三、融会贯通,从创建到消亡
创建
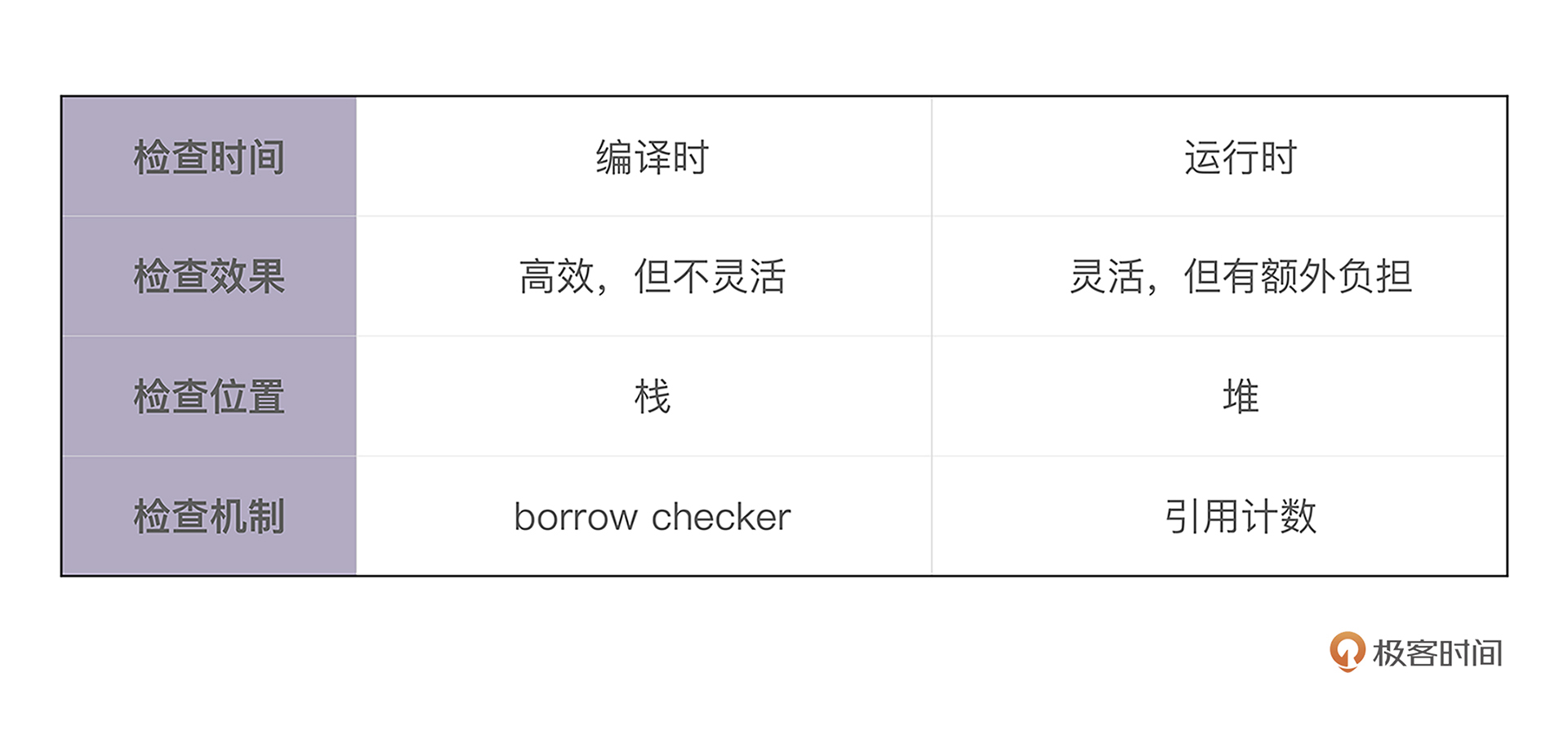
堆内存生命周期管理发展史

堆内存管理需求:动态大小 or 生命周期
Rust 的创造者们,重新审视了堆内存的生命周期,发现:
- 大部分堆内存的需求在于动态大小
- 小部分需求是更长的生命周期。
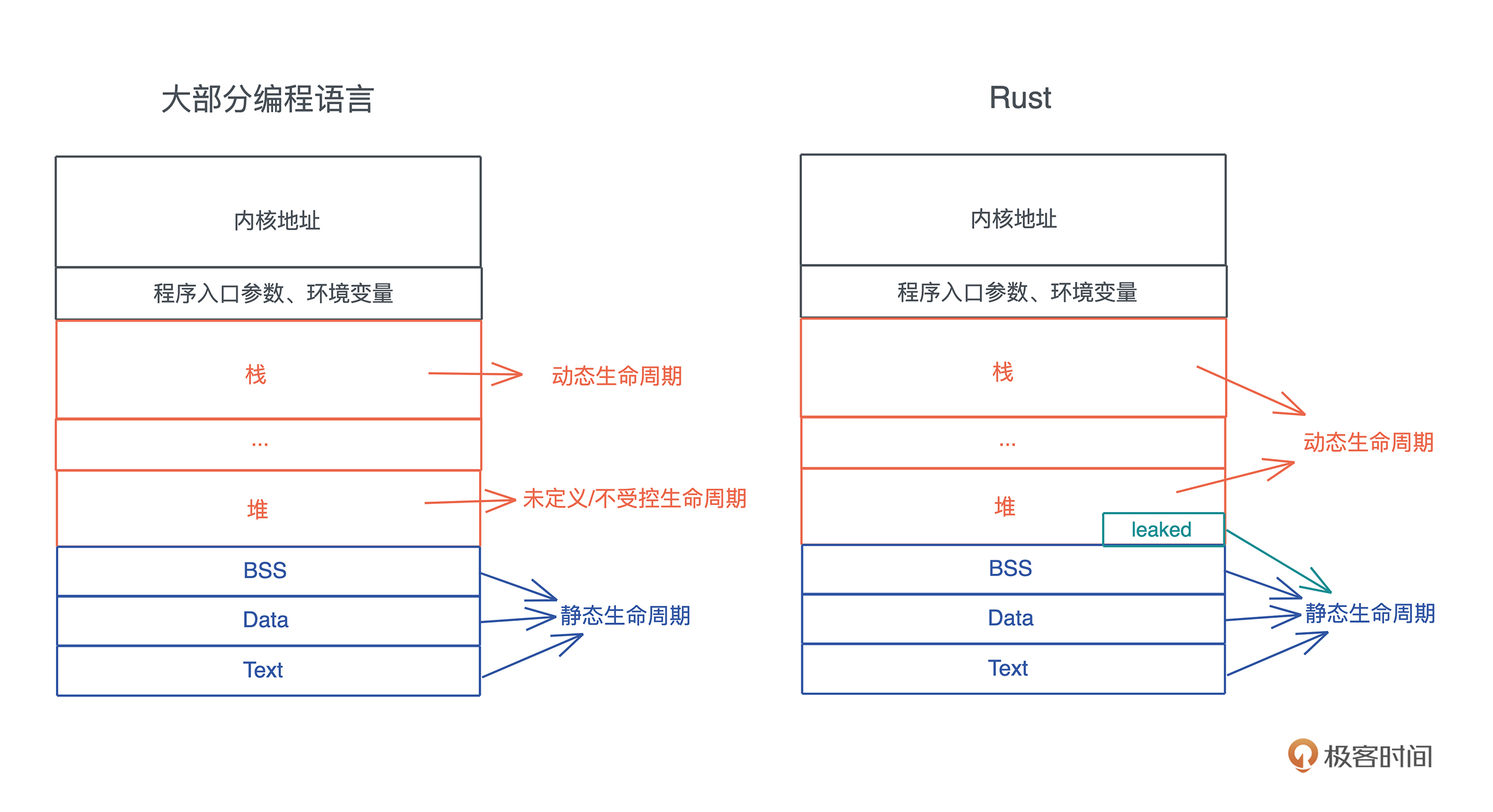
所以它默认将堆内存的生命周期和使用它的栈内存的生命周期绑在一起,并留了个小口子 leaked 机制,让堆内存在需要的时候,可以有超出帧存活期的生命周期。
struct/enum/vec/String创建时的内存布局
内存布局优化什么意思?
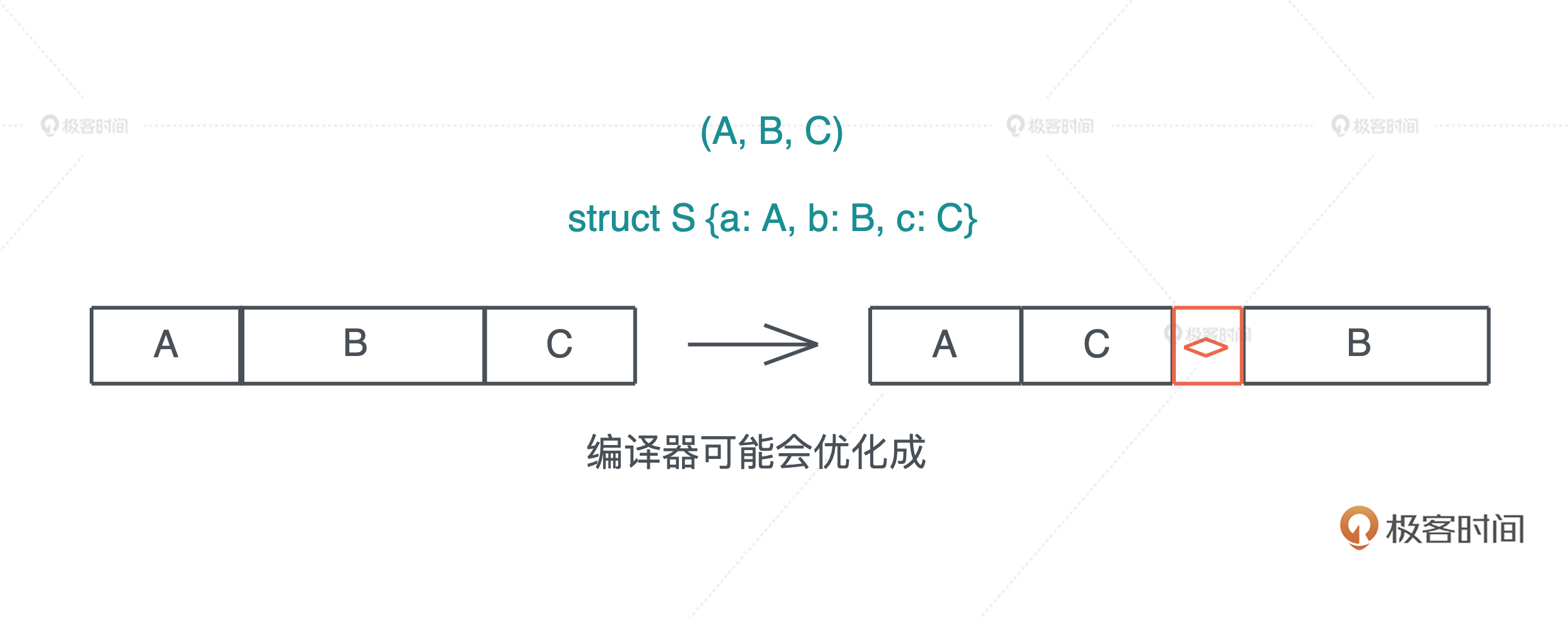
struct

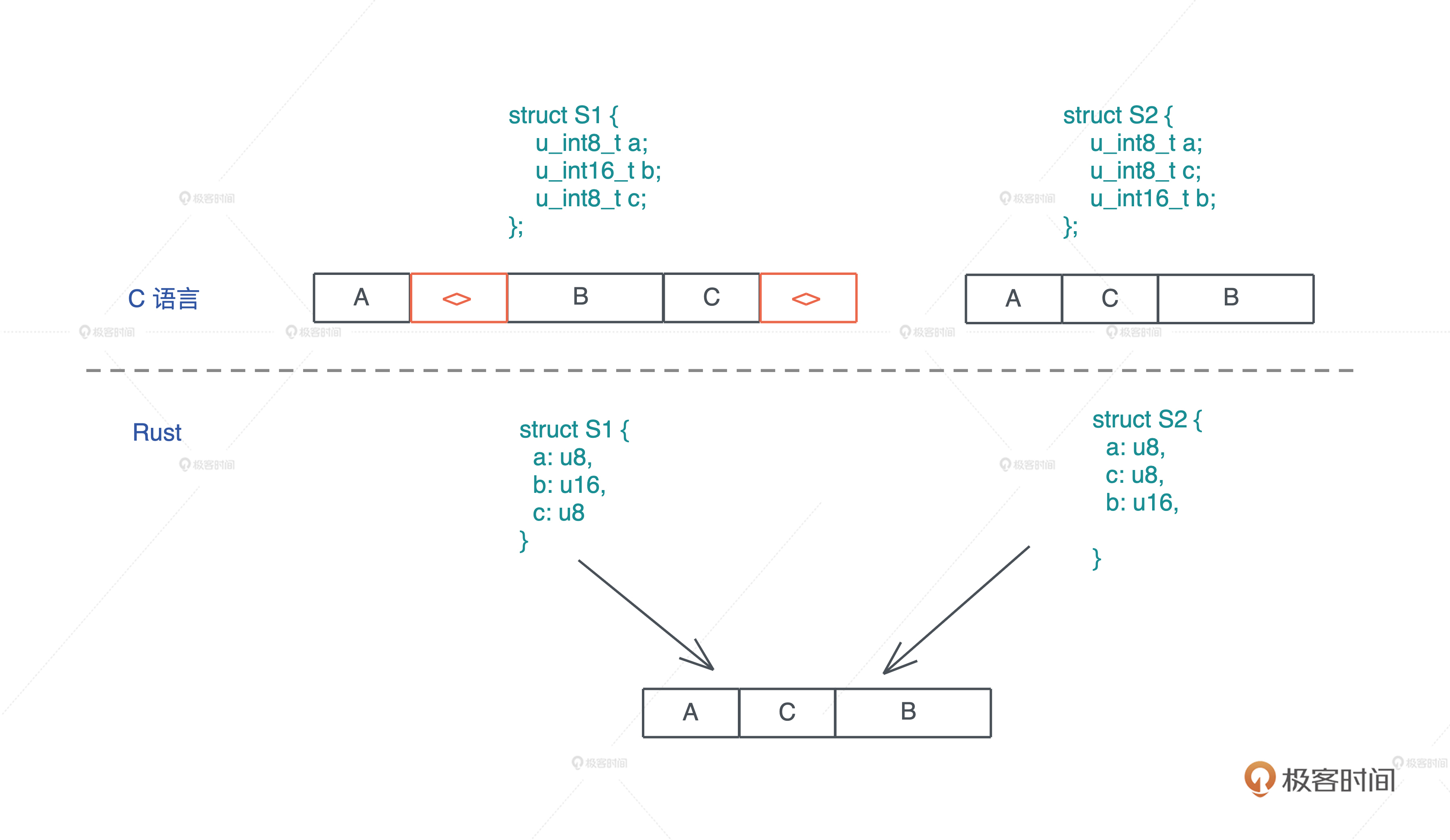
代码对比rust和clang的内存布局优化
#include <stdio.h>
struct S1 {
u_int8_t a;
u_int16_t b;
u_int8_t c;
};
struct S2 {
u_int8_t a;
u_int8_t c;
u_int16_t b;
};
void main() {
printf("size of S1: %d, S2: %d", sizeof(struct S1), sizeof(struct S2));
}
use std::mem::{align_of, size_of}; #[allow(dead_code)] struct S1 { a: u8, b: u16, c: u8, } #[allow(dead_code)] struct S2 { a: u8, c: u8, b: u16, } fn main() { println!("sizeof S1: {}, S2: {}", size_of::<S1>(), size_of::<S2>()); println!("alignof S1: {}, S2: {}", align_of::<S1>(), align_of::<S2>()); }
enum
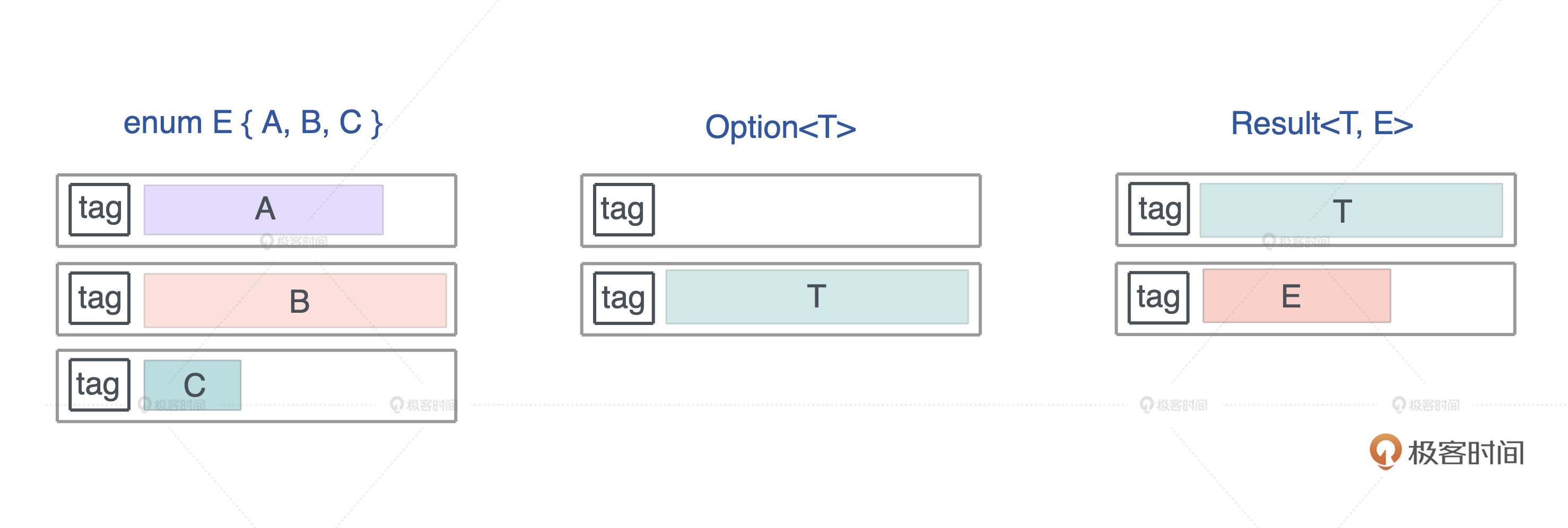
Rust 编译器会对 enum 做一些额外的优化,让某些常用结构的内存布局更紧凑。
use std::collections::HashMap; use std::mem::size_of; #[allow(dead_code)] enum E { A(f64), B(HashMap<String, String>), C(Result<Vec<u8>, String>), } macro_rules! show_size { (header) => { println!( "{:<24} {:>4} {} {}", "Type", "T", "Option<T>", "Result<T, io::Error>" ); println!("{}", "-".repeat(64)); }; ($t:ty) => { println!( "{:<24} {:4} {:8} {:12}", stringify!($t), size_of::<$t>(), size_of::<Option<$t>>(), size_of::<Result<$t, std::io::Error>>(), ) }; } fn main() { show_size!(header); show_size!(u8); show_size!(f64); show_size!(&u8); show_size!(Box<u8>); show_size!(&[u8]); show_size!(String); show_size!(Vec<u8>); show_size!(HashMap<String, String>); show_size!(E); }
你会发现,Option 配合带有引用类型的数据结构,比如 &u8、Box、Vec、HashMap ,没有额外占用空间,这就很有意思了
Type T Option<T> Result<T, io::Error>
----------------------------------------------------------------
u8 1 2 24
f64 8 16 24
&u8 8 8 24
Box<u8> 8 8 24
&[u8] 16 16 24
String 24 24 32
Vec<u8> 24 24 32
HashMap<String, String> 48 48 56
E 56 56 64
Rust 是这么处理的:
- 我们知道,引用类型的第一个域是个指针,而指针是不可能等于 0 的,
- 但是我们可以复用这个指针:当其为 0 时,表示 None,否则是 Some,减少了内存占用,这是个非常巧妙的优化
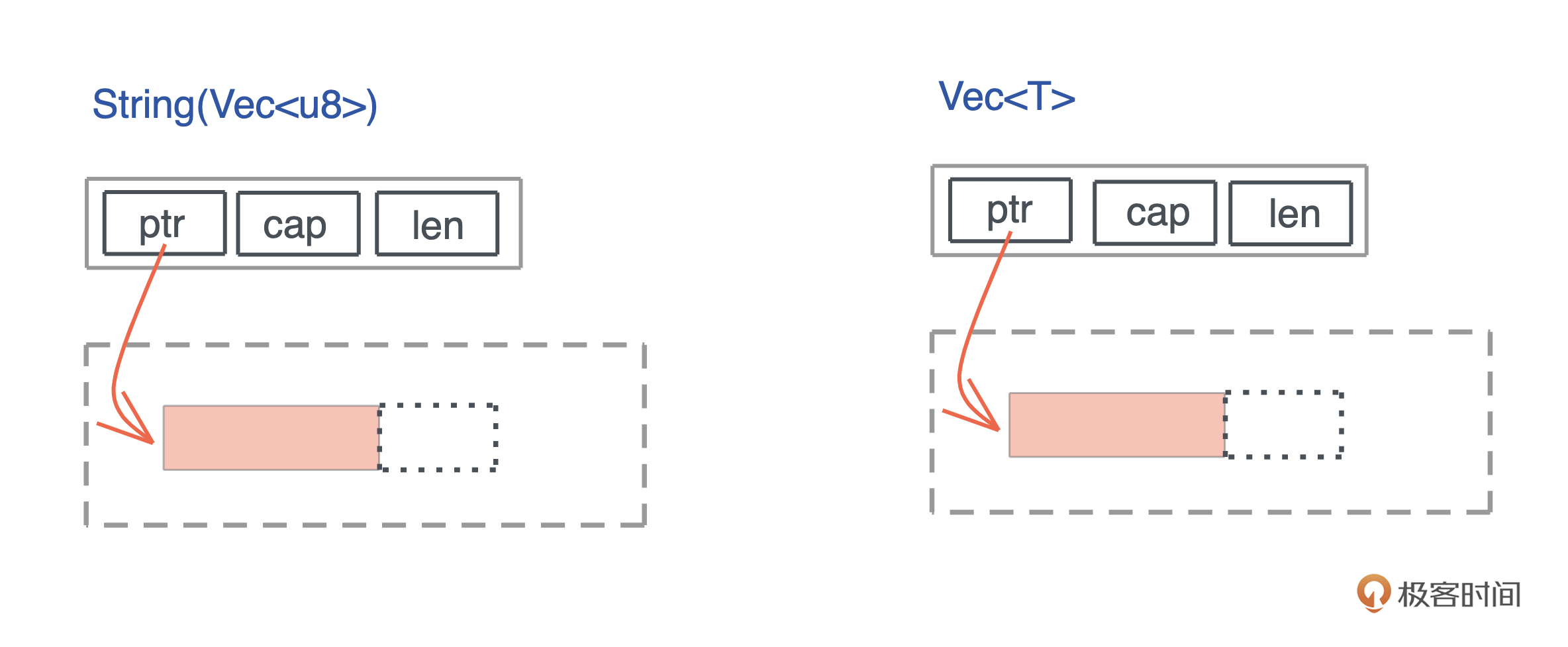
vec和String
String其实就是Vec
String 和 Vec 占用相同的大小,都是 24 个字节。其实,如果你打开 String 结构的源码,可以看到,它内部就是一个 Vec
引用类型的内存布局
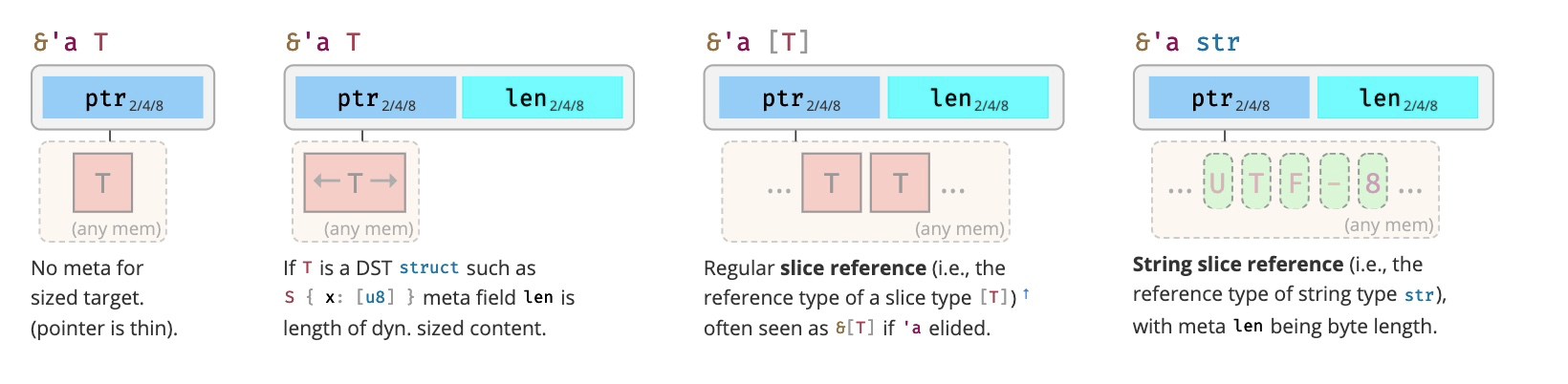
更多可见cheats.rs
使用
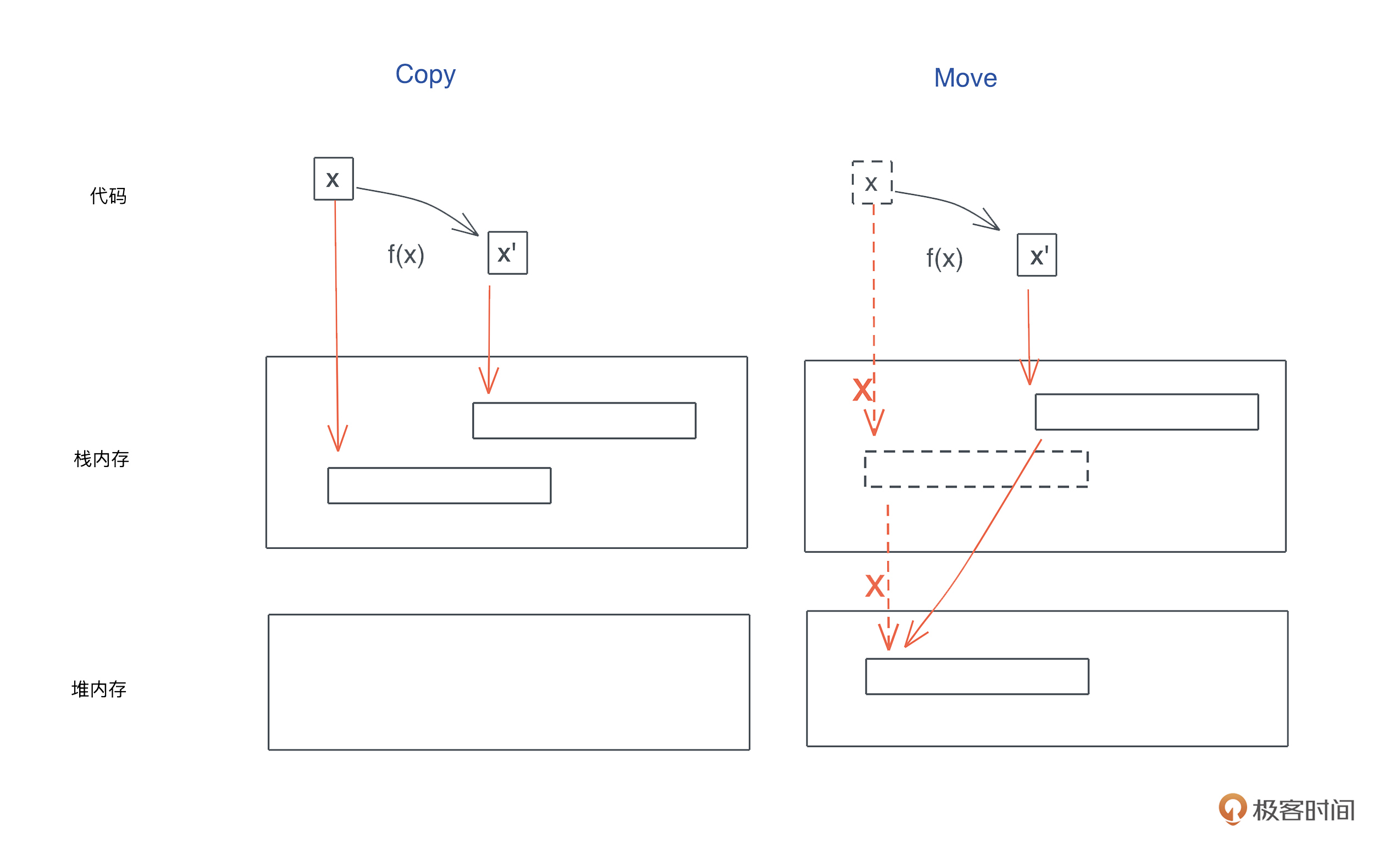
copy和move
销毁
drop释放堆内存
当一个值被释放,其实就是调用它的drop方法
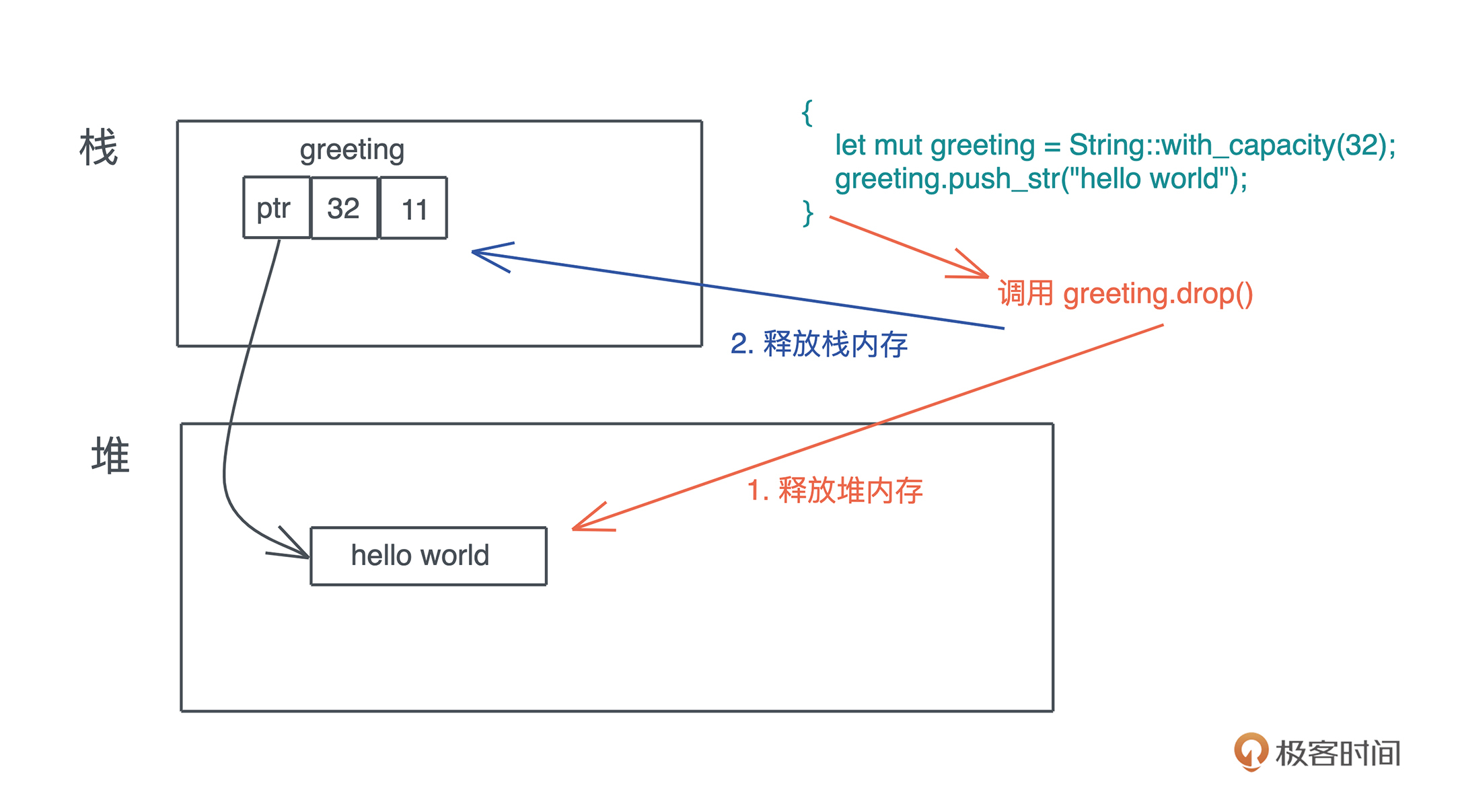
- 变量 greeting 是一个字符串,在退出作用域时,其 drop() 函数被自动调用
- 释放堆上包含 “hello world” 的内存
- 然后再释放栈上的内存
复杂结构递归调用drop
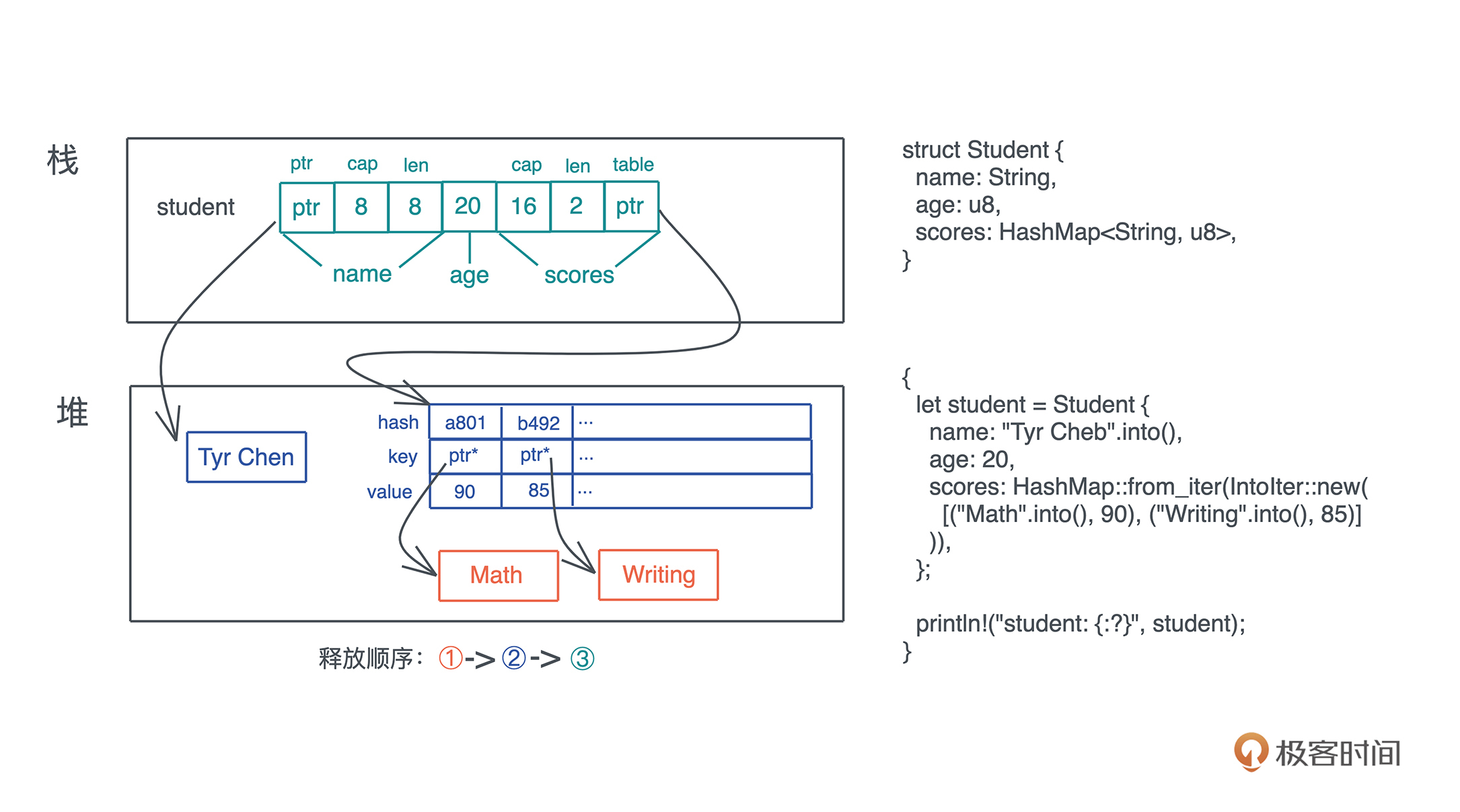
如果要释放的值是一个复杂的数据结构,比如一个结构体,那么:
- 这个结构体在调用 drop() 时,会依次调用每一个域的 drop() 函数
- 如果域又是一个复杂的结构或者集合类型,就会递归下去
- 直到每一个域都释放干净。
- student 变量是一个结构体,有 name、age、scores。
- 其中 name 是 String,scores 是 HashMap,它们本身需要额外 drop()。
- 又因为 HashMap 的 key 是 String,所以还需要进一步调用这些 key 的 drop()。
整个释放顺序从内到外是:先释放 HashMap 下的 key,然后释放 HashMap 堆上的表结构,最后释放栈上的内存