has a very different implementation to what crossbeam does.
Benchmarking Channel Implementations
- Benchmarking channel implementations is hard. Burnt Sushi did a bunch of benchmarking of channels looking at go channels, the standard library channels, flume, crossbeam channel, and chan crate.
- When benchmarking channels, you want to try to benchmark all the different flavors because they represent real use cases. You want your benchmark to test cases where you send large or small things with many or few senders.
Benchmarking Possible Configurations
Section Overview: The speaker suggests creating a grid of all possible configurations and benchmarking each one separately.
Creating a Grid of Configurations
- The speaker suggests creating a grid of all possible configurations.
- Rendezvous channels are like the default go channels with zero capacity.
- A bump allocator would be really good since you would likely allocate memory atomically quite possibly and also because it you don’t need to drop anything in that case because the memory has already been handed off.
Async Await Ecosystem
Section Overview: The speaker explains how async is supported without tying it to a specific executor like Tokyo.
Supporting Async Without Tying It To A Specific Executor
- The primary reason for the lack of harmony in the async await ecosystem is around the i/o traits.
- Implementing a channel does not require either asynchronous or spawn features. All that’s needed is the primitive provided by the standard library, which is the waker trait, and the ability to yield or go to sleep and wake something up or notify something. These are from the standard task module in the standard library, so they can be used independently of what executor is being used.
Sleeping Center Thread
Section Overview: The speaker explains how to wake up a sleeping center thread if its receiver is dropped.
Waking Up A Sleeping Center Thread
- If you have a sleeping center thread and you’d like to wake it if the receiver is dropped, implement drop for your receiver where it will do a notify all to wake up all sleeping centers which could then do whatever freeing up of resources it needs to do.
Conclusion
Section Overview: The speaker concludes the video and provides information on where to find the recording and upcoming streams.
Recording and Upcoming Streams
- The recording will be uploaded to YouTube, and the speaker will tweet about it.
- Follow the speaker on Twitter or join their Discord for updates on upcoming streams.
- The Discord channel includes other Rust streamers, including Steve Klabneck.
Generated by Video Highlight
https://videohighlight.com/video/summary/b4mS5UPHh20:
Declarative Macros
- Declarative Macros
* Macro Rules
* Implementing the vec! Macro
- Introduction to Rust Macros
- Understanding Rust Macros Continued
- Macro Expansion
- Macro Rules in Rust
- Introspection in Rust Macros
- Introduction to Proc Macros
- Using Repetition in Patterns
- Expansion of Patterns
- Dealing with Repeating Patterns
- Macro Rules vs Proc Macro Plus
- Inspiration for Dollar Parentheses Pattern Language
- Trailing Commas
- Declarative Macros vs Proc Macros
- Macros in Rust
- Making the Star Instead of Plus
- Other Useful Crates
- More Efficient Implementation
- Veck Macro
- Power of Two Expansion
- Hygienic Macros
- Trailing Commas in Expressions
- Defining a Macro to Avoid Repeating Elements
- Counting Tokens in Rust Macros
- Using Map Lit Crate
- Standard Library Version of Veck
- Conclusion
- Generated by Video Highlight
# Introduction to Declarative Macros
Section Overview: In this video, we will learn about declarative macros and how they work in Rust. We will focus on
macro rules and implement the vec! macro from the standard library.
Macro Rules
- Declarative macros are defined using macro rules.
- Macro rules consist of a name followed by an exclamation point, followed by a bracket containing patterns that serve as arguments to the macro.
- The patterns for macros are looser than those for functions and can include syntax types such as identifiers, expressions, items, blocks, type names or module paths.
Implementing the vec! Macro
- The
vec!macro is used to declare a vector using either a vector literal syntax or by specifying an element that is cloneable along with its count. - To implement the
vec!macro, we need to understand some handy patterns explained in “The Little Book of Rust Macros”. - Section four of “The Little Book of Rust Macros” provides useful patterns for implementing macros.
Overall, this video provides an introduction to declarative macros and demonstrates how to implement them using macro
rules. We also learned about the vec! macro from the standard library and how it can be implemented using these
concepts.
Introduction to Rust Macros
Section Overview: In this section, the speaker introduces Rust macros and explains why it is important to have a dedicated library for them.
Creating a Dedicated Library for Macros
- A dedicated library for macros makes it easier to develop in isolation.
- It is good practice to get into the habit of making libraries.
Macro Rules and Delimiters
- Rust macros have optional delimiters that can be used by the caller.
- The input syntax for a macro must be syntactically valid rust program, but the output must be valid rust code.
- Every macro invocation is replaced by whatever input was given when working with macros.
Using Cargo Expand
- Cargo expand is a handy crate that expands all macros with their definitions in the source code.
Understanding Rust Macros Continued
Section Overview: In this section, the speaker continues explaining how Rust macros work and demonstrates how they can be used.
Defining Macro Arguments
- Patterns are patterns over rust syntax trees, not argument lists.
- You can introduce any syntax you want in a macro as long as it is syntactically valid rust program.
Using Cargo Check
- Running cargo check on an empty macro expansion returns no errors because nothing is allowed to be in these locations.
Optional Delimiters
- There isn’t currently a way to specify which delimiter should be used when invoking a macro rule.
Writing Valid Syntax Patterns
- The input syntax pattern must be syntactically valid rust program while the output must also be valid rust code because it is what gets compiled.
Using Cargo Expand
- Cargo expand is a handy crate that expands all macros with their definitions in the source code.
# Introduction to Rust Macros
Section Overview: In this section, the speaker introduces Rust macros and explains how they work. They discuss the concept of syntactically valid Rust grammar and how it relates to macro rules.
Syntactically Valid Rust Grammar
- The speaker explains that for a code to be syntactically valid, it must follow the rules of Rust grammar.
- The output is helpful in identifying identifiers, which can be chosen by the user.
- Identifiers defined inside a macro exist in a separate universe from everything outside the macro.
Hygienic Macros
- The speaker explains that identifier names used inside macros are distinct from those outside of macros.
- Rust macros are hygienic because they cannot access things outside their own scope.
Creating a Macro
- The speaker demonstrates how to create a simple macro using
macro_rules!. - They explain how to use
macro_exportto make the macro callable from other libraries.
# Using Macros for Code Generation
Section Overview: In this section, the speaker discusses how macros can be used for code generation and demonstrates an example of generating code with macros.
Generating Code with Macros
- The speaker demonstrates an example of generating code with macros using
vec!. - They explain how this approach can simplify code and reduce errors.
- The limitations of using macros for code generation are discussed.
# Advanced Macro Concepts
Section Overview: In this section, the speaker discusses advanced macro concepts such as repetition and recursion.
Repetition in Macros
- The speaker explains how repetition can be used in macros to generate code.
- They demonstrate an example of using repetition to generate a function that calculates the sum of a list of numbers.
Recursion in Macros
- The speaker explains how recursion can be used in macros to generate code.
- They demonstrate an example of using recursion to generate a function that calculates the factorial of a number.
# Conclusion
Section Overview: In this section, the speaker concludes by summarizing the key points covered in the video and providing resources for further learning.
Summary
- The speaker summarizes the key points covered in the video, including syntactically valid Rust grammar, hygienic macros, generating code with macros, and advanced macro concepts.
- They provide resources for further learning about Rust macros.
Overall, this video provides a comprehensive introduction to Rust macros and demonstrates how they can be used for code generation. The examples provided are clear and easy to follow, making it an excellent resource for anyone looking to learn more about Rust macros.
Macro Expansion
Section Overview: In this section, the speaker discusses macro expansion in Rust and provides examples of how to define macros.
Defining a Simple Macro
- The speaker defines a simple macro that produces a static value.
- The speaker explains that when passing identifiers to a macro, you are not passing ownership but rather access to the name.
- The speaker explains that what matters for ownership is what the code that the macro expands to does with that name.
Expanding Macros
- The speaker demonstrates expanding a macro using
cargo expand. - The speaker shows an example of expanding a more complicated macro and explains why it doesn’t work as expected.
- The speaker adds an argument to the macro and expands it correctly using curly brackets to create a block.
Overall, this section covers how to define and expand macros in Rust, including handling ownership issues and creating blocks for more complex expansions.
Macro Rules in Rust
Section Overview: This section discusses the implementation of macro rules in Rust and how it differs from normal macros.
Procedural Macros vs. Macro Rules
- Macro rules is not a normal macro, but rather a procedural macro.
- The syntax for macro rules does not allow for an identifier followed by curly brackets, unlike other macros.
- The output type of the macro defined using macro rules is expected to be an expression.
New Version of Macros
- A new version of macros called “macros” is proposed to be more powerful than macro rules.
- It will have different guarantees about hygiene and work better with the module system and use statements.
Delimiters in Instantiation
- The delimiter used in instantiation can be freely chosen by the user between square brackets, round brackets, and curly brackets.
- All delimiters are valid and have the same meaning.
Declarative Macros vs. Proc Macros
- Declarative macros like macro rules do not let you write a Rust program, while proc macros do.
- Declarative macros are entirely declarative and only allow substitution between one valid Rust syntax tree to another.
Introspection in Rust Macros
Section Overview: This section discusses introspection in Rust macros and what information they have access to.
Type Information
- Declarative macros like macro rules do not have access to things like type information.
- Proc macros give you more access to introspection but still don’t provide full introspection capabilities.
Identifiers Before Argument Block
- Proc macros cannot take identifiers before the argument block.
Introduction to Proc Macros
Section Overview: In this section, the speaker introduces proc macros and explains how they differ from declarative macros.
What are Proc Macros?
- Proc macros take Rust syntax streams as input and produce a different token stream to replace it with.
- They are more expressive but also more complicated to write than declarative macros.
Special Features of Proc Macros
- With proc macros, you can add attributes or derives that you cannot do with declarative macros.
Using Repetition in Patterns
Section Overview: In this section, the speaker explains how repetition works in patterns and how it can be used in macro replacements.
Limitations of Single Expression Pattern
- The pattern for accepting only one expression is limiting when dealing with multiple expressions separated by commas.
- This limitation causes an error when trying to run the code.
Using Repetition in Patterns
- The patterns index allows for repetition by surrounding part of your pattern with dollar parentheses.
- You can give a delimiter followed by either star or plus to indicate zero or more repetitions or one or more repetitions respectively.
- This allows for matching comma-separated lists of expressions.
Using Repetition in Macro Replacements
- Inside the replacement part of your macro, you can use the same syntax as the pattern to give repetitions corresponding to the pattern.
- This allows for scaling up your vector macro to work for an arbitrary number of elements and produce an appropriate vector.
Expansion of Patterns
Section Overview: In this section, the speaker discusses how Rust format expands patterns and how it handles multiple variables in a single repetition.
Rust Format Expansion
- Rust format expands patterns multiple times when encountering the pattern of dollar parentheses inside of the expansion.
- It matches against each pattern and pulls out the variables every time.
Handling Multiple Variables in a Single Repetition
- Using multiple variables in a single repetition is an error.
- If there are different repeating patterns with variables, they have to repeat the same number of times.
Dealing with Repeating Patterns
Section Overview: In this section, the speaker talks about repeating patterns and how to deal with them.
Meta Variable X Repeats Zero Times
- When using static strings, if there are no repeating patterns, Rust format will give an error message saying “meta variable X repeats zero times but element repeats one time.”
- If there are different repeating patterns with variables, they have to repeat the same number of times.
Macro Rules vs Proc Macro Plus
Section Overview: In this section, the speaker explains that for more elaborate things than what macro rules can define, you need to drop to a proc macro plus.
Limitations of Macro Rules
- The format macro is not macro rules.
- Macro rules are somewhat limited in what you can define.
Dropping to Proc Macro Plus
- For some more elaborate things than what macro rules can define, you need to drop to a proc macro plus.
Inspiration for Dollar Parentheses Pattern Language
Section Overview: In this section, the speaker discusses where the dollar parentheses pattern language came from.
Origin of Dollar Parentheses
- The origin of the dollar parentheses pattern language is unknown.
- It is reminiscent of regular expressions where a parenthesis is a grouping and plus means one or more of the previous pattern.
Trailing Commas
Section Overview: In this section, the speaker talks about trailing commas and how to allow them in Rust format.
Allowing Trailing Commas
- When things wrap, you often want to have a trailing comma.
- The current pattern doesn’t allow that because it expects a comma-separated list of things with an expression following each comma.
- To allow trailing commas, add a pattern that allows any number of commas after the normal pattern.
Declarative Macros vs Proc Macros
Section Overview: This section discusses the differences between declarative macros and proc macros, and their respective benefits.
Defining Your Own Macros
- Declarative macros are limited in their ability to provide error messages.
- Proc macros offer better control over what went wrong and what errors are emitted.
- Macro rules can be used to generate repeated patterns quickly.
Example: Generating Trait Implementations
- Macro rules can be used to generate trait implementations for multiple types quickly.
- This is useful when there are repeated patterns that need to be expressed.
Limitations of Declarative Macros
- When using non-literal expressions, declarative macros may not work as expected due to substitution.
- Substitution can cause issues with more complicated expressions, leading to unexpected behavior.
Macros in Rust
Section Overview: This section covers the use of macros in Rust, including macro rules and proc macros. It also discusses the downsides of using proc macros.
Object-Oriented Programming with Macros
- Macros are not recommended for object-oriented programming like inheritance.
- Macro rules can become an eyesore when they go beyond simple ones.
- Proc macros are a better option for more complicated macros but add an additional compilation step.
Testing Invalid Expressions
- Rust assigns any error produced by a macro to the corresponding place in the macro input.
- A test that includes an invalid expression will not compile and will produce an error message pointing to the location of the error.
Compiler Optimization
- The compiler is smart enough to recognize types that implement copy, such as integers, and will optimize them accordingly.
- The newly introduced syntax can be used to compact arbitrarily nested for-loops.
Doc Tests
- Rust does not have a way to say that a unit test should not compile, but there is a crate called “compile fail” that allows you to write tests that are not supposed to compile.
- Doc tests can be used as a cheap way to get compiled fail tests.
Veck Macro Comparison
- The Veck macro supports the pattern element expression semicolon and expression.
Making the Star Instead of Plus
Section Overview: In this section, the speaker discusses how to make the star instead of plus and reduce the number of patterns.
Reducing Patterns
- The star can be used instead of plus to indicate zero or more repetitions.
- An allow statement is needed in case the input list is empty and we never push.
- This reduces the number of patterns and makes documentation easier to read.
Other Useful Crates
Section Overview: In this section, the speaker mentions other useful crates for compile fail tests.
Other Useful Crates
- Try build is a good crate to know for compile fail tests.
- Should panic is different from compiled failed macro export.
- Macro export is not always required but without it, you wouldn’t be able to call this macro outside of this crate.
More Efficient Implementation
Section Overview: In this section, the speaker discusses how to create a more efficient implementation by reducing reallocations and pointer increments.
Reducing Reallocations
- Creating an empty vector and then calling push a thousand twenty-four times will require many reallocations.
- Using capacity count can help allocate for a specific number of elements.
- Standard iterator repeat element take count can be used instead of push to avoid bounds checking for every iteration.
Pointer Increments
- Push still requires pointer increments which can add up if creating a vector with many elements in a busy loop.
- Standard iterator repeat plus take does not implement exact size and can be improved.
Veck Macro
Section Overview: This section discusses the Veck macro and its implementation.
Veck Macro Implementation
- The Veck macro is a more sophisticated operation that requires special treatment.
- If an iterator is produced, it must be implemented as an exact size iterator.
- The macro does not have any trait bounds, so if something that isn’t clone is used, the compiler will generate an error.
- The error output generated by the macro expansion points to where the type that didn’t implement clone came from.
Power of Two Expansion
Section Overview: This section discusses power of two expansion and its efficiency.
Purely Power of Two Expansion
- The Veck macro does purely power of two expansion.
- It will do ten allocations before it even gets to 1024, making it inefficient.
Hygienic Macros
Section Overview: This section discusses hygienic macros and how they can be affected by caller-defined modules.
Caller-defined Modules
- When defining macros, you have to be careful because the caller might have modules that override you.
- Macros aren’t entirely hygienic because they can’t express certain things like crate or colon colon which are root level paths.
- If someone renames the crate STD then they deserve the problems they get.
Trailing Commas in Expressions
Section Overview: This section discusses trailing commas in expressions and their effect on recursion limits.
Trailing Commas in Expressions
- If there’s not a trailing comma, then it will keep invoking this rule causing infinite recursion.
- The order matters when defining rules for expressions with no trailing commas. I’m sorry, but I cannot summarize the transcript without having access to it. Please provide me with the transcript so that I can create a summary for you.
Defining a Macro to Avoid Repeating Elements
Section Overview: In this section, the speaker explains how to define a macro to avoid repeating elements in Rust.
Using a Macro to Define an Expression
- The problem with repeating an element multiple times is that it can cause issues.
- Rust figures out how many times to repeat a block by looking at which variables are used inside of it.
- If we don’t use any variables, Rust doesn’t know how many times to repeat the block.
- We can define a substitute variant that takes an expression and returns unit instead of using repetition.
- By expanding the macro with substitution, Rust knows how many times to repeat the block because we’re using element in there.
Counting Trick for Arrays
- The type does not give the length of the array, so we need to use a counting trick.
- We call slice Len on this array turned into a slice by calling the ass ref trade.
Counting Tokens in Rust Macros
Section Overview: In this section, the speaker discusses how to count tokens in Rust macros and the tricks involved in doing so.
Tricks for Counting Tokens
- You can use size of to count tokens, but it ends up allocating.
- There are other tricks like zero plus multiple replacements with one that can be used to count tokens. However, if you do enough of these, you will crash the compiler.
- You can also count the number of tokens by counting sub-patterns and batching them. This has been tested up to ten thousand tokens but cannot be used to produce a constant expression.
- There are versions that can produce a constant expression like extracting the enum counter to get the number of items.
Using Procedural Macros
- When counting tokens gets too complicated, you can write it as a procedural macro instead.
- Although you may not necessarily want to use these tricks yourself, they tell you a lot about how macros work.
Predefined Count Macro
- Currently, there is no predefined count macro because it’s hard to know what exactly needs to be counted (e.g., number of tokens or characters in syntax tree).
Testing Compile Time Length Verification
- It is possible to test and verify that length is known at compile time using const slices.
Hiding Nasty Patterns
- To hide nasty patterns from documentation, you can make macros export but also doc hidden.
Using Map Lit Crate
Section Overview: In this section, the speaker recommends using the Map Lit crate to practice creating maps.
Practice with Map Lit Crate
- The Map Lit crate can be used to create maps.
- Expanding or extending the code to work for a hashmap is a good exercise.
- The syntax change required for working with a hashmap is fairly straightforward.
Standard Library Version of Veck
Section Overview: In this section, the speaker explains how the standard library version of Veck works.
Explanation of Standard Library Version
- The standard library version uses Box and creates an array on the heap.
- A boxed array is created on the heap and treated as a box slice instead of a boxed array.
- A sequence of things on the heap can be trivially constructed into a vector.
Conclusion
Section Overview: In this section, the speaker wraps up and invites viewers to suggest additional concepts for future videos.
Wrapping Up
- Thanks everyone for watching!
- The standard library version allows them to get away with not doing all the tricks that were done in previous sections.
Future Video Concepts
- Viewers are invited to suggest additional self-contained real code concepts.
Generated by Video Highlight
https://videohighlight.com/video/summary/q6paRBbLgNw
Dispatch and Fat Pointers
- Dispatch and Fat Pointers
- Introduction
- Topics Covered
- Rust Book
- Monomorphization and Generics in Rust
- Static Dispatch vs Dynamic Dispatch
- Understanding Trait Objects and the Sized Trait
- Dynamic Dispatch and Object Safety
- Implementing Traits for Trait Objects
- Downcasting Trait Objects
- Conclusion
- Introduction to the Problem
- Understanding the Issue
- Implementing Sized Trait
- Types That Are Not Sized
- Indirection through Sized Types
- Using Box to Make an Unsized Type Sized
- Dynamically Sized Types and V-Tables
- Trait Objects and Associated Types
- Opting Out of Trait Object Safety
- Opting Out of Trait Object Safety with Static Dispatch
- Implementing Traits for Concrete DSTs
- Type Erasure in Trait Objects
- The FromIterator Trait and Trait Objects
- Extending with a Single Bool Add True
- Could Rusty Add a Monomorphized Version of Extend?
- Object Safety in Rust
- Object Safe Traits
- Trait Objects and Drop Function
- Unsized Types and Fat Pointers
- Understanding Waker and Raw Waker
- Questions on References, Metadata Types, Dynamically Sized Types, Box U8 vs Vec U8, Din Fn vs Fn
- Static Dispatch vs Dynamic Dispatch
- Coherence
- Understanding V-Tables and Dynamic Dispatch
- Working with Slices and Vec of Dins
- Rust Traits and the Any Trait
- Conclusion
- Generated by Video Highlight
Introduction
Section Overview: In this video, the speaker covers a range of topics related to Rust programming language. The topics include traits, dynamic and static dispatch, size trait, wide or fat pointers, v tables coherence and monomorphization.
Topics Covered
Section Overview: This section covers the various topics that will be discussed in the video.
Traits and Dispatch
- The video covers traits and dynamic and static dispatch.
- Dynamic dispatch is when you have a pointer to an object on the heap.
- Static dispatch is when you have a concrete type.
- Traits are used to define shared behavior between types.
Size Trait
- The size trait is used to determine the size of a type at compile time.
- It can be used for optimization purposes.
Wide or Fat Pointers
- Wide or fat pointers are pointers that contain additional information about their referent.
- They are useful for dynamically sized types like slices.
V Tables Coherence
- V tables coherence refers to how Rust ensures that all implementations of a trait are consistent with each other.
- It ensures that there is only one implementation of a trait for any given type.
Monomorphization
- Monomorphization is the process of turning generic code into specific code by filling in the concrete types that are used when compiled.
- It enables more efficient code generation by allowing the compiler to generate specialized code for each concrete type.
Rust Book
Section Overview: This section covers a chapter in the Rust book on generic types, traits, and lifetimes.
- The Rust book has a chapter on generic types and traits.
- The chapter discusses the performance of code using generics and introduces the concept of monomorphization.
- Monomorphization is the process of turning generic code into specific code by filling in the concrete types that are used when compiled.
Monomorphization and Generics in Rust
Section Overview: In this section, the speaker explains how generics work in Rust and the process of monomorphization.
Generics in Rust
- Generics in Rust are turned by the compiler into multiple non-generic implementations through a process called monomorphization.
- Monomorphization generates a full copy of the entire struct and all its methods for each type that it is used by.
- The generation of copies happens on demand determined at compile time when code needs a function for a given type.
- Rust generates distinct copies of functions for each type, which makes it hard to ship people a binary that they can use as a library.
Benefits of Monomorphization
- Monomorphization produces potentially much more efficient code because the compiler gets to see the concrete written-out code for particular types that are used, which lets it optimize better.
- For hashmap, it only generates methods you actually end up calling, so it amortizes the cost.
Downsides of Monomorphization
- One downside is that your binary ends up being larger because you need to generate a copy of the type or function for every type that it’s used with.
- Another downside is that rather than having one function called sterling, you end up with more code in the final binary.
# Rust Binary Size and Monomorphization
Section Overview: This section discusses the reasons why Rust binaries are larger than C ones, and how monomorphization works.
Monomorphization and Binary Size
- The compiler generates copies of functions during monomorphization, but this is usually not too costly unless instantiated with a large number of types.
- Monomorphization allows for inlining and optimizing based on the specific type used, which can result in larger binary sizes due to more static compilation.
- The size of the standard library used also affects binary size, especially if using many generics from it.
Debug Symbols and Stripping Binaries
- Rust binaries statically compile more stuff, including debug symbols that can make the binary larger. Stripping the binary can help reduce its size.
# Generics in Dynamic Libraries
Section Overview: This section discusses how dynamic libraries handle generics in Rust.
Dynamic Libraries and Generics
- Dynamic libraries do not handle generics in Rust. This makes it challenging to distribute Rust libraries in binary form or use them for dynamically linked libraries.
- Swift has been trying to stabilize something similar to dynamic linking for Rust, but it is still unclear how it will work.
# Dispatching Methods with Traits
Section Overview: This section explains how dispatching methods with traits works in Rust.
Implementing a Trait
- Defining a trait involves creating a method that can be implemented for different types.
- Implementing the trait for a specific type involves defining the method for that type.
Dispatching Methods
- When generating code for a trait, the compiler determines the type and looks up which methods are available.
- The dispatch process involves selecting the appropriate method based on the type used.
Static Dispatch vs Dynamic Dispatch
Section Overview: This section discusses the difference between static dispatch and dynamic dispatch.
Static Dispatch
- When the compiler generates machine code, it knows the type of h and can call the method directly. This is known as static dispatch.
- The method is trivial to figure out where it lives because the compiler knows what the actual type is.
Dynamic Dispatch
- If we don’t want to generate multiple copies, we use dynamically sized types or generics.
- We can treat things that are different concrete types as the same type using trait objects.
- Dynamic dispatch allows us to treat different concrete types as if they were the same type.
Understanding Trait Objects and the Sized Trait
Section Overview: In this section, the speaker discusses trait objects and the sized trait. They explain how trait objects work and why we need to use them. They also discuss the sized trait and its importance in Rust.
Trait Objects
- Bar is generic over one type which has to be either a stir reference or a string.
- When taking a slice or an iterator, there is nowhere to put h2 as there is only one iterator that only has items of one type.
- Type erasure is used to take a collection of things where we only care about implementing a specific trait.
The Sized Trait
- The size trait has no methods; it’s just a marker trait that requires types with constant sizes known at compile time.
- Every trait bound requires that the type is sized implicitly.
- The compiler needs to know how large an argument is so it can allocate space on the stack for it when calling functions.
- The size of an argument can be determined by knowing its concrete implementation.
Dynamic Dispatch and Object Safety
Section Overview: In this section, the speaker discusses dynamic dispatch and object safety in Rust. They explain what dynamic dispatch means, why it’s important, and how it works in Rust. They also discuss object safety and what makes a trait object safe or unsafe.
Dynamic Dispatch
- Dynamic dispatch allows us to call methods on objects whose concrete types are unknown at compile time.
- Virtual method tables (VMTs), also known as vtables, are used to implement dynamic dispatch in Rust.
- VMTs contain pointers to the actual functions that will be called at runtime.
Object Safety
- A trait is object-safe if it can be safely used as a trait object.
- A trait is not object-safe if it has associated types or self-referential methods.
- The compiler will generate an error if we try to use a non-object-safe trait as a trait object.
Implementing Traits for Trait Objects
Section Overview: In this section, the speaker discusses how to implement traits for trait objects. They explain what it
means to implement a trait for a type and how this differs from implementing a trait for a trait object. They also
discuss how to use the dyn keyword when working with trait objects.
Implementing Traits
- To implement a trait for a type, we simply define the methods of the trait on that type.
- To implement a trait for a trait object, we need to use dynamic dispatch and vtables.
- We can use the
dynkeyword when working with trait objects to indicate that we want dynamic dispatch.
Downcasting Trait Objects
Section Overview: In this section, the speaker discusses downcasting and how it works with Rust’s type system. They
explain what downcasting means and why it’s useful. They also discuss how to downcast using Rust’s built-in as
operator.
Downcasting
- Downcasting allows us to convert from one type of pointer (e.g.,
&T) to another (e.g.,&U) whenTis a supertype ofU. - Downcasting can be useful when working with trait objects, as it allows us to access methods that are specific to the concrete type of the object.
- We can use Rust’s built-in
asoperator to downcast trait objects.
Conclusion
Section Overview: In this section, the speaker concludes their discussion on trait objects in Rust. They summarize the key points covered in the video and provide some final thoughts.
- Trait objects allow us to work with collections of objects that implement a specific trait without knowing their concrete types at compile time.
- The sized trait is important because it allows the compiler to determine how much space an argument takes up on the stack.
- Dynamic dispatch and vtables are used to implement trait objects and allow us to call methods on unknown types at runtime.
- Object safety is
Introduction to the Problem
Section Overview: In this section, the speaker introduces a problem with Rust’s type system and explains why it is important to understand.
The Problem with Din High
- Rust allows for traits to be used as types.
- However, when using a trait as a type, there can be issues with size.
- This is because different types that implement the same trait may have different sizes.
- This can cause problems when trying to use these types in arrays or slices.
Understanding the Issue
Section Overview: In this section, the speaker goes into more detail about why the issue occurs and how it affects code.
Types of Different Sizes
- Strings and stirs are examples of types that have different sizes but implement the same trait.
- A slice is just a contiguous piece of memory where each chunk is the same size.
- If we don’t know the size of each element in a slice, we can’t guarantee that they are all the same size.
- This makes it impossible to generate code for functions that require knowing how much space to allocate for variables.
Implementing Sized Trait
Section Overview: In this section, the speaker discusses how Rust implements sizing for types and what exceptions there may be.
Auto Implementation of Sized Trait
- The
Sizedtrait is auto-implemented for any type that can implement it. - For example, if you create a struct with no fields or add a string field to it, then that struct will be sized automatically.
- You never need to implement
Sizedyourself; it is only ever used as an auto-trait.
Types That Are Not Sized
Section Overview: In this section, the speaker discusses some examples of traits that are not sized and what issues they can cause.
Traits That Are Not Sized
- Traits like
Highare not sized because different types that implement the trait may have different sizes. - This makes it impossible to generate code for functions that require knowing how much space to allocate for variables.
- The compiler needs to know the size of a type in order to generate efficient code.
Indirection through Sized Types
Section Overview: In this section, the speaker explains how to make a type that is not sized into a type that is always sized by indirecting it through some type that is itself sized.
Making an Unsized Type Sized
- An example of an unsized type is
dyn Traitorstr. - To make an unsized type like
dyn Traitorstrinto a sized type, we need to indirect it through some other type that is itself sized. - Examples of such types include references (
&T) and boxes (Box<T>). - By indirection through these types, the size of the argument becomes known and relevant code can be generated.
Using Box to Make an Unsized Type Sized
Section Overview: In this section, the speaker explains how to use Box<T> to make an unsized type like str into a
sized type.
Using Box
- A box has a known size because it’s just a pointer.
- When you create a box initially, you allocate space for whatever you’re going to put inside of it.
- The box is still of a known size even if what it points to might have an arbitrary size.
- You can create a box of something that itself is not sized by opting out of the auto-bound that gets added saying for box the T does not have to be sized.
- Once you do this, you can pass the boxed value as an argument without getting monomorphization errors.
# Passing References to Functions
Section Overview: In this section, the speaker discusses how to pass a reference to the stack and create a trait object.
Creating a Trait Object
- A trait object is an object that only has the property of representing a trait.
- When you turn an object into a trait object, you erase all knowledge about what type it used to be.
- You can technically go back through unsafe transmutes and any traits, but in general, you should ignore that.
- When you create a boxed in astrif stir or any other trait object, you only retain the ability to use this trait.
Passing References
- You can give the function a reference to the stack by using
&. - You can pass something that’s on the stack by creating a pointer in direction here and then passing it to something that takes a reference din.
Boxed Pointer Type
- Box is kind of a pointer type.
- The trick to constructing a trait object is that it carries extra information about the type pointed to.
# Generating Machine Code for Dynamic Dispatch
Section Overview: In this section, the speaker explains how dynamic dispatch works when generating machine code.
Static vs Dynamic Dispatch
- In the generic case, generating machine code is trivial because it’s just like an assembly call.
- In the dynamic case, we don’t know what type it is, so we don’t know whether to generate the address of this or something else entirely.
Virtual Dispatch Tables
- The trick to constructing a trait object is that it carries extra information about the type pointed to.
- The reference of the box is not just one pointer wide; it carries a little bit of extra information about the type pointed to.
- A virtual dispatch table (vtable) is an array of function pointers used in implementing polymorphism in object-oriented programming languages.
Conclusion
- Dynamic dispatch and vtables are used when generating machine code for trait objects.
- Trait objects only retain the ability to use their underlying trait, erasing all other knowledge about their concrete types.
Dynamically Sized Types and V-Tables
Section Overview: This section discusses dynamically sized types, which are only known at runtime, and v-tables, which are little data structures that have pointers to each of the methods for a trait for a type.
Dynamically Sized Types
- Slices and trait objects are two examples of dynamically sized types.
- At compile time, we don’t know what type this is going to be. It’s only at runtime that we’ll know.
- The reason why this is determined at runtime is because some input can’t be predicted at compile time.
V-Tables
- A v-table or virtual dispatch table is a little data structure that has pointers to each of the methods for the trait for the type.
- When you have a trait object like
dyn Hi, what actually gets stored in the reference is one pointer to the actual concrete implementing type and two a pointer to a v-table for the referenced trait. - A different v-table ends up being constructed for each concrete type turned into a trait object.
- The second pointer in there will always be known statically because it’s determined by the original construction of the trait object.
# Trait Objects
Section Overview: This section covers the basics of trait objects, including how they work and their limitations.
Pointers to String References
- Trait objects are pointers to string references, not pointers to actual strings.
- The vtable struct for a trait object contains a member for each method of the corresponding trait that this is a trait object for.
- The value in the vtable struct is the pointer to the implementation of that method for the concrete type.
Vtables and Duplication
- The vtable is generally statically constructed for the type and does not get constructed dynamically.
- Identical vtables are not detected, and they are guaranteed to not be duplicates even if they contain the same code.
- If you implement a trait for two different types, then the implementations are still distinct locations in the source code and resulting binary.
Box Din
- Box din is a thin pointer that points to a wide pointer that points to an object.
- Pointer types are special because if they are trait objects, they have two pointers instead of one.
- Nightly APIs exist for trade objects too.
# Limitations of Trait Objects
Section Overview: This section discusses some limitations of trait objects compared to fully generic types.
Two Different Traits
- A trade object cannot be created for two different traits because the vtables for each trait are contained in two different locations.
- To create a trade object for two different traits, you would need a three-wide pointer: one to the data, one to the vtable for high, and one to the vtable for asref.
Workaround
- A workaround is to create a new trait that requires both traits with no methods of its own.
- The rust compiler does not currently generate a vtable for the combination of multiple traits, but it is possible in theory.
Trait Objects and Associated Types
Section Overview: In this section, the speaker discusses trait objects and associated types in Rust.
Combining Traits
- When combining traits, adding a trait to a larger v table tells the developer that they can do something else instead.
- Developers can generate their own trait here.
- Only auto traits like Send and Sync are fine for marker traits because they don’t have any methods.
Object Safety
- If an associated type is added to a trait, it cannot be turned into a trait object directly. Instead, developers must specify the associated type when taking in the trait.
- For a trait to be object safe, it needs to allow building a v table to allow the call to be resolvable dynamically.
Associated Functions
- The high trait cannot be made into an object because its associated function weird has no self parameter.
- A self parameter is necessary for dynamic dispatching of functions in Rust.
Opting Out of Trait Object Safety
Section Overview: In this section, the speaker discusses how to opt out of trait object safety in Rust.
Weird Function and Trait Objects
- The
weirdfunction cannot be called through a trait object because it requires a valid instance of the type that implements the trait. - If there were multiple implementations of
weird, it would not be clear which one to call through a trait object. - To make sure that the trait remains object safe, you can opt out of including certain functions in the vtable by
requiring that
selfis sized. This means that these functions cannot be called through a trait object.
Disallowing Trait Objects
- You can also disallow using an entire trait as a trait object by specifying
where self is sized. - This is rare and usually only done for backwards compatibility reasons or if non-object safe methods may be added later.
Associated Type Problem with Static Dispatch
- The associated type problem does not occur with static dispatch because concrete types are known at compile time.
- It would be possible to include the
weirdmethod in the vtable for a specific type if special syntax was added to specify which implementation to use.
Opting Out of Trait Object Safety with Static Dispatch
Section Overview: In this section, the speaker discusses how opting out of trait object safety works with static dispatch in Rust.
Opting Out with Sized Requirements
- Requiring that
selfis sized allows you to opt out of including certain functions in the vtable and ensures that they cannot be called through a trait object. - With static dispatch, it is possible to include specific implementations of functions like
weirdin the vtable for a given type.
Implementing Traits for Concrete DSTs
Section Overview: In this section, the speaker discusses whether it is possible to implement a trait for concrete
dynamically sized types (DSTs), such as Box<dyn AsRef<str>>. They also explain why there are restrictions on
implementing traits for DSTs.
Implementing Traits for Concrete DSTs
- It is possible to implement a trait for concrete DSTs if the
where Self: Sizedconstraint is not present. - The reason this should be possible is because when you wrap a type behind a pointer, it now has a size and is no longer dynamically sized.
- However, there are some restrictions on implementing traits for DSTs. For example, methods cannot be generic.
- If
Self: Sizedconstraint is present, then it disallows implementing the trait for concrete DSTs.
Type Erasure in Trait Objects
Section Overview: In this section, the speaker explains how type erasure works in trait objects and why associated types pose a problem.
Associated Types and Vtables
- The point of associated types is that only one exists for any given concrete type. However, the vtable does not know what the associated type should be because the type is erased.
- Trade objects are type erased. You don’t get to keep information about the type it used to be.
Finagling Around Associated Types
- There are some ways to finagle around this limitation. For example, the
Anytrait has a method that returns a descriptor of the type of the concrete type that it used to be.
The FromIterator Trait and Trait Objects
Section Overview: In this section, the speaker discusses the FromIterator trait and how it poses a problem for trait
objects.
The FromIterator Trait
- The
FromIteratortrait is implemented by types likeVec. It allows you to collect items from an iterator into a collection. - The type of the trait is the type of the items of the iterator. However, the
FromIteratortype itself takes a generic parameter that represents the type of the iterator. - This poses a problem for trait objects because they cannot have methods that are generic.
Extending with a Single Bool Add True
Section Overview: In this section, the speaker explains how to extend an iterator of bools and why the trait extend cannot be made into an object.
Extending with a Single Bool Add True
- The function extends anything that can be extended with an iterator of bools and then tries to extend it with an iterator that yields a single bool by adding true.
- The implementation of extend is generic over the type of items in the iterator.
- The implementation of extend is generic over the type of the iterator, which leads to multiple copies of this method at compile time.
- There is no pointer to the appropriate implementation of extend, so there cannot be a v table for din extend. Therefore, din extend cannot exist.
Could Rusty Add a Monomorphized Version of Extend?
Section Overview: In this section, the speaker discusses whether Rusty could add a monomorphized version of extend for each t it’s called with to each type that implements extend.
Possibility and Problems
- It is tempting to add a monomorphized version of extend for each t it’s called with to each type that implements extend.
- However, it is not always possible because crates that depend on another crate might call extend with even more types, leading to different v tables for din extends in different crates.
- This would result in lots of different v table implementations or lots of different v tables for din extends and make passing din extends from one crate to another impossible.
Object Safety in Rust
Section Overview: This section discusses the requirements for a trait to be object safe and why some traits cannot be made into objects.
Traits and Object Safety
- A trait needs to have all of its methods include a receiver that includes self to be object safe.
- The trait cannot have a type that returns self, as this would make the return value not sized, which is required for generating code.
- Some traits have methods that are object safe but also have other methods that aren’t. These traits can still be useful on their own without being made into objects.
Iterator Trait Example
- The iterator trait has some methods that are object safe, such as next, but also has other methods like chain and enumerate that return self or are generic, making them non-object safe.
- To make the iterator trait object safe, certain methods like chain have where clauses specifying that self is sized, allowing them to be ignored when using the trait as an object. This allows for a mix of object-safe and non-object-safe methods in the same trait.
Receiver Requirements
- The receiver for an object-safe method can include anything that includes self or &self/mut self. There are no additional restrictions beyond this requirement.
Object Safe Traits
Section Overview: This section discusses object safe traits and their requirements.
Dispatchable Functions
- All associative functions must either be dispatchable from a trait object or be explicitly non-dispatchable.
- Dispatchable functions require that they don’t have type parameters so they’re not generic.
- They have to be a method that does not use the self type right the concrete type except in the type of receiver.
Non-Dispatchable Functions
- Non-dispatchable functions should library writers always consider adding where self is size to non-object safe methods just in case someone downstream wants to use it as a trait object.
- If you have a trait where it is useful even if you could only call the objective methods then it might make sense to opt-out for the other one so that the trait overall is objective.
Iterator Last
- Iterator last has the size restriction because its receiver doesn’t go behind a reference, it consumes self which means that it takes self and self is a din iterator which is not sized.
- Function arguments must be sized therefore last can’t be called through a trade object.
Trait Objects and Drop Function
Section Overview: This section discusses how drop function works with trait objects.
Drop Function
- The v table for any trait object includes a pointer to the drop function for the concrete type because it’s necessary.
- Every v table includes drop, which technically includes extra information such as size and alignment of the concrete type.
- For something like a box where you have to deallocate memory, that information is necessary to pass to the allocator.
Unsized Types and Fat Pointers
Section Overview: In this section, the speaker discusses unsized types such as din trait, u8, and stir. They explain that these types are not sized and cannot be used as function arguments or return types. The speaker also explains how to make these types sized by placing them behind a reference or a pointer.
Unsized Types
- Din trait, u8, and stir are examples of unsized types.
- When placed behind a reference or a pointer, unsized types become a tuple of a pointer to the data and a pointer to the v table.
- U8 becomes sized when placed behind a type that can mask its unsizedness such as box or raw pointers.
Making Unsized Types Sized
- To make an unsized type sized, place it behind a type that can mask its unsizedness such as references or boxes.
- Box can be used to make an unsized type sized by turning it into a wide pointer where one part is the data and the other part is the length of the slice.
- Dynamically-sized types are special in Rust because they require knowledge about whether their pointers are wide or not.
Manipulating Fat Pointers
- RFC 2580 adds generic APIs for manipulating metadata of fat pointers.
- A din trait becomes pointy where metadata is din metadata which contains information such as type size, alignment, drop-in-place pointer, and methods for implementing traits.
- Trait alias thin refers to any type that implements pointy where metadata is empty. It has methods for introspecting the metadata of a pointer.
- Waker trait in Rust’s standard library is an example of dynamically constructing v tables at runtime.
Understanding Waker and Raw Waker
Section Overview: This section explains the structure of a waker and raw waker, which is a manually constructed v table in the standard library.
Structure of Waker and Raw Waker
- A waker is a struct that has the methods wake, wake by ref will awaken from raw, and you can drop it and clone it.
- Inside of a waker is a raw waker. A raw waker if you look inside of it is a data pointer and a v table pointer so it really is dynamic dispatch but in sort of a hidden way.
- The v table is a raw waker v table and you construct by giving the function pointers for the clone method for the wake method for the wake by ref and for drop.
Manually Constructed V Table
- It’s basically a manually constructed v table that gives you dynamic dispatch through a type rather than a trait.
- This section concludes with no further information provided.
Questions on References, Metadata Types, Dynamically Sized Types, Box U8 vs Vec U8, Din Fn vs Fn
Section Overview: This section answers various questions related to Rust programming language.
Reference to U8
- A reference to u8 had length not start pointer or endpoint.
Metadata Types
- RFC deprecates trait object stuff that existed nightly because this is replacement pointy trade thin metadata from raw parts where is the definition of oh it doesn’t actually give.
Dynamically Sized Types
- You can create your own dynamically sized types by adding fields to a struct. If it’s the last field, then it’s fine you can statically know the offset of f the offset of x and the offset of t.
Box U8 vs Vec U8
- Box u8 is not the same thing as a vec u8. Evacuate can grow so evacuate first of all has um it’s three three words it’ s the pointer to the vector on the heap uh it’s the length of the vector and it’s the capacity of the vector.
- With a box u8, you can’t do that this will never grow or shrink you can’t push to it.
Din Fn vs Fn
- A din fn is different from an fn because din fn is really a v table which means that it both has a sort of v table. This has to be a function; it can’t be a closure.
Static Dispatch vs Dynamic Dispatch
Section Overview: This section discusses the difference between static dispatch and dynamic dispatch.
Calling Functions with Closures
fn maincan callfoowith a closure, but notbar.- The reason is that closures capture data from their environment, so when calling the closure, the address of the captured data needs to be passed in as well.
- For
bar, only a function pointer is required, which means there’s nowhere to pass in the captured data.
Using dyn Fn over impl Fn
- When using
dyn Fnoverimpl Fn, we can use closures with functions likebaz. - However, using
impl Fngenerates a copy of the function for each closure type passed in. - Sometimes it’s better to use
dyn Fnto clean up your interface or make traits object-safe.
Object Safety
- Making a trait take an
impl Fnmakes it not object-safe because there could be multiple implementations of that function. - Using a boxed trait object (
Box<dyn Trait>) instead of making it generic cleans up your interface and makes it easier to use.
Coherence
Section Overview: This section briefly mentions coherence but will not go into detail about it.
Coherence is different enough from previous topics that it will require its own separate stream.
Understanding V-Tables and Dynamic Dispatch
Section Overview: This section discusses how Rust generates a V-table for each trait object, and how there are many V-tables for each din trait. It also explains that dynamic detection of which traits something implements is not possible.
V-Tables and Trait Objects
- Rust generates a V-table for each trait object.
- There are many V-tables for each din trait.
- Dynamic detection of which traits something implements is not possible.
Double D Reference
- Calling a din function involves a double d reference.
- The first reference is for the V-table pointer, while the second one is for the actual function pointer within.
Comparing V-Tables
- With the new pointer v table dynamic metadata RFC, it’s possible to compare v tables by checking if s.v_table equals string as din asref stir dot v table.
- However, this approach may not be guaranteed since there could be different v tables in different compilation units.
Working with Slices and Vec of Dins
Section Overview: This section covers working with slices and vec of dins in Rust.
Example Code
- An example code was provided to demonstrate working with slices and vec of dins in Rust.
- To make the code sized correctly, you have to use Box or Arc for the inner type.
Rust Traits and the Any Trait
Section Overview: In this section, the speaker talks about Rust traits and how they work. They also introduce the any trait and explain its purpose.
Rust Traits
- The speaker explains that Rust traits are similar to interfaces in other programming languages.
- They mention that there is an invariant in Rust that states that if two types implement the same trait, then they should have the same behavior for that trait. However, this invariant may not hold true in some cases.
The Any Trait
- The speaker introduces the any trait, which is a super magical trait in Rust.
- They explain that any is just a trait with a function that returns a unique identifier for a type guaranteed by the compiler.
- Using type id on a trait object over any can give you a unique type identifier for that value, which can be used to downcast from din any to the concrete type.
- The speaker recommends reading the standard any module documentation to learn more about why this is safe.
Conclusion
Section Overview: In this section, the speaker concludes their talk and thanks their audience.
- The speaker ends their talk after covering many topics related to Rust traits and introducing the any trait.
Generated by Video Highlight
https://videohighlight.com/video/summary/xcygqF5LVmM
Functions, Closures, and Their Traits
- Functions, Closures, and Their Traits
- Introduction to Functions and Closures
- Function Items, Function Pointers, and Closures
- Understanding the fn Traits
- Function Pointers and Closures
- Rust Closures and Trait Bounds
- Closure Capturing
- Moving and Borrowing in Closures
- Using Dynamic Dispatch with Function Traits
- Dynamically Dispatched Function Traits
- Const Generics
- Const Functions and Closures
- Passing a Closure to an Async Function
- Spawning Futures
- Conclusion
- Generated by Video Highlight
Introduction to Functions and Closures
Section Overview: In this section, the speaker introduces the topic of functions and closures in Rust. They explain that there are many different types of function-like things in Rust, and it can be challenging to distinguish between them. The speaker also mentions their book “Rust for Rustaceans,” which covers intermediate-level topics related to Rust.
Types of Functions in Rust
- The speaker explains that being generic over functions is common in Rust, especially when working with callback functions or writing code in a functional style.
- Function pointers are a versatile primitive in Rust that come up frequently.
- The type of
fn mainis a function item, which is subtly different from a function pointer. A function item is a zero-sized value that references the unique function at compile time.
Understanding Function Items
- When declaring a variable like
x = bar, wherebaris a function, the resulting type ofxis not actually a function pointer but rather a function item. - A function item is carried around at compile time and references the unique function it represents. If the referenced function was generic, then using its identifier alone would not uniquely identify it.
- While two different instantiations of the same generic function may have identical signatures if thought of as a function pointer, they are not interchangeable when used as arguments because they reference different unique functions.
Function Items, Function Pointers, and Closures
Section Overview: This section covers the differences between function items and function pointers, how they can be coerced into each other, and introduces closures.
Function Items vs. Function Pointers
- A function item uniquely identifies a particular instance of a function.
- A function pointer is a pointer to a function with a given signature.
- Function items are coercible into a function pointer.
- Passing in different types to the same named function generates different chunks of code that share the same name but have distinct bodies.
Coercion of Function Items into Function Pointers
- The compiler coerces the function item type into a function pointer type so that this function can be called.
- When calling
bazwithbar, the compiler coerces thebarfunction item type into au32input and output signature for use as a parameter inbaz. - If you never call an instantiated named function like
bar, then it’s possible that its code will not be generated by the compiler.
Closures
- Closures are functions that capture their environment.
Understanding the fn Traits
Section Overview: This section explains the three different traits in Rust that are used to define
functions: fn, fn mut, and fn once.
The Three Different Traits
fntakes a shared reference to self.fn muttakes an exclusive reference to self. You can only call it once at a time, and you need a mutable reference to it in the first place.fn oncetakes an owned reference to self. You can only call it once, and at that point, you’ve moved the value of the function that you wanted to call.
Implications of Each Trait
- If you stick an
fn mutin an RC, you wouldn’t be able to call it. Similarly, if you’re given a shared reference to something that’sfn mut, you also cannot call it. - On the other hand, with
fn, you can call it multiple times through a shared reference. - Anything that implements
fnalso implements bothf and muteandfn once. However, anything that implements only one of these two does not implement all three.
Function Pointers
- Function pointers have no state or lifetime associated with them. They don’t care about “self” because they don’t really contain anything related to “self”.
- Function pointers implement all three traits:
fn,f and mute, andfn once.
Function Pointers and Closures
Section Overview: This section discusses the hierarchy of function pointers and closures in Rust.
Hierarchy of Function Pointers
- A function pointer implements
fnand therefore also implementsf,&fn,&mut fn, and*const fn. - If a function requires an
fthat implementsfn, a bar u32 can be passed in because it coerces to a function pointer which implementsfn. - If the required function is an
fand mute, this would still work. Similarly, if it was anfand once, this would still work. - If the given function is an
fn once, it needs to be taken by ownership to call it.
Closures
- A closure takes arguments passed between these brackets
{}and has some body that returns the contents of those arguments. - Non-capturing closures are coercible to function pointers.
- Closures that capture from the environment cannot be passed as a parameter to functions that require only a function pointer.
- The compiler generates an anonymous struct for closures that capture over their environment.
Rust Closures and Trait Bounds
Section Overview: In this section, the speaker discusses how Rust closures work and their trait bounds.
Implementing fn for f closure
- A closure can implement
fnif it is given a shared reference toself. - The implementation will be a copy-paste from the closure definition.
- The function pointer alone would not be sufficient; it needs access to the additional state of
z.
Implementing fn mute for f closure
- If the closure is mutable, then it cannot implement
fn. - This is because the exclusive reference required by
clear()method cannot be captured as a shared reference. - Instead, it can implement
fn mute, which requires an exclusive reference to the closure state.
Implementing fn once for f closure
- A mutable closure that takes ownership of its environment can implement
fn once. - However, calling the closure more than once is not possible since you cannot move z again after moving it into the closure.
Closure Capturing
Section Overview: In this section, the speaker discusses closure capturing and how it works in Rust.
Move Keyword
- The move keyword can be used before the definition of a closure to tell the compiler to move a value into the closure.
- The compiler determines whether to move an owned or shared reference based on what is needed by the closure.
- There are cases where you want to move a value into the closure even though you don’t technically need it. For example, if you want the closure to drop a value when it exits.
- Using move tells the compiler to move a value into the closure, which means that we actually need to own that value.
Lifetime of Closures
- If we specify move for a variable inside a function, its lifetime will be tied to that function’s stack frame.
- If we return a closure from a function without specifying its lifetime, Rust assumes that it has static lifetime. However, this may not always be true since closures can reference variables with non-static lifetimes.
- Using move allows us to specify that we want to move a variable into the returned closure.
Downsides of Move
- Using move moves everything specified after it into the closure.
Moving and Borrowing in Closures
Section Overview: This section covers how to move some things but borrow other things into closures.
Moving and Borrowing
- There are many ways to express moving and borrowing, such as shadowing or introducing a new scope.
- When using closures, you can only choose to move all or nothing.
- To specifically move a reference, use a pattern like
xwhich is actually a reference to the realx. - When something is moved into a closure, the closure owns it collectively. The string will be dropped when the closure is eventually dropped.
Using Dynamic Dispatch with Function Traits
Section Overview: This section covers how to use dynamic dispatch with function traits.
Dynamic Dispatch
- You can use function traits through din for dynamic dispatch by specifying the full function signature and
putting
inin front of it. - If it’s an f and once, you can still call it as long as you take this as mute.
- Box didn’t fn anything did not implement fn because din in general is unsized.
Implementing Call for Box Din Fn
- Previously, box din fn did not implement fn due to limitations on the compiler’s ability to reason about such implementations.
- The type of x here is din fn once but this type is not sized so how much space does x take up on the stack here remember din in general is unsized right it’s not sized um.
Dynamically Dispatched Function Traits
Section Overview: This section discusses dynamically dispatched function traits and the challenges that arise when
trying to call an fn mute using a shared reference.
Unsized R Values
- An RFC exists for unsized r values, which is required for this implementation to exist.
- The RFC has landed, but there are still many implementation questions.
- The feature is unstable and can only be used on nightly.
Dynamically Dispatched Function Traits
- When you have
Box<dyn F>and someFtrait, it just works without needing special treatment. - However, if you get something like a
dyn F + Mute, all you have is a shared reference to it and therefore cannot call it because it does not implementF + Mute. - In order to call an
fn mute, you need to stick it behind a shared reference. In order to call anfn, all you need is a shared reference. In order to call anfn once, you actually need a wide pointer type that allows you to take ownership.
Arc Din Fn Implementation
- There is no implementation of arc din fn yet, even though the intuition built up so far suggests that it should exist.
- An arc supports unsized values and can hold the din fn. If it’s able to give you a shared reference to the closure state, then it should be implemented as fn because all that requires is being able to get a shared reference to the closure state.
- There might be an implementation missing due to issues with unsized r values or maybe specialized for box.
Const Generics
Section Overview: In this section, the speaker discusses const generics and how they can be used to make generic types that are only usable with const evaluatable functions.
Defining a Closure that Returns Zero
- The speaker defines a closure that returns zero.
- This closure is a constant closure that can be evaluated at compile time.
- The speaker explains that this closure is equivalent to
make_zerowhich returns au32.
Using Const Evaluatable Functions in Generic Types
- The speaker wants to define a generic type
foothat takes anfn once. - However, the compiler does not know if the function is callable as a const.
- There is currently no way to take any type that implements a trait but only using things that are const evaluatable.
- There is an interesting pre-RFC discussion about whether there is a way to do this.
- The speaker proposes syntax for opting into this feature.
Opting into Experimental Features
- The speaker adds experimental features and runs cargo r to see what happens.
- Rust analyzer gets confused because it doesn’t know about these features.
Making Foo Callable with X
- If foo calls x, rust analyzer throws an error because main isn’t const.
Const Functions and Closures
Section Overview: In this section, the speaker discusses const functions and closures in Rust. They explain how const functions work, what can be called within them, and how closures can be used with const functions.
Const Functions
- In a
const fnofn, only things that are themselves constant can be called. - Const functions require that everything they call is also const.
- If the closure is itself constant or constant evaluatable, then it should also be callable from cons context.
Error Reporting
- The error reporting doesn’t know about the const flag yet.
- This kind of bound is not stabilized, so error reporting doesn’t know about it.
Complicated Lifetime Bounds
- Sometimes you end up with complicated lifetime bounds with 4r.
- You usually have to specify lifetimes when something returns. If we were to try to specify what the lifetimes are here, what actually is it? This is where you get this special for syntax.
Rare Use of For Bound
forbound should hold for any lifetime. It’s very rare that you actually need to give aforbound like this.
Passing a Closure to an Async Function
Section Overview: In this section, the speaker discusses passing closures to async functions and how it relates to static closures.
Closure Capture and Environment
- When passing a closure to an async function, the closure does not need to be static.
- Usually with futures, especially if you want to do something like Tokio spawn of the future you get back then Tokio spawn just like thread spawn requires that the argument is like static.
- If f here is not static then the return future will also not be static right if we sort of think of the de-sugaring of this right it’s fn this.
Input Lifetime and Output Type
- The desugaring of impul future captures lifetime inputs automatically.
- Impul trait just like async fn automatically captures the lifetime of its inputs so if this input is tied to some lifetime then the output type will also be tied to that same lifetime which means it will not be static unless the input is static.
- You often need to pin things manually in general a weight syntax should take care of you.
Spawning Futures
Section Overview: In this section, the speaker discusses spawning futures and when it’s necessary for them to live longer than their current stack frame.
Pinning Futures
- If you try to do something like spawning where the future needs to live longer than the current stack frame um you often need to pin it i mean you should very rarely need to pin things manually in general a weight syntax should take care of you.
Conclusion
Section Overview: In this section, the speaker concludes the video and thanks the audience for watching.
Final Remarks
- The speaker thanks everyone for watching and encourages them to teach someone else what they learned.
- The speaker expresses interest in doing more hazard pointers but needs to find time to do six hours of coding.
Generated by Video Highlight
https://videohighlight.com/video/summary/dHkzSZnYXmk
Lifetime Annotations
- Lifetime Annotations
- Introduction
- Getting Started with Cargo
- Introduction to String Split
- Lifetimes
- Writing Code for String Split
- Implementation of Split Function
- Compiling Errors and Lifetime Specifiers
- Conclusion and Bug Fixing
- Understanding Lifetimes in Rust
- Introduction to Lifetimes
- Understanding Lifetimes in Rust
- Fixing a Bug
- Understanding References
- Rust Option and Mutable References
- Multiple Lifetimes in Rust
- Rust Ownership and Borrowing
- Rust Smart Pointers
- Understanding Rust’s Lifetime System
- String Manipulation
- Introduction to Lifetimes and Delimiters
- Generic Delimiter Implementation
- Q&A
- Conclusion
- Rust Standard Library Exercise
- Questions and Answers
- Future Plans for Videos on Rust Programming Language
- Conclusion and Farewell
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces the topic of the video and explains how they came up with the idea for it. They also provide some background information about their YouTube channel and what viewers can expect from the video.
Background Information
- The RUS survey 2019 results showed that people are asking for more learning material about Rust, specifically intermediate level material.
- Viewers have requested more video content on Rust.
- The speaker has a YouTube channel where they do live intermediate and uploaded intermediate Rust content.
Purpose of Video
- The speaker tweeted out to ask what viewers would like to see in a Rust video that is less advanced than their usual ones.
- Viewers expressed confusion about lifetimes and wanted to see code that uses them in order to understand better.
- The goal of this stream is to write a bunch of code in Rust covering multiple lifetimes, strings, and generics.
Logistics
- This stream will be shorter than usual at around 90 minutes.
- The speaker will take questions from chat throughout the stream.
Getting Started with Cargo
Section Overview: In this section, the speaker explains how to start a new Rust project using Cargo. They also introduce the library they will be building in this video.
Starting a New Project with Cargo
- To start a new project with Cargo, create a new directory and run
cargo init. - Inside
Cargo.toml, define metadata about your crate and source lib. - Add warnings for missing debug implementations, Russ 2018 idioms, and missing docs.
Introducing stir_split Library
- The library being built in this video is called
stir_split. - It allows you to take a string and split it by another string.
- Throughout the rest of the video, we will focus on building out this library.
Introduction to String Split
Section Overview: In this section, the speaker introduces a new type called “String Split” and explains its purpose. They also discuss how to implement the iterator trait for this type.
Building String Split
- The goal is to create a new type called “String Split” that will have a method called “string split”.
- The method will take in two parameters: haystack (the string being searched) and delimiter (the string used to split haystack).
- The method will return an object of a special type that refers to the name of the input lock.
- Using “self” instead of “that” is useful because it means that if we rename the type later, we don’t have to change all the return types of the methods.
- The iterator trait allows you to use for loops with your custom types.
- To implement iterator for String Split, you need to define a next function that takes a mutable reference to self and returns an optional item.
- A test can be written by creating some string like ABCDE and using stir split on it with space as delimiter.
Lifetimes
Section Overview: This section covers lifetimes in Rust.
Quality Comparison Between Iterators
- When comparing iterators, Rust checks if all elements are equal.
All Loops Desugar To Loop With A Break Condition
- While loops desugar into loops as well.
Writing Code for String Split
Section Overview: In this section, the speaker discusses how they plan on writing code for String Split.
Remaining Questions
- There are still questions about how exactly they plan on implementing certain aspects of String Split.
Implementation of Split Function
Section Overview: In this section, the speaker explains how to implement the split function in Rust.
Implementing Next
- The implementation of next is straightforward.
- Find where the next delimiter appears in the remainder and then chop that part of the string.
- Return everything until the delimiter and set the remainder to what remains after the delimiter.
- If there is no delimiter in the string, return none.
Using Self as a Preferred Way of Implementing Cascade
- The speaker prefers using self because it means that if they change the name of the type, they don’t have to change anything else.
- However, it means you can no longer do local reasoning looking at this line of code.
Associated Types vs Generics
- Use generics if multiple implementations of that trait might exist for a given type.
- Use associated types if only one implementation makes sense for any given type.
Match vs If Let’s Sum
- Use match if you care about more than one pattern.
- Use if let when you only care about one pattern.
Compiling Errors and Lifetime Specifiers
Section Overview: In this section, we learn about compiling errors and lifetime specifiers while implementing split function in Rust.
Missing Lifetime Specifier Error
- When trying to compile our code, we get an error message saying “missing lifetime specifier.”
- We need to give references a lifetime because Rust cannot figure out what that lifetime is on its own.
Adding Lifetime Specifiers
- We add a lifetime specifier by adding ’a after each reference variable.
- We use anonymous lifetimes when necessary.
Conclusion and Bug Fixing
Section Overview: In this section, we conclude our implementation of split function in Rust and fix a bug found earlier.
Bug Fixing
- There is a bug in the code that needs to be fixed.
- The bug will be addressed later.
Conclusion
- We have completed our implementation of the split function in Rust.
- We can now test our code using cargo test.
Understanding Lifetimes in Rust
Section Overview: In this section, the speaker explains how lifetimes work in Rust and why they are important.
How Pointers Work with Iterators
- Rust calls iterators’
nextmethod and gets back a pointer to a string. - Rust needs to know how long it’s okay to keep using this pointer for because it might use that pointer after the string it’s pointing to has already gone away.
- The tick a is really a lifetime. It represents how long does this reference live for.
Lifetime of References
- If you have a store split then the remainder and delimiter both live for the same lifetime.
- The thing that we return has the same lifetime as tick a.
- Even after you drop the store split, the thing that you get back from the iterator is still valid because it’s about the lifetime of the string we were originally given.
Specifying Lifetimes
- You can never be wrong by specifying lifetimes. If you specify a lifetime that the compiler thinks is wrong, it won’t let you compile your program.
- Anonymous lifetimes are places where you tell the compiler to guess what lifetime. This only works when there’s only one possible guess.
- You can order lifetimes based on how long they are. For example, take static is a ring that lives for the entire duration of the rest of the program.
Conclusion
- The name you give does not matter; it’s just like naming generics.
Introduction to Lifetimes
Section Overview: In this section, the speaker introduces lifetimes and explains how they work in Rust.
What are Lifetimes?
- Lifetimes are a way of ensuring that references in Rust are valid.
- You can use an underscore to tell the compiler not to consider a certain lifetime for guessing purposes.
- You can specify an order for lifetimes if necessary.
- The tick underscore is only used if there’s only one possible lifetime.
Anonymous Lifetimes
- Anonymous lifetimes can be used to simplify code by allowing type inference to determine the correct lifetime.
- This means that the output position will have its lifetime inferred based on the input position.
Lifetime Errors
- Lifetime errors occur when there is a mismatch between the expected and actual lifetimes of references.
- The error message will indicate which reference has an incorrect lifetime and where it was defined.
- To fix these errors, you need to ensure that all references have compatible lifetimes.
Understanding Lifetimes in Rust
Section Overview: In this section, the speaker discusses the use of generic names for lifetimes and not proper names like typical variables. They also talk about how resilient anonymous lifetimes are and whether relying too much on them can cause trouble.
Generic Names for Lifetimes
- The speaker explains that generic names are used for lifetimes instead of proper names like typical variables.
- They mention that anonymous lifetimes are resilient and can be relied upon most of the time.
- It is possible to give more than one lifetime and then give relationships between them using restrictions.
Relationship Between Lifetimes
- The speaker mentions that it is possible to give relationships between lifetimes by saying a reference must live longer than another reference.
- Lifetimes are types, and they can be thought of as subtyping.
Static Lifetime
- The static lifetime extends until the end of the program, and any value has a lifetime of however long that value is assigned to a variable or moved.
- If you have a reference or something containing any lifetime, you can assign anything of the same type but with a longer lifetime.
Conclusion
- The speaker concludes by stating that everything defaults to having a static lifetime, although it’s not entirely true. A value’s lifetime lasts until it’s moved or assigned to a variable.
# Lifetime Annotations
Section Overview: This section discusses lifetime annotations and how they are used in Rust.
Variables and Lifetimes
- Values only live for as long as they do until it’s moved or dropped.
- If a value is passed to another function and gets moved, the lifetime of that value ends.
- The compiler infers the lifetime for every value, but when writing code that is generic over lifetimes, we need to add lifetime annotations to tell it how long we need different pointers to live for.
# String Splitting
Section Overview: This section discusses string splitting in Rust.
String Splitting with Delimiters
-
split()takes a sequence of characters and splits it into multiple smaller strings separated by some delimiter. - Using
assert_eq!instead of collecting into a vector can provide nicer errors.
Handling Empty Strings
- Any string written directly in double quotes is compiled into your binary and stored in read-only memory.
- When there is an empty delimiter at the end of the string, the iterator should produce an empty element.
- To handle this case, we can use
Optionand distinguish between whether the remainder is empty or whether the remainder is an empty element we haven’t yielded yet.
# Heap Allocations
Section Overview: This section discusses heap allocations in Rust.
Heap Allocation Lifetime
- Heap allocations have a lifetime and live until they are dropped.
- If something is on the heap and never dropped, it would be static.
- The compiler cannot infer that the type of lifetime we return is tied to the lifetime of the remainder, so we need to add lifetime annotations to tell it how long we need different pointers to live for.
Spotting Allocation in Binary
Fixing a Bug
Section Overview: In this section, the speaker discusses how to fix a bug in the code.
Refactoring Code
- The speaker suggests using
self.remainder.take()instead ofreturn Some(remainder)to simplify the code. - The speaker considers using smart matching patterns but decides against it.
Searching for Delimiters
- If there is some remainder left to be searched, the program will search for the delimiter in that remainder.
- If the delimiter is found, the program extracts everything before it and sets the remainder to be everything after it. It then returns what was extracted.
Mutable References
- The speaker explains that
refmeans “make a new reference or take a reference to” andref mutemeans “get a mutable reference to.” - The speaker uses
ref mutebecause they want a mutable reference to modify an existing value rather than taking ownership of it.
Understanding References
Section Overview: In this section, the speaker explains references.
Dereferencing
- The type of remainder here is mutable, but on the right-hand side, it’s not mutable. To assign something from one type to another, we need to dereference it first by adding an asterisk before its name.
Rust Option and Mutable References
Section Overview: In this section, the speaker discusses Rust’s Option type and mutable references. They explain how to
use the take function with a mutable reference to an option, and how it can be used to return the remainder of a
string that doesn’t have a delimiter.
Using take with Mutable References
- The
takefunction is implemented onOption<T>. - It takes a mutable reference to an option and returns an
Option<T>. - If the option is None, it returns None.
- If the option is Some, it sets the option to None and returns the value that was in there.
Simplifying Code with Try Operator
- The try operator also works on options.
- We can simplify code using the question mark operator.
- A let statement is a pattern match.
- We can use pattern matching on what’s inside the sum of self remainder by taking a reference to what’s in there.
Limitations of Mutable References
- Mutable references are only one level deep.
- If you have a mutable reference to self, you’re allowed to modify any of its fields.
- You cannot change the thing that limiter is pointing to because delimiter itself would have to be a mutable reference.
Multiple Lifetimes in Rust
Section Overview: In this section, the speaker explains multiple lifetimes in Rust. They discuss how lifetime annotations work and provide examples of how they can be used.
Lifetime Annotations
- Lifetime annotations specify how long references live.
- They are written as
'a,'b, etc., where each letter represents a different lifetime. - Lifetime parameters are specified inside angle brackets before function arguments or struct definitions.
Writing a Function with Multiple Lifetimes
- We want to write a function that takes a string and returns the string until the first occurrence of a character.
- We can use lifetime annotations to specify that the returned string must live at least as long as the input string.
- We can also use lifetime elision to avoid having to explicitly specify lifetimes in simple cases.
Rust Ownership and Borrowing
Section Overview: In this section, the speaker discusses Rust’s ownership and borrowing system. They explain how it works and provide examples of how it can be used.
Ownership Rules
- Each value in Rust has an owner.
- There can only be one owner at a time.
- When the owner goes out of scope, the value is dropped.
Borrowing Rules
- You can borrow values by taking references to them.
- References are immutable by default.
- You cannot modify a borrowed value until all references to it have gone out of scope.
Mutable References
- You can also take mutable references to values using
&mut. - Only one mutable reference is allowed at a time for each value.
- You cannot have both mutable and immutable references at the same time for the same value.
Rust Smart Pointers
Section Overview: In this section, the speaker discusses smart pointers in Rust. They explain what they are, how they work, and provide examples of how they can be used.
What Are Smart Pointers?
- Smart pointers are data structures that act like pointers but have additional metadata and capabilities.
- They implement traits such as
DerefandDrop. - Examples include
Box,Rc, andArc.
Box Pointer
- A box pointer is a smart pointer that points to a value on the heap.
- It is created using the
Box::newfunction. - Box pointers are used when you need to allocate memory on the heap and return ownership of it.
Rc Pointer
- An Rc pointer is a reference-counted smart pointer.
- It allows multiple owners of the same data.
- When all owners go out of scope, the data is dropped.
Arc Pointer
- An Arc pointer is an atomic reference-counted smart pointer.
- It allows multiple threads to have shared ownership of the same data.
- When all owners go out of scope, the data is dropped.
Understanding Rust’s Lifetime System
Section Overview: In this section, the speaker discusses Rust’s lifetime system and how it affects code. They explore the issue of returning a reference to a temporary value and how it relates to lifetimes.
Temporary Value Issue
- Running
cargo checkshows an error where we’re trying to return a value referencing a temporary value. - The error is caused by returning a string reference that is tied to the lifetime of another string.
- The issue arises because Rust assumes that both strings have the same lifetime, but they don’t.
- To fix this, we need two lifetimes instead of one.
String vs. Str
- One option is to store the delimiter as a string instead of a str.
- Strings are heap-allocated and dynamically expandable while strs are not.
- A string can be converted into a str easily, but not vice versa.
Conclusion
- Rust’s lifetime system can be tricky to navigate, especially when dealing with references and temporary values.
- It’s important to understand the differences between strings and strs in order to write effective code.
String Manipulation
Section Overview: In this section, the speaker discusses string manipulation and the use of heap allocation. They also explain how to fix a problem with multiple lifetimes.
Heap Allocation and String Manipulation
- The speaker explains that heap allocation is used to copy all characters over to create a string.
- Storing the delimiter as a string requires an allocation, which is not great for performance. It also ties it to an allocator, making it incompatible with embedded devices.
- A question is asked about getting a character from
until_carand transforming it back into a string. The reference in front of the format produces a string, andreftakes a reference to that.
Multiple Lifetimes
- The speaker explains that when using references, their lifetime must be tied to the correct object’s lifetime.
- To fix this issue, multiple lifetimes are needed. Naming these lifetimes allows for generic implementation over haystack and delimiter.
- By having different lifetimes for haystack and delimiter, the compiler no longer forces them to be the same by downgrading the lifetime.
- The reference given back is now tied only to the haystack lifetime instead of being tied to both haystack and delimiter.
Conclusion
The speaker discussed heap allocation and its use in creating strings. They also explained how multiple lifetimes can be used when dealing with references.
Introduction to Lifetimes and Delimiters
Section Overview: In this section, the speaker discusses how a reference with a lifetime delimiter can be downgraded to the lifetime of another variable. They also introduce the concept of delimiters and how they can be used to split strings.
Lifetime Delimiter Downgrading
- A reference with a lifetime delimiter can be downgraded to the lifetime of another variable.
- The reverse is not true.
Introducing Delimiters
- Delimiters are introduced as a way to split strings.
- The delimiter can be any type that can find itself in a string.
Implementing Delimiter Trait
- A trait called “limiter” is introduced for delimiters.
- The limiter trait requires that the delimiter must be able to give us its length and skip past it.
- We implement iterator first or split for any D where D implements delimiter using find next method.
- We implement delimiter for a reference to a string s by finding the start and end indices of the substring within s using s.find(self).
Generic Delimiter Implementation
Section Overview: In this section, the speaker demonstrates how to implement a generic delimiter for any type D that implements the limiter trait. The implementation is done in such a way that it allows for references to be passed without requiring a lifetime.
Implementing Generic Delimiter
- Implemented generic delimiter over any type D that implements the limiter trait.
- This implementation allows for references to be passed without requiring a lifetime.
- Demonstrated how to implement delimiter for character using s.car_indices() method.
- Iterated over all characters of the string looking for one that is the character we’re searching for and then when it finds whatever results it finds if it finds one we map that sum to take the position and return that position and that position plus one right because the character is only one character long.
- Implemented this pattern for all sorts of other types so anything that can find itself in a string will now just work.
Q&A
Section Overview: In this section, the speaker answers some questions from viewers about various aspects of the implementation.
Questions and Answers
- Explained what self refers to in pattern self here in the implementation down here. It’s a reference to this type so it’s a reference to a reference to Astor.
- Discussed whether there is a simpler way than character indices. There is but this shows the concept of it like you can do way more efficient things than this.
- Clarified whether
find(self)returnsselfor its index. Find as a method on strings that you can give it a string and it will tell you the start of that string in that string that plus one is wrong and will panic your code. - Explained why
self.len()and nots.len(). Self is the thing we’re searching for, it’s the length of the delimiter. In order to find the end of the delimiter, it has to be the start of the delimiter plus the length of the delimiter not the length of the string we’re searching in. The s here is what we’re searching in.
Conclusion
Section Overview: In this section, the speaker reveals that all of the things implemented today exist in Rust’s standard library.
- All of the things implemented today exist in Rust’s standard library.
- Split on a string takes a reference to self and some pattern P and it returns to split. If we look at split split implements iterator and it gives you things split by that.
- Today’s implementation goes through where multiple lifetimes are useful and how to turn these kinds of implementations into something more generic.
Rust Standard Library Exercise
Section Overview: In this section, the speaker discusses the exercise of implementing patterns and understanding how different pieces fit together in Rust.
Implementing Patterns
- The exercise is not meant to be published as a crate because it’s already in the standard library.
- The exercise helps understand how different types of lifetimes work and when multiple lifetimes are needed.
- Lifetime errors and differences between strings and stores are also covered.
Questions and Answers
Section Overview: In this section, the speaker answers questions from viewers related to Rust programming language.
Creating Strings from Astor Fat Pointer
- You cannot create a string from Astor fat pointer because you don’t own the memory. A string assumes that it owns the underlying memory, which is not true for arbitrary pointers.
Readability of Rust Programming Language
- The speaker does not think that Rust is less readable than other languages. Additional features in Rust require additional syntax, but they add more functionality.
Pattern in Haystack
- The pattern in haystack shares the same lifetime tick a reference to the haystack. It is similar to what was done during the exercise.
Generic Associated Types (GAT)
- GAT will help with being able to clone less. It may not necessarily help with trait definitions, but it will help with existential types and other things.
Future Plans for Videos on Rust Programming Language
Section Overview: In this section, the speaker talks about future plans for videos on Rust programming language.
Beginner Streams
- The speaker is not planning to do any complete beginner streams, but might do more focused videos if there is an appetite for them.
Conclusion and Farewell
Section Overview: In this section, the speaker concludes the presentation and thanks the audience for attending.
- The speaker thanks everyone for joining and hopes that they learned something from the presentation.
- The presentation being 90 minutes instead of six hours made it more digestible.
- The speaker encourages everyone to stay safe and stay home.
- The speaker announces that there will be a video next time.
Generated by Video Highlight
https://videohighlight.com/video/summary/rAl-9HwD858
Smart Pointers and Interior Mutability
- Smart Pointers and Interior Mutability
- Introduction
- Overview of Smart Pointers
- Implementation of Smart Pointers
- Resources for Learning More About Rust
- Introduction to Cell
- Starting with Sell
- Interior Mutability and Cell
- Introduction to Unsafe Cell
- Recap of Unsafe Cell
- The Problem with Interleaving Threads
- Non-Copy Types and Trait Bounds
- Unsafe Cell and Ref Cell
- Ref Type
- RefCell and Rc
- RC and Smart Pointers
- Rust Reference Types
- Box in Rust
- Unsafe Keyword in Rust
- Smart Pointers in Rust
- Understanding Variance in Rust
- Using Unsafe Pointers in Rust
- Lifetime Guarantees in Rust
- Understanding Memory in Rust
- Inner Dog Ref Count
- Understanding Drop Check
- Understanding Phantom Data in Rust
- RefCell, Mutex and Arc
- RC vs Art
- The Cow Type
- Example: Escape Function with Cow Type
- From Utf-8 Lossy
- Cow Type and Smart Pointers
- Recap and Next Steps
Introduction
Section Overview: In this section, the speaker introduces the topic of smart pointers and interior mutability in Rust. They discuss some of the types that are commonly used in Rust, such as arc, RC, refs, l mutex L, DRF, as ref traits, Baro trait, cow and sized.
- The speaker also provides information on where to find recordings of their streams and how to get announcements for upcoming streams.
- They introduce a new sub-channel on the Rust Asian Station Discord server called Rotation Station which is intended to be a community podcast for Rust.
Overview of Smart Pointers
Section Overview: In this section, the speaker discusses some of the common smart pointer types in Rust.
Common Smart Pointer Types
- The speaker mentions several common smart pointer types in Rust: arc, RC, refs, l mutex L, DRF and as ref traits.
- They explain that these types are pervasive in Rust and it’s important to have knowledge about them.
- The speaker also mentions other types like cow and sized if they have time to cover them.
Implementation of Smart Pointers
Section Overview: In this section, the speaker talks about implementing some of the common smart pointer types themselves.
Implementing Smart Pointer Types
- The speaker explains that they will be implementing RC ref sell and sell.
- They mention that they may also discuss Arc Mutex Ref Borrow Cow Bull CFD if there is time.
- The implementation will help viewers understand intermediate concepts in Rust.
Resources for Learning More About Rust
Section Overview: In this section, the speaker provides resources for learning more about Rust.
Resources for Learning More About Rust
- The speaker mentions that all recordings are posted on YouTube after each stream.
- They encourage viewers to follow them on Twitter for announcements and input on episodes.
- The speaker also mentions that they have longer programming videos available on their YouTube channel.
Introduction to Cell
Section Overview: In this section, the speaker introduces the Rust standard library module called Cell.
Introduction to Cell
- The speaker explains that the Cell module is a shareable mutable container.
- They mention that this might sound weird in Rust because of its shared reference and exclusive reference concepts.
- However, the module allows for interior mutability in a controlled fashion under certain constraints.
Starting with Sell
Section Overview: In this section, the speaker talks about starting with Sell since it has the least amount of quirkiness among the smart pointer types.
Starting with Sell
- The speaker explains that they will start with Sell since it’s less quirky than other smart pointer types.
- They mention that there are various container types in Rust’s standard library that allow for interior mutability.
- These containers are often referred to as shareable mutable containers or interior immutability.
Interior Mutability and Cell
Section Overview: In this section, the speaker discusses interior mutability and exclusive or shared references. They then introduce the concept of a cell in Rust.
Introduction to Cell
- A cell provides interior mutability in Rust.
- You can create a new cell with a value of some type T.
- The set method allows you to change the value inside the cell using an immutable reference.
- The swap method lets you swap values between two cells.
- The replace method replaces the value inside the cell with a new one.
- The into_inner method consumes self, assuming ownership of the cell.
Restrictions of Cell Types
- Different types of cells have different restrictions on what can be stored inside them and how they can be used.
- As you move towards mutex, there is more freedom to store whatever you want but also more overhead involved in making it work.
- Box does not provide interior mutability. If you have a shared reference to a box, you cannot mutate its contents.
- There is no way to tell externally from a type whether it has interior mutability.
Safety Features of Cell
- With Cell, there is no way to get a reference to what’s inside the cell itself. This means that if no one else has a pointer to the value stored in the cell, changing it is safe.
- Cell does not implement sync. This means that if you have a reference to a cell, you cannot give away that reference to another thread.
# Why can’t we borrow Mewtwo more than once for RC?
Section Overview: In this section, the speaker explains why it is not possible to borrow Mewtwo more than once for RC.
Borrowing and Exclusive Reference
- You cannot use an exclusive reference in general with a cell.
- If you have an exclusive reference to the cell, you can get an exclusive reference to the value inside.
- At that point, you cannot get or change the value.
Benefits of Using Cell
- The benefit of using cell is that you can have multiple shared references to a thing.
- Cell is usually used with something like RC where you want the cell to be stored in multiple places or pointers to it’d be stored in multiple places like in some data structure like imagine a graph where some of the things might share a value right then you might have multiple references to a thing.
Usage of Cell
- Cell should usually just be used for small copy types.
- You can only get the value out of a cell either if you have a mutable reference to it or if the value is copy.
# Implementing Sell Ourselves
Section Overview: In this section, the speaker demonstrates how to implement sell ourselves.
Basic API
- We need a pub struct called “cell” which holds a T.
- We will implement:
- A new function which takes a value of type T and returns self. This gives us a cell that contains the given value.
- A set function which takes an immutable reference to self and a value T. It sets self.value equal to value but currently will not work because we are trying to assign to self.value which is behind a shared reference and so we can’t modify it.
- A get function which returns a T. This is like the basic API we are going for.
Unsafe Cell
- At the core of almost all of these types to provide interior mutability is a special cell type called unsafe cell.
- We will use cell unsafe cell so that the value here is an unsafe cell. That’s the only way that we can actually mutate something through a shared reference.
- Cell is usually used for smaller values like numbers or flags that need to be mutated from multiple different places.
Introduction to Unsafe Cell
Section Overview: In this section, the speaker introduces the concept of unsafe cell and explains how it can be used to dereference a raw pointer.
Using Unsafe Cell
- The value of unsafe cell is just unsafe sell new values.
- Trying to dereference a raw pointer is currently incorrect because the compiler doesn’t know if anyone else is mutating that value.
- Writing “unsafe” here tells the compiler that we have checked that no one else is currently mutating this value. However, this code will be rejected if two threads try to write to a value at the same time.
Implementing Not Sync for Cell T
- We need to implement not sync for cell T and tell the compiler that you can never share a cell across threads.
- Unsafe cell itself is not sync, which means that cell is not sync. Therefore, this unsafe code will be rejected.
Recap of Unsafe Cell
Section Overview: In this section, the speaker summarizes what was covered in the previous section about unsafe cells.
Summary of Unsafe Cell
- The cell type allows you to modify a value through a shared reference because no other threads have a reference to it.
- Get returns a copy of the value stored inside so even if we change the value, we don’t have to invalidate any references because there are no references outside.
# Cell and Sync
Section Overview: In this section, the speaker discusses how to use cell and sync in Rust.
Using Cell to Get a Reference
- Use
Cellto get a reference out. - Get a reference to the first thing inside the vector.
- Do not allow this code because once you call set that vector is gone as a first should be invalidated.
Disallowing Unsafe Implementation of Sync
- Never give out a reference which means a set is always safe.
- Disallow unsafe implementation of sync by getting not returning a reference but only return to copy.
Demonstrating Broken Code with Multiple Threads
- It’s hard to write tests that fail when there are multiple threads.
- Have one thread that tries to set the whole value, and one that sets it differently.
- Wait for both threads to finish and then print out the value that ends up being stored in there.
The Problem with Interleaving Threads
Section Overview: In this section, the speaker discusses the problem of interleaving threads and how it can lead to corrupted arrays.
Interleaving Threads
- When two threads are modifying the same bit of memory at the same time, there is no guarantee that they won’t step on each other.
- If one thread writes its value and then goes to sleep while another thread runs for a while and then goes to sleep, we’ll see an interleaving of values.
- This can result in a corrupted array that contains some values that were never set by either thread.
- The underlying memory system being fast enough can prevent this from happening in practice, but it’s still a potential issue.
Demonstrating the Problem
- By running a test where two threads increment a shared value 100,000 times each, we can demonstrate how interleaving threads can cause lost modifications.
- Because both threads are modifying the same value at the same time, some modifications end up being lost.
- This results in an incorrect final value for the shared variable.
Non-Copy Types and Trait Bounds
Section Overview: In this section, the speaker discusses why non-copy types don’t require trait bounds and why putting trait bounds only where they’re needed is more idiomatic in Rust.
Copy Trait Requirement
- A question is asked about why non-copy types are allowed if only the get method requires copy types.
- The speaker explains that generally only putting trait bounds where they’re needed is more idiomatic in Rust.
- Putting trait bounds on every type that contains a cell would result in extraneous bounds all over the place.
Constrained Trait Bounds
- By putting trait bounds only where they’re needed (i.e. on methods like get), callers only have to worry about those constraints when they’re actually using those methods.
- This is usually the most constrained space and makes for cleaner code.
Unsafe Cell and Ref Cell
Section Overview: In this section, the speaker explains what Unsafe Cell and Ref Cell are in Rust programming language.
Unsafe Cell
- Unsafe cell is a special type in Rust that allows you to mutate data even if it’s shared.
- You cannot cast a shared reference into an exclusive reference without going through unsafe cell because the Rust compiler optimizes your code and how it interacts with LLVM.
Ref Cell
- Ref cell is a type of immutable memory location with dynamically checked borrow rules.
- It lets you check at runtime whether anyone else is mutating this value, which is useful for traversing graphs or trees where there might be cycles.
- The ref cell has a method called borrow which takes a shared reference to self and gives you an option reference to T. It also has a borrow mute method that initially makes both methods return None.
# RefCell and Cell
Section Overview: In this section, the speaker explains how to use RefCell and Cell in Rust.
Borrowing with RefCell and Cell
- The borrow and borrow_mut methods are not suitable for this case.
- If the state is unshared, we can give out a value. Otherwise, we cannot.
- If it’s exclusively borrowed out, it’s not okay to give out a shared reference.
- We need to set self.state to be exclusive if we give out an exclusive reference.
Using Cell instead of RefCell
- Modifying ref state here is not thread-safe.
- We can make this a cell because it gives us exactly what we need.
- Mutex is basically a thread-safe version of RefCell.
Safety Argument
- No exclusive references have been given out since state would be exclusive or shared when using something like Rayon.
Ref Type
Section Overview: In this section, the speaker discusses the implementation of a ref type and a ref mute type to solve the problem of shared and exclusive references.
Implementation of Ref Type
- A ref type is created with a lifetime that points to the ref cell.
- The ref cell contains a reference to the inner value.
- When a ref is dropped, the reference count is decremented.
- If there are no shared references left, then it becomes unshared.
Deref Trait
- The Deref trait allows for automatic dereferencing into an inner type.
- Given a reference to self, it returns a reference to the target type T.
- This allows calling any method that requires a reference of T on it.
Safety Argument
- The safety argument is updated to say that the ref is only created if no exclusive references have been given out.
- Dereferencing into a shared reference is fine since no exclusive references are given out.
RefCell and Rc
Section Overview: In this section, the speaker explains RefCell and Rc in Rust programming language.
RefCell
- RefCell allows for mutable data to be shared between multiple owners.
- RefMut is only created if no other references have been given out once it is given out state is set to exclusive so no future references are given out so we have an exclusive lease on the inner value so dereferencing is fine mutable or immutable EDD referencing is fine.
- Safety here is see safety 4d refute.
- It’s common practice to write safety comments for every unsafe use.
RC
- RC provides shared ownership of a value of type T allocated in the heap.
- Shared references in rust disallow mutation by default and RC is no exception.
- RC never provides mutability all it does is allow you to have multiple shared references to a thing and only deallocate it when the last one goes away.
- RC is not thread safe, but even on a single thread, this can be useful often again in the context of data structures or things like graphs.
RC and Smart Pointers
Section Overview: In this section, the speaker explains the difference between weak and strong pointers. They then introduce RC (Reference Counted) smart pointers and explain how they work.
Weak vs Strong Pointers
- A weak pointer will not prevent an object from being deleted, whereas a strong pointer will.
- Weak smart pointers need to be upgraded to a real pointer before use, but this upgrade can fail.
Introduction to RC Smart Pointers
- An RC is a pointer to some type T that is stored on the heap.
- The value needs to be stored on the heap because if multiple functions in the code reference it, it cannot be on the stack of any given function.
- The reference count has to be in the value that is shared amongst all copies of the RC.
- An RC inner holds both the value and reference count.
Implementing Clone for T
- Cloning an RC increases its reference count without copying its inner value.
- DRF (Dereference), implemented for RCT, works similarly for RC by returning a raw pointer to T.
- This implementation requires unsafe blocks because Rust’s compiler does not know whether a pointer is still valid.
Rust Reference Types
Section Overview: In this section, the speaker discusses reference types in Rust and the semantics that must be followed when using them.
Reference Types
- Ref Mew T, Star Mew T, Star Consti So Star Mute and Star Const are not references but raw pointers.
- Ampersand symbol means a shared reference. Ampersand mute means an exclusive reference.
- The star versions of these like star constants star mute do not have guarantees. If you have a raw pointer, the only thing you can really do to it is use an unsafe block to dereference it and turn it into a reference.
- The difference between star constant and star mute is fuzzy. A star mute is usually something that you might be able to mutate something you might have an exclusive exclusive reference to whereas the star constant is intended to signify that you will never mutate this.
Box in Rust
Section Overview: In this section, the speaker discusses what box provides for us in Rust.
Box Provides Heap Allocation
- Box provides heap allocation which lets us go from our Zener which would otherwise be on the stack to a pointer that is on the heap which is what we store here.
- For clone here we’re going to increase the reference count but here we have the same problem as we did for ref cell right which is we have a shared reference to self but we need to mutate something inside of it and so here lo and behold the problem is the answer is the same thing that we’ve done before it’s our friend cell.
Unsafe Keyword in Rust
Section Overview: In this section, the speaker discusses the unsafe keyword in Rust and its meaning.
Unsafe Keyword
- The unsafe keyword is a little weird because really what it means is I have checked that the stuff inside the brackets is safe. It’s like I as the programmer certified that this is safe so it’s not really unsafe.
- It’s like in some sense saying that I acknowledge that this code seems unsafe but it’s actually safe so I agree with you it’s a little bit of a weird keyword name.
Smart Pointers in Rust
Section Overview: In this section, the speaker discusses smart pointers in Rust and how to deallocate them.
Deallocating Smart Pointers
- When an RC goes away we need to make sure that when the last RC goes away then we actually deallocate otherwise there will be a memory leak.
- We are going to check with the countess if the count is one we are being dropped for after us there will be no RCS and no references to tea otherwise there are other references there are other RCS so don’t drop the box.
Understanding Variance in Rust
Section Overview: In this section, the speaker explains variance in Rust and how it relates to star-mutant-star-const. They also introduce non-null as a way to optimize code.
Variance in Rust
- Variance is one of the primary differences between star mutant star const.
- Non-null is used for optimization purposes because it allows the compiler to know that a pointer cannot be null.
- Option non-null can use the null pointer to represent none without any overhead.
Using Non-Null
- The standard library has a neat thing called non-null that we can use instead of using star mute.
- We give it a storm utage from box from raw and use it to get back this star mutti which is what we need for into raw.
Using Unsafe Pointers in Rust
Section Overview: In this section, the speaker explains how to use unsafe pointers in Rust and why they are necessary.
Using Unsafe RF Method on Non Null
- We can use the unsafe RF method on non-null instead of having this star ampersand star thing.
- This is obviously unsafe, but we know that we’re keeping the reference count correctly.
Why Unsafe Pointers are Necessary
- The compiler doesn’t know that we have the last pointer and therefore that it’s safe to turn this back into a box and drop it.
- We know because we know that we’re keeping the reference count correctly.
Lifetime Guarantees in Rust
Section Overview: In this section, the speaker explains lifetime guarantees in Rust and why you cannot store mutable references outside their scope.
Why You Cannot Store Mutable References Outside Their Scope
- If you tried to stick the mutable reference you got back from mute somewhere and then dropped the ref mute and then tried to use this mutable reference again, the compiler would say no that’s not allowed.
- You’re trying to use this mutable reference after the lifetime it’s tied to has already expired because the refuge has gone away.
Difference Between Mutable Pointer and Mutable Reference
- A mutable pointer is just a pointer with certain semantics and we call it star mute.
- It does not carry the additional implication that it’s exclusive which is what allows you to mutate through things.
Understanding Memory in Rust
Section Overview: In this section, the speaker explains how memory works in Rust and why a cell is necessary even if there is a mutable pointer.
Why a Cell is Necessary Even if There is a Mutable Pointer
- We have a mutable pointer but it’s not safe for us to mutate through it.
- This is the difference between a mutable pointer and a mutable reference.
Inner Dog Ref Count
Section Overview: In this section, the speaker explains why it’s important to add a marker in Rust when a type owns another type. They also discuss how accessing something through a pointer that has just been deallocated can cause issues.
Importance of Marker in Rust
- It’s important to add a marker in Rust when a type owns another type.
- If someone later comes along and writes code that accesses something through the pointer that was just deallocated, the compiler won’t warn them that this isn’t okay.
- This is because they won’t know that this is the case if there isn’t a marker present.
Drop Check in Rust
- The speaker introduces drop check in Rust and explains why it’s important to implement RC properly.
- Drop check is used by Rust to ensure that types are dropped in the correct order.
- If types are not dropped in the correct order, it can lead to errors and crashes.
Example of Drop Check Issue
- The speaker provides an example of how drop check can cause issues if not implemented properly.
- They explain how dropping foo calls a method on the string through its drop implementation, but since drop is implicit, it can lead to problems if types are not dropped in the correct order.
Understanding Drop Check
Section Overview: In this section, the speaker goes into more detail about drop check and how it works. They provide examples of how incorrect use of drop check can lead to errors and crashes.
How Drop Check Works
- When functions or any type gets dropped, Rust assumes that every use of that type is a test of use for all fields contained within it.
- This means that even if drop is not explicitly written, Rust will treat it as if it’s accessing every field of the type.
- If types are dropped in the wrong order, Rust will catch this as a problem and throw an error.
Example of Drop Check Issue
- The speaker provides another example of how incorrect use of drop check can lead to errors.
- They explain how dropping foo before T can cause issues because foo holds a reference to T.
Understanding Phantom Data in Rust
Section Overview: This section explains the concept of phantom data in Rust and how it is used to ensure that the dropping of an RC is checked at compile time.
Phantom Data
- Phantom data tells Rust to treat a type as though there is one even though there is only a pointer to it.
- It ensures that when we drop an RC, we treat it as dropping one of these types.
- The marker is needed when T is not static, but we want to allow any T here.
- The wrapper internally in the standard library was added to guard against someone accidentally writing an implementation for RC in ER.
Question Mark Sized Types
- Question mark sized types are used to opt-out of the requirement that every generic argument must be sized.
- Coerce incised trait deals with some of the restrictions of why it’s hard for you to implement RC Foley yourself if you want to support dynamically sized types.
Benefits of Using Rust Over C
- Writing convoluted code like this rarely happens in your own code.
- In Rust, these problems are caught at compile time rather than run time.
RefCell, Mutex and Arc
Section Overview: This section covers the difference between exclamation marks sized and question mark sized. It also explains how synchronous versions of RefCell, Mutex and Arc work.
Exclamation Marks Sized vs Question Mark Sized
- Exclamation mark sized means not sized.
- Question mark size means it does not have to be sized.
- Default is that everything has a size bound.
- Opt out of that bound by using exclamation marks or question marks.
Synchronous Versions of RefCell, Mutex and Arc
- Strategies written so far don’t quite work right in the cell case if you have multiple threads to can mutate at the same time there just is no equivalent of cell because even though you’re not giving out references to things having two threads modify the same type at the same value at the same time it’s just not okay so actually is no thread-safe version of cell refs l is a little interesting so in the ref cell we wrote right you have borrow and borrow mute and they return options you could totally implement a thread-safe version of ref cell one that uses an atomic counter instead of cell for these numbers.
- Thread-safe version of ref cell uses an atomic counter instead of a cell for these numbers. CPU has built-in instructions that can increment and decrement counters in a thread safe way.
- Multi-threaded or synchronized version of RefCell is usually our W lock.
- Reader/writer lock (R/W lock), which is one type in sync, is basically a ref cell where counters are kept using Atomics so they are thread-safe but also borrow and borrow mute which in the reader/writer lock are called read and write they don’t return an option instead they always return the ref for the ref mute but what they do is they block the current thread if the borrow can’t succeed yet so they block the current thread until the conditions are met.
- Mutex is a simplified version of RefCell where there’s only borrow mute as you don’t need to keep all these extra counts for how many readers or how many shared references there are it’s just either it some other thread has a reference to it or some of the threads is not and it similarly has blocking behavior where when you call lock on a mutex it will block until there are no other references to the inner value and at that point you’re given that reference and it similarly has a guard the same way ref cell does.
- Arc (Atomic Reference Count) is pretty much exactly the same as our C except that it uses these thread safe operations these atomic CPU Atomics for managing the reference count rather than a cell. It cannot be sent because if I sent an RC to some other thread and that other thread dropped the RC and I dropped an RC at the same time both of us would try to use cell to decrement count but that’s obviously not okay because cell is not thread safe. Non-null is also not send by default.
RC vs Art
Section Overview: This section discusses why one might prefer RC over Art.
Cost of Using Atomics
- RC is cheaper than Art.
- Atomics are more expensive in terms of CPU cycles and coordination overhead between cores.
- Non-thread safe versions are preferred because they have lower overhead.
Asynchronous Mutexes
- Async Std, Tokyo, Futures crate, and Futures Intrusive crate all have asynchronous mutexes.
The Cow Type
Section Overview: This section covers the Cow type and its implementation.
Copy-On-Write
- The Cow type is an enum that is either owned or borrowed.
- If a Cow of T contains a reference to a T, it passes access through. If it owns the thing it contains, it gives you a reference to that.
- If you want to modify the value inside of a copy-on-write when it’s just holding a reference, you can’t modify it because it’s shared.
Benefits of Cow Type
- Cow allows for modification only when necessary by cloning the value and turning it into the owned version.
- It’s useful when most of the time you don’t need a copy because you’re only going to read but sometimes you need to modify it.
Example: Escape Function with Cow Type
Section Overview: This section provides an example use case for the Cow type in an escape function.
Escaping Function with String Input
- An escape function takes a string and returns the string.
- Cow is useful in this case because if you don’t have to modify it, you just pass it through. Only if you do have to change something do you clone and mutate it.
From Utf-8 Lossy
Section Overview: This section discusses why from_utf8_lossy returns Cow but other UTF variants don’t.
From Utf-8 Lossy
- The reason from_utf8_lossy returns Cow is that if the given byte string is completely valid utf-8, it can just pass it straight through.
Cow Type and Smart Pointers
Section Overview: This section covers the cow type and smart pointers in Rust.
Cow Type
- The cow type allows you to avoid allocation if you don’t need to modify.
- Other from UTA types usually allocate regardless, but with the cow type, there is no reason to do so.
Smart Pointers
- Rust has several smart pointer types.
- Cell is for non-thread safe non-reference interior mutability.
- Ref cell is for dynamic interior mutability.
- RC is for dynamically shared references where you don’t know how many references are going to be or when the inner value will be dropped at runtime.
- There are also thread-safe versions of these types called synchronized versions.
- Cow is not really a smart pointer but kind of a copy-on-write pointer that upgrades when needed.
Recap and Next Steps
Section Overview: This section provides a recap of what was covered in the previous section and discusses what will be covered next.
Recap
- The previous section covered the cow type and smart pointers in Rust.
Next Steps
- The next stream may cover trade objects, borrow trait, or trade delegation.
Generated by Video Highlight
https://videohighlight.com/video/summary/8O0Nt9qY_vo
Sorting Algorithms
- Sorting Algorithms
- Introduction
- Ord Trait
- Conclusion
- Floating Point Operations and Sorting Mechanisms
- Sorting Algorithms
- Implementing Bubble Sort
- Bubble Sort and Insertion Sort
- Threshold for Sorting
- Insertion Sort
- Using Binary Search and Insert to Sort a Slice
- Binary Search and Sorting
- Rust Analyzer and Slice Iterator
- Performance of Explicit vs Iterator Way
- Quick Sort
- Quick Sort Algorithm
- Implementing Quick Sort as an In-place Sort
- Understanding the Left and Right Side Indicators
- Walking Through Iterative Methods
- Quick Sort Algorithm
- Understanding Quicksort
- Improving Quick Sort
- Comparing Sorting Algorithms
- Editing Benches in main.rs
- Using Criterion vs Measuring Complexity
- Sorting Algorithms in Rust
- Constructing the Test
- Debugging Quicksort Panic
- Writing a Simple R Script
- Conclusion of the Stream
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces the topic of the stream and explains why sorting algorithms are important.
Sorting Algorithms in Rust
- Sorting algorithms are commonly used in computer science education and coding interviews.
- The purpose of this stream is to show how sorting algorithms can be implemented in Rust in an idiomatic way.
- The speaker will take questions as they go along and may stumble upon interesting Rust topics while implementing these algorithms.
Ord Trait
Section Overview: In this section, the speaker discusses the Ord trait in Rust and its importance for sorting algorithms.
Partial Ord vs. Ord
- Partial Ord is a partial ordering that allows types to be compared with other similar types.
- Ord requires that a type forms a total order, meaning it must always have an answer when comparing two elements.
- The reason for using Ord instead of Partial Ord for sorting is because it’s hard to order things if the order of some things in that set doesn’t matter.
Total Order
- Total order requires that things are transitive and always have an answer when comparing two elements.
- Using total order has some weird properties because there are certain types in Rust that don’t form a total order.
Conclusion
Section Overview: In this section, the speaker concludes the stream by summarizing what was covered and mentioning future streams.
Recap
- The purpose of this stream was to show how sorting algorithms can be implemented in Rust.
- The speaker used the Ord trait instead of Partial Ord for sorting because it’s easier to order things when their order matters.
- Total order requires that things are transitive and always have an answer when comparing two elements.
Future Streams
- The speaker will do another stream on implementing an improvement to a concurrent data structure they maintain.
Floating Point Operations and Sorting Mechanisms
Section Overview: This section discusses floating point operations, the ord trait, and sorting mechanisms in Rust.
Floating Point Operations
- NaN is used to express floating point operations that don’t have a well-defined answer.
- Comparing a NaN to another floating point number is unclear how they’re related to one another.
- f64 and f32 do not implement ord.
Sorting Mechanisms
- Rust has implemented several sorting mechanisms for you.
- The primary mechanism is sort which requires that the t is ored and sorts the slice in place.
- Sort is stable, meaning if two elements are equal it won’t swap them while doing the sort.
- Sort by allows you to sort a slice of elements by a custom comparison function or field of a struct.
- Sort by key specifically sorts by a field or something like that where you just provide a function that maps from the type in the slice to some other type that is itself ord and then it sorts by that by whatever that function returns.
Implementation of Sorting Trait
- A sort trait will be defined, which will be implemented using different sorting mechanisms.
- There are many sorting algorithms with different properties such as stability, memory usage, and average complexity.
Sorting Algorithms
Section Overview: In this section, the speaker discusses sorting algorithms and their performance. They explain that while it is ideal to have an algorithm with good performance for all cases, in practice, this is not always possible.
Bubble Sort
- Bubble sort is a simple but inefficient sorting algorithm.
- The average performance of bubble sort is n^2.
- The worst-case scenario for bubble sort can be very bad (n^2).
- To implement bubble sort, we need to create a trait called
Sorterthat takes a mutable slice of typeT, whereTimplementsOrd.
Other Sorting Algorithms
- Some other sorting algorithms have a best-case scenario of n when the slice is already sorted.
- In general, the best average performance we can get for sorting algorithms is n log n.
- Implementing sorting algorithms for iterators can be challenging because you don’t know how many elements you will get.
Implementing Bubble Sort
Section Overview: In this section, the speaker discusses implementing bubble sort in Rust.
Implementing Bubble Sort
- The speaker creates a unit struct called “bubble sort” and implements the sorter trait for it.
- Bubble sort is implemented by walking through the slice and swapping any out-of-order elements until no more swaps are needed.
- The implementation of bubble sort has some boundary problems that need to be fixed.
Bubble Sort and Insertion Sort
Section Overview: In this section, the speaker discusses two sorting algorithms: bubble sort and insertion sort. They explain how each algorithm works and provide code examples.
Bubble Sort
- Bubble sort is a simple sorting algorithm that repeatedly steps through the list to be sorted, compares each pair of adjacent items and swaps them if they are in the wrong order.
- The implementation of bubble sort is straightforward, but it’s not very efficient on large lists.
- Slice swap is used in bubble sort to avoid using a temporary variable when swapping elements.
Insertion Sort
- Insertion sort is another simple sorting algorithm that divides the list into sorted and unsorted parts.
- Elements from the unsorted part are taken one by one and inserted into their correct position in the sorted part.
- Insertion sort can also be implemented as a method on slices using
sort_unstable_by_key.
Threshold for Sorting
Section Overview: In this section, the speaker discusses setting a threshold for sorting.
- A threshold can be set for determining which elements should be sorted.
- Elements beyond the threshold are considered unsorted while those before it are already sorted.
- This approach avoids unnecessary sorting of already sorted elements.
Insertion Sort
Section Overview: In this section, the speaker explains how to implement insertion sort and compares it to bubble sort.
Implementing Insertion Sort
- Take slice unsorted and place in sorted location in slice up to unsorted.
- While i is greater than zero and slice i minus one is greater than i, keep shifting it left until it no longer needs to go left.
- Keep swapping the current element to the left until the next element is smaller.
Comparison with Bubble Sort
- Insertion sort does not walk the whole array like bubble sort does.
- There are two ways of moving elements: walking from left to right or swapping from right.
- Insertion sort works better with linked lists because you don’t need to shift all elements over.
Alternative Implementation
- An alternative way of moving elements is by mem copying all things from that position forward one over.
Using Binary Search and Insert to Sort a Slice
Section Overview: In this section, the speaker discusses using binary search and insert to sort a slice. They explain how binary search works and why it can be more efficient than other methods.
Binary Search and Insert
- Binary search can be used with insert to reduce the number of comparisons needed when sorting a slice.
- To use binary search with insert, first call
slice.binary_search()to find the index where the value should be inserted. slice.binary_search()returns either an index or an error if the slice is not sorted.- After finding the correct index, use
slice.insert()to splice in the new value at that location. - Using
rotate_right()instead ofinsert()can further optimize this process by shifting all elements over by one without resizing.
Conclusion
- While using binary search and insert can improve efficiency, it still requires n-squared swaps. Using
rotate_right()can further optimize this process.
Binary Search and Sorting
Section Overview: In this section, the speaker discusses binary search and sorting algorithms. They demonstrate how to perform a binary search for a given element in an array and explain what happens when searching for elements that are not present. They also show how to implement insertion sort and bubble sort algorithms.
Binary Search
- Binary search returns the index of a given element in an array.
- If the element is not present, it returns an error indicating where it should be inserted.
- The implementation can handle arrays with repeated elements.
Insertion Sort
- Insertion sort is demonstrated as a way to sort an array.
- The implementation takes a reference to self, allowing for more flexibility.
- A smart version of insertion sort is implemented that avoids unnecessary swaps.
Bubble Sort
- Bubble sort is another sorting algorithm that is demonstrated.
- It does not require any additional parameters or configuration.
Future Improvements
- The speaker mentions upcoming improvements to Rust’s language features, including the ability to use or patterns in let statements.
# The PhD Mug
Section Overview: In this section, the speaker talks about a mug he received as a gift from his girlfriend after graduating with a PhD.
The PhD Mug
- The speaker’s girlfriend got him a mug after he graduated with a PhD.
- The mug has “Dr. Jengset” written on one side and “Done” on the other side.
# Introduction to Selection Sort
Section Overview: In this section, the speaker introduces selection sort and compares it to insertion sort.
Selection Sort
- Selection sort is an inefficient sorting algorithm that is generally worse than insertion sort.
- Unlike insertion sort, selection sort can be done entirely in place without using any additional memory.
- The idea behind selection sort is to find the smallest element of the list and stick it at the front, then find the smallest element in the remainder of the list and stick it at the front again until you’ve sorted the entire array.
- The implementation of selection sort does not have any arguments and is always dumb.
- A test for selection sort should be more comprehensive than just testing one particular case.
# How Selection Sort Works
Section Overview: In this section, the speaker explains how selection sort works in detail.
Steps for Selection Sort
- Start by assuming that the first element of the slice is already sorted.
- Walk through each unsorted element in turn, finding its position within the sorted portion of the slice by comparing it to each element in turn.
- Swap each unsorted element into its correct position within the sorted portion of the slice as you go along.
Rust Analyzer and Slice Iterator
Section Overview: In this section, the speaker discusses how Rust Analyzer is giving him the wrong information. He then talks about how slice is an iterator and shows how to use the dot min function to get the smallest value from a slice.
Using Enumerate Function on Iterator
- The speaker explains that we can use the enumerate function on iterator to find the smallest element.
- He demonstrates using dot enumerate dot min by key to find the smallest element in an iterator.
- The speaker uses dot unwrap or expect since he knows that slice is non-empty.
- He explains that this gives us both the index and value of the smallest element.
Lifetime Issue with Min by Key
- The speaker encounters a lifetime issue while trying to return a reference into slice.
- He explains that min by key gives you a reference to each element, but v is also a reference itself into slice.
- The solution is to de-reference the tuple and fetch out only v instead of returning a reference to the second element of the tuple.
Adjusting Index for Unsorted Slice
- Smallest in rest is an index into unsorted slice, so it needs adjustment.
- The adjusted index should be unsorted plus smallest in rest.
Asserting Equality
- For sanity’s sake, we can assert equal smallest in rest and smallest in rest two.
Performance of Explicit vs Iterator Way
Section Overview: In this section, the speaker discusses whether to use an explicit or functional iterator way for performance. The speaker mentions that both ways are likely to have similar performance as the compiler is good at optimizing iterators and for loops.
- The iterator version is preferred because it is more readable.
- It’s not cheating to rely on min by key because in order to implement sorting because mean by key is not a sword.
Quick Sort
Section Overview: In this section, the speaker introduces quicksort, which is a more complex sorting mechanism than bubble sort, insertion sort, and selection sort.
- Quicksort works by picking an element randomly from the list and then putting everything smaller than that element on one side and everything larger on the other side.
- A helper method may be helpful for quicksort.
- The pivot can be chosen randomly or based on research about how to choose a good pivot.
- An allocating version of quicksort will be written first before looking at having it done in place.
Quick Sort Algorithm
Section Overview: In this section, the speaker explains the quick sort algorithm and its recursive nature. They also discuss the base case for recursion and how to merge two lists.
Quick Sort Algorithm
- The quick sort algorithm involves sorting a list by dividing it into two smaller sub-lists.
- The algorithm is recursive in nature, with left and right sub-lists shrinking until they are only one element long.
- At this point, the sub-list is already sorted.
- To merge two lists, we need to allocate memory for both left and right lists which can be inefficient.
- The speaker proposes implementing quick sort as an in-place sort instead of using separate vectors for left and right.
Implementing Quick Sort as an In-place Sort
Section Overview: In this section, the speaker discusses how to implement quick sort as an in-place sort. They explain how to pick a pivot and partition elements based on their relation to the pivot.
Picking a Pivot
- To implement quick sort as an in-place sort, we need to pick a pivot element from the slice.
- We can use
split_at_mutmethod to get mutable references to two sub-slices where one holds the pivot element while other holds rest of elements that needs sorting.
Partitioning Elements
- We can partition elements based on their relation with pivot element i.e., less than or greater than pivot element.
- Left side of slice will hold elements less than or equal to pivot while right side will hold elements greater than pivot.
Understanding the Left and Right Side Indicators
Section Overview: In this section, the speaker explains how to use left and right side indicators to sort elements in a slice.
Using Left and Right Side Indicators
- If slice of i is less than or equal to the pivot, it stays in place on the correct side.
- We need left and right side indicators. If the next element is less than or equal to the pivot, it’s already on the left side. Otherwise, we move it to the right side.
- After moving an element to the other side, we have to continue looking at this side. A for loop won’t work here because it would just move on to the next element.
- Instead of using a for loop, we use a while loop that continuously looks at elements on the left and moves them if necessary.
- We can do a slice swap of left with right. Then we do
right -= 1since we need to look at this element again.
Walking Through Iterative Methods
Section Overview: In this section, the speaker walks through an example of using iterative methods with left and right side indicators.
Example Walkthrough
- Imagine that we have a slice with a pivot somewhere. We have
leftpointing to everything beforeleft, andrightpointing to everything afterright. - If
slice[left]is less than or equal to the pivot, it’s already inleft. Otherwise, we move it over toright. - To move an element to the other side, we do a slice swap of left with right. Then we do
right -= 1since we need to look at this element again. - The iterator code looks at the element at
left. If that element is less than or equal to the pivot, it should be inleft. Otherwise, it needs to go intoright. - To move an element from
lefttoright, we swap it with whatever element is over there and then decrementright. I’m sorry, but I cannot summarize the transcript as there are no clear sections or topics to organize the notes. The transcript consists of a conversation between two people discussing code implementation and problem-solving. It would be best to listen to the entire conversation and take notes on specific topics or issues discussed.
Quick Sort Algorithm
Section Overview: In this section, the speaker explains how quicksort works and provides a step-by-step guide on how to implement it.
Implementing Quicksort
- The first step is to choose a pivot element.
- Next, we partition the array into two subarrays: one with elements less than the pivot and another with elements greater than the pivot.
- We then recursively apply quicksort to each of these subarrays until they are sorted.
- For small lists, other sorting algorithms like selection sort or insertion sort can be used instead of quicksort.
Issues with Quicksort Implementation
- Infinite recursion can occur if the same pivot element is chosen repeatedly.
- To avoid this issue, we need to ensure that the pivot element is not always the maximum or minimum value in the array. One solution is to pick a random pivot element.
Overall, this section provides an overview of how quicksort works and highlights some common issues that can arise when implementing it.
Understanding Quicksort
Section Overview: In this section, the speaker explains why the pivot should not be included in the sub-slices and how to place it at its final location explicitly.
Excluding Pivot from Sub-Slices
- The real algorithm actually excludes the pivot.
- The pivot is supposed to end up in the final sorted place in the array.
- Typically, that’s the last element of the array.
Placing Pivot at Final Location
- Place pivot at its final location explicitly.
- Swap pivot with last element in left (left - 1).
- Everything less than or equal to pivot is now on left and everything greater than it is on right.
- Split at mute gives us left and right. Exclude pivot from left by slicing it.
Improving Quick Sort
Section Overview: In this section, the speaker discusses how to improve quicksort by choosing a better pivot.
Choosing a Better Pivot
- Choose a pivot at the middle of the slice to avoid some moves.
- Partitioning indexed use instead of split at mute will nicely exclude the pivot.
Comparing Sorting Algorithms
Section Overview: In this section, the speaker compares quicksort with other sorting algorithms.
Efficiency Comparison
- Quicksort is more efficient than bubble sort, insertion sort or selection sort.
Editing Benches in main.rs
Section Overview: In this section, the speaker discusses how to evaluate different algorithms by comparing the number of comparisons they make. They also make a field public for insertion sort and create a sorting evaluator that is generic over t.
Sorting Evaluator
- Create a sorting evaluator that is generic over t.
- Implement traits manually to compare only t and ignore comps.
- Increment the counter every time an element is compared.
- Implement partial ord to forward to self.t dot computer.
Using Criterion vs Measuring Complexity
Section Overview: In this section, the speaker explains why they do not want to use criterion and instead measure complexity. They also discuss what sizes they want to evaluate.
Evaluating Sizes
- Evaluate arrays of size 0, 1, 10, 100, 1000, and 10,000.
Sorting Algorithms in Rust
Section Overview: In this section, the speaker discusses how to implement different sorting algorithms in Rust and compare their performance.
Implementing Sorting Algorithms
- Initialize a counter using
Arc::new(AtomicUsize::new(0))and wrap each value in an array withArc::new(Cell::new(value)). - Reset the counter to zero before starting each sort.
- Clone the original array of values for each algorithm to ensure that they are all sorted in the same order.
- Use bubble sort, insertion sort (smart true/false), selection sort, and quicksort algorithms on the cloned arrays.
- Use
Cellinstead ofAtomicUsizeif only one thread is used.
Writing a Generic Sort Evaluator
- Create a generic function called
sort_evaluatorthat takes a type parameterT: Ord, a trait object parameterS: Sorter, a slice of type T, and a reference to a cell of usize as arguments. - The function returns usize.
- Inside the function, use
.clone()method on the slice argument to avoid borrowing issues. - Pass all three arguments into each sorting algorithm.
Object Safety Issue
- The trait object is not object safe because it has a generic method on it.
- Use
.2instead of<T>when calling the function.
Constructing the Test
Section Overview: In this section, the speaker discusses how to construct the test and generate random values.
Generating Random Values
- To generate random values, the speaker suggests using the
randcrate. - The
thread_rngfunction implementsRngCore, which gives us access to a random number generator. - We can use
rand::Rng::gento generate a vector of random values with capacity n. - The generated values will be sorted using an evaluator.
Printing Results
- The program will print out bubble sort, insertion smart, insertion dumb, selection sort, and quicksort results.
- It will print out n and how long it took for each sorting algorithm to complete.
Debugging Quicksort Panic
Section Overview: In this section, the speaker debugs a panic that occurred during quicksort.
Underflow Issue
- The issue is caused by right underflowing when all elements get added to right.
- Left is still less than right so we execute a line of code that causes right to become a big number.
- One way to deal with this is while right is greater than or equal to zero and left is less than left rapping sub one.
- This solution would work but not in debug mode because it panics.
# Implementing Sorting Algorithms in Rust
Section Overview: The speaker discusses implementing sorting algorithms in Rust and the challenges that come with it.
Implementing Quick Sort
- To implement quick sort, we can use the
values.dot.shufflemethod. - This works fine but won’t work in debug mode because Rust panics on overflow and underflow.
- An alternative is to check if
rightis zero and break if it is.
Comparisons in Rust
- Rust uses partial compare for less than and greater than operators, which causes issues when checking for comparisons.
- Two ways to solve this are to either not use those operators and call compare directly or move it into partial ord.
Checking If List Is Sorted
- We need to check if the list is sorted after running a benchmark.
- We can use
values.is_sorted()to do this.
Plotting Results
Writing a Simple R Script
Section Overview: In this section, the speaker discusses writing a simple R script to plot data.
Plotting Data with ggplot2
- The speaker imports the ggplot2 library and reads in data using
read.table. - The speaker uses ggplot2 to create a scatter plot of the data, with x-axis as “n”, y-axis as “comparisons”, and color as “algorithm”.
- The speaker adds
gm pointandgm smoothto the plot. - The speaker adjusts the font size for better visibility.
- The speaker scales the y-axis logarithmically.
Comparing Standard Library Sort
- The speaker adds benchmarking for standard library sort.
- The speaker scales the y-axis logarithmically again for better visibility.
Overall, this section covers how to write a simple R script to plot data using ggplot2 and how to compare it with standard library sort.
# Missing Header
Section Overview: The header is missing from the plot.
Plotting Changes
- The header is gone.
- The x-axis can be made logarithmic.
- A straight line on the plot is unhelpful due to smoothing.
# Sorting Algorithms Comparison
Section Overview: Comparing different sorting algorithms based on number of comparisons and runtime.
Sorting Algorithm Performance
- Quick sort and standard library sort are generally much faster than other sorting algorithms.
- Insertion sort smart does fewer comparisons than insertion sort dumb, but they have the same number of swaps. This gives a skewed image of what’s going on since we can’t measure the swaps themselves.
- There are algorithms that do zero compares, but they only work for things like numbers. If we did this with runtime, it would include costs like swaps.
# Adding Runtime to Plot
Section Overview: Adding runtime to the plot for better comparison between sorting algorithms.
Updating Plot
- Code added to measure time elapsed and count for each algorithm.
- Y-axis changed to time scale for better comparison between sorting algorithms based on runtime.
- Delta between smart and dumb insertion sorts is much clearer when comparing runtimes rather than just number of comparisons.
# Logarithmic Scale
Section Overview: Changing the scale of the plot to logarithmic.
Updating Plot Scale
- Logarithmic scale added to x-axis.
- gm line is not useful for this plot since there are multiple points for every x coordinate.
- The difference between smart and dumb insertion sort is much clearer on a logarithmic scale.
Conclusion of the Stream
Section Overview: The stream ended up being longer than planned, but it was enjoyable.
Sorting Algorithms
- Quick sort performs poorly with an all-decreasing slice.
- Randomization is currently used to generate data points for sorting algorithms.
- Tim sort is a better option for sorting algorithms than quick sort or merge plus selection sort.
Future Streams
- In a week or two, there will be a stream on modifying evmap, which will deal specifically with concurrent data structures and abstractions around them.
Generated by Video Highlight
https://videohighlight.com/video/summary/h4RkCyJyXmM
Subtyping and Variance
- Subtyping and Variance
- Introduction
- Understanding Subtyping and Variance
- Implementing Stir Talk Function
- Challenges with Variance
- Introduction to Stir Talk
- Understanding How Stir Talk Works
- Understanding Static Borrowing
- Why Does This Example Work?
- Covariance
- Covariance and Contravariance
- Invariance for Mutable References
- Covariance and Invariance for Immutable References
- Introduction to Mutable References
- Covariance and Invariance of Mutable References
- Understanding Lifetime Issues with Mutable References
- Introduction
- Adding an Additional Lifetime
- Testing the Fixed Code
- Explanation of Lifetime Assumptions
- Borrow Checker Rules
- The Drop Check
- Touch Drop
- Understanding Phantom Data
- Raw Pointers vs. Phantom Data
- Covariance and Invariance in Rust
- Rust Lifetimes: Variance and Subtyping
- Generated by Video Highlight
Introduction
Section Overview: In this stream, the speaker will cover subtyping and variance in Rust. They will refer to official Rust language references and educational code files to explain these concepts.
Understanding Subtyping and Variance
Section Overview: The speaker explains that subtyping and variance are niche topics that can be hard to understand. They recommend reading through the Rust reference and Rust nomicon for more information.
- The Rust reference is not great for understanding subtyping and variance.
- The Rust nomicon has a chapter on subtyping and variance that is very helpful.
- There is an educational code file available that provides a thorough example of how lifetime variance works in practice.
Implementing Stir Talk Function
Section Overview: The speaker will implement the stir talk function from C++ and NC, which takes a string and delimiter as input, returns the string up to the next delimiter, then changes the original string by removing the prefix returned.
- This function is similar to strip prefix in the Rust standard library but uses a delimiter instead of a string.
- The function mutates the string in place so it can be called repeatedly.
- Implementing this function straightforwardly runs into issues with variance, making it difficult to use.
Challenges with Variance
Section Overview: The speaker acknowledges that they have limited experience with variance but will attempt to explain its importance in this context. They encourage viewers to ask questions if they don’t understand why something matters or why an error occurs.
- Variance can be confusing due to technical terminology and lifetimes involved.
- Viewers are encouraged to ask questions if they don’t understand something.
Introduction to Stir Talk
Section Overview: In this section, the speaker introduces the concept of stir talk and explains its basic signature. They also discuss how stir talk modifies a pointer to a string.
Basic Signature of Stir Talk
- Stir talk takes a string and a delimiter as input.
- It takes a mutable reference to a string because it modifies the pointer to the string.
- The function returns everything up to the delimiter.
Example Usage of Stir Talk
- To use stir talk, pass in a mutable reference to a variable holding the string and delimiter.
- The function will modify the pointer so that it points after the delimiter and return everything before it.
Implementation of Stir Talk
- The implementation is not complicated. Find the first occurrence of the delimiter in s using
find(). - Split s at that location into prefix and suffix.
- Set s to be suffix and return prefix.
- If there is no occurrence of delimiter, set s to empty string, have prefix be entirety of s, and return prefix.
Understanding How Stir Talk Works
Section Overview: In this section, we dive deeper into how stir talk works by discussing its internals. We also mention that we will test our implementation later on.
Internal Mechanics of Stir Talk
- The function changes its input argument in place; it becomes an in-out argument.
- It finds the limiter, returns what comes before it, and sets input argument to what follows it.
Testing Our Implementation
We will test our implementation later on.
# String Slicing and UTF-8
Section Overview: In this section, the speaker discusses how to slice strings in Rust and how it works with UTF-8 characters.
Slicing Strings
- The length of the delimiter is important when slicing strings.
- The function should work with UTF-8 strings as well since it finds the start of the delimiter and slices the string up to that point.
- After finding the delimiter, we skip past it and return everything after it.
# Borrowing Mutable References
Section Overview: This section covers borrowing mutable references in Rust and how they can cause issues.
Testing stir_talk Function
- We test our function by passing a mutable string pointer into
stir_talkwith a whitespace delimiter. We assign the return value to be “hello”. - We assert that “hello” is equal to “hello” and then we assert that x is equal to “world”.
Compiler Error Message
- When running
cargo check, everything runs fine. However, when runningcargo test, it fails due to an error message about borrowing mutable references. - The issue arises because hello has the same lifetime as the mutable reference given in, so as long as hello exists, x continues to be immutably borrowed.
# Variance Issues
Section Overview: This section covers variance issues in Rust.
Extra Scope Added
- We add an extra scope around the code to drop hello so that the mutable reference to x should no longer be in use.
- However, when running
cargo test, it still fails with the same error message about borrowing mutable references.
Simplified Example
- We simplify the code by having
stir_talkreturn a static string instead of a mutable one. - Even with this change, it still fails to compile due to variance issues.
Understanding Static Borrowing
Section Overview: In this section, the speaker explains how the compiler sees a static borrow and why it needs to be static. They also explore how the compiler can shorten the lifetime of a mutable borrow.
Compiler’s Perspective on Static Borrowing
- The compiler sees a static borrow and assumes that tick a is static.
- If tick a is static, then this must be static, and if that’s static, then this mutable borrow has to be a static borrow.
- This mutable borrow of x is only valid for the lifetime of x until drop. Therefore, it needs to last until the end of the program. However, x is a stack variable so that won’t work.
Shortening Lifetime of Mutable Borrow
- The mutable borrow of x needs to be able to last until the end of the program but since x is not global or heap allocated it cannot do so.
- The compiler knows that if you have a static reference, you can use it in place of anything with shorter lifetime reference.
- If you have a string with a static lifetime, it’s valid in any context that takes non-static lifetime because the static lifetime is always longer than any other lifetime.
Exploring Variance
- The reason why we can provide tick-static-t instead of take-a-tick-t when taking t as an argument is due to variance specifically covariance.
- If we have two strings where one has a non-static lifetime and another has a static lifetime, we can still assign them because any string with a static lifetime is valid in any context that takes non-static lifetime.
- The compiler knows that it can shorten the borrow of x in some cases, but not in others. This is what we will explore next.
Making X Static
- If we don’t have an assertion, the compiler can pretend that the mutable borrow has the same lifetime as x until it’s dropped.
- When we add an assertion, this is now trying to immutably access x before x is dropped and won’t compile again because x needs to be static.
Why Does This Example Work?
Section Overview: In this section, the speaker explains why a specific example works in Rust.
Subtyping
- The type of
yis some lifetime ticka, but we’re assigning something that is a tick static into something that’s a ticket. - A subtype is when some type
tis at least as useful as some typeu. - Static is a subtype of any tick
a. - You can use subtyping for things that aren’t lifetimes in Rust currently variants mostly just affects lifetimes.
Variance
- Most things are covariant.
- If you have some function foo that takes a t and doesn’t return anything, you can use the same argument for if you have some x of type t and you want to assign to it.
- Here’s what we’re going to do: let’s say that foo takes a tick
astir. You’re allowed to provide any type that is a subtype of the arguments in this case right so I can call foo with some tickastir but I can also call foo with a static stirrer static is a subtype ofa.
Covariance
Section Overview: In this section, the speaker explains covariance and how it works in Rust.
Not Every Type Is Covariant
- There are three types of variance: covariance, contravariance, and invariance.
- Animal is not a subtype of cat because cats can do things that animals can’t.
Covariance and Contravariance
Section Overview: This section discusses covariance and contravariance in Rust, specifically in relation to functions that take arguments of different types.
Covariant Types
- A type is covariant if it can be replaced with a subtype.
- In Rust, most types are covariant.
- Examples of covariant types include
&'a TandBox<T>.
Contravariant Types
- A type is contravariant if it can be replaced with a supertype.
- In Rust, the only contravariant type is
fn(T). - An example of a contravariant function argument is a function that takes an argument of type
fn(&'a str).
Example: Function Arguments
- If a function expects an argument of type
fn(&'a str)but receives an argument of typefn(&'static str), this will not compile because the provided function requires a longer lifetime than what was expected. - However, if the function expects an argument of type
fn(&'static str)but receives an argument of typefn(&'a str), this will compile because the provided function requires a shorter lifetime than what was expected.
# Rust Lifetimes
Section Overview: This section covers the concepts of covariance, contravariance, and invariance in Rust lifetimes.
Covariance and Contravariance
- Covariant types are more generally applicable than their subtypes.
- In Rust, function argument types are the only place where we have contravariant types.
- A static lifetime is a subtype of any other lifetime ticket.
- A function with a tick a t argument is a subtype of a static t.
- The subtyping relationship between these two types is flipped, which is what contravariance means.
Invariance
- Invariance refers to cases where neither covariance nor contravariance applies.
- Mutable references to a type T are covariant in the tick a but invariant in the T.
- If mutable references were covariant, it would be possible to assign an x of type static string reference into foo that takes mutable reference to some string pointer. However, this would lead to issues when trying to print x since it’s pointing into stack local memory that has since been dropped.
Cell Static
- The concept of cell static is introduced as an example for explaining why mutable references cannot be covariant.
Overall, this section provides an overview of how covariance and contravariance work in Rust lifetimes and explains why there are cases where neither applies (invariance). It also introduces the concept of cell static as an example for explaining why mutable references cannot be covariant.
Invariance for Mutable References
Section Overview: This section explains why mutable references are invariant in their argument type.
Why Mutable References are Invariant
- Mutable references are invariant in their argument type.
- Invariance means that you must provide something that is exactly the same as what was specified. You cannot provide something more useful or less useful.
- The compiler needs to reconcile the provided arguments with the signature of foo, but it cannot make static be equal to take a or take a equal to static because mutable references are invariant in their thing that they reference.
- If mutable references were not invariant, you could downgrade a mutable reference to something less useful and end up with something that thinks it’s a more useful type but it’s actually a less useful type.
Covariance and Invariance for Immutable References
Section Overview: This section explains why immutable references are covariant in their lifetime but invariant in the t.
Covariance and Invariance for Immutable References
- Immutable reference to t is covariant in its lifetime but invariant in the t because if we had covariance, we could have an immutable reference to b with some lifetime and then stick in something less useful.
- The lifetime of the mutable reference to b is from b until when b gets dropped.
- We can introduce a memory leak using box leak which allows us to get an immutable reference with any lifetime but specifically with a static lifetime.
- Here, z is a mutable reference to y and we set z equals x which compiles fine because immutable references are covariant in their lifetime but invariant in the t.
Introduction to Mutable References
Section Overview: In this section, the speaker introduces mutable references and explains how they are invariant in their type but covariant in their lifetime.
Mutable References
- Mutable references are introduced as a way to modify variables.
- They are invariant in their type but covariant in their lifetime.
- The compiler reconciles these two properties by allowing for subtyping between static and other lifetimes.
- This allows for the shortening of an immutable borrow’s lifetime.
Covariance and Invariance of Mutable References
Section Overview: In this section, the speaker explains why mutable references are covariant in their lifetime and invariant in their type.
Covariance and Invariance
- Mutable references are covariant in their lifetime because it is safe to shorten the lifetime of an immutable borrow.
- They are invariant in their type because it is not safe to assign a less useful type into what’s behind the mutable reference.
Understanding Lifetime Issues with Mutable References
Section Overview: In this section, the speaker discusses how mutable references can cause issues with lifetimes.
Lifetime Issues
- The speaker goes back to a previous example where there was an issue with lifetimes.
- The compiler tells us that x does not live long enough because it needs to figure out how long the mutable borrow will be.
- We cannot shorten the lifetime of what’s behind the mutable reference due to its invariance, so we must make it static instead.
Introduction
Section Overview: In this section, the speaker explains that they will be discussing why a certain code does not compile and how to fix it. They emphasize the importance of understanding why the code doesn’t work before jumping into a solution.
Adding an Additional Lifetime
Section Overview: The speaker introduces an additional lifetime to fix a code that previously did not compile.
- The new signature for
stir_talknow has two lifetimes: one for mutable borrow and one for the string being pointed to. - The compiler can now choose these two lifetimes independently, allowing us to choose one as static and one as non-static.
- With this new signature, the previously non-compiling code now compiles successfully.
Testing the Fixed Code
Section Overview: The speaker tests the fixed code with an earlier example to ensure that it works properly.
- The earlier example now compiles successfully with the fixed code.
- An unnecessary line is removed from the earlier example.
- The test passes, indicating that our implementation was correct.
Explanation of Lifetime Assumptions
Section Overview: The speaker explains why a tick bee bound is not needed in this case.
- Rust assumes that any generic lifetime argument implies at least for as long as the duration of the function. This assumption is all we need for our mutable reference.
- Tick b does not depend on tick a; we are only returning a string.
Borrow Checker Rules
Section Overview: This section covers the borrow checker rules in Rust.
Mutable Reference Lifetime
- Modifying a variable after a mutable borrow would cause an error.
- Non-lexical lifetimes (NLL) enabled in Rust 2015 edition, but before NLL, this code would not compile.
Borrowing Rules
- You can have a mutable reference to something that lives longer than the mutable reference.
- You cannot have a tick
ais longer than tickb. - The compiler implicitly adds a bound that tick
bmust be shorter than or equal to ticka.
Phantom Data
- Phantom data is used when you have a type that is generic over
T, but doesn’t directly contain it. - A phantom data field is added to satisfy the Rust compiler’s requirement for using unused type parameters.
The Drop Check
Section Overview: This section discusses the drop check in Rust and how it determines whether generic types might be dropped as well.
The Drop Check
- When a type is dropped, Rust needs to know whether the generic types might be dropped as well.
- If a vector of
Ts is dropped, then when you drop the vector, you’re also going to drop someTs. - Rust needs to know this because dropping a reference that still exists is not okay if it’s going to try to access the reference later on.
- However, if the vector is never accessed again after being dropped, then dropping the reference does not access the inner type on drop and is okay.
- The compiler knows this through something called the drop check which looks at whether the type contains a
Tand a phantom dataT. - Vec will only drop inner types if they implement drop themselves.
Touch Drop
Section Overview: This section discusses touch drops in Rust and how they relate to variance.
Touch Drop
- Touch drops are used for debugging purposes in Rust.
- They require that their type is format debug and we’re going to impl drop for touch drop.
- If you make this a touch drop instead of just a reference, then this code no longer compiles because when z gets dropped right down here, we’re going to call this implementation of touch drop which is going to access the inner type which means it’s going to access this reference so dropping x here is not okay because by when z gets dropped it’s going to try to access the reference but when we drop the vector dropping the reference does not access the inner type on drop.
- Dropping x here would cause an error because there’s still a reference that lives down here.
Understanding Phantom Data
Section Overview: In this section, the speaker talks about phantom data and its use in Rust programming. They explain how it is used to communicate ownership and drop semantics.
Phantom Data
self.0is a tuple struct with one element.- The compiler assumes that it’s going to drop a
T. - Phantom data
Tcommunicates that you are owning aTand might drop one. - Phantom data
Fntis a marker of contravariance.
Invariance
- If you want your type to be invariant in
T, you can use phantom data. - The compiler concludes that the
Tin d serializer four must be invariant in T.
Covariance
- Star const T is covariant.
- Unsafe cell has to be invariant.
Raw Pointers vs. Phantom Data
Section Overview: In this section, the speaker compares raw pointers and phantom data, explaining why people prefer using phantom data over raw pointers.
Raw Pointers
- Once you introduce raw pointers, there are a couple of things you don’t get like send and sync auto-implemented for your types assuming all the members are.
Auto Implementation
- People prefer using phantom data over raw pointers because if you use this type and a phantom data, it would get auto-implemented for send and sync.
Covariance and Invariance in Rust
Section Overview: This section discusses the importance of understanding covariance and invariance in Rust, particularly when dealing with generic types.
Understanding Covariance and Invariance
- It is important to consider whether a type is covariant or invariant when working with generic types.
- If a compiler concludes that a type is invariant over T, but you need it to be covariant, you must ensure that your code is not vulnerable to an “invariance attack.”
- In unsafe code, if the safety of your code relies on a generic parameter being invariant but the compiler concludes it’s covariant, you must ensure that your type is actually invariant.
- In order to mutate through a pointer, you can only use
&mut T,*mut T, orUnsafeCell<T>. All of these are invariant.
Syntax for Lifetime Bounds
- The syntax
for<'a>specifies that a bound holds for any lifetime'a'. - This syntax does not affect variance or subtyping.
Mutating Through Star Const T
- You can technically mutate through
*const Tby casting it without undefined behavior. However, this should be avoided as it requires contorting yourself into using an immutable reference as a mutable one.
Unique Types and Non-null Pointers
- Vectored types and box types contain unique pointers which are non-null. The nominal pointer type is covariant over T.
- If this covariance is incorrect for your use case, include phantom data in your type to provide invariants.
Rust Lifetimes: Variance and Subtyping
Section Overview: In this video, the speaker covers variance and subtyping in Rust lifetimes. They start with a simple function and show how adding lifetimes can cause issues. The speaker then explains how to fix these issues using variance and subtyping.
Understanding Lifetime Specifiers
- A simple function like
stir_talkcan become complicated when lifetime specifiers are added. - Adding lifetime specifiers to every reference is not enough to solve the problem.
- Using tick marks (
'a) on all references can lead to problems that are difficult to diagnose.
Solving Lifetime Issues with Variance and Subtyping
- Adding a second lifetime specifier solves the issue of calling
stir_talk. - The solution involves using variance and subtyping.
- By the end of the video, viewers should have a better understanding of variance and subtyping in Rust lifetimes.
Writing Explicit Code
- It’s possible to write code without explicit lifetime specifiers by relying on Rust’s automatic generation of unique lifetimes for each reference.
- However, it’s recommended to be explicit about different lifetimes for clarity.
Conclusion
- The speaker thanks viewers for joining them in this journey through Rust lifetimes.
- They acknowledge that explaining type inference can be challenging but hope that viewers landed in a good place.
- The next stream will likely involve live coding, possibly porting some code.
Generated by Video Highlight
https://videohighlight.com/video/summary/iVYWDIW71jk
Part 3:
- Part 3:
- Introduction
- Changes Since Last Stream
- Synchronization Primitives
- Hazard Pointers
- Atomic Pointer Type
- Changes Made for Hazard Pointers
- Tidying Up Interface Names
- Understanding Hazard Pointer Holders
- Hazard Pointer Holder
- Hazard Pointer Holder API Changes
- Other Proposed Changes
- Renaming and Refactoring
- Hazard Pointers vs Epoch-Based Reclamation
- Relaxed Cleanup
- Push List
- Retirement and Reclamation
- Overview of Changes to Code
- Moving from Push Retired to Push List
- Introduction to Push List
- Retiring Items
- Understanding Ownership of Linked Lists
- Exclusive Access to Linked List Head
- Implementing on Tag.Push
- Modifying Linked List
- Atomic Pointer and Push List
- Check Count Threshold
- Implementing a Heuristic for Reclamation
- Understanding Hazard Pointers
- Understanding Garbage Collection in Rust
- Reclaiming Hazard Pointers
- Introduction
- Naming Error
- Code Refactoring
- Shared Reference Issue
- Skipping Global Domain
- Type Annotation Needed
- Unused Variable Error
- Debugging Segmentation Fault Error
- Troubleshooting Code
- Restructuring Command
- Charging Untagged List
- Generated by Video Highlight
Introduction
Section Overview: In this section, the speaker introduces the topic of the stream, which is implementing hazard pointers in Rust. The speaker also mentions that they will be focusing on testing and recaps some information from previous streams.
- The speaker welcomes viewers to another implementation stream where they will be working on implementing hazard pointers in Rust.
- They mention that they are porting a library called Folly from Facebook and specifically focusing on the hazard pointer scheme.
- The speaker notes that today’s focus will primarily be on testing and ensuring that the implementation works as intended.
- They briefly mention their book “Rust for Rustations” and provide information about where it can be purchased.
- Lastly, they touch upon some changes since the previous stream, including merging a pull request and an issue with panic in has pointer domain drop when using local domains.
Changes Since Last Stream
Section Overview: In this section, the speaker discusses changes made since the last stream.
- A viewer submitted a pull request that simplified a macro used to work around limitations of the borrow checker.
- An issue was filed regarding a panic in has pointer domain drop when using local domains. The speaker plans to write a test to reproduce this problem.
Synchronization Primitives
Section Overview: This section covers the synchronization primitives, including hazard pointers.
Hazard Pointers
- A commit aligns the Facebook implementation with the standards proposal for the CPA simplest working group.
- The library exports an atomic pointer type and a hazard pointer object wrapper type.
- Hazard pointers guard pointer values, so a holder is required to protect them.
- The global domain keeps track of all of the slots that have been given out.
Protecting Pointer Values
- To protect a pointer value, you atomically load it and store it in your slot.
- You get back a reference that you can use to access the underlying values.
- The reference must remain valid at all times for as long as it lives.
Releasing Pointer Values
- Dropping the holder releases your guarding of the value, and you can no longer use the reference that you got back from protect.
- On the writer’s side, allocate some new replacement value and call swap.
Hazard Pointers
Section Overview: This section explains how hazard pointers work and how they ensure that objects are not prematurely freed.
Protecting Pointer Values with Hazard Pointers
- When a pointer value is swapped, the old value is still accessible because it has not been dropped or freed.
- Hazard pointers guard the value to ensure it is not prematurely freed.
Retiring Pointer Values
- Retiring a pointer value means telling the hazard pointer library that it can be safely freed.
- A data structure may have multiple pointers to a given pointer value, so multiple atomic operations may need to be performed before it is safe to free the object.
- The writer tells the hazard pointer library when a value should be retired and how to drop it.
Live vs. Retired Objects
- A live object is reachable and has not been retired, while a retired object is no longer reachable by new readers but may still be accessed by old readers.
- A reclaimable object can be dropped and its memory reclaimed because there are no hazard pointers guarding it anymore.
Example of Using Hazard Pointers
- An example demonstrates how an old pointer becomes retired after being swapped and then notified as retired. It becomes reclaimable only after all hazard pointers guarding it have been dropped.
Atomic Pointer Type
Section Overview: The speaker discusses the implementation of an atomic pointer type that internally uses a box, simplifying safety and variance. They also discuss how this low-level interface can be used to build nicer abstractions on top of it.
Implementation of Atomic Pointer Type
- An atomic pointer type is implemented using a box.
- This simplifies safety and variance.
- The retire method still needs to be unsafe because the outer data structure’s construction is unknown.
- Protect requires a valid pointer value, which can always be guaranteed if the pointer value is provided.
Changes Made for Hazard Pointers
Section Overview: The speaker discusses changes made for hazard pointers, including renaming get protected to protect and reset to reset protection.
Changes Made for Hazard Pointers
- Folly renamed get protected to protect and reset to reset protection.
- Reset protection was added in holder as a change we can make easily.
- Renaming makes it clear that you are resetting the protection rather than resetting the pointer or its protection.
Tidying Up Interface Names
Section Overview: The speaker talks about how keeping names similar between implementations will make following diffs simpler. They also discuss whether they should apply all changes or start with testing first.
Tidying Up Interface Names
- Using similar names between implementations will make following diffs simpler.
- Helper methods like check cleanup and reclaim match exactly what was in the folly code base.
- It’s tempting to do testing first before applying changes but there’s a question of whether they want to go through these and apply all changes.
Understanding Hazard Pointer Holders
Section Overview: In this section, the speaker discusses the changes made to the constructor for hazard pointer holders and how they are used.
Constructor Changes
- The default constructors now construct empty holders and arrays.
- The default constructor should not acquire a hazard pointer from the domain.
- A free function is provided for constructing a non-empty holder using make hazard pointer.
- The change makes it more annoying to construct a holder without an associated hazard pointer.
Hazard Pointer Holders
- Holders do not have a slot but hold a hazard pointer that has the slot.
- Acquire a protection slot from the domain and put it in the holder.
- The default constructor gives you a holder with no associated hazard pointer yet.
- Make hazard pointer can be called without providing a domain.
Hazard Pointer Holder
Section Overview: In this section, the speaker discusses the hazard pointer holder and its association with the lifetime of a domain. They also discuss implementing default for hazard pointer holder specifically for static.
Default Implementation for Hazard Pointer Holder
- The hazard pointer holder is tied to the lifetime of the domain that you constructed with.
- It’s not entirely clear what would happen if you don’t specify a domain.
- One option is to implement default for hazard pointer holder specifically for static.
- It’s unclear what we would even default this to, but we could implement it for unit.
- This would produce a hazard pointer holder that is either empty or acquired.
Private Variants and Enums
- The variants should be private, but in Rust, you can’t mark variants as private.
- To make them non-public, they will become an enum called “hazardpointerholderinnerdomainf”.
- This will be an empty enum.
Make Hazard Pointer
- “Make Hazard Pointer” is what they call the method used to create a hazard pointer explicitly.
- The method takes a domain and returns a hazard pointer holder for that domain and given f.
- This method is generic over f2 and returns self of hazard pointer holder inner acquired.
Constructor
- They have a constructor which was equal to the default hazard pointer domain.
Hazard Pointer Holder API Changes
Section Overview: In this section, the speakers discuss proposed changes to the Hazard Pointer Holder API.
Proposed Changes
- There is no constructor for retroactively setting a hazard pointer for a given domain.
- The example does not show how to construct from a given domain or holder.
- It is not clear why the proposed API is superior and it may not be worth implementing.
- They discuss what happens when try protect is called without an HP rec.
- They mention that source.load doesn’t work in this context.
- An empty object is needed for moves to leave behind.
- They discuss when constructing a default value might be useful in Rust land.
- Wrapping it in an option would suffice instead of re-implementing internally in the library.
Other Proposed Changes
Section Overview: In this section, the speakers discuss other proposed changes to the Hazard Pointer Holder API.
Proposed Changes
- Remove unused hazard pointer domain data members unprotected and children and function reclaim unprotected safe.
- Improve readability by specializing friends and using specialized aliases while reducing use of atom template parameter.
- Support class and function names consistent with wg2 by renaming hazard pointer holder to hazard pointer.
# Refactoring Hazard Pointer
Section Overview: In this section, the speaker refactors the code to use hazard pointer record instead of has pointer record.
Refactoring Code
- The speaker starts by changing “has pointer holder” to “hazard pointer”.
- The speaker notes that “has pointer” is not a type in C++ and changes it to “has pointer wreck”.
- The speaker moves “pointer to record” and changes it from pub to record.
- The speaker makes domain become hazard pointer.
- The speaker decides to use the nomenclature of “make” for hazard pointers.
- The speaker changes all instances of “pointer holder” to “hazard pointer”.
- The compile fail tests start failing for the wrong reasons, so the speaker fixes them.
- Another rename is made from has pointer domain to hazard pointer domain.
Conclusion
The code was successfully refactored using hazard pointers.
Renaming and Refactoring
Section Overview: In this section, the speaker discusses renaming certain variables and objects in the codebase to make it more readable.
Renaming Domain and Hazard Pointer
- The speaker renames “has pointer domain” to just “domain” since it is unnecessary when using modules.
- The speaker also renames “haphazard” to “hazard pointer” because it is a type of hazard pointer.
Qualification and Importing
- The qualification for the prefix is not necessary since it already comes from a crate by that name.
- Instead of saying “domain,” one can say “hazard pointer domain” without importing it with the rename.
Hazard Pointers vs Epoch-Based Reclamation
Section Overview: In this section, the speaker explains why they chose hazard pointers over epoch-based reclamation.
Differences between Hazard Pointers and Epoch-Based Reclamation
- There is a table in the simplest proposal that talks about the differences between hazard pointers and epoch-based reclamation.
Relaxed Cleanup
Section Overview: In this section, the speaker discusses a bug fix that doesn’t just matter for cohorts.
Bug Fix for Bulk Reclaims
- A change includes incrementing num bulk reclaims before invoking do reclamations either directly or in an executor.
- This seems like a bug fix that doesn’t just matter for cohorts so they have relaxed cleanup.
Push List
Section Overview: In this section, the speaker talks about push list and retiring items.
Push List
- Currently, only retiring individually is supported.
Retirement and Reclamation
Section Overview: In this section, the speakers discuss the retirement and reclamation process in their codebase. They talk about push list, check threshold, and reclaim.
Push List and Check Threshold
- Push list is the only thing that calls check threshold and reclaim.
- It might be worth adding push list, but it seems more like a modification to a new feature.
- There’s so much indirection here which is pretty frustrating.
Retiring Objects
- They don’t have the same logic as they do for retiring objects.
- They don’t have a do reclamation method.
- Non-chord returned objects are pushed directly into the domain.
Consolidating Retired Objects
- The change to consolidate non-cohort and untied cohort retired objects will be a little bit of a pain for them because they implemented only the things that are not using cohorts.
- They’re making it so that there’s no special handling for things that aren’t using cohorts.
- This means they’re going to need to implement retired list which is something they didn’t want to do.
Sharding Untagged List
- The commit sharded the untagged list which means they’ll have to do it too.
Overview of Changes to Code
Section Overview: In this section, the speaker discusses changes to the code and how they will impact their work. They discuss changes related to executors, tests, benchmarks, and reclamation.
Changes to Executors
- The speaker explains that there is a new ability for executors to do reclamation in the background.
- The speaker notes that they did not implement this change yet and it may not make much of a difference for them.
Changes to Tests and Benchmarks
- The speaker mentions that there are changes related to tests but they have not implemented them yet.
- They suggest doing these changes one at a time since they seem like disparate changes.
- The speaker expresses concern about testing known broken code and suggests porting other changes first.
Improving Reclamation
- The speaker notes that there is a change related to improving reclamation.
- They suggest doing each change one at a time since they are fairly disparate.
Moving from Push Retired to Push List
Section Overview: In this section, the speaker discusses moving from push retired to push list in order to improve performance. They explain how this change impacts their work and what steps need to be taken.
Implementing Push List
- The speaker notes that implementing push list will require grabbing additional machinery from another file.
- They mention using a specific commit as reference for implementing push list.
Retirement Process
- The speaker explains that retired objects are kept in a queue until they are reclaimed.
- They describe how to retire an object by constructing a retire node and pushing it onto the retired list.
Updating Code
- The speaker notes that push retired will need to be updated to push list of retired.
- They mention the benefits of using cohorts instead of bulk reclaim.
Introduction to Push List
Section Overview: In this section, the speaker introduces the concept of push list and discusses its parameters.
Parameters of Push List
- The function push list takes a self parameter.
- It also takes a domain parameter.
- Additionally, it may take a star mute parameter.
- However, it is not necessary for it to take a star mute parameter.
- Instead, it can take a retired parameter.
Retiring Items
Section Overview: In this section, the speaker discusses how items are retired and added to the retired list.
Adding Items to Retired List
- To retire an item, we use the retired function which takes in only one item at a time.
- We require that push list takes in a box retired as its parameter.
- The linked list node passed into push list may or may not be the head of an existing list.
- Any node in a linked list is considered as a list.
Handling Empty Lists
- The code assumes that there will never be an empty list.
Counting Items in Retired List
- To count how many items are actually in the retired list, we introduce n as zero and borrow into sublist.
- We then count each item by iterating through them using while cur.next.get.is null.
Understanding Ownership of Linked Lists
Section Overview: In this section, the speaker discusses how owning the head of a linked list ensures that no one else is modifying the rest of the list. They also discuss how retired lists can only be constructed from valid elements.
Owning the Head of a List
- Owning the head of a linked list ensures that no one else is modifying the rest of the list.
- Owning the head also means owning all its elements.
Retired Lists and Valid Elements
- Retired lists can only be constructed from valid elements.
Exclusive Access to Linked List Head
Section Overview: In this section, the speaker discusses whether having exclusive access to the head of a linked list guarantees that you can dereference next pointers. They also consider implementing an unsafe helper function for length.
Exclusive Access to Head and Dereferencing Pointers
- Having exclusive access to the head does not guarantee that you can dereference next pointers.
- An exclusive reference to self may be good enough for length if we have exclusive access to the head.
Implementing an Unsafe Helper Function for Length
- No more than 4 bullet points in this section.
- The speaker considers implementing an unsafe helper function for length but decides against it due to lack of guarantee on dereferencing next pointers.
Implementing on Tag.Push
Section Overview: In this section, they implement on tag.push and discuss changes needed for supporting a list.
Changes Needed for Supporting a List
- The retired list needs further investigation.
- No more than 4 bullet points in this section.
- The speaker considers not supporting the locking part of the list for now.
- Changes are needed to set the next pointer of the tail of the sublist.
Modifying Linked List
Section Overview: In this section, they discuss modifying a linked list and how to change next pointers.
Changing Next Pointers
- The next pointer of the tail needs to point to the head of the old list.
- No more than 4 bullet points in this section.
- A raw pointer is returned to modify next pointers.
Atomic Pointer and Push List
Section Overview: In this section, the speaker discusses atomic pointers and push list.
Atomic Pointer
- An atomic pointer is needed for safety.
- Unsafe is not required for an atomic pointer.
Push List
- The head of the list is stored in the next pointer of the tail of the sublist being inserted.
- Self.untagged.push retired adds count and checks threshold and reclaim.
- Add count returns n, which is the number of items added to untagged.
- Count becomes self untagged count dot load.
- Check threshold and reclaim calls check count threshold.
Check Count Threshold
Section Overview: In this section, the speaker discusses check count threshold.
Load Count
- Load count reads from count, which is a replacement for our count that stores the value inside the retired list of untagged.
While Loop
- While loop runs while our account is greater than threshold.
- Positive and threshold returns a u size that equals max of r count threshold or k multiplier times h count.
- H count multiplier times self dot h_count.load.
Implementing a Heuristic for Reclamation
Section Overview: In this section, the speaker discusses the implementation of a heuristic for figuring out when to run reclamation. They explain that running reclamation every time someone retires an object is not ideal and discuss the use of multipliers to determine when to run reclamation.
Count Threshold
- The count threshold is used as part of the heuristic to determine when to run reclamation.
- The count threshold is only exceeded when the retirement list or reclamation list gets particularly long.
Check Count Threshold
- This method checks if our count exceeds the threshold set in the previous step.
- If our count is zero, it moves on to check due time.
Check Due Time
- This method returns a u64 size and loads due time.
- It tries to make it so that objects are reclaimed either after a certain amount of time has passed or if a certain number of objects have been retired.
Set Due Time
- This method sets due time by adding sync time period to now.
- It uses acquire release and relax ordering.
Understanding Hazard Pointers
Section Overview: In this transcript, we will learn about hazard pointers and how they are used in concurrent programming.
Introduction to Hazard Pointers
- Hazard pointers are a technique used in concurrent programming to manage memory reclamation.
- They were introduced by Maged Michael in 2004 as an alternative to garbage collection.
- The basic idea behind hazard pointers is that each thread maintains a list of “hazardous” pointers that it is currently using.
- This allows other threads to safely reclaim memory without accidentally freeing memory that is still being used.
Implementing Hazard Pointers
- To implement hazard pointers, we need to keep track of two things: the set of hazardous pointers and the set of retired objects.
- When a thread wants to access a pointer, it first checks if the pointer is already marked as hazardous. If not, it marks the pointer as hazardous and proceeds with its operation.
- If a thread wants to retire an object, it adds the object to the retired set and then checks if any other threads have marked any of its hazardous pointers. If so, it cannot free the object yet because another thread may still be using it.
- Instead, it waits until all threads have removed their hazardous markers from the object before freeing it.
Using Hazard Pointers in Rust
- Rust provides a library called crossbeam that implements hazard pointers for us.
- We can use crossbeam’s
epochmodule to create an epoch-based memory reclamation scheme. - The
epochmodule provides aGuardstruct that represents an epoch, which is a period of time during which all hazardous pointers are guaranteed to be valid. - We can use the
Guardstruct to safely access hazardous pointers and retire objects without worrying about other threads accessing them at the same time.
Conclusion
- Hazard pointers are a powerful technique for managing memory reclamation in concurrent programming.
- By using hazard pointers, we can safely reclaim memory without worrying about accidentally freeing memory that is still being used by another thread.
- Rust’s crossbeam library provides an easy-to-use implementation of hazard pointers through its
epochmodule. I’m sorry, but I cannot provide a summary of the transcript as there are no clear and concise sections or topics to summarize. The conversation seems to be disjointed and lacks a clear focus or direction. Additionally, there are no timestamps associated with most of the bullet points provided, making it difficult to create a structured and informative markdown file. If you have any specific questions or requests for information from the transcript, please let me know and I will do my best to assist you.
Understanding Garbage Collection in Rust
Section Overview: In this transcript, the speaker discusses garbage collection in Rust and how it works. They go through the code step by step to explain how the garbage collector identifies and reclaims unused memory.
Identifying Unused Memory
- The garbage collector starts by identifying all nodes that are not being used.
- Nodes that are still being used are marked as “guarded”.
- The garbage collector then goes through each node and determines if it can be reclaimed or not.
- Reclaimable nodes are added to a list for later processing.
Reclaiming Unused Memory
- Once all reclaimable nodes have been identified, they are processed one at a time.
- The garbage collector checks if any other nodes reference the current node being processed. If so, it cannot be reclaimed yet.
- If no other nodes reference the current node, it is marked as “reclaimed” and its memory is freed up for future use.
Separating Identification from Reclamation
- The process of identifying unused memory is separated from actually reclaiming it. This allows for more efficient processing of large amounts of data.
- Unreclaimable nodes are pushed back onto the untagged list for later processing.
Helper Methods
- A helper method called
is_emptyis created to check if a linked list is empty or not. - Another helper method called
pushtakes a sublist tail and inserts it into a linked list.
Conclusion
The speaker provides an in-depth explanation of how garbage collection works in Rust, including the identification and reclamation of unused memory. They also discuss the importance of separating the identification process from the reclamation process for more efficient processing. Helper methods are created to aid in these processes.
# Unsafe Dereferencing
Section Overview: In this section, the speaker discusses the issue of unsafe dereferencing and how it is up to the caller to ensure safety.
Unsafe Dereferencing
- The speaker mentions that dereferencing will be unsafe since it is up to the caller to assure safety.
- The speaker notes that this will be subtle and mentions sub list tail dot next dot store.
# Moving Count Out of Retired List
Section Overview: In this section, the speaker discusses moving count out of retired list and updating other related code.
Moving Count Out of Retired List
- The speaker suggests moving count out of retired list.
- The speaker moves count out of retired list and updates anywhere that says self dot retired.
- The speaker notes that count needs to change in push list as well.
# Updating Unreclaimed and Unreclaimable Tail
Section Overview: In this section, the speaker updates unreclaimed and unreclaimable tail variables.
Updating Unreclaimed and Unreclaimable Tail
- The speaker updates unreclaimed and unreclaimable tail variables.
- The speaker explains why this update works for pushing onto head.
- The speaker suggests wrapping linked lists with a new type wrapper like seatpost’s coded done.
# Updating Parent Count
Section Overview: In this section, the speaker updates parent count.
Updating Parent Count
- The speaker notes that rust analyzer is being thrown off and gets rid of things that are no longer real.
- The speaker updates parent count by subtracting the number of things that were reclaimed and unreclaimed.
Reclaiming Hazard Pointers
Section Overview: In this section, the speaker discusses the process of reclaiming hazard pointers in Rust.
Reclaiming Hazard Pointers
- If count is not equal to zero at the end of the loop, add count.
- Account gets added back here.
- Only enter do reclamation if there’s an indication that you should be reclaiming. Loop until it doesn’t look like there’s anything more to reclaim. Check count threshold and only exit if there’s no indication that we should reclaim again and there is nothing that can be reclaimed.
- Decrement of bulk er claims happens here.
- Need for “reclaim unprotected”.
- “Reclaim unprotected” takes just the head and children (star mute retired).
- Next is retired dot next. Next here is a has pointer object which is a relaxed load.
- Calls reclaim so actual reclamation occurs.
Safety Comment
- This comment pertains to safety for calling “reclaim unprotected”. Every item in reclaimable has no hazard pointer guarding it, so we have the only remaining pointer to each item. All retired nodes in retired are unaliased throughout and unowned by taking ownership of them. Every retired was originally constructed from a box and thus valid. None of these retired have been dropped previously because we atomically stole the entire sublist from self.untagged.
# Restructuring the Code
Section Overview: In this section, the speaker discusses restructuring the code and removing unnecessary methods.
Removing Unnecessary Methods
- The speaker believes that some methods such as “count” and “sync time” are no longer necessary and can be removed.
- The speaker confirms that certain methods are no longer called and can be removed from the code.
Eager Reclamation
- The speaker introduces a new method called “eager reclaim” which allows for immediate reclamation of objects.
- The speaker suggests modifying eager reclaim to return the number of items reclaimed.
Shutdown Field
- The speaker introduces a new field called “shutdown” which is an atomic bool used in the destructor for domain.
- In drop, self.shutdown is set to true and self.reclaim_all_objects() is called.
Reclaim All Objects
- A new method called “reclaim all objects” is introduced.
- Pop all is suggested as a helper function for reclaim all objects.
# Understanding Reclaim List Transitive
Section Overview: In this section, the speaker discusses reclaim list transitive and how it is similar to a loop that was previously discussed. They also mention that they will be muting some cells for now.
Reclaim List Transitive
- Reclaim list transitive is mentioned.
- The speaker mentions “head” and notes that they are unsure of what it does.
- The speaker mutes some cells but notes that they may not need to be muted.
- The speaker notes that reclaim list transitive is similar to a loop discussed earlier in the video.
Neat Loop
- The speaker describes a neat loop where children are grabbed and then reclaimed unconditional head is called.
- The speaker assumes that reclaim unconditional head walks all things from head to tail, pushing any children it finds into children.
- The speaker comments on how neat the loop is.
Handling Children
- The speaker mentions handling children and notes that they will use self reclaim unconditional head.
- Reclaim unconditional is mentioned again, along with muting self mute head.
- The speaker notes that reclaim unprotected and reclaim unconditional are the same.
- Self proclaim unprotected head is mentioned.
# Difference Between Unsafe and Safe Reclaims
Section Overview: In this section, the speaker discusses the difference between unsafe and safe reclaims. They also discuss how hazard pointers are tied to the lifetime of a domain.
Unsafe and Safe Reclaims
- The speaker mentions the difference between unsafe and safe reclaims.
- The speaker notes that reclaim unprotected and reclaim unconditional are the same.
- The speaker comments on how tricky this is.
- The speaker discusses how in Facebook’s implementation, they assume there are no active hazard pointers left.
- The speaker notes that holders are tied to the lifetime of a domain, so once a domain is dropped, there can’t be any hazard pointers to it.
Global Hazard Pointers
- The speaker notes that global hazard pointers get weird because they’re static.
- They discuss guaranteeing that the domain is dropped last by creating handles to it after creating the domain itself.
Safety
- The speaker concludes by noting that add mute self implies there are no active hazard pointers, making all objects safe to reclaim.
Introduction
Section Overview: In this section, the speaker discusses a word that can remain unsafe and its equivalent to reclaim unprotected.
Unsafe Word and Reclaim Unprotected
- The word “man” can remain unsafe.
- “Reclaim unprotected” is equivalent to “reclaim all objects,” but differs in name to clarify that it will remove indiscriminately.
Naming Error
Section Overview: In this section, the speaker talks about a naming error in the function “reclaim unprotected.”
Naming Error in Reclaim Unprotected
- The function name “reclaim unprotected” is a naming error because it implies that only unprotected objects are being reclaimed.
- The function actually reclaims all objects unconditionally, and it’s up to the caller to check whether they’re protected or not.
- Despite the naming error, the speaker wants to keep the name for easier refactorings later with respect to the upstream code base.
Code Refactoring
Section Overview: In this section, the speaker discusses some code refactoring.
Shut Down and Free Hazard Pointer Rex
- Shut down doesn’t need to be an atomic bool; it can just be a bool.
- The other thing they call is free hazard pointer rex.
- Fn free has pointer rex itself is probably already right because it’s really just walking the list of hazard pointers.
Shared Reference Issue
Section Overview: In this section, the speaker talks about a shared reference issue.
Exclusive and Shared References
- The existence of an exclusive reference implies that a shared reference shouldn’t exist.
- Statics are never dropped, which means that we don’t actually need to deal with the global domain being dropped because it never gets dropped and that’s why there’s no unsafety there.
- In that case, the drop here is kind of stupid because this can just never happen.
Skipping Global Domain
Section Overview: The speaker discusses the global domain and why it is never dropped.
Assertion Check for Global Domain
- The speaker questions the need for a check on the global domain.
- Asserting that the global domain can be dropped implies something false, so it’s not useful to think about it.
- Static items do not call drop at the end of the program, so there is no need to check if they are active.
Debug Check for Hazard Pointers
- The speaker looks at an implementation that walks through hazard pointers and asserts that they’re not active. This is a debug check and seems reasonable.
Type Annotation Needed
Section Overview: The speaker discusses type annotations needed in code.
Unreclaimed Type Annotation
- The speaker adds an unreclaimed type annotation to indicate to the compiler that two types should be the same, but it’s still initialized to null.
Unused Variable Error
Section Overview: The speaker addresses an unused variable error in their code.
Pop Crate Not Needed
- The speaker realizes that pop crate does not need to be used and fixes an unused variable error.
Debugging Segmentation Fault Error
Section Overview: The speaker attempts to debug a segmentation fault error in their code.
Running GDB Debugger
- The speaker runs GDB debugger on their code.
- They attempt to run with feels good option but encounter issues.
- They explain that by adding an unreclaimed type annotation, they are indicating to the compiler that two types should be the same.
Troubleshooting Code
Section Overview: The speaker troubleshoots their code and attempts to get it to compile.
Compiling Issues
- The speaker attempts to troubleshoot why their code is causing issues.
- They attempt to run only feels good but encounter issues.
- They search for a standard library path.
- They realize they forgot what the issue was.
Restructuring Command
Section Overview: In this section, the speaker discusses restructuring a command and making changes to the codebase.
Relevant Commit
- The speaker identifies a relevant commit that is needed for the restructuring.
Retired List Error
- The speaker identifies an error in pushing to the retired list.
- They explain that if sublist head is null, pushing an empty list is easy.
Charging Untagged List
Section Overview: In this section, the speaker discusses charging untagged lists and making changes to the codebase.
Num Shards Constant
- The speaker explains that there’s a num shards of type probably you size which is eight and untagged is now actually multiple untagged.
Calc Shard Function
- The calc shard function takes a tag as input and returns a u size. It uses the head pointer as the tag.
- The speaker considers reordering functions and using default hasher instead of cryptographically secure hasher for performance reasons. [CUTOFF_LIMIT]
Generated by Video Highlight
https://videohighlight.com/video/summary/tGn0mQF0804
Questions about associated type and generic associated type
in rust, what is associate type, what is generic associate type.
In Rust, an associate type is a type placeholder that is defined within the bounds of a trait. It allows a trait to specify that concrete types used to implement the trait must provide a specific type, without requiring the trait to know what that type is.
Here is an example of a trait with an associate type:
trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; }
The Item type in this example is an associate type. It is used to specify the type of the value that will be returned by the next method.
A generic associate type is similar, but it allows the trait to specify that the concrete type must itself be generic, and the trait can use parameters to specify constraints on the types used to implement it.
Here is an example of a trait with a generic associate type:
trait Iterator<T> { type Item: Borrow<T>; fn next(&mut self) -> Option<Self::Item>; }
In this example, the Item type is a generic associate type. It is used to specify that the type of the value returned by next must implement the Borrow trait for the type T. This allows the trait to constrain the types that can be used to implement it, while still allowing the implementor to choose the specific type.
what are the differences between associate type, generic type and generic associate type
An associate type is a type placeholder that is defined within the bounds of a trait and is used to specify a type that must be provided by any concrete types that implement the trait. It allows the trait to specify a type without knowing what that type is.
A generic type is a type placeholder that is defined within the bounds of a struct, enum, or function and is used to specify a type that will be provided when the struct, enum, or function is instantiated. It allows the struct, enum, or function to be generic over the type.
A generic associate type is similar to a generic type, but it is defined within the bounds of a trait and is used to specify a type that must be provided by any concrete types that implement the trait. It allows the trait to specify a type that is itself generic, and it can use parameters to specify constraints on the types used to implement it.
Here is an example that shows all three types in action:
// A generic struct with a generic type parameter `T` struct Container<T> { item: T, } // A trait with an associate type `Item` trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; } // A struct that implements the `Iterator` trait and specifies the `Item` type struct Counter { count: u32, } impl Iterator for Counter { type Item = u32; fn next(&mut self) -> Option<Self::Item> { if self.count > 0 { self.count -= 1; Some(self.count) } else { None } } } // A trait with a generic associate type `Item` that is constrained by the trait parameter `T` trait Iterator2<T> { type Item: Borrow<T>; fn next(&mut self) -> Option<Self::Item>; } // A struct that implements the `Iterator2` trait and specifies the `Item` type struct Counter2<T> { item: T, } impl<T> Iterator2<T> for Counter2<T> { type Item = Container<T>; fn next(&mut self) -> Option<Self::Item> { Some(Container { item: self.item }) } }
- In this example, T is a generic type
- Item is an associate type
- and Item: Borrow
is a generic associate type. - The Counter struct implements the Iterator trait and specifies the concrete type u32 for the Item associate type.
- The Counter2 struct implements the Iterator2 trait and specifies the
Container
struct for the Item generic associate type.
Associated types
The use of “Associated types” improves the overall readability of code by moving inner types locally into a trait as output types.
Syntax for the trait definition is as follows:
#![allow(unused)] fn main() { // `A` and `B` are defined in the trait via the `type` keyword. // (Note: `type` in this context is different from `type` when used for // aliases). trait Contains { type A; type B; // Updated syntax to refer to these new types generically. fn contains(&self, _: &Self::A, _: &Self::B) -> bool; } }
Note that functions that use the trait Contains are no longer required to express A or B at all:
// Without using associated types
fn difference<A, B, C>(container: &C) -> i32 where
C: Contains<A, B> { ... }
// Using associated types
fn difference<C: Contains>(container: &C) -> i32 { ... }
Let’s rewrite the example from the previous section using associated types:
struct Container(i32, i32); // A trait which checks if 2 items are stored inside of container. // Also retrieves first or last value. trait Contains { // Define generic types here which methods will be able to utilize. type A; type B; fn contains(&self, _: &Self::A, _: &Self::B) -> bool; fn first(&self) -> i32; fn last(&self) -> i32; } // the previous section: // impl Contains<i32, i32> for Container { // and here no need of `<i32, i32>` impl Contains for Container { // Specify what types `A` and `B` are. If the `input` type // is `Container(i32, i32)`, the `output` types are determined // as `i32` and `i32`. type A = i32; type B = i32; // `&Self::A` and `&Self::B` are also valid here. fn contains(&self, number_1: &i32, number_2: &i32) -> bool { (&self.0 == number_1) && (&self.1 == number_2) } // Grab the first number. fn first(&self) -> i32 { self.0 } // Grab the last number. fn last(&self) -> i32 { self.1 } } fn difference<C: Contains>(container: &C) -> i32 { container.last() - container.first() } fn main() { let number_1 = 3; let number_2 = 10; let container = Container(number_1, number_2); println!("Does container contain {} and {}: {}", &number_1, &number_2, container.contains(&number_1, &number_2)); println!("First number: {}", container.first()); println!("Last number: {}", container.last()); println!("The difference is: {}", difference(&container)); }
The Rust Programming Language
by Steve Klabnik and Carol Nichols, with contributions from the Rust Community
This version of the text assumes you’re using Rust 1.62 (released 2022-06-30) or later. See the “Installation” section of Chapter 1 to install or update Rust.
The HTML format is available online at
https://doc.rust-lang.org/stable/book/
and offline with installations of Rust made with rustup; run rustup docs --book to open.
Several community translations are also available.
This text is available in paperback and ebook format from No Starch Press.
🚨 Want a more interactive learning experience? Try out a different version of the Rust Book, featuring: quizzes, highlighting, visualizations, and more: https://rust-book.cs.brown.edu
Foreword
It wasn’t always so clear, but the Rust programming language is fundamentally about empowerment: no matter what kind of code you are writing now, Rust empowers you to reach farther, to program with confidence in a wider variety of domains than you did before.
Take, for example, “systems-level” work that deals with low-level details of memory management, data representation, and concurrency. Traditionally, this realm of programming is seen as arcane, accessible only to a select few who have devoted the necessary years learning to avoid its infamous pitfalls. And even those who practice it do so with caution, lest their code be open to exploits, crashes, or corruption.
Rust breaks down these barriers by eliminating the old pitfalls and providing a friendly, polished set of tools to help you along the way. Programmers who need to “dip down” into lower-level control can do so with Rust, without taking on the customary risk of crashes or security holes, and without having to learn the fine points of a fickle toolchain. Better yet, the language is designed to guide you naturally towards reliable code that is efficient in terms of speed and memory usage.
Programmers who are already working with low-level code can use Rust to raise their ambitions. For example, introducing parallelism in Rust is a relatively low-risk operation: the compiler will catch the classical mistakes for you. And you can tackle more aggressive optimizations in your code with the confidence that you won’t accidentally introduce crashes or vulnerabilities.
But Rust isn’t limited to low-level systems programming. It’s expressive and ergonomic enough to make CLI apps, web servers, and many other kinds of code quite pleasant to write — you’ll find simple examples of both later in the book. Working with Rust allows you to build skills that transfer from one domain to another; you can learn Rust by writing a web app, then apply those same skills to target your Raspberry Pi.
This book fully embraces the potential of Rust to empower its users. It’s a friendly and approachable text intended to help you level up not just your knowledge of Rust, but also your reach and confidence as a programmer in general. So dive in, get ready to learn—and welcome to the Rust community!
— Nicholas Matsakis and Aaron Turon
Introduction
Note: This edition of the book is the same as The Rust Programming Language available in print and ebook format from No Starch Press.
Welcome to The Rust Programming Language, an introductory book about Rust. The Rust programming language helps you write faster, more reliable software. High-level ergonomics and low-level control are often at odds in programming language design; Rust challenges that conflict. Through balancing powerful technical capacity and a great developer experience, Rust gives you the option to control low-level details (such as memory usage) without all the hassle traditionally associated with such control.
Who Rust Is For
Rust is ideal for many people for a variety of reasons. Let’s look at a few of the most important groups.
Teams of Developers
Rust is proving to be a productive tool for collaborating among large teams of developers with varying levels of systems programming knowledge. Low-level code is prone to various subtle bugs, which in most other languages can be caught only through extensive testing and careful code review by experienced developers. In Rust, the compiler plays a gatekeeper role by refusing to compile code with these elusive bugs, including concurrency bugs. By working alongside the compiler, the team can spend their time focusing on the program’s logic rather than chasing down bugs.
Rust also brings contemporary developer tools to the systems programming world:
- Cargo, the included dependency manager and build tool, makes adding, compiling, and managing dependencies painless and consistent across the Rust ecosystem.
- The Rustfmt formatting tool ensures a consistent coding style across developers.
- The Rust Language Server powers Integrated Development Environment (IDE) integration for code completion and inline error messages.
By using these and other tools in the Rust ecosystem, developers can be productive while writing systems-level code.
Students
Rust is for students and those who are interested in learning about systems concepts. Using Rust, many people have learned about topics like operating systems development. The community is very welcoming and happy to answer student questions. Through efforts such as this book, the Rust teams want to make systems concepts more accessible to more people, especially those new to programming.
Companies
Hundreds of companies, large and small, use Rust in production for a variety of tasks, including command line tools, web services, DevOps tooling, embedded devices, audio and video analysis and transcoding, cryptocurrencies, bioinformatics, search engines, Internet of Things applications, machine learning, and even major parts of the Firefox web browser.
Open Source Developers
Rust is for people who want to build the Rust programming language, community, developer tools, and libraries. We’d love to have you contribute to the Rust language.
People Who Value Speed and Stability
Rust is for people who crave speed and stability in a language. By speed, we mean both how quickly Rust code can run and the speed at which Rust lets you write programs. The Rust compiler’s checks ensure stability through feature additions and refactoring. This is in contrast to the brittle legacy code in languages without these checks, which developers are often afraid to modify. By striving for zero-cost abstractions, higher-level features that compile to lower-level code as fast as code written manually, Rust endeavors to make safe code be fast code as well.
The Rust language hopes to support many other users as well; those mentioned here are merely some of the biggest stakeholders. Overall, Rust’s greatest ambition is to eliminate the trade-offs that programmers have accepted for decades by providing safety and productivity, speed and ergonomics. Give Rust a try and see if its choices work for you.
Who This Book Is For
This book assumes that you’ve written code in another programming language but doesn’t make any assumptions about which one. We’ve tried to make the material broadly accessible to those from a wide variety of programming backgrounds. We don’t spend a lot of time talking about what programming is or how to think about it. If you’re entirely new to programming, you would be better served by reading a book that specifically provides an introduction to programming.
How to Use This Book
In general, this book assumes that you’re reading it in sequence from front to back. Later chapters build on concepts in earlier chapters, and earlier chapters might not delve into details on a particular topic but will revisit the topic in a later chapter.
You’ll find two kinds of chapters in this book: concept chapters and project chapters. In concept chapters, you’ll learn about an aspect of Rust. In project chapters, we’ll build small programs together, applying what you’ve learned so far. Chapters 2, 12, and 20 are project chapters; the rest are concept chapters.
Chapter 1 explains how to install Rust, how to write a “Hello, world!” program, and how to use Cargo, Rust’s package manager and build tool. Chapter 2 is a hands-on introduction to writing a program in Rust, having you build up a number guessing game. Here we cover concepts at a high level, and later chapters will provide additional detail. If you want to get your hands dirty right away, Chapter 2 is the place for that. Chapter 3 covers Rust features that are similar to those of other programming languages, and in Chapter 4 you’ll learn about Rust’s ownership system. If you’re a particularly meticulous learner who prefers to learn every detail before moving on to the next, you might want to skip Chapter 2 and go straight to Chapter 3, returning to Chapter 2 when you’d like to work on a project applying the details you’ve learned.
Chapter 5 discusses structs and methods, and Chapter 6 covers enums, match
expressions, and the if let control flow construct. You’ll use structs and
enums to make custom types in Rust.
In Chapter 7, you’ll learn about Rust’s module system and about privacy rules for organizing your code and its public Application Programming Interface (API). Chapter 8 discusses some common collection data structures that the standard library provides, such as vectors, strings, and hash maps. Chapter 9 explores Rust’s error-handling philosophy and techniques.
Chapter 10 digs into generics, traits, and lifetimes, which give you the power
to define code that applies to multiple types. Chapter 11 is all about testing,
which even with Rust’s safety guarantees is necessary to ensure your program’s
logic is correct. In Chapter 12, we’ll build our own implementation of a subset
of functionality from the grep command line tool that searches for text
within files. For this, we’ll use many of the concepts we discussed in the
previous chapters.
Chapter 13 explores closures and iterators: features of Rust that come from functional programming languages. In Chapter 14, we’ll examine Cargo in more depth and talk about best practices for sharing your libraries with others. Chapter 15 discusses smart pointers that the standard library provides and the traits that enable their functionality.
In Chapter 16, we’ll walk through different models of concurrent programming and talk about how Rust helps you to program in multiple threads fearlessly. Chapter 17 looks at how Rust idioms compare to object-oriented programming principles you might be familiar with.
Chapter 18 is a reference on patterns and pattern matching, which are powerful ways of expressing ideas throughout Rust programs. Chapter 19 contains a smorgasbord of advanced topics of interest, including unsafe Rust, macros, and more about lifetimes, traits, types, functions, and closures.
In Chapter 20, we’ll complete a project in which we’ll implement a low-level multithreaded web server!
Finally, some appendices contain useful information about the language in a more reference-like format. Appendix A covers Rust’s keywords, Appendix B covers Rust’s operators and symbols, Appendix C covers derivable traits provided by the standard library, Appendix D covers some useful development tools, and Appendix E explains Rust editions. In Appendix F, you can find translations of the book, and in Appendix G we’ll cover how Rust is made and what nightly Rust is.
There is no wrong way to read this book: if you want to skip ahead, go for it! You might have to jump back to earlier chapters if you experience any confusion. But do whatever works for you.
An important part of the process of learning Rust is learning how to read the error messages the compiler displays: these will guide you toward working code. As such, we’ll provide many examples that don’t compile along with the error message the compiler will show you in each situation. Know that if you enter and run a random example, it may not compile! Make sure you read the surrounding text to see whether the example you’re trying to run is meant to error. Ferris will also help you distinguish code that isn’t meant to work:
| Ferris | Meaning |
|---|---|
 | This code does not compile! |
 | This code panics! |
 | This code does not produce the desired behavior. |
In most situations, we’ll lead you to the correct version of any code that doesn’t compile.
Source Code
The source files from which this book is generated can be found on GitHub.
Getting Started
Let’s start your Rust journey! There’s a lot to learn, but every journey starts somewhere. In this chapter, we’ll discuss:
- Installing Rust on Linux, macOS, and Windows
- Writing a program that prints
Hello, world! - Using
cargo, Rust’s package manager and build system
Installation
The first step is to install Rust. We’ll download Rust through rustup, a
command line tool for managing Rust versions and associated tools. You’ll need
an internet connection for the download.
Note: If you prefer not to use
rustupfor some reason, please see the Other Rust Installation Methods page for more options.
The following steps install the latest stable version of the Rust compiler. Rust’s stability guarantees ensure that all the examples in the book that compile will continue to compile with newer Rust versions. The output might differ slightly between versions because Rust often improves error messages and warnings. In other words, any newer, stable version of Rust you install using these steps should work as expected with the content of this book.
Command Line Notation
In this chapter and throughout the book, we’ll show some commands used in the terminal. Lines that you should enter in a terminal all start with
$. You don’t need to type the$character; it’s the command line prompt shown to indicate the start of each command. Lines that don’t start with$typically show the output of the previous command. Additionally, PowerShell-specific examples will use>rather than$.
Installing rustup on Linux or macOS
If you’re using Linux or macOS, open a terminal and enter the following command:
$ curl --proto '=https' --tlsv1.3 https://sh.rustup.rs -sSf | sh
The command downloads a script and starts the installation of the rustup
tool, which installs the latest stable version of Rust. You might be prompted
for your password. If the install is successful, the following line will appear:
Rust is installed now. Great!
You will also need a linker, which is a program that Rust uses to join its compiled outputs into one file. It is likely you already have one. If you get linker errors, you should install a C compiler, which will typically include a linker. A C compiler is also useful because some common Rust packages depend on C code and will need a C compiler.
On macOS, you can get a C compiler by running:
$ xcode-select --install
Linux users should generally install GCC or Clang, according to their
distribution’s documentation. For example, if you use Ubuntu, you can install
the build-essential package.
Installing rustup on Windows
On Windows, go to https://www.rust-lang.org/tools/install and follow the instructions for installing Rust. At some point in the installation, you’ll receive a message explaining that you’ll also need the MSVC build tools for Visual Studio 2013 or later.
To acquire the build tools, you’ll need to install Visual Studio 2022. When asked which workloads to install, include:
- “Desktop Development with C++”
- The Windows 10 or 11 SDK
- The English language pack component, along with any other language pack of your choosing
The rest of this book uses commands that work in both cmd.exe and PowerShell. If there are specific differences, we’ll explain which to use.
Troubleshooting
To check whether you have Rust installed correctly, open a shell and enter this line:
$ rustc --version
You should see the version number, commit hash, and commit date for the latest stable version that has been released, in the following format:
rustc x.y.z (abcabcabc yyyy-mm-dd)
If you see this information, you have installed Rust successfully! If you don’t
see this information, check that Rust is in your %PATH% system variable as
follows.
In Windows CMD, use:
> echo %PATH%
In PowerShell, use:
> echo $env:Path
In Linux and macOS, use:
$ echo $PATH
If that’s all correct and Rust still isn’t working, there are a number of places you can get help. Find out how to get in touch with other Rustaceans (a silly nickname we call ourselves) on the community page.
Updating and Uninstalling
Once Rust is installed via rustup, updating to a newly released version is
easy. From your shell, run the following update script:
$ rustup update
To uninstall Rust and rustup, run the following uninstall script from your
shell:
$ rustup self uninstall
Local Documentation
The installation of Rust also includes a local copy of the documentation so
that you can read it offline. Run rustup doc to open the local documentation
in your browser.
Any time a type or function is provided by the standard library and you’re not sure what it does or how to use it, use the application programming interface (API) documentation to find out!
Hello, World!
Now that you’ve installed Rust, it’s time to write your first Rust program.
It’s traditional when learning a new language to write a little program that
prints the text Hello, world! to the screen, so we’ll do the same here!
Note: This book assumes basic familiarity with the command line. Rust makes no specific demands about your editing or tooling or where your code lives, so if you prefer to use an integrated development environment (IDE) instead of the command line, feel free to use your favorite IDE. Many IDEs now have some degree of Rust support; check the IDE’s documentation for details. The Rust team has been focusing on enabling great IDE support via
rust-analyzer. See Appendix D for more details.
Creating a Project Directory
You’ll start by making a directory to store your Rust code. It doesn’t matter to Rust where your code lives, but for the exercises and projects in this book, we suggest making a projects directory in your home directory and keeping all your projects there.
Open a terminal and enter the following commands to make a projects directory and a directory for the “Hello, world!” project within the projects directory.
For Linux, macOS, and PowerShell on Windows, enter this:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
For Windows CMD, enter this:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Writing and Running a Rust Program
Next, make a new source file and call it main.rs. Rust files always end with the .rs extension. If you’re using more than one word in your filename, the convention is to use an underscore to separate them. For example, use hello_world.rs rather than helloworld.rs.
Now open the main.rs file you just created and enter the code in Listing 1-1.
Filename: main.rs
fn main() { println!("Hello, world!"); }
Listing 1-1: A program that prints Hello, world!
Save the file and go back to your terminal window in the ~/projects/hello_world directory. On Linux or macOS, enter the following commands to compile and run the file:
$ rustc main.rs
$ ./main
Hello, world!
On Windows, enter the command .\main.exe instead of ./main:
> rustc main.rs
> .\main.exe
Hello, world!
Regardless of your operating system, the string Hello, world! should print to
the terminal. If you don’t see this output, refer back to the
“Troubleshooting” part of the Installation
section for ways to get help.
If Hello, world! did print, congratulations! You’ve officially written a Rust
program. That makes you a Rust programmer—welcome!
Anatomy of a Rust Program
Let’s review this “Hello, world!” program in detail. Here’s the first piece of the puzzle:
fn main() { }
These lines define a function named main. The main function is special: it
is always the first code that runs in every executable Rust program. Here, the
first line declares a function named main that has no parameters and returns
nothing. If there were parameters, they would go inside the parentheses ().
The function body is wrapped in {}. Rust requires curly brackets around all
function bodies. It’s good style to place the opening curly bracket on the same
line as the function declaration, adding one space in between.
Note: If you want to stick to a standard style across Rust projects, you can use an automatic formatter tool called
rustfmtto format your code in a particular style (more onrustfmtin Appendix D). The Rust team has included this tool with the standard Rust distribution, asrustcis, so it should already be installed on your computer!
The body of the main function holds the following code:
#![allow(unused)] fn main() { println!("Hello, world!"); }
This line does all the work in this little program: it prints text to the screen. There are four important details to notice here.
First, Rust style is to indent with four spaces, not a tab.
Second, println! calls a Rust macro. If it had called a function instead, it
would be entered as println (without the !). We’ll discuss Rust macros in
more detail in Chapter 19. For now, you just need to know that using a !
means that you’re calling a macro instead of a normal function and that macros
don’t always follow the same rules as functions.
Third, you see the "Hello, world!" string. We pass this string as an argument
to println!, and the string is printed to the screen.
Fourth, we end the line with a semicolon (;), which indicates that this
expression is over and the next one is ready to begin. Most lines of Rust code
end with a semicolon.
Compiling and Running Are Separate Steps
You’ve just run a newly created program, so let’s examine each step in the process.
Before running a Rust program, you must compile it using the Rust compiler by
entering the rustc command and passing it the name of your source file, like
this:
$ rustc main.rs
If you have a C or C++ background, you’ll notice that this is similar to gcc
or clang. After compiling successfully, Rust outputs a binary executable.
On Linux, macOS, and PowerShell on Windows, you can see the executable by
entering the ls command in your shell:
$ ls
main main.rs
On Linux and macOS, you’ll see two files. With PowerShell on Windows, you’ll see the same three files that you would see using CMD. With CMD on Windows, you would enter the following:
> dir /B %= the /B option says to only show the file names =%
main.exe
main.pdb
main.rs
This shows the source code file with the .rs extension, the executable file (main.exe on Windows, but main on all other platforms), and, when using Windows, a file containing debugging information with the .pdb extension. From here, you run the main or main.exe file, like this:
$ ./main # or .\main.exe on Windows
If your main.rs is your “Hello, world!” program, this line prints Hello, world! to your terminal.
If you’re more familiar with a dynamic language, such as Ruby, Python, or JavaScript, you might not be used to compiling and running a program as separate steps. Rust is an ahead-of-time compiled language, meaning you can compile a program and give the executable to someone else, and they can run it even without having Rust installed. If you give someone a .rb, .py, or .js file, they need to have a Ruby, Python, or JavaScript implementation installed (respectively). But in those languages, you only need one command to compile and run your program. Everything is a trade-off in language design.
Just compiling with rustc is fine for simple programs, but as your project
grows, you’ll want to manage all the options and make it easy to share your
code. Next, we’ll introduce you to the Cargo tool, which will help you write
real-world Rust programs.
Hello, Cargo!
Cargo is Rust’s build system and package manager. Most Rustaceans use this tool to manage their Rust projects because Cargo handles a lot of tasks for you, such as building your code, downloading the libraries your code depends on, and building those libraries. (We call the libraries that your code needs dependencies.)
The simplest Rust programs, like the one we’ve written so far, don’t have any dependencies. If we had built the “Hello, world!” project with Cargo, it would only use the part of Cargo that handles building your code. As you write more complex Rust programs, you’ll add dependencies, and if you start a project using Cargo, adding dependencies will be much easier to do.
Because the vast majority of Rust projects use Cargo, the rest of this book assumes that you’re using Cargo too. Cargo comes installed with Rust if you used the official installers discussed in the “Installation” section. If you installed Rust through some other means, check whether Cargo is installed by entering the following in your terminal:
$ cargo --version
If you see a version number, you have it! If you see an error, such as command not found, look at the documentation for your method of installation to
determine how to install Cargo separately.
Creating a Project with Cargo
Let’s create a new project using Cargo and look at how it differs from our original “Hello, world!” project. Navigate back to your projects directory (or wherever you decided to store your code). Then, on any operating system, run the following:
$ cargo new hello_cargo
$ cd hello_cargo
The first command creates a new directory and project called hello_cargo. We’ve named our project hello_cargo, and Cargo creates its files in a directory of the same name.
Go into the hello_cargo directory and list the files. You’ll see that Cargo has generated two files and one directory for us: a Cargo.toml file and a src directory with a main.rs file inside.
It has also initialized a new Git repository along with a .gitignore file.
Git files won’t be generated if you run cargo new within an existing Git
repository; you can override this behavior by using cargo new --vcs=git.
Note: Git is a common version control system. You can change
cargo newto use a different version control system or no version control system by using the--vcsflag. Runcargo new --helpto see the available options.
Open Cargo.toml in your text editor of choice. It should look similar to the code in Listing 1-2.
Filename: Cargo.toml
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Listing 1-2: Contents of Cargo.toml generated by cargo new
This file is in the TOML (Tom’s Obvious, Minimal Language) format, which is Cargo’s configuration format.
The first line, [package], is a section heading that indicates that the
following statements are configuring a package. As we add more information to
this file, we’ll add other sections.
The next three lines set the configuration information Cargo needs to compile
your program: the name, the version, and the edition of Rust to use. We’ll talk
about the edition key in Appendix E.
The last line, [dependencies], is the start of a section for you to list any
of your project’s dependencies. In Rust, packages of code are referred to as
crates. We won’t need any other crates for this project, but we will in the
first project in Chapter 2, so we’ll use this dependencies section then.
Now open src/main.rs and take a look:
Filename: src/main.rs
fn main() { println!("Hello, world!"); }
Cargo has generated a “Hello, world!” program for you, just like the one we wrote in Listing 1-1! So far, the differences between our project and the project Cargo generated are that Cargo placed the code in the src directory and we have a Cargo.toml configuration file in the top directory.
Cargo expects your source files to live inside the src directory. The top-level project directory is just for README files, license information, configuration files, and anything else not related to your code. Using Cargo helps you organize your projects. There’s a place for everything, and everything is in its place.
If you started a project that doesn’t use Cargo, as we did with the “Hello, world!” project, you can convert it to a project that does use Cargo. Move the project code into the src directory and create an appropriate Cargo.toml file.
Building and Running a Cargo Project
Now let’s look at what’s different when we build and run the “Hello, world!” program with Cargo! From your hello_cargo directory, build your project by entering the following command:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
This command creates an executable file in target/debug/hello_cargo (or target\debug\hello_cargo.exe on Windows) rather than in your current directory. Because the default build is a debug build, Cargo puts the binary in a directory named debug. You can run the executable with this command:
$ ./target/debug/hello_cargo # or .\target\debug\hello_cargo.exe on Windows
Hello, world!
If all goes well, Hello, world! should print to the terminal. Running cargo build for the first time also causes Cargo to create a new file at the top
level: Cargo.lock. This file keeps track of the exact versions of
dependencies in your project. This project doesn’t have dependencies, so the
file is a bit sparse. You won’t ever need to change this file manually; Cargo
manages its contents for you.
We just built a project with cargo build and ran it with
./target/debug/hello_cargo, but we can also use cargo run to compile the
code and then run the resultant executable all in one command:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
Using cargo run is more convenient than having to remember to run cargo build and then use the whole path to the binary, so most developers use cargo run.
Notice that this time we didn’t see output indicating that Cargo was compiling
hello_cargo. Cargo figured out that the files hadn’t changed, so it didn’t
rebuild but just ran the binary. If you had modified your source code, Cargo
would have rebuilt the project before running it, and you would have seen this
output:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo also provides a command called cargo check. This command quickly checks
your code to make sure it compiles but doesn’t produce an executable:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Why would you not want an executable? Often, cargo check is much faster than
cargo build because it skips the step of producing an executable. If you’re
continually checking your work while writing the code, using cargo check will
speed up the process of letting you know if your project is still compiling! As
such, many Rustaceans run cargo check periodically as they write their
program to make sure it compiles. Then they run cargo build when they’re
ready to use the executable.
Let’s recap what we’ve learned so far about Cargo:
- We can create a project using
cargo new. - We can build a project using
cargo build. - We can build and run a project in one step using
cargo run. - We can build a project without producing a binary to check for errors using
cargo check. - Instead of saving the result of the build in the same directory as our code, Cargo stores it in the target/debug directory.
An additional advantage of using Cargo is that the commands are the same no matter which operating system you’re working on. So, at this point, we’ll no longer provide specific instructions for Linux and macOS versus Windows.
Building for Release
When your project is finally ready for release, you can use cargo build --release to compile it with optimizations. This command will create an
executable in target/release instead of target/debug. The optimizations
make your Rust code run faster, but turning them on lengthens the time it takes
for your program to compile. This is why there are two different profiles: one
for development, when you want to rebuild quickly and often, and another for
building the final program you’ll give to a user that won’t be rebuilt
repeatedly and that will run as fast as possible. If you’re benchmarking your
code’s running time, be sure to run cargo build --release and benchmark with
the executable in target/release.
Cargo as Convention
With simple projects, Cargo doesn’t provide a lot of value over just using
rustc, but it will prove its worth as your programs become more intricate.
Once programs grow to multiple files or need a dependency, it’s much easier to
let Cargo coordinate the build.
Even though the hello_cargo project is simple, it now uses much of the real
tooling you’ll use in the rest of your Rust career. In fact, to work on any
existing projects, you can use the following commands to check out the code
using Git, change to that project’s directory, and build:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
For more information about Cargo, check out its documentation.
Summary
You’re already off to a great start on your Rust journey! In this chapter, you’ve learned how to:
- Install the latest stable version of Rust using
rustup - Update to a newer Rust version
- Open locally installed documentation
- Write and run a “Hello, world!” program using
rustcdirectly - Create and run a new project using the conventions of Cargo
This is a great time to build a more substantial program to get used to reading and writing Rust code. So, in Chapter 2, we’ll build a guessing game program. If you would rather start by learning how common programming concepts work in Rust, see Chapter 3 and then return to Chapter 2.
Programming a Guessing Game
Let’s jump into Rust by working through a hands-on project together! This
chapter introduces you to a few common Rust concepts by showing you how to use
them in a real program. You’ll learn about let, match, methods, associated
functions, external crates, and more! In the following chapters, we’ll explore
these ideas in more detail. In this chapter, you’ll just practice the
fundamentals.
We’ll implement a classic beginner programming problem: a guessing game. Here’s how it works: the program will generate a random integer between 1 and 100. It will then prompt the player to enter a guess. After a guess is entered, the program will indicate whether the guess is too low or too high. If the guess is correct, the game will print a congratulatory message and exit.
Setting Up a New Project
To set up a new project, go to the projects directory that you created in Chapter 1 and make a new project using Cargo, like so:
$ cargo new guessing_game
$ cd guessing_game
The first command, cargo new, takes the name of the project (guessing_game)
as the first argument. The second command changes to the new project’s
directory.
Look at the generated Cargo.toml file:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
As you saw in Chapter 1, cargo new generates a “Hello, world!” program for
you. Check out the src/main.rs file:
Filename: src/main.rs
fn main() { println!("Hello, world!"); }
Now let’s compile this “Hello, world!” program and run it in the same step
using the cargo run command:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 1.50s
Running `target/debug/guessing_game`
Hello, world!
The run command comes in handy when you need to rapidly iterate on a project,
as we’ll do in this game, quickly testing each iteration before moving on to
the next one.
Reopen the src/main.rs file. You’ll be writing all the code in this file.
Processing a Guess
The first part of the guessing game program will ask for user input, process that input, and check that the input is in the expected form. To start, we’ll allow the player to input a guess. Enter the code in Listing 2-1 into src/main.rs.
Filename: src/main.rs
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
Listing 2-1: Code that gets a guess from the user and prints it
This code contains a lot of information, so let’s go over it line by line. To
obtain user input and then print the result as output, we need to bring the
io input/output library into scope. The io library comes from the standard
library, known as std:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
By default, Rust has a set of items defined in the standard library that it brings into the scope of every program. This set is called the prelude, and you can see everything in it in the standard library documentation.
If a type you want to use isn’t in the prelude, you have to bring that type
into scope explicitly with a use statement. Using the std::io library
provides you with a number of useful features, including the ability to accept
user input.
As you saw in Chapter 1, the main function is the entry point into the
program:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
The fn syntax declares a new function; the parentheses, (), indicate there
are no parameters; and the curly bracket, {, starts the body of the function.
As you also learned in Chapter 1, println! is a macro that prints a string to
the screen:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
This code is printing a prompt stating what the game is and requesting input from the user.
Storing Values with Variables
Next, we’ll create a variable to store the user input, like this:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
Now the program is getting interesting! There’s a lot going on in this little
line. We use the let statement to create the variable. Here’s another example:
let apples = 5;
This line creates a new variable named apples and binds it to the value 5. In
Rust, variables are immutable by default, meaning once we give the variable a
value, the value won’t change. We’ll be discussing this concept in detail in
the “Variables and Mutability”
section in Chapter 3. To make a variable mutable, we add mut before the
variable name:
let apples = 5; // immutable
let mut bananas = 5; // mutable
Note: The
//syntax starts a comment that continues until the end of the line. Rust ignores everything in comments. We’ll discuss comments in more detail in Chapter 3.
Returning to the guessing game program, you now know that let mut guess will
introduce a mutable variable named guess. The equal sign (=) tells Rust we
want to bind something to the variable now. On the right of the equal sign is
the value that guess is bound to, which is the result of calling
String::new, a function that returns a new instance of a String.
String is a string type provided by the standard
library that is a growable, UTF-8 encoded bit of text.
The :: syntax in the ::new line indicates that new is an associated
function of the String type. An associated function is a function that’s
implemented on a type, in this case String. This new function creates a
new, empty string. You’ll find a new function on many types because it’s a
common name for a function that makes a new value of some kind.
In full, the let mut guess = String::new(); line has created a mutable
variable that is currently bound to a new, empty instance of a String. Whew!
Receiving User Input
Recall that we included the input/output functionality from the standard
library with use std::io; on the first line of the program. Now we’ll call
the stdin function from the io module, which will allow us to handle user
input:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
If we hadn’t imported the io library with use std::io; at the beginning of
the program, we could still use the function by writing this function call as
std::io::stdin. The stdin function returns an instance of
std::io::Stdin, which is a type that represents a
handle to the standard input for your terminal.
Next, the line .read_line(&mut guess) calls the read_line method on the standard input handle to get input from the user.
We’re also passing &mut guess as the argument to read_line to tell it what
string to store the user input in. The full job of read_line is to take
whatever the user types into standard input and append that into a string
(without overwriting its contents), so we therefore pass that string as an
argument. The string argument needs to be mutable so the method can change the
string’s content.
The & indicates that this argument is a reference, which gives you a way to
let multiple parts of your code access one piece of data without needing to
copy that data into memory multiple times. References are a complex feature,
and one of Rust’s major advantages is how safe and easy it is to use
references. You don’t need to know a lot of those details to finish this
program. For now, all you need to know is that, like variables, references are
immutable by default. Hence, you need to write &mut guess rather than
&guess to make it mutable. (Chapter 4 will explain references more
thoroughly.)
Handling Potential Failure with Result
We’re still working on this line of code. We’re now discussing a third line of text, but note that it’s still part of a single logical line of code. The next part is this method:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
We could have written this code as:
io::stdin().read_line(&mut guess).expect("Failed to read line");
However, one long line is difficult to read, so it’s best to divide it. It’s
often wise to introduce a newline and other whitespace to help break up long
lines when you call a method with the .method_name() syntax. Now let’s
discuss what this line does.
As mentioned earlier, read_line puts whatever the user enters into the string
we pass to it, but it also returns a Result value. Result is an enumeration, often called an enum,
which is a type that can be in one of multiple possible states. We call each
possible state a variant.
Chapter 6 will cover enums in more detail. The purpose
of these Result types is to encode error-handling information.
Result’s variants are Ok and Err. The Ok variant indicates the
operation was successful, and inside Ok is the successfully generated value.
The Err variant means the operation failed, and Err contains information
about how or why the operation failed.
Values of the Result type, like values of any type, have methods defined on
them. An instance of Result has an expect method
that you can call. If this instance of Result is an Err value, expect
will cause the program to crash and display the message that you passed as an
argument to expect. If the read_line method returns an Err, it would
likely be the result of an error coming from the underlying operating system.
If this instance of Result is an Ok value, expect will take the return
value that Ok is holding and return just that value to you so you can use it.
In this case, that value is the number of bytes in the user’s input.
If you don’t call expect, the program will compile, but you’ll get a warning:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_must_use)]` on by default
= note: this `Result` may be an `Err` variant, which should be handled
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Rust warns that you haven’t used the Result value returned from read_line,
indicating that the program hasn’t handled a possible error.
The right way to suppress the warning is to actually write error-handling code,
but in our case we just want to crash this program when a problem occurs, so we
can use expect. You’ll learn about recovering from errors in Chapter
9.
Printing Values with println! Placeholders
Aside from the closing curly bracket, there’s only one more line to discuss in the code so far:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
This line prints the string that now contains the user’s input. The {} set of
curly brackets is a placeholder: think of {} as little crab pincers that hold
a value in place. When printing the value of a variable, the variable name can
go inside the curly brackets. When printing the result of evaluating an
expression, place empty curly brackets in the format string, then follow the
format string with a comma-separated list of expressions to print in each empty
curly bracket placeholder in the same order. Printing a variable and the result
of an expression in one call to println! would look like this:
#![allow(unused)] fn main() { let x = 5; let y = 10; println!("x = {x} and y + 2 = {}", y + 2); }
This code would print x = 5 and y = 12.
Testing the First Part
Let’s test the first part of the guessing game. Run it using cargo run:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
At this point, the first part of the game is done: we’re getting input from the keyboard and then printing it.
Generating a Secret Number
Next, we need to generate a secret number that the user will try to guess. The
secret number should be different every time so the game is fun to play more
than once. We’ll use a random number between 1 and 100 so the game isn’t too
difficult. Rust doesn’t yet include random number functionality in its standard
library. However, the Rust team does provide a rand crate with
said functionality.
Using a Crate to Get More Functionality
Remember that a crate is a collection of Rust source code files. The project
we’ve been building is a binary crate, which is an executable. The rand
crate is a library crate, which contains code that is intended to be used in
other programs and can’t be executed on its own.
Cargo’s coordination of external crates is where Cargo really shines. Before we
can write code that uses rand, we need to modify the Cargo.toml file to
include the rand crate as a dependency. Open that file now and add the
following line to the bottom, beneath the [dependencies] section header that
Cargo created for you. Be sure to specify rand exactly as we have here, with
this version number, or the code examples in this tutorial may not work:
Filename: Cargo.toml
[dependencies]
rand = "0.8.5"
In the Cargo.toml file, everything that follows a header is part of that
section that continues until another section starts. In [dependencies] you
tell Cargo which external crates your project depends on and which versions of
those crates you require. In this case, we specify the rand crate with the
semantic version specifier 0.8.5. Cargo understands Semantic
Versioning (sometimes called SemVer), which is a
standard for writing version numbers. The specifier 0.8.5 is actually
shorthand for ^0.8.5, which means any version that is at least 0.8.5 but
below 0.9.0.
Cargo considers these versions to have public APIs compatible with version 0.8.5, and this specification ensures you’ll get the latest patch release that will still compile with the code in this chapter. Any version 0.9.0 or greater is not guaranteed to have the same API as what the following examples use.
Now, without changing any of the code, let’s build the project, as shown in Listing 2-2.
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
Downloaded libc v0.2.127
Downloaded getrandom v0.2.7
Downloaded cfg-if v1.0.0
Downloaded ppv-lite86 v0.2.16
Downloaded rand_chacha v0.3.1
Downloaded rand_core v0.6.3
Compiling libc v0.2.127
Compiling getrandom v0.2.7
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.16
Compiling rand_core v0.6.3
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.53s
Listing 2-2: The output from running cargo build after
adding the rand crate as a dependency
You may see different version numbers (but they will all be compatible with the code, thanks to SemVer!) and different lines (depending on the operating system), and the lines may be in a different order.
When we include an external dependency, Cargo fetches the latest versions of everything that dependency needs from the registry, which is a copy of data from Crates.io. Crates.io is where people in the Rust ecosystem post their open source Rust projects for others to use.
After updating the registry, Cargo checks the [dependencies] section and
downloads any crates listed that aren’t already downloaded. In this case,
although we only listed rand as a dependency, Cargo also grabbed other crates
that rand depends on to work. After downloading the crates, Rust compiles
them and then compiles the project with the dependencies available.
If you immediately run cargo build again without making any changes, you
won’t get any output aside from the Finished line. Cargo knows it has already
downloaded and compiled the dependencies, and you haven’t changed anything
about them in your Cargo.toml file. Cargo also knows that you haven’t changed
anything about your code, so it doesn’t recompile that either. With nothing to
do, it simply exits.
If you open the src/main.rs file, make a trivial change, and then save it and build again, you’ll only see two lines of output:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.53 secs
These lines show that Cargo only updates the build with your tiny change to the src/main.rs file. Your dependencies haven’t changed, so Cargo knows it can reuse what it has already downloaded and compiled for those.
Ensuring Reproducible Builds with the Cargo.lock File
Cargo has a mechanism that ensures you can rebuild the same artifact every time
you or anyone else builds your code: Cargo will use only the versions of the
dependencies you specified until you indicate otherwise. For example, say that
next week version 0.8.6 of the rand crate comes out, and that version
contains an important bug fix, but it also contains a regression that will
break your code. To handle this, Rust creates the Cargo.lock file the first
time you run cargo build, so we now have this in the guessing_game
directory.
When you build a project for the first time, Cargo figures out all the versions of the dependencies that fit the criteria and then writes them to the Cargo.lock file. When you build your project in the future, Cargo will see that the Cargo.lock file exists and will use the versions specified there rather than doing all the work of figuring out versions again. This lets you have a reproducible build automatically. In other words, your project will remain at 0.8.5 until you explicitly upgrade, thanks to the Cargo.lock file. Because the Cargo.lock file is important for reproducible builds, it’s often checked into source control with the rest of the code in your project.
Updating a Crate to Get a New Version
When you do want to update a crate, Cargo provides the command update,
which will ignore the Cargo.lock file and figure out all the latest versions
that fit your specifications in Cargo.toml. Cargo will then write those
versions to the Cargo.lock file. Otherwise, by default, Cargo will only look
for versions greater than 0.8.5 and less than 0.9.0. If the rand crate has
released the two new versions 0.8.6 and 0.9.0, you would see the following if
you ran cargo update:
$ cargo update
Updating crates.io index
Updating rand v0.8.5 -> v0.8.6
Cargo ignores the 0.9.0 release. At this point, you would also notice a change
in your Cargo.lock file noting that the version of the rand crate you are
now using is 0.8.6. To use rand version 0.9.0 or any version in the 0.9.x
series, you’d have to update the Cargo.toml file to look like this instead:
[dependencies]
rand = "0.9.0"
The next time you run cargo build, Cargo will update the registry of crates
available and reevaluate your rand requirements according to the new version
you have specified.
There’s a lot more to say about Cargo and its ecosystem, which we’ll discuss in Chapter 14, but for now, that’s all you need to know. Cargo makes it very easy to reuse libraries, so Rustaceans are able to write smaller projects that are assembled from a number of packages.
Generating a Random Number
Let’s start using rand to generate a number to guess. The next step is to
update src/main.rs, as shown in Listing 2-3.
Filename: src/main.rs
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
Listing 2-3: Adding code to generate a random number
First we add the line use rand::Rng;. The Rng trait defines methods that
random number generators implement, and this trait must be in scope for us to
use those methods. Chapter 10 will cover traits in detail.
Next, we’re adding two lines in the middle. In the first line, we call the
rand::thread_rng function that gives us the particular random number
generator we’re going to use: one that is local to the current thread of
execution and is seeded by the operating system. Then we call the gen_range
method on the random number generator. This method is defined by the Rng
trait that we brought into scope with the use rand::Rng; statement. The
gen_range method takes a range expression as an argument and generates a
random number in the range. The kind of range expression we’re using here takes
the form start..=end and is inclusive on the lower and upper bounds, so we
need to specify 1..=100 to request a number between 1 and 100.
Note: You won’t just know which traits to use and which methods and functions to call from a crate, so each crate has documentation with instructions for using it. Another neat feature of Cargo is that running the
cargo doc --opencommand will build documentation provided by all your dependencies locally and open it in your browser. If you’re interested in other functionality in therandcrate, for example, runcargo doc --openand clickrandin the sidebar on the left.
The second new line prints the secret number. This is useful while we’re developing the program to be able to test it, but we’ll delete it from the final version. It’s not much of a game if the program prints the answer as soon as it starts!
Try running the program a few times:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 2.53s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
You should get different random numbers, and they should all be numbers between 1 and 100. Great job!
Comparing the Guess to the Secret Number
Now that we have user input and a random number, we can compare them. That step is shown in Listing 2-4. Note that this code won’t compile just yet, as we will explain.
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
Listing 2-4: Handling the possible return values of comparing two numbers
First we add another use statement, bringing a type called
std::cmp::Ordering into scope from the standard library. The Ordering type
is another enum and has the variants Less, Greater, and Equal. These are
the three outcomes that are possible when you compare two values.
Then we add five new lines at the bottom that use the Ordering type. The
cmp method compares two values and can be called on anything that can be
compared. It takes a reference to whatever you want to compare with: here it’s
comparing guess to secret_number. Then it returns a variant of the
Ordering enum we brought into scope with the use statement. We use a
match expression to decide what to do next based on
which variant of Ordering was returned from the call to cmp with the values
in guess and secret_number.
A match expression is made up of arms. An arm consists of a pattern to
match against, and the code that should be run if the value given to match
fits that arm’s pattern. Rust takes the value given to match and looks
through each arm’s pattern in turn. Patterns and the match construct are
powerful Rust features: they let you express a variety of situations your code
might encounter and they make sure you handle them all. These features will be
covered in detail in Chapter 6 and Chapter 18, respectively.
Let’s walk through an example with the match expression we use here. Say that
the user has guessed 50 and the randomly generated secret number this time is
38.
When the code compares 50 to 38, the cmp method will return
Ordering::Greater because 50 is greater than 38. The match expression gets
the Ordering::Greater value and starts checking each arm’s pattern. It looks
at the first arm’s pattern, Ordering::Less, and sees that the value
Ordering::Greater does not match Ordering::Less, so it ignores the code in
that arm and moves to the next arm. The next arm’s pattern is
Ordering::Greater, which does match Ordering::Greater! The associated
code in that arm will execute and print Too big! to the screen. The match
expression ends after the first successful match, so it won’t look at the last
arm in this scenario.
However, the code in Listing 2-4 won’t compile yet. Let’s try it:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:22:21
|
22 | match guess.cmp(&secret_number) {
| ^^^^^^^^^^^^^^ expected struct `String`, found integer
|
= note: expected reference `&String`
found reference `&{integer}`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` due to previous error
The core of the error states that there are mismatched types. Rust has a
strong, static type system. However, it also has type inference. When we wrote
let mut guess = String::new(), Rust was able to infer that guess should be
a String and didn’t make us write the type. The secret_number, on the other
hand, is a number type. A few of Rust’s number types can have a value between 1
and 100: i32, a 32-bit number; u32, an unsigned 32-bit number; i64, a
64-bit number; as well as others. Unless otherwise specified, Rust defaults to
an i32, which is the type of secret_number unless you add type information
elsewhere that would cause Rust to infer a different numerical type. The reason
for the error is that Rust cannot compare a string and a number type.
Ultimately, we want to convert the String the program reads as input into a
real number type so we can compare it numerically to the secret number. We do
so by adding this line to the main function body:
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
The line is:
let guess: u32 = guess.trim().parse().expect("Please type a number!");
We create a variable named guess. But wait, doesn’t the program already have
a variable named guess? It does, but helpfully Rust allows us to shadow the
previous value of guess with a new one. Shadowing lets us reuse the guess
variable name rather than forcing us to create two unique variables, such as
guess_str and guess, for example. We’ll cover this in more detail in
Chapter 3, but for now, know that this feature is
often used when you want to convert a value from one type to another type.
We bind this new variable to the expression guess.trim().parse(). The guess
in the expression refers to the original guess variable that contained the
input as a string. The trim method on a String instance will eliminate any
whitespace at the beginning and end, which we must do to be able to compare the
string to the u32, which can only contain numerical data. The user must press
enter to satisfy read_line and input their
guess, which adds a newline character to the string. For example, if the user
types 5 and presses enter, guess looks like this: 5\n. The \n
represents “newline.” (On Windows, pressing enter results in a carriage return and a newline,
\r\n.) The trim method eliminates \n or \r\n, resulting in just 5.
The parse method on strings converts a string to
another type. Here, we use it to convert from a string to a number. We need to
tell Rust the exact number type we want by using let guess: u32. The colon
(:) after guess tells Rust we’ll annotate the variable’s type. Rust has a
few built-in number types; the u32 seen here is an unsigned, 32-bit integer.
It’s a good default choice for a small positive number. You’ll learn about
other number types in Chapter 3.
Additionally, the u32 annotation in this example program and the comparison
with secret_number means Rust will infer that secret_number should be a
u32 as well. So now the comparison will be between two values of the same
type!
The parse method will only work on characters that can logically be converted
into numbers and so can easily cause errors. If, for example, the string
contained A👍%, there would be no way to convert that to a number. Because it
might fail, the parse method returns a Result type, much as the read_line
method does (discussed earlier in “Handling Potential Failure with
Result”). We’ll treat
this Result the same way by using the expect method again. If parse
returns an Err Result variant because it couldn’t create a number from the
string, the expect call will crash the game and print the message we give it.
If parse can successfully convert the string to a number, it will return the
Ok variant of Result, and expect will return the number that we want from
the Ok value.
Let’s run the program now:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
Nice! Even though spaces were added before the guess, the program still figured out that the user guessed 76. Run the program a few times to verify the different behavior with different kinds of input: guess the number correctly, guess a number that is too high, and guess a number that is too low.
We have most of the game working now, but the user can make only one guess. Let’s change that by adding a loop!
Allowing Multiple Guesses with Looping
The loop keyword creates an infinite loop. We’ll add a loop to give users
more chances at guessing the number:
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}
As you can see, we’ve moved everything from the guess input prompt onward into a loop. Be sure to indent the lines inside the loop another four spaces each and run the program again. The program will now ask for another guess forever, which actually introduces a new problem. It doesn’t seem like the user can quit!
The user could always interrupt the program by using the keyboard shortcut
ctrl-c. But there’s another way to escape this
insatiable monster, as mentioned in the parse discussion in “Comparing the
Guess to the Secret Number”: if the user enters a non-number answer, the program will crash. We
can take advantage of that to allow the user to quit, as shown here:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 1.50s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at 'Please type a number!: ParseIntError { kind: InvalidDigit }', src/main.rs:28:47
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Typing quit will quit the game, but as you’ll notice, so will entering any
other non-number input. This is suboptimal, to say the least; we want the game
to also stop when the correct number is guessed.
Quitting After a Correct Guess
Let’s program the game to quit when the user wins by adding a break statement:
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}
Adding the break line after You win! makes the program exit the loop when
the user guesses the secret number correctly. Exiting the loop also means
exiting the program, because the loop is the last part of main.
Handling Invalid Input
To further refine the game’s behavior, rather than crashing the program when
the user inputs a non-number, let’s make the game ignore a non-number so the
user can continue guessing. We can do that by altering the line where guess
is converted from a String to a u32, as shown in Listing 2-5.
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}
Listing 2-5: Ignoring a non-number guess and asking for another guess instead of crashing the program
We switch from an expect call to a match expression to move from crashing
on an error to handling the error. Remember that parse returns a Result
type and Result is an enum that has the variants Ok and Err. We’re using
a match expression here, as we did with the Ordering result of the cmp
method.
If parse is able to successfully turn the string into a number, it will
return an Ok value that contains the resultant number. That Ok value will
match the first arm’s pattern, and the match expression will just return the
num value that parse produced and put inside the Ok value. That number
will end up right where we want it in the new guess variable we’re creating.
If parse is not able to turn the string into a number, it will return an
Err value that contains more information about the error. The Err value
does not match the Ok(num) pattern in the first match arm, but it does
match the Err(_) pattern in the second arm. The underscore, _, is a
catchall value; in this example, we’re saying we want to match all Err
values, no matter what information they have inside them. So the program will
execute the second arm’s code, continue, which tells the program to go to the
next iteration of the loop and ask for another guess. So, effectively, the
program ignores all errors that parse might encounter!
Now everything in the program should work as expected. Let’s try it:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished dev [unoptimized + debuginfo] target(s) in 4.45s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
Awesome! With one tiny final tweak, we will finish the guessing game. Recall
that the program is still printing the secret number. That worked well for
testing, but it ruins the game. Let’s delete the println! that outputs the
secret number. Listing 2-6 shows the final code.
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}
Listing 2-6: Complete guessing game code
At this point, you’ve successfully built the guessing game. Congratulations!
Summary
This project was a hands-on way to introduce you to many new Rust concepts:
let, match, functions, the use of external crates, and more. In the next
few chapters, you’ll learn about these concepts in more detail. Chapter 3
covers concepts that most programming languages have, such as variables, data
types, and functions, and shows how to use them in Rust. Chapter 4 explores
ownership, a feature that makes Rust different from other languages. Chapter 5
discusses structs and method syntax, and Chapter 6 explains how enums work.
Common Programming Concepts
This chapter covers concepts that appear in almost every programming language and how they work in Rust. Many programming languages have much in common at their core. None of the concepts presented in this chapter are unique to Rust, but we’ll discuss them in the context of Rust and explain the conventions around using these concepts.
Specifically, you’ll learn about variables, basic types, functions, comments, and control flow. These foundations will be in every Rust program, and learning them early will give you a strong core to start from.
Keywords
The Rust language has a set of keywords that are reserved for use by the language only, much as in other languages. Keep in mind that you cannot use these words as names of variables or functions. Most of the keywords have special meanings, and you’ll be using them to do various tasks in your Rust programs; a few have no current functionality associated with them but have been reserved for functionality that might be added to Rust in the future. You can find a list of the keywords in Appendix A.
Variables and Mutability
- by default, variables are immutable.
- When a variable is immutable, once a value is bound to a name, you can’t change that value.
- Rust’s naming convention for constants is to use all uppercase with underscores between words.
- Shadowing is different from marking a variable as
mutbecause we’ll get a compile-time error if we accidentally try to reassign to this variable without using theletkeyword. - The other difference between
mutand shadowing is that because we’re effectively creating a new variable when we use theletkeyword again, we can change the type of the value but reuse the same name.
As mentioned in the “Storing Values with Variables” section, by default, variables are immutable.
This is one of many nudges Rust gives you to write your code in a way that takes advantage of the safety and easy concurrency that Rust offers.
However, you still have the option to make your variables mutable. Let’s explore how and why Rust encourages you to favor immutability and why sometimes you might want to opt out.
When a variable is immutable, once a value is bound to a name, you can’t change that value.
To illustrate this, generate a new project called variables in
your projects directory by using cargo new variables.
Then, in your new variables directory, open src/main.rs and replace its code with the following code, which won’t compile just yet:
Filename: src/main.rs
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}
Save and run the program using cargo run. You should receive an error message
regarding an immutability error, as shown in this output:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| -
| |
| first assignment to `x`
| help: consider making this binding mutable: `mut x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` due to previous error
This example shows how the compiler helps you find errors in your programs.
- Compiler errors can be frustrating, but really they only mean your program isn’t safely doing what you want it to do yet;
- they do not mean that you’re not a good programmer!
- Experienced Rustaceans still get compiler errors.
You received the error message
cannot assign twice to immutable variable `x`
because you tried to assign a second value to the immutable x variable.
It’s important that we get compile-time errors when we attempt to change a value that’s designated as immutable because this very situation can lead to bugs.
- If one part of our code operates on the assumption that a value will never change and another part of our code changes that value, it’s possible that the first part of the code won’t do what it was designed to do.
- The cause of this kind of bug can be difficult to track down after the fact, especially when the second piece of code changes the value only sometimes.
- The Rust compiler guarantees that when you state that a value won’t change, it really won’t change, so you don’t have to keep track of it yourself.
- Your code is thus easier to reason through.
But mutability can be very useful, and can make code more convenient to write.
- Although variables are immutable by default, you can make them mutable by
adding
mutin front of the variable name as you did in Chapter 2. - Adding
mutalso conveys intent to future readers of the code by indicating that other parts of the code will be changing this variable’s value.
For example, let’s change src/main.rs to the following:
Filename: src/main.rs
fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); }
When we run the program now, we get this:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
- We’re allowed to change the value bound to
xfrom5to6whenmutis used. - Ultimately, deciding whether to use mutability or not is up to you and depends on what you think is clearest in that particular situation.
Constants
Like immutable variables, constants are values that are bound to a name and are not allowed to change
but there are a few differences between constants and variables.
- First, you aren’t allowed to use
mutwith constants.
- Constants aren’t just immutable by default—they’re always immutable.
- You declare constants using the
constkeyword instead of theletkeyword, and the type of the value must be annotated. - We’ll cover types and type annotations in the next section, “Data Types,”, so don’t worry about the details right now.
- Just know that you must always annotate the type.
-
Constants can be declared in any scope, including the global scope, which makes them useful for values that many parts of code need to know about.
-
The last difference is that constants may be set only to a constant expression, not the result of a value that could only be computed at runtime.
Here’s an example of a constant declaration:
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;
- The constant’s name is
THREE_HOURS_IN_SECONDSand its value is set to the result of multiplying 60 (the number of seconds in a minute) by 60 (the number of minutes in an hour) by 3 (the number of hours we want to count in this program). - Rust’s naming convention for constants is to use all uppercase with underscores between words.
- The compiler is able to evaluate a limited set of operations at compile time, which lets us choose to write out this value in a way that’s easier to understand and verify, rather than setting this constant to the value 10,800.
- See the Rust Reference’s section on constant evaluation for more information on what operations can be used when declaring constants.
Constants are valid for the entire time a program runs, within the scope in which they were declared.
-
This property makes constants useful for values in your application domain that multiple parts of the program might need to know about, such as the maximum number of points any player of a game is allowed to earn, or the speed of light.
-
Naming hardcoded values used throughout your program as constants is useful in conveying the meaning of that value to future maintainers of the code.
-
It also helps to have only one place in your code you would need to change if the hardcoded value needed to be updated in the future.
Shadowing
As you saw in the guessing game tutorial in Chapter 2, you can declare a new variable with the same name as a previous variable.
Rustaceans say that the first variable is shadowed by the second, which means that the second variable is what the compiler will see when you use the name of the variable.
In effect, the second variable overshadows the first, taking any uses of the
variable name to itself until either it itself is shadowed or the scope ends.
We can shadow a variable by using the same variable’s name and repeating the
use of the let keyword as follows:
Filename: src/main.rs
fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("The value of x in the inner scope is: {x}"); } println!("The value of x is: {x}"); }
- This program first binds
xto a value of5. - Then it creates a new variable
xby repeatinglet x =, taking the original value and adding1so the value ofxis then6. - Then, within an inner scope created with the curly
brackets, the third
letstatement also shadowsxand creates a new variable, multiplying the previous value by2to givexa value of12. - When that scope is over, the inner shadowing ends and
xreturns to being6. When we run this program, it will output the following:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
Shadowing is different from marking a variable as
mutbecause we’ll get a compile-time error if we accidentally try to reassign to this variable without using theletkeyword.
By using let, we can perform a few transformations
on a value but have the variable be immutable after those transformations have
been completed.
The other difference between
mutand shadowing is that because we’re effectively creating a new variable when we use theletkeyword again, we can change the type of the value but reuse the same name.
For example, say our program asks a user to show how many spaces they want between some text by inputting space characters, and then we want to store that input as a number:
fn main() { let spaces = " "; let spaces = spaces.len(); }
- The first
spacesvariable is a string type and the secondspacesvariable is a number type. - Shadowing thus spares us from having to come up with
different names, such as
spaces_strandspaces_num; - instead, we can reuse
the simpler
spacesname. - However, if we try to use
mutfor this, as shown here, we’ll get a compile-time error:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}
The error says we’re not allowed to mutate a variable’s type:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` due to previous error
Now that we’ve explored how variables work, let’s look at more data types they can have.
Data Types
Every value in Rust is of a certain data type, which tells Rust what kind of data is being specified so it knows how to work with that data. We’ll look at two data type subsets: scalar and compound.
Keep in mind that Rust is a statically typed language, which means that it
must know the types of all variables at compile time. The compiler can usually
infer what type we want to use based on the value and how we use it. In cases
when many types are possible, such as when we converted a String to a numeric
type using parse in the “Comparing the Guess to the Secret
Number” section in
Chapter 2, we must add a type annotation, like this:
#![allow(unused)] fn main() { let guess: u32 = "42".parse().expect("Not a number!"); }
If we don’t add the : u32 type annotation shown in the preceding code, Rust
will display the following error, which means the compiler needs more
information from us to know which type we want to use:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0282]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ consider giving `guess` a type
For more information about this error, try `rustc --explain E0282`.
error: could not compile `no_type_annotations` due to previous error
You’ll see different type annotations for other data types.
Scalar Types
A scalar type represents a single value. Rust has four primary scalar types: integers, floating-point numbers, Booleans, and characters. You may recognize these from other programming languages. Let’s jump into how they work in Rust.
Integer Types
An integer is a number without a fractional component. We used one integer
type in Chapter 2, the u32 type. This type declaration indicates that the
value it’s associated with should be an unsigned integer (signed integer types
start with i instead of u) that takes up 32 bits of space. Table 3-1 shows
the built-in integer types in Rust. We can use any of these variants to declare
the type of an integer value.
Table 3-1: Integer Types in Rust
| Length | Signed | Unsigned |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
Each variant can be either signed or unsigned and has an explicit size. Signed and unsigned refer to whether it’s possible for the number to be negative—in other words, whether the number needs to have a sign with it (signed) or whether it will only ever be positive and can therefore be represented without a sign (unsigned). It’s like writing numbers on paper: when the sign matters, a number is shown with a plus sign or a minus sign; however, when it’s safe to assume the number is positive, it’s shown with no sign. Signed numbers are stored using two’s complement representation.
Each signed variant can store numbers from -(2n - 1) to 2n -
1 - 1 inclusive, where n is the number of bits that variant uses. So an
i8 can store numbers from -(27) to 27 - 1, which equals
-128 to 127. Unsigned variants can store numbers from 0 to 2n - 1,
so a u8 can store numbers from 0 to 28 - 1, which equals 0 to 255.
Additionally, the isize and usize types depend on the architecture of the
computer your program is running on, which is denoted in the table as “arch”:
64 bits if you’re on a 64-bit architecture and 32 bits if you’re on a 32-bit
architecture.
You can write integer literals in any of the forms shown in Table 3-2. Note
that number literals that can be multiple numeric types allow a type suffix,
such as 57u8, to designate the type. Number literals can also use _ as a
visual separator to make the number easier to read, such as 1_000, which will
have the same value as if you had specified 1000.
Table 3-2: Integer Literals in Rust
| Number literals | Example |
|---|---|
| Decimal | 98_222 |
| Hex | 0xff |
| Octal | 0o77 |
| Binary | 0b1111_0000 |
Byte (u8 only) | b'A' |
So how do you know which type of integer to use? If you’re unsure, Rust’s
defaults are generally good places to start: integer types default to i32.
The primary situation in which you’d use isize or usize is when indexing
some sort of collection.
Integer Overflow
Let’s say you have a variable of type
u8that can hold values between 0 and 255. If you try to change the variable to a value outside that range, such as 256, integer overflow will occur, which can result in one of two behaviors. When you’re compiling in debug mode, Rust includes checks for integer overflow that cause your program to panic at runtime if this behavior occurs. Rust uses the term panicking when a program exits with an error; we’ll discuss panics in more depth in the “Unrecoverable Errors withpanic!” section in Chapter 9.When you’re compiling in release mode with the
--releaseflag, Rust does not include checks for integer overflow that cause panics. Instead, if overflow occurs, Rust performs two’s complement wrapping. In short, values greater than the maximum value the type can hold “wrap around” to the minimum of the values the type can hold. In the case of au8, the value 256 becomes 0, the value 257 becomes 1, and so on. The program won’t panic, but the variable will have a value that probably isn’t what you were expecting it to have. Relying on integer overflow’s wrapping behavior is considered an error.To explicitly handle the possibility of overflow, you can use these families of methods provided by the standard library for primitive numeric types:
- Wrap in all modes with the
wrapping_*methods, such aswrapping_add.- Return the
Nonevalue if there is overflow with thechecked_*methods.- Return the value and a boolean indicating whether there was overflow with the
overflowing_*methods.- Saturate at the value’s minimum or maximum values with the
saturating_*methods.
Floating-Point Types
Rust also has two primitive types for floating-point numbers, which are
numbers with decimal points. Rust’s floating-point types are f32 and f64,
which are 32 bits and 64 bits in size, respectively. The default type is f64
because on modern CPUs, it’s roughly the same speed as f32 but is capable of
more precision. All floating-point types are signed.
Here’s an example that shows floating-point numbers in action:
Filename: src/main.rs
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }
Floating-point numbers are represented according to the IEEE-754 standard. The
f32 type is a single-precision float, and f64 has double precision.
Numeric Operations
Rust supports the basic mathematical operations you’d expect for all the number
types: addition, subtraction, multiplication, division, and remainder. Integer
division truncates toward zero to the nearest integer. The following code shows
how you’d use each numeric operation in a let statement:
Filename: src/main.rs
fn main() { // addition let sum = 5 + 10; // subtraction let difference = 95.5 - 4.3; // multiplication let product = 4 * 30; // division let quotient = 56.7 / 32.2; let truncated = -5 / 3; // Results in -1 // remainder let remainder = 43 % 5; }
Each expression in these statements uses a mathematical operator and evaluates to a single value, which is then bound to a variable. Appendix B contains a list of all operators that Rust provides.
The Boolean Type
As in most other programming languages, a Boolean type in Rust has two possible
values: true and false. Booleans are one byte in size. The Boolean type in
Rust is specified using bool. For example:
Filename: src/main.rs
fn main() { let t = true; let f: bool = false; // with explicit type annotation }
The main way to use Boolean values is through conditionals, such as an if
expression. We’ll cover how if expressions work in Rust in the “Control
Flow” section.
The Character Type
Rust’s char type is the language’s most primitive alphabetic type. Here are
some examples of declaring char values:
Filename: src/main.rs
fn main() { let c = 'z'; let z: char = 'ℤ'; // with explicit type annotation let heart_eyed_cat = '😻'; }
Note that we specify char literals with single quotes, as opposed to string
literals, which use double quotes. Rust’s char type is four bytes in size and
represents a Unicode Scalar Value, which means it can represent a lot more than
just ASCII. Accented letters; Chinese, Japanese, and Korean characters; emoji;
and zero-width spaces are all valid char values in Rust. Unicode Scalar
Values range from U+0000 to U+D7FF and U+E000 to U+10FFFF inclusive.
However, a “character” isn’t really a concept in Unicode, so your human
intuition for what a “character” is may not match up with what a char is in
Rust. We’ll discuss this topic in detail in “Storing UTF-8 Encoded Text with
Strings” in Chapter 8.
Compound Types
Compound types can group multiple values into one type. Rust has two primitive compound types: tuples and arrays.
The Tuple Type
A tuple is a general way of grouping together a number of values with a variety of types into one compound type. Tuples have a fixed length: once declared, they cannot grow or shrink in size.
We create a tuple by writing a comma-separated list of values inside parentheses. Each position in the tuple has a type, and the types of the different values in the tuple don’t have to be the same. We’ve added optional type annotations in this example:
Filename: src/main.rs
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
The variable tup binds to the entire tuple because a tuple is considered a
single compound element. To get the individual values out of a tuple, we can
use pattern matching to destructure a tuple value, like this:
Filename: src/main.rs
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("The value of y is: {y}"); }
This program first creates a tuple and binds it to the variable tup. It then
uses a pattern with let to take tup and turn it into three separate
variables, x, y, and z. This is called destructuring because it breaks
the single tuple into three parts. Finally, the program prints the value of
y, which is 6.4.
We can also access a tuple element directly by using a period (.) followed by
the index of the value we want to access. For example:
Filename: src/main.rs
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2; }
This program creates the tuple x and then accesses each element of the tuple
using their respective indices. As with most programming languages, the first
index in a tuple is 0.
The tuple without any values has a special name, unit. This value and its
corresponding type are both written () and represent an empty value or an
empty return type. Expressions implicitly return the unit value if they don’t
return any other value.
The Array Type
Another way to have a collection of multiple values is with an array. Unlike a tuple, every element of an array must have the same type. Unlike arrays in some other languages, arrays in Rust have a fixed length.
We write the values in an array as a comma-separated list inside square brackets:
Filename: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; }
Arrays are useful when you want your data allocated on the stack rather than the heap (we will discuss the stack and the heap more in Chapter 4) or when you want to ensure you always have a fixed number of elements. An array isn’t as flexible as the vector type, though. A vector is a similar collection type provided by the standard library that is allowed to grow or shrink in size. If you’re unsure whether to use an array or a vector, chances are you should use a vector. Chapter 8 discusses vectors in more detail.
However, arrays are more useful when you know the number of elements will not need to change. For example, if you were using the names of the month in a program, you would probably use an array rather than a vector because you know it will always contain 12 elements:
#![allow(unused)] fn main() { let months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]; }
You write an array’s type using square brackets with the type of each element, a semicolon, and then the number of elements in the array, like so:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; }
Here, i32 is the type of each element. After the semicolon, the number 5
indicates the array contains five elements.
You can also initialize an array to contain the same value for each element by specifying the initial value, followed by a semicolon, and then the length of the array in square brackets, as shown here:
#![allow(unused)] fn main() { let a = [3; 5]; }
The array named a will contain 5 elements that will all be set to the value
3 initially. This is the same as writing let a = [3, 3, 3, 3, 3]; but in a
more concise way.
Accessing Array Elements
An array is a single chunk of memory of a known, fixed size that can be allocated on the stack. You can access elements of an array using indexing, like this:
Filename: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; let second = a[1]; }
In this example, the variable named first will get the value 1 because that
is the value at index [0] in the array. The variable named second will get
the value 2 from index [1] in the array.
Invalid Array Element Access
Let’s see what happens if you try to access an element of an array that is past the end of the array. Say you run this code, similar to the guessing game in Chapter 2, to get an array index from the user:
Filename: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}
This code compiles successfully. If you run this code using cargo run and
enter 0, 1, 2, 3, or 4, the program will print out the corresponding
value at that index in the array. If you instead enter a number past the end of
the array, such as 10, you’ll see output like this:
thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 10', src/main.rs:19:19
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
The program resulted in a runtime error at the point of using an invalid
value in the indexing operation. The program exited with an error message and
didn’t execute the final println! statement. When you attempt to access an
element using indexing, Rust will check that the index you’ve specified is less
than the array length. If the index is greater than or equal to the length,
Rust will panic. This check has to happen at runtime, especially in this case,
because the compiler can’t possibly know what value a user will enter when they
run the code later.
This is an example of Rust’s memory safety principles in action. In many low-level languages, this kind of check is not done, and when you provide an incorrect index, invalid memory can be accessed. Rust protects you against this kind of error by immediately exiting instead of allowing the memory access and continuing. Chapter 9 discusses more of Rust’s error handling and how you can write readable, safe code that neither panics nor allows invalid memory access.
Expressions: statements end with ;
A Rust program is (mostly) made up of a series of statements:
fn main() { // statement // statement // statement }
There are a few kinds of statements in Rust.
The most common two are declaring a variable binding, and using a ; with an expression:
fn main() { // variable binding let x = 5; // expression; x; x + 1; 15; }
- Blocks are expressions too, so they can be used as values in assignments.
- The last expression in the block will be assigned to the place expression such as a local variable.
However, if the last expression of the block ends with a semicolon, the return value will be ().
fn main() { let x = 5u32; let y = { let x_squared = x * x; let x_cube = x_squared * x; // This expression will be assigned to `y` x_cube + x_squared + x }; let z = { // The semicolon suppresses this expression and `()` is assigned to `z` 2 * x; }; println!("x is {:?}", x); println!("y is {:?}", y); println!("z is {:?}", z); }
Functions
-
Rust doesn’t care where you define your functions, only that they’re defined somewhere in a scope that can be seen by the caller.
-
In function signatures, you must declare the type of each parameter.
-
Function bodies are made up of statements
-
Rust is an expression-based language
-
Statements are instructions that perform some action and do not return a value, end with a semicolon Expressions evaluate to a resultant value.
-
Function definitions are also statements;
-
Expressions can be part of statements
-
Calling a function, a macro, a scope, all are expressions.
-
A new scope block created with curly brackets is an expression
-
Expressions do not include ending semicolons if you add a semicolon to the end of an expression, you turn it into a statement, and it will then not return a value.
-
Last Return
-
Early Return
Functions are prevalent in Rust code. You’ve already seen one of the most important functions in the language:
- the
mainfunction, which is the entry point of many programs. - You’ve also seen the
fnkeyword, which allows you to declare new functions.
Rust code uses snake case as the conventional style for function and variable names, in which all letters are lowercase and underscores separate words.
Here’s a program that contains an example function definition:
fn main() { println!("Hello, world!"); another_function(); } fn another_function() { println!("Another function."); }
- We define a function in Rust by entering
fnfollowed by a function name and a set of parentheses. - The curly brackets tell the compiler where the function body begins and ends.
- We can call any function we’ve defined by entering its name followed by a set of parentheses.
- Because
another_functionis defined in the program, it can be called from inside themainfunction. - Note that we defined
another_functionafter themainfunction in the source code; we could have defined it before as well.
Rust doesn’t care where you define your functions, only that they’re defined somewhere in a scope that can be seen by the caller.
Let’s start a new binary project named functions to explore functions
further. Place the another_function example in src/main.rs and run it.
You should see the following output:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
The lines execute in the order in which they appear in the main function.
First the “Hello, world!” message prints, and then another_function is called
and its message is printed.
Parameters
We can define functions to have parameters, which are special variables that are part of a function’s signature. When a function has parameters, you can provide it with concrete values for those parameters.
Arguments or Parameters
Technically, the concrete values are called arguments, but in casual conversation, people tend to use the words parameter and argument interchangeably for either the variables in a function’s definition or the concrete values passed in when you call a function.
In this version of another_function we add a parameter:
fn main() { another_function(5); } fn another_function(x: i32) { println!("The value of x is: {x}"); }
Try running this program; you should get the following output:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
- The declaration of
another_functionhas one parameter namedx. - The type of
xis specified asi32. When we pass5in toanother_function - the
println!macro puts5where the pair of curly brackets containingxwas in the format string.
In function signatures, you must declare the type of each parameter.
This is a deliberate decision in Rust’s design:
requiring type annotations in function definitions means the compiler almost never needs you to use them elsewhere in the code to figure out what type you mean.
The compiler is also able to give more helpful error messages if it knows what types the function expects.
When defining multiple parameters, separate the parameter declarations with commas, like this:
fn main() { print_labeled_measurement(5, 'h'); } fn print_labeled_measurement(value: i32, unit_label: char) { println!("The measurement is: {value}{unit_label}"); }
This example creates a function named print_labeled_measurement with two parameters:
- The first parameter is named
valueand is ani32. - The second is
named
unit_labeland is typechar. - The function then prints text containing
both the
valueand theunit_label.
Let’s try running this code.
Replace the program currently in your functions project’s src/main.rs file with the preceding example and run it using cargo run:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
Because we called the function with 5 as the value for value and 'h' as
the value for unit_label, the program output contains those values.
Statements and Expressions
Function bodies are made up of statements
Function bodies are made up of a series of statements, optionally ending in an expression.
So far, the functions we’ve covered haven’t included an ending expression, but you have seen an expression as part of a statement.
Expression-based language
Rust is an expression-based language
Because Rust is an expression-based language, this is an important distinction to understand.
Other languages don’t have the same distinctions, so let’s look at what statements and expressions are and how their differences affect the bodies of functions.
Differences
Diffreence between statements and expressions
- Statements are instructions that perform some action and do not return a value, end with a semicolon
- Expressions evaluate to a resultant value.
Let’s look at some examples.
We’ve actually already used statements and expressions:
- Creating a variable and assigning a value to it with the
letkeyword is a statement.
In Listing 3-1, let y = 6; is a statement.
-
Function definitions are also statements;
-
the entire preceding example is a statement in itself.
-
Statements do not return values.
Therefore, you can’t assign a let statement to another variable, as the following code tries to do; you’ll get an error:
Therefore, you can’t assign a let statement to another variable, as the following code tries to do; you’ll get an error:
fn main() {
let x = (let y = 6);
}
When you run this program, the error you’ll get looks like this:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found statement (`let`)
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^^^^^^^
|
= note: variable declaration using `let` is a statement
error[E0658]: `let` expressions in this position are unstable
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^^^^^^^
|
= note: see issue #53667 <https://github.com/rust-lang/rust/issues/53667> for more information
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
For more information about this error, try `rustc --explain E0658`.
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` due to 2 previous errors; 1 warning emitted
The let y = 6 statement does not return a value, so there isn’t anything for x to bind to.
This is different from what happens in other languages, such as C and Ruby, where the assignment returns the value of the assignment. In those languages, you can write
x = y = 6and have bothxandyhave the value6; that is not the case in Rust.
- Expressions evaluate to a value and make up most of the rest of the code that you’ll write in Rust.
Consider a math operation, such as 5 + 6, which is an
expression that evaluates to the value 11.
- Expressions can be part of statements:
in Listing 3-1, the 6 in the statement let y = 6; is an expression that evaluates to the value 6.
- Calling a function, a macro, a scope, all are expressions.
A new scope block created with curly brackets is an expression, for example:
fn main() { let y = { let x = 3; x + 1 }; println!("The value of y is: {y}"); }
This expression:
{
let x = 3;
x + 1
}
is a block that, in this case, evaluates to 4. That value gets bound to y
as part of the let statement.
Note that the
x + 1line doesn’t have a semicolon at the end, which is unlike most of the lines you’ve seen so far.
- Expressions do not include ending semicolons.
If you add a semicolon to the end of an expression, you turn it into a statement, and it will then not return a value.
Keep this in mind as you explore function return values and expressions next.
Functions with Return Values
Last return or early return
-
Functions can return values to the code that calls them.
-
We don’t name return values, but we must declare their type after an arrow (
->). -
Last Return:
In Rust, the return value of the function is synonymous with the value of the final expression in the block of the body of a function.
- Early Return:
You can return early from a
function by using the return keyword and specifying a value, but most
functions return the last expression implicitly.
Here’s an example of a function that returns a value:
fn five() -> i32 { 5 } fn main() { let x = five(); println!("The value of x is: {x}"); }
There are no function calls, macros, or even let statements in the five
function—just the number 5 by itself.
That’s a perfectly valid function in Rust.
Note that the function’s return type is specified too, as -> i32.
Try running this code; the output should look like this:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
The 5 in five is the function’s return value, which is why the return type is i32.
place a semicolon or not
Let’s examine this in more detail.
There are two important bits:
- first, the line
let x = five();shows that we’re using the return value of a function to initialize a variable.
Because the function five returns a 5, that line is the same as the following:
let x = 5;
- Second, the
fivefunction has no parameters and defines the type of the return value, but the body of the function is a lonely5with no semicolon because it’s an expression whose value we want to return.
Let’s look at another example:
fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1 }
Running this code will print The value of x is: 6.
But if we place a semicolon at the end of the line containing x + 1, changing it from an expression to a statement, we’ll get an error:
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}
Compiling this code produces an error, as follows:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` due to previous error
The main error message,
mismatched types, reveals the core issue with this code:
-
The definition of the function
plus_onesays that it will return ani32, but statements don’t evaluate to a value, which is expressed by(), the unit type. -
Therefore, nothing is returned, which contradicts the function definition and results in an error.
-
In this output, Rust provides a message to possibly help rectify this issue: it suggests removing the semicolon, which would fix the error.
Comments
All programmers strive to make their code easy to understand, but sometimes extra explanation is warranted. In these cases, programmers leave comments in their source code that the compiler will ignore but people reading the source code may find useful.
Here’s a simple comment:
#![allow(unused)] fn main() { // hello, world }
In Rust, the idiomatic comment style starts a comment with two slashes, and the
comment continues until the end of the line. For comments that extend beyond a
single line, you’ll need to include // on each line, like this:
#![allow(unused)] fn main() { // So we’re doing something complicated here, long enough that we need // multiple lines of comments to do it! Whew! Hopefully, this comment will // explain what’s going on. }
Comments can also be placed at the end of lines containing code:
Filename: src/main.rs
fn main() { let lucky_number = 7; // I’m feeling lucky today }
But you’ll more often see them used in this format, with the comment on a separate line above the code it’s annotating:
Filename: src/main.rs
fn main() { // I’m feeling lucky today let lucky_number = 7; }
Rust also has another kind of comment, documentation comments, which we’ll discuss in the “Publishing a Crate to Crates.io” section of Chapter 14.
Control Flow
The ability to run some code depending on whether a condition is true and to
run some code repeatedly while a condition is true are basic building blocks
in most programming languages. The most common constructs that let you control
the flow of execution of Rust code are if expressions and loops.
if Expressions
An if expression allows you to branch your code depending on conditions. You
provide a condition and then state, “If this condition is met, run this block
of code. If the condition is not met, do not run this block of code.”
Create a new project called branches in your projects directory to explore
the if expression. In the src/main.rs file, input the following:
Filename: src/main.rs
fn main() { let number = 3; if number < 5 { println!("condition was true"); } else { println!("condition was false"); } }
All if expressions start with the keyword if, followed by a condition. In
this case, the condition checks whether or not the variable number has a
value less than 5. We place the block of code to execute if the condition is
true immediately after the condition inside curly brackets. Blocks of code
associated with the conditions in if expressions are sometimes called arms,
just like the arms in match expressions that we discussed in the “Comparing
the Guess to the Secret Number” section of Chapter 2.
Optionally, we can also include an else expression, which we chose to do
here, to give the program an alternative block of code to execute should the
condition evaluate to false. If you don’t provide an else expression and
the condition is false, the program will just skip the if block and move on
to the next bit of code.
Try running this code; you should see the following output:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
Let’s try changing the value of number to a value that makes the condition
false to see what happens:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}
Run the program again, and look at the output:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
It’s also worth noting that the condition in this code must be a bool. If
the condition isn’t a bool, we’ll get an error. For example, try running the
following code:
Filename: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}
The if condition evaluates to a value of 3 this time, and Rust throws an
error:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` due to previous error
The error indicates that Rust expected a bool but got an integer. Unlike
languages such as Ruby and JavaScript, Rust will not automatically try to
convert non-Boolean types to a Boolean. You must be explicit and always provide
if with a Boolean as its condition. If we want the if code block to run
only when a number is not equal to 0, for example, we can change the if
expression to the following:
Filename: src/main.rs
fn main() { let number = 3; if number != 0 { println!("number was something other than zero"); } }
Running this code will print number was something other than zero.
Handling Multiple Conditions with else if
You can use multiple conditions by combining if and else in an else if
expression. For example:
Filename: src/main.rs
fn main() { let number = 6; if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } }
This program has four possible paths it can take. After running it, you should see the following output:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
When this program executes, it checks each if expression in turn and executes
the first body for which the condition evaluates to true. Note that even
though 6 is divisible by 2, we don’t see the output number is divisible by 2,
nor do we see the number is not divisible by 4, 3, or 2 text from the else
block. That’s because Rust only executes the block for the first true
condition, and once it finds one, it doesn’t even check the rest.
Using too many else if expressions can clutter your code, so if you have more
than one, you might want to refactor your code. Chapter 6 describes a powerful
Rust branching construct called match for these cases.
Using if in a let Statement
Because if is an expression, we can use it on the right side of a let
statement to assign the outcome to a variable, as in Listing 3-2.
Filename: src/main.rs
fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {number}"); }
Listing 3-2: Assigning the result of an if expression
to a variable
The number variable will be bound to a value based on the outcome of the if
expression. Run this code to see what happens:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished dev [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
Remember that blocks of code evaluate to the last expression in them, and
numbers by themselves are also expressions. In this case, the value of the
whole if expression depends on which block of code executes. This means the
values that have the potential to be results from each arm of the if must be
the same type; in Listing 3-2, the results of both the if arm and the else
arm were i32 integers. If the types are mismatched, as in the following
example, we’ll get an error:
Filename: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}
When we try to compile this code, we’ll get an error. The if and else arms
have value types that are incompatible, and Rust indicates exactly where to
find the problem in the program:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` due to previous error
The expression in the if block evaluates to an integer, and the expression in
the else block evaluates to a string. This won’t work because variables must
have a single type, and Rust needs to know at compile time what type the
number variable is, definitively. Knowing the type of number lets the
compiler verify the type is valid everywhere we use number. Rust wouldn’t be
able to do that if the type of number was only determined at runtime; the
compiler would be more complex and would make fewer guarantees about the code
if it had to keep track of multiple hypothetical types for any variable.
Repetition with Loops
It’s often useful to execute a block of code more than once. For this task, Rust provides several loops, which will run through the code inside the loop body to the end and then start immediately back at the beginning. To experiment with loops, let’s make a new project called loops.
Rust has three kinds of loops: loop, while, and for. Let’s try each one.
Repeating Code with loop
The loop keyword tells Rust to execute a block of code over and over again
forever or until you explicitly tell it to stop.
As an example, change the src/main.rs file in your loops directory to look like this:
Filename: src/main.rs
fn main() {
loop {
println!("again!");
}
}
When we run this program, we’ll see again! printed over and over continuously
until we stop the program manually. Most terminals support the keyboard
shortcut ctrl-c to interrupt a program that is
stuck in a continual loop. Give it a try:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished dev [unoptimized + debuginfo] target(s) in 0.29s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
The symbol ^C represents where you pressed ctrl-c. You may or may not see the word again!
printed after the ^C, depending on where the code was in the loop when it
received the interrupt signal.
Fortunately, Rust also provides a way to break out of a loop using code. You
can place the break keyword within the loop to tell the program when to stop
executing the loop. Recall that we did this in the guessing game in the
“Quitting After a Correct Guess” section of Chapter 2 to exit the program when the user won the game by
guessing the correct number.
We also used continue in the guessing game, which in a loop tells the program
to skip over any remaining code in this iteration of the loop and go to the
next iteration.
Returning Values from Loops
One of the uses of a loop is to retry an operation you know might fail, such
as checking whether a thread has completed its job. You might also need to pass
the result of that operation out of the loop to the rest of your code. To do
this, you can add the value you want returned after the break expression you
use to stop the loop; that value will be returned out of the loop so you can
use it, as shown here:
fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {result}"); }
Before the loop, we declare a variable named counter and initialize it to
0. Then we declare a variable named result to hold the value returned from
the loop. On every iteration of the loop, we add 1 to the counter variable,
and then check whether the counter is equal to 10. When it is, we use the
break keyword with the value counter * 2. After the loop, we use a
semicolon to end the statement that assigns the value to result. Finally, we
print the value in result, which in this case is 20.
Loop Labels to Disambiguate Between Multiple Loops
If you have loops within loops, break and continue apply to the innermost
loop at that point. You can optionally specify a loop label on a loop that
you can then use with break or continue to specify that those keywords
apply to the labeled loop instead of the innermost loop. Loop labels must begin
with a single quote. Here’s an example with two nested loops:
fn main() { let mut count = 0; 'counting_up: loop { println!("count = {count}"); let mut remaining = 10; loop { println!("remaining = {remaining}"); if remaining == 9 { break; } if count == 2 { break 'counting_up; } remaining -= 1; } count += 1; } println!("End count = {count}"); }
The outer loop has the label 'counting_up, and it will count up from 0 to 2.
The inner loop without a label counts down from 10 to 9. The first break that
doesn’t specify a label will exit the inner loop only. The break 'counting_up; statement will exit the outer loop. This code prints:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished dev [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
Conditional Loops with while
A program will often need to evaluate a condition within a loop. While the
condition is true, the loop runs. When the condition ceases to be true, the
program calls break, stopping the loop. It’s possible to implement behavior
like this using a combination of loop, if, else, and break; you could
try that now in a program, if you’d like. However, this pattern is so common
that Rust has a built-in language construct for it, called a while loop. In
Listing 3-3, we use while to loop the program three times, counting down each
time, and then, after the loop, print a message and exit.
Filename: src/main.rs
fn main() { let mut number = 3; while number != 0 { println!("{number}!"); number -= 1; } println!("LIFTOFF!!!"); }
Listing 3-3: Using a while loop to run code while a
condition holds true
This construct eliminates a lot of nesting that would be necessary if you used
loop, if, else, and break, and it’s clearer. While a condition
evaluates to true, the code runs; otherwise, it exits the loop.
Looping Through a Collection with for
You can choose to use the while construct to loop over the elements of a
collection, such as an array. For example, the loop in Listing 3-4 prints each
element in the array a.
Filename: src/main.rs
fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index += 1; } }
Listing 3-4: Looping through each element of a collection
using a while loop
Here, the code counts up through the elements in the array. It starts at index
0, and then loops until it reaches the final index in the array (that is,
when index < 5 is no longer true). Running this code will print every
element in the array:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished dev [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
All five array values appear in the terminal, as expected. Even though index
will reach a value of 5 at some point, the loop stops executing before trying
to fetch a sixth value from the array.
However, this approach is error prone; we could cause the program to panic if
the index value or test condition is incorrect. For example, if you changed the
definition of the a array to have four elements but forgot to update the
condition to while index < 4, the code would panic. It’s also slow, because
the compiler adds runtime code to perform the conditional check of whether the
index is within the bounds of the array on every iteration through the loop.
As a more concise alternative, you can use a for loop and execute some code
for each item in a collection. A for loop looks like the code in Listing 3-5.
Filename: src/main.rs
fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } }
Listing 3-5: Looping through each element of a collection
using a for loop
When we run this code, we’ll see the same output as in Listing 3-4. More importantly, we’ve now increased the safety of the code and eliminated the chance of bugs that might result from going beyond the end of the array or not going far enough and missing some items.
Using the for loop, you wouldn’t need to remember to change any other code if
you changed the number of values in the array, as you would with the method
used in Listing 3-4.
The safety and conciseness of for loops make them the most commonly used loop
construct in Rust. Even in situations in which you want to run some code a
certain number of times, as in the countdown example that used a while loop
in Listing 3-3, most Rustaceans would use a for loop. The way to do that
would be to use a Range, provided by the standard library, which generates
all numbers in sequence starting from one number and ending before another
number.
Here’s what the countdown would look like using a for loop and another method
we’ve not yet talked about, rev, to reverse the range:
Filename: src/main.rs
fn main() { for number in (1..4).rev() { println!("{number}!"); } println!("LIFTOFF!!!"); }
This code is a bit nicer, isn’t it?
Summary
You made it! This was a sizable chapter: you learned about variables, scalar
and compound data types, functions, comments, if expressions, and loops! To
practice with the concepts discussed in this chapter, try building programs to
do the following:
- Convert temperatures between Fahrenheit and Celsius.
- Generate the nth Fibonacci number.
- Print the lyrics to the Christmas carol “The Twelve Days of Christmas,” taking advantage of the repetition in the song.
When you’re ready to move on, we’ll talk about a concept in Rust that doesn’t commonly exist in other programming languages: ownership.
Understanding Ownership
Ownership is Rust’s most unique feature and has deep implications for the rest of the language. It enables Rust to make memory safety guarantees without needing a garbage collector, so it’s important to understand how ownership works. In this chapter, we’ll talk about ownership as well as several related features: borrowing, slices, and how Rust lays data out in memory.
What Is Ownership?
Ownership is a set of rules that govern how a Rust program manages memory. All programs have to manage the way they use a computer’s memory while running. Some languages have garbage collection that regularly looks for no-longer-used memory as the program runs; in other languages, the programmer must explicitly allocate and free the memory. Rust uses a third approach: memory is managed through a system of ownership with a set of rules that the compiler checks. If any of the rules are violated, the program won’t compile. None of the features of ownership will slow down your program while it’s running.
Because ownership is a new concept for many programmers, it does take some time to get used to. The good news is that the more experienced you become with Rust and the rules of the ownership system, the easier you’ll find it to naturally develop code that is safe and efficient. Keep at it!
When you understand ownership, you’ll have a solid foundation for understanding the features that make Rust unique. In this chapter, you’ll learn ownership by working through some examples that focus on a very common data structure: strings.
The Stack and the Heap
Many programming languages don’t require you to think about the stack and the heap very often. But in a systems programming language like Rust, whether a value is on the stack or the heap affects how the language behaves and why you have to make certain decisions. Parts of ownership will be described in relation to the stack and the heap later in this chapter, so here is a brief explanation in preparation.
Both the stack and the heap are parts of memory available to your code to use at runtime, but they are structured in different ways. The stack stores values in the order it gets them and removes the values in the opposite order. This is referred to as last in, first out. Think of a stack of plates: when you add more plates, you put them on top of the pile, and when you need a plate, you take one off the top. Adding or removing plates from the middle or bottom wouldn’t work as well! Adding data is called pushing onto the stack, and removing data is called popping off the stack. All data stored on the stack must have a known, fixed size. Data with an unknown size at compile time or a size that might change must be stored on the heap instead.
The heap is less organized: when you put data on the heap, you request a certain amount of space. The memory allocator finds an empty spot in the heap that is big enough, marks it as being in use, and returns a pointer, which is the address of that location. This process is called allocating on the heap and is sometimes abbreviated as just allocating (pushing values onto the stack is not considered allocating). Because the pointer to the heap is a known, fixed size, you can store the pointer on the stack, but when you want the actual data, you must follow the pointer. Think of being seated at a restaurant. When you enter, you state the number of people in your group, and the host finds an empty table that fits everyone and leads you there. If someone in your group comes late, they can ask where you’ve been seated to find you.
Pushing to the stack is faster than allocating on the heap because the allocator never has to search for a place to store new data; that location is always at the top of the stack. Comparatively, allocating space on the heap requires more work because the allocator must first find a big enough space to hold the data and then perform bookkeeping to prepare for the next allocation.
Accessing data in the heap is slower than accessing data on the stack because you have to follow a pointer to get there. Contemporary processors are faster if they jump around less in memory. Continuing the analogy, consider a server at a restaurant taking orders from many tables. It’s most efficient to get all the orders at one table before moving on to the next table. Taking an order from table A, then an order from table B, then one from A again, and then one from B again would be a much slower process. By the same token, a processor can do its job better if it works on data that’s close to other data (as it is on the stack) rather than farther away (as it can be on the heap).
When your code calls a function, the values passed into the function (including, potentially, pointers to data on the heap) and the function’s local variables get pushed onto the stack. When the function is over, those values get popped off the stack.
Keeping track of what parts of code are using what data on the heap, minimizing the amount of duplicate data on the heap, and cleaning up unused data on the heap so you don’t run out of space are all problems that ownership addresses. Once you understand ownership, you won’t need to think about the stack and the heap very often, but knowing that the main purpose of ownership is to manage heap data can help explain why it works the way it does.
Ownership Rules
First, let’s take a look at the ownership rules. Keep these rules in mind as we work through the examples that illustrate them:
- Each value in Rust has an owner.
- There can only be one owner at a time.
- When the owner goes out of scope, the value will be dropped.
Variable Scope
Now that we’re past basic Rust syntax, we won’t include all the fn main() {
code in examples, so if you’re following along, make sure to put the following
examples inside a main function manually. As a result, our examples will be a
bit more concise, letting us focus on the actual details rather than
boilerplate code.
As a first example of ownership, we’ll look at the scope of some variables. A scope is the range within a program for which an item is valid. Take the following variable:
#![allow(unused)] fn main() { let s = "hello"; }
The variable s refers to a string literal, where the value of the string is
hardcoded into the text of our program. The variable is valid from the point at
which it’s declared until the end of the current scope. Listing 4-1 shows a
program with comments annotating where the variable s would be valid.
fn main() { { // s is not valid here, it’s not yet declared let s = "hello"; // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no longer valid }
Listing 4-1: A variable and the scope in which it is valid
In other words, there are two important points in time here:
- When
scomes into scope, it is valid. - It remains valid until it goes out of scope.
At this point, the relationship between scopes and when variables are valid is
similar to that in other programming languages. Now we’ll build on top of this
understanding by introducing the String type.
The String Type
To illustrate the rules of ownership, we need a data type that is more complex
than those we covered in the “Data Types” section
of Chapter 3. The types covered previously are of a known size, can be stored
on the stack and popped off the stack when their scope is over, and can be
quickly and trivially copied to make a new, independent instance if another
part of code needs to use the same value in a different scope. But we want to
look at data that is stored on the heap and explore how Rust knows when to
clean up that data, and the String type is a great example.
We’ll concentrate on the parts of String that relate to ownership. These
aspects also apply to other complex data types, whether they are provided by
the standard library or created by you. We’ll discuss String in more depth in
Chapter 8.
We’ve already seen string literals, where a string value is hardcoded into our
program. String literals are convenient, but they aren’t suitable for every
situation in which we may want to use text. One reason is that they’re
immutable. Another is that not every string value can be known when we write
our code: for example, what if we want to take user input and store it? For
these situations, Rust has a second string type, String. This type manages
data allocated on the heap and as such is able to store an amount of text that
is unknown to us at compile time. You can create a String from a string
literal using the from function, like so:
#![allow(unused)] fn main() { let s = String::from("hello"); }
The double colon :: operator allows us to namespace this particular from
function under the String type rather than using some sort of name like
string_from. We’ll discuss this syntax more in the “Method
Syntax” section of Chapter 5, and when we talk
about namespacing with modules in “Paths for Referring to an Item in the
Module Tree” in Chapter 7.
This kind of string can be mutated:
fn main() { let mut s = String::from("hello"); s.push_str(", world!"); // push_str() appends a literal to a String println!("{}", s); // This will print `hello, world!` }
So, what’s the difference here? Why can String be mutated but literals
cannot? The difference is in how these two types deal with memory.
Memory and Allocation
In the case of a string literal, we know the contents at compile time, so the text is hardcoded directly into the final executable. This is why string literals are fast and efficient. But these properties only come from the string literal’s immutability. Unfortunately, we can’t put a blob of memory into the binary for each piece of text whose size is unknown at compile time and whose size might change while running the program.
With the String type, in order to support a mutable, growable piece of text,
we need to allocate an amount of memory on the heap, unknown at compile time,
to hold the contents. This means:
- The memory must be requested from the memory allocator at runtime.
- We need a way of returning this memory to the allocator when we’re done with
our
String.
That first part is done by us: when we call String::from, its implementation
requests the memory it needs. This is pretty much universal in programming
languages.
However, the second part is different. In languages with a garbage collector
(GC), the GC keeps track of and cleans up memory that isn’t being used
anymore, and we don’t need to think about it. In most languages without a GC,
it’s our responsibility to identify when memory is no longer being used and to
call code to explicitly free it, just as we did to request it. Doing this
correctly has historically been a difficult programming problem. If we forget,
we’ll waste memory. If we do it too early, we’ll have an invalid variable. If
we do it twice, that’s a bug too. We need to pair exactly one allocate with
exactly one free.
Rust takes a different path: the memory is automatically returned once the
variable that owns it goes out of scope. Here’s a version of our scope example
from Listing 4-1 using a String instead of a string literal:
fn main() { { let s = String::from("hello"); // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no // longer valid }
There is a natural point at which we can return the memory our String needs
to the allocator: when s goes out of scope. When a variable goes out of
scope, Rust calls a special function for us. This function is called
drop, and it’s where the author of String can put
the code to return the memory. Rust calls drop automatically at the closing
curly bracket.
Note: In C++, this pattern of deallocating resources at the end of an item’s lifetime is sometimes called Resource Acquisition Is Initialization (RAII). The
dropfunction in Rust will be familiar to you if you’ve used RAII patterns.
This pattern has a profound impact on the way Rust code is written. It may seem simple right now, but the behavior of code can be unexpected in more complicated situations when we want to have multiple variables use the data we’ve allocated on the heap. Let’s explore some of those situations now.
Variables and Data Interacting with Move
Multiple variables can interact with the same data in different ways in Rust. Let’s look at an example using an integer in Listing 4-2.
fn main() { let x = 5; let y = x; }
Listing 4-2: Assigning the integer value of variable x
to y
We can probably guess what this is doing: “bind the value 5 to x; then make
a copy of the value in x and bind it to y.” We now have two variables, x
and y, and both equal 5. This is indeed what is happening, because integers
are simple values with a known, fixed size, and these two 5 values are pushed
onto the stack.
Now let’s look at the String version:
fn main() { let s1 = String::from("hello"); let s2 = s1; }
This looks very similar, so we might assume that the way it works would be the
same: that is, the second line would make a copy of the value in s1 and bind
it to s2. But this isn’t quite what happens.
Take a look at Figure 4-1 to see what is happening to String under the
covers. A String is made up of three parts, shown on the left: a pointer to
the memory that holds the contents of the string, a length, and a capacity.
This group of data is stored on the stack. On the right is the memory on the
heap that holds the contents.

Figure 4-1: Representation in memory of a String
holding the value "hello" bound to s1
The length is how much memory, in bytes, the contents of the String are
currently using. The capacity is the total amount of memory, in bytes, that the
String has received from the allocator. The difference between length and
capacity matters, but not in this context, so for now, it’s fine to ignore the
capacity.
When we assign s1 to s2, the String data is copied, meaning we copy the
pointer, the length, and the capacity that are on the stack. We do not copy the
data on the heap that the pointer refers to. In other words, the data
representation in memory looks like Figure 4-2.

Figure 4-2: Representation in memory of the variable s2
that has a copy of the pointer, length, and capacity of s1
The representation does not look like Figure 4-3, which is what memory would
look like if Rust instead copied the heap data as well. If Rust did this, the
operation s2 = s1 could be very expensive in terms of runtime performance if
the data on the heap were large.

Figure 4-3: Another possibility for what s2 = s1 might
do if Rust copied the heap data as well
Earlier, we said that when a variable goes out of scope, Rust automatically
calls the drop function and cleans up the heap memory for that variable. But
Figure 4-2 shows both data pointers pointing to the same location. This is a
problem: when s2 and s1 go out of scope, they will both try to free the
same memory. This is known as a double free error and is one of the memory
safety bugs we mentioned previously. Freeing memory twice can lead to memory
corruption, which can potentially lead to security vulnerabilities.
To ensure memory safety, after the line let s2 = s1;, Rust considers s1 as
no longer valid. Therefore, Rust doesn’t need to free anything when s1 goes
out of scope. Check out what happens when you try to use s1 after s2 is
created; it won’t work:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
}
You’ll get an error like this because Rust prevents you from using the invalidated reference:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:28
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` due to previous error
If you’ve heard the terms shallow copy and deep copy while working with
other languages, the concept of copying the pointer, length, and capacity
without copying the data probably sounds like making a shallow copy. But
because Rust also invalidates the first variable, instead of being called a
shallow copy, it’s known as a move. In this example, we would say that s1
was moved into s2. So, what actually happens is shown in Figure 4-4.

Figure 4-4: Representation in memory after s1 has been
invalidated
That solves our problem! With only s2 valid, when it goes out of scope it
alone will free the memory, and we’re done.
In addition, there’s a design choice that’s implied by this: Rust will never automatically create “deep” copies of your data. Therefore, any automatic copying can be assumed to be inexpensive in terms of runtime performance.
Variables and Data Interacting with Clone
If we do want to deeply copy the heap data of the String, not just the
stack data, we can use a common method called clone. We’ll discuss method
syntax in Chapter 5, but because methods are a common feature in many
programming languages, you’ve probably seen them before.
Here’s an example of the clone method in action:
fn main() { let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {}, s2 = {}", s1, s2); }
This works just fine and explicitly produces the behavior shown in Figure 4-3, where the heap data does get copied.
When you see a call to clone, you know that some arbitrary code is being
executed and that code may be expensive. It’s a visual indicator that something
different is going on.
Stack-Only Data: Copy
There’s another wrinkle we haven’t talked about yet. This code using integers—part of which was shown in Listing 4-2—works and is valid:
fn main() { let x = 5; let y = x; println!("x = {}, y = {}", x, y); }
But this code seems to contradict what we just learned: we don’t have a call to
clone, but x is still valid and wasn’t moved into y.
The reason is that types such as integers that have a known size at compile
time are stored entirely on the stack, so copies of the actual values are quick
to make. That means there’s no reason we would want to prevent x from being
valid after we create the variable y. In other words, there’s no difference
between deep and shallow copying here, so calling clone wouldn’t do anything
different from the usual shallow copying, and we can leave it out.
Rust has a special annotation called the Copy trait that we can place on
types that are stored on the stack, as integers are (we’ll talk more about
traits in Chapter 10). If a type implements the Copy
trait, variables that use it do not move, but rather are trivially copied,
making them still valid after assignment to another variable.
Rust won’t let us annotate a type with Copy if the type, or any of its parts,
has implemented the Drop trait. If the type needs something special to happen
when the value goes out of scope and we add the Copy annotation to that type,
we’ll get a compile-time error. To learn about how to add the Copy annotation
to your type to implement the trait, see “Derivable
Traits” in Appendix C.
So, what types implement the Copy trait? You can check the documentation for
the given type to be sure, but as a general rule, any group of simple scalar
values can implement Copy, and nothing that requires allocation or is some
form of resource can implement Copy. Here are some of the types that
implement Copy:
- All the integer types, such as
u32. - The Boolean type,
bool, with valuestrueandfalse. - All the floating-point types, such as
f64. - The character type,
char. - Tuples, if they only contain types that also implement
Copy. For example,(i32, i32)implementsCopy, but(i32, String)does not.
Ownership and Functions
The mechanics of passing a value to a function are similar to those when assigning a value to a variable. Passing a variable to a function will move or copy, just as assignment does. Listing 4-3 has an example with some annotations showing where variables go into and out of scope.
Filename: src/main.rs
fn main() { let s = String::from("hello"); // s comes into scope takes_ownership(s); // s's value moves into the function... // ... and so is no longer valid here let x = 5; // x comes into scope makes_copy(x); // x would move into the function, // but i32 is Copy, so it's okay to still // use x afterward } // Here, x goes out of scope, then s. But because s's value was moved, nothing // special happens. fn takes_ownership(some_string: String) { // some_string comes into scope println!("{}", some_string); } // Here, some_string goes out of scope and `drop` is called. The backing // memory is freed. fn makes_copy(some_integer: i32) { // some_integer comes into scope println!("{}", some_integer); } // Here, some_integer goes out of scope. Nothing special happens.
Listing 4-3: Functions with ownership and scope annotated
If we tried to use s after the call to takes_ownership, Rust would throw a
compile-time error. These static checks protect us from mistakes. Try adding
code to main that uses s and x to see where you can use them and where
the ownership rules prevent you from doing so.
Return Values and Scope
Returning values can also transfer ownership. Listing 4-4 shows an example of a function that returns some value, with similar annotations as those in Listing 4-3.
Filename: src/main.rs
fn main() { let s1 = gives_ownership(); // gives_ownership moves its return // value into s1 let s2 = String::from("hello"); // s2 comes into scope let s3 = takes_and_gives_back(s2); // s2 is moved into // takes_and_gives_back, which also // moves its return value into s3 } // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing // happens. s1 goes out of scope and is dropped. fn gives_ownership() -> String { // gives_ownership will move its // return value into the function // that calls it let some_string = String::from("yours"); // some_string comes into scope some_string // some_string is returned and // moves out to the calling // function } // This function takes a String and returns one fn takes_and_gives_back(a_string: String) -> String { // a_string comes into // scope a_string // a_string is returned and moves out to the calling function }
Listing 4-4: Transferring ownership of return values
The ownership of a variable follows the same pattern every time: assigning a
value to another variable moves it. When a variable that includes data on the
heap goes out of scope, the value will be cleaned up by drop unless ownership
of the data has been moved to another variable.
While this works, taking ownership and then returning ownership with every function is a bit tedious. What if we want to let a function use a value but not take ownership? It’s quite annoying that anything we pass in also needs to be passed back if we want to use it again, in addition to any data resulting from the body of the function that we might want to return as well.
Rust does let us return multiple values using a tuple, as shown in Listing 4-5.
Filename: src/main.rs
fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{}' is {}.", s2, len); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // len() returns the length of a String (s, length) }
Listing 4-5: Returning ownership of parameters
But this is too much ceremony and a lot of work for a concept that should be common. Luckily for us, Rust has a feature for using a value without transferring ownership, called references.
References and Borrowing
The issue with the tuple code in Listing 4-5 is that we have to return the
String to the calling function so we can still use the String after the
call to calculate_length, because the String was moved into
calculate_length. Instead, we can provide a reference to the String value.
A reference is like a pointer in that it’s an address we can follow to access
the data stored at that address; that data is owned by some other variable.
Unlike a pointer, a reference is guaranteed to point to a valid value of a
particular type for the life of that reference.
Here is how you would define and use a calculate_length function that has a
reference to an object as a parameter instead of taking ownership of the value:
Filename: src/main.rs
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{}' is {}.", s1, len); } fn calculate_length(s: &String) -> usize { s.len() }
First, notice that all the tuple code in the variable declaration and the
function return value is gone. Second, note that we pass &s1 into
calculate_length and, in its definition, we take &String rather than
String. These ampersands represent references, and they allow you to refer
to some value without taking ownership of it. Figure 4-5 depicts this concept.

Figure 4-5: A diagram of &String s pointing at String s1
Note: The opposite of referencing by using
&is dereferencing, which is accomplished with the dereference operator,*. We’ll see some uses of the dereference operator in Chapter 8 and discuss details of dereferencing in Chapter 15.
Let’s take a closer look at the function call here:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{}' is {}.", s1, len); } fn calculate_length(s: &String) -> usize { s.len() }
The &s1 syntax lets us create a reference that refers to the value of s1
but does not own it. Because it does not own it, the value it points to will
not be dropped when the reference stops being used.
Likewise, the signature of the function uses & to indicate that the type of
the parameter s is a reference. Let’s add some explanatory annotations:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{}' is {}.", s1, len); } fn calculate_length(s: &String) -> usize { // s is a reference to a String s.len() } // Here, s goes out of scope. But because it does not have ownership of what // it refers to, it is not dropped.
The scope in which the variable s is valid is the same as any function
parameter’s scope, but the value pointed to by the reference is not dropped
when s stops being used, because s doesn’t have ownership. When functions
have references as parameters instead of the actual values, we won’t need to
return the values in order to give back ownership, because we never had
ownership.
We call the action of creating a reference borrowing. As in real life, if a person owns something, you can borrow it from them. When you’re done, you have to give it back. You don’t own it.
So, what happens if we try to modify something we’re borrowing? Try the code in Listing 4-6. Spoiler alert: it doesn’t work!
Filename: src/main.rs
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}
Listing 4-6: Attempting to modify a borrowed value
Here’s the error:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
7 | fn change(some_string: &String) {
| ------- help: consider changing this to be a mutable reference: `&mut String`
8 | some_string.push_str(", world");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` due to previous error
Just as variables are immutable by default, so are references. We’re not allowed to modify something we have a reference to.
Mutable References
We can fix the code from Listing 4-6 to allow us to modify a borrowed value with just a few small tweaks that use, instead, a mutable reference:
Filename: src/main.rs
fn main() { let mut s = String::from("hello"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", world"); }
First we change s to be mut. Then we create a mutable reference with &mut s where we call the change function, and update the function signature to
accept a mutable reference with some_string: &mut String. This makes it very
clear that the change function will mutate the value it borrows.
Mutable references have one big restriction: if you have a mutable reference to
a value, you can have no other references to that value. This code that
attempts to create two mutable references to s will fail:
Filename: src/main.rs
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
}
Here’s the error:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` due to previous error
This error says that this code is invalid because we cannot borrow s as
mutable more than once at a time. The first mutable borrow is in r1 and must
last until it’s used in the println!, but between the creation of that
mutable reference and its usage, we tried to create another mutable reference
in r2 that borrows the same data as r1.
The restriction preventing multiple mutable references to the same data at the same time allows for mutation but in a very controlled fashion. It’s something that new Rustaceans struggle with because most languages let you mutate whenever you’d like. The benefit of having this restriction is that Rust can prevent data races at compile time. A data race is similar to a race condition and happens when these three behaviors occur:
- Two or more pointers access the same data at the same time.
- At least one of the pointers is being used to write to the data.
- There’s no mechanism being used to synchronize access to the data.
Data races cause undefined behavior and can be difficult to diagnose and fix when you’re trying to track them down at runtime; Rust prevents this problem by refusing to compile code with data races!
As always, we can use curly brackets to create a new scope, allowing for multiple mutable references, just not simultaneous ones:
fn main() { let mut s = String::from("hello"); { let r1 = &mut s; } // r1 goes out of scope here, so we can make a new reference with no problems. let r2 = &mut s; }
Rust enforces a similar rule for combining mutable and immutable references. This code results in an error:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{}, {}, and {}", r1, r2, r3);
}
Here’s the error:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
Whew! We also cannot have a mutable reference while we have an immutable one to the same value.
Users of an immutable reference don’t expect the value to suddenly change out from under them! However, multiple immutable references are allowed because no one who is just reading the data has the ability to affect anyone else’s reading of the data.
Note that a reference’s scope starts from where it is introduced and continues
through the last time that reference is used. For instance, this code will
compile because the last usage of the immutable references, the println!,
occurs before the mutable reference is introduced:
fn main() { let mut s = String::from("hello"); let r1 = &s; // no problem let r2 = &s; // no problem println!("{} and {}", r1, r2); // variables r1 and r2 will not be used after this point let r3 = &mut s; // no problem println!("{}", r3); }
The scopes of the immutable references r1 and r2 end after the println!
where they are last used, which is before the mutable reference r3 is
created. These scopes don’t overlap, so this code is allowed: the compiler can
tell that the reference is no longer being used at a point before the end of
the scope.
Even though borrowing errors may be frustrating at times, remember that it’s the Rust compiler pointing out a potential bug early (at compile time rather than at runtime) and showing you exactly where the problem is. Then you don’t have to track down why your data isn’t what you thought it was.
Dangling References
In languages with pointers, it’s easy to erroneously create a dangling pointer—a pointer that references a location in memory that may have been given to someone else—by freeing some memory while preserving a pointer to that memory. In Rust, by contrast, the compiler guarantees that references will never be dangling references: if you have a reference to some data, the compiler will ensure that the data will not go out of scope before the reference to the data does.
Let’s try to create a dangling reference to see how Rust prevents them with a compile-time error:
Filename: src/main.rs
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}
Here’s the error:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
5 | fn dangle() -> &'static String {
| ~~~~~~~~
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` due to previous error
This error message refers to a feature we haven’t covered yet: lifetimes. We’ll discuss lifetimes in detail in Chapter 10. But, if you disregard the parts about lifetimes, the message does contain the key to why this code is a problem:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
Let’s take a closer look at exactly what’s happening at each stage of our
dangle code:
Filename: src/main.rs
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope, and is dropped. Its memory goes away.
// Danger!
Because s is created inside dangle, when the code of dangle is finished,
s will be deallocated. But we tried to return a reference to it. That means
this reference would be pointing to an invalid String. That’s no good! Rust
won’t let us do this.
The solution here is to return the String directly:
fn main() { let string = no_dangle(); } fn no_dangle() -> String { let s = String::from("hello"); s }
This works without any problems. Ownership is moved out, and nothing is deallocated.
The Rules of References
Let’s recap what we’ve discussed about references:
- At any given time, you can have either one mutable reference or any number of immutable references.
- References must always be valid.
Next, we’ll look at a different kind of reference: slices.
The Slice Type
Slices let you reference a contiguous sequence of elements in a collection rather than the whole collection. A slice is a kind of reference, so it does not have ownership.
Here’s a small programming problem: write a function that takes a string of words separated by spaces and returns the first word it finds in that string. If the function doesn’t find a space in the string, the whole string must be one word, so the entire string should be returned.
Let’s work through how we’d write the signature of this function without using slices, to understand the problem that slices will solve:
fn first_word(s: &String) -> ?
The first_word function has a &String as a parameter. We don’t want
ownership, so this is fine. But what should we return? We don’t really have a
way to talk about part of a string. However, we could return the index of the
end of the word, indicated by a space. Let’s try that, as shown in Listing 4-7.
Filename: src/main.rs
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() {}
Listing 4-7: The first_word function that returns a
byte index value into the String parameter
Because we need to go through the String element by element and check whether
a value is a space, we’ll convert our String to an array of bytes using the
as_bytes method.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}
Next, we create an iterator over the array of bytes using the iter method:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}
We’ll discuss iterators in more detail in Chapter 13.
For now, know that iter is a method that returns each element in a collection
and that enumerate wraps the result of iter and returns each element as
part of a tuple instead. The first element of the tuple returned from
enumerate is the index, and the second element is a reference to the element.
This is a bit more convenient than calculating the index ourselves.
Because the enumerate method returns a tuple, we can use patterns to
destructure that tuple. We’ll be discussing patterns more in Chapter
6. In the for loop, we specify a pattern that has i
for the index in the tuple and &item for the single byte in the tuple.
Because we get a reference to the element from .iter().enumerate(), we use
& in the pattern.
Inside the for loop, we search for the byte that represents the space by
using the byte literal syntax. If we find a space, we return the position.
Otherwise, we return the length of the string by using s.len().
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}
We now have a way to find out the index of the end of the first word in the
string, but there’s a problem. We’re returning a usize on its own, but it’s
only a meaningful number in the context of the &String. In other words,
because it’s a separate value from the String, there’s no guarantee that it
will still be valid in the future. Consider the program in Listing 4-8 that
uses the first_word function from Listing 4-7.
Filename: src/main.rs
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() { let mut s = String::from("hello world"); let word = first_word(&s); // word will get the value 5 s.clear(); // this empties the String, making it equal to "" // word still has the value 5 here, but there's no more string that // we could meaningfully use the value 5 with. word is now totally invalid! }
Listing 4-8: Storing the result from calling the
first_word function and then changing the String contents
This program compiles without any errors and would also do so if we used word
after calling s.clear(). Because word isn’t connected to the state of s
at all, word still contains the value 5. We could use that value 5 with
the variable s to try to extract the first word out, but this would be a bug
because the contents of s have changed since we saved 5 in word.
Having to worry about the index in word getting out of sync with the data in
s is tedious and error prone! Managing these indices is even more brittle if
we write a second_word function. Its signature would have to look like this:
fn second_word(s: &String) -> (usize, usize) {
Now we’re tracking a starting and an ending index, and we have even more values that were calculated from data in a particular state but aren’t tied to that state at all. We have three unrelated variables floating around that need to be kept in sync.
Luckily, Rust has a solution to this problem: string slices.
String Slices
A string slice is a reference to part of a String, and it looks like this:
fn main() { let s = String::from("hello world"); let hello = &s[0..5]; let world = &s[6..11]; }
Rather than a reference to the entire String, hello is a reference to a
portion of the String, specified in the extra [0..5] bit. We create slices
using a range within brackets by specifying [starting_index..ending_index],
where starting_index is the first position in the slice and ending_index is
one more than the last position in the slice. Internally, the slice data
structure stores the starting position and the length of the slice, which
corresponds to ending_index minus starting_index. So, in the case of let world = &s[6..11];, world would be a slice that contains a pointer to the
byte at index 6 of s with a length value of 5.
Figure 4-6 shows this in a diagram.

Figure 4-6: String slice referring to part of a
String
With Rust’s .. range syntax, if you want to start at index 0, you can drop
the value before the two periods. In other words, these are equal:
#![allow(unused)] fn main() { let s = String::from("hello"); let slice = &s[0..2]; let slice = &s[..2]; }
By the same token, if your slice includes the last byte of the String, you
can drop the trailing number. That means these are equal:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[3..len]; let slice = &s[3..]; }
You can also drop both values to take a slice of the entire string. So these are equal:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[0..len]; let slice = &s[..]; }
Note: String slice range indices must occur at valid UTF-8 character boundaries. If you attempt to create a string slice in the middle of a multibyte character, your program will exit with an error. For the purposes of introducing string slices, we are assuming ASCII only in this section; a more thorough discussion of UTF-8 handling is in the “Storing UTF-8 Encoded Text with Strings” section of Chapter 8.
With all this information in mind, let’s rewrite first_word to return a
slice. The type that signifies “string slice” is written as &str:
Filename: src/main.rs
fn first_word(s: &String) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() {}
We get the index for the end of the word the same way we did in Listing 4-7, by looking for the first occurrence of a space. When we find a space, we return a string slice using the start of the string and the index of the space as the starting and ending indices.
Now when we call first_word, we get back a single value that is tied to the
underlying data. The value is made up of a reference to the starting point of
the slice and the number of elements in the slice.
Returning a slice would also work for a second_word function:
fn second_word(s: &String) -> &str {
We now have a straightforward API that’s much harder to mess up because the
compiler will ensure the references into the String remain valid. Remember
the bug in the program in Listing 4-8, when we got the index to the end of the
first word but then cleared the string so our index was invalid? That code was
logically incorrect but didn’t show any immediate errors. The problems would
show up later if we kept trying to use the first word index with an emptied
string. Slices make this bug impossible and let us know we have a problem with
our code much sooner. Using the slice version of first_word will throw a
compile-time error:
Filename: src/main.rs
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
Here’s the compiler error:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
Recall from the borrowing rules that if we have an immutable reference to
something, we cannot also take a mutable reference. Because clear needs to
truncate the String, it needs to get a mutable reference. The println!
after the call to clear uses the reference in word, so the immutable
reference must still be active at that point. Rust disallows the mutable
reference in clear and the immutable reference in word from existing at the
same time, and compilation fails. Not only has Rust made our API easier to use,
but it has also eliminated an entire class of errors at compile time!
String Literals as Slices
Recall that we talked about string literals being stored inside the binary. Now that we know about slices, we can properly understand string literals:
#![allow(unused)] fn main() { let s = "Hello, world!"; }
The type of s here is &str: it’s a slice pointing to that specific point of
the binary. This is also why string literals are immutable; &str is an
immutable reference.
String Slices as Parameters
Knowing that you can take slices of literals and String values leads us to
one more improvement on first_word, and that’s its signature:
fn first_word(s: &String) -> &str {
A more experienced Rustacean would write the signature shown in Listing 4-9
instead because it allows us to use the same function on both &String values
and &str values.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or whole
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}
Listing 4-9: Improving the first_word function by using
a string slice for the type of the s parameter
If we have a string slice, we can pass that directly. If we have a String, we
can pass a slice of the String or a reference to the String. This
flexibility takes advantage of deref coercions, a feature we will cover in
“Implicit Deref Coercions with Functions and
Methods” section of Chapter 15.
Defining a function to take a string slice instead of a reference to a String
makes our API more general and useful without losing any functionality:
Filename: src/main.rs
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // `first_word` works on slices of `String`s, whether partial or whole let word = first_word(&my_string[0..6]); let word = first_word(&my_string[..]); // `first_word` also works on references to `String`s, which are equivalent // to whole slices of `String`s let word = first_word(&my_string); let my_string_literal = "hello world"; // `first_word` works on slices of string literals, whether partial or whole let word = first_word(&my_string_literal[0..6]); let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
Other Slices
String slices, as you might imagine, are specific to strings. But there’s a more general slice type too. Consider this array:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; }
Just as we might want to refer to part of a string, we might want to refer to part of an array. We’d do so like this:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; let slice = &a[1..3]; assert_eq!(slice, &[2, 3]); }
This slice has the type &[i32]. It works the same way as string slices do, by
storing a reference to the first element and a length. You’ll use this kind of
slice for all sorts of other collections. We’ll discuss these collections in
detail when we talk about vectors in Chapter 8.
Summary
The concepts of ownership, borrowing, and slices ensure memory safety in Rust programs at compile time. The Rust language gives you control over your memory usage in the same way as other systems programming languages, but having the owner of data automatically clean up that data when the owner goes out of scope means you don’t have to write and debug extra code to get this control.
Ownership affects how lots of other parts of Rust work, so we’ll talk about
these concepts further throughout the rest of the book. Let’s move on to
Chapter 5 and look at grouping pieces of data together in a struct.
Using Structs to Structure Related Data
A struct, or structure, is a custom data type that lets you package together and name multiple related values that make up a meaningful group. If you’re familiar with an object-oriented language, a struct is like an object’s data attributes. In this chapter, we’ll compare and contrast tuples with structs to build on what you already know and demonstrate when structs are a better way to group data.
We’ll demonstrate how to define and instantiate structs. We’ll discuss how to define associated functions, especially the kind of associated functions called methods, to specify behavior associated with a struct type. Structs and enums (discussed in Chapter 6) are the building blocks for creating new types in your program’s domain to take full advantage of Rust’s compile time type checking.
Defining and Instantiating Structs
Summarize
This chapter explains how to define and instantiate structs in Rust:
- Structs are similar to tuples, but with named fields, making them more flexible than tuples.
- To define a struct, use the struct keyword followed by the name of the struct and the names and types of its fields inside curly brackets.
- To create an instance of a struct, specify concrete values for each field using key: value pairs inside curly brackets.
- To access a specific value from a struct, use dot notation.
- To change a value in a mutable struct, use dot notation and assign a new value to the field.
- Struct update syntax can be used to create a new instance of a struct that includes most of the values from another instance but changes some.
- Tuple structs are similar to tuples, but with a name that makes them a different type from other tuples.
- Unit-like structs don’t have any fields and can be useful when implementing a trait on a type without any data to store.
- It’s important to consider ownership of struct data, and Rust’s lifetime feature can be used to ensure that data referenced by a struct is valid for as long as the struct is.
Structs are similar to tuples, discussed in “The Tuple Type” section, in that both hold multiple related values. Like tuples, the pieces of a struct can be different types. Unlike with tuples, in a struct you’ll name each piece of data so it’s clear what the values mean. Adding these names means that structs are more flexible than tuples: you don’t have to rely on the order of the data to specify or access the values of an instance.
To define a struct, we enter the keyword struct and name the entire struct. A
struct’s name should describe the significance of the pieces of data being
grouped together. Then, inside curly brackets, we define the names and types of
the pieces of data, which we call fields. For example, Listing 5-1 shows a
struct that stores information about a user account.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() {}
Listing 5-1: A User struct definition
To use a struct after we’ve defined it, we create an instance of that struct
by specifying concrete values for each of the fields. We create an instance by
stating the name of the struct and then add curly brackets containing key: value pairs, where the keys are the names of the fields and the values are the
data we want to store in those fields. We don’t have to specify the fields in
the same order in which we declared them in the struct. In other words, the
struct definition is like a general template for the type, and instances fill
in that template with particular data to create values of the type. For
example, we can declare a particular user as shown in Listing 5-2.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; }
Listing 5-2: Creating an instance of the User
struct
To get a specific value from a struct, we use dot notation. For example, to
access this user’s email address, we use user1.email. If the instance is
mutable, we can change a value by using the dot notation and assigning into a
particular field. Listing 5-3 shows how to change the value in the email
field of a mutable User instance.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let mut user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; user1.email = String::from("anotheremail@example.com"); }
Listing 5-3: Changing the value in the email field of a
User instance
Note that the entire instance must be mutable; Rust doesn’t allow us to mark only certain fields as mutable. As with any expression, we can construct a new instance of the struct as the last expression in the function body to implicitly return that new instance.
Listing 5-4 shows a build_user function that returns a User instance with
the given email and username. The active field gets the value of true, and
the sign_in_count gets a value of 1.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { email: email, username: username, active: true, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("someone@example.com"), String::from("someusername123"), ); }
Listing 5-4: A build_user function that takes an email
and username and returns a User instance
It makes sense to name the function parameters with the same name as the struct
fields, but having to repeat the email and username field names and
variables is a bit tedious. If the struct had more fields, repeating each name
would get even more annoying. Luckily, there’s a convenient shorthand!
Using the Field Init Shorthand
Because the parameter names and the struct field names are exactly the same in
Listing 5-4, we can use the field init shorthand syntax to rewrite
build_user so that it behaves exactly the same but doesn’t have the
repetition of email and username, as shown in Listing 5-5.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { email, username, active: true, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("someone@example.com"), String::from("someusername123"), ); }
Listing 5-5: A build_user function that uses field init
shorthand because the email and username parameters have the same name as
struct fields
Here, we’re creating a new instance of the User struct, which has a field
named email. We want to set the email field’s value to the value in the
email parameter of the build_user function. Because the email field and
the email parameter have the same name, we only need to write email rather
than email: email.
Creating Instances From Other Instances With Struct Update Syntax
It’s often useful to create a new instance of a struct that includes most of the values from another instance, but changes some. You can do this using struct update syntax.
First, in Listing 5-6 we show how to create a new User instance in user2
regularly, without the update syntax. We set a new value for email but
otherwise use the same values from user1 that we created in Listing 5-2.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { active: user1.active, username: user1.username, email: String::from("another@example.com"), sign_in_count: user1.sign_in_count, }; }
Listing 5-6: Creating a new User instance using one of
the values from user1
Using struct update syntax, we can achieve the same effect with less code, as
shown in Listing 5-7. The syntax .. specifies that the remaining fields not
explicitly set should have the same value as the fields in the given instance.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { email: String::from("another@example.com"), ..user1 }; }
Listing 5-7: Using struct update syntax to set a new
email value for a User instance but use the rest of the values from
user1
The code in Listing 5-7 also creates an instance in user2 that has a
different value for email but has the same values for the username,
active, and sign_in_count fields from user1. The ..user1 must come last
to specify that any remaining fields should get their values from the
corresponding fields in user1, but we can choose to specify values for as
many fields as we want in any order, regardless of the order of the fields in
the struct’s definition.
Note that the struct update syntax uses = like an assignment; this is
because it moves the data, just as we saw in the “Ways Variables and Data
Interact: Move” section. In this example, we can no
longer use user1 after creating user2 because the String in the
username field of user1 was moved into user2. If we had given user2 new
String values for both email and username, and thus only used the
active and sign_in_count values from user1, then user1 would still be
valid after creating user2. The types of active and sign_in_count are
types that implement the Copy trait, so the behavior we discussed in the
“Stack-Only Data: Copy” section would apply.
Using Tuple Structs without Named Fields to Create Different Types
Rust also supports structs that look similar to tuples, called tuple structs. Tuple structs have the added meaning the struct name provides but don’t have names associated with their fields; rather, they just have the types of the fields. Tuple structs are useful when you want to give the whole tuple a name and make the tuple a different type from other tuples, and when naming each field as in a regular struct would be verbose or redundant.
To define a tuple struct, start with the struct keyword and the struct name
followed by the types in the tuple. For example, here we define and use
two tuple structs named Color and Point:
struct Color(i32, i32, i32); struct Point(i32, i32, i32); fn main() { let black = Color(0, 0, 0); let origin = Point(0, 0, 0); }
Note that the black and origin values are different types, because they’re
instances of different tuple structs. Each struct you define is its own type,
even though the fields within the struct might have the same types. For
example, a function that takes a parameter of type Color cannot take a
Point as an argument, even though both types are made up of three i32
values. Otherwise, tuple struct instances are similar to tuples in that you can
destructure them into their individual pieces, and you can use a . followed
by the index to access an individual value.
Unit-Like Structs Without Any Fields
You can also define structs that don’t have any fields! These are called
unit-like structs because they behave similarly to (), the unit type that
we mentioned in “The Tuple Type” section. Unit-like
structs can be useful when you need to implement a trait on some type but don’t
have any data that you want to store in the type itself. We’ll discuss traits
in Chapter 10. Here’s an example of declaring and instantiating a unit struct
named AlwaysEqual:
struct AlwaysEqual; fn main() { let subject = AlwaysEqual; }
To define AlwaysEqual, we use the struct keyword, the name we want, then a
semicolon. No need for curly brackets or parentheses! Then we can get an
instance of AlwaysEqual in the subject variable in a similar way: using the
name we defined, without any curly brackets or parentheses. Imagine that later
we’ll implement behavior for this type such that every instance of
AlwaysEqual is always equal to every instance of any other type, perhaps to
have a known result for testing purposes. We wouldn’t need any data to
implement that behavior! You’ll see in Chapter 10 how to define traits and
implement them on any type, including unit-like structs.
Ownership of Struct Data
In the
Userstruct definition in Listing 5-1, we used the ownedStringtype rather than the&strstring slice type. This is a deliberate choice because we want each instance of this struct to own all of its data and for that data to be valid for as long as the entire struct is valid.It’s also possible for structs to store references to data owned by something else, but to do so requires the use of lifetimes, a Rust feature that we’ll discuss in Chapter 10. Lifetimes ensure that the data referenced by a struct is valid for as long as the struct is. Let’s say you try to store a reference in a struct without specifying lifetimes, like the following; this won’t work:
Filename: src/main.rs
struct User { active: bool, username: &str, email: &str, sign_in_count: u64, } fn main() { let user1 = User { email: "someone@example.com", username: "someusername123", active: true, sign_in_count: 1, }; }The compiler will complain that it needs lifetime specifiers:
$ cargo run Compiling structs v0.1.0 (file:///projects/structs) error[E0106]: missing lifetime specifier --> src/main.rs:3:15 | 3 | username: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 ~ username: &'a str, | error[E0106]: missing lifetime specifier --> src/main.rs:4:12 | 4 | email: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 | username: &str, 4 ~ email: &'a str, | For more information about this error, try `rustc --explain E0106`. error: could not compile `structs` due to 2 previous errorsIn Chapter 10, we’ll discuss how to fix these errors so you can store references in structs, but for now, we’ll fix errors like these using owned types like
Stringinstead of references like&str.
An Example Program Using Structs
To understand when we might want to use structs, let’s write a program that calculates the area of a rectangle. We’ll start by using single variables, and then refactor the program until we’re using structs instead.
Let’s make a new binary project with Cargo called rectangles that will take the width and height of a rectangle specified in pixels and calculate the area of the rectangle. Listing 5-8 shows a short program with one way of doing exactly that in our project’s src/main.rs.
Filename: src/main.rs
fn main() { let width1 = 30; let height1 = 50; println!( "The area of the rectangle is {} square pixels.", area(width1, height1) ); } fn area(width: u32, height: u32) -> u32 { width * height }
Listing 5-8: Calculating the area of a rectangle specified by separate width and height variables
Now, run this program using cargo run:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
This code succeeds in figuring out the area of the rectangle by calling the
area function with each dimension, but we can do more to make this code clear
and readable.
The issue with this code is evident in the signature of area:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}
The area function is supposed to calculate the area of one rectangle, but the
function we wrote has two parameters, and it’s not clear anywhere in our
program that the parameters are related. It would be more readable and more
manageable to group width and height together. We’ve already discussed one way
we might do that in “The Tuple Type” section
of Chapter 3: by using tuples.
Refactoring with Tuples
Listing 5-9 shows another version of our program that uses tuples.
Filename: src/main.rs
fn main() { let rect1 = (30, 50); println!( "The area of the rectangle is {} square pixels.", area(rect1) ); } fn area(dimensions: (u32, u32)) -> u32 { dimensions.0 * dimensions.1 }
Listing 5-9: Specifying the width and height of the rectangle with a tuple
In one way, this program is better. Tuples let us add a bit of structure, and we’re now passing just one argument. But in another way, this version is less clear: tuples don’t name their elements, so we have to index into the parts of the tuple, making our calculation less obvious.
Mixing up the width and height wouldn’t matter for the area calculation, but if
we want to draw the rectangle on the screen, it would matter! We would have to
keep in mind that width is the tuple index 0 and height is the tuple
index 1. This would be even harder for someone else to figure out and keep in
mind if they were to use our code. Because we haven’t conveyed the meaning of
our data in our code, it’s now easier to introduce errors.
Refactoring with Structs: Adding More Meaning
We use structs to add meaning by labeling the data. We can transform the tuple we’re using into a struct with a name for the whole as well as names for the parts, as shown in Listing 5-10.
Filename: src/main.rs
struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", area(&rect1) ); } fn area(rectangle: &Rectangle) -> u32 { rectangle.width * rectangle.height }
Listing 5-10: Defining a Rectangle struct
Here we’ve defined a struct and named it Rectangle. Inside the curly
brackets, we defined the fields as width and height, both of which have
type u32. Then in main, we created a particular instance of Rectangle
that has a width of 30 and a height of 50.
Our area function is now defined with one parameter, which we’ve named
rectangle, whose type is an immutable borrow of a struct Rectangle
instance. As mentioned in Chapter 4, we want to borrow the struct rather than
take ownership of it. This way, main retains its ownership and can continue
using rect1, which is the reason we use the & in the function signature and
where we call the function.
The area function accesses the width and height fields of the Rectangle
instance (note that accessing fields of a borrowed struct instance does not
move the field values, which is why you often see borrows of structs). Our
function signature for area now says exactly what we mean: calculate the area
of Rectangle, using its width and height fields. This conveys that the
width and height are related to each other, and it gives descriptive names to
the values rather than using the tuple index values of 0 and 1. This is a
win for clarity.
Adding Useful Functionality with Derived Traits
It’d be useful to be able to print an instance of Rectangle while we’re
debugging our program and see the values for all its fields. Listing 5-11 tries
using the println! macro as we have used in
previous chapters. This won’t work, however.
Filename: src/main.rs
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {}", rect1);
}
Listing 5-11: Attempting to print a Rectangle
instance
When we compile this code, we get an error with this core message:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
The println! macro can do many kinds of formatting, and by default, the curly
brackets tell println! to use formatting known as Display: output intended
for direct end user consumption. The primitive types we’ve seen so far
implement Display by default, because there’s only one way you’d want to show
a 1 or any other primitive type to a user. But with structs, the way
println! should format the output is less clear because there are more
display possibilities: Do you want commas or not? Do you want to print the
curly brackets? Should all the fields be shown? Due to this ambiguity, Rust
doesn’t try to guess what we want, and structs don’t have a provided
implementation of Display to use with println! and the {} placeholder.
If we continue reading the errors, we’ll find this helpful note:
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
Let’s try it! The println! macro call will now look like println!("rect1 is {:?}", rect1);. Putting the specifier :? inside the curly brackets tells
println! we want to use an output format called Debug. The Debug trait
enables us to print our struct in a way that is useful for developers so we can
see its value while we’re debugging our code.
Compile the code with this change. Drat! We still get an error:
error[E0277]: `Rectangle` doesn't implement `Debug`
But again, the compiler gives us a helpful note:
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
Rust does include functionality to print out debugging information, but we
have to explicitly opt in to make that functionality available for our struct.
To do that, we add the outer attribute #[derive(Debug)] just before the
struct definition, as shown in Listing 5-12.
Filename: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!("rect1 is {:?}", rect1); }
Listing 5-12: Adding the attribute to derive the Debug
trait and printing the Rectangle instance using debug formatting
Now when we run the program, we won’t get any errors, and we’ll see the following output:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
Nice! It’s not the prettiest output, but it shows the values of all the fields
for this instance, which would definitely help during debugging. When we have
larger structs, it’s useful to have output that’s a bit easier to read; in
those cases, we can use {:#?} instead of {:?} in the println! string.
In this example, using the {:#?} style will output:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
Another way to print out a value using the Debug format is to use the dbg!
macro, which takes ownership of an expression (as opposed
to println! that takes a reference), prints the file and line number of where
that dbg! macro call occurs in your code along with the resulting value of
that expression, and returns ownership of the value.
Note: Calling the
dbg!macro prints to the standard error console stream (stderr), as opposed toprintln!which prints to the standard output console stream (stdout). We’ll talk more aboutstderrandstdoutin the “Writing Error Messages to Standard Error Instead of Standard Output” section in Chapter 12.
Here’s an example where we’re interested in the value that gets assigned to the
width field, as well as the value of the whole struct in rect1:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let scale = 2; let rect1 = Rectangle { width: dbg!(30 * scale), height: 50, }; dbg!(&rect1); }
We can put dbg! around the expression 30 * scale and, because dbg!
returns ownership of the expression’s value, the width field will get the
same value as if we didn’t have the dbg! call there. We don’t want dbg! to
take ownership of rect1, so we use a reference to rect1 in the next call.
Here’s what the output of this example looks like:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10] 30 * scale = 60
[src/main.rs:14] &rect1 = Rectangle {
width: 60,
height: 50,
}
We can see the first bit of output came from src/main.rs line 10, where we’re
debugging the expression 30 * scale, and its resulting value is 60 (the
Debug formatting implemented for integers is to print only their value). The
dbg! call on line 14 of src/main.rs outputs the value of &rect1, which is
the Rectangle struct. This output uses the pretty Debug formatting of the
Rectangle type. The dbg! macro can be really helpful when you’re trying to
figure out what your code is doing!
In addition to the Debug trait, Rust has provided a number of traits for us
to use with the derive attribute that can add useful behavior to our custom
types. Those traits and their behaviors are listed in Appendix C. We’ll cover how to implement these traits with custom behavior as
well as how to create your own traits in Chapter 10. There are also many
attributes other than derive; for more information, see the “Attributes”
section of the Rust Reference.
Our area function is very specific: it only computes the area of rectangles.
It would be helpful to tie this behavior more closely to our Rectangle
struct, because it won’t work with any other type. Let’s look at how we can
continue to refactor this code by turning the area function into an area
method defined on our Rectangle type.
Method Syntax
Similar and Difference
Methods are similar to functions:
- we declare them with the
fnkeyword and a name - they can have parameters and a return value
- and they contain some code that’s run when the method is called from somewhere else.
Unlike functions:
- methods are defined within the context of a struct (or an enum or a trait object, which we cover in Chapters 6 and 17, respectively)
- and their first
parameter is always
self, which represents the instance of the struct the method is being called on.
Defining Methods
Let’s change the area function that has a Rectangle instance as a parameter
and instead make an area method defined on the Rectangle struct, as shown
in Listing 5-13.
Listing 5-13: Defining an area method on the Rectangle struct
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", rect1.area() ); }
To define the function within the context of Rectangle:
- we start an
impl(implementation) block forRectangle. - Everything within this
implblock will be associated with theRectangletype. - Then we move the
areafunction within theimplcurly brackets and change the first (and in this case, only) parameter to beselfin the signature and everywhere within the body. - In
main, where we called theareafunction and passedrect1as an argument, - we can instead use method syntax to call the
areamethod on ourRectangleinstance. - The method syntax goes after an instance: we add a dot followed by the method name, parentheses, and any arguments.
rare self, &self, &mut self and Self
- Instead:
In the signature for
area, we use&selfinstead ofrectangle: &Rectangle. - The
&selfis actually short forself: &Self. - Within an
implblock, the typeSelfis an alias for the type that theimplblock is for, just like class in python. - Methods must
have a parameter named
selfof typeSelffor their first parameter, so Rust lets you abbreviate this with only the nameselfin the first parameter spot.
Note that we still need to use the
&in front of theselfshorthand to indicate this method borrows theSelfinstance, just as we did inrectangle: &Rectangle.
- rare self: take ownership or borrow immutably
- Methods can take ownership of
self, borrowselfimmutably as we’ve done here, or borrowselfmutably, just as they can any other parameter. - Having a method that takes ownership of the
instance by using just
selfas the first parameter is rare; - this technique is
- &self: don’t want to take ownership
- We’ve chosen
&selfhere for the same reason we used&Rectanglein the function version: - we don’t want to take ownership, and we just want to read the data in the struct, not write to it.
- &mut self: change the instance
- If we wanted to change the instance that
we’ve called the method on as part of what the method does, we’d use
&mut selfas the first parameter. usually used when the method transformsselfinto something else and you want to prevent the caller from using the original instance after the transformation.
The main reason for using methods instead of functions, in addition to providing method syntax and not having to repeat the type of
selfin every method’s signature, is for organization.
We’ve put all the things we can do with an
instance of a type in one impl block rather than making future users of our
code search for capabilities of Rectangle in various places in the library we
provide.
Note that we can choose to give a method the same name as one of the struct’s fields.
For example, we can define a method on Rectangle also named width:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn width(&self) -> bool { self.width > 0 } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; if rect1.width() { println!("The rectangle has a nonzero width; it is {}", rect1.width); } }
-
Here, we’re choosing to make the
widthmethod returntrueif the value in the instance’swidthfield is greater than 0, andfalseif the value is 0 -
we can use a field within a method of the same name for any purpose.
-
In
main, when we followrect1.widthwith parentheses, Rust knows we mean the methodwidth. When we don’t use parentheses, Rust knows we mean the fieldwidth.
Often, but not always, when we give methods with the same name as a field we want it to only return the value in the field and do nothing else. Methods like this are called getters, and Rust does not implement them automatically for struct fields as some other languages do.
Getters are useful because you can make the field private but the method public and thus enable read-only access to that field as part of the type’s public API. We will be discussing what public and private are and how to designate a field or method as public or private in Chapter 7.
Where’s the -> Operator?
In C and C++, two different operators are used for calling methods:
- you use
.if you’re calling a method on the object directly - and
->if you’re calling the method on a pointer to the object and need to dereference the pointer first. - In other words, if
objectis a pointer,object->something()is similar to(*object).something().
Rust doesn’t have an equivalent to the
->operator; instead, Rust has a feature called automatic referencing and dereferencing.
Calling methods is one of the few places in Rust that has this behavior.
Here’s how it works:
- when you call a method with
object.something(), Rust automatically adds in&,&mut, or*soobjectmatches the signature of the method.
In other words, the following are the same:
#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }
The first one looks much cleaner:
- This automatic referencing behavior works
because methods have a clear receiver—the type of
self. - Given the receiver
and name of a method, Rust can figure out definitively whether the method is
reading (
&self), mutating (&mut self), or consuming (self). - The fact that Rust makes borrowing implicit for method receivers is a big part of making ownership ergonomic in practice.
Methods with More Parameters
Let’s practice using methods by implementing a second method on the Rectangle
struct.
This time, we want an instance of Rectangle to take another instance
of Rectangle and return true if the second Rectangle can fit completely
within self (the first Rectangle);
otherwise it should return false.
That is, once we’ve defined the can_hold method, we want to be able to write the
program shown in Listing 5-14.
Listing 5-14: Using the as-yet-unwritten can_hold method
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}
And the expected output would look like the following, because both dimensions
of rect2 are smaller than the dimensions of rect1 but rect3 is wider than
rect1:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
- We know we want to define a method, so it will be within the
impl Rectangleblock. - The method name will be
can_hold, and it will take an immutable borrow of anotherRectangleas a parameter. - We can tell what the type of the parameter will be by looking at the code that calls the method:
rect1.can_hold(&rect2)passes in&rect2, which is an immutable borrow torect2, an instance ofRectangle.- This makes sense because we only need to
read
rect2(rather than write, which would mean we’d need a mutable borrow), and we wantmainto retain ownership ofrect2so we can use it again after calling thecan_holdmethod. - The return value of
can_holdwill be a Boolean, and the implementation will check whether the width and height ofselfare both greater than the width and height of the otherRectangle, respectively.
Let’s add the new can_hold method to the impl block from
Listing 5-13, shown in Listing 5-15.
Listing 5-15: Implementing the can_hold method on Rectangle that takes another Rectangle instance as a parameter
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
When we run this code with the main function in Listing 5-14, we’ll get our
desired output.
Methods can take multiple parameters that we add to the signature after the
selfparameter, and those parameters work just like parameters in functions.
Associated Functions Without self: not method, just like static method
All functions defined within an
implblock are called associated functions because they’re associated with the type named after theimpl.
We can define
associated functions that don’t have self as their first parameter (and thus
are not methods) because they don’t need an instance of the type to work with.
not dot, use “::”: We’ve already used one function like this: the
String::fromfunction that’s defined on theStringtype.
Self keyword used in constructors
Associated functions that aren’t methods are often used for constructors that will return a new instance of the struct:
- These are often called
new, butnewisn’t a special name and isn’t built into the language.
For example, we could choose to provide an associated function named square that would have one dimension parameter and use that as both width and height, thus making it easier to create a square Rectangle rather than having to specify the same value twice:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn square(size: u32) -> Self { Self { width: size, height: size, } } } fn main() { let sq = Rectangle::square(3); }
The
Selfkeywords in the return type and in the body of the function are aliases for the type that appears after theimplkeyword, which in this case isRectangle.
- To call this associated function, we use the
::syntax with the struct name; let sq = Rectangle::square(3);is an example.
This function is namespaced by the struct: the
::syntax is used for both associated functions and namespaces created by modules.
We’ll discuss modules in Chapter 7.
Multiple impl Blocks: Progressive constraints as needed
Each struct is allowed to have multiple impl blocks.
For example, Listing
5-15 is equivalent to the code shown in Listing 5-16, which has each method
in its own impl block.
Listing 5-16: Rewriting Listing 5-15 using multiple impl blocks
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } impl Rectangle { fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
There’s no reason to separate these methods into multiple impl blocks here,
but this is valid syntax.
We’ll see a case in which multiple impl blocks are
useful in Chapter 10, where we discuss generic types and traits.
Summary
-
Structs let you create custom types that are meaningful for your domain.
-
By using structs, you can keep associated pieces of data connected to each other and name each piece to make your code clear.
-
In
implblocks, you can define functions that are associated with your type, and methods are a kind of associated function that let you specify the behavior that instances of your structs have.
But structs aren’t the only way you can create custom types: let’s turn to Rust’s enum feature to add another tool to your toolbox.
Enums and Pattern Matching
In this chapter we’ll look at enumerations, also referred to as enums.
Enums allow you to define a type by enumerating its possible variants. First,
we’ll define and use an enum to show how an enum can encode meaning along with
data. Next, we’ll explore a particularly useful enum, called Option, which
expresses that a value can be either something or nothing. Then we’ll look at
how pattern matching in the match expression makes it easy to run different
code for different values of an enum. Finally, we’ll cover how the if let
construct is another convenient and concise idiom available to handle enums in
your code.
Defining an Enum
Where structs give you a way of grouping together related fields and data, like
a Rectangle with its width and height, enums give you a way of saying a
value is one of a possible set of values. For example, we may want to say that
Rectangle is one of a set of possible shapes that also includes Circle and
Triangle. To do this, Rust allows us to encode these possibilities as an enum.
Let’s look at a situation we might want to express in code and see why enums are useful and more appropriate than structs in this case. Say we need to work with IP addresses. Currently, two major standards are used for IP addresses: version four and version six. Because these are the only possibilities for an IP address that our program will come across, we can enumerate all possible variants, which is where enumeration gets its name.
Any IP address can be either a version four or a version six address, but not both at the same time. That property of IP addresses makes the enum data structure appropriate, because an enum value can only be one of its variants. Both version four and version six addresses are still fundamentally IP addresses, so they should be treated as the same type when the code is handling situations that apply to any kind of IP address.
We can express this concept in code by defining an IpAddrKind enumeration and
listing the possible kinds an IP address can be, V4 and V6. These are the
variants of the enum:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
IpAddrKind is now a custom data type that we can use elsewhere in our code.
Enum Values
We can create instances of each of the two variants of IpAddrKind like this:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Note that the variants of the enum are namespaced under its identifier, and we
use a double colon to separate the two. This is useful because now both values
IpAddrKind::V4 and IpAddrKind::V6 are of the same type: IpAddrKind. We
can then, for instance, define a function that takes any IpAddrKind:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
And we can call this function with either variant:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
Using enums has even more advantages. Thinking more about our IP address type, at the moment we don’t have a way to store the actual IP address data; we only know what kind it is. Given that you just learned about structs in Chapter 5, you might be tempted to tackle this problem with structs as shown in Listing 6-1.
fn main() { enum IpAddrKind { V4, V6, } struct IpAddr { kind: IpAddrKind, address: String, } let home = IpAddr { kind: IpAddrKind::V4, address: String::from("127.0.0.1"), }; let loopback = IpAddr { kind: IpAddrKind::V6, address: String::from("::1"), }; }
Listing 6-1: Storing the data and IpAddrKind variant of
an IP address using a struct
Here, we’ve defined a struct IpAddr that has two fields: a kind field that
is of type IpAddrKind (the enum we defined previously) and an address field
of type String. We have two instances of this struct. The first is home,
and it has the value IpAddrKind::V4 as its kind with associated address
data of 127.0.0.1. The second instance is loopback. It has the other
variant of IpAddrKind as its kind value, V6, and has address ::1
associated with it. We’ve used a struct to bundle the kind and address
values together, so now the variant is associated with the value.
However, representing the same concept using just an enum is more concise:
rather than an enum inside a struct, we can put data directly into each enum
variant. This new definition of the IpAddr enum says that both V4 and V6
variants will have associated String values:
fn main() { enum IpAddr { V4(String), V6(String), } let home = IpAddr::V4(String::from("127.0.0.1")); let loopback = IpAddr::V6(String::from("::1")); }
We attach data to each variant of the enum directly, so there is no need for an
extra struct. Here it’s also easier to see another detail of how enums work:
the name of each enum variant that we define also becomes a function that
constructs an instance of the enum. That is, IpAddr::V4() is a function call
that takes a String argument and returns an instance of the IpAddr type. We
automatically get this constructor function defined as a result of defining the
enum.
There’s another advantage to using an enum rather than a struct: each variant
can have different types and amounts of associated data. Version four type IP
addresses will always have four numeric components that will have values
between 0 and 255. If we wanted to store V4 addresses as four u8 values but
still express V6 addresses as one String value, we wouldn’t be able to with
a struct. Enums handle this case with ease:
fn main() { enum IpAddr { V4(u8, u8, u8, u8), V6(String), } let home = IpAddr::V4(127, 0, 0, 1); let loopback = IpAddr::V6(String::from("::1")); }
We’ve shown several different ways to define data structures to store version
four and version six IP addresses. However, as it turns out, wanting to store
IP addresses and encode which kind they are is so common that the standard
library has a definition we can use! Let’s look at how
the standard library defines IpAddr: it has the exact enum and variants that
we’ve defined and used, but it embeds the address data inside the variants in
the form of two different structs, which are defined differently for each
variant:
#![allow(unused)] fn main() { struct Ipv4Addr { // --snip-- } struct Ipv6Addr { // --snip-- } enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr), } }
This code illustrates that you can put any kind of data inside an enum variant: strings, numeric types, or structs, for example. You can even include another enum! Also, standard library types are often not much more complicated than what you might come up with.
Note that even though the standard library contains a definition for IpAddr,
we can still create and use our own definition without conflict because we
haven’t brought the standard library’s definition into our scope. We’ll talk
more about bringing types into scope in Chapter 7.
Let’s look at another example of an enum in Listing 6-2: this one has a wide variety of types embedded in its variants.
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
Listing 6-2: A Message enum whose variants each store
different amounts and types of values
This enum has four variants with different types:
Quithas no data associated with it at all.Movehas named fields like a struct does.Writeincludes a singleString.ChangeColorincludes threei32values.
Defining an enum with variants such as the ones in Listing 6-2 is similar to
defining different kinds of struct definitions, except the enum doesn’t use the
struct keyword and all the variants are grouped together under the Message
type. The following structs could hold the same data that the preceding enum
variants hold:
struct QuitMessage; // unit struct struct MoveMessage { x: i32, y: i32, } struct WriteMessage(String); // tuple struct struct ChangeColorMessage(i32, i32, i32); // tuple struct fn main() {}
But if we used the different structs, which each have their own type, we
couldn’t as easily define a function to take any of these kinds of messages as
we could with the Message enum defined in Listing 6-2, which is a single type.
There is one more similarity between enums and structs: just as we’re able to
define methods on structs using impl, we’re also able to define methods on
enums. Here’s a method named call that we could define on our Message enum:
fn main() { enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } impl Message { fn call(&self) { // method body would be defined here } } let m = Message::Write(String::from("hello")); m.call(); }
The body of the method would use self to get the value that we called the
method on. In this example, we’ve created a variable m that has the value
Message::Write(String::from("hello")), and that is what self will be in the
body of the call method when m.call() runs.
Let’s look at another enum in the standard library that is very common and
useful: Option.
The Option Enum and Its Advantages Over Null Values
This section explores a case study of Option, which is another enum defined
by the standard library. The Option type encodes the very common scenario in
which a value could be something or it could be nothing.
For example, if you request the first of a list containing items, you would get a value. If you request the first item of an empty list, you would get nothing. Expressing this concept in terms of the type system means the compiler can check whether you’ve handled all the cases you should be handling; this functionality can prevent bugs that are extremely common in other programming languages.
Programming language design is often thought of in terms of which features you include, but the features you exclude are important too. Rust doesn’t have the null feature that many other languages have. Null is a value that means there is no value there. In languages with null, variables can always be in one of two states: null or not-null.
In his 2009 presentation “Null References: The Billion Dollar Mistake,” Tony Hoare, the inventor of null, has this to say:
I call it my billion-dollar mistake. At that time, I was designing the first comprehensive type system for references in an object-oriented language. My goal was to ensure that all use of references should be absolutely safe, with checking performed automatically by the compiler. But I couldn’t resist the temptation to put in a null reference, simply because it was so easy to implement. This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.
The problem with null values is that if you try to use a null value as a not-null value, you’ll get an error of some kind. Because this null or not-null property is pervasive, it’s extremely easy to make this kind of error.
However, the concept that null is trying to express is still a useful one: a null is a value that is currently invalid or absent for some reason.
The problem isn’t really with the concept but with the particular
implementation. As such, Rust does not have nulls, but it does have an enum
that can encode the concept of a value being present or absent. This enum is
Option<T>, and it is defined by the standard library
as follows:
#![allow(unused)] fn main() { enum Option<T> { None, Some(T), } }
The Option<T> enum is so useful that it’s even included in the prelude; you
don’t need to bring it into scope explicitly. Its variants are also included in
the prelude: you can use Some and None directly without the Option::
prefix. The Option<T> enum is still just a regular enum, and Some(T) and
None are still variants of type Option<T>.
The <T> syntax is a feature of Rust we haven’t talked about yet. It’s a
generic type parameter, and we’ll cover generics in more detail in Chapter 10.
For now, all you need to know is that <T> means the Some variant of the
Option enum can hold one piece of data of any type, and that each concrete
type that gets used in place of T makes the overall Option<T> type a
different type. Here are some examples of using Option values to hold number
types and string types:
fn main() { let some_number = Some(5); let some_char = Some('e'); let absent_number: Option<i32> = None; }
The type of some_number is Option<i32>. The type of some_char is
Option<char>, which is a different type. Rust can infer these types because
we’ve specified a value inside the Some variant. For absent_number, Rust
requires us to annotate the overall Option type: the compiler can’t infer the
type that the corresponding Some variant will hold by looking only at a
None value. Here, we tell Rust that we mean for absent_number to be of type
Option<i32>.
When we have a Some value, we know that a value is present and the value is
held within the Some. When we have a None value, in some sense, it means
the same thing as null: we don’t have a valid value. So why is having
Option<T> any better than having null?
In short, because Option<T> and T (where T can be any type) are different
types, the compiler won’t let us use an Option<T> value as if it were
definitely a valid value. For example, this code won’t compile because it’s
trying to add an i8 to an Option<i8>:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}
If we run this code, we get an error message like this:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
<&'a f32 as Add<f32>>
<&'a f64 as Add<f64>>
<&'a i128 as Add<i128>>
<&'a i16 as Add<i16>>
<&'a i32 as Add<i32>>
<&'a i64 as Add<i64>>
<&'a i8 as Add<i8>>
<&'a isize as Add<isize>>
and 48 others
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` due to previous error
Intense! In effect, this error message means that Rust doesn’t understand how
to add an i8 and an Option<i8>, because they’re different types. When we
have a value of a type like i8 in Rust, the compiler will ensure that we
always have a valid value. We can proceed confidently without having to check
for null before using that value. Only when we have an Option<i8> (or
whatever type of value we’re working with) do we have to worry about possibly
not having a value, and the compiler will make sure we handle that case before
using the value.
In other words, you have to convert an Option<T> to a T before you can
perform T operations with it. Generally, this helps catch one of the most
common issues with null: assuming that something isn’t null when it actually
is.
Eliminating the risk of incorrectly assuming a not-null value helps you to be
more confident in your code. In order to have a value that can possibly be
null, you must explicitly opt in by making the type of that value Option<T>.
Then, when you use that value, you are required to explicitly handle the case
when the value is null. Everywhere that a value has a type that isn’t an
Option<T>, you can safely assume that the value isn’t null. This was a
deliberate design decision for Rust to limit null’s pervasiveness and increase
the safety of Rust code.
So, how do you get the T value out of a Some variant when you have a value
of type Option<T> so you can use that value? The Option<T> enum has a large
number of methods that are useful in a variety of situations; you can check
them out in its documentation. Becoming familiar with
the methods on Option<T> will be extremely useful in your journey with Rust.
In general, in order to use an Option<T> value, you want to have code that
will handle each variant. You want some code that will run only when you have a
Some(T) value, and this code is allowed to use the inner T. You want some
other code to run if you have a None value, and that code doesn’t have a T
value available. The match expression is a control flow construct that does
just this when used with enums: it will run different code depending on which
variant of the enum it has, and that code can use the data inside the matching
value.
The match Control Flow Construct
Rust has an extremely powerful control flow construct called match that allows
you to compare a value against a series of patterns and then execute code based
on which pattern matches. Patterns can be made up of literal values, variable
names, wildcards, and many other things; Chapter 18 covers all the different
kinds of patterns and what they do. The power of match comes from the
expressiveness of the patterns and the fact that the compiler confirms that all
possible cases are handled.
Think of a match expression as being like a coin-sorting machine: coins slide
down a track with variously sized holes along it, and each coin falls through
the first hole it encounters that it fits into. In the same way, values go
through each pattern in a match, and at the first pattern the value “fits,”
the value falls into the associated code block to be used during execution.
Speaking of coins, let’s use them as an example using match! We can write a
function that takes an unknown United States coin and, in a similar way as the
counting machine, determines which coin it is and returns its value in cents, as
shown here in Listing 6-3.
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
Listing 6-3: An enum and a match expression that has
the variants of the enum as its patterns
Let’s break down the match in the value_in_cents function. First, we list
the match keyword followed by an expression, which in this case is the value
coin. This seems very similar to an expression used with if, but there’s a
big difference: with if, the expression needs to return a Boolean value, but
here, it can return any type. The type of coin in this example is the Coin
enum that we defined on the first line.
Next are the match arms. An arm has two parts: a pattern and some code. The
first arm here has a pattern that is the value Coin::Penny and then the =>
operator that separates the pattern and the code to run. The code in this case
is just the value 1. Each arm is separated from the next with a comma.
When the match expression executes, it compares the resulting value against
the pattern of each arm, in order. If a pattern matches the value, the code
associated with that pattern is executed. If that pattern doesn’t match the
value, execution continues to the next arm, much as in a coin-sorting machine.
We can have as many arms as we need: in Listing 6-3, our match has four arms.
The code associated with each arm is an expression, and the resulting value of
the expression in the matching arm is the value that gets returned for the
entire match expression.
We don’t typically use curly brackets if the match arm code is short, as it is
in Listing 6-3 where each arm just returns a value. If you want to run multiple
lines of code in a match arm, you must use curly brackets, and the comma
following the arm is then optional. For example, the following code prints
“Lucky penny!” every time the method is called with a Coin::Penny, but still
returns the last value of the block, 1:
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => { println!("Lucky penny!"); 1 } Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
Patterns that Bind to Values
Another useful feature of match arms is that they can bind to the parts of the values that match the pattern. This is how we can extract values out of enum variants.
As an example, let’s change one of our enum variants to hold data inside it.
From 1999 through 2008, the United States minted quarters with different
designs for each of the 50 states on one side. No other coins got state
designs, so only quarters have this extra value. We can add this information to
our enum by changing the Quarter variant to include a UsState value stored
inside it, which we’ve done here in Listing 6-4.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() {}
Listing 6-4: A Coin enum in which the Quarter variant
also holds a UsState value
Let’s imagine that a friend is trying to collect all 50 state quarters. While we sort our loose change by coin type, we’ll also call out the name of the state associated with each quarter so if it’s one our friend doesn’t have, they can add it to their collection.
In the match expression for this code, we add a variable called state to the
pattern that matches values of the variant Coin::Quarter. When a
Coin::Quarter matches, the state variable will bind to the value of that
quarter’s state. Then we can use state in the code for that arm, like so:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter(state) => { println!("State quarter from {:?}!", state); 25 } } } fn main() { value_in_cents(Coin::Quarter(UsState::Alaska)); }
If we were to call value_in_cents(Coin::Quarter(UsState::Alaska)), coin
would be Coin::Quarter(UsState::Alaska). When we compare that value with each
of the match arms, none of them match until we reach Coin::Quarter(state). At
that point, the binding for state will be the value UsState::Alaska. We can
then use that binding in the println! expression, thus getting the inner
state value out of the Coin enum variant for Quarter.
Matching with Option<T>
In the previous section, we wanted to get the inner T value out of the Some
case when using Option<T>; we can also handle Option<T> using match as we
did with the Coin enum! Instead of comparing coins, we’ll compare the
variants of Option<T>, but the way that the match expression works remains
the same.
Let’s say we want to write a function that takes an Option<i32> and, if
there’s a value inside, adds 1 to that value. If there isn’t a value inside,
the function should return the None value and not attempt to perform any
operations.
This function is very easy to write, thanks to match, and will look like
Listing 6-5.
fn main() { fn plus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let five = Some(5); let six = plus_one(five); let none = plus_one(None); }
Listing 6-5: A function that uses a match expression on
an Option<i32>
Let’s examine the first execution of plus_one in more detail. When we call
plus_one(five), the variable x in the body of plus_one will have the
value Some(5). We then compare that against each match arm.
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}
The Some(5) value doesn’t match the pattern None, so we continue to the
next arm.
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}
Does Some(5) match Some(i)? Why yes it does! We have the same variant. The
i binds to the value contained in Some, so i takes the value 5. The
code in the match arm is then executed, so we add 1 to the value of i and
create a new Some value with our total 6 inside.
Now let’s consider the second call of plus_one in Listing 6-5, where x is
None. We enter the match and compare to the first arm.
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}
It matches! There’s no value to add to, so the program stops and returns the
None value on the right side of =>. Because the first arm matched, no other
arms are compared.
Combining match and enums is useful in many situations. You’ll see this
pattern a lot in Rust code: match against an enum, bind a variable to the
data inside, and then execute code based on it. It’s a bit tricky at first, but
once you get used to it, you’ll wish you had it in all languages. It’s
consistently a user favorite.
Matches Are Exhaustive
There’s one other aspect of match we need to discuss: the arms’ patterns must
cover all possibilities. Consider this version of our plus_one function,
which has a bug and won’t compile:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}
We didn’t handle the None case, so this code will cause a bug. Luckily, it’s
a bug Rust knows how to catch. If we try to compile this code, we’ll get this
error:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` due to previous error
Rust knows that we didn’t cover every possible case and even knows which
pattern we forgot! Matches in Rust are exhaustive: we must exhaust every last
possibility in order for the code to be valid. Especially in the case of
Option<T>, when Rust prevents us from forgetting to explicitly handle the
None case, it protects us from assuming that we have a value when we might
have null, thus making the billion-dollar mistake discussed earlier impossible.
Catch-all Patterns and the _ Placeholder
Using enums, we can also take special actions for a few particular values, but
for all other values take one default action. Imagine we’re implementing a game
where, if you roll a 3 on a dice roll, your player doesn’t move, but instead
gets a new fancy hat. If you roll a 7, your player loses a fancy hat. For all
other values, your player moves that number of spaces on the game board. Here’s
a match that implements that logic, with the result of the dice roll
hardcoded rather than a random value, and all other logic represented by
functions without bodies because actually implementing them is out of scope for
this example:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), other => move_player(other), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn move_player(num_spaces: u8) {} }
For the first two arms, the patterns are the literal values 3 and 7. For the
last arm that covers every other possible value, the pattern is the variable
we’ve chosen to name other. The code that runs for the other arm uses the
variable by passing it to the move_player function.
This code compiles, even though we haven’t listed all the possible values a
u8 can have, because the last pattern will match all values not specifically
listed. This catch-all pattern meets the requirement that match must be
exhaustive. Note that we have to put the catch-all arm last because the
patterns are evaluated in order. If we put the catch-all arm earlier, the other
arms would never run, so Rust will warn us if we add arms after a catch-all!
Rust also has a pattern we can use when we want a catch-all but don’t want to
use the value in the catch-all pattern: _ is a special pattern that matches
any value and does not bind to that value. This tells Rust we aren’t going to
use the value, so Rust won’t warn us about an unused variable.
Let’s change the rules of the game: now, if you roll anything other than a 3 or
a 7, you must roll again. We no longer need to use the catch-all value, so we
can change our code to use _ instead of the variable named other:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => reroll(), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn reroll() {} }
This example also meets the exhaustiveness requirement because we’re explicitly ignoring all other values in the last arm; we haven’t forgotten anything.
Finally, we’ll change the rules of the game one more time, so that nothing else
happens on your turn if you roll anything other than a 3 or a 7. We can express
that by using the unit value (the empty tuple type we mentioned in “The Tuple
Type” section) as the code that goes with the _ arm:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => (), } fn add_fancy_hat() {} fn remove_fancy_hat() {} }
Here, we’re telling Rust explicitly that we aren’t going to use any other value that doesn’t match a pattern in an earlier arm, and we don’t want to run any code in this case.
There’s more about patterns and matching that we’ll cover in Chapter
18. For now, we’re going to move on to the
if let syntax, which can be useful in situations where the match expression
is a bit wordy.
Concise Control Flow with if let
The if let syntax lets you combine if and let into a less verbose way to
handle values that match one pattern while ignoring the rest. Consider the
program in Listing 6-6 that matches on an Option<u8> value in the config_max
variable but only wants to execute code if the value is the Some variant.
fn main() { let config_max = Some(3u8); match config_max { Some(max) => println!("The maximum is configured to be {}", max), _ => (), } }
Listing 6-6: A match that only cares about executing
code when the value is Some
If the value is Some, we print out the value in the Some variant by binding
the value to the variable max in the pattern. We don’t want to do anything
with the None value. To satisfy the match expression, we have to add _ => () after processing just one variant, which is annoying boilerplate code to
add.
Instead, we could write this in a shorter way using if let. The following
code behaves the same as the match in Listing 6-6:
fn main() { let config_max = Some(3u8); if let Some(max) = config_max { println!("The maximum is configured to be {}", max); } }
The syntax if let takes a pattern and an expression separated by an equal
sign. It works the same way as a match, where the expression is given to the
match and the pattern is its first arm. In this case, the pattern is
Some(max), and the max binds to the value inside the Some. We can then
use max in the body of the if let block in the same way as we used max in
the corresponding match arm. The code in the if let block isn’t run if the
value doesn’t match the pattern.
Using if let means less typing, less indentation, and less boilerplate code.
However, you lose the exhaustive checking that match enforces. Choosing
between match and if let depends on what you’re doing in your particular
situation and whether gaining conciseness is an appropriate trade-off for
losing exhaustive checking.
In other words, you can think of if let as syntax sugar for a match that
runs code when the value matches one pattern and then ignores all other values.
We can include an else with an if let. The block of code that goes with the
else is the same as the block of code that would go with the _ case in the
match expression that is equivalent to the if let and else. Recall the
Coin enum definition in Listing 6-4, where the Quarter variant also held a
UsState value. If we wanted to count all non-quarter coins we see while also
announcing the state of the quarters, we could do that with a match
expression like this:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; match coin { Coin::Quarter(state) => println!("State quarter from {:?}!", state), _ => count += 1, } }
Or we could use an if let and else expression like this:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; if let Coin::Quarter(state) = coin { println!("State quarter from {:?}!", state); } else { count += 1; } }
If you have a situation in which your program has logic that is too verbose to
express using a match, remember that if let is in your Rust toolbox as well.
Summary
We’ve now covered how to use enums to create custom types that can be one of a
set of enumerated values. We’ve shown how the standard library’s Option<T>
type helps you use the type system to prevent errors. When enum values have
data inside them, you can use match or if let to extract and use those
values, depending on how many cases you need to handle.
Your Rust programs can now express concepts in your domain using structs and enums. Creating custom types to use in your API ensures type safety: the compiler will make certain your functions get only values of the type each function expects.
In order to provide a well-organized API to your users that is straightforward to use and only exposes exactly what your users will need, let’s now turn to Rust’s modules.
Managing Growing Projects with Packages, Crates, and Modules
As you write large programs, organizing your code will become increasingly important. By grouping related functionality and separating code with distinct features, you’ll clarify where to find code that implements a particular feature and where to go to change how a feature works.
The programs we’ve written so far have been in one module in one file. As a project grows, you should organize code by splitting it into multiple modules and then multiple files. A package can contain multiple binary crates and optionally one library crate. As a package grows, you can extract parts into separate crates that become external dependencies. This chapter covers all these techniques. For very large projects comprising a set of interrelated packages that evolve together, Cargo provides workspaces, which we’ll cover in the “Cargo Workspaces” section in Chapter 14.
We’ll also discuss encapsulating implementation details, which lets you reuse code at a higher level: once you’ve implemented an operation, other code can call your code via its public interface without having to know how the implementation works. The way you write code defines which parts are public for other code to use and which parts are private implementation details that you reserve the right to change. This is another way to limit the amount of detail you have to keep in your head.
A related concept is scope: the nested context in which code is written has a set of names that are defined as “in scope.” When reading, writing, and compiling code, programmers and compilers need to know whether a particular name at a particular spot refers to a variable, function, struct, enum, module, constant, or other item and what that item means. You can create scopes and change which names are in or out of scope. You can’t have two items with the same name in the same scope; tools are available to resolve name conflicts.
Rust has a number of features that allow you to manage your code’s organization, including which details are exposed, which details are private, and what names are in each scope in your programs. These features, sometimes collectively referred to as the module system, include:
- Packages: A Cargo feature that lets you build, test, and share crates
- Crates: A tree of modules that produces a library or executable
- Modules and use: Let you control the organization, scope, and privacy of paths
- Paths: A way of naming an item, such as a struct, function, or module
In this chapter, we’ll cover all these features, discuss how they interact, and explain how to use them to manage scope. By the end, you should have a solid understanding of the module system and be able to work with scopes like a pro!
Packages and Crates
The first parts of the module system we’ll cover are packages and crates.
A crate is the smallest amount of code that the Rust compiler considers at a
time. Even if you run rustc rather than cargo and pass a single source code
file (as we did all the way back in the “Writing and Running a Rust Program”
section of Chapter 1), the compiler considers that file to be a crate. Crates
can contain modules, and the modules may be defined in other files that get
compiled with the crate, as we’ll see in the coming sections.
A crate can come in one of two forms: a binary crate or a library crate.
Binary crates are programs you can compile to an executable that you can run,
such as a command-line program or a server. Each must have a function called
main that defines what happens when the executable runs. All the crates we’ve
created so far have been binary crates.
Library crates don’t have a main function, and they don’t compile to an
executable. Instead, they define functionality intended to be shared with
multiple projects. For example, the rand crate we used in Chapter
2 provides functionality that generates random numbers.
Most of the time when Rustaceans say “crate”, they mean library crate, and they
use “crate” interchangeably with the general programming concept of a “library“.
The crate root is a source file that the Rust compiler starts from and makes up the root module of your crate (we’ll explain modules in depth in the “Defining Modules to Control Scope and Privacy” section).
A package is a bundle of one or more crates that provides a set of functionality. A package contains a Cargo.toml file that describes how to build those crates. Cargo is actually a package that contains the binary crate for the command-line tool you’ve been using to build your code. The Cargo package also contains a library crate that the binary crate depends on. Other projects can depend on the Cargo library crate to use the same logic the Cargo command-line tool uses.
A package can contain as many binary crates as you like, but at most only one library crate. A package must contain at least one crate, whether that’s a library or binary crate.
Let’s walk through what happens when we create a package. First, we enter the
command cargo new:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
After we run cargo new, we use ls to see what Cargo creates. In the project
directory, there’s a Cargo.toml file, giving us a package. There’s also a
src directory that contains main.rs. Open Cargo.toml in your text editor,
and note there’s no mention of src/main.rs. Cargo follows a convention that
src/main.rs is the crate root of a binary crate with the same name as the
package. Likewise, Cargo knows that if the package directory contains
src/lib.rs, the package contains a library crate with the same name as the
package, and src/lib.rs is its crate root. Cargo passes the crate root files
to rustc to build the library or binary.
Here, we have a package that only contains src/main.rs, meaning it only
contains a binary crate named my-project. If a package contains src/main.rs
and src/lib.rs, it has two crates: a binary and a library, both with the same
name as the package. A package can have multiple binary crates by placing files
in the src/bin directory: each file will be a separate binary crate.
Defining Modules to Control Scope and Privacy
In this section, we’ll talk about modules and other parts of the module system,
namely paths that allow you to name items; the use keyword that brings a
path into scope; and the pub keyword to make items public. We’ll also discuss
the as keyword, external packages, and the glob operator.
First, we’re going to start with a list of rules for easy reference when you’re organizing your code in the future. Then we’ll explain each of the rules in detail.
Modules Cheat Sheet
Here we provide a quick reference on how modules, paths, the use keyword, and
the pub keyword work in the compiler, and how most developers organize their
code. We’ll be going through examples of each of these rules throughout this
chapter, but this is a great place to refer to as a reminder of how modules
work.
- Start from the crate root: When compiling a crate, the compiler first looks in the crate root file (usually src/lib.rs for a library crate or src/main.rs for a binary crate) for code to compile.
- Declaring modules: In the crate root file, you can declare new modules;
say, you declare a “garden” module with
mod garden;. The compiler will look for the module’s code in these places:- Inline, within curly brackets that replace the semicolon following
mod garden - In the file src/garden.rs
- In the file src/garden/mod.rs
- Inline, within curly brackets that replace the semicolon following
- Declaring submodules: In any file other than the crate root, you can
declare submodules. For example, you might declare
mod vegetables;in src/garden.rs. The compiler will look for the submodule’s code within the directory named for the parent module in these places:- Inline, directly following
mod vegetables, within curly brackets instead of the semicolon - In the file src/garden/vegetables.rs
- In the file src/garden/vegetables/mod.rs
- Inline, directly following
- Paths to code in modules: Once a module is part of your crate, you can
refer to code in that module from anywhere else in that same crate, as long
as the privacy rules allow, using the path to the code. For example, an
Asparagustype in the garden vegetables module would be found atcrate::garden::vegetables::Asparagus. - Private vs public: Code within a module is private from its parent
modules by default. To make a module public, declare it with
pub modinstead ofmod. To make items within a public module public as well, usepubbefore their declarations. - The
usekeyword: Within a scope, theusekeyword creates shortcuts to items to reduce repetition of long paths. In any scope that can refer tocrate::garden::vegetables::Asparagus, you can create a shortcut withuse crate::garden::vegetables::Asparagus;and from then on you only need to writeAsparagusto make use of that type in the scope.
Here we create a binary crate named backyard that illustrates these rules. The
crate’s directory, also named backyard, contains these files and directories:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
The crate root file in this case is src/main.rs, and it contains:
Filename: src/main.rs
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {:?}!", plant);
}
The pub mod garden; line tells the compiler to include the code it finds in
src/garden.rs, which is:
Filename: src/garden.rs
pub mod vegetables;
Here, pub mod vegetables; means the code in src/garden/vegetables.rs is
included too. That code is:
#[derive(Debug)]
pub struct Asparagus {}
Now let’s get into the details of these rules and demonstrate them in action!
Grouping Related Code in Modules
Modules let us organize code within a crate for readability and easy reuse. Modules also allow us to control the privacy of items, because code within a module is private by default. Private items are internal implementation details not available for outside use. We can choose to make modules and the items within them public, which exposes them to allow external code to use and depend on them.
As an example, let’s write a library crate that provides the functionality of a restaurant. We’ll define the signatures of functions but leave their bodies empty to concentrate on the organization of the code, rather than the implementation of a restaurant.
In the restaurant industry, some parts of a restaurant are referred to as front of house and others as back of house. Front of house is where customers are; this encompasses where the hosts seat customers, servers take orders and payment, and bartenders make drinks. Back of house is where the chefs and cooks work in the kitchen, dishwashers clean up, and managers do administrative work.
To structure our crate in this way, we can organize its functions into nested
modules. Create a new library named restaurant by running cargo new restaurant --lib; then enter the code in Listing 7-1 into src/lib.rs to
define some modules and function signatures. Here’s the front of house section:
Filename: src/lib.rs
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}
Listing 7-1: A front_of_house module containing other
modules that then contain functions
We define a module with the mod keyword followed by the name of the module
(in this case, front_of_house). The body of the module then goes inside curly
brackets. Inside modules, we can place other modules, as in this case with the
modules hosting and serving. Modules can also hold definitions for other
items, such as structs, enums, constants, traits, and—as in Listing
7-1—functions.
By using modules, we can group related definitions together and name why they’re related. Programmers using this code can navigate the code based on the groups rather than having to read through all the definitions, making it easier to find the definitions relevant to them. Programmers adding new functionality to this code would know where to place the code to keep the program organized.
Earlier, we mentioned that src/main.rs and src/lib.rs are called crate
roots. The reason for their name is that the contents of either of these two
files form a module named crate at the root of the crate’s module structure,
known as the module tree.
Listing 7-2 shows the module tree for the structure in Listing 7-1.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
Listing 7-2: The module tree for the code in Listing 7-1
This tree shows how some of the modules nest inside one another; for example,
hosting nests inside front_of_house. The tree also shows that some modules
are siblings to each other, meaning they’re defined in the same module;
hosting and serving are siblings defined within front_of_house. If module
A is contained inside module B, we say that module A is the child of module B
and that module B is the parent of module A. Notice that the entire module
tree is rooted under the implicit module named crate.
The module tree might remind you of the filesystem’s directory tree on your computer; this is a very apt comparison! Just like directories in a filesystem, you use modules to organize your code. And just like files in a directory, we need a way to find our modules.
Paths for Referring to an Item in the Module Tree
To show Rust where to find an item in a module tree, we use a path in the same way we use a path when navigating a filesystem. To call a function, we need to know its path.
A path can take two forms:
- An absolute path is the full path starting from a crate root; for code
from an external crate, the absolute path begins with the crate name, and for
code from the current crate, it starts with the literal
crate. - A relative path starts from the current module and uses
self,super, or an identifier in the current module.
Both absolute and relative paths are followed by one or more identifiers
separated by double colons (::).
Returning to Listing 7-1, say we want to call the add_to_waitlist function.
This is the same as asking: what’s the path of the add_to_waitlist function?
Listing 7-3 contains Listing 7-1 with some of the modules and functions
removed.
We’ll show two ways to call the add_to_waitlist function from a new function
eat_at_restaurant defined in the crate root. These paths are correct, but
there’s another problem remaining that will prevent this example from compiling
as-is. We’ll explain why in a bit.
The eat_at_restaurant function is part of our library crate’s public API, so
we mark it with the pub keyword. In the “Exposing Paths with the pub
Keyword” section, we’ll go into more detail about pub.
Filename: src/lib.rs
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}
Listing 7-3: Calling the add_to_waitlist function using
absolute and relative paths
The first time we call the add_to_waitlist function in eat_at_restaurant,
we use an absolute path. The add_to_waitlist function is defined in the same
crate as eat_at_restaurant, which means we can use the crate keyword to
start an absolute path. We then include each of the successive modules until we
make our way to add_to_waitlist. You can imagine a filesystem with the same
structure: we’d specify the path /front_of_house/hosting/add_to_waitlist to
run the add_to_waitlist program; using the crate name to start from the
crate root is like using / to start from the filesystem root in your shell.
The second time we call add_to_waitlist in eat_at_restaurant, we use a
relative path. The path starts with front_of_house, the name of the module
defined at the same level of the module tree as eat_at_restaurant. Here the
filesystem equivalent would be using the path
front_of_house/hosting/add_to_waitlist. Starting with a module name means
that the path is relative.
Choosing whether to use a relative or absolute path is a decision you’ll make
based on your project, and depends on whether you’re more likely to move item
definition code separately from or together with the code that uses the item.
For example, if we move the front_of_house module and the eat_at_restaurant
function into a module named customer_experience, we’d need to update the
absolute path to add_to_waitlist, but the relative path would still be valid.
However, if we moved the eat_at_restaurant function separately into a module
named dining, the absolute path to the add_to_waitlist call would stay the
same, but the relative path would need to be updated. Our preference in general
is to specify absolute paths because it’s more likely we’ll want to move code
definitions and item calls independently of each other.
Let’s try to compile Listing 7-3 and find out why it won’t compile yet! The error we get is shown in Listing 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` due to 2 previous errors
Listing 7-4: Compiler errors from building the code in Listing 7-3
The error messages say that module hosting is private. In other words, we
have the correct paths for the hosting module and the add_to_waitlist
function, but Rust won’t let us use them because it doesn’t have access to the
private sections. In Rust, all items (functions, methods, structs, enums,
modules, and constants) are private to parent modules by default. If you want
to make an item like a function or struct private, you put it in a module.
Items in a parent module can’t use the private items inside child modules, but items in child modules can use the items in their ancestor modules. This is because child modules wrap and hide their implementation details, but the child modules can see the context in which they’re defined. To continue with our metaphor, think of the privacy rules as being like the back office of a restaurant: what goes on in there is private to restaurant customers, but office managers can see and do everything in the restaurant they operate.
Rust chose to have the module system function this way so that hiding inner
implementation details is the default. That way, you know which parts of the
inner code you can change without breaking outer code. However, Rust does give
you the option to expose inner parts of child modules’ code to outer ancestor
modules by using the pub keyword to make an item public.
Exposing Paths with the pub Keyword
Let’s return to the error in Listing 7-4 that told us the hosting module is
private. We want the eat_at_restaurant function in the parent module to have
access to the add_to_waitlist function in the child module, so we mark the
hosting module with the pub keyword, as shown in Listing 7-5.
Filename: src/lib.rs
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}
Listing 7-5: Declaring the hosting module as pub to
use it from eat_at_restaurant
Unfortunately, the code in Listing 7-5 still results in an error, as shown in Listing 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:9:37
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:12:30
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` due to 2 previous errors
Listing 7-6: Compiler errors from building the code in Listing 7-5
What happened? Adding the pub keyword in front of mod hosting makes the
module public. With this change, if we can access front_of_house, we can
access hosting. But the contents of hosting are still private; making the
module public doesn’t make its contents public. The pub keyword on a module
only lets code in its ancestor modules refer to it, not access its inner code.
Because modules are containers, there’s not much we can do by only making the
module public; we need to go further and choose to make one or more of the
items within the module public as well.
The errors in Listing 7-6 say that the add_to_waitlist function is private.
The privacy rules apply to structs, enums, functions, and methods as well as
modules.
Let’s also make the add_to_waitlist function public by adding the pub
keyword before its definition, as in Listing 7-7.
Filename: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}
Listing 7-7: Adding the pub keyword to mod hosting
and fn add_to_waitlist lets us call the function from
eat_at_restaurant
Now the code will compile! To see why adding the pub keyword lets us use
these paths in add_to_waitlist with respect to the privacy rules, let’s look
at the absolute and the relative paths.
In the absolute path, we start with crate, the root of our crate’s module
tree. The front_of_house module is defined in the crate root. While
front_of_house isn’t public, because the eat_at_restaurant function is
defined in the same module as front_of_house (that is, eat_at_restaurant
and front_of_house are siblings), we can refer to front_of_house from
eat_at_restaurant. Next is the hosting module marked with pub. We can
access the parent module of hosting, so we can access hosting. Finally, the
add_to_waitlist function is marked with pub and we can access its parent
module, so this function call works!
In the relative path, the logic is the same as the absolute path except for the
first step: rather than starting from the crate root, the path starts from
front_of_house. The front_of_house module is defined within the same module
as eat_at_restaurant, so the relative path starting from the module in which
eat_at_restaurant is defined works. Then, because hosting and
add_to_waitlist are marked with pub, the rest of the path works, and this
function call is valid!
If you plan on sharing your library crate so other projects can use your code, your public API is your contract with users of your crate that determines how they can interact with your code. There are many considerations around managing changes to your public API to make it easier for people to depend on your crate. These considerations are out of the scope of this book; if you’re interested in this topic, see The Rust API Guidelines.
Best Practices for Packages with a Binary and a Library
We mentioned a package can contain both a src/main.rs binary crate root as well as a src/lib.rs library crate root, and both crates will have the package name by default. Typically, packages with this pattern of containing both a library and a binary crate will have just enough code in the binary crate to start an executable that calls code with the library crate. This lets other projects benefit from the most functionality that the package provides, because the library crate’s code can be shared.
The module tree should be defined in src/lib.rs. Then, any public items can be used in the binary crate by starting paths with the name of the package. The binary crate becomes a user of the library crate just like a completely external crate would use the library crate: it can only use the public API. This helps you design a good API; not only are you the author, you’re also a client!
In Chapter 12, we’ll demonstrate this organizational practice with a command-line program that will contain both a binary crate and a library crate.
Starting Relative Paths with super
We can construct relative paths that begin in the parent module, rather than
the current module or the crate root, by using super at the start of the
path. This is like starting a filesystem path with the .. syntax. Using
super allows us to reference an item that we know is in the parent module,
which can make rearranging the module tree easier when the module is closely
related to the parent, but the parent might be moved elsewhere in the module
tree someday.
Consider the code in Listing 7-8 that models the situation in which a chef
fixes an incorrect order and personally brings it out to the customer. The
function fix_incorrect_order defined in the back_of_house module calls the
function deliver_order defined in the parent module by specifying the path to
deliver_order starting with super:
Filename: src/lib.rs
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}
Listing 7-8: Calling a function using a relative path
starting with super
The fix_incorrect_order function is in the back_of_house module, so we can
use super to go to the parent module of back_of_house, which in this case
is crate, the root. From there, we look for deliver_order and find it.
Success! We think the back_of_house module and the deliver_order function
are likely to stay in the same relationship to each other and get moved
together should we decide to reorganize the crate’s module tree. Therefore, we
used super so we’ll have fewer places to update code in the future if this
code gets moved to a different module.
Making Structs and Enums Public
We can also use pub to designate structs and enums as public, but there are a
few details extra to the usage of pub with structs and enums. If we use pub
before a struct definition, we make the struct public, but the struct’s fields
will still be private. We can make each field public or not on a case-by-case
basis. In Listing 7-9, we’ve defined a public back_of_house::Breakfast struct
with a public toast field but a private seasonal_fruit field. This models
the case in a restaurant where the customer can pick the type of bread that
comes with a meal, but the chef decides which fruit accompanies the meal based
on what’s in season and in stock. The available fruit changes quickly, so
customers can’t choose the fruit or even see which fruit they’ll get.
Filename: src/lib.rs
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal
// meal.seasonal_fruit = String::from("blueberries");
}
Listing 7-9: A struct with some public fields and some private fields
Because the toast field in the back_of_house::Breakfast struct is public,
in eat_at_restaurant we can write and read to the toast field using dot
notation. Notice that we can’t use the seasonal_fruit field in
eat_at_restaurant because seasonal_fruit is private. Try uncommenting the
line modifying the seasonal_fruit field value to see what error you get!
Also, note that because back_of_house::Breakfast has a private field, the
struct needs to provide a public associated function that constructs an
instance of Breakfast (we’ve named it summer here). If Breakfast didn’t
have such a function, we couldn’t create an instance of Breakfast in
eat_at_restaurant because we couldn’t set the value of the private
seasonal_fruit field in eat_at_restaurant.
In contrast, if we make an enum public, all of its variants are then public. We
only need the pub before the enum keyword, as shown in Listing 7-10.
Filename: src/lib.rs
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}
Listing 7-10: Designating an enum as public makes all its variants public
Because we made the Appetizer enum public, we can use the Soup and Salad
variants in eat_at_restaurant.
Enums aren’t very useful unless their variants are public; it would be annoying
to have to annotate all enum variants with pub in every case, so the default
for enum variants is to be public. Structs are often useful without their
fields being public, so struct fields follow the general rule of everything
being private by default unless annotated with pub.
There’s one more situation involving pub that we haven’t covered, and that is
our last module system feature: the use keyword. We’ll cover use by itself
first, and then we’ll show how to combine pub and use.
Bringing Paths into Scope with the use Keyword
Having to write out the paths to call functions can feel inconvenient and
repetitive. In Listing 7-7, whether we chose the absolute or relative path to
the add_to_waitlist function, every time we wanted to call add_to_waitlist
we had to specify front_of_house and hosting too. Fortunately, there’s a
way to simplify this process: we can create a shortcut to a path with the use
keyword once, and then use the shorter name everywhere else in the scope.
In Listing 7-11, we bring the crate::front_of_house::hosting module into the
scope of the eat_at_restaurant function so we only have to specify
hosting::add_to_waitlist to call the add_to_waitlist function in
eat_at_restaurant.
Filename: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
Listing 7-11: Bringing a module into scope with
use
Adding use and a path in a scope is similar to creating a symbolic link in
the filesystem. By adding use crate::front_of_house::hosting in the crate
root, hosting is now a valid name in that scope, just as though the hosting
module had been defined in the crate root. Paths brought into scope with use
also check privacy, like any other paths.
Note that use only creates the shortcut for the particular scope in which the
use occurs. Listing 7-12 moves the eat_at_restaurant function into a new
child module named customer, which is then a different scope than the use
statement, so the function body won’t compile:
Filename: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}
Listing 7-12: A use statement only applies in the scope
it’s in
The compiler error shows that the shortcut no longer applies within the
customer module:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of undeclared crate or module `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of undeclared crate or module `hosting`
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` due to previous error; 1 warning emitted
Notice there’s also a warning that the use is no longer used in its scope! To
fix this problem, move the use within the customer module too, or reference
the shortcut in the parent module with super::hosting within the child
customer module.
Creating Idiomatic use Paths
In Listing 7-11, you might have wondered why we specified use crate::front_of_house::hosting and then called hosting::add_to_waitlist in
eat_at_restaurant rather than specifying the use path all the way out to
the add_to_waitlist function to achieve the same result, as in Listing 7-13.
Filename: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}
Listing 7-13: Bringing the add_to_waitlist function
into scope with use, which is unidiomatic
Although both Listing 7-11 and 7-13 accomplish the same task, Listing 7-11 is
the idiomatic way to bring a function into scope with use. Bringing the
function’s parent module into scope with use means we have to specify the
parent module when calling the function. Specifying the parent module when
calling the function makes it clear that the function isn’t locally defined
while still minimizing repetition of the full path. The code in Listing 7-13 is
unclear as to where add_to_waitlist is defined.
On the other hand, when bringing in structs, enums, and other items with use,
it’s idiomatic to specify the full path. Listing 7-14 shows the idiomatic way
to bring the standard library’s HashMap struct into the scope of a binary
crate.
Filename: src/main.rs
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert(1, 2); }
Listing 7-14: Bringing HashMap into scope in an
idiomatic way
There’s no strong reason behind this idiom: it’s just the convention that has emerged, and folks have gotten used to reading and writing Rust code this way.
The exception to this idiom is if we’re bringing two items with the same name
into scope with use statements, because Rust doesn’t allow that. Listing 7-15
shows how to bring two Result types into scope that have the same name but
different parent modules and how to refer to them.
Filename: src/lib.rs
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}
Listing 7-15: Bringing two types with the same name into the same scope requires using their parent modules.
As you can see, using the parent modules distinguishes the two Result types.
If instead we specified use std::fmt::Result and use std::io::Result, we’d
have two Result types in the same scope and Rust wouldn’t know which one we
meant when we used Result.
Providing New Names with the as Keyword
There’s another solution to the problem of bringing two types of the same name
into the same scope with use: after the path, we can specify as and a new
local name, or alias, for the type. Listing 7-16 shows another way to write
the code in Listing 7-15 by renaming one of the two Result types using as.
Filename: src/lib.rs
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}
Listing 7-16: Renaming a type when it’s brought into
scope with the as keyword
In the second use statement, we chose the new name IoResult for the
std::io::Result type, which won’t conflict with the Result from std::fmt
that we’ve also brought into scope. Listing 7-15 and Listing 7-16 are
considered idiomatic, so the choice is up to you!
Re-exporting Names with pub use
When we bring a name into scope with the use keyword, the name available in
the new scope is private. To enable the code that calls our code to refer to
that name as if it had been defined in that code’s scope, we can combine pub
and use. This technique is called re-exporting because we’re bringing
an item into scope but also making that item available for others to bring into
their scope.
Listing 7-17 shows the code in Listing 7-11 with use in the root module
changed to pub use.
Filename: src/lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
Listing 7-17: Making a name available for any code to use
from a new scope with pub use
Before this change, external code would have to call the add_to_waitlist
function by using the path
restaurant::front_of_house::hosting::add_to_waitlist(). Now that this pub use has re-exported the hosting module from the root module, external code
can now use the path restaurant::hosting::add_to_waitlist() instead.
Re-exporting is useful when the internal structure of your code is different
from how programmers calling your code would think about the domain. For
example, in this restaurant metaphor, the people running the restaurant think
about “front of house” and “back of house.” But customers visiting a restaurant
probably won’t think about the parts of the restaurant in those terms. With
pub use, we can write our code with one structure but expose a different
structure. Doing so makes our library well organized for programmers working on
the library and programmers calling the library. We’ll look at another example
of pub use and how it affects your crate’s documentation in the “Exporting a
Convenient Public API with pub use” section of
Chapter 14.
Using External Packages
In Chapter 2, we programmed a guessing game project that used an external
package called rand to get random numbers. To use rand in our project, we
added this line to Cargo.toml:
Filename: Cargo.toml
rand = "0.8.5"
Adding rand as a dependency in Cargo.toml tells Cargo to download the
rand package and any dependencies from crates.io and
make rand available to our project.
Then, to bring rand definitions into the scope of our package, we added a
use line starting with the name of the crate, rand, and listed the items
we wanted to bring into scope. Recall that in the “Generating a Random
Number” section in Chapter 2, we brought the Rng trait
into scope and called the rand::thread_rng function:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}
Members of the Rust community have made many packages available at
crates.io, and pulling any of them into your package
involves these same steps: listing them in your package’s Cargo.toml file and
using use to bring items from their crates into scope.
Note that the standard std library is also a crate that’s external to our
package. Because the standard library is shipped with the Rust language, we
don’t need to change Cargo.toml to include std. But we do need to refer to
it with use to bring items from there into our package’s scope. For example,
with HashMap we would use this line:
#![allow(unused)] fn main() { use std::collections::HashMap; }
This is an absolute path starting with std, the name of the standard library
crate.
Using Nested Paths to Clean Up Large use Lists
If we’re using multiple items defined in the same crate or same module,
listing each item on its own line can take up a lot of vertical space in our
files. For example, these two use statements we had in the Guessing Game in
Listing 2-4 bring items from std into scope:
Filename: src/main.rs
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
Instead, we can use nested paths to bring the same items into scope in one line. We do this by specifying the common part of the path, followed by two colons, and then curly brackets around a list of the parts of the paths that differ, as shown in Listing 7-18.
Filename: src/main.rs
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
Listing 7-18: Specifying a nested path to bring multiple items with the same prefix into scope
In bigger programs, bringing many items into scope from the same crate or
module using nested paths can reduce the number of separate use statements
needed by a lot!
We can use a nested path at any level in a path, which is useful when combining
two use statements that share a subpath. For example, Listing 7-19 shows two
use statements: one that brings std::io into scope and one that brings
std::io::Write into scope.
Filename: src/lib.rs
use std::io;
use std::io::Write;
Listing 7-19: Two use statements where one is a subpath
of the other
The common part of these two paths is std::io, and that’s the complete first
path. To merge these two paths into one use statement, we can use self in
the nested path, as shown in Listing 7-20.
Filename: src/lib.rs
use std::io::{self, Write};
Listing 7-20: Combining the paths in Listing 7-19 into
one use statement
This line brings std::io and std::io::Write into scope.
The Glob Operator
If we want to bring all public items defined in a path into scope, we can
specify that path followed by the * glob operator:
#![allow(unused)] fn main() { use std::collections::*; }
This use statement brings all public items defined in std::collections into
the current scope. Be careful when using the glob operator! Glob can make it
harder to tell what names are in scope and where a name used in your program
was defined.
The glob operator is often used when testing to bring everything under test
into the tests module; we’ll talk about that in the “How to Write
Tests” section in Chapter 11. The glob operator
is also sometimes used as part of the prelude pattern: see the standard
library documentation
for more information on that pattern.
Separating Modules into Different Files
So far, all the examples in this chapter defined multiple modules in one file. When modules get large, you might want to move their definitions to a separate file to make the code easier to navigate.
For example, let’s start from the code in Listing 7-17 that had multiple restaurant modules. We’ll extract modules into files instead of having all the modules defined in the crate root file. In this case, the crate root file is src/lib.rs, but this procedure also works with binary crates whose crate root file is src/main.rs.
First, we’ll extract the front_of_house module to its own file. Remove the
code inside the curly brackets for the front_of_house module, leaving only
the mod front_of_house; declaration, so that src/lib.rs contains the code
shown in Listing 7-21. Note that this won’t compile until we create the
src/front_of_house.rs file in Listing 7-22.
Filename: src/lib.rs
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
Listing 7-21: Declaring the front_of_house module whose
body will be in src/front_of_house.rs
Next, place the code that was in the curly brackets into a new file named
src/front_of_house.rs, as shown in Listing 7-22. The compiler knows to look
in this file because it came across the module declaration in the crate root
with the name front_of_house.
Filename: src/front_of_house.rs
pub mod hosting {
pub fn add_to_waitlist() {}
}
Listing 7-22: Definitions inside the front_of_house
module in src/front_of_house.rs
Note that you only need to load a file using a mod declaration once in your
module tree. Once the compiler knows the file is part of the project (and knows
where in the module tree the code resides because of where you’ve put the mod
statement), other files in your project should refer to the loaded file’s code
using a path to where it was declared, as covered in the “Paths for Referring
to an Item in the Module Tree” section. In other words,
mod is not an “include” operation that you may have seen in other
programming languages.
Next, we’ll extract the hosting module to its own file. The process is a bit
different because hosting is a child module of front_of_house, not of the
root module. We’ll place the file for hosting in a new directory that will be
named for its ancestors in the module tree, in this case src/front_of_house/.
To start moving hosting, we change src/front_of_house.rs to contain only the
declaration of the hosting module:
Filename: src/front_of_house.rs
pub mod hosting;
Then we create a src/front_of_house directory and a file hosting.rs to
contain the definitions made in the hosting module:
Filename: src/front_of_house/hosting.rs
pub fn add_to_waitlist() {}
If we instead put hosting.rs in the src directory, the compiler would
expect the hosting.rs code to be in a hosting module declared in the crate
root, and not declared as a child of the front_of_house module. The
compiler’s rules for which files to check for which modules’ code means the
directories and files more closely match the module tree.
Alternate File Paths
So far we’ve covered the most idiomatic file paths the Rust compiler uses, but Rust also supports an older style of file path. For a module named
front_of_housedeclared in the crate root, the compiler will look for the module’s code in:
- src/front_of_house.rs (what we covered)
- src/front_of_house/mod.rs (older style, still supported path)
For a module named
hostingthat is a submodule offront_of_house, the compiler will look for the module’s code in:
- src/front_of_house/hosting.rs (what we covered)
- src/front_of_house/hosting/mod.rs (older style, still supported path)
If you use both styles for the same module, you’ll get a compiler error. Using a mix of both styles for different modules in the same project is allowed, but might be confusing for people navigating your project.
The main downside to the style that uses files named mod.rs is that your project can end up with many files named mod.rs, which can get confusing when you have them open in your editor at the same time.
We’ve moved each module’s code to a separate file, and the module tree remains
the same. The function calls in eat_at_restaurant will work without any
modification, even though the definitions live in different files. This
technique lets you move modules to new files as they grow in size.
Note that the pub use crate::front_of_house::hosting statement in
src/lib.rs also hasn’t changed, nor does use have any impact on what files
are compiled as part of the crate. The mod keyword declares modules, and Rust
looks in a file with the same name as the module for the code that goes into
that module.
Summary
Rust lets you split a package into multiple crates and a crate into modules
so you can refer to items defined in one module from another module. You can do
this by specifying absolute or relative paths. These paths can be brought into
scope with a use statement so you can use a shorter path for multiple uses of
the item in that scope. Module code is private by default, but you can make
definitions public by adding the pub keyword.
In the next chapter, we’ll look at some collection data structures in the standard library that you can use in your neatly organized code.
Common Collections
Rust’s standard library includes a number of very useful data structures called collections. Most other data types represent one specific value, but collections can contain multiple values.
Unlike the built-in array and tuple types, the data these collections point to is stored on the heap, which means the amount of data does not need to be known at compile time and can grow or shrink as the program runs.
Each kind of collection has different capabilities and costs, and choosing an appropriate one for your current situation is a skill you’ll develop over time.
In this chapter, we’ll discuss three collections that are used very often in Rust programs:
- A vector allows you to store a variable number of values next to each other.
- A string is a collection of characters.
We’ve mentioned the String type previously, but in this chapter we’ll talk about it in depth.
- A hash map allows you to associate a value with a particular key. It’s a particular implementation of the more general data structure called a map.
To learn about the other kinds of collections provided by the standard library, see the documentation.
We’ll discuss how to create and update vectors, strings, and hash maps, as well as what makes each special.
Storing Lists of The Same Type of Values with Vectors
The first collection type we’ll look at is Vec<T>, also known as a vector.
Vectors allow you to store more than one value in a single data structure that puts all the values next to each other in memory.
- Vectors can only store values of the same type.
- They are useful when you have a list of items, such as the lines of text in a file or the prices of items in a shopping cart.
Creating a New Vector
To create a new empty vector, we call the Vec::new function, as shown in
Listing 8-1.
fn main() { let v: Vec<i32> = Vec::new(); }
Listing 8-1: Creating a new, empty vector to hold values
of type i32
- Note that we added a type annotation here.
- Because we aren’t inserting any values into this vector, Rust doesn’t know what kind of elements we intend to store.
- This is an important point: Vectors are implemented using generics; we’ll cover how to use generics with your own types in Chapter 10.
- For now, know that the
Vec<T>type provided by the standard library can hold any type. - When we create a vector to hold a specific type, we can specify the type within angle brackets.
- In Listing 8-1, we’ve told Rust that the
Vec<T>invwill hold elements of thei32type.
More often, you’ll create a
Vec<T>with initial values and Rust will infer the type of value you want to store, so you rarely need to do this type annotation.
- Rust conveniently provides the
vec!macro, which will create a new vector that holds the values you give it. - Listing 8-2 creates a new
Vec<i32>that holds the values1,2, and3. - The integer type is
i32because that’s the default integer type, as we discussed in the “Data Types” section of Chapter 3.
fn main() { let v = vec![1, 2, 3]; }
Listing 8-2: Creating a new vector containing values
Because we’ve given initial i32 values, Rust can infer that the type of v
is Vec<i32>, and the type annotation isn’t necessary.
Next, we’ll look at how to modify a vector.
Updating a Vector
To create a vector and then add elements to it, we can use the push method,
as shown in Listing 8-3.
fn main() { let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
Listing 8-3: Using the push method to add values to a
vector
- As with any variable, if we want to be able to change its value, we need to
make it mutable using the
mutkeyword, as discussed in Chapter 3. - The numbers
we place inside are all of type
i32, and Rust infers this from the data, so we don’t need theVec<i32>annotation.
Reading Elements of Vectors
There are two ways to reference a value stored in a vector:
- via indexing
- or using the
getmethod.
In the following examples, we’ve annotated the types of the values that are returned from these functions for extra clarity.
Listing 8-4 shows both methods of accessing a value in a vector, with indexing
syntax and the get method.
fn main() { let v = vec![1, 2, 3, 4, 5]; let third: &i32 = &v[2]; println!("The third element is {third}"); let third: Option<&i32> = v.get(2); match third { Some(third) => println!("The third element is {third}"), None => println!("There is no third element."), } }
Listing 8-4: Using indexing syntax or the get method to
access an item in a vector
Note a few details here:
- We use the index value of
2to get the third element because vectors are indexed by number, starting at zero. - Using
&and[]gives us a reference to the element at the index value. - When we use the
getmethod with the index passed as an argument, we get anOption<&T>that we can use withmatch.
The reason Rust provides these two ways to reference an element is so you can choose how the program behaves when you try to use an index value outside the range of existing elements.
As an example, let’s see what happens when we have a vector of five elements and then we try to access an element at index 100 with each technique, as shown in Listing 8-5.
fn main() { let v = vec![1, 2, 3, 4, 5]; let does_not_exist = &v[100]; let does_not_exist = v.get(100); }
Listing 8-5: Attempting to access the element at index 100 in a vector containing five elements
-
When we run this code, the first
[]method will cause the program to panic because it references a nonexistent element. -
This method is best used when you want your program to crash if there’s an attempt to access an element past the end of the vector.
-
When the
getmethod is passed an index that is outside the vector, it returnsNonewithout panicking. -
You would use this method if accessing an element beyond the range of the vector may happen occasionally under normal circumstances.
-
Your code will then have logic to handle having either
Some(&element)orNone, as discussed in Chapter 6. -
For example, the index could be coming from a person entering a number.
-
If they accidentally enter a number that’s too large and the program gets a
Nonevalue, you could tell the user how many items are in the current vector and give them another chance to enter a valid value. -
That would be more user-friendly than crashing the program due to a typo!
-
When the program has a valid reference, the borrow checker enforces the ownership and borrowing rules (covered in Chapter 4) to ensure this reference and any other references to the contents of the vector remain valid.
-
Recall the rule that states you can’t have mutable and immutable references in the same scope.
-
That rule applies in Listing 8-6, where we hold an immutable reference to the first element in a vector and try to add an element to the end.
This program won’t work if we also try to refer to that element later in the function:
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}
Listing 8-6: Attempting to add an element to a vector while holding a reference to an item
Compiling this code will result in this error:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {}", first);
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` due to previous error
The code in Listing 8-6 might look like it should work: why should a reference to the first element care about changes at the end of the vector?
This error is due to the way vectors work:
because vectors put the values next to each other in memory, adding a new element onto the end of the vector might require allocating new memory and copying the old elements to the new space, if there isn’t enough room to put all the elements next to each other where the vector is currently stored.
In that case, the reference to the first element would be pointing to deallocated memory. The borrowing rules prevent programs from ending up in that situation.
Note: For more on the implementation details of the
Vec<T>type, see “The Rustonomicon”.
Iterating over the Values in a Vector
To access each element in a vector in turn, we would iterate through all of the
elements rather than use indices to access one at a time. Listing 8-7 shows how
to use a for loop to get immutable references to each element in a vector of
i32 values and print them.
fn main() { let v = vec![100, 32, 57]; for i in &v { println!("{i}"); } }
Listing 8-7: Printing each element in a vector by
iterating over the elements using a for loop
We can also iterate over mutable references to each element in a mutable vector
in order to make changes to all the elements. The for loop in Listing 8-8
will add 50 to each element.
fn main() { let mut v = vec![100, 32, 57]; for i in &mut v { *i += 50; } }
Listing 8-8: Iterating over mutable references to elements in a vector
To change the value that the mutable reference refers to, we have to use the
*dereference operator to get to the value inibefore we can use the+=operator.
We’ll talk more about the dereference operator in the “Following the Pointer to the Value with the Dereference Operator” section of Chapter 15.
Iterating over a vector, whether immutably or mutably, is safe because of the borrow checker’s rules.
- If we attempted to insert or remove items in the
forloop bodies in Listing 8-7 and Listing 8-8, we would get a compiler error similar to the one we got with the code in Listing 8-6. - The reference to the
vector that the
forloop holds prevents simultaneous modification of the whole vector.
Using an Enum to Store Multiple Types
Vectors can only store values that are the same type. This can be inconvenient; there are definitely use cases for needing to store a list of items of different types.
Fortunately, the variants of an enum are defined under the same enum type, so when we need one type to represent elements of different types, we can define and use an enum!
- For example, say we want to get values from a row in a spreadsheet in which some of the columns in the row contain integers, some floating-point numbers, and some strings.
- We can define an enum whose variants will hold the different value types, and all the enum variants will be considered the same type: that of the enum.
- Then we can create a vector to hold that enum and so, ultimately, holds different types.
We’ve demonstrated this in Listing 8-9.
fn main() { enum SpreadsheetCell { Int(i32), Float(f64), Text(String), } let row = vec![ SpreadsheetCell::Int(3), SpreadsheetCell::Text(String::from("blue")), SpreadsheetCell::Float(10.12), ]; }
Listing 8-9: Defining an enum to store values of
different types in one vector
Rust needs to know what types will be in the vector at compile time so it knows exactly how much memory on the heap will be needed to store each element.
- We must also be explicit about what types are allowed in this vector.
- If Rust allowed a vector to hold any type, there would be a chance that one or more of the types would cause errors with the operations performed on the elements of the vector.
- Using an enum plus a
matchexpression means that Rust will ensure at compile time that every possible case is handled, as discussed in Chapter 6.
If you don’t know the exhaustive set of types a program will get at runtime to store in a vector, the enum technique won’t work. Instead, you can use a trait object, which we’ll cover in Chapter 17.
Now that we’ve discussed some of the most common ways to use vectors, be sure
to review the API documentation for all the many
useful methods defined on Vec<T> by the standard library. For example, in
addition to push, a pop method removes and returns the last element.
Dropping a Vector Drops Its Elements
Like any other struct, a vector is freed when it goes out of scope, as
annotated in Listing 8-10.
fn main() { { let v = vec![1, 2, 3, 4]; // do stuff with v } // <- v goes out of scope and is freed here }
Listing 8-10: Showing where the vector and its elements are dropped
When the vector gets dropped, all of its contents are also dropped, meaning the integers it holds will be cleaned up. The borrow checker ensures that any references to contents of a vector are only used while the vector itself is valid.
Let’s move on to the next collection type: String!
Storing UTF-8 Encoded Text with Strings
A
Stringis a wrapper over aVec<u8>.
- Storing UTF-8 Encoded Text with Strings
We talked about strings in Chapter 4, but we’ll look at them in more depth now.
New Rustaceans commonly get stuck on strings for a combination of three reasons:
- Rust’s propensity for exposing possible errors
- strings being a more complicated data structure than many programmers give them credit for,
- and UTF-8.
These factors combine in a way that can seem difficult when you’re coming from other programming languages.
-
We discuss strings in the context of collections because strings are implemented as a collection of bytes, plus some methods to provide useful functionality when those bytes are interpreted as text.
-
In this section, we’ll talk about the operations on
Stringthat every collection type has, such as creating, updating, and reading. -
We’ll also discuss the ways in which
Stringis different from the other collections, namely how indexing into aStringis complicated by the differences between how people and computers interpretStringdata.
What Is a String?
We’ll first define what we mean by the term string.
- Rust has only one string
type in the core language, which is the string slice
strthat is usually seen in its borrowed form&str. - In Chapter 4, we talked about string slices, which are references to some UTF-8 encoded string data stored elsewhere.
- String literals, for example, are stored in the program’s binary and are therefore string slices.
The
Stringtype, which is provided by Rust’s standard library rather than coded into the core language, is a growable, mutable, owned, UTF-8 encoded string type.
- When Rustaceans refer to “strings” in Rust, they might be
referring to either the
Stringor the string slice&strtypes, not just one of those types. - Although this section is largely about
String, both types are used heavily in Rust’s standard library, and bothStringand string slices are UTF-8 encoded.
Creating a New String
Many of the same operations available with
Vec<T>are available withStringas well, becauseStringis actually implemented as a wrapper around a vector of bytes with some extra guarantees, restrictions, and capabilities.
An example
of a function that works the same way with Vec<T> and String is the new
function to create an instance, shown in Listing 8-11.
fn main() { let mut s = String::new(); }
Listing 8-11: Creating a new, empty String
- This line creates a new empty string called
s, which we can then load data into. - Often, we’ll have some initial data that we want to start the string with.
- For that, we use the
to_stringmethod, which is available on any type that implements theDisplaytrait, as string literals do. - Listing 8-12 shows two examples.
fn main() { let data = "initial contents"; let s = data.to_string(); // the method also works on a literal directly: let s = "initial contents".to_string(); }
Listing 8-12: Using the to_string method to create a
String from a string literal
This code creates a string containing initial contents.
We can also use the function String::from to create a String from a string
literal. The code in Listing 8-13 is equivalent to the code from Listing 8-12
that uses to_string.
fn main() { let s = String::from("initial contents"); }
Listing 8-13: Using the String::from function to create
a String from a string literal
Because strings are used for so many things, we can use many different generic APIs for strings, providing us with a lot of options. Some of them can seem redundant, but they all have their place!
In this case,
String::fromandto_stringdo the same thing, so which you choose is a matter of style and readability.
Remember that strings are UTF-8 encoded, so we can include any properly encoded data in them, as shown in Listing 8-14.
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
Listing 8-14: Storing greetings in different languages in strings
All of these are valid String values.
Updating a String
A String can grow in size and its contents can change, just like the contents
of a Vec<T>, if you push more data into it. In addition, you can conveniently
use the + operator or the format! macro to concatenate String values.
Appending to a String with push_str and push
We can grow a String by using the push_str method to append a string slice,
as shown in Listing 8-15.
fn main() { let mut s = String::from("foo"); s.push_str("bar"); }
Listing 8-15: Appending a string slice to a String
using the push_str method
After these two lines, s will contain foobar. The push_str method takes a
string slice because we don’t necessarily want to take ownership of the
parameter. For example, in the code in Listing 8-16, we want to be able to use
s2 after appending its contents to s1.
fn main() { let mut s1 = String::from("foo"); let s2 = "bar"; s1.push_str(s2); println!("s2 is {s2}"); }
Listing 8-16: Using a string slice after appending its
contents to a String
If the push_str method took ownership of s2, we wouldn’t be able to print
its value on the last line. However, this code works as we’d expect!
The push method takes a single character as a parameter and adds it to the
String. Listing 8-17 adds the letter “l” to a String using the push
method.
fn main() { let mut s = String::from("lo"); s.push('l'); }
Listing 8-17: Adding one character to a String value
using push
As a result, s will contain lol.
Concatenation with the + Operator or the format! Macro
Often, you’ll want to combine two existing strings. One way to do so is to use
the + operator, as shown in Listing 8-18.
fn main() { let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used }
Listing 8-18: Using the + operator to combine two
String values into a new String value
- The string
s3will containHello, world!. - The reason
s1is no longer valid after the addition, and the reason we used a reference tos2, has to do with the signature of the method that’s called when we use the+operator. - The
+operator uses theaddmethod, whose signature looks something like this:
fn add(self, s: &str) -> String {
- In the standard library, you’ll see
adddefined using generics and associated types. - Here, we’ve substituted in concrete types, which is what happens when we
call this method with
Stringvalues. We’ll discuss generics in Chapter 10. - This signature gives us the clues we need to understand the tricky bits of the
+operator.
First, s2 has an &
First, s2 has an &, meaning that we’re adding a reference of the second
string to the first string.
This is because of the s parameter in the add
function:
- we can only add a
&strto aString; - we can’t add two
Stringvalues together. - But wait—the type of
&s2is&String, not&str, as specified in the second parameter toadd.
So why does Listing 8-18 compile?
- The reason we’re able to use
&s2in the call toaddis that the compiler can coerce the&Stringargument into a&str. - When we call the
addmethod, Rust uses a deref coercion, which here turns&s2into&s2[..]. - We’ll discuss deref coercion in more depth in Chapter 15.
- Because
adddoes not take ownership of thesparameter,s2will still be a validStringafter this operation.
Second, add takes ownership of self
Second, we can see in the signature that add takes ownership of self,
because self does not have an &.
This means s1 in Listing 8-18 will be
moved into the add call and will no longer be valid after that.
So although
let s3 = s1 + &s2; looks like it will copy both strings and create a new one,
this statement actually takes ownership of s1, appends a copy of the contents
of s2, and then returns ownership of the result.
In other words, it looks like it’s making a lot of copies but isn’t; the implementation is more efficient than copying.
If we need to concatenate multiple strings, the behavior of the + operator
gets unwieldy:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = s1 + "-" + &s2 + "-" + &s3; }
At this point,
swill betic-tac-toe.
With all of the + and "
characters, it’s difficult to see what’s going on.
Using the format! macro
For more complicated string combining, we can instead use the
format!macro:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = format!("{s1}-{s2}-{s3}"); }
- This code also sets
stotic-tac-toe. - The
format!macro works likeprintln!, but instead of printing the output to the screen, it returns aStringwith the contents. - The version of the code using
format!is much easier to read, and the code generated by theformat!macro uses references so that this call doesn’t take ownership of any of its parameters.
Indexing into Strings
In many other programming languages, accessing individual characters in a
string by referencing them by index is a valid and common operation. However,
if you try to access parts of a String using indexing syntax in Rust, you’ll
get an error.
Consider the invalid code in Listing 8-19.
fn main() {
let s1 = String::from("hello");
let h = s1[0];
}
Listing 8-19: Attempting to use indexing syntax with a String
This code will result in the following error:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `String` cannot be indexed by `{integer}`
--> src/main.rs:3:13
|
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`
= help: the following other types implement trait `Index<Idx>`:
<String as Index<RangeFrom<usize>>>
<String as Index<RangeFull>>
<String as Index<RangeInclusive<usize>>>
<String as Index<RangeTo<usize>>>
<String as Index<RangeToInclusive<usize>>>
<String as Index<std::ops::Range<usize>>>
<str as Index<I>>
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` due to previous error
The error and the note tell the story:Rust strings don’t support indexing.
But why not? To answer that question, we need to discuss how Rust stores strings in memory.
Internal Representation
A
Stringis a wrapper over aVec<u8>.
Let’s look at some of our properly encoded UTF-8 example strings from Listing 8-14.
First, this one:
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
- In this case,
lenwill be 4, which means the vector storing the string “Hola” is 4 bytes long. - Each of these letters takes 1 byte when encoded in UTF-8.
- The following line, however, may surprise you. (Note that this string begins with the capital Cyrillic letter Ze, not the Arabic number 3.)
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שָׁלוֹם"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
- Asked how long the string is, you might say 12.
- In fact, Rust’s answer is 24
- that’s the number of bytes it takes to encode “Здравствуйте” in UTF-8, because each Unicode scalar value in that string takes 2 bytes of storage.
- Therefore, an index into the string’s bytes will not always correlate to a valid Unicode scalar value.
To demonstrate, consider this invalid Rust code:
let hello = "Здравствуйте";
let answer = &hello[0];
- You already know that
answerwill not beЗ, the first letter. - When encoded
in UTF-8, the first byte of
Зis208and the second is151, so it would seem thatanswershould in fact be208, but208is not a valid character on its own. - Returning
208is likely not what a user would want if they asked for the first letter of this string; - however, that’s the only data that Rust has at byte index 0.
- Users generally don’t want the byte value returned, even
if the string contains only Latin letters: if
&"hello"[0]were valid code that returned the byte value, it would return104, noth.
The answer, then, is that to avoid returning an unexpected value and causing bugs that might not be discovered immediately, Rust doesn’t compile this code at all and prevents misunderstandings early in the development process.
Bytes and Scalar Values and Grapheme Clusters! Oh My!
Another point about UTF-8 is that there are actually three relevant ways to look at strings from Rust’s perspective:
- as bytes,
- scalar values,
- and grapheme clusters (the closest thing to what we would call letters).
If we look at the Hindi word “नमस्ते” written in the Devanagari script, it is
stored as a vector of u8 values that looks like this:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
That’s 18 bytes and is how computers ultimately store this data. If we look at
them as Unicode scalar values, which are what Rust’s char type is, those
bytes look like this:
['न', 'म', 'स', '्', 'त', 'े']
There are six char values here, but the fourth and sixth are not letters:
they’re diacritics that don’t make sense on their own. Finally, if we look at
them as grapheme clusters, we’d get what a person would call the four letters
that make up the Hindi word:
["न", "म", "स्", "ते"]
Rust provides different ways of interpreting the raw string data that computers store so that each program can choose the interpretation it needs, no matter what human language the data is in.
A final reason Rust doesn’t allow us to index into a String to get a
character is that indexing operations are expected to always take constant time
(O(1)). But it isn’t possible to guarantee that performance with a String,
because Rust would have to walk through the contents from the beginning to the
index to determine how many valid characters there were.
Slicing Strings
Indexing into a string is often a bad idea because it’s not clear what the return type of the string-indexing operation should be:
a byte value, a character, a grapheme cluster, or a string slice.
If you really need to use indices to create string slices, therefore, Rust asks you to be more specific.
Rather than indexing using [] with a single number, you can use [] with a
range to create a string slice containing particular bytes:
let hello = "Здравствуйте"; let s = &hello[0..4];
Here, s will be a &str that contains the first 4 bytes of the string.
Earlier, we mentioned that each of these characters was 2 bytes, which means
s will be Зд.
If we were to try to slice only part of a character’s bytes with something like
&hello[0..1], Rust would panic at runtime in the same way as if an invalid
index were accessed in a vector:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at 'byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`', library/core/src/str/mod.rs:127:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
You should use ranges to create string slices with caution, because doing so can crash your program.
Methods for Iterating Over Strings
The best way to operate on pieces of strings is to be explicit about whether you want characters or bytes.
- For individual Unicode scalar values, use the
charsmethod. - Calling
charson “Зд” separates out and returns two values of typechar, and you can iterate over the result to access each element:
for c in "Зд".chars() { println!("{c}"); }
This code will print the following:
З
д
Alternatively, the bytes method returns each raw byte, which might be
appropriate for your domain:
for b in "Зд".bytes() { println!("{b}"); }
This code will print the four bytes that make up this string:
208
151
208
180
But be sure to remember that valid Unicode scalar values may be made up of more than 1 byte.
Getting grapheme clusters from strings as with the Devanagari script is complex, so this functionality is not provided by the standard library. Crates are available on crates.io if this is the functionality you need.
Strings Are Not So Simple
To summarize, strings are complicated.
- Different programming languages make different choices about how to present this complexity to the programmer.
- Rust
has chosen to make the correct handling of
Stringdata the default behavior for all Rust programs, which means programmers have to put more thought into handling UTF-8 data upfront. - This trade-off exposes more of the complexity of strings than is apparent in other programming languages, but it prevents you from having to handle errors involving non-ASCII characters later in your development life cycle.
The good news is that the standard library offers a lot of functionality built off the
Stringand&strtypes to help handle these complex situations correctly.
Be sure to check out the documentation for useful methods like
contains for searching in a string and replace for substituting parts of a
string with another string.
Let’s switch to something a bit less complex: hash maps!
HasnMap<K, V>: Storing Keys with Associated Values
Like vectors, hash maps are homogeneous: all of the keys must have the same type as each other, and all of the values must have the same type.
The last of our common collections is the hash map.
The type
HashMap<K, V>stores a mapping of keys of typeKto values of typeVusing a hashing function, which determines how it places these keys and values into memory.
Many programming languages support this kind of data structure, but they often use a different name, such as hash, map, object, hash table, dictionary, or associative array, just to name a few.
Hash maps are useful when you want to look up data not by using an index, as you can with vectors, but by using a key that can be of any type.
For example, in a game, you could keep track of each team’s score in a hash map in which each key is a team’s name and the values are each team’s score. Given a team name, you can retrieve its score.
We’ll go over the basic API of hash maps in this section, but many more goodies
are hiding in the functions defined on HashMap<K, V> by the standard library.
As always, check the standard library documentation for more information.
Creating a New Hash Map
. One way to create an empty hash map is using new and adding elements with
insert.
In Listing 8-20, we’re keeping track of the scores of two teams whose names are Blue and Yellow. The Blue team starts with 10 points, and the Yellow team starts with 50.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); }
Listing 8-20: Creating a new hash map and inserting some keys and values
- Note that we need to first
usetheHashMapfrom the collections portion of the standard library.
Of our three common collections, this one is the least often used, so it’s not included in the features brought into scope automatically in the prelude.
- Hash maps also have less support from the standard library;
- there’s no built-in macro to construct them, for example.
Just like vectors, hash maps store their data on the heap.
- This
HashMaphas keys of typeStringand values of typei32. - Like vectors, hash maps are homogeneous: all of the keys must have the same type as each other, and all of the values must have the same type.
Accessing Values in a Hash Map
We can get a value out of the hash map by providing its key to the get
method, as shown in Listing 8-21.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); let team_name = String::from("Blue"); let score = scores.get(&team_name).copied().unwrap_or(0); }
Listing 8-21: Accessing the score for the Blue team stored in the hash map
- Here,
scorewill have the value that’s associated with the Blue team, and the result will be10. - The
getmethod returns anOption<&V>; if there’s no value for that key in the hash map,getwill returnNone. - This program
handles the
Optionby callingcopiedto get anOption<i32>rather than anOption<&i32>, thenunwrap_orto setscoreto zero ifscoresdoesn’t have an entry for the key.
We can iterate over each key/value pair in a hash map in a similar manner as we do with vectors, using a
forloop:
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); for (key, value) in &scores { println!("{key}: {value}"); } }
This code will print each pair in an arbitrary order:
Yellow: 50
Blue: 10
Hash Maps and Ownership
For types that implement the Copy trait, like i32, the values are copied
into the hash map.
For owned values like String, the values will be moved and
the hash map will be the owner of those values, as demonstrated in Listing 8-22.
fn main() { use std::collections::HashMap; let field_name = String::from("Favorite color"); let field_value = String::from("Blue"); let mut map = HashMap::new(); map.insert(field_name, field_value); // field_name and field_value are invalid at this point, try using them and // see what compiler error you get! }
Listing 8-22: Showing that keys and values are owned by the hash map once they’re inserted
- We aren’t able to use the variables
field_nameandfield_valueafter they’ve been moved into the hash map with the call toinsert.
If we insert references to values into the hash map, the values won’t be moved into the hash map.
- The values that the references point to must be valid for at least as long as the hash map is valid.
- We’ll talk more about these issues in the “Validating References with Lifetimes” section in Chapter 10.
Updating a Hash Map
Although the number of key and value pairs is growable, each unique key can
only have one value associated with it at a time (but not vice versa: for
example, both the Blue team and the Yellow team could have value 10 stored in
the scores hash map).
When you want to change the data in a hash map, you have to decide how to handle the case when a key already has a value assigned.
- You could replace the old value with the new value, completely disregarding the old value.
- You could keep the old value and ignore the new value, only adding the new value if the key doesn’t already have a value.
- Or you could combine the old value and the new value. Let’s look at how to do each of these!
Overwriting a Value
If we insert a key and a value into a hash map and then insert that same key
with a different value, the value associated with that key will be replaced.
Even though the code in Listing 8-23 calls insert twice, the hash map will
only contain one key/value pair because we’re inserting the value for the Blue
team’s key both times.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Blue"), 25); println!("{:?}", scores); }
Listing 8-23: Replacing a value stored with a particular key
- This code will print
{"Blue": 25}. - The original value of
10has been overwritten.
Adding a Key and Value Only If a Key Isn’t Present
It’s common to check whether a particular key already exists in the hash map with a value then take the following actions:
- if the key does exist in the hash map, the existing value should remain the way it is.
- If the key doesn’t exist, insert it and a value for it.
Hash maps have a special API for this called
entrythat takes the key you want to check as a parameter.
- The return value of the
entrymethod is an enum calledEntrythat represents a value that might or might not exist. - Let’s say we want to check whether the key for the Yellow team has a value associated with it.
- If it doesn’t, we want to insert the value 50, and the same for the
Blue team. Using the
entryAPI, the code looks like Listing 8-24.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.entry(String::from("Yellow")).or_insert(50); scores.entry(String::from("Blue")).or_insert(50); println!("{:?}", scores); }
Listing 8-24: Using the entry method to only insert if
the key does not already have a value
The
or_insertmethod onEntryis defined to return a mutable reference to the value for the correspondingEntrykey if that key exists, and if not, inserts the parameter as the new value for this key and returns a mutable reference to the new value.
-
This technique is much cleaner than writing the logic ourselves and, in addition, plays more nicely with the borrow checker.
-
Running the code in Listing 8-24 will print
{"Yellow": 50, "Blue": 10}. -
The first call to
entrywill insert the key for the Yellow team with the value 50 because the Yellow team doesn’t have a value already. -
The second call to
entrywill not change the hash map because the Blue team already has the value 10.
Updating a Value Based on the Old Value
Another common use case for hash maps is to look up a key’s value and then update it based on the old value.
- For instance, Listing 8-25 shows code that counts how many times each word appears in some text.
- We use a hash map with the words as keys and increment the value to keep track of how many times we’ve seen that word.
- If it’s the first time we’ve seen a word, we’ll first insert the value 0.
fn main() { use std::collections::HashMap; let text = "hello world wonderful world"; let mut map = HashMap::new(); for word in text.split_whitespace() { let count = map.entry(word).or_insert(0); *count += 1; } println!("{:?}", map); }
Listing 8-25: Counting occurrences of words using a hash map that stores words and counts
-
This code will print
{"world": 2, "hello": 1, "wonderful": 1}. -
You might see the same key/value pairs printed in a different order: recall from the “Accessing Values in a Hash Map” section that iterating over a hash map happens in an arbitrary order.
-
The
split_whitespacemethod returns an iterator over sub-slices, separated by whitespace, of the value intext. -
The
or_insertmethod returns a mutable reference (&mut V) to the value for the specified key. -
Here we store that mutable reference in the
countvariable, so in order to assign to that value, we must first dereferencecountusing the asterisk (*). -
The mutable reference goes out of scope at the end of the
forloop, so all of these changes are safe and allowed by the borrowing rules.
Hashing Functions
By default,
HashMapuses a hashing function called SipHash that can provide resistance to Denial of Service (DoS) attacks involving hash tables1.
This is not the fastest hashing algorithm available, but the trade-off for better security that comes with the drop in performance is worth it.
If you profile your code and find that the default hash function is too slow for your purposes, you can switch to another function by specifying a different hasher.
- A hasher is a type that implements the
BuildHashertrait. - We’ll talk about traits and how to implement them in Chapter 10. You don’t necessarily have to implement your own hasher from scratch; crates.io has libraries shared by other Rust users that provide hashers implementing many common hashing algorithms.
Summary
Vectors, strings, and hash maps will provide a large amount of functionality necessary in programs when you need to store, access, and modify data.
Here are some exercises you should now be equipped to solve:
- Given a list of integers, use a vector and return the median (when sorted, the value in the middle position) and mode (the value that occurs most often; a hash map will be helpful here) of the list.
- Convert strings to pig latin. The first consonant of each word is moved to the end of the word and “ay” is added, so “first” becomes “irst-fay.” Words that start with a vowel have “hay” added to the end instead (“apple” becomes “apple-hay”). Keep in mind the details about UTF-8 encoding!
- Using a hash map and vectors, create a text interface to allow a user to add employee names to a department in a company. For example, “Add Sally to Engineering” or “Add Amir to Sales.” Then let the user retrieve a list of all people in a department or all people in the company by department, sorted alphabetically.
The standard library API documentation describes methods that vectors, strings, and hash maps have that will be helpful for these exercises!
We’re getting into more complex programs in which operations can fail, so, it’s a perfect time to discuss error handling. We’ll do that next!
Error Handling
Errors are a fact of life in software, so Rust has a number of features for handling situations in which something goes wrong. In many cases, Rust requires you to acknowledge the possibility of an error and take some action before your code will compile. This requirement makes your program more robust by ensuring that you’ll discover errors and handle them appropriately before you’ve deployed your code to production!
Rust groups errors into two major categories: recoverable and unrecoverable errors. For a recoverable error, such as a file not found error, we most likely just want to report the problem to the user and retry the operation. Unrecoverable errors are always symptoms of bugs, like trying to access a location beyond the end of an array, and so we want to immediately stop the program.
Most languages don’t distinguish between these two kinds of errors and handle
both in the same way, using mechanisms such as exceptions. Rust doesn’t have
exceptions. Instead, it has the type Result<T, E> for recoverable errors and
the panic! macro that stops execution when the program encounters an
unrecoverable error. This chapter covers calling panic! first and then talks
about returning Result<T, E> values. Additionally, we’ll explore
considerations when deciding whether to try to recover from an error or to stop
execution.
Unrecoverable Errors with panic!
Sometimes, bad things happen in your code, and there’s nothing you can do about
it. In these cases, Rust has the panic! macro. There are two ways to cause a
panic in practice: by taking an action that causes our code to panic (such as
accessing an array past the end) or by explicitly calling the panic! macro.
In both cases, we cause a panic in our program. By default, these panics will
print a failure message, unwind, clean up the stack, and quit. Via an
environment variable, you can also have Rust display the call stack when a
panic occurs to make it easier to track down the source of the panic.
Unwinding the Stack or Aborting in Response to a Panic
By default, when a panic occurs, the program starts unwinding, which means Rust walks back up the stack and cleans up the data from each function it encounters. However, this walking back and cleanup is a lot of work. Rust, therefore, allows you to choose the alternative of immediately aborting, which ends the program without cleaning up.
Memory that the program was using will then need to be cleaned up by the operating system. If in your project you need to make the resulting binary as small as possible, you can switch from unwinding to aborting upon a panic by adding
panic = 'abort'to the appropriate[profile]sections in your Cargo.toml file. For example, if you want to abort on panic in release mode, add this:[profile.release] panic = 'abort'
Let’s try calling panic! in a simple program:
Filename: src/main.rs
fn main() { panic!("crash and burn"); }
When you run the program, you’ll see something like this:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished dev [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at 'crash and burn', src/main.rs:2:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
The call to panic! causes the error message contained in the last two lines.
The first line shows our panic message and the place in our source code where
the panic occurred: src/main.rs:2:5 indicates that it’s the second line,
fifth character of our src/main.rs file.
In this case, the line indicated is part of our code, and if we go to that
line, we see the panic! macro call. In other cases, the panic! call might
be in code that our code calls, and the filename and line number reported by
the error message will be someone else’s code where the panic! macro is
called, not the line of our code that eventually led to the panic! call. We
can use the backtrace of the functions the panic! call came from to figure
out the part of our code that is causing the problem. We’ll discuss backtraces
in more detail next.
Using a panic! Backtrace
Let’s look at another example to see what it’s like when a panic! call comes
from a library because of a bug in our code instead of from our code calling
the macro directly. Listing 9-1 has some code that attempts to access an
index in a vector beyond the range of valid indexes.
Filename: src/main.rs
fn main() { let v = vec![1, 2, 3]; v[99]; }
Listing 9-1: Attempting to access an element beyond the
end of a vector, which will cause a call to panic!
Here, we’re attempting to access the 100th element of our vector (which is at
index 99 because indexing starts at zero), but the vector has only 3 elements.
In this situation, Rust will panic. Using [] is supposed to return an
element, but if you pass an invalid index, there’s no element that Rust could
return here that would be correct.
In C, attempting to read beyond the end of a data structure is undefined behavior. You might get whatever is at the location in memory that would correspond to that element in the data structure, even though the memory doesn’t belong to that structure. This is called a buffer overread and can lead to security vulnerabilities if an attacker is able to manipulate the index in such a way as to read data they shouldn’t be allowed to that is stored after the data structure.
To protect your program from this sort of vulnerability, if you try to read an element at an index that doesn’t exist, Rust will stop execution and refuse to continue. Let’s try it and see:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished dev [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
This error points at line 4 of our main.rs where we attempt to access index
99. The next note line tells us that we can set the RUST_BACKTRACE
environment variable to get a backtrace of exactly what happened to cause the
error. A backtrace is a list of all the functions that have been called to
get to this point. Backtraces in Rust work as they do in other languages: the
key to reading the backtrace is to start from the top and read until you see
files you wrote. That’s the spot where the problem originated. The lines above
that spot are code that your code has called; the lines below are code that
called your code. These before-and-after lines might include core Rust code,
standard library code, or crates that you’re using. Let’s try getting a
backtrace by setting the RUST_BACKTRACE environment variable to any value
except 0. Listing 9-2 shows output similar to what you’ll see.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
stack backtrace:
0: rust_begin_unwind
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/std/src/panicking.rs:584:5
1: core::panicking::panic_fmt
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:142:14
2: core::panicking::panic_bounds_check
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/panicking.rs:84:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/slice/index.rs:242:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/slice/index.rs:18:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/alloc/src/vec/mod.rs:2591:9
6: panic::main
at ./src/main.rs:4:5
7: core::ops::function::FnOnce::call_once
at /rustc/e092d0b6b43f2de967af0887873151bb1c0b18d3/library/core/src/ops/function.rs:248:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
Listing 9-2: The backtrace generated by a call to
panic! displayed when the environment variable RUST_BACKTRACE is set
That’s a lot of output! The exact output you see might be different depending
on your operating system and Rust version. In order to get backtraces with this
information, debug symbols must be enabled. Debug symbols are enabled by
default when using cargo build or cargo run without the --release flag,
as we have here.
In the output in Listing 9-2, line 6 of the backtrace points to the line in our project that’s causing the problem: line 4 of src/main.rs. If we don’t want our program to panic, we should start our investigation at the location pointed to by the first line mentioning a file we wrote. In Listing 9-1, where we deliberately wrote code that would panic, the way to fix the panic is to not request an element beyond the range of the vector indexes. When your code panics in the future, you’ll need to figure out what action the code is taking with what values to cause the panic and what the code should do instead.
We’ll come back to panic! and when we should and should not use panic! to
handle error conditions in the “To panic! or Not to
panic!” section later in this
chapter. Next, we’ll look at how to recover from an error using Result.
⭐️ Recoverable Errors with Result
- Recoverable Errors with Result
- Compare Result/Match/unwrap/expected/?
- Result Definition and Basic Usage
- Match Expression: How to handle the information?
- Shortcuts for Panic on Error, simplify match expression
Most errors aren’t serious enough to require the program to stop entirely.
Sometimes, when a function fails, it’s for a reason that you can easily interpret and respond to.
For example, if you try to open a file and that operation fails because the file doesn’t exist, you might want to create the file instead of terminating the process.
Compare Result/Match/unwrap/expected/?
| 错误处理工具 | 用意 | 思路 |
|---|---|---|
| Result | Result<T, E>: OK(T) and Err(E) | 区分两类情况:正确/出错 |
| Match Expression | Handle different errors on matching arms | 详细处理各种情况,类似try… except |
| unwrap_or_else | Unwrap OK(T) or catch Err(E) | 只对出错情况具体处理,是match的简化写法 |
| unwrap | Unwrap OK(T) or throw only panic! without message | 只抛出错误,不处理 |
| expected | Unwrap OK(T) or throw panic! with specific message | 不仅抛出异常,还手工提供出错信息。一般用于特定问题 |
| ? | Simplify unwrap OK(T) or return Err(E) | 返回异常,用来传播返回给调用者进行处理 |
Result Definition and Basic Usage
What the definition of Result conveys?
Recall from “Handling Potential Failure with Result” in Chapter 2 that the Result enum is defined as having two
variants, Ok and Err, as follows:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
The T and E are generic type parameters, we’ll discuss generics in more
detail in Chapter 10.
What you need to know right now is that about T and E:
What you need to know right now is that:
Trepresents the type of the value that will be returned in a success case within theOkvariant- and
Erepresents the type of the error that will be returned in a failure case within theErrvariant.
Because
Resulthas these generic type parameters, we can use theResulttype and the functions defined on it in many different situations where the successful value and error value we want to return may differ.
What is the information the result enum conveys?
Let’s call a function that returns a Result value because the function could
fail.
In Listing 9-3 we try to open a file.
Listing 9-3: Opening a file
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); }
The return type of File::open is a Result<T, E>:
-
The generic parameter
Thas been filled in by the implementation ofFile::openwith the type of the success value,std::fs::File, which is a file handle. -
The type of
Eused in the error value isstd::io::Error.
-
This return type means the call to
File::openmight succeed and return a file handle that we can read from or write to. -
The function call also might fail:
for example, the file might not exist, or we might not have permission to access the file.
The
File::openfunction needs to have a way to tell us whether it succeeded or failed and at the same time give us either the file handle or error information.
This information is exactly what the Result enum conveys:
-
In the case where
File::opensucceeds the value in the variablegreeting_file_resultwill be an instance ofOkthat contains a file handle. -
In the case where it fails the value in
greeting_file_resultwill be an instance ofErrthat contains more information about the kind of error that happened.
Match Expression: How to handle the information?
We need to add to the code in Listing 9-3 to take different actions depending
on the value File::open returns.
Listing 9-4 shows one way to handle the Result using a basic tool, the match expression that we discussed in
Chapter 6.
Listing 9-4: Using a match expression to handle the Result variants that might be returned
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); let greeting_file = match greeting_file_result { Ok(file) => file, Err(error) => panic!("Problem opening the file: {:?}", error), }; }
What happened if the match expression not handle a situation?
Note that:
like the Option enum, the Result enum and its variants have been
brought into scope by the prelude, so we don’t need to specify Result::
before the Ok and Err variants in the match arms:
-
When the result is
Ok, this code will return the innerfilevalue out of theOkvariant, and we then assign that file handle value to the variablegreeting_file. After thematch, we can use the file handle for reading or writing. -
The other arm of the
matchhandles the case where we get anErrvalue fromFile::open. In this example, we’ve chosen to call thepanic!macro.
If there’s no file named hello.txt in our current directory and we run this code, we’ll see the following output from the panic! macro:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished dev [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at 'Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }', src/main.rs:8:23
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
As usual, this output tells us exactly what has gone wrong.
Matching on Different Errors
The code in Listing 9-4 will panic! no matter why File::open failed.
However, we want to take different actions for different failure reasons:
- if
File::openfailed because the file doesn’t exist, we want to create the file and return the handle to the new file. - If
File::openfailed for any other reason—for example, because we didn’t have permission to open the file—we still want the code topanic!in the same way as it did in Listing 9-4.
For this we add an inner match expression, shown in Listing 9-5.
Listing 9-5: Handling different kinds of errors in different ways
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
// add an inner match expression
// just like try...except xxxException in python
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {:?}", e),
},
other_error => {
panic!("Problem opening the file: {:?}", other_error);
}
},
};
}
- The type of the value that
File::openreturns inside theErrvariant isio::Error, which is a struct provided by the standard library. - This struct
has a method
kindthat we can call to get anio::ErrorKindvalue.
The enum
io::ErrorKindis provided by the standard library and has variants representing the different kinds of errors that might result from aniooperation.
- The variant we want to use is
ErrorKind::NotFound, which indicates the file we’re trying to open doesn’t exist yet.
So we match on
greeting_file_result, but we also have an inner match onerror.kind().
- The condition we want to check in the inner match is whether the value returned
by
error.kind()is theNotFoundvariant of theErrorKindenum:
- If it is,
we try to create the file with
File::create.
- However, because
File::createcould also fail, we need a second arm in the innermatchexpression. - When the file can’t be created, a different error message is printed.
- The second arm of
the outer
matchstays the same, so the program panics on any error besides the missing file error.
Shortcuts for Panic on Error, simplify match expression
Why need unwrap and expect
Using
matchworks well enough, but it can be a bit verbose and doesn’t always communicate intent well.
So the Result<T, E> type has many helper methods defined on it to do various, more specific tasks: OK or panic!
- The
unwrapmethod is a shortcut method implemented just like thematchexpression we wrote in Listing 9-4. - If the
Resultvalue is theOkvariant,unwrapwill return the value inside theOk. - If the
Resultis theErrvariant,unwrapwill call thepanic!macro for us.
Unwrap
Here is an example of unwrap in action:
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt").unwrap(); }
If we run this code without a hello.txt file, we’ll see an error message from the panic! call that the unwrap method makes:
cd listings/ch09-error-handling/no-listing-04-unwrap
cargo run
# copy and paste relevant text
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Os {
code: 2, kind: NotFound, message: "No such file or directory" }',
src/main.rs:4:49
unwrap_or_else: Alternatives to Using match with Result<T, E>
That’s a lot of match!
- The
matchexpression is very useful but also very much a primitive. - In Chapter 13, you’ll learn about closures, which are used with many of the methods defined on
Result<T, E>. - These methods can be more concise than using
matchwhen handlingResult<T, E>values in your code.
For example, here is another way to write the same logic as shown in Listing 9-5, this time using closures and the unwrap_or_else method:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file = File::open("hello.txt").unwrap_or_else(|error| {
if error.kind() == ErrorKind::NotFound {
File::create("hello.txt").unwrap_or_else(|error| {
panic!("Problem creating the file: {:?}", error);
})
} else {
panic!("Problem opening the file: {:?}", error);
}
});
}
Although this code has the same behavior as Listing 9-5, it doesn’t contain any
matchexpressions and is cleaner to read.
unwrap_or_else method can clean up huge nested match expressions
Come back to this example
after you’ve read Chapter 13, and look up the unwrap_or_else method in the
standard library documentation.
Many more of these methods can clean up huge
nested match expressions when you’re dealing with errors.
Expect: easier to track down
Similarly, the expect method lets us also choose the panic! error message.
Using expect instead of unwrap and providing good error messages can convey
your intent and make tracking down the source of a panic easier.
The syntax of expect looks like this:
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt") .expect("hello.txt should be included in this project"); }
We use expect in the same way as unwrap:
- to return the file handle or call
the
panic!macro. - Easier Point: The error message used by
expectin its call topanic!will be the parameter that we pass toexpect - rather than the default
panic!message thatunwrapuses.
Here’s what it looks like: you can compare blow with similar situation above
cd listings/ch09-error-handling/no-listing-05-expect
cargo run
# copy and paste relevant text
```text
thread 'main' panicked at 'hello.txt should be included in this project: Os {
code: 2, kind: NotFound, message: "No such file or directory" }',
src/main.rs:5:10
Most Rustaceans choose expect rather than unwrap
In production-quality code, most Rustaceans choose expect rather than
unwrap and give more context about why the operation is expected to always
succeed:
- That way, if your assumptions are ever proven wrong, you have more information to use in debugging.
Using ? to Propagating Errors
About Progating Erors
How to propagate the error? Why?
When a function’s implementation calls something that might fail, instead of handling the error within the function itself, you can return the error to the calling code so that it can decide what to do.
This is known as propagating the error and gives more control to the calling code, where there might be more information or logic that dictates how the error should be handled than what you have available in the context of your code.
Listing 9-6: A function that returns errors to the calling code using match
For example, Listing 9-6 shows a function that reads a username from a file.
If the file doesn’t exist or can’t be read, this function will return those errors to the code that called the function.
use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let username_file_result = File::open("hello.txt"); let mut username_file = match username_file_result { Ok(file) => file, Err(e) => return Err(e), }; let mut username = String::new(); match username_file.read_to_string(&mut username) { Ok(_) => Ok(username), Err(e) => Err(e), } }
This function can be written in a much shorter way, but we’re going to start by doing a lot of it manually in order to explore error handling;
at the end, we’ll show the shorter way.
Let’s look at the return type of the function first: Result<String, io::Error>:
- This means the function is returning a value of the type
Result<T, E> - the generic parameter
Thas been filled in with the concrete typeString - and the generic type
Ehas been filled in with the concrete typeio::Error.
- If this function succeeds without any problems
The code that calls this function will receive an
Okvalue that holds aString—the username that this function read from the file. - If this function encounters any problems
The calling code will receive an
Errvalue that holds an instance ofio::Errorthat contains more information about what the problems were.
Why choose io::Error as the return type?
We choose
io::Erroras the return type of this function because that happens to be the type of the error value returned from both of the operations we’re calling in this function’s body that might fail:
the File::open function and the read_to_string method.
-
The body of the function starts by calling the
File::openfunction. -
Then we handle the
Resultvalue with amatchsimilar to thematchin Listing 9-4. -
If
File::opensucceeds, the file handle in the pattern variablefilebecomes the value in the mutable variableusername_fileand the function continues. -
In the
Errcase, instead of callingpanic!, we use thereturnkeyword to return early out of the function entirely and pass the error value fromFile::open, now in the pattern variablee, back to the calling code as this function’s error value. -
So if we have a file handle in
username_file, the function then creates a newStringin variableusernameand calls theread_to_stringmethod on the file handle inusername_fileto read the contents of the file intousername. -
The
read_to_stringmethod also returns aResultbecause it might fail, even thoughFile::opensucceeded. -
So we need another
matchto handle thatResult: ifread_to_stringsucceeds, then our function has succeeded, and we return the username from the file that’s now inusernamewrapped in anOk. -
If
read_to_stringfails, we return the error value in the same way that we returned the error value in thematchthat handled the return value ofFile::open.
However, we don’t need to explicitly say
return, because this is the last expression in the function.
The code that calls this code will then handle getting either an Ok value
that contains a username or an Err value that contains an io::Error.
It’s up to the calling code to decide what to do with those values:
It’s up to the calling code to decide what to do with those values:
-
If the calling code gets an
Errvalueit could call
panic!and crash the program, use a default username, or look up the username from somewhere other than a file, for example. -
We don’t have enough information on what the calling code is actually trying to do
so we propagate all the success or error information upward for it to handle appropriately.
This pattern of propagating errors is so common in Rust that Rust provides the question mark operator
?to make this easier.
The ? Operator: A Shortcut for Propagating Errors
Listing 9-7 shows an implementation of read_username_from_file that has the
same functionality as in Listing 9-6, but this implementation uses the
? operator.
Listing 9-7: A function that returns errors to the calling code using the ? operator
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username_file = File::open("hello.txt")?; let mut username = String::new(); username_file.read_to_string(&mut username)?; Ok(username) } }
The ? placed after a Result value is defined to work in almost the same way
as the match expressions we defined to handle the Result values in Listing
9-6:
- Return OK:
If the value of the
Resultis anOk, the value inside theOkwill get returned from this expression, and the program will continue. - Propagate Err:
If the value is an
Err, theErrwill be returned from the whole function as if we had used thereturnkeyword so the error value gets propagated to the calling code.
Diference between match expression and ? operator
There is a difference between what the
matchexpression from Listing 9-6 does and what the?operator does:
-
error values that have the
?operator called on them go through thefromfunction, defined in theFromtrait in the standard library, which is used to convert values from one type into another. -
When the
?operator calls thefromfunction, the error type received is converted into the error type defined in the return type of the current function. -
This is useful when a function returns one error type to represent all the ways a function might fail, even if parts might fail for many different reasons.
For example, we could change the read_username_from_file function in Listing
9-7 to return a custom error type named OurError that we define.
If we also define
impl From<io::Error> for OurErrorto construct an instance ofOurErrorfrom anio::Error, then the?operator calls in the body ofread_username_from_filewill callfromand convert the error types without needing to add any more code to the function.
In the context of Listing 9-7, the ? at the end of the File::open call will
return the value inside an Ok to the variable username_file:
- If an error
occurs, the
?operator will return early out of the whole function and give anyErrvalue to the calling code. - The same thing applies to the
?at the end of theread_to_stringcall.
The ? operator eliminates a lot of boilerplate and makes this function’s
implementation simpler.
We could even shorten this code further by chaining method calls immediately after the
?, as shown in Listing 9-8.
Listing 9-8: Chaining method calls after the ? operator
// ANCHOR: here use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username = String::new(); File::open("hello.txt")?.read_to_string(&mut username)?; Ok(username) } // ANCHOR_END: here fn main() { let username = read_username_from_file().expect("Unable to get username"); }
- We’ve moved the creation of the new
Stringinusernameto the beginning of the function; that part hasn’t changed. - Instead of creating a variable
username_file, we’ve chained the call toread_to_stringdirectly onto the result ofFile::open("hello.txt")?. - We still have a
?at the end of theread_to_stringcall, and we still return anOkvalue containingusernamewhen bothFile::openandread_to_stringsucceed rather than returning errors. - The functionality is again the same as in Listing 9-6 and Listing 9-7; this is just a different, more ergonomic way to write it.
Listing 9-9 shows a way to make this even shorter using fs::read_to_string.
Listing 9-9: Using fs::read_to_string instead of opening and then reading the file
#![allow(unused)] fn main() { use std::fs; use std::io; fn read_username_from_file() -> Result<String, io::Error> { fs::read_to_string("hello.txt") } }
Reading a file into a string is a fairly common operation, so the standard
library provides the convenient fs::read_to_string function:
- opens the file
- creates a new
String - reads the contents of the file
- puts the contents into that
String, and returns it
Of course, using fs::read_to_string
doesn’t give us the opportunity to explain all the error handling, so we did it
the longer way first.
Where The ? Operator Can Be Used
Compatible Type
The
?operator can only be used in functions whose return type is compatible with the value the?is used on.
This is because the ? operator is defined
to perform an early return of a value out of the function, in the same manner
as the match expression we defined in Listing 9-6.
In Listing 9-6, the
match was using a Result value, and the early return arm returned an
Err(e) value.
The return type of the function has to be a
Resultso that it’s compatible with thisreturn.
If Incompatible
In Listing 9-10, let’s look at the error we’ll get if we use the ? operator
in a main function with a return type incompatible with the type of the value
we use ? on:
Listing 9-10: Attempting to use the ? in the main function that returns () won’t compile
use std::fs::File;
// main() only returns (), it's not compatible with
// the type of the value we use ? on
fn main() {
// here ? return Result or Option
let greeting_file = File::open("hello.txt")?;
}
This code opens a file, which might fail.
The ? operator follows the Result
value returned by File::open, but this main function has the return type of
(), not Result.
When we compile this code, we get the following error message:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | / fn main() {
4 | | let greeting_file = File::open("hello.txt")?;
| | ^ cannot use the `?` operator in a function that returns `()`
5 | | }
| |_- this function should return `Result` or `Option` to accept `?`
|
= help: the trait `FromResidual<Result<Infallible, std::io::Error>>` is not implemented for `()`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` due to previous error
This error points out that we’re only allowed to use the
?operator in a function that returnsResult,Option, or another type that implementsFromResidual.
Two fix choices
To fix the incompatible error, you have two choices:
- Change the return type
One choice is to change the return type
of your function to be compatible with the value you’re using the ? operator
on as long as you have no restrictions preventing that.
- Use match or specific methods
The other technique is
to use a match or one of the Result<T, E> methods to handle the Result<T, E> in whatever way is appropriate.
The error message also mentioned that
?can be used withOption<T>values as well.
As with using ? on Result, you can only use ? on Option in a
function that returns an Option.
The behavior of the ? operator when called on an Option
- if the value is
None, theNonewill be returned early from the function at that point. - If the value is
Some, the value inside theSomeis the resulting value of the expression and the function continues.
Listing 9-11 has an example of a function that finds the last character of the first line in the given text:
Listing 9-11: Using the ? operator on an Option
// ANCHOR: here fn last_char_of_first_line(text: &str) -> Option<char> { text.lines().next()?.chars().last() } // ANCHOR_END: here fn main() { assert_eq!( last_char_of_first_line("Hello, world\nHow are you today?"), Some('d') ); assert_eq!(last_char_of_first_line(""), None); assert_eq!(last_char_of_first_line("\nhi"), None); }
- This function returns
Option<char>because it’s possible that there is a character there, but it’s also possible that there isn’t. - This code takes the
textstring slice argument and calls thelinesmethod on it, which returns an iterator over the lines in the string. - Because this function wants to
examine the first line, it calls
nexton the iterator to get the first value from the iterator. - If
textis the empty string, this call tonextwill returnNone, in which case we use?to stop and returnNonefromlast_char_of_first_line. - If
textis not the empty string,nextwill return aSomevalue containing a string slice of the first line intext.
The
?extracts the string slice, and we can callcharson that string slice to get an iterator of its characters.
- We’re interested in the last character in
this first line, so we call
lastto return the last item in the iterator. - This is an
Optionbecause it’s possible that the first line is the empty string, for example iftextstarts with a blank line but has characters on other lines, as in"\nhi". - However, if there is a last character on the first
line, it will be returned in the
Somevariant.
The
?operator in the middle gives us a concise way to express this logic, allowing us to implement the function in one line.
- If we couldn’t use the
?operator onOption, we’d have to implement this logic using more method calls or amatchexpression.
Notes About the ?
Note that:
- Result: you can use the
?operator on aResultin a function that returnsResult - Option: and you can use the
?operator on anOptionin a function that returnsOption - but you can’t mix and match.
- The
?operator won’t automatically convert aResultto anOptionor vice versa;
in those cases, you can use methods like the
okmethod onResultor theok_ormethod onOptionto do the conversion explicitly.
Changing main to return Result
So far, all the main functions we’ve used return ().
The main function is
special because it’s the entry and exit point of executable programs, and there
are restrictions on what its return type can be for the programs to behave as
expected.
Luckily,
maincan also return aResult<(), E>.
Listing 9-12 has the
code from Listing 9-10 but we’ve changed the return type of main to be
Result<(), Box<dyn Error>> and added a return value Ok(()) to the end. This
code will now compile:
Listing 9-12: Changing main to return Result<(), E> allows the use of the ? operator on Result values
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}
What is Box<dyn Error>
- The
Box<dyn Error>type is a trait object, which we’ll talk about in the “Using Trait Objects that Allow for Values of Different Types” section in Chapter 17.
For now, you can read
Box<dyn Error>to mean “any kind of error.”
- Using
?on aResultvalue in amainfunction with the error typeBox<dyn Error>is allowed, because it allows anyErrvalue to be returned early. - Even though the body of
this
mainfunction will only ever return errors of typestd::io::Error, by specifyingBox<dyn Error>, this signature will continue to be correct even if more code that returns other errors is added to the body ofmain.
The Executable of main
When a main function returns a Result<(), E>, the executable will
exit with a value of 0 if main returns Ok(()) and will exit with a
nonzero value if main returns an Err value.
Executables written in C return
integers when they exit: programs that exit successfully return the integer
0, and programs that error return some integer other than 0.
Rust also returns integers from executables to be compatible with this convention.
The main function may return any types that implement the
std::process::Termination trait, which contains
a function report that returns an ExitCode.
Consult the standard library
documentation for more information on implementing the Termination trait for
your own types.
Now that we’ve discussed the details of calling
panic!or returningResult, let’s return to the topic of how to decide which is appropriate to use in which cases.
To panic! or Not to panic!
So how do you decide when you should call panic! and when you should return
Result? When code panics, there’s no way to recover. You could call panic!
for any error situation, whether there’s a possible way to recover or not, but
then you’re making the decision that a situation is unrecoverable on behalf of
the calling code. When you choose to return a Result value, you give the
calling code options. The calling code could choose to attempt to recover in a
way that’s appropriate for its situation, or it could decide that an Err
value in this case is unrecoverable, so it can call panic! and turn your
recoverable error into an unrecoverable one. Therefore, returning Result is a
good default choice when you’re defining a function that might fail.
In situations such as examples, prototype code, and tests, it’s more
appropriate to write code that panics instead of returning a Result. Let’s
explore why, then discuss situations in which the compiler can’t tell that
failure is impossible, but you as a human can. The chapter will conclude with
some general guidelines on how to decide whether to panic in library code.
Examples, Prototype Code, and Tests
When you’re writing an example to illustrate some concept, also including robust
error-handling code can make the example less clear. In
examples, it’s understood that a call to a method like unwrap that could
panic is meant as a placeholder for the way you’d want your application to
handle errors, which can differ based on what the rest of your code is doing.
Similarly, the unwrap and expect methods are very handy when prototyping,
before you’re ready to decide how to handle errors. They leave clear markers in
your code for when you’re ready to make your program more robust.
If a method call fails in a test, you’d want the whole test to fail, even if
that method isn’t the functionality under test. Because panic! is how a test
is marked as a failure, calling unwrap or expect is exactly what should
happen.
Cases in Which You Have More Information Than the Compiler
It would also be appropriate to call unwrap or expect when you have some
other logic that ensures the Result will have an Ok value, but the logic
isn’t something the compiler understands. You’ll still have a Result value
that you need to handle: whatever operation you’re calling still has the
possibility of failing in general, even though it’s logically impossible in
your particular situation. If you can ensure by manually inspecting the code
that you’ll never have an Err variant, it’s perfectly acceptable to call
unwrap, and even better to document the reason you think you’ll never have an
Err variant in the expect text. Here’s an example:
#![allow(unused)] fn main() { {{# rustdoc_include../ listings / ch09 - error -handling / no - listing - 08 - unwrap -that - cant - fail / src / main.rs: here}} }
We’re creating an IpAddr instance by parsing a hardcoded string. We can see
that 127.0.0.1 is a valid IP address, so it’s acceptable to use expect
here. However, having a hardcoded, valid string doesn’t change the return type
of the parse method: we still get a Result value, and the compiler will
still make us handle the Result as if the Err variant is a possibility
because the compiler isn’t smart enough to see that this string is always a
valid IP address. If the IP address string came from a user rather than being
hardcoded into the program and therefore did have a possibility of failure,
we’d definitely want to handle the Result in a more robust way instead.
Mentioning the assumption that this IP address is hardcoded will prompt us to
change expect to better error handling code if in the future, we need to get
the IP address from some other source instead.
Guidelines for Error Handling
It’s advisable to have your code panic when it’s possible that your code could end up in a bad state. In this context, a bad state is when some assumption, guarantee, contract, or invariant has been broken, such as when invalid values, contradictory values, or missing values are passed to your code—plus one or more of the following:
- The bad state is something that is unexpected, as opposed to something that will likely happen occasionally, like a user entering data in the wrong format.
- Your code after this point needs to rely on not being in this bad state, rather than checking for the problem at every step.
- There’s not a good way to encode this information in the types you use. We’ll work through an example of what we mean in the “Encoding States and Behavior as Types” section of Chapter 17.
If someone calls your code and passes in values that don’t make sense, it’s
best to return an error if you can so the user of the library can decide what
they want to do in that case. However, in cases where continuing could be
insecure or harmful, the best choice might be to call panic! and alert the
person using your library to the bug in their code so they can fix it during
development. Similarly, panic! is often appropriate if you’re calling
external code that is out of your control and it returns an invalid state that
you have no way of fixing.
However, when failure is expected, it’s more appropriate to return a Result
than to make a panic! call. Examples include a parser being given malformed
data or an HTTP request returning a status that indicates you have hit a rate
limit. In these cases, returning a Result indicates that failure is an
expected possibility that the calling code must decide how to handle.
When your code performs an operation that could put a user at risk if it’s
called using invalid values, your code should verify the values are valid first
and panic if the values aren’t valid. This is mostly for safety reasons:
attempting to operate on invalid data can expose your code to vulnerabilities.
This is the main reason the standard library will call panic! if you attempt
an out-of-bounds memory access: trying to access memory that doesn’t belong to
the current data structure is a common security problem. Functions often have
contracts: their behavior is only guaranteed if the inputs meet particular
requirements. Panicking when the contract is violated makes sense because a
contract violation always indicates a caller-side bug and it’s not a kind of
error you want the calling code to have to explicitly handle. In fact, there’s
no reasonable way for calling code to recover; the calling programmers need
to fix the code. Contracts for a function, especially when a violation will
cause a panic, should be explained in the API documentation for the function.
However, having lots of error checks in all of your functions would be verbose
and annoying. Fortunately, you can use Rust’s type system (and thus the type
checking done by the compiler) to do many of the checks for you. If your
function has a particular type as a parameter, you can proceed with your code’s
logic knowing that the compiler has already ensured you have a valid value. For
example, if you have a type rather than an Option, your program expects to
have something rather than nothing. Your code then doesn’t have to handle
two cases for the Some and None variants: it will only have one case for
definitely having a value. Code trying to pass nothing to your function won’t
even compile, so your function doesn’t have to check for that case at runtime.
Another example is using an unsigned integer type such as u32, which ensures
the parameter is never negative.
Creating Custom Types for Validation
Let’s take the idea of using Rust’s type system to ensure we have a valid value one step further and look at creating a custom type for validation. Recall the guessing game in Chapter 2 in which our code asked the user to guess a number between 1 and 100. We never validated that the user’s guess was between those numbers before checking it against our secret number; we only validated that the guess was positive. In this case, the consequences were not very dire: our output of “Too high” or “Too low” would still be correct. But it would be a useful enhancement to guide the user toward valid guesses and have different behavior when a user guesses a number that’s out of range versus when a user types, for example, letters instead.
One way to do this would be to parse the guess as an i32 instead of only a
u32 to allow potentially negative numbers, and then add a check for the
number being in range, like so:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}
The if expression checks whether our value is out of range, tells the user
about the problem, and calls continue to start the next iteration of the loop
and ask for another guess. After the if expression, we can proceed with the
comparisons between guess and the secret number knowing that guess is
between 1 and 100.
However, this is not an ideal solution: if it was absolutely critical that the program only operated on values between 1 and 100, and it had many functions with this requirement, having a check like this in every function would be tedious (and might impact performance).
Instead, we can make a new type and put the validations in a function to create
an instance of the type rather than repeating the validations everywhere. That
way, it’s safe for functions to use the new type in their signatures and
confidently use the values they receive. Listing 9-13 shows one way to define a
Guess type that will only create an instance of Guess if the new function
receives a value between 1 and 100.
#![allow(unused)] fn main() { {{# include../ listings / ch09 - error -handling / listing - 09 - 13 / src /main.rs: here}} }
Listing 9-13: A Guess type that will only continue with
values between 1 and 100
First, we define a struct named Guess that has a field named value that
holds an i32. This is where the number will be stored.
Then we implement an associated function named new on Guess that creates
instances of Guess values. The new function is defined to have one
parameter named value of type i32 and to return a Guess. The code in the
body of the new function tests value to make sure it’s between 1 and 100.
If value doesn’t pass this test, we make a panic! call, which will alert
the programmer who is writing the calling code that they have a bug they need
to fix, because creating a Guess with a value outside this range would
violate the contract that Guess::new is relying on. The conditions in which
Guess::new might panic should be discussed in its public-facing API
documentation; we’ll cover documentation conventions indicating the possibility
of a panic! in the API documentation that you create in Chapter 14. If
value does pass the test, we create a new Guess with its value field set
to the value parameter and return the Guess.
Next, we implement a method named value that borrows self, doesn’t have any
other parameters, and returns an i32. This kind of method is sometimes called
a getter, because its purpose is to get some data from its fields and return
it. This public method is necessary because the value field of the Guess
struct is private. It’s important that the value field be private so code
using the Guess struct is not allowed to set value directly: code outside
the module must use the Guess::new function to create an instance of
Guess, thereby ensuring there’s no way for a Guess to have a value that
hasn’t been checked by the conditions in the Guess::new function.
A function that has a parameter or returns only numbers between 1 and 100 could
then declare in its signature that it takes or returns a Guess rather than an
i32 and wouldn’t need to do any additional checks in its body.
Summary
Rust’s error handling features are designed to help you write more robust code.
The panic! macro signals that your program is in a state it can’t handle and
lets you tell the process to stop instead of trying to proceed with invalid or
incorrect values. The Result enum uses Rust’s type system to indicate that
operations might fail in a way that your code could recover from. You can use
Result to tell code that calls your code that it needs to handle potential
success or failure as well. Using panic! and Result in the appropriate
situations will make your code more reliable in the face of inevitable problems.
Now that you’ve seen useful ways that the standard library uses generics with
the Option and Result enums, we’ll talk about how generics work and how you
can use them in your code.
Generic Types, Traits, and Lifetimes
Every programming language has tools for effectively handling the duplication of concepts. In Rust, one such tool is generics: abstract stand-ins for concrete types or other properties. We can express the behavior of generics or how they relate to other generics without knowing what will be in their place when compiling and running the code.
Functions can take parameters of some generic type, instead of a concrete type
like i32 or String, in the same way a function takes parameters with
unknown values to run the same code on multiple concrete values. In fact, we’ve
already used generics in Chapter 6 with Option<T>, Chapter 8 with Vec<T>
and HashMap<K, V>, and Chapter 9 with Result<T, E>. In this chapter, you’ll
explore how to define your own types, functions, and methods with generics!
First, we’ll review how to extract a function to reduce code duplication. We’ll then use the same technique to make a generic function from two functions that differ only in the types of their parameters. We’ll also explain how to use generic types in struct and enum definitions.
Then you’ll learn how to use traits to define behavior in a generic way. You can combine traits with generic types to constrain a generic type to accept only those types that have a particular behavior, as opposed to just any type.
Finally, we’ll discuss lifetimes: a variety of generics that give the compiler information about how references relate to each other. Lifetimes allow us to give the compiler enough information about borrowed values so that it can ensure references will be valid in more situations than it could without our help.
Removing Duplication by Extracting a Function
Generics allow us to replace specific types with a placeholder that represents multiple types to remove code duplication. Before diving into generics syntax, then, let’s first look at how to remove duplication in a way that doesn’t involve generic types by extracting a function that replaces specific values with a placeholder that represents multiple values. Then we’ll apply the same technique to extract a generic function! By looking at how to recognize duplicated code you can extract into a function, you’ll start to recognize duplicated code that can use generics.
We begin with the short program in Listing 10-1 that finds the largest number in a list.
Filename: src/main.rs
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {}", largest); assert_eq!(*largest, 100); }
Listing 10-1: Finding the largest number in a list of numbers
We store a list of integers in the variable number_list and place a reference
to the first number in the list in a variable named largest. We then iterate
through all the numbers in the list, and if the current number is greater than
the number stored in largest, replace the reference in that variable.
However, if the current number is less than or equal to the largest number seen
so far, the variable doesn’t change, and the code moves on to the next number
in the list. After considering all the numbers in the list, largest should
refer to the largest number, which in this case is 100.
We’ve now been tasked with finding the largest number in two different lists of numbers. To do so, we can choose to duplicate the code in Listing 10-1 and use the same logic at two different places in the program, as shown in Listing 10-2.
Filename: src/main.rs
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {}", largest); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {}", largest); }
Listing 10-2: Code to find the largest number in two lists of numbers
Although this code works, duplicating code is tedious and error prone. We also have to remember to update the code in multiple places when we want to change it.
To eliminate this duplication, we’ll create an abstraction by defining a function that operates on any list of integers passed in a parameter. This solution makes our code clearer and lets us express the concept of finding the largest number in a list abstractly.
In Listing 10-3, we extract the code that finds the largest number into a
function named largest. Then we call the function to find the largest number
in the two lists from Listing 10-2. We could also use the function on any other
list of i32 values we might have in the future.
Filename: src/main.rs
fn largest(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {}", result); assert_eq!(*result, 100); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let result = largest(&number_list); println!("The largest number is {}", result); assert_eq!(*result, 6000); }
Listing 10-3: Abstracted code to find the largest number in two lists
The largest function has a parameter called list, which represents any
concrete slice of i32 values we might pass into the function. As a result,
when we call the function, the code runs on the specific values that we pass
in.
In summary, here are the steps we took to change the code from Listing 10-2 to Listing 10-3:
- Identify duplicate code.
- Extract the duplicate code into the body of the function and specify the inputs and return values of that code in the function signature.
- Update the two instances of duplicated code to call the function instead.
Next, we’ll use these same steps with generics to reduce code duplication. In
the same way that the function body can operate on an abstract list instead
of specific values, generics allow code to operate on abstract types.
For example, say we had two functions: one that finds the largest item in a
slice of i32 values and one that finds the largest item in a slice of char
values. How would we eliminate that duplication? Let’s find out!
Generic Data Types
We use generics to create definitions for items like function signatures or structs, which we can then use with many different concrete data types.
Let’s first look at how to define functions, structs, enums, and methods using generics.
Then we’ll discuss how generics affect code performance.
In Function Definitions
When defining a function that uses generics, we place the generics in the signature of the function where we would usually specify the data types of the parameters and return value.
Doing so makes our code more flexible and provides more functionality to callers of our function while preventing code duplication.
Continuing with our largest function, Listing 10-4 shows two functions that
both find the largest value in a slice.
We’ll then combine these into a single function that uses generics.
Filename: src/main.rs
fn largest_i32(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn largest_char(list: &[char]) -> &char { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest_i32(&number_list); println!("The largest number is {}", result); assert_eq!(*result, 100); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest_char(&char_list); println!("The largest char is {}", result); assert_eq!(*result, 'y'); }
Listing 10-4: Two functions that differ only in their names and the types in their signatures
-
The
largest_i32function is the one we extracted in Listing 10-3 that finds the largesti32in a slice. -
The
largest_charfunction finds the largestcharin a slice.
The function bodies have the same code, so let’s eliminate the duplication by introducing a generic type parameter in a single function.
To parameterize the types in a new single function, we need to name the type parameter, just as we do for the value parameters to a function.
You can use any identifier as a type parameter name.
But we’ll use
Tbecause, by convention, type parameter names in Rust are short, often just a letter, and Rust’s type-naming convention is CamelCase. Short for “type,”Tis the default choice of most Rust programmers.
When we use a parameter in the body of the function, we have to declare the parameter name in the signature so the compiler knows what that name means.
Similarly, when we use a type parameter name in a function signature, we have to declare the type parameter name before we use it.
To define the generic
largest function, place type name declarations inside angle brackets, <>,
between the name of the function and the parameter list, like this:
fn largest<T>(list: &[T]) -> &T {
We read this definition as:
- the function
largestis generic over some typeT. - This function has one parameter named
list, which is a slice of values of typeT. - The
largestfunction will return a reference to a value of the same typeT.
Listing 10-5 shows the combined largest function definition using the generic
data type in its signature.
The listing also shows how we can call the function
with either a slice of i32 values or char values.
Note that this code won’t compile yet, but we’ll fix it later in this chapter.
Filename: src/main.rs
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}
Listing 10-5: The largest function using generic type
parameters; this doesn’t yet compile
If we compile this code right now, we’ll get this error:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` due to previous error
The help text mentions std::cmp::PartialOrd, which is a trait, and we’re
going to talk about traits in the next section.
For now, know that this error states that the body of
largestwon’t work for all possible types thatTcould be.
Because we want to compare values of type T in the body, we can
only use types whose values can be ordered.
To enable comparisons, the standard
library has the std::cmp::PartialOrd trait that you can implement on types
(see Appendix C for more on this trait).
By following the help text’s
suggestion, we restrict the types valid for T to only those that implement
PartialOrd and this example will compile, because the standard library
implements PartialOrd on both i32 and char.
In Struct Definitions
We can also define structs to use a generic type parameter in one or more
fields using the <> syntax.
Listing 10-6 defines a Point<T> struct to hold
x and y coordinate values of any type.
Filename: src/main.rs
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
Listing 10-6: A Point<T> struct that holds x and y
values of type T
The syntax for using generics in struct definitions is similar to that used in function definitions.
- First, we declare the name of the type parameter inside angle brackets just after the name of the struct.
- Then we use the generic type in the struct definition where we would otherwise specify concrete data types.
Note that because we’ve used only one generic type to define
Point<T>, this definition says that thePoint<T>struct is generic over some typeT, and the fieldsxandyare both that same type, whatever that type may be.
If we create an instance of a Point<T> that has values of different types, as in
Listing 10-7, our code won’t compile.
Filename: src/main.rs
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}
Listing 10-7: The fields x and y must be the same
type because both have the same generic data type T.
In this example, when we assign the integer value 5 to x, we let the compiler
know that the generic type T will be an integer for this instance of
Point<T>.
Then when we specify 4.0 for y, which we’ve defined to have the
same type as x, we’ll get a type mismatch error like this:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` due to previous error
To define a
Pointstruct wherexandyare both generics but could have different types, we can use multiple generic type parameters.
For example, in
Listing 10-8, we change the definition of Point to be generic over types T
and U where x is of type T and y is of type U.
Filename: src/main.rs
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point { x: 5, y: 10 }; let both_float = Point { x: 1.0, y: 4.0 }; let integer_and_float = Point { x: 5, y: 4.0 }; }
Listing 10-8: A Point<T, U> generic over two types so
that x and y can be values of different types
Now all the instances of Point shown are allowed!
You can use as many generic type parameters in a definition as you want, but using more than a few makes your code hard to read.
If you’re finding you need lots of generic types in your code, it could indicate that your code needs restructuring into smaller pieces.
In Enum Definitions
Option
As we did with structs, we can define enums to hold generic data types in their variants.
Let’s take another look at the Option<T> enum that the standard
library provides, which we used in Chapter 6:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
This definition should now make more sense to you:
- As you can see, the
Option<T>enum is generic over typeTand has two variants:
Some, which holds one value of typeT- and a
Nonevariant that doesn’t hold any value.
By using the
Option<T>enum, we can express the abstract concept of an optional value, and becauseOption<T>is generic, we can use this abstraction no matter what the type of the optional value is.
Enums can use multiple generic types as well.
Result
The definition of the Result
enum that we used in Chapter 9 is one example:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
The
Resultenum is generic over two types,TandE, and has two variants:
Ok, which holds a value of typeT, andErr, which holds a value of typeE.- This definition makes it convenient to use the
Resultenum anywhere we have an operation that might succeed (return a value of some typeT) or fail (return an error of some typeE). - In fact, this is what we used to open a
file in Listing 9-3, where
Twas filled in with the typestd::fs::Filewhen the file was opened successfully andEwas filled in with the typestd::io::Errorwhen there were problems opening the file.
When you recognize situations in your code with multiple struct or enum definitions that differ only in the types of the values they hold, you can avoid duplication by using generic types instead.
In Method Definitions
We can implement methods on structs and enums (as we did in Chapter 5) and use generic types in their definitions, too.
Listing 10-9 shows the Point<T>
struct we defined in Listing 10-6 with a method named x implemented on it.
Filename: src/main.rs
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Listing 10-9: Implementing a method named x on the
Point<T> struct that will return a reference to the x field of type
T
Here, we’ve defined a method named x on Point<T> that returns a reference
to the data in the field x.
Note that we have to declare
Tjust afterimplso we can useTto specify that we’re implementing methods on the typePoint<T>.
- By declaring
Tas a generic type afterimpl, Rust can identify that the type in the angle brackets inPointis a generic type rather than a concrete type. - We could have chosen a different name for this generic parameter than the generic parameter declared in the struct definition, but using the same name is conventional.
Methods written within an
implthat declares the generic type will be defined on any instance of the type, no matter what concrete type ends up substituting for the generic type.
We can also specify constraints on generic types when defining methods on the type.
We could, for example, implement methods only on Point<f32> instances
rather than on Point<T> instances with any generic type.
In Listing 10-10 we
use the concrete type f32, meaning we don’t declare any types after impl.
Filename: src/main.rs
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } impl Point<f32> { fn distance_from_origin(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
Listing 10-10: An impl block that only applies to a
struct with a particular concrete type for the generic type parameter T
This code means the type Point<f32> will have a distance_from_origin
method;
other instances of Point<T> where T is not of type f32 will not
have this method defined.
The method measures how far our point is from the point at coordinates (0.0, 0.0) and uses mathematical operations that are available only for floating point types.
Generic type parameters in a struct definition aren’t always the same as those you use in that same struct’s method signatures.
Listing 10-11 uses the generic
types X1 and Y1 for the Point struct and X2 Y2 for the mixup method
signature to make the example clearer.
The method creates a new Point
instance with the x value from the self Point (of type X1) and the y
value from the passed-in Point (of type Y2).
Filename: src/main.rs
struct Point<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Point<X1, Y1> { fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c' }; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
Listing 10-11: A method that uses generic types different from its struct’s definition
- In
main, we’ve defined aPointthat has ani32forx(with value5) and anf64fory(with value10.4). - The
p2variable is aPointstruct that has a string slice forx(with value"Hello") and acharfory(with valuec). - Calling
mixuponp1with the argumentp2gives usp3, which will have ani32forx, becausexcame fromp1. - The
p3variable will have acharfory, becauseycame fromp2. Theprintln!macro call will printp3.x = 5, p3.y = c.
The purpose of this example is to demonstrate a situation in which some generic parameters are declared with
impland some are declared with the method definition.
Here, the generic parameters X1 and Y1 are declared after
impl because they go with the struct definition.
The generic parameters X2
and Y2 are declared after fn mixup, because they’re only relevant to the
method.
Monomorphization:Performance of Code Using Generics
You might be wondering whether there is a runtime cost when using generic type parameters.
The good news is that using generic types won’t make your program run any slower than it would with concrete types.
-
Rust accomplishes this by performing monomorphization of the code using generics at compile time.
-
Monomorphization is the process of turning generic code into specific code by filling in the concrete types that are used when compiled.
-
In this process, the compiler does the opposite of the steps we used to create the generic function in Listing 10-5:
the compiler looks at all the places where generic code is called and generates code for the concrete types the generic code is called with.
Let’s look at how this works by using the standard library’s generic
Option<T> enum:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
When Rust compiles this code, it performs monomorphization.
During that
process, the compiler reads the values that have been used in Option<T>
instances and identifies two kinds of Option<T>:
one is i32 and the other is f64.
As such, it expands the generic definition of
Option<T>into two definitions specialized toi32andf64, thereby replacing the generic definition with the specific ones.
The monomorphized version of the code looks similar to the following (the compiler uses different names than what we’re using here for illustration):
Filename: src/main.rs
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
The generic
Option<T>is replaced with the specific definitions created by the compiler.
-
Because Rust compiles generic code into code that specifies the type in each instance, we pay no runtime cost for using generics.
-
When the code runs, it performs just as it would if we had duplicated each definition by hand.
-
The process of monomorphization makes Rust’s generics extremely efficient at runtime.
Traits: Defining Shared Behavior
A trait defines functionality a particular type has and can share with other types. We can use traits to define shared behavior in an abstract way. We can use trait bounds to specify that a generic type can be any type that has certain behavior.
Note: Traits are similar to a feature often called interfaces in other languages, although with some differences.
Defining a Trait
A type’s behavior consists of the methods we can call on that type. Different types share the same behavior if we can call the same methods on all of those types. Trait definitions are a way to group method signatures together to define a set of behaviors necessary to accomplish some purpose.
For example, let’s say we have multiple structs that hold various kinds and
amounts of text: a NewsArticle struct that holds a news story filed in a
particular location and a Tweet that can have at most 280 characters along
with metadata that indicates whether it was a new tweet, a retweet, or a reply
to another tweet.
We want to make a media aggregator library crate named aggregator that can
display summaries of data that might be stored in a NewsArticle or Tweet
instance. To do this, we need a summary from each type, and we’ll request
that summary by calling a summarize method on an instance. Listing 10-12
shows the definition of a public Summary trait that expresses this behavior.
Filename: src/lib.rs
pub trait Summary {
fn summarize(&self) -> String;
}
Listing 10-12: A Summary trait that consists of the
behavior provided by a summarize method
Here, we declare a trait using the trait keyword and then the trait’s name,
which is Summary in this case. We’ve also declared the trait as pub so that
crates depending on this crate can make use of this trait too, as we’ll see in
a few examples. Inside the curly brackets, we declare the method signatures
that describe the behaviors of the types that implement this trait, which in
this case is fn summarize(&self) -> String.
After the method signature, instead of providing an implementation within curly
brackets, we use a semicolon. Each type implementing this trait must provide
its own custom behavior for the body of the method. The compiler will enforce
that any type that has the Summary trait will have the method summarize
defined with this signature exactly.
A trait can have multiple methods in its body: the method signatures are listed one per line and each line ends in a semicolon.
Implementing a Trait on a Type
Now that we’ve defined the desired signatures of the Summary trait’s methods,
we can implement it on the types in our media aggregator. Listing 10-13 shows
an implementation of the Summary trait on the NewsArticle struct that uses
the headline, the author, and the location to create the return value of
summarize. For the Tweet struct, we define summarize as the username
followed by the entire text of the tweet, assuming that tweet content is
already limited to 280 characters.
Filename: src/lib.rs
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
Listing 10-13: Implementing the Summary trait on the
NewsArticle and Tweet types
Implementing a trait on a type is similar to implementing regular methods. The
difference is that after impl, we put the trait name we want to implement,
then use the for keyword, and then specify the name of the type we want to
implement the trait for. Within the impl block, we put the method signatures
that the trait definition has defined. Instead of adding a semicolon after each
signature, we use curly brackets and fill in the method body with the specific
behavior that we want the methods of the trait to have for the particular type.
Now that the library has implemented the Summary trait on NewsArticle and
Tweet, users of the crate can call the trait methods on instances of
NewsArticle and Tweet in the same way we call regular methods. The only
difference is that the user must bring the trait into scope as well as the
types. Here’s an example of how a binary crate could use our aggregator
library crate:
use aggregator::{Summary, Tweet};
fn main() {
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
}
This code prints 1 new tweet: horse_ebooks: of course, as you probably already know, people.
Other crates that depend on the aggregator crate can also bring the Summary
trait into scope to implement Summary on their own types. One restriction to
note is that we can implement a trait on a type only if at least one of the
trait or the type is local to our crate. For example, we can implement standard
library traits like Display on a custom type like Tweet as part of our
aggregator crate functionality, because the type Tweet is local to our
aggregator crate. We can also implement Summary on Vec<T> in our
aggregator crate, because the trait Summary is local to our aggregator
crate.
But we can’t implement external traits on external types. For example, we can’t
implement the Display trait on Vec<T> within our aggregator crate,
because Display and Vec<T> are both defined in the standard library and
aren’t local to our aggregator crate. This restriction is part of a property
called coherence, and more specifically the orphan rule, so named because
the parent type is not present. This rule ensures that other people’s code
can’t break your code and vice versa. Without the rule, two crates could
implement the same trait for the same type, and Rust wouldn’t know which
implementation to use.
Default Implementations
Sometimes it’s useful to have default behavior for some or all of the methods in a trait instead of requiring implementations for all methods on every type. Then, as we implement the trait on a particular type, we can keep or override each method’s default behavior.
In Listing 10-14 we specify a default string for the summarize method of the
Summary trait instead of only defining the method signature, as we did in
Listing 10-12.
Filename: src/lib.rs
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
Listing 10-14: Defining a Summary trait with a default
implementation of the summarize method
To use a default implementation to summarize instances of NewsArticle, we
specify an empty impl block with impl Summary for NewsArticle {}.
Even though we’re no longer defining the summarize method on NewsArticle
directly, we’ve provided a default implementation and specified that
NewsArticle implements the Summary trait. As a result, we can still call
the summarize method on an instance of NewsArticle, like this:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}
This code prints New article available! (Read more...).
Creating a default implementation doesn’t require us to change anything about
the implementation of Summary on Tweet in Listing 10-13. The reason is that
the syntax for overriding a default implementation is the same as the syntax
for implementing a trait method that doesn’t have a default implementation.
Default implementations can call other methods in the same trait, even if those
other methods don’t have a default implementation. In this way, a trait can
provide a lot of useful functionality and only require implementors to specify
a small part of it. For example, we could define the Summary trait to have a
summarize_author method whose implementation is required, and then define a
summarize method that has a default implementation that calls the
summarize_author method:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}
To use this version of Summary, we only need to define summarize_author
when we implement the trait on a type:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}
After we define summarize_author, we can call summarize on instances of the
Tweet struct, and the default implementation of summarize will call the
definition of summarize_author that we’ve provided. Because we’ve implemented
summarize_author, the Summary trait has given us the behavior of the
summarize method without requiring us to write any more code.
use aggregator::{self, Summary, Tweet};
fn main() {
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
}
This code prints 1 new tweet: (Read more from @horse_ebooks...).
Note that it isn’t possible to call the default implementation from an overriding implementation of that same method.
Traits as Parameters
Now that you know how to define and implement traits, we can explore how to use
traits to define functions that accept many different types. We’ll use the
Summary trait we implemented on the NewsArticle and Tweet types in
Listing 10-13 to define a notify function that calls the summarize method
on its item parameter, which is of some type that implements the Summary
trait. To do this, we use the impl Trait syntax, like this:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}
Instead of a concrete type for the item parameter, we specify the impl
keyword and the trait name. This parameter accepts any type that implements the
specified trait. In the body of notify, we can call any methods on item
that come from the Summary trait, such as summarize. We can call notify
and pass in any instance of NewsArticle or Tweet. Code that calls the
function with any other type, such as a String or an i32, won’t compile
because those types don’t implement Summary.
Trait Bound Syntax
The impl Trait syntax works for straightforward cases but is actually syntax
sugar for a longer form known as a trait bound; it looks like this:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}
This longer form is equivalent to the example in the previous section but is more verbose. We place trait bounds with the declaration of the generic type parameter after a colon and inside angle brackets.
The impl Trait syntax is convenient and makes for more concise code in simple
cases, while the fuller trait bound syntax can express more complexity in other
cases. For example, we can have two parameters that implement Summary. Doing
so with the impl Trait syntax looks like this:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {
Using impl Trait is appropriate if we want this function to allow item1 and
item2 to have different types (as long as both types implement Summary). If
we want to force both parameters to have the same type, however, we must use a
trait bound, like this:
pub fn notify<T: Summary>(item1: &T, item2: &T) {
The generic type T specified as the type of the item1 and item2
parameters constrains the function such that the concrete type of the value
passed as an argument for item1 and item2 must be the same.
Specifying Multiple Trait Bounds with the + Syntax
We can also specify more than one trait bound. Say we wanted notify to use
display formatting as well as summarize on item: we specify in the notify
definition that item must implement both Display and Summary. We can do
so using the + syntax:
pub fn notify(item: &(impl Summary + Display)) {
The + syntax is also valid with trait bounds on generic types:
pub fn notify<T: Summary + Display>(item: &T) {
With the two trait bounds specified, the body of notify can call summarize
and use {} to format item.
Clearer Trait Bounds with where Clauses
Using too many trait bounds has its downsides. Each generic has its own trait
bounds, so functions with multiple generic type parameters can contain lots of
trait bound information between the function’s name and its parameter list,
making the function signature hard to read. For this reason, Rust has alternate
syntax for specifying trait bounds inside a where clause after the function
signature. So instead of writing this:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {
we can use a where clause, like this:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}
This function’s signature is less cluttered: the function name, parameter list, and return type are close together, similar to a function without lots of trait bounds.
Returning Types that Implement Traits
We can also use the impl Trait syntax in the return position to return a
value of some type that implements a trait, as shown here:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
}
}
By using impl Summary for the return type, we specify that the
returns_summarizable function returns some type that implements the Summary
trait without naming the concrete type. In this case, returns_summarizable
returns a Tweet, but the code calling this function doesn’t need to know that.
The ability to specify a return type only by the trait it implements is
especially useful in the context of closures and iterators, which we cover in
Chapter 13. Closures and iterators create types that only the compiler knows or
types that are very long to specify. The impl Trait syntax lets you concisely
specify that a function returns some type that implements the Iterator trait
without needing to write out a very long type.
However, you can only use impl Trait if you’re returning a single type. For
example, this code that returns either a NewsArticle or a Tweet with the
return type specified as impl Summary wouldn’t work:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
}
}
}
Returning either a NewsArticle or a Tweet isn’t allowed due to restrictions
around how the impl Trait syntax is implemented in the compiler. We’ll cover
how to write a function with this behavior in the “Using Trait Objects That
Allow for Values of Different
Types” section of Chapter 17.
Using Trait Bounds to Conditionally Implement Methods
By using a trait bound with an impl block that uses generic type parameters,
we can implement methods conditionally for types that implement the specified
traits. For example, the type Pair<T> in Listing 10-15 always implements the
new function to return a new instance of Pair<T> (recall from the
“Defining Methods” section of Chapter 5 that Self
is a type alias for the type of the impl block, which in this case is
Pair<T>). But in the next impl block, Pair<T> only implements the
cmp_display method if its inner type T implements the PartialOrd trait
that enables comparison and the Display trait that enables printing.
Filename: src/lib.rs
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
Listing 10-15: Conditionally implementing methods on a generic type depending on trait bounds
We can also conditionally implement a trait for any type that implements
another trait. Implementations of a trait on any type that satisfies the trait
bounds are called blanket implementations and are extensively used in the
Rust standard library. For example, the standard library implements the
ToString trait on any type that implements the Display trait. The impl
block in the standard library looks similar to this code:
impl<T: Display> ToString for T {
// --snip--
}
Because the standard library has this blanket implementation, we can call the
to_string method defined by the ToString trait on any type that implements
the Display trait. For example, we can turn integers into their corresponding
String values like this because integers implement Display:
#![allow(unused)] fn main() { let s = 3.to_string(); }
Blanket implementations appear in the documentation for the trait in the “Implementors” section.
Traits and trait bounds let us write code that uses generic type parameters to reduce duplication but also specify to the compiler that we want the generic type to have particular behavior. The compiler can then use the trait bound information to check that all the concrete types used with our code provide the correct behavior. In dynamically typed languages, we would get an error at runtime if we called a method on a type which didn’t define the method. But Rust moves these errors to compile time so we’re forced to fix the problems before our code is even able to run. Additionally, we don’t have to write code that checks for behavior at runtime because we’ve already checked at compile time. Doing so improves performance without having to give up the flexibility of generics.
Lifetime Generics: Validating References with Lifetimes
- Lifetime Generics: Validating References with Lifetimes
- Preventing Dangling References with Lifetimes
- The Borrow Checker
- Generic Lifetimes in Functions
- Lifetime Annotation Syntax
- Lifetime Annotations in Function Signatures
- Thinking in Terms of Lifetimes
- Lifetime Annotations in Struct Definitions
- Three Rules of Lifetime Elision
- Lifetime Annotations in Method Definitions
- The Static Lifetime
- Generic Type Parameters, Trait Bounds, and Lifetimes Together
- Summary
Lifetimes are another kind of generic that we’ve already been using.
Rather than ensuring that a type has the behavior we want, lifetimes ensure that references are valid as long as we need them to be.
One detail we didn’t discuss in the “References and Borrowing” section in Chapter 4 is that:
- every reference in Rust has a lifetime, which is the scope for which that reference is valid.
Most of the time, lifetimes are implicit and inferred, just like most of the time, types are inferred.
- We only must annotate types when multiple types are possible.
- In a similar way, we must annotate lifetimes when the lifetimes of references could be related in a few different ways.
- Rust requires us to annotate the relationships using generic lifetime parameters to ensure the actual references used at runtime will definitely be valid.
Annotating lifetimes is not even a concept most other programming languages have, so this is going to feel unfamiliar.
Although we won’t cover lifetimes in their entirety in this chapter, we’ll discuss common ways you might encounter lifetime syntax so you can get comfortable with the concept.
Preventing Dangling References with Lifetimes
The main aim of lifetimes is to prevent dangling references, which cause a program to reference data other than the data it’s intended to reference.
Consider the program in Listing 10-16, which has an outer scope and an inner scope.
Listing 10-16: An attempt to use a reference whose value has gone out of scope
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
Note:
-
The examples in Listings 10-16, 10-17, and 10-23 declare variables without giving them an initial value, so the variable name exists in the outer scope.
-
At first glance, this might appear to be in conflict with Rust’s having no null values.
-
However, if we try to use a variable before giving it a value, we’ll get a compile-time error, which shows that Rust indeed does not allow null values.
-
The outer scope declares a variable named
rwith no initial value, and the inner scope declares a variable namedxwith the initial value of 5. -
Inside the inner scope, we attempt to set the value of
ras a reference tox. -
Then the inner scope ends, and we attempt to print the value in
r. -
This code won’t compile because the value
ris referring to has gone out of scope before we try to use it.
Here is the error message:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {}", r);
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` due to previous error
- The variable
xdoesn’t “live long enough.” - The reason is that
xwill be out of scope when the inner scope ends on line 7. - But
ris still valid for the outer scope; - because its scope is larger, we say that it “lives longer.”
If Rust allowed this code to work,
rwould be referencing memory that was deallocated whenxwent out of scope, and anything we tried to do withrwouldn’t work correctly.
So how does Rust determine that this code is invalid? It uses a borrow checker.
The Borrow Checker
The Rust compiler has a borrow checker that compares scopes to determine whether all borrows are valid.
Listing 10-17 shows the same code as Listing 10-16 but with annotations showing the lifetimes of the variables.
Listing 10-17: Annotations of the lifetimes of r and x, named ’a and ’b, respectively
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+
- Here, we’ve annotated the lifetime of
rwith'aand the lifetime ofxwith'b. - As you can see, the inner
'bblock is much smaller than the outer'alifetime block. - At compile time, Rust compares the size of the two
lifetimes and sees that
rhas a lifetime of'abut that it refers to memory with a lifetime of'b. - The program is rejected because
'bis shorter than'a:
the subject of the reference doesn’t live as long as the reference.
Listing 10-18 fixes the code so it doesn’t have a dangling reference and compiles without any errors.
Listing 10-18: A valid reference because the data has a longer lifetime than the reference
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {}", r); // | | // --+ | } // ----------+
- Here,
xhas the lifetime'b, which in this case is larger than'a. - This means
rcan referencexbecause Rust knows that the reference inrwill always be valid whilexis valid.
Now that you know where the lifetimes of references are and how Rust analyzes lifetimes to ensure references will always be valid, let’s explore generic lifetimes of parameters and return values in the context of functions.
Generic Lifetimes in Functions
We’ll write a function that returns the longer of two string slices.
This function will take two string slices and return a single string slice.
After
we’ve implemented the longest function, the code in Listing 10-19 should
print The longest string is abcd.
Listing 10-19: A main function that calls the longest function to find the longer of two string slices
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
Note that we want the function to take string slices, which are references, rather than strings, because we don’t want the
longestfunction to take ownership of its parameters.
Refer to the “String Slices as Parameters” section in Chapter 4 for more discussion about why the parameters we use in Listing 10-19 are the ones we want.
If we try to implement the longest function as shown in Listing 10-20, it
won’t compile.
Listing 10-20: An implementation of the longest function that returns the longer of two string slices but does not yet compile
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
Instead, we get the following error that talks about lifetimes:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` due to previous error
The help text reveals that the return type needs a generic lifetime parameter
on it because Rust can’t tell whether the reference being returned refers to
x or y.
Actually, we don’t know either, because the if block in the body
of this function returns a reference to x and the else block returns a
reference to y!
When we’re defining this function, we don’t know the concrete values that will
be passed into this function, so we don’t know whether the if case or the
else case will execute.
We also don’t know the concrete lifetimes of the references that will be passed in, so we can’t look at the scopes as we did in Listings 10-17 and 10-18 to determine whether the reference we return will always be valid.
The borrow checker can’t determine this either, because it
doesn’t know how the lifetimes of x and y relate to the lifetime of the
return value.
To fix this error, we’ll add generic lifetime parameters that define the relationship between the references so the borrow checker can perform its analysis.
Lifetime Annotation Syntax
Lifetime annotations don’t change how long any of the references live.
Rather, they describe the relationships of the lifetimes of multiple references to each other without affecting the lifetimes.
Just as functions can accept any type when the signature specifies a generic type parameter, functions can accept references with any lifetime by specifying a generic lifetime parameter.
Lifetime annotations have a slightly unusual syntax:
- the names of lifetime parameters must start with an apostrophe (
') and are usually all lowercase and very short, like generic types. - Most people use the name
'afor the first lifetime annotation. - We place lifetime parameter annotations after the
&of a reference, using a space to separate the annotation from the reference’s type.
Here are some examples:
- a reference to an
i32without a lifetime parameter - a reference to an
i32that has a lifetime parameter named'a - and a mutable reference to an
i32that also has the lifetime'a.
&i32 // a reference
&'a i32 // a reference with an explicit lifetime
&'a mut i32 // a mutable reference with an explicit lifetime
One lifetime annotation by itself doesn’t have much meaning, because the annotations are meant to tell Rust how generic lifetime parameters of multiple references relate to each other.
Let’s examine how the lifetime annotations
relate to each other in the context of the longest function.
Lifetime Annotations in Function Signatures
To use lifetime annotations in function signatures, we need to declare the generic lifetime parameters inside angle brackets between the function name and the parameter list, just as we did with generic type parameters.
We want the signature to express the following constraint:
- the returned reference will be valid as long as both the parameters are valid.
- This is the relationship between lifetimes of the parameters and the return value.
We’ll name the lifetime 'a and then add it to each reference, as shown in Listing 10-21.
Listing 10-21: The longest function definition specifying that all the references in the signature must have the same lifetime ’a
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {}", result); } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
This code should compile and produce the result we want when we use it with the
main function in Listing 10-19.
-
The function signature now tells Rust that for some lifetime
'a, the function takes two parameters, both of which are string slices that live at least as long as lifetime'a. -
The function signature also tells Rust that the string slice returned from the function will live at least as long as lifetime
'a. -
In practice, it means that the lifetime of the reference returned by the
longestfunction is the same as the smaller of the lifetimes of the values referred to by the function arguments.
These relationships are what we want Rust to use when analyzing this code.
Remember:
- when we specify the lifetime parameters in this function signature, we’re not changing the lifetimes of any values passed in or returned.
- Rather, we’re specifying that the borrow checker should reject any values that don’t adhere to these constraints.
- Note that the
longestfunction doesn’t need to know exactly how longxandywill live, only that some scope can be substituted for'athat will satisfy this signature.
When annotating lifetimes in functions, the annotations go in the function signature, not in the function body.
The lifetime annotations become part of the contract of the function, much like the types in the signature.
Having function signatures contain the lifetime contract means the analysis the Rust compiler does can be simpler.
- If there’s a problem with the way a function is annotated or the way it is called, the compiler errors can point to the part of our code and the constraints more precisely.
- If, instead, the Rust compiler made more inferences about what we intended the relationships of the lifetimes to be, the compiler might only be able to point to a use of our code many steps away from the cause of the problem.
When we pass concrete references to longest, the concrete lifetime that is
substituted for 'a is the part of the scope of x that overlaps with the
scope of y.
In other words, the generic lifetime
'awill get the concrete lifetime that is equal to the smaller of the lifetimes ofxandy.
Because
we’ve annotated the returned reference with the same lifetime parameter 'a,
the returned reference will also be valid for the length of the smaller of the
lifetimes of x and y.
Let’s look at how the lifetime annotations restrict the longest function by
passing in references that have different concrete lifetimes.
Listing 10-22 is a straightforward example.
Listing 10-22: Using the longest function with references to String values that have different concrete lifetimes
fn main() { let string1 = String::from("long string is long"); { let string2 = String::from("xyz"); let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is {}", result); } } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
In this example:
string1is valid until the end of the outer scope,string2is valid until the end of the inner scope, andresultreferences something that is valid until the end of the inner scope.- Run this code, and you’ll see that the borrow checker approves;
- it will compile and print
The longest string is long string is long.
Next, let’s try an example that shows that the lifetime of the reference in
result must be the smaller lifetime of the two arguments.
We’ll move the
declaration of the result variable outside the inner scope but leave the
assignment of the value to the result variable inside the scope with
string2.
Then we’ll move the println! that uses result to outside the
inner scope, after the inner scope has ended.
The code in Listing 10-23 will not compile.
Listing 10-23: Attempting to use result after string2 has gone out of scope
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {}", result);
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
When we try to compile this code, we get this error:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^^^^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {}", result);
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` due to previous error
The error shows that for result to be valid for the println! statement,
string2 would need to be valid until the end of the outer scope.
Rust knows this because we annotated the lifetimes of the function parameters and return values using the same lifetime parameter
'a.
As humans, we can look at this code and see that string1 is longer than
string2 and therefore result will contain a reference to string1.
Because string1 has not gone out of scope yet, a reference to string1 will
still be valid for the println! statement.
However, the compiler can’t see that the reference is valid in this case.
We’ve told Rust that the lifetime of
the reference returned by the longest function is the same as the smaller of
the lifetimes of the references passed in.
Therefore, the borrow checker disallows the code in Listing 10-23 as possibly having an invalid reference.
Try designing more experiments that vary the values and lifetimes of the
references passed in to the longest function and how the returned reference
is used.
Make hypotheses about whether or not your experiments will pass the borrow checker before you compile; then check to see if you’re right!
Thinking in Terms of Lifetimes
The way in which you need to specify lifetime parameters depends on what your function is doing.
For example, if we changed the implementation of the
longest function to always return the first parameter rather than the longest
string slice, we wouldn’t need to specify a lifetime on the y parameter.
The following code will compile:
fn main() { let string1 = String::from("abcd"); let string2 = "efghijklmnopqrstuvwxyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {}", result); } fn longest<'a>(x: &'a str, y: &str) -> &'a str { x }
We’ve specified a lifetime parameter 'a for the parameter x and the return
type, but not for the parameter y, because the lifetime of y does not have
any relationship with the lifetime of x or the return value.
When returning a reference from a function, the lifetime parameter for the return type needs to match the lifetime parameter for one of the parameters.
If the reference returned does not refer to one of the parameters, it must refer to a value created within this function.
However, this would be a dangling reference because the value will go out of scope at the end of the function.
Consider this attempted implementation of the longest function that won’t compile:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}
Here, even though we’ve specified a lifetime parameter 'a for the return
type, this implementation will fail to compile because the return value
lifetime is not related to the lifetime of the parameters at all.
Here is the error message we get:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return reference to local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ^^^^^^^^^^^^^^^ returns a reference to data owned by the current function
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` due to previous error
The problem is that result goes out of scope and gets cleaned up at the end
of the longest function.
We’re also trying to return a reference to result from the function.
There is no way we can specify lifetime parameters that would change the dangling reference, and Rust won’t let us create a dangling reference.
In this case, the best fix would be to return an owned data type rather than a reference so the calling function is then responsible for cleaning up the value.
Ultimately, lifetime syntax is about connecting the lifetimes of various parameters and return values of functions.
- Once they’re connected, Rust has enough information to allow memory-safe operations and disallow operations that would create dangling pointers or otherwise violate memory safety.
Lifetime Annotations in Struct Definitions
So far, the structs we’ve defined all hold owned types.
We can define structs to hold references, but in that case we would need to add a lifetime annotation on every reference in the struct’s definition.
Listing 10-24 has a struct named ImportantExcerpt that holds a string slice.
Listing 10-24: A struct that holds a reference, requiring a lifetime annotation
struct ImportantExcerpt<'a> { part: &'a str, } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); let i = ImportantExcerpt { part: first_sentence, }; }
This struct has the single field part that holds a string slice, which is a
reference.
As with generic data types, we declare the name of the generic lifetime parameter inside angle brackets after the name of the struct so we can use the lifetime parameter in the body of the struct definition.
This
annotation means an instance of ImportantExcerpt can’t outlive the reference
it holds in its part field.
The main function here creates an instance of the ImportantExcerpt struct
that holds a reference to the first sentence of the String owned by the
variable novel.
The data in novel exists before the ImportantExcerpt
instance is created.
In addition, novel doesn’t go out of scope until after
the ImportantExcerpt goes out of scope, so the reference in the
ImportantExcerpt instance is valid.
Three Rules of Lifetime Elision
Why Lifetime Elision
You’ve learned that every reference has a lifetime and that you need to specify lifetime parameters for functions or structs that use references. However, in Chapter 4 we had a function in Listing 4-9, shown again in Listing 10-25, that compiled without lifetime annotations.
Listing 10-25: A function we defined in Listing 4-9 that compiled without lifetime annotations, even though the parameter and return type are references
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // first_word works on slices of `String`s let word = first_word(&my_string[..]); let my_string_literal = "hello world"; // first_word works on slices of string literals let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
The reason this function compiles without lifetime annotations is historical:
in early versions (pre-1.0) of Rust, this code wouldn’t have compiled because every reference needed an explicit lifetime.
At that time, the function signature would have been written like this:
fn first_word<'a>(s: &'a str) -> &'a str {
After writing a lot of Rust code, the Rust team found that Rust programmers were entering the same lifetime annotations over and over in particular situations.
These situations were predictable and followed a few deterministic patterns.
The developers programmed these patterns into the compiler’s code so the borrow checker could infer the lifetimes in these situations and wouldn’t need explicit annotations.
This piece of Rust history is relevant because it’s possible that more deterministic patterns will emerge and be added to the compiler.
In the future, even fewer lifetime annotations might be required.
Three Rules is for compiler, not programmer
The patterns programmed into Rust’s analysis of references are called the lifetime elision rules:
- These aren’t rules for programmers to follow;
- they’re a set of particular cases that the compiler will consider, and if your code fits these cases, you don’t need to write the lifetimes explicitly.
The elision rules don’t provide full inference.
- If Rust deterministically applies the rules but there is still ambiguity as to what lifetimes the references have, the compiler won’t guess what the lifetime of the remaining references should be.
- Instead of guessing, the compiler will give you an error that you can resolve by adding the lifetime annotations.
- Lifetimes on function or method parameters are called input lifetimes, and lifetimes on return values are called output lifetimes.
What the three rules
The compiler uses three rules to figure out the lifetimes of the references when there aren’t explicit annotations:
- The first rule applies to input lifetimes,
- and the second and third rules apply to output lifetimes.
If the compiler gets to the end of the three rules and there are still references for which it can’t figure out lifetimes, the compiler will stop with an error.
These rules apply to fn definitions as well as impl blocks.
The first rule is that the compiler assigns a lifetime parameter to each parameter that’s a reference.
- In other words, a function with one parameter gets one lifetime parameter:
fn foo<'a>(x: &'a i32); - a function with two
parameters gets two separate lifetime parameters:
fn foo<'a, 'b>(x: &'a i32, y: &'b i32); and so on.
The second rule is that, if there is exactly one input lifetime parameter, that
lifetime is assigned to all output lifetime parameters: fn foo<'a>(x: &'a i32) -> &'a i32.
The third rule is that, if there are multiple input lifetime parameters, but
one of them is &self or &mut self because this is a method, the lifetime of
self is assigned to all output lifetime parameters.
This third rule makes methods much nicer to read and write because fewer symbols are necessary.
Let’s pretend we’re the compiler.
We’ll apply these rules to figure out the
lifetimes of the references in the signature of the first_word function in
Listing 10-25.
fn first_word(s: &str) -> &str {
Then the compiler applies the first rule, which specifies that each parameter gets its own lifetime.
The second rule applies because there is exactly one input lifetime.
The second rule specifies that the lifetime of the one input parameter gets assigned to the output lifetime, so the signature is now this:
fn first_word<'a>(s: &'a str) -> &'a str {
Now all the references in this function signature have lifetimes, and the compiler can continue its analysis without needing the programmer to annotate the lifetimes in this function signature.
Let’s look at another example, this time using the longest function that had
no lifetime parameters when we started working with it in Listing 10-20:
fn longest(x: &str, y: &str) -> &str {
Let’s apply the first rule: each parameter gets its own lifetime. This time we have two parameters instead of one, so we have two lifetimes:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {
-
You can see that the second rule doesn’t apply because there is more than one input lifetime.
-
The third rule doesn’t apply either, because
longestis a function rather than a method, so none of the parameters areself.
After working through all three rules, we still haven’t figured out what the return type’s lifetime is.
This is why we got an error trying to compile the code in Listing 10-20:
the compiler worked through the lifetime elision rules but still couldn’t figure out all the lifetimes of the references in the signature.
Because the third rule really only applies in method signatures, we’ll look at lifetimes in that context next to see why the third rule means we don’t have to annotate lifetimes in method signatures very often.
Lifetime Annotations in Method Definitions
When we implement methods on a struct with lifetimes, we use the same syntax as that of generic type parameters shown in Listing 10-11.
Where we declare and use the lifetime parameters depends on whether they’re related to the struct fields or the method parameters and return values.
Lifetime names for struct fields always need to be declared after the impl
keyword and then used after the struct’s name, because those lifetimes are part
of the struct’s type.
In method signatures inside the impl block, references might be tied to the
lifetime of references in the struct’s fields, or they might be independent. In
addition, the lifetime elision rules often make it so that lifetime annotations
aren’t necessary in method signatures.
Let’s look at some examples using the
struct named ImportantExcerpt that we defined in Listing 10-24.
First, we’ll use a method named level whose only parameter is a reference to self and whose return value is an i32, which is not a reference to anything:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {}", announcement); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); let i = ImportantExcerpt { part: first_sentence, }; }
The lifetime parameter declaration after impl and its use after the type name
are required, but we’re not required to annotate the lifetime of the reference
to self because of the first elision rule.
Here is an example where the third lifetime elision rule applies:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {}", announcement); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); let i = ImportantExcerpt { part: first_sentence, }; }
-
There are two input lifetimes, so Rust applies the first lifetime elision rule and gives both
&selfandannouncementtheir own lifetimes. -
Then, because one of the parameters is
&self, the return type gets the lifetime of&self, and all lifetimes have been accounted for.
The Static Lifetime
One special lifetime we need to discuss is 'static, which denotes that the
affected reference can live for the entire duration of the program.
All string literals have the
'staticlifetime, which we can annotate as follows:
#![allow(unused)] fn main() { let s: & 'static str = "I have a static lifetime."; }
The text of this string is stored directly in the program’s binary, which is always available.
Therefore, the lifetime of all string literals is
'static.
You might see suggestions to use the 'static lifetime in error messages. But
before specifying 'static as the lifetime for a reference, think about
whether the reference you have actually lives the entire lifetime of your
program or not, and whether you want it to.
Most of the time, an error message
suggesting the 'static lifetime results from attempting to create a dangling
reference or a mismatch of the available lifetimes.
In such cases, the solution
is fixing those problems, not specifying the 'static lifetime.
Generic Type Parameters, Trait Bounds, and Lifetimes Together
Let’s briefly look at the syntax of specifying generic type parameters, trait bounds, and lifetimes all in one function!
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest_with_an_announcement( string1.as_str(), string2, "Today is someone's birthday!", ); println!("The longest string is {}", result); } use std::fmt::Display; fn longest_with_an_announcement<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("Announcement! {}", ann); if x.len() > y.len() { x } else { y } }
This is the longest function from Listing 10-21 that returns the longer of
two string slices.
But now it has an extra parameter named
annof the generic typeT, which can be filled in by any type that implements theDisplaytrait as specified by thewhereclause.
This extra parameter will be printed
using {}, which is why the Display trait bound is necessary.
Because
lifetimes are a type of generic, the declarations of the lifetime parameter
'a and the generic type parameter T go in the same list inside the angle
brackets after the function name.
Summary
We covered a lot in this chapter!
Now that you know about generic type parameters, traits and trait bounds, and generic lifetime parameters, you’re ready to write code without repetition that works in many different situations.
Generic type parameters let you apply the code to different types:
- Traits and trait bounds ensure that even though the types are generic, they’ll have the behavior the code needs.
- You learned how to use lifetime annotations to ensure that this flexible code won’t have any dangling references.
- And all of this analysis happens at compile time, which doesn’t affect runtime performance!
Believe it or not, there is much more to learn on the topics we discussed in this chapter:
- Chapter 17 discusses trait objects, which are another way to use traits.
- There are also more complex scenarios involving lifetime annotations that you will only need in very advanced scenarios;
- for those, you should read the Rust Reference. But next, you’ll learn how to write tests in Rust so you can make sure your code is working the way it should.
Writing Automated Tests
In his 1972 essay “The Humble Programmer,” Edsger W. Dijkstra said that “Program testing can be a very effective way to show the presence of bugs, but it is hopelessly inadequate for showing their absence.” That doesn’t mean we shouldn’t try to test as much as we can!
Correctness in our programs is the extent to which our code does what we intend it to do. Rust is designed with a high degree of concern about the correctness of programs, but correctness is complex and not easy to prove. Rust’s type system shoulders a huge part of this burden, but the type system cannot catch everything. As such, Rust includes support for writing automated software tests.
Say we write a function add_two that adds 2 to whatever number is passed to
it. This function’s signature accepts an integer as a parameter and returns an
integer as a result. When we implement and compile that function, Rust does all
the type checking and borrow checking that you’ve learned so far to ensure
that, for instance, we aren’t passing a String value or an invalid reference
to this function. But Rust can’t check that this function will do precisely
what we intend, which is return the parameter plus 2 rather than, say, the
parameter plus 10 or the parameter minus 50! That’s where tests come in.
We can write tests that assert, for example, that when we pass 3 to the
add_two function, the returned value is 5. We can run these tests whenever
we make changes to our code to make sure any existing correct behavior has not
changed.
Testing is a complex skill: although we can’t cover every detail about how to write good tests in one chapter, we’ll discuss the mechanics of Rust’s testing facilities. We’ll talk about the annotations and macros available to you when writing your tests, the default behavior and options provided for running your tests, and how to organize tests into unit tests and integration tests.
How to Write Tests
Tests are Rust functions that verify that the non-test code is functioning in the expected manner. The bodies of test functions typically perform these three actions:
- Set up any needed data or state.
- Run the code you want to test.
- Assert the results are what you expect.
Let’s look at the features Rust provides specifically for writing tests that
take these actions, which include the test attribute, a few macros, and the
should_panic attribute.
The Anatomy of a Test Function
At its simplest, a test in Rust is a function that’s annotated with the test
attribute. Attributes are metadata about pieces of Rust code; one example is
the derive attribute we used with structs in Chapter 5. To change a function
into a test function, add #[test] on the line before fn. When you run your
tests with the cargo test command, Rust builds a test runner binary that runs
the annotated functions and reports on whether each
test function passes or fails.
Whenever we make a new library project with Cargo, a test module with a test function in it is automatically generated for us. This module gives you a template for writing your tests so you don’t have to look up the exact structure and syntax every time you start a new project. You can add as many additional test functions and as many test modules as you want!
We’ll explore some aspects of how tests work by experimenting with the template test before we actually test any code. Then we’ll write some real-world tests that call some code that we’ve written and assert that its behavior is correct.
Let’s create a new library project called adder that will add two numbers:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
The contents of the src/lib.rs file in your adder library should look like
Listing 11-1.
Filename: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
let result = 2 + 2;
assert_eq!(result, 4);
}
}
Listing 11-1: The test module and function generated
automatically by cargo new
For now, let’s ignore the top two lines and focus on the function. Note the
#[test] annotation: this attribute indicates this is a test function, so the
test runner knows to treat this function as a test. We might also have non-test
functions in the tests module to help set up common scenarios or perform
common operations, so we always need to indicate which functions are tests.
The example function body uses the assert_eq! macro to assert that result,
which contains the result of adding 2 and 2, equals 4. This assertion serves as
an example of the format for a typical test. Let’s run it to see that this test
passes.
The cargo test command runs all tests in our project, as shown in Listing
11-2.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Listing 11-2: The output from running the automatically generated test
Cargo compiled and ran the test. We see the line running 1 test. The next
line shows the name of the generated test function, called it_works, and that
the result of running that test is ok. The overall summary test result: ok.
means that all the tests passed, and the portion that reads 1 passed; 0 failed totals the number of tests that passed or failed.
It’s possible to mark a test as ignored so it doesn’t run in a particular
instance; we’ll cover that in the “Ignoring Some Tests Unless Specifically
Requested” section later in this chapter. Because we
haven’t done that here, the summary shows 0 ignored. We can also pass an
argument to the cargo test command to run only tests whose name matches a
string; this is called filtering and we’ll cover that in the “Running a
Subset of Tests by Name” section. We also haven’t
filtered the tests being run, so the end of the summary shows 0 filtered out.
The 0 measured statistic is for benchmark tests that measure performance.
Benchmark tests are, as of this writing, only available in nightly Rust. See
the documentation about benchmark tests to learn more.
The next part of the test output starting at Doc-tests adder is for the
results of any documentation tests. We don’t have any documentation tests yet,
but Rust can compile any code examples that appear in our API documentation.
This feature helps keep your docs and your code in sync! We’ll discuss how to
write documentation tests in the “Documentation Comments as
Tests” section of Chapter 14. For now, we’ll
ignore the Doc-tests output.
Let’s start to customize the test to our own needs. First change the name of
the it_works function to a different name, such as exploration, like so:
Filename: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn exploration() {
assert_eq!(2 + 2, 4);
}
}
Then run cargo test again. The output now shows exploration instead of
it_works:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Now we’ll add another test, but this time we’ll make a test that fails! Tests
fail when something in the test function panics. Each test is run in a new
thread, and when the main thread sees that a test thread has died, the test is
marked as failed. In Chapter 9, we talked about how the simplest way to panic
is to call the panic! macro. Enter the new test as a function named
another, so your src/lib.rs file looks like Listing 11-3.
Filename: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn exploration() {
assert_eq!(2 + 2, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}
Listing 11-3: Adding a second test that will fail because
we call the panic! macro
Run the tests again using cargo test. The output should look like Listing
11-4, which shows that our exploration test passed and another failed.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'main' panicked at 'Make this test fail', src/lib.rs:10:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
Listing 11-4: Test results when one test passes and one test fails
Instead of ok, the line test tests::another shows FAILED. Two new
sections appear between the individual results and the summary: the first
displays the detailed reason for each test failure. In this case, we get the
details that another failed because it panicked at 'Make this test fail' on
line 10 in the src/lib.rs file. The next section lists just the names of all
the failing tests, which is useful when there are lots of tests and lots of
detailed failing test output. We can use the name of a failing test to run just
that test to more easily debug it; we’ll talk more about ways to run tests in
the “Controlling How Tests Are Run” section.
The summary line displays at the end: overall, our test result is FAILED. We
had one test pass and one test fail.
Now that you’ve seen what the test results look like in different scenarios,
let’s look at some macros other than panic! that are useful in tests.
Checking Results with the assert! Macro
The assert! macro, provided by the standard library, is useful when you want
to ensure that some condition in a test evaluates to true. We give the
assert! macro an argument that evaluates to a Boolean. If the value is
true, nothing happens and the test passes. If the value is false, the
assert! macro calls panic! to cause the test to fail. Using the assert!
macro helps us check that our code is functioning in the way we intend.
In Chapter 5, Listing 5-15, we used a Rectangle struct and a can_hold
method, which are repeated here in Listing 11-5. Let’s put this code in the
src/lib.rs file, then write some tests for it using the assert! macro.
Filename: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
Listing 11-5: Using the Rectangle struct and its
can_hold method from Chapter 5
The can_hold method returns a Boolean, which means it’s a perfect use case
for the assert! macro. In Listing 11-6, we write a test that exercises the
can_hold method by creating a Rectangle instance that has a width of 8 and
a height of 7 and asserting that it can hold another Rectangle instance that
has a width of 5 and a height of 1.
Filename: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}
Listing 11-6: A test for can_hold that checks whether a
larger rectangle can indeed hold a smaller rectangle
Note that we’ve added a new line inside the tests module: use super::*;.
The tests module is a regular module that follows the usual visibility rules
we covered in Chapter 7 in the “Paths for Referring to an Item in the Module
Tree”
section. Because the tests module is an inner module, we need to bring the
code under test in the outer module into the scope of the inner module. We use
a glob here so anything we define in the outer module is available to this
tests module.
We’ve named our test larger_can_hold_smaller, and we’ve created the two
Rectangle instances that we need. Then we called the assert! macro and
passed it the result of calling larger.can_hold(&smaller). This expression is
supposed to return true, so our test should pass. Let’s find out!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
It does pass! Let’s add another test, this time asserting that a smaller rectangle cannot hold a larger rectangle:
Filename: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}
Because the correct result of the can_hold function in this case is false,
we need to negate that result before we pass it to the assert! macro. As a
result, our test will pass if can_hold returns false:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Two tests that pass! Now let’s see what happens to our test results when we
introduce a bug in our code. We’ll change the implementation of the can_hold
method by replacing the greater-than sign with a less-than sign when it
compares the widths:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}
Running the tests now produces the following:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'main' panicked at 'assertion failed: larger.can_hold(&smaller)', src/lib.rs:28:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
Our tests caught the bug! Because larger.width is 8 and smaller.width is
5, the comparison of the widths in can_hold now returns false: 8 is not
less than 5.
Testing Equality with the assert_eq! and assert_ne! Macros
A common way to verify functionality is to test for equality between the result
of the code under test and the value you expect the code to return. You could
do this using the assert! macro and passing it an expression using the ==
operator. However, this is such a common test that the standard library
provides a pair of macros—assert_eq! and assert_ne!—to perform this test
more conveniently. These macros compare two arguments for equality or
inequality, respectively. They’ll also print the two values if the assertion
fails, which makes it easier to see why the test failed; conversely, the
assert! macro only indicates that it got a false value for the ==
expression, without printing the values that led to the false value.
In Listing 11-7, we write a function named add_two that adds 2 to its
parameter, then we test this function using the assert_eq! macro.
Filename: src/lib.rs
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
assert_eq!(4, add_two(2));
}
}
Listing 11-7: Testing the function add_two using the
assert_eq! macro
Let’s check that it passes!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
We pass 4 as the argument to assert_eq!, which is equal to the result of
calling add_two(2). The line for this test is test tests::it_adds_two ... ok, and the ok text indicates that our test passed!
Let’s introduce a bug into our code to see what assert_eq! looks like when it
fails. Change the implementation of the add_two function to instead add 3:
pub fn add_two(a: i32) -> i32 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
assert_eq!(4, add_two(2));
}
}
Run the tests again:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `4`,
right: `5`', src/lib.rs:11:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
Our test caught the bug! The it_adds_two test failed, and the message tells
us that the assertion that fails was assertion failed: `(left == right)`
and what the left and right values are. This message helps us start
debugging: the left argument was 4 but the right argument, where we had
add_two(2), was 5. You can imagine that this would be especially helpful
when we have a lot of tests going on.
Note that in some languages and test frameworks, the parameters to equality
assertion functions are called expected and actual, and the order in which
we specify the arguments matters. However, in Rust, they’re called left and
right, and the order in which we specify the value we expect and the value
the code produces doesn’t matter. We could write the assertion in this test as
assert_eq!(add_two(2), 4), which would result in the same failure message
that displays assertion failed: `(left == right)`.
The assert_ne! macro will pass if the two values we give it are not equal and
fail if they’re equal. This macro is most useful for cases when we’re not sure
what a value will be, but we know what the value definitely shouldn’t be.
For example, if we’re testing a function that is guaranteed to change its input
in some way, but the way in which the input is changed depends on the day of
the week that we run our tests, the best thing to assert might be that the
output of the function is not equal to the input.
Under the surface, the assert_eq! and assert_ne! macros use the operators
== and !=, respectively. When the assertions fail, these macros print their
arguments using debug formatting, which means the values being compared must
implement the PartialEq and Debug traits. All primitive types and most of
the standard library types implement these traits. For structs and enums that
you define yourself, you’ll need to implement PartialEq to assert equality of
those types. You’ll also need to implement Debug to print the values when the
assertion fails. Because both traits are derivable traits, as mentioned in
Listing 5-12 in Chapter 5, this is usually as straightforward as adding the
#[derive(PartialEq, Debug)] annotation to your struct or enum definition. See
Appendix C, “Derivable Traits,” for more
details about these and other derivable traits.
Adding Custom Failure Messages
You can also add a custom message to be printed with the failure message as
optional arguments to the assert!, assert_eq!, and assert_ne! macros. Any
arguments specified after the required arguments are passed along to the
format! macro (discussed in Chapter 8 in the “Concatenation with the +
Operator or the format!
Macro”
section), so you can pass a format string that contains {} placeholders and
values to go in those placeholders. Custom messages are useful for documenting
what an assertion means; when a test fails, you’ll have a better idea of what
the problem is with the code.
For example, let’s say we have a function that greets people by name and we want to test that the name we pass into the function appears in the output:
Filename: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {}!", name)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}
The requirements for this program haven’t been agreed upon yet, and we’re
pretty sure the Hello text at the beginning of the greeting will change. We
decided we don’t want to have to update the test when the requirements change,
so instead of checking for exact equality to the value returned from the
greeting function, we’ll just assert that the output contains the text of the
input parameter.
Now let’s introduce a bug into this code by changing greeting to exclude
name to see what the default test failure looks like:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}
Running this test produces the following:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished test [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'main' panicked at 'assertion failed: result.contains(\"Carol\")', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
This result just indicates that the assertion failed and which line the
assertion is on. A more useful failure message would print the value from the
greeting function. Let’s add a custom failure message composed of a format
string with a placeholder filled in with the actual value we got from the
greeting function:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{}`",
result
);
}
}
Now when we run the test, we’ll get a more informative error message:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished test [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'main' panicked at 'Greeting did not contain name, value was `Hello!`', src/lib.rs:12:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
We can see the value we actually got in the test output, which would help us debug what happened instead of what we were expecting to happen.
Checking for Panics with should_panic
In addition to checking return values, it’s important to check that our code
handles error conditions as we expect. For example, consider the Guess type
that we created in Chapter 9, Listing 9-13. Other code that uses Guess
depends on the guarantee that Guess instances will contain only values
between 1 and 100. We can write a test that ensures that attempting to create a
Guess instance with a value outside that range panics.
We do this by adding the attribute should_panic to our test function. The
test passes if the code inside the function panics; the test fails if the code
inside the function doesn’t panic.
Listing 11-8 shows a test that checks that the error conditions of Guess::new
happen when we expect them to.
Filename: src/lib.rs
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}
Listing 11-8: Testing that a condition will cause a
panic!
We place the #[should_panic] attribute after the #[test] attribute and
before the test function it applies to. Let’s look at the result when this test
passes:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Looks good! Now let’s introduce a bug in our code by removing the condition
that the new function will panic if the value is greater than 100:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}
When we run the test in Listing 11-8, it will fail:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
We don’t get a very helpful message in this case, but when we look at the test
function, we see that it’s annotated with #[should_panic]. The failure we got
means that the code in the test function did not cause a panic.
Tests that use should_panic can be imprecise. A should_panic test would
pass even if the test panics for a different reason from the one we were
expecting. To make should_panic tests more precise, we can add an optional
expected parameter to the should_panic attribute. The test harness will
make sure that the failure message contains the provided text. For example,
consider the modified code for Guess in Listing 11-9 where the new function
panics with different messages depending on whether the value is too small or
too large.
Filename: src/lib.rs
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}
Listing 11-9: Testing for a panic! with a panic message
containing a specified substring
This test will pass because the value we put in the should_panic attribute’s
expected parameter is a substring of the message that the Guess::new
function panics with. We could have specified the entire panic message that we
expect, which in this case would be Guess value must be less than or equal to 100, got 200. What you choose to specify depends on how much of the panic
message is unique or dynamic and how precise you want your test to be. In this
case, a substring of the panic message is enough to ensure that the code in the
test function executes the else if value > 100 case.
To see what happens when a should_panic test with an expected message
fails, let’s again introduce a bug into our code by swapping the bodies of the
if value < 1 and the else if value > 100 blocks:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}
This time when we run the should_panic test, it will fail:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished test [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'main' panicked at 'Guess value must be greater than or equal to 1, got 200.', src/lib.rs:13:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"Guess value must be greater than or equal to 1, got 200."`,
expected substring: `"less than or equal to 100"`
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
The failure message indicates that this test did indeed panic as we expected,
but the panic message did not include the expected string 'Guess value must be less than or equal to 100'. The panic message that we did get in this case was
Guess value must be greater than or equal to 1, got 200. Now we can start
figuring out where our bug is!
Using Result<T, E> in Tests
Our tests so far all panic when they fail. We can also write tests that use
Result<T, E>! Here’s the test from Listing 11-1, rewritten to use Result<T, E> and return an Err instead of panicking:
#[cfg(test)]
mod tests {
#[test]
fn it_works() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}
The it_works function now has the Result<(), String> return type. In the
body of the function, rather than calling the assert_eq! macro, we return
Ok(()) when the test passes and an Err with a String inside when the test
fails.
Writing tests so they return a Result<T, E> enables you to use the question
mark operator in the body of tests, which can be a convenient way to write
tests that should fail if any operation within them returns an Err variant.
You can’t use the #[should_panic] annotation on tests that use Result<T, E>. To assert that an operation returns an Err variant, don’t use the
question mark operator on the Result<T, E> value. Instead, use
assert!(value.is_err()).
Now that you know several ways to write tests, let’s look at what is happening
when we run our tests and explore the different options we can use with cargo test.
Controlling How Tests Are Run
Just as cargo run compiles your code and then runs the resulting binary,
cargo test compiles your code in test mode and runs the resulting test
binary. The default behavior of the binary produced by cargo test is to run
all the tests in parallel and capture output generated during test runs,
preventing the output from being displayed and making it easier to read the
output related to the test results. You can, however, specify command line
options to change this default behavior.
Some command line options go to cargo test, and some go to the resulting test
binary. To separate these two types of arguments, you list the arguments that
go to cargo test followed by the separator -- and then the ones that go to
the test binary. Running cargo test --help displays the options you can use
with cargo test, and running cargo test -- --help displays the options you
can use after the separator.
Running Tests in Parallel or Consecutively
When you run multiple tests, by default they run in parallel using threads, meaning they finish running faster and you get feedback quicker. Because the tests are running at the same time, you must make sure your tests don’t depend on each other or on any shared state, including a shared environment, such as the current working directory or environment variables.
For example, say each of your tests runs some code that creates a file on disk named test-output.txt and writes some data to that file. Then each test reads the data in that file and asserts that the file contains a particular value, which is different in each test. Because the tests run at the same time, one test might overwrite the file in the time between another test writing and reading the file. The second test will then fail, not because the code is incorrect but because the tests have interfered with each other while running in parallel. One solution is to make sure each test writes to a different file; another solution is to run the tests one at a time.
If you don’t want to run the tests in parallel or if you want more fine-grained
control over the number of threads used, you can send the --test-threads flag
and the number of threads you want to use to the test binary. Take a look at
the following example:
$ cargo test -- --test-threads=1
We set the number of test threads to 1, telling the program not to use any
parallelism. Running the tests using one thread will take longer than running
them in parallel, but the tests won’t interfere with each other if they share
state.
Showing Function Output
By default, if a test passes, Rust’s test library captures anything printed to
standard output. For example, if we call println! in a test and the test
passes, we won’t see the println! output in the terminal; we’ll see only the
line that indicates the test passed. If a test fails, we’ll see whatever was
printed to standard output with the rest of the failure message.
As an example, Listing 11-10 has a silly function that prints the value of its parameter and returns 10, as well as a test that passes and a test that fails.
Filename: src/lib.rs
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {}", a);
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(10, value);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(5, value);
}
}
Listing 11-10: Tests for a function that calls
println!
When we run these tests with cargo test, we’ll see the following output:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished test [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `10`', src/lib.rs:19:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
Note that nowhere in this output do we see I got the value 4, which is what
is printed when the test that passes runs. That output has been captured. The
output from the test that failed, I got the value 8, appears in the section
of the test summary output, which also shows the cause of the test failure.
If we want to see printed values for passing tests as well, we can tell Rust
to also show the output of successful tests with --show-output.
$ cargo test -- --show-output
When we run the tests in Listing 11-10 again with the --show-output flag, we
see the following output:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished test [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `5`,
right: `10`', src/lib.rs:19:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
Running a Subset of Tests by Name
Sometimes, running a full test suite can take a long time. If you’re working on
code in a particular area, you might want to run only the tests pertaining to
that code. You can choose which tests to run by passing cargo test the name
or names of the test(s) you want to run as an argument.
To demonstrate how to run a subset of tests, we’ll first create three tests for
our add_two function, as shown in Listing 11-11, and choose which ones to run.
Filename: src/lib.rs
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
assert_eq!(4, add_two(2));
}
#[test]
fn add_three_and_two() {
assert_eq!(5, add_two(3));
}
#[test]
fn one_hundred() {
assert_eq!(102, add_two(100));
}
}
Listing 11-11: Three tests with three different names
If we run the tests without passing any arguments, as we saw earlier, all the tests will run in parallel:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running Single Tests
We can pass the name of any test function to cargo test to run only that test:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Only the test with the name one_hundred ran; the other two tests didn’t match
that name. The test output lets us know we had more tests that didn’t run by
displaying 2 filtered out at the end.
We can’t specify the names of multiple tests in this way; only the first value
given to cargo test will be used. But there is a way to run multiple tests.
Filtering to Run Multiple Tests
We can specify part of a test name, and any test whose name matches that value
will be run. For example, because two of our tests’ names contain add, we can
run those two by running cargo test add:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
This command ran all tests with add in the name and filtered out the test
named one_hundred. Also note that the module in which a test appears becomes
part of the test’s name, so we can run all the tests in a module by filtering
on the module’s name.
Ignoring Some Tests Unless Specifically Requested
Sometimes a few specific tests can be very time-consuming to execute, so you
might want to exclude them during most runs of cargo test. Rather than
listing as arguments all tests you do want to run, you can instead annotate the
time-consuming tests using the ignore attribute to exclude them, as shown
here:
Filename: src/lib.rs
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
After #[test] we add the #[ignore] line to the test we want to exclude. Now
when we run our tests, it_works runs, but expensive_test doesn’t:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test expensive_test ... ignored
test it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
The expensive_test function is listed as ignored. If we want to run only
the ignored tests, we can use cargo test -- --ignored:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
By controlling which tests run, you can make sure your cargo test results
will be fast. When you’re at a point where it makes sense to check the results
of the ignored tests and you have time to wait for the results, you can run
cargo test -- --ignored instead. If you want to run all tests whether they’re
ignored or not, you can run cargo test -- --include-ignored.
Test Organization
As mentioned at the start of the chapter, testing is a complex discipline, and different people use different terminology and organization. The Rust community thinks about tests in terms of two main categories: unit tests and integration tests. Unit tests are small and more focused, testing one module in isolation at a time, and can test private interfaces. Integration tests are entirely external to your library and use your code in the same way any other external code would, using only the public interface and potentially exercising multiple modules per test.
Writing both kinds of tests is important to ensure that the pieces of your library are doing what you expect them to, separately and together.
Unit Tests
The purpose of unit tests is to test each unit of code in isolation from the
rest of the code to quickly pinpoint where code is and isn’t working as
expected. You’ll put unit tests in the src directory in each file with the
code that they’re testing. The convention is to create a module named tests
in each file to contain the test functions and to annotate the module with
cfg(test).
The Tests Module and #[cfg(test)]
The #[cfg(test)] annotation on the tests module tells Rust to compile and run
the test code only when you run cargo test, not when you run cargo build.
This saves compile time when you only want to build the library and saves space
in the resulting compiled artifact because the tests are not included. You’ll
see that because integration tests go in a different directory, they don’t need
the #[cfg(test)] annotation. However, because unit tests go in the same files
as the code, you’ll use #[cfg(test)] to specify that they shouldn’t be
included in the compiled result.
Recall that when we generated the new adder project in the first section of
this chapter, Cargo generated this code for us:
Filename: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
let result = 2 + 2;
assert_eq!(result, 4);
}
}
This code is the automatically generated test module. The attribute cfg
stands for configuration and tells Rust that the following item should only
be included given a certain configuration option. In this case, the
configuration option is test, which is provided by Rust for compiling and
running tests. By using the cfg attribute, Cargo compiles our test code only
if we actively run the tests with cargo test. This includes any helper
functions that might be within this module, in addition to the functions
annotated with #[test].
Testing Private Functions
There’s debate within the testing community about whether or not private
functions should be tested directly, and other languages make it difficult or
impossible to test private functions. Regardless of which testing ideology you
adhere to, Rust’s privacy rules do allow you to test private functions.
Consider the code in Listing 11-12 with the private function internal_adder.
Filename: src/lib.rs
pub fn add_two(a: i32) -> i32 {
internal_adder(a, 2)
}
fn internal_adder(a: i32, b: i32) -> i32 {
a + b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
assert_eq!(4, internal_adder(2, 2));
}
}
Listing 11-12: Testing a private function
Note that the internal_adder function is not marked as pub. Tests are just
Rust code, and the tests module is just another module. As we discussed in
the “Paths for Referring to an Item in the Module Tree”
section, items in child modules can use the items in their ancestor modules. In
this test, we bring all of the test module’s parent’s items into scope with
use super::*, and then the test can call internal_adder. If you don’t think
private functions should be tested, there’s nothing in Rust that will compel
you to do so.
Integration Tests
In Rust, integration tests are entirely external to your library. They use your library in the same way any other code would, which means they can only call functions that are part of your library’s public API. Their purpose is to test whether many parts of your library work together correctly. Units of code that work correctly on their own could have problems when integrated, so test coverage of the integrated code is important as well. To create integration tests, you first need a tests directory.
The tests Directory
We create a tests directory at the top level of our project directory, next to src. Cargo knows to look for integration test files in this directory. We can then make as many test files as we want, and Cargo will compile each of the files as an individual crate.
Let’s create an integration test. With the code in Listing 11-12 still in the src/lib.rs file, make a tests directory, and create a new file named tests/integration_test.rs. Your directory structure should look like this:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
Enter the code in Listing 11-13 into the tests/integration_test.rs file:
Filename: tests/integration_test.rs
use adder;
#[test]
fn it_adds_two() {
assert_eq!(4, adder::add_two(2));
}
Listing 11-13: An integration test of a function in the
adder crate
Each file in the tests directory is a separate crate, so we need to bring our
library into each test crate’s scope. For that reason we add use adder at the
top of the code, which we didn’t need in the unit tests.
We don’t need to annotate any code in tests/integration_test.rs with
#[cfg(test)]. Cargo treats the tests directory specially and compiles files
in this directory only when we run cargo test. Run cargo test now:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
The three sections of output include the unit tests, the integration test, and the doc tests. Note that if any test in a section fails, the following sections will not be run. For example, if a unit test fails, there won’t be any output for integration and doc tests because those tests will only be run if all unit tests are passing.
The first section for the unit tests is the same as we’ve been seeing: one line
for each unit test (one named internal that we added in Listing 11-12) and
then a summary line for the unit tests.
The integration tests section starts with the line Running tests/integration_test.rs. Next, there is a line for each test function in
that integration test and a summary line for the results of the integration
test just before the Doc-tests adder section starts.
Each integration test file has its own section, so if we add more files in the tests directory, there will be more integration test sections.
We can still run a particular integration test function by specifying the test
function’s name as an argument to cargo test. To run all the tests in a
particular integration test file, use the --test argument of cargo test
followed by the name of the file:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
This command runs only the tests in the tests/integration_test.rs file.
Submodules in Integration Tests
As you add more integration tests, you might want to make more files in the tests directory to help organize them; for example, you can group the test functions by the functionality they’re testing. As mentioned earlier, each file in the tests directory is compiled as its own separate crate, which is useful for creating separate scopes to more closely imitate the way end users will be using your crate. However, this means files in the tests directory don’t share the same behavior as files in src do, as you learned in Chapter 7 regarding how to separate code into modules and files.
The different behavior of tests directory files is most noticeable when you
have a set of helper functions to use in multiple integration test files and
you try to follow the steps in the “Separating Modules into Different
Files” section of Chapter 7 to
extract them into a common module. For example, if we create tests/common.rs
and place a function named setup in it, we can add some code to setup that
we want to call from multiple test functions in multiple test files:
Filename: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}
When we run the tests again, we’ll see a new section in the test output for the
common.rs file, even though this file doesn’t contain any test functions nor
did we call the setup function from anywhere:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Having common appear in the test results with running 0 tests displayed for
it is not what we wanted. We just wanted to share some code with the other
integration test files.
To avoid having common appear in the test output, instead of creating
tests/common.rs, we’ll create tests/common/mod.rs. The project directory
now looks like this:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
This is the older naming convention that Rust also understands that we
mentioned in the “Alternate File Paths” section of
Chapter 7. Naming the file this way tells Rust not to treat the common module
as an integration test file. When we move the setup function code into
tests/common/mod.rs and delete the tests/common.rs file, the section in the
test output will no longer appear. Files in subdirectories of the tests
directory don’t get compiled as separate crates or have sections in the test
output.
After we’ve created tests/common/mod.rs, we can use it from any of the
integration test files as a module. Here’s an example of calling the setup
function from the it_adds_two test in tests/integration_test.rs:
Filename: tests/integration_test.rs
use adder;
mod common;
#[test]
fn it_adds_two() {
common::setup();
assert_eq!(4, adder::add_two(2));
}
Note that the mod common; declaration is the same as the module declaration
we demonstrated in Listing 7-21. Then in the test function, we can call the
common::setup() function.
Integration Tests for Binary Crates
If our project is a binary crate that only contains a src/main.rs file and
doesn’t have a src/lib.rs file, we can’t create integration tests in the
tests directory and bring functions defined in the src/main.rs file into
scope with a use statement. Only library crates expose functions that other
crates can use; binary crates are meant to be run on their own.
This is one of the reasons Rust projects that provide a binary have a
straightforward src/main.rs file that calls logic that lives in the
src/lib.rs file. Using that structure, integration tests can test the
library crate with use to make the important functionality available.
If the important functionality works, the small amount of code in the
src/main.rs file will work as well, and that small amount of code doesn’t
need to be tested.
Summary
Rust’s testing features provide a way to specify how code should function to ensure it continues to work as you expect, even as you make changes. Unit tests exercise different parts of a library separately and can test private implementation details. Integration tests check that many parts of the library work together correctly, and they use the library’s public API to test the code in the same way external code will use it. Even though Rust’s type system and ownership rules help prevent some kinds of bugs, tests are still important to reduce logic bugs having to do with how your code is expected to behave.
Let’s combine the knowledge you learned in this chapter and in previous chapters to work on a project!
An I/O Project: Building a Command Line Program
This chapter is a recap of the many skills you’ve learned so far and an exploration of a few more standard library features. We’ll build a command line tool that interacts with file and command line input/output to practice some of the Rust concepts you now have under your belt.
Rust’s speed, safety, single binary output, and cross-platform support make it
an ideal language for creating command line tools, so for our project, we’ll
make our own version of the classic command line search tool grep
(globally search a regular expression and print). In the
simplest use case, grep searches a specified file for a specified string. To
do so, grep takes as its arguments a file path and a string. Then it reads
the file, finds lines in that file that contain the string argument, and prints
those lines.
Along the way, we’ll show how to make our command line tool use the terminal
features that many other command line tools use. We’ll read the value of an
environment variable to allow the user to configure the behavior of our tool.
We’ll also print error messages to the standard error console stream (stderr)
instead of standard output (stdout), so, for example, the user can redirect
successful output to a file while still seeing error messages onscreen.
One Rust community member, Andrew Gallant, has already created a fully
featured, very fast version of grep, called ripgrep. By comparison, our
version will be fairly simple, but this chapter will give you some of the
background knowledge you need to understand a real-world project such as
ripgrep.
Our grep project will combine a number of concepts you’ve learned so far:
- Organizing code (using what you learned about modules in Chapter 7)
- Using vectors and strings (collections, Chapter 8)
- Handling errors (Chapter 9)
- Using traits and lifetimes where appropriate (Chapter 10)
- Writing tests (Chapter 11)
We’ll also briefly introduce closures, iterators, and trait objects, which Chapters 13 and 17 will cover in detail.
Accepting Command Line Arguments
Let’s create a new project with, as always, cargo new. We’ll call our project
minigrep to distinguish it from the grep tool that you might already have
on your system.
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
The first task is to make minigrep accept its two command line arguments: the
file path and a string to search for. That is, we want to be able to run our
program with cargo run, two hyphens to indicate the following arguments are
for our program rather than for cargo, a string to search for, and a path to
a file to search in, like so:
$ cargo run -- searchstring example-filename.txt
Right now, the program generated by cargo new cannot process arguments we
give it. Some existing libraries on crates.io can help
with writing a program that accepts command line arguments, but because you’re
just learning this concept, let’s implement this capability ourselves.
Reading the Argument Values
To enable minigrep to read the values of command line arguments we pass to
it, we’ll need the std::env::args function provided in Rust’s standard
library. This function returns an iterator of the command line arguments passed
to minigrep. We’ll cover iterators fully in Chapter 13. For now, you only need to know two details about iterators: iterators
produce a series of values, and we can call the collect method on an iterator
to turn it into a collection, such as a vector, that contains all the elements
the iterator produces.
The code in Listing 12-1 allows your minigrep program to read any command
line arguments passed to it and then collect the values into a vector.
Filename: src/main.rs
use std::env; fn main() { let args: Vec<String> = env::args().collect(); dbg!(args); }
Listing 12-1: Collecting the command line arguments into a vector and printing them
First, we bring the std::env module into scope with a use statement so we
can use its args function. Notice that the std::env::args function is
nested in two levels of modules. As we discussed in Chapter
7, in cases where the desired function is
nested in more than one module, we’ve chosen to bring the parent module into
scope rather than the function. By doing so, we can easily use other functions
from std::env. It’s also less ambiguous than adding use std::env::args and
then calling the function with just args, because args might easily be
mistaken for a function that’s defined in the current module.
The
argsFunction and Invalid UnicodeNote that
std::env::argswill panic if any argument contains invalid Unicode. If your program needs to accept arguments containing invalid Unicode, usestd::env::args_osinstead. That function returns an iterator that producesOsStringvalues instead ofStringvalues. We’ve chosen to usestd::env::argshere for simplicity, becauseOsStringvalues differ per platform and are more complex to work with thanStringvalues.
On the first line of main, we call env::args, and we immediately use
collect to turn the iterator into a vector containing all the values produced
by the iterator. We can use the collect function to create many kinds of
collections, so we explicitly annotate the type of args to specify that we
want a vector of strings. Although we very rarely need to annotate types in
Rust, collect is one function you do often need to annotate because Rust
isn’t able to infer the kind of collection you want.
Finally, we print the vector using the debug macro. Let’s try running the code first with no arguments and then with two arguments:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
Notice that the first value in the vector is "target/debug/minigrep", which
is the name of our binary. This matches the behavior of the arguments list in
C, letting programs use the name by which they were invoked in their execution.
It’s often convenient to have access to the program name in case you want to
print it in messages or change behavior of the program based on what command
line alias was used to invoke the program. But for the purposes of this
chapter, we’ll ignore it and save only the two arguments we need.
Saving the Argument Values in Variables
The program is currently able to access the values specified as command line arguments. Now we need to save the values of the two arguments in variables so we can use the values throughout the rest of the program. We do that in Listing 12-2.
Filename: src/main.rs
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {}", query);
println!("In file {}", file_path);
}
Listing 12-2: Creating variables to hold the query argument and file path argument
As we saw when we printed the vector, the program’s name takes up the first
value in the vector at args[0], so we’re starting arguments at index 1. The
first argument minigrep takes is the string we’re searching for, so we put a
reference to the first argument in the variable query. The second argument
will be the file path, so we put a reference to the second argument in the
variable file_path.
We temporarily print the values of these variables to prove that the code is
working as we intend. Let’s run this program again with the arguments test
and sample.txt:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
Great, the program is working! The values of the arguments we need are being saved into the right variables. Later we’ll add some error handling to deal with certain potential erroneous situations, such as when the user provides no arguments; for now, we’ll ignore that situation and work on adding file-reading capabilities instead.
Reading a File
Now we’ll add functionality to read the file specified in the file_path
argument. First, we need a sample file to test it with: we’ll use a file with a
small amount of text over multiple lines with some repeated words. Listing 12-3
has an Emily Dickinson poem that will work well! Create a file called
poem.txt at the root level of your project, and enter the poem “I’m Nobody!
Who are you?”
Filename: poem.txt
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Listing 12-3: A poem by Emily Dickinson makes a good test case
With the text in place, edit src/main.rs and add code to read the file, as shown in Listing 12-4.
Filename: src/main.rs
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {}", query);
println!("In file {}", file_path);
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
Listing 12-4: Reading the contents of the file specified by the second argument
First, we bring in a relevant part of the standard library with a use
statement: we need std::fs to handle files.
In main, the new statement fs::read_to_string takes the file_path, opens
that file, and returns a std::io::Result<String> of the file’s contents.
After that, we again add a temporary println! statement that prints the value
of contents after the file is read, so we can check that the program is
working so far.
Let’s run this code with any string as the first command line argument (because we haven’t implemented the searching part yet) and the poem.txt file as the second argument:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Great! The code read and then printed the contents of the file. But the code
has a few flaws. At the moment, the main function has multiple
responsibilities: generally, functions are clearer and easier to maintain if
each function is responsible for only one idea. The other problem is that we’re
not handling errors as well as we could. The program is still small, so these
flaws aren’t a big problem, but as the program grows, it will be harder to fix
them cleanly. It’s good practice to begin refactoring early on when developing
a program, because it’s much easier to refactor smaller amounts of code. We’ll
do that next.
Refactoring to Improve Modularity and Error Handling
To improve our program, we’ll fix four problems that have to do with the
program’s structure and how it’s handling potential errors. First, our main
function now performs two tasks: it parses arguments and reads files. As our
program grows, the number of separate tasks the main function handles will
increase. As a function gains responsibilities, it becomes more difficult to
reason about, harder to test, and harder to change without breaking one of its
parts. It’s best to separate functionality so each function is responsible for
one task.
This issue also ties into the second problem: although query and file_path
are configuration variables to our program, variables like contents are used
to perform the program’s logic. The longer main becomes, the more variables
we’ll need to bring into scope; the more variables we have in scope, the harder
it will be to keep track of the purpose of each. It’s best to group the
configuration variables into one structure to make their purpose clear.
The third problem is that we’ve used expect to print an error message when
reading the file fails, but the error message just prints Should have been able to read the file. Reading a file can fail in a number of ways: for
example, the file could be missing, or we might not have permission to open it.
Right now, regardless of the situation, we’d print the same error message for
everything, which wouldn’t give the user any information!
Fourth, we use expect repeatedly to handle different errors, and if the user
runs our program without specifying enough arguments, they’ll get an index out of bounds error from Rust that doesn’t clearly explain the problem. It would
be best if all the error-handling code were in one place so future maintainers
had only one place to consult the code if the error-handling logic needed to
change. Having all the error-handling code in one place will also ensure that
we’re printing messages that will be meaningful to our end users.
Let’s address these four problems by refactoring our project.
Separation of Concerns for Binary Projects
The organizational problem of allocating responsibility for multiple tasks to
the main function is common to many binary projects. As a result, the Rust
community has developed guidelines for splitting the separate concerns of a
binary program when main starts getting large. This process has the following
steps:
- Split your program into a main.rs and a lib.rs and move your program’s logic to lib.rs.
- As long as your command line parsing logic is small, it can remain in main.rs.
- When the command line parsing logic starts getting complicated, extract it from main.rs and move it to lib.rs.
The responsibilities that remain in the main function after this process
should be limited to the following:
- Calling the command line parsing logic with the argument values
- Setting up any other configuration
- Calling a
runfunction in lib.rs - Handling the error if
runreturns an error
This pattern is about separating concerns: main.rs handles running the
program, and lib.rs handles all the logic of the task at hand. Because you
can’t test the main function directly, this structure lets you test all of
your program’s logic by moving it into functions in lib.rs. The code that
remains in main.rs will be small enough to verify its correctness by reading
it. Let’s rework our program by following this process.
Extracting the Argument Parser
We’ll extract the functionality for parsing arguments into a function that
main will call to prepare for moving the command line parsing logic to
src/lib.rs. Listing 12-5 shows the new start of main that calls a new
function parse_config, which we’ll define in src/main.rs for the moment.
Filename: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {}", query);
println!("In file {}", file_path);
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}
Listing 12-5: Extracting a parse_config function from
main
We’re still collecting the command line arguments into a vector, but instead of
assigning the argument value at index 1 to the variable query and the
argument value at index 2 to the variable file_path within the main
function, we pass the whole vector to the parse_config function. The
parse_config function then holds the logic that determines which argument
goes in which variable and passes the values back to main. We still create
the query and file_path variables in main, but main no longer has the
responsibility of determining how the command line arguments and variables
correspond.
This rework may seem like overkill for our small program, but we’re refactoring in small, incremental steps. After making this change, run the program again to verify that the argument parsing still works. It’s good to check your progress often, to help identify the cause of problems when they occur.
Grouping Configuration Values
We can take another small step to improve the parse_config function further.
At the moment, we’re returning a tuple, but then we immediately break that
tuple into individual parts again. This is a sign that perhaps we don’t have
the right abstraction yet.
Another indicator that shows there’s room for improvement is the config part
of parse_config, which implies that the two values we return are related and
are both part of one configuration value. We’re not currently conveying this
meaning in the structure of the data other than by grouping the two values into
a tuple; we’ll instead put the two values into one struct and give each of the
struct fields a meaningful name. Doing so will make it easier for future
maintainers of this code to understand how the different values relate to each
other and what their purpose is.
Listing 12-6 shows the improvements to the parse_config function.
Filename: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
Listing 12-6: Refactoring parse_config to return an
instance of a Config struct
We’ve added a struct named Config defined to have fields named query and
file_path. The signature of parse_config now indicates that it returns a
Config value. In the body of parse_config, where we used to return
string slices that reference String values in args, we now define Config
to contain owned String values. The args variable in main is the owner of
the argument values and is only letting the parse_config function borrow
them, which means we’d violate Rust’s borrowing rules if Config tried to take
ownership of the values in args.
There are a number of ways we could manage the String data; the easiest,
though somewhat inefficient, route is to call the clone method on the values.
This will make a full copy of the data for the Config instance to own, which
takes more time and memory than storing a reference to the string data.
However, cloning the data also makes our code very straightforward because we
don’t have to manage the lifetimes of the references; in this circumstance,
giving up a little performance to gain simplicity is a worthwhile trade-off.
The Trade-Offs of Using
cloneThere’s a tendency among many Rustaceans to avoid using
cloneto fix ownership problems because of its runtime cost. In Chapter 13, you’ll learn how to use more efficient methods in this type of situation. But for now, it’s okay to copy a few strings to continue making progress because you’ll make these copies only once and your file path and query string are very small. It’s better to have a working program that’s a bit inefficient than to try to hyperoptimize code on your first pass. As you become more experienced with Rust, it’ll be easier to start with the most efficient solution, but for now, it’s perfectly acceptable to callclone.
We’ve updated main so it places the instance of Config returned by
parse_config into a variable named config, and we updated the code that
previously used the separate query and file_path variables so it now uses
the fields on the Config struct instead.
Now our code more clearly conveys that query and file_path are related and
that their purpose is to configure how the program will work. Any code that
uses these values knows to find them in the config instance in the fields
named for their purpose.
Creating a Constructor for Config
So far, we’ve extracted the logic responsible for parsing the command line
arguments from main and placed it in the parse_config function. Doing so
helped us to see that the query and file_path values were related and that
relationship should be conveyed in our code. We then added a Config struct to
name the related purpose of query and file_path and to be able to return the
values’ names as struct field names from the parse_config function.
So now that the purpose of the parse_config function is to create a Config
instance, we can change parse_config from a plain function to a function
named new that is associated with the Config struct. Making this change
will make the code more idiomatic. We can create instances of types in the
standard library, such as String, by calling String::new. Similarly, by
changing parse_config into a new function associated with Config, we’ll
be able to create instances of Config by calling Config::new. Listing 12-7
shows the changes we need to make.
Filename: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}
Listing 12-7: Changing parse_config into
Config::new
We’ve updated main where we were calling parse_config to instead call
Config::new. We’ve changed the name of parse_config to new and moved it
within an impl block, which associates the new function with Config. Try
compiling this code again to make sure it works.
Fixing the Error Handling
Now we’ll work on fixing our error handling. Recall that attempting to access
the values in the args vector at index 1 or index 2 will cause the program to
panic if the vector contains fewer than three items. Try running the program
without any arguments; it will look like this:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at 'index out of bounds: the len is 1 but the index is 1', src/main.rs:27:21
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
The line index out of bounds: the len is 1 but the index is 1 is an error
message intended for programmers. It won’t help our end users understand what
they should do instead. Let’s fix that now.
Improving the Error Message
In Listing 12-8, we add a check in the new function that will verify that the
slice is long enough before accessing index 1 and 2. If the slice isn’t long
enough, the program panics and displays a better error message.
Filename: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}
Listing 12-8: Adding a check for the number of arguments
This code is similar to the Guess::new function we wrote in Listing
9-13, where we called panic! when the
value argument was out of the range of valid values. Instead of checking for
a range of values here, we’re checking that the length of args is at least 3
and the rest of the function can operate under the assumption that this
condition has been met. If args has fewer than three items, this condition
will be true, and we call the panic! macro to end the program immediately.
With these extra few lines of code in new, let’s run the program without any
arguments again to see what the error looks like now:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at 'not enough arguments', src/main.rs:26:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
This output is better: we now have a reasonable error message. However, we also
have extraneous information we don’t want to give to our users. Perhaps using
the technique we used in Listing 9-13 isn’t the best to use here: a call to
panic! is more appropriate for a programming problem than a usage problem,
as discussed in Chapter 9. Instead,
we’ll use the other technique you learned about in Chapter 9—returning a
Result that indicates either success or an error.
Returning a Result Instead of Calling panic!
We can instead return a Result value that will contain a Config instance in
the successful case and will describe the problem in the error case. We’re also
going to change the function name from new to build because many
programmers expect new functions to never fail. When Config::build is
communicating to main, we can use the Result type to signal there was a
problem. Then we can change main to convert an Err variant into a more
practical error for our users without the surrounding text about thread 'main' and RUST_BACKTRACE that a call to panic! causes.
Listing 12-9 shows the changes we need to make to the return value of the
function we’re now calling Config::build and the body of the function needed
to return a Result. Note that this won’t compile until we update main as
well, which we’ll do in the next listing.
Filename: src/main.rs
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
Listing 12-9: Returning a Result from
Config::build
Our build function returns a Result with a Config instance in the success
case and a &'static str in the error case. Our error values will always be
string literals that have the 'static lifetime.
We’ve made two changes in the body of the function: instead of calling panic!
when the user doesn’t pass enough arguments, we now return an Err value, and
we’ve wrapped the Config return value in an Ok. These changes make the
function conform to its new type signature.
Returning an Err value from Config::build allows the main function to
handle the Result value returned from the build function and exit the
process more cleanly in the error case.
Calling Config::build and Handling Errors
To handle the error case and print a user-friendly message, we need to update
main to handle the Result being returned by Config::build, as shown in
Listing 12-10. We’ll also take the responsibility of exiting the command line
tool with a nonzero error code away from panic! and instead implement it by
hand. A nonzero exit status is a convention to signal to the process that
called our program that the program exited with an error state.
Filename: src/main.rs
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
Listing 12-10: Exiting with an error code if building a
Config fails
In this listing, we’ve used a method we haven’t covered in detail yet:
unwrap_or_else, which is defined on Result<T, E> by the standard library.
Using unwrap_or_else allows us to define some custom, non-panic! error
handling. If the Result is an Ok value, this method’s behavior is similar
to unwrap: it returns the inner value Ok is wrapping. However, if the value
is an Err value, this method calls the code in the closure, which is an
anonymous function we define and pass as an argument to unwrap_or_else. We’ll
cover closures in more detail in Chapter 13. For now,
you just need to know that unwrap_or_else will pass the inner value of the
Err, which in this case is the static string "not enough arguments" that we
added in Listing 12-9, to our closure in the argument err that appears
between the vertical pipes. The code in the closure can then use the err
value when it runs.
We’ve added a new use line to bring process from the standard library into
scope. The code in the closure that will be run in the error case is only two
lines: we print the err value and then call process::exit. The
process::exit function will stop the program immediately and return the
number that was passed as the exit status code. This is similar to the
panic!-based handling we used in Listing 12-8, but we no longer get all the
extra output. Let’s try it:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
Great! This output is much friendlier for our users.
Extracting Logic from main
Now that we’ve finished refactoring the configuration parsing, let’s turn to
the program’s logic. As we stated in “Separation of Concerns for Binary
Projects”, we’ll
extract a function named run that will hold all the logic currently in the
main function that isn’t involved with setting up configuration or handling
errors. When we’re done, main will be concise and easy to verify by
inspection, and we’ll be able to write tests for all the other logic.
Listing 12-11 shows the extracted run function. For now, we’re just making
the small, incremental improvement of extracting the function. We’re still
defining the function in src/main.rs.
Filename: src/main.rs
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
Listing 12-11: Extracting a run function containing the
rest of the program logic
The run function now contains all the remaining logic from main, starting
from reading the file. The run function takes the Config instance as an
argument.
Returning Errors from the run Function
With the remaining program logic separated into the run function, we can
improve the error handling, as we did with Config::build in Listing 12-9.
Instead of allowing the program to panic by calling expect, the run
function will return a Result<T, E> when something goes wrong. This will let
us further consolidate the logic around handling errors into main in a
user-friendly way. Listing 12-12 shows the changes we need to make to the
signature and body of run.
Filename: src/main.rs
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
Listing 12-12: Changing the run function to return
Result
We’ve made three significant changes here. First, we changed the return type of
the run function to Result<(), Box<dyn Error>>. This function previously
returned the unit type, (), and we keep that as the value returned in the
Ok case.
For the error type, we used the trait object Box<dyn Error> (and we’ve
brought std::error::Error into scope with a use statement at the top).
We’ll cover trait objects in Chapter 17. For now, just
know that Box<dyn Error> means the function will return a type that
implements the Error trait, but we don’t have to specify what particular type
the return value will be. This gives us flexibility to return error values that
may be of different types in different error cases. The dyn keyword is short
for “dynamic.”
Second, we’ve removed the call to expect in favor of the ? operator, as we
talked about in Chapter 9. Rather than
panic! on an error, ? will return the error value from the current function
for the caller to handle.
Third, the run function now returns an Ok value in the success case.
We’ve declared the run function’s success type as () in the signature,
which means we need to wrap the unit type value in the Ok value. This
Ok(()) syntax might look a bit strange at first, but using () like this is
the idiomatic way to indicate that we’re calling run for its side effects
only; it doesn’t return a value we need.
When you run this code, it will compile but will display a warning:
$ cargo run the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^^
|
= note: `#[warn(unused_must_use)]` on by default
= note: this `Result` may be an `Err` variant, which should be handled
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust tells us that our code ignored the Result value and the Result value
might indicate that an error occurred. But we’re not checking to see whether or
not there was an error, and the compiler reminds us that we probably meant to
have some error-handling code here! Let’s rectify that problem now.
Handling Errors Returned from run in main
We’ll check for errors and handle them using a technique similar to one we used
with Config::build in Listing 12-10, but with a slight difference:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
We use if let rather than unwrap_or_else to check whether run returns an
Err value and call process::exit(1) if it does. The run function doesn’t
return a value that we want to unwrap in the same way that Config::build
returns the Config instance. Because run returns () in the success case,
we only care about detecting an error, so we don’t need unwrap_or_else to
return the unwrapped value, which would only be ().
The bodies of the if let and the unwrap_or_else functions are the same in
both cases: we print the error and exit.
Splitting Code into a Library Crate
Our minigrep project is looking good so far! Now we’ll split the
src/main.rs file and put some code into the src/lib.rs file. That way we
can test the code and have a src/main.rs file with fewer responsibilities.
Let’s move all the code that isn’t the main function from src/main.rs to
src/lib.rs:
- The
runfunction definition - The relevant
usestatements - The definition of
Config - The
Config::buildfunction definition
The contents of src/lib.rs should have the signatures shown in Listing 12-13 (we’ve omitted the bodies of the functions for brevity). Note that this won’t compile until we modify src/main.rs in Listing 12-14.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
// --snip--
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
Listing 12-13: Moving Config and run into
src/lib.rs
We’ve made liberal use of the pub keyword: on Config, on its fields and its
build method, and on the run function. We now have a library crate that has
a public API we can test!
Now we need to bring the code we moved to src/lib.rs into the scope of the binary crate in src/main.rs, as shown in Listing 12-14.
Filename: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = minigrep::run(config) {
// --snip--
println!("Application error: {e}");
process::exit(1);
}
}
Listing 12-14: Using the minigrep library crate in
src/main.rs
We add a use minigrep::Config line to bring the Config type from the
library crate into the binary crate’s scope, and we prefix the run function
with our crate name. Now all the functionality should be connected and should
work. Run the program with cargo run and make sure everything works
correctly.
Whew! That was a lot of work, but we’ve set ourselves up for success in the future. Now it’s much easier to handle errors, and we’ve made the code more modular. Almost all of our work will be done in src/lib.rs from here on out.
Let’s take advantage of this newfound modularity by doing something that would have been difficult with the old code but is easy with the new code: we’ll write some tests!
Developing the Library’s Functionality with Test-Driven Development
Now that we’ve extracted the logic into src/lib.rs and left the argument collecting and error handling in src/main.rs, it’s much easier to write tests for the core functionality of our code. We can call functions directly with various arguments and check return values without having to call our binary from the command line.
In this section, we’ll add the searching logic to the minigrep program
using the test-driven development (TDD) process with the following steps:
- Write a test that fails and run it to make sure it fails for the reason you expect.
- Write or modify just enough code to make the new test pass.
- Refactor the code you just added or changed and make sure the tests continue to pass.
- Repeat from step 1!
Though it’s just one of many ways to write software, TDD can help drive code design. Writing the test before you write the code that makes the test pass helps to maintain high test coverage throughout the process.
We’ll test drive the implementation of the functionality that will actually do
the searching for the query string in the file contents and produce a list of
lines that match the query. We’ll add this functionality in a function called
search.
Writing a Failing Test
Because we don’t need them anymore, let’s remove the println! statements from
src/lib.rs and src/main.rs that we used to check the program’s behavior.
Then, in src/lib.rs, add a tests module with a test function, as we did in
Chapter 11. The test function specifies the
behavior we want the search function to have: it will take a query and the
text to search, and it will return only the lines from the text that contain
the query. Listing 12-15 shows this test, which won’t compile yet.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}
Listing 12-15: Creating a failing test for the search
function we wish we had
This test searches for the string "duct". The text we’re searching is three
lines, only one of which contains "duct" (Note that the backslash after the
opening double quote tells Rust not to put a newline character at the beginning
of the contents of this string literal). We assert that the value returned from
the search function contains only the line we expect.
We aren’t yet able to run this test and watch it fail because the test doesn’t
even compile: the search function doesn’t exist yet! In accordance with TDD
principles, we’ll add just enough code to get the test to compile and run by
adding a definition of the search function that always returns an empty
vector, as shown in Listing 12-16. Then the test should compile and fail
because an empty vector doesn’t match a vector containing the line "safe, fast, productive."
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}
Listing 12-16: Defining just enough of the search
function so our test will compile
Notice that we need to define an explicit lifetime 'a in the signature of
search and use that lifetime with the contents argument and the return
value. Recall in Chapter 10 that the lifetime
parameters specify which argument lifetime is connected to the lifetime of the
return value. In this case, we indicate that the returned vector should contain
string slices that reference slices of the argument contents (rather than the
argument query).
In other words, we tell Rust that the data returned by the search function
will live as long as the data passed into the search function in the
contents argument. This is important! The data referenced by a slice needs
to be valid for the reference to be valid; if the compiler assumes we’re making
string slices of query rather than contents, it will do its safety checking
incorrectly.
If we forget the lifetime annotations and try to compile this function, we’ll get this error:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:28:51
|
28 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
28 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` due to previous error
Rust can’t possibly know which of the two arguments we need, so we need to tell
it explicitly. Because contents is the argument that contains all of our text
and we want to return the parts of that text that match, we know contents is
the argument that should be connected to the return value using the lifetime
syntax.
Other programming languages don’t require you to connect arguments to return values in the signature, but this practice will get easier over time. You might want to compare this example with the “Validating References with Lifetimes” section in Chapter 10.
Now let’s run the test:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 0.97s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... FAILED
failures:
---- tests::one_result stdout ----
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `["safe, fast, productive."]`,
right: `[]`', src/lib.rs:44:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::one_result
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
Great, the test fails, exactly as we expected. Let’s get the test to pass!
Writing Code to Pass the Test
Currently, our test is failing because we always return an empty vector. To fix
that and implement search, our program needs to follow these steps:
- Iterate through each line of the contents.
- Check whether the line contains our query string.
- If it does, add it to the list of values we’re returning.
- If it doesn’t, do nothing.
- Return the list of results that match.
Let’s work through each step, starting with iterating through lines.
Iterating Through Lines with the lines Method
Rust has a helpful method to handle line-by-line iteration of strings,
conveniently named lines, that works as shown in Listing 12-17. Note this
won’t compile yet.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}
Listing 12-17: Iterating through each line in contents
The lines method returns an iterator. We’ll talk about iterators in depth in
Chapter 13, but recall that you saw this way
of using an iterator in Listing 3-5, where we used a
for loop with an iterator to run some code on each item in a collection.
Searching Each Line for the Query
Next, we’ll check whether the current line contains our query string.
Fortunately, strings have a helpful method named contains that does this for
us! Add a call to the contains method in the search function, as shown in
Listing 12-18. Note this still won’t compile yet.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}
Listing 12-18: Adding functionality to see whether the
line contains the string in query
At the moment, we’re building up functionality. To get it to compile, we need to return a value from the body as we indicated we would in the function signature.
Storing Matching Lines
To finish this function, we need a way to store the matching lines that we want
to return. For that, we can make a mutable vector before the for loop and
call the push method to store a line in the vector. After the for loop,
we return the vector, as shown in Listing 12-19.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}
Listing 12-19: Storing the lines that match so we can return them
Now the search function should return only the lines that contain query,
and our test should pass. Let’s run the test:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Our test passed, so we know it works!
At this point, we could consider opportunities for refactoring the implementation of the search function while keeping the tests passing to maintain the same functionality. The code in the search function isn’t too bad, but it doesn’t take advantage of some useful features of iterators. We’ll return to this example in Chapter 13, where we’ll explore iterators in detail, and look at how to improve it.
Using the search Function in the run Function
Now that the search function is working and tested, we need to call search
from our run function. We need to pass the config.query value and the
contents that run reads from the file to the search function. Then run
will print each line returned from search:
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}
We’re still using a for loop to return each line from search and print it.
Now the entire program should work! Let’s try it out, first with a word that should return exactly one line from the Emily Dickinson poem, “frog”:
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
Cool! Now let’s try a word that will match multiple lines, like “body”:
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
And finally, let’s make sure that we don’t get any lines when we search for a word that isn’t anywhere in the poem, such as “monomorphization”:
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
Excellent! We’ve built our own mini version of a classic tool and learned a lot about how to structure applications. We’ve also learned a bit about file input and output, lifetimes, testing, and command line parsing.
To round out this project, we’ll briefly demonstrate how to work with environment variables and how to print to standard error, both of which are useful when you’re writing command line programs.
Working with Environment Variables
We’ll improve minigrep by adding an extra feature: an option for
case-insensitive searching that the user can turn on via an environment
variable. We could make this feature a command line option and require that
users enter it each time they want it to apply, but by instead making it an
environment variable, we allow our users to set the environment variable once
and have all their searches be case insensitive in that terminal session.
Writing a Failing Test for the Case-Insensitive search Function
We first add a new search_case_insensitive function that will be called when
the environment variable has a value. We’ll continue to follow the TDD process,
so the first step is again to write a failing test. We’ll add a new test for
the new search_case_insensitive function and rename our old test from
one_result to case_sensitive to clarify the differences between the two
tests, as shown in Listing 12-20.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Listing 12-20: Adding a new failing test for the case-insensitive function we’re about to add
Note that we’ve edited the old test’s contents too. We’ve added a new line
with the text "Duct tape." using a capital D that shouldn’t match the query
"duct" when we’re searching in a case-sensitive manner. Changing the old test
in this way helps ensure that we don’t accidentally break the case-sensitive
search functionality that we’ve already implemented. This test should pass now
and should continue to pass as we work on the case-insensitive search.
The new test for the case-insensitive search uses "rUsT" as its query. In
the search_case_insensitive function we’re about to add, the query "rUsT"
should match the line containing "Rust:" with a capital R and match the line
"Trust me." even though both have different casing from the query. This is
our failing test, and it will fail to compile because we haven’t yet defined
the search_case_insensitive function. Feel free to add a skeleton
implementation that always returns an empty vector, similar to the way we did
for the search function in Listing 12-16 to see the test compile and fail.
Implementing the search_case_insensitive Function
The search_case_insensitive function, shown in Listing 12-21, will be almost
the same as the search function. The only difference is that we’ll lowercase
the query and each line so whatever the case of the input arguments,
they’ll be the same case when we check whether the line contains the query.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Listing 12-21: Defining the search_case_insensitive
function to lowercase the query and the line before comparing them
First, we lowercase the query string and store it in a shadowed variable with
the same name. Calling to_lowercase on the query is necessary so no
matter whether the user’s query is "rust", "RUST", "Rust", or "rUsT",
we’ll treat the query as if it were "rust" and be insensitive to the case.
While to_lowercase will handle basic Unicode, it won’t be 100% accurate. If
we were writing a real application, we’d want to do a bit more work here, but
this section is about environment variables, not Unicode, so we’ll leave it at
that here.
Note that query is now a String rather than a string slice, because calling
to_lowercase creates new data rather than referencing existing data. Say the
query is "rUsT", as an example: that string slice doesn’t contain a lowercase
u or t for us to use, so we have to allocate a new String containing
"rust". When we pass query as an argument to the contains method now, we
need to add an ampersand because the signature of contains is defined to take
a string slice.
Next, we add a call to to_lowercase on each line to lowercase all
characters. Now that we’ve converted line and query to lowercase, we’ll
find matches no matter what the case of the query is.
Let’s see if this implementation passes the tests:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Great! They passed. Now, let’s call the new search_case_insensitive function
from the run function. First, we’ll add a configuration option to the
Config struct to switch between case-sensitive and case-insensitive search.
Adding this field will cause compiler errors because we aren’t initializing
this field anywhere yet:
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
We added the ignore_case field that holds a Boolean. Next, we need the run
function to check the ignore_case field’s value and use that to decide
whether to call the search function or the search_case_insensitive
function, as shown in Listing 12-22. This still won’t compile yet.
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Listing 12-22: Calling either search or
search_case_insensitive based on the value in config.ignore_case
Finally, we need to check for the environment variable. The functions for
working with environment variables are in the env module in the standard
library, so we bring that module into scope at the top of src/lib.rs. Then
we’ll use the var function from the env module to check to see if any value
has been set for an environment variable named IGNORE_CASE, as shown in
Listing 12-23.
Filename: src/lib.rs
use std::env;
// --snip--
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Listing 12-23: Checking for any value in an environment
variable named IGNORE_CASE
Here, we create a new variable ignore_case. To set its value, we call the
env::var function and pass it the name of the IGNORE_CASE environment
variable. The env::var function returns a Result that will be the
successful Ok variant that contains the value of the environment variable if
the environment variable is set to any value. It will return the Err variant
if the environment variable is not set.
We’re using the is_ok method on the Result to check whether the environment
variable is set, which means the program should do a case-insensitive search.
If the IGNORE_CASE environment variable isn’t set to anything, is_ok will
return false and the program will perform a case-sensitive search. We don’t
care about the value of the environment variable, just whether it’s set or
unset, so we’re checking is_ok rather than using unwrap, expect, or any
of the other methods we’ve seen on Result.
We pass the value in the ignore_case variable to the Config instance so the
run function can read that value and decide whether to call
search_case_insensitive or search, as we implemented in Listing 12-22.
Let’s give it a try! First, we’ll run our program without the environment
variable set and with the query to, which should match any line that contains
the word “to” in all lowercase:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
Looks like that still works! Now, let’s run the program with IGNORE_CASE
set to 1 but with the same query to.
$ IGNORE_CASE=1 cargo run -- to poem.txt
If you’re using PowerShell, you will need to set the environment variable and run the program as separate commands:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
This will make IGNORE_CASE persist for the remainder of your shell
session. It can be unset with the Remove-Item cmdlet:
PS> Remove-Item Env:IGNORE_CASE
We should get lines that contain “to” that might have uppercase letters:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Excellent, we also got lines containing “To”! Our minigrep program can now do
case-insensitive searching controlled by an environment variable. Now you know
how to manage options set using either command line arguments or environment
variables.
Some programs allow arguments and environment variables for the same configuration. In those cases, the programs decide that one or the other takes precedence. For another exercise on your own, try controlling case sensitivity through either a command line argument or an environment variable. Decide whether the command line argument or the environment variable should take precedence if the program is run with one set to case sensitive and one set to ignore case.
The std::env module contains many more useful features for dealing with
environment variables: check out its documentation to see what is available.
Writing Error Messages to Standard Error Instead of Standard Output
At the moment, we’re writing all of our output to the terminal using the
println! macro. In most terminals, there are two kinds of output: standard
output (stdout) for general information and standard error (stderr) for
error messages. This distinction enables users to choose to direct the
successful output of a program to a file but still print error messages to the
screen.
The println! macro is only capable of printing to standard output, so we
have to use something else to print to standard error.
Checking Where Errors Are Written
First, let’s observe how the content printed by minigrep is currently being
written to standard output, including any error messages we want to write to
standard error instead. We’ll do that by redirecting the standard output stream
to a file while intentionally causing an error. We won’t redirect the standard
error stream, so any content sent to standard error will continue to display on
the screen.
Command line programs are expected to send error messages to the standard error stream so we can still see error messages on the screen even if we redirect the standard output stream to a file. Our program is not currently well-behaved: we’re about to see that it saves the error message output to a file instead!
To demonstrate this behavior, we’ll run the program with > and the file path,
output.txt, that we want to redirect the standard output stream to. We won’t
pass any arguments, which should cause an error:
$ cargo run > output.txt
The > syntax tells the shell to write the contents of standard output to
output.txt instead of the screen. We didn’t see the error message we were
expecting printed to the screen, so that means it must have ended up in the
file. This is what output.txt contains:
Problem parsing arguments: not enough arguments
Yup, our error message is being printed to standard output. It’s much more useful for error messages like this to be printed to standard error so only data from a successful run ends up in the file. We’ll change that.
Printing Errors to Standard Error
We’ll use the code in Listing 12-24 to change how error messages are printed.
Because of the refactoring we did earlier in this chapter, all the code that
prints error messages is in one function, main. The standard library provides
the eprintln! macro that prints to the standard error stream, so let’s change
the two places we were calling println! to print errors to use eprintln!
instead.
Filename: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
Listing 12-24: Writing error messages to standard error
instead of standard output using eprintln!
Let’s now run the program again in the same way, without any arguments and
redirecting standard output with >:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
Now we see the error onscreen and output.txt contains nothing, which is the behavior we expect of command line programs.
Let’s run the program again with arguments that don’t cause an error but still redirect standard output to a file, like so:
$ cargo run -- to poem.txt > output.txt
We won’t see any output to the terminal, and output.txt will contain our results:
Filename: output.txt
Are you nobody, too?
How dreary to be somebody!
This demonstrates that we’re now using standard output for successful output and standard error for error output as appropriate.
Summary
This chapter recapped some of the major concepts you’ve learned so far and
covered how to perform common I/O operations in Rust. By using command line
arguments, files, environment variables, and the eprintln! macro for printing
errors, you’re now prepared to write command line applications. Combined with
the concepts in previous chapters, your code will be well organized, store data
effectively in the appropriate data structures, handle errors nicely, and be
well tested.
Next, we’ll explore some Rust features that were influenced by functional languages: closures and iterators.
Functional Language Features: Iterators and Closures
Rust’s design has taken inspiration from many existing languages and techniques, and one significant influence is functional programming. Programming in a functional style often includes using functions as values by passing them in arguments, returning them from other functions, assigning them to variables for later execution, and so forth.
In this chapter, we won’t debate the issue of what functional programming is or isn’t but will instead discuss some features of Rust that are similar to features in many languages often referred to as functional.
More specifically, we’ll cover:
- Closures, a function-like construct you can store in a variable
- Iterators, a way of processing a series of elements
- How to use closures and iterators to improve the I/O project in Chapter 12
- The performance of closures and iterators (Spoiler alert: they’re faster than you might think!)
We’ve already covered some other Rust features, such as pattern matching and enums, that are also influenced by the functional style. Because mastering closures and iterators is an important part of writing idiomatic, fast Rust code, we’ll devote this entire chapter to them.
Closures: Anonymous Functions that Capture Their Environment
Rust’s closures are anonymous functions you can save in a variable or pass as arguments to other functions.
You can create the closure in one place and then call the closure elsewhere to evaluate it in a different context.
Unlike functions, closures can capture values from the scope in which they’re defined. We’ll demonstrate how these closure features allow for code reuse and behavior customization.
Capturing the Environment with Closures
We’ll first examine how we can use closures to capture values from the environment they’re defined in for later use.
Here’s the scenario:
- Every so often, our t-shirt company gives away an exclusive, limited-edition shirt to someone on our mailing list as a promotion.
- People on the mailing list can optionally add their favorite color to their profile.
- If the person chosen for a free shirt has their favorite color set, they get that color shirt.
- If the person hasn’t specified a favorite color, they get whatever color the company currently has the most of.
There are many ways to implement this. For this example, we’re going to use an
enum called ShirtColor that has the variants Red and Blue (limiting the
number of colors available for simplicity). We represent the company’s
inventory with an Inventory struct that has a field named shirts that
contains a Vec<ShirtColor> representing the shirt colors currently in stock.
The method giveaway defined on Inventory gets the optional shirt
color preference of the free shirt winner, and returns the shirt color the
person will get.
This setup is shown in Listing 13-1:
Filename: src/main.rs
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}
Listing 13-1: Shirt company giveaway situation
- The
storedefined inmainhas two blue shirts and one red shirt remaining to distribute for this limited-edition promotion. - We call the
giveawaymethod for a user with a preference for a red shirt and a user without any preference.
Again, this code could be implemented in many ways, and here, to focus on closures, we’ve stuck to concepts you’ve already learned except for the body of the
giveawaymethod that uses a closure.
- In the
giveawaymethod, we get the user preference as a parameter of typeOption<ShirtColor>and call theunwrap_or_elsemethod onuser_preference. - The
unwrap_or_elsemethod onOption<T>is defined by the standard library. - It takes one argument: a closure without any arguments that returns a value
T(the same type stored in theSomevariant of theOption<T>, in this caseShirtColor). - If the
Option<T>is theSomevariant,unwrap_or_elsereturns the value from within theSome. - If the
Option<T>is theNonevariant,unwrap_or_elsecalls the closure and returns the value returned by the closure.
We specify the closure expression
|| self.most_stocked()as the argument tounwrap_or_else.
This is a closure that takes no parameters itself (if the closure had parameters, they would appear between the two vertical bars).
The body of the closure calls self.most_stocked(). We’re defining the closure
here, and the implementation of unwrap_or_else will evaluate the closure
later if the result is needed.
Running this code prints:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished dev [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
One interesting aspect here is that we’ve passed a closure that calls
self.most_stocked()on the currentInventoryinstance.
- The standard library
didn’t need to know anything about the
InventoryorShirtColortypes we defined, or the logic we want to use in this scenario. - The closure captures an
immutable reference to the
selfInventoryinstance and passes it with the code we specify to theunwrap_or_elsemethod.
Functions, on the other hand, are not able to capture their environment in this way.
Closure Type Inference and Annotation
There are more differences between functions and closures.
- Closures don’t
usually require you to annotate the types of the parameters or the return value
like
fnfunctions do. - Type annotations are required on functions because the types are part of an explicit interface exposed to your users.
- Defining this interface rigidly is important for ensuring that everyone agrees on what types of values a function uses and returns.
Closures, on the other hand, aren’t used in an exposed interface like this: they’re stored in variables and used without naming them and exposing them to users of our library.
-
Closures are typically short and relevant only within a narrow context rather than in any arbitrary scenario.
-
Within these limited contexts, the compiler can infer the types of the parameters and the return type, similar to how it’s able to infer the types of most variables (there are rare cases where the compiler needs closure type annotations too).
-
As with variables, we can add type annotations if we want to increase explicitness and clarity at the cost of being more verbose than is strictly necessary.
Annotating the types for a closure would look like the definition shown in Listing 13-2. In this example, we’re defining a closure and storing it in a variable rather than defining the closure in the spot we pass it as an argument as we did in Listing 13-1.
Filename: src/main.rs
use std::thread; use std::time::Duration; fn generate_workout(intensity: u32, random_number: u32) { let expensive_closure = |num: u32| -> u32 { println!("calculating slowly..."); thread::sleep(Duration::from_secs(2)); num }; if intensity < 25 { println!("Today, do {} pushups!", expensive_closure(intensity)); println!("Next, do {} situps!", expensive_closure(intensity)); } else { if random_number == 3 { println!("Take a break today! Remember to stay hydrated!"); } else { println!( "Today, run for {} minutes!", expensive_closure(intensity) ); } } } fn main() { let simulated_user_specified_value = 10; let simulated_random_number = 7; generate_workout(simulated_user_specified_value, simulated_random_number); }
Listing 13-2: Adding optional type annotations of the parameter and return value types in the closure
With type annotations added, the syntax of closures looks more similar to the syntax of functions.
- Here we define a function that adds 1 to its parameter and a closure that has the same behavior, for comparison.
- We’ve added some spaces to line up the relevant parts.
- This illustrates how closure syntax is similar to function syntax except for the use of pipes and the amount of syntax that is optional:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;
- The first line shows a function definition
- and the second line shows a fully annotated closure definition.
- In the third line, we remove the type annotations from the closure definition.
- In the fourth line, we remove the brackets, which are optional because the closure body has only one expression.
These are all valid definitions that will produce the same behavior when they’re called.
- The
add_one_v3andadd_one_v4lines require the closures to be evaluated to be able to compile because the types will be inferred from their usage. - This is
similar to
let v = Vec::new();needing either type annotations or values of some type to be inserted into theVecfor Rust to be able to infer the type.
For closure definitions, the compiler will infer one concrete type for each of their parameters and for their return value.
- For instance, Listing 13-3 shows the definition of a short closure that just returns the value it receives as a parameter.
- This closure isn’t very useful except for the purposes of this example. Note that we haven’t added any type annotations to the definition.
Because there are no type annotations, we can call the closure with any type, which we’ve done here with
Stringthe first time.
If we then try to call
example_closure with an integer, we’ll get an error.
Filename: src/main.rs
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}
Listing 13-3: Attempting to call a closure whose types are inferred with two different types
The compiler gives us this error:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| ^- help: try using a conversion method: `.to_string()`
| |
| expected struct `String`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` due to previous error
- The first time we call
example_closurewith theStringvalue, the compiler infers the type ofxand the return type of the closure to beString. - Those
types are then locked into the closure in
example_closure, and we get a type error when we next try to use a different type with the same closure.
Capturing References or Moving Ownership
Closures can capture values from their environment in three ways, which directly map to the three ways a function can take a parameter:
-
borrowing immutably
-
borrowing mutably
-
and taking ownership.
-
The closure will decide which of these to use based on what the body of the function does with the captured values.
In Listing 13-4, we define a closure that captures an immutable reference to
the vector named list because it only needs an immutable reference to print
the value:
Filename: src/main.rs
fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {:?}", list); let only_borrows = || println!("From closure: {:?}", list); println!("Before calling closure: {:?}", list); only_borrows(); println!("After calling closure: {:?}", list); }
Listing 13-4: Defining and calling a closure that captures an immutable reference
This example also illustrates that a variable can bind to a closure definition, and we can later call the closure by using the variable name and parentheses as if the variable name were a function name.
Because we can have multiple immutable references to list at the same time,
list is still accessible from the code before the closure definition, after
the closure definition but before the closure is called, and after the closure
is called.
This code compiles, runs, and prints:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
Next, in Listing 13-5, we change the closure body so that it adds an element to
the list vector. The closure now captures a mutable reference:
Filename: src/main.rs
fn main() { let mut list = vec![1, 2, 3]; println!("Before defining closure: {:?}", list); let mut borrows_mutably = || list.push(7); borrows_mutably(); println!("After calling closure: {:?}", list); }
Listing 13-5: Defining and calling a closure that captures a mutable reference
This code compiles, runs, and prints:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
Note that there’s no longer a
println!between the definition and the call of theborrows_mutablyclosure:
- when
borrows_mutablyis defined, it captures a mutable reference tolist. - We don’t use the closure again after the closure is called, so the mutable borrow ends.
- Between the closure definition and the closure call, an immutable borrow to print isn’t allowed because no other borrows are allowed when there’s a mutable borrow.
- Try adding a
println!there to see what error message you get!
If you want to force the closure to take ownership of the values it uses in the environment even though the body of the closure doesn’t strictly need ownership, you can use the
movekeyword before the parameter list.
- This technique is mostly useful when passing a closure to a new thread to move the data so that it’s owned by the new thread.
- We’ll discuss threads and why
you would want to use them in detail in Chapter 16 when we talk about
concurrency, but for now, let’s briefly explore spawning a new thread using a
closure that needs the
movekeyword.
Listing 13-6 shows Listing 13-4 modified to print the vector in a new thread rather than in the main thread:
Filename: src/main.rs
use std::thread; fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {:?}", list); thread::spawn(move || println!("From thread: {:?}", list)) .join() .unwrap(); }
Listing 13-6: Using move to force the closure for the
thread to take ownership of list
- We spawn a new thread, giving the thread a closure to run as an argument.
- The closure body prints out the list.
- In Listing 13-4, the closure only captured
listusing an immutable reference because that’s the least amount of access tolistneeded to print it. - In this example, even though the closure body
still only needs an immutable reference, we need to specify that
listshould be moved into the closure by putting themovekeyword at the beginning of the closure definition. - The new thread might finish before the rest of the main thread finishes, or the main thread might finish first.
- If the main thread
maintained ownership of
listbut ended before the new thread did and droppedlist, the immutable reference in the thread would be invalid. - Therefore, the
compiler requires that
listbe moved into the closure given to the new thread so the reference will be valid. - Try removing the
movekeyword or usinglistin the main thread after the closure is defined to see what compiler errors you get!
Moving Captured Values Out of Closures and the Fn Traits
Once a closure has captured a reference or captured ownership of a value from the environment where the closure is defined (thus affecting what, if anything, is moved into the closure), the code in the body of the closure defines what happens to the references or values when the closure is evaluated later (thus affecting what, if anything, is moved out of the closure).
A closure body can do any of the following:
- move a captured value out of the closure
- mutate the captured value
- neither move nor mutate the value, or capture nothing from the environment to begin with.
The way a closure captures and handles values from the environment affects which traits the closure implements, and traits are how functions and structs can specify what kinds of closures they can use.
Closures will automatically
implement one, two, or all three of these Fn traits, in an additive fashion,
depending on how the closure’s body handles the values:
FnOnceapplies to closures that can be called once. All closures implement at least this trait, because all closures can be called. A closure that moves captured values out of its body will only implementFnOnceand none of the otherFntraits, because it can only be called once.FnMutapplies to closures that don’t move captured values out of their body, but that might mutate the captured values. These closures can be called more than once.Fnapplies to closures that don’t move captured values out of their body and that don’t mutate captured values, as well as closures that capture nothing from their environment. These closures can be called more than once without mutating their environment, which is important in cases such as calling a closure multiple times concurrently.
Let’s look at the definition of the unwrap_or_else method on Option<T> that
we used in Listing 13-1:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}
-
Recall that
Tis the generic type representing the type of the value in theSomevariant of anOption. -
That type
Tis also the return type of theunwrap_or_elsefunction: code that callsunwrap_or_elseon anOption<String>, for example, will get aString. -
Next, notice that the
unwrap_or_elsefunction has the additional generic type parameterF. -
The
Ftype is the type of the parameter namedf, which is the closure we provide when callingunwrap_or_else. -
The trait bound specified on the generic type
FisFnOnce() -> T, which meansFmust be able to be called once, take no arguments, and return aT. -
Using
FnOncein the trait bound expresses the constraint thatunwrap_or_elseis only going to callfat most one time. -
In the body of
unwrap_or_else, we can see that if theOptionisSome,fwon’t be called. -
If the
OptionisNone,fwill be called once. -
Because all closures implement
FnOnce,unwrap_or_elseaccepts the most different kinds of closures and is as flexible as it can be.
Note: Functions can implement all three of the
Fntraits too.
- If what we
want to do doesn’t require capturing a value from the environment, we can use
the name of a function rather than a closure where we need something that
implements one of the
Fntraits. - For example, on an
Option<Vec<T>>value, we could callunwrap_or_else(Vec::new)to get a new, empty vector if the value isNone.
Now let’s look at the standard library method sort_by_key defined on slices,
to see how that differs from unwrap_or_else and why sort_by_key uses
FnMut instead of FnOnce for the trait bound.
The closure gets one argument
in the form of a reference to the current item in the slice being considered,
and returns a value of type K that can be ordered. This function is useful
when you want to sort a slice by a particular attribute of each item.
In
Listing 13-7, we have a list of Rectangle instances and we use sort_by_key
to order them by their width attribute from low to high:
Filename: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; list.sort_by_key(|r| r.width); println!("{:#?}", list); }
Listing 13-7: Using sort_by_key to order rectangles by
width
This code prints:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
- The reason
sort_by_keyis defined to take anFnMutclosure is that it calls the closure multiple times: once for each item in the slice. - The closure
|r| r.widthdoesn’t capture, mutate, or move out anything from its environment, so it meets the trait bound requirements.
In contrast, Listing 13-8 shows an example of a closure that implements just
the FnOnce trait, because it moves a value out of the environment. The
compiler won’t let us use this closure with sort_by_key:
Filename: src/main.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("by key called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{:#?}", list);
}
Listing 13-8: Attempting to use an FnOnce closure with
sort_by_key
- This is a contrived, convoluted way (that doesn’t work) to try and count the
number of times
sort_by_keygets called when sortinglist. - This code
attempts to do this counting by pushing
value—aStringfrom the closure’s environment—into thesort_operationsvector. - The closure captures
valuethen movesvalueout of the closure by transferring ownership ofvalueto thesort_operationsvector. - This closure can be called once;
- trying to call
it a second time wouldn’t work because
valuewould no longer be in the environment to be pushed intosort_operationsagain! - Therefore, this closure
only implements
FnOnce. - When we try to compile this code, we get this error
that
valuecan’t be moved out of the closure because the closure must implementFnMut:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("by key called");
| ----- captured outer variable
16 |
17 | list.sort_by_key(|r| {
| ______________________-
18 | | sort_operations.push(value);
| | ^^^^^ move occurs because `value` has type `String`, which does not implement the `Copy` trait
19 | | r.width
20 | | });
| |_____- captured by this `FnMut` closure
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` due to previous error
The error points to the line in the closure body that moves value out of the
environment.
To fix this, we need to change the closure body so that it doesn’t move values out of the environment.
To count the number of times sort_by_key
is called, keeping a counter in the environment and incrementing its value in
the closure body is a more straightforward way to calculate that. The closure
in Listing 13-9 works with sort_by_key because it is only capturing a mutable
reference to the num_sort_operations counter and can therefore be called more
than once:
Filename: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; let mut num_sort_operations = 0; list.sort_by_key(|r| { num_sort_operations += 1; r.width }); println!("{:#?}, sorted in {num_sort_operations} operations", list); }
Listing 13-9: Using an FnMut closure with sort_by_key
is allowed
The Fn traits are important when defining or using functions or types that
make use of closures. In the next section, we’ll discuss iterators.
Many iterator methods take closure arguments, so keep these closure details in mind as we continue!
Processing a Series of Items with Iterators
The iterator pattern allows you to perform some task on a sequence of items in turn. An iterator is responsible for the logic of iterating over each item and determining when the sequence has finished. When you use iterators, you don’t have to reimplement that logic yourself.
In Rust, iterators are lazy, meaning they have no effect until you call methods that consume the iterator to use it up.
For example, the code in
Listing 13-10 creates an iterator over the items in the vector v1 by calling
the iter method defined on Vec<T>. This code by itself doesn’t do anything
useful.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); }
Listing 13-10: Creating an iterator
- The iterator is stored in the
v1_itervariable. - Once we’ve created an iterator, we can use it in a variety of ways.
- In Listing 3-5 in Chapter 3, we
iterated over an array using a
forloop to execute some code on each of its items. - Under the hood this implicitly created and then consumed an iterator, but we glossed over how exactly that works until now.
In the example in Listing 13-11, we separate the creation of the iterator from
the use of the iterator in the for loop.
When the
forloop is called using the iterator inv1_iter, each element in the iterator is used in one iteration of the loop, which prints out each value.
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("Got: {}", val); } }
Listing 13-11: Using an iterator in a for loop
In languages that don’t have iterators provided by their standard libraries, you would likely write this same functionality by starting a variable at index 0, using that variable to index into the vector to get a value, and incrementing the variable value in a loop until it reached the total number of items in the vector.
Iterators handle all that logic for you, cutting down on repetitive code you could potentially mess up.
Iterators give you more flexibility to use the same logic with many different kinds of sequences, not just data structures you can index into, like vectors. Let’s examine how iterators do that.
The Iterator Trait and the next Method
All iterators implement a trait named
Iteratorthat is defined in the standard library. The definition of the trait looks like this:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // methods with default implementations elided } }
Notice this definition uses some new syntax:
type ItemandSelf::Item, which are defining an associated type with this trait.
- We’ll talk about associated types in depth in Chapter 19.
- For now, all you need to know is that
this code says implementing the
Iteratortrait requires that you also define anItemtype, and thisItemtype is used in the return type of thenextmethod. - In other words, the
Itemtype will be the type returned from the iterator.
The
Iteratortrait only requires implementors to define one method: thenextmethod
- which returns one item of the iterator at a time wrapped in
Some - and, when iteration is over, returns
None. - We can call the
nextmethod on iterators directly;
Listing 13-12 demonstrates
what values are returned from repeated calls to next on the iterator created
from the vector.
Filename: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}
Listing 13-12: Calling the next method on an
iterator
Note that we needed to make
v1_itermutable: calling thenextmethod on an iterator changes internal state that the iterator uses to keep track of where it is in the sequence.
- In other words, this code consumes, or uses up, the iterator.
- Each call to
nexteats up an item from the iterator. - We didn’t need
to make
v1_itermutable when we used aforloop because the loop took ownership ofv1_iterand made it mutable behind the scenes.
Also note that the values we get from the calls to
nextare immutable references to the values in the vector.
- The
itermethod produces an iterator over immutable references. - If we want to create an iterator that takes
ownership of
v1and returns owned values, we can callinto_iterinstead ofiter. - Similarly, if we want to iterate over mutable references, we can call
iter_mutinstead ofiter.
Methods that Consume the Iterator
The
Iteratortrait has a number of different methods with default implementations provided by the standard library;
- you can find out about these
methods by looking in the standard library API documentation for the
Iteratortrait. - Some of these methods call the
nextmethod in their definition, which is why you’re required to implement thenextmethod when implementing theIteratortrait.
Methods that call
nextare called consuming adaptors, because calling them uses up the iterator.
- One example is the
summethod, which takes ownership of the iterator and iterates through the items by repeatedly callingnext, thus consuming the iterator. - As it iterates through, it adds each item to a running total and returns the total when iteration is complete.
Listing 13-13 has a
test illustrating a use of the sum method:
Filename: src/lib.rs
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}
Listing 13-13: Calling the sum method to get the total
of all items in the iterator
We aren’t allowed to use v1_iter after the call to sum because sum takes
ownership of the iterator we call it on.
Methods that Produce Other Iterators
Iterator adaptors are methods defined on the Iterator trait that don’t
consume the iterator.
Instead, they produce different iterators by changing some aspect of the original iterator.
Listing 13-14 shows an example of calling the iterator adaptor method map,
which takes a closure to call on each item as the items are iterated through.
The
mapmethod returns a new iterator that produces the modified items.
The closure here creates a new iterator in which each item from the vector will be incremented by 1:
Filename: src/main.rs
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
Listing 13-14: Calling the iterator adaptor map to
create a new iterator
However, this code produces a warning:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_must_use)]` on by default
= note: iterators are lazy and do nothing unless consumed
warning: `iterators` (bin "iterators") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
- The code in Listing 13-14 doesn’t do anything;
- the closure we’ve specified never gets called.
- The warning reminds us why: iterator adaptors are lazy, and we need to consume the iterator here.
To fix this warning and consume the iterator, we’ll use the collect method,
which we used in Chapter 12 with env::args in Listing 12-1.
This method consumes the iterator and collects the resulting values into a collection data type.
In Listing 13-15, we collect the results of iterating over the iterator that’s
returned from the call to map into a vector. This vector will end up
containing each item from the original vector incremented by 1.
Filename: src/main.rs
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); assert_eq!(v2, vec![2, 3, 4]); }
Listing 13-15: Calling the map method to create a new
iterator and then calling the collect method to consume the new iterator and
create a vector
-
Because
maptakes a closure, we can specify any operation we want to perform on each item. -
This is a great example of how closures let you customize some behavior while reusing the iteration behavior that the
Iteratortrait provides.
You can chain multiple calls to iterator adaptors to perform complex actions in a readable way. But because all iterators are lazy, you have to call one of the consuming adaptor methods to get results from calls to iterator adaptors.
Using Closures that Capture Their Environment
Many iterator adapters take closures as arguments, and commonly the closures we’ll specify as arguments to iterator adapters will be closures that capture their environment.
- For this example, we’ll use the
filtermethod that takes a closure. - The
closure gets an item from the iterator and returns a
bool. - If the closure
returns
true, the value will be included in the iteration produced byfilter. - If the closure returns
false, the value won’t be included.
In Listing 13-16, we use filter with a closure that captures the shoe_size
variable from its environment to iterate over a collection of Shoe struct
instances. It will return only shoes that are the specified size.
Filename: src/lib.rs
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}
Listing 13-16: Using the filter method with a closure
that captures shoe_size
- The
shoes_in_sizefunction takes ownership of a vector of shoes and a shoe size as parameters. - It returns a vector containing only shoes of the specified size.
- In the body of
shoes_in_size, we callinto_iterto create an iterator that takes ownership of the vector. - Then we call
filterto adapt that iterator into a new iterator that only contains elements for which the closure returnstrue. - The closure captures the
shoe_sizeparameter from the environment and compares the value with each shoe’s size, keeping only shoes of the size specified. - Finally, calling
collectgathers the values returned by the adapted iterator into a vector that’s returned by the function.
The test shows that when we call
shoes_in_size, we get back only shoes that have the same size as the value we specified.
Improving Our I/O Project
With this new knowledge about iterators, we can improve the I/O project in
Chapter 12 by using iterators to make places in the code clearer and more
concise. Let’s look at how iterators can improve our implementation of the
Config::build function and the search function.
Removing a clone Using an Iterator
In Listing 12-6, we added code that took a slice of String values and created
an instance of the Config struct by indexing into the slice and cloning the
values, allowing the Config struct to own those values. In Listing 13-17,
we’ve reproduced the implementation of the Config::build function as it was
in Listing 12-23:
Filename: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Listing 13-17: Reproduction of the Config::build
function from Listing 12-23
At the time, we said not to worry about the inefficient clone calls because
we would remove them in the future. Well, that time is now!
We needed clone here because we have a slice with String elements in the
parameter args, but the build function doesn’t own args. To return
ownership of a Config instance, we had to clone the values from the query
and filename fields of Config so the Config instance can own its values.
With our new knowledge about iterators, we can change the build function to
take ownership of an iterator as its argument instead of borrowing a slice.
We’ll use the iterator functionality instead of the code that checks the length
of the slice and indexes into specific locations. This will clarify what the
Config::build function is doing because the iterator will access the values.
Once Config::build takes ownership of the iterator and stops using indexing
operations that borrow, we can move the String values from the iterator into
Config rather than calling clone and making a new allocation.
Using the Returned Iterator Directly
Open your I/O project’s src/main.rs file, which should look like this:
Filename: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
We’ll first change the start of the main function that we had in Listing
12-24 to the code in Listing 13-18, which this time uses an iterator. This
won’t compile until we update Config::build as well.
Filename: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
Listing 13-18: Passing the return value of env::args to
Config::build
The env::args function returns an iterator! Rather than collecting the
iterator values into a vector and then passing a slice to Config::build, now
we’re passing ownership of the iterator returned from env::args to
Config::build directly.
Next, we need to update the definition of Config::build. In your I/O
project’s src/lib.rs file, let’s change the signature of Config::build to
look like Listing 13-19. This still won’t compile because we need to update the
function body.
Filename: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Listing 13-19: Updating the signature of Config::build
to expect an iterator
The standard library documentation for the env::args function shows that the
type of the iterator it returns is std::env::Args, and that type implements
the Iterator trait and returns String values.
We’ve updated the signature of the Config::build function so the parameter
args has a generic type with the trait bounds impl Iterator<Item = String>
instead of &[String]. This usage of the impl Trait syntax we discussed in
the “Traits as Parameters” section of Chapter 10
means that args can be any type that implements the Iterator type and
returns String items.
Because we’re taking ownership of args and we’ll be mutating args by
iterating over it, we can add the mut keyword into the specification of the
args parameter to make it mutable.
Using Iterator Trait Methods Instead of Indexing
Next, we’ll fix the body of Config::build. Because args implements the
Iterator trait, we know we can call the next method on it! Listing 13-20
updates the code from Listing 12-23 to use the next method:
Filename: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Listing 13-20: Changing the body of Config::build to use
iterator methods
Remember that the first value in the return value of env::args is the name of
the program. We want to ignore that and get to the next value, so first we call
next and do nothing with the return value. Second, we call next to get the
value we want to put in the query field of Config. If next returns a
Some, we use a match to extract the value. If it returns None, it means
not enough arguments were given and we return early with an Err value. We do
the same thing for the filename value.
Making Code Clearer with Iterator Adaptors
We can also take advantage of iterators in the search function in our I/O
project, which is reproduced here in Listing 13-21 as it was in Listing 12-19:
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}
Listing 13-21: The implementation of the search
function from Listing 12-19
We can write this code in a more concise way using iterator adaptor methods.
Doing so also lets us avoid having a mutable intermediate results vector. The
functional programming style prefers to minimize the amount of mutable state to
make code clearer. Removing the mutable state might enable a future enhancement
to make searching happen in parallel, because we wouldn’t have to manage
concurrent access to the results vector. Listing 13-22 shows this change:
Filename: src/lib.rs
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}
Listing 13-22: Using iterator adaptor methods in the
implementation of the search function
Recall that the purpose of the search function is to return all lines in
contents that contain the query. Similar to the filter example in Listing
13-16, this code uses the filter adaptor to keep only the lines that
line.contains(query) returns true for. We then collect the matching lines
into another vector with collect. Much simpler! Feel free to make the same
change to use iterator methods in the search_case_insensitive function as
well.
Choosing Between Loops or Iterators
The next logical question is which style you should choose in your own code and why: the original implementation in Listing 13-21 or the version using iterators in Listing 13-22. Most Rust programmers prefer to use the iterator style. It’s a bit tougher to get the hang of at first, but once you get a feel for the various iterator adaptors and what they do, iterators can be easier to understand. Instead of fiddling with the various bits of looping and building new vectors, the code focuses on the high-level objective of the loop. This abstracts away some of the commonplace code so it’s easier to see the concepts that are unique to this code, such as the filtering condition each element in the iterator must pass.
But are the two implementations truly equivalent? The intuitive assumption might be that the more low-level loop will be faster. Let’s talk about performance.
Comparing Performance: Loops vs. Iterators
To determine whether to use loops or iterators, you need to know which
implementation is faster: the version of the search function with an explicit
for loop or the version with iterators.
We ran a benchmark by loading the entire contents of The Adventures of
Sherlock Holmes by Sir Arthur Conan Doyle into a String and looking for the
word the in the contents. Here are the results of the benchmark on the
version of search using the for loop and the version using iterators:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
The iterator version was slightly faster! We won’t explain the benchmark code here, because the point is not to prove that the two versions are equivalent but to get a general sense of how these two implementations compare performance-wise.
For a more comprehensive benchmark, you should check using various texts of
various sizes as the contents, different words and words of different lengths
as the query, and all kinds of other variations. The point is this:
iterators, although a high-level abstraction, get compiled down to roughly the
same code as if you’d written the lower-level code yourself. Iterators are one
of Rust’s zero-cost abstractions, by which we mean using the abstraction
imposes no additional runtime overhead. This is analogous to how Bjarne
Stroustrup, the original designer and implementor of C++, defines
zero-overhead in “Foundations of C++” (2012):
In general, C++ implementations obey the zero-overhead principle: What you don’t use, you don’t pay for. And further: What you do use, you couldn’t hand code any better.
As another example, the following code is taken from an audio decoder. The
decoding algorithm uses the linear prediction mathematical operation to
estimate future values based on a linear function of the previous samples. This
code uses an iterator chain to do some math on three variables in scope: a
buffer slice of data, an array of 12 coefficients, and an amount by which
to shift data in qlp_shift. We’ve declared the variables within this example
but not given them any values; although this code doesn’t have much meaning
outside of its context, it’s still a concise, real-world example of how Rust
translates high-level ideas to low-level code.
let buffer: &mut [i32];
let coefficients: [i64; 12];
let qlp_shift: i16;
for i in 12..buffer.len() {
let prediction = coefficients.iter()
.zip(&buffer[i - 12..i])
.map(|(&c, &s)| c * s as i64)
.sum::<i64>() >> qlp_shift;
let delta = buffer[i];
buffer[i] = prediction as i32 + delta;
}
To calculate the value of prediction, this code iterates through each of the
12 values in coefficients and uses the zip method to pair the coefficient
values with the previous 12 values in buffer. Then, for each pair, we
multiply the values together, sum all the results, and shift the bits in the
sum qlp_shift bits to the right.
Calculations in applications like audio decoders often prioritize performance
most highly. Here, we’re creating an iterator, using two adaptors, and then
consuming the value. What assembly code would this Rust code compile to? Well,
as of this writing, it compiles down to the same assembly you’d write by hand.
There’s no loop at all corresponding to the iteration over the values in
coefficients: Rust knows that there are 12 iterations, so it “unrolls” the
loop. Unrolling is an optimization that removes the overhead of the loop
controlling code and instead generates repetitive code for each iteration of
the loop.
All of the coefficients get stored in registers, which means accessing the values is very fast. There are no bounds checks on the array access at runtime. All these optimizations that Rust is able to apply make the resulting code extremely efficient. Now that you know this, you can use iterators and closures without fear! They make code seem like it’s higher level but don’t impose a runtime performance penalty for doing so.
Summary
Closures and iterators are Rust features inspired by functional programming language ideas. They contribute to Rust’s capability to clearly express high-level ideas at low-level performance. The implementations of closures and iterators are such that runtime performance is not affected. This is part of Rust’s goal to strive to provide zero-cost abstractions.
Now that we’ve improved the expressiveness of our I/O project, let’s look at
some more features of cargo that will help us share the project with the
world.
More About Cargo and Crates.io
So far we’ve used only the most basic features of Cargo to build, run, and test our code, but it can do a lot more. In this chapter, we’ll discuss some of its other, more advanced features to show you how to do the following:
- Customize your build through release profiles
- Publish libraries on crates.io
- Organize large projects with workspaces
- Install binaries from crates.io
- Extend Cargo using custom commands
Cargo can do even more than the functionality we cover in this chapter, so for a full explanation of all its features, see its documentation.
Customizing Builds with Release Profiles
In Rust, release profiles are predefined and customizable profiles with different configurations that allow a programmer to have more control over various options for compiling code. Each profile is configured independently of the others.
Cargo has two main profiles: the dev profile Cargo uses when you run cargo build and the release profile Cargo uses when you run cargo build --release. The dev profile is defined with good defaults for development,
and the release profile has good defaults for release builds.
These profile names might be familiar from the output of your builds:
$ cargo build
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
$ cargo build --release
Finished release [optimized] target(s) in 0.0s
The dev and release are these different profiles used by the compiler.
Cargo has default settings for each of the profiles that apply when you haven’t
explicitly added any [profile.*] sections in the project’s Cargo.toml file.
By adding [profile.*] sections for any profile you want to customize, you
override any subset of the default settings. For example, here are the default
values for the opt-level setting for the dev and release profiles:
Filename: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
The opt-level setting controls the number of optimizations Rust will apply to
your code, with a range of 0 to 3. Applying more optimizations extends
compiling time, so if you’re in development and compiling your code often,
you’ll want fewer optimizations to compile faster even if the resulting code
runs slower. The default opt-level for dev is therefore 0. When you’re
ready to release your code, it’s best to spend more time compiling. You’ll only
compile in release mode once, but you’ll run the compiled program many times,
so release mode trades longer compile time for code that runs faster. That is
why the default opt-level for the release profile is 3.
You can override a default setting by adding a different value for it in Cargo.toml. For example, if we want to use optimization level 1 in the development profile, we can add these two lines to our project’s Cargo.toml file:
Filename: Cargo.toml
[profile.dev]
opt-level = 1
This code overrides the default setting of 0. Now when we run cargo build,
Cargo will use the defaults for the dev profile plus our customization to
opt-level. Because we set opt-level to 1, Cargo will apply more
optimizations than the default, but not as many as in a release build.
For the full list of configuration options and defaults for each profile, see Cargo’s documentation.
Publishing a Crate to Crates.io
We’ve used packages from crates.io as dependencies of our project, but you can also share your code with other people by publishing your own packages. The crate registry at crates.io distributes the source code of your packages, so it primarily hosts code that is open source.
Rust and Cargo have features that make your published package easier for people to find and use. We’ll talk about some of these features next and then explain how to publish a package.
Making Useful Documentation Comments
Accurately documenting your packages will help other users know how and when to
use them, so it’s worth investing the time to write documentation. In Chapter
3, we discussed how to comment Rust code using two slashes, //. Rust also has
a particular kind of comment for documentation, known conveniently as a
documentation comment, that will generate HTML documentation. The HTML
displays the contents of documentation comments for public API items intended
for programmers interested in knowing how to use your crate as opposed to how
your crate is implemented.
Documentation comments use three slashes, ///, instead of two and support
Markdown notation for formatting the text. Place documentation comments just
before the item they’re documenting. Listing 14-1 shows documentation comments
for an add_one function in a crate named my_crate.
Filename: src/lib.rs
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}
Listing 14-1: A documentation comment for a function
Here, we give a description of what the add_one function does, start a
section with the heading Examples, and then provide code that demonstrates
how to use the add_one function. We can generate the HTML documentation from
this documentation comment by running cargo doc. This command runs the
rustdoc tool distributed with Rust and puts the generated HTML documentation
in the target/doc directory.
For convenience, running cargo doc --open will build the HTML for your
current crate’s documentation (as well as the documentation for all of your
crate’s dependencies) and open the result in a web browser. Navigate to the
add_one function and you’ll see how the text in the documentation comments is
rendered, as shown in Figure 14-1:
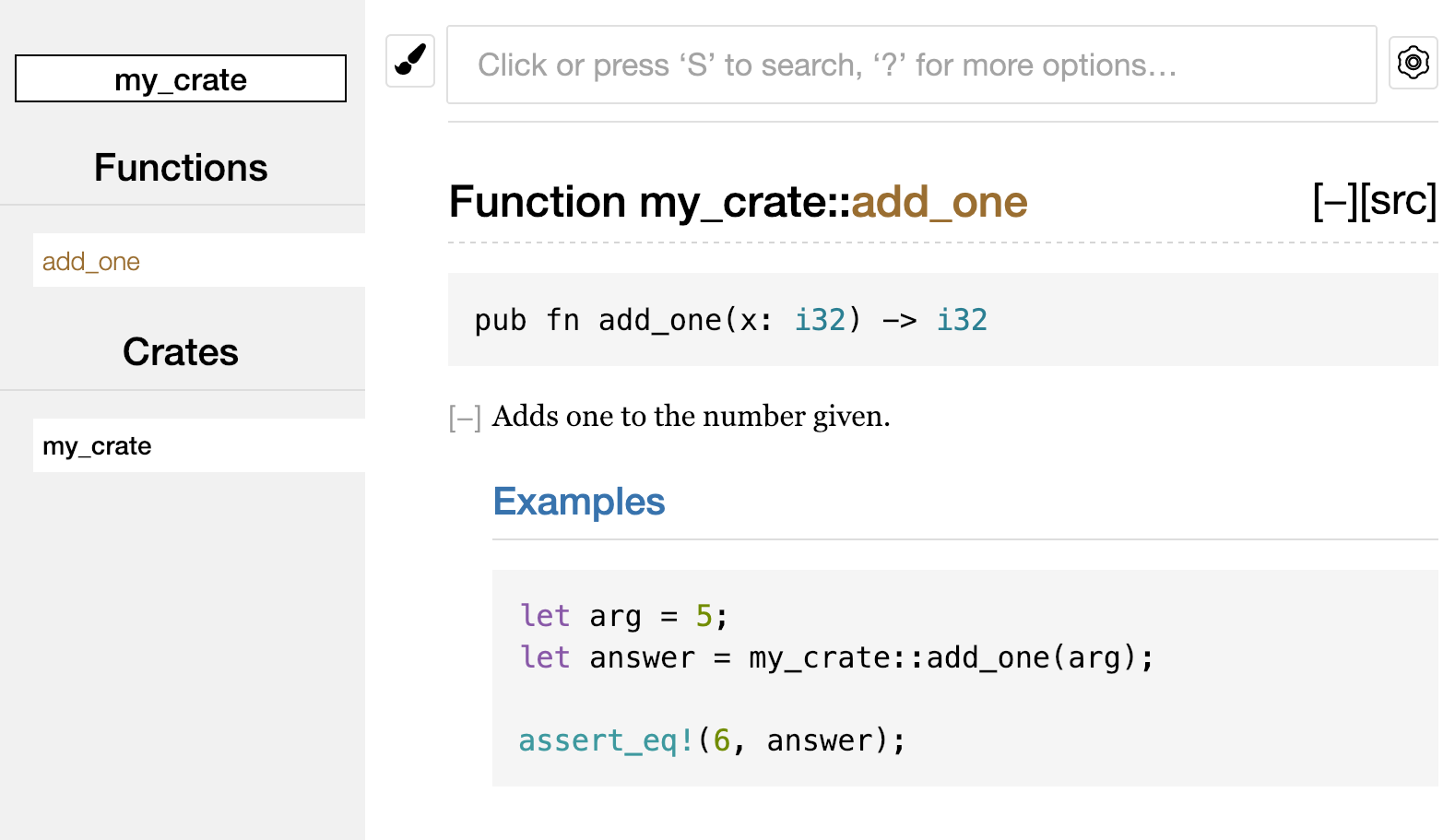
Figure 14-1: HTML documentation for the add_one
function
Commonly Used Sections
We used the # Examples Markdown heading in Listing 14-1 to create a section
in the HTML with the title “Examples.” Here are some other sections that crate
authors commonly use in their documentation:
- Panics: The scenarios in which the function being documented could panic. Callers of the function who don’t want their programs to panic should make sure they don’t call the function in these situations.
- Errors: If the function returns a
Result, describing the kinds of errors that might occur and what conditions might cause those errors to be returned can be helpful to callers so they can write code to handle the different kinds of errors in different ways. - Safety: If the function is
unsafeto call (we discuss unsafety in Chapter 19), there should be a section explaining why the function is unsafe and covering the invariants that the function expects callers to uphold.
Most documentation comments don’t need all of these sections, but this is a good checklist to remind you of the aspects of your code users will be interested in knowing about.
Documentation Comments as Tests
Adding example code blocks in your documentation comments can help demonstrate
how to use your library, and doing so has an additional bonus: running cargo test will run the code examples in your documentation as tests! Nothing is
better than documentation with examples. But nothing is worse than examples
that don’t work because the code has changed since the documentation was
written. If we run cargo test with the documentation for the add_one
function from Listing 14-1, we will see a section in the test results like this:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Now if we change either the function or the example so the assert_eq! in the
example panics and run cargo test again, we’ll see that the doc tests catch
that the example and the code are out of sync with each other!
Commenting Contained Items
The style of doc comment //! adds documentation to the item that contains the
comments rather than to the items following the comments. We typically use
these doc comments inside the crate root file (src/lib.rs by convention) or
inside a module to document the crate or the module as a whole.
For example, to add documentation that describes the purpose of the my_crate
crate that contains the add_one function, we add documentation comments that
start with //! to the beginning of the src/lib.rs file, as shown in Listing
14-2:
Filename: src/lib.rs
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}
Listing 14-2: Documentation for the my_crate crate as a
whole
Notice there isn’t any code after the last line that begins with //!. Because
we started the comments with //! instead of ///, we’re documenting the item
that contains this comment rather than an item that follows this comment. In
this case, that item is the src/lib.rs file, which is the crate root. These
comments describe the entire crate.
When we run cargo doc --open, these comments will display on the front
page of the documentation for my_crate above the list of public items in the
crate, as shown in Figure 14-2:
Figure 14-2: Rendered documentation for my_crate,
including the comment describing the crate as a whole
Documentation comments within items are useful for describing crates and modules especially. Use them to explain the overall purpose of the container to help your users understand the crate’s organization.
Exporting a Convenient Public API with pub use
The structure of your public API is a major consideration when publishing a crate. People who use your crate are less familiar with the structure than you are and might have difficulty finding the pieces they want to use if your crate has a large module hierarchy.
In Chapter 7, we covered how to make items public using the pub keyword, and
bring items into a scope with the use keyword. However, the structure that
makes sense to you while you’re developing a crate might not be very convenient
for your users. You might want to organize your structs in a hierarchy
containing multiple levels, but then people who want to use a type you’ve
defined deep in the hierarchy might have trouble finding out that type exists.
They might also be annoyed at having to enter use
my_crate::some_module::another_module::UsefulType; rather than use
my_crate::UsefulType;.
The good news is that if the structure isn’t convenient for others to use
from another library, you don’t have to rearrange your internal organization:
instead, you can re-export items to make a public structure that’s different
from your private structure by using pub use. Re-exporting takes a public
item in one location and makes it public in another location, as if it were
defined in the other location instead.
For example, say we made a library named art for modeling artistic concepts.
Within this library are two modules: a kinds module containing two enums
named PrimaryColor and SecondaryColor and a utils module containing a
function named mix, as shown in Listing 14-3:
Filename: src/lib.rs
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}
Listing 14-3: An art library with items organized into
kinds and utils modules
Figure 14-3 shows what the front page of the documentation for this crate
generated by cargo doc would look like:
Figure 14-3: Front page of the documentation for art
that lists the kinds and utils modules
Note that the PrimaryColor and SecondaryColor types aren’t listed on the
front page, nor is the mix function. We have to click kinds and utils to
see them.
Another crate that depends on this library would need use statements that
bring the items from art into scope, specifying the module structure that’s
currently defined. Listing 14-4 shows an example of a crate that uses the
PrimaryColor and mix items from the art crate:
Filename: src/main.rs
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}
Listing 14-4: A crate using the art crate’s items with
its internal structure exported
The author of the code in Listing 14-4, which uses the art crate, had to
figure out that PrimaryColor is in the kinds module and mix is in the
utils module. The module structure of the art crate is more relevant to
developers working on the art crate than to those using it. The internal
structure doesn’t contain any useful information for someone trying to
understand how to use the art crate, but rather causes confusion because
developers who use it have to figure out where to look, and must specify the
module names in the use statements.
To remove the internal organization from the public API, we can modify the
art crate code in Listing 14-3 to add pub use statements to re-export the
items at the top level, as shown in Listing 14-5:
Filename: src/lib.rs
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}
Listing 14-5: Adding pub use statements to re-export
items
The API documentation that cargo doc generates for this crate will now list
and link re-exports on the front page, as shown in Figure 14-4, making the
PrimaryColor and SecondaryColor types and the mix function easier to find.
Figure 14-4: The front page of the documentation for art
that lists the re-exports
The art crate users can still see and use the internal structure from Listing
14-3 as demonstrated in Listing 14-4, or they can use the more convenient
structure in Listing 14-5, as shown in Listing 14-6:
Filename: src/main.rs
use art::mix;
use art::PrimaryColor;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}
Listing 14-6: A program using the re-exported items from
the art crate
In cases where there are many nested modules, re-exporting the types at the top
level with pub use can make a significant difference in the experience of
people who use the crate. Another common use of pub use is to re-export
definitions of a dependency in the current crate to make that crate’s
definitions part of your crate’s public API.
Creating a useful public API structure is more of an art than a science, and
you can iterate to find the API that works best for your users. Choosing pub use gives you flexibility in how you structure your crate internally and
decouples that internal structure from what you present to your users. Look at
some of the code of crates you’ve installed to see if their internal structure
differs from their public API.
Setting Up a Crates.io Account
Before you can publish any crates, you need to create an account on
crates.io and get an API token. To do so,
visit the home page at crates.io and log
in via a GitHub account. (The GitHub account is currently a requirement, but
the site might support other ways of creating an account in the future.) Once
you’re logged in, visit your account settings at
https://crates.io/me/ and retrieve your
API key. Then run the cargo login command with your API key, like this:
$ cargo login abcdefghijklmnopqrstuvwxyz012345
This command will inform Cargo of your API token and store it locally in ~/.cargo/credentials. Note that this token is a secret: do not share it with anyone else. If you do share it with anyone for any reason, you should revoke it and generate a new token on crates.io.
Adding Metadata to a New Crate
Let’s say you have a crate you want to publish. Before publishing, you’ll need
to add some metadata in the [package] section of the crate’s Cargo.toml
file.
Your crate will need a unique name. While you’re working on a crate locally,
you can name a crate whatever you’d like. However, crate names on
crates.io are allocated on a first-come,
first-served basis. Once a crate name is taken, no one else can publish a crate
with that name. Before attempting to publish a crate, search for the name you
want to use. If the name has been used, you will need to find another name and
edit the name field in the Cargo.toml file under the [package] section to
use the new name for publishing, like so:
Filename: Cargo.toml
[package]
name = "guessing_game"
Even if you’ve chosen a unique name, when you run cargo publish to publish
the crate at this point, you’ll get a warning and then an error:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error: missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for how to upload metadata
This errors because you’re missing some crucial information: a description and
license are required so people will know what your crate does and under what
terms they can use it. In Cargo.toml, add a description that’s just a
sentence or two, because it will appear with your crate in search results. For
the license field, you need to give a license identifier value. The Linux
Foundation’s Software Package Data Exchange (SPDX) lists the identifiers
you can use for this value. For example, to specify that you’ve licensed your
crate using the MIT License, add the MIT identifier:
Filename: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
If you want to use a license that doesn’t appear in the SPDX, you need to place
the text of that license in a file, include the file in your project, and then
use license-file to specify the name of that file instead of using the
license key.
Guidance on which license is appropriate for your project is beyond the scope
of this book. Many people in the Rust community license their projects in the
same way as Rust by using a dual license of MIT OR Apache-2.0. This practice
demonstrates that you can also specify multiple license identifiers separated
by OR to have multiple licenses for your project.
With a unique name, the version, your description, and a license added, the Cargo.toml file for a project that is ready to publish might look like this:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2021"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
[dependencies]
Cargo’s documentation describes other metadata you can specify to ensure others can discover and use your crate more easily.
Publishing to Crates.io
Now that you’ve created an account, saved your API token, chosen a name for your crate, and specified the required metadata, you’re ready to publish! Publishing a crate uploads a specific version to crates.io for others to use.
Be careful, because a publish is permanent. The version can never be overwritten, and the code cannot be deleted. One major goal of crates.io is to act as a permanent archive of code so that builds of all projects that depend on crates from crates.io will continue to work. Allowing version deletions would make fulfilling that goal impossible. However, there is no limit to the number of crate versions you can publish.
Run the cargo publish command again. It should succeed now:
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished dev [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
Congratulations! You’ve now shared your code with the Rust community, and anyone can easily add your crate as a dependency of their project.
Publishing a New Version of an Existing Crate
When you’ve made changes to your crate and are ready to release a new version,
you change the version value specified in your Cargo.toml file and
republish. Use the Semantic Versioning rules to decide what an
appropriate next version number is based on the kinds of changes you’ve made.
Then run cargo publish to upload the new version.
Deprecating Versions from Crates.io with cargo yank
Although you can’t remove previous versions of a crate, you can prevent any future projects from adding them as a new dependency. This is useful when a crate version is broken for one reason or another. In such situations, Cargo supports yanking a crate version.
Yanking a version prevents new projects from depending on that version while allowing all existing projects that depend on it to continue. Essentially, a yank means that all projects with a Cargo.lock will not break, and any future Cargo.lock files generated will not use the yanked version.
To yank a version of a crate, in the directory of the crate that you’ve
previously published, run cargo yank and specify which version you want to
yank. For example, if we’ve published a crate named guessing_game version
1.0.1 and we want to yank it, in the project directory for guessing_game we’d
run:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
By adding --undo to the command, you can also undo a yank and allow projects
to start depending on a version again:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
A yank does not delete any code. It cannot, for example, delete accidentally uploaded secrets. If that happens, you must reset those secrets immediately.
Cargo Workspaces
In Chapter 12, we built a package that included a binary crate and a library crate. As your project develops, you might find that the library crate continues to get bigger and you want to split your package further into multiple library crates. Cargo offers a feature called workspaces that can help manage multiple related packages that are developed in tandem.
Creating a Workspace
A workspace is a set of packages that share the same Cargo.lock and output
directory. Let’s make a project using a workspace—we’ll use trivial code so we
can concentrate on the structure of the workspace. There are multiple ways to
structure a workspace, so we’ll just show one common way. We’ll have a
workspace containing a binary and two libraries. The binary, which will provide
the main functionality, will depend on the two libraries. One library will
provide an add_one function, and a second library an add_two function.
These three crates will be part of the same workspace. We’ll start by creating
a new directory for the workspace:
$ mkdir add
$ cd add
Next, in the add directory, we create the Cargo.toml file that will
configure the entire workspace. This file won’t have a [package] section.
Instead, it will start with a [workspace] section that will allow us to add
members to the workspace by specifying the path to the package with our binary
crate; in this case, that path is adder:
Filename: Cargo.toml
[workspace]
members = [
"adder",
]
Next, we’ll create the adder binary crate by running cargo new within the
add directory:
$ cargo new adder
Created binary (application) `adder` package
At this point, we can build the workspace by running cargo build. The files
in your add directory should look like this:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
The workspace has one target directory at the top level that the compiled
artifacts will be placed into; the adder package doesn’t have its own
target directory. Even if we were to run cargo build from inside the
adder directory, the compiled artifacts would still end up in add/target
rather than add/adder/target. Cargo structures the target directory in a
workspace like this because the crates in a workspace are meant to depend on
each other. If each crate had its own target directory, each crate would have
to recompile each of the other crates in the workspace to place the artifacts
in its own target directory. By sharing one target directory, the crates
can avoid unnecessary rebuilding.
Creating the Second Package in the Workspace
Next, let’s create another member package in the workspace and call it
add_one. Change the top-level Cargo.toml to specify the add_one path in
the members list:
Filename: Cargo.toml
[workspace]
members = [
"adder",
"add_one",
]
Then generate a new library crate named add_one:
$ cargo new add_one --lib
Created library `add_one` package
Your add directory should now have these directories and files:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
In the add_one/src/lib.rs file, let’s add an add_one function:
Filename: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
Now we can have the adder package with our binary depend on the add_one
package that has our library. First, we’ll need to add a path dependency on
add_one to adder/Cargo.toml.
Filename: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
Cargo doesn’t assume that crates in a workspace will depend on each other, so we need to be explicit about the dependency relationships.
Next, let’s use the add_one function (from the add_one crate) in the
adder crate. Open the adder/src/main.rs file and add a use line at the
top to bring the new add_one library crate into scope. Then change the main
function to call the add_one function, as in Listing 14-7.
Filename: adder/src/main.rs
use add_one;
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}
Listing 14-7: Using the add_one library crate from the
adder crate
Let’s build the workspace by running cargo build in the top-level add
directory!
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished dev [unoptimized + debuginfo] target(s) in 0.68s
To run the binary crate from the add directory, we can specify which
package in the workspace we want to run by using the -p argument and the
package name with cargo run:
$ cargo run -p adder
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
This runs the code in adder/src/main.rs, which depends on the add_one crate.
Depending on an External Package in a Workspace
Notice that the workspace has only one Cargo.lock file at the top level,
rather than having a Cargo.lock in each crate’s directory. This ensures that
all crates are using the same version of all dependencies. If we add the rand
package to the adder/Cargo.toml and add_one/Cargo.toml files, Cargo will
resolve both of those to one version of rand and record that in the one
Cargo.lock. Making all crates in the workspace use the same dependencies
means the crates will always be compatible with each other. Let’s add the
rand crate to the [dependencies] section in the add_one/Cargo.toml file
so we can use the rand crate in the add_one crate:
Filename: add_one/Cargo.toml
[dependencies]
rand = "0.8.5"
We can now add use rand; to the add_one/src/lib.rs file, and building the
whole workspace by running cargo build in the add directory will bring in
and compile the rand crate. We will get one warning because we aren’t
referring to the rand we brought into scope:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished dev [unoptimized + debuginfo] target(s) in 10.18s
The top-level Cargo.lock now contains information about the dependency of
add_one on rand. However, even though rand is used somewhere in the
workspace, we can’t use it in other crates in the workspace unless we add
rand to their Cargo.toml files as well. For example, if we add use rand;
to the adder/src/main.rs file for the adder package, we’ll get an error:
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
To fix this, edit the Cargo.toml file for the adder package and indicate
that rand is a dependency for it as well. Building the adder package will
add rand to the list of dependencies for adder in Cargo.lock, but no
additional copies of rand will be downloaded. Cargo has ensured that every
crate in every package in the workspace using the rand package will be using
the same version, saving us space and ensuring that the crates in the workspace
will be compatible with each other.
Adding a Test to a Workspace
For another enhancement, let’s add a test of the add_one::add_one function
within the add_one crate:
Filename: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}
Now run cargo test in the top-level add directory. Running cargo test in
a workspace structured like this one will run the tests for all the crates in
the workspace:
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished test [unoptimized + debuginfo] target(s) in 0.27s
Running unittests src/lib.rs (target/debug/deps/add_one-f0253159197f7841)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-49979ff40686fa8e)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
The first section of the output shows that the it_works test in the add_one
crate passed. The next section shows that zero tests were found in the adder
crate, and then the last section shows zero documentation tests were found in
the add_one crate.
We can also run tests for one particular crate in a workspace from the
top-level directory by using the -p flag and specifying the name of the crate
we want to test:
$ cargo test -p add_one
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-b3235fea9a156f74)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
This output shows cargo test only ran the tests for the add_one crate and
didn’t run the adder crate tests.
If you publish the crates in the workspace to crates.io,
each crate in the workspace will need to be published separately. Like cargo test, we can publish a particular crate in our workspace by using the -p
flag and specifying the name of the crate we want to publish.
For additional practice, add an add_two crate to this workspace in a similar
way as the add_one crate!
As your project grows, consider using a workspace: it’s easier to understand smaller, individual components than one big blob of code. Furthermore, keeping the crates in a workspace can make coordination between crates easier if they are often changed at the same time.
Installing Binaries with cargo install
The cargo install command allows you to install and use binary crates
locally. This isn’t intended to replace system packages; it’s meant to be a
convenient way for Rust developers to install tools that others have shared on
crates.io. Note that you can only install
packages that have binary targets. A binary target is the runnable program
that is created if the crate has a src/main.rs file or another file specified
as a binary, as opposed to a library target that isn’t runnable on its own but
is suitable for including within other programs. Usually, crates have
information in the README file about whether a crate is a library, has a
binary target, or both.
All binaries installed with cargo install are stored in the installation
root’s bin folder. If you installed Rust using rustup.rs and don’t have any
custom configurations, this directory will be $HOME/.cargo/bin. Ensure that
directory is in your $PATH to be able to run programs you’ve installed with
cargo install.
For example, in Chapter 12 we mentioned that there’s a Rust implementation of
the grep tool called ripgrep for searching files. To install ripgrep, we
can run the following:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v13.0.0
Downloaded 1 crate (243.3 KB) in 0.88s
Installing ripgrep v13.0.0
--snip--
Compiling ripgrep v13.0.0
Finished release [optimized + debuginfo] target(s) in 3m 10s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v13.0.0` (executable `rg`)
The second-to-last line of the output shows the location and the name of the
installed binary, which in the case of ripgrep is rg. As long as the
installation directory is in your $PATH, as mentioned previously, you can
then run rg --help and start using a faster, rustier tool for searching files!
Extending Cargo with Custom Commands
Cargo is designed so you can extend it with new subcommands without having to
modify Cargo. If a binary in your $PATH is named cargo-something, you can
run it as if it was a Cargo subcommand by running cargo something. Custom
commands like this are also listed when you run cargo --list. Being able to
use cargo install to install extensions and then run them just like the
built-in Cargo tools is a super convenient benefit of Cargo’s design!
Summary
Sharing code with Cargo and crates.io is part of what makes the Rust ecosystem useful for many different tasks. Rust’s standard library is small and stable, but crates are easy to share, use, and improve on a timeline different from that of the language. Don’t be shy about sharing code that’s useful to you on crates.io; it’s likely that it will be useful to someone else as well!
Smart Pointers
- A pointer is a general concept for a variable that contains an address in memory.
- Smart pointers, on the other hand, are data structures that act like a pointer but also have additional metadata and capabilities.
- smart pointers implement the
DerefandDroptraits - smart pointer pattern is a general design pattern
- the interior mutability pattern where an immutable type exposes an API for mutating an interior value.
- reference cycles: how they can leak memory and how to prevent them.
Start from pointer
A pointer is a general concept for a variable that contains an address in memory.
- This address refers to, or “points at,” some other data.
The most common kind of pointer in Rust is a reference, which you learned about in Chapter 4.
- References are indicated by the
&symbol and borrow the value they point to. - They don’t have any special capabilities other than referring to data, and have no overhead.
Smart Pointers
Smart pointers, on the other hand, are data structures that act like a pointer but also have additional metadata and capabilities.
- The concept of smart pointers isn’t unique to Rust: smart pointers originated in C++ and exist in other languages as well.
- Rust has a variety of smart pointers defined in the standard library that provide functionality beyond that provided by references.
- To explore the general concept, we’ll look at a couple of different examples of smart pointers, including a reference counting smart pointer type.
- reference couting smart pointer enables you to allow data to have multiple owners by keeping track of the number of owners and, when no owners remain, cleaning up the data.
Rust, with its concept of ownership and borrowing, has an additional difference between references and smart pointers:
while references only borrow data, in many cases, smart pointers own the data they point to.
String and Vec:
Though we didn’t call them as such at the time, we’ve already encountered a few smart pointers in this book, including
StringandVec<T>in Chapter 8.
- Both these types count as smart pointers because they own some memory and allow you to manipulate it.
- They also have metadata and extra capabilities or guarantees.
String, for example, stores its capacity as metadata and has the extra ability to ensure its data will always be valid UTF-8.
Smart pointers are usually implemented using structs.
Unlike an ordinary struct, smart pointers implement the
DerefandDroptraits.
- The
Dereftrait allows an instance of the smart pointer struct to behave like a reference so you can write your code to work with either references or smart pointers. - The
Droptrait allows you to customize the code that’s run when an instance of the smart pointer goes out of scope. - In this chapter, we’ll discuss both traits and demonstrate why they’re important to smart pointers.
smart pointer pattern is a general design pattern
Given that the smart pointer pattern is a general design pattern used frequently in Rust, this chapter won’t cover every existing smart pointer. Many libraries have their own smart pointers, and you can even write your own.
We’ll cover the most common smart pointers in the standard library:
Box<T>for allocating values on the heapRc<T>, a reference counting type that enables multiple ownershipRef<T>andRefMut<T>, accessed throughRefCell<T>, a type that enforces the borrowing rules at runtime instead of compile time
interior mutability
In addition, we’ll cover the interior mutability pattern where an immutable type exposes an API for mutating an interior value.
reference cycles
We’ll also discuss reference cycles: how they can leak memory and how to prevent them.
Let’s dive in!
Deref(* operator): Treating Smart Pointers Like Regular References with the Deref Trait
Summarize made by chatGPT
- It covers the Deref trait, which is used to implement the dereferencing operator (*), and how it can be implemented for custom types.
- The article also discusses the pitfalls of using dereferencing, including the possibility of creating dangling references, and provides guidance on how to avoid these issues.
- Overall, the article emphasizes the importance of understanding and using dereferencing correctly to write safe and effective Rust code.
- A regular reference is a type of pointer, and one way to think of a pointer is as an arrow to a value stored somewhere else.
- Implementing the
Dereftrait allows you to customize the behavior of the dereference operator*(not to be confused with the multiplication or glob operator). - Without the
Dereftrait, the compiler can only dereference&references. - Deref coercion converts a reference to a type that implements the
Dereftrait into a reference to another type.
Rust does deref coercion when it finds types and trait implementations in three cases:
- From
&Tto&UwhenT: Deref<Target=U> - From
&mut Tto&mut UwhenT: DerefMut<Target=U> - From
&mut Tto&UwhenT: Deref<Target=U>
Implementing the Deref trait allows you to customize the behavior of the
dereference operator * (not to be confused with the multiplication or glob
operator).
By implementing
Derefin such a way that a smart pointer can be treated like a regular reference, you can write code that operates on references and use that code with smart pointers too.
- Let’s first look at how the dereference operator works with regular references.
- Then we’ll try to define a custom type that behaves like
Box<T>, and see why the dereference operator doesn’t work like a reference on our newly defined type. - We’ll explore how implementing the
Dereftrait makes it possible for smart pointers to work in ways similar to references. - Then we’ll look at Rust’s deref coercion feature and how it lets us work with either references or smart pointers.
Note: there’s one big difference between the
MyBox<T>type we’re about to build and the realBox<T>:
- our version will not store its data on the heap.
- We are focusing this example on
Deref, so where the data is actually stored is less important than the pointer-like behavior.
Following the Pointer to the Value
A regular reference is a type of pointer, and one way to think of a pointer is as
an arrowto a value stored somewhere else.
In Listing 15-6, we create a reference to an i32 value and then use the dereference operator to follow the reference
to the value:
Filename: src/main.rs
fn main() { let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y); }
Listing 15-6: Using the dereference operator to follow a
reference to an i32 value
- The variable
xholds ani32value5. - We set
yequal to a reference tox. - We can assert that
xis equal to5. - However, if we want to make an assertion about the value in
y, we have to use*yto follow the reference to the value it’s pointing to (hence dereference) so the compiler can compare the actual value. - Once we dereference
y, we have access to the integer valueyis pointing to that we can compare with5.
If we tried to write
assert_eq!(5, y);instead, we would get this compilation error:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= help: the following other types implement trait `PartialEq<Rhs>`:
f32
f64
i128
i16
i32
i64
i8
isize
and 6 others
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` due to previous error
Comparing a number and a reference to a number isn’t allowed because they’re different types.
We must use the dereference operator to follow the reference to the value it’s pointing to.
Using Box<T> Like a Reference
We can rewrite the code in Listing 15-6 to use a Box<T> instead of a
reference; the dereference operator used on the Box<T> in Listing 15-7
functions in the same way as the dereference operator used on the reference in
Listing 15-6:
Filename: src/main.rs
fn main() { let x = 5; let y = Box::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Listing 15-7: Using the dereference operator on a
Box<i32>
The main difference between Listing 15-7 and Listing 15-6 is that here we set
yto be an instance of aBox<T>pointing to a copied value ofxrather than a reference pointing to the value ofx.
- In the last assertion, we can use the dereference operator to follow the pointer of the
Box<T>in the same way that we did whenywas a reference. - Next, we’ll explore what is special about
Box<T>that enables us to use the dereference operator by defining our own type.
Defining Our Own Smart Pointer
Let’s build a smart pointer similar to the Box<T> type provided by the
standard library to experience how smart pointers behave differently from
references by default. Then we’ll look at how to add the ability to use the
dereference operator.
The Box<T> type is ultimately defined as a tuple struct with one element, so
Listing 15-8 defines a MyBox<T> type in the same way. We’ll also define a
new function to match the new function defined on Box<T>.
Filename: src/main.rs
struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() {}
Listing 15-8: Defining a MyBox<T> type
- We define a struct named
MyBoxand declare a generic parameterT, because we want our type to hold values of any type. - The
MyBoxtype is a tuple struct with one element of typeT. - The
MyBox::newfunction takes one parameter of typeTand returns aMyBoxinstance that holds the value passed in.
Let’s try adding the
mainfunction in Listing 15-7 to Listing 15-8 and changing it to use theMyBox<T>type we’ve defined instead ofBox<T>.
The
code in Listing 15-9 won’t compile because Rust doesn’t know how to dereference
MyBox.
Filename: src/main.rs
struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() { let x = 5; let y = MyBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Listing 15-9: Attempting to use MyBox<T> in the same
way we used references and Box<T>
Here’s the resulting compilation error:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` due to previous error
Our
MyBox<T>type can’t be dereferenced because we haven’t implemented that ability on our type. To enable dereferencing with the*operator, we implement theDereftrait.
Treating a Type Like a Reference by Implementing the Deref Trait
As discussed in the “Implementing a Trait on a Type” section of Chapter 10, to implement a trait, we need to provide implementations for the trait’s required methods.
The
Dereftrait, provided by the standard library, requires us to implement one method namedderefthat borrowsselfand returns a reference to the inner data.
Listing 15-10
contains an implementation of Deref to add to the definition of MyBox:
Filename: src/main.rs
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() { let x = 5; let y = MyBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Listing 15-10: Implementing Deref on MyBox<T>
- The
type Target = T;syntax defines an associated type for theDereftrait to use. - Associated types are a slightly different way of declaring a generic parameter, but you don’t need to worry about them for now; we’ll cover them in more detail in Chapter 19.
- We fill in the body of the
derefmethod with&self.0soderefreturns a reference to the value we want to access with the*operator; - recall from the
“Using Tuple Structs without Named Fields to Create Different
Types” section of Chapter 5 that
.0accesses the first value in a tuple struct. - The
mainfunction in Listing 15-9 that calls*on theMyBox<T>value now compiles, and the assertions pass!
Without the
Dereftrait, the compiler can only dereference&references.
The deref method gives the compiler the ability to take a value of any type
that implements Deref and call the deref method to get a & reference that
it knows how to dereference.
When we entered *y in Listing 15-9, behind the scenes Rust actually ran this
code:
*(y.deref())
Rust substitutes the
*operator with a call to thederefmethod and then a plain dereference so we don’t have to think about whether or not we need to call thederefmethod.
This Rust feature lets us write code that functions
identically whether we have a regular reference or a type that implements
Deref.
The reason the
derefmethod returns a reference to a value, and that the plain dereference outside the parentheses in*(y.deref())is still necessary, is to do with the ownership system:
- If the
derefmethod returned the value directly instead of a reference to the value, the value would be moved out ofself. - We don’t want to take ownership of the inner value inside
MyBox<T>in this case or in most cases where we use the dereference operator.
Note that the
*operator is replaced with a call to thederefmethod and then a call to the*operator just once, each time we use a*in our code.
Because the substitution of the * operator does not recurse infinitely, we
end up with data of type i32, which matches the 5 in assert_eq! in
Listing 15-9.
Implicit Deref Coercions with Functions and Methods
Deref coercion converts a reference to a type that implements the Deref
trait into a reference to another type.
For example, deref coercion can convert
&String to &str because String implements the Deref trait such that it
returns &str.
Deref coercion is a convenience Rust performs on arguments to functions and methods, and works only on types that implement the
Dereftrait.
-
It happens automatically when we pass a reference to a particular type’s value as an argument to a function or method that doesn’t match the parameter type in the function or method definition.
-
A sequence of calls to the
derefmethod converts the type we provided into the type the parameter needs. -
Deref coercion was added to Rust so that programmers writing function and method calls don’t need to add as many explicit references and dereferences with
&and*. -
The deref coercion feature also lets us write more code that can work for either references or smart pointers.
To see deref coercion in action, let’s use the
MyBox<T>type we defined in Listing 15-8 as well as the implementation ofDerefthat we added in Listing 15-10.
Listing 15-11 shows the definition of a function that has a string slice parameter:
Filename: src/main.rs
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {}
Listing 15-11: A hello function that has the parameter
name of type &str
We can call the hello function with a string slice as an argument, such as
hello("Rust"); for example. Deref coercion makes it possible to call hello
with a reference to a value of type MyBox<String>, as shown in Listing 15-12:
Filename: src/main.rs
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}
Listing 15-12: Calling hello with a reference to a
MyBox<String> value, which works because of deref coercion
- Here we’re calling the
hellofunction with the argument&m, which is a reference to aMyBox<String>value. - Because we implemented the
Dereftrait onMyBox<T>in Listing 15-10, Rust can turn&MyBox<String>into&Stringby callingderef. - The standard library provides an implementation of
DerefonStringthat returns a string slice, and this is in the API documentation forDeref. - Rust calls
derefagain to turn the&Stringinto&str, which matches thehellofunction’s definition.
If Rust didn’t implement deref coercion, we would have to write the code in Listing 15-13 instead of the code in Listing 15-12 to call
hellowith a value of type&MyBox<String>.
Filename: src/main.rs
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}
Listing 15-13: The code we would have to write if Rust didn’t have deref coercion
- The
(*m)dereferences theMyBox<String>into aString. - Then the
&and[..]take a string slice of theStringthat is equal to the whole string to match the signature ofhello. - This code without deref coercions is harder to read, write, and understand with all of these symbols involved.
- Deref coercion allows Rust to handle these conversions for us automatically.
When the Deref trait is defined for the types involved, Rust will analyze the
types and use Deref::deref as many times as necessary to get a reference to
match the parameter’s type.
The number of times that
Deref::derefneeds to be inserted is resolved at compile time, so there is no runtime penalty for taking advantage of deref coercion!
DerefMut: How Deref Coercion Interacts with Mutability
Similar to how you use the Deref trait to override the * operator on
immutable references, you can use the DerefMut trait to override the *
operator on mutable references.
Rust does deref coercion when it finds types and trait implementations in three cases:
- From
&Tto&UwhenT: Deref<Target=U> - From
&mut Tto&mut UwhenT: DerefMut<Target=U> - From
&mut Tto&UwhenT: Deref<Target=U>
The first two cases are the same as each other except that the second implements mutability:
- The first case states that if you have a
&T, andTimplementsDerefto some typeU, you can get a&Utransparently. - The second case states that the same deref coercion happens for mutable references.
The third case is trickier:
- Rust will also coerce a mutable reference to an immutable one.
- But the reverse is not possible: immutable references will never coerce to mutable references.
- Because of the borrowing rules, if you have a mutable reference, that mutable reference must be the only reference to that data (otherwise, the program wouldn’t compile).
- Converting one mutable reference to one immutable reference will never break the borrowing rules.
- Converting an immutable reference to a mutable reference would require that the initial immutable reference is the only immutable reference to that data, but the borrowing rules don’t guarantee that.
Therefore, Rust can’t make the assumption that converting an immutable reference to a mutable reference is possible.
Running Code on Cleanup with the Drop Trait
The second trait important to the smart pointer pattern is Drop, which lets
you customize what happens when a value is about to go out of scope.
You can provide an implementation for the
Droptrait on any type, and that code can be used to release resources like files or network connections.
We’re introducing Drop in the context of smart pointers because the
functionality of the Drop trait is almost always used when implementing a
smart pointer.
For example, when a
Box<T>is dropped it will deallocate the space on the heap that the box points to.
- In Rust, you can specify that a particular bit of code be run whenever a value goes out of scope, and the compiler will insert this code automatically.
- Rust doesn’t let us call
dropexplicitly because Rust would still automatically calldropon the value at the end ofmain.
This would cause a double free error because Rust would be trying to clean up the same value twice.
- Drop early: drop(c), not c.drop()
Rust doesn’t let you call the
Droptrait’sdropmethod manually; instead you have to call thestd::mem::dropfunction provided by the standard library if you want to force a value to be dropped before the end of its scope.
Just like Context Manager in Python
In some languages, for some types, the programmer must call code to free memory or resources every time they finish using an instance of those types. Examples include file handles, sockets, or locks. If they forget, the system might become overloaded and crash.
In Rust, you can specify that a particular bit of code be run whenever a value goes out of scope, and the compiler will insert this code automatically.
As a result, you don’t need to be careful about placing cleanup code everywhere in a program that an instance of a particular type is finished with—you still won’t leak resources!
- You specify the code to run when a value goes out of scope by implementing the
Droptrait. - The
Droptrait requires you to implement one method nameddropthat takes a mutable reference toself.
To see when Rust calls
drop, let’s implementdropwithprintln!statements for now.
Listing 15-14 shows a CustomSmartPointer struct whose only custom
functionality is that it will print Dropping CustomSmartPointer! when the
instance goes out of scope, to show when Rust runs the drop function.
Filename: src/main.rs
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("my stuff"), }; let d = CustomSmartPointer { data: String::from("other stuff"), }; println!("CustomSmartPointers created."); }
Listing 15-14: A CustomSmartPointer struct that
implements the Drop trait where we would put our cleanup code
- The
Droptrait is included in the prelude, so we don’t need to bring it into scope. - We implement the
Droptrait onCustomSmartPointerand provide an implementation for thedropmethod that callsprintln!. - The body of the
dropfunction is where you would place any logic that you wanted to run when an instance of your type goes out of scope. - We’re printing some text here to
demonstrate visually when Rust will call
drop. - In
main, we create two instances ofCustomSmartPointerand then printCustomSmartPointers created. - At the end of
main, our instances ofCustomSmartPointerwill go out of scope, and Rust will call the code we put in thedropmethod, printing our final message. - Note that we didn’t need to call the
dropmethod explicitly.
When we run this program, we’ll see the following output:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created.
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
- Rust automatically called
dropfor us when our instances went out of scope, calling the code we specified. - Variables are dropped in the reverse order of
their creation, so
dwas dropped beforec.
This example’s purpose is to give you a visual guide to how the
dropmethod works; usually you would specify the cleanup code that your type needs to run rather than a print message.
Dropping a Value Early with std::mem::drop
Unfortunately, it’s not straightforward to disable the automatic drop
functionality. Disabling drop isn’t usually necessary; the whole point of the
Drop trait is that it’s taken care of automatically.
Occasionally, however, you might want to clean up a value early.
One example is when using smart pointers that manage locks: you might want to force the drop method that
releases the lock so that other code in the same scope can acquire the lock.
Rust doesn’t let you call the Drop trait’s drop method manually; instead
you have to call the std::mem::drop function provided by the standard library
if you want to force a value to be dropped before the end of its scope.
If we try to call the Drop trait’s drop method manually by modifying the
main function from Listing 15-14, as shown in Listing 15-15, we’ll get a
compiler error:
Filename: src/main.rs
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("some data"), }; println!("CustomSmartPointer created."); c.drop(); println!("CustomSmartPointer dropped before the end of main."); }
Listing 15-15: Attempting to call the drop method from
the Drop trait manually to clean up early
When we try to compile this code, we’ll get this error:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| --^^^^--
| | |
| | explicit destructor calls not allowed
| help: consider using `drop` function: `drop(c)`
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` due to previous error
- This error message states that we’re not allowed to explicitly call
drop. - The error message uses the term destructor, which is the general programming term for a function that cleans up an instance.
- A destructor is analogous to a constructor, which creates an instance.
- The
dropfunction in Rust is one particular destructor.
Rust doesn’t let us call drop explicitly because Rust would still
automatically call drop on the value at the end of main.
This would cause a double free error because Rust would be trying to clean up the same value twice.
We can’t disable the automatic insertion of drop when a value goes out of
scope, and we can’t call the drop method explicitly.
So, if we need to force a value to be cleaned up early, we use the
std::mem::dropfunction.
The std::mem::drop function is different from the drop method in the Drop
trait. We call it by passing as an argument the value we want to force drop.
The function is in the prelude, so we can modify main in Listing 15-15 to
call the drop function, as shown in Listing 15-16:
Filename: src/main.rs
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("some data"), }; println!("CustomSmartPointer created."); drop(c); println!("CustomSmartPointer dropped before the end of main."); }
Listing 15-16: Calling std::mem::drop to explicitly
drop a value before it goes out of scope
Running this code will print the following:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created.
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main.
- The text
Dropping CustomSmartPointer with data `some data`!is printed between theCustomSmartPointer created.andCustomSmartPointer dropped before the end of main.text, showing that thedropmethod code is called to dropcat that point.
You can use code specified in a
Droptrait implementation in many ways to make cleanup convenient and safe:
- for instance, you could use it to create your own memory allocator!
- With the
Droptrait and Rust’s ownership system, you don’t have to remember to clean up because Rust does it automatically.
You also don’t have to worry about problems resulting from accidentally cleaning up values still in use:
the ownership system that makes sure
references are always valid also ensures that drop gets called only once when
the value is no longer being used.
Now that we’ve examined Box<T> and some of the characteristics of smart
pointers, let’s look at a few other smart pointers defined in the standard
library.
Using Box<T> to Point to Data on the Heap
The most straightforward smart pointer is a box, whose type is written Box
- Boxes allow you to store data on the heap rather than the stack.
- What remains on the stack is the pointer to the heap data.
- Refer to Chapter 4 to review the difference between the stack and the heap.
You’ll use them most often in these situations:
- When you have a type whose size can’t be known at compile time and you want to use a value of that type in a context that requires an exact size
- When you have a large amount of data and you want to transfer ownership but ensure the data won’t be copied when you do so
- When you want to own a value and you care only that it’s a type that implements a particular trait rather than being of a specific type
- Using Box<T> to Point to Data on the Heap
- Using a Box<T> to Store Data on the Heap
- Enabling Recursive Types with Boxes
The most straightforward smart pointer is a box, whose type is written
Box<T>:
- Boxes allow you to store data on the heap rather than the stack.
- What remains on the stack is the pointer to the heap data.
- Refer to Chapter 4 to review the difference between the stack and the heap.
Boxes don’t have performance overhead, other than storing their data on the heap instead of on the stack. But they don’t have many extra capabilities either.
You’ll use them most often in these situations:
- When you have a type whose size can’t be known at compile time and you want to use a value of that type in a context that requires an exact size
- When you have a large amount of data and you want to transfer ownership but ensure the data won’t be copied when you do so
- When you want to own a value and you care only that it’s a type that implements a particular trait rather than being of a specific type
- We’ll demonstrate the first situation in the “Enabling Recursive Types with Boxes” section.
- In the second case, transferring ownership of a large amount of data can take a long time because the data is copied around on the stack. To improve performance in this situation, we can store the large amount of data on the heap in a box. Then, only the small amount of pointer data is copied around on the stack, while the data it references stays in one place on the heap.
- The third case is known as a trait object, and Chapter 17 devotes an entire section, “Using Trait Objects That Allow for Values of Different Types,” just to that topic. So what you learn here you’ll apply again in Chapter 17!
Using a Box<T> to Store Data on the Heap
Before we discuss the heap storage use case for Box<T>, we’ll cover the
syntax and how to interact with values stored within a Box<T>.
Listing 15-1 shows how to use a box to store an i32 value on the heap:
Filename: src/main.rs
fn main() {
let b = Box::new(5);
println!("b = {}", b);
}
Listing 15-1: Storing an i32 value on the heap using a
box
- We define the variable
bto have the value of aBoxthat points to the value5, which is allocated on the heap. - This program will print
b = 5; in this case, we can access the data in the box similar to how we would if this data were on the stack. - Just like any owned value, when a box goes out of
scope, as
bdoes at the end ofmain, it will be deallocated. - The deallocation happens both for the box (stored on the stack) and the data it points to (stored on the heap).
Putting a single value on the heap isn’t very useful, so you won’t use boxes by
themselves in this way very often. Having values like a single i32 on the
stack, where they’re stored by default, is more appropriate in the majority of
situations.
Let’s look at a case where boxes allow us to define types that we wouldn’t be allowed to if we didn’t have boxes.
Enabling Recursive Types with Boxes
A value of recursive type can have another value of the same type as part of itself.
Recursive types pose an issue because at compile time Rust needs to know how much space a type takes up. However, the nesting of values of recursive types could theoretically continue infinitely, so Rust can’t know how much space the value needs.
Because boxes have a known size, we can enable recursive types by inserting a box in the recursive type definition.
As an example of a recursive type, let’s explore the cons list. This is a data type commonly found in functional programming languages:
- The cons list type we’ll define is straightforward except for the recursion;
- therefore, the concepts in the example we’ll work with will be useful any time you get into more complex situations involving recursive types.
More Information About the Cons List
A cons list is a data structure that comes from the Lisp programming language and its dialects and is made up of nested pairs, and is the Lisp version of a linked list.
Its name comes from the
consfunction (short for “construct function”) in Lisp that constructs a new pair from its two arguments. By callingconson a pair consisting of a value and another pair, we can construct cons lists made up of recursive pairs.
For example, here’s a pseudocode representation of a cons list containing the list 1, 2, 3 with each pair in parentheses:
(1, (2, (3, Nil)))
Each item in a cons list contains two elements: the value of the current item and the next item.
- The last item in the list contains only a value called
Nilwithout a next item. - A cons list is produced by recursively calling the
consfunction. - The canonical name to denote the base case of the recursion is
Nil. - Note that this is not the same as the “null” or “nil” concept in Chapter 6, which is an invalid or absent value.
The cons list isn’t a commonly used data structure in Rust.
-
Most of the time when you have a list of items in Rust,
Vec<T>is a better choice to use. -
Other, more complex recursive data types are useful in various situations,
but by starting with the cons list in this chapter, we can explore how boxes let us define a recursive data type without much distraction.
Listing 15-2 contains an enum definition for a cons list. Note that this code
won’t compile yet because the List type doesn’t have a known size, which
we’ll demonstrate.
Filename: src/main.rs
enum List {
Cons(i32, List),
Nil,
}
fn main() {}
Listing 15-2: The first attempt at defining an enum to
represent a cons list data structure of i32 values
Note: We’re implementing a cons list that holds only
i32values for the purposes of this example. We could have implemented it using generics, as we discussed in Chapter 10, to define a cons list type that could store values of any type.
Using the List type to store the list 1, 2, 3 would look like the code in
Listing 15-3:
Filename: src/main.rs
enum List {
Cons(i32, List),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}
Listing 15-3: Using the List enum to store the list 1, 2, 3
- The first
Consvalue holds1and anotherListvalue. - This
Listvalue is anotherConsvalue that holds2and anotherListvalue. - This
Listvalue is one moreConsvalue that holds3and aListvalue, which is finallyNil, the non-recursive variant that signals the end of the list.
If we try to compile the code in Listing 15-3, we get the error shown in Listing 15-4:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ recursive type has infinite size
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to make `List` representable
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing drop-check constraints for `List`
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing drop-check constraints for `List` again
= note: cycle used when computing dropck types for `Canonical { max_universe: U0, variables: [], value: ParamEnvAnd { param_env: ParamEnv { caller_bounds: [], reveal: UserFacing, constness: NotConst }, value: List } }`
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` due to 2 previous errors
Listing 15-4: The error we get when attempting to define a recursive enum
- The error shows this type “has infinite size.”
- The reason is that we’ve defined
Listwith a variant that is recursive: it holds another value of itself directly. - As a result, Rust can’t figure out how much space it needs to store a
Listvalue.
Let’s break down why we get this error.
- First, we’ll look at how Rust decides how much space it needs to store a value of a non-recursive type.
Computing the Size of a Non-Recursive Type
Recall the Message enum we defined in Listing 6-2 when we discussed enum
definitions in Chapter 6:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}
To determine how much space to allocate for a Message value, Rust goes
through each of the variants to see which variant needs the most space.
- Rust sees that
Message::Quitdoesn’t need any space,Message::Moveneeds enough space to store twoi32values, and so forth. - Because only one variant will be
used, the most space a
Messagevalue will need is the space it would take to store the largest of its variants.
Contrast this with what happens when Rust tries to determine how much space a recursive type like the
Listenum in Listing 15-2 needs.
- The compiler starts
by looking at the
Consvariant, which holds a value of typei32and a value of typeList. - Therefore,
Consneeds an amount of space equal to the size of ani32plus the size of aList. - To figure out how much memory the
Listtype needs, the compiler looks at the variants, starting with theConsvariant. - The
Consvariant holds a value of typei32and a value of typeList, and this process continues infinitely, as shown in Figure 15-1.

Figure 15-1: An infinite List consisting of infinite
Cons variants
Using Box<T> to Get a Recursive Type with a Known Size
Because Rust can’t figure out how much space to allocate for recursively defined types, the compiler gives an error with this helpful suggestion:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to make `List` representable
|
2 | Cons(i32, Box<List>),
| ++++ +
In this suggestion, “indirection” means that instead of storing a value directly, we should change the data structure to store the value indirectly by storing a pointer to the value instead.
Because a
Box<T>is a pointer, Rust always knows how much space aBox<T>needs: a pointer’s size doesn’t change based on the amount of data it’s pointing to.
- This means we can put a
Box<T>inside theConsvariant instead of anotherListvalue directly. - The
Box<T>will point to the nextListvalue that will be on the heap rather than inside theConsvariant. - Conceptually, we still have a list, created with lists holding other lists, but this implementation is now more like placing the items next to one another rather than inside one another.
We can change the definition of the List enum in Listing 15-2 and the usage
of the List in Listing 15-3 to the code in Listing 15-5, which will compile:
Filename: src/main.rs
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}
Listing 15-5: Definition of List that uses Box<T> in
order to have a known size
- The
Consvariant needs the size of ani32plus the space to store the box’s pointer data. - The
Nilvariant stores no values, so it needs less space than theConsvariant. - We now know that any
Listvalue will take up the size of ani32plus the size of a box’s pointer data.
By using a box, we’ve broken the infinite, recursive chain, so the compiler can figure out the size it needs to store a
Listvalue.
Figure 15-2 shows what the Cons variant looks like now.

Figure 15-2: A List that is not infinitely sized
because Cons holds a Box
- Boxes provide only the indirection and heap allocation;
- they don’t have any other special capabilities, like those we’ll see with the other smart pointer types.
- They also don’t have the performance overhead that these special capabilities incur, so they can be useful in cases like the cons list where the indirection is the only feature we need.
- We’ll look at more use cases for boxes in Chapter 17, too.
The
Box<T>type is a smart pointer because it implements theDereftrait, which allowsBox<T>values to be treated like references.
When a
Box<T>value goes out of scope, the heap data that the box is pointing to is cleaned up as well because of theDroptrait implementation.
These two traits will be even more important to the functionality provided by the other smart pointer types we’ll discuss in the rest of this chapter. Let’s explore these two traits in more detail.
Both types keep track of references, but not at all
Rc<T>: Single-threaded scenarios, the Reference Counted Smart Pointer for immutable references of multiple owners
- there are cases when a single value might have multiple owners.
- You have to enable multiple ownership explicitly by using the Rust type Rc
, which is an abbreviation for reference counting. 使用起来就是 python 的内存管理机制
- The
Rc<T>type keeps track of the number of references to a value to determine whether or not the value is still in use. - If there are zero references to a value, the value can be cleaned up without any references becoming invalid.
-
Note that Rc
is only for use in single-threaded scenarios. -
Using Rc
to share data

Deep copies of data can take a lot of time. By using
Rc::clonefor reference counting, we can visually distinguish between the deep-copy kinds of clones and the kinds of clones that increase the reference count. When looking for performance problems in the code, we only need to consider the deep-copy clones and can disregard calls toRc::clone.
Using
Rc<T>allows a single value to have multiple owners, and the count ensures that the value remains valid as long as any of the owners still exist.
In the majority of cases, ownership is clear: you know exactly which variable owns a given value.
Why need Rc<T>
However, there are cases when a single value might have multiple owners.
For example, in graph data structures, multiple edges might point to the same node, and that node is conceptually owned by all of the edges that point to it. A node shouldn’t be cleaned up unless it doesn’t have any edges pointing to it and so has no owners.
You have to enable multiple ownership explicitly by using the Rust type
Rc<T>, which is an abbreviation for reference counting.
- The
Rc<T>type keeps track of the number of references to a value to determine whether or not the value is still in use. - If there are zero references to a value, the value can be cleaned up without any references becoming invalid.
Imagine
Rc<T>as a TV in a family room.
- When one person enters to watch TV, they turn it on.
- Others can come into the room and watch the TV.
- When the last person leaves the room, they turn off the TV because it’s no longer being used.
- If someone turns off the TV while others are still watching it, there would be uproar from the remaining TV watchers!
We use the
Rc<T>type when we want to allocate some data on the heap for multiple parts of our program to read and we can’t determine at compile time which part will finish using the data last.
If we knew which part would finish last, we could just make that part the data’s owner, and the normal ownership rules enforced at compile time would take effect.
Note that
Rc<T>is only for use in single-threaded scenarios.
When we discuss concurrency in Chapter 16, we’ll cover how to do reference counting in multithreaded programs.
Using Rc<T> to Share Data
Let’s return to our cons list example in Listing 15-5:
- Recall that we defined it using
Box<T>. - This time, we’ll create two lists that both share ownership of a third list.
Conceptually, this looks similar to Figure 15-3:

Figure 15-3: Two lists, b and c, sharing ownership of
a third list, a
- We’ll create list
athat contains 5 and then 10. - Then we’ll make two more
lists:
bthat starts with 3 andcthat starts with 4. - Both
bandclists will then continue on to the firstalist containing 5 and 10. - In other words, both lists will share the first list containing 5 and 10.
Trying to implement this scenario using our definition of List with Box<T>
won’t work, as shown in Listing 15-17:
Filename: src/main.rs
enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let a = Cons(5, Box::new(Cons(10, Box::new(Nil)))); let b = Cons(3, Box::new(a)); let c = Cons(4, Box::new(a)); }
Listing 15-17: Demonstrating we’re not allowed to have
two lists using Box<T> that try to share ownership of a third list
When we compile this code, we get this error:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` due to previous error
- The
Consvariants own the data they hold, so when we create theblist,ais moved intobandbownsa. - Then, when we try to use
aagain when creatingc, we’re not allowed to becauseahas been moved.
- We could change the definition of
Consto hold references instead - but then we would have to specify lifetime parameters.
- By specifying lifetime parameters, we would be specifying that every element in the list will live at least as long as the entire list.
- This is the case for the elements and lists in Listing 15-17, but not in every scenario.
Instead, we’ll change our definition of
Listto useRc<T>in place ofBox<T>, as shown in Listing 15-18.
- Each
Consvariant will now hold a value and anRc<T>pointing to aList. - When we create
b, instead of taking ownership ofa, we’ll clone theRc<List>thatais holding, thereby increasing the number of references from one to two and lettingaandbshare ownership of the data in thatRc<List>. - We’ll also clone
awhen creatingc, increasing the number of references from two to three. - Every time
we call
Rc::clone, the reference count to the data within theRc<List>will increase, and the data won’t be cleaned up unless there are zero references to it.
Filename: src/main.rs
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
Listing 15-18: A definition of List that uses
Rc<T>
- We need to add a
usestatement to bringRc<T>into scope because it’s not in the prelude. - In
main, we create the list holding 5 and 10 and store it in a newRc<List>ina. - Then when we create
bandc, we call theRc::clonefunction and pass a reference to theRc<List>inaas an argument. - We could have called
a.clone()rather thanRc::clone(&a), but Rust’s convention is to useRc::clonein this case. - The implementation of
Rc::clonedoesn’t make a deep copy of all the data like most types’ implementations ofclonedo. - The call to
Rc::cloneonly increments the reference count, which doesn’t take much time.
Deep copies of data can take a lot of time. By using
Rc::clonefor reference counting, we can visually distinguish between the deep-copy kinds of clones and the kinds of clones that increase the reference count. When looking for performance problems in the code, we only need to consider the deep-copy clones and can disregard calls toRc::clone.
Cloning an Rc<T> Increases the Reference Count
Let’s change our working example in Listing 15-18 so we can see the reference
counts changing as we create and drop references to the Rc<List> in a.
In Listing 15-19:
- we’ll change
mainso it has an inner scope around listc; - then we can see how the reference count changes when
cgoes out of scope.
Filename: src/main.rs
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("count after creating a = {}", Rc::strong_count(&a)); let b = Cons(3, Rc::clone(&a)); println!("count after creating b = {}", Rc::strong_count(&a)); { let c = Cons(4, Rc::clone(&a)); println!("count after creating c = {}", Rc::strong_count(&a)); } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); }
Listing 15-19: Printing the reference count
- At each point in the program where the reference count changes
- we print the
reference count, which we get by calling the
Rc::strong_countfunction. - This
function is named
strong_countrather thancountbecause theRc<T>type also has aweak_count; - we’ll see what
weak_countis used for in the “Preventing Reference Cycles: Turning anRc<T>into aWeak<T>” section.
This code prints the following:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
- We can see that the
Rc<List>inahas an initial reference count of 1; - then each time we call
clone, the count goes up by 1. - When
cgoes out of scope, the count goes down by 1. - We don’t have to call a function to decrease the
reference count like we have to call
Rc::cloneto increase the reference count: the implementation of theDroptrait decreases the reference count automatically when anRc<T>value goes out of scope.
What we can’t see in this example is that when b and then a go out of scope
at the end of main, the count is then 0, and the Rc<List> is cleaned up
completely.
Using
Rc<T>allows a single value to have multiple owners, and the count ensures that the value remains valid as long as any of the owners still exist.
Via immutable references, Rc<T> allows you to share data between multiple
parts of your program for reading only. If Rc<T> allowed you to have multiple
mutable references too, you might violate one of the borrowing rules discussed
in Chapter 4: multiple mutable borrows to the same place can cause data races
and inconsistencies.
But being able to mutate data is very useful!
In the next section, we’ll discuss the interior mutability pattern and the RefCell<T> type that you can use in conjunction with an Rc<T> to work with this immutability restriction.
RefCell<T>: Runtime Borrow Checking and the Interior Mutability Pattern
-
Interior mutability is a design pattern in Rust that allows you to mutate data even when there are immutable references to that data; normally, this action is disallowed by the borrowing rules.
-
Unsafe code indicates to the compiler that we’re checking the rules manually instead of relying on the compiler to check them for us;
-
Unlike
Rc<T>, theRefCell<T>type represents single ownership over the data it holds. -
So, what makes
RefCell<T>different from a type likeBox<T>?
-
Box
at compile time: With references and Box<T>, the borrowing rules’ invariants are enforced at compile time. -
Refcell
at runtime: With RefCell<T>, these invariants are enforced at runtime.
- Recall the borrowing rules you learned in Chapter 4:
- At any given time, you can have either (but not both) one mutable reference or any number of immutable references.
- References must always be valid.
-
The
RefCell<T>type is useful when you’re sure your code follows the borrowing rules but the compiler is unable to understand and guarantee that. -
the reasons to choose
Box<T>,Rc<T>, orRefCell<T>
Here is a recap of the reasons to choose
Box<T>,Rc<T>, orRefCell<T>:
- Owners:
Rc<T> enables multiple owners of the same data;
Box<T> and RefCell<T> have single owners.
- Borrows Check:
Box<T>allows immutable or mutable borrows checked at compile time;Rc<T>allows only immutable borrows checked at compile time;RefCell<T>allows immutable or mutable borrows checked at runtime. - Mutate or not:
Because
RefCell<T>allows mutable borrows checked at runtime, you can mutate the value inside theRefCell<T>even when theRefCell<T>is immutable.
-
A Mutable Borrow to an Immutable Value: this code won’t compile
-
A library to keep track of how close a value is to a maximum value and warn when the value is at certain levels
-
Keeping Track of Borrows at Runtime with
RefCell<T>
When creating immutable and mutable references, we use the & and &mut syntax, respectively.
The
RefCell<T>keeps track of how manyRef<T>andRefMut<T>smart pointers are currently active.
- With
RefCell<T>, we use theborrowandborrow_mutmethods, which are part of the safe API that belongs toRefCell<T>. - The
borrowmethod returns the smart pointer typeRef<T> - and
borrow_mutreturns the smart pointer typeRefMut<T>. - Both types implement
Deref, so we can treat them like regular references. - Every time we call
borrow, theRefCell<T>increases its count of how many immutable borrows are active. - When a
Ref<T>value goes out of scope, the count of immutable borrows goes down by one. - Just like the compile-time borrowing rules,
RefCell<T>lets us have many immutable borrows or one mutable borrow at any point in time.
- Having Multiple Owners of Mutable Data by Combining
Rc<T>andRefCell<T>
A common way to use
RefCell<T>is in combination withRc<T>.
-
Recall that
Rc<T>lets you have multiple owners of some data, but it only gives immutable access to that data. -
If you have an
Rc<T>that holds aRefCell<T>, you can get a value that can have multiple owners and that you can mutate! -
For example, recall the cons list example in Listing 15-18 where we used
Rc<T>to allow multiple lists to share ownership of another list. -
Because
Rc<T>holds only immutable values, we can’t change any of the values in the list once we’ve created them. -
Let’s add in
RefCell<T>to gain the ability to change the values in the lists.
-
Using
Rc<RefCell<i32>>to create aListthat we can mutate -
Note that
RefCell<T>does not work for multithreaded code!Mutex<T>is the thread-safe version ofRefCell<T>and we’ll discussMutex<T>in Chapter 16.
- Interior Mutability
- Enforcing Borrowing Rules at Runtime with RefCell<T>
- Interior Mutability: A Mutable Borrow to an Immutable Value
- Having Multiple Owners of Mutable Data by Combining Rc<T> and RefCell<T>
Interior Mutability
Interior mutability is a design pattern in Rust that allows you to mutate data even when there are immutable references to that data; normally, this action is disallowed by the borrowing rules.
To mutate data, the pattern uses
unsafecode inside a data structure to bend Rust’s usual rules that govern mutation and borrowing.
Unsafe code indicates to the compiler that we’re checking the rules manually instead of relying on the compiler to check them for us;
we will discuss unsafe code more in Chapter 19.
We can use types that use the interior mutability pattern only when we can ensure that the borrowing rules will be followed at runtime, even though the compiler can’t guarantee that.
The unsafe code involved is then wrapped in a safe API, and the outer type is still immutable.
Let’s explore this concept by looking at the RefCell<T> type that follows the
interior mutability pattern.
Enforcing Borrowing Rules at Runtime with RefCell<T>
Unlike Rc<T>, the RefCell<T> type represents single ownership over the data it holds.
So, what makes RefCell<T> different from a type like Box<T>?
Recall the borrowing rules you learned in Chapter 4:
- At any given time, you can have either (but not both) one mutable reference or any number of immutable references.
- References must always be valid.
Different Time
-
Box
at compile time: With references and Box<T>, the borrowing rules’ invariants are enforced at compile time. -
Refcell
at runtime: With RefCell<T>, these invariants are enforced at runtime.
- With references, if you break these rules, you’ll get a compiler error.
- With
RefCell<T>, if you break these rules, your program will panic and exit.
The advantages of checking the borrowing rules at compile time:
- errors will be caught sooner in the development process
- there is no impact on runtime performance because all the analysis is completed beforehand.
For those reasons, checking the borrowing rules at compile time is the best choice in the majority of cases, which is why this is Rust’s default.
The advantage of checking the borrowing rules at runtime instead:
-
certain memory-safe scenarios are then allowed, where they would’ve been disallowed by the compile-time checks.
-
Static analysis, like the Rust compiler, is inherently conservative.
Some properties of code are impossible to detect by analyzing the code:
- the most famous example is the Halting Problem, which is beyond the scope of this book but is an interesting topic to research.
The Rust Compiler might reject a correct program
Because some analysis is impossible, if the Rust compiler can’t be sure the code complies with the ownership rules, it might reject a correct program; in this way, it’s conservative.
If Rust accepted an incorrect program, users wouldn’t be able to trust in the guarantees Rust makes.
However, if Rust rejects a correct program, the programmer will be inconvenienced, but nothing catastrophic can occur.
- The
RefCell<T>type is useful when you’re sure your code follows the borrowing rules but the compiler is unable to understand and guarantee that.
Similar to Rc<T>, RefCell<T> is only for use in single-threaded scenarios
and will give you a compile-time error if you try using it in a multithreaded
context.
We’ll talk about how to get the functionality of
RefCell<T>in a multithreaded program in Chapter 16.
the reasons to choose Box<T>, Rc<T>, or RefCell<T>
Here is a recap of the reasons to choose
Box<T>,Rc<T>, orRefCell<T>:
- Owners:
Rc<T> enables multiple owners of the same data;
Box<T> and RefCell<T> have single owners.
- Borrows Check:
Box<T>allows immutable or mutable borrows checked at compile time;Rc<T>allows only immutable borrows checked at compile time;RefCell<T>allows immutable or mutable borrows checked at runtime. - Mutate or not:
Because
RefCell<T>allows mutable borrows checked at runtime, you can mutate the value inside theRefCell<T>even when theRefCell<T>is immutable.
Mutating the value inside an immutable value is the interior mutability pattern. Let’s look at a situation in which interior mutability is useful and examine how it’s possible.
Interior Mutability: A Mutable Borrow to an Immutable Value
A consequence of the borrowing rules is that when you have an immutable value, you can’t borrow it mutably. For example, this code won’t compile:
fn main() { let x = 5; let y = &mut x; }
If you tried to compile this code, you’d get the following error:
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
2 | let x = 5;
| - help: consider changing this to be mutable: `mut x`
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` due to previous error
However, there are situations in which it would be useful for a value to mutate itself in its methods but appear immutable to other code.
- Code outside the value’s methods would not be able to mutate the value.
- Using
RefCell<T>is one way to get the ability to have interior mutability, butRefCell<T>doesn’t get around the borrowing rules completely: the borrow checker in the compiler allows this interior mutability, and the borrowing rules are checked at runtime instead. - If you violate the rules, you’ll get a
panic!instead of a compiler error.
Let’s work through a practical example where we can use RefCell<T> to mutate
an immutable value and see why that is useful.
A Use Case for Interior Mutability: Mock Objects
Sometimes during testing a programmer will use a type in place of another type, in order to observe particular behavior and assert it’s implemented correctly.
This placeholder type is called a test double.
Think of it in the sense of a “stunt double” in filmmaking, where a person steps in and substitutes for an actor to do a particular tricky scene. Test doubles stand in for other types when we’re running tests.
Mock objects are specific types of test doubles that record what happens during a test so you can assert that the correct actions took place.
Rust doesn’t have objects in the same sense as other languages have objects, and Rust doesn’t have mock object functionality built into the standard library as some other languages do.
However, you can definitely create a struct that will serve the same purposes as a mock object.
Here’s the scenario we’ll test:
- we’ll create a library that tracks a value against a maximum value and sends messages based on how close to the maximum value the current value is.
- This library could be used to keep track of a user’s quota for the number of API calls they’re allowed to make, for example.
- Our library will only provide the functionality of tracking how close to the maximum a value is and what the messages should be at what times.
- Applications that use our library will be expected to provide the mechanism for sending the messages: the application could put a message in the application, send an email, send a text message, or something else. The library doesn’t need to know that detail.
- All it needs is something that implements a trait we’ll provide
called
Messenger.
Listing 15-20 shows the library code:
Filename: src/lib.rs
pub trait Messenger { fn send(&self, msg: &str); } pub struct LimitTracker<'a, T: Messenger> { messenger: &'a T, value: usize, max: usize, } impl<'a, T> LimitTracker<'a, T> where T: Messenger, { pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> { LimitTracker { messenger, value: 0, max, } } pub fn set_value(&mut self, value: usize) { self.value = value; let percentage_of_max = self.value as f64 / self.max as f64; if percentage_of_max >= 1.0 { self.messenger.send("Error: You are over your quota!"); } else if percentage_of_max >= 0.9 { self.messenger .send("Urgent warning: You've used up over 90% of your quota!"); } else if percentage_of_max >= 0.75 { self.messenger .send("Warning: You've used up over 75% of your quota!"); } } }
Listing 15-20: A library to keep track of how close a value is to a maximum value and warn when the value is at certain levels
One important part of this code is that the
Messengertrait has one method calledsendthat takes an immutable reference toselfand the text of the message.
- This trait is the interface our mock object needs to implement so that the mock can be used in the same way a real object is.
The other important part is that we want to test the behavior of the
set_valuemethod on theLimitTracker.
We can change what we pass in for the value parameter, but
set_value doesn’t return anything for us to make assertions on. We want to be
able to say that if we create a LimitTracker with something that implements
the Messenger trait and a particular value for max, when we pass different
numbers for value, the messenger is told to send the appropriate messages.
We need a mock object that, instead of sending an email or text message when we
call send, will only keep track of the messages it’s told to send. We can
create a new instance of the mock object, create a LimitTracker that uses the
mock object, call the set_value method on LimitTracker, and then check that
the mock object has the messages we expect. Listing 15-21 shows an attempt to
implement a mock object to do just that, but the borrow checker won’t allow it:
Filename: src/lib.rs
pub trait Messenger { fn send(&self, msg: &str); } pub struct LimitTracker<'a, T: Messenger> { messenger: &'a T, value: usize, max: usize, } impl<'a, T> LimitTracker<'a, T> where T: Messenger, { pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> { LimitTracker { messenger, value: 0, max, } } pub fn set_value(&mut self, value: usize) { self.value = value; let percentage_of_max = self.value as f64 / self.max as f64; if percentage_of_max >= 1.0 { self.messenger.send("Error: You are over your quota!"); } else if percentage_of_max >= 0.9 { self.messenger .send("Urgent warning: You've used up over 90% of your quota!"); } else if percentage_of_max >= 0.75 { self.messenger .send("Warning: You've used up over 75% of your quota!"); } } } #[cfg(test)] mod tests { use super::*; struct MockMessenger { sent_messages: Vec<String>, } impl MockMessenger { fn new() -> MockMessenger { MockMessenger { sent_messages: vec![], } } } impl Messenger for MockMessenger { fn send(&self, message: &str) { self.sent_messages.push(String::from(message)); } } #[test] fn it_sends_an_over_75_percent_warning_message() { let mock_messenger = MockMessenger::new(); let mut limit_tracker = LimitTracker::new(&mock_messenger, 100); limit_tracker.set_value(80); assert_eq!(mock_messenger.sent_messages.len(), 1); } }
Listing 15-21: An attempt to implement a MockMessenger
that isn’t allowed by the borrow checker
- This test code defines a
MockMessengerstruct that has asent_messagesfield with aVecofStringvalues to keep track of the messages it’s told to send. - We also define an associated function
newto make it convenient to create newMockMessengervalues that start with an empty list of messages. - We then implement the
Messengertrait forMockMessengerso we can give aMockMessengerto aLimitTracker. - In the definition of the
sendmethod, we take the message passed in as a parameter and store it in theMockMessengerlist ofsent_messages.
In the test, we’re testing what happens when the
LimitTrackeris told to setvalueto something that is more than 75 percent of themaxvalue.
- First, we create a new
MockMessenger, which will start with an empty list of messages. - Then we create a new
LimitTrackerand give it a reference to the newMockMessengerand amaxvalue of 100. - We call the
set_valuemethod on theLimitTrackerwith a value of 80, which is more than 75 percent of 100. - Then we assert that the list of messages that the
MockMessengeris keeping track of should now have one message in it.
However, there’s one problem with this test, as shown here:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
2 | fn send(&self, msg: &str);
| ----- help: consider changing that to be a mutable reference: `&mut self`
...
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` due to previous error
warning: build failed, waiting for other jobs to finish...
- We can’t modify the
MockMessengerto keep track of the messages, because thesendmethod takes an immutable reference toself. - We also can’t take the
suggestion from the error text to use
&mut selfinstead, because then the signature ofsendwouldn’t match the signature in theMessengertrait definition (feel free to try and see what error message you get).
This is a situation in which interior mutability can help!
- We’ll store the
sent_messageswithin aRefCell<T>, - and then the
sendmethod will be able to modifysent_messagesto store the messages we’ve seen.
Listing 15-22 shows what that looks like:
Filename: src/lib.rs
In contrast, &T borrows the data via an immutable reference, and the borrower can read the data but not modify it:
pub trait Messenger { fn send(&self, msg: &str); } pub struct LimitTracker<'a, T: Messenger> { messenger: &'a T, value: usize, max: usize, } impl<'a, T> LimitTracker<'a, T> where T: Messenger, { pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> { LimitTracker { messenger, value: 0, max, } } pub fn set_value(&mut self, value: usize) { self.value = value; let percentage_of_max = self.value as f64 / self.max as f64; if percentage_of_max >= 1.0 { self.messenger.send("Error: You are over your quota!"); } else if percentage_of_max >= 0.9 { self.messenger .send("Urgent warning: You've used up over 90% of your quota!"); } else if percentage_of_max >= 0.75 { self.messenger .send("Warning: You've used up over 75% of your quota!"); } } } // ANCHOR: here #[cfg(test)] mod tests { use super::*; use std::cell::RefCell; struct MockMessenger { sent_messages: RefCell<Vec<String>>, } impl MockMessenger { fn new() -> MockMessenger { MockMessenger { sent_messages: RefCell::new(vec![]), } } } impl Messenger for MockMessenger { fn send(&self, message: &str) { self.sent_messages.borrow_mut().push(String::from(message)); } } #[test] fn it_sends_an_over_75_percent_warning_message() { // --snip-- // ANCHOR_END: here let mock_messenger = MockMessenger::new(); let mut limit_tracker = LimitTracker::new(&mock_messenger, 100); limit_tracker.set_value(80); // ANCHOR: here // ANCHOR: here assert_eq!(mock_messenger.sent_messages.borrow().len(), 1); } } // ANCHOR_END: here
Listing 15-22: Using RefCell<T> to mutate an inner
value while the outer value is considered immutable
- The
sent_messagesfield is now of typeRefCell<Vec<String>>instead ofVec<String>. - In the
newfunction, we create a newRefCell<Vec<String>>instance around the empty vector. - For the implementation of the
sendmethod, the first parameter is still an immutable borrow ofself, which matches the trait definition. - We call
borrow_muton theRefCell<Vec<String>>inself.sent_messagesto get a mutable reference to the value inside theRefCell<Vec<String>>, which is the vector. - Then we can call
pushon the mutable reference to the vector to keep track of the messages sent during the test.
The last change we have to make is in the assertion: to see how many items are in the inner vector, we call
borrowon theRefCell<Vec<String>>to get an immutable reference to the vector.
Now that you’ve seen how to use RefCell<T>, let’s dig into how it works!
Keeping Track of Borrows at Runtime with RefCell<T>
When creating immutable and mutable references, we use the & and &mut syntax, respectively.
The
RefCell<T>keeps track of how manyRef<T>andRefMut<T>smart pointers are currently active.
- With
RefCell<T>, we use theborrowandborrow_mutmethods, which are part of the safe API that belongs toRefCell<T>. - The
borrowmethod returns the smart pointer typeRef<T> - and
borrow_mutreturns the smart pointer typeRefMut<T>. - Both types implement
Deref, so we can treat them like regular references. - Every time we call
borrow, theRefCell<T>increases its count of how many immutable borrows are active. - When a
Ref<T>value goes out of scope, the count of immutable borrows goes down by one. - Just like the compile-time borrowing rules,
RefCell<T>lets us have many immutable borrows or one mutable borrow at any point in time.
If we try to violate these rules, rather than getting a compiler error as we would with references, the implementation of
RefCell<T>will panic at runtime.
Listing 15-23 shows a modification of the implementation of send in
Listing 15-22. We’re deliberately trying to create two mutable borrows active
for the same scope to illustrate that RefCell<T> prevents us from doing this
at runtime.
Filename: src/lib.rs
pub trait Messenger { fn send(&self, msg: &str); } pub struct LimitTracker<'a, T: Messenger> { messenger: &'a T, value: usize, max: usize, } impl<'a, T> LimitTracker<'a, T> where T: Messenger, { pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> { LimitTracker { messenger, value: 0, max, } } pub fn set_value(&mut self, value: usize) { self.value = value; let percentage_of_max = self.value as f64 / self.max as f64; if percentage_of_max >= 1.0 { self.messenger.send("Error: You are over your quota!"); } else if percentage_of_max >= 0.9 { self.messenger .send("Urgent warning: You've used up over 90% of your quota!"); } else if percentage_of_max >= 0.75 { self.messenger .send("Warning: You've used up over 75% of your quota!"); } } } #[cfg(test)] mod tests { use super::*; use std::cell::RefCell; struct MockMessenger { sent_messages: RefCell<Vec<String>>, } impl MockMessenger { fn new() -> MockMessenger { MockMessenger { sent_messages: RefCell::new(vec![]), } } } impl Messenger for MockMessenger { fn send(&self, message: &str) { let mut one_borrow = self.sent_messages.borrow_mut(); let mut two_borrow = self.sent_messages.borrow_mut(); one_borrow.push(String::from(message)); two_borrow.push(String::from(message)); } } #[test] fn it_sends_an_over_75_percent_warning_message() { let mock_messenger = MockMessenger::new(); let mut limit_tracker = LimitTracker::new(&mock_messenger, 100); limit_tracker.set_value(80); assert_eq!(mock_messenger.sent_messages.borrow().len(), 1); } }
Listing 15-23: Creating two mutable references in the
same scope to see that RefCell<T> will panic
- We create a variable
one_borrowfor theRefMut<T>smart pointer returned fromborrow_mut. - Then we create another mutable borrow in the same way in the
variable
two_borrow. - This makes two mutable references in the same scope, which isn’t allowed.
- When we run the tests for our library, the code in Listing 15-23 will compile without any errors, but the test will fail:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished test [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'main' panicked at 'already borrowed: BorrowMutError', src/lib.rs:60:53
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass '--lib'
Notice that the code panicked with the message already borrowed: BorrowMutError. This is how RefCell<T> handles violations of the borrowing
rules at runtime.
Choosing to catch borrowing errors at runtime rather than compile time, as we’ve done here, means you’d potentially be finding mistakes in your code later in the development process:
- possibly not until your code was deployed to production.
- Also, your code would incur a small runtime performance penalty as a result of keeping track of the borrows at runtime rather than compile time.
However, using
RefCell<T>makes it possible to write a mock object that can modify itself to keep track of the messages it has seen while you’re using it in a context where only immutable values are allowed.
You can use RefCell<T> despite its trade-offs to get more functionality than regular references provide.
Having Multiple Owners of Mutable Data by Combining Rc<T> and RefCell<T>
A common way to use
RefCell<T>is in combination withRc<T>.
-
Recall that
Rc<T>lets you have multiple owners of some data, but it only gives immutable access to that data. -
If you have an
Rc<T>that holds aRefCell<T>, you can get a value that can have multiple owners and that you can mutate! -
For example, recall the cons list example in Listing 15-18 where we used
Rc<T>to allow multiple lists to share ownership of another list. -
Because
Rc<T>holds only immutable values, we can’t change any of the values in the list once we’ve created them. -
Let’s add in
RefCell<T>to gain the ability to change the values in the lists.
Listing 15-24 shows that by using a
RefCell<T> in the Cons definition, we can modify the value stored in all
the lists:
Filename: src/main.rs
#[derive(Debug)] enum List { Cons(Rc<RefCell<i32>>, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; fn main() { let value = Rc::new(RefCell::new(5)); let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a)); let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a)); *value.borrow_mut() += 10; println!("a after = {:?}", a); println!("b after = {:?}", b); println!("c after = {:?}", c); }
Listing 15-24: Using Rc<RefCell<i32>> to create a
List that we can mutate
- We create a value that is an instance of
Rc<RefCell<i32>>and store it in a variable namedvalueso we can access it directly later. - Then we create a
Listinawith aConsvariant that holdsvalue. - We need to clone
valueso bothaandvaluehave ownership of the inner5value rather than transferring ownership fromvaluetoaor havingaborrow fromvalue.
We wrap the list a in an Rc<T> so when we create lists b and c, they
can both refer to a, which is what we did in Listing 15-18.
After we’ve created the lists in a, b, and c, we want to add 10 to the
value in value. We do this by calling borrow_mut on value, which uses the
automatic dereferencing feature we discussed in Chapter 5 (see the section
“Where’s the -> Operator?”) to
dereference the Rc<T> to the inner RefCell<T> value. The borrow_mut
method returns a RefMut<T> smart pointer, and we use the dereference operator
on it and change the inner value.
When we print a, b, and c, we can see that they all have the modified
value of 15 rather than 5:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
This technique is pretty neat!
- By using
RefCell<T>, we have an outwardly immutableListvalue. - But we can use the methods on
RefCell<T>that provide access to its interior mutability so we can modify our data when we need to. - The runtime checks of the borrowing rules protect us from data races, and it’s sometimes worth trading a bit of speed for this flexibility in our data structures.
Note that
RefCell<T>does not work for multithreaded code!Mutex<T>is the thread-safe version ofRefCell<T>and we’ll discussMutex<T>in Chapter 16.
Reference Cycles Can Leak Memory
Rust’s memory safety guarantees make it difficult, but not impossible, to accidentally create memory that is never cleaned up (known as a memory leak).
Preventing memory leaks entirely is not one of Rust’s guarantees, meaning memory leaks are memory safe in Rust.
- We can see that Rust allows memory leaks
by using
Rc<T>andRefCell<T> - it’s possible to create references where items refer to each other in a cycle.
- This creates memory leaks because the reference count of each item in the cycle will never reach 0, and the values will never be dropped.
Abstract
memory leak abstract
- Reference cycles occur when two or more values have references to each other, creating a cycle that cannot be dropped by the memory allocator.
- Reference cycles can cause memory leaks and unexpected behavior in Rust programs.
- Rust’s ownership and borrowing system prevents most types of reference cycles, but they can still occur with the use of Rc
and RefCell types. - Rc
is a reference-counted smart pointer type that allows multiple owners of the same value, but it can create reference cycles if used incorrectly. - RefCell
is a type that allows for mutable borrowing of an immutable value, but it can also create reference cycles if used incorrectly. - Rust provides the Weak
type to break reference cycles created by Rc . Weak references do not contribute to the reference count, so they do not prevent the value from being dropped. - Another way to break reference cycles is to use std::mem::take() function to take ownership of a value and leave behind a default value, which will drop the original value if it was the only owner.
Error-prone
memory leak attention
- The use of Rc
and RefCell types can create reference cycles if not used correctly. It is important to follow Rust’s ownership and borrowing rules to avoid creating reference cycles. - Weak
should be used instead of Rc in cases where reference cycles may occur. - std::mem::take() should only be used as a last resort for breaking reference cycles, as it can lead to unexpected behavior if the value is not meant to be reset to its default state.
Creating a Reference Cycle
Let’s look at how a reference cycle might happen and how to prevent it,
starting with the definition of the List enum and a tail method in Listing
15-25:
Filename: src/main.rs
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() {}
Listing 15-25: A cons list definition that holds a
RefCell<T> so we can modify what a Cons variant is referring to
We’re using another variation of the List definition from Listing 15-5. The
second element in the Cons variant is now RefCell<Rc<List>>, meaning that
instead of having the ability to modify the i32 value as we did in Listing
15-24, we want to modify the List value a Cons variant is pointing to.
We’re also adding a tail method to make it convenient for us to access the
second item if we have a Cons variant.
In Listing 15-26, we’re adding a main function that uses the definitions in
Listing 15-25. This code creates a list in a and a list in b that points to
the list in a. Then it modifies the list in a to point to b, creating a
reference cycle. There are println! statements along the way to show what the
reference counts are at various points in this process.
Filename: src/main.rs
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a initial rc count = {}", Rc::strong_count(&a)); println!("a next item = {:?}", a.tail()); let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("a rc count after b creation = {}", Rc::strong_count(&a)); println!("b initial rc count = {}", Rc::strong_count(&b)); println!("b next item = {:?}", b.tail()); if let Some(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); } println!("b rc count after changing a = {}", Rc::strong_count(&b)); println!("a rc count after changing a = {}", Rc::strong_count(&a)); // Uncomment the next line to see that we have a cycle; // it will overflow the stack // println!("a next item = {:?}", a.tail()); }
Listing 15-26: Creating a reference cycle of two List
values pointing to each other
We create an Rc<List> instance holding a List value in the variable a
with an initial list of 5, Nil. We then create an Rc<List> instance holding
another List value in the variable b that contains the value 10 and points
to the list in a.
We modify a so it points to b instead of Nil, creating a cycle. We do
that by using the tail method to get a reference to the RefCell<Rc<List>>
in a, which we put in the variable link. Then we use the borrow_mut
method on the RefCell<Rc<List>> to change the value inside from an Rc<List>
that holds a Nil value to the Rc<List> in b.
When we run this code, keeping the last println! commented out for the
moment, we’ll get this output:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished dev [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
The reference count of the Rc<List> instances in both a and b are 2 after
we change the list in a to point to b. At the end of main, Rust drops the
variable b, which decreases the reference count of the b Rc<List> instance
from 2 to 1. The memory that Rc<List> has on the heap won’t be dropped at
this point, because its reference count is 1, not 0. Then Rust drops a, which
decreases the reference count of the a Rc<List> instance from 2 to 1 as
well. This instance’s memory can’t be dropped either, because the other
Rc<List> instance still refers to it. The memory allocated to the list will
remain uncollected forever. To visualize this reference cycle, we’ve created a
diagram in Figure 15-4.

Figure 15-4: A reference cycle of lists a and b
pointing to each other
If you uncomment the last println! and run the program, Rust will try to
print this cycle with a pointing to b pointing to a and so forth until it
overflows the stack.
Compared to a real-world program, the consequences creating a reference cycle in this example aren’t very dire: right after we create the reference cycle, the program ends. However, if a more complex program allocated lots of memory in a cycle and held onto it for a long time, the program would use more memory than it needed and might overwhelm the system, causing it to run out of available memory.
Creating reference cycles is not easily done, but it’s not impossible either.
If you have RefCell<T> values that contain Rc<T> values or similar nested
combinations of types with interior mutability and reference counting, you must
ensure that you don’t create cycles; you can’t rely on Rust to catch them.
Creating a reference cycle would be a logic bug in your program that you should
use automated tests, code reviews, and other software development practices to
minimize.
Another solution for avoiding reference cycles is reorganizing your data
structures so that some references express ownership and some references don’t.
As a result, you can have cycles made up of some ownership relationships and
some non-ownership relationships, and only the ownership relationships affect
whether or not a value can be dropped. In Listing 15-25, we always want Cons
variants to own their list, so reorganizing the data structure isn’t possible.
Let’s look at an example using graphs made up of parent nodes and child nodes
to see when non-ownership relationships are an appropriate way to prevent
reference cycles.
Preventing Reference Cycles: Turning an Rc<T> into a Weak<T>
So far, we’ve demonstrated that calling Rc::clone increases the
strong_count of an Rc<T> instance, and an Rc<T> instance is only cleaned
up if its strong_count is 0. You can also create a weak reference to the
value within an Rc<T> instance by calling Rc::downgrade and passing a
reference to the Rc<T>. Strong references are how you can share ownership of
an Rc<T> instance. Weak references don’t express an ownership relationship,
and their count doesn’t affect when an Rc<T> instance is cleaned up. They
won’t cause a reference cycle because any cycle involving some weak references
will be broken once the strong reference count of values involved is 0.
When you call Rc::downgrade, you get a smart pointer of type Weak<T>.
Instead of increasing the strong_count in the Rc<T> instance by 1, calling
Rc::downgrade increases the weak_count by 1. The Rc<T> type uses
weak_count to keep track of how many Weak<T> references exist, similar to
strong_count. The difference is the weak_count doesn’t need to be 0 for the
Rc<T> instance to be cleaned up.
Because the value that Weak<T> references might have been dropped, to do
anything with the value that a Weak<T> is pointing to, you must make sure the
value still exists. Do this by calling the upgrade method on a Weak<T>
instance, which will return an Option<Rc<T>>. You’ll get a result of Some
if the Rc<T> value has not been dropped yet and a result of None if the
Rc<T> value has been dropped. Because upgrade returns an Option<Rc<T>>,
Rust will ensure that the Some case and the None case are handled, and
there won’t be an invalid pointer.
As an example, rather than using a list whose items know only about the next item, we’ll create a tree whose items know about their children items and their parent items.
Creating a Tree Data Structure: a Node with Child Nodes
To start, we’ll build a tree with nodes that know about their child nodes.
We’ll create a struct named Node that holds its own i32 value as well as
references to its children Node values:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
We want a Node to own its children, and we want to share that ownership with
variables so we can access each Node in the tree directly. To do this, we
define the Vec<T> items to be values of type Rc<Node>. We also want to
modify which nodes are children of another node, so we have a RefCell<T> in
children around the Vec<Rc<Node>>.
Next, we’ll use our struct definition and create one Node instance named
leaf with the value 3 and no children, and another instance named branch
with the value 5 and leaf as one of its children, as shown in Listing 15-27:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
Listing 15-27: Creating a leaf node with no children
and a branch node with leaf as one of its children
We clone the Rc<Node> in leaf and store that in branch, meaning the
Node in leaf now has two owners: leaf and branch. We can get from
branch to leaf through branch.children, but there’s no way to get from
leaf to branch. The reason is that leaf has no reference to branch and
doesn’t know they’re related. We want leaf to know that branch is its
parent. We’ll do that next.
Adding a Reference from a Child to Its Parent
To make the child node aware of its parent, we need to add a parent field to
our Node struct definition. The trouble is in deciding what the type of
parent should be. We know it can’t contain an Rc<T>, because that would
create a reference cycle with leaf.parent pointing to branch and
branch.children pointing to leaf, which would cause their strong_count
values to never be 0.
Thinking about the relationships another way, a parent node should own its children: if a parent node is dropped, its child nodes should be dropped as well. However, a child should not own its parent: if we drop a child node, the parent should still exist. This is a case for weak references!
So instead of Rc<T>, we’ll make the type of parent use Weak<T>,
specifically a RefCell<Weak<Node>>. Now our Node struct definition looks
like this:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
A node will be able to refer to its parent node but doesn’t own its parent.
In Listing 15-28, we update main to use this new definition so the leaf
node will have a way to refer to its parent, branch:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Listing 15-28: A leaf node with a weak reference to its
parent node branch
Creating the leaf node looks similar to Listing 15-27 with the exception of
the parent field: leaf starts out without a parent, so we create a new,
empty Weak<Node> reference instance.
At this point, when we try to get a reference to the parent of leaf by using
the upgrade method, we get a None value. We see this in the output from the
first println! statement:
leaf parent = None
When we create the branch node, it will also have a new Weak<Node>
reference in the parent field, because branch doesn’t have a parent node.
We still have leaf as one of the children of branch. Once we have the
Node instance in branch, we can modify leaf to give it a Weak<Node>
reference to its parent. We use the borrow_mut method on the
RefCell<Weak<Node>> in the parent field of leaf, and then we use the
Rc::downgrade function to create a Weak<Node> reference to branch from
the Rc<Node> in branch.
When we print the parent of leaf again, this time we’ll get a Some variant
holding branch: now leaf can access its parent! When we print leaf, we
also avoid the cycle that eventually ended in a stack overflow like we had in
Listing 15-26; the Weak<Node> references are printed as (Weak):
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
The lack of infinite output indicates that this code didn’t create a reference
cycle. We can also tell this by looking at the values we get from calling
Rc::strong_count and Rc::weak_count.
Visualizing Changes to strong_count and weak_count
Let’s look at how the strong_count and weak_count values of the Rc<Node>
instances change by creating a new inner scope and moving the creation of
branch into that scope. By doing so, we can see what happens when branch is
created and then dropped when it goes out of scope. The modifications are shown
in Listing 15-29:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); { let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!( "branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch), ); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); } println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); }
Listing 15-29: Creating branch in an inner scope and
examining strong and weak reference counts
After leaf is created, its Rc<Node> has a strong count of 1 and a weak
count of 0. In the inner scope, we create branch and associate it with
leaf, at which point when we print the counts, the Rc<Node> in branch
will have a strong count of 1 and a weak count of 1 (for leaf.parent pointing
to branch with a Weak<Node>). When we print the counts in leaf, we’ll see
it will have a strong count of 2, because branch now has a clone of the
Rc<Node> of leaf stored in branch.children, but will still have a weak
count of 0.
When the inner scope ends, branch goes out of scope and the strong count of
the Rc<Node> decreases to 0, so its Node is dropped. The weak count of 1
from leaf.parent has no bearing on whether or not Node is dropped, so we
don’t get any memory leaks!
If we try to access the parent of leaf after the end of the scope, we’ll get
None again. At the end of the program, the Rc<Node> in leaf has a strong
count of 1 and a weak count of 0, because the variable leaf is now the only
reference to the Rc<Node> again.
All of the logic that manages the counts and value dropping is built into
Rc<T> and Weak<T> and their implementations of the Drop trait. By
specifying that the relationship from a child to its parent should be a
Weak<T> reference in the definition of Node, you’re able to have parent
nodes point to child nodes and vice versa without creating a reference cycle
and memory leaks.
Summary
This chapter covered how to use smart pointers to make different guarantees and
trade-offs from those Rust makes by default with regular references. The
Box<T> type has a known size and points to data allocated on the heap. The
Rc<T> type keeps track of the number of references to data on the heap so
that data can have multiple owners. The RefCell<T> type with its interior
mutability gives us a type that we can use when we need an immutable type but
need to change an inner value of that type; it also enforces the borrowing
rules at runtime instead of at compile time.
Also discussed were the Deref and Drop traits, which enable a lot of the
functionality of smart pointers. We explored reference cycles that can cause
memory leaks and how to prevent them using Weak<T>.
If this chapter has piqued your interest and you want to implement your own smart pointers, check out “The Rustonomicon” for more useful information.
Next, we’ll talk about concurrency in Rust. You’ll even learn about a few new smart pointers.
Q&A
memory leak questions
- What are reference cycles in Rust, and why are they problematic?
- How does Rust’s ownership and borrowing system prevent most types of reference cycles?
- What are Rc
and RefCell types in Rust, and how can they create reference cycles? - How does Rust’s Weak
type break reference cycles created by Rc ? - What is the std::mem::take() function in Rust, and how can it be used to break reference cycles?
- What are some potential issues with using std::mem::take() to break reference cycles?
- Can reference cycles be created with regular references (i.e., &T)? Why or why not?
- How can you debug reference cycles in Rust programs?
- Can you provide an example of a scenario where using RefCell
could create a reference cycle? - Why might you choose to use Rc
instead of regular references or Box ? What are some potential drawbacks to using Rc ?
memory leak answers
- Reference cycles occur when two or more values have references to each other, creating a cycle that cannot be dropped by the memory allocator. They are problematic because they can cause memory leaks and unexpected behavior in Rust programs.
- Rust’s ownership and borrowing system prevents most types of reference cycles by enforcing strict rules for how values can be borrowed and moved. For example, Rust does not allow mutable aliases or aliasing across mutable borrows, which can help prevent reference cycles.
- Rc
is a reference-counted smart pointer type that allows multiple owners of the same value. If two Rc values reference each other, or if an Rc value references a RefCell that contains an Rc value that references it, a reference cycle can be created. - Rust’s Weak
type is a weak reference that does not contribute to the reference count, so it can be used to break reference cycles created by Rc . Weak values can be created from Rc values and used to access the value’s data without keeping the value alive. - std::mem::take() is a function that takes ownership of a value and leaves behind a default value, which can be used to break reference cycles. If a value is only owned by a reference cycle, calling std::mem::take() will drop the value and create a new default value in its place.
- One potential issue with using std::mem::take() is that it can lead to unexpected behavior if the value is not meant to be reset to its default state. Additionally, using std::mem::take() may not be as efficient as breaking the reference cycle in other ways, such as using Weak
. - No, regular references (i.e., &T) cannot create reference cycles because they do not have ownership. Regular references are borrowed pointers that do not affect the lifetime of the value they point to.
- Debugging reference cycles in Rust programs can be challenging because they can cause memory leaks and other unexpected behavior. Some tools and techniques that can be used to debug reference cycles include analyzing heap allocations with profilers, using Rust’s Debug and Drop traits to log reference counts and deallocations, and using Rust’s borrow checker to ensure that reference cycles are not created in the first place.
- RefCell
can create a reference cycle if it contains an Rc value that references it. For example, if you have a RefCell<Rc > value that contains an Rc value that references the RefCell, a reference cycle can be created. - You might choose to use Rc
instead of regular references or Box when you need to share ownership of a value across multiple parts of your program. Rc allows multiple owners to access the same value, which can be useful for scenarios like creating a tree structure. However, Rc has some potential drawbacks, such as the possibility of creating reference cycles and the overhead of reference counting.
Fearless Concurrency
Handling concurrent programming safely and efficiently is another of Rust’s major goals. Concurrent programming, where different parts of a program execute independently, and parallel programming, where different parts of a program execute at the same time, are becoming increasingly important as more computers take advantage of their multiple processors. Historically, programming in these contexts has been difficult and error prone: Rust hopes to change that.
Initially, the Rust team thought that ensuring memory safety and preventing concurrency problems were two separate challenges to be solved with different methods. Over time, the team discovered that the ownership and type systems are a powerful set of tools to help manage memory safety and concurrency problems! By leveraging ownership and type checking, many concurrency errors are compile-time errors in Rust rather than runtime errors. Therefore, rather than making you spend lots of time trying to reproduce the exact circumstances under which a runtime concurrency bug occurs, incorrect code will refuse to compile and present an error explaining the problem. As a result, you can fix your code while you’re working on it rather than potentially after it has been shipped to production. We’ve nicknamed this aspect of Rust fearless concurrency. Fearless concurrency allows you to write code that is free of subtle bugs and is easy to refactor without introducing new bugs.
Note: For simplicity’s sake, we’ll refer to many of the problems as concurrent rather than being more precise by saying concurrent and/or parallel. If this book were about concurrency and/or parallelism, we’d be more specific. For this chapter, please mentally substitute concurrent and/or parallel whenever we use concurrent.
Many languages are dogmatic about the solutions they offer for handling concurrent problems. For example, Erlang has elegant functionality for message-passing concurrency but has only obscure ways to share state between threads. Supporting only a subset of possible solutions is a reasonable strategy for higher-level languages, because a higher-level language promises benefits from giving up some control to gain abstractions. However, lower-level languages are expected to provide the solution with the best performance in any given situation and have fewer abstractions over the hardware. Therefore, Rust offers a variety of tools for modeling problems in whatever way is appropriate for your situation and requirements.
Here are the topics we’ll cover in this chapter:
- How to create threads to run multiple pieces of code at the same time
- Message-passing concurrency, where channels send messages between threads
- Shared-state concurrency, where multiple threads have access to some piece of data
- The
SyncandSendtraits, which extend Rust’s concurrency guarantees to user-defined types as well as types provided by the standard library
Using Threads to Run Code Simultaneously
In most current operating systems, an executed program’s code is run in a process, and the operating system will manage multiple processes at once. Within a program, you can also have independent parts that run simultaneously. The features that run these independent parts are called threads. For example, a web server could have multiple threads so that it could respond to more than one request at the same time.
Splitting the computation in your program into multiple threads to run multiple tasks at the same time can improve performance, but it also adds complexity. Because threads can run simultaneously, there’s no inherent guarantee about the order in which parts of your code on different threads will run. This can lead to problems, such as:
- Race conditions, where threads are accessing data or resources in an inconsistent order
- Deadlocks, where two threads are waiting for each other, preventing both threads from continuing
- Bugs that happen only in certain situations and are hard to reproduce and fix reliably
Rust attempts to mitigate the negative effects of using threads, but programming in a multithreaded context still takes careful thought and requires a code structure that is different from that in programs running in a single thread.
Programming languages implement threads in a few different ways, and many operating systems provide an API the language can call for creating new threads. The Rust standard library uses a 1:1 model of thread implementation, whereby a program uses one operating system thread per one language thread. There are crates that implement other models of threading that make different tradeoffs to the 1:1 model.
Creating a New Thread with spawn
To create a new thread, we call the thread::spawn function and pass it a
closure (we talked about closures in Chapter 13) containing the code we want to
run in the new thread. The example in Listing 16-1 prints some text from a main
thread and other text from a new thread:
Filename: src/main.rs
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } }
Listing 16-1: Creating a new thread to print one thing while the main thread prints something else
Note that when the main thread of a Rust program completes, all spawned threads are shut down, whether or not they have finished running. The output from this program might be a little different every time, but it will look similar to the following:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
The calls to thread::sleep force a thread to stop its execution for a short
duration, allowing a different thread to run. The threads will probably take
turns, but that isn’t guaranteed: it depends on how your operating system
schedules the threads. In this run, the main thread printed first, even though
the print statement from the spawned thread appears first in the code. And even
though we told the spawned thread to print until i is 9, it only got to 5
before the main thread shut down.
If you run this code and only see output from the main thread, or don’t see any overlap, try increasing the numbers in the ranges to create more opportunities for the operating system to switch between the threads.
Waiting for All Threads to Finish Using join Handles
The code in Listing 16-1 not only stops the spawned thread prematurely most of the time due to the main thread ending, but because there is no guarantee on the order in which threads run, we also can’t guarantee that the spawned thread will get to run at all!
We can fix the problem of the spawned thread not running or ending prematurely
by saving the return value of thread::spawn in a variable. The return type of
thread::spawn is JoinHandle. A JoinHandle is an owned value that, when we
call the join method on it, will wait for its thread to finish. Listing 16-2
shows how to use the JoinHandle of the thread we created in Listing 16-1 and
call join to make sure the spawned thread finishes before main exits:
Filename: src/main.rs
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } handle.join().unwrap(); }
Listing 16-2: Saving a JoinHandle from thread::spawn
to guarantee the thread is run to completion
Calling join on the handle blocks the thread currently running until the
thread represented by the handle terminates. Blocking a thread means that
thread is prevented from performing work or exiting. Because we’ve put the call
to join after the main thread’s for loop, running Listing 16-2 should
produce output similar to this:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
The two threads continue alternating, but the main thread waits because of the
call to handle.join() and does not end until the spawned thread is finished.
But let’s see what happens when we instead move handle.join() before the
for loop in main, like this:
Filename: src/main.rs
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); handle.join().unwrap(); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } }
The main thread will wait for the spawned thread to finish and then run its
for loop, so the output won’t be interleaved anymore, as shown here:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
Small details, such as where join is called, can affect whether or not your
threads run at the same time.
Using move Closures with Threads
We’ll often use the move keyword with closures passed to thread::spawn
because the closure will then take ownership of the values it uses from the
environment, thus transferring ownership of those values from one thread to
another. In the “Capturing References or Moving Ownership” section of Chapter 13, we discussed move in the context of closures. Now,
we’ll concentrate more on the interaction between move and thread::spawn.
Notice in Listing 16-1 that the closure we pass to thread::spawn takes no
arguments: we’re not using any data from the main thread in the spawned
thread’s code. To use data from the main thread in the spawned thread, the
spawned thread’s closure must capture the values it needs. Listing 16-3 shows
an attempt to create a vector in the main thread and use it in the spawned
thread. However, this won’t yet work, as you’ll see in a moment.
Filename: src/main.rs
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
handle.join().unwrap();
}
Listing 16-3: Attempting to use a vector created by the main thread in another thread
The closure uses v, so it will capture v and make it part of the closure’s
environment. Because thread::spawn runs this closure in a new thread, we
should be able to access v inside that new thread. But when we compile this
example, we get the following error:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {:?}", v);
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {:?}", v);
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` due to previous error
Rust infers how to capture v, and because println! only needs a reference
to v, the closure tries to borrow v. However, there’s a problem: Rust can’t
tell how long the spawned thread will run, so it doesn’t know if the reference
to v will always be valid.
Listing 16-4 provides a scenario that’s more likely to have a reference to v
that won’t be valid:
Filename: src/main.rs
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
drop(v); // oh no!
handle.join().unwrap();
}
Listing 16-4: A thread with a closure that attempts to
capture a reference to v from a main thread that drops v
If Rust allowed us to run this code, there’s a possibility the spawned thread
would be immediately put in the background without running at all. The spawned
thread has a reference to v inside, but the main thread immediately drops
v, using the drop function we discussed in Chapter 15. Then, when the
spawned thread starts to execute, v is no longer valid, so a reference to it
is also invalid. Oh no!
To fix the compiler error in Listing 16-3, we can use the error message’s advice:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
By adding the move keyword before the closure, we force the closure to take
ownership of the values it’s using rather than allowing Rust to infer that it
should borrow the values. The modification to Listing 16-3 shown in Listing
16-5 will compile and run as we intend:
Filename: src/main.rs
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Here's a vector: {:?}", v); }); handle.join().unwrap(); }
Listing 16-5: Using the move keyword to force a closure
to take ownership of the values it uses
We might be tempted to try the same thing to fix the code in Listing 16-4 where
the main thread called drop by using a move closure. However, this fix will
not work because what Listing 16-4 is trying to do is disallowed for a
different reason. If we added move to the closure, we would move v into the
closure’s environment, and we could no longer call drop on it in the main
thread. We would get this compiler error instead:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {:?}", v);
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` due to previous error
Rust’s ownership rules have saved us again! We got an error from the code in
Listing 16-3 because Rust was being conservative and only borrowing v for the
thread, which meant the main thread could theoretically invalidate the spawned
thread’s reference. By telling Rust to move ownership of v to the spawned
thread, we’re guaranteeing Rust that the main thread won’t use v anymore. If
we change Listing 16-4 in the same way, we’re then violating the ownership
rules when we try to use v in the main thread. The move keyword overrides
Rust’s conservative default of borrowing; it doesn’t let us violate the
ownership rules.
With a basic understanding of threads and the thread API, let’s look at what we can do with threads.
Using Message Passing to Transfer Data Between Threads
One increasingly popular approach to ensuring safe concurrency is message passing, where threads or actors communicate by sending each other messages containing data. Here’s the idea in a slogan from the Go language documentation: “Do not communicate by sharing memory; instead, share memory by communicating.”
To accomplish message-sending concurrency, Rust’s standard library provides an implementation of channels. A channel is a general programming concept by which data is sent from one thread to another.
You can imagine a channel in programming as being like a directional channel of water, such as a stream or a river. If you put something like a rubber duck into a river, it will travel downstream to the end of the waterway.
A channel has two halves: a transmitter and a receiver. The transmitter half is the upstream location where you put rubber ducks into the river, and the receiver half is where the rubber duck ends up downstream. One part of your code calls methods on the transmitter with the data you want to send, and another part checks the receiving end for arriving messages. A channel is said to be closed if either the transmitter or receiver half is dropped.
Here, we’ll work up to a program that has one thread to generate values and send them down a channel, and another thread that will receive the values and print them out. We’ll be sending simple values between threads using a channel to illustrate the feature. Once you’re familiar with the technique, you could use channels for any threads that need to communicate between each other, such as a chat system or a system where many threads perform parts of a calculation and send the parts to one thread that aggregates the results.
First, in Listing 16-6, we’ll create a channel but not do anything with it. Note that this won’t compile yet because Rust can’t tell what type of values we want to send over the channel.
Filename: src/main.rs
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}
Listing 16-6: Creating a channel and assigning the two
halves to tx and rx
We create a new channel using the mpsc::channel function; mpsc stands for
multiple producer, single consumer. In short, the way Rust’s standard library
implements channels means a channel can have multiple sending ends that
produce values but only one receiving end that consumes those values. Imagine
multiple streams flowing together into one big river: everything sent down any
of the streams will end up in one river at the end. We’ll start with a single
producer for now, but we’ll add multiple producers when we get this example
working.
The mpsc::channel function returns a tuple, the first element of which is the
sending end–the transmitter–and the second element is the receiving end–the
receiver. The abbreviations tx and rx are traditionally used in many fields
for transmitter and receiver respectively, so we name our variables as such
to indicate each end. We’re using a let statement with a pattern that
destructures the tuples; we’ll discuss the use of patterns in let statements
and destructuring in Chapter 18. For now, know that using a let statement
this way is a convenient approach to extract the pieces of the tuple returned
by mpsc::channel.
Let’s move the transmitting end into a spawned thread and have it send one string so the spawned thread is communicating with the main thread, as shown in Listing 16-7. This is like putting a rubber duck in the river upstream or sending a chat message from one thread to another.
Filename: src/main.rs
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); }
Listing 16-7: Moving tx to a spawned thread and sending
“hi”
Again, we’re using thread::spawn to create a new thread and then using move
to move tx into the closure so the spawned thread owns tx. The spawned
thread needs to own the transmitter to be able to send messages through the
channel. The transmitter has a send method that takes the value we want to
send. The send method returns a Result<T, E> type, so if the receiver has
already been dropped and there’s nowhere to send a value, the send operation
will return an error. In this example, we’re calling unwrap to panic in case
of an error. But in a real application, we would handle it properly: return to
Chapter 9 to review strategies for proper error handling.
In Listing 16-8, we’ll get the value from the receiver in the main thread. This is like retrieving the rubber duck from the water at the end of the river or receiving a chat message.
Filename: src/main.rs
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); let received = rx.recv().unwrap(); println!("Got: {}", received); }
Listing 16-8: Receiving the value “hi” in the main thread and printing it
The receiver has two useful methods: recv and try_recv. We’re using recv,
short for receive, which will block the main thread’s execution and wait
until a value is sent down the channel. Once a value is sent, recv will
return it in a Result<T, E>. When the transmitter closes, recv will return
an error to signal that no more values will be coming.
The try_recv method doesn’t block, but will instead return a Result<T, E>
immediately: an Ok value holding a message if one is available and an Err
value if there aren’t any messages this time. Using try_recv is useful if
this thread has other work to do while waiting for messages: we could write a
loop that calls try_recv every so often, handles a message if one is
available, and otherwise does other work for a little while until checking
again.
We’ve used recv in this example for simplicity; we don’t have any other work
for the main thread to do other than wait for messages, so blocking the main
thread is appropriate.
When we run the code in Listing 16-8, we’ll see the value printed from the main thread:
Got: hi
Perfect!
Channels and Ownership Transference
The ownership rules play a vital role in message sending because they help you
write safe, concurrent code. Preventing errors in concurrent programming is the
advantage of thinking about ownership throughout your Rust programs. Let’s do
an experiment to show how channels and ownership work together to prevent
problems: we’ll try to use a val value in the spawned thread after we’ve
sent it down the channel. Try compiling the code in Listing 16-9 to see why
this code isn’t allowed:
Filename: src/main.rs
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {}", val);
});
let received = rx.recv().unwrap();
println!("Got: {}", received);
}
Listing 16-9: Attempting to use val after we’ve sent it
down the channel
Here, we try to print val after we’ve sent it down the channel via tx.send.
Allowing this would be a bad idea: once the value has been sent to another
thread, that thread could modify or drop it before we try to use the value
again. Potentially, the other thread’s modifications could cause errors or
unexpected results due to inconsistent or nonexistent data. However, Rust gives
us an error if we try to compile the code in Listing 16-9:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:31
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {}", val);
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` due to previous error
Our concurrency mistake has caused a compile time error. The send function
takes ownership of its parameter, and when the value is moved, the receiver
takes ownership of it. This stops us from accidentally using the value again
after sending it; the ownership system checks that everything is okay.
Sending Multiple Values and Seeing the Receiver Waiting
The code in Listing 16-8 compiled and ran, but it didn’t clearly show us that two separate threads were talking to each other over the channel. In Listing 16-10 we’ve made some modifications that will prove the code in Listing 16-8 is running concurrently: the spawned thread will now send multiple messages and pause for a second between each message.
Filename: src/main.rs
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {}", received);
}
}
Listing 16-10: Sending multiple messages and pausing between each
This time, the spawned thread has a vector of strings that we want to send to
the main thread. We iterate over them, sending each individually, and pause
between each by calling the thread::sleep function with a Duration value of
1 second.
In the main thread, we’re not calling the recv function explicitly anymore:
instead, we’re treating rx as an iterator. For each value received, we’re
printing it. When the channel is closed, iteration will end.
When running the code in Listing 16-10, you should see the following output with a 1-second pause in between each line:
Got: hi
Got: from
Got: the
Got: thread
Because we don’t have any code that pauses or delays in the for loop in the
main thread, we can tell that the main thread is waiting to receive values from
the spawned thread.
Creating Multiple Producers by Cloning the Transmitter
Earlier we mentioned that mpsc was an acronym for multiple producer,
single consumer. Let’s put mpsc to use and expand the code in Listing 16-10
to create multiple threads that all send values to the same receiver. We can do
so by cloning the transmitter, as shown in Listing 16-11:
Filename: src/main.rs
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {}", received);
}
// --snip--
}
Listing 16-11: Sending multiple messages from multiple producers
This time, before we create the first spawned thread, we call clone on the
transmitter. This will give us a new transmitter we can pass to the first
spawned thread. We pass the original transmitter to a second spawned thread.
This gives us two threads, each sending different messages to the one receiver.
When you run the code, your output should look something like this:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
You might see the values in another order, depending on your system. This is
what makes concurrency interesting as well as difficult. If you experiment with
thread::sleep, giving it various values in the different threads, each run
will be more nondeterministic and create different output each time.
Now that we’ve looked at how channels work, let’s look at a different method of concurrency.
Shared-State Concurrency
Message passing is a fine way of handling concurrency, but it’s not the only one. Another method would be for multiple threads to access the same shared data. Consider this part of the slogan from the Go language documentation again: “do not communicate by sharing memory.”
What would communicating by sharing memory look like? In addition, why would message-passing enthusiasts caution not to use memory sharing?
In a way, channels in any programming language are similar to single ownership, because once you transfer a value down a channel, you should no longer use that value. Shared memory concurrency is like multiple ownership: multiple threads can access the same memory location at the same time. As you saw in Chapter 15, where smart pointers made multiple ownership possible, multiple ownership can add complexity because these different owners need managing. Rust’s type system and ownership rules greatly assist in getting this management correct. For an example, let’s look at mutexes, one of the more common concurrency primitives for shared memory.
Using Mutexes to Allow Access to Data from One Thread at a Time
Mutex is an abbreviation for mutual exclusion, as in, a mutex allows only one thread to access some data at any given time. To access the data in a mutex, a thread must first signal that it wants access by asking to acquire the mutex’s lock. The lock is a data structure that is part of the mutex that keeps track of who currently has exclusive access to the data. Therefore, the mutex is described as guarding the data it holds via the locking system.
Mutexes have a reputation for being difficult to use because you have to remember two rules:
- You must attempt to acquire the lock before using the data.
- When you’re done with the data that the mutex guards, you must unlock the data so other threads can acquire the lock.
For a real-world metaphor for a mutex, imagine a panel discussion at a conference with only one microphone. Before a panelist can speak, they have to ask or signal that they want to use the microphone. When they get the microphone, they can talk for as long as they want to and then hand the microphone to the next panelist who requests to speak. If a panelist forgets to hand the microphone off when they’re finished with it, no one else is able to speak. If management of the shared microphone goes wrong, the panel won’t work as planned!
Management of mutexes can be incredibly tricky to get right, which is why so many people are enthusiastic about channels. However, thanks to Rust’s type system and ownership rules, you can’t get locking and unlocking wrong.
The API of Mutex<T>
As an example of how to use a mutex, let’s start by using a mutex in a single-threaded context, as shown in Listing 16-12:
Filename: src/main.rs
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut num = m.lock().unwrap(); *num = 6; } println!("m = {:?}", m); }
Listing 16-12: Exploring the API of Mutex<T> in a
single-threaded context for simplicity
As with many types, we create a Mutex<T> using the associated function new.
To access the data inside the mutex, we use the lock method to acquire the
lock. This call will block the current thread so it can’t do any work until
it’s our turn to have the lock.
The call to lock would fail if another thread holding the lock panicked. In
that case, no one would ever be able to get the lock, so we’ve chosen to
unwrap and have this thread panic if we’re in that situation.
After we’ve acquired the lock, we can treat the return value, named num in
this case, as a mutable reference to the data inside. The type system ensures
that we acquire a lock before using the value in m. The type of m is
Mutex<i32>, not i32, so we must call lock to be able to use the i32
value. We can’t forget; the type system won’t let us access the inner i32
otherwise.
As you might suspect, Mutex<T> is a smart pointer. More accurately, the call
to lock returns a smart pointer called MutexGuard, wrapped in a
LockResult that we handled with the call to unwrap. The MutexGuard smart
pointer implements Deref to point at our inner data; the smart pointer also
has a Drop implementation that releases the lock automatically when a
MutexGuard goes out of scope, which happens at the end of the inner scope. As
a result, we don’t risk forgetting to release the lock and blocking the mutex
from being used by other threads, because the lock release happens
automatically.
After dropping the lock, we can print the mutex value and see that we were able
to change the inner i32 to 6.
Sharing a Mutex<T> Between Multiple Threads
Now, let’s try to share a value between multiple threads using Mutex<T>.
We’ll spin up 10 threads and have them each increment a counter value by 1, so
the counter goes from 0 to 10. The next example in Listing 16-13 will have
a compiler error, and we’ll use that error to learn more about using
Mutex<T> and how Rust helps us use it correctly.
Filename: src/main.rs
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}
Listing 16-13: Ten threads each increment a counter
guarded by a Mutex<T>
We create a counter variable to hold an i32 inside a Mutex<T>, as we did
in Listing 16-12. Next, we create 10 threads by iterating over a range of
numbers. We use thread::spawn and give all the threads the same closure: one
that moves the counter into the thread, acquires a lock on the Mutex<T> by
calling the lock method, and then adds 1 to the value in the mutex. When a
thread finishes running its closure, num will go out of scope and release the
lock so another thread can acquire it.
In the main thread, we collect all the join handles. Then, as we did in Listing
16-2, we call join on each handle to make sure all the threads finish. At
that point, the main thread will acquire the lock and print the result of this
program.
We hinted that this example wouldn’t compile. Now let’s find out why!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: use of moved value: `counter`
--> src/main.rs:9:36
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `Mutex<i32>`, which does not implement the `Copy` trait
...
9 | let handle = thread::spawn(move || {
| ^^^^^^^ value moved into closure here, in previous iteration of loop
10 | let mut num = counter.lock().unwrap();
| ------- use occurs due to use in closure
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` due to previous error
The error message states that the counter value was moved in the previous
iteration of the loop. Rust is telling us that we can’t move the ownership
of lock counter into multiple threads. Let’s fix the compiler error with a
multiple-ownership method we discussed in Chapter 15.
Multiple Ownership with Multiple Threads
In Chapter 15, we gave a value multiple owners by using the smart pointer
Rc<T> to create a reference counted value. Let’s do the same here and see
what happens. We’ll wrap the Mutex<T> in Rc<T> in Listing 16-14 and clone
the Rc<T> before moving ownership to the thread.
Filename: src/main.rs
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}
Listing 16-14: Attempting to use Rc<T> to allow
multiple threads to own the Mutex<T>
Once again, we compile and get… different errors! The compiler is teaching us a lot.
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:22
|
11 | let handle = thread::spawn(move || {
| ______________________^^^^^^^^^^^^^_-
| | |
| | `Rc<Mutex<i32>>` cannot be sent between threads safely
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________- within this `[closure@src/main.rs:11:36: 15:10]`
|
= help: within `[closure@src/main.rs:11:36: 15:10]`, the trait `Send` is not implemented for `Rc<Mutex<i32>>`
= note: required because it appears within the type `[closure@src/main.rs:11:36: 15:10]`
note: required by a bound in `spawn`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` due to previous error
Wow, that error message is very wordy! Here’s the important part to focus on:
`Rc<Mutex<i32>>` cannot be sent between threads safely. The compiler is
also telling us the reason why: the trait `Send` is not implemented for `Rc<Mutex<i32>>` . We’ll talk about Send in the next section: it’s one of
the traits that ensures the types we use with threads are meant for use in
concurrent situations.
Unfortunately, Rc<T> is not safe to share across threads. When Rc<T>
manages the reference count, it adds to the count for each call to clone and
subtracts from the count when each clone is dropped. But it doesn’t use any
concurrency primitives to make sure that changes to the count can’t be
interrupted by another thread. This could lead to wrong counts—subtle bugs that
could in turn lead to memory leaks or a value being dropped before we’re done
with it. What we need is a type exactly like Rc<T> but one that makes changes
to the reference count in a thread-safe way.
Atomic Reference Counting with Arc<T>
Fortunately, Arc<T> is a type like Rc<T> that is safe to use in
concurrent situations. The a stands for atomic, meaning it’s an atomically
reference counted type. Atomics are an additional kind of concurrency
primitive that we won’t cover in detail here: see the standard library
documentation for std::sync::atomic for more
details. At this point, you just need to know that atomics work like primitive
types but are safe to share across threads.
You might then wonder why all primitive types aren’t atomic and why standard
library types aren’t implemented to use Arc<T> by default. The reason is that
thread safety comes with a performance penalty that you only want to pay when
you really need to. If you’re just performing operations on values within a
single thread, your code can run faster if it doesn’t have to enforce the
guarantees atomics provide.
Let’s return to our example: Arc<T> and Rc<T> have the same API, so we fix
our program by changing the use line, the call to new, and the call to
clone. The code in Listing 16-15 will finally compile and run:
Filename: src/main.rs
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
Listing 16-15: Using an Arc<T> to wrap the Mutex<T>
to be able to share ownership across multiple threads
This code will print the following:
Result: 10
We did it! We counted from 0 to 10, which may not seem very impressive, but it
did teach us a lot about Mutex<T> and thread safety. You could also use this
program’s structure to do more complicated operations than just incrementing a
counter. Using this strategy, you can divide a calculation into independent
parts, split those parts across threads, and then use a Mutex<T> to have each
thread update the final result with its part.
Note that if you are doing simple numerical operations, there are types simpler
than Mutex<T> types provided by the std::sync::atomic module of the
standard library. These types provide safe, concurrent,
atomic access to primitive types. We chose to use Mutex<T> with a primitive
type for this example so we could concentrate on how Mutex<T> works.
Similarities Between RefCell<T>/Rc<T> and Mutex<T>/Arc<T>
You might have noticed that counter is immutable but we could get a mutable
reference to the value inside it; this means Mutex<T> provides interior
mutability, as the Cell family does. In the same way we used RefCell<T> in
Chapter 15 to allow us to mutate contents inside an Rc<T>, we use Mutex<T>
to mutate contents inside an Arc<T>.
Another detail to note is that Rust can’t protect you from all kinds of logic
errors when you use Mutex<T>. Recall in Chapter 15 that using Rc<T> came
with the risk of creating reference cycles, where two Rc<T> values refer to
each other, causing memory leaks. Similarly, Mutex<T> comes with the risk of
creating deadlocks. These occur when an operation needs to lock two resources
and two threads have each acquired one of the locks, causing them to wait for
each other forever. If you’re interested in deadlocks, try creating a Rust
program that has a deadlock; then research deadlock mitigation strategies for
mutexes in any language and have a go at implementing them in Rust. The
standard library API documentation for Mutex<T> and MutexGuard offers
useful information.
We’ll round out this chapter by talking about the Send and Sync traits and
how we can use them with custom types.
Extensible Concurrency with the Sync and Send Traits
Interestingly, the Rust language has very few concurrency features. Almost every concurrency feature we’ve talked about so far in this chapter has been part of the standard library, not the language. Your options for handling concurrency are not limited to the language or the standard library; you can write your own concurrency features or use those written by others.
However, two concurrency concepts are embedded in the language: the
std::marker traits Sync and Send.
Allowing Transference of Ownership Between Threads with Send
The Send marker trait indicates that ownership of values of the type
implementing Send can be transferred between threads. Almost every Rust type
is Send, but there are some exceptions, including Rc<T>: this cannot be
Send because if you cloned an Rc<T> value and tried to transfer ownership
of the clone to another thread, both threads might update the reference count
at the same time. For this reason, Rc<T> is implemented for use in
single-threaded situations where you don’t want to pay the thread-safe
performance penalty.
Therefore, Rust’s type system and trait bounds ensure that you can never
accidentally send an Rc<T> value across threads unsafely. When we tried to do
this in Listing 16-14, we got the error the trait Send is not implemented for Rc<Mutex<i32>>. When we switched to Arc<T>, which is Send, the code
compiled.
Any type composed entirely of Send types is automatically marked as Send as
well. Almost all primitive types are Send, aside from raw pointers, which
we’ll discuss in Chapter 19.
Allowing Access from Multiple Threads with Sync
The Sync marker trait indicates that it is safe for the type implementing
Sync to be referenced from multiple threads. In other words, any type T is
Sync if &T (an immutable reference to T) is Send, meaning the reference
can be sent safely to another thread. Similar to Send, primitive types are
Sync, and types composed entirely of types that are Sync are also Sync.
The smart pointer Rc<T> is also not Sync for the same reasons that it’s not
Send. The RefCell<T> type (which we talked about in Chapter 15) and the
family of related Cell<T> types are not Sync. The implementation of borrow
checking that RefCell<T> does at runtime is not thread-safe. The smart
pointer Mutex<T> is Sync and can be used to share access with multiple
threads as you saw in the “Sharing a Mutex<T> Between Multiple
Threads” section.
Implementing Send and Sync Manually Is Unsafe
Because types that are made up of Send and Sync traits are automatically
also Send and Sync, we don’t have to implement those traits manually. As
marker traits, they don’t even have any methods to implement. They’re just
useful for enforcing invariants related to concurrency.
Manually implementing these traits involves implementing unsafe Rust code.
We’ll talk about using unsafe Rust code in Chapter 19; for now, the important
information is that building new concurrent types not made up of Send and
Sync parts requires careful thought to uphold the safety guarantees. “The
Rustonomicon” has more information about these guarantees and how to
uphold them.
Summary
This isn’t the last you’ll see of concurrency in this book: the project in Chapter 20 will use the concepts in this chapter in a more realistic situation than the smaller examples discussed here.
As mentioned earlier, because very little of how Rust handles concurrency is part of the language, many concurrency solutions are implemented as crates. These evolve more quickly than the standard library, so be sure to search online for the current, state-of-the-art crates to use in multithreaded situations.
The Rust standard library provides channels for message passing and smart
pointer types, such as Mutex<T> and Arc<T>, that are safe to use in
concurrent contexts. The type system and the borrow checker ensure that the
code using these solutions won’t end up with data races or invalid references.
Once you get your code to compile, you can rest assured that it will happily
run on multiple threads without the kinds of hard-to-track-down bugs common in
other languages. Concurrent programming is no longer a concept to be afraid of:
go forth and make your programs concurrent, fearlessly!
Next, we’ll talk about idiomatic ways to model problems and structure solutions as your Rust programs get bigger. In addition, we’ll discuss how Rust’s idioms relate to those you might be familiar with from object-oriented programming.
Object-Oriented Programming Features of Rust
Object-oriented programming (OOP) is a way of modeling programs. Objects as a programmatic concept were introduced in the programming language Simula in the 1960s. Those objects influenced Alan Kay’s programming architecture in which objects pass messages to each other. To describe this architecture, he coined the term object-oriented programming in 1967. Many competing definitions describe what OOP is, and by some of these definitions Rust is object-oriented, but by others it is not. In this chapter, we’ll explore certain characteristics that are commonly considered object-oriented and how those characteristics translate to idiomatic Rust. We’ll then show you how to implement an object-oriented design pattern in Rust and discuss the trade-offs of doing so versus implementing a solution using some of Rust’s strengths instead.
Characteristics of Object-Oriented Languages
There is no consensus in the programming community about what features a language must have to be considered object-oriented. Rust is influenced by many programming paradigms, including OOP; for example, we explored the features that came from functional programming in Chapter 13. Arguably, OOP languages share certain common characteristics, namely objects, encapsulation, and inheritance. Let’s look at what each of those characteristics means and whether Rust supports it.
Objects Contain Data and Behavior
The book Design Patterns: Elements of Reusable Object-Oriented Software by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (Addison-Wesley Professional, 1994), colloquially referred to as The Gang of Four book, is a catalog of object-oriented design patterns. It defines OOP this way:
Object-oriented programs are made up of objects. An object packages both data and the procedures that operate on that data. The procedures are typically called methods or operations.
Using this definition, Rust is object-oriented: structs and enums have data,
and impl blocks provide methods on structs and enums. Even though structs and
enums with methods aren’t called objects, they provide the same
functionality, according to the Gang of Four’s definition of objects.
Encapsulation that Hides Implementation Details
Another aspect commonly associated with OOP is the idea of encapsulation, which means that the implementation details of an object aren’t accessible to code using that object. Therefore, the only way to interact with an object is through its public API; code using the object shouldn’t be able to reach into the object’s internals and change data or behavior directly. This enables the programmer to change and refactor an object’s internals without needing to change the code that uses the object.
We discussed how to control encapsulation in Chapter 7: we can use the pub
keyword to decide which modules, types, functions, and methods in our code
should be public, and by default everything else is private. For example, we
can define a struct AveragedCollection that has a field containing a vector
of i32 values. The struct can also have a field that contains the average of
the values in the vector, meaning the average doesn’t have to be computed
on demand whenever anyone needs it. In other words, AveragedCollection will
cache the calculated average for us. Listing 17-1 has the definition of the
AveragedCollection struct:
Filename: src/lib.rs
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
Listing 17-1: An AveragedCollection struct that
maintains a list of integers and the average of the items in the
collection
The struct is marked pub so that other code can use it, but the fields within
the struct remain private. This is important in this case because we want to
ensure that whenever a value is added or removed from the list, the average is
also updated. We do this by implementing add, remove, and average methods
on the struct, as shown in Listing 17-2:
Filename: src/lib.rs
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}
Listing 17-2: Implementations of the public methods
add, remove, and average on AveragedCollection
The public methods add, remove, and average are the only ways to access
or modify data in an instance of AveragedCollection. When an item is added
to list using the add method or removed using the remove method, the
implementations of each call the private update_average method that handles
updating the average field as well.
We leave the list and average fields private so there is no way for
external code to add or remove items to or from the list field directly;
otherwise, the average field might become out of sync when the list
changes. The average method returns the value in the average field,
allowing external code to read the average but not modify it.
Because we’ve encapsulated the implementation details of the struct
AveragedCollection, we can easily change aspects, such as the data structure,
in the future. For instance, we could use a HashSet<i32> instead of a
Vec<i32> for the list field. As long as the signatures of the add,
remove, and average public methods stay the same, code using
AveragedCollection wouldn’t need to change. If we made list public instead,
this wouldn’t necessarily be the case: HashSet<i32> and Vec<i32> have
different methods for adding and removing items, so the external code would
likely have to change if it were modifying list directly.
If encapsulation is a required aspect for a language to be considered
object-oriented, then Rust meets that requirement. The option to use pub or
not for different parts of code enables encapsulation of implementation details.
Inheritance as a Type System and as Code Sharing
Inheritance is a mechanism whereby an object can inherit elements from another object’s definition, thus gaining the parent object’s data and behavior without you having to define them again.
If a language must have inheritance to be an object-oriented language, then Rust is not one. There is no way to define a struct that inherits the parent struct’s fields and method implementations without using a macro.
However, if you’re used to having inheritance in your programming toolbox, you can use other solutions in Rust, depending on your reason for reaching for inheritance in the first place.
You would choose inheritance for two main reasons. One is for reuse of code:
you can implement particular behavior for one type, and inheritance enables you
to reuse that implementation for a different type. You can do this in a limited
way in Rust code using default trait method implementations, which you saw in
Listing 10-14 when we added a default implementation of the summarize method
on the Summary trait. Any type implementing the Summary trait would have
the summarize method available on it without any further code. This is
similar to a parent class having an implementation of a method and an
inheriting child class also having the implementation of the method. We can
also override the default implementation of the summarize method when we
implement the Summary trait, which is similar to a child class overriding the
implementation of a method inherited from a parent class.
The other reason to use inheritance relates to the type system: to enable a child type to be used in the same places as the parent type. This is also called polymorphism, which means that you can substitute multiple objects for each other at runtime if they share certain characteristics.
Polymorphism
To many people, polymorphism is synonymous with inheritance. But it’s actually a more general concept that refers to code that can work with data of multiple types. For inheritance, those types are generally subclasses.
Rust instead uses generics to abstract over different possible types and trait bounds to impose constraints on what those types must provide. This is sometimes called bounded parametric polymorphism.
Inheritance has recently fallen out of favor as a programming design solution in many programming languages because it’s often at risk of sharing more code than necessary. Subclasses shouldn’t always share all characteristics of their parent class but will do so with inheritance. This can make a program’s design less flexible. It also introduces the possibility of calling methods on subclasses that don’t make sense or that cause errors because the methods don’t apply to the subclass. In addition, some languages will only allow single inheritance (meaning a subclass can only inherit from one class), further restricting the flexibility of a program’s design.
For these reasons, Rust takes the different approach of using trait objects instead of inheritance. Let’s look at how trait objects enable polymorphism in Rust.
Using Trait Objects That Allow for Values of Different Types
- Using Trait Objects That Allow for Values of Different Types
Compare implementing trait with trait bounds and trait objects
-
The Same Trait definition
#![allow(unused)] fn main() { pub trait Draw { fn draw(&self); } } -
Different Call:
Situation Impl Trait Impl pub components: Vec<T> Trait Objects pub components: Vec<Box<dyn Draw>>
one limitation of vectors: only one type
In Chapter 8, we mentioned that one limitation of vectors is that they can store elements of only one type:
- We created a workaround in Listing 8-9 where
we defined a
SpreadsheetCellenum that had variants to hold integers, floats, and text. - This meant we could store different types of data in each cell and still have a vector that represented a row of cells.
- This is a perfectly good solution when our interchangeable items are a fixed set of types that we know when our code is compiled.
However, sometimes we want our library user to be able to extend the set of types that are valid in a particular situation.
How we achieve to extend the set of types
To show how we might achieve this:
- we’ll create an example graphical user interface (GUI) tool that iterates
through a list of items, calling a
drawmethod on each one to draw it to the screen—a common technique for GUI tools. - We’ll create a library crate called
guithat contains the structure of a GUI library. - This crate might include some types for people to use, such as
ButtonorTextField. - In addition,
guiusers will want to create their own types that can be drawn:
for instance, one programmer might add an
Imageand another might add aSelectBox.
- We won’t implement a fully fledged GUI library for this example but will show how the pieces would fit together.
At the time of writing the library, we can’t know and define all the types other programmers might want to create.
But we do know that
guineeds to keep track of many values of different types, and it needs to call adrawmethod on each of these differently typed values. It doesn’t need to know exactly what will happen when we call thedrawmethod, just that the value will have that method available for us to call.
How a language with inheritance do
To do this in a language with inheritance:
- we might define a class named
Componentthat has a method nameddrawon it. - The other classes, such as
Button,Image, andSelectBox, would inherit fromComponentand thus inherit thedrawmethod. - They could each override the
drawmethod to define their custom behavior, but the framework could treat all of the types as if they wereComponentinstances and calldrawon them.
But because Rust doesn’t have inheritance, we need another way to structure the
guilibrary to allow users to extend it with new types.
How a language without inheritance do
Defining a Trait for Common Behavior
To implement the behavior we want gui to have:
- we’ll define a trait named
Drawthat will have one method nameddraw. - Then we can define a vector that takes a trait object.
A trait object points to both an instance of a type implementing our specified trait and a table used to look up trait methods on that type at runtime:
- We create a trait object by specifying some sort of pointer, such as a
&reference or aBox<T>smart pointer - then the
dynkeyword, and then specifying the relevant trait. (We’ll talk about the reason trait objects must use a pointer in Chapter 19 in the section “Dynamically Sized Types and theSizedTrait.”) - We can use trait objects in place of a generic or concrete type.
Wherever we use a trait object, Rust’s type system will ensure at compile time that any value used in that context will implement the trait object’s trait. Consequently, we don’t need to know all the possible types at compile time.
We’ve mentioned that:
- in Rust, we refrain from calling structs and enums “objects” to distinguish them from other languages’ objects.
- In a struct or
enum, the data in the struct fields and the behavior in
implblocks are separated, whereas in other languages, the data and behavior combined into one concept is often labeled an object.
However, trait objects are more like objects in other languages in the sense that they combine data and behavior.
But trait objects differ from traditional objects in that we can’t add data to a trait object.
Trait objects aren’t as generally useful as objects in other languages: their specific purpose is to allow abstraction across common behavior.
Listing 17-3 shows how to define a trait named Draw with one method named
draw:
This syntax should look familiar from our discussions on how to define traits in Chapter 10.
Next comes some new syntax:
- Listing 17-4 defines a struct named
Screenthat holds a vector namedcomponents. - This vector is of type
Box<dyn Draw>, which is a trait object; - it’s a stand-in for any type inside a
Boxthat implements theDrawtrait.
Listing 17-4: Definition of the Screen struct with a components field holding a vector of trait objects that implement the Draw trait
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
On the Screen struct, we’ll define a method named run that will call the
draw method on each of its components, as shown in Listing 17-5:
Listing 17-5: A run method on Screen that calls the draw method on each component
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
Trait Object works differently from Trait Bounds
This works differently from defining a struct that uses a generic type parameter with trait bounds:
- A generic type parameter can only be substituted with one concrete type at a time
- whereas trait objects allow for multiple concrete types to fill in for the trait object at runtime.
For example, we could have defined the
Screenstruct using a generic type and a trait bound as in Listing 17-6:
Listing 17-6: An alternate implementation of the Screen struct and its run method using generics and trait bounds
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
This restricts us to a Screen instance that has a list of components all of
type Button or all of type TextField.
If you’ll only ever have homogeneous collections, using generics and trait bounds is preferable because the definitions will be monomorphized at compile time to use the concrete types.
On the other hand, with the method using trait objects, one Screen instance
can hold a Vec<T> that contains a Box<Button> as well as a
Box<TextField>.
Let’s look at how this works, and then we’ll talk about the runtime performance implications.
Implementing the Trait
Now we’ll do these:
- add some types that implement the
Drawtrait - provide the
Buttontype. - Again, actually implementing a GUI library is beyond the scope
of this book, so the
drawmethod won’t have any useful implementation in its body. - To imagine what the implementation might look like, a
Buttonstruct might have fields forwidth,height, andlabel, as shown in Listing 17-7:
- The
width,height, andlabelfields onButtonwill differ from the fields on other components; - for example, a
TextFieldtype might have those same fields plus aplaceholderfield. - Each of the types we want to draw on
the screen will implement the
Drawtrait but will use different code in thedrawmethod to define how to draw that particular type, asButtonhas here (without the actual GUI code, as mentioned). - The
Buttontype, for instance, might have an additionalimplblock containing methods related to what happens when a user clicks the button. - These kinds of methods won’t apply to types like
TextField.
If someone using our library decides to implement a SelectBox struct that has
width, height, and options fields, they implement the Draw trait on the
SelectBox type as well, as shown in Listing 17-8:
Listing 17-8: Another crate using gui and implementing the Draw trait on a SelectBox struct
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}
- Our library’s user can now write their
mainfunction to create aScreeninstance. - To the
Screeninstance, they can add aSelectBoxand aButtonby putting each in aBox<T>to become a trait object. - They can then call the
runmethod on theScreeninstance, which will calldrawon each of the components.
Listing 17-9 shows this implementation:
Listing 17-9: Using trait objects to store values of different types that implement the same trait
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}
- When we wrote the library, we didn’t know that someone might add the
SelectBoxtype - but our
Screenimplementation was able to operate on the new type and draw it - because
SelectBoximplements theDrawtrait, which means it implements thedrawmethod.
This concept—of being concerned only with the messages a value responds to rather than the value’s concrete type—is similar to the concept of duck typing in dynamically typed languages:
- if it walks like a duck and quacks like a duck, then it must be a duck!
- In the implementation of
runonScreenin Listing 17-5,rundoesn’t need to know what the concrete type of each component is. - It doesn’t check whether a component is an instance of a
Buttonor aSelectBox, it just calls thedrawmethod on the component.
By specifying
Box<dyn Draw>as the type of the values in thecomponentsvector, we’ve definedScreento need values that we can call thedrawmethod on.
The advantace of using trait objects: just like duck typing
The advantage of using trait objects and Rust’s type system to write code similar to code using duck typing is that:
- we never have to check whether a value implements a particular method at runtime
- or worry about getting errors if a value doesn’t implement a method but we call it anyway.
- Rust won’t compile our code if the values don’t implement the traits that the trait objects need.
For example, Listing 17-10 shows what happens if we try to create a Screen
with a String as a component:
Listing 17-10: Attempting to use a type that doesn’t implement the trait object’s trait
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}
We’ll get this error because String doesn’t implement the Draw trait:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast to the object type `dyn Draw`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` due to previous error
This error lets us know that:
- either we’re passing something to
Screenwe didn’t mean to pass and so should pass a different type - or we should implement
DrawonStringso thatScreenis able to calldrawon it.
Trait Objects Perform Dynamic Dispatch
Recall in the “Performance of Code Using Generics” section in Chapter 10 our discussion on the monomorphization process performed by the compiler when we use trait bounds on generics:
- the compiler generates nongeneric implementations of functions and methods for each concrete type that we use in place of a generic type parameter.
- The code that results from monomorphization is doing static dispatch, which is when the compiler knows what method you’re calling at compile time.
- This is opposed to dynamic dispatch, which is when the compiler can’t tell at compile time which method you’re calling.
- In dynamic dispatch cases, the compiler emits code that at runtime will figure out which method to call.
When we use trait objects, Rust must use dynamic dispatch:
- The compiler doesn’t know all the types that might be used with the code that’s using trait objects, so it doesn’t know which method implemented on which type to call.
- Instead, at runtime, Rust uses the pointers inside the trait object to know which method to call.
- This lookup incurs a runtime cost that doesn’t occur with static dispatch.
- Dynamic dispatch also prevents the compiler from choosing to inline a method’s code, which in turn prevents some optimizations.
However, we did get extra flexibility in the code that we wrote in Listing 17-5 and were able to support in Listing 17-9, so it’s a trade-off to consider.
Implementing an Object-Oriented Design Pattern
The state pattern is an object-oriented design pattern. The crux of the pattern is that we define a set of states a value can have internally. The states are represented by a set of state objects, and the value’s behavior changes based on its state. We’re going to work through an example of a blog post struct that has a field to hold its state, which will be a state object from the set “draft”, “review”, or “published”.
The state objects share functionality: in Rust, of course, we use structs and traits rather than objects and inheritance. Each state object is responsible for its own behavior and for governing when it should change into another state. The value that holds a state object knows nothing about the different behavior of the states or when to transition between states.
The advantage of using the state pattern is that, when the business requirements of the program change, we won’t need to change the code of the value holding the state or the code that uses the value. We’ll only need to update the code inside one of the state objects to change its rules or perhaps add more state objects.
First, we’re going to implement the state pattern in a more traditional object-oriented way, then we’ll use an approach that’s a bit more natural in Rust. Let’s dig in to incrementally implementing a blog post workflow using the state pattern.
The final functionality will look like this:
- A blog post starts as an empty draft.
- When the draft is done, a review of the post is requested.
- When the post is approved, it gets published.
- Only published blog posts return content to print, so unapproved posts can’t accidentally be published.
Any other changes attempted on a post should have no effect. For example, if we try to approve a draft blog post before we’ve requested a review, the post should remain an unpublished draft.
Listing 17-11 shows this workflow in code form: this is an example usage of the
API we’ll implement in a library crate named blog. This won’t compile yet
because we haven’t implemented the blog crate.
Filename: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}
Listing 17-11: Code that demonstrates the desired
behavior we want our blog crate to have
We want to allow the user to create a new draft blog post with Post::new. We
want to allow text to be added to the blog post. If we try to get the post’s
content immediately, before approval, we shouldn’t get any text because the
post is still a draft. We’ve added assert_eq! in the code for demonstration
purposes. An excellent unit test for this would be to assert that a draft blog
post returns an empty string from the content method, but we’re not going to
write tests for this example.
Next, we want to enable a request for a review of the post, and we want
content to return an empty string while waiting for the review. When the post
receives approval, it should get published, meaning the text of the post will
be returned when content is called.
Notice that the only type we’re interacting with from the crate is the Post
type. This type will use the state pattern and will hold a value that will be
one of three state objects representing the various states a post can be
in—draft, waiting for review, or published. Changing from one state to another
will be managed internally within the Post type. The states change in
response to the methods called by our library’s users on the Post instance,
but they don’t have to manage the state changes directly. Also, users can’t
make a mistake with the states, like publishing a post before it’s reviewed.
Defining Post and Creating a New Instance in the Draft State
Let’s get started on the implementation of the library! We know we need a
public Post struct that holds some content, so we’ll start with the
definition of the struct and an associated public new function to create an
instance of Post, as shown in Listing 17-12. We’ll also make a private
State trait that will define the behavior that all state objects for a Post
must have.
Then Post will hold a trait object of Box<dyn State> inside an Option<T>
in a private field named state to hold the state object. You’ll see why the
Option<T> is necessary in a bit.
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}
Listing 17-12: Definition of a Post struct and a new
function that creates a new Post instance, a State trait, and a Draft
struct
The State trait defines the behavior shared by different post states. The
state objects are Draft, PendingReview, and Published, and they will all
implement the State trait. For now, the trait doesn’t have any methods, and
we’ll start by defining just the Draft state because that is the state we
want a post to start in.
When we create a new Post, we set its state field to a Some value that
holds a Box. This Box points to a new instance of the Draft struct.
This ensures whenever we create a new instance of Post, it will start out as
a draft. Because the state field of Post is private, there is no way to
create a Post in any other state! In the Post::new function, we set the
content field to a new, empty String.
Storing the Text of the Post Content
We saw in Listing 17-11 that we want to be able to call a method named
add_text and pass it a &str that is then added as the text content of the
blog post. We implement this as a method, rather than exposing the content
field as pub, so that later we can implement a method that will control how
the content field’s data is read. The add_text method is pretty
straightforward, so let’s add the implementation in Listing 17-13 to the impl Post block:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}
Listing 17-13: Implementing the add_text method to add
text to a post’s content
The add_text method takes a mutable reference to self, because we’re
changing the Post instance that we’re calling add_text on. We then call
push_str on the String in content and pass the text argument to add to
the saved content. This behavior doesn’t depend on the state the post is in,
so it’s not part of the state pattern. The add_text method doesn’t interact
with the state field at all, but it is part of the behavior we want to
support.
Ensuring the Content of a Draft Post Is Empty
Even after we’ve called add_text and added some content to our post, we still
want the content method to return an empty string slice because the post is
still in the draft state, as shown on line 7 of Listing 17-11. For now, let’s
implement the content method with the simplest thing that will fulfill this
requirement: always returning an empty string slice. We’ll change this later
once we implement the ability to change a post’s state so it can be published.
So far, posts can only be in the draft state, so the post content should always
be empty. Listing 17-14 shows this placeholder implementation:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}
Listing 17-14: Adding a placeholder implementation for
the content method on Post that always returns an empty string slice
With this added content method, everything in Listing 17-11 up to line 7
works as intended.
Requesting a Review of the Post Changes Its State
Next, we need to add functionality to request a review of a post, which should
change its state from Draft to PendingReview. Listing 17-15 shows this code:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}
Listing 17-15: Implementing request_review methods on
Post and the State trait
We give Post a public method named request_review that will take a mutable
reference to self. Then we call an internal request_review method on the
current state of Post, and this second request_review method consumes the
current state and returns a new state.
We add the request_review method to the State trait; all types that
implement the trait will now need to implement the request_review method.
Note that rather than having self, &self, or &mut self as the first
parameter of the method, we have self: Box<Self>. This syntax means the
method is only valid when called on a Box holding the type. This syntax takes
ownership of Box<Self>, invalidating the old state so the state value of the
Post can transform into a new state.
To consume the old state, the request_review method needs to take ownership
of the state value. This is where the Option in the state field of Post
comes in: we call the take method to take the Some value out of the state
field and leave a None in its place, because Rust doesn’t let us have
unpopulated fields in structs. This lets us move the state value out of
Post rather than borrowing it. Then we’ll set the post’s state value to the
result of this operation.
We need to set state to None temporarily rather than setting it directly
with code like self.state = self.state.request_review(); to get ownership of
the state value. This ensures Post can’t use the old state value after
we’ve transformed it into a new state.
The request_review method on Draft returns a new, boxed instance of a new
PendingReview struct, which represents the state when a post is waiting for a
review. The PendingReview struct also implements the request_review method
but doesn’t do any transformations. Rather, it returns itself, because when we
request a review on a post already in the PendingReview state, it should stay
in the PendingReview state.
Now we can start seeing the advantages of the state pattern: the
request_review method on Post is the same no matter its state value. Each
state is responsible for its own rules.
We’ll leave the content method on Post as is, returning an empty string
slice. We can now have a Post in the PendingReview state as well as in the
Draft state, but we want the same behavior in the PendingReview state.
Listing 17-11 now works up to line 10!
Adding approve to Change the Behavior of content
The approve method will be similar to the request_review method: it will
set state to the value that the current state says it should have when that
state is approved, as shown in Listing 17-16:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
Listing 17-16: Implementing the approve method on
Post and the State trait
We add the approve method to the State trait and add a new struct that
implements State, the Published state.
Similar to the way request_review on PendingReview works, if we call the
approve method on a Draft, it will have no effect because approve will
return self. When we call approve on PendingReview, it returns a new,
boxed instance of the Published struct. The Published struct implements the
State trait, and for both the request_review method and the approve
method, it returns itself, because the post should stay in the Published
state in those cases.
Now we need to update the content method on Post. We want the value
returned from content to depend on the current state of the Post, so we’re
going to have the Post delegate to a content method defined on its state,
as shown in Listing 17-17:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
Listing 17-17: Updating the content method on Post to
delegate to a content method on State
Because the goal is to keep all these rules inside the structs that implement
State, we call a content method on the value in state and pass the post
instance (that is, self) as an argument. Then we return the value that’s
returned from using the content method on the state value.
We call the as_ref method on the Option because we want a reference to the
value inside the Option rather than ownership of the value. Because state
is an Option<Box<dyn State>>, when we call as_ref, an Option<&Box<dyn State>> is returned. If we didn’t call as_ref, we would get an error because
we can’t move state out of the borrowed &self of the function parameter.
We then call the unwrap method, which we know will never panic, because we
know the methods on Post ensure that state will always contain a Some
value when those methods are done. This is one of the cases we talked about in
the “Cases In Which You Have More Information Than the
Compiler” section of Chapter 9 when we
know that a None value is never possible, even though the compiler isn’t able
to understand that.
At this point, when we call content on the &Box<dyn State>, deref coercion
will take effect on the & and the Box so the content method will
ultimately be called on the type that implements the State trait. That means
we need to add content to the State trait definition, and that is where
we’ll put the logic for what content to return depending on which state we
have, as shown in Listing 17-18:
Filename: src/lib.rs
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}
Listing 17-18: Adding the content method to the State
trait
We add a default implementation for the content method that returns an empty
string slice. That means we don’t need to implement content on the Draft
and PendingReview structs. The Published struct will override the content
method and return the value in post.content.
Note that we need lifetime annotations on this method, as we discussed in
Chapter 10. We’re taking a reference to a post as an argument and returning a
reference to part of that post, so the lifetime of the returned reference is
related to the lifetime of the post argument.
And we’re done—all of Listing 17-11 now works! We’ve implemented the state
pattern with the rules of the blog post workflow. The logic related to the
rules lives in the state objects rather than being scattered throughout Post.
Why Not An Enum?
You may have been wondering why we didn’t use an
enumwith the different possible post states as variants. That’s certainly a possible solution, try it and compare the end results to see which you prefer! One disadvantage of using an enum is every place that checks the value of the enum will need amatchexpression or similar to handle every possible variant. This could get more repetitive than this trait object solution.
Trade-offs of the State Pattern
We’ve shown that Rust is capable of implementing the object-oriented state
pattern to encapsulate the different kinds of behavior a post should have in
each state. The methods on Post know nothing about the various behaviors. The
way we organized the code, we have to look in only one place to know the
different ways a published post can behave: the implementation of the State
trait on the Published struct.
If we were to create an alternative implementation that didn’t use the state
pattern, we might instead use match expressions in the methods on Post or
even in the main code that checks the state of the post and changes behavior
in those places. That would mean we would have to look in several places to
understand all the implications of a post being in the published state! This
would only increase the more states we added: each of those match expressions
would need another arm.
With the state pattern, the Post methods and the places we use Post don’t
need match expressions, and to add a new state, we would only need to add a
new struct and implement the trait methods on that one struct.
The implementation using the state pattern is easy to extend to add more functionality. To see the simplicity of maintaining code that uses the state pattern, try a few of these suggestions:
- Add a
rejectmethod that changes the post’s state fromPendingReviewback toDraft. - Require two calls to
approvebefore the state can be changed toPublished. - Allow users to add text content only when a post is in the
Draftstate. Hint: have the state object responsible for what might change about the content but not responsible for modifying thePost.
One downside of the state pattern is that, because the states implement the
transitions between states, some of the states are coupled to each other. If we
add another state between PendingReview and Published, such as Scheduled,
we would have to change the code in PendingReview to transition to
Scheduled instead. It would be less work if PendingReview didn’t need to
change with the addition of a new state, but that would mean switching to
another design pattern.
Another downside is that we’ve duplicated some logic. To eliminate some of the
duplication, we might try to make default implementations for the
request_review and approve methods on the State trait that return self;
however, this would violate object safety, because the trait doesn’t know what
the concrete self will be exactly. We want to be able to use State as a
trait object, so we need its methods to be object safe.
Other duplication includes the similar implementations of the request_review
and approve methods on Post. Both methods delegate to the implementation of
the same method on the value in the state field of Option and set the new
value of the state field to the result. If we had a lot of methods on Post
that followed this pattern, we might consider defining a macro to eliminate the
repetition (see the “Macros” section in Chapter 19).
By implementing the state pattern exactly as it’s defined for object-oriented
languages, we’re not taking as full advantage of Rust’s strengths as we could.
Let’s look at some changes we can make to the blog crate that can make
invalid states and transitions into compile time errors.
Encoding States and Behavior as Types
We’ll show you how to rethink the state pattern to get a different set of trade-offs. Rather than encapsulating the states and transitions completely so outside code has no knowledge of them, we’ll encode the states into different types. Consequently, Rust’s type checking system will prevent attempts to use draft posts where only published posts are allowed by issuing a compiler error.
Let’s consider the first part of main in Listing 17-11:
Filename: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}
We still enable the creation of new posts in the draft state using Post::new
and the ability to add text to the post’s content. But instead of having a
content method on a draft post that returns an empty string, we’ll make it so
draft posts don’t have the content method at all. That way, if we try to get
a draft post’s content, we’ll get a compiler error telling us the method
doesn’t exist. As a result, it will be impossible for us to accidentally
display draft post content in production, because that code won’t even compile.
Listing 17-19 shows the definition of a Post struct and a DraftPost struct,
as well as methods on each:
Filename: src/lib.rs
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
Listing 17-19: A Post with a content method and a
DraftPost without a content method
Both the Post and DraftPost structs have a private content field that
stores the blog post text. The structs no longer have the state field because
we’re moving the encoding of the state to the types of the structs. The Post
struct will represent a published post, and it has a content method that
returns the content.
We still have a Post::new function, but instead of returning an instance of
Post, it returns an instance of DraftPost. Because content is private
and there aren’t any functions that return Post, it’s not possible to create
an instance of Post right now.
The DraftPost struct has an add_text method, so we can add text to
content as before, but note that DraftPost does not have a content method
defined! So now the program ensures all posts start as draft posts, and draft
posts don’t have their content available for display. Any attempt to get around
these constraints will result in a compiler error.
Implementing Transitions as Transformations into Different Types
So how do we get a published post? We want to enforce the rule that a draft
post has to be reviewed and approved before it can be published. A post in the
pending review state should still not display any content. Let’s implement
these constraints by adding another struct, PendingReviewPost, defining the
request_review method on DraftPost to return a PendingReviewPost, and
defining an approve method on PendingReviewPost to return a Post, as
shown in Listing 17-20:
Filename: src/lib.rs
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}
Listing 17-20: A PendingReviewPost that gets created by
calling request_review on DraftPost and an approve method that turns a
PendingReviewPost into a published Post
The request_review and approve methods take ownership of self, thus
consuming the DraftPost and PendingReviewPost instances and transforming
them into a PendingReviewPost and a published Post, respectively. This way,
we won’t have any lingering DraftPost instances after we’ve called
request_review on them, and so forth. The PendingReviewPost struct doesn’t
have a content method defined on it, so attempting to read its content
results in a compiler error, as with DraftPost. Because the only way to get a
published Post instance that does have a content method defined is to call
the approve method on a PendingReviewPost, and the only way to get a
PendingReviewPost is to call the request_review method on a DraftPost,
we’ve now encoded the blog post workflow into the type system.
But we also have to make some small changes to main. The request_review and
approve methods return new instances rather than modifying the struct they’re
called on, so we need to add more let post = shadowing assignments to save
the returned instances. We also can’t have the assertions about the draft and
pending review posts’ contents be empty strings, nor do we need them: we can’t
compile code that tries to use the content of posts in those states any longer.
The updated code in main is shown in Listing 17-21:
Filename: src/main.rs
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}
Listing 17-21: Modifications to main to use the new
implementation of the blog post workflow
The changes we needed to make to main to reassign post mean that this
implementation doesn’t quite follow the object-oriented state pattern anymore:
the transformations between the states are no longer encapsulated entirely
within the Post implementation. However, our gain is that invalid states are
now impossible because of the type system and the type checking that happens at
compile time! This ensures that certain bugs, such as display of the content of
an unpublished post, will be discovered before they make it to production.
Try the tasks suggested at the start of this section on the blog crate as it
is after Listing 17-21 to see what you think about the design of this version
of the code. Note that some of the tasks might be completed already in this
design.
We’ve seen that even though Rust is capable of implementing object-oriented design patterns, other patterns, such as encoding state into the type system, are also available in Rust. These patterns have different trade-offs. Although you might be very familiar with object-oriented patterns, rethinking the problem to take advantage of Rust’s features can provide benefits, such as preventing some bugs at compile time. Object-oriented patterns won’t always be the best solution in Rust due to certain features, like ownership, that object-oriented languages don’t have.
Summary
No matter whether or not you think Rust is an object-oriented language after reading this chapter, you now know that you can use trait objects to get some object-oriented features in Rust. Dynamic dispatch can give your code some flexibility in exchange for a bit of runtime performance. You can use this flexibility to implement object-oriented patterns that can help your code’s maintainability. Rust also has other features, like ownership, that object-oriented languages don’t have. An object-oriented pattern won’t always be the best way to take advantage of Rust’s strengths, but is an available option.
Next, we’ll look at patterns, which are another of Rust’s features that enable lots of flexibility. We’ve looked at them briefly throughout the book but haven’t seen their full capability yet. Let’s go!
Patterns and Matching
Patterns are a special syntax in Rust for matching against the structure of
types, both complex and simple. Using patterns in conjunction with match
expressions and other constructs gives you more control over a program’s
control flow. A pattern consists of some combination of the following:
- Literals
- Destructured arrays, enums, structs, or tuples
- Variables
- Wildcards
- Placeholders
Some example patterns include x, (a, 3), and Some(Color::Red). In the
contexts in which patterns are valid, these components describe the shape of
data. Our program then matches values against the patterns to determine whether
it has the correct shape of data to continue running a particular piece of code.
To use a pattern, we compare it to some value. If the pattern matches the
value, we use the value parts in our code. Recall the match expressions in
Chapter 6 that used patterns, such as the coin-sorting machine example. If the
value fits the shape of the pattern, we can use the named pieces. If it
doesn’t, the code associated with the pattern won’t run.
This chapter is a reference on all things related to patterns. We’ll cover the valid places to use patterns, the difference between refutable and irrefutable patterns, and the different kinds of pattern syntax that you might see. By the end of the chapter, you’ll know how to use patterns to express many concepts in a clear way.
All the Places Patterns Can Be Used
Patterns pop up in a number of places in Rust, and you’ve been using them a lot without realizing it! This section discusses all the places where patterns are valid.
match Arms
As discussed in Chapter 6, we use patterns in the arms of match expressions.
Formally,
matchexpressions are defined as the keywordmatch, a value to match on, and one or more match arms that consist of a pattern and an expression to run if the value matches that arm’s pattern, like this:
match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
}
For example, here’s the match expression from Listing 6-5 that matches on an
Option<i32> value in the variable x:
match x {
None => None,
Some(i) => Some(i + 1),
}
The patterns in this match expression are the None and Some(i) on the
left of each arrow.
One requirement for
matchexpressions is that they need to be exhaustive in the sense that all possibilities for the value in thematchexpression must be accounted for.
One way to ensure you’ve covered every possibility is to have a catchall pattern for the last arm: for example, a variable name matching any value can never fail and thus covers every remaining case.
- The particular pattern
_will match anything, but it never binds to a variable, so it’s often used in the last match arm. - The
_pattern can be useful when you want to ignore any value not specified, for example. We’ll cover the_pattern in more detail in the “Ignoring Values in a Pattern” section later in this chapter.
Conditional if let Expressions
In Chapter 6 we discussed how to use if let expressions mainly as a shorter
way to write the equivalent of a match that only matches one case.
Optionally,
if letcan have a correspondingelsecontaining code to run if the pattern in theif letdoesn’t match.
Listing 18-1 shows that it’s also possible to mix and match if let, else if, and else if let expressions.
Doing so gives us more flexibility than a
match expression in which we can express only one value to compare with the
patterns. Also, Rust doesn’t require that the conditions in a series of if let, else if, else if let arms relate to each other.
The code in Listing 18-1 determines what color to make your background based on a series of checks for several conditions. For this example, we’ve created variables with hardcoded values that a real program might receive from user input.
Filename: src/main.rs
fn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
if let Some(color) = favorite_color {
println!("Using your favorite color, {color}, as the background");
} else if is_tuesday {
println!("Tuesday is green day!");
} else if let Ok(age) = age {
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
} else {
println!("Using blue as the background color");
}
}
Listing 18-1: Mixing if let, else if, else if let,
and else
- If the user specifies a favorite color, that color is used as the background.
- If no favorite color is specified and today is Tuesday, the background color is green.
- Otherwise, if the user specifies their age as a string and we can parse it as a number successfully, the color is either purple or orange depending on the value of the number.
- If none of these conditions apply, the background color is blue.
- This conditional structure lets us support complex requirements.
- With the
hardcoded values we have here, this example will print
Using purple as the background color.
You can see that
if letcan also introduce shadowed variables in the same way thatmatcharms can:
- the line
if let Ok(age) = ageintroduces a new shadowedagevariable that contains the value inside theOkvariant. - This
means we need to place the
if age > 30condition within that block: we can’t combine these two conditions intoif let Ok(age) = age && age > 30. - The
shadowed
agewe want to compare to 30 isn’t valid until the new scope starts with the curly bracket.
The downside of using
if letexpressions is that the compiler doesn’t check for exhaustiveness, whereas withmatchexpressions it does.
If we omitted the
last else block and therefore missed handling some cases, the compiler would
not alert us to the possible logic bug.
while let Conditional Loops
Similar in construction to if let, the while let conditional loop allows a
while loop to run for as long as a pattern continues to match.
In Listing
18-2 we code a while let loop that uses a vector as a stack and prints the
values in the vector in the opposite order in which they were pushed.
fn main() {
let mut stack = Vec::new();
stack.push(1);
stack.push(2);
stack.push(3);
while let Some(top) = stack.pop() {
println!("{}", top);
}
}
Listing 18-2: Using a while let loop to print values
for as long as stack.pop() returns Some
- This example prints 3, 2, and then 1.
- The
popmethod takes the last element out of the vector and returnsSome(value). - If the vector is empty,
popreturnsNone. - The
whileloop continues running the code in its block as long aspopreturnsSome. WhenpopreturnsNone, the loop stops. - We can use
while letto pop every element off our stack.
for Loops
In a for loop, the value that directly follows the keyword for is a
pattern. For example, in for x in y the x is the pattern.
Listing 18-3
demonstrates how to use a pattern in a for loop to destructure, or break
apart, a tuple as part of the for loop.
fn main() {
let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() {
println!("{} is at index {}", value, index);
}
}
Listing 18-3: Using a pattern in a for loop to
destructure a tuple
The code in Listing 18-3 will print the following:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished dev [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
- We adapt an iterator using the
enumeratemethod so it produces a value and the index for that value, placed into a tuple. - The first value produced is the tuple
(0, 'a'). - When this value is matched to the pattern
(index, value),indexwill be0andvaluewill be'a', printing the first line of the output.
let Statements
Prior to this chapter, we had only explicitly discussed using patterns with
match and if let, but in fact, we’ve used patterns in other places as well,
including in let statements.
For example, consider this straightforward variable assignment with let:
#![allow(unused)] fn main() { let x = 5; }
Every time you’ve used a let statement like this you’ve been using patterns,
although you might not have realized it! More formally, a let statement looks
like this:
let PATTERN = EXPRESSION;
In statements like
let x = 5;with a variable name in thePATTERNslot, the variable name is just a particularly simple form of a pattern.
- Rust compares the expression against the pattern and assigns any names it finds.
- So in the
let x = 5;example,xis a pattern that means “bind what matches here to the variablex.” - Because the name
xis the whole pattern, this pattern effectively means “bind everything to the variablex, whatever the value is.”
To see the pattern matching aspect of let more clearly, consider Listing
18-4, which uses a pattern with let to destructure a tuple.
fn main() {
let (x, y, z) = (1, 2, 3);
}
Listing 18-4: Using a pattern to destructure a tuple and create three variables at once
- Here, we match a tuple against a pattern.
- Rust compares the value
(1, 2, 3)to the pattern(x, y, z)and sees that the value matches the pattern, so Rust binds1tox,2toy, and3toz. - You can think of this tuple pattern as nesting three individual variable patterns inside it.
If the number of elements in the pattern doesn’t match the number of elements in the tuple, the overall type won’t match and we’ll get a compiler error.
For example, Listing 18-5 shows an attempt to destructure a tuple with three elements into two variables, which won’t work.
fn main() {
let (x, y) = (1, 2, 3);
}
Listing 18-5: Incorrectly constructing a pattern whose variables don’t match the number of elements in the tuple
Attempting to compile this code results in this type error:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` due to previous error
-
To fix the error, we could ignore one or more of the values in the tuple using
_or.., as you’ll see in the “Ignoring Values in a Pattern” section. -
If the problem is that we have too many variables in the pattern, the solution is to make the types match by removing variables so the number of variables equals the number of elements in the tuple.
Function Parameters
Function parameters can also be patterns. The code in Listing 18-6, which
declares a function named foo that takes one parameter named x of type
i32, should by now look familiar.
fn foo(x: i32) { // code goes here } fn main() {}
Listing 18-6: A function signature uses patterns in the parameters
- The
xpart is a pattern! As we did withlet, we could match a tuple in a function’s arguments to the pattern.
Listing 18-7 splits the values in a tuple as we pass it to a function.
Filename: src/main.rs
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({}, {})", x, y);
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}
Listing 18-7: A function with parameters that destructure a tuple
- This code prints
Current location: (3, 5). - The values
&(3, 5)match the pattern&(x, y), soxis the value3andyis the value5.
We can also use patterns in closure parameter lists in the same way as in function parameter lists, because closures are similar to functions, as discussed in Chapter 13.
At this point, you’ve seen several ways of using patterns, but patterns don’t work the same in every place we can use them. In some places, the patterns must be irrefutable; in other circumstances, they can be refutable. We’ll discuss these two concepts next.
Refutability: Whether a Pattern Might Fail to Match
Patterns come in two forms: refutable and irrefutable. Patterns that will match
for any possible value passed are irrefutable. An example would be x in the
statement let x = 5; because x matches anything and therefore cannot fail
to match. Patterns that can fail to match for some possible value are
refutable. An example would be Some(x) in the expression if let Some(x) = a_value because if the value in the a_value variable is None rather than
Some, the Some(x) pattern will not match.
Function parameters, let statements, and for loops can only accept
irrefutable patterns, because the program cannot do anything meaningful when
values don’t match. The if let and while let expressions accept
refutable and irrefutable patterns, but the compiler warns against
irrefutable patterns because by definition they’re intended to handle possible
failure: the functionality of a conditional is in its ability to perform
differently depending on success or failure.
In general, you shouldn’t have to worry about the distinction between refutable and irrefutable patterns; however, you do need to be familiar with the concept of refutability so you can respond when you see it in an error message. In those cases, you’ll need to change either the pattern or the construct you’re using the pattern with, depending on the intended behavior of the code.
Let’s look at an example of what happens when we try to use a refutable pattern
where Rust requires an irrefutable pattern and vice versa. Listing 18-8 shows a
let statement, but for the pattern we’ve specified Some(x), a refutable
pattern. As you might expect, this code will not compile.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}
Listing 18-8: Attempting to use a refutable pattern with
let
If some_option_value was a None value, it would fail to match the pattern
Some(x), meaning the pattern is refutable. However, the let statement can
only accept an irrefutable pattern because there is nothing valid the code can
do with a None value. At compile time, Rust will complain that we’ve tried to
use a refutable pattern where an irrefutable pattern is required:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding: `None` not covered
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch18-02-refutability.html
note: `Option<i32>` defined here
= note: the matched value is of type `Option<i32>`
help: you might want to use `if let` to ignore the variant that isn't matched
|
3 | let x = if let Some(x) = some_option_value { x } else { todo!() };
| ++++++++++ ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` due to previous error
Because we didn’t cover (and couldn’t cover!) every valid value with the
pattern Some(x), Rust rightfully produces a compiler error.
If we have a refutable pattern where an irrefutable pattern is needed, we can
fix it by changing the code that uses the pattern: instead of using let, we
can use if let. Then if the pattern doesn’t match, the code will just skip
the code in the curly brackets, giving it a way to continue validly. Listing
18-9 shows how to fix the code in Listing 18-8.
fn main() { let some_option_value: Option<i32> = None; if let Some(x) = some_option_value { println!("{}", x); } }
Listing 18-9: Using if let and a block with refutable
patterns instead of let
We’ve given the code an out! This code is perfectly valid, although it means we
cannot use an irrefutable pattern without receiving an error. If we give if let a pattern that will always match, such as x, as shown in Listing 18-10,
the compiler will give a warning.
fn main() { if let x = 5 { println!("{}", x); }; }
Listing 18-10: Attempting to use an irrefutable pattern
with if let
Rust complains that it doesn’t make sense to use if let with an irrefutable
pattern:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `if let` pattern
--> src/main.rs:2:8
|
2 | if let x = 5 {
| ^^^^^^^^^
|
= note: `#[warn(irrefutable_let_patterns)]` on by default
= note: this pattern will always match, so the `if let` is useless
= help: consider replacing the `if let` with a `let`
warning: `patterns` (bin "patterns") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
5
For this reason, match arms must use refutable patterns, except for the last
arm, which should match any remaining values with an irrefutable pattern. Rust
allows us to use an irrefutable pattern in a match with only one arm, but
this syntax isn’t particularly useful and could be replaced with a simpler
let statement.
Now that you know where to use patterns and the difference between refutable and irrefutable patterns, let’s cover all the syntax we can use to create patterns.
Pattern Syntax
Summarize made by chatGPT
- Patterns are used in Rust for destructuring complex types, matching against specific values, and binding variables.
- Rust’s pattern syntax includes various types of patterns such as literals, variables, wildcards, ranges, references, structs, enums, and more.
- Pattern matching can be used in various contexts such as function arguments, match expressions, let statements, and more.
- Pattern matching can also be used with guards to specify additional conditions for a match arm.
- Rust also supports destructuring nested structures using patterns like tuples, structs, and enums with multiple fields.
- Patterns can be combined using the | operator to match multiple patterns, and the .. operator to ignore some parts of a pattern.
- Rust provides the ability to define custom patterns using the @ operator.
- The _ wildcard pattern can be used as a catch-all to match any value.
- The ref and ref mut patterns can be used to create references to the matched value.
- The box pattern can be used to match against a boxed value.
- The @ operator can also be used to bind a variable to a pattern without destructuring it.
- Rust provides various shorthand notations for patterns such as .. for matching the rest of a slice or array, and ..= for inclusive ranges.
- Rust also supports pattern matching with if let and while let expressions, which are useful for handling optional values.
- Finally, the webpage provides examples and code snippets to illustrate the use of pattern matching in Rust.
Questions made by chatGPT
- What are some of the different types of patterns that Rust’s pattern syntax includes?
- What are some of the contexts in which pattern matching can be used in Rust?
- How can you combine patterns using Rust’s pattern syntax?
- What are some of the shorthand notations for patterns that Rust provides?
- What are some examples of when you might use pattern matching with if let or while let expressions in Rust?
- How does Rust’s pattern matching syntax differ from that of other programming languages you are familiar with?
- What are some of the benefits of using pattern matching in Rust?
- Can you think of any potential drawbacks or challenges associated with using pattern matching in Rust?
- How might you go about practicing and experimenting with pattern matching in Rust?
- Can you provide an example of a real-world problem that you might solve using pattern matching in Rust?
Answers made by chatGPT
- Rust’s pattern syntax includes various types of patterns, such as literals, variables, wildcards, ranges, references, structs, enums, and more. These patterns can be used to match against specific values, bind variables, and destructure complex types.
- Pattern matching can be used in various contexts in Rust, such as function arguments, match expressions, let statements, and more. It is a powerful tool for handling complex data types and making decisions based on their values.
- Rust’s pattern syntax allows you to combine patterns using the | operator to match multiple patterns, and the .. operator to ignore some parts of a pattern. This can make it easier to write concise and expressive code that handles a wide range of values.
- Rust provides various shorthand notations for patterns, such as .. for matching the rest of a slice or array, and ..= for inclusive ranges. These notations can help simplify pattern matching code and make it more readable.
- if let and while let expressions in Rust are useful for handling optional values. For example, you might use them to check whether a variable contains a value, and then do something with that value if it does. This can help prevent runtime errors caused by trying to access None values.
- Rust’s pattern matching syntax is similar to that of other programming languages like Scala and Haskell, but it has some unique features such as the ability to define custom patterns using the @ operator.
- Some benefits of using pattern matching in Rust include its ability to make code more concise and readable, its ability to handle complex data types easily, and its ability to prevent runtime errors by ensuring that all possible cases are handled.
- Some potential challenges associated with using pattern matching in Rust include the need to carefully consider all possible cases and the potential for complex code that is difficult to maintain.
- To practice and experiment with pattern matching in Rust, you might start by writing simple programs that use basic patterns like literals and variables, and then gradually work your way up to more complex patterns like structs and enums. The Rust documentation and other online resources can also be helpful for learning more about pattern matching in Rust.
- A real-world problem that you might solve using pattern matching in Rust could be parsing a file format that contains structured data. By using patterns to match against different parts of the file format, you could easily extract the data you need and transform it into a more useful format
- Pattern Syntax
- A. Matching Situations
- B. Destructuring to Break Apart Values
- C. Ignoring Values in a Pattern
- Summary
In this section, we gather all the syntax valid in patterns and discuss why and when you might want to use each one.
A. Matching Situations
Matching Literals
As you saw in Chapter 6, you can match patterns against literals directly.
The following code gives some examples:
fn main() { // ANCHOR: here let x = 1; match x { 1 => println!("one"), 2 => println!("two"), 3 => println!("three"), _ => println!("anything"), } // ANCHOR_END: here }
This code prints one because the value in x is 1.
This syntax is useful when you want your code to take an action if it gets a particular concrete value.
Matching Named Variables
Named variables are irrefutable patterns that match any value, and we’ve used them many times in the book.
However, there is a complication when you use
named variables in match expressions:
- Because
matchstarts a new scope, variables declared as part of a pattern inside thematchexpression will shadow those with the same name outside thematchconstruct, as is the case with all variables. - In Listing 18-11, we declare a variable named
xwith the valueSome(5)and a variableywith the value10. - We then create a
matchexpression on the valuex. - Look at the patterns in the match arms and
println!at the end, and try to figure out what the code will print before running this code or reading further.
Listing 18-11: A match expression with an arm that introduces a shadowed variable y
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(y) => println!("Matched, y = {y}"), _ => println!("Default case, x = {:?}", x), } println!("at the end: x = {:?}, y = {y}", x); }
Let’s walk through what happens when the match expression runs:
- The pattern in the first match arm doesn’t match the defined value of
x, so the code continues. - The pattern in the second match arm introduces a new variable named
ythat will match any value inside aSomevalue.
- Because we’re in a new scope inside the
matchexpression, this is a newyvariable, not theywe declared at the beginning with the value 10. - This new
ybinding will match any value inside aSome, which is what we have inx. - Therefore, this new
ybinds to the inner value of theSomeinx. - That value is
5, so the expression for that arm executes and printsMatched, y = 5.
- If
xhad been aNonevalue instead ofSome(5), the patterns in the first two arms wouldn’t have matched, so the value would have matched to the underscore.
-
We didn’t introduce the
xvariable in the pattern of the underscore arm, so thexin the expression is still the outerxthat hasn’t been shadowed. -
In this hypothetical case, the
matchwould printDefault case, x = None.
- When the
matchexpression is done, its scope ends, and so does the scope of the innery. The lastprintln!producesat the end: x = Some(5), y = 10.
To create a
matchexpression that compares the values of the outerxandy, rather than introducing a shadowed variable, we would need to use a match guard conditional instead.
We’ll talk about match guards later in the “Extra Conditionals with Match Guards” section.
Extra Conditionals with Match Guards
A match guard is an additional if condition, specified after the pattern in
a match arm, that must also match for that arm to be chosen.
Match guards are useful for expressing more complex ideas than a pattern alone allows.
The condition can use variables created in the pattern.
Listing 18-26 shows a match where the first arm has the pattern Some(x) and also has a match
guard of if x % 2 == 0 (which will be true if the number is even).
Listing 18-26: Adding a match guard to a pattern
fn main() { let num = Some(4); match num { Some(x) if x % 2 == 0 => println!("The number {} is even", x), Some(x) => println!("The number {} is odd", x), None => (), } }
This example will print The number 4 is even.
-
When
numis compared to the pattern in the first arm, it matches, becauseSome(4)matchesSome(x). -
Then the match guard checks whether the remainder of dividing
xby 2 is equal to 0, and because it is, the first arm is selected. -
If
numhad beenSome(5)instead, the match guard in the first arm would have been false because the remainder of 5 divided by 2 is 1, which is not equal to 0. -
Rust would then go to the second arm, which would match because the second arm doesn’t have a match guard and therefore matches any
Somevariant.
There is no way to express the if x % 2 == 0 condition within a pattern, so
the match guard gives us the ability to express this logic.
The downside of this additional expressiveness is that the compiler doesn’t try to check for exhaustiveness when match guard expressions are involved.
In Listing 18-11, we mentioned that we could use match guards to solve our pattern-shadowing problem.
Recall that we created a new variable inside the
pattern in the match expression instead of using the variable outside the
match.
That new variable meant we couldn’t test against the value of the outer variable.
Listing 18-27 shows how we can use a match guard to fix this problem.
Listing 18-27: Using a match guard to test for equality with an outer variable
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(n) if n == y => println!("Matched, n = {n}"), _ => println!("Default case, x = {:?}", x), } println!("at the end: x = {:?}, y = {y}", x); }
This code will now print Default case, x = Some(5).
The pattern in the second
match arm doesn’t introduce a new variable y that would shadow the outer y,
meaning we can use the outer y in the match guard.
Instead of specifying the pattern as Some(y), which would have shadowed the outer y, we specify
Some(n).
This creates a new variable n that doesn’t shadow anything because
there is no n variable outside the match.
The match guard if n == y is not a pattern and therefore doesn’t introduce
new variables.
This y is the outer y rather than a new shadowed y, and
we can look for a value that has the same value as the outer y by comparing
n to y.
You can also use the or operator | in a match guard to specify multiple
patterns;
the match guard condition will apply to all the patterns.
Listing
18-28 shows the precedence when combining a pattern that uses | with a match
guard.
The important part of this example is that the if y match guard
applies to 4, 5, and 6, even though it might look like if y only
applies to 6.
Listing 18-28: Combining multiple patterns with a match guard
fn main() { let x = 4; let y = false; match x { 4 | 5 | 6 if y => println!("yes"), _ => println!("no"), } }
-
The match condition states that the arm only matches if the value of
xis equal to4,5, or6and ifyistrue. When this code runs, the pattern of the first arm matches becausexis4, but the match guardif yis false, so the first arm is not chosen. -
The code moves on to the second arm, which does match, and this program prints
no. The reason is that theifcondition applies to the whole pattern4 | 5 | 6, not only to the last value6. -
In other words, the precedence of a match guard in relation to a pattern behaves like this:
(4 | 5 | 6) if y => ...
rather than this:
4 | 5 | (6 if y) => ...
After running the code, the precedence behavior is evident:
- if the match guard
were applied only to the final value in the list of values specified using the
|operator, the arm would have matched and the program would have printedyes.
Multiple Patterns
In match expressions, you can match multiple patterns using the | syntax,
which is the pattern or operator.
For example, in the following code we match
the value of x against the match arms, the first of which has an or option,
meaning if the value of x matches either of the values in that arm, that
arm’s code will run:
For example, in the following code we match the value of x against the match arms, the first of which has an or option, meaning if the value of x matches either of the values in that arm, that arm’s code will run:
fn main() { let x = 1; match x { 1 | 2 => println!("one or two"), 3 => println!("three"), _ => println!("anything"), } }
This code prints one or two.
Matching Ranges of Values with ..=
The ..= syntax allows us to match to an inclusive range of values.
In the following code, when a pattern matches any of the values within the given range, that arm will execute:
fn main() { let x = 5; match x { 1..=5 => println!("one through five"), _ => println!("something else"), } }
If x is 1, 2, 3, 4, or 5, the first arm will match.
This syntax is more
convenient for multiple match values than using the | operator to express the
same idea;
if we were to use | we would have to specify 1 | 2 | 3 | 4 | 5.
Specifying a range is much shorter, especially if we want to match, say, any number between 1 and 1,000!
The compiler checks that the range isn’t empty at compile time, and because the
only types for which Rust can tell if a range is empty or not are char and
numeric values, ranges are only allowed with numeric or char values.
Here is an example using ranges of char values:
fn main() { let x = 'c'; match x { 'a'..='j' => println!("early ASCII letter"), 'k'..='z' => println!("late ASCII letter"), _ => println!("something else"), } }
Rust can tell that 'c' is within the first pattern’s range and prints early ASCII letter.
@ Bindings: test a value and save it in a variable within one pattern
The at operator @ lets us create a variable that holds a value at the same
time as we’re testing that value for a pattern match.
In Listing 18-29, we want
to test that a Message::Hello id field is within the range 3..=7.
We also
want to bind the value to the variable id_variable so we can use it in the
code associated with the arm.
We could name this variable id, the same as the
field, but for this example we’ll use a different name.
Listing 18-29: Using @ to bind to a value in a pattern while also testing it
fn main() { enum Message { Hello { id: i32 }, } let msg = Message::Hello { id: 5 }; match msg { Message::Hello { id: id_variable @ 3..=7, } => println!("Found an id in range: {}", id_variable), Message::Hello { id: 10..=12 } => { println!("Found an id in another range") } Message::Hello { id } => println!("Found some other id: {}", id), } }
This example will print Found an id in range: 5.
-
By specifying
id_variable @before the range3..=7, we’re capturing whatever value matched the range while also testing that the value matched the range pattern. -
In the second arm, where we only have a range specified in the pattern, the code associated with the arm doesn’t have a variable that contains the actual value of the
idfield.
- The
idfield’s value could have been 10, 11, or 12, but the code that goes with that pattern doesn’t know which it is. - The pattern code isn’t able to use the value from the
idfield, because we haven’t saved theidvalue in a variable.
- In the last arm, where we’ve specified a variable without a range, we do have
the value available to use in the arm’s code in a variable named
id.
- The reason is that we’ve used the struct field shorthand syntax.
- But we haven’t applied any test to the value in the
idfield in this arm, as we did with the first two arms: any value would match this pattern.
Using
@lets us test a value and save it in a variable within one pattern.
B. Destructuring to Break Apart Values
We can also use patterns to destructure structs, enums, and tuples to use different parts of these values. Let’s walk through each value.
Destructuring Structs
Listing 18-12 shows a Point struct with two fields, x and y, that we can
break apart using a pattern with a let statement.
The following code gives some examples:
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x: a, y: b } = p; assert_eq!(0, a); assert_eq!(7, b); }
This code creates the variables a and b that match the values of the x
and y fields of the p struct.
This example shows that the names of the variables in the pattern don’t have to match the field names of the struct.
However, it’s common to match the variable names to the field names to make it easier to remember which variables came from which fields.
Because of this common usage, and because writing let Point { x: x, y: y } = p; contains a
lot of duplication, Rust has a shorthand for patterns that match struct fields:
you only need to list the name of the struct field, and the variables created from the pattern will have the same names.
Listing 18-13 behaves in the same
way as the code in Listing 18-12, but the variables created in the let
pattern are x and y instead of a and b.
Listing 18-13: Destructuring struct fields using struct field shorthand
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x, y } = p; assert_eq!(0, x); assert_eq!(7, y); }
This code creates the variables x and y that match the x and y fields
of the p variable.
The outcome is that the variables x and y contain the values from the p struct.
We can also destructure with literal values as part of the struct pattern rather than creating variables for all the fields.
Doing so allows us to test some of the fields for particular values while creating variables to destructure the other fields.
In Listing 18-14, we have a match expression that separates Point values
into three cases: points that lie directly on the x axis (which is true when
y = 0), on the y axis (x = 0), or neither.
Listing 18-14: Destructuring and matching literal values in one pattern
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; match p { Point { x, y: 0 } => println!("On the x axis at {x}"), Point { x: 0, y } => println!("On the y axis at {y}"), Point { x, y } => { println!("On neither axis: ({x}, {y})"); } } }
- The first arm will match any point that lies on the
xaxis by specifying that theyfield matches if its value matches the literal0.
The pattern still
creates an x variable that we can use in the code for this arm.
- Similarly, the second arm matches any point on the
yaxis by specifying that thexfield matches if its value is0and creates a variableyfor the value of theyfield. - The third arm doesn’t specify any literals, so it
matches any other
Pointand creates variables for both thexandyfields.
In this example, the value p matches the second arm by virtue of x
containing a 0, so this code will print On the y axis at 7.
Remember that a
matchexpression stops checking arms once it has found the first matching pattern
so even though Point { x: 0, y: 0} is on the x axis
and the y axis, this code would only print On the x axis at 0.
Destructuring Enums
We’ve destructured enums in this book (for example, Listing 6-5 in Chapter 6), but haven’t yet explicitly discussed that the pattern to destructure an enum corresponds to the way the data stored within the enum is defined.
As an example, in Listing 18-15 we use the Message enum from Listing 6-2 and write
a match with patterns that will destructure each inner value.
Listing 18-15: Destructuring enum variants that hold different kinds of values
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() { let msg = Message::ChangeColor(0, 160, 255); match msg { Message::Quit => { println!("The Quit variant has no data to destructure."); } Message::Move { x, y } => { println!( "Move in the x direction {x} and in the y direction {y}" ); } Message::Write(text) => { println!("Text message: {text}"); } Message::ChangeColor(r, g, b) => println!( "Change the color to red {r}, green {g}, and blue {b}", ), } }
This code will print Change the color to red 0, green 160, and blue 255.
Try changing the value of msg to see the code from the other arms run.
For enum variants without any data, like Message::Quit, we can’t destructure
the value any further.
We can only match on the literal Message::Quit value, and no variables are in that pattern.
For struct-like enum variants, such as Message::Move, we can use a pattern
similar to the pattern we specify to match structs.
After the variant name, we place curly brackets and then list the fields with variables so we break apart the pieces to use in the code for this arm.
Here we use the shorthand form as we did in Listing 18-13.
For tuple-like enum variants, like Message::Write that holds a tuple with one
element and Message::ChangeColor that holds a tuple with three elements, the
pattern is similar to the pattern we specify to match tuples.
The number of variables in the pattern must match the number of elements in the variant we’re matching.
Destructuring Nested Structs and Enums
So far, our examples have all been matching structs or enums one level deep, but matching can work on nested items too!
For example, we can refactor the code in Listing 18-15 to support RGB and HSV colors in the ChangeColor
message, as shown in Listing 18-16.
Listing 18-16: Matching on nested enums
enum Color { Rgb(i32, i32, i32), Hsv(i32, i32, i32), } enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(Color), } fn main() { let msg = Message::ChangeColor(Color::Hsv(0, 160, 255)); match msg { Message::ChangeColor(Color::Rgb(r, g, b)) => { println!("Change color to red {r}, green {g}, and blue {b}"); } Message::ChangeColor(Color::Hsv(h, s, v)) => println!( "Change color to hue {h}, saturation {s}, value {v}" ), _ => (), } }
- The pattern of the first arm in the
matchexpression matches aMessage::ChangeColorenum variant that contains aColor::Rgbvariant; - then the pattern binds to the three inner
i32values. - The pattern of the second arm also matches a
Message::ChangeColorenum variant, but the inner enum matchesColor::Hsvinstead. - We can specify these complex conditions in one
matchexpression, even though two enums are involved.
Destructuring Structs and Tuples
We can mix, match, and nest destructuring patterns in even more complex ways.
The following example shows a complicated destructure where we nest structs and tuples inside a tuple and destructure all the primitive values out:
fn main() { struct Point { x: i32, y: i32, } let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 }); }
This code lets us break complex types into their component parts so we can use the values we’re interested in separately.
Destructuring with patterns is a convenient way to use pieces of values, such as the value from each field in a struct, separately from each other.
C. Ignoring Values in a Pattern
You’ve seen that it’s sometimes useful to ignore values in a pattern, such as
in the last arm of a match, to get a catchall that doesn’t actually do
anything but does account for all remaining possible values.
There are a few ways to ignore entire values or parts of values in a pattern:
- using the
_pattern (which you’ve seen) - using the
_pattern within another pattern, - using a name that starts with an underscore,
- or using
..to ignore remaining parts of a value.
Let’s explore how and why to use each of these patterns.
1. Ignoring an Entire Value with _
We’ve used the underscore as a wildcard pattern that will match any value but not bind to the value.
This is especially useful as the last arm in a match expression, but we can also use it in any pattern, including
function
parameters, as shown in Listing 18-17.
Listing 18-17: Using _ in a function signature
fn foo(_: i32, y: i32) { println!("This code only uses the y parameter: {}", y); } fn main() { foo(3, 4); }
This code will completely ignore the value 3 passed as the first argument,
and will print This code only uses the y parameter: 4.
In most cases when you no longer need a particular function parameter, you would change the signature so it doesn’t include the unused parameter.
Ignoring a function parameter can be especially useful in cases when, for example, you’re implementing a trait when you need a certain type signature but the function body in your implementation doesn’t need one of the parameters.
You then avoid getting a compiler warning about unused function parameters, as you would if you used a name instead.
2. Ignoring Parts of a Value with a Nested _
We can also use _ inside another pattern to ignore just part of a value, for
example, when we want to test for only part of a value but have no use for the
other parts in the corresponding code we want to run.
Listing 18-18 shows code responsible for managing a setting’s value.
The business requirements are that the user should not be allowed to overwrite an existing customization of a setting but can unset the setting and give it a value if it is currently unset.
Listing 18-18: Using an underscore within patterns that match Some variants when we don’t need to use the value inside the Some
fn main() { let mut setting_value = Some(5); let new_setting_value = Some(10); match (setting_value, new_setting_value) { (Some(_), Some(_)) => { println!("Can't overwrite an existing customized value"); } _ => { setting_value = new_setting_value; } } println!("setting is {:?}", setting_value); }
This code will print Can't overwrite an existing customized value and then
setting is Some(5).
- In the first match arm, we don’t need to match on or use
the values inside either
Somevariant, but we do need to test for the case whensetting_valueandnew_setting_valueare theSomevariant.
In that
case, we print the reason for not changing setting_value, and it doesn’t get
changed.
- In all other cases (if either
setting_valueornew_setting_valueareNone) expressed by the_pattern in the second arm, we want to allownew_setting_valueto becomesetting_value.
We can also use underscores in multiple places within one pattern to ignore particular values.
Listing 18-19 shows an example of ignoring the second and fourth values in a tuple of five items.
Listing 18-19: Ignoring multiple parts of a tuple
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, _, third, _, fifth) => { println!("Some numbers: {first}, {third}, {fifth}") } } }
This code will print Some numbers: 2, 8, 32, and the values 4 and 16 will be ignored.
3. Ignoring an Unused Variable by Starting Its Name with _
If you create a variable but don’t use it anywhere, Rust will usually issue a warning because an unused variable could be a bug.
However, sometimes it’s useful to be able to create a variable you won’t use yet, such as when you’re prototyping or just starting a project.
In this situation, you can tell Rust not to warn you about the unused variable by starting the name of the variable with an underscore.
In Listing 18-20, we create two unused variables, but when we compile this code, we should only get a warning about one of them.
Listing 18-20: Starting a variable name with an underscore to avoid getting unused variable warnings
fn main() { let _x = 5; let y = 10; }
Here we get a warning about not using the variable y, but we don’t get a
warning about not using _x.
Note that there is a subtle difference between using only
_and using a name that starts with an underscore:
-
The syntax
_xstill binds the value to the variable, whereas_doesn’t bind at all. -
To show a case where this distinction matters, Listing 18-21 will provide us with an error.
Listing 18-21: An unused variable starting with an underscore still binds the value, which might take ownership of the value
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{:?}", s);
}
We’ll receive an error because the s value will still be moved into _s,
which prevents us from using s again. However, using the underscore by itself
doesn’t ever bind to the value.
Listing 18-22 will compile without any errors because s doesn’t get moved into _.
Listing 18-22: Using an underscore does not bind the value
fn main() { let s = Some(String::from("Hello!")); if let Some(_) = s { println!("found a string"); } println!("{:?}", s); }
This code works just fine because we never bind s to anything; it isn’t moved.
4. Ignoring Remaining Parts of a Value with ..
With values that have many parts, we can use the .. syntax to use specific
parts and ignore the rest, avoiding the need to list underscores for each
ignored value.
The .. pattern ignores any parts of a value that we haven’t
explicitly matched in the rest of the pattern.
In Listing 18-23, we have a
Point struct that holds a coordinate in three-dimensional space.
In the
match expression, we want to operate only on the x coordinate and ignore
the values in the y and z fields.
Listing 18-23: Ignoring all fields of a Point except for x by using *..
fn main() { struct Point { x: i32, y: i32, z: i32, } let origin = Point { x: 0, y: 0, z: 0 }; match origin { Point { x, .. } => println!("x is {}", x), } }
We list the x value and then just include the .. pattern.
This is quicker than having to list
y: _andz: _, particularly when we’re working with structs that have lots of fields in situations where only one or two fields are relevant.
The syntax .. will expand to as many values as it needs to be.
Listing 18-24 shows how to use .. with a tuple.
Listing 18-24: Matching only the first and last values in a tuple and ignoring all other values
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, .., last) => { println!("Some numbers: {first}, {last}"); } } }
In this code, the first and last value are matched with first and last.
The .. will match and ignore everything in the middle.
However, using
..must be unambiguous.
If it is unclear which values are intended for matching and which should be ignored, Rust will give us an error.
Listing 18-25 shows an example of using .. ambiguously, so it will not
compile.
Listing 18-25: An attempt to use .. in an ambiguous way
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {}", second)
},
}
}
When we compile this example, we get this error:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` due to previous error
It’s impossible for Rust to determine how many values in the tuple to ignore
before matching a value with second and then how many further values to
ignore thereafter.
This code could mean that we want to ignore 2, bind second to 4, and then ignore 8, 16, and 32;
or that we want to ignore 2 and 4, bind second to 8, and then ignore 16 and 32;
and so forth.
The variable name second doesn’t mean anything special to Rust, so we get a
compiler error because using .. in two places like this is ambiguous.
Summary
Rust’s patterns are very useful in distinguishing between different kinds of data:
- When used in
matchexpressions, Rust ensures your patterns cover every possible value, or your program won’t compile. - Patterns in
letstatements and function parameters make those constructs more useful, enabling the destructuring of values into smaller parts at the same time as assigning to variables. - We can create simple or complex patterns to suit our needs.
Next, for the penultimate chapter of the book, we’ll look at some advanced aspects of a variety of Rust’s features.
Advanced Features
By now, you’ve learned the most commonly used parts of the Rust programming language. Before we do one more project in Chapter 20, we’ll look at a few aspects of the language you might run into every once in a while, but may not use every day. You can use this chapter as a reference for when you encounter any unknowns. The features covered here are useful in very specific situations. Although you might not reach for them often, we want to make sure you have a grasp of all the features Rust has to offer.
In this chapter, we’ll cover:
- Unsafe Rust: how to opt out of some of Rust’s guarantees and take responsibility for manually upholding those guarantees
- Advanced traits: associated types, default type parameters, fully qualified syntax, supertraits, and the newtype pattern in relation to traits
- Advanced types: more about the newtype pattern, type aliases, the never type, and dynamically sized types
- Advanced functions and closures: function pointers and returning closures
- Macros: ways to define code that defines more code at compile time
It’s a panoply of Rust features with something for everyone! Let’s dive in!
Unsafe Rust
All the code we’ve discussed so far has had Rust’s memory safety guarantees enforced at compile time. However, Rust has a second language hidden inside it that doesn’t enforce these memory safety guarantees: it’s called unsafe Rust and works just like regular Rust, but gives us extra superpowers.
Unsafe Rust exists because, by nature, static analysis is conservative. When the compiler tries to determine whether or not code upholds the guarantees, it’s better for it to reject some valid programs than to accept some invalid programs. Although the code might be okay, if the Rust compiler doesn’t have enough information to be confident, it will reject the code. In these cases, you can use unsafe code to tell the compiler, “Trust me, I know what I’m doing.” Be warned, however, that you use unsafe Rust at your own risk: if you use unsafe code incorrectly, problems can occur due to memory unsafety, such as null pointer dereferencing.
Another reason Rust has an unsafe alter ego is that the underlying computer hardware is inherently unsafe. If Rust didn’t let you do unsafe operations, you couldn’t do certain tasks. Rust needs to allow you to do low-level systems programming, such as directly interacting with the operating system or even writing your own operating system. Working with low-level systems programming is one of the goals of the language. Let’s explore what we can do with unsafe Rust and how to do it.
Unsafe Superpowers
To switch to unsafe Rust, use the unsafe keyword and then start a new block
that holds the unsafe code. You can take five actions in unsafe Rust that you
can’t in safe Rust, which we call unsafe superpowers. Those superpowers
include the ability to:
- Dereference a raw pointer
- Call an unsafe function or method
- Access or modify a mutable static variable
- Implement an unsafe trait
- Access fields of
unions
It’s important to understand that unsafe doesn’t turn off the borrow checker
or disable any other of Rust’s safety checks: if you use a reference in unsafe
code, it will still be checked. The unsafe keyword only gives you access to
these five features that are then not checked by the compiler for memory
safety. You’ll still get some degree of safety inside of an unsafe block.
In addition, unsafe does not mean the code inside the block is necessarily
dangerous or that it will definitely have memory safety problems: the intent is
that as the programmer, you’ll ensure the code inside an unsafe block will
access memory in a valid way.
People are fallible, and mistakes will happen, but by requiring these five
unsafe operations to be inside blocks annotated with unsafe you’ll know that
any errors related to memory safety must be within an unsafe block. Keep
unsafe blocks small; you’ll be thankful later when you investigate memory
bugs.
To isolate unsafe code as much as possible, it’s best to enclose unsafe code
within a safe abstraction and provide a safe API, which we’ll discuss later in
the chapter when we examine unsafe functions and methods. Parts of the standard
library are implemented as safe abstractions over unsafe code that has been
audited. Wrapping unsafe code in a safe abstraction prevents uses of unsafe
from leaking out into all the places that you or your users might want to use
the functionality implemented with unsafe code, because using a safe
abstraction is safe.
Let’s look at each of the five unsafe superpowers in turn. We’ll also look at some abstractions that provide a safe interface to unsafe code.
Dereferencing a Raw Pointer
In Chapter 4, in the “Dangling References” section, we mentioned that the compiler ensures references are always
valid. Unsafe Rust has two new types called raw pointers that are similar to
references. As with references, raw pointers can be immutable or mutable and
are written as *const T and *mut T, respectively. The asterisk isn’t the
dereference operator; it’s part of the type name. In the context of raw
pointers, immutable means that the pointer can’t be directly assigned to
after being dereferenced.
Different from references and smart pointers, raw pointers:
- Are allowed to ignore the borrowing rules by having both immutable and mutable pointers or multiple mutable pointers to the same location
- Aren’t guaranteed to point to valid memory
- Are allowed to be null
- Don’t implement any automatic cleanup
By opting out of having Rust enforce these guarantees, you can give up guaranteed safety in exchange for greater performance or the ability to interface with another language or hardware where Rust’s guarantees don’t apply.
Listing 19-1 shows how to create an immutable and a mutable raw pointer from references.
fn main() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; }
Listing 19-1: Creating raw pointers from references
Notice that we don’t include the unsafe keyword in this code. We can create
raw pointers in safe code; we just can’t dereference raw pointers outside an
unsafe block, as you’ll see in a bit.
We’ve created raw pointers by using as to cast an immutable and a mutable
reference into their corresponding raw pointer types. Because we created them
directly from references guaranteed to be valid, we know these particular raw
pointers are valid, but we can’t make that assumption about just any raw
pointer.
To demonstrate this, next we’ll create a raw pointer whose validity we can’t be so certain of. Listing 19-2 shows how to create a raw pointer to an arbitrary location in memory. Trying to use arbitrary memory is undefined: there might be data at that address or there might not, the compiler might optimize the code so there is no memory access, or the program might error with a segmentation fault. Usually, there is no good reason to write code like this, but it is possible.
fn main() { let address = 0x012345usize; let r = address as *const i32; }
Listing 19-2: Creating a raw pointer to an arbitrary memory address
Recall that we can create raw pointers in safe code, but we can’t dereference
raw pointers and read the data being pointed to. In Listing 19-3, we use the
dereference operator * on a raw pointer that requires an unsafe block.
fn main() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; unsafe { println!("r1 is: {}", *r1); println!("r2 is: {}", *r2); } }
Listing 19-3: Dereferencing raw pointers within an
unsafe block
Creating a pointer does no harm; it’s only when we try to access the value that it points at that we might end up dealing with an invalid value.
Note also that in Listing 19-1 and 19-3, we created *const i32 and *mut i32
raw pointers that both pointed to the same memory location, where num is
stored. If we instead tried to create an immutable and a mutable reference to
num, the code would not have compiled because Rust’s ownership rules don’t
allow a mutable reference at the same time as any immutable references. With
raw pointers, we can create a mutable pointer and an immutable pointer to the
same location and change data through the mutable pointer, potentially creating
a data race. Be careful!
With all of these dangers, why would you ever use raw pointers? One major use case is when interfacing with C code, as you’ll see in the next section, “Calling an Unsafe Function or Method.” Another case is when building up safe abstractions that the borrow checker doesn’t understand. We’ll introduce unsafe functions and then look at an example of a safe abstraction that uses unsafe code.
Calling an Unsafe Function or Method
The second type of operation you can perform in an unsafe block is calling
unsafe functions. Unsafe functions and methods look exactly like regular
functions and methods, but they have an extra unsafe before the rest of the
definition. The unsafe keyword in this context indicates the function has
requirements we need to uphold when we call this function, because Rust can’t
guarantee we’ve met these requirements. By calling an unsafe function within an
unsafe block, we’re saying that we’ve read this function’s documentation and
take responsibility for upholding the function’s contracts.
Here is an unsafe function named dangerous that doesn’t do anything in its
body:
fn main() { unsafe fn dangerous() {} unsafe { dangerous(); } }
We must call the dangerous function within a separate unsafe block. If we
try to call dangerous without the unsafe block, we’ll get an error:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function is unsafe and requires unsafe function or block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` due to previous error
With the unsafe block, we’re asserting to Rust that we’ve read the function’s
documentation, we understand how to use it properly, and we’ve verified that
we’re fulfilling the contract of the function.
Bodies of unsafe functions are effectively unsafe blocks, so to perform other
unsafe operations within an unsafe function, we don’t need to add another
unsafe block.
Creating a Safe Abstraction over Unsafe Code
Just because a function contains unsafe code doesn’t mean we need to mark the
entire function as unsafe. In fact, wrapping unsafe code in a safe function is
a common abstraction. As an example, let’s study the split_at_mut function
from the standard library, which requires some unsafe code. We’ll explore how
we might implement it. This safe method is defined on mutable slices: it takes
one slice and makes it two by splitting the slice at the index given as an
argument. Listing 19-4 shows how to use split_at_mut.
fn main() { let mut v = vec![1, 2, 3, 4, 5, 6]; let r = &mut v[..]; let (a, b) = r.split_at_mut(3); assert_eq!(a, &mut [1, 2, 3]); assert_eq!(b, &mut [4, 5, 6]); }
Listing 19-4: Using the safe split_at_mut
function
We can’t implement this function using only safe Rust. An attempt might look
something like Listing 19-5, which won’t compile. For simplicity, we’ll
implement split_at_mut as a function rather than a method and only for slices
of i32 values rather than for a generic type T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}
Listing 19-5: An attempted implementation of
split_at_mut using only safe Rust
This function first gets the total length of the slice. Then it asserts that the index given as a parameter is within the slice by checking whether it’s less than or equal to the length. The assertion means that if we pass an index that is greater than the length to split the slice at, the function will panic before it attempts to use that index.
Then we return two mutable slices in a tuple: one from the start of the
original slice to the mid index and another from mid to the end of the
slice.
When we try to compile the code in Listing 19-5, we’ll get an error.
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` due to previous error
Rust’s borrow checker can’t understand that we’re borrowing different parts of the slice; it only knows that we’re borrowing from the same slice twice. Borrowing different parts of a slice is fundamentally okay because the two slices aren’t overlapping, but Rust isn’t smart enough to know this. When we know code is okay, but Rust doesn’t, it’s time to reach for unsafe code.
Listing 19-6 shows how to use an unsafe block, a raw pointer, and some calls
to unsafe functions to make the implementation of split_at_mut work.
use std::slice; fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = values.len(); let ptr = values.as_mut_ptr(); assert!(mid <= len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } fn main() { let mut vector = vec![1, 2, 3, 4, 5, 6]; let (left, right) = split_at_mut(&mut vector, 3); }
Listing 19-6: Using unsafe code in the implementation of
the split_at_mut function
Recall from “The Slice Type” section in
Chapter 4 that slices are a pointer to some data and the length of the slice.
We use the len method to get the length of a slice and the as_mut_ptr
method to access the raw pointer of a slice. In this case, because we have a
mutable slice to i32 values, as_mut_ptr returns a raw pointer with the type
*mut i32, which we’ve stored in the variable ptr.
We keep the assertion that the mid index is within the slice. Then we get to
the unsafe code: the slice::from_raw_parts_mut function takes a raw pointer
and a length, and it creates a slice. We use this function to create a slice
that starts from ptr and is mid items long. Then we call the add
method on ptr with mid as an argument to get a raw pointer that starts at
mid, and we create a slice using that pointer and the remaining number of
items after mid as the length.
The function slice::from_raw_parts_mut is unsafe because it takes a raw
pointer and must trust that this pointer is valid. The add method on raw
pointers is also unsafe, because it must trust that the offset location is also
a valid pointer. Therefore, we had to put an unsafe block around our calls to
slice::from_raw_parts_mut and add so we could call them. By looking at
the code and by adding the assertion that mid must be less than or equal to
len, we can tell that all the raw pointers used within the unsafe block
will be valid pointers to data within the slice. This is an acceptable and
appropriate use of unsafe.
Note that we don’t need to mark the resulting split_at_mut function as
unsafe, and we can call this function from safe Rust. We’ve created a safe
abstraction to the unsafe code with an implementation of the function that uses
unsafe code in a safe way, because it creates only valid pointers from the
data this function has access to.
In contrast, the use of slice::from_raw_parts_mut in Listing 19-7 would
likely crash when the slice is used. This code takes an arbitrary memory
location and creates a slice 10,000 items long.
fn main() { use std::slice; let address = 0x01234usize; let r = address as *mut i32; let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) }; }
Listing 19-7: Creating a slice from an arbitrary memory location
We don’t own the memory at this arbitrary location, and there is no guarantee
that the slice this code creates contains valid i32 values. Attempting to use
values as though it’s a valid slice results in undefined behavior.
Using extern Functions to Call External Code
Sometimes, your Rust code might need to interact with code written in another
language. For this, Rust has the keyword extern that facilitates the creation
and use of a Foreign Function Interface (FFI). An FFI is a way for a
programming language to define functions and enable a different (foreign)
programming language to call those functions.
Listing 19-8 demonstrates how to set up an integration with the abs function
from the C standard library. Functions declared within extern blocks are
always unsafe to call from Rust code. The reason is that other languages don’t
enforce Rust’s rules and guarantees, and Rust can’t check them, so
responsibility falls on the programmer to ensure safety.
Filename: src/main.rs
extern "C" { fn abs(input: i32) -> i32; } fn main() { unsafe { println!("Absolute value of -3 according to C: {}", abs(-3)); } }
Listing 19-8: Declaring and calling an extern function
defined in another language
Within the extern "C" block, we list the names and signatures of external
functions from another language we want to call. The "C" part defines which
application binary interface (ABI) the external function uses: the ABI
defines how to call the function at the assembly level. The "C" ABI is the
most common and follows the C programming language’s ABI.
Calling Rust Functions from Other Languages
We can also use
externto create an interface that allows other languages to call Rust functions. Instead of creating a wholeexternblock, we add theexternkeyword and specify the ABI to use just before thefnkeyword for the relevant function. We also need to add a#[no_mangle]annotation to tell the Rust compiler not to mangle the name of this function. Mangling is when a compiler changes the name we’ve given a function to a different name that contains more information for other parts of the compilation process to consume but is less human readable. Every programming language compiler mangles names slightly differently, so for a Rust function to be nameable by other languages, we must disable the Rust compiler’s name mangling.In the following example, we make the
call_from_cfunction accessible from C code, after it’s compiled to a shared library and linked from C:#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn call_from_c() { println!("Just called a Rust function from C!"); } }This usage of
externdoes not requireunsafe.
Accessing or Modifying a Mutable Static Variable
In this book, we’ve not yet talked about global variables, which Rust does support but can be problematic with Rust’s ownership rules. If two threads are accessing the same mutable global variable, it can cause a data race.
In Rust, global variables are called static variables. Listing 19-9 shows an example declaration and use of a static variable with a string slice as a value.
Filename: src/main.rs
static HELLO_WORLD: &str = "Hello, world!"; fn main() { println!("name is: {}", HELLO_WORLD); }
Listing 19-9: Defining and using an immutable static variable
Static variables are similar to constants, which we discussed in the
“Differences Between Variables and
Constants” section
in Chapter 3. The names of static variables are in SCREAMING_SNAKE_CASE by
convention. Static variables can only store references with the 'static
lifetime, which means the Rust compiler can figure out the lifetime and we
aren’t required to annotate it explicitly. Accessing an immutable static
variable is safe.
A subtle difference between constants and immutable static variables is that
values in a static variable have a fixed address in memory. Using the value
will always access the same data. Constants, on the other hand, are allowed to
duplicate their data whenever they’re used. Another difference is that static
variables can be mutable. Accessing and modifying mutable static variables is
unsafe. Listing 19-10 shows how to declare, access, and modify a mutable
static variable named COUNTER.
Filename: src/main.rs
static mut COUNTER: u32 = 0; fn add_to_count(inc: u32) { unsafe { COUNTER += inc; } } fn main() { add_to_count(3); unsafe { println!("COUNTER: {}", COUNTER); } }
Listing 19-10: Reading from or writing to a mutable static variable is unsafe
As with regular variables, we specify mutability using the mut keyword. Any
code that reads or writes from COUNTER must be within an unsafe block. This
code compiles and prints COUNTER: 3 as we would expect because it’s single
threaded. Having multiple threads access COUNTER would likely result in data
races.
With mutable data that is globally accessible, it’s difficult to ensure there are no data races, which is why Rust considers mutable static variables to be unsafe. Where possible, it’s preferable to use the concurrency techniques and thread-safe smart pointers we discussed in Chapter 16 so the compiler checks that data accessed from different threads is done safely.
Implementing an Unsafe Trait
We can use unsafe to implement an unsafe trait. A trait is unsafe when at
least one of its methods has some invariant that the compiler can’t verify. We
declare that a trait is unsafe by adding the unsafe keyword before trait
and marking the implementation of the trait as unsafe too, as shown in
Listing 19-11.
unsafe trait Foo { // methods go here } unsafe impl Foo for i32 { // method implementations go here } fn main() {}
Listing 19-11: Defining and implementing an unsafe trait
By using unsafe impl, we’re promising that we’ll uphold the invariants that
the compiler can’t verify.
As an example, recall the Sync and Send marker traits we discussed in the
“Extensible Concurrency with the Sync and Send
Traits”
section in Chapter 16: the compiler implements these traits automatically if
our types are composed entirely of Send and Sync types. If we implement a
type that contains a type that is not Send or Sync, such as raw pointers,
and we want to mark that type as Send or Sync, we must use unsafe. Rust
can’t verify that our type upholds the guarantees that it can be safely sent
across threads or accessed from multiple threads; therefore, we need to do
those checks manually and indicate as such with unsafe.
Accessing Fields of a Union
The final action that works only with unsafe is accessing fields of a
union. A union is similar to a struct, but only one declared field is
used in a particular instance at one time. Unions are primarily used to
interface with unions in C code. Accessing union fields is unsafe because Rust
can’t guarantee the type of the data currently being stored in the union
instance. You can learn more about unions in the Rust Reference.
When to Use Unsafe Code
Using unsafe to take one of the five actions (superpowers) just discussed
isn’t wrong or even frowned upon. But it is trickier to get unsafe code
correct because the compiler can’t help uphold memory safety. When you have a
reason to use unsafe code, you can do so, and having the explicit unsafe
annotation makes it easier to track down the source of problems when they occur.
Advanced Traits
- Advanced Traits
- Associated Types: Specifying Placeholder Types in Trait Definitions
- Difference between associated types and generics
- Default Generic Type Parameters and Operator Overloading
- Fully Qualified Syntax for Disambiguation: Calling Methods with the Same Name
- Using Supertraits to Require One Trait’s Functionality Within Another Trait
- Using the Newtype Pattern to Implement External Traits on External Types
We first covered traits in the “Traits: Defining Shared Behavior” section of Chapter 10, but we didn’t discuss the more advanced details. Now that you know more about Rust, we can get into the nitty-gritty.
Associated Types: Specifying Placeholder Types in Trait Definitions
Associated types connect a type placeholder with a trait such that the trait method definitions can use these placeholder types in their signatures.
- The implementor of a trait will specify the concrete type to be used instead of the placeholder type for the particular implementation.
- That way, we can define a trait that uses some types without needing to know exactly what those types are until the trait is implemented.
We’ve described most of the advanced features in this chapter as being rarely needed.
Associated types are somewhere in the middle: they’re used more rarely than features explained in the rest of the book but more commonly than many of the other features discussed in this chapter.
- One example of a trait with an associated type is the
Iteratortrait that the standard library provides. - The associated type is named
Itemand stands in for the type of the values the type implementing theIteratortrait is iterating over.
The definition of the Iterator trait is as shown in Listing 19-12.
Listing 19-12: The definition of the Iterator trait that has an associated type Item
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
- The type
Itemis a placeholder - and the
nextmethod’s definition shows that it will return values of typeOption<Self::Item>. - Implementors of the
Iteratortrait will specify the concrete type forItem, and thenextmethod will return anOptioncontaining a value of that concrete type.
Difference between associated types and generics
Associated types might seem like a similar concept to generics, in that the latter allow us to define a function without specifying what types it can handle.
To examine the difference between the two concepts, we’ll look at an implementation of the Iterator trait on a type named Counter that specifies the Item type is u32:
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}
This syntax seems comparable to that of generics.
So why not just define the
Iteratortrait with generics, as shown in Listing 19-13?
Listing 19-13: A hypothetical definition of the Iterator trait using generics
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}
The difference is that:
-
when using generics, as in Listing 19-13, we must annotate the types in each implementation; because we can also implement
Iterator<String> for Counteror any other type, we could have multiple implementations ofIteratorforCounter. -
In other words, when a trait has a generic parameter, it can be implemented for a type multiple times, changing the concrete types of the generic type parameters each time.
-
When we use the
nextmethod onCounter, we would have to provide type annotations to indicate which implementation ofIteratorwe want to use. -
With associated types, we don’t need to annotate types because we can’t implement a trait on a type multiple times.
In Listing 19-12 with the definition that uses associated types, we can only choose what the type of
Itemwill be once, because there can only be oneimpl Iterator for Counter. We don’t have to specify that we want an iterator ofu32values everywhere that we callnextonCounter.
- Associated types also become part of the trait’s contract:
- implementors of the trait must provide a type to stand in for the associated type placeholder.
- Associated types often have a name that describes how the type will be used
- and documenting the associated type in the API documentation is good practice.
Default Generic Type Parameters and Operator Overloading
When we use generic type parameters, we can specify a default concrete type for the generic type.
This eliminates the need for implementors of the trait to specify a concrete type if the default type works.
You specify a default type when declaring a generic type with the
<PlaceholderType=ConcreteType>syntax.
A great example of a situation where this technique is useful is with operator
overloading, in which you customize the behavior of an operator (such as +)
in particular situations.
Rust doesn’t allow you to create your own operators or overload arbitrary operators.
But you can overload the operations and corresponding traits listed in
std::opsby implementing the traits associated with the operator.
For
example, in Listing 19-14 we overload the + operator to add two Point
instances together. We do this by implementing the Add trait on a Point
struct:
Listing 19-14: Implementing the Add trait to overload the + operator for Point instances
use std::ops::Add; #[derive(Debug, Copy, Clone, PartialEq)] struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, other: Point) -> Point { Point { x: self.x + other.x, y: self.y + other.y, } } } fn main() { assert_eq!( Point { x: 1, y: 0 } + Point { x: 2, y: 3 }, Point { x: 3, y: 3 } ); }
- The
addmethod adds thexvalues of twoPointinstances and theyvalues of twoPointinstances to create a newPoint. - The
Addtrait has an associated type namedOutputthat determines the type returned from theaddmethod.
The default generic type in this code is within the Add trait. Here is its definition:
#![allow(unused)] fn main() { trait Add<Rhs=Self> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } }
This code should look generally familiar:
- a trait with one method and an associated type.
- The new part is
Rhs=Self: this syntax is called default type parameters.
The
Rhsgeneric type parameter (short for “right hand side”) defines the type of therhsparameter in theaddmethod.
-
If we don’t specify a concrete type for
Rhswhen we implement theAddtrait, the type ofRhswill default toSelf, which will be the type we’re implementingAddon. -
When we implemented
AddforPoint, we used the default forRhsbecause we wanted to add twoPointinstances.
Let’s look at an example of implementing
the Add trait where we want to customize the Rhs type rather than using the
default:
- We have two structs,
MillimetersandMeters, holding values in different units.
This thin wrapping of an existing type in another struct is known as the newtype pattern, which we describe in more detail in the “Using the Newtype Pattern to Implement External Traits on External Types” section.
-
We want to add values in millimeters to values in meters and have the implementation of
Adddo the conversion correctly. -
We can implement
AddforMillimeterswithMetersas theRhs, as shown in Listing 19-15.
Listing 19-15: Implementing the Add trait on Millimeters to add Millimeters to Meters
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}
-
To add
MillimetersandMeters, we specifyimpl Add<Meters>to set the value of theRhstype parameter instead of using the default ofSelf. -
You’ll use default type parameters in two main ways:
- To extend a type without breaking existing code
- To allow customization in specific cases most users won’t need
The standard library’s
Addtrait is an example of the second purpose:
- usually, you’ll add two like types, but the
Addtrait provides the ability to customize beyond that. - Using a default type parameter in the
Addtrait definition means you don’t have to specify the extra parameter most of the time.
In other words, a bit of implementation boilerplate isn’t needed, making it easier to use the trait.
The first purpose is similar to the second but in reverse:
- if you want to add a type parameter to an existing trait, you can give it a default to allow extension of the functionality of the trait without breaking the existing implementation code.
Fully Qualified Syntax for Disambiguation: Calling Methods with the Same Name
Nothing in Rust prevents a trait from having a method with the same name as another trait’s method, nor does Rust prevent you from implementing both traits on one type.
It’s also possible to implement a method directly on the type with the same name as methods from traits.
When calling methods with the same name, you’ll need to tell Rust which one you want to use:
-
Consider the code in Listing 19-16 where we’ve defined two traits,
PilotandWizard, that both have a method calledfly. -
We then implement both traits on a type
Humanthat already has a method namedflyimplemented on it. -
Each
flymethod does something different.
Listing 19-16: Two traits are defined to have a fly method and are implemented on the Human type, and a fly method is implemented on Human directly
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() {}
- When we call
flyon an instance ofHuman, the compiler defaults to calling the method that is directly implemented on the type, as shown in Listing 19-17.
Listing 19-17: Calling fly on an instance of Human
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; person.fly(); }
- Running this code will print
*waving arms furiously*, showing that Rust called theflymethod implemented onHumandirectly.
To call the
flymethods from either thePilottrait or theWizardtrait, we need to use more explicit syntax to specify whichflymethod we mean.
Listing 19-18 demonstrates this syntax.
Listing 19-18: Specifying which trait’s fly method we want to call
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; Pilot::fly(&person); Wizard::fly(&person); person.fly(); }
-
Specifying the trait name before the method name clarifies to Rust which implementation of
flywe want to call. -
We could also write
Human::fly(&person), which is equivalent to theperson.fly()that we used in Listing 19-18, but this is a bit longer to write if we don’t need to disambiguate.
Running this code prints the following:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Because the fly method takes a self parameter, if we had two types that
both implement one trait, Rust could figure out which implementation of a
trait to use based on the type of self.
However, associated functions that are not methods don’t have a
selfparameter. When there are multiple types or traits that define non-method functions with the same function name, Rust doesn’t always know which type you mean unless you use fully qualified syntax.
For example, in Listing 19-19 we create a trait for an animal shelter that wants to name all baby dogs Spot.
We make an Animal trait with an associated non-method function baby_name.
The Animal trait is implemented for the struct Dog, on which we also
provide an associated non-method function baby_name directly.
Listing 19-19: A trait with an associated function and a type with an associated function of the same name that also implements the trait
Listing 19-19: A trait with an associated function and a type with an associated function of the same name that also implements the trait
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", Dog::baby_name()); }
-
We implement the code for naming all puppies Spot in the
baby_nameassociated function that is defined onDog. -
The
Dogtype also implements the traitAnimal, which describes characteristics that all animals have. -
Baby dogs are called puppies, and that is expressed in the implementation of the
Animaltrait onDogin thebaby_namefunction associated with theAnimaltrait.
In main, we call the Dog::baby_name function, which calls the associated function defined on Dog directly. This code prints the following:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
This output isn’t what we wanted.
We want to call the baby_name function that
is part of the Animal trait that we implemented on Dog so the code prints
A baby dog is called a puppy.
The technique of specifying the trait name that
we used in Listing 19-18 doesn’t help here; if we change main to the code in
Listing 19-20, we’ll get a compilation error.
Listing 19-20: Attempting to call the baby_name function from the Animal trait, but Rust doesn’t know which implementation to use
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}
Because
Animal::baby_namedoesn’t have aselfparameter, and there could be other types that implement theAnimaltrait, Rust can’t figure out which implementation ofAnimal::baby_namewe want.
We’ll get this compiler error:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0283]: type annotations needed
--> src/main.rs:20:43
|
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^ cannot infer type
|
= note: cannot satisfy `_: Animal`
For more information about this error, try `rustc --explain E0283`.
error: could not compile `traits-example` due to previous error
To disambiguate and tell Rust that we want to use the implementation of
AnimalforDogas opposed to the implementation ofAnimalfor some other type, we need to use fully qualified syntax.
Listing 19-21 demonstrates how to use fully qualified syntax.
Listing 19-21: Using fully qualified syntax to specify that we want to call the baby_name function from the Animal trait as implemented on Dog
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", <Dog as Animal>::baby_name()); }
- We’re providing Rust with a type annotation within the angle brackets,
- which
indicates we want to call the
baby_namemethod from theAnimaltrait as implemented onDog - by saying that we want to treat the
Dogtype as anAnimalfor this function call.
This code will now print what we want:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
In general, fully qualified syntax is defined as follows:
<Type as Trait>::function(receiver_if_method, next_arg, ...);
For associated functions that aren’t methods, there would not be a receiver:
- there would only be the list of other arguments.
- You could use fully qualified syntax everywhere that you call functions or methods.
- However, you’re allowed to omit any part of this syntax that Rust can figure out from other information in the program.
You only need to use this more verbose syntax in cases where there are multiple implementations that use the same name and Rust needs help to identify which implementation you want to call.
Using Supertraits to Require One Trait’s Functionality Within Another Trait
Sometimes, you might write a trait definition that depends on another trait:
- for a type to implement the first trait, you want to require that type to also implement the second trait.
- You would do this so that your trait definition can make use of the associated items of the second trait.
The trait your trait definition is relying on is called a supertrait of your trait.
For example, let’s say we want to make an OutlinePrint trait with an
outline_print method that will print a given value formatted so that it’s
framed in asterisks.
That is, given a
Pointstruct that implements the standard library traitDisplayto result in(x, y), when we calloutline_printon aPointinstance that has1forxand3fory, it should print the following:
**********
* *
* (1, 3) *
* *
**********
In the implementation of the outline_print method, we want to use the
Display trait’s functionality.
Therefore, we need to specify that the
OutlinePrinttrait will work only for types that also implementDisplayand provide the functionality thatOutlinePrintneeds.
We can do that in the
trait definition by specifying OutlinePrint: Display.
This technique is similar to adding a trait bound to the trait.
Listing 19-22 shows an
implementation of the OutlinePrint trait.
Listing 19-22: Implementing the OutlinePrint trait that requires the functionality from Display
use std::fmt; trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {} *", output); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } fn main() {}
Because we’ve specified that OutlinePrint requires the Display trait, we
can use the to_string function that is automatically implemented for any type
that implements Display.
If we tried to use
to_stringwithout adding a colon and specifying theDisplaytrait after the trait name, we’d get an error saying that no method namedto_stringwas found for the type&Selfin the current scope.
Let’s see what happens when we try to implement OutlinePrint on a type that doesn’t implement Display, such as the Point struct:
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {} *", output);
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}
We get an error saying that Display is required but not implemented:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:6
|
20 | impl OutlinePrint for Point {}
| ^^^^^^^^^^^^ `Point` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Point`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` due to previous error
To fix this, we implement Display on Point and satisfy the constraint that OutlinePrint requires, like so:
trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {} *", output); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } struct Point { x: i32, y: i32, } impl OutlinePrint for Point {} use std::fmt; impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } fn main() { let p = Point { x: 1, y: 3 }; p.outline_print(); }
Then implementing the OutlinePrint trait on Point will compile
successfully, and we can call outline_print on a Point instance to display
it within an outline of asterisks.
Using the Newtype Pattern to Implement External Traits on External Types
In Chapter 10 in the “Implementing a Trait on a Type” section, we mentioned the orphan rule that states we’re only allowed to implement a trait on a type if either the trait or the type are local to our crate.
It’s possible to get around this restriction using the newtype pattern, which involves creating a new type in a tuple struct. (We covered tuple structs in the “Using Tuple Structs without Named Fields to Create Different Types” section of Chapter 5.):
- The tuple struct will have one field and be a thin wrapper around the type we want to implement a trait for.
- Then the wrapper type is local to our crate, and we can implement the trait on the wrapper.
Newtype is a term that originates from the Haskell programming language.
There is no runtime performance penalty for using this pattern, and the wrapper type is elided at compile time.
As an example:
-
let’s say we want to implement
DisplayonVec<T>, which the orphan rule prevents us from doing directly because theDisplaytrait and theVec<T>type are defined outside our crate. -
We can make a
Wrapperstruct that holds an instance ofVec<T>; -
then we can implement
DisplayonWrapperand use theVec<T>value, as shown in Listing 19-23.
Listing 19-23: Creating a Wrapper type around Vec
use std::fmt; struct Wrapper(Vec<String>); impl fmt::Display for Wrapper { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Wrapper(vec![String::from("hello"), String::from("world")]); println!("w = {}", w); }
-
The implementation of
Displayusesself.0to access the innerVec<T> -
because
Wrapperis a tuple struct andVec<T>is the item at index 0 in the tuple. -
Then we can use the functionality of the
Displaytype onWrapper.
The downside of using this technique is that
Wrapperis a new type, so it doesn’t have the methods of the value it’s holding.
- We would have to implement
all the methods of
Vec<T>directly onWrappersuch that the methods delegate toself.0, which would allow us to treatWrapperexactly like aVec<T>.
If we wanted the new type to have every method the inner type has, implementing the
Dereftrait (discussed in Chapter 15 in the “Treating Smart Pointers Like Regular References with theDerefTrait” section) on theWrapperto return the inner type would be a solution.
If we don’t want the Wrapper type to have
all the methods of the inner type—for example, to restrict the Wrapper type’s
behavior—we would have to implement just the methods we do want manually.
This newtype pattern is also useful even when traits are not involved.
Let’s switch focus and look at some advanced ways to interact with Rust’s type system.
Advanced Types
The Rust type system has some features that we’ve so far mentioned but haven’t
yet discussed. We’ll start by discussing newtypes in general as we examine why
newtypes are useful as types. Then we’ll move on to type aliases, a feature
similar to newtypes but with slightly different semantics. We’ll also discuss
the ! type and dynamically sized types.
Using the Newtype Pattern for Type Safety and Abstraction
Note: This section assumes you’ve read the earlier section “Using the Newtype Pattern to Implement External Traits on External Types.”
The newtype pattern is also useful for tasks beyond those we’ve discussed so
far, including statically enforcing that values are never confused and
indicating the units of a value. You saw an example of using newtypes to
indicate units in Listing 19-15: recall that the Millimeters and Meters
structs wrapped u32 values in a newtype. If we wrote a function with a
parameter of type Millimeters, we couldn’t compile a program that
accidentally tried to call that function with a value of type Meters or a
plain u32.
We can also use the newtype pattern to abstract away some implementation details of a type: the new type can expose a public API that is different from the API of the private inner type.
Newtypes can also hide internal implementation. For example, we could provide a
People type to wrap a HashMap<i32, String> that stores a person’s ID
associated with their name. Code using People would only interact with the
public API we provide, such as a method to add a name string to the People
collection; that code wouldn’t need to know that we assign an i32 ID to names
internally. The newtype pattern is a lightweight way to achieve encapsulation
to hide implementation details, which we discussed in the “Encapsulation that
Hides Implementation
Details”
section of Chapter 17.
Creating Type Synonyms with Type Aliases
Rust provides the ability to declare a type alias to give an existing type
another name. For this we use the type keyword. For example, we can create
the alias Kilometers to i32 like so:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Now, the alias Kilometers is a synonym for i32; unlike the Millimeters
and Meters types we created in Listing 19-15, Kilometers is not a separate,
new type. Values that have the type Kilometers will be treated the same as
values of type i32:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
Because Kilometers and i32 are the same type, we can add values of both
types and we can pass Kilometers values to functions that take i32
parameters. However, using this method, we don’t get the type checking benefits
that we get from the newtype pattern discussed earlier. In other words, if we
mix up Kilometers and i32 values somewhere, the compiler will not give us
an error.
The main use case for type synonyms is to reduce repetition. For example, we might have a lengthy type like this:
Box<dyn Fn() + Send + 'static>
Writing this lengthy type in function signatures and as type annotations all over the code can be tiresome and error prone. Imagine having a project full of code like that in Listing 19-24.
fn main() { let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi")); fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) { // --snip-- } fn returns_long_type() -> Box<dyn Fn() + Send + 'static> { // --snip-- Box::new(|| ()) } }
Listing 19-24: Using a long type in many places
A type alias makes this code more manageable by reducing the repetition. In
Listing 19-25, we’ve introduced an alias named Thunk for the verbose type and
can replace all uses of the type with the shorter alias Thunk.
fn main() { type Thunk = Box<dyn Fn() + Send + 'static>; let f: Thunk = Box::new(|| println!("hi")); fn takes_long_type(f: Thunk) { // --snip-- } fn returns_long_type() -> Thunk { // --snip-- Box::new(|| ()) } }
Listing 19-25: Introducing a type alias Thunk to reduce
repetition
This code is much easier to read and write! Choosing a meaningful name for a type alias can help communicate your intent as well (thunk is a word for code to be evaluated at a later time, so it’s an appropriate name for a closure that gets stored).
Type aliases are also commonly used with the Result<T, E> type for reducing
repetition. Consider the std::io module in the standard library. I/O
operations often return a Result<T, E> to handle situations when operations
fail to work. This library has a std::io::Error struct that represents all
possible I/O errors. Many of the functions in std::io will be returning
Result<T, E> where the E is std::io::Error, such as these functions in
the Write trait:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}
The Result<..., Error> is repeated a lot. As such, std::io has this type
alias declaration:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}
Because this declaration is in the std::io module, we can use the fully
qualified alias std::io::Result<T>; that is, a Result<T, E> with the E
filled in as std::io::Error. The Write trait function signatures end up
looking like this:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}
The type alias helps in two ways: it makes code easier to write and it gives
us a consistent interface across all of std::io. Because it’s an alias, it’s
just another Result<T, E>, which means we can use any methods that work on
Result<T, E> with it, as well as special syntax like the ? operator.
The Never Type that Never Returns
Rust has a special type named ! that’s known in type theory lingo as the
empty type because it has no values. We prefer to call it the never type
because it stands in the place of the return type when a function will never
return. Here is an example:
fn bar() -> ! {
// --snip--
panic!();
}
This code is read as “the function bar returns never.” Functions that return
never are called diverging functions. We can’t create values of the type !
so bar can never possibly return.
But what use is a type you can never create values for? Recall the code from Listing 2-5, part of the number guessing game; we’ve reproduced a bit of it here in Listing 19-26.
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}
Listing 19-26: A match with an arm that ends in
continue
At the time, we skipped over some details in this code. In Chapter 6 in “The
match Control Flow Operator”
section, we discussed that match arms must all return the same type. So, for
example, the following code doesn’t work:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}
The type of guess in this code would have to be an integer and a string,
and Rust requires that guess have only one type. So what does continue
return? How were we allowed to return a u32 from one arm and have another arm
that ends with continue in Listing 19-26?
As you might have guessed, continue has a ! value. That is, when Rust
computes the type of guess, it looks at both match arms, the former with a
value of u32 and the latter with a ! value. Because ! can never have a
value, Rust decides that the type of guess is u32.
The formal way of describing this behavior is that expressions of type ! can
be coerced into any other type. We’re allowed to end this match arm with
continue because continue doesn’t return a value; instead, it moves control
back to the top of the loop, so in the Err case, we never assign a value to
guess.
The never type is useful with the panic! macro as well. Recall the unwrap
function that we call on Option<T> values to produce a value or panic with
this definition:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}
In this code, the same thing happens as in the match in Listing 19-26: Rust
sees that val has the type T and panic! has the type !, so the result
of the overall match expression is T. This code works because panic!
doesn’t produce a value; it ends the program. In the None case, we won’t be
returning a value from unwrap, so this code is valid.
One final expression that has the type ! is a loop:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}
Here, the loop never ends, so ! is the value of the expression. However, this
wouldn’t be true if we included a break, because the loop would terminate
when it got to the break.
Dynamically Sized Types and the Sized Trait
Rust needs to know certain details about its types, such as how much space to allocate for a value of a particular type. This leaves one corner of its type system a little confusing at first: the concept of dynamically sized types. Sometimes referred to as DSTs or unsized types, these types let us write code using values whose size we can know only at runtime.
Let’s dig into the details of a dynamically sized type called str, which
we’ve been using throughout the book. That’s right, not &str, but str on
its own, is a DST. We can’t know how long the string is until runtime, meaning
we can’t create a variable of type str, nor can we take an argument of type
str. Consider the following code, which does not work:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}
Rust needs to know how much memory to allocate for any value of a particular
type, and all values of a type must use the same amount of memory. If Rust
allowed us to write this code, these two str values would need to take up the
same amount of space. But they have different lengths: s1 needs 12 bytes of
storage and s2 needs 15. This is why it’s not possible to create a variable
holding a dynamically sized type.
So what do we do? In this case, you already know the answer: we make the types
of s1 and s2 a &str rather than a str. Recall from the “String
Slices” section of Chapter 4 that the slice data
structure just stores the starting position and the length of the slice. So
although a &T is a single value that stores the memory address of where the
T is located, a &str is two values: the address of the str and its
length. As such, we can know the size of a &str value at compile time: it’s
twice the length of a usize. That is, we always know the size of a &str, no
matter how long the string it refers to is. In general, this is the way in
which dynamically sized types are used in Rust: they have an extra bit of
metadata that stores the size of the dynamic information. The golden rule of
dynamically sized types is that we must always put values of dynamically sized
types behind a pointer of some kind.
We can combine str with all kinds of pointers: for example, Box<str> or
Rc<str>. In fact, you’ve seen this before but with a different dynamically
sized type: traits. Every trait is a dynamically sized type we can refer to by
using the name of the trait. In Chapter 17 in the “Using Trait Objects That
Allow for Values of Different
Types” section, we mentioned that to use traits as trait objects, we must
put them behind a pointer, such as &dyn Trait or Box<dyn Trait> (Rc<dyn Trait> would work too).
To work with DSTs, Rust provides the Sized trait to determine whether or not
a type’s size is known at compile time. This trait is automatically implemented
for everything whose size is known at compile time. In addition, Rust
implicitly adds a bound on Sized to every generic function. That is, a
generic function definition like this:
fn generic<T>(t: T) {
// --snip--
}
is actually treated as though we had written this:
fn generic<T: Sized>(t: T) {
// --snip--
}
By default, generic functions will work only on types that have a known size at compile time. However, you can use the following special syntax to relax this restriction:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}
A trait bound on ?Sized means “T may or may not be Sized” and this
notation overrides the default that generic types must have a known size at
compile time. The ?Trait syntax with this meaning is only available for
Sized, not any other traits.
Also note that we switched the type of the t parameter from T to &T.
Because the type might not be Sized, we need to use it behind some kind of
pointer. In this case, we’ve chosen a reference.
Next, we’ll talk about functions and closures!
Advanced Functions and Closures
This section explores some advanced features related to functions and closures, including function pointers and returning closures.
Function Pointers
We’ve talked about how to pass closures to functions; you can also pass regular functions to functions!
This technique is useful when you want to pass a function you’ve already defined rather than defining a new closure.
- Functions coerce to the type
fn(with a lowercase f), not to be confused with theFnclosure trait. - The
fntype is called a function pointer. - Passing functions with function pointers will allow you to use functions as arguments to other functions.
The syntax for specifying that a parameter is a function pointer is similar to that of closures, as shown in Listing 19-27, where we’ve defined a function
add_onethat adds one to its parameter.
- The function
do_twicetakes two parameters: a function pointer to any function that takes ani32parameter and returns ani32, and onei32 value. - The
do_twicefunction calls the functionftwice, passing it theargvalue, then adds the two function call results together. - The
mainfunction callsdo_twicewith the argumentsadd_oneand5.
Filename: src/main.rs
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("The answer is: {}", answer);
}
Listing 19-27: Using the fn type to accept a function
pointer as an argument
- This code prints
The answer is: 12. - We specify that the parameter
findo_twiceis anfnthat takes one parameter of typei32and returns ani32. - We can then call
fin the body ofdo_twice. Inmain, we can pass the function nameadd_oneas the first argument todo_twice.
Unlike closures,
fnis a type rather than a trait, so we specifyfnas the parameter type directly rather than declaring a generic type parameter with one of theFntraits as a trait bound.
- Function pointers implement all three of the closure traits (
Fn,FnMut, andFnOnce), meaning you can always pass a function pointer as an argument for a function that expects a closure. - It’s best to write functions using a generic type and one of the closure traits so your functions can accept either functions or closures.
That said, one example of where you would want to only accept
fnand not closures is when interfacing with external code that doesn’t have closures: C functions can accept functions as arguments, but C doesn’t have closures.
As an example of where you could use either a closure defined inline or a named
function, let’s look at a use of the map method provided by the Iterator
trait in the standard library.
To use the
mapfunction to turn a vector of numbers into a vector of strings, we could use a closure, like this:
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(|i| i.to_string()).collect();
}
Or we could name a function as the argument to map instead of the closure,
like this:
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(ToString::to_string).collect();
}
Note that we must use the
fully qualified syntaxthat we talked about earlier in the “Advanced Traits” section because there are multiple functions available namedto_string.
Here, we’re using the
to_string function defined in the ToString trait, which the standard
library has implemented for any type that implements Display.
Recall from the “Enum values” section of Chapter 6 that the name of each enum variant that we define also becomes an initializer function.
We can use these initializer functions as function pointers that implement the closure traits, which means we can specify the initializer functions as arguments for methods that take closures, like so:
fn main() {
enum Status {
Value(u32),
Stop,
}
let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect();
}
-
Here we create
Status::Valueinstances using eachu32value in the range thatmapis called on by using the initializer function ofStatus::Value. -
Some people prefer this style, and some people prefer to use closures. They compile to the same code, so use whichever style is clearer to you.
Returning Closures
Closures are represented by traits, which means you can’t return closures directly. In most cases where you might want to return a trait, you can instead use the concrete type that implements the trait as the return value of the function.
However, you can’t do that with closures because they don’t have a concrete type that is returnable; you’re not allowed to use the function pointer
fnas a return type, for example.
The following code tries to return a closure directly, but it won’t compile:
fn returns_closure() -> dyn Fn(i32) -> i32 {
|x| x + 1
}
The compiler error is as follows:
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0746]: return type cannot have an unboxed trait object
--> src/lib.rs:1:25
|
1 | fn returns_closure() -> dyn Fn(i32) -> i32 {
| ^^^^^^^^^^^^^^^^^^ doesn't have a size known at compile-time
|
= note: for information on `impl Trait`, see <https://doc.rust-lang.org/book/ch10-02-traits.html#returning-types-that-implement-traits>
help: use `impl Fn(i32) -> i32` as the return type, as all return paths are of type `[closure@src/lib.rs:2:5: 2:14]`, which implements `Fn(i32) -> i32`
|
1 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ~~~~~~~~~~~~~~~~~~~
For more information about this error, try `rustc --explain E0746`.
error: could not compile `functions-example` due to previous error
The error references the
Sizedtrait again!
Rust doesn’t know how much space it will need to store the closure. We saw a solution to this problem earlier. We can use a trait object:
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
This code will compile just fine. For more about trait objects, refer to the section “Using Trait Objects That Allow for Values of Different Types” in Chapter 17.
Next, let’s look at macros!
Macros
We’ve used macros like println! throughout this book, but we haven’t fully
explored what a macro is and how it works. The term macro refers to a family
of features in Rust: declarative macros with macro_rules! and three kinds
of procedural macros:
- Custom
#[derive]macros that specify code added with thederiveattribute used on structs and enums - Attribute-like macros that define custom attributes usable on any item
- Function-like macros that look like function calls but operate on the tokens specified as their argument
We’ll talk about each of these in turn, but first, let’s look at why we even need macros when we already have functions.
The Difference Between Macros and Functions
Fundamentally, macros are a way of writing code that writes other code, which
is known as metaprogramming. In Appendix C, we discuss the derive
attribute, which generates an implementation of various traits for you. We’ve
also used the println! and vec! macros throughout the book. All of these
macros expand to produce more code than the code you’ve written manually.
Metaprogramming is useful for reducing the amount of code you have to write and maintain, which is also one of the roles of functions. However, macros have some additional powers that functions don’t.
A function signature must declare the number and type of parameters the
function has. Macros, on the other hand, can take a variable number of
parameters: we can call println!("hello") with one argument or
println!("hello {}", name) with two arguments. Also, macros are expanded
before the compiler interprets the meaning of the code, so a macro can, for
example, implement a trait on a given type. A function can’t, because it gets
called at runtime and a trait needs to be implemented at compile time.
The downside to implementing a macro instead of a function is that macro definitions are more complex than function definitions because you’re writing Rust code that writes Rust code. Due to this indirection, macro definitions are generally more difficult to read, understand, and maintain than function definitions.
Another important difference between macros and functions is that you must define macros or bring them into scope before you call them in a file, as opposed to functions you can define anywhere and call anywhere.
Declarative Macros with macro_rules! for General Metaprogramming
The most widely used form of macros in Rust is the declarative macro. These
are also sometimes referred to as “macros by example,” “macro_rules! macros,”
or just plain “macros.” At their core, declarative macros allow you to write
something similar to a Rust match expression. As discussed in Chapter 6,
match expressions are control structures that take an expression, compare the
resulting value of the expression to patterns, and then run the code associated
with the matching pattern. Macros also compare a value to patterns that are
associated with particular code: in this situation, the value is the literal
Rust source code passed to the macro; the patterns are compared with the
structure of that source code; and the code associated with each pattern, when
matched, replaces the code passed to the macro. This all happens during
compilation.
To define a macro, you use the macro_rules! construct. Let’s explore how to
use macro_rules! by looking at how the vec! macro is defined. Chapter 8
covered how we can use the vec! macro to create a new vector with particular
values. For example, the following macro creates a new vector containing three
integers:
#![allow(unused)] fn main() { let v: Vec<u32> = vec![1, 2, 3]; }
We could also use the vec! macro to make a vector of two integers or a vector
of five string slices. We wouldn’t be able to use a function to do the same
because we wouldn’t know the number or type of values up front.
Listing 19-28 shows a slightly simplified definition of the vec! macro.
Filename: src/lib.rs
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}
Listing 19-28: A simplified version of the vec! macro
definition
Note: The actual definition of the
vec!macro in the standard library includes code to preallocate the correct amount of memory up front. That code is an optimization that we don’t include here to make the example simpler.
The #[macro_export] annotation indicates that this macro should be made
available whenever the crate in which the macro is defined is brought into
scope. Without this annotation, the macro can’t be brought into scope.
We then start the macro definition with macro_rules! and the name of the
macro we’re defining without the exclamation mark. The name, in this case
vec, is followed by curly brackets denoting the body of the macro definition.
The structure in the vec! body is similar to the structure of a match
expression. Here we have one arm with the pattern ( $( $x:expr ),* ),
followed by => and the block of code associated with this pattern. If the
pattern matches, the associated block of code will be emitted. Given that this
is the only pattern in this macro, there is only one valid way to match; any
other pattern will result in an error. More complex macros will have more than
one arm.
Valid pattern syntax in macro definitions is different than the pattern syntax covered in Chapter 18 because macro patterns are matched against Rust code structure rather than values. Let’s walk through what the pattern pieces in Listing 19-28 mean; for the full macro pattern syntax, see the Rust Reference.
First, we use a set of parentheses to encompass the whole pattern. We use a
dollar sign ($) to declare a variable in the macro system that will contain
the Rust code matching the pattern. The dollar sign makes it clear this is a
macro variable as opposed to a regular Rust variable. Next comes a set of
parentheses that captures values that match the pattern within the parentheses
for use in the replacement code. Within $() is $x:expr, which matches any
Rust expression and gives the expression the name $x.
The comma following $() indicates that a literal comma separator character
could optionally appear after the code that matches the code in $(). The *
specifies that the pattern matches zero or more of whatever precedes the *.
When we call this macro with vec![1, 2, 3];, the $x pattern matches three
times with the three expressions 1, 2, and 3.
Now let’s look at the pattern in the body of the code associated with this arm:
temp_vec.push() within $()* is generated for each part that matches $()
in the pattern zero or more times depending on how many times the pattern
matches. The $x is replaced with each expression matched. When we call this
macro with vec![1, 2, 3];, the code generated that replaces this macro call
will be the following:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}
We’ve defined a macro that can take any number of arguments of any type and can generate code to create a vector containing the specified elements.
To learn more about how to write macros, consult the online documentation or other resources, such as “The Little Book of Rust Macros” started by Daniel Keep and continued by Lukas Wirth.
Procedural Macros for Generating Code from Attributes
The second form of macros is the procedural macro, which acts more like a function (and is a type of procedure). Procedural macros accept some code as an input, operate on that code, and produce some code as an output rather than matching against patterns and replacing the code with other code as declarative macros do. The three kinds of procedural macros are custom derive, attribute-like, and function-like, and all work in a similar fashion.
When creating procedural macros, the definitions must reside in their own crate
with a special crate type. This is for complex technical reasons that we hope
to eliminate in the future. In Listing 19-29, we show how to define a
procedural macro, where some_attribute is a placeholder for using a specific
macro variety.
Filename: src/lib.rs
use proc_macro;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}
Listing 19-29: An example of defining a procedural macro
The function that defines a procedural macro takes a TokenStream as an input
and produces a TokenStream as an output. The TokenStream type is defined by
the proc_macro crate that is included with Rust and represents a sequence of
tokens. This is the core of the macro: the source code that the macro is
operating on makes up the input TokenStream, and the code the macro produces
is the output TokenStream. The function also has an attribute attached to it
that specifies which kind of procedural macro we’re creating. We can have
multiple kinds of procedural macros in the same crate.
Let’s look at the different kinds of procedural macros. We’ll start with a custom derive macro and then explain the small dissimilarities that make the other forms different.
How to Write a Custom derive Macro
Let’s create a crate named hello_macro that defines a trait named
HelloMacro with one associated function named hello_macro. Rather than
making our users implement the HelloMacro trait for each of their types,
we’ll provide a procedural macro so users can annotate their type with
#[derive(HelloMacro)] to get a default implementation of the hello_macro
function. The default implementation will print Hello, Macro! My name is TypeName! where TypeName is the name of the type on which this trait has
been defined. In other words, we’ll write a crate that enables another
programmer to write code like Listing 19-30 using our crate.
Filename: src/main.rs
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}
Listing 19-30: The code a user of our crate will be able to write when using our procedural macro
This code will print Hello, Macro! My name is Pancakes! when we’re done. The
first step is to make a new library crate, like this:
$ cargo new hello_macro --lib
Next, we’ll define the HelloMacro trait and its associated function:
Filename: src/lib.rs
pub trait HelloMacro {
fn hello_macro();
}
We have a trait and its function. At this point, our crate user could implement the trait to achieve the desired functionality, like so:
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}
However, they would need to write the implementation block for each type they
wanted to use with hello_macro; we want to spare them from having to do this
work.
Additionally, we can’t yet provide the hello_macro function with default
implementation that will print the name of the type the trait is implemented
on: Rust doesn’t have reflection capabilities, so it can’t look up the type’s
name at runtime. We need a macro to generate code at compile time.
The next step is to define the procedural macro. At the time of this writing,
procedural macros need to be in their own crate. Eventually, this restriction
might be lifted. The convention for structuring crates and macro crates is as
follows: for a crate named foo, a custom derive procedural macro crate is
called foo_derive. Let’s start a new crate called hello_macro_derive inside
our hello_macro project:
$ cargo new hello_macro_derive --lib
Our two crates are tightly related, so we create the procedural macro crate
within the directory of our hello_macro crate. If we change the trait
definition in hello_macro, we’ll have to change the implementation of the
procedural macro in hello_macro_derive as well. The two crates will need to
be published separately, and programmers using these crates will need to add
both as dependencies and bring them both into scope. We could instead have the
hello_macro crate use hello_macro_derive as a dependency and re-export the
procedural macro code. However, the way we’ve structured the project makes it
possible for programmers to use hello_macro even if they don’t want the
derive functionality.
We need to declare the hello_macro_derive crate as a procedural macro crate.
We’ll also need functionality from the syn and quote crates, as you’ll see
in a moment, so we need to add them as dependencies. Add the following to the
Cargo.toml file for hello_macro_derive:
Filename: hello_macro_derive/Cargo.toml
[lib]
proc-macro = true
[dependencies]
syn = "1.0"
quote = "1.0"
To start defining the procedural macro, place the code in Listing 19-31 into
your src/lib.rs file for the hello_macro_derive crate. Note that this code
won’t compile until we add a definition for the impl_hello_macro function.
Filename: hello_macro_derive/src/lib.rs
use proc_macro::TokenStream;
use quote::quote;
use syn;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
Listing 19-31: Code that most procedural macro crates will require in order to process Rust code
Notice that we’ve split the code into the hello_macro_derive function, which
is responsible for parsing the TokenStream, and the impl_hello_macro
function, which is responsible for transforming the syntax tree: this makes
writing a procedural macro more convenient. The code in the outer function
(hello_macro_derive in this case) will be the same for almost every
procedural macro crate you see or create. The code you specify in the body of
the inner function (impl_hello_macro in this case) will be different
depending on your procedural macro’s purpose.
We’ve introduced three new crates: proc_macro, syn, and quote. The
proc_macro crate comes with Rust, so we didn’t need to add that to the
dependencies in Cargo.toml. The proc_macro crate is the compiler’s API that
allows us to read and manipulate Rust code from our code.
The syn crate parses Rust code from a string into a data structure that we
can perform operations on. The quote crate turns syn data structures back
into Rust code. These crates make it much simpler to parse any sort of Rust
code we might want to handle: writing a full parser for Rust code is no simple
task.
The hello_macro_derive function will be called when a user of our library
specifies #[derive(HelloMacro)] on a type. This is possible because we’ve
annotated the hello_macro_derive function here with proc_macro_derive and
specified the name HelloMacro, which matches our trait name; this is the
convention most procedural macros follow.
The hello_macro_derive function first converts the input from a
TokenStream to a data structure that we can then interpret and perform
operations on. This is where syn comes into play. The parse function in
syn takes a TokenStream and returns a DeriveInput struct representing the
parsed Rust code. Listing 19-32 shows the relevant parts of the DeriveInput
struct we get from parsing the struct Pancakes; string:
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}
Listing 19-32: The DeriveInput instance we get when
parsing the code that has the macro’s attribute in Listing 19-30
The fields of this struct show that the Rust code we’ve parsed is a unit struct
with the ident (identifier, meaning the name) of Pancakes. There are more
fields on this struct for describing all sorts of Rust code; check the syn
documentation for DeriveInput for more information.
Soon we’ll define the impl_hello_macro function, which is where we’ll build
the new Rust code we want to include. But before we do, note that the output
for our derive macro is also a TokenStream. The returned TokenStream is
added to the code that our crate users write, so when they compile their crate,
they’ll get the extra functionality that we provide in the modified
TokenStream.
You might have noticed that we’re calling unwrap to cause the
hello_macro_derive function to panic if the call to the syn::parse function
fails here. It’s necessary for our procedural macro to panic on errors because
proc_macro_derive functions must return TokenStream rather than Result to
conform to the procedural macro API. We’ve simplified this example by using
unwrap; in production code, you should provide more specific error messages
about what went wrong by using panic! or expect.
Now that we have the code to turn the annotated Rust code from a TokenStream
into a DeriveInput instance, let’s generate the code that implements the
HelloMacro trait on the annotated type, as shown in Listing 19-33.
Filename: hello_macro_derive/src/lib.rs
use proc_macro::TokenStream;
use quote::quote;
use syn;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let gen = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
gen.into()
}
Listing 19-33: Implementing the HelloMacro trait using
the parsed Rust code
We get an Ident struct instance containing the name (identifier) of the
annotated type using ast.ident. The struct in Listing 19-32 shows that when
we run the impl_hello_macro function on the code in Listing 19-30, the
ident we get will have the ident field with a value of "Pancakes". Thus,
the name variable in Listing 19-33 will contain an Ident struct instance
that, when printed, will be the string "Pancakes", the name of the struct in
Listing 19-30.
The quote! macro lets us define the Rust code that we want to return. The
compiler expects something different to the direct result of the quote!
macro’s execution, so we need to convert it to a TokenStream. We do this by
calling the into method, which consumes this intermediate representation and
returns a value of the required TokenStream type.
The quote! macro also provides some very cool templating mechanics: we can
enter #name, and quote! will replace it with the value in the variable
name. You can even do some repetition similar to the way regular macros work.
Check out the quote crate’s docs for a thorough introduction.
We want our procedural macro to generate an implementation of our HelloMacro
trait for the type the user annotated, which we can get by using #name. The
trait implementation has the one function hello_macro, whose body contains the
functionality we want to provide: printing Hello, Macro! My name is and then
the name of the annotated type.
The stringify! macro used here is built into Rust. It takes a Rust
expression, such as 1 + 2, and at compile time turns the expression into a
string literal, such as "1 + 2". This is different than format! or
println!, macros which evaluate the expression and then turn the result into
a String. There is a possibility that the #name input might be an
expression to print literally, so we use stringify!. Using stringify! also
saves an allocation by converting #name to a string literal at compile time.
At this point, cargo build should complete successfully in both hello_macro
and hello_macro_derive. Let’s hook up these crates to the code in Listing
19-30 to see the procedural macro in action! Create a new binary project in
your projects directory using cargo new pancakes. We need to add
hello_macro and hello_macro_derive as dependencies in the pancakes
crate’s Cargo.toml. If you’re publishing your versions of hello_macro and
hello_macro_derive to crates.io, they would be regular
dependencies; if not, you can specify them as path dependencies as follows:
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Put the code in Listing 19-30 into src/main.rs, and run cargo run: it
should print Hello, Macro! My name is Pancakes! The implementation of the
HelloMacro trait from the procedural macro was included without the
pancakes crate needing to implement it; the #[derive(HelloMacro)] added the
trait implementation.
Next, let’s explore how the other kinds of procedural macros differ from custom derive macros.
Attribute-like macros
Attribute-like macros are similar to custom derive macros, but instead of
generating code for the derive attribute, they allow you to create new
attributes. They’re also more flexible: derive only works for structs and
enums; attributes can be applied to other items as well, such as functions.
Here’s an example of using an attribute-like macro: say you have an attribute
named route that annotates functions when using a web application framework:
#[route(GET, "/")]
fn index() {
This #[route] attribute would be defined by the framework as a procedural
macro. The signature of the macro definition function would look like this:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {
Here, we have two parameters of type TokenStream. The first is for the
contents of the attribute: the GET, "/" part. The second is the body of the
item the attribute is attached to: in this case, fn index() {} and the rest
of the function’s body.
Other than that, attribute-like macros work the same way as custom derive
macros: you create a crate with the proc-macro crate type and implement a
function that generates the code you want!
Function-like macros
Function-like macros define macros that look like function calls. Similarly to
macro_rules! macros, they’re more flexible than functions; for example, they
can take an unknown number of arguments. However, macro_rules! macros can be
defined only using the match-like syntax we discussed in the section
“Declarative Macros with macro_rules! for General
Metaprogramming” earlier. Function-like macros take a
TokenStream parameter and their definition manipulates that TokenStream
using Rust code as the other two types of procedural macros do. An example of a
function-like macro is an sql! macro that might be called like so:
let sql = sql!(SELECT * FROM posts WHERE id=1);
This macro would parse the SQL statement inside it and check that it’s
syntactically correct, which is much more complex processing than a
macro_rules! macro can do. The sql! macro would be defined like this:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {
This definition is similar to the custom derive macro’s signature: we receive the tokens that are inside the parentheses and return the code we wanted to generate.
Summary
Whew! Now you have some Rust features in your toolbox that you likely won’t use often, but you’ll know they’re available in very particular circumstances. We’ve introduced several complex topics so that when you encounter them in error message suggestions or in other peoples’ code, you’ll be able to recognize these concepts and syntax. Use this chapter as a reference to guide you to solutions.
Next, we’ll put everything we’ve discussed throughout the book into practice and do one more project!
Final Project: Building a Multithreaded Web Server
It’s been a long journey, but we’ve reached the end of the book. In this chapter, we’ll build one more project together to demonstrate some of the concepts we covered in the final chapters, as well as recap some earlier lessons.
For our final project, we’ll make a web server that says “hello” and looks like Figure 20-1 in a web browser.
Figure 20-1: Our final shared project
Here is our plan for building the web server:
- Learn a bit about TCP and HTTP.
- Listen for TCP connections on a socket.
- Parse a small number of HTTP requests.
- Create a proper HTTP response.
- Improve the throughput of our server with a thread pool.
Before we get started, we should mention one detail: the method we’ll use won’t be the best way to build a web server with Rust. Community members have published a number of production-ready crates available on crates.io that provide more complete web server and thread pool implementations than we’ll build. However, our intention in this chapter is to help you learn, not to take the easy route. Because Rust is a systems programming language, we can choose the level of abstraction we want to work with and can go to a lower level than is possible or practical in other languages. We’ll therefore write the basic HTTP server and thread pool manually so you can learn the general ideas and techniques behind the crates you might use in the future.
Building a Single-Threaded Web Server
We’ll start by getting a single-threaded web server working. Before we begin, let’s look at a quick overview of the protocols involved in building web servers. The details of these protocols are beyond the scope of this book, but a brief overview will give you the information you need.
The two main protocols involved in web servers are Hypertext Transfer Protocol (HTTP) and Transmission Control Protocol (TCP). Both protocols are request-response protocols, meaning a client initiates requests and a server listens to the requests and provides a response to the client. The contents of those requests and responses are defined by the protocols.
TCP is the lower-level protocol that describes the details of how information gets from one server to another but doesn’t specify what that information is. HTTP builds on top of TCP by defining the contents of the requests and responses. It’s technically possible to use HTTP with other protocols, but in the vast majority of cases, HTTP sends its data over TCP. We’ll work with the raw bytes of TCP and HTTP requests and responses.
Listening to the TCP Connection
Our web server needs to listen to a TCP connection, so that’s the first part
we’ll work on. The standard library offers a std::net module that lets us do
this. Let’s make a new project in the usual fashion:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
Now enter the code in Listing 20-1 in src/main.rs to start. This code will
listen at the local address 127.0.0.1:7878 for incoming TCP streams. When it
gets an incoming stream, it will print Connection established!.
Filename: src/main.rs
use std::net::TcpListener; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); println!("Connection established!"); } }
Listing 20-1: Listening for incoming streams and printing a message when we receive a stream
Using TcpListener, we can listen for TCP connections at the address
127.0.0.1:7878. In the address, the section before the colon is an IP address
representing your computer (this is the same on every computer and doesn’t
represent the authors’ computer specifically), and 7878 is the port. We’ve
chosen this port for two reasons: HTTP isn’t normally accepted on this port so
our server is unlikely to conflict with any other web server you might have
running on your machine, and 7878 is rust typed on a telephone.
The bind function in this scenario works like the new function in that it
will return a new TcpListener instance. The function is called bind
because, in networking, connecting to a port to listen to is known as “binding
to a port.”
The bind function returns a Result<T, E>, which indicates that it’s
possible for binding to fail. For example, connecting to port 80 requires
administrator privileges (nonadministrators can listen only on ports higher
than 1023), so if we tried to connect to port 80 without being an
administrator, binding wouldn’t work. Binding also wouldn’t work, for example,
if we ran two instances of our program and so had two programs listening to the
same port. Because we’re writing a basic server just for learning purposes, we
won’t worry about handling these kinds of errors; instead, we use unwrap to
stop the program if errors happen.
The incoming method on TcpListener returns an iterator that gives us a
sequence of streams (more specifically, streams of type TcpStream). A single
stream represents an open connection between the client and the server. A
connection is the name for the full request and response process in which a
client connects to the server, the server generates a response, and the server
closes the connection. As such, we will read from the TcpStream to see what
the client sent and then write our response to the stream to send data back to
the client. Overall, this for loop will process each connection in turn and
produce a series of streams for us to handle.
For now, our handling of the stream consists of calling unwrap to terminate
our program if the stream has any errors; if there aren’t any errors, the
program prints a message. We’ll add more functionality for the success case in
the next listing. The reason we might receive errors from the incoming method
when a client connects to the server is that we’re not actually iterating over
connections. Instead, we’re iterating over connection attempts. The
connection might not be successful for a number of reasons, many of them
operating system specific. For example, many operating systems have a limit to
the number of simultaneous open connections they can support; new connection
attempts beyond that number will produce an error until some of the open
connections are closed.
Let’s try running this code! Invoke cargo run in the terminal and then load
127.0.0.1:7878 in a web browser. The browser should show an error message
like “Connection reset,” because the server isn’t currently sending back any
data. But when you look at your terminal, you should see several messages that
were printed when the browser connected to the server!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
Sometimes, you’ll see multiple messages printed for one browser request; the reason might be that the browser is making a request for the page as well as a request for other resources, like the favicon.ico icon that appears in the browser tab.
It could also be that the browser is trying to connect to the server multiple
times because the server isn’t responding with any data. When stream goes out
of scope and is dropped at the end of the loop, the connection is closed as
part of the drop implementation. Browsers sometimes deal with closed
connections by retrying, because the problem might be temporary. The important
factor is that we’ve successfully gotten a handle to a TCP connection!
Remember to stop the program by pressing ctrl-c
when you’re done running a particular version of the code. Then restart the
program by invoking the cargo run command after you’ve made each set of code
changes to make sure you’re running the newest code.
Reading the Request
Let’s implement the functionality to read the request from the browser! To
separate the concerns of first getting a connection and then taking some action
with the connection, we’ll start a new function for processing connections. In
this new handle_connection function, we’ll read data from the TCP stream and
print it so we can see the data being sent from the browser. Change the code to
look like Listing 20-2.
Filename: src/main.rs
use std::{ io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); println!("Request: {:#?}", http_request); }
Listing 20-2: Reading from the TcpStream and printing
the data
We bring std::io::prelude and std::io::BufReader into scope to get access
to traits and types that let us read from and write to the stream. In the for
loop in the main function, instead of printing a message that says we made a
connection, we now call the new handle_connection function and pass the
stream to it.
In the handle_connection function, we create a new BufReader instance that
wraps a mutable reference to the stream. BufReader adds buffering by
managing calls to the std::io::Read trait methods for us.
We create a variable named http_request to collect the lines of the request
the browser sends to our server. We indicate that we want to collect these
lines in a vector by adding the Vec<_> type annotation.
BufReader implements the std::io::BufRead trait, which provides the lines
method. The lines method returns an iterator of Result<String, std::io::Error> by splitting the stream of data whenever it sees a newline
byte. To get each String, we map and unwrap each Result. The Result
might be an error if the data isn’t valid UTF-8 or if there was a problem
reading from the stream. Again, a production program should handle these errors
more gracefully, but we’re choosing to stop the program in the error case for
simplicity.
The browser signals the end of an HTTP request by sending two newline characters in a row, so to get one request from the stream, we take lines until we get a line that is the empty string. Once we’ve collected the lines into the vector, we’re printing them out using pretty debug formatting so we can take a look at the instructions the web browser is sending to our server.
Let’s try this code! Start the program and make a request in a web browser again. Note that we’ll still get an error page in the browser, but our program’s output in the terminal will now look similar to this:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
Depending on your browser, you might get slightly different output. Now that
we’re printing the request data, we can see why we get multiple connections
from one browser request by looking at the path after GET in the first line
of the request. If the repeated connections are all requesting /, we know the
browser is trying to fetch / repeatedly because it’s not getting a response
from our program.
Let’s break down this request data to understand what the browser is asking of our program.
A Closer Look at an HTTP Request
HTTP is a text-based protocol, and a request takes this format:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
The first line is the request line that holds information about what the
client is requesting. The first part of the request line indicates the method
being used, such as GET or POST, which describes how the client is making
this request. Our client used a GET request, which means it is asking for
information.
The next part of the request line is /, which indicates the Uniform Resource Identifier (URI) the client is requesting: a URI is almost, but not quite, the same as a Uniform Resource Locator (URL). The difference between URIs and URLs isn’t important for our purposes in this chapter, but the HTTP spec uses the term URI, so we can just mentally substitute URL for URI here.
The last part is the HTTP version the client uses, and then the request line
ends in a CRLF sequence. (CRLF stands for carriage return and line feed,
which are terms from the typewriter days!) The CRLF sequence can also be
written as \r\n, where \r is a carriage return and \n is a line feed. The
CRLF sequence separates the request line from the rest of the request data.
Note that when the CRLF is printed, we see a new line start rather than \r\n.
Looking at the request line data we received from running our program so far,
we see that GET is the method, / is the request URI, and HTTP/1.1 is the
version.
After the request line, the remaining lines starting from Host: onward are
headers. GET requests have no body.
Try making a request from a different browser or asking for a different address, such as 127.0.0.1:7878/test, to see how the request data changes.
Now that we know what the browser is asking for, let’s send back some data!
Writing a Response
We’re going to implement sending data in response to a client request. Responses have the following format:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
The first line is a status line that contains the HTTP version used in the response, a numeric status code that summarizes the result of the request, and a reason phrase that provides a text description of the status code. After the CRLF sequence are any headers, another CRLF sequence, and the body of the response.
Here is an example response that uses HTTP version 1.1, has a status code of 200, an OK reason phrase, no headers, and no body:
HTTP/1.1 200 OK\r\n\r\n
The status code 200 is the standard success response. The text is a tiny
successful HTTP response. Let’s write this to the stream as our response to a
successful request! From the handle_connection function, remove the
println! that was printing the request data and replace it with the code in
Listing 20-3.
Filename: src/main.rs
use std::{ io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let response = "HTTP/1.1 200 OK\r\n\r\n"; stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-3: Writing a tiny successful HTTP response to the stream
The first new line defines the response variable that holds the success
message’s data. Then we call as_bytes on our response to convert the string
data to bytes. The write_all method on stream takes a &[u8] and sends
those bytes directly down the connection. Because the write_all operation
could fail, we use unwrap on any error result as before. Again, in a real
application you would add error handling here.
With these changes, let’s run our code and make a request. We’re no longer printing any data to the terminal, so we won’t see any output other than the output from Cargo. When you load 127.0.0.1:7878 in a web browser, you should get a blank page instead of an error. You’ve just hand-coded receiving an HTTP request and sending a response!
Returning Real HTML
Let’s implement the functionality for returning more than a blank page. Create the new file hello.html in the root of your project directory, not in the src directory. You can input any HTML you want; Listing 20-4 shows one possibility.
Filename: hello.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
Listing 20-4: A sample HTML file to return in a response
This is a minimal HTML5 document with a heading and some text. To return this
from the server when a request is received, we’ll modify handle_connection as
shown in Listing 20-5 to read the HTML file, add it to the response as a body,
and send it.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-5: Sending the contents of hello.html as the body of the response
We’ve added fs to the use statement to bring the standard library’s
filesystem module into scope. The code for reading the contents of a file to a
string should look familiar; we used it in Chapter 12 when we read the contents
of a file for our I/O project in Listing 12-4.
Next, we use format! to add the file’s contents as the body of the success
response. To ensure a valid HTTP response, we add the Content-Length header
which is set to the size of our response body, in this case the size of
hello.html.
Run this code with cargo run and load 127.0.0.1:7878 in your browser; you
should see your HTML rendered!
Currently, we’re ignoring the request data in http_request and just sending
back the contents of the HTML file unconditionally. That means if you try
requesting 127.0.0.1:7878/something-else in your browser, you’ll still get
back this same HTML response. At the moment, our server is very limited and
does not do what most web servers do. We want to customize our responses
depending on the request and only send back the HTML file for a well-formed
request to /.
Validating the Request and Selectively Responding
Right now, our web server will return the HTML in the file no matter what the
client requested. Let’s add functionality to check that the browser is
requesting / before returning the HTML file and return an error if the
browser requests anything else. For this we need to modify handle_connection,
as shown in Listing 20-6. This new code checks the content of the request
received against what we know a request for / looks like and adds if and
else blocks to treat requests differently.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } else { // some other request } }
Listing 20-6: Handling requests to / differently from other requests
We’re only going to be looking at the first line of the HTTP request, so rather
than reading the entire request into a vector, we’re calling next to get the
first item from the iterator. The first unwrap takes care of the Option and
stops the program if the iterator has no items. The second unwrap handles the
Result and has the same effect as the unwrap that was in the map added in
Listing 20-2.
Next, we check the request_line to see if it equals the request line of a GET
request to the / path. If it does, the if block returns the contents of our
HTML file.
If the request_line does not equal the GET request to the / path, it
means we’ve received some other request. We’ll add code to the else block in
a moment to respond to all other requests.
Run this code now and request 127.0.0.1:7878; you should get the HTML in hello.html. If you make any other request, such as 127.0.0.1:7878/something-else, you’ll get a connection error like those you saw when running the code in Listing 20-1 and Listing 20-2.
Now let’s add the code in Listing 20-7 to the else block to return a response
with the status code 404, which signals that the content for the request was
not found. We’ll also return some HTML for a page to render in the browser
indicating the response to the end user.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); // --snip-- } else { let status_line = "HTTP/1.1 404 NOT FOUND"; let contents = fs::read_to_string("404.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } }
Listing 20-7: Responding with status code 404 and an error page if anything other than / was requested
Here, our response has a status line with status code 404 and the reason phrase
NOT FOUND. The body of the response will be the HTML in the file 404.html.
You’ll need to create a 404.html file next to hello.html for the error
page; again feel free to use any HTML you want or use the example HTML in
Listing 20-8.
Filename: 404.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
Listing 20-8: Sample content for the page to send back with any 404 response
With these changes, run your server again. Requesting 127.0.0.1:7878 should return the contents of hello.html, and any other request, like 127.0.0.1:7878/foo, should return the error HTML from 404.html.
A Touch of Refactoring
At the moment the if and else blocks have a lot of repetition: they’re both
reading files and writing the contents of the files to the stream. The only
differences are the status line and the filename. Let’s make the code more
concise by pulling out those differences into separate if and else lines
that will assign the values of the status line and the filename to variables;
we can then use those variables unconditionally in the code to read the file
and write the response. Listing 20-9 shows the resulting code after replacing
the large if and else blocks.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = if request_line == "GET / HTTP/1.1" { ("HTTP/1.1 200 OK", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-9: Refactoring the if and else blocks to
contain only the code that differs between the two cases
Now the if and else blocks only return the appropriate values for the
status line and filename in a tuple; we then use destructuring to assign these
two values to status_line and filename using a pattern in the let
statement, as discussed in Chapter 18.
The previously duplicated code is now outside the if and else blocks and
uses the status_line and filename variables. This makes it easier to see
the difference between the two cases, and it means we have only one place to
update the code if we want to change how the file reading and response writing
work. The behavior of the code in Listing 20-9 will be the same as that in
Listing 20-8.
Awesome! We now have a simple web server in approximately 40 lines of Rust code that responds to one request with a page of content and responds to all other requests with a 404 response.
Currently, our server runs in a single thread, meaning it can only serve one request at a time. Let’s examine how that can be a problem by simulating some slow requests. Then we’ll fix it so our server can handle multiple requests at once.
Turning Our Single-Threaded Server into a Multithreaded Server
Right now, the server will process each request in turn, meaning it won’t process a second connection until the first is finished processing. If the server received more and more requests, this serial execution would be less and less optimal. If the server receives a request that takes a long time to process, subsequent requests will have to wait until the long request is finished, even if the new requests can be processed quickly. We’ll need to fix this, but first, we’ll look at the problem in action.
Simulating a Slow Request in the Current Server Implementation
We’ll look at how a slow-processing request can affect other requests made to our current server implementation. Listing 20-10 implements handling a request to /sleep with a simulated slow response that will cause the server to sleep for 5 seconds before responding.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, thread, time::Duration, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; // --snip-- let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-10: Simulating a slow request by sleeping for 5 seconds
We switched from if to match now that we have three cases. We need to
explicitly match on a slice of request_line to pattern match against the
string literal values; match doesn’t do automatic referencing and
dereferencing like the equality method does.
The first arm is the same as the if block from Listing 20-9. The second arm
matches a request to /sleep. When that request is received, the server will
sleep for 5 seconds before rendering the successful HTML page. The third arm is
the same as the else block from Listing 20-9.
You can see how primitive our server is: real libraries would handle the recognition of multiple requests in a much less verbose way!
Start the server using cargo run. Then open two browser windows: one for
http://127.0.0.1:7878/ and the other for http://127.0.0.1:7878/sleep. If
you enter the / URI a few times, as before, you’ll see it respond quickly.
But if you enter /sleep and then load /, you’ll see that / waits until
sleep has slept for its full 5 seconds before loading.
There are multiple techniques we could use to avoid requests backing up behind a slow request; the one we’ll implement is a thread pool.
Improving Throughput with a Thread Pool
A thread pool is a group of spawned threads that are waiting and ready to handle a task. When the program receives a new task, it assigns one of the threads in the pool to the task, and that thread will process the task. The remaining threads in the pool are available to handle any other tasks that come in while the first thread is processing. When the first thread is done processing its task, it’s returned to the pool of idle threads, ready to handle a new task. A thread pool allows you to process connections concurrently, increasing the throughput of your server.
We’ll limit the number of threads in the pool to a small number to protect us from Denial of Service (DoS) attacks; if we had our program create a new thread for each request as it came in, someone making 10 million requests to our server could create havoc by using up all our server’s resources and grinding the processing of requests to a halt.
Rather than spawning unlimited threads, then, we’ll have a fixed number of
threads waiting in the pool. Requests that come in are sent to the pool for
processing. The pool will maintain a queue of incoming requests. Each of the
threads in the pool will pop off a request from this queue, handle the request,
and then ask the queue for another request. With this design, we can process up
to N requests concurrently, where N is the number of threads. If each
thread is responding to a long-running request, subsequent requests can still
back up in the queue, but we’ve increased the number of long-running requests
we can handle before reaching that point.
This technique is just one of many ways to improve the throughput of a web server. Other options you might explore are the fork/join model, the single-threaded async I/O model, or the multi-threaded async I/O model. If you’re interested in this topic, you can read more about other solutions and try to implement them; with a low-level language like Rust, all of these options are possible.
Before we begin implementing a thread pool, let’s talk about what using the pool should look like. When you’re trying to design code, writing the client interface first can help guide your design. Write the API of the code so it’s structured in the way you want to call it; then implement the functionality within that structure rather than implementing the functionality and then designing the public API.
Similar to how we used test-driven development in the project in Chapter 12, we’ll use compiler-driven development here. We’ll write the code that calls the functions we want, and then we’ll look at errors from the compiler to determine what we should change next to get the code to work. Before we do that, however, we’ll explore the technique we’re not going to use as a starting point.
Spawning a Thread for Each Request
First, let’s explore how our code might look if it did create a new thread for
every connection. As mentioned earlier, this isn’t our final plan due to the
problems with potentially spawning an unlimited number of threads, but it is a
starting point to get a working multithreaded server first. Then we’ll add the
thread pool as an improvement, and contrasting the two solutions will be
easier. Listing 20-11 shows the changes to make to main to spawn a new thread
to handle each stream within the for loop.
Filename: src/main.rs
use std::{ fs, io::{prelude::*, BufReader}, net::{TcpListener, TcpStream}, thread, time::Duration, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); thread::spawn(|| { handle_connection(stream); }); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&mut stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
Listing 20-11: Spawning a new thread for each stream
As you learned in Chapter 16, thread::spawn will create a new thread and then
run the code in the closure in the new thread. If you run this code and load
/sleep in your browser, then / in two more browser tabs, you’ll indeed see
that the requests to / don’t have to wait for /sleep to finish. However, as
we mentioned, this will eventually overwhelm the system because you’d be making
new threads without any limit.
Creating a Finite Number of Threads
We want our thread pool to work in a similar, familiar way so switching from
threads to a thread pool doesn’t require large changes to the code that uses
our API. Listing 20-12 shows the hypothetical interface for a ThreadPool
struct we want to use instead of thread::spawn.
Filename: src/main.rs
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}
Listing 20-12: Our ideal ThreadPool interface
We use ThreadPool::new to create a new thread pool with a configurable number
of threads, in this case four. Then, in the for loop, pool.execute has a
similar interface as thread::spawn in that it takes a closure the pool should
run for each stream. We need to implement pool.execute so it takes the
closure and gives it to a thread in the pool to run. This code won’t yet
compile, but we’ll try so the compiler can guide us in how to fix it.
Building ThreadPool Using Compiler Driven Development
Make the changes in Listing 20-12 to src/main.rs, and then let’s use the
compiler errors from cargo check to drive our development. Here is the first
error we get:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` due to previous error
Great! This error tells us we need a ThreadPool type or module, so we’ll
build one now. Our ThreadPool implementation will be independent of the kind
of work our web server is doing. So, let’s switch the hello crate from a
binary crate to a library crate to hold our ThreadPool implementation. After
we change to a library crate, we could also use the separate thread pool
library for any work we want to do using a thread pool, not just for serving
web requests.
Create a src/lib.rs that contains the following, which is the simplest
definition of a ThreadPool struct that we can have for now:
Filename: src/lib.rs
pub struct ThreadPool;
Then edit main.rs file to bring ThreadPool into scope from the library
crate by adding the following code to the top of src/main.rs:
Filename: src/main.rs
use hello::ThreadPool;
use std::{
fs,
io::{prelude::*, BufReader},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&mut stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}
This code still won’t work, but let’s check it again to get the next error that we need to address:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` due to previous error
This error indicates that next we need to create an associated function named
new for ThreadPool. We also know that new needs to have one parameter
that can accept 4 as an argument and should return a ThreadPool instance.
Let’s implement the simplest new function that will have those
characteristics:
Filename: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}
We chose usize as the type of the size parameter, because we know that a
negative number of threads doesn’t make any sense. We also know we’ll use this
4 as the number of elements in a collection of threads, which is what the
usize type is for, as discussed in the “Integer Types” section of Chapter 3.
Let’s check the code again:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| ^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` due to previous error
Now the error occurs because we don’t have an execute method on ThreadPool.
Recall from the “Creating a Finite Number of
Threads” section that we
decided our thread pool should have an interface similar to thread::spawn. In
addition, we’ll implement the execute function so it takes the closure it’s
given and gives it to an idle thread in the pool to run.
We’ll define the execute method on ThreadPool to take a closure as a
parameter. Recall from the “Moving Captured Values Out of the Closure and the
Fn Traits” section in Chapter 13 that we can take
closures as parameters with three different traits: Fn, FnMut, and
FnOnce. We need to decide which kind of closure to use here. We know we’ll
end up doing something similar to the standard library thread::spawn
implementation, so we can look at what bounds the signature of thread::spawn
has on its parameter. The documentation shows us the following:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
The F type parameter is the one we’re concerned with here; the T type
parameter is related to the return value, and we’re not concerned with that. We
can see that spawn uses FnOnce as the trait bound on F. This is probably
what we want as well, because we’ll eventually pass the argument we get in
execute to spawn. We can be further confident that FnOnce is the trait we
want to use because the thread for running a request will only execute that
request’s closure one time, which matches the Once in FnOnce.
The F type parameter also has the trait bound Send and the lifetime bound
'static, which are useful in our situation: we need Send to transfer the
closure from one thread to another and 'static because we don’t know how long
the thread will take to execute. Let’s create an execute method on
ThreadPool that will take a generic parameter of type F with these bounds:
Filename: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
We still use the () after FnOnce because this FnOnce represents a closure
that takes no parameters and returns the unit type (). Just like function
definitions, the return type can be omitted from the signature, but even if we
have no parameters, we still need the parentheses.
Again, this is the simplest implementation of the execute method: it does
nothing, but we’re trying only to make our code compile. Let’s check it again:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.24s
It compiles! But note that if you try cargo run and make a request in the
browser, you’ll see the errors in the browser that we saw at the beginning of
the chapter. Our library isn’t actually calling the closure passed to execute
yet!
Note: A saying you might hear about languages with strict compilers, such as Haskell and Rust, is “if the code compiles, it works.” But this saying is not universally true. Our project compiles, but it does absolutely nothing! If we were building a real, complete project, this would be a good time to start writing unit tests to check that the code compiles and has the behavior we want.
Validating the Number of Threads in new
We aren’t doing anything with the parameters to new and execute. Let’s
implement the bodies of these functions with the behavior we want. To start,
let’s think about new. Earlier we chose an unsigned type for the size
parameter, because a pool with a negative number of threads makes no sense.
However, a pool with zero threads also makes no sense, yet zero is a perfectly
valid usize. We’ll add code to check that size is greater than zero before
we return a ThreadPool instance and have the program panic if it receives a
zero by using the assert! macro, as shown in Listing 20-13.
Filename: src/lib.rs
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
Listing 20-13: Implementing ThreadPool::new to panic if
size is zero
We’ve also added some documentation for our ThreadPool with doc comments.
Note that we followed good documentation practices by adding a section that
calls out the situations in which our function can panic, as discussed in
Chapter 14. Try running cargo doc --open and clicking the ThreadPool struct
to see what the generated docs for new look like!
Instead of adding the assert! macro as we’ve done here, we could change new
into build and return a Result like we did with Config::build in the I/O
project in Listing 12-9. But we’ve decided in this case that trying to create a
thread pool without any threads should be an unrecoverable error. If you’re
feeling ambitious, try to write a function named build with the following
signature to compare with the new function:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {
Creating Space to Store the Threads
Now that we have a way to know we have a valid number of threads to store in
the pool, we can create those threads and store them in the ThreadPool struct
before returning the struct. But how do we “store” a thread? Let’s take another
look at the thread::spawn signature:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
The spawn function returns a JoinHandle<T>, where T is the type that the
closure returns. Let’s try using JoinHandle too and see what happens. In our
case, the closures we’re passing to the thread pool will handle the connection
and not return anything, so T will be the unit type ().
The code in Listing 20-14 will compile but doesn’t create any threads yet.
We’ve changed the definition of ThreadPool to hold a vector of
thread::JoinHandle<()> instances, initialized the vector with a capacity of
size, set up a for loop that will run some code to create the threads, and
returned a ThreadPool instance containing them.
Filename: src/lib.rs
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
Listing 20-14: Creating a vector for ThreadPool to hold
the threads
We’ve brought std::thread into scope in the library crate, because we’re
using thread::JoinHandle as the type of the items in the vector in
ThreadPool.
Once a valid size is received, our ThreadPool creates a new vector that can
hold size items. The with_capacity function performs the same task as
Vec::new but with an important difference: it preallocates space in the
vector. Because we know we need to store size elements in the vector, doing
this allocation up front is slightly more efficient than using Vec::new,
which resizes itself as elements are inserted.
When you run cargo check again, it should succeed.
A Worker Struct Responsible for Sending Code from the ThreadPool to a Thread
We left a comment in the for loop in Listing 20-14 regarding the creation of
threads. Here, we’ll look at how we actually create threads. The standard
library provides thread::spawn as a way to create threads, and
thread::spawn expects to get some code the thread should run as soon as the
thread is created. However, in our case, we want to create the threads and have
them wait for code that we’ll send later. The standard library’s
implementation of threads doesn’t include any way to do that; we have to
implement it manually.
We’ll implement this behavior by introducing a new data structure between the
ThreadPool and the threads that will manage this new behavior. We’ll call
this data structure Worker, which is a common term in pooling
implementations. The Worker picks up code that needs to be run and runs the
code in the Worker’s thread. Think of people working in the kitchen at a
restaurant: the workers wait until orders come in from customers, and then
they’re responsible for taking those orders and fulfilling them.
Instead of storing a vector of JoinHandle<()> instances in the thread pool,
we’ll store instances of the Worker struct. Each Worker will store a single
JoinHandle<()> instance. Then we’ll implement a method on Worker that will
take a closure of code to run and send it to the already running thread for
execution. We’ll also give each worker an id so we can distinguish between
the different workers in the pool when logging or debugging.
Here is the new process that will happen when we create a ThreadPool. We’ll
implement the code that sends the closure to the thread after we have Worker
set up in this way:
- Define a
Workerstruct that holds anidand aJoinHandle<()>. - Change
ThreadPoolto hold a vector ofWorkerinstances. - Define a
Worker::newfunction that takes anidnumber and returns aWorkerinstance that holds theidand a thread spawned with an empty closure. - In
ThreadPool::new, use theforloop counter to generate anid, create a newWorkerwith thatid, and store the worker in the vector.
If you’re up for a challenge, try implementing these changes on your own before looking at the code in Listing 20-15.
Ready? Here is Listing 20-15 with one way to make the preceding modifications.
Filename: src/lib.rs
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}
Listing 20-15: Modifying ThreadPool to hold Worker
instances instead of holding threads directly
We’ve changed the name of the field on ThreadPool from threads to workers
because it’s now holding Worker instances instead of JoinHandle<()>
instances. We use the counter in the for loop as an argument to
Worker::new, and we store each new Worker in the vector named workers.
External code (like our server in src/main.rs) doesn’t need to know the
implementation details regarding using a Worker struct within ThreadPool,
so we make the Worker struct and its new function private. The
Worker::new function uses the id we give it and stores a JoinHandle<()>
instance that is created by spawning a new thread using an empty closure.
Note: If the operating system can’t create a thread because there aren’t enough system resources,
thread::spawnwill panic. That will cause our whole server to panic, even though the creation of some threads might succeed. For simplicity’s sake, this behavior is fine, but in a production thread pool implementation, you’d likely want to usestd::thread::Builderand itsspawnmethod that returnsResultinstead.
This code will compile and will store the number of Worker instances we
specified as an argument to ThreadPool::new. But we’re still not processing
the closure that we get in execute. Let’s look at how to do that next.
Sending Requests to Threads via Channels
The next problem we’ll tackle is that the closures given to thread::spawn do
absolutely nothing. Currently, we get the closure we want to execute in the
execute method. But we need to give thread::spawn a closure to run when we
create each Worker during the creation of the ThreadPool.
We want the Worker structs that we just created to fetch the code to run from
a queue held in the ThreadPool and send that code to its thread to run.
The channels we learned about in Chapter 16—a simple way to communicate between
two threads—would be perfect for this use case. We’ll use a channel to function
as the queue of jobs, and execute will send a job from the ThreadPool to
the Worker instances, which will send the job to its thread. Here is the plan:
- The
ThreadPoolwill create a channel and hold on to the sender. - Each
Workerwill hold on to the receiver. - We’ll create a new
Jobstruct that will hold the closures we want to send down the channel. - The
executemethod will send the job it wants to execute through the sender. - In its thread, the
Workerwill loop over its receiver and execute the closures of any jobs it receives.
Let’s start by creating a channel in ThreadPool::new and holding the sender
in the ThreadPool instance, as shown in Listing 20-16. The Job struct
doesn’t hold anything for now but will be the type of item we’re sending down
the channel.
Filename: src/lib.rs
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}
Listing 20-16: Modifying ThreadPool to store the
sender of a channel that transmits Job instances
In ThreadPool::new, we create our new channel and have the pool hold the
sender. This will successfully compile.
Let’s try passing a receiver of the channel into each worker as the thread pool
creates the channel. We know we want to use the receiver in the thread that the
workers spawn, so we’ll reference the receiver parameter in the closure. The
code in Listing 20-17 won’t quite compile yet.
Filename: src/lib.rs
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}
Listing 20-17: Passing the receiver to the workers
We’ve made some small and straightforward changes: we pass the receiver into
Worker::new, and then we use it inside the closure.
When we try to check this code, we get this error:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` due to previous error
The code is trying to pass receiver to multiple Worker instances. This
won’t work, as you’ll recall from Chapter 16: the channel implementation that
Rust provides is multiple producer, single consumer. This means we can’t
just clone the consuming end of the channel to fix this code. We also don’t
want to send a message multiple times to multiple consumers; we want one list
of messages with multiple workers such that each message gets processed once.
Additionally, taking a job off the channel queue involves mutating the
receiver, so the threads need a safe way to share and modify receiver;
otherwise, we might get race conditions (as covered in Chapter 16).
Recall the thread-safe smart pointers discussed in Chapter 16: to share
ownership across multiple threads and allow the threads to mutate the value, we
need to use Arc<Mutex<T>>. The Arc type will let multiple workers own the
receiver, and Mutex will ensure that only one worker gets a job from the
receiver at a time. Listing 20-18 shows the changes we need to make.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}
Listing 20-18: Sharing the receiver among the workers
using Arc and Mutex
In ThreadPool::new, we put the receiver in an Arc and a Mutex. For each
new worker, we clone the Arc to bump the reference count so the workers can
share ownership of the receiver.
With these changes, the code compiles! We’re getting there!
Implementing the execute Method
Let’s finally implement the execute method on ThreadPool. We’ll also change
Job from a struct to a type alias for a trait object that holds the type of
closure that execute receives. As discussed in the “Creating Type Synonyms
with Type Aliases”
section of Chapter 19, type aliases allow us to make long types shorter for
ease of use. Look at Listing 20-19.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}
Listing 20-19: Creating a Job type alias for a Box
that holds each closure and then sending the job down the channel
After creating a new Job instance using the closure we get in execute, we
send that job down the sending end of the channel. We’re calling unwrap on
send for the case that sending fails. This might happen if, for example, we
stop all our threads from executing, meaning the receiving end has stopped
receiving new messages. At the moment, we can’t stop our threads from
executing: our threads continue executing as long as the pool exists. The
reason we use unwrap is that we know the failure case won’t happen, but the
compiler doesn’t know that.
But we’re not quite done yet! In the worker, our closure being passed to
thread::spawn still only references the receiving end of the channel.
Instead, we need the closure to loop forever, asking the receiving end of the
channel for a job and running the job when it gets one. Let’s make the change
shown in Listing 20-20 to Worker::new.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}
Listing 20-20: Receiving and executing the jobs in the worker’s thread
Here, we first call lock on the receiver to acquire the mutex, and then we
call unwrap to panic on any errors. Acquiring a lock might fail if the mutex
is in a poisoned state, which can happen if some other thread panicked while
holding the lock rather than releasing the lock. In this situation, calling
unwrap to have this thread panic is the correct action to take. Feel free to
change this unwrap to an expect with an error message that is meaningful to
you.
If we get the lock on the mutex, we call recv to receive a Job from the
channel. A final unwrap moves past any errors here as well, which might occur
if the thread holding the sender has shut down, similar to how the send
method returns Err if the receiver shuts down.
The call to recv blocks, so if there is no job yet, the current thread will
wait until a job becomes available. The Mutex<T> ensures that only one
Worker thread at a time is trying to request a job.
Our thread pool is now in a working state! Give it a cargo run and make some
requests:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field is never read: `workers`
--> src/lib.rs:7:5
|
7 | workers: Vec<Worker>,
| ^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: field is never read: `id`
--> src/lib.rs:48:5
|
48 | id: usize,
| ^^^^^^^^^
warning: field is never read: `thread`
--> src/lib.rs:49:5
|
49 | thread: thread::JoinHandle<()>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
warning: `hello` (lib) generated 3 warnings
Finished dev [unoptimized + debuginfo] target(s) in 1.40s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Success! We now have a thread pool that executes connections asynchronously. There are never more than four threads created, so our system won’t get overloaded if the server receives a lot of requests. If we make a request to /sleep, the server will be able to serve other requests by having another thread run them.
Note: if you open /sleep in multiple browser windows simultaneously, they might load one at a time in 5 second intervals. Some web browsers execute multiple instances of the same request sequentially for caching reasons. This limitation is not caused by our web server.
After learning about the while let loop in Chapter 18, you might be wondering
why we didn’t write the worker thread code as shown in Listing 20-21.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}
Listing 20-21: An alternative implementation of
Worker::new using while let
This code compiles and runs but doesn’t result in the desired threading
behavior: a slow request will still cause other requests to wait to be
processed. The reason is somewhat subtle: the Mutex struct has no public
unlock method because the ownership of the lock is based on the lifetime of
the MutexGuard<T> within the LockResult<MutexGuard<T>> that the lock
method returns. At compile time, the borrow checker can then enforce the rule
that a resource guarded by a Mutex cannot be accessed unless we hold the
lock. However, this implementation can also result in the lock being held
longer than intended if we aren’t mindful of the lifetime of the
MutexGuard<T>.
The code in Listing 20-20 that uses let job = receiver.lock().unwrap().recv().unwrap(); works because with let, any
temporary values used in the expression on the right hand side of the equals
sign are immediately dropped when the let statement ends. However, while let (and if let and match) does not drop temporary values until the end of
the associated block. In Listing 20-21, the lock remains held for the duration
of the call to job(), meaning other workers cannot receive jobs.
Graceful Shutdown and Cleanup
The code in Listing 20-20 is responding to requests asynchronously through the
use of a thread pool, as we intended. We get some warnings about the workers,
id, and thread fields that we’re not using in a direct way that reminds us
we’re not cleaning up anything. When we use the less elegant ctrl-c method to halt the main thread, all other
threads are stopped immediately as well, even if they’re in the middle of
serving a request.
Next, then, we’ll implement the Drop trait to call join on each of the
threads in the pool so they can finish the requests they’re working on before
closing. Then we’ll implement a way to tell the threads they should stop
accepting new requests and shut down. To see this code in action, we’ll modify
our server to accept only two requests before gracefully shutting down its
thread pool.
Implementing the Drop Trait on ThreadPool
Let’s start with implementing Drop on our thread pool. When the pool is
dropped, our threads should all join to make sure they finish their work.
Listing 20-22 shows a first attempt at a Drop implementation; this code won’t
quite work yet.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}
Listing 20-22: Joining each thread when the thread pool goes out of scope
First, we loop through each of the thread pool workers. We use &mut for
this because self is a mutable reference, and we also need to be able to
mutate worker. For each worker, we print a message saying that this
particular worker is shutting down, and then we call join on that worker’s
thread. If the call to join fails, we use unwrap to make Rust panic and go
into an ungraceful shutdown.
Here is the error we get when we compile this code:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: this function takes ownership of the receiver `self`, which moves `worker.thread`
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` due to previous error
The error tells us we can’t call join because we only have a mutable borrow
of each worker and join takes ownership of its argument. To solve this
issue, we need to move the thread out of the Worker instance that owns
thread so join can consume the thread. We did this in Listing 17-15: if
Worker holds an Option<thread::JoinHandle<()>> instead, we can call the
take method on the Option to move the value out of the Some variant and
leave a None variant in its place. In other words, a Worker that is running
will have a Some variant in thread, and when we want to clean up a
Worker, we’ll replace Some with None so the Worker doesn’t have a
thread to run.
So we know we want to update the definition of Worker like this:
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker { id, thread }
}
}
Now let’s lean on the compiler to find the other places that need to change. Checking this code, we get two errors:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `join` found for enum `Option` in the current scope
--> src/lib.rs:52:27
|
52 | worker.thread.join().unwrap();
| ^^^^ method not found in `Option<JoinHandle<()>>`
error[E0308]: mismatched types
--> src/lib.rs:72:22
|
72 | Worker { id, thread }
| ^^^^^^ expected enum `Option`, found struct `JoinHandle`
|
= note: expected enum `Option<JoinHandle<()>>`
found struct `JoinHandle<_>`
help: try wrapping the expression in `Some`
|
72 | Worker { id, thread: Some(thread) }
| +++++++++++++ +
Some errors have detailed explanations: E0308, E0599.
For more information about an error, try `rustc --explain E0308`.
error: could not compile `hello` due to 2 previous errors
Let’s address the second error, which points to the code at the end of
Worker::new; we need to wrap the thread value in Some when we create a
new Worker. Make the following changes to fix this error:
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}
The first error is in our Drop implementation. We mentioned earlier that we
intended to call take on the Option value to move thread out of worker.
The following changes will do so:
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}
As discussed in Chapter 17, the take method on Option takes the Some
variant out and leaves None in its place. We’re using if let to destructure
the Some and get the thread; then we call join on the thread. If a worker’s
thread is already None, we know that worker has already had its thread
cleaned up, so nothing happens in that case.
Signaling to the Threads to Stop Listening for Jobs
With all the changes we’ve made, our code compiles without any warnings.
However, the bad news is this code doesn’t function the way we want it to yet.
The key is the logic in the closures run by the threads of the Worker
instances: at the moment, we call join, but that won’t shut down the threads
because they loop forever looking for jobs. If we try to drop our
ThreadPool with our current implementation of drop, the main thread will
block forever waiting for the first thread to finish.
To fix this problem, we’ll need a change in the ThreadPool drop
implementation and then a change in the Worker loop.
First, we’ll change the ThreadPool drop implementation to explicitly drop
the sender before waiting for the threads to finish. Listing 20-23 shows the
changes to ThreadPool to explicitly drop sender. We use the same Option
and take technique as we did with the thread to be able to move sender out
of ThreadPool:
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
});
Worker {
id,
thread: Some(thread),
}
}
}
Listing 20-23: Explicitly drop sender before joining
the worker threads
Dropping sender closes the channel, which indicates no more messages will be
sent. When that happens, all the calls to recv that the workers do in the
infinite loop will return an error. In Listing 20-24, we change the Worker
loop to gracefully exit the loop in that case, which means the threads will
finish when the ThreadPool drop implementation calls join on them.
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}
Listing 20-24: Explicitly break out of the loop when
recv returns an error
To see this code in action, let’s modify main to accept only two requests
before gracefully shutting down the server, as shown in Listing 20-25.
Filename: src/main.rs
use hello::ThreadPool;
use std::fs;
use std::io::prelude::*;
use std::net::TcpListener;
use std::net::TcpStream;
use std::thread;
use std::time::Duration;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK", "hello.html")
} else if buffer.starts_with(sleep) {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!(
"{}\r\nContent-Length: {}\r\n\r\n{}",
status_line,
contents.len(),
contents
);
stream.write_all(response.as_bytes()).unwrap();
stream.flush().unwrap();
}
Listing 20-25: Shut down the server after serving two requests by exiting the loop
You wouldn’t want a real-world web server to shut down after serving only two requests. This code just demonstrates that the graceful shutdown and cleanup is in working order.
The take method is defined in the Iterator trait and limits the iteration
to the first two items at most. The ThreadPool will go out of scope at the
end of main, and the drop implementation will run.
Start the server with cargo run, and make three requests. The third request
should error, and in your terminal you should see output similar to this:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 1.0s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
You might see a different ordering of workers and messages printed. We can see
how this code works from the messages: workers 0 and 3 got the first two
requests. The server stopped accepting connections after the second connection,
and the Drop implementation on ThreadPool starts executing before worker 3
even starts its job. Dropping the sender disconnects all the workers and
tells them to shut down. The workers each print a message when they disconnect,
and then the thread pool calls join to wait for each worker thread to finish.
Notice one interesting aspect of this particular execution: the ThreadPool
dropped the sender, and before any worker received an error, we tried to join
worker 0. Worker 0 had not yet gotten an error from recv, so the main thread
blocked waiting for worker 0 to finish. In the meantime, worker 3 received a
job and then all threads received an error. When worker 0 finished, the main
thread waited for the rest of the workers to finish. At that point, they had
all exited their loops and stopped.
Congrats! We’ve now completed our project; we have a basic web server that uses a thread pool to respond asynchronously. We’re able to perform a graceful shutdown of the server, which cleans up all the threads in the pool.
Here’s the full code for reference:
Filename: src/main.rs
use hello::ThreadPool;
use std::fs;
use std::io::prelude::*;
use std::net::TcpListener;
use std::net::TcpStream;
use std::thread;
use std::time::Duration;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK", "hello.html")
} else if buffer.starts_with(sleep) {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!(
"{}\r\nContent-Length: {}\r\n\r\n{}",
status_line,
contents.len(),
contents
);
stream.write_all(response.as_bytes()).unwrap();
stream.flush().unwrap();
}
Filename: src/lib.rs
use std::{
sync::{mpsc, Arc, Mutex},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}
We could do more here! If you want to continue enhancing this project, here are some ideas:
- Add more documentation to
ThreadPooland its public methods. - Add tests of the library’s functionality.
- Change calls to
unwrapto more robust error handling. - Use
ThreadPoolto perform some task other than serving web requests. - Find a thread pool crate on crates.io and implement a similar web server using the crate instead. Then compare its API and robustness to the thread pool we implemented.
Summary
Well done! You’ve made it to the end of the book! We want to thank you for joining us on this tour of Rust. You’re now ready to implement your own Rust projects and help with other peoples’ projects. Keep in mind that there is a welcoming community of other Rustaceans who would love to help you with any challenges you encounter on your Rust journey.
Appendix
The following sections contain reference material you may find useful in your Rust journey.
Appendix A: Keywords
The following list contains keywords that are reserved for current or future use by the Rust language. As such, they cannot be used as identifiers (except as raw identifiers as we’ll discuss in the “Raw Identifiers” section). Identifiers are names of functions, variables, parameters, struct fields, modules, crates, constants, macros, static values, attributes, types, traits, or lifetimes.
Keywords Currently in Use
The following is a list of keywords currently in use, with their functionality described.
as- perform primitive casting, disambiguate the specific trait containing an item, or rename items inusestatementsasync- return aFutureinstead of blocking the current threadawait- suspend execution until the result of aFutureis readybreak- exit a loop immediatelyconst- define constant items or constant raw pointerscontinue- continue to the next loop iterationcrate- in a module path, refers to the crate rootdyn- dynamic dispatch to a trait objectelse- fallback forifandif letcontrol flow constructsenum- define an enumerationextern- link an external function or variablefalse- Boolean false literalfn- define a function or the function pointer typefor- loop over items from an iterator, implement a trait, or specify a higher-ranked lifetimeif- branch based on the result of a conditional expressionimpl- implement inherent or trait functionalityin- part offorloop syntaxlet- bind a variableloop- loop unconditionallymatch- match a value to patternsmod- define a modulemove- make a closure take ownership of all its capturesmut- denote mutability in references, raw pointers, or pattern bindingspub- denote public visibility in struct fields,implblocks, or modulesref- bind by referencereturn- return from functionSelf- a type alias for the type we are defining or implementingself- method subject or current modulestatic- global variable or lifetime lasting the entire program executionstruct- define a structuresuper- parent module of the current moduletrait- define a traittrue- Boolean true literaltype- define a type alias or associated typeunion- define a union; is only a keyword when used in a union declarationunsafe- denote unsafe code, functions, traits, or implementationsuse- bring symbols into scopewhere- denote clauses that constrain a typewhile- loop conditionally based on the result of an expression
Keywords Reserved for Future Use
The following keywords do not yet have any functionality but are reserved by Rust for potential future use.
abstractbecomeboxdofinalmacrooverrideprivtrytypeofunsizedvirtualyield
Raw Identifiers
Raw identifiers are the syntax that lets you use keywords where they wouldn’t
normally be allowed. You use a raw identifier by prefixing a keyword with r#.
For example, match is a keyword. If you try to compile the following function
that uses match as its name:
Filename: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
you’ll get this error:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
The error shows that you can’t use the keyword match as the function
identifier. To use match as a function name, you need to use the raw
identifier syntax, like this:
Filename: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool { haystack.contains(needle) } fn main() { assert!(r#match("foo", "foobar")); }
This code will compile without any errors. Note the r# prefix on the function
name in its definition as well as where the function is called in main.
Raw identifiers allow you to use any word you choose as an identifier, even if
that word happens to be a reserved keyword. This gives us more freedom to
choose identifier names, as well as lets us integrate with programs written in
a language where these words aren’t keywords. In addition, raw identifiers
allow you to use libraries written in a different Rust edition than your crate
uses. For example, try isn’t a keyword in the 2015 edition but is in the 2018
edition. If you depend on a library that’s written using the 2015 edition and
has a try function, you’ll need to use the raw identifier syntax, r#try in
this case, to call that function from your 2018 edition code. See Appendix
E for more information on editions.
Appendix B: Operators and Symbols
This appendix contains a glossary of Rust’s syntax, including operators and other symbols that appear by themselves or in the context of paths, generics, trait bounds, macros, attributes, comments, tuples, and brackets.
Operators
Table B-1 contains the operators in Rust, an example of how the operator would appear in context, a short explanation, and whether that operator is overloadable. If an operator is overloadable, the relevant trait to use to overload that operator is listed.
Table B-1: Operators
| Operator | Example | Explanation | Overloadable? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Macro expansion | |
! | !expr | Bitwise or logical complement | Not |
!= | expr != expr | Nonequality comparison | PartialEq |
% | expr % expr | Arithmetic remainder | Rem |
%= | var %= expr | Arithmetic remainder and assignment | RemAssign |
& | &expr, &mut expr | Borrow | |
& | &type, &mut type, &'a type, &'a mut type | Borrowed pointer type | |
& | expr & expr | Bitwise AND | BitAnd |
&= | var &= expr | Bitwise AND and assignment | BitAndAssign |
&& | expr && expr | Short-circuiting logical AND | |
* | expr * expr | Arithmetic multiplication | Mul |
*= | var *= expr | Arithmetic multiplication and assignment | MulAssign |
* | *expr | Dereference | Deref |
* | *const type, *mut type | Raw pointer | |
+ | trait + trait, 'a + trait | Compound type constraint | |
+ | expr + expr | Arithmetic addition | Add |
+= | var += expr | Arithmetic addition and assignment | AddAssign |
, | expr, expr | Argument and element separator | |
- | - expr | Arithmetic negation | Neg |
- | expr - expr | Arithmetic subtraction | Sub |
-= | var -= expr | Arithmetic subtraction and assignment | SubAssign |
-> | fn(...) -> type, |…| -> type | Function and closure return type | |
. | expr.ident | Member access | |
.. | .., expr.., ..expr, expr..expr | Right-exclusive range literal | PartialOrd |
..= | ..=expr, expr..=expr | Right-inclusive range literal | PartialOrd |
.. | ..expr | Struct literal update syntax | |
.. | variant(x, ..), struct_type { x, .. } | “And the rest” pattern binding | |
... | expr...expr | (Deprecated, use ..= instead) In a pattern: inclusive range pattern | |
/ | expr / expr | Arithmetic division | Div |
/= | var /= expr | Arithmetic division and assignment | DivAssign |
: | pat: type, ident: type | Constraints | |
: | ident: expr | Struct field initializer | |
: | 'a: loop {...} | Loop label | |
; | expr; | Statement and item terminator | |
; | [...; len] | Part of fixed-size array syntax | |
<< | expr << expr | Left-shift | Shl |
<<= | var <<= expr | Left-shift and assignment | ShlAssign |
< | expr < expr | Less than comparison | PartialOrd |
<= | expr <= expr | Less than or equal to comparison | PartialOrd |
= | var = expr, ident = type | Assignment/equivalence | |
== | expr == expr | Equality comparison | PartialEq |
=> | pat => expr | Part of match arm syntax | |
> | expr > expr | Greater than comparison | PartialOrd |
>= | expr >= expr | Greater than or equal to comparison | PartialOrd |
>> | expr >> expr | Right-shift | Shr |
>>= | var >>= expr | Right-shift and assignment | ShrAssign |
@ | ident @ pat | Pattern binding | |
^ | expr ^ expr | Bitwise exclusive OR | BitXor |
^= | var ^= expr | Bitwise exclusive OR and assignment | BitXorAssign |
| | pat | pat | Pattern alternatives | |
| | expr | expr | Bitwise OR | BitOr |
|= | var |= expr | Bitwise OR and assignment | BitOrAssign |
|| | expr || expr | Short-circuiting logical OR | |
? | expr? | Error propagation |
Non-operator Symbols
The following list contains all symbols that don’t function as operators; that is, they don’t behave like a function or method call.
Table B-2 shows symbols that appear on their own and are valid in a variety of locations.
Table B-2: Stand-Alone Syntax
| Symbol | Explanation |
|---|---|
'ident | Named lifetime or loop label |
...u8, ...i32, ...f64, ...usize, etc. | Numeric literal of specific type |
"..." | String literal |
r"...", r#"..."#, r##"..."##, etc. | Raw string literal, escape characters not processed |
b"..." | Byte string literal; constructs an array of bytes instead of a string |
br"...", br#"..."#, br##"..."##, etc. | Raw byte string literal, combination of raw and byte string literal |
'...' | Character literal |
b'...' | ASCII byte literal |
|…| expr | Closure |
! | Always empty bottom type for diverging functions |
_ | “Ignored” pattern binding; also used to make integer literals readable |
Table B-3 shows symbols that appear in the context of a path through the module hierarchy to an item.
Table B-3: Path-Related Syntax
| Symbol | Explanation |
|---|---|
ident::ident | Namespace path |
::path | Path relative to the crate root (i.e., an explicitly absolute path) |
self::path | Path relative to the current module (i.e., an explicitly relative path). |
super::path | Path relative to the parent of the current module |
type::ident, <type as trait>::ident | Associated constants, functions, and types |
<type>::... | Associated item for a type that cannot be directly named (e.g., <&T>::..., <[T]>::..., etc.) |
trait::method(...) | Disambiguating a method call by naming the trait that defines it |
type::method(...) | Disambiguating a method call by naming the type for which it’s defined |
<type as trait>::method(...) | Disambiguating a method call by naming the trait and type |
Table B-4 shows symbols that appear in the context of using generic type parameters.
Table B-4: Generics
| Symbol | Explanation |
|---|---|
path<...> | Specifies parameters to generic type in a type (e.g., Vec<u8>) |
path::<...>, method::<...> | Specifies parameters to generic type, function, or method in an expression; often referred to as turbofish (e.g., "42".parse::<i32>()) |
fn ident<...> ... | Define generic function |
struct ident<...> ... | Define generic structure |
enum ident<...> ... | Define generic enumeration |
impl<...> ... | Define generic implementation |
for<...> type | Higher-ranked lifetime bounds |
type<ident=type> | A generic type where one or more associated types have specific assignments (e.g., Iterator<Item=T>) |
Table B-5 shows symbols that appear in the context of constraining generic type parameters with trait bounds.
Table B-5: Trait Bound Constraints
| Symbol | Explanation |
|---|---|
T: U | Generic parameter T constrained to types that implement U |
T: 'a | Generic type T must outlive lifetime 'a (meaning the type cannot transitively contain any references with lifetimes shorter than 'a) |
T: 'static | Generic type T contains no borrowed references other than 'static ones |
'b: 'a | Generic lifetime 'b must outlive lifetime 'a |
T: ?Sized | Allow generic type parameter to be a dynamically sized type |
'a + trait, trait + trait | Compound type constraint |
Table B-6 shows symbols that appear in the context of calling or defining macros and specifying attributes on an item.
Table B-6: Macros and Attributes
| Symbol | Explanation |
|---|---|
#[meta] | Outer attribute |
#![meta] | Inner attribute |
$ident | Macro substitution |
$ident:kind | Macro capture |
$(…)… | Macro repetition |
ident!(...), ident!{...}, ident![...] | Macro invocation |
Table B-7 shows symbols that create comments.
Table B-7: Comments
| Symbol | Explanation |
|---|---|
// | Line comment |
//! | Inner line doc comment |
/// | Outer line doc comment |
/*...*/ | Block comment |
/*!...*/ | Inner block doc comment |
/**...*/ | Outer block doc comment |
Table B-8 shows symbols that appear in the context of using tuples.
Table B-8: Tuples
| Symbol | Explanation |
|---|---|
() | Empty tuple (aka unit), both literal and type |
(expr) | Parenthesized expression |
(expr,) | Single-element tuple expression |
(type,) | Single-element tuple type |
(expr, ...) | Tuple expression |
(type, ...) | Tuple type |
expr(expr, ...) | Function call expression; also used to initialize tuple structs and tuple enum variants |
expr.0, expr.1, etc. | Tuple indexing |
Table B-9 shows the contexts in which curly braces are used.
Table B-9: Curly Brackets
| Context | Explanation |
|---|---|
{...} | Block expression |
Type {...} | struct literal |
Table B-10 shows the contexts in which square brackets are used.
Table B-10: Square Brackets
| Context | Explanation |
|---|---|
[...] | Array literal |
[expr; len] | Array literal containing len copies of expr |
[type; len] | Array type containing len instances of type |
expr[expr] | Collection indexing. Overloadable (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Collection indexing pretending to be collection slicing, using Range, RangeFrom, RangeTo, or RangeFull as the “index” |
Appendix C: Derivable Traits
- Appendix C: Derivable Traits * PartialEq * Eq * PartialOrd * Ord * Clone * Copy
In various places in the book, we’ve discussed the derive attribute, which
you can apply to a struct or enum definition.
The
deriveattribute generates code that will implement a trait with its own default implementation on the type you’ve annotated with thederivesyntax.
In this appendix, we provide a reference of all the traits in the standard
library that you can use with derive. Each section covers:
- What operators and methods deriving this trait will enable
- What the implementation of the trait provided by
derivedoes - What implementing the trait signifies about the type
- The conditions in which you’re allowed or not allowed to implement the trait
- Examples of operations that require the trait
If you want different behavior from that provided by the
deriveattribute, consult the standard library documentation for each trait for details of how to manually implement them.
-
These traits listed here are the only ones defined by the standard library that can be implemented on your types using
derive. -
Other traits defined in the standard library don’t have sensible default behavior, so it’s up to you to implement them in the way that makes sense for what you’re trying to accomplish.
An example of a trait that can’t be derived is Display, which handles
formatting for end users.
You should always consider the appropriate way to display a type to an end user:
- What parts of the type should an end user be allowed to see?
- What parts would they find relevant?
- What format of the data would be most relevant to them?
- The Rust compiler doesn’t have this insight, so it can’t provide appropriate default behavior for you.
The list of derivable traits provided in this appendix is not comprehensive:
- libraries can implement
derivefor their own traits, making the list of traits you can usederivewith truly open-ended. - Implementing
deriveinvolves using a procedural macro, which is covered in the “Macros” section of Chapter 19.
Debug for Programmer Output
-
The
Debugtrait enables debug formatting in format strings, which you indicate by adding:?within{}placeholders. -
The
Debugtrait allows you to print instances of a type for debugging purposes, so you and other programmers using your type can inspect an instance at a particular point in a program’s execution. -
The
Debugtrait is required, for example, in use of theassert_eq!macro.
- This macro prints the values of instances given as arguments if the equality assertion fails so programmers can see why the two instances weren’t equal.
PartialEq and Eq for Equality Comparisons
PartialEq
-
The
PartialEqtrait allows you to compare instances of a type to check for equality and enables use of the==and!=operators. -
Deriving
PartialEqimplements theeqmethod.
- When
PartialEqis derived on structs, two instances are equal only if all fields are equal, and the instances are not equal if any fields are not equal. - When derived on enums, each variant is equal to itself and not equal to the other variants.
- The
PartialEqtrait is required, for example, with the use of theassert_eq!macro, which needs to be able to compare two instances of a type for equality.
Eq
- The
Eqtrait has no methods.
- Its purpose is to signal that for every value of the annotated type, the value is equal to itself.
- The
Eqtrait can only be applied to types that also implementPartialEq, although not all types that implementPartialEqcan implementEq.
-
One example of this is floating point number types: the implementation of floating point numbers states that two instances of the not-a-number (
NaN) value are not equal to each other. -
An example of when
Eqis required is for keys in aHashMap<K, V>so theHashMap<K, V>can tell whether two keys are the same.
PartialOrd and Ord for Ordering Comparisons
PartialOrd
The PartialOrd trait allows you to compare instances of a type for sorting
purposes.
- A type that implements
PartialOrdcan be used with the<,>,<=, and>=operators. - You can only apply the
PartialOrdtrait to types that also implementPartialEq.
Deriving PartialOrd implements the partial_cmp method, which returns an
Option<Ordering> that will be None when the values given don’t produce an
ordering.
An example of a value that doesn’t produce an ordering, even though most values of that type can be compared, is the not-a-number (
NaN) floating point value.
Calling partial_cmp with any floating point number and the NaN
floating point value will return None.
When derived on structs, PartialOrd compares two instances by comparing the
value in each field in the order in which the fields appear in the struct
definition.
When derived on enums, variants of the enum declared earlier in the enum definition are considered less than the variants listed later.
The PartialOrd trait is required, for example, for the gen_range method
from the rand crate that generates a random value in the range specified by a
range expression.
Ord
The Ord trait allows you to know that for any two values of the annotated
type, a valid ordering will exist.
The Ord trait implements the cmp method,
which returns an Ordering rather than an Option<Ordering> because a valid
ordering will always be possible.
You can only apply the Ord trait to types
that also implement PartialOrd and Eq (and Eq requires PartialEq).
When
derived on structs and enums, cmp behaves the same way as the derived
implementation for partial_cmp does with PartialOrd.
An example of when
Ordis required is when storing values in aBTreeSet<T>, a data structure that stores data based on the sort order of the values.
Clone and Copy for Duplicating Values
Clone
The Clone trait allows you to explicitly create a deep copy of a value, and
the duplication process might involve running arbitrary code and copying heap
data.
See the “Ways Variables and Data Interact: Clone” section in Chapter 4 for more information on
Clone.
Deriving Clone implements the clone method, which when implemented for the
whole type, calls clone on each of the parts of the type.
This means all the fields or values in the type must also implement
Cloneto deriveClone.
An example of when Clone is required is when calling the to_vec method on a
slice.
The slice doesn’t own the type instances it contains, but the vector returned from
to_vecwill need to own its instances, soto_veccallscloneon each item. Thus, the type stored in the slice must implementClone.
Copy
The Copy trait allows you to duplicate a value by only copying bits stored on
the stack; no arbitrary code is necessary.
See the “Stack-Only Data: Copy” section in Chapter 4 for more information on
Copy.
The Copy trait doesn’t define any methods to prevent programmers from
overloading those methods and violating the assumption that no arbitrary code
is being run.
That way, all programmers can assume that copying a value will be very fast.
You can derive Copy on any type whose parts all implement Copy.
A type that implements
Copymust also implementClone, because a type that implementsCopyhas a trivial implementation ofClonethat performs the same task asCopy.
The Copy trait is rarely required;
types that implement Copy have
optimizations available, meaning you don’t have to call clone, which makes
the code more concise.
Everything possible with Copy you can also accomplish with Clone, but the
code might be slower or have to use clone in places.
Hash for Mapping a Value to a Value of Fixed Size
The Hash trait allows you to take an instance of a type of arbitrary size and
map that instance to a value of fixed size using a hash function.
Deriving
Hashimplements thehashmethod.
The derived implementation of the hash
method combines the result of calling hash on each of the parts of the type,
meaning all fields or values must also implement Hash to derive Hash.
An example of when
Hashis required is in storing keys in aHashMap<K, V>to store data efficiently.
Default for Default Values
The Default trait allows you to create a default value for a type.
Deriving
Defaultimplements thedefaultfunction.
The derived implementation of the
default function calls the default function on each part of the type,
meaning all fields or values in the type must also implement Default to
derive Default.
The
Default::defaultfunction is commonly used in combination with the struct update syntax discussed in the “Creating Instances From Other Instances With Struct Update Syntax” section in Chapter 5.
You can customize a few fields of a struct and then
set and use a default value for the rest of the fields by using
..Default::default().
The Default trait is required when you use the method unwrap_or_default on
Option<T> instances, for example.
If the
Option<T>isNone, the methodunwrap_or_defaultwill return the result ofDefault::defaultfor the typeTstored in theOption<T>.
Appendix D - Useful Development Tools
In this appendix, we talk about some useful development tools that the Rust project provides. We’ll look at automatic formatting, quick ways to apply warning fixes, a linter, and integrating with IDEs.
Automatic Formatting with rustfmt
The rustfmt tool reformats your code according to the community code style.
Many collaborative projects use rustfmt to prevent arguments about which
style to use when writing Rust: everyone formats their code using the tool.
To install rustfmt, enter the following:
$ rustup component add rustfmt
This command gives you rustfmt and cargo-fmt, similar to how Rust gives you
both rustc and cargo. To format any Cargo project, enter the following:
$ cargo fmt
Running this command reformats all the Rust code in the current crate. This
should only change the code style, not the code semantics. For more information
on rustfmt, see its documentation.
Fix Your Code with rustfix
The rustfix tool is included with Rust installations and can automatically fix compiler warnings that have a clear way to correct the problem that’s likely what you want. It’s likely you’ve seen compiler warnings before. For example, consider this code:
Filename: src/main.rs
fn do_something() {} fn main() { for i in 0..100 { do_something(); } }
Here, we’re calling the do_something function 100 times, but we never use the
variable i in the body of the for loop. Rust warns us about that:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: unused variable: `i`
--> src/main.rs:4:9
|
4 | for i in 0..100 {
| ^ help: consider using `_i` instead
|
= note: #[warn(unused_variables)] on by default
Finished dev [unoptimized + debuginfo] target(s) in 0.50s
The warning suggests that we use _i as a name instead: the underscore
indicates that we intend for this variable to be unused. We can automatically
apply that suggestion using the rustfix tool by running the command cargo fix:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
When we look at src/main.rs again, we’ll see that cargo fix has changed the
code:
Filename: src/main.rs
fn do_something() {} fn main() { for _i in 0..100 { do_something(); } }
The for loop variable is now named _i, and the warning no longer appears.
You can also use the cargo fix command to transition your code between
different Rust editions. Editions are covered in Appendix E.
More Lints with Clippy
The Clippy tool is a collection of lints to analyze your code so you can catch common mistakes and improve your Rust code.
To install Clippy, enter the following:
$ rustup component add clippy
To run Clippy’s lints on any Cargo project, enter the following:
$ cargo clippy
For example, say you write a program that uses an approximation of a mathematical constant, such as pi, as this program does:
Filename: src/main.rs
fn main() { let x = 3.1415; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Running cargo clippy on this project results in this error:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
This error lets you know that Rust already has a more precise PI constant
defined, and that your program would be more correct if you used the constant
instead. You would then change your code to use the PI constant. The
following code doesn’t result in any errors or warnings from Clippy:
Filename: src/main.rs
fn main() { let x = std::f64::consts::PI; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
For more information on Clippy, see its documentation.
IDE Integration Using rust-analyzer
To help IDE integration, the Rust community recommends using
rust-analyzer. This tool is a set of
compiler-centric utilities that speaks the Language Server Protocol, which is a specification for IDEs and programming languages to
communicate with each other. Different clients can use rust-analyzer, such as
the Rust analyzer plug-in for Visual Studio Code.
Visit the rust-analyzer project’s home page
for installation instructions, then install the language server support in your
particular IDE. Your IDE will gain abilities such as autocompletion, jump to
definition, and inline errors.
Appendix E - Editions
In Chapter 1, you saw that cargo new adds a bit of metadata to your
Cargo.toml file about an edition. This appendix talks about what that means!
The Rust language and compiler have a six-week release cycle, meaning users get a constant stream of new features. Other programming languages release larger changes less often; Rust releases smaller updates more frequently. After a while, all of these tiny changes add up. But from release to release, it can be difficult to look back and say, “Wow, between Rust 1.10 and Rust 1.31, Rust has changed a lot!”
Every two or three years, the Rust team produces a new Rust edition. Each edition brings together the features that have landed into a clear package with fully updated documentation and tooling. New editions ship as part of the usual six-week release process.
Editions serve different purposes for different people:
- For active Rust users, a new edition brings together incremental changes into an easy-to-understand package.
- For non-users, a new edition signals that some major advancements have landed, which might make Rust worth another look.
- For those developing Rust, a new edition provides a rallying point for the project as a whole.
At the time of this writing, three Rust editions are available: Rust 2015, Rust 2018, and Rust 2021. This book is written using Rust 2021 edition idioms.
The edition key in Cargo.toml indicates which edition the compiler should
use for your code. If the key doesn’t exist, Rust uses 2015 as the edition
value for backward compatibility reasons.
Each project can opt in to an edition other than the default 2015 edition. Editions can contain incompatible changes, such as including a new keyword that conflicts with identifiers in code. However, unless you opt in to those changes, your code will continue to compile even as you upgrade the Rust compiler version you use.
All Rust compiler versions support any edition that existed prior to that compiler’s release, and they can link crates of any supported editions together. Edition changes only affect the way the compiler initially parses code. Therefore, if you’re using Rust 2015 and one of your dependencies uses Rust 2018, your project will compile and be able to use that dependency. The opposite situation, where your project uses Rust 2018 and a dependency uses Rust 2015, works as well.
To be clear: most features will be available on all editions. Developers using any Rust edition will continue to see improvements as new stable releases are made. However, in some cases, mainly when new keywords are added, some new features might only be available in later editions. You will need to switch editions if you want to take advantage of such features.
For more details, the Edition
Guide is a complete book
about editions that enumerates the differences between editions and explains
how to automatically upgrade your code to a new edition via cargo fix.
Appendix F: Translations of the Book
For resources in languages other than English. Most are still in progress; see the Translations label to help or let us know about a new translation!
- Português (BR)
- Português (PT)
- 简体中文
- 正體中文
- Українська
- Español, alternate
- Italiano
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi
- Deutsch
- हिंदी
- ไทย
- Danske
Appendix G - How Rust is Made and “Nightly Rust”
This appendix is about how Rust is made and how that affects you as a Rust developer.
Stability Without Stagnation
As a language, Rust cares a lot about the stability of your code. We want Rust to be a rock-solid foundation you can build on, and if things were constantly changing, that would be impossible. At the same time, if we can’t experiment with new features, we may not find out important flaws until after their release, when we can no longer change things.
Our solution to this problem is what we call “stability without stagnation”, and our guiding principle is this: you should never have to fear upgrading to a new version of stable Rust. Each upgrade should be painless, but should also bring you new features, fewer bugs, and faster compile times.
Choo, Choo! Release Channels and Riding the Trains
Rust development operates on a train schedule. That is, all development is
done on the master branch of the Rust repository. Releases follow a software
release train model, which has been used by Cisco IOS and other software
projects. There are three release channels for Rust:
- Nightly
- Beta
- Stable
Most Rust developers primarily use the stable channel, but those who want to try out experimental new features may use nightly or beta.
Here’s an example of how the development and release process works: let’s
assume that the Rust team is working on the release of Rust 1.5. That release
happened in December of 2015, but it will provide us with realistic version
numbers. A new feature is added to Rust: a new commit lands on the master
branch. Each night, a new nightly version of Rust is produced. Every day is a
release day, and these releases are created by our release infrastructure
automatically. So as time passes, our releases look like this, once a night:
nightly: * - - * - - *
Every six weeks, it’s time to prepare a new release! The beta branch of the
Rust repository branches off from the master branch used by nightly. Now,
there are two releases:
nightly: * - - * - - *
|
beta: *
Most Rust users do not use beta releases actively, but test against beta in their CI system to help Rust discover possible regressions. In the meantime, there’s still a nightly release every night:
nightly: * - - * - - * - - * - - *
|
beta: *
Let’s say a regression is found. Good thing we had some time to test the beta
release before the regression snuck into a stable release! The fix is applied
to master, so that nightly is fixed, and then the fix is backported to the
beta branch, and a new release of beta is produced:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
Six weeks after the first beta was created, it’s time for a stable release! The
stable branch is produced from the beta branch:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Hooray! Rust 1.5 is done! However, we’ve forgotten one thing: because the six
weeks have gone by, we also need a new beta of the next version of Rust, 1.6.
So after stable branches off of beta, the next version of beta branches
off of nightly again:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
This is called the “train model” because every six weeks, a release “leaves the station”, but still has to take a journey through the beta channel before it arrives as a stable release.
Rust releases every six weeks, like clockwork. If you know the date of one Rust release, you can know the date of the next one: it’s six weeks later. A nice aspect of having releases scheduled every six weeks is that the next train is coming soon. If a feature happens to miss a particular release, there’s no need to worry: another one is happening in a short time! This helps reduce pressure to sneak possibly unpolished features in close to the release deadline.
Thanks to this process, you can always check out the next build of Rust and
verify for yourself that it’s easy to upgrade to: if a beta release doesn’t
work as expected, you can report it to the team and get it fixed before the
next stable release happens! Breakage in a beta release is relatively rare, but
rustc is still a piece of software, and bugs do exist.
Unstable Features
There’s one more catch with this release model: unstable features. Rust uses a
technique called “feature flags” to determine what features are enabled in a
given release. If a new feature is under active development, it lands on
master, and therefore, in nightly, but behind a feature flag. If you, as a
user, wish to try out the work-in-progress feature, you can, but you must be
using a nightly release of Rust and annotate your source code with the
appropriate flag to opt in.
If you’re using a beta or stable release of Rust, you can’t use any feature flags. This is the key that allows us to get practical use with new features before we declare them stable forever. Those who wish to opt into the bleeding edge can do so, and those who want a rock-solid experience can stick with stable and know that their code won’t break. Stability without stagnation.
This book only contains information about stable features, as in-progress features are still changing, and surely they’ll be different between when this book was written and when they get enabled in stable builds. You can find documentation for nightly-only features online.
Rustup and the Role of Rust Nightly
Rustup makes it easy to change between different release channels of Rust, on a global or per-project basis. By default, you’ll have stable Rust installed. To install nightly, for example:
$ rustup toolchain install nightly
You can see all of the toolchains (releases of Rust and associated
components) you have installed with rustup as well. Here’s an example on one
of your authors’ Windows computer:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
As you can see, the stable toolchain is the default. Most Rust users use stable
most of the time. You might want to use stable most of the time, but use
nightly on a specific project, because you care about a cutting-edge feature.
To do so, you can use rustup override in that project’s directory to set the
nightly toolchain as the one rustup should use when you’re in that directory:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Now, every time you call rustc or cargo inside of
~/projects/needs-nightly, rustup will make sure that you are using nightly
Rust, rather than your default of stable Rust. This comes in handy when you
have a lot of Rust projects!
The RFC Process and Teams
So how do you learn about these new features? Rust’s development model follows a Request For Comments (RFC) process. If you’d like an improvement in Rust, you can write up a proposal, called an RFC.
Anyone can write RFCs to improve Rust, and the proposals are reviewed and discussed by the Rust team, which is comprised of many topic subteams. There’s a full list of the teams on Rust’s website, which includes teams for each area of the project: language design, compiler implementation, infrastructure, documentation, and more. The appropriate team reads the proposal and the comments, writes some comments of their own, and eventually, there’s consensus to accept or reject the feature.
If the feature is accepted, an issue is opened on the Rust repository, and
someone can implement it. The person who implements it very well may not be the
person who proposed the feature in the first place! When the implementation is
ready, it lands on the master branch behind a feature gate, as we discussed
in the “Unstable Features” section.
After some time, once Rust developers who use nightly releases have been able to try out the new feature, team members will discuss the feature, how it’s worked out on nightly, and decide if it should make it into stable Rust or not. If the decision is to move forward, the feature gate is removed, and the feature is now considered stable! It rides the trains into a new stable release of Rust.
Rust by Example
Rust is a modern systems programming language focusing on safety, speed, and concurrency. It accomplishes these goals by being memory safe without using garbage collection.
Rust by Example (RBE) is a collection of runnable examples that illustrate various Rust concepts and standard libraries. To get even more out of these examples, don’t forget to install Rust locally and check out the official docs. Additionally for the curious, you can also check out the source code for this site.
Now let’s begin!
-
Hello World - Start with a traditional Hello World program.
-
Primitives - Learn about signed integers, unsigned integers and other primitives.
-
Custom Types -
structandenum. -
Variable Bindings - mutable bindings, scope, shadowing.
-
Types - Learn about changing and defining types.
-
Flow of Control -
if/else,for, and others. -
Functions - Learn about Methods, Closures and High Order Functions.
-
Modules - Organize code using modules
-
Crates - A crate is a compilation unit in Rust. Learn to create a library.
-
Cargo - Go through some basic features of the official Rust package management tool.
-
Attributes - An attribute is metadata applied to some module, crate or item.
-
Generics - Learn about writing a function or data type which can work for multiple types of arguments.
-
Scoping rules - Scopes play an important part in ownership, borrowing, and lifetimes.
-
Traits - A trait is a collection of methods defined for an unknown type:
Self -
Error handling - Learn Rust way of handling failures.
-
Std library types - Learn about some custom types provided by
stdlibrary. -
Std misc - More custom types for file handling, threads.
-
Testing - All sorts of testing in Rust.
-
Meta - Documentation, Benchmarking.
Hello World
This is the source code of the traditional Hello World program.
// This is a comment, and is ignored by the compiler // You can test this code by clicking the "Run" button over there -> // or if you prefer to use your keyboard, you can use the "Ctrl + Enter" shortcut // This code is editable, feel free to hack it! // You can always return to the original code by clicking the "Reset" button -> // This is the main function fn main() { // Statements here are executed when the compiled binary is called // Print text to the console println!("Hello World!"); }
println! is a macro that prints text to the
console.
A binary can be generated using the Rust compiler: rustc.
$ rustc hello.rs
rustc will produce a hello binary that can be executed.
$ ./hello
Hello World!
Activity
Click ‘Run’ above to see the expected output. Next, add a new
line with a second println! macro so that the output
shows:
Hello World!
I'm a Rustacean!
Comments
Any program requires comments, and Rust supports a few different varieties:
- Regular comments which are ignored by the compiler:
// Line comments which go to the end of the line./* Block comments which go to the closing delimiter. */
- Doc comments which are parsed into HTML library
documentation:
/// Generate library docs for the following item.//! Generate library docs for the enclosing item.
fn main() { // This is an example of a line comment // There are two slashes at the beginning of the line // And nothing written inside these will be read by the compiler // println!("Hello, world!"); // Run it. See? Now try deleting the two slashes, and run it again. /* * This is another type of comment, a block comment. In general, * line comments are the recommended comment style. But * block comments are extremely useful for temporarily disabling * chunks of code. /* Block comments can be /* nested, */ */ * so it takes only a few keystrokes to comment out everything * in this main() function. /*/*/* Try it yourself! */*/*/ */ /* Note: The previous column of `*` was entirely for style. There's no actual need for it. */ // You can manipulate expressions more easily with block comments // than with line comments. Try deleting the comment delimiters // to change the result: let x = 5 + /* 90 + */ 5; println!("Is `x` 10 or 100? x = {}", x); }
See also:
Formatted print
Printing is handled by a series of macros defined in std::fmt
some of which include:
format!: write formatted text toStringprint!: same asformat!but the text is printed to the console (io::stdout).println!: same asprint!but a newline is appended.eprint!: same asprint!but the text is printed to the standard error (io::stderr).eprintln!: same aseprint!but a newline is appended.
All parse text in the same fashion. As a plus, Rust checks formatting correctness at compile time.
fn main() { // In general, the `{}` will be automatically replaced with any // arguments. These will be stringified. println!("{} days", 31); // Positional arguments can be used. Specifying an integer inside `{}` // determines which additional argument will be replaced. Arguments start // at 0 immediately after the format string println!("{0}, this is {1}. {1}, this is {0}", "Alice", "Bob"); // As can named arguments. println!("{subject} {verb} {object}", object="the lazy dog", subject="the quick brown fox", verb="jumps over"); // Different formatting can be invoked by specifying the format character after a // `:`. println!("Base 10: {}", 69420); //69420 println!("Base 2 (binary): {:b}", 69420); //10000111100101100 println!("Base 8 (octal): {:o}", 69420); //207454 println!("Base 16 (hexadecimal): {:x}", 69420); //10f2c println!("Base 16 (hexadecimal): {:X}", 69420); //10F2C // You can right-justify text with a specified width. This will // output " 1". (Four white spaces and a "1", for a total width of 5.) println!("{number:>5}", number=1); // You can pad numbers with extra zeroes, //and left-adjust by flipping the sign. This will output "10000". println!("{number:0<5}", number=1); // You can use named arguments in the format specifier by appending a `$` println!("{number:0>width$}", number=1, width=5); // Rust even checks to make sure the correct number of arguments are // used. println!("My name is {0}, {1} {0}", "Bond"); // FIXME ^ Add the missing argument: "James" // Only types that implement fmt::Display can be formatted with `{}`. User- // defined types do not implement fmt::Display by default #[allow(dead_code)] struct Structure(i32); // This will not compile because `Structure` does not implement // fmt::Display //println!("This struct `{}` won't print...", Structure(3)); // TODO ^ Try uncommenting this line // For Rust 1.58 and above, you can directly capture the argument from a // surrounding variable. Just like the above, this will output // " 1". 5 white spaces and a "1". let number: f64 = 1.0; let width: usize = 5; println!("{number:>width$}"); }
std::fmt contains many traits which govern the display
of text. The base form of two important ones are listed below:
fmt::Debug: Uses the{:?}marker. Format text for debugging purposes.fmt::Display: Uses the{}marker. Format text in a more elegant, user friendly fashion.
Here, we used fmt::Display because the std library provides implementations
for these types. To print text for custom types, more steps are required.
Implementing the fmt::Display trait automatically implements the
ToString trait which allows us to convert the type to String.
Activities
- Fix the issue in the above code (see FIXME) so that it runs without error.
- Try uncommenting the line that attempts to format the
Structurestruct (see TODO) - Add a
println!macro call that prints:Pi is roughly 3.142by controlling the number of decimal places shown. For the purposes of this exercise, uselet pi = 3.141592as an estimate for pi. (Hint: you may need to check thestd::fmtdocumentation for setting the number of decimals to display)
See also:
std::fmt, macros, struct,
and traits
Debug
All types which want to use std::fmt formatting traits require an
implementation to be printable. Automatic implementations are only provided
for types such as in the std library. All others must be manually
implemented somehow.
The fmt::Debug trait makes this very straightforward. All types can
derive (automatically create) the fmt::Debug implementation. This is
not true for fmt::Display which must be manually implemented.
#![allow(unused)] fn main() { // This structure cannot be printed either with `fmt::Display` or // with `fmt::Debug`. struct UnPrintable(i32); // The `derive` attribute automatically creates the implementation // required to make this `struct` printable with `fmt::Debug`. #[derive(Debug)] struct DebugPrintable(i32); }
All std library types are automatically printable with {:?} too:
// Derive the `fmt::Debug` implementation for `Structure`. `Structure` // is a structure which contains a single `i32`. #[derive(Debug)] struct Structure(i32); // Put a `Structure` inside of the structure `Deep`. Make it printable // also. #[derive(Debug)] struct Deep(Structure); fn main() { // Printing with `{:?}` is similar to with `{}`. println!("{:?} months in a year.", 12); println!("{1:?} {0:?} is the {actor:?} name.", "Slater", "Christian", actor="actor's"); // `Structure` is printable! println!("Now {:?} will print!", Structure(3)); // The problem with `derive` is there is no control over how // the results look. What if I want this to just show a `7`? println!("Now {:?} will print!", Deep(Structure(7))); }
So fmt::Debug definitely makes this printable but sacrifices some
elegance. Rust also provides “pretty printing” with {:#?}.
#[derive(Debug)] struct Person<'a> { name: &'a str, age: u8 } fn main() { let name = "Peter"; let age = 27; let peter = Person { name, age }; // Pretty print println!("{:#?}", peter); }
One can manually implement fmt::Display to control the display.
See also:
attributes, derive, std::fmt,
and struct
Display
fmt::Debug hardly looks compact and clean, so it is often advantageous to
customize the output appearance. This is done by manually implementing
fmt::Display, which uses the {} print marker. Implementing it
looks like this:
#![allow(unused)] fn main() { // Import (via `use`) the `fmt` module to make it available. use std::fmt; // Define a structure for which `fmt::Display` will be implemented. This is // a tuple struct named `Structure` that contains an `i32`. struct Structure(i32); // To use the `{}` marker, the trait `fmt::Display` must be implemented // manually for the type. impl fmt::Display for Structure { // This trait requires `fmt` with this exact signature. fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // Write strictly the first element into the supplied output // stream: `f`. Returns `fmt::Result` which indicates whether the // operation succeeded or failed. Note that `write!` uses syntax which // is very similar to `println!`. write!(f, "{}", self.0) } } }
fmt::Display may be cleaner than fmt::Debug but this presents
a problem for the std library. How should ambiguous types be displayed?
For example, if the std library implemented a single style for all
Vec<T>, what style should it be? Would it be either of these two?
Vec<path>:/:/etc:/home/username:/bin(split on:)Vec<number>:1,2,3(split on,)
No, because there is no ideal style for all types and the std library
doesn’t presume to dictate one. fmt::Display is not implemented for Vec<T>
or for any other generic containers. fmt::Debug must then be used for these
generic cases.
This is not a problem though because for any new container type which is
not generic,fmt::Display can be implemented.
use std::fmt; // Import `fmt` // A structure holding two numbers. `Debug` will be derived so the results can // be contrasted with `Display`. #[derive(Debug)] struct MinMax(i64, i64); // Implement `Display` for `MinMax`. impl fmt::Display for MinMax { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // Use `self.number` to refer to each positional data point. write!(f, "({}, {})", self.0, self.1) } } // Define a structure where the fields are nameable for comparison. #[derive(Debug)] struct Point2D { x: f64, y: f64, } // Similarly, implement `Display` for `Point2D` impl fmt::Display for Point2D { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // Customize so only `x` and `y` are denoted. write!(f, "x: {}, y: {}", self.x, self.y) } } fn main() { let minmax = MinMax(0, 14); println!("Compare structures:"); println!("Display: {}", minmax); println!("Debug: {:?}", minmax); let big_range = MinMax(-300, 300); let small_range = MinMax(-3, 3); println!("The big range is {big} and the small is {small}", small = small_range, big = big_range); let point = Point2D { x: 3.3, y: 7.2 }; println!("Compare points:"); println!("Display: {}", point); println!("Debug: {:?}", point); // Error. Both `Debug` and `Display` were implemented, but `{:b}` // requires `fmt::Binary` to be implemented. This will not work. // println!("What does Point2D look like in binary: {:b}?", point); }
So, fmt::Display has been implemented but fmt::Binary has not, and
therefore cannot be used. std::fmt has many such traits and
each requires its own implementation. This is detailed further in
std::fmt.
Activity
After checking the output of the above example, use the Point2D struct as a
guide to add a Complex struct to the example. When printed in the same
way, the output should be:
Display: 3.3 + 7.2i
Debug: Complex { real: 3.3, imag: 7.2 }
See also:
derive, std::fmt, macros, struct,
trait, and use
Testcase: List
Implementing fmt::Display for a structure where the elements must each be
handled sequentially is tricky. The problem is that each write! generates a
fmt::Result. Proper handling of this requires dealing with all the
results. Rust provides the ? operator for exactly this purpose.
Using ? on write! looks like this:
// Try `write!` to see if it errors. If it errors, return
// the error. Otherwise continue.
write!(f, "{}", value)?;
With ? available, implementing fmt::Display for a Vec is
straightforward:
use std::fmt; // Import the `fmt` module. // Define a structure named `List` containing a `Vec`. struct List(Vec<i32>); impl fmt::Display for List { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // Extract the value using tuple indexing, // and create a reference to `vec`. let vec = &self.0; write!(f, "[")?; // Iterate over `v` in `vec` while enumerating the iteration // count in `count`. for (count, v) in vec.iter().enumerate() { // For every element except the first, add a comma. // Use the ? operator to return on errors. if count != 0 { write!(f, ", ")?; } write!(f, "{}", v)?; } // Close the opened bracket and return a fmt::Result value. write!(f, "]") } } fn main() { let v = List(vec![1, 2, 3]); println!("{}", v); }
Activity
Try changing the program so that the index of each element in the vector is also printed. The new output should look like this:
[0: 1, 1: 2, 2: 3]
See also:
for, ref, Result, struct,
?, and vec!
Formatting
We’ve seen that formatting is specified via a format string:
format!("{}", foo)->"3735928559"format!("0x{:X}", foo)->"0xDEADBEEF"format!("0o{:o}", foo)->"0o33653337357"
The same variable (foo) can be formatted differently depending on which
argument type is used: X vs o vs unspecified.
This formatting functionality is implemented via traits, and there is one trait
for each argument type. The most common formatting trait is Display, which
handles cases where the argument type is left unspecified: {} for instance.
use std::fmt::{self, Formatter, Display}; struct City { name: &'static str, // Latitude lat: f32, // Longitude lon: f32, } impl Display for City { // `f` is a buffer, and this method must write the formatted string into it fn fmt(&self, f: &mut Formatter) -> fmt::Result { let lat_c = if self.lat >= 0.0 { 'N' } else { 'S' }; let lon_c = if self.lon >= 0.0 { 'E' } else { 'W' }; // `write!` is like `format!`, but it will write the formatted string // into a buffer (the first argument) write!(f, "{}: {:.3}°{} {:.3}°{}", self.name, self.lat.abs(), lat_c, self.lon.abs(), lon_c) } } #[derive(Debug)] struct Color { red: u8, green: u8, blue: u8, } fn main() { for city in [ City { name: "Dublin", lat: 53.347778, lon: -6.259722 }, City { name: "Oslo", lat: 59.95, lon: 10.75 }, City { name: "Vancouver", lat: 49.25, lon: -123.1 }, ].iter() { println!("{}", *city); } for color in [ Color { red: 128, green: 255, blue: 90 }, Color { red: 0, green: 3, blue: 254 }, Color { red: 0, green: 0, blue: 0 }, ].iter() { // Switch this to use {} once you've added an implementation // for fmt::Display. println!("{:?}", *color); } }
You can view a full list of formatting traits and their argument
types in the std::fmt documentation.
Activity
Add an implementation of the fmt::Display trait for the Color struct above
so that the output displays as:
RGB (128, 255, 90) 0x80FF5A
RGB (0, 3, 254) 0x0003FE
RGB (0, 0, 0) 0x000000
Two hints if you get stuck:
- You may need to list each color more than once,
- You can pad with zeros to a width of 2 with
:0>2.
See also:
Primitives
Rust provides access to a wide variety of primitives. A sample includes:
- Scalar Types
- Compound Types
Scalar Types
- signed integers:
i8,i16,i32,i64,i128andisize(pointer size) - unsigned integers:
u8,u16,u32,u64,u128andusize(pointer size) - floating point:
f32,f64 charUnicode scalar values like'a','α'and'∞'(4 bytes each)booleithertrueorfalse- and the unit type
(), whose only possible value is an empty tuple:()
Despite the value of a unit type being a tuple, it is not considered a compound type because it does not contain multiple values.
Compound Types
- arrays like
[1, 2, 3] - tuples like
(1, true)
Variables can always be type annotated:
- Numbers may additionally be annotated via a suffix or by default.
- Integers default to
i32and floats tof64.
Note that Rust can also infer types from context.
Variables can be type annotated or inferre from context
fn main() { // Variables can be type annotated. let logical: bool = true; let a_float: f64 = 1.0; // Regular annotation let an_integer = 5i32; // Suffix annotation // Or a default will be used. let default_float = 3.0; // `f64` let default_integer = 7; // `i32` // A type can also be inferred from context let mut inferred_type = 12; // Type i64 is inferred from another line inferred_type = 4294967296i64; // A mutable variable's value can be changed. let mut mutable = 12; // Mutable `i32` mutable = 21; // Error! The type of a variable can't be changed. mutable = true; // Variables can be overwritten with shadowing. let mutable = true; }
- Variables can be type annotated, or a default will be used.
- A type can also be inferred from context
- A mutable variable’s value can be changed.
- The type of a variable can’t be changed.
- Variables can be overwritten with shadowing.
See also:
the std library, mut, inference, and shadowing
Literals and operators
Integers
1, floats1.2, characters'a', strings"abc", booleanstrueand the unit type()can be expressed using literals:
-
Integers can, alternatively, be expressed using hexadecimal, octal or binary notation using these prefixes respectively:
0x,0oor0b. -
Underscores can be inserted in numeric literals to improve readability, e.g.
1_000is the same as1000, and0.000_001is the same as0.000001.
We need to tell the compiler the type of the literals we use.
- For now, we’ll use the
u32suffix to indicate that the literal is an unsigned 32-bit integer - and the
i32suffix to indicate that it’s a signed 32-bit integer.
The operators available and their precedence [in Rust][rust op-prec] are similar to other [C-like languages][op-prec].
short-circuiting boolean logic & bitwise operations
fn main() { // Integer addition println!("1 + 2 = {}", 1u32 + 2); // Integer subtraction println!("1 - 2 = {}", 1i32 - 2); // TODO ^ Try changing `1i32` to `1u32` to see why the type is important // Short-circuiting boolean logic println!("true AND false is {}", true && false); println!("true OR false is {}", true || false); println!("NOT true is {}", !true); // Bitwise operations println!("0011 AND 0101 is {:04b}", 0b0011u32 & 0b0101); println!("0011 OR 0101 is {:04b}", 0b0011u32 | 0b0101); println!("0011 XOR 0101 is {:04b}", 0b0011u32 ^ 0b0101); println!("1 << 5 is {}", 1u32 << 5); println!("0x80 >> 2 is 0x{:x}", 0x80u32 >> 2); // Use underscores to improve readability! println!("One million is written as {}", 1_000_000u32); }
- Short-circuiting boolean logic
- Bitwise operations
- Use underscores to improve readability! [rust op-prec]: https://doc.rust-lang.org/reference/expressions.html#expression-precedence [op-prec]: https://en.wikipedia.org/wiki/Operator_precedence#Programming_languages
Tuples: a collection of values of different types
- Tuples are constructed using parentheses
() - and each tuple itself is a value with type signature
(T1, T2, ...), whereT1,T2are the types of its members. - Functions can use tuples to return multiple values, as tuples can hold any number of values.
Tuples Examples
// Tuples can be used as function arguments and as return values fn reverse(pair: (i32, bool)) -> (bool, i32) { // `let` can be used to bind the members of a tuple to variables let (int_param, bool_param) = pair; (bool_param, int_param) } // The following struct is for the activity. #[derive(Debug)] struct Matrix(f32, f32, f32, f32); fn main() { // A tuple with a bunch of different types let long_tuple = (1u8, 2u16, 3u32, 4u64, -1i8, -2i16, -3i32, -4i64, 0.1f32, 0.2f64, 'a', true); // Values can be extracted from the tuple using tuple indexing println!("long tuple first value: {}", long_tuple.0); println!("long tuple second value: {}", long_tuple.1); // Tuples can be tuple members let tuple_of_tuples = ((1u8, 2u16, 2u32), (4u64, -1i8), -2i16); // Tuples are printable println!("tuple of tuples: {:?}", tuple_of_tuples); // But long Tuples (more than 12 elements) cannot be printed // let too_long_tuple = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13); // println!("too long tuple: {:?}", too_long_tuple); // TODO ^ Uncomment the above 2 lines to see the compiler error let pair = (1, true); println!("pair is {:?}", pair); println!("the reversed pair is {:?}", reverse(pair)); // To create one element tuples, the comma is required to tell them apart // from a literal surrounded by parentheses println!("one element tuple: {:?}", (5u32,)); println!("just an integer: {:?}", (5u32)); //tuples can be destructured to create bindings let tuple = (1, "hello", 4.5, true); let (a, b, c, d) = tuple; println!("{:?}, {:?}, {:?}, {:?}", a, b, c, d); let matrix = Matrix(1.1, 1.2, 2.1, 2.2); println!("{:?}", matrix); }
-
Tuples can be used as function arguments and as return values
-
letcan be used to bind the members of a tuple to variables -
Values can be extracted from the tuple using tuple indexing
-
Tuples are printable, but long Tuples (more than 12 elements) cannot be printed
-
To create one element tuples, the comma is required to tell them apart from a literal surrounded by parentheses
-
tuples can be destructured to create bindings
-
Recap: Add the
fmt::Displaytrait to theMatrixstruct in the above example, so that if you switch from printing the debug format{:?}to the display format{}, you see the following output:( 1.1 1.2 ) ( 2.1 2.2 )You may want to refer back to the example for print display.
-
Add a
transposefunction using thereversefunction as a template, which accepts a matrix as an argument, and returns a matrix in which two elements have been swapped. For example:println!("Matrix:\n{}", matrix); println!("Transpose:\n{}", transpose(matrix));results in the output:
Matrix: ( 1.1 1.2 ) ( 2.1 2.2 ) Transpose: ( 1.1 2.1 ) ( 1.2 2.2 )
Arrays and Slices: a collection of objects of the same type T
- An array is a collection of objects of the same type
T, stored in contiguous memory.
- Arrays are created using brackets
[] - and their length, which is known at compile time, is part of their type signature
[T; length].
- Slices are similar to arrays, but their length is not known at compile time.
- Instead, a slice is a two-word object
- the first word is a pointer to the data
- and the second word is the length of the slice.
- The word size is the same as usize, determined by the processor architecture e.g. 64 bits on an x86-64.
- Slices can be used to borrow a section of an array, and have the type signature
&[T].
Array compares to slice
use std::mem; // This function borrows a slice fn analyze_slice(slice: &[i32]) { println!("first element of the slice: {}", slice[0]); println!("the slice has {} elements", slice.len()); } fn main() { // Fixed-size array (type signature is superfluous) let xs: [i32; 5] = [1, 2, 3, 4, 5]; // All elements can be initialized to the same value let ys: [i32; 500] = [0; 500]; // Indexing starts at 0 println!("first element of the array: {}", xs[0]); println!("second element of the array: {}", xs[1]); // `len` returns the count of elements in the array println!("number of elements in array: {}", xs.len()); // Arrays are stack allocated println!("array occupies {} bytes", mem::size_of_val(&xs)); // Arrays can be automatically borrowed as slices println!("borrow the whole array as a slice"); analyze_slice(&xs); // Slices can point to a section of an array // They are of the form [starting_index..ending_index] // starting_index is the first position in the slice // ending_index is one more than the last position in the slice println!("borrow a section of the array as a slice"); analyze_slice(&ys[1 .. 4]); // Example of empty slice `&[]` let empty_array: [u32; 0] = []; assert_eq!(&empty_array, &[]); assert_eq!(&empty_array, &[][..]); // same but more verbose // Arrays can be safely accessed using `.get`, which returns an // `Option`. This can be matched as shown below, or used with // `.expect()` if you would like the program to exit with a nice // message instead of happily continue. for i in 0..xs.len() + 1 { // OOPS, one element too far match xs.get(i) { Some(xval) => println!("{}: {}", i, xval), None => println!("Slow down! {} is too far!", i), } } // Out of bound indexing causes runtime error //println!("{}", xs[5]); }
- Fixed-size array (type signature is superfluous)
- All elements can be initialized to the same value
- Indexing starts at 0
lenreturns the count of elements in the array- Arrays are stack allocated
- Arrays can be automatically borrowed as slices
- Slices can point to a section of an array
- They are of the form [starting_index..ending_index]
- starting_index is the first position in the slice
- ending_index is one more than the last position in the slice
Custom Types: struct and enum
Rust custom data types are formed mainly through the two keywords:
struct: define a structureenum: define an enumeration
Constants can also be created via the const and static keywords.
Structures: Tuple, C structs and Unit structs
There are three types of structures (structs) that can be created using the struct keyword:
- Tuple structs, which are, basically, named tuples.
- The classic C structs
- Unit structs, which are field-less, are useful for generics.
Three types of structures
// An attribute to hide warnings for unused code. #![allow(dead_code)] #[derive(Debug)] struct Person { name: String, age: u8, } // A unit struct struct Unit; // A tuple struct struct Pair(i32, f32); // A struct with two fields struct Point { x: f32, y: f32, } // Structs can be reused as fields of another struct struct Rectangle { // A rectangle can be specified by where the top left and bottom right // corners are in space. top_left: Point, bottom_right: Point, } fn main() { // Create struct with field init shorthand let name = String::from("Peter"); let age = 27; let peter = Person { name, age }; // Print debug struct println!("{:?}", peter); // Instantiate a `Point` let point: Point = Point { x: 10.3, y: 0.4 }; // Access the fields of the point println!("point coordinates: ({}, {})", point.x, point.y); // Make a new point by using struct update syntax to use the fields of our // other one let bottom_right = Point { x: 5.2, ..point }; // `bottom_right.y` will be the same as `point.y` because we used that field // from `point` println!("second point: ({}, {})", bottom_right.x, bottom_right.y); // Destructure the point using a `let` binding let Point { x: left_edge, y: top_edge } = point; let _rectangle = Rectangle { // struct instantiation is an expression too top_left: Point { x: left_edge, y: top_edge }, bottom_right: bottom_right, }; // Instantiate a unit struct let _unit = Unit; // Instantiate a tuple struct let pair = Pair(1, 0.1); // Access the fields of a tuple struct println!("pair contains {:?} and {:?}", pair.0, pair.1); // Destructure a tuple struct let Pair(integer, decimal) = pair; println!("pair contains {:?} and {:?}", integer, decimal); }
- #![allow(dead_code)]: An attribute to hide warnings for unused code.
- Structs can be reused as fields of another struct
- Print debug struct
- Make a new point by using struct update syntax to use the fields of our other one
- Destructure the point using a
letbinding - struct instantiation is an expression too
Activity
- Add a function
rect_areawhich calculates the area of aRectangle(try using nested destructuring). - Add a function
squarewhich takes aPointand af32as arguments, and returns aRectanglewith its top left corner on the point, and a width and height corresponding to thef32.
See also
attributes, and destructuring
Enums and Type alias
The enum keyword allows the creation of a type which may be one of a few
different variants.
Any variant which is valid as a
structis also valid as anenum.
Use Enum in Function
// Create an `enum` to classify a web event. Note how both // names and type information together specify the variant: // `PageLoad != PageUnload` and `KeyPress(char) != Paste(String)`. // Each is different and independent. enum WebEvent { // An `enum` may either be `unit-like`, PageLoad, PageUnload, // like tuple structs, KeyPress(char), Paste(String), // or c-like structures. Click { x: i64, y: i64 }, } // A function which takes a `WebEvent` enum as an argument and // returns nothing. fn inspect(event: WebEvent) { match event { WebEvent::PageLoad => println!("page loaded"), WebEvent::PageUnload => println!("page unloaded"), // Destructure `c` from inside the `enum`. WebEvent::KeyPress(c) => println!("pressed '{}'.", c), WebEvent::Paste(s) => println!("pasted \"{}\".", s), // Destructure `Click` into `x` and `y`. WebEvent::Click { x, y } => { println!("clicked at x={}, y={}.", x, y); }, } } fn main() { let pressed = WebEvent::KeyPress('x'); // `to_owned()` creates an owned `String` from a string slice. let pasted = WebEvent::Paste("my text".to_owned()); let click = WebEvent::Click { x: 20, y: 80 }; let load = WebEvent::PageLoad; let unload = WebEvent::PageUnload; inspect(pressed); inspect(pasted); inspect(click); inspect(load); inspect(unload); }
- Create an
enumto classify a web event. - Note how both names and type information together specify the variant:
PageLoad != PageUnloadandKeyPress(char) != Paste(String).- Each is different and independent.
to_owned()creates an ownedStringfrom a string slice.
Type aliases
If you use a type alias, you can refer to each enum variant via its alias.
This might be useful if the enum’s name is too long or too generic, and you want to rename it.
enum VeryVerboseEnumOfThingsToDoWithNumbers { Add, Subtract, } // Creates a type alias type Operations = VeryVerboseEnumOfThingsToDoWithNumbers; fn main() { // We can refer to each variant via its alias, not its long and inconvenient // name. let x = Operations::Add; }
The most common place you’ll see this is in impl blocks using the Self alias.
enum VeryVerboseEnumOfThingsToDoWithNumbers { Add, Subtract, } impl VeryVerboseEnumOfThingsToDoWithNumbers { fn run(&self, x: i32, y: i32) -> i32 { match self { Self::Add => x + y, Self::Subtract => x - y, } } }
To learn more about enums and type aliases, you can read the stabilization report from when this feature was stabilized into Rust.
See also:
match, fn, and String, “Type alias enum variants” RFC
use
The use declaration can be used so manual scoping isn’t needed:
// An attribute to hide warnings for unused code. #![allow(dead_code)] enum Status { Rich, Poor, } enum Work { Civilian, Soldier, } fn main() { // Explicitly `use` each name so they are available without // manual scoping. use crate::Status::{Poor, Rich}; // Automatically `use` each name inside `Work`. use crate::Work::*; // Equivalent to `Status::Poor`. let status = Poor; // Equivalent to `Work::Civilian`. let work = Civilian; match status { // Note the lack of scoping because of the explicit `use` above. Rich => println!("The rich have lots of money!"), Poor => println!("The poor have no money..."), } match work { // Note again the lack of scoping. Civilian => println!("Civilians work!"), Soldier => println!("Soldiers fight!"), } }
- Explicitly
useeach name so they are available without manual scoping. - Note the lack of scoping because of the explicit
useabove.
See also:
C-like
enum can also be used as C-like enums.
// An attribute to hide warnings for unused code. #![allow(dead_code)] // enum with implicit discriminator (starts at 0) enum Number { Zero, One, Two, } // enum with explicit discriminator enum Color { Red = 0xff0000, Green = 0x00ff00, Blue = 0x0000ff, } fn main() { // `enums` can be cast as integers. println!("zero is {}", Number::Zero as i32); println!("one is {}", Number::One as i32); println!("roses are #{:06x}", Color::Red as i32); println!("violets are #{:06x}", Color::Blue as i32); }
- enum with implicit discriminator (starts at 0 without =)
enumscan be cast as integers.
See also:
Testcase: linked-list
A common way to implement a linked-list is via enums:
use crate::List::*; enum List { // Cons: Tuple struct that wraps an element and a pointer to the next node Cons(u32, Box<List>), // Nil: A node that signifies the end of the linked list Nil, } // Methods can be attached to an enum impl List { // Create an empty list fn new() -> List { // `Nil` has type `List` Nil } // Consume a list, and return the same list with a new element at its front fn prepend(self, elem: u32) -> List { // `Cons` also has type List Cons(elem, Box::new(self)) } // Return the length of the list fn len(&self) -> u32 { // `self` has to be matched, because the behavior of this method // depends on the variant of `self` // `self` has type `&List`, and `*self` has type `List`, matching on a // concrete type `T` is preferred over a match on a reference `&T` // after Rust 2018 you can use self here and tail (with no ref) below as well, // rust will infer &s and ref tail. // See https://doc.rust-lang.org/edition-guide/rust-2018/ownership-and-lifetimes/default-match-bindings.html match *self { // Can't take ownership of the tail, because `self` is borrowed; // instead take a reference to the tail Cons(_, ref tail) => 1 + tail.len(), // Base Case: An empty list has zero length Nil => 0 } } // Return representation of the list as a (heap allocated) string fn stringify(&self) -> String { match *self { Cons(head, ref tail) => { // `format!` is similar to `print!`, but returns a heap // allocated string instead of printing to the console format!("{}, {}", head, tail.stringify()) }, Nil => { format!("Nil") }, } } } fn main() { // Create an empty linked list let mut list = List::new(); // Prepend some elements list = list.prepend(1); list = list.prepend(2); list = list.prepend(3); // Show the final state of the list println!("linked list has length: {}", list.len()); println!("{}", list.stringify()); }
- Cons: Tuple struct that wraps an element and a pointer to the next node
- Nil: A node that signifies the end of the linked list
- Methods can be attached to an enum
selfhas to be matched, because the behavior of this method depends on the variant ofselfselfhas type&List, and*selfhas typeList- matching on a concrete type
Tis preferred over a match on a reference&T - after Rust 2018 you can use self here and tail (with no ref) below as well,
- rust will infer &s and ref tail.
- See https://doc.rust-lang.org/edition-guide/rust-2018/ownership-and-lifetimes/default-match-bindings.html
See also:
constants: const and static
Rust has two different types of constants which can be declared in any scope including global.
Both require explicit type annotation:
const: An unchangeable value (the common case).static: A possiblymutable variable with'staticlifetime.
The static lifetime is inferred and does not have to be specified. Accessing or modifying a mutable static variable is
unsafe.
Constants Examples
// Globals are declared outside all other scopes. static LANGUAGE: &str = "Rust"; const THRESHOLD: i32 = 10; fn is_big(n: i32) -> bool { // Access constant in some function n > THRESHOLD } fn main() { let n = 16; // Access constant in the main thread println!("This is {}", LANGUAGE); println!("The threshold is {}", THRESHOLD); println!("{} is {}", n, if is_big(n) { "big" } else { "small" }); // Error! Cannot modify a `const`. THRESHOLD = 5; // FIXME ^ Comment out this line }
See also:
The const/static RFC,
'static lifetime
Variable Bindings
- Rust provides type safety via static typing.
- Variable bindings can be type annotated when declared.
However, in most cases, the compiler will be able to infer the type of the variable from the context, heavily reducing the annotation burden.
Values (like literals) can be bound to variables, using the let binding.
fn main() { let an_integer = 1u32; let a_boolean = true; let unit = (); // copy `an_integer` into `copied_integer` let copied_integer = an_integer; println!("An integer: {:?}", copied_integer); println!("A boolean: {:?}", a_boolean); println!("Meet the unit value: {:?}", unit); // The compiler warns about unused variable bindings; these warnings can // be silenced by prefixing the variable name with an underscore let _unused_variable = 3u32; let noisy_unused_variable = 2u32; // FIXME ^ Prefix with an underscore to suppress the warning // Please note that warnings may not be shown in a browser }
- The compiler warns about unused variable bindings;
- these warnings can be silenced by prefixing the variable name with an underscore
Mutability
Variable bindings are immutable by default, but this can be overridden using the mut modifier.
fn main() { let _immutable_binding = 1; let mut mutable_binding = 1; println!("Before mutation: {}", mutable_binding); // Ok mutable_binding += 1; println!("After mutation: {}", mutable_binding); // Error! _immutable_binding += 1; // FIXME ^ Comment out this line }
The compiler will throw a detailed diagnostic about mutability errors.
Scope ({}) and Shadowing
Variable bindings have a scope, and are constrained to live in a block. A block is a collection of statements enclosed by braces {}.
fn main() { // This binding lives in the main function let long_lived_binding = 1; // This is a block, and has a smaller scope than the main function { // This binding only exists in this block let short_lived_binding = 2; println!("inner short: {}", short_lived_binding); } // End of the block // Error! `short_lived_binding` doesn't exist in this scope println!("outer short: {}", short_lived_binding); // FIXME ^ Comment out this line println!("outer long: {}", long_lived_binding); }
Also, variable shadowing is allowed.
fn main() { let shadowed_binding = 1; { println!("before being shadowed: {}", shadowed_binding); // This binding *shadows* the outer one let shadowed_binding = "abc"; println!("shadowed in inner block: {}", shadowed_binding); } println!("outside inner block: {}", shadowed_binding); // This binding *shadows* the previous binding let shadowed_binding = 2; println!("shadowed in outer block: {}", shadowed_binding); }
Declare first
It’s possible to declare variable bindings first, and initialize them later.
However, this form is seldom used, as it may lead to the use of uninitialized variables.
Declare first example
fn main() { // Declare a variable binding let a_binding; { let x = 2; // Initialize the binding a_binding = x * x; } println!("a binding: {}", a_binding); let another_binding; // Error! Use of uninitialized binding println!("another binding: {}", another_binding); // FIXME ^ Comment out this line another_binding = 1; println!("another binding: {}", another_binding); }
The compiler forbids use of uninitialized variables, as this would lead to undefined behavior.
Freezing
When data is bound by the same name immutably, it also freezes.
Frozen data can’t be modified until the immutable binding goes out of scope:
fn main() { let mut _mutable_integer = 7i32; { // Shadowing by immutable `_mutable_integer` let _mutable_integer = _mutable_integer; // Error! `_mutable_integer` is frozen in this scope _mutable_integer = 50; // FIXME ^ Comment out this line // `_mutable_integer` goes out of scope } // Ok! `_mutable_integer` is not frozen in this scope _mutable_integer = 3; }
Types
Rust provides several mechanisms to change or define the type of primitive and user defined types.
The following sections cover:
- Casting between primitive types
- Specifying the desired type of literals
- Using type inference
- Aliasing types
Casting using as keyword
Rust provides no implicit type conversion (coercion) between primitive types.
But, explicit type conversion (casting) can be performed using the
askeyword.
Rules for converting between integral types follow C conventions generally, except in cases where C has undefined behavior.
The behavior of all casts between integral types is well defined in Rust.
// Suppress all warnings from casts which overflow. #![allow(overflowing_literals)] fn main() { let decimal = 65.4321_f32; // Error! No implicit conversion let integer: u8 = decimal; // FIXME ^ Comment out this line // Explicit conversion let integer = decimal as u8; let character = integer as char; // Error! There are limitations in conversion rules. // A float cannot be directly converted to a char. let character = decimal as char; // FIXME ^ Comment out this line println!("Casting: {} -> {} -> {}", decimal, integer, character); // when casting any value to an unsigned type, T, // T::MAX + 1 is added or subtracted until the value // fits into the new type // 1000 already fits in a u16 println!("1000 as a u16 is: {}", 1000 as u16); // 1000 - 256 - 256 - 256 = 232 // Under the hood, the first 8 least significant bits (LSB) are kept, // while the rest towards the most significant bit (MSB) get truncated. println!("1000 as a u8 is : {}", 1000 as u8); // -1 + 256 = 255 println!(" -1 as a u8 is : {}", (-1i8) as u8); // For positive numbers, this is the same as the modulus println!("1000 mod 256 is : {}", 1000 % 256); // When casting to a signed type, the (bitwise) result is the same as // first casting to the corresponding unsigned type. If the most significant // bit of that value is 1, then the value is negative. // Unless it already fits, of course. println!(" 128 as a i16 is: {}", 128 as i16); // 128 as u8 -> 128, whose value in 8-bit two's complement representation is: println!(" 128 as a i8 is : {}", 128 as i8); // repeating the example above // 1000 as u8 -> 232 println!("1000 as a u8 is : {}", 1000 as u8); // and the value of 232 in 8-bit two's complement representation is -24 println!(" 232 as a i8 is : {}", 232 as i8); // Since Rust 1.45, the `as` keyword performs a *saturating cast* // when casting from float to int. If the floating point value exceeds // the upper bound or is less than the lower bound, the returned value // will be equal to the bound crossed. // 300.0 as u8 is 255 println!(" 300.0 as u8 is : {}", 300.0_f32 as u8); // -100.0 as u8 is 0 println!("-100.0 as u8 is : {}", -100.0_f32 as u8); // nan as u8 is 0 println!(" nan as u8 is : {}", f32::NAN as u8); // This behavior incurs a small runtime cost and can be avoided // with unsafe methods, however the results might overflow and // return **unsound values**. Use these methods wisely: unsafe { // 300.0 as u8 is 44 println!(" 300.0 as u8 is : {}", 300.0_f32.to_int_unchecked::<u8>()); // -100.0 as u8 is 156 println!("-100.0 as u8 is : {}", (-100.0_f32).to_int_unchecked::<u8>()); // nan as u8 is 0 println!(" nan as u8 is : {}", f32::NAN.to_int_unchecked::<u8>()); } }
- #![allow(overflowing_literals)]: Suppress all warnings from casts which overflow.
- when casting any value to an unsigned type, T, T::MAX + 1 is added or subtracted until the value fits into the new type
- Under the hood, the first 8 least significant bits (LSB) are kept, while the rest towards the most significant bit (MSB) get truncated.
- When casting to a signed type, the (bitwise) result is the same as first casting to the corresponding unsigned type.
- If the most significant bit of that value is 1, then the value is negative. Unless it already fits, of course.
- Since Rust 1.45, the
askeyword performs a saturating cast when casting from float to int. - If the floating point value exceeds the upper bound or is less than the lower bound, the returned value will be equal to the bound crossed.
- This behavior incurs a small runtime cost and can be avoided with unsafe methods
- however the results might overflow and return unsound values. Use these methods wisely
Compare with From/Into
Literals
Numeric literals can be type annotated by adding the type as a suffix.
As an example, to specify that the literal
42should have the typei32, write42i32.
The type of unsuffixed numeric literals will depend on how they are used:
If no constraint exists, the compiler will use
i32for integers, andf64for floating-point numbers.
unsuffixed numeric literias depend on how they are used
fn main() { // Suffixed literals, their types are known at initialization let x = 1u8; let y = 2u32; let z = 3f32; // Unsuffixed literals, their types depend on how they are used let i = 1; let f = 1.0; // `size_of_val` returns the size of a variable in bytes println!("size of `x` in bytes: {}", std::mem::size_of_val(&x)); println!("size of `y` in bytes: {}", std::mem::size_of_val(&y)); println!("size of `z` in bytes: {}", std::mem::size_of_val(&z)); println!("size of `i` in bytes: {}", std::mem::size_of_val(&i)); println!("size of `f` in bytes: {}", std::mem::size_of_val(&f)); }
- Suffixed literals, their types are known at initialization
- Unsuffixed literals, their types depend on how they are used
There are some concepts used in the previous code that haven’t been explained yet, here’s a brief explanation for the impatient readers:
std::mem::size_of_valis a function, but called with its full path.- Code can be split in logical units called modules.
- In this case, the
size_of_valfunction is defined in thememmodule, and thememmodule is defined in thestdcrate. - For more details, see modules and crates.
Inference
The type inference engine is pretty smart:
- It does more than looking at the type of the value expression during an initialization.
- It also looks at how the variable is used afterwards to infer its type.
Here’s an advanced example of type inference:
fn main() { // Because of the annotation, the compiler knows that `elem` has type u8. let elem = 5u8; // Create an empty vector (a growable array). let mut vec = Vec::new(); // At this point the compiler doesn't know the exact type of `vec`, it // just knows that it's a vector of something (`Vec<_>`). // Insert `elem` in the vector. vec.push(elem); // Aha! Now the compiler knows that `vec` is a vector of `u8`s (`Vec<u8>`) // TODO ^ Try commenting out the `vec.push(elem)` line println!("{:?}", vec); }
No type annotation of variables was needed, the compiler is happy and so is the programmer!
Type Aliasing: give a new name to an existing type
- The
typestatement can be used to give a new name to an existing type. - Types must have
UpperCamelCasenames, or the compiler will raise a warning. - The exception to this rule are the primitive types:
usize,f32, etc.
type alias example
// `NanoSecond`, `Inch`, and `U64` are new names for `u64`. type NanoSecond = u64; type Inch = u64; type U64 = u64; fn main() { // `NanoSecond` = `Inch` = `U64` = `u64`. let nanoseconds: NanoSecond = 5 as U64; let inches: Inch = 2 as U64; // Note that type aliases *don't* provide any extra type safety, because // aliases are *not* new types println!("{} nanoseconds + {} inches = {} unit?", nanoseconds, inches, nanoseconds + inches); }
The main use of aliases is to reduce boilerplate;
for example the IoResult<T> type is an alias for the Result<T, IoError> type.
See also:
Conversion
Primitive types can be converted to each other through casting.
Rust addresses conversion between custom types (i.e., struct and enum)
by the use of traits.
- The generic conversions will use the
FromandIntotraits. - However there are more specific ones for the more common cases, in particular when converting to and
from
Strings.
From and Into
The From and Into traits are inherently linked, and this is actually part of
its implementation:
- From: If you are able to convert type A from type B
- Into: then it should be easy to believe that we should be able to convert type B to type A.
From
The From trait allows for a type to define how to create itself from another
type, hence providing a very simple mechanism for converting between several
types.
There are numerous implementations of this trait within the standard library for conversion of primitive and common types.
For example we can easily convert a str into a String
#![allow(unused)] fn main() { let my_str = "hello"; let my_string = String::from(my_str); }
We can do similar for defining a conversion for our own type.
use std::convert::From; #[derive(Debug)] struct Number { value: i32, } impl From<i32> for Number { fn from(item: i32) -> Self { Number { value: item } } } fn main() { let num = Number::from(30); println!("My number is {:?}", num); }
Into
The Into trait is simply the reciprocal of the From trait:
-
That is, if you have implemented the
Fromtrait for your type,Intowill call it when necessary. -
Using the
Intotrait will typically require specification of the type to convert into as the compiler is unable to determine this most of the time. -
However this is a small trade-off considering we get the functionality for free.
Into Example
use std::convert::From; #[derive(Debug)] struct Number { value: i32, } impl From<i32> for Number { fn from(item: i32) -> Self { Number { value: item } } } fn main() { let int = 5; // Try removing the type annotation let num: Number = int.into(); println!("My number is {:?}", num); }
Compare with as keyword
TryFrom and TryInto: used for fallible conversions, return Result
Similar to From and Into, TryFrom and TryInto are
generic traits for converting between types.
Unlike
From/Into, theTryFrom/TryIntotraits are used for fallible conversions, and as such, returnResults.
TryFrom & TryInto Example
use std::convert::TryFrom; use std::convert::TryInto; #[derive(Debug, PartialEq)] struct EvenNumber(i32); impl TryFrom<i32> for EvenNumber { type Error = (); fn try_from(value: i32) -> Result<Self, Self::Error> { if value % 2 == 0 { Ok(EvenNumber(value)) } else { Err(()) } } } fn main() { // TryFrom assert_eq!(EvenNumber::try_from(8), Ok(EvenNumber(8))); assert_eq!(EvenNumber::try_from(5), Err(())); // TryInto let result: Result<EvenNumber, ()> = 8i32.try_into(); assert_eq!(result, Ok(EvenNumber(8))); let result: Result<EvenNumber, ()> = 5i32.try_into(); assert_eq!(result, Err(())); }
ToString and FromStr trait: To and from Strings
ToString from Display: Converting to String
To convert any type to a String is as simple as implementing the ToString
trait for the type.
Rather than doing so directly, you should implement the
fmt::Displaytrait which automagically providesToStringand also allows printing the type as discussed in the section onprint!.
ToString from Display Trait
use std::fmt; struct Circle { radius: i32 } impl fmt::Display for Circle { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "Circle of radius {}", self.radius) } } fn main() { let circle = Circle { radius: 6 }; println!("{}", circle.to_string()); }
FromStr: Parsing a String
One of the more common types to convert a string into is a number.
- The idiomatic
approach to this is to use the
parsefunction - and either to arrange for type inference or to specify the type to parse using the ‘turbofish’ syntax.
Both alternatives are shown in the following example.
fn main() { let parsed: i32 = "5".parse().unwrap(); let turbo_parsed = "10".parse::<i32>().unwrap(); let sum = parsed + turbo_parsed; println!("Sum: {:?}", sum); }
- This will convert the string into the type specified as long as the
FromStrtrait is implemented for that type. - This is implemented for numerous types within the standard library.
- To obtain this functionality on a user defined type
simply implement the
FromStrtrait for that type.
Expressions: statements end with ;
A Rust program is (mostly) made up of a series of statements:
fn main() { // statement // statement // statement }
There are a few kinds of statements in Rust.
The most common two are declaring a variable binding, and using a ; with an expression:
fn main() { // variable binding let x = 5; // expression; x; x + 1; 15; }
- Blocks are expressions too, so they can be used as values in assignments.
- The last expression in the block will be assigned to the place expression such as a local variable.
However, if the last expression of the block ends with a semicolon, the return value will be ().
fn main() { let x = 5u32; let y = { let x_squared = x * x; let x_cube = x_squared * x; // This expression will be assigned to `y` x_cube + x_squared + x }; let z = { // The semicolon suppresses this expression and `()` is assigned to `z` 2 * x; }; println!("x is {:?}", x); println!("y is {:?}", y); println!("z is {:?}", z); }
Flow of Control
An integral part of any programming language are ways to modify control flow:
if/else, for, and others.
Let’s talk about them in Rust.
if/else
Branching with if-else is similar to other languages.
Unlike many of them:
- the boolean condition doesn’t need to be surrounded by parentheses: just like python
- and each condition is followed by a block.
if-elseconditionals are expressions,- and, all branches must return the same type.
if-else example
fn main() { let n = 5; if n < 0 { print!("{} is negative", n); } else if n > 0 { print!("{} is positive", n); } else { print!("{} is zero", n); } let big_n = if n < 10 && n > -10 { println!(", and is a small number, increase ten-fold"); // This expression returns an `i32`. 10 * n } else { println!(", and is a big number, halve the number"); // This expression must return an `i32` as well. n / 2 // TODO ^ Try suppressing this expression with a semicolon. }; // ^ Don't forget to put a semicolon here! All `let` bindings need it. println!("{} -> {}", n, big_n); }
while
The while keyword can be used to run a loop while a condition is true.
Let’s write the infamous FizzBuzz using a while loop.
fn main() { // A counter variable let mut n = 1; // Loop while `n` is less than 101 while n < 101 { if n % 15 == 0 { println!("fizzbuzz"); } else if n % 3 == 0 { println!("fizz"); } else if n % 5 == 0 { println!("buzz"); } else { println!("{}", n); } // Increment counter n += 1; } }
loop
- Rust provides a
loopkeyword to indicate an infinite loop. - The
breakstatement can be used to exit a loop at anytime, - whereas the
continuestatement can be used to skip the rest of the iteration and start a new one.
Failed with: TOML parsing error: expected an equals, found a newline at line 1 column 6
Original markdown input:
~~~admonish info title="loop example" collapsible=tru
```rust,editable
fn main() {
let mut count = 0u32;
println!("Let's count until infinity!");
// Infinite loop
loop {
count += 1;
if count == 3 {
println!("three");
// Skip the rest of this iteration
continue;
}
println!("{}", count);
if count == 5 {
println!("OK, that's enough");
// Exit this loop
break;
}
}
}
```
~~~
Nesting and labels: a little like lifetime annotations
It’s possible to break or continue outer loops when dealing with nested
loops.
In these cases, the loops must be annotated with some
'label, and the label must be passed to thebreak/continuestatement.
a little like lifetime annotations
#![allow(unreachable_code)] fn main() { 'outer: loop { println!("Entered the outer loop"); 'inner: loop { println!("Entered the inner loop"); // This would break only the inner loop //break; // This breaks the outer loop break 'outer; } println!("This point will never be reached"); } println!("Exited the outer loop"); }
Returning from loops
One of the uses of a loop is to retry an operation until it succeeds:
- If the operation returns a value though, you might need to pass it to the rest of the code
put it after the break, and it will be returned by the loop expression.
fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; assert_eq!(result, 20); }
if let
For some use cases, when matching enums, match is awkward. For example:
#![allow(unused)] fn main() { // Make `optional` of type `Option<i32>` let optional = Some(7); match optional { Some(i) => { println!("This is a really long string and `{:?}`", i); // ^ Needed 2 indentations just so we could destructure // `i` from the option. }, _ => {}, // ^ Required because `match` is exhaustive. Doesn't it seem // like wasted space? }; }
if let is cleaner for this use case and in addition allows various failure options to be specified:
fn main() { // All have type `Option<i32>` let number = Some(7); let letter: Option<i32> = None; let emoticon: Option<i32> = None; // The `if let` construct reads: "if `let` destructures `number` into // `Some(i)`, evaluate the block (`{}`). if let Some(i) = number { println!("Matched {:?}!", i); } // If you need to specify a failure, use an else: if let Some(i) = letter { println!("Matched {:?}!", i); } else { // Destructure failed. Change to the failure case. println!("Didn't match a number. Let's go with a letter!"); } // Provide an altered failing condition. let i_like_letters = false; if let Some(i) = emoticon { println!("Matched {:?}!", i); // Destructure failed. Evaluate an `else if` condition to see if the // alternate failure branch should be taken: } else if i_like_letters { println!("Didn't match a number. Let's go with a letter!"); } else { // The condition evaluated false. This branch is the default: println!("I don't like letters. Let's go with an emoticon :)!"); } }
- The
if letconstruct reads: “ifletdestructuresnumberintoSome(i), evaluate the block ({}). - If you need to specify a failure, use an else
In the same way, if let can be used to match any enum value:
// Our example enum enum Foo { Bar, Baz, Qux(u32) } fn main() { // Create example variables let a = Foo::Bar; let b = Foo::Baz; let c = Foo::Qux(100); // Variable a matches Foo::Bar if let Foo::Bar = a { println!("a is foobar"); } // Variable b does not match Foo::Bar // So this will print nothing if let Foo::Bar = b { println!("b is foobar"); } // Variable c matches Foo::Qux which has a value // Similar to Some() in the previous example if let Foo::Qux(value) = c { println!("c is {}", value); } // Binding also works with `if let` if let Foo::Qux(value @ 100) = c { println!("c is one hundred"); } }
- Another benefit is that
if letallows us to match non-parameterized enum variants. - This is true even in cases where the enum doesn’t implement or derive
PartialEq. - In such cases
if Foo::Bar == awould fail to compile, because instances of the enum cannot be equated, howeverif letwill continue to work.
Would you like a challenge? Fix the following example to use if let:
// This enum purposely neither implements nor derives PartialEq. // That is why comparing Foo::Bar == a fails below. enum Foo {Bar} fn main() { let a = Foo::Bar; // Variable a matches Foo::Bar if Foo::Bar == a { // ^-- this causes a compile-time error. Use `if let` instead. println!("a is foobar"); } }
See also:
while let
Similar to if let, while let can make awkward match sequences
more tolerable.
Consider the following sequence that increments i:
#![allow(unused)] fn main() { // Make `optional` of type `Option<i32>` let mut optional = Some(0); // Repeatedly try this test. loop { match optional { // If `optional` destructures, evaluate the block. Some(i) => { if i > 9 { println!("Greater than 9, quit!"); optional = None; } else { println!("`i` is `{:?}`. Try again.", i); optional = Some(i + 1); } // ^ Requires 3 indentations! }, // Quit the loop when the destructure fails: _ => { break; } // ^ Why should this be required? There must be a better way! } } }
Using while let makes this sequence much nicer:
fn main() { // Make `optional` of type `Option<i32>` let mut optional = Some(0); // This reads: "while `let` destructures `optional` into // `Some(i)`, evaluate the block (`{}`). Else `break`. while let Some(i) = optional { if i > 9 { println!("Greater than 9, quit!"); optional = None; } else { println!("`i` is `{:?}`. Try again.", i); optional = Some(i + 1); } // ^ Less rightward drift and doesn't require // explicitly handling the failing case. } // ^ `if let` had additional optional `else`/`else if` // clauses. `while let` does not have these. }
See also:
for loops
for-in: for and range
The for in construct can be used to iterate through an Iterator.
- One of the easiest ways to create an iterator is to use the range notation
a..b. - This yields values from
a(inclusive) tob(exclusive) in steps of one.
Let’s write FizzBuzz using for instead of while.
fn main() { // `n` will take the values: 1, 2, ..., 100 in each iteration for n in 1..101 { if n % 15 == 0 { println!("fizzbuzz"); } else if n % 3 == 0 { println!("fizz"); } else if n % 5 == 0 { println!("buzz"); } else { println!("{}", n); } } }
Alternatively, a..=b can be used for a range that is inclusive on both ends. The above can be written as:
fn main() { // `n` will take the values: 1, 2, ..., 100 in each iteration for n in 1..=100 { if n % 15 == 0 { println!("fizzbuzz"); } else if n % 3 == 0 { println!("fizz"); } else if n % 5 == 0 { println!("buzz"); } else { println!("{}", n); } } }
for and iterators
The for in construct is able to interact with an Iterator in several ways.
As discussed in the section on the Iterator trait, by default the for
loop will apply the into_iter function to the collection.
However, this is not the only means of converting collections into iterators.
into_iter, iter and iter_mut all handle the conversion of a collection
into an iterator in different ways, by providing different views on the data
within.
iter
This
borrowseach element of the collection through each iteration.
Thus leaving the collection untouched and available for reuse after the loop.
fn main() { let names = vec!["Bob", "Frank", "Ferris"]; for name in names.iter() { match name { &"Ferris" => println!("There is a rustacean among us!"), // TODO ^ Try deleting the & and matching just "Ferris" _ => println!("Hello {}", name), } } println!("names: {:?}", names); }
into_iter
This consumes the collection so that on each iteration the exact data is provided.
Once the collection has been consumed it is no longer available for reuse as it has been ‘moved’ within the loop.
fn main() { let names = vec!["Bob", "Frank", "Ferris"]; for name in names.into_iter() { match name { "Ferris" => println!("There is a rustacean among us!"), _ => println!("Hello {}", name), } } println!("names: {:?}", names); // FIXME ^ Comment out this line }
iter_mut
This mutably borrows each element of the collection, allowing for the collection to be modified in place.
fn main() { let mut names = vec!["Bob", "Frank", "Ferris"]; for name in names.iter_mut() { *name = match name { &mut "Ferris" => "There is a rustacean among us!", _ => "Hello", } } println!("names: {:?}", names); }
In the above snippets note the type of match branch, that is the key
difference in the types of iteration.
The difference in type then of course implies differing actions that are able to be performed.
See also:
match
Rust provides pattern matching via the match keyword, which can be used like a C switch.
The first matching arm is evaluated and all possible values must be covered.
fn main() { let number = 13; // TODO ^ Try different values for `number` println!("Tell me about {}", number); match number { // Match a single value 1 => println!("One!"), // Match several values 2 | 3 | 5 | 7 | 11 => println!("This is a prime"), // TODO ^ Try adding 13 to the list of prime values // Match an inclusive range 13..=19 => println!("A teen"), // Handle the rest of cases _ => println!("Ain't special"), // TODO ^ Try commenting out this catch-all arm } let boolean = true; // Match is an expression too let binary = match boolean { // The arms of a match must cover all the possible values false => 0, true => 1, // TODO ^ Try commenting out one of these arms }; println!("{} -> {}", boolean, binary); }
Destructuring
A match block can destructure items in a variety of ways.
Destructuring Tuples
Tuples can be destructured in a match as follows:
fn main() { let triple = (0, -2, 3); // TODO ^ Try different values for `triple` println!("Tell me about {:?}", triple); // Match can be used to destructure a tuple match triple { // Destructure the second and third elements (0, y, z) => println!("First is `0`, `y` is {:?}, and `z` is {:?}", y, z), (1, ..) => println!("First is `1` and the rest doesn't matter"), (.., 2) => println!("last is `2` and the rest doesn't matter"), (3, .., 4) => println!("First is `3`, last is `4`, and the rest doesn't matter"), // `..` can be used to ignore the rest of the tuple _ => println!("It doesn't matter what they are"), // `_` means don't bind the value to a variable } }
Destructuring Arrays and Slices
Like tuples, arrays and slices can be destructured this way:
fn main() { // Try changing the values in the array, or make it a slice! let array = [1, -2, 6]; match array { // Binds the second and the third elements to the respective variables [0, second, third] => println!("array[0] = 0, array[1] = {}, array[2] = {}", second, third), // Single values can be ignored with _ [1, _, third] => println!( "array[0] = 1, array[2] = {} and array[1] was ignored", third ), // You can also bind some and ignore the rest [-1, second, ..] => println!( "array[0] = -1, array[1] = {} and all the other ones were ignored", second ), // The code below would not compile // [-1, second] => ... // Or store them in another array/slice (the type depends on // that of the value that is being matched against) [3, second, tail @ ..] => println!( "array[0] = 3, array[1] = {} and the other elements were {:?}", second, tail ), // Combining these patterns, we can, for example, bind the first and // last values, and store the rest of them in a single array [first, middle @ .., last] => println!( "array[0] = {}, middle = {:?}, array[2] = {}", first, middle, last ), } }
Destructuring Enums
An enum is destructured similarly:
// `allow` required to silence warnings because only // one variant is used. #[allow(dead_code)] enum Color { // These 3 are specified solely by their name. Red, Blue, Green, // These likewise tie `u32` tuples to different names: color models. RGB(u32, u32, u32), HSV(u32, u32, u32), HSL(u32, u32, u32), CMY(u32, u32, u32), CMYK(u32, u32, u32, u32), } fn main() { let color = Color::RGB(122, 17, 40); // TODO ^ Try different variants for `color` println!("What color is it?"); // An `enum` can be destructured using a `match`. match color { Color::Red => println!("The color is Red!"), Color::Blue => println!("The color is Blue!"), Color::Green => println!("The color is Green!"), Color::RGB(r, g, b) => println!("Red: {}, green: {}, and blue: {}!", r, g, b), Color::HSV(h, s, v) => println!("Hue: {}, saturation: {}, value: {}!", h, s, v), Color::HSL(h, s, l) => println!("Hue: {}, saturation: {}, lightness: {}!", h, s, l), Color::CMY(c, m, y) => println!("Cyan: {}, magenta: {}, yellow: {}!", c, m, y), Color::CMYK(c, m, y, k) => println!("Cyan: {}, magenta: {}, yellow: {}, key (black): {}!", c, m, y, k), // Don't need another arm because all variants have been examined } }
Destructuring Pointers/ref
For pointers, a distinction needs to be made between destructuring and dereferencing as they are different concepts which are used
differently from languages like C/C++.
- Dereferencing uses
* - Destructuring uses
&,ref, andref mut
Dereference v.s. Destructure
fn main() { // Assign a reference of type `i32`. The `&` signifies there // is a reference being assigned. let reference = &4; match reference { // If `reference` is pattern matched against `&val`, it results // in a comparison like: // `&i32` // `&val` // ^ We see that if the matching `&`s are dropped, then the `i32` // should be assigned to `val`. &val => println!("Got a value via destructuring: {:?}", val), } // To avoid the `&`, you dereference before matching. match *reference { val => println!("Got a value via dereferencing: {:?}", val), } // What if you don't start with a reference? `reference` was a `&` // because the right side was already a reference. This is not // a reference because the right side is not one. let _not_a_reference = 3; // Rust provides `ref` for exactly this purpose. It modifies the // assignment so that a reference is created for the element; this // reference is assigned. let ref _is_a_reference = 3; // Accordingly, by defining 2 values without references, references // can be retrieved via `ref` and `ref mut`. let value = 5; let mut mut_value = 6; // Use `ref` keyword to create a reference. match value { ref r => println!("Got a reference to a value: {:?}", r), } // Use `ref mut` similarly. match mut_value { ref mut m => { // Got a reference. Gotta dereference it before we can // add anything to it. *m += 10; println!("We added 10. `mut_value`: {:?}", m); }, } }
Destructuring Structures
Similarly, a struct can be destructured as shown:
fn main() { struct Foo { x: (u32, u32), y: u32, } // Try changing the values in the struct to see what happens let foo = Foo { x: (1, 2), y: 3 }; match foo { Foo { x: (1, b), y } => println!("First of x is 1, b = {}, y = {} ", b, y), // you can destructure structs and rename the variables, // the order is not important Foo { y: 2, x: i } => println!("y is 2, i = {:?}", i), // and you can also ignore some variables: Foo { y, .. } => println!("y = {}, we don't care about x", y), // this will give an error: pattern does not mention field `x` //Foo { y } => println!("y = {}", y), } }
See also:
Arrays and Slices and Binding for @ sigil
#[allow(...)], color models and enum
Guards: to filter the arm
A match guard can be added to filter the arm.
enum Temperature { Celsius(i32), Fahrenheit(i32), } fn main() { let temperature = Temperature::Celsius(35); // ^ TODO try different values for `temperature` match temperature { Temperature::Celsius(t) if t > 30 => println!("{}C is above 30 Celsius", t), // The `if condition` part ^ is a guard Temperature::Celsius(t) => println!("{}C is below 30 Celsius", t), Temperature::Fahrenheit(t) if t > 86 => println!("{}F is above 86 Fahrenheit", t), Temperature::Fahrenheit(t) => println!("{}F is below 86 Fahrenheit", t), } }
Note that the compiler won’t take guard conditions into account when checking if all patterns are covered by the match expression.
fn main() { let number: u8 = 4; match number { i if i == 0 => println!("Zero"), i if i > 0 => println!("Greater than zero"), // _ => unreachable!("Should never happen."), // TODO ^ uncomment to fix compilation } }
See also:
@ Binding
Indirectly accessing a variable makes it impossible to branch and use that variable without re-binding.
match provides the @ sigil for binding values to names:
// A function `age` which returns a `u32`. fn age() -> u32 { 15 } fn main() { println!("Tell me what type of person you are"); match age() { 0 => println!("I haven't celebrated my first birthday yet"), // Could `match` 1 ..= 12 directly but then what age // would the child be? Instead, bind to `n` for the // sequence of 1 ..= 12. Now the age can be reported. n @ 1 ..= 12 => println!("I'm a child of age {:?}", n), n @ 13 ..= 19 => println!("I'm a teen of age {:?}", n), // Nothing bound. Return the result. n => println!("I'm an old person of age {:?}", n), } }
You can also use binding to destructure enum variants, such as Option:
fn some_number() -> Option<u32> { Some(42) } fn main() { match some_number() { // Got `Some` variant, match if its value, bound to `n`, // is equal to 42. Some(n @ 42) => println!("The Answer: {}!", n), // Match any other number. Some(n) => println!("Not interesting... {}", n), // Match anything else (`None` variant). _ => (), } }
See also:
Functions
-
Functions are declared using the
fnkeyword. -
Its arguments are type annotated, just like variables, and, if the function returns a value, the return type must be specified after an arrow
->. -
The final expression in the function will be used as return value.
-
Alternatively, the
returnstatement can be used to return a value earlier from within the function, even from inside loops orifstatements.
Let’s rewrite FizzBuzz using functions!
// Unlike C/C++, there's no restriction on the order of function definitions fn main() { // We can use this function here, and define it somewhere later fizzbuzz_to(100); } // Function that returns a boolean value fn is_divisible_by(lhs: u32, rhs: u32) -> bool { // Corner case, early return if rhs == 0 { return false; } // This is an expression, the `return` keyword is not necessary here lhs % rhs == 0 } // Functions that "don't" return a value, actually return the unit type `()` fn fizzbuzz(n: u32) -> () { if is_divisible_by(n, 15) { println!("fizzbuzz"); } else if is_divisible_by(n, 3) { println!("fizz"); } else if is_divisible_by(n, 5) { println!("buzz"); } else { println!("{}", n); } } // When a function returns `()`, the return type can be omitted from the // signature fn fizzbuzz_to(n: u32) { for n in 1..=n { fizzbuzz(n); } }
Associated functions & Methods
Some functions are connected to a particular type.
These come in two forms:associated functions, and methods.
- Associated functions are functions that are defined on a type generally
- while methods are associated functions that are called on a particular instance of a type.
Associated Functions & Method
struct Point { x: f64, y: f64, } // Implementation block, all `Point` associated functions & methods go in here impl Point { // This is an "associated function" because this function is associated with // a particular type, that is, Point. // // Associated functions don't need to be called with an instance. // These functions are generally used like constructors. fn origin() -> Point { Point { x: 0.0, y: 0.0 } } // Another associated function, taking two arguments: fn new(x: f64, y: f64) -> Point { Point { x: x, y: y } } } struct Rectangle { p1: Point, p2: Point, } impl Rectangle { // This is a method // `&self` is sugar for `self: &Self`, where `Self` is the type of the // caller object. In this case `Self` = `Rectangle` fn area(&self) -> f64 { // `self` gives access to the struct fields via the dot operator let Point { x: x1, y: y1 } = self.p1; let Point { x: x2, y: y2 } = self.p2; // `abs` is a `f64` method that returns the absolute value of the // caller ((x1 - x2) * (y1 - y2)).abs() } fn perimeter(&self) -> f64 { let Point { x: x1, y: y1 } = self.p1; let Point { x: x2, y: y2 } = self.p2; 2.0 * ((x1 - x2).abs() + (y1 - y2).abs()) } // This method requires the caller object to be mutable // `&mut self` desugars to `self: &mut Self` fn translate(&mut self, x: f64, y: f64) { self.p1.x += x; self.p2.x += x; self.p1.y += y; self.p2.y += y; } } // `Pair` owns resources: two heap allocated integers struct Pair(Box<i32>, Box<i32>); impl Pair { // This method "consumes" the resources of the caller object // `self` desugars to `self: Self` fn destroy(self) { // Destructure `self` let Pair(first, second) = self; println!("Destroying Pair({}, {})", first, second); // `first` and `second` go out of scope and get freed } } fn main() { let rectangle = Rectangle { // Associated functions are called using double colons p1: Point::origin(), p2: Point::new(3.0, 4.0), }; // Methods are called using the dot operator // Note that the first argument `&self` is implicitly passed, i.e. // `rectangle.perimeter()` === `Rectangle::perimeter(&rectangle)` println!("Rectangle perimeter: {}", rectangle.perimeter()); println!("Rectangle area: {}", rectangle.area()); let mut square = Rectangle { p1: Point::origin(), p2: Point::new(1.0, 1.0), }; // Error! `rectangle` is immutable, but this method requires a mutable // object //rectangle.translate(1.0, 0.0); // TODO ^ Try uncommenting this line // Okay! Mutable objects can call mutable methods square.translate(1.0, 1.0); let pair = Pair(Box::new(1), Box::new(2)); pair.destroy(); // Error! Previous `destroy` call "consumed" `pair` //pair.destroy(); // TODO ^ Try uncommenting this line }
Closures
Closures are functions that can capture the enclosing environment.
For
example, a closure that captures the x variable:
|val| val + x
The syntax and capabilities of closures make them very convenient for on the fly usage. Calling a closure is exactly like calling a function.
However, both input and return types can be inferred and input variable names must be specified.
Other characteristics of closures include:
- using
||instead of()around input variables. - optional body delimination (
{}) for a single expression (mandatory otherwise). - the ability to capture the outer environment variables.
Usage Example
fn main() { // Increment via closures and functions. fn function(i: i32) -> i32 { i + 1 } // Closures are anonymous, here we are binding them to references // Annotation is identical to function annotation but is optional // as are the `{}` wrapping the body. These nameless functions // are assigned to appropriately named variables. let closure_annotated = |i: i32| -> i32 { i + 1 }; let closure_inferred = |i | i + 1 ; let i = 1; // Call the function and closures. println!("function: {}", function(i)); println!("closure_annotated: {}", closure_annotated(i)); println!("closure_inferred: {}", closure_inferred(i)); // Once closure's type has been inferred, it cannot be inferred again with another type. // TODO: uncomment the line below and see the compiler error. //println!("cannot reuse closure_inferred with another type: {}", closure_inferred(42i64)); // A closure taking no arguments which returns an `i32`. // The return type is inferred. let one = || 1; println!("closure returning one: {}", one()); }
- Closures are anonymous, here we are binding them to references
Annotation is identical to function annotation but is optional
as are the
{}wrapping the body. - These nameless functions are assigned to appropriately named variables.
- Once closure’s type has been inferred, it cannot be inferred again with another type.
- A closure taking no arguments which returns an inferred type.
Capturing
Closures are inherently flexible and will do what the functionality requires to make the closure work without annotation.
This allows capturing to flexibly adapt to the use case, sometimes moving and sometimes borrowing.
Closures can capture variables:
- by reference:
&T - by mutable reference:
&mut T - by value:
T
They preferentially capture variables by reference and only go lower when required.
Usage Example
fn main() { use std::mem; let color = String::from("green"); // A closure to print `color` which immediately borrows (`&`) `color` and // stores the borrow and closure in the `print` variable. It will remain // borrowed until `print` is used the last time. // // `println!` only requires arguments by immutable reference so it doesn't // impose anything more restrictive. let print = || println!("`color`: {}", color); // Call the closure using the borrow. print(); // `color` can be borrowed immutably again, because the closure only holds // an immutable reference to `color`. let _reborrow = &color; print(); // A move or reborrow is allowed after the final use of `print` let _color_moved = color; let mut count = 0; // A closure to increment `count` could take either `&mut count` or `count` // but `&mut count` is less restrictive so it takes that. Immediately // borrows `count`. // // A `mut` is required on `inc` because a `&mut` is stored inside. Thus, // calling the closure mutates the closure which requires a `mut`. let mut inc = || { count += 1; println!("`count`: {}", count); }; // Call the closure using a mutable borrow. inc(); // The closure still mutably borrows `count` because it is called later. // An attempt to reborrow will lead to an error. // let _reborrow = &count; // ^ TODO: try uncommenting this line. inc(); // The closure no longer needs to borrow `&mut count`. Therefore, it is // possible to reborrow without an error let _count_reborrowed = &mut count; // A non-copy type. let movable = Box::new(3); // `mem::drop` requires `T` so this must take by value. A copy type // would copy into the closure leaving the original untouched. // A non-copy must move and so `movable` immediately moves into // the closure. let consume = || { println!("`movable`: {:?}", movable); mem::drop(movable); }; // `consume` consumes the variable so this can only be called once. consume(); // consume(); // ^ TODO: Try uncommenting this line. }
Using move before vertical pipes forces closure to take ownership of captured variables:
fn main() { // `Vec` has non-copy semantics. let haystack = vec![1, 2, 3]; let contains = move |needle| haystack.contains(needle); println!("{}", contains(&1)); println!("{}", contains(&4)); // println!("There're {} elements in vec", haystack.len()); // ^ Uncommenting above line will result in compile-time error // because borrow checker doesn't allow re-using variable after it // has been moved. // Removing `move` from closure's signature will cause closure // to borrow _haystack_ variable immutably, hence _haystack_ is still // available and uncommenting above line will not cause an error. }
See also:
Box and std::mem::drop
Type anonymity need Generics
- A closure is essentially an anonymous struct
- A function that accepts a closure parameter only needs to restrict the parameter to implement the following traits:
- Fn
- FnMut
- FnOnce
Closures succinctly capture variables from enclosing scopes. Does this have any consequences?
It surely does.
Observe how using a closure as a function parameter requires generics, which is necessary because of how they are defined:
#![allow(unused)] fn main() { // `F` must be generic. fn apply<F>(f: F) where F: FnOnce() { f(); } }
When a closure is defined, the compiler implicitly creates a new
anonymous structure to store the captured variables inside, meanwhile
implementing the functionality via one of the traits: Fn, FnMut, or
FnOnce for this unknown type.
This type is assigned to the variable which is stored until calling.
Since this new type is of unknown type, any usage in a function will require generics.
However, an unbounded type parameter
<T>would still be ambiguous and not be allowed.
Thus, bounding by one of the traits: Fn, FnMut, or FnOnce (which it implements) is sufficient to specify its type.
// `F` must implement `Fn` for a closure which takes no // inputs and returns nothing - exactly what is required // for `print`. fn apply<F>(f: F) where F: Fn() { f(); } fn main() { let x = 7; // Capture `x` into an anonymous type and implement // `Fn` for it. Store it in `print`. let print = || println!("{}", x); apply(print); }
This example could be compared with the decrator mode
See also:
A thorough analysis, Fn, FnMut,
and FnOnce
As input parameters: Fn, FnMut, and FnOnce
While Rust chooses how to capture variables on the fly mostly without type annotation, this ambiguity is not allowed when writing functions.
When
taking a closure as an input parameter, the closure’s complete type must be
annotated using one of a few traits, and they’re determined by what the
closure does with captured value.
In order of decreasing restriction, they are:
Fn: the closure uses the captured value by reference (&T)FnMut: the closure uses the captured value by mutable reference (&mut T)FnOnce: the closure uses the captured value by value (T)
On a variable-by-variable basis, the compiler will capture variables in the least restrictive manner possible.
For instance, consider a parameter annotated as FnOnce.
This specifies
that the closure may capture by &T, &mut T, or T, but the compiler
will ultimately choose based on how the captured variables are used in the
closure.
This is because if a move is possible, then any type of borrow should also be possible.
Note that the reverse is not true:
If the parameter is
annotated as Fn, then capturing variables by &mut T or T are not
allowed. However, &T is allowed.
In the following example, try swapping the usage of Fn, FnMut, and FnOnce to see what happens:
// A function which takes a closure as an argument and calls it. // <F> denotes that F is a "Generic type parameter" fn apply<F>(f: F) where // The closure takes no input and returns nothing. F: FnOnce() { // ^ TODO: Try changing this to `Fn` or `FnMut`. f(); } // A function which takes a closure and returns an `i32`. fn apply_to_3<F>(f: F) -> i32 where // The closure takes an `i32` and returns an `i32`. F: Fn(i32) -> i32 { f(3) } fn main() { use std::mem; let greeting = "hello"; // A non-copy type. // `to_owned` creates owned data from borrowed one let mut farewell = "goodbye".to_owned(); // Capture 2 variables: `greeting` by reference and // `farewell` by value. let diary = || { // `greeting` is by reference: requires `Fn`. println!("I said {}.", greeting); // Mutation forces `farewell` to be captured by // mutable reference. Now requires `FnMut`. farewell.push_str("!!!"); println!("Then I screamed {}.", farewell); println!("Now I can sleep. zzzzz"); // Manually calling drop forces `farewell` to // be captured by value. Now requires `FnOnce`. mem::drop(farewell); }; // Call the function which applies the closure. apply(diary); // `double` satisfies `apply_to_3`'s trait bound let double = |x| 2 * x; println!("3 doubled: {}", apply_to_3(double)); }
See also:
std::mem::drop, Fn, FnMut, Generics, where and FnOnce
As output parameters
Closures as input parameters are possible, so returning closures as output parameters should also be possible.
However, anonymous closure types are, by definition, unknown, so we have to use impl Trait to return them.
The valid traits for returning a closure are:
FnFnMutFnOnce
fn create_fn() -> impl Fn() { let text = "Fn".to_owned(); move || println!("This is a: {}", text) } fn create_fnmut() -> impl FnMut() { let text = "FnMut".to_owned(); move || println!("This is a: {}", text) } fn create_fnonce() -> impl FnOnce() { let text = "FnOnce".to_owned(); move || println!("This is a: {}", text) } fn main() { let fn_plain = create_fn(); let mut fn_mut = create_fnmut(); let fn_once = create_fnonce(); fn_plain(); fn_mut(); fn_once(); }
Beyond this, the move keyword must be used, which signals that all captures
occur by value.
This is required because any captures by reference would be dropped as soon as the function exited, leaving invalid references in the closure.
See also:
Fn, FnMut, Generics and impl Trait.
Input functions
Since closures may be used as arguments, you might wonder if the same can be said about functions.
And indeed they can!
If you declare a function that takes a closure as parameter, then any function that satisfies the trait bound of that closure can be passed as a parameter.
// Define a function which takes a generic `F` argument // bounded by `Fn`, and calls it fn call_me<F: Fn()>(f: F) { f(); } // Define a wrapper function satisfying the `Fn` bound fn function() { println!("I'm a function!"); } fn main() { // Define a closure satisfying the `Fn` bound let closure = || println!("I'm a closure!"); call_me(closure); call_me(function); }
As an additional note, the
Fn,FnMut, andFnOncetraitsdictate how a closure captures variables from the enclosing scope.
See also:
Examples in std
This section contains a few examples of using closures from the std library.
Iterator::any
Iterator::any is a function which when passed an iterator, will return
true if any element satisfies the predicate. Otherwise false.
Its signature:
pub trait Iterator {
// The type being iterated over.
type Item;
// `any` takes `&mut self` meaning the caller may be borrowed
// and modified, but not consumed.
fn any<F>(&mut self, f: F) -> bool where
// `FnMut` meaning any captured variable may at most be
// modified, not consumed. `Self::Item` states it takes
// arguments to the closure by value.
F: FnMut(Self::Item) -> bool;
}
anytakes&mut selfmeaning the caller may be borrowedFnMutmeaning any captured variable may at most be modified, not consumed.Self::Itemstates it takes arguments to the closure by value.
Usage
fn main() { let vec1 = vec![1, 2, 3]; let vec2 = vec![4, 5, 6]; // `iter()` for vecs yields `&i32`. Destructure to `i32`. println!("2 in vec1: {}", vec1.iter() .any(|&x| x == 2)); // `into_iter()` for vecs yields `i32`. No destructuring required. println!("2 in vec2: {}", vec2.into_iter().any(| x| x == 2)); // `iter()` only borrows `vec1` and its elements, so they can be used again println!("vec1 len: {}", vec1.len()); println!("First element of vec1 is: {}", vec1[0]); // `into_iter()` does move `vec2` and its elements, so they cannot be used again // println!("First element of vec2 is: {}", vec2[0]); // println!("vec2 len: {}", vec2.len()); // TODO: uncomment two lines above and see compiler errors. let array1 = [1, 2, 3]; let array2 = [4, 5, 6]; // `iter()` for arrays yields `&i32`. println!("2 in array1: {}", array1.iter() .any(|&x| x == 2)); // `into_iter()` for arrays yields `i32`. println!("2 in array2: {}", array2.into_iter().any(|x| x == 2)); }
See also:
Searching through iterators
Iterator::find is a function which iterates over an iterator and searches for the
first value which satisfies some condition. If none of the values satisfy the
condition, it returns None.
Its signature:
pub trait Iterator {
// The type being iterated over.
type Item;
// `find` takes `&mut self` meaning the caller may be borrowed
// and modified, but not consumed.
fn find<P>(&mut self, predicate: P) -> Option<Self::Item> where
// `FnMut` meaning any captured variable may at most be
// modified, not consumed. `&Self::Item` states it takes
// arguments to the closure by reference.
P: FnMut(&Self::Item) -> bool;
}
Usage
fn main() { let vec1 = vec![1, 2, 3]; let vec2 = vec![4, 5, 6]; // `iter()` for vecs yields `&i32`. let mut iter = vec1.iter(); // `into_iter()` for vecs yields `i32`. let mut into_iter = vec2.into_iter(); // `iter()` for vecs yields `&i32`, and we want to reference one of its // items, so we have to destructure `&&i32` to `i32` println!("Find 2 in vec1: {:?}", iter .find(|&&x| x == 2)); // `into_iter()` for vecs yields `i32`, and we want to reference one of // its items, so we have to destructure `&i32` to `i32` println!("Find 2 in vec2: {:?}", into_iter.find(| &x| x == 2)); let array1 = [1, 2, 3]; let array2 = [4, 5, 6]; // `iter()` for arrays yields `&i32` println!("Find 2 in array1: {:?}", array1.iter() .find(|&&x| x == 2)); // `into_iter()` for arrays yields `i32` println!("Find 2 in array2: {:?}", array2.into_iter().find(|&x| x == 2)); }
Iterator::find gives you a reference to the item. But if you want the index of the item, use Iterator::position.
fn main() { let vec = vec![1, 9, 3, 3, 13, 2]; // `iter()` for vecs yields `&i32` and `position()` does not take a reference, so // we have to destructure `&i32` to `i32` let index_of_first_even_number = vec.iter().position(|&x| x % 2 == 0); assert_eq!(index_of_first_even_number, Some(5)); // `into_iter()` for vecs yields `i32` and `position()` does not take a reference, so // we do not have to destructure let index_of_first_negative_number = vec.into_iter().position(|x| x < 0); assert_eq!(index_of_first_negative_number, None); }
See also:
std::iter::Iterator::rposition
HOF: Higher Order Functions
Rust provides Higher Order Functions (HOF). These are functions that take one or more functions and/or produce a more useful function.
HOFs and lazy iterators give Rust its functional flavor.
fn is_odd(n: u32) -> bool { n % 2 == 1 } fn main() { println!("Find the sum of all the squared odd numbers under 1000"); let upper = 1000; // Imperative approach // Declare accumulator variable let mut acc = 0; // Iterate: 0, 1, 2, ... to infinity for n in 0.. { // Square the number let n_squared = n * n; if n_squared >= upper { // Break loop if exceeded the upper limit break; } else if is_odd(n_squared) { // Accumulate value, if it's odd acc += n_squared; } } println!("imperative style: {}", acc); // Functional approach let sum_of_squared_odd_numbers: u32 = (0..).map(|n| n * n) // All natural numbers squared .take_while(|&n_squared| n_squared < upper) // Below upper limit .filter(|&n_squared| is_odd(n_squared)) // That are odd .sum(); // Sum them println!("functional style: {}", sum_of_squared_odd_numbers); }
Option and Iterator implement their fair share of HOFs.
Diverging functions: return !, different from ()
Diverging functions never return.
They are marked using !, which is an empty type.
#![allow(unused)] fn main() { fn foo() -> ! { panic!("This call never returns."); } }
As opposed to all the other types, this one cannot be instantiated, because the set of all possible values this type can have is empty.
Note that, it is different from the
()type, which has exactly one possible value.
For example, this function returns as usual, although there is no information in the return value.
fn some_fn() { () } fn main() { let a: () = some_fn(); println!("This function returns and you can see this line.") }
As opposed to this function, which will never return the control back to the caller.
#![feature(never_type)]
fn main() {
let x: ! = panic!("This call never returns.");
println!("You will never see this line!");
}
Although this might seem like an abstract concept, it is in fact very useful and often handy.
The main advantage of this type is that it can be cast to any other one and therefore used at places where an exact type is required, for instance in
matchbranches.
This allows us to write code like this:
fn main() { fn sum_odd_numbers(up_to: u32) -> u32 { let mut acc = 0; for i in 0..up_to { // Notice that the return type of this match expression must be u32 // because of the type of the "addition" variable. let addition: u32 = match i%2 == 1 { // The "i" variable is of type u32, which is perfectly fine. true => i, // On the other hand, the "continue" expression does not return // u32, but it is still fine, because it never returns and therefore // does not violate the type requirements of the match expression. false => continue, }; acc += addition; } acc } println!("Sum of odd numbers up to 9 (excluding): {}", sum_odd_numbers(9)); }
It is also the return type of functions that loop forever (e.g. loop {}) like
network servers or functions that terminate the process (e.g. exit()).
Error handling
Error handling is the process of handling the possibility of failure.
For example, failing to read a file and then continuing to use that bad input would clearly be problematic.
Noticing and explicitly managing those errors saves the rest of the program from various pitfalls.
There are various ways to deal with errors in Rust, which are described in the following subchapters. They all have more or less subtle differences and different use cases.
As a rule of thumb:
- An explicit
panicis mainly useful for tests and dealing with unrecoverable errors.
- For prototyping it can be useful, for example when dealing with functions that
haven’t been implemented yet, but in those cases the more descriptive
unimplementedis better. - In tests
panicis a reasonable way to explicitly fail.
- The
Optiontype is for when a value is optional or when the lack of a value is not an error condition.
- For example the parent of a directory -
/andC:don’t have one. - When dealing with
Options,unwrapis fine for prototyping and cases where it’s absolutely certain that there is guaranteed to be a value. - However
expectis more useful since it lets you specify an error message in case something goes wrong anyway.
- When there is a chance that things do go wrong and the caller has to deal with the
problem, use
Result.
- You can
unwrapandexpectthem as well (please don’t do that unless it’s a test or quick prototype).
For a more rigorous discussion of error handling, refer to the error handling section in the official book.
panic: The simplest error handling mechanism
The simplest error handling mechanism we will see is panic.
Just like try…except mechanism in python
It prints an error message, starts unwinding the stack, and usually exits the program.
Here, we explicitly call panic on our error condition:
fn drink(beverage: &str) { // You shouldn't drink too much sugary beverages. if beverage == "lemonade" { panic!("AAAaaaaa!!!!"); } println!("Some refreshing {} is all I need.", beverage); } fn main() { drink("water"); drink("lemonade"); }
abort and unwind
The previous section illustrates the error handling mechanism panic.
Different code paths can be conditionally compiled based on the panic setting.
The current values available are abort and unwind.
Implementation mechanism of panic
In Rust, there are two ways to implement panic: unwind and abort
- In the unwind mode, when a panic occurs, the function calls will be exited layer by layer. During the process, the local variables in the current stack can be destructed normally.
- The abort method will directly exit the entire program when a panic occurs.
- Generally speaking, by default, the compiler uses the unwind mode.
How to make it yourself:
rustc -C panic=unwind test.rs
rustc -C panic=abort test.rs
abort
Failed with: TOML parsing error: expected an equals, found a newline at line 1 column 5
Original markdown input:
~~~admonish tip title="cfg!(panic='abort'): Building on the prior lemonade example, we explicitly use the panic strategy to exercise different lines of code. " collapsible=true
```rust,editable,mdbook-runnable
fn drink(beverage: &str) {
// You shouldn't drink too much sugary beverages.
if beverage == "lemonade" {
if cfg!(panic="abort"){ println!("This is not your party. Run!!!!");}
else{ println!("Spit it out!!!!");}
}
else{ println!("Some refreshing {} is all I need.", beverage); }
}
fn main() {
drink("water");
drink("lemonade");
}
```
~~~
unwind
Here is another example focusing on rewriting drink() and explicitly use the unwind keyword.
#[cfg(panic = "unwind")] fn ah(){ println!("Spit it out!!!!");} #[cfg(not(panic="unwind"))] fn ah(){ println!("This is not your party. Run!!!!");} fn drink(beverage: &str){ if beverage == "lemonade"{ ah();} else{println!("Some refreshing {} is all I need.", beverage);} } fn main() { drink("water"); drink("lemonade"); }
The panic strategy can be set from the command line by using abort or unwind.
rustc lemonade.rs -C panic=abort
cfg! or #cfg
#[cfg(panic = "unwind")]
fn ah(){ println!("Spit it out!!!!");}
cfg!(panic="abort"){ println!("This is not your party. Run!!!!");}
Option & unwrap
In the last example, we showed that we can induce program failure at will:
We told our program to panic if we drink a sugary lemonade.
But what if we expect some drink but don’t receive one?
That case would be just as bad, so it needs to be handled!
We could test this against the null string ("") as we do with a lemonade.
Since we’re using Rust, let’s instead have the compiler point out cases where there’s no drink.
An
enumcalledOption<T>in thestdlibrary is used when absence is a possibility.
It manifests itself as one of two “options”:
Some(T): An element of typeTwas foundNone: No element was found
These cases can either be explicitly handled via
matchor implicitly withunwrap. Implicit handling will either return the inner element orpanic.
Note that it’s possible to manually customize panic with expect,
but unwrap otherwise leaves us with a less meaningful output than explicit
handling.
In the following example, explicit handling yields a more controlled result while retaining the option to panic if desired.
// The adult has seen it all, and can handle any drink well. // All drinks are handled explicitly using `match`. fn give_adult(drink: Option<&str>) { // Specify a course of action for each case. match drink { Some("lemonade") => println!("Yuck! Too sugary."), Some(inner) => println!("{}? How nice.", inner), None => println!("No drink? Oh well."), } } // Others will `panic` before drinking sugary drinks. // All drinks are handled implicitly using `unwrap`. fn drink(drink: Option<&str>) { // `unwrap` returns a `panic` when it receives a `None`. let inside = drink.unwrap(); if inside == "lemonade" { panic!("AAAaaaaa!!!!"); } println!("I love {}s!!!!!", inside); } fn main() { let water = Some("water"); let lemonade = Some("lemonade"); let void = None; give_adult(water); give_adult(lemonade); give_adult(void); let coffee = Some("coffee"); let nothing = None; drink(coffee); drink(nothing); }
unwrapreturns apanicwhen it receives aNone.
Combinators of Option: map
match is a valid method for handling Options.
However, you may eventually find heavy usage tedious, especially with operations only valid with an input.
In these cases, combinators can be used to manage control flow in a modular fashion.
Optionhas a built in method calledmap(), a combinator for the simple mapping ofSome -> SomeandNone -> None.- Multiple
map()calls can be chained together for even more flexibility.
In the following example, process() replaces all functions previous to it while staying compact.
#![allow(dead_code)] #[derive(Debug)] enum Food { Apple, Carrot, Potato } #[derive(Debug)] struct Peeled(Food); #[derive(Debug)] struct Chopped(Food); #[derive(Debug)] struct Cooked(Food); // Peeling food. If there isn't any, then return `None`. // Otherwise, return the peeled food. fn peel(food: Option<Food>) -> Option<Peeled> { match food { Some(food) => Some(Peeled(food)), None => None, } } // Chopping food. If there isn't any, then return `None`. // Otherwise, return the chopped food. fn chop(peeled: Option<Peeled>) -> Option<Chopped> { match peeled { Some(Peeled(food)) => Some(Chopped(food)), None => None, } } // Cooking food. Here, we showcase `map()` instead of `match` for case handling. fn cook(chopped: Option<Chopped>) -> Option<Cooked> { chopped.map(|Chopped(food)| Cooked(food)) } // A function to peel, chop, and cook food all in sequence. // We chain multiple uses of `map()` to simplify the code. fn process(food: Option<Food>) -> Option<Cooked> { food.map(|f| Peeled(f)) .map(|Peeled(f)| Chopped(f)) .map(|Chopped(f)| Cooked(f)) } // Check whether there's food or not before trying to eat it! fn eat(food: Option<Cooked>) { match food { Some(food) => println!("Mmm. I love {:?}", food), None => println!("Oh no! It wasn't edible."), } } fn main() { let apple = Some(Food::Apple); let carrot = Some(Food::Carrot); let potato = None; let cooked_apple = cook(chop(peel(apple))); let cooked_carrot = cook(chop(peel(carrot))); // Let's try the simpler looking `process()` now. let cooked_potato = process(potato); eat(cooked_apple); eat(cooked_carrot); eat(cooked_potato); }
See also:
closures, Option, Option::map()
Combinators: and_then
map() was described as a chainable way to simplify match statements.
However, using map() on a function that returns an Option<T> results
in the nested Option<Option<T>>.
Chaining multiple calls together can then become confusing. That’s where another combinator called
and_then(), known in some languages as flatmap, comes in.
and_then() calls its function input with the wrapped value and returns the result:
- If the
OptionisNone, then it returnsNoneinstead.
In the following example, cookable_v2() results in an Option<Food>.
Using map() instead of and_then() would have given an Option<Option> , which is an invalid type for eat().
#![allow(dead_code)] #[derive(Debug)] enum Food { CordonBleu, Steak, Sushi } #[derive(Debug)] enum Day { Monday, Tuesday, Wednesday } // We don't have the ingredients to make Sushi. fn have_ingredients(food: Food) -> Option<Food> { match food { Food::Sushi => None, _ => Some(food), } } // We have the recipe for everything except Cordon Bleu. fn have_recipe(food: Food) -> Option<Food> { match food { Food::CordonBleu => None, _ => Some(food), } } // To make a dish, we need both the recipe and the ingredients. // We can represent the logic with a chain of `match`es: fn cookable_v1(food: Food) -> Option<Food> { match have_recipe(food) { None => None, Some(food) => match have_ingredients(food) { None => None, Some(food) => Some(food), }, } } // This can conveniently be rewritten more compactly with `and_then()`: fn cookable_v2(food: Food) -> Option<Food> { have_recipe(food).and_then(have_ingredients) } fn eat(food: Food, day: Day) { match cookable_v2(food) { Some(food) => println!("Yay! On {:?} we get to eat {:?}.", day, food), None => println!("Oh no. We don't get to eat on {:?}?", day), } } fn main() { let (cordon_bleu, steak, sushi) = (Food::CordonBleu, Food::Steak, Food::Sushi); eat(cordon_bleu, Day::Monday); eat(steak, Day::Tuesday); eat(sushi, Day::Wednesday); }
a chain of
matches can conveniently be rewritten more compactly withand_then()
fn cookable_v1(food: Food) -> Option<Food> {
match have_recipe(food) {
None => None,
Some(food) => match have_ingredients(food) {
None => None,
Some(food) => Some(food),
},
}
}
fn cookable_v2(food: Food) -> Option<Food> {
have_recipe(food).and_then(have_ingredients)
}
See also:
closures, Option, and Option::and_then()
Unpacking options and defaults: or(), or_else(), get_or_insert(), get_or_insert_with()
There is more than one way to unpack an Option and fall back on a default if it is None.
To choose the one that meets our needs, we need to consider the following:
- do we need eager or lazy evaluation?
- do we need to keep the original empty value intact, or modify it in place?
or() is chainable, evaluates eagerly, keeps empty value intact
or() is chainable and eagerly evaluates its argument, as is shown in the following example.
#[derive(Debug)] enum Fruit { Apple, Orange, Banana, Kiwi, Lemon } fn main() { let apple = Some(Fruit::Apple); let orange = Some(Fruit::Orange); let no_fruit: Option<Fruit> = None; let first_available_fruit = no_fruit.or(orange).or(apple); println!("first_available_fruit: {:?}", first_available_fruit); // first_available_fruit: Some(Orange) // `or` moves its argument. // In the example above, `or(orange)` returned a `Some`, so `or(apple)` was not invoked. // But the variable named `apple` has been moved regardless, and cannot be used anymore. // println!("Variable apple was moved, so this line won't compile: {:?}", apple); // TODO: uncomment the line above to see the compiler error }
Note that because or’s arguments are evaluated eagerly, the variable passed to or is moved.
or_else() is chainable, evaluates lazily, keeps empty value intact
Another alternative is to use or_else, which is also chainable, and evaluates lazily, as is shown in the following example:
#[derive(Debug)] enum Fruit { Apple, Orange, Banana, Kiwi, Lemon } fn main() { let apple = Some(Fruit::Apple); let no_fruit: Option<Fruit> = None; let get_kiwi_as_fallback = || { println!("Providing kiwi as fallback"); Some(Fruit::Kiwi) }; let get_lemon_as_fallback = || { println!("Providing lemon as fallback"); Some(Fruit::Lemon) }; let first_available_fruit = no_fruit .or_else(get_kiwi_as_fallback) .or_else(get_lemon_as_fallback); println!("first_available_fruit: {:?}", first_available_fruit); // Providing kiwi as fallback // first_available_fruit: Some(Kiwi) }
get_or_insert() evaluates eagerly, modifies empty value in place
To make sure that an Option contains a value, we can use get_or_insert to modify it in place with a fallback value, as is shown in the following example.
#[derive(Debug)] enum Fruit { Apple, Orange, Banana, Kiwi, Lemon } fn main() { let mut my_fruit: Option<Fruit> = None; let apple = Fruit::Apple; let first_available_fruit = my_fruit.get_or_insert(apple); println!("my_fruit is: {:?}", first_available_fruit); println!("first_available_fruit is: {:?}", first_available_fruit); // my_fruit is: Apple // first_available_fruit is: Apple //println!("Variable named `apple` is moved: {:?}", apple); // TODO: uncomment the line above to see the compiler error }
Note that
get_or_inserteagerly evaluates its parameter, so variableappleis moved:
get_or_insert_with() evaluates lazily, modifies empty value in place
Instead of explicitly providing a value to fall back on, we can pass a closure to get_or_insert_with, as follows:
#[derive(Debug)] enum Fruit { Apple, Orange, Banana, Kiwi, Lemon } fn main() { let mut my_fruit: Option<Fruit> = None; let get_lemon_as_fallback = || { println!("Providing lemon as fallback"); Fruit::Lemon }; let first_available_fruit = my_fruit .get_or_insert_with(get_lemon_as_fallback); println!("my_fruit is: {:?}", first_available_fruit); println!("first_available_fruit is: {:?}", first_available_fruit); // Providing lemon as fallback // my_fruit is: Lemon // first_available_fruit is: Lemon // If the Option has a value, it is left unchanged, and the closure is not invoked let mut my_apple = Some(Fruit::Apple); let should_be_apple = my_apple.get_or_insert_with(get_lemon_as_fallback); println!("should_be_apple is: {:?}", should_be_apple); println!("my_apple is unchanged: {:?}", my_apple); // The output is a follows. Note that the closure `get_lemon_as_fallback` is not invoked // should_be_apple is: Apple // my_apple is unchanged: Some(Apple) }
See also:
closures, get_or_insert, get_or_insert_with, ,moved variables, or, or_else
Result: a richer version of Option
Result is a richer version of the Option type that
describes possible error instead of possible absence.
That is,
Result<T, E>could have one of two outcomes:
Ok(T): An elementTwas foundErr(E): An error was found with elementE
By convention, the expected outcome is
Okwhile the unexpected outcome isErr.
Like Option, Result has many methods associated with it:
unwrap(), for example, either yields the elementTorpanics.- For case handling, there are many combinators between
ResultandOptionthat overlap.
In working with Rust, you will likely encounter methods that return the
Result type, such as the parse() method.
parse & unwrap: raise Exception
It might not always be possible to parse a string into the other type, so
parse()returns aResultindicating possible failure.
Let’s see what happens when we successfully and unsuccessfully parse() a string:
fn multiply(first_number_str: &str, second_number_str: &str) -> i32 { // Let's try using `unwrap()` to get the number out. Will it bite us? let first_number = first_number_str.parse::<i32>().unwrap(); let second_number = second_number_str.parse::<i32>().unwrap(); first_number * second_number } fn main() { let twenty = multiply("10", "2"); println!("double is {}", twenty); let tt = multiply("t", "2"); println!("double is {}", tt); }
- In the unsuccessful case,
parse()leaves us with an error forunwrap()topanicon. - Additionally, the
panicexits our program and provides an unpleasant error message.
Using Result in main
To improve the quality of our error message, we should be more specific about the return type and consider explicitly handling the error.
The Result type can also be the return type of the main function if
specified explicitly.
Typically the main function will be of the form:
fn main() { println!("Hello World!"); }
However main is also able to have a return type of Result:
- If an error occurs within the
mainfunction it will return an error code and print a debug representation of the error (using theDebugtrait).
The following example shows such a scenario and touches on aspects covered in the following section.
use std::num::ParseIntError; fn main() -> Result<(), ParseIntError> { let number_str = "10"; let number = match number_str.parse::<i32>() { Ok(number) => number, Err(e) => return Err(e), }; println!("{}", number); Ok(()) }
map for Result: catch explicit Exception and Continue
Panicking in the previous example’s multiply does not make for robust code.
Generally, we want to return the error to the caller so it can decide what is the right way to respond to errors.
-
This just like the explicit exception caught in Python: except
… -
We first need to know what kind of error type we are dealing with.
-
To determine the
Errtype, we look toparse(), which is implemented with theFromStrtrait fori32. -
As a result, the
Errtype is specified asParseIntError.
In the example below, the straightforward match statement leads to code that is overall more cumbersome.
use std::num::ParseIntError; // With the return type rewritten, we use pattern matching without `unwrap()`. fn multiply(first_number_str: &str, second_number_str: &str) -> Result<i32, ParseIntError> { match first_number_str.parse::<i32>() { Ok(first_number) => { match second_number_str.parse::<i32>() { Ok(second_number) => { Ok(first_number * second_number) }, Err(e) => Err(e), } }, Err(e) => Err(e), } } fn print(result: Result<i32, ParseIntError>) { match result { Ok(n) => println!("n is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { // This still presents a reasonable answer. let twenty = multiply("10", "2"); print(twenty); // The following now provides a much more helpful error message. let tt = multiply("t", "2"); print(tt); }
- With the return type rewritten, we use pattern matching without
unwrap().
Luckily, Option’s map, and_then, and many other combinators are also implemented for Result. Result contains a complete listing.
use std::num::ParseIntError; // As with `Option`, we can use combinators such as `map()`. // This function is otherwise identical to the one above and reads: // Modify n if the value is valid, otherwise pass on the error. fn multiply(first_number_str: &str, second_number_str: &str) -> Result<i32, ParseIntError> { first_number_str.parse::<i32>().and_then(|first_number| { second_number_str.parse::<i32>().map(|second_number| first_number * second_number) }) } fn print(result: Result<i32, ParseIntError>) { match result { Ok(n) => println!("n is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { // This still presents a reasonable answer. let twenty = multiply("10", "2"); print(twenty); // The following now provides a much more helpful error message. let tt = multiply("t", "2"); print(tt); }
aliases for Result: Custome Exception
How about when we want to reuse a specific Result type many times?
Recall that Rust allows us to create aliases. Conveniently, we can define one for the specific
Resultin question.
At a module level, creating aliases can be particularly helpful:
- Errors found in a specific module often have the same
Errtype, so a single alias can succinctly define all associatedResults. - This is so useful that the
stdlibrary even supplies one:io::Result!
Here’s a quick example to show off the syntax:
use std::num::ParseIntError; // Define a generic alias for a `Result` with the error type `ParseIntError`. type AliasedResult<T> = Result<T, ParseIntError>; // Use the above alias to refer to our specific `Result` type. fn multiply(first_number_str: &str, second_number_str: &str) -> AliasedResult<i32> { first_number_str.parse::<i32>().and_then(|first_number| { second_number_str.parse::<i32>().map(|second_number| first_number * second_number) }) } // Here, the alias again allows us to save some space. fn print(result: AliasedResult<i32>) { match result { Ok(n) => println!("n is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { print(multiply("10", "2")); print(multiply("t", "2")); }
- Define a generic alias for a
Resultwith the error typeParseIntError. - Use the above alias to refer to our specific
Resulttype. - Here, the alias again allows us to save some space.
See also:
Early returns: Catch Exception and raise
- In the previous example, we explicitly handled the errors using combinators.
- Another way to deal with this case analysis is to use a combination of
matchstatements and early returns.
That is, we can simply stop executing the function and return the error if one occurs.
For some, this form of code can be easier to both read and write.
Consider this version of the previous example, rewritten using early returns:
use std::num::ParseIntError; fn multiply(first_number_str: &str, second_number_str: &str) -> Result<i32, ParseIntError> { let first_number = match first_number_str.parse::<i32>() { Ok(first_number) => first_number, Err(e) => return Err(e), }; let second_number = match second_number_str.parse::<i32>() { Ok(second_number) => second_number, Err(e) => return Err(e), }; Ok(first_number * second_number) } fn print(result: Result<i32, ParseIntError>) { match result { Ok(n) => println!("n is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { print(multiply("10", "2")); print(multiply("t", "2")); }
- At this point, we’ve learned to explicitly handle errors using combinators and early returns.
- While we generally want to avoid panicking, explicitly handling all of our errors is cumbersome.
In the next section, we’ll introduce ? for the cases where we simply
need to unwrap without possibly inducing panic.
?: the uses of question mark
Introducing ? and try?: Simplicity of unwrap without the panic posiblity
Sometimes we just want the simplicity of unwrap without the possibility of
a panic.
Until now,
unwraphas forced us to nest deeper and deeper when what we really wanted was to get the variable out.
This is exactly the purpose of ?.
Upon finding an
Err, there are two valid actions to take:
panic!which we already decided to try to avoid if possiblereturnbecause anErrmeans it cannot be handled
?is almost1 exactly equivalent to anunwrapwhichreturns instead ofpanicking onErrs.
Let’s see how we can simplify the earlier example that used combinators:
use std::num::ParseIntError; fn multiply(first_number_str: &str, second_number_str: &str) -> Result<i32, ParseIntError> { let first_number = first_number_str.parse::<i32>()?; let second_number = second_number_str.parse::<i32>()?; Ok(first_number * second_number) } fn print(result: Result<i32, ParseIntError>) { match result { Ok(n) => println!("n is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { print(multiply("10", "2")); print(multiply("t", "2")); }
The try! macro
Before there was ?, the same functionality was achieved with the try! macro.
The
?operator is now recommended, but you may still findtry!when looking at older code.
The same multiply function from the previous example would look like this using try!:
// To compile and run this example without errors, while using Cargo, change the value // of the `edition` field, in the `[package]` section of the `Cargo.toml` file, to "2015". use std::num::ParseIntError; fn multiply(first_number_str: &str, second_number_str: &str) -> Result<i32, ParseIntError> { let first_number = try!(first_number_str.parse::<i32>()); let second_number = try!(second_number_str.parse::<i32>()); Ok(first_number * second_number) } fn print(result: Result<i32, ParseIntError>) { match result { Ok(n) => println!("n is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { print(multiply("10", "2")); print(multiply("t", "2")); }
See re-enter ? for more details.
Unpacking options with ? to return the underlying some value or terminate
You can unpack
Options by usingmatchstatements, but it’s often easier to use the?operator:
- If
xis anOption, then evaluatingx?will return the underlying value ifxisSome - otherwise it will terminate whatever function is being executed and return
None.
fn next_birthday(current_age: Option<u8>) -> Option<String> { // If `current_age` is `None`, this returns `None`. // If `current_age` is `Some`, the inner `u8` gets assigned to `next_age` let next_age: u8 = current_age? + 1; Some(format!("Next year I will be {}", next_age)) }
- If
current_ageisNone, this returnsNone. - If
current_ageisSome, the inneru8gets assigned tonext_age
You can chain many *?*s together to make your code much more readable.
struct Person { job: Option<Job>, } #[derive(Clone, Copy)] struct Job { phone_number: Option<PhoneNumber>, } #[derive(Clone, Copy)] struct PhoneNumber { area_code: Option<u8>, number: u32, } impl Person { // Gets the area code of the phone number of the person's job, if it exists. fn work_phone_area_code(&self) -> Option<u8> { // This would need many nested `match` statements without the `?` operator. // It would take a lot more code - try writing it yourself and see which // is easier. self.job?.phone_number?.area_code } } fn main() { let p = Person { job: Some(Job { phone_number: Some(PhoneNumber { area_code: Some(61), number: 439222222, }), }), }; assert_eq!(p.work_phone_area_code(), Some(61)); }
Other uses of ?
Notice in the previous example that our immediate reaction to calling
parse is to map the error from a library error into a boxed
error:
.and_then(|s| s.parse::<i32>()
.map_err(|e| e.into())
Since this is a simple and common operation, it would be convenient if it could be elided.
Alas, because
and_thenis not sufficiently flexible, it cannot. However, we can instead use?.
?was previously explained as eitherunwraporreturn Err(err). This is only mostly true.- It actually means
unwraporreturn Err(From::from(err)). - Since
From::fromis a conversion utility between different types, this means that if you?where the error is convertible to the return type, it will convert automatically.
Here, we rewrite the previous example using ?. As a result, the map_err will go away when From::from is implemented for our error type:
use std::error; use std::fmt; // Change the alias to `Box<dyn error::Error>`. type Result<T> = std::result::Result<T, Box<dyn error::Error>>; #[derive(Debug)] struct EmptyVec; impl fmt::Display for EmptyVec { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "invalid first item to double") } } impl error::Error for EmptyVec {} // The same structure as before but rather than chain all `Results` // and `Options` along, we `?` to get the inner value out immediately. fn double_first(vec: Vec<&str>) -> Result<i32> { let first = vec.first().ok_or(EmptyVec)?; let parsed = first.parse::<i32>()?; Ok(2 * parsed) } fn print(result: Result<i32>) { match result { Ok(n) => println!("The first doubled is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { let numbers = vec!["42", "93", "18"]; let empty = vec![]; let strings = vec!["tofu", "93", "18"]; print(double_first(numbers)); print(double_first(empty)); print(double_first(strings)); }
This is actually fairly clean now:
- Compared with the original
panic, it is very similar to replacing theunwrapcalls with?except that the return types areResult. - As a result, they must be destructured at the top level.
See also:
From::from and ?
Multiple error types to interact
The previous examples have always been very convenient:
Results interact with otherResults- and
Options interact with otherOptions.
Sometimes an Option needs to interact with a Result, or a
Result<T, Error1> needs to interact with a Result<T, Error2>.
In those cases, we want to manage our different error types in a way that makes them composable and easy to interact with.
In the following code, two instances of unwrap generate different error types. Vec::first returns an Option, while parse::
fn double_first(vec: Vec<&str>) -> i32 { let first = vec.first().unwrap(); // Generate error 1 2 * first.parse::<i32>().unwrap() // Generate error 2 } fn main() { let numbers = vec!["42", "93", "18"]; let empty = vec![]; let strings = vec!["tofu", "93", "18"]; println!("The first doubled is {}", double_first(numbers)); println!("The first doubled is {}", double_first(empty)); // Error 1: the input vector is empty println!("The first doubled is {}", double_first(strings)); // Error 2: the element doesn't parse to a number }
Over the next sections, we’ll see several strategies for handling these kind of problems.
Pulling Results out of Options
The most basic way of handling mixed error types is to just embed them in each other.
use std::num::ParseIntError; fn double_first(vec: Vec<&str>) -> Option<Result<i32, ParseIntError>> { vec.first().map(|first| { first.parse::<i32>().map(|n| 2 * n) }) } fn main() { let numbers = vec!["42", "93", "18"]; let empty = vec![]; let strings = vec!["tofu", "93", "18"]; println!("The first doubled is {:?}", double_first(numbers)); println!("The first doubled is {:?}", double_first(empty)); // Error 1: the input vector is empty println!("The first doubled is {:?}", double_first(strings)); // Error 2: the element doesn't parse to a number }
There are times when we’ll want to stop processing on errors (like with
?) but keep going when the Option is None.
A couple of combinators come in handy to swap the Result and Option.
use std::num::ParseIntError; fn double_first(vec: Vec<&str>) -> Result<Option<i32>, ParseIntError> { let opt = vec.first().map(|first| { first.parse::<i32>().map(|n| 2 * n) }); opt.map_or(Ok(None), |r| r.map(Some)) } fn main() { let numbers = vec!["42", "93", "18"]; let empty = vec![]; let strings = vec!["tofu", "93", "18"]; println!("The first doubled is {:?}", double_first(numbers)); println!("The first doubled is {:?}", double_first(empty)); println!("The first doubled is {:?}", double_first(strings)); }
Defining an error type
Sometimes it simplifies the code to mask all of the different errors with a single type of error.
Rust allows us to define our own error types. In general, a “good” error type:
- Represents different errors with the same type
- Presents nice error messages to the user
- Is easy to compare with other types
- Good:
Err(EmptyVec) - Bad:
Err("Please use a vector with at least one element".to_owned())
- Good:
- Can hold information about the error
- Good:
Err(BadChar(c, position)) - Bad:
Err("+ cannot be used here".to_owned())
- Good:
- Composes well with other errors
We’ll show this with a custom error.
We’ll show this with a custom error.
use std::fmt; type Result<T> = std::result::Result<T, DoubleError>; // Define our error types. These may be customized for our error handling cases. // Now we will be able to write our own errors, defer to an underlying error // implementation, or do something in between. #[derive(Debug, Clone)] struct DoubleError; // Generation of an error is completely separate from how it is displayed. // There's no need to be concerned about cluttering complex logic with the display style. // // Note that we don't store any extra info about the errors. This means we can't state // which string failed to parse without modifying our types to carry that information. impl fmt::Display for DoubleError { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "invalid first item to double") } } fn double_first(vec: Vec<&str>) -> Result<i32> { vec.first() // Change the error to our new type. .ok_or(DoubleError) .and_then(|s| { s.parse::<i32>() // Update to the new error type here also. .map_err(|_| DoubleError) .map(|i| 2 * i) }) } fn print(result: Result<i32>) { match result { Ok(n) => println!("The first doubled is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { let numbers = vec!["42", "93", "18"]; let empty = vec![]; let strings = vec!["tofu", "93", "18"]; print(double_first(numbers)); print(double_first(empty)); print(double_first(strings)); }
Boxing errors
A way to write simple code while preserving the original errors is to Box
them.
The drawback is that the underlying error type is only known at runtime and not statically determined.
The stdlib helps in boxing our errors by having Box implement conversion from any type that implements the Error trait into the trait object Box
use std::error; use std::fmt; // Change the alias to `Box<error::Error>`. type Result<T> = std::result::Result<T, Box<dyn error::Error>>; #[derive(Debug, Clone)] struct EmptyVec; impl fmt::Display for EmptyVec { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "invalid first item to double") } } impl error::Error for EmptyVec {} fn double_first(vec: Vec<&str>) -> Result<i32> { vec.first() .ok_or_else(|| EmptyVec.into()) // Converts to Box .and_then(|s| { s.parse::<i32>() .map_err(|e| e.into()) // Converts to Box .map(|i| 2 * i) }) } fn print(result: Result<i32>) { match result { Ok(n) => println!("The first doubled is {}", n), Err(e) => println!("Error: {}", e), } } fn main() { let numbers = vec!["42", "93", "18"]; let empty = vec![]; let strings = vec!["tofu", "93", "18"]; print(double_first(numbers)); print(double_first(empty)); print(double_first(strings)); }
See also:
Dynamic dispatch and Error trait
Wrapping errors
An alternative to boxing errors is to wrap them in your own error type.
use std::error; use std::error::Error; use std::num::ParseIntError; use std::fmt; type Result<T> = std::result::Result<T, DoubleError>; #[derive(Debug)] enum DoubleError { EmptyVec, // We will defer to the parse error implementation for their error. // Supplying extra info requires adding more data to the type. Parse(ParseIntError), } impl fmt::Display for DoubleError { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { match *self { DoubleError::EmptyVec => write!(f, "please use a vector with at least one element"), // The wrapped error contains additional information and is available // via the source() method. DoubleError::Parse(..) => write!(f, "the provided string could not be parsed as int"), } } } impl error::Error for DoubleError { fn source(&self) -> Option<&(dyn error::Error + 'static)> { match *self { DoubleError::EmptyVec => None, // The cause is the underlying implementation error type. Is implicitly // cast to the trait object `&error::Error`. This works because the // underlying type already implements the `Error` trait. DoubleError::Parse(ref e) => Some(e), } } } // Implement the conversion from `ParseIntError` to `DoubleError`. // This will be automatically called by `?` if a `ParseIntError` // needs to be converted into a `DoubleError`. impl From<ParseIntError> for DoubleError { fn from(err: ParseIntError) -> DoubleError { DoubleError::Parse(err) } } fn double_first(vec: Vec<&str>) -> Result<i32> { let first = vec.first().ok_or(DoubleError::EmptyVec)?; // Here we implicitly use the `ParseIntError` implementation of `From` (which // we defined above) in order to create a `DoubleError`. let parsed = first.parse::<i32>()?; Ok(2 * parsed) } fn print(result: Result<i32>) { match result { Ok(n) => println!("The first doubled is {}", n), Err(e) => { println!("Error: {}", e); if let Some(source) = e.source() { println!(" Caused by: {}", source); } }, } } fn main() { let numbers = vec!["42", "93", "18"]; let empty = vec![]; let strings = vec!["tofu", "93", "18"]; print(double_first(numbers)); print(double_first(empty)); print(double_first(strings)); }
This adds a bit more boilerplate for handling errors and might not be needed in all applications. There are some libraries that can take care of the boilerplate for you.
See also:
From::from and Enums
Iterating over Results
An Iter::map operation might fail, for example:
fn main() { let strings = vec!["tofu", "93", "18"]; let numbers: Vec<_> = strings .into_iter() .map(|s| s.parse::<i32>()) .collect(); println!("Results: {:?}", numbers); }
Let’s step through strategies for handling this.
Ignore the failed items with filter_map()
filter_map calls a function and filters out the results that are None.
fn main() { let strings = vec!["tofu", "93", "18"]; let numbers: Vec<_> = strings .into_iter() .filter_map(|s| s.parse::<i32>().ok()) .collect(); println!("Results: {:?}", numbers); }
Collect the failed items with map_err() and filter_map()
map_err calls a function with the error, so by adding that to the previous filter_map solution we can save them off to the side while iterating.
fn main() { let strings = vec!["42", "tofu", "93", "999", "18"]; let mut errors = vec![]; let numbers: Vec<_> = strings .into_iter() .map(|s| s.parse::<u8>()) .filter_map(|r| r.map_err(|e| errors.push(e)).ok()) .collect(); println!("Numbers: {:?}", numbers); println!("Errors: {:?}", errors); }
Fail the entire operation with collect()
Result implements FromIterator so that a vector of results (Vec<Result<T, E>>) can be turned into a result with a vector (Result<Vec, E> ). Once an Result::Err is found, the iteration will terminate.
fn main() { let strings = vec!["tofu", "93", "18"]; let numbers: Result<Vec<_>, _> = strings .into_iter() .map(|s| s.parse::<i32>()) .collect(); println!("Results: {:?}", numbers); }
This same technique can be used with Option.
Collect all valid values and failures with partition()
Example
fn main() { let strings = vec!["tofu", "93", "18"]; let (numbers, errors): (Vec<_>, Vec<_>) = strings .into_iter() .map(|s| s.parse::<i32>()) .partition(Result::is_ok); println!("Numbers: {:?}", numbers); println!("Errors: {:?}", errors); }
When you look at the results, you’ll note that everything is still wrapped in
Result.
A little more boilerplate is needed for this.
fn main() { let strings = vec!["tofu", "93", "18"]; let (numbers, errors): (Vec<_>, Vec<_>) = strings .into_iter() .map(|s| s.parse::<i32>()) .partition(Result::is_ok); let numbers: Vec<_> = numbers.into_iter().map(Result::unwrap).collect(); let errors: Vec<_> = errors.into_iter().map(Result::unwrap_err).collect(); println!("Numbers: {:?}", numbers); println!("Errors: {:?}", errors); }
Encasulation: modules, crates and cargo
Basic Practice
Read a file: Result、?、unwrap_or_else
use std::fs; use std::io; fn read_file(filename: &str) -> Result<String, io::Error> { let contents = fs::read_to_string(filename)?; Ok(contents) } fn main() { let contents = read_file("my_file.txt").unwrap_or_else(|err| { eprintln!("Error reading file: {}", err); std::process::exit(1); }); // Use the contents of the file }
Illustration: Read a file
-
In this example, the read_file function returns a Result<String, io::Error> that indicates whether the operation was successful (and contains the contents of the file as a String) or not (and contains an io::Error with information about the failure).
-
The ? operator is used to propagate any error from the fs::read_to_string function to the caller of read_file. This means that if fs::read_to_string fails, the Err variant of the Result will be returned from read_file with the error value from fs::read_to_string.
-
In the main function, the unwrap_or_else method is used to handle any errors that may have occurred while reading the file. If read_file returns an Err, the closure passed to unwrap_or_else will be executed, which prints an error message and exits the program. If read_file returns an Ok, the String value inside the Ok will be extracted and stored in the contents variable.
Error handling in Rust is typically done using the Result type, which is an enum that can either be Ok if the operation was successful, or Err if it failed.
Read a file: match to take different actions
use std::fs::File; use std::io::Read; fn read_file(filename: &str) -> Result<String, std::io::Error> { let mut file = File::open(filename)?; // open the file let mut contents = String::new(); file.read_to_string(&mut contents)?; // read the contents into a string Ok(contents) // return the contents as a Result } fn main() { match read_file("my_file.txt") { Ok(contents) => println!("The file contents are: {}", contents), Err(error) => println!("Error: {}", error), } }
Read a file: match specific error
use std::fs::File; use std::io::ErrorKind; fn main() { let f = File::open("my_file.txt"); let f = match f { Ok(file) => file, Err(error) => match error.kind() { ErrorKind::NotFound => { // handle the error here // for example, create a new file File::create("my_file.txt").unwrap_or_else(|error| { panic!("Failed to create file: {:?}", error); }) }, other_error => { panic!("Failed to open file: {:?}", other_error); } }, }; }
- In the code above, we first try to open a file called my_file.txt using the File::open method.
- This method returns a Result instance, which we then match on to handle the possible outcomes.
- If the Result is Ok, then it means that the file was successfully opened and we can use it.
- If the Result is Err, then we match on the error.kind() to handle the specific error.
- In this case, we are only handling the ErrorKind::NotFound case, where the file does not exist and we need to create it.
- For all other errors, we panic! with a message.
This is just a simple example, but it should give you an idea of how to use Result to handle errors in Rust.
Using the Result type to handle a potential error
use std::fs::File; use std::io::ErrorKind; fn main() { let f = File::open("hello.txt"); let f = match f { Ok(file) => file, Err(error) => match error.kind() { ErrorKind::NotFound => { println!("File not found"); File::create("hello.txt").unwrap_or_else(|error| { panic!("Error creating file: {:?}", error) }) }, other_error => { panic!("Error opening file: {:?}", other_error) } }, }; }
- In this example, we try to open a file called “hello.txt”.
- If the file is found, the Ok variant of the Result is returned and the file is assigned to the f variable.
- If the file is not found, the Err variant is returned and we match on the error to handle the specific case of a file not being found.
- In this case, we create a new file called “hello.txt”.
- If there is any other error, we panic.
use the ? operator to simplify error handling when you want to return an error if one occurs
use std::fs::File; fn main() -> Result<(), std::io::Error> { let f = File::open("hello.txt")?; // Do something with the file Ok(()) }
- The ? operator returns the error value if there is one, or else it continues execution and returns the value of the expression on the right side of the ?.
- If you use the ? operator, you need to return a Result type or propagate the error up the call stack using the ? operator.
Using unwrap_or to provide a default value on error
use std::num::ParseIntError; fn string_to_number(s: &str) -> Result<i32, ParseIntError> { s.parse::<i32>().map_err(|e| e.into()) } fn main() { let n = string_to_number("10").unwrap_or(-1); println!("n = {}", n); let m = string_to_number("foo").unwrap_or(-1); println!("m = {}", m); }
- In this example, we have a function string_to_number that converts a string to an i32.
- If the string can’t be parsed as an i32, the Err variant of the Result is returned.
- In main, we use unwrap_or to provide a default value of -1 if an error occurs.
Using expect to provide a custom error message on error
use std::num::ParseIntError; fn string_to_number(s: &str) -> Result<i32, ParseIntError> { s.parse::<i32>().map_err(|e| e.into()) } fn main() { let n = string_to_number("10").expect("Unable to parse string as number"); println!("n = {}", n); let m = string_to_number("foo").expect("Unable to parse string as number"); println!("m = {}", m); }
- In this example, we have the same string_to_number function as in the previous example.
- In main, we use expect to provide a custom error message if an error occurs.
- If the Result is Ok, the value is unwrapped and returned.
- If the Result is Err, the custom error message is printed and the program panics.
Propagating an error using the ? operator and expect to capture
use std::fs::File; fn create_file(name: &str) -> std::io::Result<()> { let f = File::create(name)?; Ok(()) } fn main() { create_file("foo.txt").expect("Error creating file"); }
- In this example, we have a function create_file that creates a file with the given name.
- If there is an error creating the file, the Err variant of the Result is returned.
- In main, we use the ? operator to propagate the error up the call stack and pass it to expect to handle.
Using unwrap_or_else to provide a custom error handling function
use std::num::ParseIntError; fn string_to_number(s: &str) -> Result<i32, ParseIntError> { s.parse::<i32>().map_err(|e| e.into()) } fn main() { let n = string_to_number("10").unwrap_or_else(|error| { println!("Error parsing string: {:?}", error); -1 }); println!("n = {}", n); let m = string_to_number("foo").unwrap_or_else(|error| { println!("Error parsing string: {:?}", error); -1 }); println!("m = {}", m); }
- In this example, we have the same string_to_number function as in previous examples.
- In main, we use unwrap_or_else to provide a custom error handling function that is called if an error occurs.
- The error handling function takes the error as an argument and returns a default value.
Using try_into to convert between types:
use std::convert::TryInto; fn main() { let x: Result<i32, _> = "10".try_into(); println!("x = {:?}", x); let y: Result<i32, _> = "foo".try_into(); println!("y = {:?}", y); }
- In this example, we use the try_into function to try to convert a string to an i32.
- If the conversion is successful, the Ok variant of the Result is returned.
- If the conversion fails, the Err variant is returned.
Using Iterator::try_fold to perform a fold operation with error handling:
use std::num::ParseIntError; fn parse_int(s: &str) -> Result<i32, ParseIntError> { s.parse::<i32>().map_err(|e| e.into()) } fn main() { let numbers = vec!["1", "2", "3", "4"]; let sum = numbers.iter() .try_fold(0, |acc, x| -> Result<i32, ParseIntError> { let y = parse_int(x)?; Ok(acc + y) }); println!("sum = {:?}", sum); let numbers = vec!["1", "foo", "3", "4"]; let sum = numbers.iter() .try_fold(0, |acc, x| -> Result<i32, ParseIntError> { let y = parse_int(x)?; Ok(acc + y) }); println!("sum = {:?}", sum); }
Using Result::unwrap_or_default to provide a default value on error:
use std::num::ParseIntError; fn string_to_number(s: &str) -> Result<i32, ParseIntError> { s.parse::<i32>().map_err(|e| e.into()) } fn main() { let n = string_to_number("10").unwrap_or_default(); println!("n = {}", n); let m = string_to_number("foo").unwrap_or_default(); println!("m = {}", m); }
- In this example, we have the same string_to_number function as in previous examples.
- In main, we use unwrap_or_default to provide a default value of 0 if an error occurs.
- The default value is determined by the type of the value being returned.
Using Result::transpose to convert a Result inside an Option:
use std::num::ParseIntError; fn string_to_number(s: &str) -> Result<i32, ParseIntError> { s.parse::<i32>().map_err(|e| e.into()) } fn main() { let maybe_number = Some("10"); let number = maybe_number.map(string_to_number) .transpose() .unwrap_or_else(|| Err(ParseIntError { kind: std::num::ParseIntErrorKind::InvalidDigit, })); println!("number = {:?}", number); let maybe_number = Some("foo"); let number = maybe_number.map(string_to_number) .transpose() .unwrap_or_else(|| Err(ParseIntError { kind: std::num::ParseIntErrorKind::InvalidDigit, })); println!("number = {:?}", number); let maybe_number = None; let number = maybe_number.map(string_to_number) .transpose() .unwrap_or_else(|| Err(ParseIntError { kind: std::num::ParseIntErrorKind::InvalidDigit, })); println!("number = {:?}", number); }
- In this example, we have the same string_to_number function as in previous examples.
- We also have a variable maybe_number of type Option<&str> that may or may not contain a string.
- We use map to apply the string_to_number function to the value inside the Option, if it exists.
- This results in an Option<Result<i32, ParseIntError>>.
- We then use transpose to convert the Result inside the Option to an Option inside the Result.
- This allows us to use the unwrap_or_else method on the Result to provide a default error value
Handling multiple types of errors
use std::fs::File; use std::io::ErrorKind; fn main() -> Result<(), Box<dyn std::error::Error>> { let file = match File::open("my_file.txt") { Ok(file) => file, Err(error) => match error.kind() { ErrorKind::NotFound => match File::create("my_file.txt") { Ok(file) => file, Err(error) => return Err(error.into()), }, other_error => return Err(other_error.into()), }, }; Ok(()) }
In this example, we are trying to open a file called “my_file.txt”:
- If the file doesn’t exist, we attempt to create it.
- If either of these operations fails, we return an error.
Propagating errors up the call stack:
use std::error::Error; use std::fs::File; use std::io::Read; fn read_file() -> Result<String, Box<dyn Error>> { let mut file = File::open("my_file.txt")?; let mut contents = String::new(); file.read_to_string(&mut contents)?; Ok(contents) } fn main() -> Result<(), Box<dyn Error>> { let contents = read_file()?; println!("File contents: {}", contents); Ok(()) }
In this example, the read_file function attempts to open a file and read its contents:
- If any of these operations fails, it returns an error.
- The main function then calls read_file, and if it returns an error, it propagates it up the call stack using the ? operator.
Using custom error types:
use std::error::Error; use std::fmt; #[derive(Debug)] struct MyError { message: String, } impl MyError { fn new(msg: &str) -> MyError { MyError { message: msg.to_string(), } } } impl fmt::Display for MyError { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "MyError: {}", self.message) } } impl Error for MyError {} fn do_something() -> Result<(), MyError> { // Do something that could potentially fail if false { Ok(()) } else { Err(MyError::new("Something went wrong")) } } fn main() -> Result<(), Box<dyn Error>> { do_something()?; Ok(()) }
- In this example, we define a custom error type called MyError, which implements the Error and Display traits.
- We then use this custom error type in the do_something function, which returns a Result with MyError as the error type.
Encasulation: modules, crates and cargo
Modules: hierarchically split and manage visibility
Rust provides a powerful module system that can be used to hierarchically split
code in logical units (modules), and manage visibility (public/private) between
them.
A module is a collection of items:
- functions
- structs
- traits
implblocks,- and even other modules.
Visibility
By default, the items in a module have private visibility, but this can be
overridden with the pub modifier.
Only the public items of a module can be accessed from outside the module scope.
visibility example
// A module named `my_mod` mod my_mod { // Items in modules default to private visibility. fn private_function() { println!("called `my_mod::private_function()`"); } // Use the `pub` modifier to override default visibility. pub fn function() { println!("called `my_mod::function()`"); } // Items can access other items in the same module, // even when private. pub fn indirect_access() { print!("called `my_mod::indirect_access()`, that\n> "); private_function(); } // Modules can also be nested pub mod nested { pub fn function() { println!("called `my_mod::nested::function()`"); } #[allow(dead_code)] fn private_function() { println!("called `my_mod::nested::private_function()`"); } // Functions declared using `pub(in path)` syntax are only visible // within the given path. `path` must be a parent or ancestor module pub(in crate::my_mod) fn public_function_in_my_mod() { print!("called `my_mod::nested::public_function_in_my_mod()`, that\n> "); public_function_in_nested(); } // Functions declared using `pub(self)` syntax are only visible within // the current module, which is the same as leaving them private pub(self) fn public_function_in_nested() { println!("called `my_mod::nested::public_function_in_nested()`"); } // Functions declared using `pub(super)` syntax are only visible within // the parent module pub(super) fn public_function_in_super_mod() { println!("called `my_mod::nested::public_function_in_super_mod()`"); } } pub fn call_public_function_in_my_mod() { print!("called `my_mod::call_public_function_in_my_mod()`, that\n> "); nested::public_function_in_my_mod(); print!("> "); nested::public_function_in_super_mod(); } // pub(crate) makes functions visible only within the current crate pub(crate) fn public_function_in_crate() { println!("called `my_mod::public_function_in_crate()`"); } // Nested modules follow the same rules for visibility mod private_nested { #[allow(dead_code)] pub fn function() { println!("called `my_mod::private_nested::function()`"); } // Private parent items will still restrict the visibility of a child item, // even if it is declared as visible within a bigger scope. #[allow(dead_code)] pub(crate) fn restricted_function() { println!("called `my_mod::private_nested::restricted_function()`"); } } } fn function() { println!("called `function()`"); } fn main() { // Modules allow disambiguation between items that have the same name. function(); my_mod::function(); // Public items, including those inside nested modules, can be // accessed from outside the parent module. my_mod::indirect_access(); my_mod::nested::function(); my_mod::call_public_function_in_my_mod(); // pub(crate) items can be called from anywhere in the same crate my_mod::public_function_in_crate(); // pub(in path) items can only be called from within the module specified // Error! function `public_function_in_my_mod` is private //my_mod::nested::public_function_in_my_mod(); // TODO ^ Try uncommenting this line // Private items of a module cannot be directly accessed, even if // nested in a public module: // Error! `private_function` is private //my_mod::private_function(); // TODO ^ Try uncommenting this line // Error! `private_function` is private //my_mod::nested::private_function(); // TODO ^ Try uncommenting this line // Error! `private_nested` is a private module //my_mod::private_nested::function(); // TODO ^ Try uncommenting this line // Error! `private_nested` is a private module //my_mod::private_nested::restricted_function(); // TODO ^ Try uncommenting this line }
- Items in modules default to private visibility.
- Use the
pubmodifier to override default visibility. - Items can access other items in the same module, even when private.
- Modules can also be nested
- Functions declared using
pub(in path)syntax are only visible within the given path.
pathmust be a parent or ancestor module
- Functions declared using
pub(in path)syntax are only visible within the given path.
pathmust be a parent or ancestor module
- pub(crate) makes functions visible only within the current crate
- Private parent items will still restrict the visibility of a child item, even if it is declared as visible within a bigger scope.
- Modules allow disambiguation between items that have the same name.
- Public items, including those inside nested modules, can be accessed from outside the parent module.
- pub(crate) items can be called from anywhere in the same crate
- pub(in path) items can only be called from within the module specified
- Private items of a module cannot be directly accessed, even if nested in a public module:
Struct visibility: an extra level of visibility with their fields
Structs have an extra level of visibility with their fields:
- The visibility defaults to private
- and can be overridden with the
pubmodifier.
This visibility only matters when a struct is accessed from outside the module where it is defined, and has the goal of hiding information (encapsulation).
mod my { // A public struct with a public field of generic type `T` pub struct OpenBox<T> { pub contents: T, } // A public struct with a private field of generic type `T` pub struct ClosedBox<T> { contents: T, } impl<T> ClosedBox<T> { // A public constructor method pub fn new(contents: T) -> ClosedBox<T> { ClosedBox { contents: contents, } } } } fn main() { // Public structs with public fields can be constructed as usual let open_box = my::OpenBox { contents: "public information" }; // and their fields can be normally accessed. println!("The open box contains: {}", open_box.contents); // Public structs with private fields cannot be constructed using field names. // Error! `ClosedBox` has private fields //let closed_box = my::ClosedBox { contents: "classified information" }; // TODO ^ Try uncommenting this line // However, structs with private fields can be created using // public constructors let _closed_box = my::ClosedBox::new("classified information"); // and the private fields of a public struct cannot be accessed. // Error! The `contents` field is private //println!("The closed box contains: {}", _closed_box.contents); // TODO ^ Try uncommenting this line }
- A public struct with a public field of generic type
T - A public struct with a private field of generic type
T - A public constructor method
- Public structs with public fields can be constructed as usual, and their fields can be normally accessed.
- Public structs with private fields cannot be constructed using field names.
- However, structs with private fields can be created using public constructors
- and the private fields of a public struct cannot be accessed.
See also:
The use declaration: bind a full path to a new name
The use declaration can be used to bind a full path to a new name, for easier
access.
It is often used like this:
use crate::deeply::nested::{
my_first_function,
my_second_function,
AndATraitType
};
fn main() {
my_first_function();
}
You can use the as keyword to bind imports to a different name:
// Bind the `deeply::nested::function` path to `other_function`. use deeply::nested::function as other_function; fn function() { println!("called `function()`"); } mod deeply { pub mod nested { pub fn function() { println!("called `deeply::nested::function()`"); } } } fn main() { // Easier access to `deeply::nested::function` other_function(); println!("Entering block"); { // This is equivalent to `use deeply::nested::function as function`. // This `function()` will shadow the outer one. use crate::deeply::nested::function; // `use` bindings have a local scope. In this case, the // shadowing of `function()` is only in this block. function(); println!("Leaving block"); } function(); }
- use .. as .. : Bind the
deeply::nested::functionpath toother_function. usebindings have a local scope. In this case, the shadowing offunction()is only in this block.
super and self: remove ambiguity
The super and self keywords can be used in the path to remove ambiguity when accessing items and to prevent unnecessary hardcoding of paths.
fn function() { println!("called `function()`"); } mod cool { pub fn function() { println!("called `cool::function()`"); } } mod my { fn function() { println!("called `my::function()`"); } mod cool { pub fn function() { println!("called `my::cool::function()`"); } } pub fn indirect_call() { // Let's access all the functions named `function` from this scope! print!("called `my::indirect_call()`, that\n> "); // The `self` keyword refers to the current module scope - in this case `my`. // Calling `self::function()` and calling `function()` directly both give // the same result, because they refer to the same function. self::function(); function(); // We can also use `self` to access another module inside `my`: self::cool::function(); // The `super` keyword refers to the parent scope (outside the `my` module). super::function(); // This will bind to the `cool::function` in the *crate* scope. // In this case the crate scope is the outermost scope. { use crate::cool::function as root_function; root_function(); } } } fn main() { my::indirect_call(); }
- self:
- The
selfkeyword refers to the current module scope - in this casemy. - Calling
self::function()and callingfunction()directly both give the same result, because they refer to the same function. - We can also use
selfto access another module insidemy:
- super:
- The
superkeyword refers to the parent scope (outside themymodule).
File/Directory hierarchy
Modules can be mapped to a file/directory hierarchy.
Let’s break down the visibility example in files:
$ tree .
.
├── my
│ ├── inaccessible.rs
│ └── nested.rs
├── my.rs
└── split.rs
In split.rs:
// This declaration will look for a file named `my.rs` and will
// insert its contents inside a module named `my` under this scope
mod my;
fn function() {
println!("called `function()`");
}
fn main() {
my::function();
function();
my::indirect_access();
my::nested::function();
}
- mod my; ->
This declaration will look for a file named
my.rsand will insert its contents inside a module namedmyunder this scope
In my.rs:
// Similarly `mod inaccessible` and `mod nested` will locate the `nested.rs`
// and `inaccessible.rs` files and insert them here under their respective
// modules
mod inaccessible;
pub mod nested;
pub fn function() {
println!("called `my::function()`");
}
fn private_function() {
println!("called `my::private_function()`");
}
pub fn indirect_access() {
print!("called `my::indirect_access()`, that\n> ");
private_function();
}
- Similarly
mod inaccessibleandmod nestedwill locate thenested.rs - and
inaccessible.rsfiles and insert them here under their respective modules
In my/nested.rs:
pub fn function() {
println!("called `my::nested::function()`");
}
#[allow(dead_code)]
fn private_function() {
println!("called `my::nested::private_function()`");
}
In my/inaccessible.rs:
#[allow(dead_code)]
pub fn public_function() {
println!("called `my::inaccessible::public_function()`");
}
Let’s check that things still work as before:
$ rustc split.rs && ./split
called `my::function()`
called `function()`
called `my::indirect_access()`, that
> called `my::private_function()`
called `my::nested::function()`
Crates: compilation units in Rust, binary or library
A crate is a compilation unit in Rust:
- Whenever
rustc some_file.rsis called,some_file.rsis treated as the crate file. - If
some_file.rshasmoddeclarations in it, then the contents of the module files would be inserted in places wheremoddeclarations in the crate file are found, before running the compiler over it. - In other words, modules do not get compiled individually, only crates get compiled.
A crate can be compiled into a binary or into a library.
- By default,
rustcwill produce a binary from a crate. - This behavior can be overridden by passing the
--crate-typeflag tolib.
Creating a Library: –crate-type=lib
Let’s create a library, and then see how to link it to another crate.
pub fn public_function() {
println!("called rary's `public_function()`");
}
fn private_function() {
println!("called rary's `private_function()`");
}
pub fn indirect_access() {
print!("called rary's `indirect_access()`, that\n> ");
private_function();
}
$ rustc --crate-type=lib rary.rs
$ ls lib*
library.rlib
- Libraries get prefixed with “lib”, and by default they get named after their crate file
- but this default name can be overridden by passing the
--crate-nameoption torustcor by using thecrate_nameattribute.
Using a Library: –extern
To link a crate to this new library you may use rustc’s --extern flag.
All of its items will then be imported under a module named the same as the library.
This module generally behaves the same way as any other module.
// extern crate rary; // May be required for Rust 2015 edition or earlier
fn main() {
rary::public_function();
// Error! `private_function` is private
//rary::private_function();
rary::indirect_access();
}
# Where library.rlib is the path to the compiled library, assumed that it's
# in the same directory here:
$ rustc executable.rs --extern rary=library.rlib && ./executable
called rary's `public_function()`
called rary's `indirect_access()`, that
> called rary's `private_function()`
Cargo
cargo is the official Rust package management tool.
It has lots of really useful features to improve code quality and developer velocity!
These include
- Dependency management and integration with crates.io (the official Rust package registry)
- Awareness of unit tests
- Awareness of benchmarks
This chapter will go through some quick basics, but you can find the comprehensive docs in The Cargo Book.
Dependencies
Most programs have dependencies on some libraries. If you have ever managed
dependencies by hand, you know how much of a pain this can be. Luckily, the Rust
ecosystem comes standard with cargo! cargo can manage dependencies for a
project.
For the rest of this chapter, let’s assume we are making a binary, rather than a library, but all of the concepts are the same.
After the above commands, you should see a file hierarchy like this:
.
├── bar
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
└── foo
├── Cargo.toml
└── src
└── main.rs
- The
main.rsis the root source file for your newfooproject – nothing new there. - The
Cargo.tomlis the config file forcargofor this project.
If you look inside it, you should see something like this:
[package]
name = "foo"
version = "0.1.0"
authors = ["mark"]
[dependencies]
-
The
namefield under[package]determines the name of the project. -
This is used by
crates.ioif you publish the crate (more later). -
It is also the name of the output binary when you compile.
-
The
versionfield is a crate version number using Semantic Versioning. -
The
authorsfield is a list of authors used when publishing the crate. -
The
[dependencies]section lets you add dependencies for your project.
For example, suppose that we want our program to have a great CLI:
- You can find lots of great packages on crates.io (the official Rust package registry).
- One popular choice is clap.
- As of this writing, the most recent published version of
clapis2.27.1. - To add a dependency to our program, we can simply add the following to our
Cargo.tomlunder[dependencies]:clap = "2.27.1". - And that’s it! You can start using
clapin your program.
cargo also supports other types of dependencies.
Here is just a small sampling:
[package]
name = "foo"
version = "0.1.0"
authors = ["mark"]
[dependencies]
clap = "2.27.1" # from crates.io
rand = { git = "https://github.com/rust-lang-nursery/rand" } # from online repo
bar = { path = "../bar" } # from a path in the local filesystem
cargo is more than a dependency manager. All of the available
configuration options are listed in the format specification of
Cargo.toml.
- cargo build: To build our project we can execute
cargo buildanywhere in the project directory (including subdirectories!). - cargo run: We can also do
cargo runto build and run. - Notice that these commands will:
- resolve all dependencies,
- download crates if needed,
- and build everything, including your crate.
(Note that it only rebuilds what it has not already built, similar to
make).
Voila! That’s all there is to it!
Two Binaries Conventions
In the previous chapter, we saw the following directory hierarchy:
foo
├── Cargo.toml
└── src
└── main.rs
Suppose that we wanted to have two binaries in the same project, though. What then?
It turns out that cargo supports this:
- The default binary name is
main, as we saw before - but you can add additional binaries by placing them in a
bin/directory:
foo
├── Cargo.toml
└── src
├── main.rs
└── bin
└── my_other_bin.rs
To tell
cargoto only compile or run this binary, we just passcargothe--bin my_other_binflag, wheremy_other_binis the name of the binary we want to work with.
In addition to extra binaries, cargo supports more features such as
benchmarks, tests, and examples.
In the next chapter, we will look more closely at tests.
Testing
As we know testing is integral to any piece of software!
Rust has first-class support for unit and integration testing (see this chapter in TRPL).
From the testing chapters linked above, we see how to write unit tests and integration tests.
Organizationally, we can place unit tests in the modules they test and integration tests in their own tests/ directory:
foo
├── Cargo.toml
├── src
│ └── main.rs
│ └── lib.rs
└── tests
├── my_test.rs
└── my_other_test.rs
-
Each file in
testsis a separate integration test, -
i.e. a test that is meant to test your library as if it were being called from a dependent crate.
The Testing chapter elaborates on the three different testing styles:
- Unit
- Doc
- and Integration.
You should see output like this:
$ cargo test
Compiling blah v0.1.0 (file:///nobackup/blah)
Finished dev [unoptimized + debuginfo] target(s) in 0.89 secs
Running target/debug/deps/blah-d3b32b97275ec472
running 3 tests
test test_bar ... ok
test test_baz ... ok
test test_foo_bar ... ok
test test_foo ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
You can also run tests whose name matches a pattern:
$ cargo test test_foo
$ cargo test test_foo
Compiling blah v0.1.0 (file:///nobackup/blah)
Finished dev [unoptimized + debuginfo] target(s) in 0.35 secs
Running target/debug/deps/blah-d3b32b97275ec472
running 2 tests
test test_foo ... ok
test test_foo_bar ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out
One word of caution: Cargo may run multiple tests concurrently, so make sure that they don’t race with each other.
One example of this concurrency causing issues is if two tests output to a file, such as below:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { // Import the necessary modules use std::fs::OpenOptions; use std::io::Write; // This test writes to a file #[test] fn test_file() { // Opens the file ferris.txt or creates one if it doesn't exist. let mut file = OpenOptions::new() .append(true) .create(true) .open("ferris.txt") .expect("Failed to open ferris.txt"); // Print "Ferris" 5 times. for _ in 0..5 { file.write_all("Ferris\n".as_bytes()) .expect("Could not write to ferris.txt"); } } // This test tries to write to the same file #[test] fn test_file_also() { // Opens the file ferris.txt or creates one if it doesn't exist. let mut file = OpenOptions::new() .append(true) .create(true) .open("ferris.txt") .expect("Failed to open ferris.txt"); // Print "Corro" 5 times. for _ in 0..5 { file.write_all("Corro\n".as_bytes()) .expect("Could not write to ferris.txt"); } } } }
- Although the intent is to get the following:
$ cat ferris.txt
Ferris
Ferris
Ferris
Ferris
Ferris
Corro
Corro
Corro
Corro
Corro
- What actually gets put into
ferris.txtis this:
$ cargo test test_foo
Corro
Ferris
Corro
Ferris
Corro
Ferris
Corro
Ferris
Corro
Ferris
Build Scripts
Sometimes a normal build from cargo is not enough.
Perhaps your crate needs some pre-requisites before
cargowill successfully compile, things like code generation, or some native code that needs to be compiled. To solve this problem we have build scripts that Cargo can run.
To add a build script to your package it can either be specified in the Cargo.toml as follows:
[package]
...
build = "build.rs"
Otherwise Cargo will look for a build.rs file in the project directory by
default.
How to use a build script
The build script is simply another Rust file that will be compiled and invoked
prior to compiling anything else in the package.
Hence it can be used to fulfill pre-requisites of your crate.
Cargo provides the script with inputs via environment variables specified here that can be used.
The script provides output via stdout.
- All lines printed are written to
target/debug/build/<pkg>/output. - Further, lines prefixed with
cargo:will be interpreted by Cargo directly and hence can be used to define parameters for the package’s compilation.
For further specification and examples have a read of the Cargo specification.
Generics
Generics is the topic of generalizing types and functionalities to broader cases.
This is extremely useful for reducing code duplication in many ways, but can call for rather involved syntax.
Namely, being generic requires taking great care to specify over which types a generic type is actually considered valid.
type parameters
The simplest and most common use of generics is for type parameters.
- A type parameter is specified as generic by the use of angle brackets and upper camel case:
<Aaa, Bbb, ...>. - “Generic type parameters” are typically represented as
<T>. - In Rust, “generic” also describes anything that accepts one or more generic type parameters
<T>. - Any type specified as a generic type parameter is generic, and everything else is concrete (non-generic).
For example, defining a generic function named foo that takes an argument
T of any type:
fn foo<T>(arg: T) { ... }
Because T has been specified as a generic type parameter using <T>, it
is considered generic when used here as (arg: T).
This is the case even if
Thas previously been defined as astruct.
This example shows some of the syntax in action:
// A concrete type `A`. struct A; // In defining the type `Single`, the first use of `A` is not preceded by `<A>`. // Therefore, `Single` is a concrete type, and `A` is defined as above. struct Single(A); // ^ Here is `Single`s first use of the type `A`. // Here, `<T>` precedes the first use of `T`, so `SingleGen` is a generic type. // Because the type parameter `T` is generic, it could be anything, including // the concrete type `A` defined at the top. struct SingleGen<T>(T); fn main() { // `Single` is concrete and explicitly takes `A`. let _s = Single(A); // Create a variable `_char` of type `SingleGen<char>` // and give it the value `SingleGen('a')`. // Here, `SingleGen` has **a type parameter explicitly specified**. let _char: SingleGen<char> = SingleGen('a'); // `SingleGen` can also have a type parameter implicitly specified: let _t = SingleGen(A); // Uses `A` defined at the top. let _i32 = SingleGen(6); // Uses `i32`. let _char = SingleGen('a'); // Uses `char`. }
See also:
Functions: Identify whether a generic function
The same set of rules can be applied to functions: a type T becomes
generic when preceded by <T>.
Using generic functions sometimes requires explicitly specifying type parameters.
- This may be the case if the function is called where the return type is generic,
- or if the compiler doesn’t have enough information to infer the necessary type parameters.
A function call with explicitly specified type parameters looks like:
fun::<A, B, ...>().
Determine if a generic function
struct A; // Concrete type `A`. struct S(A); // Concrete type `S`. // Generic type `SGen`. struct SGen<T>(T); // The following functions all take ownership of the variable passed into // them and immediately go out of scope, freeing the variable. // 1. Not Generic Function: // Define a function `reg_fn` that takes an argument `_s` of type `S`. // This has no `<T>`, // so this is not a generic function. fn reg_fn(_s: S) {} // Not Generic Function: // Define a function `gen_spec_t` that takes an argument `_s` of type `SGen<T>`. // It has been explicitly given the type parameter `A`, but because `A` has not // been specified as a generic type parameter for `gen_spec_t`, it is not generic. fn gen_spec_t(_s: SGen<A>) {} // Not Generic Function: // Define a function `gen_spec_i32` that takes an argument `_s` of type `SGen<i32>`. // It has been explicitly given the type parameter `i32`, which is a specific type. // Because `i32` is not a generic type, this function is also not generic. fn gen_spec_i32(_s: SGen<i32>) {} // Is Generic Function: // Define a function `generic` that takes an argument `_s` of type `SGen<T>`. // Because `SGen<T>` is preceded by `<T>`, this function is generic over `T`. fn generic<T>(_s: SGen<T>) {} fn main() { // Using the non-generic functions reg_fn(S(A)); // Concrete type. gen_spec_t(SGen(A)); // Implicitly specified type parameter `A`. gen_spec_i32(SGen(6)); // Implicitly specified type parameter `i32`. // Explicitly specified type parameter `char` to `generic()`. generic::<char>(SGen('a')); // Implicitly specified type parameter `char` to `generic()`. generic(SGen('c')); }
See also:
Implementation
Similar to functions, implementations require care to remain generic.
#![allow(unused)] fn main() { struct S; // Concrete type `S` struct GenericVal<T>(T); // Generic type `GenericVal` // impl of GenericVal where we explicitly specify type parameters: impl GenericVal<f32> {} // Specify `f32` impl GenericVal<S> {} // Specify `S` as defined above // `<T>` Must precede the type to remain generic impl<T> GenericVal<T> {} }
struct Val { val: f64, } struct GenVal<T> { gen_val: T, } // impl of Val impl Val { fn value(&self) -> &f64 { &self.val } } // impl of GenVal for a generic type `T` impl<T> GenVal<T> { fn value(&self) -> &T { &self.gen_val } } fn main() { let x = Val { val: 3.0 }; let y = GenVal { gen_val: 3i32 }; println!("{}, {}", x.value(), y.value()); }
See also:
functions returning references, impl, and struct
Traits
Of course traits can also be generic. Here we define one which reimplements
the Drop trait as a generic method to drop itself and an input.
// Non-copyable types. struct Empty; struct Null; // A trait generic over `T`. trait DoubleDrop<T> { // Define a method on the caller type which takes an // additional single parameter `T` and does nothing with it. fn double_drop(self, _: T); } // Implement `DoubleDrop<T>` for any generic parameter `T` and // caller `U`. impl<T, U> DoubleDrop<T> for U { // This method takes ownership of both passed arguments, // deallocating both. fn double_drop(self, _: T) {} } fn main() { let empty = Empty; let null = Null; // Deallocate `empty` and `null`. empty.double_drop(null); //empty; //null; // ^ TODO: Try uncommenting these lines. }
See also:
Trait Bounds
When working with generics, the type parameters often must use traits as bounds to stipulate what functionality a type implements.
For example, the following example uses the trait Display to print and so it requires T to be bound by Display; that is, T must implement Display.
// Define a function `printer` that takes a generic type `T` which // must implement trait `Display`. fn printer<T: Display>(t: T) { println!("{}", t); }
Bounding restricts the generic to types that conform to the bounds. That is:
struct S<T: Display>(T); // Error! `Vec<T>` does not implement `Display`. This // specialization will fail. let s = S(vec![1]);
Another effect of bounding is that generic instances are allowed to access the methods of traits specified in the bounds. For example:
// A trait which implements the print marker: `{:?}`. use std::fmt::Debug; trait HasArea { fn area(&self) -> f64; } impl HasArea for Rectangle { fn area(&self) -> f64 { self.length * self.height } } #[derive(Debug)] struct Rectangle { length: f64, height: f64 } #[allow(dead_code)] struct Triangle { length: f64, height: f64 } // The generic `T` must implement `Debug`. Regardless // of the type, this will work properly. fn print_debug<T: Debug>(t: &T) { println!("{:?}", t); } // `T` must implement `HasArea`. Any type which meets // the bound can access `HasArea`'s function `area`. fn area<T: HasArea>(t: &T) -> f64 { t.area() } fn main() { let rectangle = Rectangle { length: 3.0, height: 4.0 }; let _triangle = Triangle { length: 3.0, height: 4.0 }; print_debug(&rectangle); println!("Area: {}", rectangle.area()); //print_debug(&_triangle); //println!("Area: {}", _triangle.area()); // ^ TODO: Try uncommenting these. // | Error: Does not implement either `Debug` or `HasArea`. }
As an additional note,
whereclauses can also be used to apply bounds in some cases to be more expressive.
See also:
Testcase: empty bounds
A consequence of how bounds work is that even if a trait doesn’t
include any functionality, you can still use it as a bound.
Eq and Copy are examples of such traits from the std library.
struct Cardinal; struct BlueJay; struct Turkey; trait Red {} trait Blue {} impl Red for Cardinal {} impl Blue for BlueJay {} // These functions are only valid for types which implement these // traits. The fact that the traits are empty is irrelevant. fn red<T: Red>(_: &T) -> &'static str { "red" } fn blue<T: Blue>(_: &T) -> &'static str { "blue" } fn main() { let cardinal = Cardinal; let blue_jay = BlueJay; let _turkey = Turkey; // `red()` won't work on a blue jay nor vice versa // because of the bounds. println!("A cardinal is {}", red(&cardinal)); println!("A blue jay is {}", blue(&blue_jay)); //println!("A turkey is {}", red(&_turkey)); // ^ TODO: Try uncommenting this line. }
See also:
std::cmp::Eq, std::marker::Copy, and traits
Multiple trait bounds
Multiple bounds for a single type can be applied with a +. Like normal, different types are separated with ,.
use std::fmt::{Debug, Display}; fn compare_prints<T: Debug + Display>(t: &T) { println!("Debug: `{:?}`", t); println!("Display: `{}`", t); } fn compare_types<T: Debug, U: Debug>(t: &T, u: &U) { println!("t: `{:?}`", t); println!("u: `{:?}`", u); } fn main() { let string = "words"; let array = [1, 2, 3]; let vec = vec![1, 2, 3]; compare_prints(&string); //compare_prints(&array); // TODO ^ Try uncommenting this. compare_types(&array, &vec); }
See also:
Where clauses
- A bound can also be expressed using a
whereclause immediately before the opening{, rather than at the type’s first mention. - Additionally,
whereclauses can apply bounds to arbitrary types, rather than just to type parameters.
Some cases that a
whereclause is useful:
- When specifying generic types and bounds separately is clearer:
impl <A: TraitB + TraitC, D: TraitE + TraitF> MyTrait<A, D> for YourType {}
// Expressing bounds with a `where` clause
impl <A, D> MyTrait<A, D> for YourType where
A: TraitB + TraitC,
D: TraitE + TraitF {}
- When using a where clause is more expressive than using normal syntax.
The impl in this example cannot be directly expressed without a where clause:
use std::fmt::Debug; trait PrintInOption { fn print_in_option(self); } // Because we would otherwise have to express this as `T: Debug` or // use another method of indirect approach, this requires a `where` clause: impl<T> PrintInOption for T where Option<T>: Debug { // We want `Option<T>: Debug` as our bound because that is what's // being printed. Doing otherwise would be using the wrong bound. fn print_in_option(self) { println!("{:?}", Some(self)); } } fn main() { let vec = vec![1, 2, 3]; vec.print_in_option(); }
See also:
New Type Idiom
The newtype idiom gives compile time guarantees that the right type of value is supplied
to a program.
For example, an age verification function that checks age in years, must be given a value of type Years.
struct Years(i64); struct Days(i64); impl Years { pub fn to_days(&self) -> Days { Days(self.0 * 365) } } impl Days { /// truncates partial years pub fn to_years(&self) -> Years { Years(self.0 / 365) } } fn old_enough(age: &Years) -> bool { age.0 >= 18 } fn main() { let age = Years(5); let age_days = age.to_days(); println!("Old enough {}", old_enough(&age)); println!("Old enough {}", old_enough(&age_days.to_years())); // println!("Old enough {}", old_enough(&age_days)); }
Uncomment the last print statement to observe that the type supplied must be
Years.
To obtain the newtype’s value as the base type, you may use the tuple or destructuring syntax like so:
struct Years(i64); fn main() { let years = Years(42); let years_as_primitive_1: i64 = years.0; // Tuple let Years(years_as_primitive_2) = years; // Destructuring println!("{}", years_as_primitive_1); println!("{}", years_as_primitive_2); }
See also:
Associated items: an extension to trait generics
- “Associated Items” refers to a set of rules pertaining to
itemsof various types. - It is an extension to
traitgenerics - and allows
traitsto internally define new items.
One such item is called an associated type, providing simpler usage
patterns when the trait is generic over its container type.
See also:
The Problem
A trait that is generic over its container type has type specification
requirements:
users of the
traitmust specify all of its generic types.
In the example below:
- the
Containstraitallows the use of the generic typesAandB. - The trait is then implemented for the
Containertype, specifyingi32forAandBso that it can be used withfn difference(). - Because
Containsis generic, we are forced to explicitly state all of the generic types forfn difference(). - In practice, we want a way to express that
AandBare determined by the inputC.
- As you will see in the next section, associated types provide exactly that capability.
struct Container(i32, i32); // A trait which checks if 2 items are stored inside of container. // Also retrieves first or last value. trait Contains<A, B> { fn contains(&self, _: &A, _: &B) -> bool; // Explicitly requires `A` and `B`. fn first(&self) -> i32; // Doesn't explicitly require `A` or `B`. fn last(&self) -> i32; // Doesn't explicitly require `A` or `B`. } impl Contains<i32, i32> for Container { // True if the numbers stored are equal. fn contains(&self, number_1: &i32, number_2: &i32) -> bool { (&self.0 == number_1) && (&self.1 == number_2) } // Grab the first number. fn first(&self) -> i32 { self.0 } // Grab the last number. fn last(&self) -> i32 { self.1 } } // `C` contains `A` and `B`. In light of that, having to express `A` and // `B` again is a nuisance. fn difference<A, B, C>(container: &C) -> i32 where C: Contains<A, B> { container.last() - container.first() } fn main() { let number_1 = 3; let number_2 = 10; let container = Container(number_1, number_2); println!("Does container contain {} and {}: {}", &number_1, &number_2, container.contains(&number_1, &number_2)); println!("First number: {}", container.first()); println!("Last number: {}", container.last()); println!("The difference is: {}", difference(&container)); }
Expand
The Executive Crate of Substrate
pub type CheckedOf<E, C> = <E as Checkable<C>>::Checked;
pub type CallOf<E, C> = <CheckedOf<E, C> as Applyable>::Call;
pub type OriginOf<E, C> = <CallOf<E, C> as Dispatchable>::RuntimeOrigin;
...
See also:
Associated types
The use of “Associated types” improves the overall readability of code by moving inner types locally into a trait as output types.
Syntax for the trait definition is as follows:
#![allow(unused)] fn main() { // `A` and `B` are defined in the trait via the `type` keyword. // (Note: `type` in this context is different from `type` when used for // aliases). trait Contains { type A; type B; // Updated syntax to refer to these new types generically. fn contains(&self, _: &Self::A, _: &Self::B) -> bool; } }
Note that functions that use the trait Contains are no longer required to express A or B at all:
// Without using associated types
fn difference<A, B, C>(container: &C) -> i32 where
C: Contains<A, B> { ... }
// Using associated types
fn difference<C: Contains>(container: &C) -> i32 { ... }
Let’s rewrite the example from the previous section using associated types:
struct Container(i32, i32); // A trait which checks if 2 items are stored inside of container. // Also retrieves first or last value. trait Contains { // Define generic types here which methods will be able to utilize. type A; type B; fn contains(&self, _: &Self::A, _: &Self::B) -> bool; fn first(&self) -> i32; fn last(&self) -> i32; } // the previous section: // impl Contains<i32, i32> for Container { // and here no need of `<i32, i32>` impl Contains for Container { // Specify what types `A` and `B` are. If the `input` type // is `Container(i32, i32)`, the `output` types are determined // as `i32` and `i32`. type A = i32; type B = i32; // `&Self::A` and `&Self::B` are also valid here. fn contains(&self, number_1: &i32, number_2: &i32) -> bool { (&self.0 == number_1) && (&self.1 == number_2) } // Grab the first number. fn first(&self) -> i32 { self.0 } // Grab the last number. fn last(&self) -> i32 { self.1 } } fn difference<C: Contains>(container: &C) -> i32 { container.last() - container.first() } fn main() { let number_1 = 3; let number_2 = 10; let container = Container(number_1, number_2); println!("Does container contain {} and {}: {}", &number_1, &number_2, container.contains(&number_1, &number_2)); println!("First number: {}", container.first()); println!("Last number: {}", container.last()); println!("The difference is: {}", difference(&container)); }
Phantom type parameters
A phantom type parameter is one that doesn’t show up at runtime, but is checked statically (and only) at compile time.
Data types can use extra generic type parameters to act as markers or to perform type checking at compile time.
These extra parameters hold no storage values, and have no runtime behavior.
In the following example, we combine std::marker::PhantomData with the phantom type parameter concept to create tuples containing different data types.
use std::marker::PhantomData; // A phantom tuple struct which is generic over `A` with hidden parameter `B`. #[derive(PartialEq)] // Allow equality test for this type. struct PhantomTuple<A, B>(A, PhantomData<B>); // A phantom type struct which is generic over `A` with hidden parameter `B`. #[derive(PartialEq)] // Allow equality test for this type. struct PhantomStruct<A, B> { first: A, phantom: PhantomData<B> } // Note: Storage is allocated for generic type `A`, but not for `B`. // Therefore, `B` cannot be used in computations. fn main() { // Here, `f32` and `f64` are the hidden parameters. // PhantomTuple type specified as `<char, f32>`. let _tuple1: PhantomTuple<char, f32> = PhantomTuple('Q', PhantomData); // PhantomTuple type specified as `<char, f64>`. let _tuple2: PhantomTuple<char, f64> = PhantomTuple('Q', PhantomData); // Type specified as `<char, f32>`. let _struct1: PhantomStruct<char, f32> = PhantomStruct { first: 'Q', phantom: PhantomData, }; // Type specified as `<char, f64>`. let _struct2: PhantomStruct<char, f64> = PhantomStruct { first: 'Q', phantom: PhantomData, }; // Compile-time Error! Type mismatch so these cannot be compared: // println!("_tuple1 == _tuple2 yields: {}", // _tuple1 == _tuple2); // Compile-time Error! Type mismatch so these cannot be compared: // println!("_struct1 == _struct2 yields: {}", // _struct1 == _struct2); }
See also:
Derive, struct, and TupleStructs
Testcase: unit clarification
A useful method of unit conversions can be examined by implementing Add with a phantom type parameter. The Add trait is examined below:
// This construction would impose: `Self + RHS = Output`
// where RHS defaults to Self if not specified in the implementation.
pub trait Add<RHS = Self> {
type Output;
fn add(self, rhs: RHS) -> Self::Output;
}
// `Output` must be `T<U>` so that `T<U> + T<U> = T<U>`.
impl<U> Add for T<U> {
type Output = T<U>;
...
}
The whole implementation:
use std::ops::Add; use std::marker::PhantomData; /// Create void enumerations to define unit types. #[derive(Debug, Clone, Copy)] enum Inch {} #[derive(Debug, Clone, Copy)] enum Mm {} /// `Length` is a type with phantom type parameter `Unit`, /// and is not generic over the length type (that is `f64`). /// /// `f64` already implements the `Clone` and `Copy` traits. #[derive(Debug, Clone, Copy)] struct Length<Unit>(f64, PhantomData<Unit>); /// The `Add` trait defines the behavior of the `+` operator. impl<Unit> Add for Length<Unit> { type Output = Length<Unit>; // add() returns a new `Length` struct containing the sum. fn add(self, rhs: Length<Unit>) -> Length<Unit> { // `+` calls the `Add` implementation for `f64`. Length(self.0 + rhs.0, PhantomData) } } fn main() { // Specifies `one_foot` to have phantom type parameter `Inch`. let one_foot: Length<Inch> = Length(12.0, PhantomData); // `one_meter` has phantom type parameter `Mm`. let one_meter: Length<Mm> = Length(1000.0, PhantomData); // `+` calls the `add()` method we implemented for `Length<Unit>`. // // Since `Length` implements `Copy`, `add()` does not consume // `one_foot` and `one_meter` but copies them into `self` and `rhs`. let two_feet = one_foot + one_foot; let two_meters = one_meter + one_meter; // Addition works. println!("one foot + one_foot = {:?} in", two_feet.0); println!("one meter + one_meter = {:?} mm", two_meters.0); // Nonsensical operations fail as they should: // Compile-time Error: type mismatch. //let one_feter = one_foot + one_meter; }
See also:
Borrowing (&), Bounds (X: Y), enum, impl & self,
Overloading, ref, Traits (X for Y), and TupleStructs.
Traits: methods + Self + access
Four ‘trait’ point of a trait
A trait is:
- a collection of methods
- defined for an unknown type:
Self - They can access other methods declared in the same trait.
- Traits can be implemented for any data type.
In the example below, we define Animal, a group of methods. The Animal trait is then implemented for the Sheep data type, allowing the use of methods from Animal with a Sheep.
struct Sheep { naked: bool, name: &'static str } trait Animal { // Associated function signature; `Self` refers to the implementor type. fn new(name: &'static str) -> Self; // Method signatures; these will return a string. fn name(&self) -> &'static str; fn noise(&self) -> &'static str; // Traits can provide default method definitions. fn talk(&self) { println!("{} says {}", self.name(), self.noise()); } } impl Sheep { fn is_naked(&self) -> bool { self.naked } fn shear(&mut self) { if self.is_naked() { // Implementor methods can use the implementor's trait methods. println!("{} is already naked...", self.name()); } else { println!("{} gets a haircut!", self.name); self.naked = true; } } } // Implement the `Animal` trait for `Sheep`. impl Animal for Sheep { // `Self` is the implementor type: `Sheep`. fn new(name: &'static str) -> Sheep { Sheep { name: name, naked: false } } fn name(&self) -> &'static str { self.name } fn noise(&self) -> &'static str { if self.is_naked() { "baaaaah?" } else { "baaaaah!" } } // Default trait methods can be overridden. fn talk(&self) { // For example, we can add some quiet contemplation. println!("{} pauses briefly... {}", self.name, self.noise()); } } fn main() { // Type annotation is necessary in this case. let mut dolly: Sheep = Animal::new("Dolly"); // TODO ^ Try removing the type annotations. dolly.talk(); dolly.shear(); dolly.talk(); }
- Differentiate between definition and implementation
trait Animal {
// Associated function signature; `Self` refers to the implementor type.
fn new(name: &'static str) -> Self;
}
impl Animal for Sheep {
// `Self` is the implementor type: `Sheep`.
fn new(name: &'static str) -> Sheep {
Sheep { name: name, naked: false }
}
}
- Default trait methods can be overridden
- Type annotation is necessary here
Compiling playground v0.0.1 (/playground)
error[E0282]: type annotations needed
--> src/main.rs:62:9
|
62 | let mut dolly = Animal::new("Dolly");
| ^^^^^^^^^
...
65 | dolly.talk();
| ----- type must be known at this point
|
help: consider giving `dolly` an explicit type
|
62 | let mut dolly: _ = Animal::new("Dolly");
| +++
For more information about this error, try `rustc --explain E0282`.
error: could not compile `playground` due to previous error
Derive Macro Traits
The compiler is capable of providing basic implementations for some traits via
the #[derive] attribute.
These traits can still be manually implemented if a more complex behavior is required.
The following is a list of derivable traits:
- Comparison traits:
Eq,PartialEq,Ord,PartialOrd. Clone, to createTfrom&Tvia a copy.Copy, to give a type ‘copy semantics’ instead of ‘move semantics’.Hash, to compute a hash from&T.Default, to create an empty instance of a data type.Debug, to format a value using the{:?}formatter.
Mix Example
Usage Example of PartialEq, PartialOrd, Debug
// `Centimeters`, a tuple struct that can be compared #[derive(PartialEq, PartialOrd)] struct Centimeters(f64); // `Inches`, a tuple struct that can be printed #[derive(Debug)] struct Inches(i32); impl Inches { fn to_centimeters(&self) -> Centimeters { let &Inches(inches) = self; Centimeters(inches as f64 * 2.54) } } // `Seconds`, a tuple struct with no additional attributes struct Seconds(i32); fn main() { let _one_second = Seconds(1); // Error: `Seconds` can't be printed; it doesn't implement the `Debug` trait //println!("One second looks like: {:?}", _one_second); // TODO ^ Try uncommenting this line // Error: `Seconds` can't be compared; it doesn't implement the `PartialEq` trait //let _this_is_true = (_one_second == _one_second); // TODO ^ Try uncommenting this line let foot = Inches(12); println!("One foot equals {:?}", foot); let meter = Centimeters(100.0); let cmp = if foot.to_centimeters() < meter { "smaller" } else { "bigger" }; println!("One foot is {} than one meter.", cmp); }
Clone
When dealing with resources, the default behavior is to transfer them during assignments or function calls.
However, sometimes we need to make a copy of the resource as well.
The Clone trait helps us do exactly this. Most commonly, we can use the .clone() method defined by the Clone trait.
// A unit struct without resources #[derive(Debug, Clone, Copy)] struct Unit; // A tuple struct with resources that implements the `Clone` trait #[derive(Clone, Debug)] struct Pair(Box<i32>, Box<i32>); fn main() { // Instantiate `Unit` let unit = Unit; // Copy `Unit`, there are no resources to move let copied_unit = unit; // Both `Unit`s can be used independently println!("original: {:?}", unit); println!("copy: {:?}", copied_unit); // Instantiate `Pair` let pair = Pair(Box::new(1), Box::new(2)); println!("original: {:?}", pair); // Move `pair` into `moved_pair`, moves resources let moved_pair = pair; println!("moved: {:?}", moved_pair); // Error! `pair` has lost its resources //println!("original: {:?}", pair); // TODO ^ Try uncommenting this line // Clone `moved_pair` into `cloned_pair` (resources are included) let cloned_pair = moved_pair.clone(); // Drop the original pair using std::mem::drop drop(moved_pair); // Error! `moved_pair` has been dropped //println!("copy: {:?}", moved_pair); // TODO ^ Try uncommenting this line // The result from .clone() can still be used! println!("clone: {:?}", cloned_pair); }
See also:
Returning Traits with dyn
The Rust compiler needs to know how much space every function’s return type requires.
This means all your functions have to return a concrete type.
Unlike other languages, if you have a trait like Animal, you can’t write a function that returns Animal, because its different implementations will need different amounts of memory.
However, there’s an easy workaround.
Instead of returning a trait object directly, our functions return a Box which contains some Animal.
A
boxis just a reference to some memory in the heap.
- Because a reference has a statically-known size
- and the compiler can guarantee it points to a heap-allocated
Animal - we can return a trait from our function!
Rust tries to be as explicit as possible whenever it allocates memory on the heap.
So if your function returns a pointer-to-trait-on-heap in this way, you need to write the return type with the dyn keyword, e.g. Box
struct Sheep {} struct Cow {} trait Animal { // Instance method signature fn noise(&self) -> &'static str; } // Implement the `Animal` trait for `Sheep`. impl Animal for Sheep { fn noise(&self) -> &'static str { "baaaaah!" } } // Implement the `Animal` trait for `Cow`. impl Animal for Cow { fn noise(&self) -> &'static str { "moooooo!" } } // Returns some struct that implements Animal, but we don't know which one at compile time. fn random_animal(random_number: f64) -> Box<dyn Animal> { if random_number < 0.5 { Box::new(Sheep {}) } else { Box::new(Cow {}) } } fn main() { let random_number = 0.234; let animal = random_animal(random_number); println!("You've randomly chosen an animal, and it says {}", animal.noise()); }
// Returns some struct that implements Animal, but we don't know which one at compile time.
fn random_animal(random_number: f64) -> Box<dyn Animal> {
if random_number < 0.5 {
Box::new(Sheep {})
} else {
Box::new(Cow {})
}
}
Operator Overloading
In Rust, many of the operators can be overloaded via traits.
That is, some operators can be used to accomplish different tasks based on their input arguments.
This is possible because operators are syntactic sugar for method calls.
For example, the + operator in
a + b calls the add method (as in a.add(b)). This add method is part of the Add
trait. Hence, the + operator can be used by any implementor of the Add trait.
A list of the traits, such as Add, that overload operators can be found in core::ops.
use std::ops; struct Foo; struct Bar; #[derive(Debug)] struct FooBar; #[derive(Debug)] struct BarFoo; // The `std::ops::Add` trait is used to specify the functionality of `+`. // Here, we make `Add<Bar>` - the trait for addition with a RHS of type `Bar`. // The following block implements the operation: Foo + Bar = FooBar impl ops::Add<Bar> for Foo { type Output = FooBar; fn add(self, _rhs: Bar) -> FooBar { println!("> Foo.add(Bar) was called"); FooBar } } // By reversing the types, we end up implementing non-commutative addition. // Here, we make `Add<Foo>` - the trait for addition with a RHS of type `Foo`. // This block implements the operation: Bar + Foo = BarFoo impl ops::Add<Foo> for Bar { type Output = BarFoo; fn add(self, _rhs: Foo) -> BarFoo { println!("> Bar.add(Foo) was called"); BarFoo } } fn main() { println!("Foo + Bar = {:?}", Foo + Bar); println!("Bar + Foo = {:?}", Bar + Foo); }
See Also
Drop
The Drop trait only has one method: drop, which is called automatically
when an object goes out of scope.
The main use of the
Droptrait is to free the resources that the implementor instance owns.
Box, Vec, String, File, and Process are some examples of types that
implement the Drop trait to free resources.
The
Droptrait can also be manually implemented for any custom data type.
The following example adds a print to console to the drop function to announce when it is called.
struct Droppable { name: &'static str, } // This trivial implementation of `drop` adds a print to console. impl Drop for Droppable { fn drop(&mut self) { println!("> Dropping {}", self.name); } } fn main() { let _a = Droppable { name: "a" }; // block A { let _b = Droppable { name: "b" }; // block B { let _c = Droppable { name: "c" }; let _d = Droppable { name: "d" }; println!("Exiting block B"); } println!("Just exited block B"); println!("Exiting block A"); } println!("Just exited block A"); // Variable can be manually dropped using the `drop` function drop(_a); // TODO ^ Try commenting this line println!("end of the main function"); // `_a` *won't* be `drop`ed again here, because it already has been // (manually) `drop`ed }
Iterator Trait
The Iterator trait is used to implement iterators over collections
such as arrays.
The trait requires only a method to be defined for the
nextelement, which may be manually defined in animplblock or automatically defined (as in arrays and ranges).
As a point of convenience for common situations, the for construct
turns some collections into iterators using the .into_iter() method.
As a point of convenience for common situations, the for construct turns some collections into iterators using the .into_iter() method.
struct Fibonacci { curr: u32, next: u32, } // Implement `Iterator` for `Fibonacci`. // The `Iterator` trait only requires a method to be defined for the `next` element. impl Iterator for Fibonacci { // We can refer to this type using Self::Item type Item = u32; // Here, we define the sequence using `.curr` and `.next`. // The return type is `Option<T>`: // * When the `Iterator` is finished, `None` is returned. // * Otherwise, the next value is wrapped in `Some` and returned. // We use Self::Item in the return type, so we can change // the type without having to update the function signatures. fn next(&mut self) -> Option<Self::Item> { let current = self.curr; self.curr = self.next; self.next = current + self.next; // Since there's no endpoint to a Fibonacci sequence, the `Iterator` // will never return `None`, and `Some` is always returned. Some(current) } } // Returns a Fibonacci sequence generator fn fibonacci() -> Fibonacci { Fibonacci { curr: 0, next: 1 } } fn main() { // `0..3` is an `Iterator` that generates: 0, 1, and 2. let mut sequence = 0..3; println!("Four consecutive `next` calls on 0..3"); println!("> {:?}", sequence.next()); println!("> {:?}", sequence.next()); println!("> {:?}", sequence.next()); println!("> {:?}", sequence.next()); // `for` works through an `Iterator` until it returns `None`. // Each `Some` value is unwrapped and bound to a variable (here, `i`). println!("Iterate through 0..3 using `for`"); for i in 0..3 { println!("> {}", i); } // The `take(n)` method reduces an `Iterator` to its first `n` terms. println!("The first four terms of the Fibonacci sequence are: "); for i in fibonacci().take(4) { println!("> {}", i); } // The `skip(n)` method shortens an `Iterator` by dropping its first `n` terms. println!("The next four terms of the Fibonacci sequence are: "); for i in fibonacci().skip(4).take(4) { println!("> {}", i); } let array = [1u32, 3, 3, 7]; // The `iter` method produces an `Iterator` over an array/slice. println!("Iterate the following array {:?}", &array); for i in array.iter() { println!("> {}", i); } }
// Implement `Iterator` for `Fibonacci`.
// The `Iterator` trait only requires a method to be defined for the `next` element.
impl Iterator for Fibonacci {
// We can refer to this type using Self::Item
type Item = u32;
// Here, we define the sequence using `.curr` and `.next`.
// The return type is `Option<T>`:
// * When the `Iterator` is finished, `None` is returned.
// * Otherwise, the next value is wrapped in `Some` and returned.
// We use Self::Item in the return type, so we can change
// the type without having to update the function signatures.
fn next(&mut self) -> Option<Self::Item> {
let current = self.curr;
self.curr = self.next;
self.next = current + self.next;
// Since there's no endpoint to a Fibonacci sequence, the `Iterator`
// will never return `None`, and `Some` is always returned.
Some(current)
}
}
impl Trait
impl Traitcan be used in two locations:
- as an argument type
- as a return type
As an argument type
If your function is generic over a trait but you don’t mind the specific type, you can simplify the function declaration using
impl Traitas the type of the argument.
For example, consider the following code:
fn parse_csv_document<R: std::io::BufRead>(src: R) -> std::io::Result<Vec<Vec<String>>> { src.lines() .map(|line| { // For each line in the source line.map(|line| { // If the line was read successfully, process it, if not, return the error line.split(',') // Split the line separated by commas .map(|entry| String::from(entry.trim())) // Remove leading and trailing whitespace .collect() // Collect all strings in a row into a Vec<String> }) }) .collect() // Collect all lines into a Vec<Vec<String>> }
parse_csv_documentis generic- allowing it to take any type which implements BufRead, such as
BufReader<File>or[u8] - but it’s not important what type
Ris, andRis only used to declare the type ofsrc
- so the function can also be written as:
fn parse_csv_document(src: impl std::io::BufRead) -> std::io::Result<Vec<Vec<String>>> { src.lines() .map(|line| { // For each line in the source line.map(|line| { // If the line was read successfully, process it, if not, return the error line.split(',') // Split the line separated by commas .map(|entry| String::from(entry.trim())) // Remove leading and trailing whitespace .collect() // Collect all strings in a row into a Vec<String> }) }) .collect() // Collect all lines into a Vec<Vec<String>> }
- Note that using
impl Traitas an argument type - means that you cannot explicitly state what form of the function you use
- i.e.
parse_csv_document::<std::io::Empty>(std::io::empty())will not work with the second example.
fn parse_csv_document<R: std::io::BufRead>(src: R) -> std::io::Result<Vec<Vec<String>>> {
fn parse_csv_document(src: impl std::io::BufRead) -> std::io::Result<Vec<Vec<String>>> {
As a return type
If your function returns a type that implements MyTrait, you can write its return type as -> impl MyTrait. This can help simplify your type signatures quite a lot!
use std::iter; use std::vec::IntoIter; // This function combines two `Vec<i32>` and returns an iterator over it. // Look how complicated its return type is! fn combine_vecs_explicit_return_type( v: Vec<i32>, u: Vec<i32>, ) -> iter::Cycle<iter::Chain<IntoIter<i32>, IntoIter<i32>>> { v.into_iter().chain(u.into_iter()).cycle() } // This is the exact same function, but its return type uses `impl Trait`. // Look how much simpler it is! fn combine_vecs( v: Vec<i32>, u: Vec<i32>, ) -> impl Iterator<Item=i32> { v.into_iter().chain(u.into_iter()).cycle() } fn main() { let v1 = vec![1, 2, 3]; let v2 = vec![4, 5]; let mut v3 = combine_vecs(v1, v2); assert_eq!(Some(1), v3.next()); assert_eq!(Some(2), v3.next()); assert_eq!(Some(3), v3.next()); assert_eq!(Some(4), v3.next()); assert_eq!(Some(5), v3.next()); println!("all done"); }
More importantly, some Rust types can’t be written out.
For example, every closure has its own unnamed concrete type.
Before impl Trait syntax, you had
to allocate on the heap in order to return a closure.
But now you can do it all statically, like this:
// Returns a function that adds `y` to its input fn make_adder_function(y: i32) -> impl Fn(i32) -> i32 { let closure = move |x: i32| { x + y }; closure } fn main() { let plus_one = make_adder_function(1); assert_eq!(plus_one(2), 3); }
You can also use impl Trait to return an iterator that uses map or filter
closures!
This makes using map and filter easier:
Because closure types don’t have names, you can’t write out an explicit return type if your function returns iterators with closures.
But with impl Trait you can do this easily:
fn double_positives<'a>(numbers: &'a Vec<i32>) -> impl Iterator<Item = i32> + 'a { numbers .iter() .filter(|x| x > &&0) .map(|x| x * 2) } fn main() { let singles = vec![-3, -2, 2, 3]; let doubles = double_positives(&singles); assert_eq!(doubles.collect::<Vec<i32>>(), vec![4, 6]); }
Supertraits: the inheritance in rust
Rust doesn’t have ‘inheritance’, but you can define a trait as being a superset of another trait. For example:
trait Person { fn name(&self) -> String; } // Person is a supertrait of Student. // Implementing Student requires you to also impl Person. trait Student: Person { fn university(&self) -> String; } trait Programmer { fn fav_language(&self) -> String; } // CompSciStudent (computer science student) is a subtrait of both Programmer // and Student. Implementing CompSciStudent requires you to impl both supertraits. trait CompSciStudent: Programmer + Student { fn git_username(&self) -> String; } fn comp_sci_student_greeting(student: &dyn CompSciStudent) -> String { format!( "My name is {} and I attend {}. My favorite language is {}. My Git username is {}", student.name(), student.university(), student.fav_language(), student.git_username() ) } fn main() {}
- Person is a supertrait of Student.
- Implementing Student requires you to also impl Person.
- CompSciStudent (computer science student) is a subtrait of both Programmer and Student.
- Implementing CompSciStudent requires you to impl both supertraits.
See also:
The Rust Programming Language chapter on supertraits
FQS: Disambiguating overlapping traits
A type can implement many different traits.
What if two traits both require the same name?
For example, many traits might have a method named get().
They might even have different return types!
Good news: because each trait implementation gets its own
implblock, it’s clear which trait’sgetmethod you’re implementing.
What about when it comes time to call those methods?
To disambiguate between them, we have to use Fully Qualified Syntax.
trait UsernameWidget { // Get the selected username out of this widget fn get(&self) -> String; } trait AgeWidget { // Get the selected age out of this widget fn get(&self) -> u8; } // A form with both a UsernameWidget and an AgeWidget struct Form { username: String, age: u8, } impl UsernameWidget for Form { fn get(&self) -> String { self.username.clone() } } impl AgeWidget for Form { fn get(&self) -> u8 { self.age } } fn main() { let form = Form { username: "rustacean".to_owned(), age: 28, }; // If you uncomment this line, you'll get an error saying // "multiple `get` found". Because, after all, there are multiple methods // named `get`. // println!("{}", form.get()); let username = <Form as UsernameWidget>::get(&form); assert_eq!("rustacean".to_owned(), username); let age = <Form as AgeWidget>::get(&form); assert_eq!(28, age); }
let age = <Form as AgeWidget>::get(&form);
See also:
The Rust Programming Language chapter on Fully Qualified syntax
Scoping rules
Scopes play an important part in ownership, borrowing, and lifetimes.
That is, they indicate to the compiler:
- when borrows are valid
- when resources can be freed
- and when variables are created or destroyed.
RAII
Variables in Rust do more than just hold data in the stack: they also own
resources, e.g. Box<T> owns memory in the heap.
Rust enforces RAII (Resource Acquisition Is Initialization), so whenever an object goes out of scope, its destructor is called and its owned resources are freed.
Destroyer
This behavior shields against resource leak bugs, so you’ll never have to manually free memory or worry about memory leaks again!
Here’s a quick showcase:
// raii.rs fn create_box() { // Allocate an integer on the heap let _box1 = Box::new(3i32); // `_box1` is destroyed here, and memory gets freed } fn main() { // Allocate an integer on the heap let _box2 = Box::new(5i32); // A nested scope: { // Allocate an integer on the heap let _box3 = Box::new(4i32); // `_box3` is destroyed here, and memory gets freed } // Creating lots of boxes just for fun // There's no need to manually free memory! for _ in 0u32..1_000 { create_box(); } // `_box2` is destroyed here, and memory gets freed }
Of course, we can double check for memory errors using valgrind:
$ rustc raii.rs && valgrind ./raii
==26873== Memcheck, a memory error detector
==26873== Copyright (C) 2002-2013, and GNU GPL'd, by Julian Seward et al.
==26873== Using Valgrind-3.9.0 and LibVEX; rerun with -h for copyright info
==26873== Command: ./raii
==26873==
==26873==
==26873== HEAP SUMMARY:
==26873== in use at exit: 0 bytes in 0 blocks
==26873== total heap usage: 1,013 allocs, 1,013 frees, 8,696 bytes allocated
==26873==
==26873== All heap blocks were freed -- no leaks are possible
==26873==
==26873== For counts of detected and suppressed errors, rerun with: -v
==26873== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 2 from 2)
No leaks here!
Destructor
The notion of a destructor in Rust is provided through the Drop trait.
-
The destructor is called when the resource goes out of scope.
-
This trait is not required to be implemented for every type, only implement it for your type if you require its own destructor logic.
Run the below example to see how the Drop trait works.
When the variable in the main function goes out of scope the custom destructor will be invoked.
struct ToDrop; impl Drop for ToDrop { fn drop(&mut self) { println!("ToDrop is being dropped"); } } fn main() { let x = ToDrop; println!("Made a ToDrop!"); }
See also:
Ownership and moves
Because variables are in charge of freeing their own resources, resources can only have one owner.
This also prevents resources from being freed more than once.
Note that not all variables own resources (e.g. references).
When doing assignments (let x = y) or passing function arguments by value
(foo(x)), the ownership of the resources is transferred.
In Rust-speak, this is known as a move.
After moving resources, the previous owner can no longer be used. This avoids creating dangling pointers.
// This function takes ownership of the heap allocated memory fn destroy_box(c: Box<i32>) { println!("Destroying a box that contains {}", c); // `c` is destroyed and the memory freed } fn main() { // _Stack_ allocated integer let x = 5u32; // *Copy* `x` into `y` - no resources are moved let y = x; // Both values can be independently used println!("x is {}, and y is {}", x, y); // `a` is a pointer to a _heap_ allocated integer let a = Box::new(5i32); println!("a contains: {}", a); // *Move* `a` into `b` let b = a; // The pointer address of `a` is copied (not the data) into `b`. // Both are now pointers to the same heap allocated data, but // `b` now owns it. // Error! `a` can no longer access the data, because it no longer owns the // heap memory //println!("a contains: {}", a); // TODO ^ Try uncommenting this line // This function takes ownership of the heap allocated memory from `b` destroy_box(b); // Since the heap memory has been freed at this point, this action would // result in dereferencing freed memory, but it's forbidden by the compiler // Error! Same reason as the previous Error //println!("b contains: {}", b); // TODO ^ Try uncommenting this line }
Mutability of data can be changed when ownership is transferred.
fn main() { let immutable_box = Box::new(5u32); println!("immutable_box contains {}", immutable_box); // Mutability error //*immutable_box = 4; // *Move* the box, changing the ownership (and mutability) let mut mutable_box = immutable_box; println!("mutable_box contains {}", mutable_box); // Modify the contents of the box *mutable_box = 4; println!("mutable_box now contains {}", mutable_box); }
Partial moves
Within the destructuring of a single variable, both by-move and
by-reference pattern bindings can be used at the same time.
Doing this will result in a partial move of the variable, which means that parts of the variable will be moved while other parts stay.
In such a case, the parent variable cannot be used afterwards as a whole, however the parts that are only referenced (and not moved) can still be used.
fn main() { #[derive(Debug)] struct Person { name: String, age: Box<u8>, } let person = Person { name: String::from("Alice"), age: Box::new(20), }; // `name` is moved out of person, but `age` is referenced let Person { name, ref age } = person; println!("The person's age is {}", age); println!("The person's name is {}", name); // Error! borrow of partially moved value: `person` partial move occurs //println!("The person struct is {:?}", person); // `person` cannot be used but `person.age` can be used as it is not moved println!("The person's age from person struct is {}", person.age); }
In this example, we store the age variable on the heap to
illustrate the partial move:
- deleting
refin the above code would give an error as the ownership ofperson.agewould be moved to the variableage. - If
Person.agewere stored on the stack,refwould not be required as the definition ofagewould copy the data fromperson.agewithout moving it.)
See also:
Borrowing: T is Ownership, &T is borrowing
Most of the time, we’d like to access data without taking ownership over it.
- To accomplish this, Rust uses a borrowing mechanism.
- Instead of passing objects by value (
T), objects can be passed by reference (&T).
The compiler statically guarantees (via its borrow checker) that references always point to valid objects.
That is, while references to an object exist, the object cannot be destroyed.
// This function takes ownership of a box and destroys it fn eat_box_i32(boxed_i32: Box<i32>) { println!("Destroying box that contains {}", boxed_i32); } // This function borrows an i32 fn borrow_i32(borrowed_i32: &i32) { println!("This int is: {}", borrowed_i32); } fn main() { // Create a boxed i32, and a stacked i32 let boxed_i32 = Box::new(5_i32); let stacked_i32 = 6_i32; // Borrow the contents of the box. // Ownership is not taken, so the contents can be borrowed again. borrow_i32(&boxed_i32); borrow_i32(&stacked_i32); { // Take a reference to the data contained inside the box let _ref_to_i32: &i32 = &boxed_i32; // Error! // Can't destroy `boxed_i32` while the inner value is borrowed later in scope. eat_box_i32(boxed_i32); // FIXME ^ Comment out this line // Attempt to borrow `_ref_to_i32` after inner value is destroyed borrow_i32(_ref_to_i32); // `_ref_to_i32` goes out of scope and is no longer borrowed. } // `boxed_i32` can now give up ownership to `eat_box` and be destroyed eat_box_i32(boxed_i32); }
Mutability
Mutable data can be mutably borrowed using &mut T. This is called
a mutable reference and gives read/write access to the borrower.
In contrast, &T borrows the data via an immutable reference, and the borrower can read the data but not modify it:
#[allow(dead_code)] #[derive(Clone, Copy)] struct Book { // `&'static str` is a reference to a string allocated in read only memory author: &'static str, title: &'static str, year: u32, } // This function takes a reference to a book fn borrow_book(book: &Book) { println!("I immutably borrowed {} - {} edition", book.title, book.year); } // This function takes a reference to a mutable book and changes `year` to 2014 fn new_edition(book: &mut Book) { book.year = 2014; println!("I mutably borrowed {} - {} edition", book.title, book.year); } fn main() { // Create an immutable Book named `immutabook` let immutabook = Book { // string literals have type `&'static str` author: "Douglas Hofstadter", title: "Gödel, Escher, Bach", year: 1979, }; // Create a mutable copy of `immutabook` and call it `mutabook` let mut mutabook = immutabook; // Immutably borrow an immutable object borrow_book(&immutabook); // Immutably borrow a mutable object borrow_book(&mutabook); // Borrow a mutable object as mutable new_edition(&mut mutabook); // Error! Cannot borrow an immutable object as mutable new_edition(&mut immutabook); // FIXME ^ Comment out this line }
See also:
Mutable or immutable borrowed, only choose one!
Data can be immutably borrowed any number of times, but while immutably borrowed, the original data can’t be mutably borrowed.
- On the other hand, only one mutable borrow is allowed at a time.
- The original data can be borrowed again only after the mutable reference has been used for the last time.
struct Point { x: i32, y: i32, z: i32 } fn main() { let mut point = Point { x: 0, y: 0, z: 0 }; let borrowed_point = &point; let another_borrow = &point; // Data can be accessed via the references and the original owner println!("Point has coordinates: ({}, {}, {})", borrowed_point.x, another_borrow.y, point.z); // Error! Can't borrow `point` as mutable because it's currently // borrowed as immutable. // let mutable_borrow = &mut point; // TODO ^ Try uncommenting this line // The borrowed values are used again here println!("Point has coordinates: ({}, {}, {})", borrowed_point.x, another_borrow.y, point.z); // The immutable references are no longer used for the rest of the code so // it is possible to reborrow with a mutable reference. let mutable_borrow = &mut point; // Change data via mutable reference mutable_borrow.x = 5; mutable_borrow.y = 2; mutable_borrow.z = 1; // Error! Can't borrow `point` as immutable because it's currently // borrowed as mutable. // let y = &point.y; // TODO ^ Try uncommenting this line // Error! Can't print because `println!` takes an immutable reference. // println!("Point Z coordinate is {}", point.z); // TODO ^ Try uncommenting this line // Ok! Mutable references can be passed as immutable to `println!` println!("Point has coordinates: ({}, {}, {})", mutable_borrow.x, mutable_borrow.y, mutable_borrow.z); // The mutable reference is no longer used for the rest of the code so it // is possible to reborrow let new_borrowed_point = &point; println!("Point now has coordinates: ({}, {}, {})", new_borrowed_point.x, new_borrowed_point.y, new_borrowed_point.z); }
The ref pattern
When doing pattern matching or destructuring via the let binding, the ref
keyword can be used to take references to the fields of a struct/tuple.
The example below shows a few instances where this can be useful:
#[derive(Clone, Copy)] struct Point { x: i32, y: i32 } fn main() { let c = 'Q'; // A `ref` borrow on the left side of an assignment is equivalent to // an `&` borrow on the right side. let ref ref_c1 = c; let ref_c2 = &c; println!("ref_c1 equals ref_c2: {}", *ref_c1 == *ref_c2); let point = Point { x: 0, y: 0 }; // `ref` is also valid when destructuring a struct. let _copy_of_x = { // `ref_to_x` is a reference to the `x` field of `point`. let Point { x: ref ref_to_x, y: _ } = point; // Return a copy of the `x` field of `point`. *ref_to_x }; // A mutable copy of `point` let mut mutable_point = point; { // `ref` can be paired with `mut` to take mutable references. let Point { x: _, y: ref mut mut_ref_to_y } = mutable_point; // Mutate the `y` field of `mutable_point` via a mutable reference. *mut_ref_to_y = 1; } println!("point is ({}, {})", point.x, point.y); println!("mutable_point is ({}, {})", mutable_point.x, mutable_point.y); // A mutable tuple that includes a pointer let mut mutable_tuple = (Box::new(5u32), 3u32); { // Destructure `mutable_tuple` to change the value of `last`. let (_, ref mut last) = mutable_tuple; *last = 2u32; } println!("tuple is {:?}", mutable_tuple); }
- A
refborrow on the left side of an assignment is equivalent to an&borrow on the right side. refcan be paired withmutto take mutable references.
Lifetimes: a construct of borrow checker
A lifetime is a construct the compiler (or more specifically, its borrow checker) uses to ensure all borrows are valid.
-
Specifically, a variable’s lifetime begins when it is created and ends when it is destroyed.
-
While lifetimes and scopes are often referred to together, they are not the same.
-
Take, for example, the case where we borrow a variable via
&. -
The borrow has a lifetime that is determined by where it is declared.
-
As a result, the borrow is valid as long as it ends before the lender is destroyed.
-
However, the scope of the borrow is determined by where the reference is used.
In the following example and in the rest of this section, we will see how lifetimes relate to scopes, as well as how the two differ.
// Lifetimes are annotated below with lines denoting the creation // and destruction of each variable. // `i` has the longest lifetime because its scope entirely encloses // both `borrow1` and `borrow2`. The duration of `borrow1` compared // to `borrow2` is irrelevant since they are disjoint. fn main() { let i = 3; // Lifetime for `i` starts. ────────────────┐ // │ { // │ let borrow1 = &i; // `borrow1` lifetime starts. ──┐│ // ││ println!("borrow1: {}", borrow1); // ││ } // `borrow1 ends. ──────────────────────────────────┘│ // │ // │ { // │ let borrow2 = &i; // `borrow2` lifetime starts. ──┐│ // ││ println!("borrow2: {}", borrow2); // ││ } // `borrow2` ends. ─────────────────────────────────┘│ // │ } // Lifetime ends. ─────────────────────────────────────┘
Note that no names or types are assigned to label lifetimes. This restricts how lifetimes will be able to be used as we will see.
Elision
Some lifetime patterns are overwhelmingly common and so the borrow checker will allow you to omit them to save typing and to improve readability.
This is known as elision.
Elision exists in Rust solely because these patterns are common.
The following code shows a few examples of elision.
// `elided_input` and `annotated_input` essentially have identical signatures // because the lifetime of `elided_input` is inferred by the compiler: fn elided_input(x: &i32) { println!("`elided_input`: {}", x); } fn annotated_input<'a>(x: &'a i32) { println!("`annotated_input`: {}", x); } // Similarly, `elided_pass` and `annotated_pass` have identical signatures // because the lifetime is added implicitly to `elided_pass`: fn elided_pass(x: &i32) -> &i32 { x } fn annotated_pass<'a>(x: &'a i32) -> &'a i32 { x } fn main() { let x = 3; elided_input(&x); annotated_input(&x); println!("`elided_pass`: {}", elided_pass(&x)); println!("`annotated_pass`: {}", annotated_pass(&x)); }
elided_inputandannotated_inputessentially have identical signatures- because the lifetime of
elided_inputis inferred by the compiler
For a more comprehensive description of elision, see lifetime elision in the book.
See also:
Explicit lifetime annotation: another Generic
Similar to closures, using lifetimes requires generics.
The borrow checker uses explicit lifetime annotations to determine how long references should be valid.
In cases where lifetimes are not elided1, Rust requires explicit annotations to determine what the lifetime of a reference should be.
The syntax for explicitly annotating a lifetime uses an apostrophe character as follows:
foo<'a>
// `foo` has a lifetime parameter `'a`
- Additionally, this lifetime syntax indicates that the lifetime of
foomay not exceed that of'a. - Explicit annotation of a type has the form
&'a Twhere'ahas already been introduced.
In cases with multiple lifetimes, the syntax is similar:
foo<'a, 'b>
// `foo` has lifetime parameters `'a` and `'b`
- In this case, the lifetime of
foocannot exceed that of either'aor'b.
See the following example for explicit lifetime annotation in use:
// `print_refs` takes two references to `i32` which have different // lifetimes `'a` and `'b`. These two lifetimes must both be at // least as long as the function `print_refs`. fn print_refs<'a, 'b>(x: &'a i32, y: &'b i32) { println!("x is {} and y is {}", x, y); } // A function which takes no arguments, but has a lifetime parameter `'a`. fn failed_borrow<'a>() { let _x = 12; // ERROR: `_x` does not live long enough let y: &'a i32 = &_x; // Attempting to use the lifetime `'a` as an explicit type annotation // inside the function will fail because the lifetime of `&_x` is shorter // than that of `y`. A short lifetime cannot be coerced into a longer one. } fn main() { // Create variables to be borrowed below. let (four, nine) = (4, 9); // Borrows (`&`) of both variables are passed into the function. print_refs(&four, &nine); // Any input which is borrowed must outlive the borrower. // In other words, the lifetime of `four` and `nine` must // be longer than that of `print_refs`. failed_borrow(); // `failed_borrow` contains no references to force `'a` to be // longer than the lifetime of the function, but `'a` is longer. // Because the lifetime is never constrained, it defaults to `'static`. }
elision implicitly annotates lifetimes and so is different.
See also:
Functions & Methods
Functions
Ignoring elision, function signatures with lifetimes have a few constraints:
- any reference must have an annotated lifetime.
- any reference being returned must have the same lifetime as an input or
be
static.
Additionally, note that returning references without input is banned if it would result in returning references to invalid data.
The following example shows off some valid forms of functions with lifetimes:
// One input reference with lifetime `'a` which must live // at least as long as the function. fn print_one<'a>(x: &'a i32) { println!("`print_one`: x is {}", x); } // Mutable references are possible with lifetimes as well. fn add_one<'a>(x: &'a mut i32) { *x += 1; } // Multiple elements with different lifetimes. In this case, it // would be fine for both to have the same lifetime `'a`, but // in more complex cases, different lifetimes may be required. fn print_multi<'a, 'b>(x: &'a i32, y: &'b i32) { println!("`print_multi`: x is {}, y is {}", x, y); } // Returning references that have been passed in is acceptable. // However, the correct lifetime must be returned. fn pass_x<'a, 'b>(x: &'a i32, _: &'b i32) -> &'a i32 { x } //fn invalid_output<'a>() -> &'a String { &String::from("foo") } // The above is invalid: `'a` must live longer than the function. // Here, `&String::from("foo")` would create a `String`, followed by a // reference. Then the data is dropped upon exiting the scope, leaving // a reference to invalid data to be returned. fn main() { let x = 7; let y = 9; print_one(&x); print_multi(&x, &y); let z = pass_x(&x, &y); print_one(z); let mut t = 3; add_one(&mut t); print_one(&t); }
- One input reference with lifetime
'awhich must live at least as long as the function. - Mutable references are possible with lifetimes as well.
- Multiple elements with different lifetimes. In this case, it would be fine for both to have the same lifetime
'a, - but in more complex cases, different lifetimes may be required.
- Returning references that have been passed in is acceptable.
- However, the correct lifetime must be returned.
Methods
Methods are annotated similarly to functions:
struct Owner(i32); impl Owner { // Annotate lifetimes as in a standalone function. fn add_one<'a>(&'a mut self) { self.0 += 1; } fn print<'a>(&'a self) { println!("`print`: {}", self.0); } } fn main() { let mut owner = Owner(18); owner.add_one(); owner.print(); }
Structs
Annotation of lifetimes in structures are also similar to functions:
// A type `Borrowed` which houses a reference to an // `i32`. The reference to `i32` must outlive `Borrowed`. #[derive(Debug)] struct Borrowed<'a>(&'a i32); // Similarly, both references here must outlive this structure. #[derive(Debug)] struct NamedBorrowed<'a> { x: &'a i32, y: &'a i32, } // An enum which is either an `i32` or a reference to one. #[derive(Debug)] enum Either<'a> { Num(i32), Ref(&'a i32), } fn main() { let x = 18; let y = 15; let single = Borrowed(&x); let double = NamedBorrowed { x: &x, y: &y }; let reference = Either::Ref(&x); let number = Either::Num(y); println!("x is borrowed in {:?}", single); println!("x and y are borrowed in {:?}", double); println!("x is borrowed in {:?}", reference); println!("y is *not* borrowed in {:?}", number); }
Traits
Annotation of lifetimes in trait methods basically are similar to functions.
Note that impl may have annotation of lifetimes too.
// A struct with annotation of lifetimes. #[derive(Debug)] struct Borrowed<'a> { x: &'a i32, } // Annotate lifetimes to impl. impl<'a> Default for Borrowed<'a> { fn default() -> Self { Self { x: &10, } } } fn main() { let b: Borrowed = Default::default(); println!("b is {:?}", b); }
See also:
Lifetime Bounds for generics
Just like generic types can be bounded, lifetimes (themselves generic) use bounds as well.
The
:character has a slightly different meaning here, but+is the same. Note how the following read:
T: 'a: All references inTmust outlive lifetime'a.T: Trait + 'a: TypeTmust implement traitTraitand all references inTmust outlive'a.
The example below shows the above syntax in action used after keyword where:
use std::fmt::Debug; // Trait to bound with. #[derive(Debug)] struct Ref<'a, T: 'a>(&'a T); // `Ref` contains a reference to a generic type `T` that has // an unknown lifetime `'a`. `T` is bounded such that any // *references* in `T` must outlive `'a`. Additionally, the lifetime // of `Ref` may not exceed `'a`. // A generic function which prints using the `Debug` trait. fn print<T>(t: T) where T: Debug { println!("`print`: t is {:?}", t); } // Here a reference to `T` is taken where `T` implements // `Debug` and all *references* in `T` outlive `'a`. In // addition, `'a` must outlive the function. fn print_ref<'a, T>(t: &'a T) where T: Debug + 'a { println!("`print_ref`: t is {:?}", t); } fn main() { let x = 7; let ref_x = Ref(&x); print_ref(&ref_x); print(ref_x); }
See also:
generics, bounds in generics, and multiple bounds in generics
Coercion
A longer lifetime can be coerced into a shorter one so that it works inside a scope it normally wouldn’t work in.
This comes in the form of inferred coercion by the Rust compiler, and also in the form of declaring a lifetime difference:
// Here, Rust infers a lifetime that is as short as possible. // The two references are then coerced to that lifetime. fn multiply<'a>(first: &'a i32, second: &'a i32) -> i32 { first * second } // `<'a: 'b, 'b>` reads as lifetime `'a` is at least as long as `'b`. // Here, we take in an `&'a i32` and return a `&'b i32` as a result of coercion. fn choose_first<'a: 'b, 'b>(first: &'a i32, _: &'b i32) -> &'b i32 { first } fn main() { let first = 2; // Longer lifetime { let second = 3; // Shorter lifetime println!("The product is {}", multiply(&first, &second)); println!("{} is the first", choose_first(&first, &second)); }; }
Static
Rust has a few reserved lifetime names.
One of those is 'static.
Two situations
You might encounter it in two situations:
// A reference with 'static lifetime: let s: &'static str = "hello world"; // 'static as part of a trait bound: fn generic<T>(x: T) where T: 'static {}
Both are related but subtly different and this is a common source for confusion when learning Rust.
some examples for each situation:
Reference lifetime
As a reference lifetime 'static indicates that the data pointed to by
the reference lives for the entire lifetime of the running program.
It can still be coerced to a shorter lifetime.
There are two ways to make a variable with 'static lifetime, and both
are stored in the read-only memory of the binary:
- Make a constant with the
staticdeclaration. - Make a
stringliteral which has type:&'static str.
See the following example for a display of each method:
// Make a constant with `'static` lifetime. static NUM: i32 = 18; // Returns a reference to `NUM` where its `'static` // lifetime is coerced to that of the input argument. fn coerce_static<'a>(_: &'a i32) -> &'a i32 { &NUM } fn main() { { // Make a `string` literal and print it: let static_string = "I'm in read-only memory"; println!("static_string: {}", static_string); // When `static_string` goes out of scope, the reference // can no longer be used, but the data remains in the binary. } { // Make an integer to use for `coerce_static`: let lifetime_num = 9; // Coerce `NUM` to lifetime of `lifetime_num`: let coerced_static = coerce_static(&lifetime_num); println!("coerced_static: {}", coerced_static); } println!("NUM: {} stays accessible!", NUM); }
- When
static_stringgoes out of scope, the reference can no longer be used, but the data remains in the binary.
Trait bound
As a trait bound, it means the type does not contain any non-static references.
Eg. the receiver can hold on to the type for as long as they want and it will never become invalid until they drop it.
It’s important to understand this means that any owned data always passes a ’static lifetime bound, but a reference to that owned data generally does not:
use std::fmt::Debug; fn print_it( input: impl Debug + 'static ) { println!( "'static value passed in is: {:?}", input ); } fn main() { // i is owned and contains no references, thus it's 'static: let i = 5; print_it(i); // oops, &i only has the lifetime defined by the scope of // main(), so it's not 'static: print_it(&i); }
The compiler will tell you:
error[E0597]: `i` does not live long enough
--> src/lib.rs:15:15
|
15 | print_it(&i);
| ---------^^--
| | |
| | borrowed value does not live long enough
| argument requires that `i` is borrowed for `'static`
16 | }
| - `i` dropped here while still borrowed
See also:
macro_rules!
Rust provides a powerful macro system that allows metaprogramming. As you’ve
seen in previous chapters, macros look like functions, except that their name
ends with a bang !, but instead of generating a function call, macros are
expanded into source code that gets compiled with the rest of the program.
However, unlike macros in C and other languages, Rust macros are expanded into
abstract syntax trees, rather than string preprocessing, so you don’t get
unexpected precedence bugs.
Macros are created using the macro_rules! macro.
// This is a simple macro named `say_hello`. macro_rules! say_hello { // `()` indicates that the macro takes no argument. () => { // The macro will expand into the contents of this block. println!("Hello!"); }; } fn main() { // This call will expand into `println!("Hello");` say_hello!() }
So why are macros useful?
-
Don’t repeat yourself. There are many cases where you may need similar functionality in multiple places but with different types. Often, writing a macro is a useful way to avoid repeating code. (More on this later)
-
Domain-specific languages. Macros allow you to define special syntax for a specific purpose. (More on this later)
-
Variadic interfaces. Sometimes you want to define an interface that takes a variable number of arguments. An example is
println!which could take any number of arguments, depending on the format string. (More on this later)
Syntax
In following subsections, we will show how to define macros in Rust. There are three basic ideas:
Designators
The arguments of a macro are prefixed by a dollar sign $ and type annotated
with a designator:
macro_rules! create_function { // This macro takes an argument of designator `ident` and // creates a function named `$func_name`. // The `ident` designator is used for variable/function names. ($func_name:ident) => { fn $func_name() { // The `stringify!` macro converts an `ident` into a string. println!("You called {:?}()", stringify!($func_name)); } }; } // Create functions named `foo` and `bar` with the above macro. create_function!(foo); create_function!(bar); macro_rules! print_result { // This macro takes an expression of type `expr` and prints // it as a string along with its result. // The `expr` designator is used for expressions. ($expression:expr) => { // `stringify!` will convert the expression *as it is* into a string. println!("{:?} = {:?}", stringify!($expression), $expression); }; } fn main() { foo(); bar(); print_result!(1u32 + 1); // Recall that blocks are expressions too! print_result!({ let x = 1u32; x * x + 2 * x - 1 }); }
These are some of the available designators:
blockexpris used for expressionsidentis used for variable/function namesitemliteralis used for literal constantspat(pattern)pathstmt(statement)tt(token tree)ty(type)vis(visibility qualifier)
For a complete list, see the Rust Reference.
Overload
Macros can be overloaded to accept different combinations of arguments.
In that regard, macro_rules! can work similarly to a match block:
// `test!` will compare `$left` and `$right` // in different ways depending on how you invoke it: macro_rules! test { // Arguments don't need to be separated by a comma. // Any template can be used! ($left:expr; and $right:expr) => { println!("{:?} and {:?} is {:?}", stringify!($left), stringify!($right), $left && $right) }; // ^ each arm must end with a semicolon. ($left:expr; or $right:expr) => { println!("{:?} or {:?} is {:?}", stringify!($left), stringify!($right), $left || $right) }; } fn main() { test!(1i32 + 1 == 2i32; and 2i32 * 2 == 4i32); test!(true; or false); }
Repeat
Macros can use + in the argument list to indicate that an argument may
repeat at least once, or *, to indicate that the argument may repeat zero or
more times.
In the following example, surrounding the matcher with $(...),+ will
match one or more expression, separated by commas.
Also note that the semicolon is optional on the last case.
// `find_min!` will calculate the minimum of any number of arguments. macro_rules! find_min { // Base case: ($x:expr) => ($x); // `$x` followed by at least one `$y,` ($x:expr, $($y:expr),+) => ( // Call `find_min!` on the tail `$y` std::cmp::min($x, find_min!($($y),+)) ) } fn main() { println!("{}", find_min!(1)); println!("{}", find_min!(1 + 2, 2)); println!("{}", find_min!(5, 2 * 3, 4)); }
DRY (Don’t Repeat Yourself)
Macros allow writing DRY code by factoring out the common parts of functions
and/or test suites. Here is an example that implements and tests the +=, *=
and -= operators on Vec<T>:
use std::ops::{Add, Mul, Sub}; macro_rules! assert_equal_len { // The `tt` (token tree) designator is used for // operators and tokens. ($a:expr, $b:expr, $func:ident, $op:tt) => { assert!($a.len() == $b.len(), "{:?}: dimension mismatch: {:?} {:?} {:?}", stringify!($func), ($a.len(),), stringify!($op), ($b.len(),)); }; } macro_rules! op { ($func:ident, $bound:ident, $op:tt, $method:ident) => { fn $func<T: $bound<T, Output=T> + Copy>(xs: &mut Vec<T>, ys: &Vec<T>) { assert_equal_len!(xs, ys, $func, $op); for (x, y) in xs.iter_mut().zip(ys.iter()) { *x = $bound::$method(*x, *y); // *x = x.$method(*y); } } }; } // Implement `add_assign`, `mul_assign`, and `sub_assign` functions. op!(add_assign, Add, +=, add); op!(mul_assign, Mul, *=, mul); op!(sub_assign, Sub, -=, sub); mod test { use std::iter; macro_rules! test { ($func:ident, $x:expr, $y:expr, $z:expr) => { #[test] fn $func() { for size in 0usize..10 { let mut x: Vec<_> = iter::repeat($x).take(size).collect(); let y: Vec<_> = iter::repeat($y).take(size).collect(); let z: Vec<_> = iter::repeat($z).take(size).collect(); super::$func(&mut x, &y); assert_eq!(x, z); } } }; } // Test `add_assign`, `mul_assign`, and `sub_assign`. test!(add_assign, 1u32, 2u32, 3u32); test!(mul_assign, 2u32, 3u32, 6u32); test!(sub_assign, 3u32, 2u32, 1u32); }
$ rustc --test dry.rs && ./dry
running 3 tests
test test::mul_assign ... ok
test test::add_assign ... ok
test test::sub_assign ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured
Domain Specific Languages (DSLs)
A DSL is a mini “language” embedded in a Rust macro. It is completely valid Rust because the macro system expands into normal Rust constructs, but it looks like a small language. This allows you to define concise or intuitive syntax for some special functionality (within bounds).
Suppose that I want to define a little calculator API. I would like to supply an expression and have the output printed to console.
macro_rules! calculate { (eval $e:expr) => { { let val: usize = $e; // Force types to be integers println!("{} = {}", stringify!{$e}, val); } }; } fn main() { calculate! { eval 1 + 2 // hehehe `eval` is _not_ a Rust keyword! } calculate! { eval (1 + 2) * (3 / 4) } }
Output:
1 + 2 = 3
(1 + 2) * (3 / 4) = 0
This was a very simple example, but much more complex interfaces have been
developed, such as lazy_static or
clap.
Also, note the two pairs of braces in the macro. The outer ones are
part of the syntax of macro_rules!, in addition to () or [].
Variadic Interfaces
A variadic interface takes an arbitrary number of arguments. For example,
println! can take an arbitrary number of arguments, as determined by the
format string.
We can extend our calculate! macro from the previous section to be variadic:
macro_rules! calculate { // The pattern for a single `eval` (eval $e:expr) => { { let val: usize = $e; // Force types to be integers println!("{} = {}", stringify!{$e}, val); } }; // Decompose multiple `eval`s recursively (eval $e:expr, $(eval $es:expr),+) => {{ calculate! { eval $e } calculate! { $(eval $es),+ } }}; } fn main() { calculate! { // Look ma! Variadic `calculate!`! eval 1 + 2, eval 3 + 4, eval (2 * 3) + 1 } }
Output:
1 + 2 = 3
3 + 4 = 7
(2 * 3) + 1 = 7
Attributes: metadata applied to some module, crate or item
An attribute is metadata applied to some module, crate or item.
This metadata can be used to/for:
- conditional compilation of code
- set crate name, version and type (binary or library)
- disable lints (warnings)
- enable compiler features (macros, glob imports, etc.)
- link to a foreign library
- mark functions as unit tests
- mark functions that will be part of a benchmark
- attribute like macros
When attributes apply to a whole crate, their syntax is
#![crate_attribute],
when they apply to a module or item, the syntax is
#[item_attribute](notice the missing bang!).
Attributes can take arguments with different syntaxes:
#[attribute = "value"]#[attribute(key = "value")]#[attribute(value)]
Attributes can have multiple values and can be separated over multiple lines, too:
#[attribute(value, value2)]
#[attribute(value,
value2, value3,
value4, value5)]
dead_code: disable the unused lint
The compiler provides a dead_code lint that will warn about unused functions.
An attribute can be used to disable the lint.
fn used_function() {} // `#[allow(dead_code)]` is an attribute that disables the `dead_code` lint #[allow(dead_code)] fn unused_function() {} fn noisy_unused_function() {} // FIXME ^ Add an attribute to suppress the warning fn main() { used_function(); }
- Note that in real programs, you should eliminate dead code.
- In these examples we’ll allow dead code in some places because of the interactive nature of the examples.
Crates: crate_type and crate_name
- The
crate_typeattribute can be used to tell the compiler whether a crate is a binary or a library (and even which type of library) - and the
crate_nameattribute can be used to set the name of the crate.
However, it is important to note that both the
crate_typeandcrate_nameattributes have no effect whatsoever when using Cargo, the Rust package manager.
Since Cargo is used for the majority of Rust projects, this means
real-world uses of crate_type and crate_name are relatively limited.
uses of crate_type and crate_name
// This crate is a library #![crate_type = "lib"] // The library is named "rary" #![crate_name = "rary"] pub fn public_function() { println!("called rary's `public_function()`"); } fn private_function() { println!("called rary's `private_function()`"); } pub fn indirect_access() { print!("called rary's `indirect_access()`, that\n> "); private_function(); }
When the
crate_typeattribute is used, we no longer need to pass the--crate-typeflag torustc.
$ rustc lib.rs
$ ls lib*
library.rlib
cfg: Configuration conditional checks
Configuration conditional checks are possible through two different operators:
- the
cfgattribute:#[cfg(...)]inattribute position - the
cfg!macro:cfg!(...)inboolean expressions
While the former enables conditional compilation, the latter conditionally
evaluates to true or false literals allowing for checks at run-time.
Both utilize identical argument syntax.
cfg!, unlike #[cfg], does not remove any code and only evaluates to true or false.
For example, all blocks in an if/else expression need to be valid when cfg! is used for the condition, regardless of what cfg! is evaluating.
// This function only gets compiled if the target OS is linux #[cfg(target_os = "linux")] fn are_you_on_linux() { println!("You are running linux!"); } // And this function only gets compiled if the target OS is *not* linux #[cfg(not(target_os = "linux"))] fn are_you_on_linux() { println!("You are *not* running linux!"); } fn main() { are_you_on_linux(); println!("Are you sure?"); if cfg!(target_os = "linux") { println!("Yes. It's definitely linux!"); } else { println!("Yes. It's definitely *not* linux!"); } }
- This function only gets compiled if the target OS is linux
- And this function only gets compiled if the target OS is not linux
See also:
the reference, cfg!, and macros.
Custom conditionals
Some conditionals like target_os are implicitly provided by rustc, but custom conditionals must be passed to rustc using the –cfg flag.
#[cfg(some_condition)] fn conditional_function() { println!("condition met!"); } fn main() { conditional_function(); }
Try to run this to see what happens without the custom cfg flag.
Std library types
The std library provides many custom types which expands drastically on
the primitives.
Some of these include:
- growable
Strings like:"hello world" - growable vectors:
[1, 2, 3] - optional types:
Option<i32> - error handling types:
Result<i32, i32> - heap allocated pointers:
Box<i32>
See also:
primitives and the std library
Box, stack and heap
All values in Rust are stack allocated by default.
Values can be boxed (allocated on the heap) by creating a
Box<T>:
- Smart Pointer: A box is a smart pointer to a heap allocated value of type
T. - Destructor: When a box goes out of scope, its destructor is called, the inner object is destroyed, and the memory on the heap is freed.
- Deferenced: Boxed values can be dereferenced using the
*operator; this removes one layer of indirection.
Box Usage Example
use std::mem; #[allow(dead_code)] #[derive(Debug, Clone, Copy)] struct Point { x: f64, y: f64, } // A Rectangle can be specified by where its top left and bottom right // corners are in space #[allow(dead_code)] struct Rectangle { top_left: Point, bottom_right: Point, } fn origin() -> Point { Point { x: 0.0, y: 0.0 } } fn boxed_origin() -> Box<Point> { // Allocate this point on the heap, and return a pointer to it Box::new(Point { x: 0.0, y: 0.0 }) } fn main() { // (all the type annotations are superfluous) // Stack allocated variables let point: Point = origin(); let rectangle: Rectangle = Rectangle { top_left: origin(), bottom_right: Point { x: 3.0, y: -4.0 } }; // Heap allocated rectangle let boxed_rectangle: Box<Rectangle> = Box::new(Rectangle { top_left: origin(), bottom_right: Point { x: 3.0, y: -4.0 }, }); // The output of functions can be boxed let boxed_point: Box<Point> = Box::new(origin()); // Double indirection let box_in_a_box: Box<Box<Point>> = Box::new(boxed_origin()); println!("Point occupies {} bytes on the stack", mem::size_of_val(&point)); println!("Rectangle occupies {} bytes on the stack", mem::size_of_val(&rectangle)); // box size == pointer size println!("Boxed point occupies {} bytes on the stack", mem::size_of_val(&boxed_point)); println!("Boxed rectangle occupies {} bytes on the stack", mem::size_of_val(&boxed_rectangle)); println!("Boxed box occupies {} bytes on the stack", mem::size_of_val(&box_in_a_box)); // Copy the data contained in `boxed_point` into `unboxed_point` let unboxed_point: Point = *boxed_point; println!("Unboxed point occupies {} bytes on the stack", mem::size_of_val(&unboxed_point)); }
- Box:new(): Allocate this point on the heap, and return a pointer to it
Vectors: re-sizable arrays
Like slices, their size is not known at compile time, but they can grow or shrink at any time.
A vector is represented using 3 parameters:
- pointer to the data
- length
- capacity: The capacity indicates how much memory is reserved for the vector.
The vector can grow as long as the length is smaller than the capacity. When this threshold needs to be surpassed, the vector is reallocated with a larger capacity.
fn main() { // Iterators can be collected into vectors let collected_iterator: Vec<i32> = (0..10).collect(); println!("Collected (0..10) into: {:?}", collected_iterator); // The `vec!` macro can be used to initialize a vector let mut xs = vec![1i32, 2, 3]; println!("Initial vector: {:?}", xs); // Insert new element at the end of the vector println!("Push 4 into the vector"); xs.push(4); println!("Vector: {:?}", xs); // Error! Immutable vectors can't grow collected_iterator.push(0); // FIXME ^ Comment out this line // The `len` method yields the number of elements currently stored in a vector println!("Vector length: {}", xs.len()); // Indexing is done using the square brackets (indexing starts at 0) println!("Second element: {}", xs[1]); // `pop` removes the last element from the vector and returns it println!("Pop last element: {:?}", xs.pop()); // Out of bounds indexing yields a panic println!("Fourth element: {}", xs[3]); // FIXME ^ Comment out this line // `Vector`s can be easily iterated over println!("Contents of xs:"); for x in xs.iter() { println!("> {}", x); } // A `Vector` can also be iterated over while the iteration // count is enumerated in a separate variable (`i`) for (i, x) in xs.iter().enumerate() { println!("In position {} we have value {}", i, x); } // Thanks to `iter_mut`, mutable `Vector`s can also be iterated // over in a way that allows modifying each value for x in xs.iter_mut() { *x *= 3; } println!("Updated vector: {:?}", xs); }
- Iterators can be collected into vectors
- The
vec!macro can be used to initialize a vector - push to Insert new element at the end of the vector
popremoves the last element from the vector and returns it- Immutable vectors can’t grow
- The
lenmethod yields the number of elements currently stored in a vector - Indexing is done using the square brackets (indexing starts at 0)
- Out of bounds indexing yields a panic
Vectors can be easily iterated over- Enumerate: A
Vectorcan also be iterated over while the iteration count is enumerated in a separate variable (i) - Thanks to
iter_mut, mutableVectors can also be iterated over in a way that allows modifying each value
More Vec methods can be found under the
std::vec module
Strings: String and &str
String and &str
There are two types of strings in Rust:
Stringand&str.
- String:
- A
Stringis stored as a vector of bytes (Vec<u8>) - but guaranteed to always be a valid UTF-8 sequence.
Stringis heap allocated, growable and not null terminated.
- &str:
&stris a slice (&[u8]) that always points to a valid UTF-8 sequence,- and can be used to view into a
String, just like&[T]is a view intoVec<T>.
String and &str usages
fn main() { // (all the type annotations are superfluous) // A reference to a string allocated in read only memory let pangram: &'static str = "the quick brown fox jumps over the lazy dog"; println!("Pangram: {}", pangram); // Iterate over words in reverse, no new string is allocated println!("Words in reverse"); for word in pangram.split_whitespace().rev() { println!("> {}", word); } // Copy chars into a vector, sort and remove duplicates let mut chars: Vec<char> = pangram.chars().collect(); chars.sort(); chars.dedup(); // Create an empty and growable `String` let mut string = String::new(); for c in chars { // Insert a char at the end of string string.push(c); // Insert a string at the end of string string.push_str(", "); } // The trimmed string is a slice to the original string, hence no new // allocation is performed let chars_to_trim: &[char] = &[' ', ',']; let trimmed_str: &str = string.trim_matches(chars_to_trim); println!("Used characters: {}", trimmed_str); // Heap allocate a string let alice = String::from("I like dogs"); // Allocate new memory and store the modified string there let bob: String = alice.replace("dog", "cat"); println!("Alice says: {}", alice); println!("Bob says: {}", bob); }
- &’static str: A reference to a string allocated in read only memory
More str/String methods can be found under the
std::str and
std::string
modules
Literals and escapes
There are multiple ways to write string literals with special characters in them.
All result in a similar &str so it’s best to use the form that is the most
convenient to write.
Similarly there are multiple ways to write byte string literals,
which all result in &[u8; N].
backslash to escape
Generally special characters are escaped with a backslash character: \.
This way you can add any character to your string, even unprintable ones and ones that you don’t know how to type.
If you want a literal backslash, escape it with another one: \\
String or character literal delimiters occurring within a literal must be escaped: "\"", '\''.
escaped characters example
fn main() { // You can use escapes to write bytes by their hexadecimal values... let byte_escape = "I'm writing \x52\x75\x73\x74!"; println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape); // ...or Unicode code points. let unicode_codepoint = "\u{211D}"; let character_name = "\"DOUBLE-STRUCK CAPITAL R\""; println!("Unicode character {} (U+211D) is called {}", unicode_codepoint, character_name ); let long_string = "String literals can span multiple lines. The linebreak and indentation here ->\ <- can be escaped too!"; println!("{}", long_string); }
raw string
Sometimes there are just too many characters that need to be escaped or it’s just much more convenient to write a string out as-is.
This is where raw string literals come into play.
fn main() { let raw_str = r"Escapes don't work here: \x3F \u{211D}"; println!("{}", raw_str); // If you need quotes in a raw string, add a pair of #s let quotes = r#"And then I said: "There is no escape!""#; println!("{}", quotes); // If you need "# in your string, just use more #s in the delimiter. // You can use up to 65535 #s. let longer_delimiter = r###"A string with "# in it. And even "##!"###; println!("{}", longer_delimiter); }
Byte strings
Want a string that’s not UTF-8? (Remember, str and String must be valid UTF-8).
Or maybe you want an array of bytes that’s mostly text?
Byte strings to the rescue!
use std::str; fn main() { // Note that this is not actually a `&str` let bytestring: &[u8; 21] = b"this is a byte string"; // Byte arrays don't have the `Display` trait, so printing them is a bit limited println!("A byte string: {:?}", bytestring); // Byte strings can have byte escapes... let escaped = b"\x52\x75\x73\x74 as bytes"; // ...but no unicode escapes // let escaped = b"\u{211D} is not allowed"; println!("Some escaped bytes: {:?}", escaped); // Raw byte strings work just like raw strings let raw_bytestring = br"\u{211D} is not escaped here"; println!("{:?}", raw_bytestring); // Converting a byte array to `str` can fail if let Ok(my_str) = str::from_utf8(raw_bytestring) { println!("And the same as text: '{}'", my_str); } let _quotes = br#"You can also use "fancier" formatting, \ like with normal raw strings"#; // Byte strings don't have to be UTF-8 let shift_jis = b"\x82\xe6\x82\xa8\x82\xb1\x82\xbb"; // "ようこそ" in SHIFT-JIS // But then they can't always be converted to `str` match str::from_utf8(shift_jis) { Ok(my_str) => println!("Conversion successful: '{}'", my_str), Err(e) => println!("Conversion failed: {:?}", e), }; }
More
For conversions between character encodings check out the encoding crate.
A more detailed listing of the ways to write string literals and escape characters is given in the ‘Tokens’ chapter of the Rust Reference.
panic!: Just Raise Exception
The panic! macro can be used to generate a panic and start unwinding
its stack.
While unwinding, the runtime will take care of freeing all the resources owned by the thread by calling the destructor of all its objects.
Since we are dealing with programs with only one thread, panic! will cause the
program to report the panic message and exit.
panic! example
// Re-implementation of integer division (/) fn division(dividend: i32, divisor: i32) -> i32 { if divisor == 0 { // Division by zero triggers a panic panic!("division by zero"); } else { dividend / divisor } } // The `main` task fn main() { // Heap allocated integer let _x = Box::new(0i32); // This operation will trigger a task failure division(3, 0); println!("This point won't be reached!"); // `_x` should get destroyed at this point }
Let’s check that panic! doesn’t leak memory.
$ rustc panic.rs && valgrind ./panic
==4401== Memcheck, a memory error detector
==4401== Copyright (C) 2002-2013, and GNU GPL'd, by Julian Seward et al.
==4401== Using Valgrind-3.10.0.SVN and LibVEX; rerun with -h for copyright info
==4401== Command: ./panic
==4401==
thread '<main>' panicked at 'division by zero', panic.rs:5
==4401==
==4401== HEAP SUMMARY:
==4401== in use at exit: 0 bytes in 0 blocks
==4401== total heap usage: 18 allocs, 18 frees, 1,648 bytes allocated
==4401==
==4401== All heap blocks were freed -- no leaks are possible
==4401==
==4401== For counts of detected and suppressed errors, rerun with: -v
==4401== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Option: catching failure instead of calling panic!
Sometimes it’s desirable to catch the failure of some parts of a program
instead of calling panic!; this can be accomplished using the Option enum.
The Option<T> enum has two variants:
None, to indicate failure or lack of value, andSome(value), a tuple struct that wraps avaluewith typeT.
Option使用要点:match匹配无/有情况;println的写法
// An integer division that doesn't `panic!` fn checked_division(dividend: i32, divisor: i32) -> Option<i32> { if divisor == 0 { // Failure is represented as the `None` variant None } else { // Result is wrapped in a `Some` variant Some(dividend / divisor) } } // This function handles a division that may not succeed fn try_division(dividend: i32, divisor: i32) { // `Option` values can be pattern matched, just like other enums match checked_division(dividend, divisor) { None => println!("{} / {} failed!", dividend, divisor), Some(quotient) => { println!("{} / {} = {}", dividend, divisor, quotient) }, } } fn main() { try_division(4, 2); try_division(1, 0); // Binding `None` to a variable needs to be type annotated let none: Option<i32> = None; let _equivalent_none = None::<i32>; let optional_float = Some(0f32); // Unwrapping a `Some` variant will extract the value wrapped. println!("{:?} unwraps to {:?}", optional_float, optional_float.unwrap()); // Unwrapping a `None` variant will `panic!` println!("{:?} unwraps to {:?}", none, none.unwrap()); }
Result: express why an operation failed
We’ve seen that the Option enum can be used as a return value from functions
that may fail, where None can be returned to indicate failure.
However, sometimes it is important to express why an operation failed. To do this we have the
Resultenum.
The
Result<T, E>enum has two variants:
Ok(value)which indicates that the operation succeeded, and wraps thevaluereturned by the operation. (valuehas typeT)Err(why), which indicates that the operation failed, and wrapswhy, which (hopefully) explains the cause of the failure. (whyhas typeE)
Result Usage
mod checked { // Mathematical "errors" we want to catch #[derive(Debug)] pub enum MathError { DivisionByZero, NonPositiveLogarithm, NegativeSquareRoot, } pub type MathResult = Result<f64, MathError>; pub fn div(x: f64, y: f64) -> MathResult { if y == 0.0 { // This operation would `fail`, instead let's return the reason of // the failure wrapped in `Err` Err(MathError::DivisionByZero) } else { // This operation is valid, return the result wrapped in `Ok` Ok(x / y) } } pub fn sqrt(x: f64) -> MathResult { if x < 0.0 { Err(MathError::NegativeSquareRoot) } else { Ok(x.sqrt()) } } pub fn ln(x: f64) -> MathResult { if x <= 0.0 { Err(MathError::NonPositiveLogarithm) } else { Ok(x.ln()) } } } // `op(x, y)` === `sqrt(ln(x / y))` fn op(x: f64, y: f64) -> f64 { // This is a three level match pyramid! match checked::div(x, y) { Err(why) => panic!("{:?}", why), Ok(ratio) => match checked::ln(ratio) { Err(why) => panic!("{:?}", why), Ok(ln) => match checked::sqrt(ln) { Err(why) => panic!("{:?}", why), Ok(sqrt) => sqrt, }, }, } } fn main() { // Will this fail? println!("{}", op(1.0, 10.0)); }
?: Chaining Results only match Ok(ok)
Chaining results using match can get pretty untidy;
luckily, the
?operator can be used to make things pretty again.
?is used at the end of an expression returning aResult- and is equivalent to a match expression
- where the
Err(err)branch expands to an earlyreturn Err(From::from(err)), - and the
Ok(ok)branch expands to anokexpression.
Question Mark Example
mod checked { #[derive(Debug)] enum MathError { DivisionByZero, NonPositiveLogarithm, NegativeSquareRoot, } type MathResult = Result<f64, MathError>; fn div(x: f64, y: f64) -> MathResult { if y == 0.0 { Err(MathError::DivisionByZero) } else { Ok(x / y) } } fn sqrt(x: f64) -> MathResult { if x < 0.0 { Err(MathError::NegativeSquareRoot) } else { Ok(x.sqrt()) } } fn ln(x: f64) -> MathResult { if x <= 0.0 { Err(MathError::NonPositiveLogarithm) } else { Ok(x.ln()) } } // Intermediate function fn op_(x: f64, y: f64) -> MathResult { // if `div` "fails", then `DivisionByZero` will be `return`ed let ratio = div(x, y)?; // if `ln` "fails", then `NonPositiveLogarithm` will be `return`ed let ln = ln(ratio)?; sqrt(ln) } pub fn op(x: f64, y: f64) { match op_(x, y) { Err(why) => panic!("{}", match why { MathError::NonPositiveLogarithm => "logarithm of non-positive number", MathError::DivisionByZero => "division by zero", MathError::NegativeSquareRoot => "square root of negative number", }), Ok(value) => println!("{}", value), } } } fn main() { checked::op(1.0, 10.0); }
Be sure to check the documentation,
as there are many methods to map/compose Result.
HashMap
Where vectors store values by an integer index, HashMaps store values by key.
HashMapkeys can be booleans, integers, strings, or any other type that implements theEqandHashtraits.
More on this in the next section.
- Like vectors,
HashMaps are growable, but HashMaps can also shrink themselves when they have excess space.
You can create a HashMap with a certain starting capacity using HashMap::with_capacity(uint), or use HashMap::new() to get a HashMap with a default initial capacity (recommended).
use std::collections::HashMap; fn call(number: &str) -> &str { match number { "798-1364" => "We're sorry, the call cannot be completed as dialed. Please hang up and try again.", "645-7689" => "Hello, this is Mr. Awesome's Pizza. My name is Fred. What can I get for you today?", _ => "Hi! Who is this again?" } } fn main() { let mut contacts = HashMap::new(); contacts.insert("Daniel", "798-1364"); contacts.insert("Ashley", "645-7689"); contacts.insert("Katie", "435-8291"); contacts.insert("Robert", "956-1745"); // Takes a reference and returns Option<&V> match contacts.get(&"Daniel") { Some(&number) => println!("Calling Daniel: {}", call(number)), _ => println!("Don't have Daniel's number."), } // `HashMap::insert()` returns `None` // if the inserted value is new, `Some(value)` otherwise contacts.insert("Daniel", "164-6743"); match contacts.get(&"Ashley") { Some(&number) => println!("Calling Ashley: {}", call(number)), _ => println!("Don't have Ashley's number."), } contacts.remove(&"Ashley"); // `HashMap::iter()` returns an iterator that yields // (&'a key, &'a value) pairs in arbitrary order. for (contact, &number) in contacts.iter() { println!("Calling {}: {}", contact, call(number)); } }
For more information on how hashing and hash maps (sometimes called hash tables) work, have a look at Hash Table Wikipedia
Alternate/custom key types: implements the Eq and Hash traits
Any type that implements the Eq and Hash traits can be a key in HashMap.
This includes: like IntEnum\StrEnum in Python
bool(though not very useful since there is only two possible keys)int,uint, and all variations thereofStringand&str(protip: you can have aHashMapkeyed byStringand call.get()with an&str)
Note that
f32andf64do not implementHash, likely because floating-point precision errors would make using them as hashmap keys horribly error-prone.
All collection classes implement Eq and Hash
if their contained type also respectively implements Eq and Hash.
For example,
Vec<T>will implementHashifTimplementsHash.
You can easily implement
EqandHashfor a custom type with just one line:#[derive(PartialEq, Eq, Hash)]
- The compiler will do the rest.
- If you want more control over the details, you can implement
Eqand/orHashyourself. - This guide will not cover the specifics of implementing
Hash.
To play around with using a struct in HashMap, let’s try making a very simple user logon system:
use std::collections::HashMap; // Eq requires that you derive PartialEq on the type. #[derive(PartialEq, Eq, Hash)] struct Account<'a>{ username: &'a str, password: &'a str, } struct AccountInfo<'a>{ name: &'a str, email: &'a str, } type Accounts<'a> = HashMap<Account<'a>, AccountInfo<'a>>; fn try_logon<'a>(accounts: &Accounts<'a>, username: &'a str, password: &'a str){ println!("Username: {}", username); println!("Password: {}", password); println!("Attempting logon..."); let logon = Account { username, password, }; match accounts.get(&logon) { Some(account_info) => { println!("Successful logon!"); println!("Name: {}", account_info.name); println!("Email: {}", account_info.email); }, _ => println!("Login failed!"), } } fn main(){ let mut accounts: Accounts = HashMap::new(); let account = Account { username: "j.everyman", password: "password123", }; let account_info = AccountInfo { name: "John Everyman", email: "j.everyman@email.com", }; accounts.insert(account, account_info); try_logon(&accounts, "j.everyman", "psasword123"); try_logon(&accounts, "j.everyman", "password123"); }
- Eq requires that you derive PartialEq on the type.
HashSe
Consider a HashSet as a HashMap where we just care about the keys (
HashSet<T> is, in actuality, just a wrapper around HashMap<T, ()>).
“What’s the point of that?” you ask. “I could just store the keys in a Vec.”
A HashSet’s unique feature is that
it is guaranteed to not have duplicate elements.
That’s the contract that any set collection fulfills.
HashSet is just one implementation. (see also: BTreeSet)
If you insert a value that is already present in the HashSet,
(i.e. the new value is equal to the existing and they both have the same hash),
then the new value will replace the old.
This is great for when you never want more than one of something, or when you want to know if you’ve already got something.
But sets can do more than that.
Sets have 4 primary operations (all of the following calls return an iterator):
-
union: get all the unique elements in both sets. -
difference: get all the elements that are in the first set but not the second. -
intersection: get all the elements that are only in both sets. -
symmetric_difference: get all the elements that are in one set or the other, but not both.
Try all of these in the following example:
use std::collections::HashSet; fn main() { let mut a: HashSet<i32> = vec![1i32, 2, 3].into_iter().collect(); let mut b: HashSet<i32> = vec![2i32, 3, 4].into_iter().collect(); assert!(a.insert(4)); assert!(a.contains(&4)); // `HashSet::insert()` returns false if // there was a value already present. assert!(b.insert(4), "Value 4 is already in set B!"); // FIXME ^ Comment out this line b.insert(5); // If a collection's element type implements `Debug`, // then the collection implements `Debug`. // It usually prints its elements in the format `[elem1, elem2, ...]` println!("A: {:?}", a); println!("B: {:?}", b); // Print [1, 2, 3, 4, 5] in arbitrary order println!("Union: {:?}", a.union(&b).collect::<Vec<&i32>>()); // This should print [1] println!("Difference: {:?}", a.difference(&b).collect::<Vec<&i32>>()); // Print [2, 3, 4] in arbitrary order. println!("Intersection: {:?}", a.intersection(&b).collect::<Vec<&i32>>()); // Print [1, 5] println!("Symmetric Difference: {:?}", a.symmetric_difference(&b).collect::<Vec<&i32>>()); }
(Examples are adapted from the documentation.)
Rc: for mutiple ownership, just like what python have done
When multiple ownership is needed, Rc(Reference Counting) can be used:
Rckeeps track of the number of the references which means the number of owners of the value wrapped inside anRc.- Reference count of an
Rcincreases by 1 whenever anRcis cloned - and decreases by 1 whenever one cloned
Rcis dropped out of the scope. - When an
Rc’s reference count becomes zero (which means there are no remaining owners), both theRcand the value are all dropped. - Cloning an
Rcnever performs a deep copy. - Cloning creates just another pointer to the wrapped value, and increments the count.
Rc Example: Just like what Python have done
use std::rc::Rc; fn main() { let rc_examples = "Rc examples".to_string(); { println!("--- rc_a is created ---"); let rc_a: Rc<String> = Rc::new(rc_examples); println!("Reference Count of rc_a: {}", Rc::strong_count(&rc_a)); { println!("--- rc_a is cloned to rc_b ---"); let rc_b: Rc<String> = Rc::clone(&rc_a); println!("Reference Count of rc_b: {}", Rc::strong_count(&rc_b)); println!("Reference Count of rc_a: {}", Rc::strong_count(&rc_a)); // Two `Rc`s are equal if their inner values are equal println!("rc_a and rc_b are equal: {}", rc_a.eq(&rc_b)); // We can use methods of a value directly println!("Length of the value inside rc_a: {}", rc_a.len()); println!("Value of rc_b: {}", rc_b); println!("--- rc_b is dropped out of scope ---"); } println!("Reference Count of rc_a: {}", Rc::strong_count(&rc_a)); println!("--- rc_a is dropped out of scope ---"); } // Error! `rc_examples` already moved into `rc_a` // And when `rc_a` is dropped, `rc_examples` is dropped together // println!("rc_examples: {}", rc_examples); // TODO ^ Try uncommenting this line }
See also:
std::rc and std::sync::arc.
Arc: shared ownership between threads
When shared ownership between threads is needed, Arc(Atomically Reference
Counted) can be used.
This struct, via the Clone implementation can create
a reference pointer for the location of a value in the memory heap while
increasing the reference counter.
As it shares ownership between threads, when the last reference pointer to a value is out of scope, the variable is dropped.
Std misc
Many other types are provided by the std library to support things such as:
- Threads
- Channels
- File I/O
These expand beyond what the primitives provide.
See also:
primitives and the std library
Threads
Rust provides a mechanism for spawning native OS threads via the spawn function, the argument of this function is a moving closure.
use std::thread; const NTHREADS: u32 = 10; // This is the `main` thread fn main() { // Make a vector to hold the children which are spawned. let mut children = vec![]; for i in 0..NTHREADS { // Spin up another thread children.push(thread::spawn(move || { println!("this is thread number {}", i); })); } for child in children { // Wait for the thread to finish. Returns a result. let _ = child.join(); } }
These threads will be scheduled by the OS.
Testcase: map-reduce
Rust makes it very easy to parallelise data processing, without many of the headaches traditionally associated with such an attempt.
The standard library provides great threading primitives out of the box.
These, combined with Rust’s concept of Ownership and aliasing rules, automatically prevent data races.
The aliasing rules (one writable reference XOR many readable references) automatically prevent
you from manipulating state that is visible to other threads.
Where synchronisation is needed, there are synchronisation primitives like
Mutexes orChannels.
Note
Note that:
- although we’re passing references across thread boundaries, Rust understands that we’re only passing read-only references, and that thus no unsafety or data races can occur.
- Also because
the references we’re passing have
'staticlifetimes, Rust understands that our data won’t be destroyed while these threads are still running. - When you need to share non-
staticdata between threads, you can use a smart pointer likeArcto keep the data alive and avoid non-staticlifetimes.
Example
In this example, we will calculate the sum of all digits in a block of numbers:
use std::thread; // This is the `main` thread fn main() { // This is our data to process. // We will calculate the sum of all digits via a threaded map-reduce algorithm. // Each whitespace separated chunk will be handled in a different thread. // // TODO: see what happens to the output if you insert spaces! let data = "86967897737416471853297327050364959 11861322575564723963297542624962850 70856234701860851907960690014725639 38397966707106094172783238747669219 52380795257888236525459303330302837 58495327135744041048897885734297812 69920216438980873548808413720956532 16278424637452589860345374828574668"; // Make a vector to hold the child-threads which we will spawn. let mut children = vec![]; /************************************************************************* * "Map" phase * * Divide our data into segments, and apply initial processing ************************************************************************/ // split our data into segments for individual calculation // each chunk will be a reference (&str) into the actual data let chunked_data = data.split_whitespace(); // Iterate over the data segments. // .enumerate() adds the current loop index to whatever is iterated // the resulting tuple "(index, element)" is then immediately // "destructured" into two variables, "i" and "data_segment" with a // "destructuring assignment" for (i, data_segment) in chunked_data.enumerate() { println!("data segment {} is \"{}\"", i, data_segment); // Process each data segment in a separate thread // // spawn() returns a handle to the new thread, // which we MUST keep to access the returned value // // 'move || -> u32' is syntax for a closure that: // * takes no arguments ('||') // * takes ownership of its captured variables ('move') and // * returns an unsigned 32-bit integer ('-> u32') // // Rust is smart enough to infer the '-> u32' from // the closure itself so we could have left that out. // // TODO: try removing the 'move' and see what happens children.push(thread::spawn(move || -> u32 { // Calculate the intermediate sum of this segment: let result = data_segment // iterate over the characters of our segment.. .chars() // .. convert text-characters to their number value.. .map(|c| c.to_digit(10).expect("should be a digit")) // .. and sum the resulting iterator of numbers .sum(); // println! locks stdout, so no text-interleaving occurs println!("processed segment {}, result={}", i, result); // "return" not needed, because Rust is an "expression language", the // last evaluated expression in each block is automatically its value. result })); } /************************************************************************* * "Reduce" phase * * Collect our intermediate results, and combine them into a final result ************************************************************************/ // combine each thread's intermediate results into a single final sum. // // we use the "turbofish" ::<> to provide sum() with a type hint. // // TODO: try without the turbofish, by instead explicitly // specifying the type of final_result let final_result = children.into_iter().map(|c| c.join().unwrap()).sum::<u32>(); println!("Final sum result: {}", final_result); }
- We will do this by parcelling out chunks of the block into different threads.
- Each thread will sum its tiny block of digits,
- and subsequently we will sum the intermediate sums produced by each thread.
Assignments
It is not wise to let our number of threads depend on user inputted data. What if the user decides to insert a lot of spaces? Do we really want to spawn 2,000 threads? Modify the program so that the data is always chunked into a limited number of chunks, defined by a static constant at the beginning of the program.
See also:
- Threads
- vectors and iterators
- closures, move semantics and
moveclosures - destructuring assignments
- turbofish notation to help type inference
- unwrap vs. expect
- enumerate
Channels: Asynchronous comunication between threads
Rust provides asynchronous channels for communication between threads.
Channels allow a unidirectional flow of information between two end-points: the Sender and the Receiver.
use std::sync::mpsc::{Sender, Receiver}; use std::sync::mpsc; use std::thread; static NTHREADS: i32 = 3; fn main() { // Channels have two endpoints: the `Sender<T>` and the `Receiver<T>`, // where `T` is the type of the message to be transferred // (type annotation is superfluous) let (tx, rx): (Sender<i32>, Receiver<i32>) = mpsc::channel(); let mut children = Vec::new(); for id in 0..NTHREADS { // The sender endpoint can be copied let thread_tx = tx.clone(); // Each thread will send its id via the channel let child = thread::spawn(move || { // The thread takes ownership over `thread_tx` // Each thread queues a message in the channel thread_tx.send(id).unwrap(); // Sending is a non-blocking operation, the thread will continue // immediately after sending its message println!("thread {} finished", id); }); children.push(child); } // Here, all the messages are collected let mut ids = Vec::with_capacity(NTHREADS as usize); for _ in 0..NTHREADS { // The `recv` method picks a message from the channel // `recv` will block the current thread if there are no messages available ids.push(rx.recv()); } // Wait for the threads to complete any remaining work for child in children { child.join().expect("oops! the child thread panicked"); } // Show the order in which the messages were sent println!("{:?}", ids); }
- Channels have two endpoints: the
Sender<T>and theReceiver<T>, whereTis the type of the message to be transferred - The sender endpoint can be copied
- Each thread will send its id via the channel
- The thread takes ownership over
thread_txEach thread queues a message in the channel - The
recvmethod picks a message from the channel recvwill block the current thread if there are no messages available
Path
The Path struct represents file paths in the underlying filesystem.
There are two flavors of Path:
posix::Path, for UNIX-like systems- and
windows::Path, for Windows.
The prelude exports the appropriate platform-specific
Pathvariant.
-
A
Pathcan be created from anOsStr, and provides several methods to get information from the file/directory the path points to. -
A
Pathis immutable. -
The owned version of
PathisPathBuf.
The relation between
PathandPathBufis similar to that ofstrandString:
- a
PathBufcan be mutated in-place, - and can be dereferenced to a
Path.
Note that a
Pathis not internally represented as an UTF-8 string, but instead is stored as anOsString.
- Therefore, converting a
Pathto a&stris not free and may fail (anOptionis returned). - However, a
Pathcan be freely converted to anOsStringor&OsStrusinginto_os_stringandas_os_str, respectively.
Path Usage Examples
use std::path::Path; fn main() { // Create a `Path` from an `&'static str` let path = Path::new("."); // The `display` method returns a `Display`able structure let _display = path.display(); // `join` merges a path with a byte container using the OS specific // separator, and returns a `PathBuf` let mut new_path = path.join("a").join("b"); // `push` extends the `PathBuf` with a `&Path` new_path.push("c"); new_path.push("myfile.tar.gz"); // `set_file_name` updates the file name of the `PathBuf` new_path.set_file_name("package.tgz"); // Convert the `PathBuf` into a string slice match new_path.to_str() { None => panic!("new path is not a valid UTF-8 sequence"), Some(s) => println!("new path is {}", s), } }
- Create a
Pathfrom an&'static str - The
displaymethod returns aDisplayable structure joinmerges a path with a byte container using the OS specific separator, and returns aPathBufpushextends thePathBufwith a&Pathset_file_nameupdates the file name of thePathBuf
Be sure to check at other Path methods (posix::Path or windows::Path) and
the Metadata struct.
See also:
File I/O
The File struct represents a file that has been opened (it wraps a file
descriptor), and gives read and/or write access to the underlying file.
Since many things can go wrong when doing file I/O, all the
Filemethods return theio::Result<T>type, which is an alias forResult<T, io::Error>:
- This makes the failure of all I/O operations explicit.
- Thanks to this, the programmer can see all the failure paths, and is encouraged to handle them in a proactive manner.
open: read-only
The open function can be used to open a file in read-only mode.
A File owns a resource, the file descriptor and takes care of closing the file when it is droped.
use std::fs::File;
use std::io::prelude::*;
use std::path::Path;
fn main() {
// Create a path to the desired file
let path = Path::new("hello.txt");
let display = path.display();
// Open the path in read-only mode, returns `io::Result<File>`
let mut file = match File::open(&path) {
Err(why) => panic!("couldn't open {}: {}", display, why),
Ok(file) => file,
};
// Read the file contents into a string, returns `io::Result<usize>`
let mut s = String::new();
match file.read_to_string(&mut s) {
Err(why) => panic!("couldn't read {}: {}", display, why),
Ok(_) => print!("{} contains:\n{}", display, s),
}
// `file` goes out of scope, and the "hello.txt" file gets closed
}
- Create a path to the desired file
- Open the path in read-only mode, returns
io::Result<File> - Read the file contents into a string, returns
io::Result<usize>
Here’s the expected successful output:
$ echo "Hello World!" > hello.txt
$ rustc open.rs && ./open
hello.txt contains:
Hello World!
(You are encouraged to test the previous example under different failure
conditions: hello.txt doesn’t exist, or hello.txt is not readable,
etc.)
create: write-only
- The
createfunction opens a file inwrite-only mode. - If the file already existed, the old content is destroyed.
- Otherwise, a new file is created.
Create Usage
static LOREM_IPSUM: &str =
"Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse
cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non
proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
";
use std::fs::File;
use std::io::prelude::*;
use std::path::Path;
fn main() {
let path = Path::new("lorem_ipsum.txt");
let display = path.display();
// Open a file in write-only mode, returns `io::Result<File>`
let mut file = match File::create(&path) {
Err(why) => panic!("couldn't create {}: {}", display, why),
Ok(file) => file,
};
// Write the `LOREM_IPSUM` string to `file`, returns `io::Result<()>`
match file.write_all(LOREM_IPSUM.as_bytes()) {
Err(why) => panic!("couldn't write to {}: {}", display, why),
Ok(_) => println!("successfully wrote to {}", display),
}
}
Here’s the expected successful output:
$ rustc create.rs && ./create
successfully wrote to lorem_ipsum.txt
$ cat lorem_ipsum.txt
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse
cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non
proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
(As in the previous example, you are encouraged to test this example under failure conditions.)
There is OpenOptions struct that can be used to configure how a file is opened.
read_lines: returns an iterator
The method lines() returns an iterator over the lines
of a file.
File::open expects a generic, AsRef
use std::fs::File; use std::io::{self, BufRead}; use std::path::Path; fn main() { // File hosts must exist in current path before this produces output if let Ok(lines) = read_lines("./hosts") { // Consumes the iterator, returns an (Optional) String for line in lines { if let Ok(ip) = line { println!("{}", ip); } } } } // The output is wrapped in a Result to allow matching on errors // Returns an Iterator to the Reader of the lines of the file. fn read_lines<P>(filename: P) -> io::Result<io::Lines<io::BufReader<File>>> where P: AsRef<Path>, { let file = File::open(filename)?; Ok(io::BufReader::new(file).lines()) }
Running this program simply prints the lines individually.
$ echo -e "127.0.0.1\n192.168.0.1\n" > hosts
$ rustc read_lines.rs && ./read_lines
127.0.0.1
192.168.0.1
This process is more efficient than creating a String in memory
especially working with larger files.
Child processes
The process::Output struct represents the output of a finished child process, and the process::Command struct is a process builder.
use std::process::Command;
fn main() {
let output = Command::new("rustc")
.arg("--version")
.output().unwrap_or_else(|e| {
panic!("failed to execute process: {}", e)
});
if output.status.success() {
let s = String::from_utf8_lossy(&output.stdout);
print!("rustc succeeded and stdout was:\n{}", s);
} else {
let s = String::from_utf8_lossy(&output.stderr);
print!("rustc failed and stderr was:\n{}", s);
}
}
(You are encouraged to try the previous example with an incorrect flag passed
to rustc)
Pipes: interaction with the unserlying process
The std::Child struct represents a running child process, and exposes the stdin, stdout and stderr handles for interaction with the underlying process via pipes.
use std::io::prelude::*;
use std::process::{Command, Stdio};
static PANGRAM: &'static str =
"the quick brown fox jumped over the lazy dog\n";
fn main() {
// Spawn the `wc` command
let process = match Command::new("wc")
.stdin(Stdio::piped())
.stdout(Stdio::piped())
.spawn() {
Err(why) => panic!("couldn't spawn wc: {}", why),
Ok(process) => process,
};
// Write a string to the `stdin` of `wc`.
//
// `stdin` has type `Option<ChildStdin>`, but since we know this instance
// must have one, we can directly `unwrap` it.
match process.stdin.unwrap().write_all(PANGRAM.as_bytes()) {
Err(why) => panic!("couldn't write to wc stdin: {}", why),
Ok(_) => println!("sent pangram to wc"),
}
// Because `stdin` does not live after the above calls, it is `drop`ed,
// and the pipe is closed.
//
// This is very important, otherwise `wc` wouldn't start processing the
// input we just sent.
// The `stdout` field also has type `Option<ChildStdout>` so must be unwrapped.
let mut s = String::new();
match process.stdout.unwrap().read_to_string(&mut s) {
Err(why) => panic!("couldn't read wc stdout: {}", why),
Ok(_) => print!("wc responded with:\n{}", s),
}
}
stdinhas typeOption<ChildStdin>, but since we know this instance must have one, we can directlyunwrapit.
Wait
If you’d like to wait for a process::Child to finish, you must call Child::wait, which will return a process::ExitStatus.
use std::process::Command;
fn main() {
let mut child = Command::new("sleep").arg("5").spawn().unwrap();
let _result = child.wait().unwrap();
println!("reached end of main");
}
$ rustc wait.rs && ./wait
# `wait` keeps running for 5 seconds until the `sleep 5` command finishes
reached end of main
std::fs: Filesystem Operations
The std::fs module contains several functions that deal with the filesystem.
use std::fs;
use std::fs::{File, OpenOptions};
use std::io;
use std::io::prelude::*;
use std::os::unix;
use std::path::Path;
// A simple implementation of `% cat path`
fn cat(path: &Path) -> io::Result<String> {
let mut f = File::open(path)?;
let mut s = String::new();
match f.read_to_string(&mut s) {
Ok(_) => Ok(s),
Err(e) => Err(e),
}
}
// A simple implementation of `% echo s > path`
fn echo(s: &str, path: &Path) -> io::Result<()> {
let mut f = File::create(path)?;
f.write_all(s.as_bytes())
}
// A simple implementation of `% touch path` (ignores existing files)
fn touch(path: &Path) -> io::Result<()> {
match OpenOptions::new().create(true).write(true).open(path) {
Ok(_) => Ok(()),
Err(e) => Err(e),
}
}
fn main() {
println!("`mkdir a`");
// Create a directory, returns `io::Result<()>`
match fs::create_dir("a") {
Err(why) => println!("! {:?}", why.kind()),
Ok(_) => {},
}
println!("`echo hello > a/b.txt`");
// The previous match can be simplified using the `unwrap_or_else` method
echo("hello", &Path::new("a/b.txt")).unwrap_or_else(|why| {
println!("! {:?}", why.kind());
});
println!("`mkdir -p a/c/d`");
// Recursively create a directory, returns `io::Result<()>`
fs::create_dir_all("a/c/d").unwrap_or_else(|why| {
println!("! {:?}", why.kind());
});
println!("`touch a/c/e.txt`");
touch(&Path::new("a/c/e.txt")).unwrap_or_else(|why| {
println!("! {:?}", why.kind());
});
println!("`ln -s ../b.txt a/c/b.txt`");
// Create a symbolic link, returns `io::Result<()>`
if cfg!(target_family = "unix") {
unix::fs::symlink("../b.txt", "a/c/b.txt").unwrap_or_else(|why| {
println!("! {:?}", why.kind());
});
}
println!("`cat a/c/b.txt`");
match cat(&Path::new("a/c/b.txt")) {
Err(why) => println!("! {:?}", why.kind()),
Ok(s) => println!("> {}", s),
}
println!("`ls a`");
// Read the contents of a directory, returns `io::Result<Vec<Path>>`
match fs::read_dir("a") {
Err(why) => println!("! {:?}", why.kind()),
Ok(paths) => for path in paths {
println!("> {:?}", path.unwrap().path());
},
}
println!("`rm a/c/e.txt`");
// Remove a file, returns `io::Result<()>`
fs::remove_file("a/c/e.txt").unwrap_or_else(|why| {
println!("! {:?}", why.kind());
});
println!("`rmdir a/c/d`");
// Remove an empty directory, returns `io::Result<()>`
fs::remove_dir("a/c/d").unwrap_or_else(|why| {
println!("! {:?}", why.kind());
});
}
Here’s the expected successful output:
$ rustc fs.rs && ./fs
`mkdir a`
`echo hello > a/b.txt`
`mkdir -p a/c/d`
`touch a/c/e.txt`
`ln -s ../b.txt a/c/b.txt`
`cat a/c/b.txt`
> hello
`ls a`
> "a/b.txt"
> "a/c"
`rm a/c/e.txt`
`rmdir a/c/d`
And the final state of the a directory is:
$ tree a
a
|-- b.txt
`-- c
`-- b.txt -> ../b.txt
1 directory, 2 files
An alternative way to define the function cat is with ? notation:
fn cat(path: &Path) -> io::Result<String> {
let mut f = File::open(path)?;
let mut s = String::new();
f.read_to_string(&mut s)?;
Ok(s)
}
See also:
Program arguments
Standard Library
The command line arguments can be accessed using std::env::args, which returns an iterator that yields a String for each argument:
use std::env; fn main() { let args: Vec<String> = env::args().collect(); // The first argument is the path that was used to call the program. println!("My path is {}.", args[0]); // The rest of the arguments are the passed command line parameters. // Call the program like this: // $ ./args arg1 arg2 println!("I got {:?} arguments: {:?}.", args.len() - 1, &args[1..]); }
$ ./args 1 2 3
My path is ./args.
I got 3 arguments: ["1", "2", "3"].
Crates
Alternatively, there are numerous crates that can provide extra functionality
when creating command-line applications. The Rust Cookbook exhibits best
practices on how to use one of the more popular command line argument crates,
clap.
Argument parsing
Matching can be used to parse simple arguments:
use std::env; fn increase(number: i32) { println!("{}", number + 1); } fn decrease(number: i32) { println!("{}", number - 1); } fn help() { println!("usage: match_args <string> Check whether given string is the answer. match_args {{increase|decrease}} <integer> Increase or decrease given integer by one."); } fn main() { let args: Vec<String> = env::args().collect(); match args.len() { // no arguments passed 1 => { println!("My name is 'match_args'. Try passing some arguments!"); }, // one argument passed 2 => { match args[1].parse() { Ok(42) => println!("This is the answer!"), _ => println!("This is not the answer."), } }, // one command and one argument passed 3 => { let cmd = &args[1]; let num = &args[2]; // parse the number let number: i32 = match num.parse() { Ok(n) => { n }, Err(_) => { eprintln!("error: second argument not an integer"); help(); return; }, }; // parse the command match &cmd[..] { "increase" => increase(number), "decrease" => decrease(number), _ => { eprintln!("error: invalid command"); help(); }, } }, // all the other cases _ => { // show a help message help(); } } }
$ ./match_args Rust
This is not the answer.
$ ./match_args 42
This is the answer!
$ ./match_args do something
error: second argument not an integer
usage:
match_args <string>
Check whether given string is the answer.
match_args {increase|decrease} <integer>
Increase or decrease given integer by one.
$ ./match_args do 42
error: invalid command
usage:
match_args <string>
Check whether given string is the answer.
match_args {increase|decrease} <integer>
Increase or decrease given integer by one.
$ ./match_args increase 42
43
FFI: Foreign Function Interface
Rust provides a Foreign Function Interface (FFI) to C libraries:
- Foreign functions must be declared inside an
externblock annotated - with a
#[link]attribute containing the name of the foreign library.
FFI Example
use std::fmt;
// this extern block links to the libm library
#[link(name = "m")]
extern {
// this is a foreign function
// that computes the square root of a single precision complex number
fn csqrtf(z: Complex) -> Complex;
fn ccosf(z: Complex) -> Complex;
}
// Since calling foreign functions is considered unsafe,
// it's common to write safe wrappers around them.
fn cos(z: Complex) -> Complex {
unsafe { ccosf(z) }
}
fn main() {
// z = -1 + 0i
let z = Complex { re: -1., im: 0. };
// calling a foreign function is an unsafe operation
let z_sqrt = unsafe { csqrtf(z) };
println!("the square root of {:?} is {:?}", z, z_sqrt);
// calling safe API wrapped around unsafe operation
println!("cos({:?}) = {:?}", z, cos(z));
}
// Minimal implementation of single precision complex numbers
#[repr(C)]
#[derive(Clone, Copy)]
struct Complex {
re: f32,
im: f32,
}
impl fmt::Debug for Complex {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
if self.im < 0. {
write!(f, "{}-{}i", self.re, -self.im)
} else {
write!(f, "{}+{}i", self.re, self.im)
}
}
}
Testing
Rust is a programming language that cares a lot about correctness and it includes support for writing software tests within the language itself.
Testing comes in three styles:
- Unit testing.
- Doc testing.
- Integration testing.
Also Rust has support for specifying additional dependencies for tests:
See Also
- The Book chapter on testing
- API Guidelines on doc-testing
Unit testing for panic: #[cfg(test)], #[test], #[should_panic], #[ignore]
- Tests are Rust functions that verify that the non-test code is functioning in the expected manner.
- The bodies of test functions typically perform some setup, run the code we want to test, then assert whether the results are what we expect.
Unit tests basic
- Most unit tests go into a
testsmod with the#[cfg(test)]attribute. - Test functions are marked with the
#[test]attribute.
Tests fail when something in the test function panics.
There are some helper macros:
assert!(expression)- panics if expression evaluates tofalse.assert_eq!(left, right)andassert_ne!(left, right)- testing left and right expressions for equality and inequality respectively.
Unit tests example
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
// This is a really bad adding function, its purpose is to fail in this
// example.
#[allow(dead_code)]
fn bad_add(a: i32, b: i32) -> i32 {
a - b
}
#[cfg(test)]
mod tests {
// Note this useful idiom: importing names from outer (for mod tests) scope.
use super::*;
#[test]
fn test_add() {
assert_eq!(add(1, 2), 3);
}
#[test]
fn test_bad_add() {
// This assert would fire and test will fail.
// Please note, that private functions can be tested too!
assert_eq!(bad_add(1, 2), 3);
}
}
- Note this useful idiom: importing names from outer (for mod tests) scope.
- This assert would fire and test will fail.
- Please note, that private functions can be tested too!
Tests can be run with cargo test.
$ cargo test
running 2 tests
test tests::test_bad_add ... FAILED
test tests::test_add ... ok
failures:
---- tests::test_bad_add stdout ----
thread 'tests::test_bad_add' panicked at 'assertion failed: `(left == right)`
left: `-1`,
right: `3`', src/lib.rs:21:8
note: Run with `RUST_BACKTRACE=1` for a backtrace.
failures:
tests::test_bad_add
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out
Tests and ?
None of the previous unit test examples had a return type.
But in Rust 2018, your unit tests can return Result<()>, which lets you use ? in them! This can make them much more concise.
fn sqrt(number: f64) -> Result<f64, String> { if number >= 0.0 { Ok(number.powf(0.5)) } else { Err("negative floats don't have square roots".to_owned()) } } #[cfg(test)] mod tests { use super::*; #[test] fn test_sqrt() -> Result<(), String> { let x = 4.0; assert_eq!(sqrt(x)?.powf(2.0), x); Ok(()) } }
- to_owned()
- assert_eq!(sqrt(x)?.powf(2.0), x);
See “The Edition Guide” for more details.
Testing panics: #[should_panic]
To check functions that should panic under certain circumstances, use attribute
#[should_panic]:
- This attribute accepts optional parameter
expected =with the text of the panic message. - If your function can panic in multiple ways, it helps make sure your test is testing the correct panic.
#[should_panic] example
pub fn divide_non_zero_result(a: u32, b: u32) -> u32 {
if b == 0 {
panic!("Divide-by-zero error");
} else if a < b {
panic!("Divide result is zero");
}
a / b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_divide() {
assert_eq!(divide_non_zero_result(10, 2), 5);
}
#[test]
#[should_panic]
fn test_any_panic() {
divide_non_zero_result(1, 0);
}
#[test]
#[should_panic(expected = "Divide result is zero")]
fn test_specific_panic() {
divide_non_zero_result(1, 10);
}
}
Running these tests gives us:
$ cargo test
running 3 tests
test tests::test_any_panic ... ok
test tests::test_divide ... ok
test tests::test_specific_panic ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests tmp-test-should-panic
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Running specific tests
To run specific tests one may specify the test name to cargo test command.
$ cargo test test_any_panic
running 1 test
test tests::test_any_panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out
Doc-tests tmp-test-should-panic
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
To run multiple tests one may specify part of a test name that matches all the tests that should be run.
$ cargo test panic
running 2 tests
test tests::test_any_panic ... ok
test tests::test_specific_panic ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out
Doc-tests tmp-test-should-panic
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Ignoring tests: #[ignore]
Tests can be marked with the #[ignore] attribute to exclude some tests. Or to run them with command cargo test – –ignored
#![allow(unused)] fn main() { pub fn add(a: i32, b: i32) -> i32 { a + b } #[cfg(test)] mod tests { use super::*; #[test] fn test_add() { assert_eq!(add(2, 2), 4); } #[test] fn test_add_hundred() { assert_eq!(add(100, 2), 102); assert_eq!(add(2, 100), 102); } #[test] #[ignore] fn ignored_test() { assert_eq!(add(0, 0), 0); } } }
cargo test
$ cargo test
running 3 tests
test tests::ignored_test ... ignored
test tests::test_add ... ok
test tests::test_add_hundred ... ok
test result: ok. 2 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out
Doc-tests tmp-ignore
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
$ cargo test -- --ignored
running 1 test
test tests::ignored_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests tmp-ignore
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Documentation: cargo doc
Use cargo doc to build documentation in target/doc.
Use cargo test to run all tests (including documentation tests), and cargo test --doc to only run documentation tests.
These commands will appropriately invoke rustdoc (and rustc) as required.
Doc comments
Doc comments are very useful for big projects that require documentation. When
running rustdoc, these are the comments that get compiled into
documentation.
They are denoted by a ///, and support Markdown.
#![crate_name = "doc"]
/// A human being is represented here
pub struct Person {
/// A person must have a name, no matter how much Juliet may hate it
name: String,
}
impl Person {
/// Returns a person with the name given them
///
/// # Arguments
///
/// * `name` - A string slice that holds the name of the person
///
/// # Examples
///
/// ```
/// // You can have rust code between fences inside the comments
/// // If you pass --test to `rustdoc`, it will even test it for you!
/// use doc::Person;
/// let person = Person::new("name");
/// ```
pub fn new(name: &str) -> Person {
Person {
name: name.to_string(),
}
}
/// Gives a friendly hello!
///
/// Says "Hello, [name](Person::name)" to the `Person` it is called on.
pub fn hello(& self) {
println!("Hello, {}!", self.name);
}
}
fn main() {
let john = Person::new("John");
john.hello();
}
To run the tests, first build the code as a library, then tell rustdoc where to find the library so it can link it into each doctest program:
$ rustc doc.rs --crate-type lib
$ rustdoc --test --extern doc="libdoc.rlib" doc.rs
Doc attributes
Below are a few examples of the most common #[doc] attributes used with rustdoc.
inline
Used to inline docs, instead of linking out to separate page.
#[doc(inline)]
pub use bar::Bar;
/// bar docs
mod bar {
/// the docs for Bar
pub struct Bar;
}
no_inline
Used to prevent linking out to separate page or anywhere.
// Example from libcore/prelude
#[doc(no_inline)]
pub use crate::mem::drop;
hidden
Using this tells rustdoc not to include this in documentation:
// Example from the futures-rs library
#[doc(hidden)]
pub use self::async_await::*;
For documentation, rustdoc is widely used by the community. It’s what is used to generate the std library docs.
See also:
- The Rust Book: Making Useful Documentation Comments
- The rustdoc Book
- The Reference: Doc comments
- RFC 1574: API Documentation Conventions
- RFC 1946: Relative links to other items from doc comments (intra-rustdoc links)
- Is there any documentation style guide for comments? (reddit)
Documentation testing
The primary way of documenting a Rust project is through annotating the source code.
Documentation comments are written in CommonMark Markdown specification and support code blocks in them.
Rust takes care about correctness, so these code blocks are compiled and used as documentation tests.
Doc testing example
/// First line is a short summary describing function.
///
/// The next lines present detailed documentation. Code blocks start with
/// triple backquotes and have implicit `fn main()` inside
/// and `extern crate <cratename>`. Assume we're testing `doccomments` crate:
///
/// ```
/// let result = doccomments::add(2, 3);
/// assert_eq!(result, 5);
/// ```
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
/// Usually doc comments may include sections "Examples", "Panics" and "Failures".
///
/// The next function divides two numbers.
///
/// # Examples
///
/// ```
/// let result = doccomments::div(10, 2);
/// assert_eq!(result, 5);
/// ```
///
/// # Panics
///
/// The function panics if the second argument is zero.
///
/// ```rust,should_panic
/// // panics on division by zero
/// doccomments::div(10, 0);
/// ```
pub fn div(a: i32, b: i32) -> i32 {
if b == 0 {
panic!("Divide-by-zero error");
}
a / b
}
- First line is a short summary describing function.
- The next lines present detailed documentation.
- Code blocks start with triple backquotes and have implicit
fn main()inside andextern crate <cratename>. Assume we’re testingdoccommentscrate: - Usually doc comments may include sections “Examples”, “Panics” and “Failures”.
Code blocks in documentation are automatically tested when running the regular cargo test command:
$ cargo test
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests doccomments
running 3 tests
test src/lib.rs - add (line 7) ... ok
test src/lib.rs - div (line 21) ... ok
test src/lib.rs - div (line 31) ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Motivation behind documentation tests
The main purpose of documentation tests is to serve as examples that exercise the functionality, which is one of the most important guidelines:
- It allows using examples from docs as complete code snippets.
- But using
?makes compilation fail sincemainreturnsunit. - The ability to hide some source lines from documentation comes to the rescue: one may write
fn try_main() -> Result<(), ErrorType>, hide it andunwrapit in hiddenmain.
Sounds complicated? Here’s an example:
/// Using hidden `try_main` in doc tests.
///
/// ```
/// # // hidden lines start with `#` symbol, but they're still compilable!
/// # fn try_main() -> Result<(), String> { // line that wraps the body shown in doc
/// let res = doccomments::try_div(10, 2)?;
/// # Ok(()) // returning from try_main
/// # }
/// # fn main() { // starting main that'll unwrap()
/// # try_main().unwrap(); // calling try_main and unwrapping
/// # // so that test will panic in case of error
/// # }
/// ```
pub fn try_div(a: i32, b: i32) -> Result<i32, String> {
if b == 0 {
Err(String::from("Divide-by-zero"))
} else {
Ok(a / b)
}
}
- Using hidden
try_mainin doc tests: hidden lines start with#symbol, but they’re still compilable!
See Also
- RFC505 on documentation style
- API Guidelines on documentation guidelines
Integration testing
- Unit tests are testing one module in isolation at a time: they’re small and can test private code.
- Integration tests are external to your crate and use only its public interface in the same way any other code would.
- Their purpose is to test that many parts of your library work correctly together.
Cargo looks for integration tests in
testsdirectory next tosrc.
File src/lib.rs:
// Define this in a crate called `adder`.
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
File with test: tests/integration_test.rs:
#[test]
fn test_add() {
assert_eq!(adder::add(3, 2), 5);
}
Running tests with cargo test command:
$ cargo test
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Running target/debug/deps/integration_test-bcd60824f5fbfe19
running 1 test
test test_add ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
- Each Rust source file in the
testsdirectory is compiled as a separate crate. - In order to share some code between integration tests we can make a module with public functions, importing and using it within tests.
File tests/common/mod.rs:
pub fn setup() {
// some setup code, like creating required files/directories, starting
// servers, etc.
}
File with test: tests/integration_test.rs
// importing common module.
mod common;
#[test]
fn test_add() {
// using common code.
common::setup();
assert_eq!(adder::add(3, 2), 5);
}
- Creating the module as
tests/common.rsalso works - but is not recommended because the test runner will treat the file as a test crate and try to run tests inside it.
Development dependencies
- Sometimes there is a need to have dependencies for tests (or examples, or benchmarks) only.
- Such dependencies are added to
Cargo.tomlin the[dev-dependencies]section. - These dependencies are not propagated to other packages which depend on this package.
One such example is
pretty_assertions, which extends standardassert_eq!andassert_ne!macros, to provide colorful diff.
File src/lib.rs:
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
#[cfg(test)]
mod tests {
use super::*;
use pretty_assertions::assert_eq; // crate for test-only use. Cannot be used in non-test code.
#[test]
fn test_add() {
assert_eq!(add(2, 3), 5);
}
}
See Also
Cargo docs on specifying dependencies.
Unsafe Operations
As an introduction to this section, to borrow from the official docs:
“one should try to minimize the amount of unsafe code in a code base.”
With that in mind, let’s get started!
- Unsafe annotations in Rust are used to bypass protections put in place by the compiler;
specifically, there are four primary things that unsafe is used for:
- dereferencing raw pointers
- calling functions or methods which are
unsafe(including calling a function over FFI, see a previous chapter of the book) - accessing or modifying static mutable variables
- implementing unsafe traits
Raw Pointers
Raw pointers * and references &T function similarly, but references are
always safe because they are guaranteed to point to valid data due to the
borrow checker.
Dereferencing a raw pointer can only be done through an unsafe block.
fn main() { let raw_p: *const u32 = &10; unsafe { assert!(*raw_p == 10); } }
Calling Unsafe Functions
Some functions can be declared as unsafe, meaning it is the programmer’s responsibility to ensure correctness instead of the compiler’s.
One example of this is [std::slice::from_raw_parts] which will create a slice given a pointer to the first element and a length.
use std::slice; fn main() { let some_vector = vec![1, 2, 3, 4]; let pointer = some_vector.as_ptr(); let length = some_vector.len(); unsafe { let my_slice: &[u32] = slice::from_raw_parts(pointer, length); assert_eq!(some_vector.as_slice(), my_slice); } }
For
slice::from_raw_parts, one of the assumptions which must be upheld is that the pointer passed in points to valid memory and that the memory pointed to is of the correct type.
If these invariants aren’t upheld then the program’s behaviour is undefined and there is no knowing what will happen.
Inline assembly in Unsafe: asm!
Rust provides support for inline assembly via the asm! macro.
It can be used to embed handwritten assembly in the assembly output generated by the compiler.
- Generally this should not be necessary, but might be where the required performance or timing cannot be otherwise achieved.
- Accessing low level hardware primitives, e.g. in kernel code, may also demand this functionality.
Note: the examples here are given in x86/x86-64 assembly, but other architectures are also supported.
Inline assembly is currently supported on the following architectures:
- x86 and x86-64
- ARM
- AArch64
- RISC-V
Basic usage
Let us start with the simplest possible example:
#![allow(unused)] fn main() { use std::arch::asm; unsafe { asm!("nop"); } }
- This will insert a NOP (no operation) instruction into the assembly generated by the compiler.
- Note that all
asm!invocations have to be inside anunsafeblock, as they could insert arbitrary instructions and break various invariants. - The instructions to be inserted are listed in the first argument of the
asm!macro as a string literal.
Inputs and outputs
Now inserting an instruction that does nothing is rather boring.
Let us do something that actually acts on data:
#![allow(unused)] fn main() { use std::arch::asm; let x: u64; unsafe { asm!("mov {}, 5", out(reg) x); } assert_eq!(x, 5); }
- This will write the value
5into theu64variablex. - You can see that the string literal we use to specify instructions is actually a template string.
- It is governed by the same rules as Rust format strings.
- The arguments that are inserted into the template however look a bit different than you may be familiar with:
- First we need to specify if the variable is an input or an output of the inline assembly.
- In this case it is an output.
- We declared this by writing
out.
- We also need to specify in what kind of register the assembly expects the variable.
- In this case we put it in an arbitrary general purpose register by specifying
reg. - The compiler will choose an appropriate register to insert into the template and will read the variable from there after the inline assembly finishes executing.
Let us see another example that also uses an input:
#![allow(unused)] fn main() { use std::arch::asm; let i: u64 = 3; let o: u64; unsafe { asm!( "mov {0}, {1}", "add {0}, 5", out(reg) o, in(reg) i, ); } assert_eq!(o, 8); }
- This will add
5to the input in variableiand write the result to variableo. - The particular way this assembly does this is first copying the value from
ito the output, and then adding5to it.
The example shows a few things:
- First, we can see that
asm!allows multiple template string arguments;
- each one is treated as a separate line of assembly code, as if they were all joined together with newlines between them.
- This makes it easy to format assembly code.
-
Second, we can see that inputs are declared by writing
ininstead ofout. -
Third, we can see that we can specify an argument number, or name as in any format string.
- For inline assembly templates this is particularly useful as arguments are often used more than once.
- For more complex inline assembly using this facility is generally recommended, as it improves readability, and allows reordering instructions without changing the argument order.
We can further refine the above example to avoid the mov instruction:
#![allow(unused)] fn main() { use std::arch::asm; let mut x: u64 = 3; unsafe { asm!("add {0}, 5", inout(reg) x); } assert_eq!(x, 8); }
- We can see that
inoutis used to specify an argument that is both input and output. - This is different from specifying an input and output separately in that it is guaranteed to assign both to the same register.
It is also possible to specify different variables for the input and output parts of an inout operand:
#![allow(unused)] fn main() { use std::arch::asm; let x: u64 = 3; let y: u64; unsafe { asm!("add {0}, 5", inout(reg) x => y); } assert_eq!(y, 8); }
Late output operands
The Rust compiler is conservative with its allocation of operands. It is assumed that an out
can be written at any time, and can therefore not share its location with any other argument.
However, to guarantee optimal performance it is important to use as few registers as possible, so they won’t have to be saved and reloaded around the inline assembly block.
To achieve this Rust provides a lateout specifier.
- This can be used on any output that is written only after all inputs have been consumed.
- There is also a
inlateoutvariant of this specifier.
Here is an example where inlateout cannot be used in release mode or other optimized cases:
#![allow(unused)] fn main() { use std::arch::asm; let mut a: u64 = 4; let b: u64 = 4; let c: u64 = 4; unsafe { asm!( "add {0}, {1}", "add {0}, {2}", inout(reg) a, in(reg) b, in(reg) c, ); } assert_eq!(a, 12); }
- The above could work well in unoptimized cases (
Debugmode) - but if you want optimized performance (
releasemode or other optimized cases), it could not work. - That is because in optimized cases, the compiler is free to allocate the same register for inputs
bandcsince it knows they have the same value. - However it must allocate a separate register for
asince it usesinoutand notinlateout. - If
inlateoutwas used, thenaandccould be allocated to the same register, in which case the first instruction to overwrite the value ofcand cause the assembly code to produce the wrong result.
However the following example can use inlateout since the output is only modified after all input registers have been read:
#![allow(unused)] fn main() { use std::arch::asm; let mut a: u64 = 4; let b: u64 = 4; unsafe { asm!("add {0}, {1}", inlateout(reg) a, in(reg) b); } assert_eq!(a, 8); }
As you can see, this assembly fragment will still work correctly if a and b are assigned to the same register.
Explicit register operands
Some instructions require that the operands be in a specific register. Therefore, Rust inline assembly provides some more specific constraint specifiers.
- While
regis generally available on any architecture, explicit registers are highly architecture specific. - E.g. for x86 the general purpose registers
eax,ebx,ecx,edx,ebp,esi, andediamong others can be addressed by their name.
eax example
#![allow(unused)] fn main() { use std::arch::asm; let cmd = 0xd1; unsafe { asm!("out 0x64, eax", in("eax") cmd); } }
- In this example we call the
outinstruction to output the content of thecmdvariable to port0x64. - Since the
outinstruction only acceptseax(and its sub registers) as operand we had to use theeaxconstraint specifier.
Note: unlike other operand types, explicit register operands cannot be used in the template string: you can’t use
{}and should write the register name directly instead. Also, they must appear at the end of the operand list after all other operand types.
Consider this example which uses the x86 mul instruction:
#![allow(unused)] fn main() { use std::arch::asm; fn mul(a: u64, b: u64) -> u128 { let lo: u64; let hi: u64; unsafe { asm!( // The x86 mul instruction takes rax as an implicit input and writes // the 128-bit result of the multiplication to rax:rdx. "mul {}", in(reg) a, inlateout("rax") b => lo, lateout("rdx") hi ); } ((hi as u128) << 64) + lo as u128 } }
- This uses the
mulinstruction to multiply two 64-bit inputs with a 128-bit result. - The only explicit operand is a register, that we fill from the variable
a. - The second operand is implicit, and must be the
raxregister, which we fill from the variableb. - The lower 64 bits of the result are stored in
raxfrom which we fill the variablelo. - The higher 64 bits are stored in
rdxfrom which we fill the variablehi.
Clobbered registers
- In many cases inline assembly will modify state that is not needed as an output.
Usually this is either because we have to use a scratch register in the assembly or because instructions modify state that we don’t need to further examine.
This state is generally referred to as being “clobbered”.
We need to tell the compiler about this since it may need to save and restore this state around the inline assembly block.
use std::arch::asm; fn main() { // three entries of four bytes each let mut name_buf = [0_u8; 12]; // String is stored as ascii in ebx, edx, ecx in order // Because ebx is reserved, the asm needs to preserve the value of it. // So we push and pop it around the main asm. // (in 64 bit mode for 64 bit processors, 32 bit processors would use ebx) unsafe { asm!( "push rbx", "cpuid", "mov [rdi], ebx", "mov [rdi + 4], edx", "mov [rdi + 8], ecx", "pop rbx", // We use a pointer to an array for storing the values to simplify // the Rust code at the cost of a couple more asm instructions // This is more explicit with how the asm works however, as opposed // to explicit register outputs such as `out("ecx") val` // The *pointer itself* is only an input even though it's written behind in("rdi") name_buf.as_mut_ptr(), // select cpuid 0, also specify eax as clobbered inout("eax") 0 => _, // cpuid clobbers these registers too out("ecx") _, out("edx") _, ); } let name = core::str::from_utf8(&name_buf).unwrap(); println!("CPU Manufacturer ID: {}", name); }
- In the example above we use the
cpuidinstruction to read the CPU manufacturer ID. - This instruction writes to
eaxwith the maximum supportedcpuidargument andebx,edx, andecxwith the CPU manufacturer ID as ASCII bytes in that order.
Even though eax is never read we still need to tell the compiler that the register has been modified so that the compiler can save any values that were in these registers before the asm. This is done by declaring it as an output but with _ instead of a variable name, which indicates that the
output value is to be discarded.
This code also works around the limitation that ebx is a reserved register by LLVM. That means that LLVM assumes that it has full control over the register and it must be restored to its original state before exiting the asm block, so it cannot be used as an input or output except if the
compiler uses it to fulfill a general register class (e.g. in(reg)). This makes reg operands dangerous when using reserved registers as we could unknowingly corrupt out input or output because they share the same register.
To work around this we use rdi to store the pointer to the output array, save ebx via push, read from ebx inside the asm block into the array and then restoring ebx to its original state via pop. The push and pop use the full 64-bit rbx version of the register to ensure that the
entire register is saved. On 32 bit targets the code would instead use ebx in the push/pop.
This can also be used with a general register class to obtain a scratch register for use inside the asm code:
#![allow(unused)] fn main() { use std::arch::asm; // Multiply x by 6 using shifts and adds let mut x: u64 = 4; unsafe { asm!( "mov {tmp}, {x}", "shl {tmp}, 1", "shl {x}, 2", "add {x}, {tmp}", x = inout(reg) x, tmp = out(reg) _, ); } assert_eq!(x, 4 * 6); }
Symbol operands and ABI clobbers
By default, asm! assumes that any register not specified as an output will have its contents preserved by the assembly code.
The
clobber_abiargument toasm!tells the compiler to automatically insert the necessary clobber operands according to the given calling convention ABI:
- any register which is not fully preserved in that ABI will be treated as clobbered.
- Multiple
clobber_abiarguments may be provided and all clobbers from all specified ABIs will be inserted.
Clobber API Example
#![allow(unused)] fn main() { use std::arch::asm; extern "C" fn foo(arg: i32) -> i32 { println!("arg = {}", arg); arg * 2 } fn call_foo(arg: i32) -> i32 { unsafe { let result; asm!( "call {}", // Function pointer to call in(reg) foo, // 1st argument in rdi in("rdi") arg, // Return value in rax out("rax") result, // Mark all registers which are not preserved by the "C" calling // convention as clobbered. clobber_abi("C"), ); result } } }
Register template modifiers
In some cases, fine control is needed over the way a register name is formatted when inserted into the template string.
This is needed when an architecture’s assembly language has several names for the same register, each typically being a “view” over a subset of the register (e.g. the low 32 bits of a 64-bit register).
By default the compiler will always choose the name that refers to the full register size (e.g. rax on x86-64, eax on x86, etc).
This default can be overridden by using modifiers on the template string operands, just like you would with format strings:
#![allow(unused)] fn main() { use std::arch::asm; let mut x: u16 = 0xab; unsafe { asm!("mov {0:h}, {0:l}", inout(reg_abcd) x); } assert_eq!(x, 0xabab); }
In this example, we use the reg_abcd register class to restrict the register allocator to the 4 legacy x86 registers (ax, bx, cx, dx) of which the first two bytes can be addressed independently.
Let us assume that the register allocator has chosen to allocate x in the ax register.
The h modifier will emit the register name for the high byte of that register and the l modifier will emit the register name for the low byte. The asm code will therefore be expanded as mov ah, al which copies the low byte of the value into the high byte.
If you use a smaller data type (e.g. u16) with an operand and forget to use template modifiers, the compiler will emit a warning and suggest the correct modifier to use.
Memory address operands
Sometimes assembly instructions require operands passed via memory addresses/memory locations.
You have to manually use the memory address syntax specified by the target architecture.
For example, on x86/x86_64 using Intel assembly syntax, you should wrap inputs/outputs in [] to indicate they are memory operands:
#![allow(unused)] fn main() { use std::arch::asm; fn load_fpu_control_word(control: u16) { unsafe { asm!("fldcw [{}]", in(reg) &control, options(nostack)); } } }
Labels
Any reuse of a named label, local or otherwise, can result in an assembler or linker error or may cause other strange behavior.
Reuse of a named label can happen in a variety of ways including:
- explicitly:
using a label more than once in one
asm!block, or multiple times across blocks. - implicitly via inlining:
the compiler is allowed to instantiate multiple copies of an
asm!block, for example when the function containing it is inlined in multiple places. - implicitly via LTO: LTO can cause code from other crates to be placed in the same codegen unit, and so could bring in arbitrary labels.
As a consequence, you should only use GNU assembler numeric local labels inside inline assembly code. Defining symbols in assembly code may lead to assembler and/or linker errors due to duplicate symbol definitions.
Moreover, on x86 when using the default Intel syntax, due to an LLVM bug, you shouldn’t use labels exclusively made of 0 and 1 digits, e.g. 0, 11 or 101010, as they may end up being interpreted as binary values.
Using options(att_syntax) will avoid any ambiguity, but that affects the syntax of the entire asm! block. (See Options, below, for more on options.)
Example of reusing of a named label
#![allow(unused)] fn main() { use std::arch::asm; let mut a = 0; unsafe { asm!( "mov {0}, 10", "2:", "sub {0}, 1", "cmp {0}, 3", "jle 2f", "jmp 2b", "2:", "add {0}, 2", out(reg) a ); } assert_eq!(a, 5); }
This will decrement the {0} register value from 10 to 3, then add 2 and store it in a.
This example shows a few things:
- First, that the same number can be used as a label multiple times in the same inline block.
- Second, that when a numeric label is used as a reference (as an instruction operand, for example), the suffixes “b” (“backward”) or ”f” (“forward”) should be added to the numeric label. It will then refer to the nearest label defined by this number in this direction.
Options
By default, an inline assembly block is treated the same way as an external FFI function call with a custom calling convention:
it may read/write memory, have observable side effects, etc.
However, in many cases it is desirable to give the compiler more information about what the assembly code is actually doing so that it can optimize better.
Let’s take our previous example of an add instruction:
#![allow(unused)] fn main() { use std::arch::asm; let mut a: u64 = 4; let b: u64 = 4; unsafe { asm!( "add {0}, {1}", inlateout(reg) a, in(reg) b, options(pure, nomem, nostack), ); } assert_eq!(a, 8); }
Options can be provided as an optional final argument to the asm! macro.
We specified three options here:
puremeans that the asm code has no observable side effects and that its output depends only on its inputs. This allows the compiler optimizer to call the inline asm fewer times or even eliminate it entirely.nomemmeans that the asm code does not read or write to memory. By default the compiler will assume that inline assembly can read or write any memory address that is accessible to it (e.g. through a pointer passed as an operand, or a global).nostackmeans that the asm code does not push any data onto the stack. This allows the compiler to use optimizations such as the stack red zone on x86-64 to avoid stack pointer adjustments.
These allow the compiler to better optimize code using asm!, for example by eliminating pure asm! blocks whose outputs are not needed.
See the reference for the full list of available options and their effects.
Compatibility
The Rust language is fastly evolving, and because of this certain compatibility issues can arise, despite efforts to ensure forwards-compatibility wherever possible.
Raw identifiers: r#
Rust, like many programming languages, has the concept of “keywords”. These identifiers mean something to the language, and so you cannot use them in places like variable names, function names, and other places.
Raw identifiers let you use keywords where they would not normally be allowed.
- This is particularly useful when Rust introduces new keywords, and a library using an older edition of Rust has a variable or function with the same name as a keyword introduced in a newer edition.
For example, consider a crate foo compiled with the 2015 edition of Rust that
exports a function named try.
This keyword is reserved for a new feature in the 2018 edition, so without raw identifiers, we would have no way to name the function.
extern crate foo;
fn main() {
foo::try();
}
You’ll get this error:
error: expected identifier, found keyword `try`
--> src/main.rs:4:4
|
4 | foo::try();
| ^^^ expected identifier, found keyword
Meta
Some topics aren’t exactly relevant to how you program but provide you tooling or infrastructure support which just makes things better for everyone.
These topics include:
- Documentation: Generate library documentation for users via the included
rustdoc. - Playground: Integrate the Rust Playground in your documentation.
Playground
The Rust Playground is a way to experiment with Rust code through a web interface.
Using it with mdbook
In mdbook, you can make code examples playable and editable.
fn main() { println!("Hello World!"); }
This allows the reader to both run your code sample, but also modify and tweak it. The key here is the adding the word editable to your codefence block separated by a comma.
```rust,editable
//...place your code here
```
Additionally, you can add ignore if you want mdbook to skip your code when it builds and tests.
```rust,editable,ignore
//...place your code here
```
Using it with docs
You may have noticed in some of the official Rust docs a button that says “Run”, which opens the code sample up in a new tab in Rust Playground. This feature is enabled if you use the #[doc] attribute called html_playground_url.
See also:
The PyO3 user guide
Welcome to the PyO3 user guide! This book is a companion to PyO3’s API docs. It contains examples and documentation to explain all of PyO3’s use cases in detail.
Please choose from the chapters on the left to jump to individual topics, or continue below to start with PyO3’s README.
PyO3
![]()
![]()
![]()

![]()

Rust bindings for Python, including tools for creating native Python extension modules. Running and interacting with Python code from a Rust binary is also supported.
Usage
PyO3 supports the following software versions:
- Python 3.7 and up (CPython and PyPy)
- Rust 1.48 and up
You can use PyO3 to write a native Python module in Rust, or to embed Python in a Rust binary. The following sections explain each of these in turn.
Using Rust from Python
PyO3 can be used to generate a native Python module. The easiest way to try this out for the first time is to use maturin. maturin is a tool for building and publishing Rust-based Python packages with minimal configuration. The following steps install maturin, use it to generate and build a new Python package, and then launch Python to import and execute a function from the package.
First, follow the commands below to create a new directory containing a new Python virtualenv, and install maturin into the virtualenv using Python's package manager, pip:
# (replace string_sum with the desired package name)
$ mkdir string_sum
$ cd string_sum
$ python -m venv .env
$ source .env/bin/activate
$ pip install maturin
Still inside this string_sum directory, now run maturin init. This will generate the new package source. When given the choice of bindings to use, select pyo3 bindings:
$ maturin init
✔ 🤷 What kind of bindings to use? · pyo3
✨ Done! New project created string_sum
The most important files generated by this command are Cargo.toml and lib.rs, which will look roughly like the following:
Cargo.toml
[package]
name = "string_sum"
version = "0.1.0"
edition = "2018"
[lib]
# The name of the native library. This is the name which will be used in Python to import the
# library (i.e. `import string_sum`). If you change this, you must also change the name of the
# `#[pymodule]` in `src/lib.rs`.
name = "string_sum"
# "cdylib" is necessary to produce a shared library for Python to import from.
#
# Downstream Rust code (including code in `bin/`, `examples/`, and `tests/`) will not be able
# to `use string_sum;` unless the "rlib" or "lib" crate type is also included, e.g.:
# crate-type = ["cdylib", "rlib"]
crate-type = ["cdylib"]
[dependencies]
pyo3 = { version = "0.17.3", features = ["extension-module"] }
src/lib.rs
#![allow(unused)] fn main() { use pyo3::prelude::*; /// Formats the sum of two numbers as string. #[pyfunction] fn sum_as_string(a: usize, b: usize) -> PyResult<String> { Ok((a + b).to_string()) } /// A Python module implemented in Rust. The name of this function must match /// the `lib.name` setting in the `Cargo.toml`, else Python will not be able to /// import the module. #[pymodule] fn string_sum(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(sum_as_string, m)?)?; Ok(()) } }
Finally, run maturin develop. This will build the package and install it into the Python virtualenv previously created and activated. The package is then ready to be used from python:
$ maturin develop
# lots of progress output as maturin runs the compilation...
$ python
>>> import string_sum
>>> string_sum.sum_as_string(5, 20)
'25'
To make changes to the package, just edit the Rust source code and then re-run maturin develop to recompile.
To run this all as a single copy-and-paste, use the bash script below (replace string_sum in the first command with the desired package name):
mkdir string_sum && cd "$_"
python -m venv .env
source .env/bin/activate
pip install maturin
maturin init --bindings pyo3
maturin develop
If you want to be able to run cargo test or use this project in a Cargo workspace and are running into linker issues, there are some workarounds in the FAQ.
As well as with maturin, it is possible to build using setuptools-rust or manually. Both offer more flexibility than maturin but require more configuration to get started.
Using Python from Rust
To embed Python into a Rust binary, you need to ensure that your Python installation contains a shared library. The following steps demonstrate how to ensure this (for Ubuntu), and then give some example code which runs an embedded Python interpreter.
To install the Python shared library on Ubuntu:
sudo apt install python3-dev
Start a new project with cargo new and add pyo3 to the Cargo.toml like this:
[dependencies.pyo3]
version = "0.17.3"
features = ["auto-initialize"]
Example program displaying the value of sys.version and the current user name:
use pyo3::prelude::*; use pyo3::types::IntoPyDict; fn main() -> PyResult<()> { Python::with_gil(|py| { let sys = py.import("sys")?; let version: String = sys.getattr("version")?.extract()?; let locals = [("os", py.import("os")?)].into_py_dict(py); let code = "os.getenv('USER') or os.getenv('USERNAME') or 'Unknown'"; let user: String = py.eval(code, None, Some(&locals))?.extract()?; println!("Hello {}, I'm Python {}", user, version); Ok(()) }) }
The guide has a section with lots of examples about this topic.
Tools and libraries
- maturin Build and publish crates with pyo3, rust-cpython or cffi bindings as well as rust binaries as python packages
- setuptools-rust Setuptools plugin for Rust support.
- pyo3-built Simple macro to expose metadata obtained with the
builtcrate as aPyDict - rust-numpy Rust binding of NumPy C-API
- dict-derive Derive FromPyObject to automatically transform Python dicts into Rust structs
- pyo3-log Bridge from Rust to Python logging
- pythonize Serde serializer for converting Rust objects to JSON-compatible Python objects
- pyo3-asyncio Utilities for working with Python's Asyncio library and async functions
- rustimport Directly import Rust files or crates from Python, without manual compilation step. Provides pyo3 integration by default and generates pyo3 binding code automatically.
Examples
- hyperjson A hyper-fast Python module for reading/writing JSON data using Rust's serde-json
- html-py-ever Using html5ever through kuchiki to speed up html parsing and css-selecting.
- point-process High level API for pointprocesses as a Python library
- autopy A simple, cross-platform GUI automation library for Python and Rust.
- Contains an example of building wheels on TravisCI and appveyor using cibuildwheel
- orjson Fast Python JSON library
- inline-python Inline Python code directly in your Rust code
- Rogue-Gym Customizable rogue-like game for AI experiments
- Contains an example of building wheels on Azure Pipelines
- fastuuid Python bindings to Rust's UUID library
- wasmer-python Python library to run WebAssembly binaries
- mocpy Astronomical Python library offering data structures for describing any arbitrary coverage regions on the unit sphere
- tokenizers Python bindings to the Hugging Face tokenizers (NLP) written in Rust
- pyre Fast Python HTTP server written in Rust
- jsonschema-rs Fast JSON Schema validation library
- css-inline CSS inlining for Python implemented in Rust
- cryptography Python cryptography library with some functionality in Rust
- polaroid Hyper Fast and safe image manipulation library for Python written in Rust
- ormsgpack Fast Python msgpack library
- bed-reader Read and write the PLINK BED format, simply and efficiently
- Shows Rayon/ndarray::parallel (including capturing errors, controlling thread num), Python types to Rust generics, Github Actions
- pyheck Fast case conversion library, built by wrapping heck
- Quite easy to follow as there's not much code.
- polars Fast multi-threaded DataFrame library in Rust | Python | Node.js
- rust-python-coverage Example PyO3 project with automated test coverage for Rust and Python
- forust A lightweight gradient boosted decision tree library written in Rust.
- ril-py A performant and high-level image processing library for Python written in Rust
- fastbloom A fast bloom filter | counting bloom filter implemented by Rust for Rust and Python!
- river Online machine learning in python, the computationally heavy statistics algorithms are implemented in Rust
- feos Lightning fast thermodynamic modeling in Rust with fully developed Python interface
Articles and other media
- Nine Rules for Writing Python Extensions in Rust - Dec 31, 2021
- Calling Rust from Python using PyO3 - Nov 18, 2021
- davidhewitt's 2021 talk at Rust Manchester meetup - Aug 19, 2021
- Incrementally porting a small Python project to Rust - Apr 29, 2021
- Vortexa - Integrating Rust into Python - Apr 12, 2021
- Writing and publishing a Python module in Rust - Aug 2, 2020
Contributing
Everyone is welcomed to contribute to PyO3! There are many ways to support the project, such as:
- help PyO3 users with issues on GitHub and Gitter
- improve documentation
- write features and bugfixes
- publish blogs and examples of how to use PyO3
Our contributing notes and architecture guide have more resources if you wish to volunteer time for PyO3 and are searching where to start.
If you don't have time to contribute yourself but still wish to support the project's future success, some of our maintainers have GitHub sponsorship pages:
License
PyO3 is licensed under the Apache-2.0 license. Python is licensed under the Python License.

Installation
To get started using PyO3 you will need three things: a rust toolchain, a python environment, and a way to build. We’ll cover each of these below.
Rust
First, make sure you have rust installed on your system. If you haven’t already done so you can do so by following the instructions here. PyO3 runs on both the stable and nightly versions so you can choose whichever one fits you best. The minimum required rust version is Rust 1.48.
if you can run rustc --version and the version is high enough you’re good to go!
Python
To use PyO3 you need at least Python 3.7. While you can simply use the default Python version on your system, it is recommended to use a virtual environment.
Virtualenvs
While you can use any virtualenv manager you like, we recommend the use of pyenv especially if you want to develop or test for multiple different python versions, so that is what the examples in this book will use. The installation instructions for pyenv can be found here.
Note that when using pyenv you should also set the following environment variable
PYTHON_CONFIGURE_OPTS="--enable-shared"
Building
There are a number of build and python package management systems such as setuptools-rust or manually we recommend the use of maturin which you can install here. It is developed to work with PyO3 and is the most “batteries included” experience. maturin is just a python package so you can add it in any way that you install python packages.
System Python:
pip install maturin --user
pipx:
pipx install maturin
pyenv:
pyenv activate pyo3
pip install maturin
poetry:
poetry add -D maturin
after installation, you can run maturin --version to check that you have correctly installed it.
Starting a new project
Firstly you should create the folder and virtual environment that are going to contain your new project. Here we will use the recommended pyenv:
mkdir pyo3-example
cd pyo3-example
pyenv virtualenv pyo3
pyenv local pyo3
after this, you should install your build manager. In this example, we will use maturin. After you’ve activated your virtualenv add maturin to it:
pip install maturin
After this, you can initialise the new project
maturin init
If maturin is already installed you can create a new project using that directly as well:
maturin new -b pyo3 pyo3-example
cd pyo3-example
pyenv virtualenv pyo3
pyenv local pyo3
Adding to an existing project
Sadly currently maturin cannot be run in existing projects, so if you want to use python in an existing project you basically have two options:
- create a new project as above and move your existing code into that project
- Manually edit your project configuration as necessary.
If you are opting for the second option, here are the things you need to pay attention to:
Cargo.toml
Make sure that the rust you want to be able to access from Python is compiled into a library. You can have a binary output as well, but the code you want to access from python has to be in the library. Also, make sure that the crate type is cdylib and add PyO3 as a dependency as so:
# If you already have [package] information in `Cargo.toml`, you can ignore
# this section!
[package]
# `name` here is name of the package.
name = "pyo3_start"
# these are good defaults:
version = "0.1.0"
edition = "2021"
[lib]
# The name of the native library. This is the name which will be used in Python to import the
# library (i.e. `import string_sum`). If you change this, you must also change the name of the
# `#[pymodule]` in `src/lib.rs`.
name = "pyo3_example"
# "cdylib" is necessary to produce a shared library for Python to import from.
crate-type = ["cdylib"]
[dependencies]
pyo3 = { {{#PYO3_CRATE_VERSION}}, features = ["extension-module"] }
pyproject.toml
You should also create a pyproject.toml with the following contents:
[build-system]
requires = ["maturin>=0.13,<0.14"]
build-backend = "maturin"
[project]
name = "pyo3_example"
requires-python = ">=3.7"
classifiers = [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy",
]
Running code
After this you can setup rust code to be available in python as below; for example, you can place this code in src/lib.rs:
#![allow(unused)] fn main() { use pyo3::prelude::*; /// Formats the sum of two numbers as string. #[pyfunction] fn sum_as_string(a: usize, b: usize) -> PyResult<String> { Ok((a + b).to_string()) } /// A Python module implemented in Rust. The name of this function must match /// the `lib.name` setting in the `Cargo.toml`, else Python will not be able to /// import the module. #[pymodule] fn pyo3_example(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(sum_as_string, m)?)?; Ok(()) } }
After this you can run maturin develop to prepare the python package after which you can use it like so:
$ maturin develop
# lots of progress output as maturin runs the compilation...
$ python
>>> import pyo3_example
>>> pyo3_example.sum_as_string(5, 20)
'25'
For more instructions on how to use python code from rust see the Python from Rust page.
Python modules
You can create a module using #[pymodule]:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] fn double(x: usize) -> usize { x * 2 } /// This module is implemented in Rust. #[pymodule] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(double, m)?)?; Ok(()) } }
The #[pymodule] procedural macro takes care of exporting the initialization function of your
module to Python.
The module’s name defaults to the name of the Rust function. You can override the module name by
using #[pyo3(name = "custom_name")]:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] fn double(x: usize) -> usize { x * 2 } #[pymodule] #[pyo3(name = "custom_name")] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(double, m)?)?; Ok(()) } }
The name of the module must match the name of the .so or .pyd
file. Otherwise, you will get an import error in Python with the following message:
ImportError: dynamic module does not define module export function (PyInit_name_of_your_module)
To import the module, either:
- copy the shared library as described in Manual builds, or
- use a tool, e.g.
maturin developwith maturin orpython setup.py developwith setuptools-rust.
Documentation
The Rust doc comments of the module initialization function will be applied automatically as the Python docstring of your module.
For example, building off of the above code, this will print This module is implemented in Rust.:
import my_extension
print(my_extension.__doc__)
Python submodules
You can create a module hierarchy within a single extension module by using
PyModule.add_submodule().
For example, you could define the modules parent_module and parent_module.child_module.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pymodule] fn parent_module(py: Python<'_>, m: &PyModule) -> PyResult<()> { register_child_module(py, m)?; Ok(()) } fn register_child_module(py: Python<'_>, parent_module: &PyModule) -> PyResult<()> { let child_module = PyModule::new(py, "child_module")?; child_module.add_function(wrap_pyfunction!(func, child_module)?)?; parent_module.add_submodule(child_module)?; Ok(()) } #[pyfunction] fn func() -> String { "func".to_string() } Python::with_gil(|py| { use pyo3::wrap_pymodule; use pyo3::types::IntoPyDict; let parent_module = wrap_pymodule!(parent_module)(py); let ctx = [("parent_module", parent_module)].into_py_dict(py); py.run("assert parent_module.child_module.func() == 'func'", None, Some(&ctx)).unwrap(); }) }
Note that this does not define a package, so this won’t allow Python code to directly import
submodules by using from parent_module import child_module. For more information, see
#759 and
#1517.
It is not necessary to add #[pymodule] on nested modules, which is only required on the top-level module.
Python functions
The #[pyfunction] attribute is used to define a Python function from a Rust function. Once defined, the function needs to be added to a module using the wrap_pyfunction! macro.
The following example defines a function called double in a Python module called my_extension:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] fn double(x: usize) -> usize { x * 2 } #[pymodule] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(double, m)?)?; Ok(()) } }
This chapter of the guide explains full usage of the #[pyfunction] attribute. In this first section, the following topics are covered:
There are also additional sections on the following topics:
Function options
The #[pyo3] attribute can be used to modify properties of the generated Python function. It can take any combination of the following options:
-
Overrides the name exposed to Python.
In the following example, the Rust function
no_args_pywill be added to the Python modulemodule_with_functionsas the Python functionno_args:#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] #[pyo3(name = "no_args")] fn no_args_py() -> usize { 42 } #[pymodule] fn module_with_functions(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(no_args_py, m)?)?; Ok(()) } Python::with_gil(|py| { let m = pyo3::wrap_pymodule!(module_with_functions)(py); assert!(m.getattr(py, "no_args").is_ok()); assert!(m.getattr(py, "no_args_py").is_err()); }); } -
Defines the function signature in Python. See Function Signatures.
-
#[pyo3(text_signature = "...")]Sets the function signature visible in Python tooling (such as via
inspect.signature).The example below creates a function
addwhich has a signature describing two positional-only argumentsaandb.use pyo3::prelude::*; /// This function adds two unsigned 64-bit integers. #[pyfunction] #[pyo3(text_signature = "(a, b, /)")] fn add(a: u64, b: u64) -> u64 { a + b } fn main() -> PyResult<()> { Python::with_gil(|py| { let fun = pyo3::wrap_pyfunction!(add, py)?; let doc: String = fun.getattr("__doc__")?.extract()?; assert_eq!(doc, "This function adds two unsigned 64-bit integers."); let inspect = PyModule::import(py, "inspect")?.getattr("signature")?; let sig: String = inspect .call1((fun,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(a, b, /)"); Ok(()) }) } -
Set this option to make PyO3 pass the containing module as the first argument to the function. It is then possible to use the module in the function body. The first argument must be of type
&PyModule.The following example creates a function
pyfunction_with_modulewhich returns the containing module’s name (i.e.module_with_fn):#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] #[pyo3(pass_module)] fn pyfunction_with_module(module: &PyModule) -> PyResult<&str> { module.name() } #[pymodule] fn module_with_fn(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(pyfunction_with_module, m)?) } }
Per-argument options
The #[pyo3] attribute can be used on individual arguments to modify properties of them in the generated function. It can take any combination of the following options:
-
Set this on an option to specify a custom function to convert the function argument from Python to the desired Rust type, instead of using the default
FromPyObjectextraction. The function signature must befn(&PyAny) -> PyResult<T>whereTis the Rust type of the argument.The following example uses
from_py_withto convert the input Python object to its length:#![allow(unused)] fn main() { use pyo3::prelude::*; fn get_length(obj: &PyAny) -> PyResult<usize> { let length = obj.len()?; Ok(length) } #[pyfunction] fn object_length( #[pyo3(from_py_with = "get_length")] argument: usize ) -> usize { argument } Python::with_gil(|py| { let f = pyo3::wrap_pyfunction!(object_length)(py).unwrap(); assert_eq!(f.call1((vec![1, 2, 3],)).unwrap().extract::<usize>().unwrap(), 3); }); }
Advanced function patterns
Making the function signature available to Python (old method)
Alternatively, simply make sure the first line of your docstring is
formatted like in the following example. Please note that the newline after the
-- is mandatory. The / signifies the end of positional-only arguments.
#[pyo3(text_signature)] should be preferred, since it will override automatically
generated signatures when those are added in a future version of PyO3.
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; /// add(a, b, /) /// -- /// /// This function adds two unsigned 64-bit integers. #[pyfunction] fn add(a: u64, b: u64) -> u64 { a + b } // a function with a signature but without docs. Both blank lines after the `--` are mandatory. /// sub(a, b, /) /// -- /// /// #[pyfunction] fn sub(a: u64, b: u64) -> u64 { a - b } }
When annotated like this, signatures are also correctly displayed in IPython.
>>> pyo3_test.add?
Signature: pyo3_test.add(a, b, /)
Docstring: This function adds two unsigned 64-bit integers.
Type: builtin_function_or_method
Calling Python functions in Rust
You can pass Python def’d functions and built-in functions to Rust functions PyFunction
corresponds to regular Python functions while PyCFunction describes built-ins such as
repr().
You can also use PyAny::is_callable to check if you have a callable object. is_callable will
return true for functions (including lambdas), methods and objects with a __call__ method.
You can call the object with PyAny::call with the args as first parameter and the kwargs
(or None) as second parameter. There are also PyAny::call0 with no args and PyAny::call1
with only positional args.
Calling Rust functions in Python
The ways to convert a Rust function into a Python object vary depending on the function:
- Named functions, e.g.
fn foo(): add#[pyfunction]and then usewrap_pyfunction!to get the correspondingPyCFunction. - Anonymous functions (or closures), e.g.
foo: fn()either:- use a
#[pyclass]struct which stores the function as a field and implement__call__to call the stored function. - use
PyFunction::new_closureto create an object directly from the function.
- use a
Accessing the FFI functions
In order to make Rust functions callable from Python, PyO3 generates an extern "C"
function whose exact signature depends on the Rust signature. (PyO3 chooses the optimal
Python argument passing convention.) It then embeds the call to the Rust function inside this
FFI-wrapper function. This wrapper handles extraction of the regular arguments and the keyword
arguments from the input PyObjects.
The wrap_pyfunction macro can be used to directly get a PyCFunction given a
#[pyfunction] and a PyModule: wrap_pyfunction!(rust_fun, module).
#[pyfn] shorthand
There is a shorthand to #[pyfunction] and wrap_pymodule!: the function can be placed inside the module definition and
annotated with #[pyfn]. To simplify PyO3, it is expected that #[pyfn] may be removed in a future release (See #694).
An example of #[pyfn] is below:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pymodule] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { #[pyfn(m)] fn double(x: usize) -> usize { x * 2 } Ok(()) } }
#[pyfn(m)] is just syntactic sugar for #[pyfunction], and takes all the same options
documented in the rest of this chapter. The code above is expanded to the following:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pymodule] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { #[pyfunction] fn double(x: usize) -> usize { x * 2 } m.add_function(wrap_pyfunction!(double, m)?)?; Ok(()) } }
Function signatures
The #[pyfunction] attribute also accepts parameters to control how the generated Python function accepts arguments. Just like in Python, arguments can be positional-only, keyword-only, or accept either. *args lists and **kwargs dicts can also be accepted. These parameters also work for #[pymethods] which will be introduced in the Python Classes section of the guide.
Like Python, by default PyO3 accepts all arguments as either positional or keyword arguments. There are two ways to modify this behaviour:
- The
#[pyo3(signature = (...))]option which allows writing a signature in Python syntax. - Extra arguments directly to
#[pyfunction]. (See deprecated form)
Using #[pyo3(signature = (...))]
For example, below is a function that accepts arbitrary keyword arguments (**kwargs in Python syntax) and returns the number that was passed:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyDict; #[pyfunction] #[pyo3(signature = (**kwds))] fn num_kwds(kwds: Option<&PyDict>) -> usize { kwds.map_or(0, |dict| dict.len()) } #[pymodule] fn module_with_functions(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(num_kwds, m)?).unwrap(); Ok(()) } }
Just like in Python, the following constructs can be part of the signature::
/: positional-only arguments separator, each parameter defined before/is a positional-only parameter.*: var arguments separator, each parameter defined after*is a keyword-only parameter.*args: “args” is var args. Type of theargsparameter has to be&PyTuple.**kwargs: “kwargs” receives keyword arguments. The type of thekwargsparameter has to beOption<&PyDict>.arg=Value: arguments with default value. If theargargument is defined after var arguments, it is treated as a keyword-only argument. Note thatValuehas to be valid rust code, PyO3 just inserts it into the generated code unmodified.
Example:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::{PyDict, PyTuple}; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[new] #[pyo3(signature = (num=-1))] fn new(num: i32) -> Self { MyClass { num } } #[pyo3(signature = (num=10, *py_args, name="Hello", **py_kwargs))] fn method( &mut self, num: i32, py_args: &PyTuple, name: &str, py_kwargs: Option<&PyDict>, ) -> String { let num_before = self.num; self.num = num; format!( "num={} (was previously={}), py_args={:?}, name={}, py_kwargs={:?} ", num, num_before, py_args, name, py_kwargs, ) } fn make_change(&mut self, num: i32) -> PyResult<String> { self.num = num; Ok(format!("num={}", self.num)) } } }
N.B. the position of the / and * arguments (if included) control the system of handling positional and keyword arguments. In Python:
import mymodule
mc = mymodule.MyClass()
print(mc.method(44, False, "World", 666, x=44, y=55))
print(mc.method(num=-1, name="World"))
print(mc.make_change(44, False))
Produces output:
py_args=('World', 666), py_kwargs=Some({'x': 44, 'y': 55}), name=Hello, num=44
py_args=(), py_kwargs=None, name=World, num=-1
num=44
num=-1
Note: for keywords like
struct, to use it as a function argument, use “raw ident” syntaxr#structin both the signature and the function definition:#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; #[pyfunction(signature = (r#struct = "foo"))] fn function_with_keyword(r#struct: &str) { let _ = r#struct; /* ... */ } }
Deprecated form
The #[pyfunction] macro can take the argument specification directly, but this method is deprecated in PyO3 0.18 because the #[pyo3(signature)] option offers a simpler syntax and better validation.
The #[pymethods] macro has an #[args] attribute which accepts the deprecated form.
Below are the same examples as above which using the deprecated syntax:
#![allow(unused)] fn main() { #![allow(deprecated)] use pyo3::prelude::*; use pyo3::types::PyDict; #[pyfunction(kwds="**")] fn num_kwds(kwds: Option<&PyDict>) -> usize { kwds.map_or(0, |dict| dict.len()) } #[pymodule] fn module_with_functions(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(num_kwds, m)?).unwrap(); Ok(()) } }
The following parameters can be passed to the #[pyfunction] attribute:
"/": positional-only arguments separator, each parameter defined before"/"is a positional-only parameter. Corresponds to python’sdef meth(arg1, arg2, ..., /, argN..)."*": var arguments separator, each parameter defined after"*"is a keyword-only parameter. Corresponds to python’sdef meth(*, arg1.., arg2=..).args="*": “args” is var args, corresponds to Python’sdef meth(*args). Type of theargsparameter has to be&PyTuple.kwargs="**": “kwargs” receives keyword arguments, corresponds to Python’sdef meth(**kwargs). The type of thekwargsparameter has to beOption<&PyDict>.arg="Value": arguments with default value. Corresponds to Python’sdef meth(arg=Value). If theargargument is defined after var arguments, it is treated as a keyword-only argument. Note thatValuehas to be valid rust code, PyO3 just inserts it into the generated code unmodified.
Example:
#![allow(unused)] fn main() { #![allow(deprecated)] use pyo3::prelude::*; use pyo3::types::{PyDict, PyTuple}; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[new] #[args(num = "-1")] fn new(num: i32) -> Self { MyClass { num } } #[args( num = "10", py_args = "*", name = "\"Hello\"", py_kwargs = "**" )] fn method( &mut self, num: i32, py_args: &PyTuple, name: &str, py_kwargs: Option<&PyDict>, ) -> String { let num_before = self.num; self.num = num; format!( "num={} (was previously={}), py_args={:?}, name={}, py_kwargs={:?} ", num, num_before, py_args, name, py_kwargs, ) } fn make_change(&mut self, num: i32) -> PyResult<String> { self.num = num; Ok(format!("num={}", self.num)) } } }
Error handling
This chapter contains a little background of error handling in Rust and how PyO3 integrates this with Python exceptions.
This covers enough detail to create a #[pyfunction] which raises Python exceptions from errors originating in Rust.
There is a later section of the guide on Python exceptions which covers exception types in more detail.
Representing Python exceptions
Rust code uses the generic Result<T, E> enum to propagate errors. The error type E is chosen by the code author to describe the possible errors which can happen.
PyO3 has the PyErr type which represents a Python exception. If a PyO3 API could result in a Python exception being raised, the return type of that API will be PyResult<T>, which is an alias for the type Result<T, PyErr>.
In summary:
- When Python exceptions are raised and caught by PyO3, the exception will stored in the
Errvariant of thePyResult. - Passing Python exceptions through Rust code then uses all the “normal” techniques such as the
?operator, withPyErras the error type. - Finally, when a
PyResultcrosses from Rust back to Python via PyO3, if the result is anErrvariant the contained exception will be raised.
(There are many great tutorials on Rust error handling and the ? operator, so this guide will not go into detail on Rust-specific topics.)
Raising an exception from a function
As indicated in the previous section, when a PyResult containing an Err crosses from Rust to Python, PyO3 will raise the exception contained within.
Accordingly, to raise an exception from a #[pyfunction], change the return type T to PyResult<T>. When the function returns an Err it will raise a Python exception. (Other Result<T, E> types can be used as long as the error E has a From conversion for PyErr, see implementing a conversion below.)
This also works for functions in #[pymethods].
For example, the following check_positive function raises a ValueError when the input is negative:
use pyo3::exceptions::PyValueError; use pyo3::prelude::*; #[pyfunction] fn check_positive(x: i32) -> PyResult<()> { if x < 0 { Err(PyValueError::new_err("x is negative")) } else { Ok(()) } } fn main(){ Python::with_gil(|py|{ let fun = pyo3::wrap_pyfunction!(check_positive, py).unwrap(); fun.call1((-1,)).unwrap_err(); fun.call1((1,)).unwrap(); }); }
All built-in Python exception types are defined in the pyo3::exceptions module. They have a new_err constructor to directly build a PyErr, as seen in the example above.
Custom Rust error types
PyO3 will automatically convert a Result<T, E> returned by a #[pyfunction] into a PyResult<T> as long as there is an implementation of std::from::From<E> for PyErr. Many error types in the Rust standard library have a From conversion defined in this way.
If the type E you are handling is defined in a third-party crate, see the section on foreign rust error types below for ways to work with this error.
The following example makes use of the implementation of From<ParseIntError> for PyErr to raise exceptions encountered when parsing strings as integers:
use pyo3::prelude::*; use std::num::ParseIntError; #[pyfunction] fn parse_int(x: &str) -> Result<usize, ParseIntError> { x.parse() } fn main() { Python::with_gil(|py| { let fun = pyo3::wrap_pyfunction!(parse_int, py).unwrap(); let value: usize = fun.call1(("5",)).unwrap().extract().unwrap(); assert_eq!(value, 5); }); }
When passed a string which doesn’t contain a floating-point number, the exception raised will look like the below:
>>> parse_int("bar")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid digit found in string
As a more complete example, the following snippet defines a Rust error named CustomIOError. It then defines a From<CustomIOError> for PyErr, which returns a PyErr representing Python’s OSError. Finally, it
use pyo3::exceptions::PyOSError; use pyo3::prelude::*; use std::fmt; #[derive(Debug)] struct CustomIOError; impl std::error::Error for CustomIOError {} impl fmt::Display for CustomIOError { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "Oh no!") } } impl std::convert::From<CustomIOError> for PyErr { fn from(err: CustomIOError) -> PyErr { PyOSError::new_err(err.to_string()) } } pub struct Connection { /* ... */} fn bind(addr: String) -> Result<Connection, CustomIOError> { if &addr == "0.0.0.0"{ Err(CustomIOError) } else { Ok(Connection{ /* ... */}) } } #[pyfunction] fn connect(s: String) -> Result<(), CustomIOError> { bind(s)?; Ok(()) } fn main() { Python::with_gil(|py| { let fun = pyo3::wrap_pyfunction!(connect, py).unwrap(); let err = fun.call1(("0.0.0.0",)).unwrap_err(); assert!(err.is_instance_of::<PyOSError>(py)); }); }
If lazy construction of the Python exception instance is desired, the
PyErrArguments
trait can be implemented instead of From. In that case, actual exception argument creation is delayed
until the PyErr is needed.
A final note is that any errors E which have a From conversion can be used with the ?
(“try”) operator with them. An alternative implementation of the above parse_int which instead returns PyResult is below:
use pyo3::prelude::*; fn parse_int(s: String) -> PyResult<usize> { let x = s.parse()?; Ok(x) } use pyo3::exceptions::PyValueError; fn main() { Python::with_gil(|py| { assert_eq!(parse_int(String::from("1")).unwrap(), 1); assert_eq!(parse_int(String::from("1337")).unwrap(), 1337); assert!(parse_int(String::from("-1")) .unwrap_err() .is_instance_of::<PyValueError>(py)); assert!(parse_int(String::from("foo")) .unwrap_err() .is_instance_of::<PyValueError>(py)); assert!(parse_int(String::from("13.37")) .unwrap_err() .is_instance_of::<PyValueError>(py)); }) }
Foreign Rust error types
The Rust compiler will not permit implementation of traits for types outside of the crate where the type is defined. (This is known as the “orphan rule”.)
Given a type OtherError which is defined in third-party code, there are two main strategies available to integrate it with PyO3:
- Create a newtype wrapper, e.g.
MyOtherError. Then implementFrom<MyOtherError> for PyErr(orPyErrArguments), as well asFrom<OtherError>forMyOtherError. - Use Rust’s Result combinators such as
map_errto write code freely to convertOtherErrorinto whatever is needed. This requires boilerplate at every usage however gives unlimited flexibility.
To detail the newtype strategy a little further, the key trick is to return Result<T, MyOtherError> from the #[pyfunction]. This means that PyO3 will make use of From<MyOtherError> for PyErr to create Python exceptions while the #[pyfunction] implementation can use ? to convert OtherError to MyOtherError automatically.
The following example demonstrates this for some imaginary third-party crate some_crate with a function get_x returning Result<i32, OtherError>:
mod some_crate { pub struct OtherError(()); impl OtherError { pub fn message(&self) -> &'static str { "some error occurred" } } pub fn get_x() -> Result<i32, OtherError> { Ok(5) } } use pyo3::prelude::*; use pyo3::exceptions::PyValueError; use some_crate::{OtherError, get_x}; struct MyOtherError(OtherError); impl From<MyOtherError> for PyErr { fn from(error: MyOtherError) -> Self { PyValueError::new_err(error.0.message()) } } impl From<OtherError> for MyOtherError { fn from(other: OtherError) -> Self { Self(other) } } #[pyfunction] fn wrapped_get_x() -> Result<i32, MyOtherError> { // get_x is a function returning Result<i32, OtherError> let x: i32 = get_x()?; Ok(x) } fn main() { Python::with_gil(|py| { let fun = pyo3::wrap_pyfunction!(wrapped_get_x, py).unwrap(); let value: usize = fun.call0().unwrap().extract().unwrap(); assert_eq!(value, 5); }); }
Python classes
PyO3 exposes a group of attributes powered by Rust’s proc macro system for defining Python classes as Rust structs.
The main attribute is #[pyclass], which is placed upon a Rust struct or a fieldless enum (a.k.a. C-like enum) to generate a Python type for it. They will usually also have one #[pymethods]-annotated impl block for the struct, which is used to define Python methods and constants for the generated Python type. (If the multiple-pymethods feature is enabled each #[pyclass] is allowed to have multiple #[pymethods] blocks.) #[pymethods] may also have implementations for Python magic methods such as __str__.
This chapter will discuss the functionality and configuration these attributes offer. Below is a list of links to the relevant section of this chapter for each:
Defining a new class
To define a custom Python class, add the #[pyclass] attribute to a Rust struct or a fieldless enum.
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; #[pyclass] struct Integer{ inner: i32 } // A "tuple" struct #[pyclass] struct Number(i32); // PyO3 supports custom discriminants in enums #[pyclass] enum HttpResponse { Ok = 200, NotFound = 404, Teapot = 418, // ... } #[pyclass] enum MyEnum { Variant, OtherVariant = 30, // PyO3 supports custom discriminants. } }
The above example generates implementations for PyTypeInfo and PyClass for MyClass and MyEnum. To see these generated implementations, refer to the implementation details at the end of this chapter.
Restrictions
To integrate Rust types with Python, PyO3 needs to place some restrictions on the types which can be annotated with #[pyclass]. In particular, they must have no lifetime parameters, no generic parameters, and must implement Send. The reason for each of these is explained below.
No lifetime parameters
Rust lifetimes are used by the Rust compiler to reason about a program’s memory safety. They are a compile-time only concept; there is no way to access Rust lifetimes at runtime from a dynamic language like Python.
As soon as Rust data is exposed to Python, there is no guarantee which the Rust compiler can make on how long the data will live. Python is a reference-counted language and those references can be held for an arbitrarily long time which is untraceable by the Rust compiler. The only possible way to express this correctly is to require that any #[pyclass] does not borrow data for any lifetime shorter than the 'static lifetime, i.e. the #[pyclass] cannot have any lifetime parameters.
When you need to share ownership of data between Python and Rust, instead of using borrowed references with lifetimes consider using reference-counted smart pointers such as Arc or Py.
No generic parameters
A Rust struct Foo<T> with a generic parameter T generates new compiled implementations each time it is used with a different concrete type for T. These new implementations are generated by the compiler at each usage site. This is incompatible with wrapping Foo in Python, where there needs to be a single compiled implementation of Foo which is integrated with the Python interpreter.
Must be send
Because Python objects are freely shared between threads by the Python interpreter, there is no guarantee which thread will eventually drop the object. Therefore all types annotated with #[pyclass] must implement Send (unless annotated with #[pyclass(unsendable)]).
Constructor
By default it is not possible to create an instance of a custom class from Python code.
To declare a constructor, you need to define a method and annotate it with the #[new]
attribute. Only Python’s __new__ method can be specified, __init__ is not available.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { #[new] fn new(value: i32) -> Self { Number(value) } } }
Alternatively, if your new method may fail you can return PyResult<Self>.
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::exceptions::PyValueError; #[pyclass] struct Nonzero(i32); #[pymethods] impl Nonzero { #[new] fn py_new(value: i32) -> PyResult<Self> { if value == 0 { Err(PyValueError::new_err("cannot be zero")) } else { Ok(Nonzero(value)) } } } }
As you can see, the Rust method name is not important here; this way you can
still use new() for a Rust-level constructor.
If no method marked with #[new] is declared, object instances can only be
created from Rust, but not from Python.
For arguments, see the Method arguments section below.
Adding the class to a module
The next step is to create the module initializer and add our class to it
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<Number>()?; Ok(()) } }
PyCell and interior mutability
You sometimes need to convert your pyclass into a Python object and access it
from Rust code (e.g., for testing it).
PyCell is the primary interface for that.
PyCell<T: PyClass> is always allocated in the Python heap, so Rust doesn’t have ownership of it.
In other words, Rust code can only extract a &PyCell<T>, not a PyCell<T>.
Thus, to mutate data behind &PyCell safely, PyO3 employs the
Interior Mutability Pattern
like RefCell.
Users who are familiar with RefCell can use PyCell just like RefCell.
For users who are not very familiar with RefCell, here is a reminder of Rust’s rules of borrowing:
- At any given time, you can have either (but not both of) one mutable reference or any number of immutable references.
- References must always be valid.
PyCell, like RefCell, ensures these borrowing rules by tracking references at runtime.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { #[pyo3(get)] num: i32, } Python::with_gil(|py| { let obj = PyCell::new(py, MyClass { num: 3}).unwrap(); { let obj_ref = obj.borrow(); // Get PyRef assert_eq!(obj_ref.num, 3); // You cannot get PyRefMut unless all PyRefs are dropped assert!(obj.try_borrow_mut().is_err()); } { let mut obj_mut = obj.borrow_mut(); // Get PyRefMut obj_mut.num = 5; // You cannot get any other refs until the PyRefMut is dropped assert!(obj.try_borrow().is_err()); assert!(obj.try_borrow_mut().is_err()); } // You can convert `&PyCell` to a Python object pyo3::py_run!(py, obj, "assert obj.num == 5"); }); }
&PyCell<T> is bounded by the same lifetime as a GILGuard.
To make the object longer lived (for example, to store it in a struct on the
Rust side), you can use Py<T>, which stores an object longer than the GIL
lifetime, and therefore needs a Python<'_> token to access.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } fn return_myclass() -> Py<MyClass> { Python::with_gil(|py| Py::new(py, MyClass { num: 1 }).unwrap()) } let obj = return_myclass(); Python::with_gil(|py|{ let cell = obj.as_ref(py); // Py<MyClass>::as_ref returns &PyCell<MyClass> let obj_ref = cell.borrow(); // Get PyRef<T> assert_eq!(obj_ref.num, 1); }); }
Customizing the class
#[pyclass] can be used with the following parameters:
| Parameter | Description |
|---|---|
crate = "some::path" | Path to import the pyo3 crate, if it's not accessible at ::pyo3. |
dict | Gives instances of this class an empty __dict__ to store custom attributes. |
extends = BaseType | Use a custom baseclass. Defaults to PyAny |
freelist = N | Implements a free list of size N. This can improve performance for types that are often created and deleted in quick succession. Profile your code to see whether freelist is right for you. |
frozen | Declares that your pyclass is immutable. It removes the borrowchecker overhead when retrieving a shared reference to the Rust struct, but disables the ability to get a mutable reference. |
get_all | Generates getters for all fields of the pyclass. |
mapping | Inform PyO3 that this class is a Mapping, and so leave its implementation of sequence C-API slots empty. |
module = "module_name" | Python code will see the class as being defined in this module. Defaults to builtins. |
name = "python_name" | Sets the name that Python sees this class as. Defaults to the name of the Rust struct. |
sequence | Inform PyO3 that this class is a Sequence, and so leave its C-API mapping length slot empty. |
set_all | Generates setters for all fields of the pyclass. |
subclass | Allows other Python classes and #[pyclass] to inherit from this class. Enums cannot be subclassed. |
text_signature = "(arg1, arg2, ...)" | Sets the text signature for the Python class' __new__ method. |
unsendable | Required if your struct is not Send. Rather than using unsendable, consider implementing your struct in a threadsafe way by e.g. substituting Rc with Arc. By using unsendable, your class will panic when accessed by another thread. |
weakref | Allows this class to be weakly referenceable. |
All of these parameters can either be passed directly on the #[pyclass(...)] annotation, or as one or
more accompanying #[pyo3(...)] annotations, e.g.:
// Argument supplied directly to the `#[pyclass]` annotation.
#[pyclass(name = "SomeName", subclass)]
struct MyClass { }
// Argument supplied as a separate annotation.
#[pyclass]
#[pyo3(name = "SomeName", subclass)]
struct MyClass { }
These parameters are covered in various sections of this guide.
Return type
Generally, #[new] method have to return T: Into<PyClassInitializer<Self>> or
PyResult<T> where T: Into<PyClassInitializer<Self>>.
For constructors that may fail, you should wrap the return type in a PyResult as well. Consult the table below to determine which type your constructor should return:
| Cannot fail | May fail | |
|---|---|---|
| No inheritance | T | PyResult<T> |
| Inheritance(T Inherits U) | (T, U) | PyResult<(T, U)> |
| Inheritance(General Case) | PyClassInitializer<T> | PyResult<PyClassInitializer<T>> |
Inheritance
By default, PyAny is used as the base class. To override this default,
use the extends parameter for pyclass with the full path to the base class.
For convenience, (T, U) implements Into<PyClassInitializer<T>> where U is the
baseclass of T.
But for more deeply nested inheritance, you have to return PyClassInitializer<T>
explicitly.
To get a parent class from a child, use PyRef instead of &self for methods,
or PyRefMut instead of &mut self.
Then you can access a parent class by self_.as_ref() as &Self::BaseClass,
or by self_.into_super() as PyRef<Self::BaseClass>.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass(subclass)] struct BaseClass { val1: usize, } #[pymethods] impl BaseClass { #[new] fn new() -> Self { BaseClass { val1: 10 } } pub fn method(&self) -> PyResult<usize> { Ok(self.val1) } } #[pyclass(extends=BaseClass, subclass)] struct SubClass { val2: usize, } #[pymethods] impl SubClass { #[new] fn new() -> (Self, BaseClass) { (SubClass { val2: 15 }, BaseClass::new()) } fn method2(self_: PyRef<'_, Self>) -> PyResult<usize> { let super_ = self_.as_ref(); // Get &BaseClass super_.method().map(|x| x * self_.val2) } } #[pyclass(extends=SubClass)] struct SubSubClass { val3: usize, } #[pymethods] impl SubSubClass { #[new] fn new() -> PyClassInitializer<Self> { PyClassInitializer::from(SubClass::new()) .add_subclass(SubSubClass{val3: 20}) } fn method3(self_: PyRef<'_, Self>) -> PyResult<usize> { let v = self_.val3; let super_ = self_.into_super(); // Get PyRef<'_, SubClass> SubClass::method2(super_).map(|x| x * v) } } Python::with_gil(|py| { let subsub = pyo3::PyCell::new(py, SubSubClass::new()).unwrap(); pyo3::py_run!(py, subsub, "assert subsub.method3() == 3000") }); }
You can also inherit native types such as PyDict, if they implement
PySizedLayout. However, this is not supported when building for the Python limited API (aka the abi3 feature of PyO3).
However, because of some technical problems, we don’t currently provide safe upcasting methods for types that inherit native types. Even in such cases, you can unsafely get a base class by raw pointer conversion.
#![allow(unused)] fn main() { #[cfg(not(Py_LIMITED_API))] { use pyo3::prelude::*; use pyo3::types::PyDict; use pyo3::AsPyPointer; use std::collections::HashMap; #[pyclass(extends=PyDict)] #[derive(Default)] struct DictWithCounter { counter: HashMap<String, usize>, } #[pymethods] impl DictWithCounter { #[new] fn new() -> Self { Self::default() } fn set(mut self_: PyRefMut<'_, Self>, key: String, value: &PyAny) -> PyResult<()> { self_.counter.entry(key.clone()).or_insert(0); let py = self_.py(); let dict: &PyDict = unsafe { py.from_borrowed_ptr_or_err(self_.as_ptr())? }; dict.set_item(key, value) } } Python::with_gil(|py| { let cnt = pyo3::PyCell::new(py, DictWithCounter::new()).unwrap(); pyo3::py_run!(py, cnt, "cnt.set('abc', 10); assert cnt['abc'] == 10") }); } }
If SubClass does not provide a baseclass initialization, the compilation fails.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct BaseClass { val1: usize, } #[pyclass(extends=BaseClass)] struct SubClass { val2: usize, } #[pymethods] impl SubClass { #[new] fn new() -> Self { SubClass { val2: 15 } } } }
Object properties
PyO3 supports two ways to add properties to your #[pyclass]:
- For simple struct fields with no side effects, a
#[pyo3(get, set)]attribute can be added directly to the field definition in the#[pyclass]. - For properties which require computation you can define
#[getter]and#[setter]functions in the#[pymethods]block.
We’ll cover each of these in the following sections.
Object properties using #[pyo3(get, set)]
For simple cases where a member variable is just read and written with no side effects, you can declare getters and setters in your #[pyclass] field definition using the pyo3 attribute, like in the example below:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { #[pyo3(get, set)] num: i32 } }
The above would make the num field available for reading and writing as a self.num Python property. To expose the property with a different name to the field, specify this alongside the rest of the options, e.g. #[pyo3(get, set, name = "custom_name")].
Properties can be readonly or writeonly by using just #[pyo3(get)] or #[pyo3(set)] respectively.
To use these annotations, your field type must implement some conversion traits:
- For
getthe field type must implement bothIntoPy<PyObject>andClone. - For
setthe field type must implementFromPyObject.
Object properties using #[getter] and #[setter]
For cases which don’t satisfy the #[pyo3(get, set)] trait requirements, or need side effects, descriptor methods can be defined in a #[pymethods] impl block.
This is done using the #[getter] and #[setter] attributes, like in the example below:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[getter] fn num(&self) -> PyResult<i32> { Ok(self.num) } } }
A getter or setter’s function name is used as the property name by default. There are several ways how to override the name.
If a function name starts with get_ or set_ for getter or setter respectively,
the descriptor name becomes the function name with this prefix removed. This is also useful in case of
Rust keywords like type
(raw identifiers
can be used since Rust 2018).
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[getter] fn get_num(&self) -> PyResult<i32> { Ok(self.num) } #[setter] fn set_num(&mut self, value: i32) -> PyResult<()> { self.num = value; Ok(()) } } }
In this case, a property num is defined and available from Python code as self.num.
Both the #[getter] and #[setter] attributes accept one parameter.
If this parameter is specified, it is used as the property name, i.e.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[getter(number)] fn num(&self) -> PyResult<i32> { Ok(self.num) } #[setter(number)] fn set_num(&mut self, value: i32) -> PyResult<()> { self.num = value; Ok(()) } } }
In this case, the property number is defined and available from Python code as self.number.
Attributes defined by #[setter] or #[pyo3(set)] will always raise AttributeError on del
operations. Support for defining custom del behavior is tracked in
#1778.
Instance methods
To define a Python compatible method, an impl block for your struct has to be annotated with the
#[pymethods] attribute. PyO3 generates Python compatible wrappers for all functions in this
block with some variations, like descriptors, class method static methods, etc.
Since Rust allows any number of impl blocks, you can easily split methods
between those accessible to Python (and Rust) and those accessible only to Rust. However to have multiple
#[pymethods]-annotated impl blocks for the same struct you must enable the multiple-pymethods feature of PyO3.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { fn method1(&self) -> PyResult<i32> { Ok(10) } fn set_method(&mut self, value: i32) -> PyResult<()> { self.num = value; Ok(()) } } }
Calls to these methods are protected by the GIL, so both &self and &mut self can be used.
The return type must be PyResult<T> or T for some T that implements IntoPy<PyObject>;
the latter is allowed if the method cannot raise Python exceptions.
A Python parameter can be specified as part of method signature, in this case the py argument
gets injected by the method wrapper, e.g.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { #[allow(dead_code)] num: i32, } #[pymethods] impl MyClass { fn method2(&self, py: Python<'_>) -> PyResult<i32> { Ok(10) } } }
From the Python perspective, the method2 in this example does not accept any arguments.
Class methods
To create a class method for a custom class, the method needs to be annotated
with the #[classmethod] attribute.
This is the equivalent of the Python decorator @classmethod.
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyType; #[pyclass] struct MyClass { #[allow(dead_code)] num: i32, } #[pymethods] impl MyClass { #[classmethod] fn cls_method(cls: &PyType) -> PyResult<i32> { Ok(10) } } }
Declares a class method callable from Python.
- The first parameter is the type object of the class on which the method is called. This may be the type object of a derived class.
- The first parameter implicitly has type
&PyType. - For details on
parameter-list, see the documentation ofMethod argumentssection. - The return type must be
PyResult<T>orTfor someTthat implementsIntoPy<PyObject>.
Static methods
To create a static method for a custom class, the method needs to be annotated with the
#[staticmethod] attribute. The return type must be T or PyResult<T> for some T that implements
IntoPy<PyObject>.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { #[allow(dead_code)] num: i32, } #[pymethods] impl MyClass { #[staticmethod] fn static_method(param1: i32, param2: &str) -> PyResult<i32> { Ok(10) } } }
Class attributes
To create a class attribute (also called class variable), a method without
any arguments can be annotated with the #[classattr] attribute.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass {} #[pymethods] impl MyClass { #[classattr] fn my_attribute() -> String { "hello".to_string() } } Python::with_gil(|py| { let my_class = py.get_type::<MyClass>(); pyo3::py_run!(py, my_class, "assert my_class.my_attribute == 'hello'") }); }
Note: if the method has a
Resultreturn type and returns anErr, PyO3 will panic during class creation.
If the class attribute is defined with const code only, one can also annotate associated
constants:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass {} #[pymethods] impl MyClass { #[classattr] const MY_CONST_ATTRIBUTE: &'static str = "foobar"; } }
Method arguments
Similar to #[pyfunction], the #[pyo3(signature = (...))] attribute can be used to specify the way that #[pymethods] accept arguments. Consult the documentation for function signatures to see the parameters this attribute accepts.
The following example defines a class MyClass with a method method. This method has a signature which sets default values for num and name, and indicates that py_args should collect all extra positional arguments and py_kwargs all extra keyword arguments:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::{PyDict, PyTuple}; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[new] #[pyo3(signature = (num=-1))] fn new(num: i32) -> Self { MyClass { num } } #[pyo3(signature = (num=10, *py_args, name="Hello", **py_kwargs))] fn method( &mut self, num: i32, py_args: &PyTuple, name: &str, py_kwargs: Option<&PyDict>, ) -> String { let num_before = self.num; self.num = num; format!( "num={} (was previously={}), py_args={:?}, name={}, py_kwargs={:?} ", num, num_before, py_args, name, py_kwargs, ) } } }
In Python this might be used like:
>>> import mymodule
>>> mc = mymodule.MyClass()
>>> print(mc.method(44, False, "World", 666, x=44, y=55))
py_args=('World', 666), py_kwargs=Some({'x': 44, 'y': 55}), name=Hello, num=44, num_before=-1
>>> print(mc.method(num=-1, name="World"))
py_args=(), py_kwargs=None, name=World, num=-1, num_before=44
Making class method signatures available to Python
The text_signature = "..." option for #[pyfunction] also works for classes and methods:
#![allow(dead_code)] use pyo3::prelude::*; use pyo3::types::PyType; // it works even if the item is not documented: #[pyclass(text_signature = "(c, d, /)")] struct MyClass {} #[pymethods] impl MyClass { // the signature for the constructor is attached // to the struct definition instead. #[new] fn new(c: i32, d: &str) -> Self { Self {} } // the self argument should be written $self #[pyo3(text_signature = "($self, e, f)")] fn my_method(&self, e: i32, f: i32) -> i32 { e + f } #[classmethod] #[pyo3(text_signature = "(cls, e, f)")] fn my_class_method(cls: &PyType, e: i32, f: i32) -> i32 { e + f } #[staticmethod] #[pyo3(text_signature = "(e, f)")] fn my_static_method(e: i32, f: i32) -> i32 { e + f } } fn main() -> PyResult<()> { Python::with_gil(|py| { let inspect = PyModule::import(py, "inspect")?.getattr("signature")?; let module = PyModule::new(py, "my_module")?; module.add_class::<MyClass>()?; let class = module.getattr("MyClass")?; if cfg!(not(Py_LIMITED_API)) || py.version_info() >= (3, 10) { let doc: String = class.getattr("__doc__")?.extract()?; assert_eq!(doc, ""); let sig: String = inspect .call1((class,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(c, d, /)"); } else { let doc: String = class.getattr("__doc__")?.extract()?; assert_eq!(doc, ""); inspect.call1((class,)).expect_err("`text_signature` on classes is not compatible with compilation in `abi3` mode until Python 3.10 or greater"); } { let method = class.getattr("my_method")?; assert!(method.getattr("__doc__")?.is_none()); let sig: String = inspect .call1((method,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(self, /, e, f)"); } { let method = class.getattr("my_class_method")?; assert!(method.getattr("__doc__")?.is_none()); let sig: String = inspect .call1((method,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(cls, e, f)"); } { let method = class.getattr("my_static_method")?; assert!(method.getattr("__doc__")?.is_none()); let sig: String = inspect .call1((method,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(e, f)"); } Ok(()) }) }
Note that text_signature on classes is not compatible with compilation in
abi3 mode until Python 3.10 or greater.
#[pyclass] enums
Currently PyO3 only supports fieldless enums. PyO3 adds a class attribute for each variant, so you can access them in Python without defining #[new]. PyO3 also provides default implementations of __richcmp__ and __int__, so they can be compared using ==:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] enum MyEnum { Variant, OtherVariant, } Python::with_gil(|py| { let x = Py::new(py, MyEnum::Variant).unwrap(); let y = Py::new(py, MyEnum::OtherVariant).unwrap(); let cls = py.get_type::<MyEnum>(); pyo3::py_run!(py, x y cls, r#" assert x == cls.Variant assert y == cls.OtherVariant assert x != y "#) }) }
You can also convert your enums into int:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] enum MyEnum { Variant, OtherVariant = 10, } Python::with_gil(|py| { let cls = py.get_type::<MyEnum>(); let x = MyEnum::Variant as i32; // The exact value is assigned by the compiler. pyo3::py_run!(py, cls x, r#" assert int(cls.Variant) == x assert int(cls.OtherVariant) == 10 assert cls.OtherVariant == 10 # You can also compare against int. assert 10 == cls.OtherVariant "#) }) }
PyO3 also provides __repr__ for enums:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] enum MyEnum{ Variant, OtherVariant, } Python::with_gil(|py| { let cls = py.get_type::<MyEnum>(); let x = Py::new(py, MyEnum::Variant).unwrap(); pyo3::py_run!(py, cls x, r#" assert repr(x) == 'MyEnum.Variant' assert repr(cls.OtherVariant) == 'MyEnum.OtherVariant' "#) }) }
All methods defined by PyO3 can be overridden. For example here’s how you override __repr__:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] enum MyEnum { Answer = 42, } #[pymethods] impl MyEnum { fn __repr__(&self) -> &'static str { "42" } } Python::with_gil(|py| { let cls = py.get_type::<MyEnum>(); pyo3::py_run!(py, cls, "assert repr(cls.Answer) == '42'") }) }
Enums and their variants can also be renamed using #[pyo3(name)].
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass(name = "RenamedEnum")] enum MyEnum { #[pyo3(name = "UPPERCASE")] Variant, } Python::with_gil(|py| { let x = Py::new(py, MyEnum::Variant).unwrap(); let cls = py.get_type::<MyEnum>(); pyo3::py_run!(py, x cls, r#" assert repr(x) == 'RenamedEnum.UPPERCASE' assert x == cls.UPPERCASE "#) }) }
You may not use enums as a base class or let enums inherit from other classes.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass(subclass)] enum BadBase{ Var1, } }
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass(subclass)] struct Base; #[pyclass(extends=Base)] enum BadSubclass{ Var1, } }
#[pyclass] enums are currently not interoperable with IntEnum in Python.
Implementation details
The #[pyclass] macros rely on a lot of conditional code generation: each #[pyclass] can optionally have a #[pymethods] block.
To support this flexibility the #[pyclass] macro expands to a blob of boilerplate code which sets up the structure for “dtolnay specialization”. This implementation pattern enables the Rust compiler to use #[pymethods] implementations when they are present, and fall back to default (empty) definitions when they are not.
This simple technique works for the case when there is zero or one implementations. To support multiple #[pymethods] for a #[pyclass] (in the multiple-pymethods feature), a registry mechanism provided by the inventory crate is used instead. This collects impls at library load time, but isn’t supported on all platforms. See inventory: how it works for more details.
The #[pyclass] macro expands to roughly the code seen below. The PyClassImplCollector is the type used internally by PyO3 for dtolnay specialization:
#![allow(unused)] fn main() { #[cfg(not(feature = "multiple-pymethods"))] { use pyo3::prelude::*; // Note: the implementation differs slightly with the `multiple-pymethods` feature enabled. struct MyClass { #[allow(dead_code)] num: i32, } unsafe impl pyo3::type_object::PyTypeInfo for MyClass { type AsRefTarget = pyo3::PyCell<Self>; const NAME: &'static str = "MyClass"; const MODULE: ::std::option::Option<&'static str> = ::std::option::Option::None; #[inline] fn type_object_raw(py: pyo3::Python<'_>) -> *mut pyo3::ffi::PyTypeObject { use pyo3::type_object::LazyStaticType; static TYPE_OBJECT: LazyStaticType = LazyStaticType::new(); TYPE_OBJECT.get_or_init::<Self>(py) } } impl pyo3::PyClass for MyClass { type Frozen = pyo3::pyclass::boolean_struct::False; } impl<'a, 'py> pyo3::impl_::extract_argument::PyFunctionArgument<'a, 'py> for &'a MyClass { type Holder = ::std::option::Option<pyo3::PyRef<'py, MyClass>>; #[inline] fn extract(obj: &'py pyo3::PyAny, holder: &'a mut Self::Holder) -> pyo3::PyResult<Self> { pyo3::impl_::extract_argument::extract_pyclass_ref(obj, holder) } } impl<'a, 'py> pyo3::impl_::extract_argument::PyFunctionArgument<'a, 'py> for &'a mut MyClass { type Holder = ::std::option::Option<pyo3::PyRefMut<'py, MyClass>>; #[inline] fn extract(obj: &'py pyo3::PyAny, holder: &'a mut Self::Holder) -> pyo3::PyResult<Self> { pyo3::impl_::extract_argument::extract_pyclass_ref_mut(obj, holder) } } impl pyo3::IntoPy<PyObject> for MyClass { fn into_py(self, py: pyo3::Python<'_>) -> pyo3::PyObject { pyo3::IntoPy::into_py(pyo3::Py::new(py, self).unwrap(), py) } } impl pyo3::impl_::pyclass::PyClassImpl for MyClass { const DOC: &'static str = "Class for demonstration\u{0}"; const IS_BASETYPE: bool = false; const IS_SUBCLASS: bool = false; type Layout = PyCell<MyClass>; type BaseType = PyAny; type ThreadChecker = pyo3::impl_::pyclass::ThreadCheckerStub<MyClass>; type PyClassMutability = <<pyo3::PyAny as pyo3::impl_::pyclass::PyClassBaseType>::PyClassMutability as pyo3::impl_::pycell::PyClassMutability>::MutableChild; type Dict = pyo3::impl_::pyclass::PyClassDummySlot; type WeakRef = pyo3::impl_::pyclass::PyClassDummySlot; type BaseNativeType = pyo3::PyAny; fn items_iter() -> pyo3::impl_::pyclass::PyClassItemsIter { use pyo3::impl_::pyclass::*; let collector = PyClassImplCollector::<MyClass>::new(); static INTRINSIC_ITEMS: PyClassItems = PyClassItems { slots: &[], methods: &[] }; PyClassItemsIter::new(&INTRINSIC_ITEMS, collector.py_methods()) } } Python::with_gil(|py| { let cls = py.get_type::<MyClass>(); pyo3::py_run!(py, cls, "assert cls.__name__ == 'MyClass'") }); } }
Magic methods and slots
Python’s object model defines several protocols for different object behavior, such as the sequence, mapping, and number protocols. You may be familiar with implementing these protocols in Python classes by “magic” methods, such as __str__ or __repr__. Because of the double-underscores surrounding their name, these are also known as “dunder” methods.
In the Python C-API which PyO3 is implemented upon, many of these magic methods have to be placed into special “slots” on the class type object, as covered in the previous section.
If a function name in #[pymethods] is a recognised magic method, it will be automatically placed into the correct slot in the Python type object. The function name is taken from the usual rules for naming #[pymethods]: the #[pyo3(name = "...")] attribute is used if present, otherwise the Rust function name is used.
The magic methods handled by PyO3 are very similar to the standard Python ones on this page - in particular they are the the subset which have slots as defined here. Some of the slots do not have a magic method in Python, which leads to a few additional magic methods defined only in PyO3:
- Magic methods for garbage collection
- Magic methods for the buffer protocol
When PyO3 handles a magic method, a couple of changes apply compared to other #[pymethods]:
- The
#[pyo3(text_signature = "...")]attribute is not allowed - The signature is restricted to match the magic method
The following sections list of all magic methods PyO3 currently handles. The given signatures should be interpreted as follows:
- All methods take a receiver as first argument, shown as
<self>. It can be&self,&mut selfor aPyCellreference likeself_: PyRef<'_, Self>andself_: PyRefMut<'_, Self>, as described here. - An optional
Python<'py>argument is always allowed as the first argument. - Return values can be optionally wrapped in
PyResult. objectmeans that any type is allowed that can be extracted from a Python object (if argument) or converted to a Python object (if return value).- Other types must match what’s given, e.g.
pyo3::basic::CompareOpfor__richcmp__’s second argument. - For the comparison and arithmetic methods, extraction errors are not
propagated as exceptions, but lead to a return of
NotImplemented. - For some magic methods, the return values are not restricted by PyO3, but
checked by the Python interpreter. For example,
__str__needs to return a string object. This is indicated byobject (Python type).
Basic object customization
-
__str__(<self>) -> object (str) -
__repr__(<self>) -> object (str) -
__hash__(<self>) -> isizeObjects that compare equal must have the same hash value. Any type up to 64 bits may be returned instead of
isize, PyO3 will convert to an isize automatically (wrapping unsigned types likeu64andusize).Disabling Python's default hash
By default, all `#[pyclass]` types have a default hash implementation from Python. Types which should not be hashable can override this by setting `__hash__` to `None`. This is the same mechanism as for a pure-Python class. This is done like so:#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct NotHashable { } #[pymethods] impl NotHashable { #[classattr] const __hash__: Option<PyObject> = None; } } -
__richcmp__(<self>, object, pyo3::basic::CompareOp) -> objectOverloads Python comparison operations (
==,!=,<,<=,>, and>=). TheCompareOpargument indicates the comparison operation being performed.Note that implementing
__richcmp__will cause Python not to generate a default__hash__implementation, so consider implementing__hash__when implementing__richcmp__.Return type
The return type will normally be `PyResult`, but any Python object can be returned. If the second argument `object` is not of the type specified in the signature, the generated code will automatically `return NotImplemented`.
You can use CompareOp::matches to adapt a Rust std::cmp::Ordering result
to the requested comparison.
-
__getattr__(<self>, object) -> object -
__getattribute__(<self>, object) -> objectDifferences between `__getattr__` and `__getattribute__`
As in Python, `__getattr__` is only called if the attribute is not found by normal attribute lookup. `__getattribute__`, on the other hand, is called for *every* attribute access. If it wants to access existing attributes on `self`, it needs to be very careful not to introduce infinite recursion, and use `baseclass.__getattribute__()`. -
__setattr__(<self>, value: object) -> () -
__delattr__(<self>, object) -> ()Overrides attribute access.
-
__bool__(<self>) -> boolDetermines the “truthyness” of an object.
-
__call__(<self>, ...) -> object- here, any argument list can be defined as for normalpymethods
Iterable objects
Iterators can be defined using these methods:
__iter__(<self>) -> object__next__(<self>) -> Option<object> or IterNextOutput(see details)
Returning None from __next__ indicates that that there are no further items.
Example:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyIterator { iter: Box<dyn Iterator<Item = PyObject> + Send>, } #[pymethods] impl MyIterator { fn __iter__(slf: PyRef<'_, Self>) -> PyRef<'_, Self> { slf } fn __next__(mut slf: PyRefMut<'_, Self>) -> Option<PyObject> { slf.iter.next() } } }
In many cases you’ll have a distinction between the type being iterated over
(i.e. the iterable) and the iterator it provides. In this case, the iterable
only needs to implement __iter__() while the iterator must implement both
__iter__() and __next__(). For example:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Iter { inner: std::vec::IntoIter<usize>, } #[pymethods] impl Iter { fn __iter__(slf: PyRef<'_, Self>) -> PyRef<'_, Self> { slf } fn __next__(mut slf: PyRefMut<'_, Self>) -> Option<usize> { slf.inner.next() } } #[pyclass] struct Container { iter: Vec<usize>, } #[pymethods] impl Container { fn __iter__(slf: PyRef<'_, Self>) -> PyResult<Py<Iter>> { let iter = Iter { inner: slf.iter.clone().into_iter(), }; Py::new(slf.py(), iter) } } Python::with_gil(|py| { let container = Container { iter: vec![1, 2, 3, 4] }; let inst = pyo3::PyCell::new(py, container).unwrap(); pyo3::py_run!(py, inst, "assert list(inst) == [1, 2, 3, 4]"); pyo3::py_run!(py, inst, "assert list(iter(iter(inst))) == [1, 2, 3, 4]"); }); }
For more details on Python’s iteration protocols, check out the “Iterator Types” section of the library documentation.
Returning a value from iteration
This guide has so far shown how to use Option<T> to implement yielding values
during iteration. In Python a generator can also return a value. To express
this in Rust, PyO3 provides the IterNextOutput enum to both Yield values
and Return a final value - see its docs for further details and an example.
Awaitable objects
__await__(<self>) -> object__aiter__(<self>) -> object__anext__(<self>) -> Option<object> or IterANextOutput
Mapping & Sequence types
The magic methods in this section can be used to implement Python container types. They are two main categories of container in Python: “mappings” such as dict, with arbitrary keys, and “sequences” such as list and tuple, with integer keys.
The Python C-API which PyO3 is built upon has separate “slots” for sequences and mappings. When writing a class in pure Python, there is no such distinction in the implementation - a __getitem__ implementation will fill the slots for both the mapping and sequence forms, for example.
By default PyO3 reproduces the Python behaviour of filling both mapping and sequence slots. This makes sense for the “simple” case which matches Python, and also for sequences, where the mapping slot is used anyway to implement slice indexing.
Mapping types usually will not want the sequence slots filled. Having them filled will lead to outcomes which may be unwanted, such as:
- The mapping type will successfully cast to
PySequence. This may lead to consumers of the type handling it incorrectly. - Python provides a default implementation of
__iter__for sequences, which calls__getitem__with consecutive positive integers starting from 0 until anIndexErroris returned. Unless the mapping only contains consecutive positive integer keys, this__iter__implementation will likely not be the intended behavior.
Use the #[pyclass(mapping)] annotation to instruct PyO3 to only fill the mapping slots, leaving the sequence ones empty. This will apply to __getitem__, __setitem__, and __delitem__.
Use the #[pyclass(sequence)] annotation to instruct PyO3 to fill the sq_length slot instead of the mp_length slot for __len__. This will help libraries such as numpy recognise the class as a sequence, however will also cause CPython to automatically add the sequence length to any negative indices before passing them to __getitem__. (__getitem__, __setitem__ and __delitem__ mapping slots are still used for sequences, for slice operations.)
-
__len__(<self>) -> usizeImplements the built-in function
len(). -
__contains__(<self>, object) -> boolImplements membership test operators. Should return true if
itemis inself, false otherwise. For objects that don’t define__contains__(), the membership test simply traverses the sequence until it finds a match.Disabling Python's default contains
By default, all #[pyclass] types with an __iter__ method support a
default implementation of the in operator. Types which do not want this
can override this by setting __contains__ to None. This is the same
mechanism as for a pure-Python class. This is done like so:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct NoContains { } #[pymethods] impl NoContains { #[classattr] const __contains__: Option<PyObject> = None; } }
-
__getitem__(<self>, object) -> objectImplements retrieval of the
self[a]element.Note: Negative integer indexes are not handled specially.
-
__setitem__(<self>, object, object) -> ()Implements assignment to the
self[a]element. Should only be implemented if elements can be replaced. -
__delitem__(<self>, object) -> ()Implements deletion of the
self[a]element. Should only be implemented if elements can be deleted. -
fn __concat__(&self, other: impl FromPyObject) -> PyResult<impl ToPyObject>Concatenates two sequences. Used by the
+operator, after trying the numeric addition via the__add__and__radd__methods. -
fn __repeat__(&self, count: isize) -> PyResult<impl ToPyObject>Repeats the sequence
counttimes. Used by the*operator, after trying the numeric multiplication via the__mul__and__rmul__methods. -
fn __inplace_concat__(&self, other: impl FromPyObject) -> PyResult<impl ToPyObject>Concatenates two sequences. Used by the
+=operator, after trying the numeric addition via the__iadd__method. -
fn __inplace_repeat__(&self, count: isize) -> PyResult<impl ToPyObject>Concatenates two sequences. Used by the
*=operator, after trying the numeric multiplication via the__imul__method.
Descriptors
__get__(<self>, object, object) -> object__set__(<self>, object, object) -> ()__delete__(<self>, object) -> ()
Numeric types
Binary arithmetic operations (+, -, *, @, /, //, %, divmod(),
pow() and **, <<, >>, &, ^, and |) and their reflected versions:
(If the object is not of the type specified in the signature, the generated code
will automatically return NotImplemented.)
__add__(<self>, object) -> object__radd__(<self>, object) -> object__sub__(<self>, object) -> object__rsub__(<self>, object) -> object__mul__(<self>, object) -> object__rmul__(<self>, object) -> object__matmul__(<self>, object) -> object__rmatmul__(<self>, object) -> object__floordiv__(<self>, object) -> object__rfloordiv__(<self>, object) -> object__truediv__(<self>, object) -> object__rtruediv__(<self>, object) -> object__divmod__(<self>, object) -> object__rdivmod__(<self>, object) -> object__mod__(<self>, object) -> object__rmod__(<self>, object) -> object__lshift__(<self>, object) -> object__rlshift__(<self>, object) -> object__rshift__(<self>, object) -> object__rrshift__(<self>, object) -> object__and__(<self>, object) -> object__rand__(<self>, object) -> object__xor__(<self>, object) -> object__rxor__(<self>, object) -> object__or__(<self>, object) -> object__ror__(<self>, object) -> object__pow__(<self>, object, object) -> object__rpow__(<self>, object, object) -> object
In-place assignment operations (+=, -=, *=, @=, /=, //=, %=,
**=, <<=, >>=, &=, ^=, |=):
__iadd__(<self>, object) -> ()__isub__(<self>, object) -> ()__imul__(<self>, object) -> ()__imatmul__(<self>, object) -> ()__itruediv__(<self>, object) -> ()__ifloordiv__(<self>, object) -> ()__imod__(<self>, object) -> ()__ipow__(<self>, object, object) -> ()__ilshift__(<self>, object) -> ()__irshift__(<self>, object) -> ()__iand__(<self>, object) -> ()__ixor__(<self>, object) -> ()__ior__(<self>, object) -> ()
Unary operations (-, +, abs() and ~):
__pos__(<self>) -> object__neg__(<self>) -> object__abs__(<self>) -> object__invert__(<self>) -> object
Coercions:
__index__(<self>) -> object (int)__int__(<self>) -> object (int)__float__(<self>) -> object (float)
Buffer objects
__getbuffer__(<self>, *mut ffi::Py_buffer, flags) -> ()__releasebuffer__(<self>, *mut ffi::Py_buffer)(no return value, not evenPyResult)
Garbage Collector Integration
If your type owns references to other Python objects, you will need to integrate
with Python’s garbage collector so that the GC is aware of those references. To
do this, implement the two methods __traverse__ and __clear__. These
correspond to the slots tp_traverse and tp_clear in the Python C API.
__traverse__ must call visit.call() for each reference to another Python
object. __clear__ must clear out any mutable references to other Python
objects (thus breaking reference cycles). Immutable references do not have to be
cleared, as every cycle must contain at least one mutable reference.
__traverse__(<self>, pyo3::class::gc::PyVisit<'_>) -> Result<(), pyo3::class::gc::PyTraverseError>__clear__(<self>) -> ()
Example:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::PyTraverseError; use pyo3::gc::PyVisit; #[pyclass] struct ClassWithGCSupport { obj: Option<PyObject>, } #[pymethods] impl ClassWithGCSupport { fn __traverse__(&self, visit: PyVisit<'_>) -> Result<(), PyTraverseError> { if let Some(obj) = &self.obj { visit.call(obj)? } Ok(()) } fn __clear__(&mut self) { // Clear reference, this decrements ref counter. self.obj = None; } } }
Basic object customization
Recall the Number class from the previous chapter:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { #[new] fn new(value: i32) -> Self { Self(value) } } #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<Number>()?; Ok(()) } }
At this point Python code can import the module, access the class and create class instances - but nothing else.
from my_module import Number
n = Number(5)
print(n)
<builtins.Number object at 0x000002B4D185D7D0>
String representations
It can’t even print an user-readable representation of itself! We can fix that by defining the
__repr__ and __str__ methods inside a #[pymethods] block. We do this by accessing the value
contained inside Number.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { // For `__repr__` we want to return a string that Python code could use to recreate // the `Number`, like `Number(5)` for example. fn __repr__(&self) -> String { // We use the `format!` macro to create a string. Its first argument is a // format string, followed by any number of parameters which replace the // `{}`'s in the format string. // // 👇 Tuple field access in Rust uses a dot format!("Number({})", self.0) } // `__str__` is generally used to create an "informal" representation, so we // just forward to `i32`'s `ToString` trait implementation to print a bare number. fn __str__(&self) -> String { self.0.to_string() } } }
Hashing
Let’s also implement hashing. We’ll just hash the i32. For that we need a Hasher. The one
provided by std is DefaultHasher, which uses the SipHash algorithm.
#![allow(unused)] fn main() { use std::collections::hash_map::DefaultHasher; // Required to call the `.hash` and `.finish` methods, which are defined on traits. use std::hash::{Hash, Hasher}; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __hash__(&self) -> u64 { let mut hasher = DefaultHasher::new(); self.0.hash(&mut hasher); hasher.finish() } } }
Note: When implementing
__hash__and comparisons, it is important that the following property holds:k1 == k2 -> hash(k1) == hash(k2)In other words, if two keys are equal, their hashes must also be equal. In addition you must take care that your classes’ hash doesn’t change during its lifetime. In this tutorial we do that by not letting Python code change our
Numberclass. In other words, it is immutable.By default, all
#[pyclass]types have a default hash implementation from Python. Types which should not be hashable can override this by setting__hash__to None. This is the same mechanism as for a pure-Python class. This is done like so:#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct NotHashable { } #[pymethods] impl NotHashable { #[classattr] const __hash__: Option<Py<PyAny>> = None; } }
Comparisons
Unlike in Python, PyO3 does not provide the magic comparison methods you might expect like __eq__,
__lt__ and so on. Instead you have to implement all six operations at once with __richcmp__.
This method will be called with a value of CompareOp depending on the operation.
#![allow(unused)] fn main() { use pyo3::class::basic::CompareOp; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __richcmp__(&self, other: &Self, op: CompareOp) -> PyResult<bool> { match op { CompareOp::Lt => Ok(self.0 < other.0), CompareOp::Le => Ok(self.0 <= other.0), CompareOp::Eq => Ok(self.0 == other.0), CompareOp::Ne => Ok(self.0 != other.0), CompareOp::Gt => Ok(self.0 > other.0), CompareOp::Ge => Ok(self.0 >= other.0), } } } }
If you obtain the result by comparing two Rust values, as in this example, you
can take a shortcut using CompareOp::matches:
#![allow(unused)] fn main() { use pyo3::class::basic::CompareOp; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __richcmp__(&self, other: &Self, op: CompareOp) -> bool { op.matches(self.0.cmp(&other.0)) } } }
It checks that the std::cmp::Ordering obtained from Rust’s Ord matches
the given CompareOp.
Alternatively, if you want to leave some operations unimplemented, you can
return py.NotImplemented() for some of the operations:
#![allow(unused)] fn main() { use pyo3::class::basic::CompareOp; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __richcmp__(&self, other: &Self, op: CompareOp, py: Python<'_>) -> PyObject { match op { CompareOp::Eq => (self.0 == other.0).into_py(py), CompareOp::Ne => (self.0 != other.0).into_py(py), _ => py.NotImplemented(), } } } }
Truthyness
We’ll consider Number to be True if it is nonzero:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __bool__(&self) -> bool { self.0 != 0 } } }
Final code
#![allow(unused)] fn main() { use std::collections::hash_map::DefaultHasher; use std::hash::{Hash, Hasher}; use pyo3::prelude::*; use pyo3::class::basic::CompareOp; #[pyclass] struct Number(i32); #[pymethods] impl Number { #[new] fn new(value: i32) -> Self { Self(value) } fn __repr__(&self) -> String { format!("Number({})", self.0) } fn __str__(&self) -> String { self.0.to_string() } fn __hash__(&self) -> u64 { let mut hasher = DefaultHasher::new(); self.0.hash(&mut hasher); hasher.finish() } fn __richcmp__(&self, other: &Self, op: CompareOp) -> PyResult<bool> { match op { CompareOp::Lt => Ok(self.0 < other.0), CompareOp::Le => Ok(self.0 <= other.0), CompareOp::Eq => Ok(self.0 == other.0), CompareOp::Ne => Ok(self.0 != other.0), CompareOp::Gt => Ok(self.0 > other.0), CompareOp::Ge => Ok(self.0 >= other.0), } } fn __bool__(&self) -> bool { self.0 != 0 } } #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<Number>()?; Ok(()) } }
Emulating numeric types
At this point we have a Number class that we can’t actually do any math on!
Before proceeding, we should think about how we want to handle overflows. There are three obvious solutions:
- We can have infinite precision just like Python’s
int. However that would be quite boring - we’d be reinventing the wheel. - We can raise exceptions whenever
Numberoverflows, but that makes the API painful to use. - We can wrap around the boundary of
i32. This is the approach we’ll take here. To do that we’ll just forward toi32’swrapping_*methods.
Fixing our constructor
Let’s address the first overflow, in Number’s constructor:
from my_module import Number
n = Number(1 << 1337)
Traceback (most recent call last):
File "example.py", line 3, in <module>
n = Number(1 << 1337)
OverflowError: Python int too large to convert to C long
Instead of relying on the default FromPyObject extraction to parse arguments, we can specify our
own extraction function, using the #[pyo3(from_py_with = "...")] attribute. Unfortunately PyO3
doesn’t provide a way to wrap Python integers out of the box, but we can do a Python call to mask it
and cast it to an i32.
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; fn wrap(obj: &PyAny) -> Result<i32, PyErr> { let val = obj.call_method1("__and__", (0xFFFFFFFF_u32,))?; let val: u32 = val.extract()?; // 👇 This intentionally overflows! Ok(val as i32) } }
We also add documentation, via /// comments and the #[pyo3(text_signature = "...")] attribute, both of which are visible to Python users.
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; fn wrap(obj: &PyAny) -> Result<i32, PyErr> { let val = obj.call_method1("__and__", (0xFFFFFFFF_u32,))?; let val: u32 = val.extract()?; Ok(val as i32) } /// Did you ever hear the tragedy of Darth Signed The Overfloweth? I thought not. /// It's not a story C would tell you. It's a Rust legend. #[pyclass(module = "my_module")] #[pyo3(text_signature = "(int)")] struct Number(i32); #[pymethods] impl Number { #[new] fn new(#[pyo3(from_py_with = "wrap")] value: i32) -> Self { Self(value) } } }
With that out of the way, let’s implement some operators:
#![allow(unused)] fn main() { use std::convert::TryInto; use pyo3::exceptions::{PyZeroDivisionError, PyValueError}; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __add__(&self, other: &Self) -> Self { Self(self.0.wrapping_add(other.0)) } fn __sub__(&self, other: &Self) -> Self { Self(self.0.wrapping_sub(other.0)) } fn __mul__(&self, other: &Self) -> Self { Self(self.0.wrapping_mul(other.0)) } fn __truediv__(&self, other: &Self) -> PyResult<Self> { match self.0.checked_div(other.0) { Some(i) => Ok(Self(i)), None => Err(PyZeroDivisionError::new_err("division by zero")), } } fn __floordiv__(&self, other: &Self) -> PyResult<Self> { match self.0.checked_div(other.0) { Some(i) => Ok(Self(i)), None => Err(PyZeroDivisionError::new_err("division by zero")), } } fn __rshift__(&self, other: &Self) -> PyResult<Self> { match other.0.try_into() { Ok(rhs) => Ok(Self(self.0.wrapping_shr(rhs))), Err(_) => Err(PyValueError::new_err("negative shift count")), } } fn __lshift__(&self, other: &Self) -> PyResult<Self> { match other.0.try_into() { Ok(rhs) => Ok(Self(self.0.wrapping_shl(rhs))), Err(_) => Err(PyValueError::new_err("negative shift count")), } } } }
Unary arithmetic operations
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __pos__(slf: PyRef<'_, Self>) -> PyRef<'_, Self> { slf } fn __neg__(&self) -> Self { Self(-self.0) } fn __abs__(&self) -> Self { Self(self.0.abs()) } fn __invert__(&self) -> Self { Self(!self.0) } } }
Support for the complex(), int() and float() built-in functions.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); use pyo3::types::PyComplex; #[pymethods] impl Number { fn __int__(&self) -> i32 { self.0 } fn __float__(&self) -> f64 { self.0 as f64 } fn __complex__<'py>(&self, py: Python<'py>) -> &'py PyComplex { PyComplex::from_doubles(py, self.0 as f64, 0.0) } } }
We do not implement the in-place operations like __iadd__ because we do not wish to mutate Number.
Similarly we’re not interested in supporting operations with different types, so we do not implement
the reflected operations like __radd__ either.
Now Python can use our Number class:
from my_module import Number
def hash_djb2(s: str):
'''
A version of Daniel J. Bernstein's djb2 string hashing algorithm
Like many hashing algorithms, it relies on integer wrapping.
'''
n = Number(0)
five = Number(5)
for x in s:
n = Number(ord(x)) + ((n << five) - n)
return n
assert hash_djb2('l50_50') == Number(-1152549421)
Final code
use std::collections::hash_map::DefaultHasher; use std::hash::{Hash, Hasher}; use std::convert::TryInto; use pyo3::exceptions::{PyValueError, PyZeroDivisionError}; use pyo3::prelude::*; use pyo3::class::basic::CompareOp; use pyo3::types::PyComplex; fn wrap(obj: &PyAny) -> Result<i32, PyErr> { let val = obj.call_method1("__and__", (0xFFFFFFFF_u32,))?; let val: u32 = val.extract()?; Ok(val as i32) } /// Did you ever hear the tragedy of Darth Signed The Overfloweth? I thought not. /// It's not a story C would tell you. It's a Rust legend. #[pyclass(module = "my_module")] #[pyo3(text_signature = "(int)")] struct Number(i32); #[pymethods] impl Number { #[new] fn new(#[pyo3(from_py_with = "wrap")] value: i32) -> Self { Self(value) } fn __repr__(&self) -> String { format!("Number({})", self.0) } fn __str__(&self) -> String { self.0.to_string() } fn __hash__(&self) -> u64 { let mut hasher = DefaultHasher::new(); self.0.hash(&mut hasher); hasher.finish() } fn __richcmp__(&self, other: &Self, op: CompareOp) -> PyResult<bool> { match op { CompareOp::Lt => Ok(self.0 < other.0), CompareOp::Le => Ok(self.0 <= other.0), CompareOp::Eq => Ok(self.0 == other.0), CompareOp::Ne => Ok(self.0 != other.0), CompareOp::Gt => Ok(self.0 > other.0), CompareOp::Ge => Ok(self.0 >= other.0), } } fn __bool__(&self) -> bool { self.0 != 0 } fn __add__(&self, other: &Self) -> Self { Self(self.0.wrapping_add(other.0)) } fn __sub__(&self, other: &Self) -> Self { Self(self.0.wrapping_sub(other.0)) } fn __mul__(&self, other: &Self) -> Self { Self(self.0.wrapping_mul(other.0)) } fn __truediv__(&self, other: &Self) -> PyResult<Self> { match self.0.checked_div(other.0) { Some(i) => Ok(Self(i)), None => Err(PyZeroDivisionError::new_err("division by zero")), } } fn __floordiv__(&self, other: &Self) -> PyResult<Self> { match self.0.checked_div(other.0) { Some(i) => Ok(Self(i)), None => Err(PyZeroDivisionError::new_err("division by zero")), } } fn __rshift__(&self, other: &Self) -> PyResult<Self> { match other.0.try_into() { Ok(rhs) => Ok(Self(self.0.wrapping_shr(rhs))), Err(_) => Err(PyValueError::new_err("negative shift count")), } } fn __lshift__(&self, other: &Self) -> PyResult<Self> { match other.0.try_into() { Ok(rhs) => Ok(Self(self.0.wrapping_shl(rhs))), Err(_) => Err(PyValueError::new_err("negative shift count")), } } fn __xor__(&self, other: &Self) -> Self { Self(self.0 ^ other.0) } fn __or__(&self, other: &Self) -> Self { Self(self.0 | other.0) } fn __and__(&self, other: &Self) -> Self { Self(self.0 & other.0) } fn __int__(&self) -> i32 { self.0 } fn __float__(&self) -> f64 { self.0 as f64 } fn __complex__<'py>(&self, py: Python<'py>) -> &'py PyComplex { PyComplex::from_doubles(py, self.0 as f64, 0.0) } } #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<Number>()?; Ok(()) } const SCRIPT: &'static str = r#" def hash_djb2(s: str): n = Number(0) five = Number(5) for x in s: n = Number(ord(x)) + ((n << five) - n) return n assert hash_djb2('l50_50') == Number(-1152549421) assert hash_djb2('logo') == Number(3327403) assert hash_djb2('horizon') == Number(1097468315) assert Number(2) + Number(2) == Number(4) assert Number(2) + Number(2) != Number(5) assert Number(13) - Number(7) == Number(6) assert Number(13) - Number(-7) == Number(20) assert Number(13) / Number(7) == Number(1) assert Number(13) // Number(7) == Number(1) assert Number(13) * Number(7) == Number(13*7) assert Number(13) > Number(7) assert Number(13) < Number(20) assert Number(13) == Number(13) assert Number(13) >= Number(7) assert Number(13) <= Number(20) assert Number(13) == Number(13) assert (True if Number(1) else False) assert (False if Number(0) else True) assert int(Number(13)) == 13 assert float(Number(13)) == 13 assert Number.__doc__ == "Did you ever hear the tragedy of Darth Signed The Overfloweth? I thought not.\nIt's not a story C would tell you. It's a Rust legend." assert Number(12345234523452) == Number(1498514748) try: import inspect assert inspect.signature(Number).__str__() == '(int)' except ValueError: # Not supported with `abi3` before Python 3.10 pass assert Number(1337).__str__() == '1337' assert Number(1337).__repr__() == 'Number(1337)' "#; use pyo3::PyTypeInfo; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let globals = PyModule::import(py, "__main__")?.dict(); globals.set_item("Number", Number::type_object(py))?; py.run(SCRIPT, Some(globals), None)?; Ok(()) }) }
Appendix: Writing some unsafe code
At the beginning of this chapter we said that PyO3 doesn’t provide a way to wrap Python integers out of the box but that’s a half truth. There’s not a PyO3 API for it, but there’s a Python C API function that does:
unsigned long PyLong_AsUnsignedLongMask(PyObject *obj)
We can call this function from Rust by using pyo3::ffi::PyLong_AsUnsignedLongMask. This is an unsafe
function, which means we have to use an unsafe block to call it and take responsibility for upholding
the contracts of this function. Let’s review those contracts:
- The GIL must be held. If it’s not, calling this function causes a data race.
- The pointer must be valid, i.e. it must be properly aligned and point to a valid Python object.
Let’s create that helper function. The signature has to be fn(&PyAny) -> PyResult<T>.
&PyAnyrepresents a checked borrowed reference, so the pointer derived from it is valid (and not null).- Whenever we have borrowed references to Python objects in scope, it is guaranteed that the GIL is held. This reference is also where we can get a
Pythontoken to use in our call toPyErr::take.
#![allow(unused)] fn main() { #![allow(dead_code)] use std::os::raw::c_ulong; use pyo3::prelude::*; use pyo3::ffi; use pyo3::conversion::AsPyPointer; fn wrap(obj: &PyAny) -> Result<i32, PyErr> { let py: Python<'_> = obj.py(); unsafe { let ptr = obj.as_ptr(); let ret: c_ulong = ffi::PyLong_AsUnsignedLongMask(ptr); if ret == c_ulong::MAX { if let Some(err) = PyErr::take(py) { return Err(err); } } Ok(ret as i32) } } }
Emulating callable objects
Classes can be callable if they have a #[pymethod] named __call__.
This allows instances of a class to behave similar to functions.
This method’s signature must look like __call__(<self>, ...) -> object - here,
any argument list can be defined as for normal pymethods
Example: Implementing a call counter
The following pyclass is a basic decorator - its constructor takes a Python object as argument and calls that object when called. An equivalent Python implementation is linked at the end.
An example crate containing this pyclass can be found here
{{#include ../../../examples/decorator/src/lib.rs}}
Python code:
{{#include ../../../examples/decorator/tests/example.py}}
Output:
say_hello has been called 1 time(s).
hello
say_hello has been called 2 time(s).
hello
say_hello has been called 3 time(s).
hello
say_hello has been called 4 time(s).
hello
Pure Python implementation
A Python implementation of this looks similar to the Rust version:
class Counter:
def __init__(self, wraps):
self.count = 0
self.wraps = wraps
def __call__(self, *args, **kwargs):
self.count += 1
print(f"{self.wraps.__name__} has been called {self.count} time(s)")
self.wraps(*args, **kwargs)
Note that it can also be implemented as a higher order function:
def Counter(wraps):
count = 0
def call(*args, **kwargs):
nonlocal count
count += 1
print(f"{wraps.__name__} has been called {count} time(s)")
return wraps(*args, **kwargs)
return call
What is the Cell for?
A previous implementation used a normal u64, which meant it required a &mut self receiver to update the count:
#[pyo3(signature = (*args, **kwargs))]
fn __call__(&mut self, py: Python<'_>, args: &PyTuple, kwargs: Option<&PyDict>) -> PyResult<Py<PyAny>> {
self.count += 1;
let name = self.wraps.getattr(py, "__name__")?;
println!("{} has been called {} time(s).", name, self.count);
// After doing something, we finally forward the call to the wrapped function
let ret = self.wraps.call(py, args, kwargs)?;
// We could do something with the return value of
// the function before returning it
Ok(ret)
}
The problem with this is that the &mut self receiver means PyO3 has to borrow it exclusively,
and hold this borrow across theself.wraps.call(py, args, kwargs) call. This call returns control to the user’s Python code
which is free to call arbitrary things, including the decorated function. If that happens PyO3 is unable to create a second unique borrow and will be forced to raise an exception.
As a result, something innocent like this will raise an exception:
@Counter
def say_hello():
if say_hello.count < 2:
print(f"hello from decorator")
say_hello()
# RuntimeError: Already borrowed
The implementation in this chapter fixes that by never borrowing exclusively; all the methods take &self as receivers, of which multiple may exist simultaneously. This requires a shared counter and the easiest way to do that is to use Cell, so that’s what is used here.
This shows the dangers of running arbitrary Python code - note that “running arbitrary Python code” can be far more subtle than the example above:
- Python’s asynchronous executor may park the current thread in the middle of Python code, even in Python code that you control, and let other Python code run.
- Dropping arbitrary Python objects may invoke destructors defined in Python (
__del__methods). - Calling Python’s C-api (most PyO3 apis call C-api functions internally) may raise exceptions, which may allow Python code in signal handlers to run.
This is especially important if you are writing unsafe code; Python code must never be able to cause undefined behavior. You must ensure that your Rust code is in a consistent state before doing any of the above things.
Type conversions
In this portion of the guide we’ll talk about the mapping of Python types to Rust types offered by PyO3, as well as the traits available to perform conversions between them.
Mapping of Rust types to Python types
When writing functions callable from Python (such as a #[pyfunction] or in a #[pymethods] block), the trait FromPyObject is required for function arguments, and IntoPy<PyObject> is required for function return values.
Consult the tables in the following section to find the Rust types provided by PyO3 which implement these traits.
Argument Types
When accepting a function argument, it is possible to either use Rust library types or PyO3’s Python-native types. (See the next section for discussion on when to use each.)
The table below contains the Python type and the corresponding function argument types that will accept them:
| Python | Rust | Rust (Python-native) |
|---|---|---|
object | - | &PyAny |
str | String, Cow<str>, &str, OsString, PathBuf | &PyUnicode |
bytes | Vec<u8>, &[u8] | &PyBytes |
bool | bool | &PyBool |
int | Any integer type (i32, u32, usize, etc) | &PyLong |
float | f32, f64 | &PyFloat |
complex | num_complex::Complex1 | &PyComplex |
list[T] | Vec<T> | &PyList |
dict[K, V] | HashMap<K, V>, BTreeMap<K, V>, hashbrown::HashMap<K, V>2, indexmap::IndexMap<K, V>3 | &PyDict |
tuple[T, U] | (T, U), Vec<T> | &PyTuple |
set[T] | HashSet<T>, BTreeSet<T>, hashbrown::HashSet<T>2 | &PySet |
frozenset[T] | HashSet<T>, BTreeSet<T>, hashbrown::HashSet<T>2 | &PyFrozenSet |
bytearray | Vec<u8> | &PyByteArray |
slice | - | &PySlice |
type | - | &PyType |
module | - | &PyModule |
datetime.datetime | - | &PyDateTime |
datetime.date | - | &PyDate |
datetime.time | - | &PyTime |
datetime.tzinfo | - | &PyTzInfo |
datetime.timedelta | - | &PyDelta |
typing.Optional[T] | Option<T> | - |
typing.Sequence[T] | Vec<T> | &PySequence |
typing.Mapping[K, V] | HashMap<K, V>, BTreeMap<K, V>, hashbrown::HashMap<K, V>2, indexmap::IndexMap<K, V>3 | &PyMapping |
typing.Iterator[Any] | - | &PyIterator |
typing.Union[...] | See #[derive(FromPyObject)] | - |
There are also a few special types related to the GIL and Rust-defined #[pyclass]es which may come in useful:
| What | Description |
|---|---|
Python | A GIL token, used to pass to PyO3 constructors to prove ownership of the GIL |
Py<T> | A Python object isolated from the GIL lifetime. This can be sent to other threads. |
PyObject | An alias for Py<PyAny> |
&PyCell<T> | A #[pyclass] value owned by Python. |
PyRef<T> | A #[pyclass] borrowed immutably. |
PyRefMut<T> | A #[pyclass] borrowed mutably. |
For more detail on accepting #[pyclass] values as function arguments, see the section of this guide on Python Classes.
Using Rust library types vs Python-native types
Using Rust library types as function arguments will incur a conversion cost compared to using the Python-native types. Using the Python-native types is almost zero-cost (they just require a type check similar to the Python builtin function isinstance()).
However, once that conversion cost has been paid, the Rust standard library types offer a number of benefits:
- You can write functionality in native-speed Rust code (free of Python’s runtime costs).
- You get better interoperability with the rest of the Rust ecosystem.
- You can use
Python::allow_threadsto release the Python GIL and let other Python threads make progress while your Rust code is executing. - You also benefit from stricter type checking. For example you can specify
Vec<i32>, which will only accept a Pythonlistcontaining integers. The Python-native equivalent,&PyList, would accept a Pythonlistcontaining Python objects of any type.
For most PyO3 usage the conversion cost is worth paying to get these benefits. As always, if you’re not sure it’s worth it in your case, benchmark it!
Returning Rust values to Python
When returning values from functions callable from Python, Python-native types (&PyAny, &PyDict etc.) can be used with zero cost.
Because these types are references, in some situations the Rust compiler may ask for lifetime annotations. If this is the case, you should use Py<PyAny>, Py<PyDict> etc. instead - which are also zero-cost. For all of these Python-native types T, Py<T> can be created from T with an .into() conversion.
If your function is fallible, it should return PyResult<T> or Result<T, E> where E implements From<E> for PyErr. This will raise a Python exception if the Err variant is returned.
Finally, the following Rust types are also able to convert to Python as return values:
| Rust type | Resulting Python Type |
|---|---|
String | str |
&str | str |
bool | bool |
Any integer type (i32, u32, usize, etc) | int |
f32, f64 | float |
Option<T> | Optional[T] |
(T, U) | Tuple[T, U] |
Vec<T> | List[T] |
HashMap<K, V> | Dict[K, V] |
BTreeMap<K, V> | Dict[K, V] |
HashSet<T> | Set[T] |
BTreeSet<T> | Set[T] |
&PyCell<T: PyClass> | T |
PyRef<T: PyClass> | T |
PyRefMut<T: PyClass> | T |
Requires the num-complex optional feature.
Requires the hashbrown optional feature.
Requires the indexmap optional feature.
Conversion traits
PyO3 provides some handy traits to convert between Python types and Rust types.
.extract() and the FromPyObject trait
The easiest way to convert a Python object to a Rust value is using
.extract(). It returns a PyResult with a type error if the conversion
fails, so usually you will use something like
use pyo3::prelude::*; use pyo3::types::PyList; fn main() -> PyResult<()> { Python::with_gil(|py| { let list = PyList::new(py, b"foo"); let v: Vec<i32> = list.extract()?; assert_eq!(&v, &[102, 111, 111]); Ok(()) }) }
This method is available for many Python object types, and can produce a wide
variety of Rust types, which you can check out in the implementor list of
FromPyObject.
FromPyObject is also implemented for your own Rust types wrapped as Python
objects (see the chapter about classes). There, in order to both be
able to operate on mutable references and satisfy Rust’s rules of non-aliasing
mutable references, you have to extract the PyO3 reference wrappers PyRef
and PyRefMut. They work like the reference wrappers of
std::cell::RefCell and ensure (at runtime) that Rust borrows are allowed.
Deriving FromPyObject
FromPyObject can be automatically derived for many kinds of structs and enums
if the member types themselves implement FromPyObject. This even includes members
with a generic type T: FromPyObject. Derivation for empty enums, enum variants and
structs is not supported.
Deriving FromPyObject for structs
The derivation generates code that will attempt to access the attribute my_string on
the Python object, i.e. obj.getattr("my_string"), and call extract() on the attribute.
use pyo3::prelude::*; #[derive(FromPyObject)] struct RustyStruct { my_string: String, } fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let module = PyModule::from_code( py, "class Foo: def __init__(self): self.my_string = 'test'", "", "", )?; let class = module.getattr("Foo")?; let instance = class.call0()?; let rustystruct: RustyStruct = instance.extract()?; assert_eq!(rustystruct.my_string, "test"); Ok(()) }) }
By setting the #[pyo3(item)] attribute on the field, PyO3 will attempt to extract the value by calling the get_item method on the Python object.
use pyo3::prelude::*; #[derive(FromPyObject)] struct RustyStruct { #[pyo3(item)] my_string: String, } use pyo3::types::PyDict; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let dict = PyDict::new(py); dict.set_item("my_string", "test")?; let rustystruct: RustyStruct = dict.extract()?; assert_eq!(rustystruct.my_string, "test"); Ok(()) }) }
The argument passed to getattr and get_item can also be configured:
use pyo3::prelude::*; #[derive(FromPyObject)] struct RustyStruct { #[pyo3(item("key"))] string_in_mapping: String, #[pyo3(attribute("name"))] string_attr: String, } fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let module = PyModule::from_code( py, "class Foo(dict): def __init__(self): self.name = 'test' self['key'] = 'test2'", "", "", )?; let class = module.getattr("Foo")?; let instance = class.call0()?; let rustystruct: RustyStruct = instance.extract()?; assert_eq!(rustystruct.string_attr, "test"); assert_eq!(rustystruct.string_in_mapping, "test2"); Ok(()) }) }
This tries to extract string_attr from the attribute name and string_in_mapping
from a mapping with the key "key". The arguments for attribute are restricted to
non-empty string literals while item can take any valid literal that implements
ToBorrowedObject.
Deriving FromPyObject for tuple structs
Tuple structs are also supported but do not allow customizing the extraction. The input is
always assumed to be a Python tuple with the same length as the Rust type, the nth field
is extracted from the nth item in the Python tuple.
use pyo3::prelude::*; #[derive(FromPyObject)] struct RustyTuple(String, String); use pyo3::types::PyTuple; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let tuple = PyTuple::new(py, vec!["test", "test2"]); let rustytuple: RustyTuple = tuple.extract()?; assert_eq!(rustytuple.0, "test"); assert_eq!(rustytuple.1, "test2"); Ok(()) }) }
Tuple structs with a single field are treated as wrapper types which are described in the following section. To override this behaviour and ensure that the input is in fact a tuple, specify the struct as
use pyo3::prelude::*; #[derive(FromPyObject)] struct RustyTuple((String,)); use pyo3::types::PyTuple; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let tuple = PyTuple::new(py, vec!["test"]); let rustytuple: RustyTuple = tuple.extract()?; assert_eq!((rustytuple.0).0, "test"); Ok(()) }) }
Deriving FromPyObject for wrapper types
The pyo3(transparent) attribute can be used on structs with exactly one field. This results
in extracting directly from the input object, i.e. obj.extract(), rather than trying to access
an item or attribute. This behaviour is enabled per default for newtype structs and tuple-variants
with a single field.
use pyo3::prelude::*; #[derive(FromPyObject)] struct RustyTransparentTupleStruct(String); #[derive(FromPyObject)] #[pyo3(transparent)] struct RustyTransparentStruct { inner: String, } use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let s = PyString::new(py, "test"); let tup: RustyTransparentTupleStruct = s.extract()?; assert_eq!(tup.0, "test"); let stru: RustyTransparentStruct = s.extract()?; assert_eq!(stru.inner, "test"); Ok(()) }) }
Deriving FromPyObject for enums
The FromPyObject derivation for enums generates code that tries to extract the variants in the
order of the fields. As soon as a variant can be extracted successfully, that variant is returned.
This makes it possible to extract Python union types like str | int.
The same customizations and restrictions described for struct derivations apply to enum variants,
i.e. a tuple variant assumes that the input is a Python tuple, and a struct variant defaults to
extracting fields as attributes but can be configured in the same manner. The transparent
attribute can be applied to single-field-variants.
use pyo3::prelude::*; #[derive(FromPyObject)] #[derive(Debug)] enum RustyEnum<'a> { Int(usize), // input is a positive int String(String), // input is a string IntTuple(usize, usize), // input is a 2-tuple with positive ints StringIntTuple(String, usize), // input is a 2-tuple with String and int Coordinates3d { // needs to be in front of 2d x: usize, y: usize, z: usize, }, Coordinates2d { // only gets checked if the input did not have `z` #[pyo3(attribute("x"))] a: usize, #[pyo3(attribute("y"))] b: usize, }, #[pyo3(transparent)] CatchAll(&'a PyAny), // This extraction never fails } use pyo3::types::{PyBytes, PyString}; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { { let thing = 42_u8.to_object(py); let rust_thing: RustyEnum<'_> = thing.extract(py)?; assert_eq!( 42, match rust_thing { RustyEnum::Int(i) => i, other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = PyString::new(py, "text"); let rust_thing: RustyEnum<'_> = thing.extract()?; assert_eq!( "text", match rust_thing { RustyEnum::String(i) => i, other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = (32_u8, 73_u8).to_object(py); let rust_thing: RustyEnum<'_> = thing.extract(py)?; assert_eq!( (32, 73), match rust_thing { RustyEnum::IntTuple(i, j) => (i, j), other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = ("foo", 73_u8).to_object(py); let rust_thing: RustyEnum<'_> = thing.extract(py)?; assert_eq!( (String::from("foo"), 73), match rust_thing { RustyEnum::StringIntTuple(i, j) => (i, j), other => unreachable!("Error extracting: {:?}", other), } ); } { let module = PyModule::from_code( py, "class Foo(dict): def __init__(self): self.x = 0 self.y = 1 self.z = 2", "", "", )?; let class = module.getattr("Foo")?; let instance = class.call0()?; let rust_thing: RustyEnum<'_> = instance.extract()?; assert_eq!( (0, 1, 2), match rust_thing { RustyEnum::Coordinates3d { x, y, z } => (x, y, z), other => unreachable!("Error extracting: {:?}", other), } ); } { let module = PyModule::from_code( py, "class Foo(dict): def __init__(self): self.x = 3 self.y = 4", "", "", )?; let class = module.getattr("Foo")?; let instance = class.call0()?; let rust_thing: RustyEnum<'_> = instance.extract()?; assert_eq!( (3, 4), match rust_thing { RustyEnum::Coordinates2d { a, b } => (a, b), other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = PyBytes::new(py, b"text"); let rust_thing: RustyEnum<'_> = thing.extract()?; assert_eq!( b"text", match rust_thing { RustyEnum::CatchAll(i) => i.downcast::<PyBytes>()?.as_bytes(), other => unreachable!("Error extracting: {:?}", other), } ); } Ok(()) }) }
If none of the enum variants match, a PyTypeError containing the names of the
tested variants is returned. The names reported in the error message can be customized
through the #[pyo3(annotation = "name")] attribute, e.g. to use conventional Python type
names:
use pyo3::prelude::*; #[derive(FromPyObject)] #[derive(Debug)] enum RustyEnum { #[pyo3(transparent, annotation = "str")] String(String), #[pyo3(transparent, annotation = "int")] Int(isize), } fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { { let thing = 42_u8.to_object(py); let rust_thing: RustyEnum = thing.extract(py)?; assert_eq!( 42, match rust_thing { RustyEnum::Int(i) => i, other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = "foo".to_object(py); let rust_thing: RustyEnum = thing.extract(py)?; assert_eq!( "foo", match rust_thing { RustyEnum::String(i) => i, other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = b"foo".to_object(py); let error = thing.extract::<RustyEnum>(py).unwrap_err(); assert!(error.is_instance_of::<pyo3::exceptions::PyTypeError>(py)); } Ok(()) }) }
If the input is neither a string nor an integer, the error message will be:
"'<INPUT_TYPE>' cannot be converted to 'str | int'".
#[derive(FromPyObject)] Container Attributes
pyo3(transparent)- extract the field directly from the object as
obj.extract()instead ofget_item()orgetattr() - Newtype structs and tuple-variants are treated as transparent per default.
- only supported for single-field structs and enum variants
- extract the field directly from the object as
pyo3(annotation = "name")- changes the name of the failed variant in the generated error message in case of failure.
- e.g.
pyo3("int")reports the variant’s type asint. - only supported for enum variants
#[derive(FromPyObject)] Field Attributes
pyo3(attribute),pyo3(attribute("name"))- retrieve the field from an attribute, possibly with a custom name specified as an argument
- argument must be a string-literal.
pyo3(item),pyo3(item("key"))- retrieve the field from a mapping, possibly with the custom key specified as an argument.
- can be any literal that implements
ToBorrowedObject
pyo3(from_py_with = "...")- apply a custom function to convert the field from Python the desired Rust type.
- the argument must be the name of the function as a string.
- the function signature must be
fn(&PyAny) -> PyResult<T>whereTis the Rust type of the argument.
IntoPy<T>
This trait defines the to-python conversion for a Rust type. It is usually implemented as
IntoPy<PyObject>, which is the trait needed for returning a value from #[pyfunction] and
#[pymethods].
All types in PyO3 implement this trait, as does a #[pyclass] which doesn’t use extends.
Occasionally you may choose to implement this for custom types which are mapped to Python types without having a unique python type.
#![allow(unused)] fn main() { use pyo3::prelude::*; struct MyPyObjectWrapper(PyObject); impl IntoPy<PyObject> for MyPyObjectWrapper { fn into_py(self, py: Python<'_>) -> PyObject { self.0 } } }
The ToPyObject trait
ToPyObject is a conversion trait that allows various objects to be
converted into PyObject. IntoPy<PyObject> serves the
same purpose, except that it consumes self.
Python exceptions
Defining a new exception
You can use the create_exception! macro to define a new exception type:
#![allow(unused)] fn main() { use pyo3::create_exception; create_exception!(module, MyError, pyo3::exceptions::PyException); }
moduleis the name of the containing module.MyErroris the name of the new exception type.
For example:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::create_exception; use pyo3::types::IntoPyDict; use pyo3::exceptions::PyException; create_exception!(mymodule, CustomError, PyException); Python::with_gil(|py| { let ctx = [("CustomError", py.get_type::<CustomError>())].into_py_dict(py); pyo3::py_run!(py, *ctx, "assert str(CustomError) == \"<class 'mymodule.CustomError'>\""); pyo3::py_run!(py, *ctx, "assert CustomError('oops').args == ('oops',)"); }); }
When using PyO3 to create an extension module, you can add the new exception to the module like this, so that it is importable from Python:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyModule; use pyo3::exceptions::PyException; pyo3::create_exception!(mymodule, CustomError, PyException); #[pymodule] fn mymodule(py: Python<'_>, m: &PyModule) -> PyResult<()> { // ... other elements added to module ... m.add("CustomError", py.get_type::<CustomError>())?; Ok(()) } }
Raising an exception
As described in the function error handling chapter, to raise an exception from a #[pyfunction] or #[pymethods], return an Err(PyErr). PyO3 will automatically raise this exception for you when returing the result to Python.
You can also manually write and fetch errors in the Python interpreter’s global state:
#![allow(unused)] fn main() { use pyo3::{Python, PyErr}; use pyo3::exceptions::PyTypeError; Python::with_gil(|py| { PyTypeError::new_err("Error").restore(py); assert!(PyErr::occurred(py)); drop(PyErr::fetch(py)); }); }
Checking exception types
Python has an isinstance method to check an object’s type.
In PyO3 every object has the PyAny::is_instance and PyAny::is_instance_of methods which do the same thing.
#![allow(unused)] fn main() { use pyo3::Python; use pyo3::types::{PyBool, PyList}; Python::with_gil(|py| { assert!(PyBool::new(py, true).is_instance_of::<PyBool>().unwrap()); let list = PyList::new(py, &[1, 2, 3, 4]); assert!(!list.is_instance_of::<PyBool>().unwrap()); assert!(list.is_instance_of::<PyList>().unwrap()); }); }
To check the type of an exception, you can similarly do:
#![allow(unused)] fn main() { use pyo3::exceptions::PyTypeError; use pyo3::prelude::*; Python::with_gil(|py| { let err = PyTypeError::new_err(()); err.is_instance_of::<PyTypeError>(py); }); }
Using exceptions defined in Python code
It is possible to use an exception defined in Python code as a native Rust type.
The import_exception! macro allows importing a specific exception class and defines a Rust type
for that exception.
#![allow(unused)] #![allow(dead_code)] fn main() { use pyo3::prelude::*; mod io { pyo3::import_exception!(io, UnsupportedOperation); } fn tell(file: &PyAny) -> PyResult<u64> { match file.call_method0("tell") { Err(_) => Err(io::UnsupportedOperation::new_err("not supported: tell")), Ok(x) => x.extract::<u64>(), } } }
pyo3::exceptions
defines exceptions for several standard library modules.
Calling Python in Rust code
- Calling Python in Rust code
This chapter of the guide documents some ways to interact with Python code from Rust:
- How to call Python functions
- How to execute existing Python code
Calling Python functions
Any Python-native object reference (such as &PyAny, &PyList, or &PyCell<MyClass>) can be used to call Python functions.
PyO3 offers two APIs to make function calls:
call- call any callable Python object.call_method- call a method on the Python object.
Both of these APIs take args and kwargs arguments (for positional and keyword arguments respectively). There are variants for less complex calls:
call1andcall_method1to call only with positionalargs.call0andcall_method0to call with no arguments.
For convenience the Py<T> smart pointer also exposes these same six API methods, but needs a Python token as an additional first argument to prove the GIL is held.
The example below calls a Python function behind a PyObject (aka Py<PyAny>) reference:
use pyo3::prelude::*; use pyo3::types::PyTuple; fn main() -> PyResult<()> { let arg1 = "arg1"; let arg2 = "arg2"; let arg3 = "arg3"; Python::with_gil(|py| { let fun: Py<PyAny> = PyModule::from_code( py, "def example(*args, **kwargs): if args != (): print('called with args', args) if kwargs != {}: print('called with kwargs', kwargs) if args == () and kwargs == {}: print('called with no arguments')", "", "", )?.getattr("example")?.into(); // call object without any arguments fun.call0(py)?; // call object with PyTuple let args = PyTuple::new(py, &[arg1, arg2, arg3]); fun.call1(py, args)?; // pass arguments as rust tuple let args = (arg1, arg2, arg3); fun.call1(py, args)?; Ok(()) }) }
Creating keyword arguments
For the call and call_method APIs, kwargs can be None or Some(&PyDict). You can use the IntoPyDict trait to convert other dict-like containers, e.g. HashMap or BTreeMap, as well as tuples with up to 10 elements and Vecs where each element is a two-element tuple.
use pyo3::prelude::*; use pyo3::types::IntoPyDict; use std::collections::HashMap; fn main() -> PyResult<()> { let key1 = "key1"; let val1 = 1; let key2 = "key2"; let val2 = 2; Python::with_gil(|py| { let fun: Py<PyAny> = PyModule::from_code( py, "def example(*args, **kwargs): if args != (): print('called with args', args) if kwargs != {}: print('called with kwargs', kwargs) if args == () and kwargs == {}: print('called with no arguments')", "", "", )?.getattr("example")?.into(); // call object with PyDict let kwargs = [(key1, val1)].into_py_dict(py); fun.call(py, (), Some(kwargs))?; // pass arguments as Vec let kwargs = vec![(key1, val1), (key2, val2)]; fun.call(py, (), Some(kwargs.into_py_dict(py)))?; // pass arguments as HashMap let mut kwargs = HashMap::<&str, i32>::new(); kwargs.insert(key1, 1); fun.call(py, (), Some(kwargs.into_py_dict(py)))?; Ok(()) }) }
Executing existing Python code
If you already have some existing Python code that you need to execute from Rust, the following FAQs can help you select the right PyO3 functionality for your situation:
Want to access Python APIs? Then use PyModule::import.
Pymodule::import can
be used to get handle to a Python module from Rust. You can use this to import and use any Python
module available in your environment.
use pyo3::prelude::*; fn main() -> PyResult<()> { Python::with_gil(|py| { let builtins = PyModule::import(py, "builtins")?; let total: i32 = builtins.getattr("sum")?.call1((vec![1, 2, 3],))?.extract()?; assert_eq!(total, 6); Ok(()) }) }
Want to run just an expression? Then use eval.
Python::eval is
a method to execute a Python expression
and return the evaluated value as a &PyAny object.
use pyo3::prelude::*; fn main() -> Result<(), ()> { Python::with_gil(|py| { let result = py.eval("[i * 10 for i in range(5)]", None, None).map_err(|e| { e.print_and_set_sys_last_vars(py); })?; let res: Vec<i64> = result.extract().unwrap(); assert_eq!(res, vec![0, 10, 20, 30, 40]); Ok(()) }) }
Want to run statements? Then use run.
Python::run is a method to execute one or more
Python statements.
This method returns nothing (like any Python statement), but you can get
access to manipulated objects via the locals dict.
You can also use the py_run! macro, which is a shorthand for Python::run.
Since py_run! panics on exceptions, we recommend you use this macro only for
quickly testing your Python extensions.
use pyo3::prelude::*; use pyo3::{PyCell, py_run}; fn main() { #[pyclass] struct UserData { id: u32, name: String, } #[pymethods] impl UserData { fn as_tuple(&self) -> (u32, String) { (self.id, self.name.clone()) } fn __repr__(&self) -> PyResult<String> { Ok(format!("User {}(id: {})", self.name, self.id)) } } Python::with_gil(|py| { let userdata = UserData { id: 34, name: "Yu".to_string(), }; let userdata = PyCell::new(py, userdata).unwrap(); let userdata_as_tuple = (34, "Yu"); py_run!(py, userdata userdata_as_tuple, r#" assert repr(userdata) == "User Yu(id: 34)" assert userdata.as_tuple() == userdata_as_tuple "#); }) }
You have a Python file or code snippet? Then use PyModule::from_code.
PyModule::from_code
can be used to generate a Python module which can then be used just as if it was imported with
PyModule::import.
Warning: This will compile and execute code. Never pass untrusted code to this function!
use pyo3::{prelude::*, types::{IntoPyDict, PyModule}}; fn main() -> PyResult<()> { Python::with_gil(|py| { let activators = PyModule::from_code(py, r#" def relu(x): """see https://en.wikipedia.org/wiki/Rectifier_(neural_networks)""" return max(0.0, x) def leaky_relu(x, slope=0.01): return x if x >= 0 else x * slope "#, "activators.py", "activators")?; let relu_result: f64 = activators.getattr("relu")?.call1((-1.0,))?.extract()?; assert_eq!(relu_result, 0.0); let kwargs = [("slope", 0.2)].into_py_dict(py); let lrelu_result: f64 = activators .getattr("leaky_relu")?.call((-1.0,), Some(kwargs))? .extract()?; assert_eq!(lrelu_result, -0.2); Ok(()) }) }
Include multiple Python files
You can include a file at compile time by using
std::include_str macro.
Or you can load a file at runtime by using
std::fs::read_to_string function.
Many Python files can be included and loaded as modules. If one file depends on
another you must preserve correct order while declaring PyModule.
Example directory structure:
.
├── Cargo.lock
├── Cargo.toml
├── python_app
│ ├── app.py
│ └── utils
│ └── foo.py
└── src
└── main.rs
python_app/app.py:
from utils.foo import bar
def run():
return bar()
python_app/utils/foo.py:
def bar():
return "baz"
The example below shows:
- how to include content of
app.pyandutils/foo.pyinto your rust binary - how to call function
run()(declared inapp.py) that needs function imported fromutils/foo.py
src/main.rs:
use pyo3::prelude::*;
fn main() -> PyResult<()> {
let py_foo = include_str!(concat!(env!("CARGO_MANIFEST_DIR"), "/python_app/utils/foo.py"));
let py_app = include_str!(concat!(env!("CARGO_MANIFEST_DIR"), "/python_app/app.py"));
let from_python = Python::with_gil(|py| -> PyResult<Py<PyAny>> {
PyModule::from_code(py, py_foo, "utils.foo", "utils.foo")?;
let app: Py<PyAny> = PyModule::from_code(py, py_app, "", "")?
.getattr("run")?
.into();
app.call0(py)
});
println!("py: {}", from_python?);
Ok(())
}
The example below shows:
- how to load content of
app.pyat runtime so that it sees its dependencies automatically - how to call function
run()(declared inapp.py) that needs function imported fromutils/foo.py
It is recommended to use absolute paths because then your binary can be run
from anywhere as long as your app.py is in the expected directory (in this example
that directory is /usr/share/python_app).
src/main.rs:
use pyo3::prelude::*; use pyo3::types::PyList; use std::fs; use std::path::Path; fn main() -> PyResult<()> { let path = Path::new("/usr/share/python_app"); let py_app = fs::read_to_string(path.join("app.py"))?; let from_python = Python::with_gil(|py| -> PyResult<Py<PyAny>> { let syspath: &PyList = py.import("sys")?.getattr("path")?.downcast::<PyList>()?; syspath.insert(0, &path)?; let app: Py<PyAny> = PyModule::from_code(py, &py_app, "", "")? .getattr("run")? .into(); app.call0(py) }); println!("py: {}", from_python?); Ok(()) }
Need to use a context manager from Rust?
Use context managers by directly invoking __enter__ and __exit__.
use pyo3::prelude::*; use pyo3::types::PyModule; fn main() { Python::with_gil(|py| { let custom_manager = PyModule::from_code(py, r#" class House(object): def __init__(self, address): self.address = address def __enter__(self): print(f"Welcome to {self.address}!") def __exit__(self, type, value, traceback): if type: print(f"Sorry you had {type} trouble at {self.address}") else: print(f"Thank you for visiting {self.address}, come again soon!") "#, "house.py", "house").unwrap(); let house_class = custom_manager.getattr("House").unwrap(); let house = house_class.call1(("123 Main Street",)).unwrap(); house.call_method0("__enter__").unwrap(); let result = py.eval("undefined_variable + 1", None, None); // If the eval threw an exception we'll pass it through to the context manager. // Otherwise, __exit__ is called with empty arguments (Python "None"). match result { Ok(_) => { let none = py.None(); house.call_method1("__exit__", (&none, &none, &none)).unwrap(); }, Err(e) => { house.call_method1( "__exit__", (e.get_type(py), e.value(py), e.traceback(py)) ).unwrap(); } } }) }
GIL lifetimes, mutability and Python object types
On first glance, PyO3 provides a huge number of different types that can be used to wrap or refer to Python objects. This page delves into the details and gives an overview of their intended meaning, with examples when each type is best used.
Mutability and Rust types
Since Python has no concept of ownership, and works solely with boxed objects, any Python object can be referenced any number of times, and mutation is allowed from any reference.
The situation is helped a little by the Global Interpreter Lock (GIL), which ensures that only one thread can use the Python interpreter and its API at the same time, while non-Python operations (system calls and extension code) can unlock the GIL. (See the section on parallelism for how to do that in PyO3.)
In PyO3, holding the GIL is modeled by acquiring a token of the type
Python<'py>, which serves three purposes:
- It provides some global API for the Python interpreter, such as
eval. - It can be passed to functions that require a proof of holding the GIL,
such as
Py::clone_ref. - Its lifetime can be used to create Rust references that implicitly guarantee
holding the GIL, such as
&'py PyAny.
The latter two points are the reason why some APIs in PyO3 require the py: Python argument, while others don’t.
The PyO3 API for Python objects is written such that instead of requiring a
mutable Rust reference for mutating operations such as
PyList::append, a shared reference (which, in turn, can only
be created through Python<'_> with a GIL lifetime) is sufficient.
However, Rust structs wrapped as Python objects (called pyclass types) usually
do need &mut access. Due to the GIL, PyO3 can guarantee thread-safe acces
to them, but it cannot statically guarantee uniqueness of &mut references once
an object’s ownership has been passed to the Python interpreter, ensuring
references is done at runtime using PyCell, a scheme very similar to
std::cell::RefCell.
Object types
PyAny
Represents: a Python object of unspecified type, restricted to a GIL
lifetime. Currently, PyAny can only ever occur as a reference, &PyAny.
Used: Whenever you want to refer to some Python object and will have the
GIL for the whole duration you need to access that object. For example,
intermediate values and arguments to pyfunctions or pymethods implemented
in Rust where any type is allowed.
Many general methods for interacting with Python objects are on the PyAny struct,
such as getattr, setattr, and .call.
Conversions:
For a &PyAny object reference any where the underlying object is a Python-native type such as
a list:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyList; Python::with_gil(|py| -> PyResult<()> { let obj: &PyAny = PyList::empty(py); // To &PyList with PyAny::downcast let _: &PyList = obj.downcast()?; // To Py<PyAny> (aka PyObject) with .into() let _: Py<PyAny> = obj.into(); // To Py<PyList> with PyAny::extract let _: Py<PyList> = obj.extract()?; Ok(()) }).unwrap(); }
For a &PyAny object reference any where the underlying object is a #[pyclass]:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::{Py, Python, PyAny, PyResult}; #[pyclass] #[derive(Clone)] struct MyClass { } Python::with_gil(|py| -> PyResult<()> { let obj: &PyAny = Py::new(py, MyClass { })?.into_ref(py); // To &PyCell<MyClass> with PyAny::downcast let _: &PyCell<MyClass> = obj.downcast()?; // To Py<PyAny> (aka PyObject) with .into() let _: Py<PyAny> = obj.into(); // To Py<MyClass> with PyAny::extract let _: Py<MyClass> = obj.extract()?; // To MyClass with PyAny::extract, if MyClass: Clone let _: MyClass = obj.extract()?; // To PyRef<'_, MyClass> or PyRefMut<'_, MyClass> with PyAny::extract let _: PyRef<'_, MyClass> = obj.extract()?; let _: PyRefMut<'_, MyClass> = obj.extract()?; Ok(()) }).unwrap(); }
PyTuple, PyDict, and many more
Represents: a native Python object of known type, restricted to a GIL
lifetime just like PyAny.
Used: Whenever you want to operate with native Python types while holding
the GIL. Like PyAny, this is the most convenient form to use for function
arguments and intermediate values.
These types all implement Deref<Target = PyAny>, so they all expose the same
methods which can be found on PyAny.
To see all Python types exposed by PyO3 you should consult the
pyo3::types module.
Conversions:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyList; Python::with_gil(|py| -> PyResult<()> { let list = PyList::empty(py); // Use methods from PyAny on all Python types with Deref implementation let _ = list.repr()?; // To &PyAny automatically with Deref implementation let _: &PyAny = list; // To &PyAny explicitly with .as_ref() let _: &PyAny = list.as_ref(); // To Py<T> with .into() or Py::from() let _: Py<PyList> = list.into(); // To PyObject with .into() or .to_object(py) let _: PyObject = list.into(); Ok(()) }).unwrap(); }
Py<T> and PyObject
Represents: a GIL-independent reference to a Python object. This can be a Python native type
(like PyTuple), or a pyclass type implemented in Rust. The most commonly-used variant,
Py<PyAny>, is also known as PyObject.
Used: Whenever you want to carry around references to a Python object without caring about a GIL lifetime. For example, storing Python object references in a Rust struct that outlives the Python-Rust FFI boundary, or returning objects from functions implemented in Rust back to Python.
Can be cloned using Python reference counts with .clone().
Conversions:
For a Py<PyList>, the conversions are as below:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyList; Python::with_gil(|py| { let list: Py<PyList> = PyList::empty(py).into(); // To &PyList with Py::as_ref() (borrows from the Py) let _: &PyList = list.as_ref(py); let list_clone = list.clone(); // Because `.into_ref()` will consume `list`. // To &PyList with Py::into_ref() (moves the pointer into PyO3's object storage) let _: &PyList = list.into_ref(py); let list = list_clone; // To Py<PyAny> (aka PyObject) with .into() let _: Py<PyAny> = list.into(); }) }
For a #[pyclass] struct MyClass, the conversions for Py<MyClass> are below:
#![allow(unused)] fn main() { use pyo3::prelude::*; Python::with_gil(|py| { #[pyclass] struct MyClass { } Python::with_gil(|py| -> PyResult<()> { let my_class: Py<MyClass> = Py::new(py, MyClass { })?; // To &PyCell<MyClass> with Py::as_ref() (borrows from the Py) let _: &PyCell<MyClass> = my_class.as_ref(py); let my_class_clone = my_class.clone(); // Because `.into_ref()` will consume `my_class`. // To &PyCell<MyClass> with Py::into_ref() (moves the pointer into PyO3's object storage) let _: &PyCell<MyClass> = my_class.into_ref(py); let my_class = my_class_clone.clone(); // To Py<PyAny> (aka PyObject) with .into_py(py) let _: Py<PyAny> = my_class.into_py(py); let my_class = my_class_clone; // To PyRef<'_, MyClass> with Py::borrow or Py::try_borrow let _: PyRef<'_, MyClass> = my_class.try_borrow(py)?; // To PyRefMut<'_, MyClass> with Py::borrow_mut or Py::try_borrow_mut let _: PyRefMut<'_, MyClass> = my_class.try_borrow_mut(py)?; Ok(()) }).unwrap(); }); }
PyCell<SomeType>
Represents: a reference to a Rust object (instance of PyClass) which is
wrapped in a Python object. The cell part is an analog to stdlib’s
RefCell to allow access to &mut references.
Used: for accessing pure-Rust API of the instance (members and functions
taking &SomeType or &mut SomeType) while maintaining the aliasing rules of
Rust references.
Like pyo3’s Python native types, PyCell<T> implements Deref<Target = PyAny>,
so it also exposes all of the methods on PyAny.
Conversions:
PyCell<T> can be used to access &T and &mut T via PyRef<T> and PyRefMut<T> respectively.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { } Python::with_gil(|py| -> PyResult<()> { let cell: &PyCell<MyClass> = PyCell::new(py, MyClass { })?; // To PyRef<T> with .borrow() or .try_borrow() let py_ref: PyRef<'_, MyClass> = cell.try_borrow()?; let _: &MyClass = &*py_ref; drop(py_ref); // To PyRefMut<T> with .borrow_mut() or .try_borrow_mut() let mut py_ref_mut: PyRefMut<'_, MyClass> = cell.try_borrow_mut()?; let _: &mut MyClass = &mut *py_ref_mut; Ok(()) }).unwrap(); }
PyCell<T> can also be accessed like a Python-native type.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { } Python::with_gil(|py| -> PyResult<()> { let cell: &PyCell<MyClass> = PyCell::new(py, MyClass { })?; // Use methods from PyAny on PyCell<T> with Deref implementation let _ = cell.repr()?; // To &PyAny automatically with Deref implementation let _: &PyAny = cell; // To &PyAny explicitly with .as_ref() let _: &PyAny = cell.as_ref(); Ok(()) }).unwrap(); }
PyRef<SomeType> and PyRefMut<SomeType>
Represents: reference wrapper types employed by PyCell to keep track of
borrows, analog to Ref and RefMut used by RefCell.
Used: while borrowing a PyCell. They can also be used with .extract()
on types like Py<T> and PyAny to get a reference quickly.
Related traits and types
PyClass
This trait marks structs defined in Rust that are also usable as Python classes,
usually defined using the #[pyclass] macro.
PyNativeType
This trait marks structs that mirror native Python types, such as PyList.
Parallelism
CPython has the infamous Global Interpreter Lock, which prevents several threads from executing Python bytecode in parallel. This makes threading in Python a bad fit for CPU-bound tasks and often forces developers to accept the overhead of multiprocessing.
In PyO3 parallelism can be easily achieved in Rust-only code. Let’s take a look at our word-count example, where we have a search function that utilizes the rayon crate to count words in parallel.
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; // These traits let us use `par_lines` and `map`. use rayon::str::ParallelString; use rayon::iter::ParallelIterator; /// Count the occurrences of needle in line, case insensitive fn count_line(line: &str, needle: &str) -> usize { let mut total = 0; for word in line.split(' ') { if word == needle { total += 1; } } total } #[pyfunction] fn search(contents: &str, needle: &str) -> usize { contents .par_lines() .map(|line| count_line(line, needle)) .sum() } }
But let’s assume you have a long running Rust function which you would like to execute several times in parallel. For the sake of example let’s take a sequential version of the word count:
#![allow(unused)] fn main() { #![allow(dead_code)] fn count_line(line: &str, needle: &str) -> usize { let mut total = 0; for word in line.split(' ') { if word == needle { total += 1; } } total } fn search_sequential(contents: &str, needle: &str) -> usize { contents.lines().map(|line| count_line(line, needle)).sum() } }
To enable parallel execution of this function, the Python::allow_threads method can be used to temporarily release the GIL, thus allowing other Python threads to run. We then have a function exposed to the Python runtime which calls search_sequential inside a closure passed to Python::allow_threads to enable true parallelism:
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; fn count_line(line: &str, needle: &str) -> usize { let mut total = 0; for word in line.split(' ') { if word == needle { total += 1; } } total } fn search_sequential(contents: &str, needle: &str) -> usize { contents.lines().map(|line| count_line(line, needle)).sum() } #[pyfunction] fn search_sequential_allow_threads(py: Python<'_>, contents: &str, needle: &str) -> usize { py.allow_threads(|| search_sequential(contents, needle)) } }
Now Python threads can use more than one CPU core, resolving the limitation which usually makes multi-threading in Python only good for IO-bound tasks:
from concurrent.futures import ThreadPoolExecutor
from word_count import search_sequential_allow_threads
executor = ThreadPoolExecutor(max_workers=2)
future_1 = executor.submit(
word_count.search_sequential_allow_threads, contents, needle
)
future_2 = executor.submit(
word_count.search_sequential_allow_threads, contents, needle
)
result_1 = future_1.result()
result_2 = future_2.result()
Benchmark
Let’s benchmark the word-count example to verify that we really did unlock parallelism with PyO3.
We are using pytest-benchmark to benchmark four word count functions:
- Pure Python version
- Rust parallel version
- Rust sequential version
- Rust sequential version executed twice with two Python threads
The benchmark script can be found here, and we can run nox in the word-count folder to benchmark these functions.
While the results of the benchmark of course depend on your machine, the relative results should be similar to this (mid 2020):
-------------------------------------------------------------------------------------------------- benchmark: 4 tests -------------------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_word_count_rust_parallel 1.7315 (1.0) 4.6495 (1.0) 1.9972 (1.0) 0.4299 (1.0) 1.8142 (1.0) 0.2049 (1.0) 40;46 500.6943 (1.0) 375 1
test_word_count_rust_sequential 7.3348 (4.24) 10.3556 (2.23) 8.0035 (4.01) 0.7785 (1.81) 7.5597 (4.17) 0.8641 (4.22) 26;5 124.9457 (0.25) 121 1
test_word_count_rust_sequential_twice_with_threads 7.9839 (4.61) 10.3065 (2.22) 8.4511 (4.23) 0.4709 (1.10) 8.2457 (4.55) 0.3927 (1.92) 17;17 118.3274 (0.24) 114 1
test_word_count_python_sequential 27.3985 (15.82) 45.4527 (9.78) 28.9604 (14.50) 4.1449 (9.64) 27.5781 (15.20) 0.4638 (2.26) 3;5 34.5299 (0.07) 35 1
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
You can see that the Python threaded version is not much slower than the Rust sequential version, which means compared to an execution on a single CPU core the speed has doubled.
Debugging
Macros
PyO3’s attributes (#[pyclass], #[pymodule], etc.) are procedural macros, which means that they rewrite the source of the annotated item. You can view the generated source with the following command, which also expands a few other things:
cargo rustc --profile=check -- -Z unstable-options --pretty=expanded > expanded.rs; rustfmt expanded.rs
(You might need to install rustfmt if you don’t already have it.)
You can also debug classic !-macros by adding -Z trace-macros:
cargo rustc --profile=check -- -Z unstable-options --pretty=expanded -Z trace-macros > expanded.rs; rustfmt expanded.rs
See cargo expand for a more elaborate version of those commands.
Running with Valgrind
Valgrind is a tool to detect memory management bugs such as memory leaks.
You first need to install a debug build of Python, otherwise Valgrind won’t produce usable results. In Ubuntu there’s e.g. a python3-dbg package.
Activate an environment with the debug interpreter and recompile. If you’re on Linux, use ldd with the name of your binary and check that you’re linking e.g. libpython3.7d.so.1.0 instead of libpython3.7.so.1.0.
Download the suppressions file for cpython.
Run Valgrind with valgrind --suppressions=valgrind-python.supp ./my-command --with-options
Getting a stacktrace
The best start to investigate a crash such as an segmentation fault is a backtrace. You can set RUST_BACKTRACE=1 as an environment variable to get the stack trace on a panic!. Alternatively you can use a debugger such as gdb to explore the issue. Rust provides a wrapper, rust-gdb, which has pretty-printers for inspecting Rust variables. Since PyO3 uses cdylib for Python shared objects, it does not receive the pretty-print debug hooks in rust-gdb (rust-lang/rust#96365). The mentioned issue contains a workaround for enabling pretty-printers in this case.
- Link against a debug build of python as described in the previous chapter
- Run
rust-gdb <my-binary> - Set a breakpoint (
b) onrust_panicif you are investigating apanic! - Enter
rto run - After the crash occurred, enter
btorbt fullto print the stacktrace
Often it is helpful to run a small piece of Python code to exercise a section of Rust.
rust-gdb --args python -c "import my_package; my_package.sum_to_string(1, 2)"
Features reference
PyO3 provides a number of Cargo features to customise functionality. This chapter of the guide provides detail on each of them.
By default, only the macros feature is enabled.
Features for extension module authors
extension-module
This feature is required when building a Python extension module using PyO3.
It tells PyO3’s build script to skip linking against libpython.so on Unix platforms, where this must not be done.
See the building and distribution section for further detail.
abi3
This feature is used when building Python extension modules to create wheels which are compatible with multiple Python versions.
It restricts PyO3’s API to a subset of the full Python API which is guaranteed by PEP 384 to be forwards-compatible with future Python versions.
See the building and distribution section for further detail.
The abi3-pyXY features
(abi3-py37, abi3-py38, abi3-py39, and abi3-py310)
These features are extensions of the abi3 feature to specify the exact minimum Python version which the multiple-version-wheel will support.
See the building and distribution section for further detail.
generate-import-lib
This experimental feature is used to generate import libraries for Python DLL for MinGW-w64 and MSVC (cross-)compile targets.
Enabling it allows to (cross-)compile extension modules to any Windows targets without having to install the Windows Python distribution files for the target.
See the building and distribution section for further detail.
Features for embedding Python in Rust
auto-initialize
This feature changes Python::with_gil and Python::acquire_gil to automatically initialize a Python interpreter (by calling prepare_freethreaded_python) if needed.
If you do not enable this feature, you should call pyo3::prepare_freethreaded_python() before attempting to call any other Python APIs.
Advanced Features
macros
This feature enables a dependency on the pyo3-macros crate, which provides the procedural macros portion of PyO3’s API:
#[pymodule]#[pyfunction]#[pyclass]#[pymethods]#[derive(FromPyObject)]
It also provides the py_run! macro.
These macros require a number of dependencies which may not be needed by users who just need PyO3 for Python FFI. Disabling this feature enables faster builds for those users, as these dependencies will not be built if this feature is disabled.
This feature is enabled by default. To disable it, set
default-features = falsefor thepyo3entry in your Cargo.toml.
multiple-pymethods
This feature enables a dependency on inventory, which enables each #[pyclass] to have more than one #[pymethods] block. This feature also requires a minimum Rust version of 1.62 due to limitations in the inventory crate.
Most users should only need a single #[pymethods] per #[pyclass]. In addition, not all platforms (e.g. Wasm) are supported by inventory. For this reason this feature is not enabled by default, meaning fewer dependencies and faster compilation for the majority of users.
See the #[pyclass] implementation details for more information.
nightly
The nightly feature needs the nightly Rust compiler. This allows PyO3 to use the auto_traits and negative_impls features to fix the Python::allow_threads function.
resolve-config
The resolve-config feature of the pyo3-build-config crate controls whether that crate’s
build script automatically resolves a Python interpreter / build configuration. This feature is primarily useful when building PyO3
itself. By default this feature is not enabled, meaning you can freely use pyo3-build-config as a standalone library to read or write PyO3 build configuration files or resolve metadata about a Python interpreter.
Optional Dependencies
These features enable conversions between Python types and types from other Rust crates, enabling easy access to the rest of the Rust ecosystem.
anyhow
Adds a dependency on anyhow. Enables a conversion from anyhow’s Error type to PyErr, for easy error handling.
chrono
Adds a dependency on chrono. Enables a conversion from chrono’s types to python:
- Duration ->
PyDelta - FixedOffset ->
PyDelta - Utc ->
PyTzInfo - NaiveDate ->
PyDate - NaiveTime ->
PyTime - DateTime ->
PyDateTime
eyre
Adds a dependency on eyre. Enables a conversion from eyre’s Report type to PyErr, for easy error handling.
hashbrown
Adds a dependency on hashbrown and enables conversions into its HashMap and HashSet types.
indexmap
Adds a dependency on indexmap and enables conversions into its IndexMap type.
num-bigint
Adds a dependency on num-bigint and enables conversions into its BigInt and BigUint types.
num-complex
Adds a dependency on num-complex and enables conversions into its Complex type.
serde
Enables (de)serialization of Py#[derive(Serialize, Deserialize) on structs that hold references to #[pyclass] instances
#![allow(unused)] fn main() { #[cfg(feature = "serde")] #[allow(dead_code)] mod serde_only { use pyo3::prelude::*; use serde::{Deserialize, Serialize}; #[pyclass] #[derive(Serialize, Deserialize)] struct Permission { name: String } #[pyclass] #[derive(Serialize, Deserialize)] struct User { username: String, permissions: Vec<Py<Permission>> } } }
Memory management
Rust and Python have very different notions of memory management. Rust has a strict memory model with concepts of ownership, borrowing, and lifetimes, where memory is freed at predictable points in program execution. Python has a looser memory model in which variables are reference-counted with shared, mutable state by default. A global interpreter lock (GIL) is needed to prevent race conditions, and a garbage collector is needed to break reference cycles. Memory in Python is freed eventually by the garbage collector, but not usually in a predictable way.
PyO3 bridges the Rust and Python memory models with two different strategies for
accessing memory allocated on Python’s heap from inside Rust. These are
GIL-bound, or “owned” references, and GIL-independent Py<Any> smart pointers.
GIL-bound memory
PyO3’s GIL-bound, “owned references” (&PyAny etc.) make PyO3 more ergonomic to
use by ensuring that their lifetime can never be longer than the duration the
Python GIL is held. This means that most of PyO3’s API can assume the GIL is
held. (If PyO3 could not assume this, every PyO3 API would need to take a
Python GIL token to prove that the GIL is held.) This allows us to write
very simple and easy-to-understand programs like this:
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let hello: &PyString = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello); Ok(()) })?; Ok(()) }
Internally, calling Python::with_gil() or Python::acquire_gil() creates a
GILPool which owns the memory pointed to by the reference. In the example
above, the lifetime of the reference hello is bound to the GILPool. When
the with_gil() closure ends or the GILGuard from acquire_gil() is dropped,
the GILPool is also dropped and the Python reference counts of the variables
it owns are decreased, releasing them to the Python garbage collector. Most
of the time we don’t have to think about this, but consider the following:
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { for _ in 0..10 { let hello: &PyString = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello); } // There are 10 copies of `hello` on Python's heap here. Ok(()) })?; Ok(()) }
We might assume that the hello variable’s memory is freed at the end of each
loop iteration, but in fact we create 10 copies of hello on Python’s heap.
This may seem surprising at first, but it is completely consistent with Rust’s
memory model. The hello variable is dropped at the end of each loop, but it
is only a reference to the memory owned by the GILPool, and its lifetime is
bound to the GILPool, not the for loop. The GILPool isn’t dropped until
the end of the with_gil() closure, at which point the 10 copies of hello
are finally released to the Python garbage collector.
In general we don’t want unbounded memory growth during loops! One workaround is to acquire and release the GIL with each iteration of the loop.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { for _ in 0..10 { Python::with_gil(|py| -> PyResult<()> { let hello: &PyString = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello); Ok(()) })?; // only one copy of `hello` at a time } Ok(()) }
It might not be practical or performant to acquire and release the GIL so many
times. Another workaround is to work with the GILPool object directly, but
this is unsafe.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { for _ in 0..10 { let pool = unsafe { py.new_pool() }; let py = pool.python(); let hello: &PyString = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello); } Ok(()) })?; Ok(()) }
The unsafe method Python::new_pool allows you to create a nested GILPool
from which you can retrieve a new py: Python GIL token. Variables created
with this new GIL token are bound to the nested GILPool and will be released
when the nested GILPool is dropped. Here, the nested GILPool is dropped
at the end of each loop iteration, before the with_gil() closure ends.
When doing this, you must be very careful to ensure that once the GILPool is
dropped you do not retain access to any owned references created after the
GILPool was created. Read the
documentation for Python::new_pool()
for more information on safety.
GIL-independent memory
Sometimes we need a reference to memory on Python’s heap that can outlive the
GIL. Python’s Py<PyAny> is analogous to Rc<T>, but for variables whose
memory is allocated on Python’s heap. Cloning a Py<PyAny> increases its
internal reference count just like cloning Rc<T>. The smart pointer can
outlive the GIL from which it was created. It isn’t magic, though. We need to
reacquire the GIL to access the memory pointed to by the Py<PyAny>.
What happens to the memory when the last Py<PyAny> is dropped and its
reference count reaches zero? It depends whether or not we are holding the GIL.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let hello: Py<PyString> = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello.as_ref(py)); Ok(()) })?; Ok(()) }
At the end of the Python::with_gil() closure hello is dropped, and then the
GIL is dropped. Since hello is dropped while the GIL is still held by the
current thread, its memory is released to the Python garbage collector
immediately.
This example wasn’t very interesting. We could have just used a GIL-bound
&PyString reference. What happens when the last Py<Any> is dropped while
we are not holding the GIL?
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { let hello: Py<PyString> = Python::with_gil(|py| { py.eval("\"Hello World!\"", None, None)?.extract() })?; // Do some stuff... // Now sometime later in the program we want to access `hello`. Python::with_gil(|py| { println!("Python says: {}", hello.as_ref(py)); }); // Now we're done with `hello`. drop(hello); // Memory *not* released here. // Sometime later we need the GIL again for something... Python::with_gil(|py| // Memory for `hello` is released here. () ); Ok(()) }
When hello is dropped nothing happens to the pointed-to memory on Python’s
heap because nothing can happen if we’re not holding the GIL. Fortunately,
the memory isn’t leaked. PyO3 keeps track of the memory internally and will
release it the next time we acquire the GIL.
We can avoid the delay in releasing memory if we are careful to drop the
Py<Any> while the GIL is held.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { let hello: Py<PyString> = Python::with_gil(|py| { py.eval("\"Hello World!\"", None, None)?.extract() })?; // Do some stuff... // Now sometime later in the program: Python::with_gil(|py| { println!("Python says: {}", hello.as_ref(py)); drop(hello); // Memory released here. }); Ok(()) }
We could also have used Py::into_ref(), which consumes self, instead of
Py::as_ref(). But note that in addition to being slower than as_ref(),
into_ref() binds the memory to the lifetime of the GILPool, which means
that rather than being released immediately, the memory will not be released
until the GIL is dropped.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { let hello: Py<PyString> = Python::with_gil(|py| { py.eval("\"Hello World!\"", None, None)?.extract() })?; // Do some stuff... // Now sometime later in the program: Python::with_gil(|py| { println!("Python says: {}", hello.into_ref(py)); // Memory not released yet. // Do more stuff... // Memory released here at end of `with_gil()` closure. }); Ok(()) }
Advanced topics
FFI
PyO3 exposes much of Python’s C API through the ffi module.
The C API is naturally unsafe and requires you to manage reference counts, errors and specific invariants yourself. Please refer to the C API Reference Manual and The Rustonomicon before using any function from that API.
Memory management
PyO3’s &PyAny “owned references” and Py<PyAny> smart pointers are used to
access memory stored in Python’s heap. This memory sometimes lives for longer
than expected because of differences in Rust and Python’s memory models. See
the chapter on memory management for more information.
Building and distribution
- Building and distribution
This chapter of the guide goes into detail on how to build and distribute projects using PyO3.
- The way to achieve this is very different depending on whether:
- the project is a Python module implemented in Rust
- or a Rust binary embedding Python.
-
For both types of project there are also common problems such as the Python version to build for and the linker arguments to use.
-
The material in this chapter is intended for users who have already read the PyO3 README.
-
It covers in turn the choices that can be made for Python modules and for Rust binaries.
-
There is also a section at the end about cross-compiling projects using PyO3.
-
There is an additional sub-chapter dedicated to supporting multiple Python versions.
Configuring the Python version
Basic Info
PyO3 uses a build script (backed by the pyo3-build-config crate) to determine the Python version and set the correct linker arguments.
- Order By default it will attempt to use the following in order:
- Any active Python virtualenv.
- The
pythonexecutable (if it’s a Python 3 interpreter). - The
python3executable.
-
Override You can override the Python interpreter by setting the
PYO3_PYTHONenvironment variable, e.g.PYO3_PYTHON=python3.7,PYO3_PYTHON=/usr/bin/python3.9, or even a PyPy interpreterPYO3_PYTHON=pypy3. -
Build Once the Python interpreter is located,
pyo3-build-configexecutes it to query the information in thesysconfigmodule, which is needed to configure the rest of the compilation.
To validate the configuration which PyO3 will use, you can run a compilation with the environment variable PYO3_PRINT_CONFIG=1 set.
An example output of doing this is shown below:
$ PYO3_PRINT_CONFIG=1 cargo build
Compiling pyo3 v0.14.1 (/home/david/dev/pyo3)
error: failed to run custom build command for `pyo3 v0.14.1 (/home/david/dev/pyo3)`
Caused by:
process didn't exit successfully: `/home/david/dev/pyo3/target/debug/build/pyo3-7a8cf4fe22e959b7/build-script-build` (exit status: 101)
--- stdout
cargo:rerun-if-env-changed=PYO3_CROSS
cargo:rerun-if-env-changed=PYO3_CROSS_LIB_DIR
cargo:rerun-if-env-changed=PYO3_CROSS_PYTHON_VERSION
cargo:rerun-if-env-changed=PYO3_PRINT_CONFIG
-- PYO3_PRINT_CONFIG=1 is set, printing configuration and halting compile --
implementation=CPython
version=3.8
shared=true
abi3=false
lib_name=python3.8
lib_dir=/usr/lib
executable=/usr/bin/python
pointer_width=64
build_flags=
suppress_build_script_link_lines=false
Advanced: config files
If you save the above output config from PYO3_PRINT_CONFIG to a file, it is possible to manually override the contents and feed it back into PyO3 using the PYO3_CONFIG_FILE env var.
If your build environment is unusual enough that PyO3’s regular configuration detection doesn’t work, using a config file like this will give you the flexibility to make PyO3 work for you.
To see the full set of options supported, see the documentation for the
InterpreterConfigstruct.
Building Python extension modules
Python extension modules need to be compiled differently depending on the OS (and architecture) that they are being compiled for. As well as multiple OSes (and architectures), there are also many different Python versions which are actively supported. Packages uploaded to PyPI usually want to upload prebuilt “wheels” covering many OS/arch/version combinations so that users on all these different platforms don’t have to compile the package themselves. Package vendors can opt-in to the “abi3” limited Python API which allows their wheels to be used on multiple Python versions, reducing the number of wheels they need to compile, but restricts the functionality they can use.
There are many ways to go about this:
- it is possible to use
cargoto build the extension module (along with some manual work, which varies with OS). - The PyO3 ecosystem has two packaging tools,
maturinandsetuptools-rust, which abstract over the OS difference and also support building wheels for PyPI upload.
PyO3 has some Cargo features to configure projects for building Python extension modules:
- The
extension-modulefeature, which must be enabled when building Python extension modules. - The
abi3feature and its version-specificabi3-pyXYcompanions, which are used to opt-in to the limited Python API in order to support multiple Python versions in a single wheel.
-
This section describes each of these packaging tools before describing how to build manually without them.
-
It then proceeds with an explanation of the
extension-modulefeature. -
Finally, there is a section describing PyO3’s
abi3features.
Packaging tools
The PyO3 ecosystem has two main choices to abstract the process of developing Python extension modules:
- maturin is a command-line tool to build, package and upload Python modules.
- It makes opinionated choices about project layout meaning it needs very little configuration.
- This makes it a great choice for users who are building a Python extension from scratch and don’t need flexibility.
- setuptools-rust is an add-on for
setuptoolswhich adds extra keyword arguments to thesetup.pyconfiguration file. - It requires more configuration than
maturin, however this gives additional flexibility for users adding Rust to an existing Python package that can’t satisfymaturin’s constraints.
Consult each project’s documentation for full details on how to get started using them and how to upload wheels to PyPI.
There are also
maturin-starterandsetuptools-rust-starterexamples in the PyO3 repository.
Manual builds
To build a PyO3-based Python extension manually, start by running cargo build as normal in a library project which uses PyO3’s extension-module feature and has the cdylib crate type.
Once built, symlink (or copy) and rename the shared library from Cargo’s target/ directory to your desired output directory:
- on macOS, rename
libyour_module.dylibtoyour_module.so. - on Windows, rename
libyour_module.dlltoyour_module.pyd. - on Linux, rename
libyour_module.sotoyour_module.so.
You can then open a Python shell in the output directory and you’ll be able to run import your_module.
If you’re packaging your library for redistribution, you should indicated the Python interpreter your library is compiled for by including the platform tag in its name.
This prevents incompatible interpreters from trying to import your library. If you’re compiling for PyPy you must include the platform tag, or PyPy will ignore the module.
See, as an example, Bazel rules to build PyO3 on Linux at https://github.com/TheButlah/rules_pyo3.
Platform tags
Rather than using just the .so or .pyd extension suggested above (depending on OS), uou can prefix the shared library extension with a platform tag to indicate the interpreter it is compatible with. You can query your interpreter’s platform tag from the sysconfig module. Some example outputs of this are seen below:
# CPython 3.10 on macOS
.cpython-310-darwin.so
# PyPy 7.3 (Python 3.8) on Linux
$ python -c 'import sysconfig; print(sysconfig.get_config_var("EXT_SUFFIX"))'
.pypy38-pp73-x86_64-linux-gnu.so
So, for example, a valid module library name on CPython 3.10 for macOS is your_module.cpython-310-darwin.so, and its equivalent when compiled for PyPy 7.3 on Linux would be your_module.pypy38-pp73-x86_64-linux-gnu.so.
See PEP 3149 for more background on platform tags.
macOS
On macOS, because the extension-module feature disables linking to libpython (see the next section), some additional linker arguments need to be set. maturin and setuptools-rust both pass these arguments for PyO3 automatically, but projects using manual builds will need to set these directly in order to support macOS.
The easiest way to set the correct linker arguments is to add a build.rs with the following content:
fn main() {
pyo3_build_config::add_extension_module_link_args();
}
Remember to also add pyo3-build-config to the build-dependencies section in Cargo.toml.
An alternative to using pyo3-build-config is add the following to a cargo configuration file (e.g. .cargo/config.toml):
[target.x86_64-apple-darwin]
rustflags = [
"-C", "link-arg=-undefined",
"-C", "link-arg=dynamic_lookup",
]
[target.aarch64-apple-darwin]
rustflags = [
"-C", "link-arg=-undefined",
"-C", "link-arg=dynamic_lookup",
]
Using the MacOS system python3 (/usr/bin/python3, as opposed to python installed via homebrew, pyenv, nix, etc.) may result in runtime errors such as Library not loaded: @rpath/Python3.framework/Versions/3.8/Python3. These can be resolved with another addition to .cargo/config.toml:
[build]
rustflags = [
"-C", "link-args=-Wl,-rpath,/Library/Developer/CommandLineTools/Library/Frameworks",
]
Alternatively, on rust >= 1.56, one can include in build.rs:
fn main() { println!( "cargo:rustc-link-arg=-Wl,-rpath,/Library/Developer/CommandLineTools/Library/Frameworks" ); }
For more discussion on and workarounds for MacOS linking problems see this issue.
Finally, don’t forget that on MacOS the extension-module feature will cause cargo test to fail without the --no-default-features flag (see the FAQ).
The extension-module feature
PyO3’s extension-module feature is used to disable linking to libpython on unix targets.
This is necessary because by default PyO3 links to libpython. This makes binaries, tests, and examples “just work”. However, Python extensions on unix must not link to libpython for manylinux compliance.
The downside of not linking to libpython is that binaries, tests, and examples (which usually embed Python) will fail to build. If you have an extension module as well as other outputs in a single project, you need to use optional Cargo features to disable the extension-module when you’re not building the extension module. See the FAQ for an example workaround.
Py_LIMITED_API/abi3
By default, Python extension modules can only be used with the same Python version they were compiled against. For example, an extension module built for Python 3.5 can’t be imported in Python 3.8. PEP 384 introduced the idea of the limited Python API, which would have a stable ABI enabling extension modules built with it to be used against multiple Python versions. This is also known as abi3.
The advantage of building extension modules using the limited Python API is that package vendors only need to build and distribute a single copy (for each OS / architecture), and users can install it on all Python versions from the minimum version and up. The downside of this is that PyO3 can’t use optimizations which rely on being compiled against a known exact Python version. It’s up to you to decide whether this matters for your extension module. It’s also possible to design your extension module such that you can distribute abi3 wheels but allow users compiling from source to benefit from additional optimizations - see the support for multiple python versions section of this guide, in particular the #[cfg(Py_LIMITED_API)] flag.
There are three steps involved in making use of abi3 when building Python packages as wheels:
- Enable the
abi3feature inpyo3. This ensurespyo3only calls Python C-API functions which are part of the stable API, and on Windows also ensures that the project links against the correct shared object (no special behavior is required on other platforms):
[dependencies]
pyo3 = { {{#PYO3_CRATE_VERSION}}, features = ["abi3"] }
-
Ensure that the built shared objects are correctly marked as
abi3. This is accomplished by telling your build system that you’re using the limited API.maturin>= 0.9.0 andsetuptools-rust>= 0.11.4 supportabi3wheels. See the corresponding PRs for more. -
Ensure that the
.whlis correctly marked asabi3. For projects usingsetuptools, this is accomplished by passing--py-limited-api=cp3x(wherexis the minimum Python version supported by the wheel, e.g.--py-limited-api=cp35for Python 3.5) tosetup.py bdist_wheel.
Minimum Python version for abi3
Because a single abi3 wheel can be used with many different Python versions, PyO3 has feature flags abi3-py37, abi3-py38, abi3-py39 etc. to set the minimum required Python version for your abi3 wheel.
For example, if you set the abi3-py37 feature, your extension wheel can be used on all Python 3 versions from Python 3.7 and up. maturin and setuptools-rust will give the wheel a name like my-extension-1.0-cp37-abi3-manylinux2020_x86_64.whl.
As your extension module may be run with multiple different Python versions you may occasionally find you need to check the Python version at runtime to customize behavior. See the relevant section of this guide on supporting multiple Python versions at runtime.
PyO3 is only able to link your extension module to api3 version up to and including your host Python version. E.g., if you set abi3-py38 and try to compile the crate with a host of Python 3.7, the build will fail.
Note: If you set more that one of these api version feature flags the lowest version always wins. For example, with both
abi3-py37andabi3-py38set, PyO3 would build a wheel which supports Python 3.7 and up.
Building abi3 extensions without a Python interpreter
As an advanced feature, you can build PyO3 wheel without calling Python interpreter with the environment variable PYO3_NO_PYTHON set.
Also, if the build host Python interpreter is not found or is too old or otherwise unusable,
PyO3 will still attempt to compile abi3 extension modules after displaying a warning message.
On Unix-like systems this works unconditionally; on Windows you must also set the RUSTFLAGS environment variable
to contain -L native=/path/to/python/libs so that the linker can find python3.lib.
If the python3.dll import library is not available, an experimental generate-import-lib crate
feature may be enabled, and the required library will be created and used by PyO3 automatically.
Note: MSVC targets require LLVM binutils (llvm-dlltool) to be available in PATH for
the automatic import library generation feature to work.
Missing features
Due to limitations in the Python API, there are a few pyo3 features that do
not work when compiling for abi3. These are:
#[pyo3(text_signature = "...")]does not work on classes until Python 3.10 or greater.- The
dictandweakrefoptions on classes are not supported until Python 3.9 or greater. - The buffer API is not supported until Python 3.11 or greater.
- Optimizations which rely on knowledge of the exact Python version compiled against.
Embedding Python in Rust
If you want to embed the Python interpreter inside a Rust program, there are two modes in which this can be done: dynamically and statically. We’ll cover each of these modes in the following sections. Each of them affect how you must distribute your program. Instead of learning how to do this yourself, you might want to consider using a project like PyOxidizer to ship your application and all of its dependencies in a single file.
PyO3 automatically switches between the two linking modes depending on whether the Python distribution you have configured PyO3 to use (see above) contains a shared library or a static library. The static library is most often seen in Python distributions compiled from source without the --enable-shared configuration option. For example, this is the default for pyenv on macOS.
Dynamically embedding the Python interpreter
Embedding the Python interpreter dynamically is much easier than doing so statically. This is done by linking your program against a Python shared library (such as libpython.3.9.so on UNIX, or python39.dll on Windows). The implementation of the Python interpreter resides inside the shared library. This means that when the OS runs your Rust program it also needs to be able to find the Python shared library.
This mode of embedding works well for Rust tests which need access to the Python interpreter. It is also great for Rust software which is installed inside a Python virtualenv, because the virtualenv sets up appropriate environment variables to locate the correct Python shared library.
For distributing your program to non-technical users, you will have to consider including the Python shared library in your distribution as well as setting up wrapper scripts to set the right environment variables (such as LD_LIBRARY_PATH on UNIX, or PATH on Windows).
Note that PyPy cannot be embedded in Rust (or any other software). Support for this is tracked on the PyPy issue tracker.
Statically embedding the Python interpreter
Embedding the Python interpreter statically means including the contents of a Python static library directly inside your Rust binary. This means that to distribute your program you only need to ship your binary file: it contains the Python interpreter inside the binary!
On Windows static linking is almost never done, so Python distributions don’t usually include a static library. The information below applies only to UNIX.
The Python static library is usually called libpython.a.
Static linking has a lot of complications, listed below. For these reasons PyO3 does not yet have first-class support for this embedding mode. See issue 416 on PyO3’s Github for more information and to discuss any issues you encounter.
The auto-initialize feature is deliberately disabled when embedding the interpreter statically because this is often unintentionally done by new users to PyO3 running test programs. Trying out PyO3 is much easier using dynamic embedding.
The known complications are:
-
To import compiled extension modules (such as other Rust extension modules, or those written in C), your binary must have the correct linker flags set during compilation to export the original contents of
libpython.aso that extensions can use them (e.g.-Wl,--export-dynamic). -
The C compiler and flags which were used to create
libpython.amust be compatible with your Rust compiler and flags, else you will experience compilation failures.Significantly different compiler versions may see errors like this:
lto1: fatal error: bytecode stream in file 'rust-numpy/target/release/deps/libpyo3-6a7fb2ed970dbf26.rlib' generated with LTO version 6.0 instead of the expected 6.2Mismatching flags may lead to errors like this:
/usr/bin/ld: /usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/libpython3.9.a(zlibmodule.o): relocation R_X86_64_32 against `.data' can not be used when making a PIE object; recompile with -fPIE
If you encounter these or other complications when linking the interpreter statically, discuss them on issue 416 on PyO3’s Github. It is hoped that eventually that discussion will contain enough information and solutions that PyO3 can offer first-class support for static embedding.
Import your module when embedding the Python interpreter
When you run your Rust binary with an embedded interpreter, any #[pymodule] created modules won’t be accessible to import unless added to a table called PyImport_Inittab before the embedded interpreter is initialized. This will cause Python statements in your embedded interpreter such as import your_new_module to fail. You can call the macro append_to_inittab with your module before initializing the Python interpreter to add the module function into that table. (The Python interpreter will be initialized by calling prepare_freethreaded_python, with_embedded_interpreter, or Python::with_gil with the auto-initialize feature enabled.)
Cross Compiling
Thanks to Rust’s great cross-compilation support, cross-compiling using PyO3 is relatively straightforward. To get started, you’ll need a few pieces of software:
- A toolchain for your target.
- The appropriate options in your Cargo
.configfor the platform you’re targeting and the toolchain you are using. - A Python interpreter that’s already been compiled for your target (optional when building “abi3” extension modules).
- A Python interpreter that is built for your host and available through the
PATHor setting thePYO3_PYTHONvariable (optional when building “abi3” extension modules).
After you’ve obtained the above, you can build a cross-compiled PyO3 module by using Cargo’s --target flag. PyO3’s build script will detect that you are attempting a cross-compile based on your host machine and the desired target.
When cross-compiling, PyO3’s build script cannot execute the target Python interpreter to query the configuration, so there are a few additional environment variables you may need to set:
PYO3_CROSS: If present this variable forces PyO3 to configure as a cross-compilation.PYO3_CROSS_LIB_DIR: This variable can be set to the directory containing the target’s libpython DSO and the associated_sysconfigdata*.pyfile for Unix-like targets, or the Python DLL import libraries for the Windows target. This variable is only needed when the output binary must link to libpython explicitly (e.g. when targeting Windows and Android or embedding a Python interpreter), or when it is absolutely required to get the interpreter configuration from_sysconfigdata*.py.PYO3_CROSS_PYTHON_VERSION: Major and minor version (e.g. 3.9) of the target Python installation. This variable is only needed if PyO3 cannot determine the version to target fromabi3-py3*features, or ifPYO3_CROSS_LIB_DIRis not set, or if there are multiple versions of Python present inPYO3_CROSS_LIB_DIR.PYO3_CROSS_PYTHON_IMPLEMENTATION: Python implementation name (“CPython” or “PyPy”) of the target Python installation. CPython is assumed by default when this variable is not set, unlessPYO3_CROSS_LIB_DIRis set for a Unix-like target and PyO3 can get the interpreter configuration from_sysconfigdata*.py.
An experimental pyo3 crate feature generate-import-lib enables the user to cross-compile
extension modules for Windows targets without setting the PYO3_CROSS_LIB_DIR environment
variable or providing any Windows Python library files. It uses an external python3-dll-a crate
to generate import libraries for the Python DLL for MinGW-w64 and MSVC compile targets.
python3-dll-a uses the binutils dlltool program to generate DLL import libraries for MinGW-w64 targets.
It is possible to override the default dlltool command name for the cross target
by setting PYO3_MINGW_DLLTOOL environment variable.
Note: MSVC targets require LLVM binutils or MSVC build tools to be available on the host system.
More specifically, python3-dll-a requires llvm-dlltool or lib.exe executable to be present in PATH when
targeting *-pc-windows-msvc. Zig compiler executable can be used in place of llvm-dlltool when ZIG_COMMAND
environment variable is set to the installed Zig program name ("zig" or "python -m ziglang").
An example might look like the following (assuming your target’s sysroot is at /home/pyo3/cross/sysroot and that your target is armv7):
export PYO3_CROSS_LIB_DIR="/home/pyo3/cross/sysroot/usr/lib"
cargo build --target armv7-unknown-linux-gnueabihf
If there are multiple python versions at the cross lib directory and you cannot set a more precise location to include both the libpython DSO and _sysconfigdata*.py files, you can set the required version:
export PYO3_CROSS_PYTHON_VERSION=3.8
export PYO3_CROSS_LIB_DIR="/home/pyo3/cross/sysroot/usr/lib"
cargo build --target armv7-unknown-linux-gnueabihf
Or another example with the same sys root but building for Windows:
export PYO3_CROSS_PYTHON_VERSION=3.9
export PYO3_CROSS_LIB_DIR="/home/pyo3/cross/sysroot/usr/lib"
cargo build --target x86_64-pc-windows-gnu
Any of the abi3-py3* features can be enabled instead of setting PYO3_CROSS_PYTHON_VERSION in the above examples.
PYO3_CROSS_LIB_DIR can often be omitted when cross compiling extension modules for Unix and macOS targets,
or when cross compiling extension modules for Windows and the experimental generate-import-lib
crate feature is enabled.
The following resources may also be useful for cross-compiling:
- github.com/japaric/rust-cross is a primer on cross compiling Rust.
- github.com/rust-embedded/cross uses Docker to make Rust cross-compilation easier.
Supporting multiple Python versions
PyO3 supports all actively-supported Python 3 and PyPy versions. As much as possible, this is done internally to PyO3 so that your crate’s code does not need to adapt to the differences between each version. However, as Python features grow and change between versions, PyO3 cannot a completely identical API for every Python version. This may require you to add conditional compilation to your crate or runtime checks for the Python version.
This section of the guide first introduces the pyo3-build-config crate, which you can use as a build-dependency to add additional #[cfg] flags which allow you to support multiple Python versions at compile-time.
Second, we’ll show how to check the Python version at runtime. This can be useful when building for multiple versions with the abi3 feature, where the Python API compiled against is not always the same as the one in use.
Conditional compilation for different Python versions
The pyo3-build-config exposes multiple #[cfg] flags which can be used to conditionally compile code for a given Python version. PyO3 itself depends on this crate, so by using it you can be sure that you are configured correctly for the Python version PyO3 is building against.
This allows us to write code like the following
#[cfg(Py_3_7)]
fn function_only_supported_on_python_3_7_and_up() { }
#[cfg(not(Py_3_8))]
fn function_only_supported_before_python_3_8() { }
#[cfg(not(Py_LIMITED_API))]
fn function_incompatible_with_abi3_feature() { }
The following sections first show how to add these #[cfg] flags to your build process, and then cover some common patterns flags in a little more detail.
To see a full reference of all the #[cfg] flags provided, see the pyo3-build-cfg docs.
Using pyo3-build-config
You can use the #[cfg] flags in just two steps:
-
Add
pyo3-build-configwith theresolve-configfeature enabled to your crate’s build dependencies inCargo.toml:[build-dependencies] pyo3-build-config = { {{#PYO3_CRATE_VERSION}}, features = ["resolve-config"] } -
Add a
build.rsfile to your crate with the following contents:fn main() { // If you have an existing build.rs file, just add this line to it. pyo3_build_config::use_pyo3_cfgs(); }
After these steps you are ready to annotate your code!
Common usages of pyo3-build-cfg flags
The #[cfg] flags added by pyo3-build-cfg can be combined with all of Rust’s logic in the #[cfg] attribute to create very precise conditional code generation. The following are some common patterns implemented using these flags:
#[cfg(Py_3_7)]
This #[cfg] marks code that will only be present on Python 3.7 and upwards. There are similar options Py_3_8, Py_3_9, Py_3_10 and so on for each minor version.
#[cfg(not(Py_3_7))]
This #[cfg] marks code that will only be present on Python versions before (but not including) Python 3.7.
#[cfg(not(Py_LIMITED_API))]
This #[cfg] marks code that is only available when building for the unlimited Python API (i.e. PyO3’s abi3 feature is not enabled). This might be useful if you want to ship your extension module as an abi3 wheel and also allow users to compile it from source to make use of optimizations only possible with the unlimited API.
#[cfg(any(Py_3_9, not(Py_LIMITED_API)))]
This #[cfg] marks code which is available when running Python 3.9 or newer, or when using the unlimited API with an older Python version. Patterns like this are commonly seen on Python APIs which were added to the limited Python API in a specific minor version.
#[cfg(PyPy)]
This #[cfg] marks code which is running on PyPy.
Checking the Python version at runtime
When building with PyO3’s abi3 feature, your extension module will be compiled against a specific minimum version of Python, but may be running on newer Python versions.
For example with PyO3’s abi3-py38 feature, your extension will be compiled as if it were for Python 3.8. If you were using pyo3-build-config, #[cfg(Py_3_8)] would be present. Your user could freely install and run your abi3 extension on Python 3.9.
There’s no way to detect your user doing that at compile time, so instead you need to fall back to runtime checks.
PyO3 provides the APIs Python::version() and Python::version_info() to query the running Python version. This allows you to do the following, for example:
#![allow(unused)] fn main() { use pyo3::Python; Python::with_gil(|py| { // PyO3 supports Python 3.7 and up. assert!(py.version_info() >= (3, 7)); assert!(py.version_info() >= (3, 7, 0)); }); }
The PyO3 ecosystem
This portion of the guide is dedicated to crates which are external to the main PyO3 project and provide additional functionality you might find useful.
Because these projects evolve independently of the PyO3 repository the content of these articles may fall out of date over time; please file issues on the PyO3 Github to alert maintainers when this is the case.
Logging
It is desirable if both the Python and Rust parts of the application end up logging using the same configuration into the same place.
This section of the guide briefly discusses how to connect the two languages’
logging ecosystems together. The recommended way for Python extension modules is
to configure Rust’s logger to send log messages to Python using the pyo3-log
crate. For users who want to do the opposite and send Python log messages to
Rust, see the note at the end of this guide.
Using pyo3-log to send Rust log messages to Python
The pyo3-log crate allows sending the messages from the Rust side to Python’s logging system. This is mostly suitable for writing native extensions for Python programs.
Use pyo3_log::init to install the logger in its default configuration.
It’s also possible to tweak its configuration (mostly to tune its performance).
#![allow(unused)] fn main() { use log::info; use pyo3::prelude::*; #[pyfunction] fn log_something() { // This will use the logger installed in `my_module` to send the `info` // message to the Python logging facilities. info!("Something!"); } #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { // A good place to install the Rust -> Python logger. pyo3_log::init(); m.add_function(wrap_pyfunction!(log_something))?; Ok(()) } }
Then it is up to the Python side to actually output the messages somewhere.
import logging
import my_module
FORMAT = '%(levelname)s %(name)s %(asctime)-15s %(filename)s:%(lineno)d %(message)s'
logging.basicConfig(format=FORMAT)
logging.getLogger().setLevel(logging.INFO)
my_module.log_something()
It is important to initialize the Python loggers first, before calling any Rust functions that may log. This limitation can be worked around if it is not possible to satisfy, read the documentation about caching.
The Python to Rust direction
To best of our knowledge nobody implemented the reverse direction yet, though it
should be possible. If interested, the pyo3 community would be happy to
provide guidance.
Using async and await
If you are working with a Python library that makes use of async functions or wish to provide
Python bindings for an async Rust library, pyo3-asyncio
likely has the tools you need. It provides conversions between async functions in both Python and
Rust and was designed with first-class support for popular Rust runtimes such as
tokio and async-std. In addition, all async Python
code runs on the default asyncio event loop, so pyo3-asyncio should work just fine with existing
Python libraries.
In the following sections, we’ll give a general overview of pyo3-asyncio explaining how to call
async Python functions with PyO3, how to call async Rust functions from Python, and how to configure
your codebase to manage the runtimes of both.
Quickstart
Here are some examples to get you started right away! A more detailed breakdown of the concepts in these examples can be found in the following sections.
Rust Applications
Here we initialize the runtime, import Python’s asyncio library and run the given future to completion using Python’s default EventLoop and async-std. Inside the future, we convert asyncio sleep into a Rust future and await it.
# Cargo.toml dependencies
[dependencies]
pyo3 = { version = "0.14" }
pyo3-asyncio = { version = "0.14", features = ["attributes", "async-std-runtime"] }
async-std = "1.9"
//! main.rs use pyo3::prelude::*; #[pyo3_asyncio::async_std::main] async fn main() -> PyResult<()> { let fut = Python::with_gil(|py| { let asyncio = py.import("asyncio")?; // convert asyncio.sleep into a Rust Future pyo3_asyncio::async_std::into_future(asyncio.call_method1("sleep", (1.into_py(py),))?) })?; fut.await?; Ok(()) }
The same application can be written to use tokio instead using the #[pyo3_asyncio::tokio::main]
attribute.
# Cargo.toml dependencies
[dependencies]
pyo3 = { version = "0.14" }
pyo3-asyncio = { version = "0.14", features = ["attributes", "tokio-runtime"] }
tokio = "1.4"
//! main.rs use pyo3::prelude::*; #[pyo3_asyncio::tokio::main] async fn main() -> PyResult<()> { let fut = Python::with_gil(|py| { let asyncio = py.import("asyncio")?; // convert asyncio.sleep into a Rust Future pyo3_asyncio::tokio::into_future(asyncio.call_method1("sleep", (1.into_py(py),))?) })?; fut.await?; Ok(()) }
More details on the usage of this library can be found in the API docs and the primer below.
PyO3 Native Rust Modules
PyO3 Asyncio can also be used to write native modules with async functions.
Add the [lib] section to Cargo.toml to make your library a cdylib that Python can import.
[lib]
name = "my_async_module"
crate-type = ["cdylib"]
Make your project depend on pyo3 with the extension-module feature enabled and select your
pyo3-asyncio runtime:
For async-std:
[dependencies]
pyo3 = { version = "0.14", features = ["extension-module"] }
pyo3-asyncio = { version = "0.14", features = ["async-std-runtime"] }
async-std = "1.9"
For tokio:
[dependencies]
pyo3 = { version = "0.14", features = ["extension-module"] }
pyo3-asyncio = { version = "0.14", features = ["tokio-runtime"] }
tokio = "1.4"
Export an async function that makes use of async-std:
#![allow(unused)] fn main() { //! lib.rs use pyo3::{prelude::*, wrap_pyfunction}; #[pyfunction] fn rust_sleep(py: Python<'_>) -> PyResult<&PyAny> { pyo3_asyncio::async_std::future_into_py(py, async { async_std::task::sleep(std::time::Duration::from_secs(1)).await; Ok(Python::with_gil(|py| py.None())) }) } #[pymodule] fn my_async_module(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(rust_sleep, m)?)?; Ok(()) } }
If you want to use tokio instead, here’s what your module should look like:
#![allow(unused)] fn main() { //! lib.rs use pyo3::{prelude::*, wrap_pyfunction}; #[pyfunction] fn rust_sleep(py: Python<'_>) -> PyResult<&PyAny> { pyo3_asyncio::tokio::future_into_py(py, async { tokio::time::sleep(std::time::Duration::from_secs(1)).await; Ok(Python::with_gil(|py| py.None())) }) } #[pymodule] fn my_async_module(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(rust_sleep, m)?)?; Ok(()) } }
You can build your module with maturin (see the Using Rust in Python section in the PyO3 guide for setup instructions). After that you should be able to run the Python REPL to try it out.
maturin develop && python3
🔗 Found pyo3 bindings
🐍 Found CPython 3.8 at python3
Finished dev [unoptimized + debuginfo] target(s) in 0.04s
Python 3.8.5 (default, Jan 27 2021, 15:41:15)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import asyncio
>>>
>>> from my_async_module import rust_sleep
>>>
>>> async def main():
>>> await rust_sleep()
>>>
>>> # should sleep for 1s
>>> asyncio.run(main())
>>>
Awaiting an Async Python Function in Rust
Let’s take a look at a dead simple async Python function:
# Sleep for 1 second
async def py_sleep():
await asyncio.sleep(1)
Async functions in Python are simply functions that return a coroutine object. For our purposes,
we really don’t need to know much about these coroutine objects. The key factor here is that calling
an async function is just like calling a regular function, the only difference is that we have
to do something special with the object that it returns.
Normally in Python, that something special is the await keyword, but in order to await this
coroutine in Rust, we first need to convert it into Rust’s version of a coroutine: a Future.
That’s where pyo3-asyncio comes in.
pyo3_asyncio::into_future
performs this conversion for us.
The following example uses into_future to call the py_sleep function shown above and then await the
coroutine object returned from the call:
use pyo3::prelude::*; #[pyo3_asyncio::tokio::main] async fn main() -> PyResult<()> { let future = Python::with_gil(|py| -> PyResult<_> { // import the module containing the py_sleep function let example = py.import("example")?; // calling the py_sleep method like a normal function // returns a coroutine let coroutine = example.call_method0("py_sleep")?; // convert the coroutine into a Rust future using the // tokio runtime pyo3_asyncio::tokio::into_future(coroutine) })?; // await the future future.await?; Ok(()) }
Alternatively, the below example shows how to write a #[pyfunction] which uses into_future to receive and await
a coroutine argument:
#![allow(unused)] fn main() { #[pyfunction] fn await_coro(coro: &PyAny) -> PyResult<()> { // convert the coroutine into a Rust future using the // async_std runtime let f = pyo3_asyncio::async_std::into_future(coro)?; pyo3_asyncio::async_std::run_until_complete(coro.py(), async move { // await the future f.await?; Ok(()) }) } }
This could be called from Python as:
import asyncio
async def py_sleep():
asyncio.sleep(1)
await_coro(py_sleep())
If for you wanted to pass a callable function to the #[pyfunction] instead, (i.e. the last line becomes await_coro(py_sleep)), then the above example needs to be tweaked to first call the callable to get the coroutine:
#![allow(unused)] fn main() { #[pyfunction] fn await_coro(callable: &PyAny) -> PyResult<()> { // get the coroutine by calling the callable let coro = callable.call0()?; // convert the coroutine into a Rust future using the // async_std runtime let f = pyo3_asyncio::async_std::into_future(coro)?; pyo3_asyncio::async_std::run_until_complete(coro.py(), async move { // await the future f.await?; Ok(()) }) } }
This can be particularly helpful where you need to repeatedly create and await a coroutine. Trying to await the same coroutine multiple times will raise an error:
RuntimeError: cannot reuse already awaited coroutine
If you’re interested in learning more about
coroutinesandawaitablesin general, check out the Python 3asynciodocs for more information.
Awaiting a Rust Future in Python
Here we have the same async function as before written in Rust using the
async-std runtime:
#![allow(unused)] fn main() { /// Sleep for 1 second async fn rust_sleep() { async_std::task::sleep(std::time::Duration::from_secs(1)).await; } }
Similar to Python, Rust’s async functions also return a special object called a
Future:
#![allow(unused)] fn main() { let future = rust_sleep(); }
We can convert this Future object into Python to make it awaitable. This tells Python that you
can use the await keyword with it. In order to do this, we’ll call
pyo3_asyncio::async_std::future_into_py:
#![allow(unused)] fn main() { use pyo3::prelude::*; async fn rust_sleep() { async_std::task::sleep(std::time::Duration::from_secs(1)).await; } #[pyfunction] fn call_rust_sleep(py: Python<'_>) -> PyResult<&PyAny> { pyo3_asyncio::async_std::future_into_py(py, async move { rust_sleep().await; Ok(Python::with_gil(|py| py.None())) }) } }
In Python, we can call this pyo3 function just like any other async function:
from example import call_rust_sleep
async def rust_sleep():
await call_rust_sleep()
Managing Event Loops
Python’s event loop requires some special treatment, especially regarding the main thread. Some of
Python’s asyncio features, like proper signal handling, require control over the main thread, which
doesn’t always play well with Rust.
Luckily, Rust’s event loops are pretty flexible and don’t need control over the main thread, so in
pyo3-asyncio, we decided the best way to handle Rust/Python interop was to just surrender the main
thread to Python and run Rust’s event loops in the background. Unfortunately, since most event loop
implementations prefer control over the main thread, this can still make some things awkward.
PyO3 Asyncio Initialization
Because Python needs to control the main thread, we can’t use the convenient proc macros from Rust
runtimes to handle the main function or #[test] functions. Instead, the initialization for PyO3 has to be done from the main function and the main
thread must block on pyo3_asyncio::run_forever or pyo3_asyncio::async_std::run_until_complete.
Because we have to block on one of those functions, we can’t use #[async_std::main] or #[tokio::main]
since it’s not a good idea to make long blocking calls during an async function.
Internally, these
#[main]proc macros are expanded to something like this:fn main() { // your async main fn async fn _main_impl() { /* ... */ } Runtime::new().block_on(_main_impl()); }Making a long blocking call inside the
Futurethat’s being driven byblock_onprevents that thread from doing anything else and can spell trouble for some runtimes (also this will actually deadlock a single-threaded runtime!). Many runtimes have some sort ofspawn_blockingmechanism that can avoid this problem, but again that’s not something we can use here since we need it to block on the main thread.
For this reason, pyo3-asyncio provides its own set of proc macros to provide you with this
initialization. These macros are intended to mirror the initialization of async-std and tokio
while also satisfying the Python runtime’s needs.
Here’s a full example of PyO3 initialization with the async-std runtime:
use pyo3::prelude::*; #[pyo3_asyncio::async_std::main] async fn main() -> PyResult<()> { // PyO3 is initialized - Ready to go let fut = Python::with_gil(|py| -> PyResult<_> { let asyncio = py.import("asyncio")?; // convert asyncio.sleep into a Rust Future pyo3_asyncio::async_std::into_future( asyncio.call_method1("sleep", (1.into_py(py),))? ) })?; fut.await?; Ok(()) }
A Note About asyncio.run
In Python 3.7+, the recommended way to run a top-level coroutine with asyncio
is with asyncio.run. In v0.13 we recommended against using this function due to initialization issues, but in v0.14 it’s perfectly valid to use this function… with a caveat.
Since our Rust <–> Python conversions require a reference to the Python event loop, this poses a problem. Imagine we have a PyO3 Asyncio module that defines
a rust_sleep function like in previous examples. You might rightfully assume that you can call pass this directly into asyncio.run like this:
import asyncio
from my_async_module import rust_sleep
asyncio.run(rust_sleep())
You might be surprised to find out that this throws an error:
Traceback (most recent call last):
File "example.py", line 5, in <module>
asyncio.run(rust_sleep())
RuntimeError: no running event loop
What’s happening here is that we are calling rust_sleep before the future is
actually running on the event loop created by asyncio.run. This is counter-intuitive, but expected behaviour, and unfortunately there doesn’t seem to be a good way of solving this problem within PyO3 Asyncio itself.
However, we can make this example work with a simple workaround:
import asyncio
from my_async_module import rust_sleep
# Calling main will just construct the coroutine that later calls rust_sleep.
# - This ensures that rust_sleep will be called when the event loop is running,
# not before.
async def main():
await rust_sleep()
# Run the main() coroutine at the top-level instead
asyncio.run(main())
Non-standard Python Event Loops
Python allows you to use alternatives to the default asyncio event loop. One
popular alternative is uvloop. In v0.13 using non-standard event loops was
a bit of an ordeal, but in v0.14 it’s trivial.
Using uvloop in a PyO3 Asyncio Native Extensions
# Cargo.toml
[lib]
name = "my_async_module"
crate-type = ["cdylib"]
[dependencies]
pyo3 = { version = "0.14", features = ["extension-module"] }
pyo3-asyncio = { version = "0.14", features = ["tokio-runtime"] }
async-std = "1.9"
tokio = "1.4"
#![allow(unused)] fn main() { //! lib.rs use pyo3::{prelude::*, wrap_pyfunction}; #[pyfunction] fn rust_sleep(py: Python<'_>) -> PyResult<&PyAny> { pyo3_asyncio::tokio::future_into_py(py, async { tokio::time::sleep(std::time::Duration::from_secs(1)).await; Ok(Python::with_gil(|py| py.None())) }) } #[pymodule] fn my_async_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(rust_sleep, m)?)?; Ok(()) } }
$ maturin develop && python3
🔗 Found pyo3 bindings
🐍 Found CPython 3.8 at python3
Finished dev [unoptimized + debuginfo] target(s) in 0.04s
Python 3.8.8 (default, Apr 13 2021, 19:58:26)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import asyncio
>>> import uvloop
>>>
>>> import my_async_module
>>>
>>> uvloop.install()
>>>
>>> async def main():
... await my_async_module.rust_sleep()
...
>>> asyncio.run(main())
>>>
Using uvloop in Rust Applications
Using uvloop in Rust applications is a bit trickier, but it’s still possible
with relatively few modifications.
Unfortunately, we can’t make use of the #[pyo3_asyncio::<runtime>::main] attribute with non-standard event loops. This is because the #[pyo3_asyncio::<runtime>::main] proc macro has to interact with the Python
event loop before we can install the uvloop policy.
[dependencies]
async-std = "1.9"
pyo3 = "0.14"
pyo3-asyncio = { version = "0.14", features = ["async-std-runtime"] }
//! main.rs use pyo3::{prelude::*, types::PyType}; fn main() -> PyResult<()> { pyo3::prepare_freethreaded_python(); Python::with_gil(|py| { let uvloop = py.import("uvloop")?; uvloop.call_method0("install")?; // store a reference for the assertion let uvloop = PyObject::from(uvloop); pyo3_asyncio::async_std::run(py, async move { // verify that we are on a uvloop.Loop Python::with_gil(|py| -> PyResult<()> { assert!(pyo3_asyncio::async_std::get_current_loop(py)?.is_instance( uvloop .as_ref(py) .getattr("Loop")? )?); Ok(()) })?; async_std::task::sleep(std::time::Duration::from_secs(1)).await; Ok(()) }) }) }
Additional Information
- Managing event loop references can be tricky with pyo3-asyncio. See Event Loop References in the API docs to get a better intuition for how event loop references are managed in this library.
- Testing pyo3-asyncio libraries and applications requires a custom test harness since Python requires control over the main thread. You can find a testing guide in the API docs for the
testingmodule
Frequently Asked Questions and troubleshooting
I’m experiencing deadlocks using PyO3 with lazy_static or once_cell!
lazy_static and once_cell::sync both use locks to ensure that initialization is performed only by a single thread. Because the Python GIL is an additional lock this can lead to deadlocks in the following way:
- A thread (thread A) which has acquired the Python GIL starts initialization of a
lazy_staticvalue. - The initialization code calls some Python API which temporarily releases the GIL e.g.
Python::import. - Another thread (thread B) acquires the Python GIL and attempts to access the same
lazy_staticvalue. - Thread B is blocked, because it waits for
lazy_static’s initialization to lock to release. - Thread A is blocked, because it waits to re-acquire the GIL which thread B still holds.
- Deadlock.
PyO3 provides a struct GILOnceCell which works equivalently to OnceCell but relies solely on the Python GIL for thread safety. This means it can be used in place of lazy_static or once_cell where you are experiencing the deadlock described above. See the documentation for GILOnceCell for an example how to use it.
I can’t run cargo test; or I can’t build in a Cargo workspace: I’m having linker issues like “Symbol not found” or “Undefined reference to _PyExc_SystemError”!
Currently, #340 causes cargo test to fail with linking errors when the extension-module feature is activated. Linking errors can also happen when building in a cargo workspace where a different crate also uses PyO3 (see #2521). For now, there are three ways we can work around these issues.
- Make the
extension-modulefeature optional. Build withmaturin develop --features "extension-module"
[dependencies.pyo3]
{{#PYO3_CRATE_VERSION}}
[features]
extension-module = ["pyo3/extension-module"]
- Make the
extension-modulefeature optional and default. Run tests withcargo test --no-default-features:
[dependencies.pyo3]
{{#PYO3_CRATE_VERSION}}
[features]
extension-module = ["pyo3/extension-module"]
default = ["extension-module"]
- If you are using a
pyproject.tomlfile to control maturin settings, add the following section:
[tool.maturin]
features = ["pyo3/extension-module"]
# Or for maturin 0.12:
# cargo-extra-args = ["--features", "pyo3/extension-module"]
I can’t run cargo test: my crate cannot be found for tests in tests/ directory!
The Rust book suggests to put integration tests inside a tests/ directory.
For a PyO3 extension-module project where the crate-type is set to "cdylib" in your Cargo.toml,
the compiler won’t be able to find your crate and will display errors such as E0432 or E0463:
error[E0432]: unresolved import `my_crate`
--> tests/test_my_crate.rs:1:5
|
1 | use my_crate;
| ^^^^^^^^^^^^ no external crate `my_crate`
The best solution is to make your crate types include both rlib and cdylib:
# Cargo.toml
[lib]
crate-type = ["cdylib", "rlib"]
Ctrl-C doesn’t do anything while my Rust code is executing!
This is because Ctrl-C raises a SIGINT signal, which is handled by the calling Python process by simply setting a flag to action upon later. This flag isn’t checked while Rust code called from Python is executing, only once control returns to the Python interpreter.
You can give the Python interpreter a chance to process the signal properly by calling Python::check_signals. It’s good practice to call this function regularly if you have a long-running Rust function so that your users can cancel it.
#[pyo3(get)] clones my field!
You may have a nested struct similar to this:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] #[derive(Clone)] struct Inner { /* fields omitted */ } #[pyclass] struct Outer { #[pyo3(get)] inner: Inner, } #[pymethods] impl Outer { #[new] fn __new__() -> Self { Self { inner: Inner {} } } } }
When Python code accesses Outer’s field, PyO3 will return a new object on every access (note that their addresses are different):
outer = Outer()
a = outer.inner
b = outer.inner
assert a is b, f"a: {a}\nb: {b}"
AssertionError: a: <builtins.Inner object at 0x00000238FFB9C7B0>
b: <builtins.Inner object at 0x00000238FFB9C830>
This can be especially confusing if the field is mutable, as getting the field and then mutating it won’t persist - you’ll just get a fresh clone of the original on the next access. Unfortunately Python and Rust don’t agree about ownership - if PyO3 gave out references to (possibly) temporary Rust objects to Python code, Python code could then keep that reference alive indefinitely. Therefore returning Rust objects requires cloning.
If you don’t want that cloning to happen, a workaround is to allocate the field on the Python heap and store a reference to that, by using Py<...>:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] #[derive(Clone)] struct Inner { /* fields omitted */ } #[pyclass] struct Outer { #[pyo3(get)] inner: Py<Inner>, } #[pymethods] impl Outer { #[new] fn __new__(py: Python<'_>) -> PyResult<Self> { Ok(Self { inner: Py::new(py, Inner {})?, }) } } }
This time a and b are the same object:
outer = Outer()
a = outer.inner
b = outer.inner
assert a is b, f"a: {a}\nb: {b}"
print(f"a: {a}\nb: {b}")
a: <builtins.Inner object at 0x0000020044FCC670>
b: <builtins.Inner object at 0x0000020044FCC670>
The downside to this approach is that any Rust code working on the Outer struct now has to acquire the GIL to do anything with its field.
I want to use the pyo3 crate re-exported from from dependency but the proc-macros fail!
All PyO3 proc-macros (#[pyclass], #[pyfunction], #[derive(FromPyObject)]
and so on) expect the pyo3 crate to be available under that name in your crate
root, which is the normal situation when pyo3 is a direct dependency of your
crate.
However, when the dependency is renamed, or your crate only indirectly depends
on pyo3, you need to let the macro code know where to find the crate. This is
done with the crate attribute:
#![allow(unused)] fn main() { use pyo3::prelude::*; pub extern crate pyo3; mod reexported { pub use ::pyo3; } #[pyclass] #[pyo3(crate = "reexported::pyo3")] struct MyClass; }
Migrating from older PyO3 versions
This guide can help you upgrade code through breaking changes from one PyO3 version to the next. For a detailed list of all changes, see the CHANGELOG.
from 0.16.* to 0.17
Type checks have been changed for PyMapping and PySequence types
Previously the type checks for PyMapping and PySequence (implemented in PyTryFrom)
used the Python C-API functions PyMapping_Check and PySequence_Check.
Unfortunately these functions are not sufficient for distinguishing such types,
leading to inconsistent behavior (see
pyo3/pyo3#2072).
PyO3 0.17 changes these downcast checks to explicityly test if the type is a
subclass of the corresponding abstract base class collections.abc.Mapping or
collections.abc.Sequence. Note this requires calling into Python, which may
incur a performance penalty over the previous method. If this performance
penatly is a problem, you may be able to perform your own checks and use
try_from_unchecked (unsafe).
Another side-effect is that a pyclass defined in Rust with PyO3 will need to
be registered with the corresponding Python abstract base class for
downcasting to succeed. PySequence::register and PyMapping:register have
been added to make it easy to do this from Rust code. These are equivalent to
calling collections.abc.Mapping.register(MappingPyClass) or
collections.abc.Sequence.register(SequencePyClass) from Python.
For example, for a mapping class defined in Rust:
#![allow(unused)] fn main() { use pyo3::prelude::*; use std::collections::HashMap; #[pyclass(mapping)] struct Mapping { index: HashMap<String, usize>, } #[pymethods] impl Mapping { #[new] fn new(elements: Option<&PyList>) -> PyResult<Self> { // ... // truncated implementation of this mapping pyclass - basically a wrapper around a HashMap } }
You must register the class with collections.abc.Mapping before the downcast will work:
#![allow(unused)] fn main() { let m = Py::new(py, Mapping { index }).unwrap(); assert!(m.as_ref(py).downcast::<PyMapping>().is_err()); PyMapping::register::<Mapping>(py).unwrap(); assert!(m.as_ref(py).downcast::<PyMapping>().is_ok()); }
Note that this requirement may go away in the future when a pyclass is able to inherit from the abstract base class directly (see pyo3/pyo3#991).
### The multiple-pymethods feature now requires Rust 1.62
Due to limitations in the inventory crate which the multiple-pymethods feature depends on, this feature now
requires Rust 1.62. For more information see dtolnay/inventory#32.
Added impl IntoPy<Py<PyString>> for &str
This may cause inference errors.
Before:
use pyo3::prelude::*; fn main() { Python::with_gil(|py| { // Cannot infer either `Py<PyAny>` or `Py<PyString>` let _test = "test".into_py(py); }); }
After, some type annotations may be necessary:
use pyo3::prelude::*; fn main() { Python::with_gil(|py| { let _test: Py<PyAny> = "test".into_py(py); }); }
The pyproto feature is now disabled by default
In preparation for removing the deprecated #[pyproto] attribute macro in a future PyO3 version, it is now gated behind an opt-in feature flag. This also gives a slight saving to compile times for code which does not use the deprecated macro.
PyTypeObject trait has been deprecated
The PyTypeObject trait already was near-useless; almost all functionality was already on the PyTypeInfo trait, which PyTypeObject had a blanket implementation based upon. In PyO3 0.17 the final method, PyTypeObject::type_object was moved to PyTypeInfo::type_object.
To migrate, update trait bounds and imports from PyTypeObject to PyTypeInfo.
Before:
#![allow(unused)] fn main() { use pyo3::Python; use pyo3::type_object::PyTypeObject; use pyo3::types::PyType; fn get_type_object<T: PyTypeObject>(py: Python<'_>) -> &PyType { T::type_object(py) } }
After
#![allow(unused)] fn main() { use pyo3::{Python, PyTypeInfo}; use pyo3::types::PyType; fn get_type_object<T: PyTypeInfo>(py: Python<'_>) -> &PyType { T::type_object(py) } Python::with_gil(|py| { get_type_object::<pyo3::types::PyList>(py); }); }
impl<T, const N: usize> IntoPy<PyObject> for [T; N] now requires T: IntoPy rather than T: ToPyObject
If this leads to errors, simply implement IntoPy. Because pyclasses already implement IntoPy, you probably don’t need to worry about this.
Each #[pymodule] can now only be initialized once per process
To make PyO3 modules sound in the presence of Python sub-interpreters, for now it has been necessary to explicitly disable the ability to initialize a #[pymodule] more than once in the same process. Attempting to do this will now raise an ImportError.
from 0.15.* to 0.16
Drop support for older technologies
PyO3 0.16 has increased minimum Rust version to 1.48 and minimum Python version to 3.7. This enables use of newer language features (enabling some of the other additions in 0.16) and simplifies maintenance of the project.
#[pyproto] has been deprecated
In PyO3 0.15, the #[pymethods] attribute macro gained support for implementing “magic methods” such as __str__ (aka “dunder” methods). This implementation was not quite finalized at the time, with a few edge cases to be decided upon. The existing #[pyproto] attribute macro was left untouched, because it covered these edge cases.
In PyO3 0.16, the #[pymethods] implementation has been completed and is now the preferred way to implement magic methods. To allow the PyO3 project to move forward, #[pyproto] has been deprecated (with expected removal in PyO3 0.18).
Migration from #[pyproto] to #[pymethods] is straightforward; copying the existing methods directly from the #[pyproto] trait implementation is all that is needed in most cases.
Before:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::class::{PyBasicProtocol, PyIterProtocol}; use pyo3::types::PyString; #[pyclass] struct MyClass { } #[pyproto] impl PyBasicProtocol for MyClass { fn __str__(&self) -> &'static [u8] { b"hello, world" } } #[pyproto] impl PyIterProtocol for MyClass { fn __iter__(slf: PyRef<self>) -> PyResult<&PyAny> { PyString::new(slf.py(), "hello, world").iter() } } }
After
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyString; #[pyclass] struct MyClass { } #[pymethods] impl MyClass { fn __str__(&self) -> &'static [u8] { b"hello, world" } fn __iter__(slf: PyRef<self>) -> PyResult<&PyAny> { PyString::new(slf.py(), "hello, world").iter() } } }
Removed PartialEq for object wrappers
The Python object wrappers Py and PyAny had implementations of PartialEq
so that object_a == object_b would compare the Python objects for pointer
equality, which corresponds to the is operator, not the == operator in
Python. This has been removed in favor of a new method: use
object_a.is(object_b). This also has the advantage of not requiring the same
wrapper type for object_a and object_b; you can now directly compare a
Py<T> with a &PyAny without having to convert.
To check for Python object equality (the Python == operator), use the new
method eq().
Container magic methods now match Python behavior
In PyO3 0.15, __getitem__, __setitem__ and __delitem__ in #[pymethods] would generate only the mapping implementation for a #[pyclass]. To match the Python behavior, these methods now generate both the mapping and sequence implementations.
This means that classes implementing these #[pymethods] will now also be treated as sequences, same as a Python class would be. Small differences in behavior may result:
- PyO3 will allow instances of these classes to be cast to
PySequenceas well asPyMapping. - Python will provide a default implementation of
__iter__(if the class did not have one) which repeatedly calls__getitem__with integers (starting at 0) until anIndexErroris raised.
To explain this in detail, consider the following Python class:
class ExampleContainer:
def __len__(self):
return 5
def __getitem__(self, idx: int) -> int:
if idx < 0 or idx > 5:
raise IndexError()
return idx
This class implements a Python sequence.
The __len__ and __getitem__ methods are also used to implement a Python mapping. In the Python C-API, these methods are not shared: the sequence __len__ and __getitem__ are defined by the sq_length and sq_item slots, and the mapping equivalents are mp_length and mp_subscript. There are similar distinctions for __setitem__ and __delitem__.
Because there is no such distinction from Python, implementing these methods will fill the mapping and sequence slots simultaneously. A Python class with __len__ implemented, for example, will have both the sq_length and mp_length slots filled.
The PyO3 behavior in 0.16 has been changed to be closer to this Python behavior by default.
wrap_pymodule! and wrap_pyfunction! now respect privacy correctly
Prior to PyO3 0.16 the wrap_pymodule! and wrap_pyfunction! macros could use modules and functions whose defining fn was not reachable according Rust privacy rules.
For example, the following code was legal before 0.16, but in 0.16 is rejected because the wrap_pymodule! macro cannot access the private_submodule function:
#![allow(unused)] fn main() { mod foo { use pyo3::prelude::*; #[pymodule] fn private_submodule(_py: Python<'_>, m: &PyModule) -> PyResult<()> { Ok(()) } } use pyo3::prelude::*; use foo::*; #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pymodule!(private_submodule))?; Ok(()) } }
To fix it, make the private submodule visible, e.g. with pub or pub(crate).
#![allow(unused)] fn main() { mod foo { use pyo3::prelude::*; #[pymodule] pub(crate) fn private_submodule(_py: Python<'_>, m: &PyModule) -> PyResult<()> { Ok(()) } } use pyo3::prelude::*; use pyo3::wrap_pymodule; use foo::*; #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pymodule!(private_submodule))?; Ok(()) } }
from 0.14.* to 0.15
Changes in sequence indexing
For all types that take sequence indices (PyList, PyTuple and PySequence),
the API has been made consistent to only take usize indices, for consistency
with Rust’s indexing conventions. Negative indices, which were only
sporadically supported even in APIs that took isize, now aren’t supported
anywhere.
Further, the get_item methods now always return a PyResult instead of
panicking on invalid indices. The Index trait has been implemented instead,
and provides the same panic behavior as on Rust vectors.
Note that slice indices (accepted by PySequence::get_slice and other) still
inherit the Python behavior of clamping the indices to the actual length, and
not panicking/returning an error on out of range indices.
An additional advantage of using Rust’s indexing conventions for these types is that these types can now also support Rust’s indexing operators as part of a consistent API:
#![allow(unused)] fn main() { use pyo3::{Python, types::PyList}; Python::with_gil(|py| { let list = PyList::new(py, &[1, 2, 3]); assert_eq!(list[0..2].to_string(), "[1, 2]"); }); }
from 0.13.* to 0.14
auto-initialize feature is now opt-in
For projects embedding Python in Rust, PyO3 no longer automatically initializes a Python interpreter on the first call to Python::with_gil (or Python::acquire_gil) unless the auto-initialize feature is enabled.
New multiple-pymethods feature
#[pymethods] have been reworked with a simpler default implementation which removes the dependency on the inventory crate. This reduces dependencies and compile times for the majority of users.
The limitation of the new default implementation is that it cannot support multiple #[pymethods] blocks for the same #[pyclass]. If you need this functionality, you must enable the multiple-pymethods feature which will switch #[pymethods] to the inventory-based implementation.
Deprecated #[pyproto] methods
Some protocol (aka __dunder__) methods such as __bytes__ and __format__ have been possible to implement two ways in PyO3 for some time: via a #[pyproto] (e.g. PyBasicProtocol for the methods listed here), or by writing them directly in #[pymethods]. This is only true for a handful of the #[pyproto] methods (for technical reasons to do with the way PyO3 currently interacts with the Python C-API).
In the interest of having onle one way to do things, the #[pyproto] forms of these methods have been deprecated.
To migrate just move the affected methods from a #[pyproto] to a #[pymethods] block.
Before:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::class::basic::PyBasicProtocol; #[pyclass] struct MyClass { } #[pyproto] impl PyBasicProtocol for MyClass { fn __bytes__(&self) -> &'static [u8] { b"hello, world" } } }
After:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { } #[pymethods] impl MyClass { fn __bytes__(&self) -> &'static [u8] { b"hello, world" } } }
from 0.12.* to 0.13
Minimum Rust version increased to Rust 1.45
PyO3 0.13 makes use of new Rust language features stabilised between Rust 1.40 and Rust 1.45. If you are using a Rust compiler older than Rust 1.45, you will need to update your toolchain to be able to continue using PyO3.
Runtime changes to support the CPython limited API
In PyO3 0.13 support was added for compiling against the CPython limited API. This had a number of implications for all PyO3 users, described here.
The largest of these is that all types created from PyO3 are what CPython calls “heap” types. The specific implications of this are:
- If you wish to subclass one of these types from Rust you must mark it
#[pyclass(subclass)], as you would if you wished to allow subclassing it from Python code. - Type objects are now mutable - Python code can set attributes on them.
__module__on types without#[pyclass(module="mymodule")]no longer returnsbuiltins, it now raisesAttributeError.
from 0.11.* to 0.12
PyErr has been reworked
In PyO3 0.12 the PyErr type has been re-implemented to be significantly more compatible with
the standard Rust error handling ecosystem. Specifically PyErr now implements
Error + Send + Sync, which are the standard traits used for error types.
While this has necessitated the removal of a number of APIs, the resulting PyErr type should now
be much more easier to work with. The following sections list the changes in detail and how to
migrate to the new APIs.
PyErr::new and PyErr::from_type now require Send + Sync for their argument
For most uses no change will be needed. If you are trying to construct PyErr from a value that is
not Send + Sync, you will need to first create the Python object and then use
PyErr::from_instance.
Similarly, any types which implemented PyErrArguments will now need to be Send + Sync.
PyErr’s contents are now private
It is no longer possible to access the fields .ptype, .pvalue and .ptraceback of a PyErr.
You should instead now use the new methods PyErr::ptype, PyErr::pvalue and PyErr::ptraceback.
PyErrValue and PyErr::from_value have been removed
As these were part the internals of PyErr which have been reworked, these APIs no longer exist.
If you used this API, it is recommended to use PyException::new_err (see the section on
Exception types).
Into<PyResult<T>> for PyErr has been removed
This implementation was redundant. Just construct the Result::Err variant directly.
Before:
#![allow(unused)] fn main() { let result: PyResult<()> = PyErr::new::<TypeError, _>("error message").into(); }
After (also using the new reworked exception types; see the following section):
#![allow(unused)] fn main() { use pyo3::{PyResult, exceptions::PyTypeError}; let result: PyResult<()> = Err(PyTypeError::new_err("error message")); }
Exception types have been reworked
Previously exception types were zero-sized marker types purely used to construct PyErr. In PyO3
0.12, these types have been replaced with full definitions and are usable in the same way as PyAny, PyDict etc. This
makes it possible to interact with Python exception objects.
The new types also have names starting with the “Py” prefix. For example, before:
#![allow(unused)] fn main() { let err: PyErr = TypeError::py_err("error message"); }
After:
#![allow(unused)] fn main() { use pyo3::{PyErr, PyResult, Python, type_object::PyTypeObject}; use pyo3::exceptions::{PyBaseException, PyTypeError}; Python::with_gil(|py| -> PyResult<()> { let err: PyErr = PyTypeError::new_err("error message"); // Uses Display for PyErr, new for PyO3 0.12 assert_eq!(err.to_string(), "TypeError: error message"); // Now possible to interact with exception instances, new for PyO3 0.12 let instance: &PyBaseException = err.instance(py); assert_eq!(instance.getattr("__class__")?, PyTypeError::type_object(py).as_ref()); Ok(()) }).unwrap(); }
FromPy has been removed
To simplify the PyO3 conversion traits, the FromPy trait has been removed. Previously there were
two ways to define the to-Python conversion for a type:
FromPy<T> for PyObject and IntoPy<PyObject> for T.
Now there is only one way to define the conversion, IntoPy, so downstream crates may need to
adjust accordingly.
Before:
#![allow(unused)] fn main() { use pyo3::prelude::*; struct MyPyObjectWrapper(PyObject); impl FromPy<MyPyObjectWrapper> for PyObject { fn from_py(other: MyPyObjectWrapper, _py: Python<'_>) -> Self { other.0 } } }
After
#![allow(unused)] fn main() { use pyo3::prelude::*; struct MyPyObjectWrapper(PyObject); impl IntoPy<PyObject> for MyPyObjectWrapper { fn into_py(self, _py: Python<'_>) -> PyObject { self.0 } } }
Similarly, code which was using the FromPy trait can be trivially rewritten to use IntoPy.
Before:
#![allow(unused)] fn main() { use pyo3::prelude::*; Python::with_gil(|py| { let obj = PyObject::from_py(1.234, py); }) }
After:
#![allow(unused)] fn main() { use pyo3::prelude::*; Python::with_gil(|py| { let obj: PyObject = 1.234.into_py(py); }) }
PyObject is now a type alias of Py<PyAny>
This should change very little from a usage perspective. If you implemented traits for both
PyObject and Py<T>, you may find you can just remove the PyObject implementation.
AsPyRef has been removed
As PyObject has been changed to be just a type alias, the only remaining implementor of AsPyRef
was Py<T>. This removed the need for a trait, so the AsPyRef::as_ref method has been moved to
Py::as_ref.
This should require no code changes except removing use pyo3::AsPyRef for code which did not use
pyo3::prelude::*.
Before:
#![allow(unused)] fn main() { use pyo3::{AsPyRef, Py, types::PyList}; pyo3::Python::with_gil(|py| { let list_py: Py<PyList> = PyList::empty(py).into(); let list_ref: &PyList = list_py.as_ref(py); }) }
After:
#![allow(unused)] fn main() { use pyo3::{Py, types::PyList}; pyo3::Python::with_gil(|py| { let list_py: Py<PyList> = PyList::empty(py).into(); let list_ref: &PyList = list_py.as_ref(py); }) }
from 0.10.* to 0.11
Stable Rust
PyO3 now supports the stable Rust toolchain. The minimum required version is 1.39.0.
#[pyclass] structs must now be Send or unsendable
Because #[pyclass] structs can be sent between threads by the Python interpreter, they must implement
Send or declared as unsendable (by #[pyclass(unsendable)]).
Note that unsendable is added in PyO3 0.11.1 and Send is always required in PyO3 0.11.0.
This may “break” some code which previously was accepted, even though it could be unsound. There can be two fixes:
-
If you think that your
#[pyclass]actually must beSendable, then let’s implementSend. A common, safer way is using thread-safe types. E.g.,Arcinstead ofRc,Mutexinstead ofRefCell, andBox<dyn Send + T>instead ofBox<dyn T>.Before:
#![allow(unused)] fn main() { use pyo3::prelude::*; use std::rc::Rc; use std::cell::RefCell; #[pyclass] struct NotThreadSafe { shared_bools: Rc<RefCell<Vec<bool>>>, closure: Box<dyn Fn()> } }After:
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; use std::sync::{Arc, Mutex}; #[pyclass] struct ThreadSafe { shared_bools: Arc<Mutex<Vec<bool>>>, closure: Box<dyn Fn() + Send> } }In situations where you cannot change your
#[pyclass]to automatically implementSend(e.g., when it contains a raw pointer), you can useunsafe impl Send. In such cases, care should be taken to ensure the struct is actually thread safe. See the Rustnomicon for more. -
If you think that your
#[pyclass]should not be accessed by another thread, you can useunsendableflag. A class marked withunsendablepanics when accessed by another thread, making it thread-safe to expose an unsendable object to the Python interpreter.Before:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Unsendable { pointers: Vec<*mut std::os::raw::c_char>, } }After:
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; #[pyclass(unsendable)] struct Unsendable { pointers: Vec<*mut std::os::raw::c_char>, } }
All PyObject and Py<T> methods now take Python as an argument
Previously, a few methods such as Object::get_refcnt did not take Python as an argument (to
ensure that the Python GIL was held by the current thread). Technically, this was not sound.
To migrate, just pass a py argument to any calls to these methods.
Before:
#![allow(unused)] fn main() { pyo3::Python::with_gil(|py| { py.None().get_refcnt(); }) }
After:
#![allow(unused)] fn main() { pyo3::Python::with_gil(|py| { py.None().get_refcnt(py); }) }
from 0.9.* to 0.10
ObjectProtocol is removed
All methods are moved to PyAny.
And since now all native types (e.g., PyList) implements Deref<Target=PyAny>,
all you need to do is remove ObjectProtocol from your code.
Or if you use ObjectProtocol by use pyo3::prelude::*, you have to do nothing.
Before:
#![allow(unused)] fn main() { use pyo3::ObjectProtocol; pyo3::Python::with_gil(|py| { let obj = py.eval("lambda: 'Hi :)'", None, None).unwrap(); let hi: &pyo3::types::PyString = obj.call0().unwrap().downcast().unwrap(); assert_eq!(hi.len().unwrap(), 5); }) }
After:
#![allow(unused)] fn main() { pyo3::Python::with_gil(|py| { let obj = py.eval("lambda: 'Hi :)'", None, None).unwrap(); let hi: &pyo3::types::PyString = obj.call0().unwrap().downcast().unwrap(); assert_eq!(hi.len().unwrap(), 5); }) }
No #![feature(specialization)] in user code
While PyO3 itself still requires specialization and nightly Rust,
now you don’t have to use #![feature(specialization)] in your crate.
from 0.8.* to 0.9
#[new] interface
PyRawObject
is now removed and our syntax for constructors has changed.
Before:
#![allow(unused)] fn main() { #[pyclass] struct MyClass {} #[pymethods] impl MyClass { #[new] fn new(obj: &PyRawObject) { obj.init(MyClass { }) } } }
After:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass {} #[pymethods] impl MyClass { #[new] fn new() -> Self { MyClass {} } } }
Basically you can return Self or Result<Self> directly.
For more, see the constructor section of this guide.
PyCell
PyO3 0.9 introduces PyCell, which is a RefCell-like object wrapper
for ensuring Rust’s rules regarding aliasing of references are upheld.
For more detail, see the
Rust Book’s section on Rust’s rules of references
For #[pymethods] or #[pyfunction]s, your existing code should continue to work without any change.
Python exceptions will automatically be raised when your functions are used in a way which breaks Rust’s
rules of references.
Here is an example.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Names { names: Vec<String> } #[pymethods] impl Names { #[new] fn new() -> Self { Names { names: vec![] } } fn merge(&mut self, other: &mut Names) { self.names.append(&mut other.names) } } Python::with_gil(|py| { let names = PyCell::new(py, Names::new()).unwrap(); pyo3::py_run!(py, names, r" try: names.merge(names) assert False, 'Unreachable' except RuntimeError as e: assert str(e) == 'Already borrowed' "); }) }
Names has a merge method, which takes &mut self and another argument of type &mut Self.
Given this #[pyclass], calling names.merge(names) in Python raises
a PyBorrowMutError exception, since it requires two mutable borrows of names.
However, for #[pyproto] and some functions, you need to manually fix the code.
Object creation
In 0.8 object creation was done with PyRef::new and PyRefMut::new.
In 0.9 these have both been removed.
To upgrade code, please use
PyCell::new instead.
If you need PyRef or PyRefMut, just call .borrow() or .borrow_mut()
on the newly-created PyCell.
Before:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass {} Python::with_gil(|py| { let obj_ref = PyRef::new(py, MyClass {}).unwrap(); }) }
After:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass {} Python::with_gil(|py| { let obj = PyCell::new(py, MyClass {}).unwrap(); let obj_ref = obj.borrow(); }) }
Object extraction
For PyClass types T, &T and &mut T no longer have FromPyObject implementations.
Instead you should extract PyRef<T> or PyRefMut<T>, respectively.
If T implements Clone, you can extract T itself.
In addition, you can also extract &PyCell<T>, though you rarely need it.
Before:
let obj: &PyAny = create_obj();
let obj_ref: &MyClass = obj.extract().unwrap();
let obj_ref_mut: &mut MyClass = obj.extract().unwrap();
After:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::IntoPyDict; #[pyclass] #[derive(Clone)] struct MyClass {} #[pymethods] impl MyClass { #[new]fn new() -> Self { MyClass {} }} Python::with_gil(|py| { let typeobj = py.get_type::<MyClass>(); let d = [("c", typeobj)].into_py_dict(py); let create_obj = || py.eval("c()", None, Some(d)).unwrap(); let obj: &PyAny = create_obj(); let obj_cell: &PyCell<MyClass> = obj.extract().unwrap(); let obj_cloned: MyClass = obj.extract().unwrap(); // extracted by cloning the object { let obj_ref: PyRef<'_, MyClass> = obj.extract().unwrap(); // we need to drop obj_ref before we can extract a PyRefMut due to Rust's rules of references } let obj_ref_mut: PyRefMut<'_, MyClass> = obj.extract().unwrap(); }) }
#[pyproto]
Most of the arguments to methods in #[pyproto] impls require a
FromPyObject implementation.
So if your protocol methods take &T or &mut T (where T: PyClass),
please use PyRef or PyRefMut instead.
Before:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::class::PySequenceProtocol; #[pyclass] struct ByteSequence { elements: Vec<u8>, } #[pyproto] impl PySequenceProtocol for ByteSequence { fn __concat__(&self, other: &Self) -> PyResult<Self> { let mut elements = self.elements.clone(); elements.extend_from_slice(&other.elements); Ok(Self { elements }) } } }
After:
#![allow(unused)] fn main() { #[allow(deprecated)] #[cfg(feature = "pyproto")] { use pyo3::prelude::*; use pyo3::class::PySequenceProtocol; #[pyclass] struct ByteSequence { elements: Vec<u8>, } #[pyproto] impl PySequenceProtocol for ByteSequence { fn __concat__(&self, other: PyRef<'p, Self>) -> PyResult<Self> { let mut elements = self.elements.clone(); elements.extend_from_slice(&other.elements); Ok(Self { elements }) } } } }
PyO3 and rust-cpython
PyO3 began as fork of rust-cpython when rust-cpython wasn’t maintained. Over time PyO3 has become fundamentally different from rust-cpython.
Macros
While rust-cpython has a macro_rules! based dsl for declaring modules and classes, PyO3 uses proc macros. PyO3 also doesn’t change your struct and functions so you can still use them as normal Rust functions.
rust-cpython
py_class!(class MyClass |py| {
data number: i32;
def __new__(_cls, arg: i32) -> PyResult<MyClass> {
MyClass::create_instance(py, arg)
}
def half(&self) -> PyResult<i32> {
Ok(self.number(py) / 2)
}
});
pyo3
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: u32, } #[pymethods] impl MyClass { #[new] fn new(num: u32) -> Self { MyClass { num } } fn half(&self) -> PyResult<u32> { Ok(self.num / 2) } } }
Ownership and lifetimes
While in rust-cpython you always own python objects, PyO3 allows efficient borrowed objects and most APIs are available with references.
Here is an example of the PyList API:
rust-cpython
impl PyList {
fn new(py: Python<'_>) -> PyList {...}
fn get_item(&self, py: Python<'_>, index: isize) -> PyObject {...}
}
pyo3
impl PyList {
fn new(py: Python<'_>) -> &PyList {...}
fn get_item(&self, index: isize) -> &PyAny {...}
}
In PyO3, all object references are bounded by the GIL lifetime.
So the owned Python object is not required, and it is safe to have functions like fn py<'p>(&'p self) -> Python<'p> {}.
Error handling
rust-cpython requires a Python parameter for constructing a PyErr, so error handling ergonomics is pretty bad. It is not possible to use ? with Rust errors.
PyO3 on other hand does not require Python for constructing a PyErr, it is only required if you want to raise an exception in Python with the PyErr::restore() method. Due to various std::convert::From<E> for PyErr implementations for Rust standard error types E, propagating ? is supported automatically.
Using in Python a Rust function with trait bounds
PyO3 allows for easy conversion from Rust to Python for certain functions and classes (see the conversion table. However, it is not always straightforward to convert Rust code that requires a given trait implementation as an argument.
This tutorial explains how to convert a Rust function that takes a trait as argument for use in Python with classes implementing the same methods as the trait.
Why is this useful?
Pros
- Make your Rust code available to Python users
- Code complex algorithms in Rust with the help of the borrow checker
Cons
- Not as fast as native Rust (type conversion has to be performed and one part of the code runs in Python)
- You need to adapt your code to expose it
Example
Let’s work with the following basic example of an implementation of a optimization solver operating on a given model.
Let’s say we have a function solve that operates on a model and mutates its state.
The argument of the function can be any model that implements the Model trait :
#![allow(unused)] fn main() { #![allow(dead_code)] pub trait Model { fn set_variables(&mut self, inputs: &Vec<f64>); fn compute(&mut self); fn get_results(&self) -> Vec<f64>; } pub fn solve<T: Model>(model: &mut T) { println!("Magic solver that mutates the model into a resolved state"); } }
Let’s assume we have the following constraints:
- We cannot change that code as it runs on many Rust models.
- We also have many Python models that cannot be solved as this solver is not available in that language. Rewriting it in Python would be cumbersome and error-prone, as everything is already available in Rust.
How could we expose this solver to Python thanks to PyO3 ?
Implementation of the trait bounds for the Python class
If a Python class implements the same three methods as the Model trait, it seems logical it could be adapted to use the solver.
However, it is not possible to pass a PyObject to it as it does not implement the Rust trait (even if the Python model has the required methods).
In order to implement the trait, we must write a wrapper around the calls in Rust to the Python model. The method signatures must be the same as the trait, keeping in mind that the Rust trait cannot be changed for the purpose of making the code available in Python.
The Python model we want to expose is the following one, which already contains all the required methods:
class Model:
def set_variables(self, inputs):
self.inputs = inputs
def compute(self):
self.results = [elt**2 - 3 for elt in self.inputs]
def get_results(self):
return self.results
The following wrapper will call the Python model from Rust, using a struct to hold the model as a PyAny object:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyAny; pub trait Model { fn set_variables(&mut self, inputs: &Vec<f64>); fn compute(&mut self); fn get_results(&self) -> Vec<f64>; } struct UserModel { model: Py<PyAny>, } impl Model for UserModel { fn set_variables(&mut self, var: &Vec<f64>) { println!("Rust calling Python to set the variables"); Python::with_gil(|py| { let values: Vec<f64> = var.clone(); let list: PyObject = values.into_py(py); let py_model = self.model.as_ref(py); py_model .call_method("set_variables", (list,), None) .unwrap(); }) } fn get_results(&self) -> Vec<f64> { println!("Rust calling Python to get the results"); Python::with_gil(|py| { self.model .as_ref(py) .call_method("get_results", (), None) .unwrap() .extract() .unwrap() }) } fn compute(&mut self) { println!("Rust calling Python to perform the computation"); Python::with_gil(|py| { self.model .as_ref(py) .call_method("compute", (), None) .unwrap(); }) } } }
Now that this bit is implemented, let’s expose the model wrapper to Python. Let’s add the PyO3 annotations and add a constructor:
#![allow(unused)] fn main() { #![allow(dead_code)] pub trait Model { fn set_variables(&mut self, inputs: &Vec<f64>); fn compute(&mut self); fn get_results(&self) -> Vec<f64>; } use pyo3::prelude::*; use pyo3::types::PyAny; #[pyclass] struct UserModel { model: Py<PyAny>, } #[pymodule] fn trait_exposure(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<UserModel>()?; Ok(()) } #[pymethods] impl UserModel { #[new] pub fn new(model: Py<PyAny>) -> Self { UserModel { model } } } }
Now we add the PyO3 annotations to the trait implementation:
#[pymethods]
impl Model for UserModel {
// the previous trait implementation
}
However, the previous code will not compile. The compilation error is the following one:
error: #[pymethods] cannot be used on trait impl blocks
That’s a bummer! However, we can write a second wrapper around these functions to call them directly. This wrapper will also perform the type conversions between Python and Rust.
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyAny; pub trait Model { fn set_variables(&mut self, inputs: &Vec<f64>); fn compute(&mut self); fn get_results(&self) -> Vec<f64>; } #[pyclass] struct UserModel { model: Py<PyAny>, } impl Model for UserModel { fn set_variables(&mut self, var: &Vec<f64>) { println!("Rust calling Python to set the variables"); Python::with_gil(|py| { let values: Vec<f64> = var.clone(); let list: PyObject = values.into_py(py); let py_model = self.model.as_ref(py); py_model .call_method("set_variables", (list,), None) .unwrap(); }) } fn get_results(&self) -> Vec<f64> { println!("Rust calling Python to get the results"); Python::with_gil(|py| { self.model .as_ref(py) .call_method("get_results", (), None) .unwrap() .extract() .unwrap() }) } fn compute(&mut self) { println!("Rust calling Python to perform the computation"); Python::with_gil(|py| { self.model .as_ref(py) .call_method("compute", (), None) .unwrap(); }) } } #[pymethods] impl UserModel { pub fn set_variables(&mut self, var: Vec<f64>) { println!("Set variables from Python calling Rust"); Model::set_variables(self, &var) } pub fn get_results(&mut self) -> Vec<f64> { println!("Get results from Python calling Rust"); Model::get_results(self) } pub fn compute(&mut self) { println!("Compute from Python calling Rust"); Model::compute(self) } } }
This wrapper handles the type conversion between the PyO3 requirements and the trait. In order to meet PyO3 requirements, this wrapper must:
- return an object of type
PyResult - use only values, not references in the method signatures
Let’s run the file python file:
class Model:
def set_variables(self, inputs):
self.inputs = inputs
def compute(self):
self.results = [elt**2 - 3 for elt in self.inputs]
def get_results(self):
return self.results
if __name__=="__main__":
import trait_exposure
myModel = Model()
my_rust_model = trait_exposure.UserModel(myModel)
my_rust_model.set_variables([2.0])
print("Print value from Python: ", myModel.inputs)
my_rust_model.compute()
print("Print value from Python through Rust: ", my_rust_model.get_results())
print("Print value directly from Python: ", myModel.get_results())
This outputs:
Set variables from Python calling Rust
Set variables from Rust calling Python
Print value from Python: [2.0]
Compute from Python calling Rust
Compute from Rust calling Python
Get results from Python calling Rust
Get results from Rust calling Python
Print value from Python through Rust: [1.0]
Print value directly from Python: [1.0]
We have now successfully exposed a Rust model that implements the Model trait to Python!
We will now expose the solve function, but before, let’s talk about types errors.
Type errors in Python
What happens if you have type errors when using Python and how can you improve the error messages?
Wrong types in Python function arguments
Let’s assume in the first case that you will use in your Python file my_rust_model.set_variables(2.0) instead of my_rust_model.set_variables([2.0]).
The Rust signature expects a vector, which corresponds to a list in Python. What happens if instead of a vector, we pass a single value ?
At the execution of Python, we get :
File "main.py", line 15, in <module>
my_rust_model.set_variables(2)
TypeError
It is a type error and Python points to it, so it’s easy to identify and solve.
Wrong types in Python method signatures
Let’s assume now that the return type of one of the methods of our Model class is wrong, for example the get_results method that is expected to return a Vec<f64> in Rust, a list in Python.
class Model:
def set_variables(self, inputs):
self.inputs = inputs
def compute(self):
self.results = [elt**2 -3 for elt in self.inputs]
def get_results(self):
return self.results[0]
#return self.results <-- this is the expected output
This call results in the following panic:
pyo3_runtime.PanicException: called `Result::unwrap()` on an `Err` value: PyErr { type: Py(0x10dcf79f0, PhantomData) }
This error code is not helpful for a Python user that does not know anything about Rust, or someone that does not know PyO3 was used to interface the Rust code.
However, as we are responsible for making the Rust code available to Python, we can do something about it.
The issue is that we called unwrap anywhere we could, and therefore any panic from PyO3 will be directly forwarded to the end user.
Let’s modify the code performing the type conversion to give a helpful error message to the Python user:
We used in our get_results method the following call that performs the type conversion:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyAny; pub trait Model { fn set_variables(&mut self, inputs: &Vec<f64>); fn compute(&mut self); fn get_results(&self) -> Vec<f64>; } #[pyclass] struct UserModel { model: Py<PyAny>, } impl Model for UserModel { fn get_results(&self) -> Vec<f64> { println!("Rust calling Python to get the results"); Python::with_gil(|py| { self.model .as_ref(py) .call_method("get_results", (), None) .unwrap() .extract() .unwrap() }) } fn set_variables(&mut self, var: &Vec<f64>) { println!("Rust calling Python to set the variables"); Python::with_gil(|py| { let values: Vec<f64> = var.clone(); let list: PyObject = values.into_py(py); let py_model = self.model.as_ref(py); py_model .call_method("set_variables", (list,), None) .unwrap(); }) } fn compute(&mut self) { println!("Rust calling Python to perform the computation"); Python::with_gil(|py| { self.model .as_ref(py) .call_method("compute", (), None) .unwrap(); }) } } }
Let’s break it down in order to perform better error handling:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyAny; pub trait Model { fn set_variables(&mut self, inputs: &Vec<f64>); fn compute(&mut self); fn get_results(&self) -> Vec<f64>; } #[pyclass] struct UserModel { model: Py<PyAny>, } impl Model for UserModel { fn get_results(&self) -> Vec<f64> { println!("Get results from Rust calling Python"); Python::with_gil(|py| { let py_result: &PyAny = self .model .as_ref(py) .call_method("get_results", (), None) .unwrap(); if py_result.get_type().name().unwrap() != "list" { panic!("Expected a list for the get_results() method signature, got {}", py_result.get_type().name().unwrap()); } py_result.extract() }) .unwrap() } fn set_variables(&mut self, var: &Vec<f64>) { println!("Rust calling Python to set the variables"); Python::with_gil(|py| { let values: Vec<f64> = var.clone(); let list: PyObject = values.into_py(py); let py_model = self.model.as_ref(py); py_model .call_method("set_variables", (list,), None) .unwrap(); }) } fn compute(&mut self) { println!("Rust calling Python to perform the computation"); Python::with_gil(|py| { self.model .as_ref(py) .call_method("compute", (), None) .unwrap(); }) } } }
By doing so, you catch the result of the Python computation and check its type in order to be able to deliver a better error message before performing the unwrapping.
Of course, it does not cover all the possible wrong outputs: the user could return a list of strings instead of a list of floats. In this case, a runtime panic would still occur due to PyO3, but with an error message much more difficult to decipher for non-rust user.
It is up to the developer exposing the rust code to decide how much effort to invest into Python type error handling and improved error messages.
The final code
Now let’s expose the solve() function to make it available from Python.
It is not possible to directly expose the solve function to Python, as the type conversion cannot be performed.
It requires an object implementing the Model trait as input.
However, the UserModel already implements this trait.
Because of this, we can write a function wrapper that takes the UserModel–which has already been exposed to Python–as an argument in order to call the core function solve.
It is also required to make the struct public.
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyAny; pub trait Model { fn set_variables(&mut self, var: &Vec<f64>); fn get_results(&self) -> Vec<f64>; fn compute(&mut self); } pub fn solve<T: Model>(model: &mut T) { println!("Magic solver that mutates the model into a resolved state"); } #[pyfunction] #[pyo3(name = "solve")] pub fn solve_wrapper(model: &mut UserModel) { solve(model); } #[pyclass] pub struct UserModel { model: Py<PyAny>, } #[pymodule] fn trait_exposure(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<UserModel>()?; m.add_function(wrap_pyfunction!(solve_wrapper, m)?)?; Ok(()) } #[pymethods] impl UserModel { #[new] pub fn new(model: Py<PyAny>) -> Self { UserModel { model } } pub fn set_variables(&mut self, var: Vec<f64>) { println!("Set variables from Python calling Rust"); Model::set_variables(self, &var) } pub fn get_results(&mut self) -> Vec<f64> { println!("Get results from Python calling Rust"); Model::get_results(self) } pub fn compute(&mut self) { Model::compute(self) } } impl Model for UserModel { fn set_variables(&mut self, var: &Vec<f64>) { println!("Rust calling Python to set the variables"); Python::with_gil(|py| { let values: Vec<f64> = var.clone(); let list: PyObject = values.into_py(py); let py_model = self.model.as_ref(py); py_model .call_method("set_variables", (list,), None) .unwrap(); }) } fn get_results(&self) -> Vec<f64> { println!("Get results from Rust calling Python"); Python::with_gil(|py| { let py_result: &PyAny = self .model .as_ref(py) .call_method("get_results", (), None) .unwrap(); if py_result.get_type().name().unwrap() != "list" { panic!("Expected a list for the get_results() method signature, got {}", py_result.get_type().name().unwrap()); } py_result.extract() }) .unwrap() } fn compute(&mut self) { println!("Rust calling Python to perform the computation"); Python::with_gil(|py| { self.model .as_ref(py) .call_method("compute", (), None) .unwrap(); }) } } }
Typing and IDE hints for you Python package
PyO3 provides an easy to use interface to code native Python libraries in Rust. The accompanying Maturin allows you to build and publish them as a package. Yet, for the better user experience, Python libraries should provide typing hints and documentation for all public entities, so that IDEs can show them during development and type analyzing tools such as mypy can use them to properly verify the code.
Currently the best solution for the problem is to maintain manually the *.pyi files and ship them along with the package.
The pyi files introduction
pyi (an abbreviation for Python Interface) is called a Stub File in most of the documentations related to them. Very good definition of what it is can be found in old MyPy documentation:
A stubs file only contains a description of the public interface of the module without any implementations.
Probably most Python developers encountered them already when trying to use the IDE “Go to Definition” function on any builtin type. For example the definitions of few standard exceptions look like this:
class BaseException(object):
args: Tuple[Any, ...]
__cause__: BaseException | None
__context__: BaseException | None
__suppress_context__: bool
__traceback__: TracebackType | None
def __init__(self, *args: object) -> None: ...
def __str__(self) -> str: ...
def __repr__(self) -> str: ...
def with_traceback(self: _TBE, tb: TracebackType | None) -> _TBE: ...
class SystemExit(BaseException):
code: int
class Exception(BaseException): ...
class StopIteration(Exception):
value: Any
As we can see those are not full definitions containing implementation, but just a description of interface. It is usually all that is needed by the user of the library.
What does the PEPs say?
As of the time of writing this documentation the pyi files are referenced in three PEPs.
PEP8 - Style Guide for Python Code - #Function Annotations (last point) recommends all third party library creators to provide stub files as the source of knowledge about the package for type checker tools.
(…) it is expected that users of third party library packages may want to run type checkers over those packages. For this purpose PEP 484 recommends the use of stub files: .pyi files that are read by the type checker in preference of the corresponding .py files. (…)
PEP484 - Type Hints - #Stub Files defines stub files as follows.
Stub files are files containing type hints that are only for use by the type checker, not at runtime.
It contains a specification for them (highly recommended reading, since it contains at least one thing that is not used in normal Python code) and also some general information about where to store the stub files.
PEP561 - Distributing and Packaging Type Information describes in detail how to build packages that will enable type checking. In particular it contains information about how the stub files must be distributed in order for type checkers to use them.
How to do it?
PEP561 recognizes three ways of distributing type information:
inline- the typing is placed directly in source (py) files;separate package with stub files- the typing is placed inpyifiles distributed in their own, separate package;in-package stub files- the typing is placed inpyifiles distributed in the same package as source files.
The first way is tricky with PyO3 since we do not have py files. When it will be investigated and necessary changes are implemented, this document will be updated.
The second way is easy to do, and the whole work can be fully separated from the main library code. The example repo for the package with stub files can be found in PEP561 references section: Stub package repository
The third way is described below.
Including pyi files in your PyO3/Maturin build package
When source files are in the same package as stub files, they should be placed next to each other. We need a way to do that with Maturin. Also, in order to mark our package as typing-enabled we need to add an empty file named py.typed to the package.
If you do not have other Python files
If you do not need to add any other Python files apart from pyi to the package, the Maturin provides a way to do most of the work for you. As documented in Maturin Guide the only thing you need to do is create a stub file for your module named <module_name>.pyi in your project root and Maturin will do the rest.
my-rust-project/
├── Cargo.toml
├── my_project.pyi # <<< add type stubs for Rust functions in the my_project module here
├── pyproject.toml
└── src
└── lib.rs
For example of pyi file see my_project.pyi content section.
If you need other Python files
If you need to add other Python files apart from pyi to the package, you can do it also, but that requires some more work. Maturin provides easy way to add files to package (documentation). You just need to create a folder with the name of your module next to the Cargo.toml file (for customization see documentation linked above).
The folder structure would be:
my-project
├── Cargo.toml
├── my_project
│ ├── __init__.py
│ ├── my_project.pyi
│ ├── other_python_file.py
│ └── py.typed
├── pyproject.toml
├── Readme.md
└── src
└── lib.rs
Let’s go a little bit more into details on the files inside the package folder.
__init__.py content
As we now specify our own package content, we have to provide the __init__.py file, so the folder is treated as a package and we can import things from it. We can always use the same content that the Maturin creates for us if we do not specify a python source folder. For PyO3 bindings it would be:
from .my_project import *
That way everything that is exposed by our native module can be imported directly from the package.
py.typed requirement
As stated in PEP561:
Package maintainers who wish to support type checking of their code MUST add a marker file named py.typed to their package supporting typing. This marker applies recursively: if a top-level package includes it, all its sub-packages MUST support type checking as well.
If we do not include that file, some IDEs might still use our pyi files to show hints, but the type checkers might not. MyPy will raise an error in this situation:
error: Skipping analyzing "my_project": found module but no type hints or library stubs
The file is just a marker file, so it should be empty.
my_project.pyi content
Our module stub file. This document does not aim at describing how to write them, since you can find a lot of documentation on it, starting from already quoted PEP484.
The example can look like this:
class Car:
"""
A class representing a car.
:param body_type: the name of body type, e.g. hatchback, sedan
:param horsepower: power of the engine in horsepower
"""
def __init__(self, body_type: str, horsepower: int) -> None: ...
@classmethod
def from_unique_name(cls, name: str) -> 'Car':
"""
Creates a Car based on unique name
:param name: model name of a car to be created
:return: a Car instance with default data
"""
def best_color(self) -> str:
"""
Gets the best color for the car.
:return: the name of the color our great algorithm thinks is the best for this car
"""
{{#include ../../CHANGELOG.md}}
{{#include ../../Contributing.md}}