Cow<’a, B>: 写时拷贝
写时复制(Copy-on-write)有异曲同工之妙
Cow 是 Rust 下用于提供写时克隆(Clone-on-Write)的一个智能指针,它跟虚拟内存管 理的写时复制(Copy-on-write)有异曲同工之妙:
包裹一个只读借用,但如果调用者需 要所有权或者需要修改内容,那么它会 clone 借用的数据
定义
Cow定义
#![allow(unused)] fn main() { pub enum Cow<'a, B> where B: 'a + ToOwned + ?Sized { Borrowed(&'a B), Owned(<B as ToOwned>::Owned), } }
它是一个 enum,可以包含一个对类型 B 的只读引用,或者包含对类型 B 的拥有所有权的 数据。
具体约束说明见泛型数据结构示例
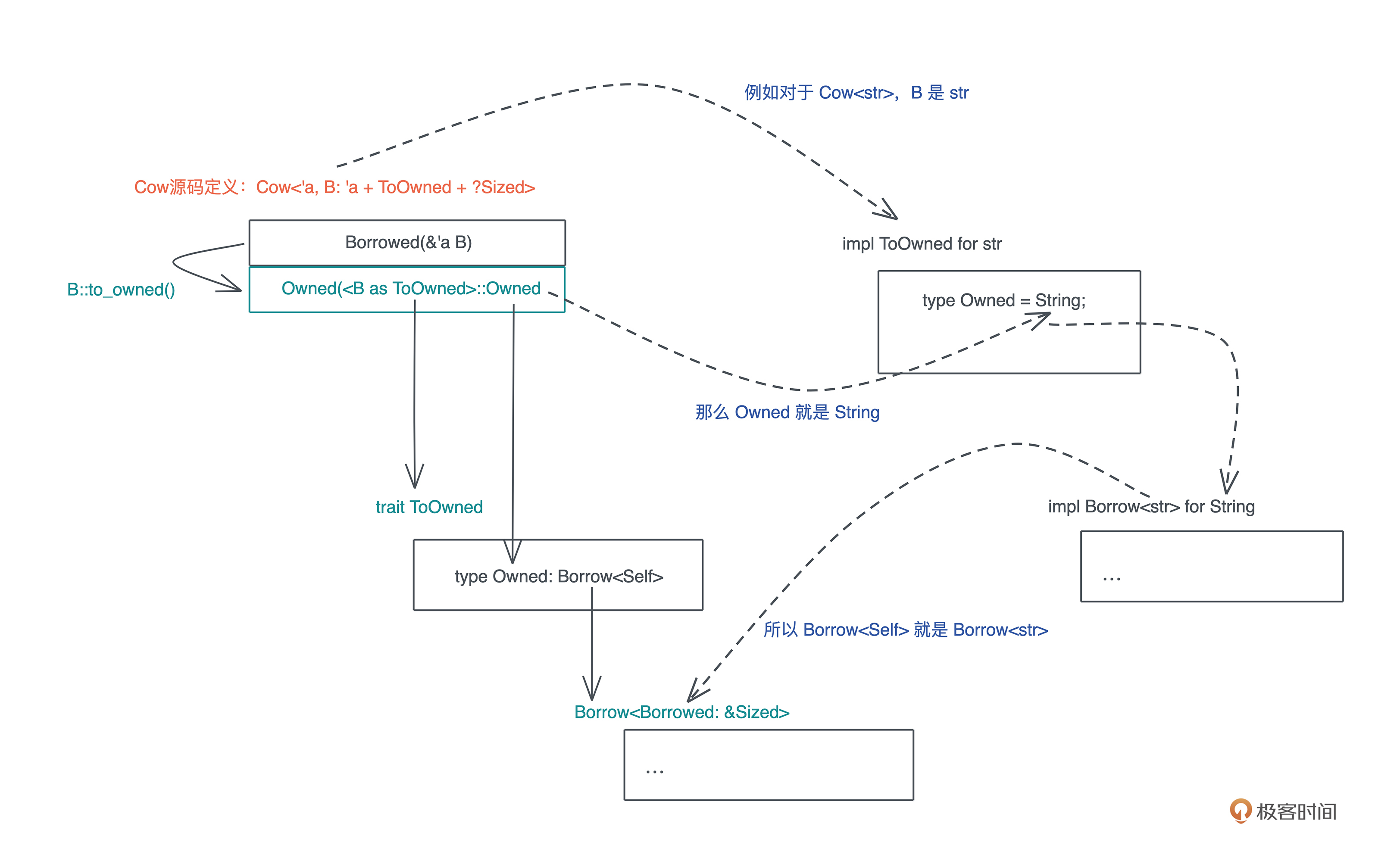
Cow定义用到ToOwned、Borrowed、Owned、ToOwned梳理
从ToOwned定义开始
想要理解 Cow trait,ToOwned trait 是一道坎: ToOwned定义 -> 关联类型用到Borrow -> Borrow是一个用到Borrowed的trait object
#![allow(unused)] fn main() { pub trait ToOwned { type Owned: Borrow<Self>; #[must_use = "cloning is often expensive and is not expected to have side effects"] fn to_owned(&self) -> Self::Owned; fn clone_into(&self, target: &mut Self::Owned) { ... } } pub trait Borrow<Borrowed> where Borrowed: ?Sized { fn borrow(&self) -> &Borrowed; } }
- 首先,type Owned: Borrow
是一个带有关联类型的 trait - 这里 Owned 是关联类型,需要使用者定义
- 这里 Owned 不能是任意类型,它必须满足 Borrow
trait。
关联类型Owned的理解
type Owned: Borrow: 参考str对ToOwned trait的实现
#![allow(unused)] fn main() { impl ToOwned for str { type Owned = String; #[inline] fn to_owned(&self) -> String { unsafe { String::from_utf8_unchecked(self.as_bytes().to_owned()) } } fn clone_into(&self, target: &mut String) { let mut b = mem::take(target).into_bytes(); self.as_bytes().clone_into(&mut b); *target = unsafe { String::from_utf8_unchecked(b) } } } }
对上面例子的type Owned 为 String如何理解?
-
ToOwned 要求关联类型Owned实现Borrow
, 而此刻实现 ToOwned 的主体是 str,所以 Borrow 是 Borrow -
Owned被定义为String,也就是说 String 要实现 Borrow
#![allow(unused)] fn main() { impl Borrow<str> for String { #[inline] fn borrow(&self) -> &str { &self[..] } } }
Borrow Trait理解: 匹配分发
为何 Borrow 要定义成一个泛型 trait 呢?
例子1:String不同借用方式
use std::borrow::Borrow; fn main() { let s = "hello world!".to_owned(); // 这里必须声明类型,因为 String 有多个 Borrow<T> 实现 // 借用为 &String let r1: &String = s.borrow(); // 借用为 &str let r2: &str = s.borrow(); println!("r1: {:p}, r2: {:p}", r1, r2); }
String 可以被借用为 &String,也可以被借用为 &str
例子2:Cow不同解引用方式
#![allow(unused)] fn main() { impl<B: ?Sized + ToOwned> Deref for Cow<'_, B> { type Target = B; fn deref(&self) -> &B { match *self { Borrowed(borrowed) => borrowed, Owned(ref owned) => owned.borrow(), } } } }
实现的原理很简单,根据 self 是 Borrowed 还是 Owned,我们分别取其内容,生成引用:
- 对于 Borrowed,直接就是引用;
- 对于 Owned,调用其 borrow() 方法,获得引用。
匹配分发
匹配分发:使用match匹配实现静态、动态分发之外的第三种分发
虽然 Cow 是一个 enum,但是通过 Deref 的实现,我们可以获得统一的 体验.
比如 Cow
关系图整理
Cow在需要时才进行内存分配拷贝
场景1:写时拷贝
写时拷贝
那么 Cow 有什么用呢?
- 显然,它可以在需要的时候才进行内存的分配和拷贝,在很多应用 场合,它可以大大提升系统的效率。
- 如果 Cow<’a, B> 中的 Owned 数据类型是一个需要 在堆上分配内存的类型,如 String、Vec
等,还能减少堆内存分配的次数。 - 相对于栈内存的分配释放来说,堆内存的分配和释放效率要低很多,其内部还 涉及系统调用和锁,减少不必要的堆内存分配是提升系统效率的关键手段。
- 而 Rust 的 Cow<’a, B>,在帮助你达成这个效果的同时,使用体验还非常简单舒服。
场景2:URL解析
举例使用Cow进行URL解析
use std::borrow::Cow; use url::Url; fn main() { let url = Url::parse("https://tyr.com/rust?page=1024&sort=desc&extra=hello%20world").unwrap(); let mut pairs = url.query_pairs(); assert_eq!(pairs.count(), 3); let (mut k, v) = pairs.next().unwrap(); // 因为 k, v 都是 Cow<str> 他们用起来感觉和 &str 或者 String 一样 // 此刻,他们都是 Borrowed println!("key: {}, v: {}", k, v); // 当修改发生时,k 变成 Owned k.to_mut().push_str("_lala"); print_pairs((k, v)); print_pairs(pairs.next().unwrap()); print_pairs(pairs.next().unwrap()); } fn print_pairs(pair: (Cow<str>, Cow<str>)) { println!("key: {}, value: {}", show_cow(pair.0), show_cow(pair.1)); } fn show_cow(cow: Cow<str>) -> String { match cow { Cow::Borrowed(v) => format!("Borrowed {}", v), Cow::Owned(v) => format!("Owned {}", v), } }
在解析 URL 的时候,我们经常需要将 querystring 中的参数,提取成 KV pair 来进一步使 用。 绝大多数语言中,提取出来的 KV 都是新的字符串,在每秒钟处理几十 k 甚至上百 k 请求的系统中,你可以想象这会带来多少次堆内存的分配。 但在 Rust 中,我们可以用 Cow 类型轻松高效处理它,在读取 URL 的过程中:
- 每解析出一个 key 或者 value,我们可以用一个 &str 指向 URL 中相应的位置,然后用 Cow 封装它
- 而当解析出来的内容不能直接使用,需要 decode 时,比如 “hello%20world”,我们 可以生成一个解析后的 String,同样用 Cow 封装它。
场景3:序列化/反序列化
举例serde使用Cow进行序列化/反序列化
use serde::Deserialize; use std::borrow::Cow; #[allow(dead_code)] #[derive(Debug, Deserialize)] struct User<'input> { #[serde(borrow)] name: Cow<'input, str>, age: u8, } fn main() { let input = r#"{ "name": "Tyr", "age": 18 }"#; let user: User = serde_json::from_str(input).unwrap(); match user.name { Cow::Borrowed(x) => println!("borrowed {}", x), Cow::Owned(x) => println!("owned {}", x), } }