错误处理主要内容和主流方法
错误处理包含这么几部分
在一门编程语言中,控制流程是语言的核心流程,而错误处理又是控制流程的重要组成部分。
语言优秀的错误处理能力,会大大减少错误处理对整体流程的破坏,让我们写代码更行云流水,读起来心智负担也更小。
错误处理包含这么几部分
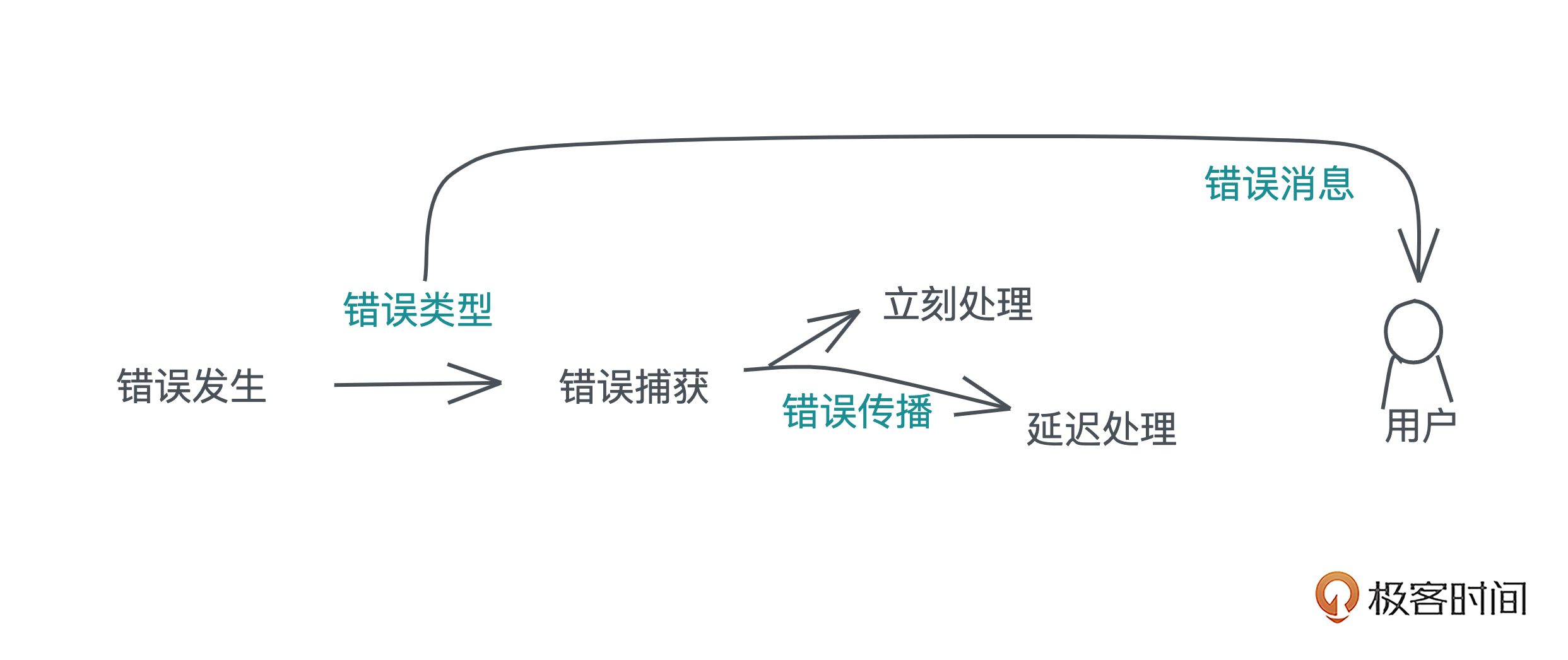
对我们开发者来说,错误处理包含这么几部分:
- 错误捕获后,可以立刻处理
- 也可以延迟到不得不处理的地方再处理,这就涉及到错误的传播(propagate)。
- 最后,根据不同的错误类型,给用户返回合适的、帮助他们理解问题所在的错误消息。
作为一门极其注重用户体验的编程语言,Rust 从其它优秀的语言中,尤其是 Haskell ,吸收了错误处理的精髓,并以自己独到的方式展现出来。
错误处理的主流方法
1. 使用返回值(错误码)
使用返回值来表征错误,是最古老也是最实用的一种方式.
它的使用范围很广:
- 从函数返回值
- 到操作系统的系统调用的错误码 errno
- 进程退出的错误码 retval
- 甚至 HTTP API 的状态码
- 都能看到这种方法的身影。
举个例子,在 C 语言中,如果 fopen(filename) 无法打开文件,会返回 NULL,调用者通过判断返回值是否为 NULL,来进行相应的错误处理。
我们再看个例子:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)
单看这个接口,我们很难直观了解,当读文件出错时,错误是如何返回的:
- 从文档中,我们得知,如果返回的 size_t 和传入的 size_t 不一致
- 那么要么发生了错误,要么是读到文件尾(EOF)
- 调用者要进一步通过 ferror 才能得到更详细的错误。
像 C 这样,通过返回值携带错误信息,有很多局限:
- 返回值有它原本的语义,强行把错误类型嵌入到返回值原本的语义中,需要全面且实时更新的文档,来确保开发者能正确区别对待,正常返回和错误返回。
Golang 对其做了扩展,在函数返回的时候,可以专门携带一个错误对象, 区分开错误返回和正常返回
所以 Golang 对其做了扩展,在函数返回的时候,可以专门携带一个错误对象。比如上文的 fread,在 Golang 下可以这么定义:
func Fread(file *File, b []byte) (n int, err error)
Golang 这样,区分开错误返回和正常返回,相对 C 来说进了一大步。
但是使用返回值的方式,始终有个致命的问题
但是使用返回值的方式,始终有个致命的问题:
在调用者调用时,错误就必须得到处理或者显式的传播。
如果函数 A 调用了函数 B,在 A 返回错误的时候,就要把 B 的错误转换成 A 的错误,显示出来。如下图所示:
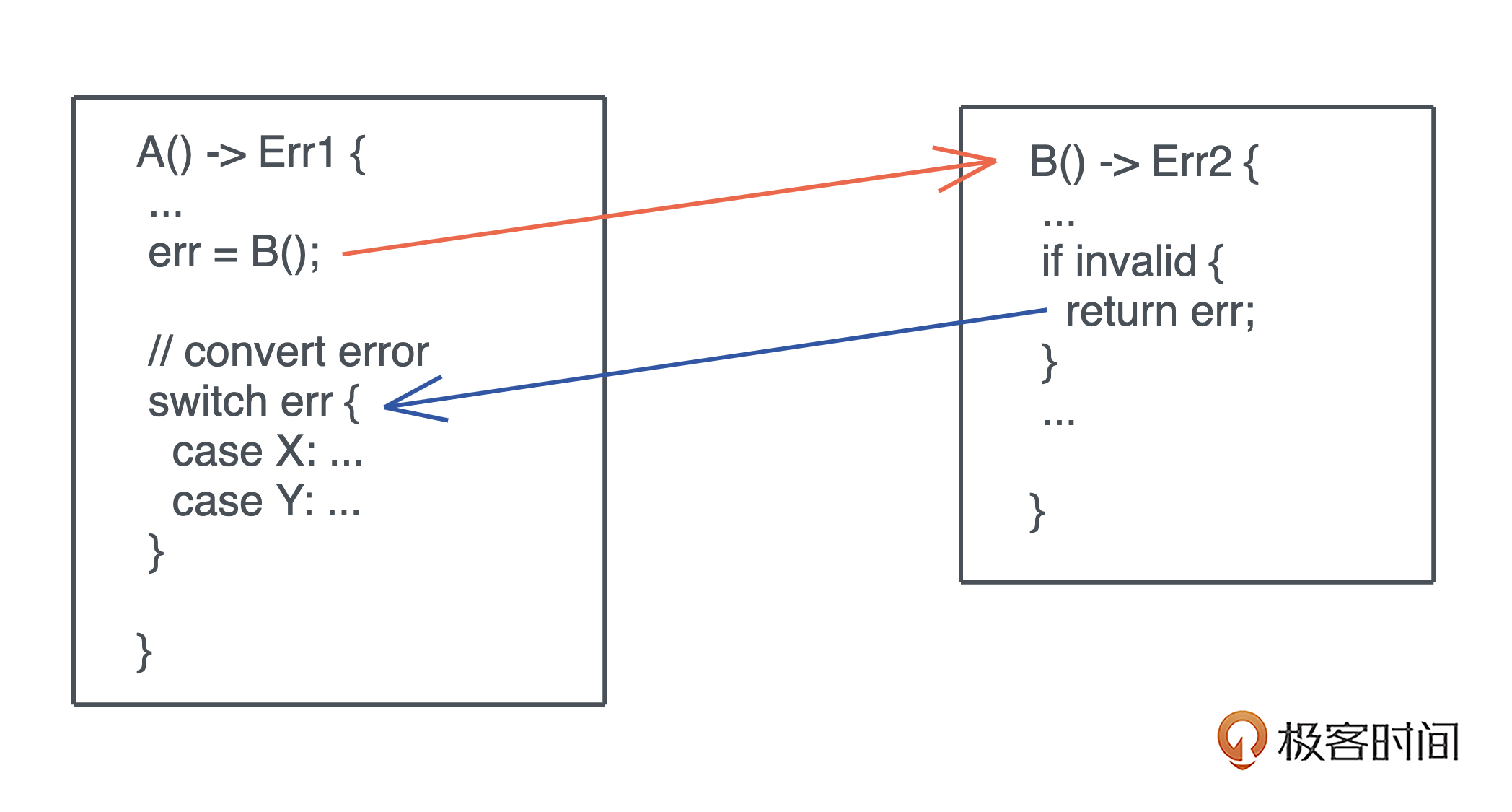
这样写出来的代码会非常冗长,对我们开发者的用户体验不太好。如果不处理,又会丢掉这个错误信息,造成隐患。
另外,大部分生产环境下的错误是嵌套的:
- 一个 SQL 执行过程中抛出的错误,可能是服务器出错,而更深层次的错误可能是,连接数据库服务器的 TLS session 状态异常。
- 其实知道服务器出错之外,我们更需要清楚服务器出错的内在原因。
因为服务器出错这个表层错误会提供给最终用户,而出错的深层原因要提供给我们自己,服务的维护者。 但是这样的嵌套错误在 C / Golang 都是很难完美表述的。
2. 使用异常: 抛出异常+捕获异常
因为返回值不利于错误的传播,有诸多限制,Java 等很多语言使用异常来处理错误。
关注点分离
你可以把异常看成一种关注点分离(Separation of Concerns):
- 错误的产生和错误的处理完全被分隔开
- 调用者不必关心错误,而被调者也不强求调用者关心错误。
- 程序中任何可能出错的地方,都可以抛出异常;
- 而异常可以通过栈回溯(stack unwind)被一层层自动传递,直到遇到捕获异常的地方,
- 如果回溯到 main 函数还无人捕获,程序就会崩溃。如下图所示:
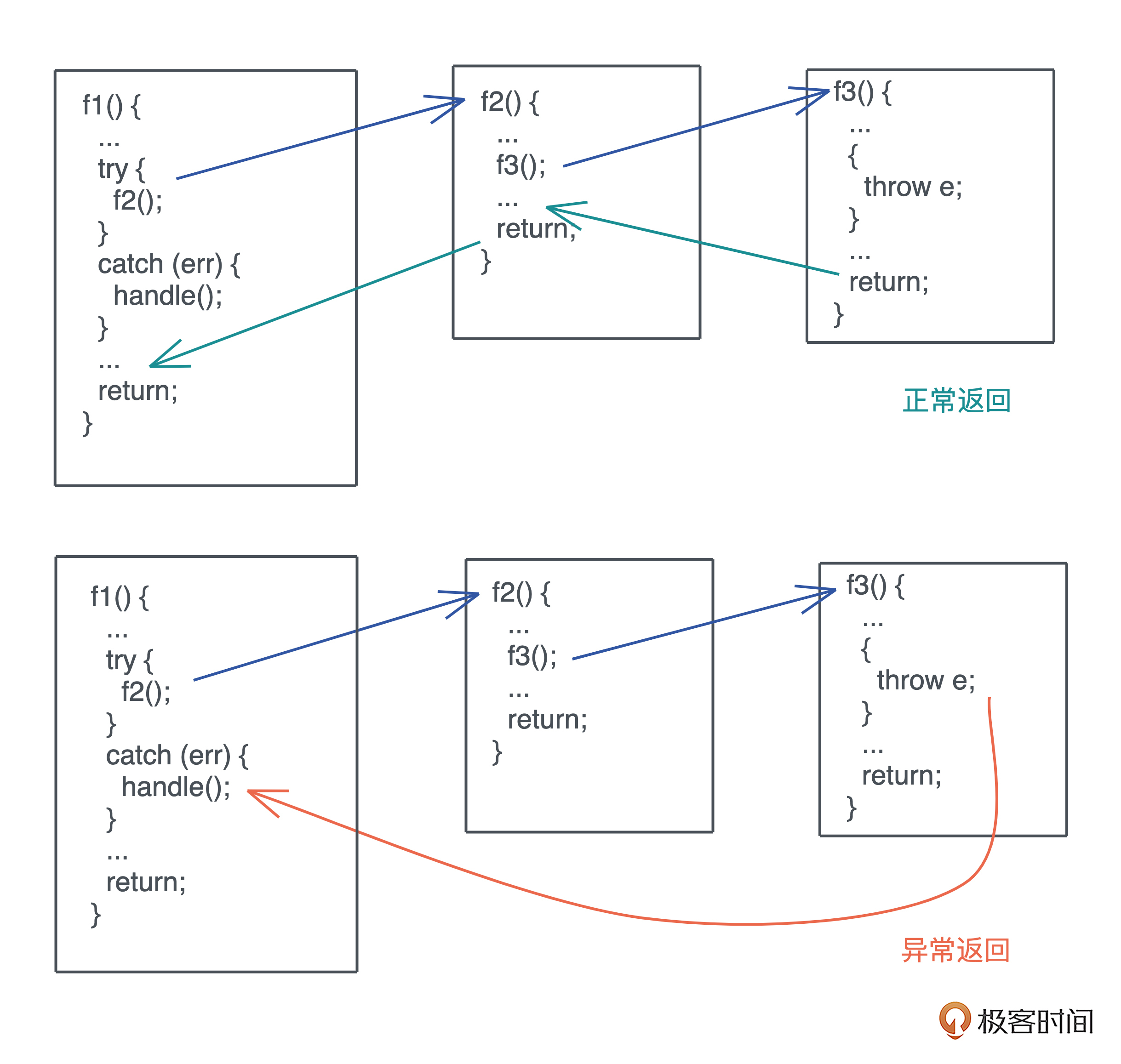
使用异常来返回错误可以极大地简化错误处理的流程,它解决了返回值的传播问题。
然而,上图中异常返回的过程看上去很直观,就像数据库中的事务(transaction)在出错时会被整体撤销(rollback)一样。
但实际上,这个过程远比你想象的复杂,而且需要额外操心异常安全(exception safety)。 我们看下面用来切换背景图片的(伪)代码:
void transition(...) {
lock(&mutex);
delete background;
++changed;
background = new Background(...);
unlock(&mutex);
}
试想, 如果在创建新的背景时失败,抛出异常,会跳过后续的处理流程,一路栈回溯到 try catch 的代码,那么,这里锁住的 mutex 无法得到释放,而已有的背景被清空,新的背景没有创建,程序进入到一个奇怪的状态。
异常的限制:异常安全+异常滥用
确实在大多数情况下,用异常更容易写代码,但当异常安全无法保证时,程序的正确性会受到很大的挑战。因此,你在使用异常处理时,需要特别注意异常安全,尤其是在并发环境下。
异常处理另外一个比较严重的问题是:开发者会滥用异常。只要有错误,不论是否严重、是否可恢复,都一股脑抛个异常。到了需要的地方,捕获一下了之。殊不知,异常处理的开销要比处理返回值大得多,滥用会有很多额外的开销。
3. 使用类型系统
第三种错误处理的方法就是使用类型系统。其实,在使用返回值处理错误的时候,我们已经看到了类型系统的雏形。
错误信息既然可以通过已有的类型携带,或者通过多返回值的方式提供,那么通过类型来表征错误,使用一个内部包含正常返回类型和错误返回类型的复合类型,通过类型系统来强制错误的处理和传递,是不是可以达到更好的效果呢?
Haskell 的 Maybe 和 Either 类型
的确如此。这种方式被大量使用在有强大类型系统支持的函数式编程语言中,如 Haskell/Scala/Swift。其中最典型的包含了错误类型的复合类型是 Haskell 的 Maybe 和 Either 类型。
-
Maybe 类型允许数据包含一个值(Just)或者没有值(Nothing),这对简单的不需要类型的错误很有用。还是以打开文件为例,如果我们只关心成功打开文件的句柄,那么 Maybe 就足够了。
-
当我们需要更为复杂的错误处理时,我们可以使用 Either 类型。它允许数据是 Left a 或者 Right b 。其中,a 是运行出错的数据类型,b 可以是成功的数据类型。
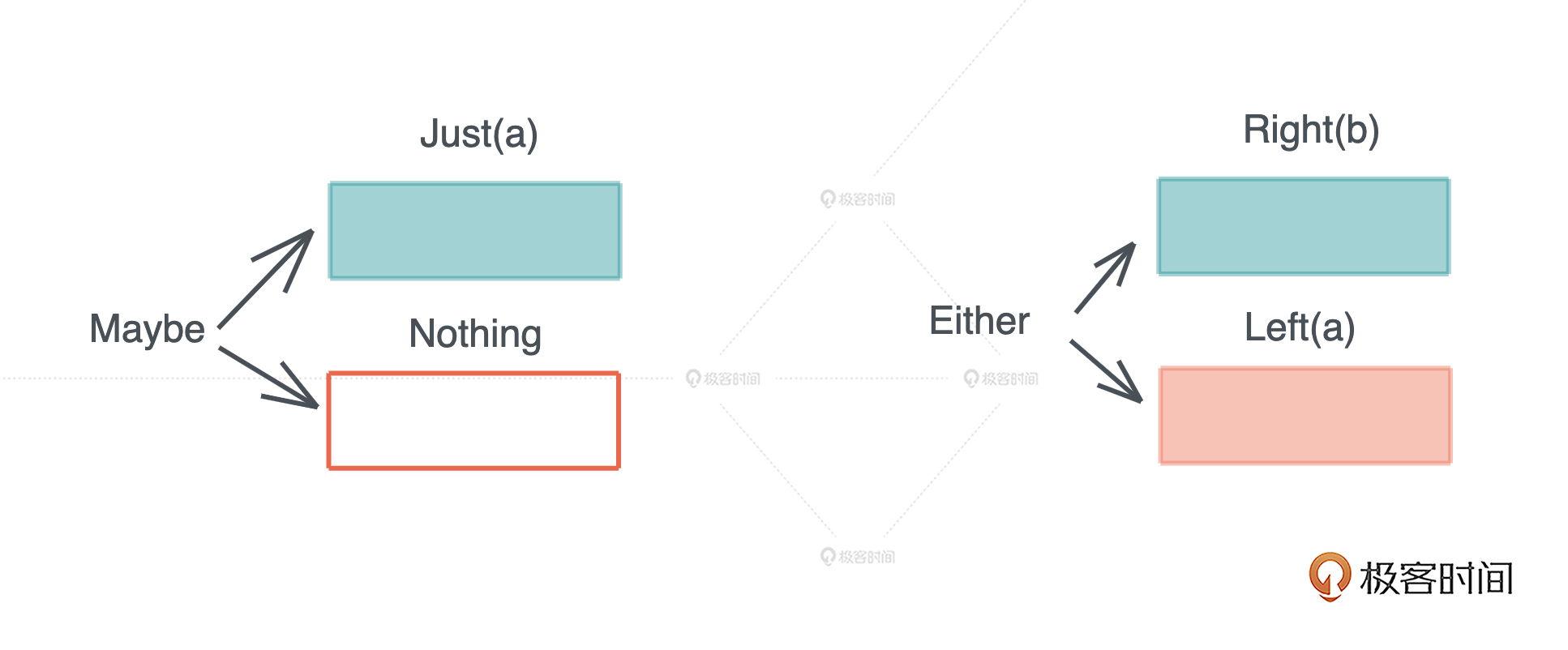
我们可以看到,这种方法依旧是通过返回值返回错误,但是错误被包裹在一个完整的、必须处理的类型中,比 Golang 的方法更安全。