源码解析逻辑
- 源码解析逻辑
项目文档
来源
- 第三方crate可以在官方文档上面搜索
- 本地crate可以使用命令
cargo doc --open.
cargo doc命令使用
–open
自动生成文档并在浏览器打开
–no-deps
默认情况下会把项目依赖的包文档也生成,这也是文档左侧Crates的来源之一。 这个参数可以屏蔽掉依赖的crates
使用区别
- 二者内容没有区别,官方文档也是执行命令生成文档。
- 官方文档还可以提供很多细节,比如git分支地址
使用细节
这里按照文档的层级进行递进说明
Crates
所有文档的首页都会有这一项,列出项目包含的crate
crate包含成员
点击Crates下的某个crate,右侧页面就会显示当前crate包含的元素, 主要有下列内容
- Re-exports
- Modules
- Macros
- Derive Macros
- Attribute Macros
- Structs
- Enums
- Constants
- Traits
- Functions
- Type Definitions
Re-exports
futures_util
#![allow(unused)] fn main() { pub use reader::DecompressorCustomIo; }
Modules
其实就是mod,点击之后将会列出某个mod里面的成员
Macros
Derive Macros
darling_macro、clap_derive
Attribute Macros
tokio_macros、futures_macro
Structs
Definition
Associated Types
Implementations
Trait Implementations
Auto Trait Implementations
Blanket Implementations
Enums
Definition
Variants
Trait Implementations
Auto Trait Implementations
Blanket Implementations
Constants
Traits
Definition
Required methods
Implementations on Foreign Types
Implementors
Functions
Definition
Type Definitions
Definition
html2md
#![allow(unused)] fn main() { pub type BoxedError = Box<dyn Error + Send + Sync>; }
gdb/lldb调试或查看内存结构
gdb/lldb
资料整理
官方数据结构cheat sheet
gdb强化插件
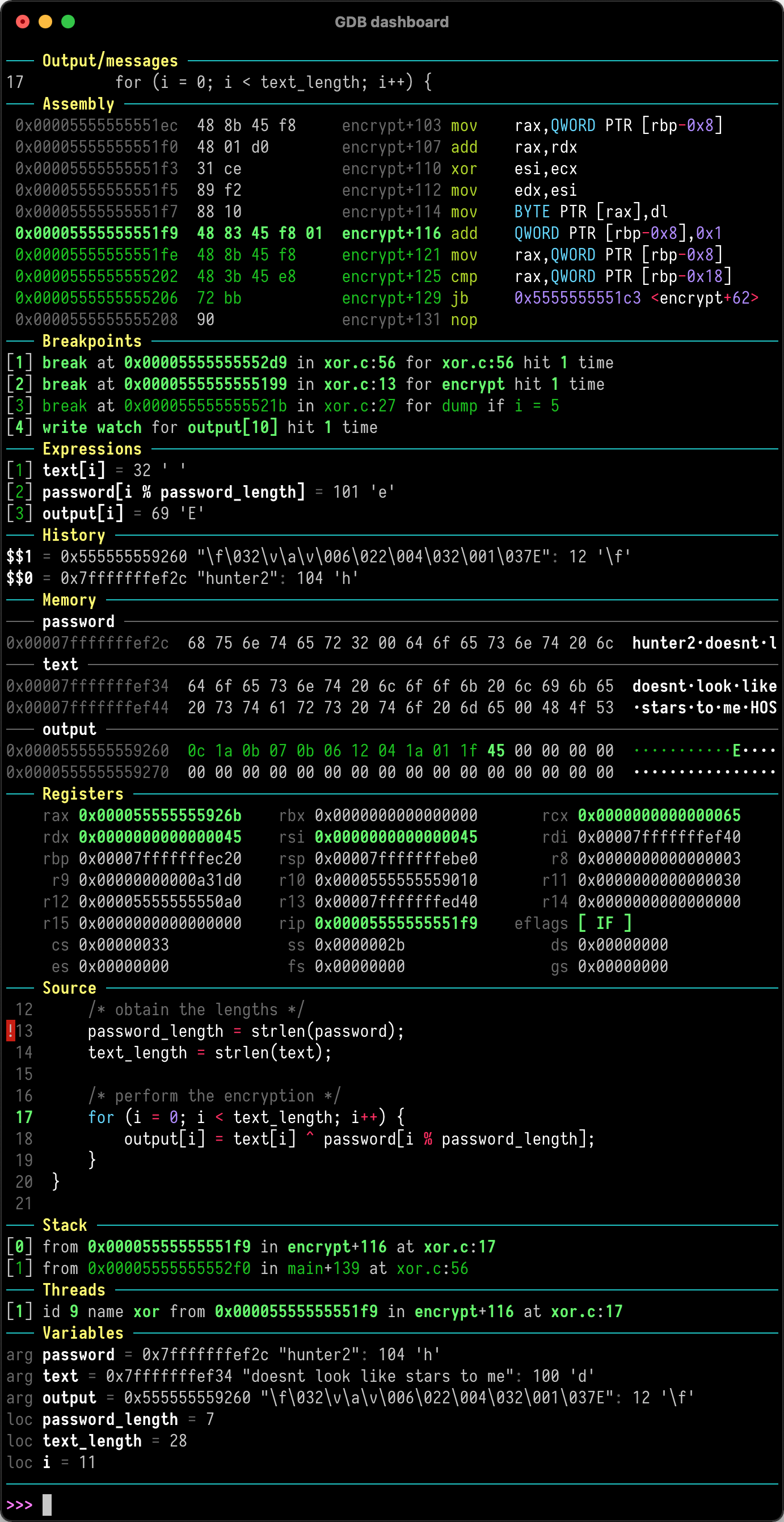
gdb: 主要是linux系统
lldb: 主要OSX系统
IDEA
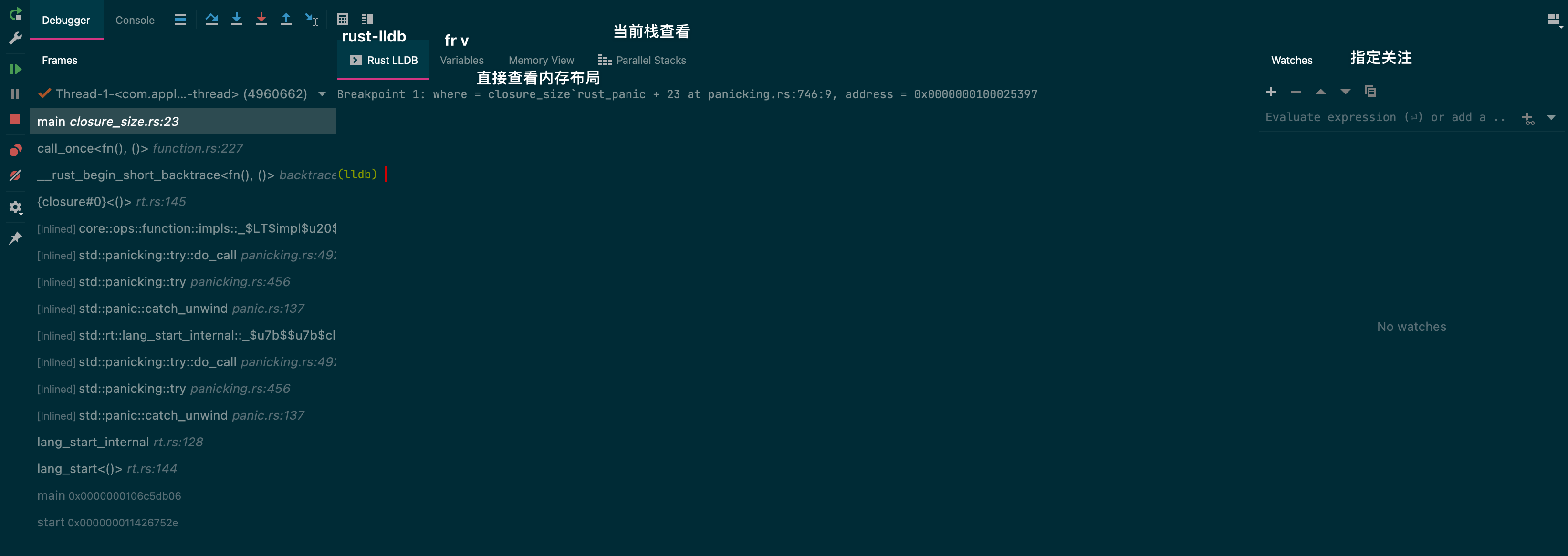
gdb与lldb命令对照
gdb与lldb命令对照
查看hashmap内存结构
- bin配置与运行
[package]
name = "hashtable"
version = "0.1.0"
edition = "2021"
[[bin]]
name = "hashmap1"
path = "src/hashmap1.rs"
[[bin]]
name = "hashmap2"
path = "src/hashmap2.rs"
[[bin]]
name = "hash"
path = "src/hash.rs"
[[bin]]
name = "siphasher"
path = "src/siphasher.rs"
doc = false
[[bin]]
name = "hashmap3"
path = "src/hashmap3.rs"
[[bin]]
name = "btreemap1"
path = "src/btreemap1.rs"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
如果要单独运行指定bin文件:
cargo run --bin hashmap2
- 目标调试代码
use std::collections::HashMap; fn main() { let map = HashMap::new(); let mut map = explain("empty", map); map.insert('a', 1); let mut map = explain("added 1", map); map.insert('b', 2); map.insert('c', 3); let mut map = explain("added 3", map); map.insert('d', 4); let mut map = explain("added 4", map); map.remove(&'a'); explain("final", map); } // HashMap 结构有两个 u64 的 RandomState,然后是四个 usize, // 分别是 bucket_mask, ctrl, growth_left 和 items // 我们 transmute 打印之后,再 transmute 回去 fn explain<K, V>(name: &str, map: HashMap<K, V>) -> HashMap<K, V> { let arr: [usize; 6] = unsafe { std::mem::transmute(map) }; println!( "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}", name, arr[2], arr[3], arr[4], arr[5] ); unsafe { std::mem::transmute(arr) } }
使用gdb/lldb进行调试查看内存结构
- 开始调试
rust-lldb target/debug/hashmap2 ─╯
(lldb) command script import "/Users/kuanhsiaokuo/.rustup/toolchains/stable-x86_64-apple-darwin/lib/rustlib/etc/lldb_lookup.py"
(lldb) command source -s 0 '/Users/kuanhsiaokuo/.rustup/toolchains/stable-x86_64-apple-darwin/lib/rustlib/etc/lldb_commands'
Executing commands in '/Users/kuanhsiaokuo/.rustup/toolchains/stable-x86_64-apple-darwin/lib/rustlib/etc/lldb_commands'.
(lldb) type synthetic add -l lldb_lookup.synthetic_lookup -x ".*" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)String$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^&(mut )?str$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^&(mut )?\\[.+\\]$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(std::ffi::([a-z_]+::)+)OsString$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)Vec<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)VecDeque<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)BTreeSet<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)BTreeMap<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(std::collections::([a-z_]+::)+)HashMap<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(std::collections::([a-z_]+::)+)HashSet<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)Rc<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)Arc<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(core::([a-z_]+::)+)Cell<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(core::([a-z_]+::)+)Ref<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(core::([a-z_]+::)+)RefMut<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(core::([a-z_]+::)+)RefCell<.+>$" --category Rust
(lldb) type category enable Rust
(lldb) target create "target/debug/hashmap2"
Current executable set to '/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/target/debug/hashmap2' (x86_64).
(lldb)
- b(reakpoint): 添加断点
在32行打断点,方便看std::mem::transmute(arr)
(lldb) b hashmap2.rs:32
Breakpoint 1: where = hashmap2`hashmap2::explain::h4091c852f38a0de4 + 406 at hashmap2.rs:32:34, address = 0x0000000100008d16
- r(un):运行到断点
(lldb) r
Process 69337 launched: '/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/target/debug/hashmap2' (x86_64)
empty: bucket_mask 0x0, ctrl 0x100043d20, growth_left: 0, items: 0
Process 69337 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100008d16 hashmap2`hashmap2::explain::h4091c852f38a0de4(name="empty", map=<unavailable>) at hashmap2.rs:32:34
29 "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}",
30 name, arr[2], arr[3], arr[4], arr[5]
31 );
-> 32 unsafe { std::mem::transmute(arr) }
33 }
Target 0: (hashmap2) stopped.
# 最初的状态,哈希表为空
empty: bucket_mask 0x0, ctrl 0x100043d20, growth_left: 0, items: 0
- c(ontinue):继续单步执行
(lldb) c
Process 69337 resuming
added 1: bucket_mask 0x3, ctrl 0x600001700160, growth_left: 2, items: 1
Process 69337 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100008d16 hashmap2`hashmap2::explain::h4091c852f38a0de4(name="added 1", map=<unavailable>) at hashmap2.rs:32:34
29 "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}",
30 name, arr[2], arr[3], arr[4], arr[5]
31 );
-> 32 unsafe { std::mem::transmute(arr) }
33 }
Target 0: (hashmap2) stopped.
# 插入了一个元素后,bucket 有 4 个(0x3+1),堆地址起始位置 0x600001700160 - 4*8(0x20)
added 1: bucket_mask 0x3, ctrl 0x600001700160, growth_left: 2, items: 1
- x: 打印内存地址
# 以12进制打印从内存地址开始的值
(lldb) x/12x 0x600001700160
0x600001700160: 0xffff6dff 0xffffffff 0xffffffff 0xffffffff
0x600001700170: 0xffff6dff 0x00000000 0x00000000 0x00000000
0x600001700180: 0x20ec913f 0x00007ff8 0x4e5ef01e 0x00000000
- c(ontinue): 继续执行到下一个断点
(lldb) c
Process 69337 resuming
added 3: bucket_mask 0x3, ctrl 0x600001700160, growth_left: 0, items: 3
Process 69337 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100008d16 hashmap2`hashmap2::explain::h4091c852f38a0de4(name="added 3", map=<unavailable>) at hashmap2.rs:32:34
29 "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}",
30 name, arr[2], arr[3], arr[4], arr[5]
31 );
-> 32 unsafe { std::mem::transmute(arr) }
33 }
Target 0: (hashmap2) stopped.
# # 插入了三个元素后,哈希表没有剩余空间,堆地址起始位置不变 0x600001700160 - 4*8(0x20)
added 3: bucket_mask 0x3, ctrl 0x600001700160, growth_left: 0, items: 3
(lldb) x/12x 0x600001700160
0x600001700160: 0x16ff6d66 0xffffffff 0xffffffff 0xffffffff
0x600001700170: 0x16ff6d66 0x00000000 0x00000000 0x00000000
0x600001700180: 0x20ec913f 0x00007ff8 0x4e5ef01e 0x00000000
(lldb) c
Process 69337 resuming
added 4: bucket_mask 0x7, ctrl 0x600002604040, growth_left: 3, items: 4
Process 69337 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100008d16 hashmap2`hashmap2::explain::h4091c852f38a0de4(name="added 4", map=<unavailable>) at hashmap2.rs:32:34
29 "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}",
30 name, arr[2], arr[3], arr[4], arr[5]
31 );
-> 32 unsafe { std::mem::transmute(arr) }
33 }
Target 0: (hashmap2) stopped.
# 插入第四个元素后,哈希表扩容,堆地址起始位置变为 0x600002604040 - 8*8(0x40)
added 4: bucket_mask 0x7, ctrl 0x600002604040, growth_left: 3, items: 4
(lldb) x/12x 0x600002604040
0x600002604040: 0x16446d66 0xffffffff 0xffffffff 0xffffffff
0x600002604050: 0x16446d66 0xffffffff 0x00000000 0x00000000
0x600002604060: 0x00000000 0x00000000 0x00000000 0x00000000
(lldb) x/20x 0x600002604040
0x600002604040: 0x16446d66 0xffffffff 0xffffffff 0xffffffff
0x600002604050: 0x16446d66 0xffffffff 0x00000000 0x00000000
0x600002604060: 0x00000000 0x00000000 0x00000000 0x00000000
0x600002604070: 0x00000000 0x00000000 0x00000000 0x00000000
0x600002604080: 0x00000000 0x00000000 0x00000000 0x00000000
(lldb) c
Process 69337 resuming
final: bucket_mask 0x7, ctrl 0x600002604040, growth_left: 4, items: 3
Process 69337 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100008d16 hashmap2`hashmap2::explain::h4091c852f38a0de4(name="final", map=<unavailable>) at hashmap2.rs:32:34
29 "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}",
30 name, arr[2], arr[3], arr[4], arr[5]
31 );
-> 32 unsafe { std::mem::transmute(arr) }
33 }
Target 0: (hashmap2) stopped.
# 删除 a 后,剩余 4 个位置。注意 ctrl bit 的变化,以及 0x61 0x1 并没有被清除
final: bucket_mask 0x7, ctrl 0x600002604040, growth_left: 4, items: 3
(lldb) x/12x 0x600002604040
0x600002604040: 0x1644ff66 0xffffffff 0xffffffff 0xffffffff
0x600002604050: 0x1644ff66 0xffffffff 0x00000000 0x00000000
0x600002604060: 0x00000000 0x00000000 0x00000000 0x00000000
(lldb) x/20x 0x600002604040
0x600002604040: 0x1644ff66 0xffffffff 0xffffffff 0xffffffff
0x600002604050: 0x1644ff66 0xffffffff 0x00000000 0x00000000
0x600002604060: 0x00000000 0x00000000 0x00000000 0x00000000
0x600002604070: 0x00000000 0x00000000 0x00000000 0x00000000
0x600002604080: 0x00000000 0x00000000 0x00000000 0x00000000
查看闭包的结构
代码:
use std::{collections::HashMap, mem::size_of_val}; fn main() { // 长度为 0 let c1 = || println!("hello world!"); // 和参数无关,长度也为 0 let c2 = |i: i32| println!("hello: {}", i); let name = String::from("tyr"); let name1 = name.clone(); let mut table = HashMap::new(); table.insert("hello", "world"); // 如果捕获一个引用,长度为 8 let c3 = || println!("hello: {}", name); // 捕获移动的数据 name1(长度 24) + table(长度 48),closure 长度 72 let c4 = move || println!("hello: {}, {:?}", name1, table); let name2 = name.clone(); // 和局部变量无关,捕获了一个 String name2,closure 长度 24 let c5 = move || { let x = 1; let name3 = String::from("lindsey"); println!("hello: {}, {:?}, {:?}", x, name2, name3); }; println!( "c1: {}, c2: {}, c3: {}, c4: {}, c5: {}, main: {}", size_of_val(&c1), size_of_val(&c2), size_of_val(&c3), size_of_val(&c4), size_of_val(&c5), size_of_val(&main), ) }
运行进入lldb
# 自动去examples目录找对应名字的代码文件
cargo run --example closure_size
rust-lldb ../target/debug/examples/closure_size ─╯
(lldb) command script import "/Users/kuanhsiaokuo/.rustup/toolchains/stable-x86_64-apple-darwin/lib/rustlib/etc/lldb_lookup.py"
(lldb) command source -s 0 '/Users/kuanhsiaokuo/.rustup/toolchains/stable-x86_64-apple-darwin/lib/rustlib/etc/lldb_commands'
Executing commands in '/Users/kuanhsiaokuo/.rustup/toolchains/stable-x86_64-apple-darwin/lib/rustlib/etc/lldb_commands'.
(lldb) type synthetic add -l lldb_lookup.synthetic_lookup -x ".*" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)String$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^&(mut )?str$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^&(mut )?\\[.+\\]$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(std::ffi::([a-z_]+::)+)OsString$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)Vec<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)VecDeque<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)BTreeSet<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)BTreeMap<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(std::collections::([a-z_]+::)+)HashMap<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(std::collections::([a-z_]+::)+)HashSet<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)Rc<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(alloc::([a-z_]+::)+)Arc<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(core::([a-z_]+::)+)Cell<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(core::([a-z_]+::)+)Ref<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(core::([a-z_]+::)+)RefMut<.+>$" --category Rust
(lldb) type summary add -F lldb_lookup.summary_lookup -e -x -h "^(core::([a-z_]+::)+)RefCell<.+>$" --category Rust
(lldb) type category enable Rust
(lldb) target create "../target/debug/examples/closure_size"
Current executable set to '/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/target/debug/examples/closure_size' (x86_64).
(lldb)
(lldb) b closure_size.rs:14
Breakpoint 1: where = closure_size`closure_size::main::h679d75437a0cd078 + 199 at closure_size.rs:14:14, address = 0x00000001000056b7
(lldb) r
Process 95084 launched: '/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/target/debug/examples/closure_size' (x86_64)
Process 95084 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x00000001000056b7 closure_size`closure_size::main::h679d75437a0cd078 at closure_size.rs:14:14
11 // 如果捕获一个引用,长度为 8
12 let c3 = || println!("hello: {}", name);
13 // 捕获移动的数据 name1(长度 24) + table(长度 48),closure 长度 72
-> 14 let c4 = move || println!("hello: {}, {:?}", name1, table);
15 let name2 = name.clone();
16 // 和局部变量无关,捕获了一个 String name2,closure 长度 24
17 let c5 = move || {
Target 0: (closure_size) stopped.
(lldb) frame variable
(closure_size::main::{closure_env#0}) c1 =
(closure_size::main::{closure_env#1}) c2 =
(alloc::string::String) name = "tyr" {
vec = size=3 {
[0] = 't'
[1] = 'y'
[2] = 'r'
}
}
(alloc::string::String) name1 = "tyr" {
vec = size=3 {
[0] = 't'
[1] = 'y'
[2] = 'r'
}
}
(std::collections::hash::map::HashMap<&str, &str, std::collections::hash::map::RandomState>) table = size=1 {
[0] = {
0 = "hello" {
data_ptr = 0x0000000100043daf "helloworld, c2: , c3: , c4: , c5: \n"
length = 5
}
1 = "world" {
data_ptr = 0x0000000100043db4 "world, c2: , c3: , c4: , c5: \n"
length = 5
}
}
}
(lldb) fr v
(closure_size::main::{closure_env#0}) c1 =
(closure_size::main::{closure_env#1}) c2 =
(alloc::string::String) name = "tyr" {
vec = size=3 {
[0] = 't'
[1] = 'y'
[2] = 'r'
}
}
(alloc::string::String) name1 = "tyr" {
vec = size=3 {
[0] = 't'
[1] = 'y'
[2] = 'r'
}
}
(std::collections::hash::map::HashMap<&str, &str, std::collections::hash::map::RandomState>) table = size=1 {
[0] = {
0 = "hello" {
data_ptr = 0x0000000100043daf "helloworld, c2: , c3: , c4: , c5: \n"
length = 5
}
1 = "world" {
data_ptr = 0x0000000100043db4 "world, c2: , c3: , c4: , c5: \n"
length = 5
}
}
}
(lldb) x/gx c1
error: memory read failed for 0x0
(lldb) x/gx &c1
0x7ff7bfefed20: 0x0000000100266000
(lldb) x/gx &c2
0x7ff7bfefed28: 0x00006000017041c0
(lldb) x/gx &c3
0x7ff7bfefed90: 0x00007ff7bfefed30
(lldb) x/gx 0x00007ff7bfefed30
0x7ff7bfefed30: 0x0000600000008010
(lldb) x/3c 0x0000600000008010
error: reading memory as characters of size 8 is not supported
(lldb) x/gx 0x0000600000008010
0x600000008010: 0x0000000000727974
- g表示八字节。当我们指定了字节长度后,GDB会从指内存定的内存地址开始,读写指定字节,并把其当作一个值取出来。
- 可以看出:c1是
(lldb) n
Process 95084 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = step over
frame #0: 0x0000000100005744 closure_size`closure_size::main::h679d75437a0cd078 at closure_size.rs:15:17
12 let c3 = || println!("hello: {}", name);
13 // 捕获移动的数据 name1(长度 24) + table(长度 48),closure 长度 72
14 let c4 = move || println!("hello: {}, {:?}", name1, table);
-> 15 let name2 = name.clone();
16 // 和局部变量无关,捕获了一个 String name2,closure 长度 24
17 let c5 = move || {
18 let x = 1;
Target 0: (closure_size) stopped.
(lldb) x/9gx c4
error: memory read failed for 0x0
(lldb) x/9gx &c4
0x7ff7bfefed98: 0x0000600000008020 0x0000000000000003
0x7ff7bfefeda8: 0x0000000000000003 0x3e49f3270a1a0fb0
0x7ff7bfefedb8: 0x79dd9a78e6c327e7 0x0000000000000003
0x7ff7bfefedc8: 0x0000600003304080 0x0000000000000002
0x7ff7bfefedd8: 0x0000000000000001
(lldb) x/3c 0x0000600000008020
error: reading memory as characters of size 8 is not supported
(lldb) x/gx 0x0000600000008020
0x600000008020: 0x0000000000727974
(lldb) x/18gx 0x0000600000008020 - 0x80
error: memory read takes a start address expression with an optional end address expression.
warning: Expressions should be quoted if they contain spaces or other special characters.
(lldb) x/18gx '0x0000600000008020 - 0x80'
0x600000007fa0: 0x0000000000000000 0x0000000000000000
0x600000007fb0: 0x0000000000000000 0x0000000000000000
0x600000007fc0: 0x0000000000000000 0x0000000000000000
0x600000007fd0: 0x0000000000000000 0x0000000000000000
0x600000007fe0: 0x0000000000000000 0x0000000000000000
0x600000007ff0: 0x0000000000000000 0x0000000000000000
0x600000008000: 0x000000006e69616d 0x0000000000000000
0x600000008010: 0x0000000000727974 0x0000000000000000
0x600000008020: 0x0000000000727974 0x0000000000000000
- 0x: C语言里的0x0和0x1分别表示十六进制的数的0和1。
C语言、C++、Shell、Python、Java语言及其他相近的语言使用字首“0x”,例如“0x5A3”。开头的“0”令解析器更易辨认数,而“x”则代表十六进制(就如“O”代表八进制)。在“0x”中的“x”可以大写或小写。对于字符量C语言中则以x+两位十六进制数的方式表示,如xFF。
因此,0x0中“0x”表示的是十六进制数,0是十六进制数值0,0x,1中“0x”表示的是十六进制数,1是十六进制数值1
- C语言中的相关数值表示法:
1、在C语言里,整数有三种表示形式:十进制,八进制,十六进制。其中以数字0开头,由0~7组成的数是八进制。以0X或0x开头,由0~9,A~F或a~f 组成是十六进制。除表示正负的符号外,以1~9开头,由0~9组成是十进制。
2、十进制:除表示正负的符号外,以1~9开头,由0~9组成。如,128,+234,-278。
3、八进制:以0开头,由0~7组成的数。如,0126,050000.
4、十六进制:以0X或0x开头,由0~9,A~F或a~f 组成。如,0x12A,0x5a000。
get hands dirty
httpie源码剖析
example的使用
Cargo.toml
[package]
name = "httpie"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[[example]]
name = "cli"
[[example]]
name = "cli_verify"
[[example]]
name = "cli_get"
[dependencies]
anyhow = "1" # 错误处理
clap = { version = "3", features = ["derive"] } # 命令行解析
colored = "2" # 命令终端多彩显示
jsonxf = "1.1" # JSON pretty print 格式化
mime = "0.3" # 处理 mime 类型
# reqwest 默认使用 openssl,有些 linux 用户如果没有安装好 openssl 会无法编译,这里我改成了使用 rustls
reqwest = { version = "0.11", default-features = false, features = ["json", "rustls-tls"] } # HTTP 客户端
tokio = { version = "1", features = ["full"] } # 异步处理库
syntect = "4"
[[example]]
name = "cli"
[[example]]
name = "cli_verify"
[[example]]
name = "cli_get"
- 示例代码放在根目录的examples文件夹,与src同级
tree -L 2 ─╯
.
├── Cargo.toml
├── examples
│ ├── cli.rs
│ ├── cli_get.rs
│ └── cli_verify.rs
└── src
└── main.rs
2 directories, 5 files
- 执行指令
cargo run --example <example-name-in-cargo>
cargo run --example cli
cargo run --example cli_get
cargo run --example cli_verify
- 使用示例
cargo run --example cli ─╯
Finished dev [unoptimized + debuginfo] target(s) in 0.70s
Running `/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/target/debug/examples/cli`
httpie 1.0
Tyr Chen <tyr@chen.com>
A naive httpie implementation with Rust, can you imagine how easy it is?
USAGE:
cli <SUBCOMMAND>
OPTIONS:
-h, --help Print help information
-V, --version Print version information
SUBCOMMANDS:
get feed get with an url and we will retrieve the response for you
help Print this message or the help of the given subcommand(s)
post feed post with an url and optional key=value pairs. We will post the data as JSON,
and retrieve the response for you
- Run a binary or example of the local package
- SUBCOMMANDS来自代码中的注释
Step1:指令解析
- 源码
use clap::Parser; // 定义 httpie 的 CLI 的主入口,它包含若干个子命令 // 下面 /// 的注释是文档,clap 会将其作为 CLI 的帮助 /// A naive httpie implementation with Rust, can you imagine how easy it is? #[derive(Parser, Debug)] #[clap(version = "1.0", author = "Tyr Chen <tyr@chen.com>")] struct Opts { #[clap(subcommand)] subcmd: SubCommand, } // 子命令分别对应不同的 HTTP 方法,目前只支持 get / post #[derive(Parser, Debug)] enum SubCommand { Get(Get), Post(Post), // 我们暂且不支持其它 HTTP 方法 } // get 子命令 /// feed get with an url and we will retrieve the response for you #[derive(Parser, Debug)] struct Get { /// HTTP 请求的 URL url: String, } // post 子命令。需要输入一个 url,和若干个可选的 key=value,用于提供 json body /// feed post with an url and optional key=value pairs. We will post the data /// as JSON, and retrieve the response for you #[derive(Parser, Debug)] struct Post { /// HTTP 请求的 URL url: String, /// HTTP 请求的 body body: Vec<String>, } fn main() { let opts: Opts = Opts::parse(); let opt_subcmd: SubCommand = opts.subcmd; // println!("{:?}", opts); println!("{:?}", opt_subcmd); // println!("{:?}", opts.subcmd); // 这里就可以看出,结构体的内在元素使用"."来获取 // println!("{:?}", opts::subcmd); }
clap::Parser相关资料
- clap的parser派生宏会自动实现parse方法来接收指令参数
struct Opts { #[clap(subcommand)] subcmd: SubCommand, } // 子命令分别对应不同的 HTTP 方法,目前只支持 get / post #[derive(Parser, Debug)]
fn main() { let opts: Opts = Opts::parse(); let opt_subcmd: SubCommand = opts.subcmd; // println!("{:?}", opts);
- 运行效果
cargo run --example cli get http://jsonplaceholder.typicode.com/posts/2 ─╯
Compiling httpie v0.1.0 (/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/04_httpie)
Finished dev [unoptimized + debuginfo] target(s) in 2.31s
Running `/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/target/debug/examples/cli get 'http://jsonplaceholder.typicode.com/posts/2'`
Opts { subcmd: Get(Get { url: "http://jsonplaceholder.typicode.com/posts/2" }) }
cargo run --example cli post http://jsonplaceholder.typicode.com/posts/2 ─╯
Finished dev [unoptimized + debuginfo] target(s) in 0.31s
Running `/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/target/debug/examples/cli post 'http://jsonplaceholder.typicode.com/posts/2'`
Opts { subcmd: Post(Post { url: "http://jsonplaceholder.typicode.com/posts/2", body: [] }) }
cargo run --example cli delete http://jsonplaceholder.typicode.com/posts/2 ─╯
Finished dev [unoptimized + debuginfo] target(s) in 0.24s
Running `/Users/kuanhsiaokuo/Developer/spare_projects/rust_lab/geektime-rust/geektime_rust_codes/target/debug/examples/cli delete 'http://jsonplaceholder.typicode.com/posts/2'`
error: Found argument 'delete' which wasn't expected, or isn't valid in this context
USAGE:
cli <SUBCOMMAND>
For more information try --help
- opts的获取:自动以空格分隔,根据
模式匹配,之后的参数依次赋值给 struct里面的元素
Step2:添加参数验证与键值对改造
- 参数验证
/// feed get with an url and we will retrieve the response for you #[derive(Parser, Debug)] struct Get { /// HTTP 请求的 URL #[clap(parse(try_from_str = parse_url))] url: String, } // post 子命令。需要输入一个 url,和若干个可选的 key=value,用于提供 json body /// feed post with an url and optional key=value pairs. We will post the data /// as JSON, and retrieve the response for you #[derive(Parser, Debug)] struct Post { /// HTTP 请求的 URL #[clap(parse(try_from_str = parse_url))] url: String, /// HTTP 请求的 body #[clap(parse(try_from_str=parse_kv_pair))] body: Vec<KvPair>, }
clap 允许你为每个解析出来的值添加自定义的解析函数,我们这里定义了parse_url和parse_kv_pair检查一下。
/// 因为我们为 KvPair 实现了 FromStr,这里可以直接 s.parse() 得到 KvPair fn parse_kv_pair(s: &str) -> Result<KvPair> { s.parse() } fn parse_url(s: &str) -> Result<String> { // 这里我们仅仅检查一下 URL 是否合法 let _url: Url = s.parse()?; Ok(s.into()) }
- 键值对改造
/// 命令行中的 key=value 可以通过 parse_kv_pair 解析成 KvPair 结构 #[allow(dead_code)] #[derive(Debug)] struct KvPair { k: String, v: String, } /// 当我们实现 FromStr trait 后,可以用 str.parse() 方法将字符串解析成 KvPair impl FromStr for KvPair { type Err = anyhow::Error; fn from_str(s: &str) -> Result<Self, Self::Err> { // 使用 = 进行 split,这会得到一个迭代器 let mut split = s.split('='); let err = || anyhow!(format!("Failed to parse {}", s)); Ok(Self { // 从迭代器中取第一个结果作为 key,迭代器返回 Some(T)/None // 我们将其转换成 Ok(T)/Err(E),然后用 ? 处理错误 k: (split.next().ok_or_else(err)?).to_string(), // 从迭代器中取第二个结果作为 value v: (split.next().ok_or_else(err)?).to_string(), }) } }
Step3:异步请求改造
Step3:异步请求改造
#[tokio::main] async fn main() -> Result<()> { let opts: Opts = Opts::parse(); // 生成一个 let client = Client::new(); match opts.subcmd { SubCommand::Get(ref args) => get(client, args).await?, SubCommand::Post(ref args) => post(client, args).await?, }; Ok(()) } async fn get(client: Client, args: &Get) -> Result<()> { let resp = client.get(&args.url).send().await?; println!("{:?}", resp.text().await?); Ok(()) } async fn post(client: Client, args: &Post) -> Result<()> { let mut body = HashMap::new(); for pair in args.body.iter() { body.insert(&pair.k, &pair.v); } let resp = client.post(&args.url).json(&body).send().await?; println!("{:?}", resp.text().await?); Ok(()) }
Step4: 语法高亮打印
Step4: 语法高亮打印
// 打印服务器版本号 + 状态码 fn print_status(resp: &Response) { let status = format!("{:?} {}", resp.version(), resp.status()).blue(); println!("{}\n", status); } // 打印服务器返回的 HTTP header fn print_headers(resp: &Response) { for (name, value) in resp.headers() { println!("{}: {:?}", name.to_string().green(), value); } println!(); } /// 打印服务器返回的 HTTP body fn print_body(m: Option<Mime>, body: &str) { match m { // 对于 "application/json" 我们 pretty print Some(v) if v == mime::APPLICATION_JSON => print_syntect(body, "json"), Some(v) if v == mime::TEXT_HTML => print_syntect(body, "html"), // 其它 mime type,我们就直接输出 _ => println!("{}", body), } } /// 打印整个响应 async fn print_resp(resp: Response) -> Result<()> { print_status(&resp); print_headers(&resp); let mime = get_content_type(&resp); let body = resp.text().await?; print_body(mime, &body); Ok(()) } /// 将服务器返回的 content-type 解析成 Mime 类型 fn get_content_type(resp: &Response) -> Option<Mime> { resp.headers() .get(header::CONTENT_TYPE) .map(|v| v.to_str().unwrap().parse().unwrap()) } fn print_syntect(s: &str, ext: &str) { // Load these once at the start of your program let ps = SyntaxSet::load_defaults_newlines(); let ts = ThemeSet::load_defaults(); let syntax = ps.find_syntax_by_extension(ext).unwrap(); let mut h = HighlightLines::new(syntax, &ts.themes["base16-ocean.dark"]); for line in LinesWithEndings::from(s) { let ranges: Vec<(Style, &str)> = h.highlight(line, &ps); let escaped = as_24_bit_terminal_escaped(&ranges[..], true); print!("{}", escaped); } }
/// 程序的入口函数,因为在 http 请求时我们使用了异步处理,所以这里引入 tokio #[tokio::main] async fn main() -> Result<()> { let opts: Opts = Opts::parse(); let mut headers = header::HeaderMap::new(); // 为我们的 http 客户端添加一些缺省的 HTTP 头 headers.insert("X-POWERED-BY", "Rust".parse()?); headers.insert(header::USER_AGENT, "Rust Httpie".parse()?); let client = Client::builder() .default_headers(headers) .build()?; let result = match opts.subcmd { SubCommand::Get(ref args) => get(client, args).await?, SubCommand::Post(ref args) => post(client, args).await?, }; Ok(result) }
Step5: 添加单元测试
Step5: 添加单元测试
// 仅在 cargo test 时才编译 #[cfg(test)] mod tests { use super::*; #[test] fn parse_url_works() { assert!(parse_url("abc").is_err()); assert!(parse_url("http://abc.xyz").is_ok()); assert!(parse_url("https://httpbin.org/post").is_ok()); } #[test] fn parse_kv_pair_works() { assert!(parse_kv_pair("a").is_err()); assert_eq!( parse_kv_pair("a=1").unwrap(), KvPair { k: "a".into(), v: "1".into(), } ); assert_eq!( parse_kv_pair("b=").unwrap(), KvPair { k: "b".into(), v: "".into(), } ); } }
rgrep
Cargo.toml
Cargo.toml
[package]
name = "rgrep"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
anyhow = "1"
clap = { version = "3", features = ["derive"] }
colored = "2"
glob = "0.3"
itertools = "0.10"
rayon = "1"
regex = "1"
thiserror = "1"
src/error.rs: thiserror会自动转换
它们都是需要进行转换的错误。thiserror 能够通过宏帮我们完成错误类型的转换。
它们都是需要进行转换的错误。thiserror 能够通过宏帮我们完成错误类型的转换。
use thiserror::Error; #[derive(Error, Debug)] pub enum GrepError { #[error("Glob pattern error")] GlobPatternError(#[from] glob::PatternError), #[error("Regex pattern error")] RegexPatternError(#[from] regex::Error), #[error("I/O error")] IoError(#[from] std::io::Error), }
src/lib.rs:定义结构体+实现方法+单元测试
定义结构体: 专门简化复杂类型
这里其实就是传入一个指定结构的函数对象
/// 定义类型,这样,在使用时可以简化复杂类型的书写 pub type StrategyFn = fn(&Path, &mut dyn BufRead, &Regex, &mut dyn Write) -> Result<(), GrepError>;
专门的结合版本grep结构体
/// 简化版本的 grep,支持正则表达式和文件通配符 #[derive(Parser, Debug)] #[clap(version = "1.0", author = "Tyr Chen <tyr@chen.com>")] pub struct GrepConfig { /// 用于查找的正则表达式 pattern: String, /// 文件通配符 glob: String, }
lib.rs: 给结构体实现方法
impl GrepConfig { /// 使用缺省策略来查找匹配 pub fn match_with_default_strategy(&self) -> Result<(), GrepError> { self.match_with(default_strategy) } /// 使用某个策略函数来查找匹配 pub fn match_with(&self, strategy: StrategyFn) -> Result<(), GrepError> { let regex = Regex::new(&self.pattern)?; // 生成所有符合通配符的文件列表 let files: Vec<_> = glob::glob(&self.glob)?.collect(); // 并行处理所有文件 files.into_par_iter().for_each(|v| { if let Ok(filename) = v { if let Ok(file) = File::open(&filename) { let mut reader = BufReader::new(file); let mut stdout = io::stdout(); if let Err(e) = strategy(filename.as_path(), &mut reader, ®ex, &mut stdout) { println!("Internal error: {:?}", e); } } } }); Ok(()) } }
主要实现两种解析策略:
- 默认策略:match_with_default_strategy, 使用default_strategy
- 指定策略:match_with, 使用传入的strategy: StrategyFn
默认策略: default_strategy
/// 缺省策略,从头到尾串行查找,最后输出到 writer pub fn default_strategy( path: &Path, reader: &mut dyn BufRead, pattern: &Regex, writer: &mut dyn Write, ) -> Result<(), GrepError> { let matches: String = reader .lines() .enumerate() .map(|(lineno, line)| { line.ok() .map(|line| { pattern .find(&line) .map(|m| format_line(&line, lineno + 1, m.range())) }) .flatten() }) .filter_map(|v| v.ok_or(()).ok()) .join("\n"); if !matches.is_empty() { writer.write_all(path.display().to_string().green().as_bytes())?; writer.write_all(b"\n")?; writer.write_all(matches.as_bytes())?; writer.write_all(b"\n")?; } Ok(()) }
格式化输出
/// 格式化输出匹配的行,包含行号,列号和带有高亮的第一个匹配项 pub fn format_line(line: &str, lineno: usize, range: Range<usize>) -> String { let Range { start, end } = range; let prefix = &line[..start]; format!( "{0: >6}:{1: <3} {2}{3}{4}", lineno.to_string().blue(), // 找到匹配项的起始位置,注意对汉字等非 ascii 字符,我们不能使用 prefix.len() // 这是一个 O(n) 的操作,会拖累效率,这里只是为了演示的效果 (prefix.chars().count() + 1).to_string().cyan(), prefix, &line[start..end].red(), &line[end..] ) }
单元测试
#[cfg(test)] mod tests { use super::*; #[test] fn format_line_should_work() { let result = format_line("Hello, Tyr~", 1000, 7..10); let expected = format!( "{0: >6}:{1: <3} Hello, {2}~", "1000".blue(), "8".cyan(), "Tyr".red() ); assert_eq!(result, expected); } #[test] fn default_strategy_should_work() { let path = Path::new("src/main.rs"); let input = b"hello world!\nhey Tyr!"; let mut reader = BufReader::new(&input[..]); let pattern = Regex::new(r"he\w+").unwrap(); let mut writer = Vec::new(); default_strategy(path, &mut reader, &pattern, &mut writer).unwrap(); let result = String::from_utf8(writer).unwrap(); let expected = [ String::from("src/main.rs"), format_line("hello world!", 1, 0..5), format_line("hey Tyr!\n", 2, 0..3), ]; assert_eq!(result, expected.join("\n")); } }
src/main.rs
主函数:main()
use regex::Regex; use std::{ fs::File, io::{self, BufRead, BufReader, Write}, ops::Range, path::Path, };
使用
示例:cargo run –quiet – “正则表达式” “src/*.rs”
cargo run --quiet -- "Re[^\\s]+" "src/*.rs" ─╯
src/main.rs
1:13 use anyhow::Result;
5:14 fn main() -> Result<()> {
src/error.rs
7:14 #[error("Regex pattern error")]
8:5 RegexPatternError(#[from] regex::Error),
src/lib.rs
5:12 use regex::Regex;
8:19 io::{self, BufRead, BufReader, Write},
17:45 pub type StrategyFn = fn(&Path, &mut dyn BufRead, &Regex, &mut dyn Write) -> Result<(), GrepError>;
31:50 pub fn match_with_default_strategy(&self) -> Result<(), GrepError> {
36:55 pub fn match_with(&self, strategy: StrategyFn) -> Result<(), GrepError> {
37:21 let regex = Regex::new(&self.pattern)?;
44:41 let mut reader = BufReader::new(file);
60:25 reader: &mut dyn BufRead,
61:15 pattern: &Regex,
63:6 ) -> Result<(), GrepError> {
126:29 let mut reader = BufReader::new(&input[..]);
127:23 let pattern = Regex::new(r"he\w+").unwrap();
thumbor图片服务
protobuf相关处理
abi.proto
syntax = "proto3"; package abi; // 一个 ImageSpec 是一个有序的数组,服务器按照 spec 的顺序处理 message ImageSpec { repeated Spec specs = 1; } // 处理图片改变大小 message Resize { uint32 width = 1; uint32 height = 2; enum ResizeType { NORMAL = 0; SEAM_CARVE = 1; } ResizeType rtype = 3; enum SampleFilter { UNDEFINED = 0; NEAREST = 1; TRIANGLE = 2; CATMULL_ROM = 3; GAUSSIAN = 4; LANCZOS3 = 5; } SampleFilter filter = 4; } // 处理图片截取 message Crop { uint32 x1 = 1; uint32 y1 = 2; uint32 x2 = 3; uint32 y2 = 4; } // 处理水平翻转 message Fliph {} // 处理垂直翻转 message Flipv {} // 处理对比度 message Contrast { float contrast = 1; } // 处理滤镜 message Filter { enum Filter { UNSPECIFIED = 0; OCEANIC = 1; ISLANDS = 2; MARINE = 3; // more: https://docs.rs/photon-rs/0.3.1/photon_rs/filters/fn.filter.html } Filter filter = 1; } // 处理水印 message Watermark { uint32 x = 1; uint32 y = 2; } // 一个 spec 可以包含上述的处理方式之一 message Spec { oneof data { Resize resize = 1; Crop crop = 2; Flipv flipv = 3; Fliph fliph = 4; Contrast contrast = 5; Filter filter = 6; Watermark watermark = 7; } }
build.rs
use std::process::Command; fn main() { // 在编译时可选择检查环境变量。 let build_enabled = option_env!("BUILD_PROTO") .map(|v| v == "1") .unwrap_or(false); // 如果没有找到环境变量的对应值,就直接return,不再进行后续编译 if !build_enabled { println!("=== Skipped compiling protos ==="); return; } // 使用 prost_build 把 abi.proto 编译到 src/pb 目录下 prost_build::Config::new() .out_dir("src/pb") .compile_protos(&["abi.proto"], &["."]) .unwrap(); Command::new("cargo") .args(&["fmt", "--", "src/*.rs"]) .status() .expect("cargo fmt failed"); }
在编译时可选择检查环境变量。
关于rust的模块
可以参考这篇:Rust 模块系统理解 - 知乎
mod全认识
- mod(mod.rs或mod关键字)将代码分为多个逻辑模块,并管理这些模块的可见性(public / private)。
- 模块是项(item)的集合,项可以是:函数,结构体,trait,impl块,甚至其它模块。
- 一个目录下的所有代码,可以通过 mod.rs 声明
- Rust模块有三种形式:
- mod.rs: 一个目录下的所有代码,可以通过 mod.rs 声明
- 文件/目录即模块:编译器的机制决定,除了mod.rs外,每一个文件和目录都是一个模块。不允许只分拆文件,但是不声明mod,我们通常使用pub use,在父空间直接调用子空间的函数。
- mod关键字: 在文件内部分拆模块
- Rust编译器只接受一个源文件,输出一个crate
- 每一个crate都有一个匿名的根命名空间,命名空间可以无限嵌套
- “mod mod-name { … }“ 将大括号中的代码置于命名空间mod-name之下
- “use mod-name1::mod-name2;“ 可以打开命名空间,减少无休止的::操作符
- “mod mod-name;“ 可以指导编译器将多个文件组装成一个文件
- “pub use mod-nam1::mod-name2::item-name;“ 语句可以将mod-name2下的item-name提升到这条语句所在的空间,item-name通常是函数或者结构体。Rust社区通常用这个方法来缩短库API的命名空间深度 编译器规定use语句一定要在mod语句之前
mod文件定义与实现分离
在rust中,一般会在模块的mod.rs文件中对供外部使用的项进行实现, 项可以是:函数,结构体,trait,impl块,甚至其它模块. 这样有个好处,高内聚,可以在代码增长时,将变动局限在服务提供者内部,对外提供的api不变,不会造成破坏性更新。
pb模块: 处理protobuf
pb/abi.rs里面还有子模块
/// Nested message and enum types in `Spec`. pub mod spec { #[derive(Clone, PartialEq, ::prost::Oneof)] pub enum Data { #[prost(message, tag = "1")] Resize(super::Resize), #[prost(message, tag = "2")] Crop(super::Crop), #[prost(message, tag = "3")] Flipv(super::Flipv), #[prost(message, tag = "4")] Fliph(super::Fliph), #[prost(message, tag = "5")] Contrast(super::Contrast), #[prost(message, tag = "6")] Filter(super::Filter), #[prost(message, tag = "7")] Watermark(super::Watermark), } }
pb/abi.rs另外定义了spec::Data里面的各个元素结构体/嵌套模块mod
/// 一个 ImageSpec 是一个有序的数组,服务器按照 spec 的顺序处理 #[derive(Clone, PartialEq, ::prost::Message)] pub struct ImageSpec { #[prost(message, repeated, tag = "1")] pub specs: ::prost::alloc::vec::Vec<Spec>, } /// 处理图片改变大小 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Resize { #[prost(uint32, tag = "1")] pub width: u32, #[prost(uint32, tag = "2")] pub height: u32, #[prost(enumeration = "resize::ResizeType", tag = "3")] pub rtype: i32, #[prost(enumeration = "resize::SampleFilter", tag = "4")] pub filter: i32, } /// Nested message and enum types in `Resize`. pub mod resize { #[derive(Clone, Copy, Debug, PartialEq, Eq, Hash, PartialOrd, Ord, ::prost::Enumeration)] #[repr(i32)] pub enum ResizeType { Normal = 0, SeamCarve = 1, } #[derive(Clone, Copy, Debug, PartialEq, Eq, Hash, PartialOrd, Ord, ::prost::Enumeration)] #[repr(i32)] pub enum SampleFilter { Undefined = 0, Nearest = 1, Triangle = 2, CatmullRom = 3, Gaussian = 4, Lanczos3 = 5, } } /// 处理图片截取 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Crop { #[prost(uint32, tag = "1")] pub x1: u32, #[prost(uint32, tag = "2")] pub y1: u32, #[prost(uint32, tag = "3")] pub x2: u32, #[prost(uint32, tag = "4")] pub y2: u32, } /// 处理水平翻转 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Fliph {} /// 处理垂直翻转 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Flipv {} /// 处理对比度 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Contrast { #[prost(float, tag = "1")] pub contrast: f32, } /// 处理滤镜 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Filter { #[prost(enumeration = "filter::Filter", tag = "1")] pub filter: i32, } /// Nested message and enum types in `Filter`. pub mod filter { #[derive(Clone, Copy, Debug, PartialEq, Eq, Hash, PartialOrd, Ord, ::prost::Enumeration)] #[repr(i32)] pub enum Filter { Unspecified = 0, Oceanic = 1, Islands = 2, /// more: <https://docs.rs/photon-rs/0.3.1/photon_rs/filters/fn.filter.html> Marine = 3, } } /// 处理水印 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Watermark { #[prost(uint32, tag = "1")] pub x: u32, #[prost(uint32, tag = "2")] pub y: u32, }
pb/abi.rs有个特殊结构体
/// 一个 spec 可以包含上述的处理方式之一 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Spec { #[prost(oneof = "spec::Data", tags = "1, 2, 3, 4, 5, 6, 7")] pub data: ::core::option::Option<spec::Data>, }
ImageSpec
定义:有序数组
- pb/abi.rs
/// 一个 ImageSpec 是一个有序的数组,服务器按照 spec 的顺序处理 #[derive(Clone, PartialEq, ::prost::Message)] pub struct ImageSpec { #[prost(message, repeated, tag = "1")] pub specs: ::prost::alloc::vec::Vec<Spec>, }
实现:new方法、From&TryFrom实现类型转化
- pb/mod.rs
impl ImageSpec { pub fn new(specs: Vec<Spec>) -> Self { Self { specs } } } // 让 ImageSpec 可以生成一个字符串 impl From<&ImageSpec> for String { fn from(image_spec: &ImageSpec) -> Self { let data = image_spec.encode_to_vec(); encode_config(data, URL_SAFE_NO_PAD) } } // 让 ImageSpec 可以通过一个字符串创建。比如 s.parse().unwrap() impl TryFrom<&str> for ImageSpec { type Error = anyhow::Error; fn try_from(value: &str) -> Result<Self, Self::Error> { let data = decode_config(value, URL_SAFE_NO_PAD)?; Ok(ImageSpec::decode(&data[..])?) } }
Filter
定义:枚举体mod
- pb/abi.rs
/// Nested message and enum types in `Filter`. pub mod filter { #[derive(Clone, Copy, Debug, PartialEq, Eq, Hash, PartialOrd, Ord, ::prost::Enumeration)] #[repr(i32)] pub enum Filter { Unspecified = 0, Oceanic = 1, Islands = 2, /// more: <https://docs.rs/photon-rs/0.3.1/photon_rs/filters/fn.filter.html> Marine = 3, } }
实现:双引号的使用、模式匹配
- pb/mod.rs
// 辅助函数,photon_rs 相应的方法里需要字符串 impl filter::Filter { pub fn to_str(self) -> Option<&'static str> { match self { filter::Filter::Unspecified => None, filter::Filter::Oceanic => Some("oceanic"), filter::Filter::Islands => Some("islands"), filter::Filter::Marine => Some("marine"), } } }
SampleFilter
定义:枚举体mod
- pb/abi.rs
/// Nested message and enum types in `Resize`. pub mod resize { #[derive(Clone, Copy, Debug, PartialEq, Eq, Hash, PartialOrd, Ord, ::prost::Enumeration)] #[repr(i32)] pub enum ResizeType { Normal = 0, SeamCarve = 1, } #[derive(Clone, Copy, Debug, PartialEq, Eq, Hash, PartialOrd, Ord, ::prost::Enumeration)] #[repr(i32)] pub enum SampleFilter { Undefined = 0, Nearest = 1, Triangle = 2, CatmullRom = 3, Gaussian = 4, Lanczos3 = 5, } }
实现:mod使用双引号、From转为不同结果
- pb/mod.rs
impl From<resize::SampleFilter> for SamplingFilter { fn from(v: resize::SampleFilter) -> Self { match v { resize::SampleFilter::Undefined => SamplingFilter::Nearest, resize::SampleFilter::Nearest => SamplingFilter::Nearest, resize::SampleFilter::Triangle => SamplingFilter::Triangle, resize::SampleFilter::CatmullRom => SamplingFilter::CatmullRom, resize::SampleFilter::Gaussian => SamplingFilter::Gaussian, resize::SampleFilter::Lanczos3 => SamplingFilter::Lanczos3, } } }
Spec
定义:结构体
- pb/abi.rs
/// 一个 spec 可以包含上述的处理方式之一 #[derive(Clone, PartialEq, ::prost::Message)] pub struct Spec { #[prost(oneof = "spec::Data", tags = "1, 2, 3, 4, 5, 6, 7")] pub data: ::core::option::Option<spec::Data>, }
注意区别Self和self的使用:
注意区别Self和self的使用:
实现:类似面向对象中添加类方法Self
- pb/mod.rs
// 提供一些辅助函数,让创建一个 spec 的过程简单一些 impl Spec { pub fn new_resize_seam_carve(width: u32, height: u32) -> Self { Self { data: Some(spec::Data::Resize(Resize { width, height, rtype: resize::ResizeType::SeamCarve as i32, filter: resize::SampleFilter::Undefined as i32, })), } } pub fn new_resize(width: u32, height: u32, filter: resize::SampleFilter) -> Self { Self { data: Some(spec::Data::Resize(Resize { width, height, rtype: resize::ResizeType::Normal as i32, filter: filter as i32, })), } } pub fn new_filter(filter: filter::Filter) -> Self { Self { data: Some(spec::Data::Filter(Filter { filter: filter as i32, })), } } pub fn new_watermark(x: u32, y: u32) -> Self { Self { data: Some(spec::Data::Watermark(Watermark { x, y })), } } }
单元测试
单元测试
#[cfg(test)] mod tests { use super::*; use std::borrow::Borrow; #[test] fn encoded_spec_could_be_decoded() { let spec1 = Spec::new_resize(600, 600, resize::SampleFilter::CatmullRom); let spec2 = Spec::new_filter(filter::Filter::Marine); let image_spec = ImageSpec::new(vec![spec1, spec2]); let s: String = image_spec.borrow().into(); assert_eq!(image_spec, s.as_str().try_into().unwrap()); } }
engine模块: 处理图片
mod.rs: 定义统一的引擎trait
// Engine trait:未来可以添加更多的 engine,主流程只需要替换 engine pub trait Engine { // 对 engine 按照 specs 进行一系列有序的处理 fn apply(&mut self, specs: &[Spec]); // 从 engine 中生成目标图片,注意这里用的是 self,而非 self 的引用 fn generate(self, format: ImageOutputFormat) -> Vec<u8>; } // SpecTransform:未来如果添加更多的 spec,只需要实现它即可 pub trait SpecTransform<T> { // 对图片使用 op 做 transform fn transform(&mut self, op: T); }
photon.rs > 静态变量加载
lazy_static! { // 预先把水印文件加载为静态变量 static ref WATERMARK: PhotonImage = { let data = include_bytes!("../../rust-logo.png"); let watermark = open_image_from_bytes(data).unwrap(); transform::resize(&watermark, 64, 64, transform::SamplingFilter::Nearest) }; }
photon.rs > 具体引擎Photon的定义与转化TryFrom
pub struct Photon(PhotonImage); // 从 Bytes 转换成 Photon 结构 impl TryFrom<Bytes> for Photon { type Error = anyhow::Error; fn try_from(data: Bytes) -> Result<Self, Self::Error> { Ok(Self(open_image_from_bytes(&data)?)) } }
photon.rs > 具体引擎Photon的trait实现
Engine Trait
impl Engine for Photon { fn apply(&mut self, specs: &[Spec]) { for spec in specs.iter() { match spec.data { Some(spec::Data::Crop(ref v)) => self.transform(v), Some(spec::Data::Contrast(ref v)) => self.transform(v), Some(spec::Data::Filter(ref v)) => self.transform(v), Some(spec::Data::Fliph(ref v)) => self.transform(v), Some(spec::Data::Flipv(ref v)) => self.transform(v), Some(spec::Data::Resize(ref v)) => self.transform(v), Some(spec::Data::Watermark(ref v)) => self.transform(v), // 对于目前不认识的 spec,不做任何处理 _ => {} } } }
SpecTransform Trait
格式语义化
#![allow(unused)] fn main() { impl SpecTransform(&OpreationName) for SpecificEngine { fn transform(&mut self, _op: &OperationName) { transform::OperationMethod(&mut self.0) } } }
impl SpecTransform<&Crop> for Photon { fn transform(&mut self, op: &Crop) { let img = transform::crop(&mut self.0, op.x1, op.y1, op.x2, op.y2); self.0 = img; } } impl SpecTransform<&Contrast> for Photon { fn transform(&mut self, op: &Contrast) { effects::adjust_contrast(&mut self.0, op.contrast); } } impl SpecTransform<&Flipv> for Photon { fn transform(&mut self, _op: &Flipv) { transform::flipv(&mut self.0) } } impl SpecTransform<&Fliph> for Photon { fn transform(&mut self, _op: &Fliph) { transform::fliph(&mut self.0) } } impl SpecTransform<&Filter> for Photon { fn transform(&mut self, op: &Filter) { match filter::Filter::from_i32(op.filter) { Some(filter::Filter::Unspecified) => {} Some(f) => filters::filter(&mut self.0, f.to_str().unwrap()), _ => {} } } } impl SpecTransform<&Resize> for Photon { fn transform(&mut self, op: &Resize) { let img = match resize::ResizeType::from_i32(op.rtype).unwrap() { resize::ResizeType::Normal => transform::resize( &self.0, op.width, op.height, resize::SampleFilter::from_i32(op.filter).unwrap().into(), ), resize::ResizeType::SeamCarve => transform::seam_carve(&self.0, op.width, op.height), }; self.0 = img; } } impl SpecTransform<&Watermark> for Photon { fn transform(&mut self, op: &Watermark) { multiple::watermark(&mut self.0, &WATERMARK, op.x, op.y); } }
photon.rs > 在内存中对图片转换格式的方法
fn image_to_buf(img: PhotonImage, format: ImageOutputFormat) -> Vec<u8> { let raw_pixels = img.get_raw_pixels(); let width = img.get_width(); let height = img.get_height(); let img_buffer = ImageBuffer::from_vec(width, height, raw_pixels).unwrap(); let dynimage = DynamicImage::ImageRgba8(img_buffer); let mut buffer = Vec::with_capacity(32768); dynimage.write_to(&mut buffer, format).unwrap(); buffer }
main.rs
先引入mod,再use
// 参数使用 serde 做 Deserialize,axum 会自动识别并解析 #[derive(Deserialize)] struct Params { spec: String, url: String, }
主流程main函数
main()
#[tokio::main] async fn main() { // 初始化 tracing tracing_subscriber::fmt::init(); let cache: Cache = Arc::new(Mutex::new(LruCache::new(1024))); // 构建路由 let app = Router::new() // `GET /` 会执行 .route("/image/:spec/:url", get(generate)) .layer( ServiceBuilder::new() .load_shed() .concurrency_limit(1024) .timeout(Duration::from_secs(10)) .layer(TraceLayer::new_for_http()) .layer(AddExtensionLayer::new(cache)) .layer(CompressionLayer::new()) .into_inner(), ); // 运行 web 服务器 let addr = "127.0.0.1:3000".parse().unwrap(); print_test_url("https://images.pexels.com/photos/1562477/pexels-photo-1562477.jpeg?auto=compress&cs=tinysrgb&dpr=3&h=750&w=1260"); info!("Listening on {}", addr); axum::Server::bind(&addr) .serve(app.into_make_service()) .await .unwrap(); }
建造者模式
ServiceBuilder::new() .load_shed() .concurrency_limit(1024) .timeout(Duration::from_secs(10)) .layer(TraceLayer::new_for_http()) .layer(AddExtensionLayer::new(cache)) .layer(CompressionLayer::new()) .into_inner(),
笔记:类型转换总结
- 数字与字符串
- String 与 & str
- 智能指针
路由绑定的处理函数handler
// basic handler that responds with a static string async fn generate( Path(Params { spec, url }): Path<Params>, Extension(cache): Extension<Cache>, ) -> Result<(HeaderMap, Vec<u8>), StatusCode> { let spec: ImageSpec = spec .as_str() .try_into() .map_err(|_| StatusCode::BAD_REQUEST)?; let url: &str = &percent_decode_str(&url).decode_utf8_lossy(); let data = retrieve_image(url, cache) .await .map_err(|_| StatusCode::BAD_REQUEST)?; // 使用 image engine 处理 let mut engine: Photon = data .try_into() .map_err(|_| StatusCode::INTERNAL_SERVER_ERROR)?; engine.apply(&spec.specs); // TODO: 这里目前类型写死了,应该使用 content negotiation let image = engine.generate(ImageOutputFormat::Jpeg(85)); info!("Finished processing: image size {}", image.len()); let mut headers = HeaderMap::new(); headers.insert("content-type", HeaderValue::from_static("image/jpeg")); Ok((headers, image)) }
处理函数用到的图片获取方法
对于图片的网络请求,我们先把 URL 做个哈希,在 LRU 缓存中查找,找不到才用 reqwest 发送请求。
#[instrument(level = "info", skip(cache))] async fn retrieve_image(url: &str, cache: Cache) -> Result<Bytes> { let mut hasher = DefaultHasher::new(); url.hash(&mut hasher); let key = hasher.finish(); let g = &mut cache.lock().await; let data = match g.get(&key) { Some(v) => { info!("Match cache {}", key); v.to_owned() } None => { info!("Retrieve url"); let resp = reqwest::get(url).await?; let data = resp.bytes().await?; g.put(key, data.clone()); data } }; Ok(data) }
一个用于调试的辅助函数
// 调试辅助函数 fn print_test_url(url: &str) { use std::borrow::Borrow; let spec1 = Spec::new_resize(500, 800, resize::SampleFilter::CatmullRom); let spec2 = Spec::new_watermark(20, 20); let spec3 = Spec::new_filter(filter::Filter::Marine); let image_spec = ImageSpec::new(vec![spec1, spec2, spec3]); let s: String = image_spec.borrow().into(); let test_image = percent_encode(url.as_bytes(), NON_ALPHANUMERIC).to_string(); println!("test url: http://localhost:3000/image/{}/{}", s, test_image); }
运行与日志
SQL查询工具
workspace: 这里使用虚拟清单(virtual manifest)方式
虚拟清单
若一个 Cargo.toml 有 [workspace] 但是没有 [package] 部分,则它是虚拟清单类型的工作空间。
对于没有主 package 的场景或你希望将所有的 package 组织在单独的目录中时,这种方式就非常适合。
workspace关键点
- 所有的 package 共享同一个 Cargo.lock 文件,该文件位于工作空间的根目录中
- 所有的 package 共享同一个输出目录,该目录默认的名称是 target ,位于工作空间根目录下
- 只有工作空间根目录的 Cargo.toml 才能包含 [patch], [replace] 和 [profile.*],而成员的 Cargo.toml 中的相应部分将被自动忽略
workspace使用方式
cargo run -p <member package>
cargo build -p queryer
使用说明
-
在工作空间中,package 相关的 Cargo 命令(例如 cargo build )可以使用 -p 、 –package 或 –workspace 命令行参数来指定想要操作的 package。
-
若没有指定任何参数,则 Cargo 将使用当前工作目录的中的 package 。若工作目录是虚拟清单类型的工作空间,则该命令将作用在所有成员上(就好像是使用了 –workspace 命令行参数)。而 default-members 可以在命令行参数没有被提供时,手动指定操作的成员
queryer package
cargo.toml
两个使用示例
- dialect.rs:SQL解析
use sqlparser::{dialect::GenericDialect, parser::Parser}; fn main() { tracing_subscriber::fmt::init(); let sql = "SELECT a a1, b, 123, myfunc(b), * \ FROM data_source \ WHERE a > b AND b < 100 AND c BETWEEN 10 AND 20 \ ORDER BY a DESC, b \ LIMIT 50 OFFSET 10"; let ast = Parser::parse_sql(&GenericDialect::default(), sql); println!("{:#?}", ast); }
- covid.rs: AST转换
use anyhow::Result; use queryer::query; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let url = "https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/latest/owid-covid-latest.csv"; // 使用 sql 从 URL 里获取数据 let sql = format!( "SELECT location name, total_cases, new_cases, total_deaths, new_deaths \ FROM {} where new_deaths >= 500 ORDER BY new_cases DESC", url ); let df1 = query(sql).await?; println!("{:?}", df1); Ok(()) }
src/convert.rs
结构体定义:sql与对应部分结构体, 注意限于孤儿原则的再包装
/// 解析出来的 SQL pub struct Sql<'a> { pub(crate) selection: Vec<Expr>, pub(crate) condition: Option<Expr>, pub(crate) source: &'a str, pub(crate) order_by: Vec<(String, bool)>, pub(crate) offset: Option<i64>, pub(crate) limit: Option<usize>, } // 因为 Rust trait 的孤儿规则,我们如果要想对已有的类型实现已有的 trait, // 需要简单包装一下 pub struct Expression(pub(crate) Box<SqlExpr>); pub struct Operation(pub(crate) SqlBinaryOperator); pub struct Projection<'a>(pub(crate) &'a SelectItem); pub struct Source<'a>(pub(crate) &'a [TableWithJoins]); pub struct Order<'a>(pub(crate) &'a OrderByExpr); pub struct Offset<'a>(pub(crate) &'a SqlOffset); pub struct Limit<'a>(pub(crate) &'a SqlExpr); pub struct Value(pub(crate) SqlValue);
sql的转换
/// 把 SqlParser 解析出来的 Statement 转换成我们需要的结构 impl<'a> TryFrom<&'a Statement> for Sql<'a> { type Error = anyhow::Error; fn try_from(sql: &'a Statement) -> Result<Self, Self::Error> { match sql { // 目前我们只关心 query (select ... from ... where ...) Statement::Query(q) => { let offset = q.offset.as_ref(); let limit = q.limit.as_ref(); let orders = &q.order_by; let Select { from: table_with_joins, selection: where_clause, projection, group_by: _, .. } = match &q.body { SetExpr::Select(statement) => statement.as_ref(), _ => return Err(anyhow!("We only support Select Query at the moment")), }; let source = Source(table_with_joins).try_into()?; let condition = match where_clause { Some(expr) => Some(Expression(Box::new(expr.to_owned())).try_into()?), None => None, }; let mut selection = Vec::with_capacity(8); for p in projection { let expr = Projection(p).try_into()?; selection.push(expr); } let mut order_by = Vec::new(); for expr in orders { order_by.push(Order(expr).try_into()?); } let offset = offset.map(|v| Offset(v).into()); let limit = limit.map(|v| Limit(v).into()); Ok(Sql { selection, condition, source, order_by, offset, limit, }) } _ => Err(anyhow!("We only support Query at the moment")), } } }
对应部分结构体的转换
/// 把 SqlParser 的 Expr 转换成 DataFrame 的 Expr impl TryFrom<Expression> for Expr { type Error = anyhow::Error; fn try_from(expr: Expression) -> Result<Self, Self::Error> { match *expr.0 { SqlExpr::BinaryOp { left, op, right } => Ok(Expr::BinaryExpr { left: Box::new(Expression(left).try_into()?), op: Operation(op).try_into()?, right: Box::new(Expression(right).try_into()?), }), SqlExpr::Wildcard => Ok(Self::Wildcard), SqlExpr::IsNull(expr) => Ok(Self::IsNull(Box::new(Expression(expr).try_into()?))), SqlExpr::IsNotNull(expr) => Ok(Self::IsNotNull(Box::new(Expression(expr).try_into()?))), SqlExpr::Identifier(id) => Ok(Self::Column(Arc::new(id.value))), SqlExpr::Value(v) => Ok(Self::Literal(Value(v).try_into()?)), v => Err(anyhow!("expr {:#?} is not supported", v)), } } } /// 把 SqlParser 的 BinaryOperator 转换成 DataFrame 的 Operator impl TryFrom<Operation> for Operator { type Error = anyhow::Error; fn try_from(op: Operation) -> Result<Self, Self::Error> { match op.0 { SqlBinaryOperator::Plus => Ok(Self::Plus), SqlBinaryOperator::Minus => Ok(Self::Minus), SqlBinaryOperator::Multiply => Ok(Self::Multiply), SqlBinaryOperator::Divide => Ok(Self::Divide), SqlBinaryOperator::Modulo => Ok(Self::Modulus), SqlBinaryOperator::Gt => Ok(Self::Gt), SqlBinaryOperator::Lt => Ok(Self::Lt), SqlBinaryOperator::GtEq => Ok(Self::GtEq), SqlBinaryOperator::LtEq => Ok(Self::LtEq), SqlBinaryOperator::Eq => Ok(Self::Eq), SqlBinaryOperator::NotEq => Ok(Self::NotEq), SqlBinaryOperator::And => Ok(Self::And), SqlBinaryOperator::Or => Ok(Self::Or), v => Err(anyhow!("Operator {} is not supported", v)), } } } /// 把 SqlParser 的 SelectItem 转换成 DataFrame 的 Expr impl<'a> TryFrom<Projection<'a>> for Expr { type Error = anyhow::Error; fn try_from(p: Projection<'a>) -> Result<Self, Self::Error> { match p.0 { SelectItem::UnnamedExpr(SqlExpr::Identifier(id)) => Ok(col(&id.to_string())), SelectItem::ExprWithAlias { expr: SqlExpr::Identifier(id), alias, } => Ok(Expr::Alias( Box::new(Expr::Column(Arc::new(id.to_string()))), Arc::new(alias.to_string()), )), SelectItem::QualifiedWildcard(v) => Ok(col(&v.to_string())), SelectItem::Wildcard => Ok(col("*")), item => Err(anyhow!("projection {} not supported", item)), } } } impl<'a> TryFrom<Source<'a>> for &'a str { type Error = anyhow::Error; fn try_from(source: Source<'a>) -> Result<Self, Self::Error> { if source.0.len() != 1 { return Err(anyhow!("We only support single data source at the moment")); } let table = &source.0[0]; if !table.joins.is_empty() { return Err(anyhow!("We do not support joint data source at the moment")); } match &table.relation { TableFactor::Table { name, .. } => Ok(&name.0.first().unwrap().value), _ => Err(anyhow!("We only support table")), } } } /// 把 SqlParser 的 order by expr 转换成 (列名, 排序方法) impl<'a> TryFrom<Order<'a>> for (String, bool) { type Error = anyhow::Error; fn try_from(o: Order) -> Result<Self, Self::Error> { let name = match &o.0.expr { SqlExpr::Identifier(id) => id.to_string(), expr => { return Err(anyhow!( "We only support identifier for order by, got {}", expr )) } }; Ok((name, !o.0.asc.unwrap_or(true))) } } /// 把 SqlParser 的 offset expr 转换成 i64 impl<'a> From<Offset<'a>> for i64 { fn from(offset: Offset) -> Self { match offset.0 { SqlOffset { value: SqlExpr::Value(SqlValue::Number(v, _b)), .. } => v.parse().unwrap_or(0), _ => 0, } } } /// 把 SqlParser 的 Limit expr 转换成 usize impl<'a> From<Limit<'a>> for usize { fn from(l: Limit<'a>) -> Self { match l.0 { SqlExpr::Value(SqlValue::Number(v, _b)) => v.parse().unwrap_or(usize::MAX), _ => usize::MAX, } } } /// 把 SqlParser 的 value 转换成 DataFrame 支持的 LiteralValue impl TryFrom<Value> for LiteralValue { type Error = anyhow::Error; fn try_from(v: Value) -> Result<Self, Self::Error> { match v.0 { SqlValue::Number(v, _) => Ok(LiteralValue::Float64(v.parse().unwrap())), SqlValue::Boolean(v) => Ok(LiteralValue::Boolean(v)), SqlValue::Null => Ok(LiteralValue::Null), v => Err(anyhow!("Value {} is not supported", v)), } } }
单元测试
#[cfg(test)] mod tests { use super::*; use crate::TyrDialect; use sqlparser::parser::Parser; #[test] fn parse_sql_works() { let url = "http://abc.xyz/abc?a=1&b=2"; let sql = format!( "select a, b, c from {} where a=1 order by c desc limit 5 offset 10", url ); let statement = &Parser::parse_sql(&TyrDialect::default(), sql.as_ref()).unwrap()[0]; let sql: Sql = statement.try_into().unwrap(); assert_eq!(sql.source, url); assert_eq!(sql.limit, Some(5)); assert_eq!(sql.offset, Some(10)); assert_eq!(sql.order_by, vec![("c".into(), true)]); assert_eq!(sql.selection, vec![col("a"), col("b"), col("c")]); } }
src/dialect.rs
给方言结构体实现trait
// 创建自己的 sql 方言。TyrDialect 支持 identifier 可以是简单的 url impl Dialect for TyrDialect { fn is_identifier_start(&self, ch: char) -> bool { ('a'..='z').contains(&ch) || ('A'..='Z').contains(&ch) || ch == '_' } // identifier 可以有 ':', '/', '?', '&', '=' fn is_identifier_part(&self, ch: char) -> bool { ('a'..='z').contains(&ch) || ('A'..='Z').contains(&ch) || ('0'..='9').contains(&ch) || [':', '/', '?', '&', '=', '-', '_', '.'].contains(&ch) } }
添加测试用函数
/// 测试辅助函数 pub fn example_sql() -> String { let url = "https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/latest/owid-covid-latest.csv"; let sql = format!( "SELECT location name, total_cases, new_cases, total_deaths, new_deaths \ FROM {} where new_deaths >= 500 ORDER BY new_cases DESC LIMIT 6 OFFSET 5", url ); sql }
单元测试
#[cfg(test)] mod tests { use super::*; use sqlparser::parser::Parser; #[test] fn it_works() { assert!(Parser::parse_sql(&TyrDialect::default(), &example_sql()).is_ok()); } }
src/loader.rs
定义Loader与CsvLoader
#[derive(Debug)] #[non_exhaustive] pub enum Loader { Csv(CsvLoader), } #[derive(Default, Debug)] pub struct CsvLoader(pub(crate) String);
定义trait并给CsvLoader实现
let sql = format!( "SELECT location name, total_cases, new_cases, total_deaths, new_deaths \ FROM {} where new_deaths >= 500 ORDER BY new_cases DESC LIMIT 6 OFFSET 5", url ); sql } #[cfg(test)] mod tests { use super::*; use sqlparser::parser::Parser;
todo: 给CsvLoader添加内容检测
fn it_works() { assert!(Parser::parse_sql(&TyrDialect::default(), &example_sql()).is_ok()); } }
src/fetcher.rs
定义UrlFetcher与FileFetcher
struct UrlFetcher<'a>(pub(crate) &'a str); struct FileFetcher<'a>(pub(crate) &'a str);
定义trait并给Fetcher与FileFetcher实现
// Rust 的 async trait 还没有稳定,可以用 async_trait 宏 #[async_trait] pub trait Fetch { type Error; async fn fetch(&self) -> Result<String, Self::Error>; } #[async_trait] impl<'a> Fetch for UrlFetcher<'a> { type Error = anyhow::Error; async fn fetch(&self) -> Result<String, Self::Error> { Ok(reqwest::get(self.0).await?.text().await?) } } #[async_trait] impl<'a> Fetch for FileFetcher<'a> { type Error = anyhow::Error; async fn fetch(&self) -> Result<String, Self::Error> { Ok(fs::read_to_string(&self.0[7..]).await?) } }
最后定义一个获取数据的方法
/// 从文件源或者 http 源中获取数据,返回字符串 pub async fn retrieve_data(source: impl AsRef<str>) -> Result<String> { let name = source.as_ref(); match &name[..4] { // 包括 http / https "http" => UrlFetcher(name).fetch().await, // 处理 file://<filename> "file" => FileFetcher(name).fetch().await, _ => Err(anyhow!("We only support http/https/file at the moment")), } }
queryer-js package: 使用neon
Cargo.toml
[package]
name = "queryer-js"
version = "0.1.0"
license = "ISC"
edition = "2021"
exclude = ["index.node"]
[lib]
crate-type = ["cdylib"]
[dependencies]
anyhow = "1"
queryer = { path = "../queryer" }
tokio = { version = "1", features = ["full"] }
[dependencies.neon]
version = "0.9"
default-features = false
features = ["napi-6"]
build in package.json
{
"name": "queryer-js",
"version": "0.1.0",
"description": "",
"main": "index.node",
"scripts": {
"build": "cargo-cp-artifact -nc index.node -- cargo build --message-format=json-render-diagnostics",
"build-debug": "npm run build --",
"build-release": "npm run build -- --release",
"install": "npm run build-release",
"test": "cargo test"
},
"author": "",
"license": "ISC",
"devDependencies": {
"cargo-cp-artifact": "^0.1"
}
}
src/lib.rs
use neon::prelude::*; pub fn example_sql(mut cx: FunctionContext) -> JsResult<JsString> { Ok(cx.string(queryer::example_sql())) } fn query(mut cx: FunctionContext) -> JsResult<JsString> { let sql = cx.argument::<JsString>(0)?.value(&mut cx); let output = match cx.argument::<JsString>(1) { Ok(v) => v.value(&mut cx), Err(_) => "csv".to_string(), }; let rt = tokio::runtime::Runtime::new().unwrap(); let data = rt.block_on(async { queryer::query(sql).await.unwrap() }); match output.as_str() { "csv" => Ok(cx.string(data.to_csv().unwrap())), v => cx.throw_type_error(format!("Output type {} not supported", v)), } } #[neon::main] fn main(mut cx: ModuleContext) -> NeonResult<()> { cx.export_function("example_sql", example_sql)?; cx.export_function("query", query)?; Ok(()) }
queryer-py package: 使用pyo3
python调用查询包
Cargo.toml
[package]
name = "queryer_py" # Python 模块需要用下划线
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib"] # 使用 cdylib 类型
[dependencies]
queryer = { path = "../queryer" } # 引入 queryer
tokio = { version = "1", features = ["full"] }
[dependencies.pyo3]
version = "0.14"
features = ["extension-module"]
[build-dependencies]
pyo3-build-config = "0.14"
src/lib.rs
#![allow(clippy::needless_option_as_deref)] use pyo3::{exceptions, prelude::*}; #[pyfunction] pub fn example_sql() -> PyResult<String> { Ok(queryer::example_sql()) } #[pyfunction] pub fn query(sql: &str, output: Option<&str>) -> PyResult<String> { let rt = tokio::runtime::Runtime::new().unwrap(); let data = rt.block_on(async { queryer::query(sql).await.unwrap() }); match output { Some("csv") | None => Ok(data.to_csv().unwrap()), Some(v) => Err(exceptions::PyTypeError::new_err(format!( "Output type {} not supported", v ))), } } #[pymodule] fn queryer_py(_py: Python, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(query, m)?)?; m.add_function(wrap_pyfunction!(example_sql, m)?)?; Ok(()) }
data-viewer package: 使用tauri
Cargo.toml
[package] name = "app" version = "0.1.0" description = "A Tauri App" authors = ["you"] license = "" repository = "" default-run = "app" edition = "2021" build = "src/build.rs" See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html [build-dependencies] tauri-build = { version = "1.0.0-beta.4" } [dependencies] anyhow = "1" serde_json = "1" queryer = { path = "../../queryer" } serde = { version = "1.0", features = ["derive"] } tauri = { version = "1.0.0-beta.8", features = ["api-all"] } [features] default = [ "custom-protocol" ] custom-protocol = [ "tauri/custom-protocol" ]
main.rs
#![cfg_attr( all(not(debug_assertions), target_os = "windows"), windows_subsystem = "windows" )] #[tauri::command] fn example_sql() -> String { queryer::example_sql() } #[tauri::command] async fn query(sql: String) -> Result<String, String> { let data = queryer::query(&sql).await.map_err(|err| err.to_string())?; Ok(data.to_csv().map_err(|err| err.to_string())?) } fn main() { tauri::Builder::default() .invoke_handler(tauri::generate_handler![example_sql, query]) .run(tauri::generate_context!()) .expect("error while running tauri application"); }
Rust核心深入
资料推荐
I. 从栈堆、所有权、生命周期开始内存管理
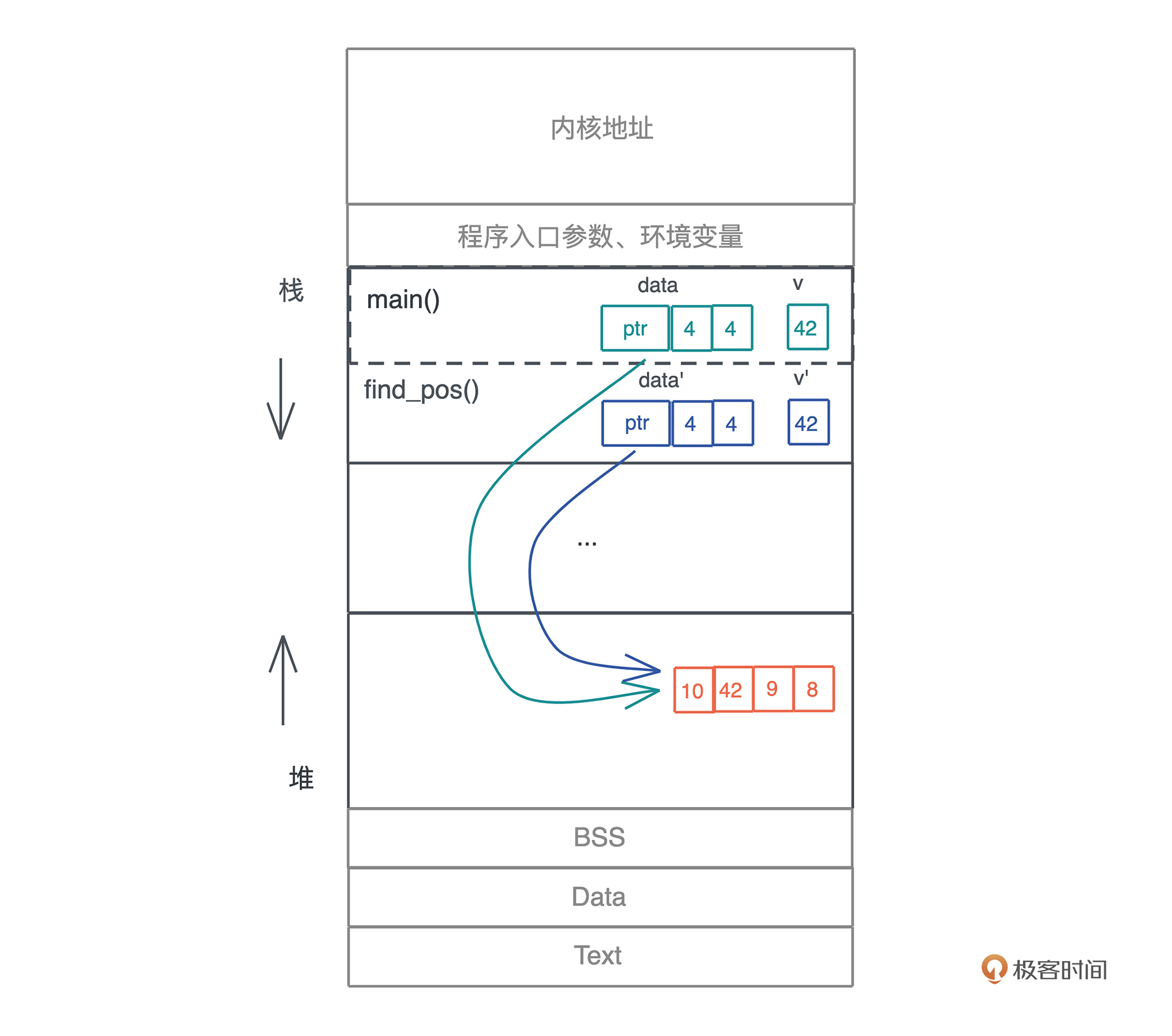
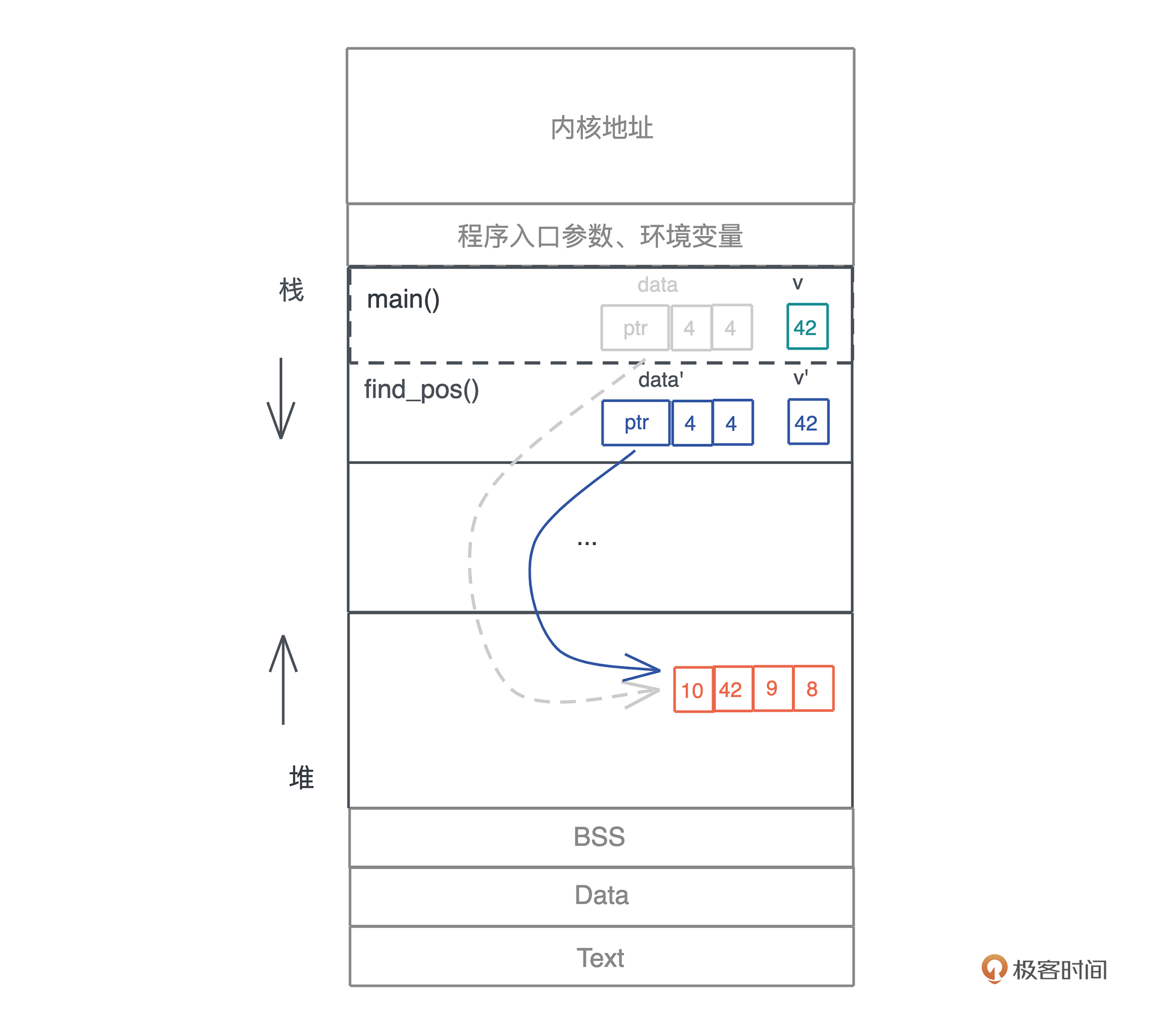
内存
graph made by cursor
graph TD
A[内存] --> B[栈]
A --> C[堆]
B --> D[栈溢出]
C --> E[堆溢出]
C --> F[使用堆引用共享数据]
B --> G[栈帧示意图]
C --> H[字符串内存使用图]
`
Summarize made by cursor
本文主要介绍了 Rust 中的内存管理:
- 包括栈和堆的概念、栈溢出和堆溢出的问题以及如何使用堆引用共享数据。
- 文章通过图片和代码示例详细讲解了这些概念和问题
- 对于 Rust 初学者来说是一篇很好的入门文章。
Answers made by cursor
-
Rust中的内存管理包括哪些概念和问题? 本文介绍了 Rust 中的内存管理,包括栈和堆的概念、栈溢出和堆溢出的问题以及如何使用堆引用共享数据。
-
什么是栈和堆?它们有什么区别? 栈和堆都是内存中的一部分,栈是一种后进先出的数据结构,用于存储函数调用时的局部变量和函数调用的返回地址等信息,而堆是一种动态分配内存的机制,用于存储程序运行时动态分配的数据。栈和堆的主要区别在于它们的分配方式和管理方式不同。
-
如何使用堆引用共享数据? 可以使用指针或引用来引用堆中的数据,从而实现数据的共享。在 Rust 中,可以使用 Box
类型来创建堆上的数据,并使用 & 操作符来创建指向堆上数据的引用。 -
如何考虑栈溢出和堆溢出的问题? 栈溢出和堆溢出都是内存管理中的常见问题。栈溢出通常是由于递归调用或者函数调用层数过多导致的,可以通过增加栈的大小或者优化代码来解决。堆溢出通常是由于动态分配内存时没有正确释放导致的,可以通过手动释放内存或者使用 Rust 的内存管理机制来解决。
字符串内存使用图
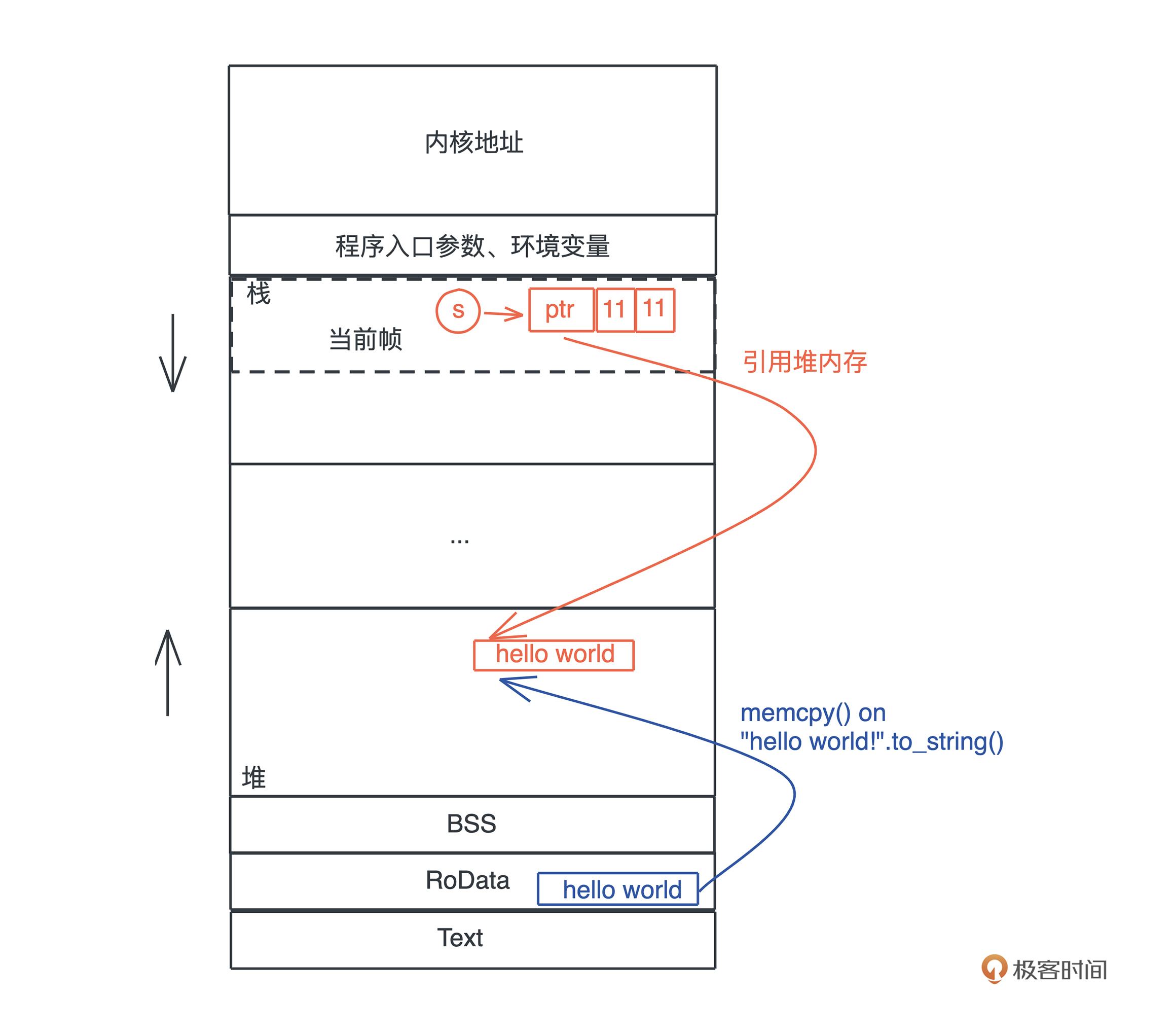
栈
栈帧示意图
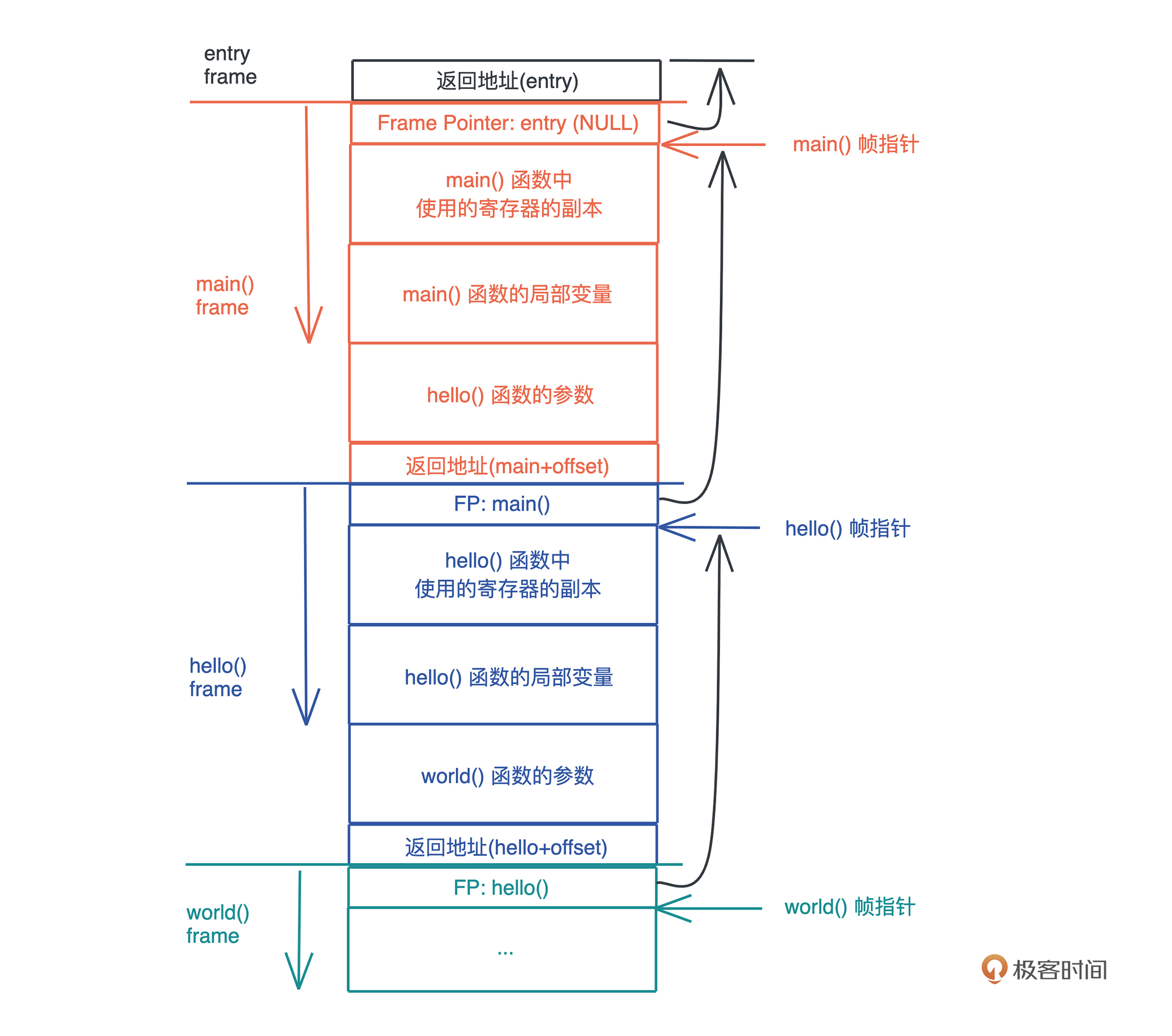
考虑栈溢出
堆
使用堆引用共享数据
考虑堆溢出
编程四大类基本概念
1. 数据
值和类型
指针和引用
2. 代码
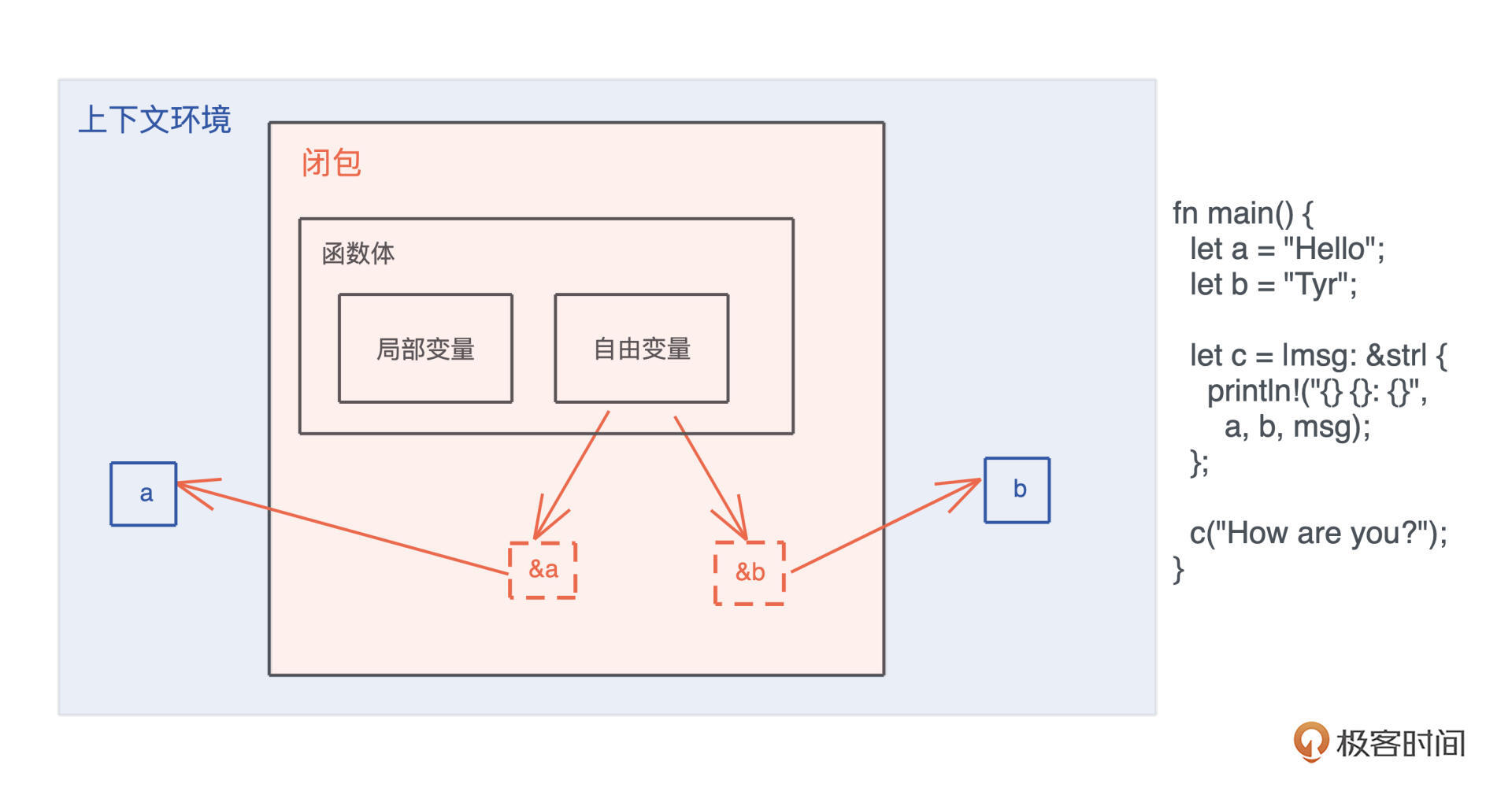
函数 -> 方法 -> 闭包
闭包示意图
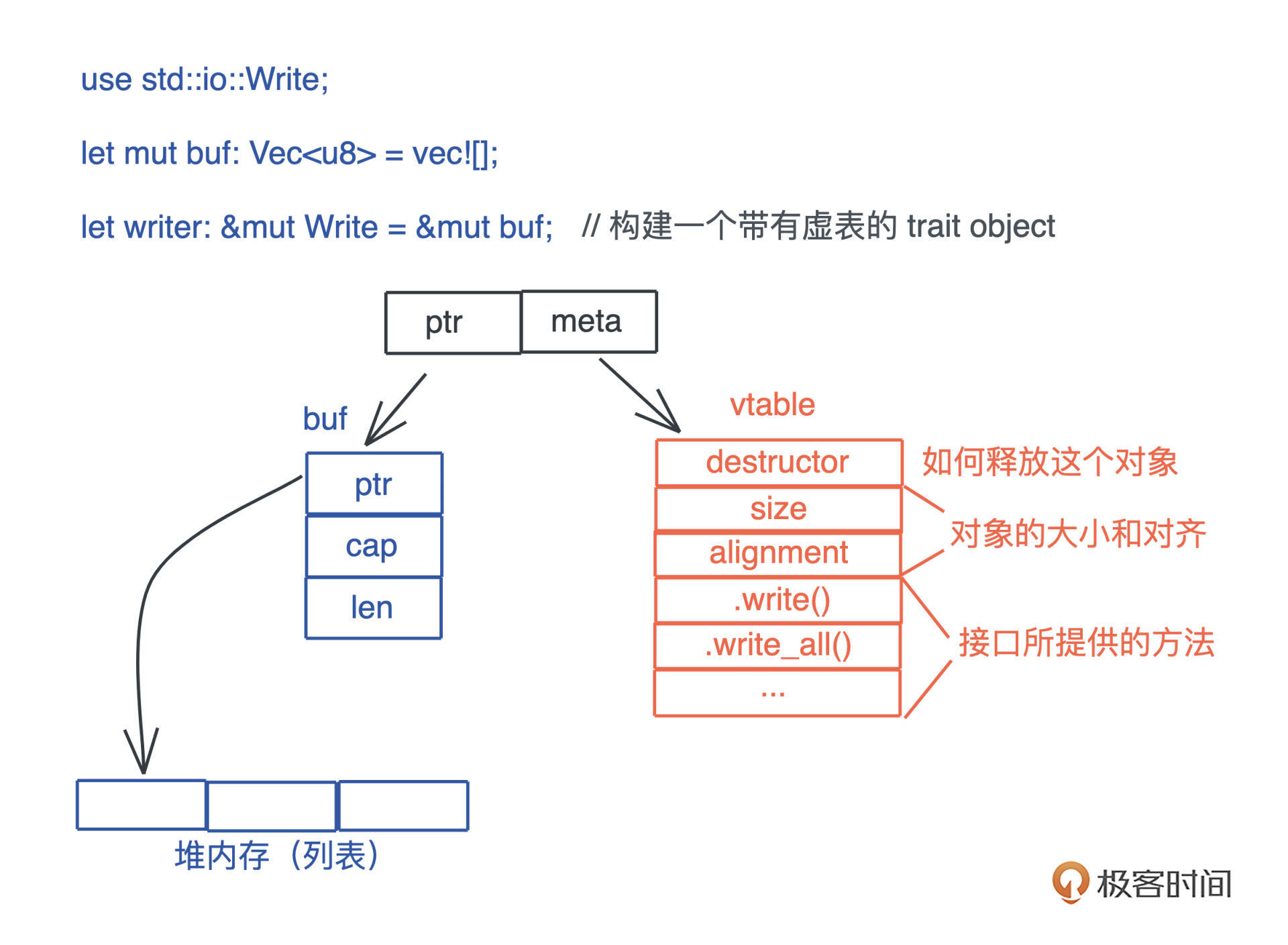
接口与虚表
3. 运行方式
并发与并行
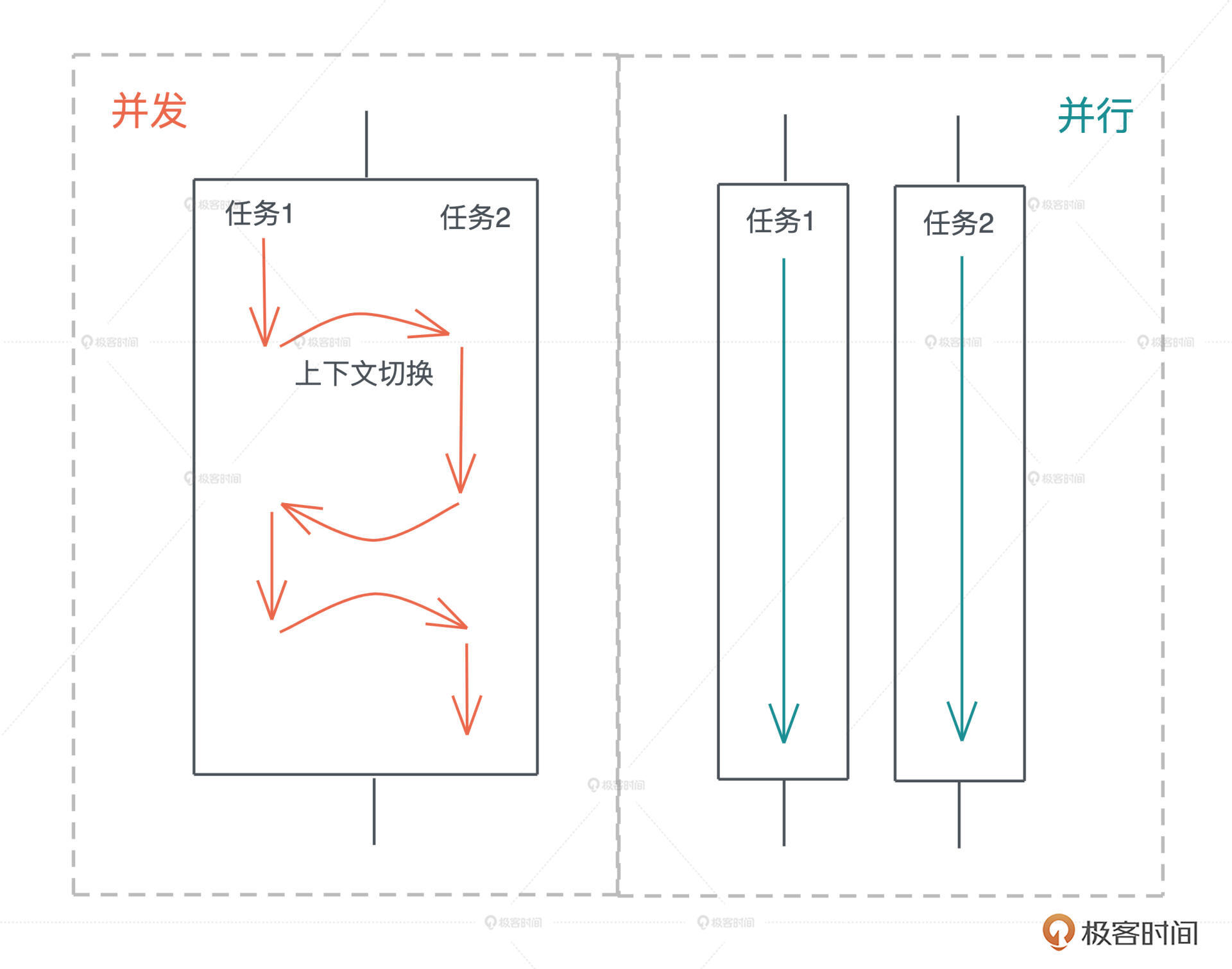
同步和异步
4. 编程范式
泛型编程
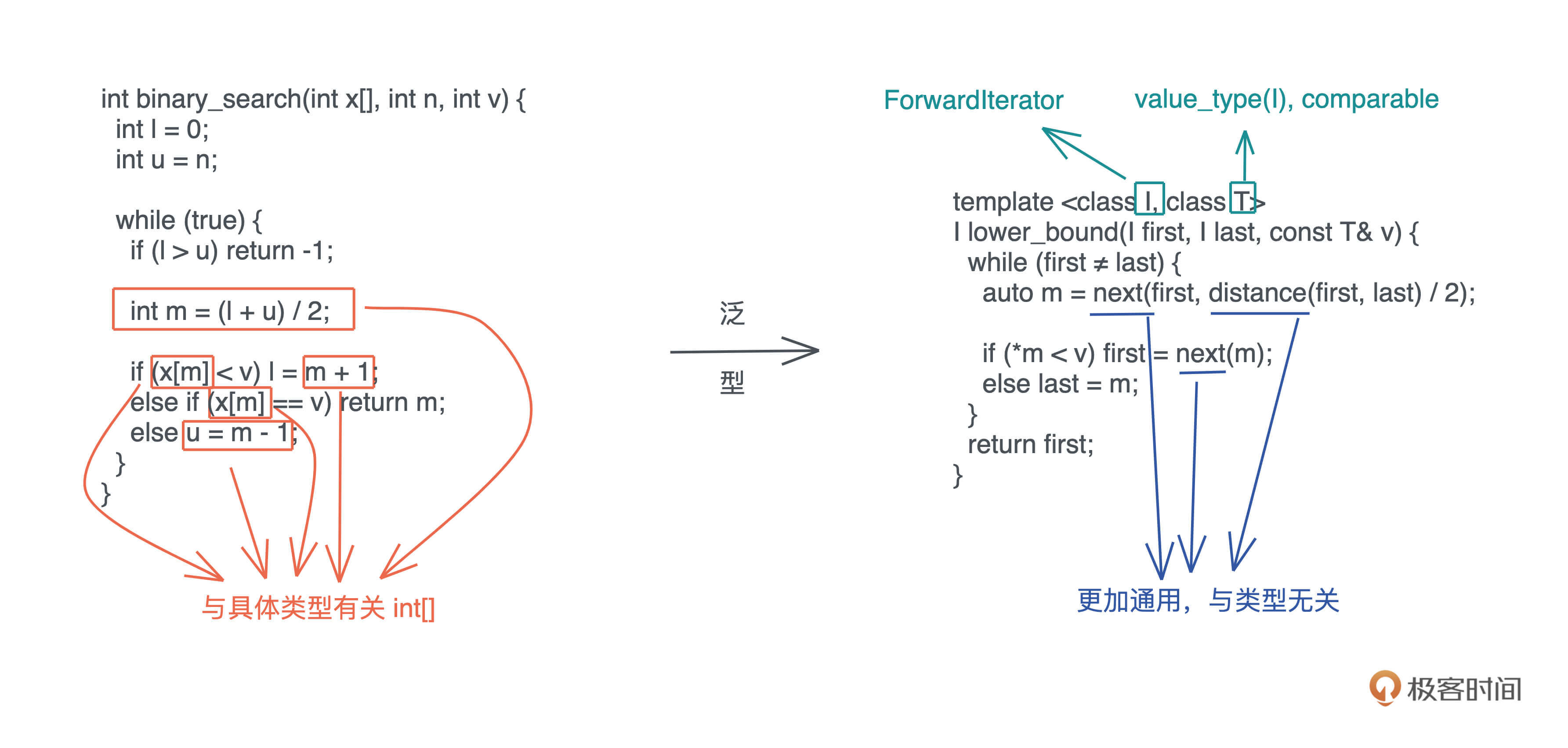
函数式编程
面向对象编程
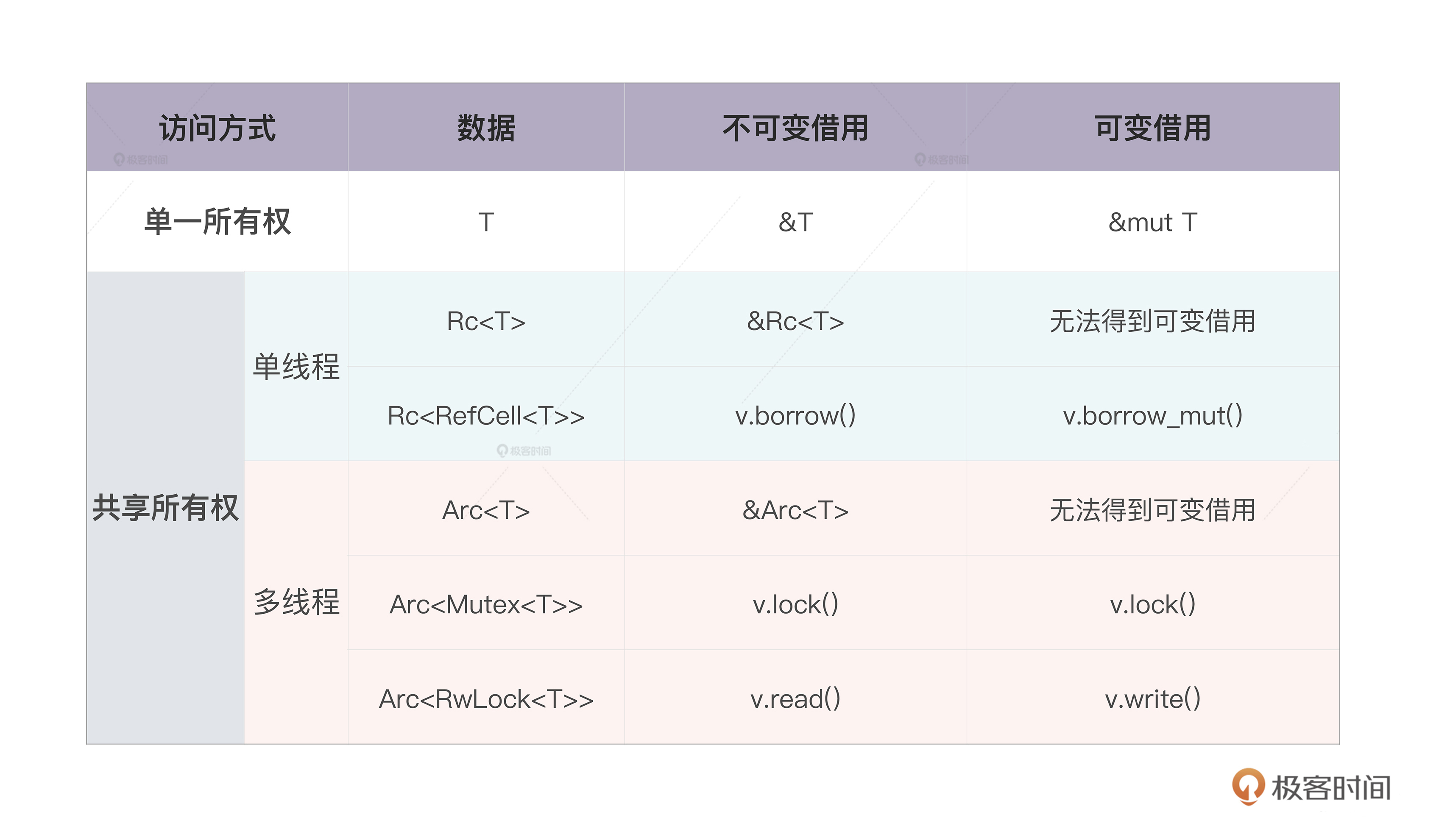
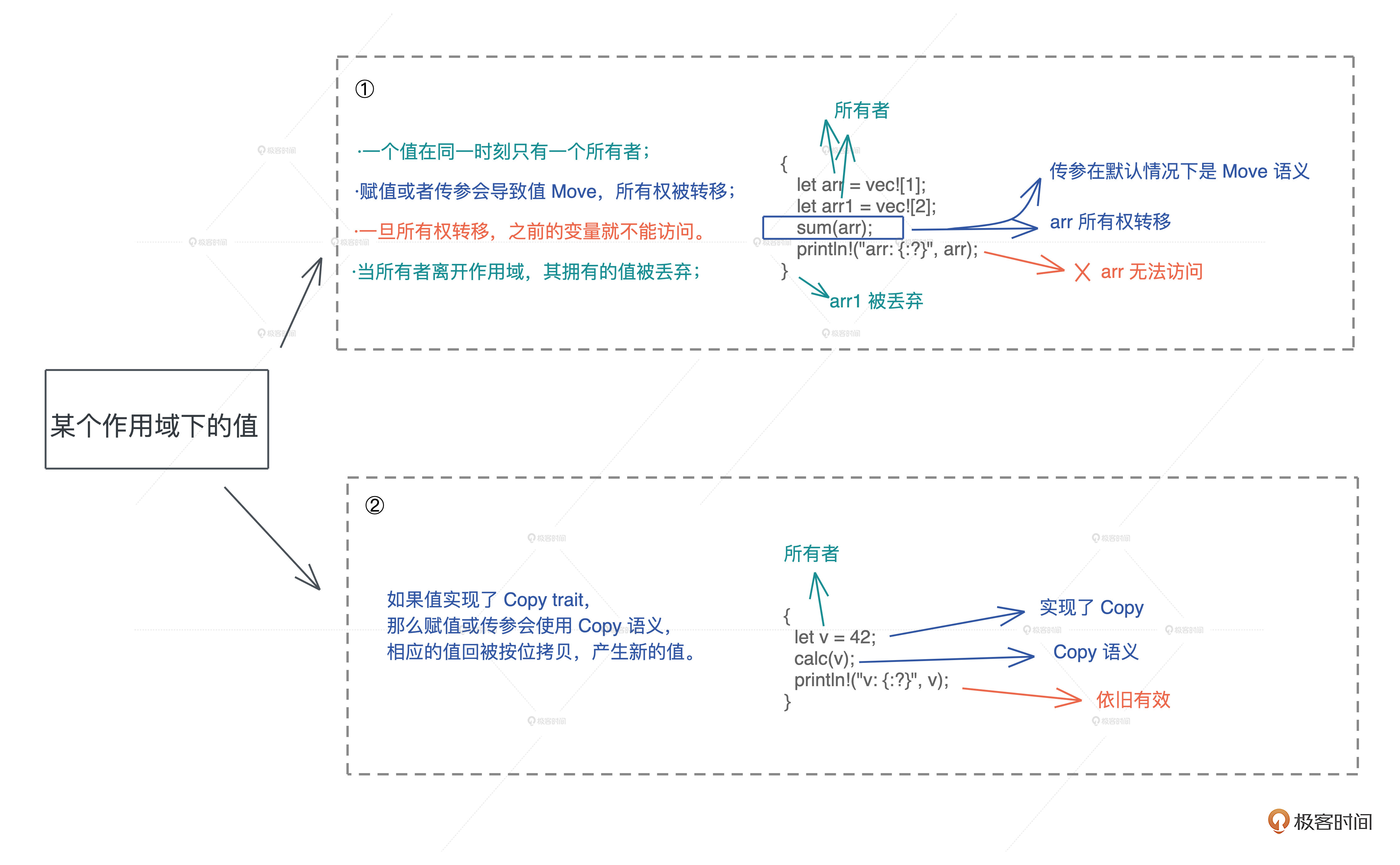
一、所有权: 单一/共享
对比单一/共享所有权
单一所有权:掌控生杀大权
从多引用开始
Rust如何解决
方案一、单一所有权
方案二、Copy
单一所有权规则整理
单一所有权借用
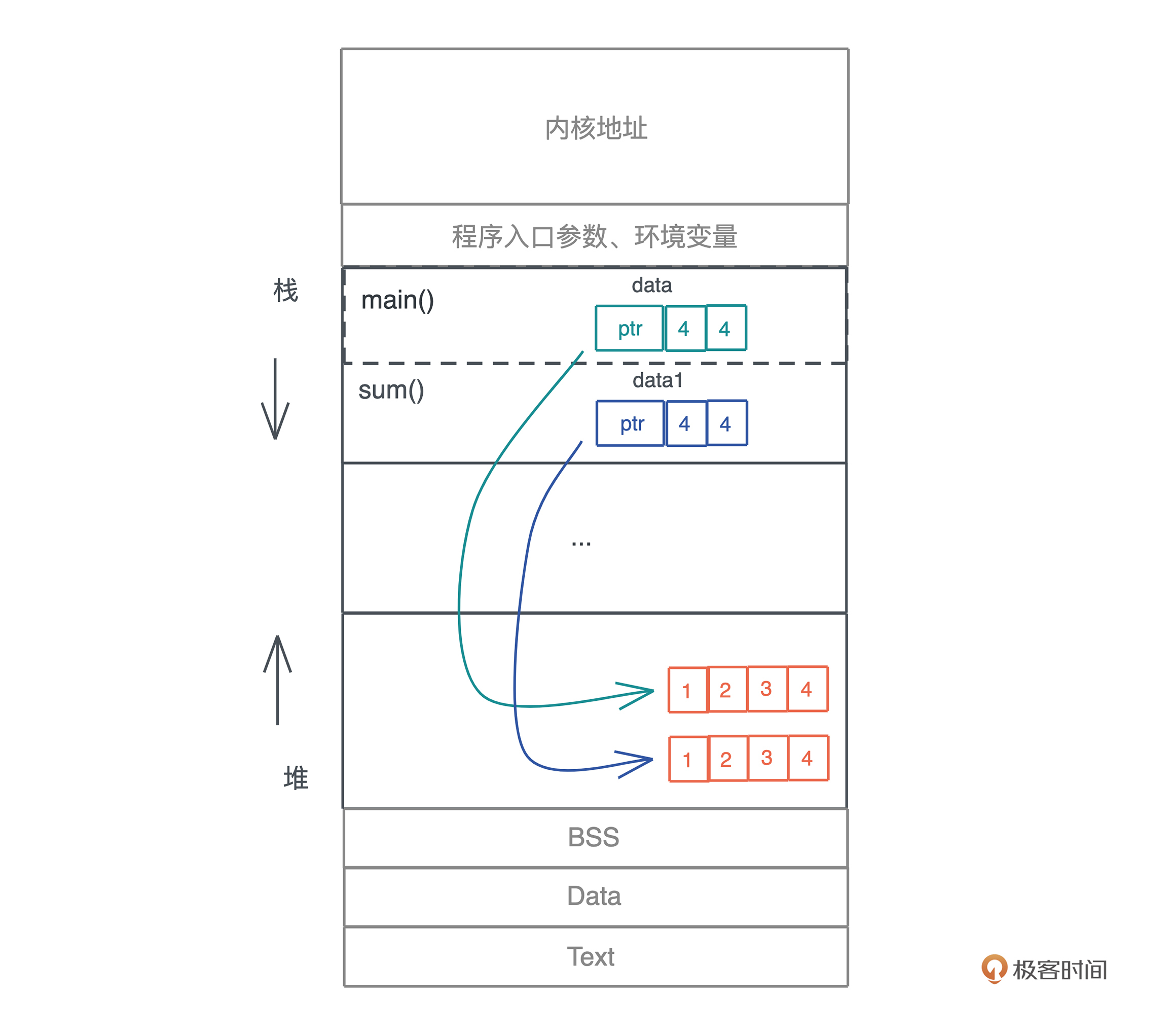
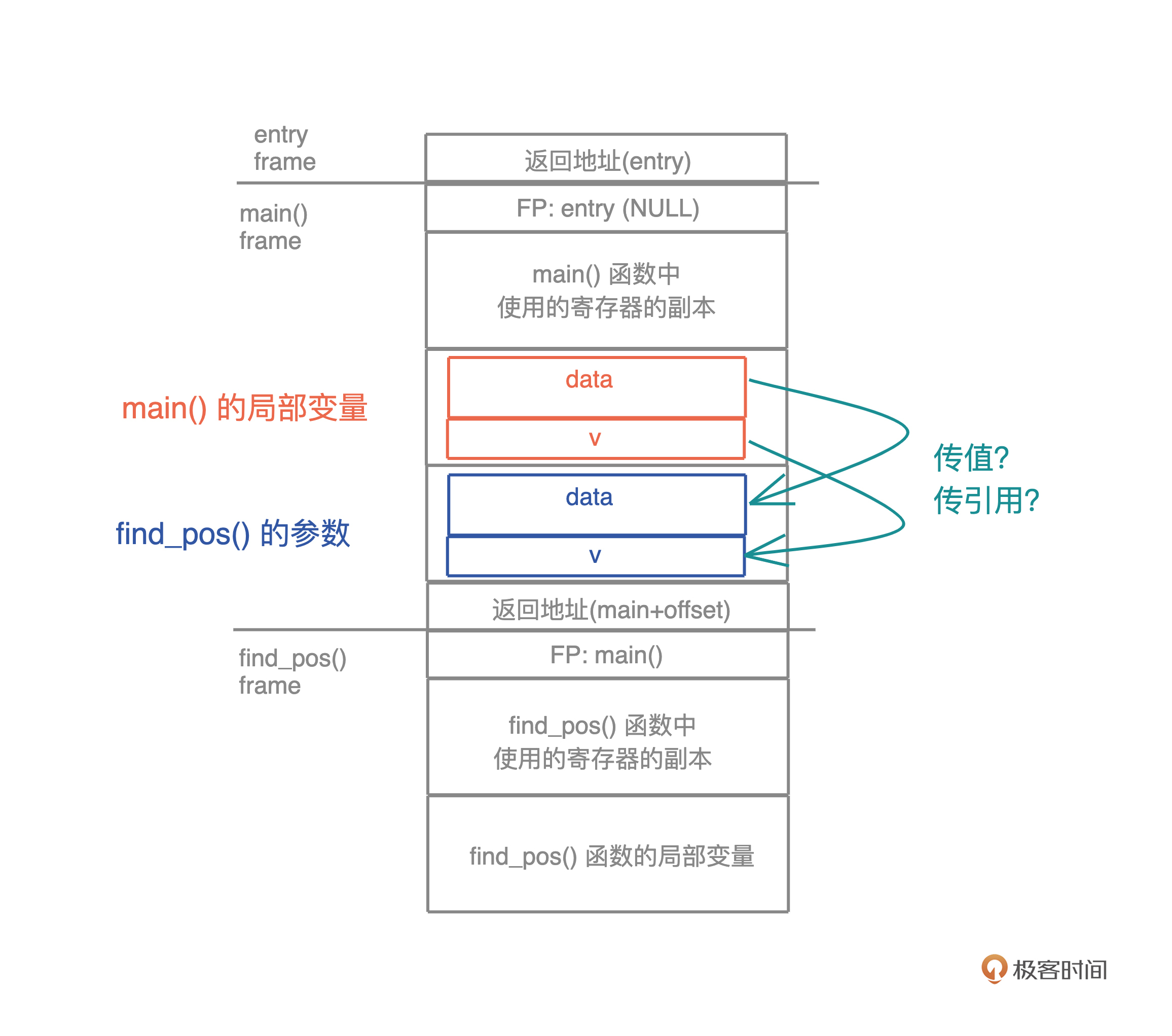
两种传参方式:传值/传址
只读借用/引用
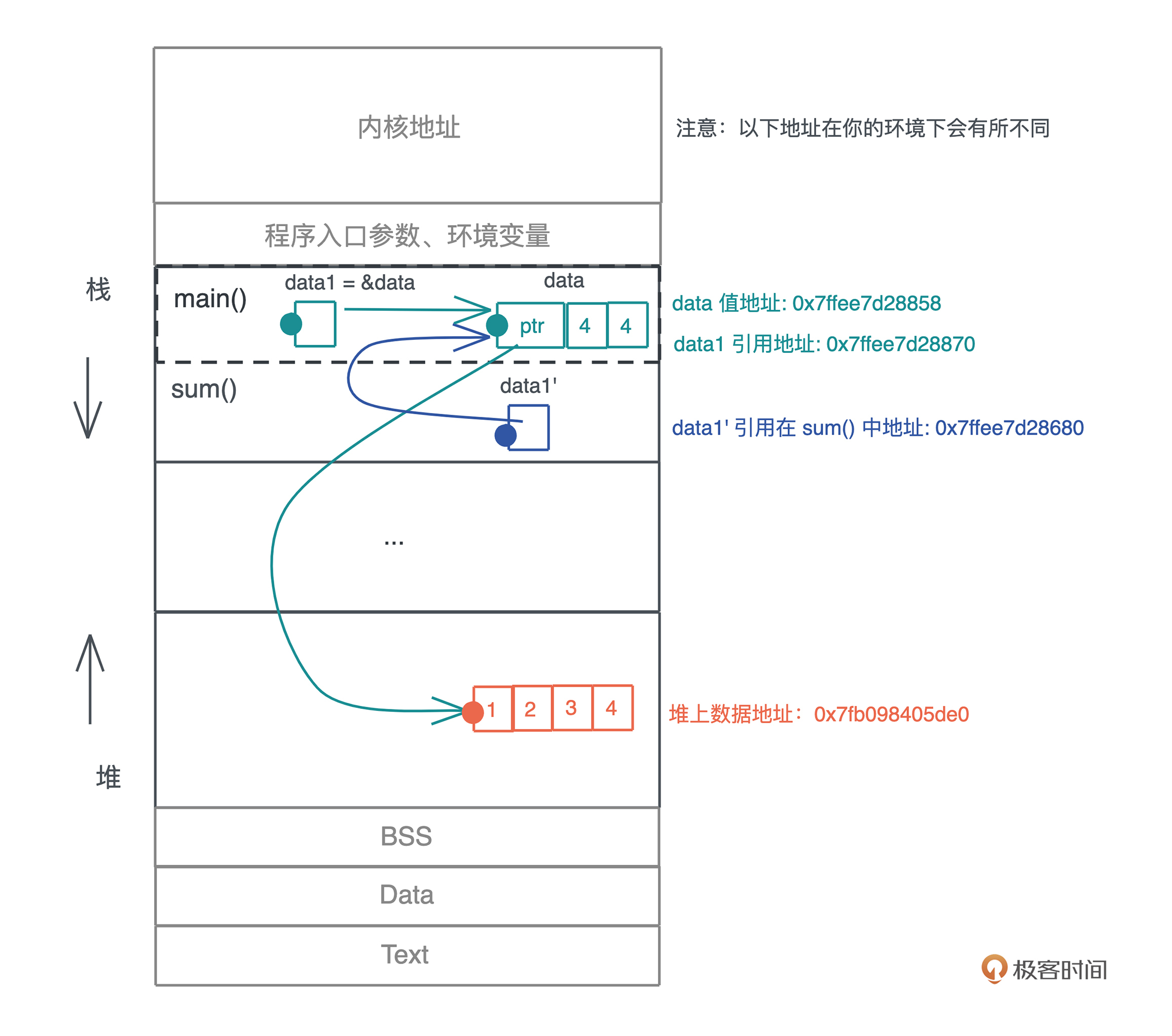
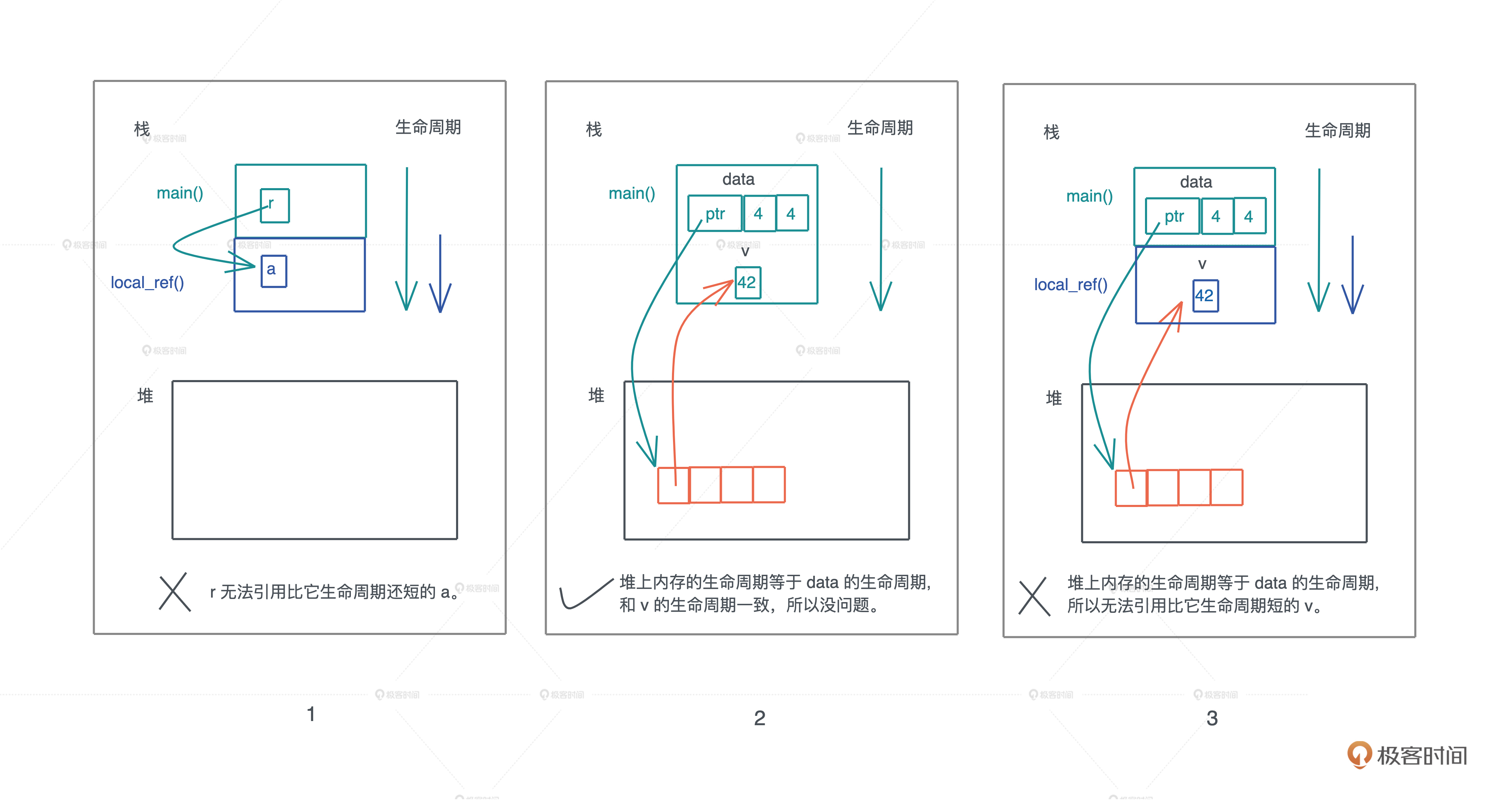
借用的生命周期与约束
可变借用/引用
同一个上下文中多个可变引用是不安全的,那如果同时有一个可变引用和若干个只读引 用就可以
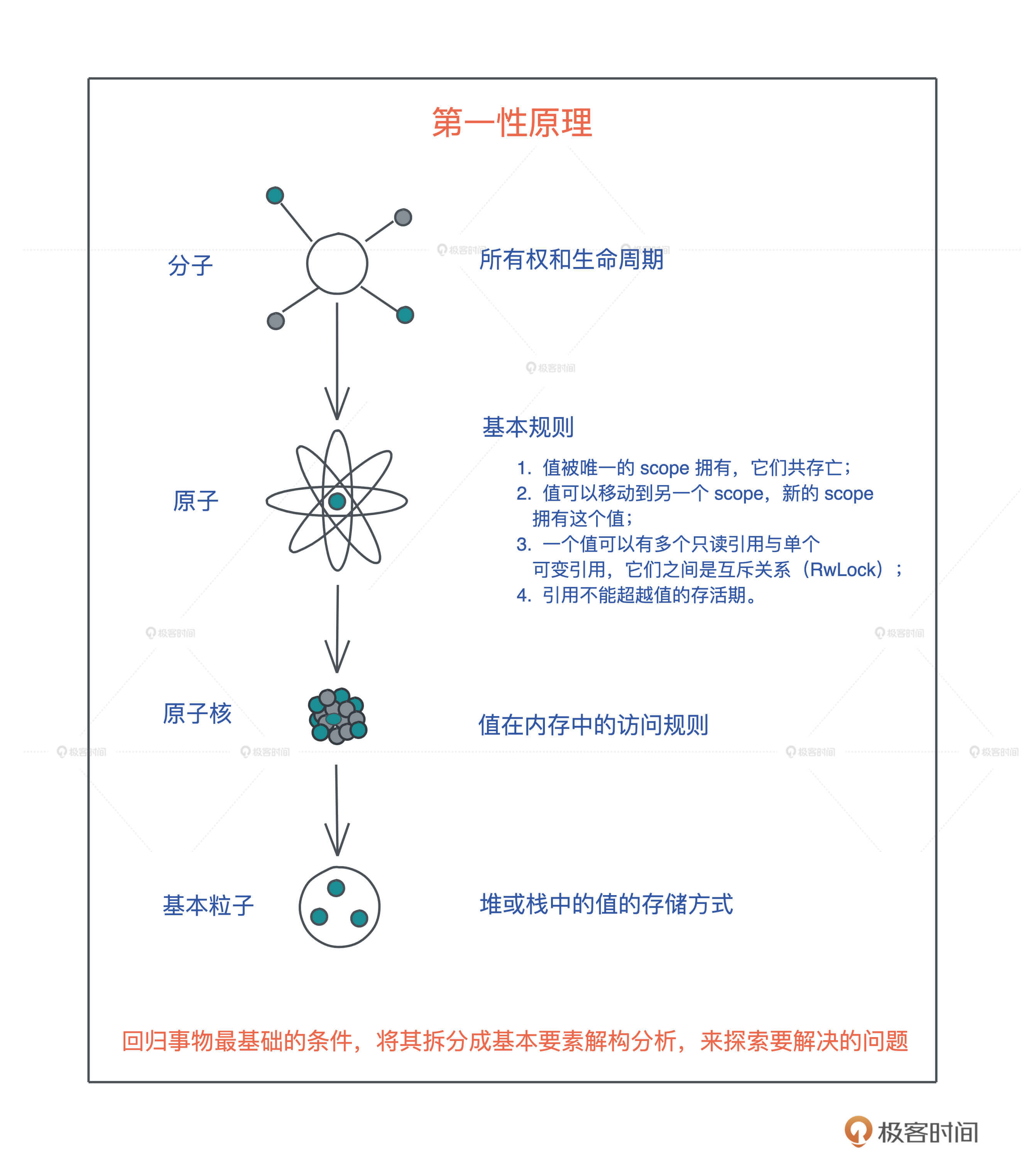
第一性原理理解单一所有权规则
共享内存-多个所有者:引用计数
单一所有权与多个所有者是否有冲突?
- 静态检查:单一所有权是rust的编译期默认检查内容
- 动态检查:多个所有者主要是用于共享内存,这是专门提供Rc/Arc、Box::leak()、RefCell/Mutex/RwLock等工具。
这里其实可以看出rust如何使用’二八法则’解决问题:
- 对于常用场景,用编译期静态检查来默认解决
- 对于特别场景,用专门的语法显式表达出来,提供运行期动态检查来专门解决
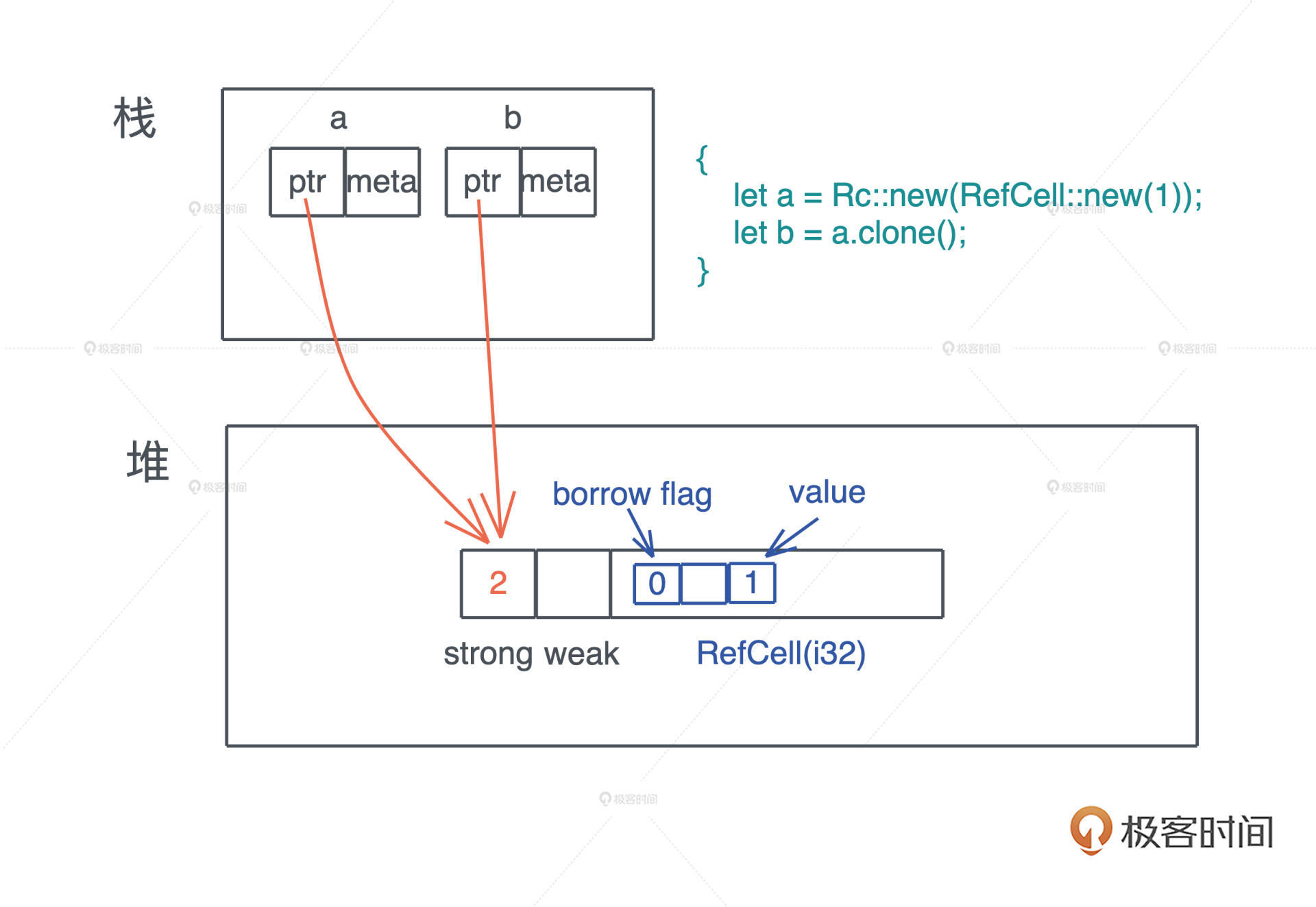
Rc使用说明: 只读引用计数
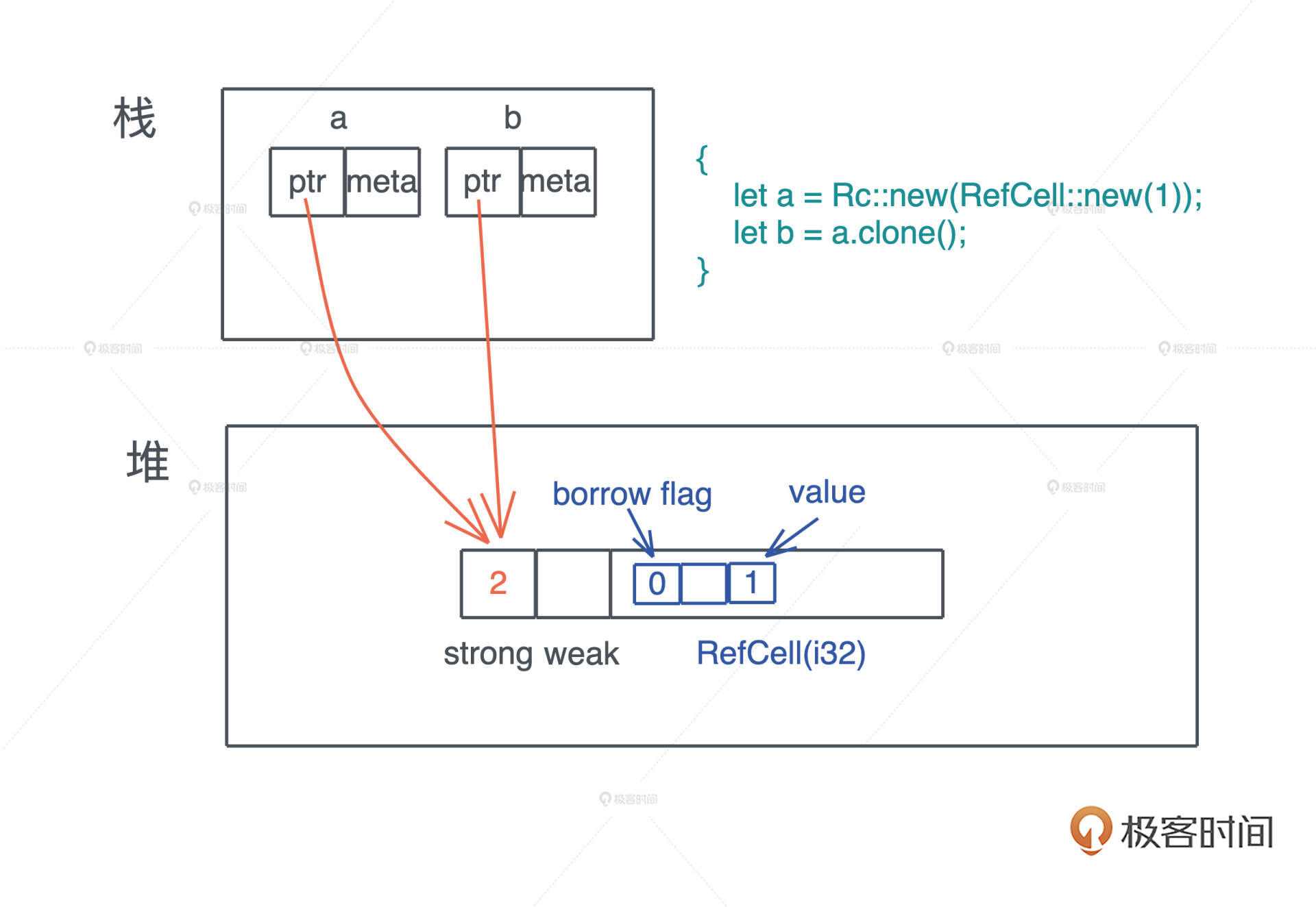
对一个 Rc 结构进行 clone(),不会将其内部的数据复制,只会增加引用计数
use std::rc::Rc; fn main() { let a = Rc::new(1); let b = a.clone(); let c = a.clone(); }
clone源码
fn clone(&self) -> Rc<T> { // 增加引用计数 self.inner().inc_strong(); // 通过 self.ptr 生成一个新的 Rc 结构 Self::from_inner(self.ptr) }
Rc使用Box::leak()
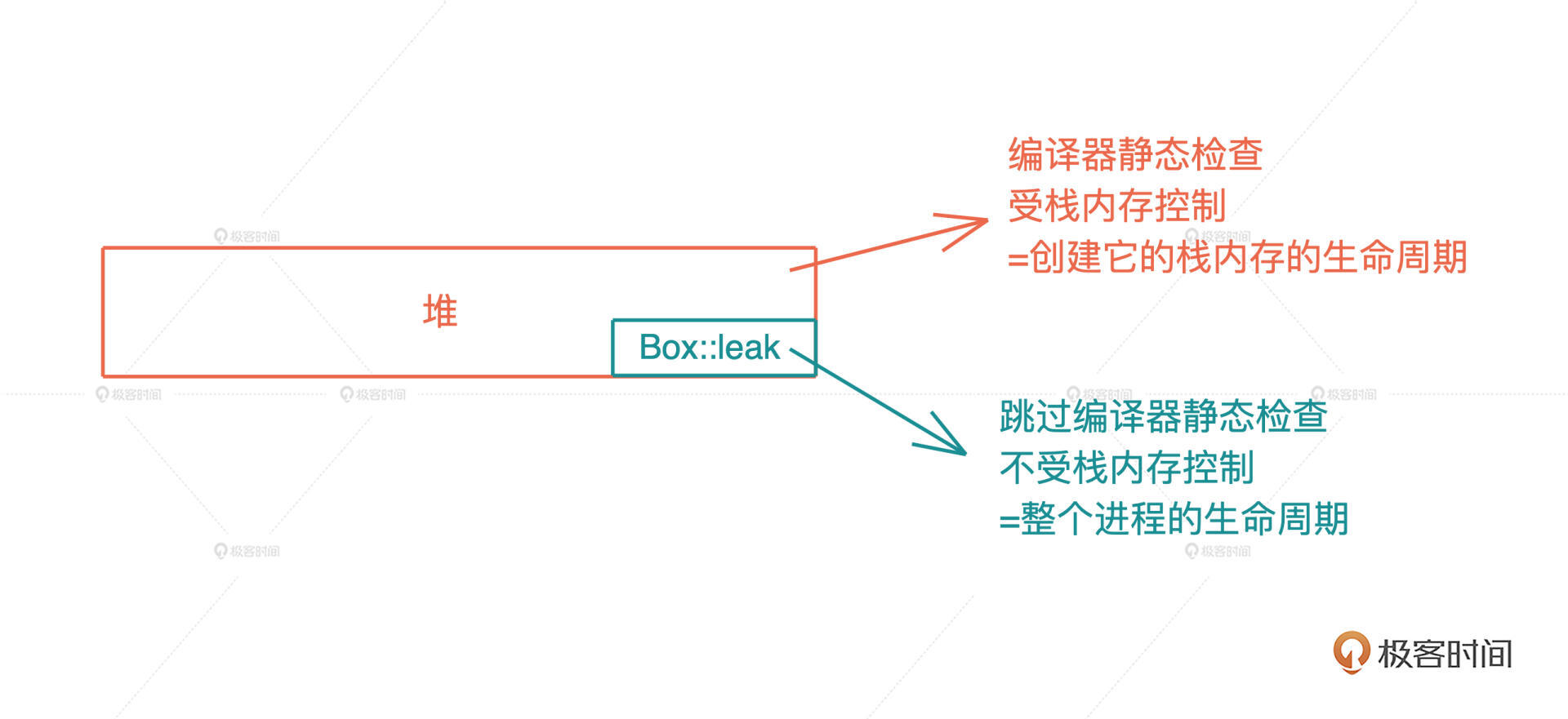
有了 Box::leak(),我们就可以跳出 Rust 编译器的静态检查
保证 Rc 指向的堆内存,有最大的生命周期,然后我们再通过引用计数,在合适的时机,结束这段内存的生命周期。如果你对此感兴趣,可以看 Rc::new() 的源码。
使用Rc实现DAG
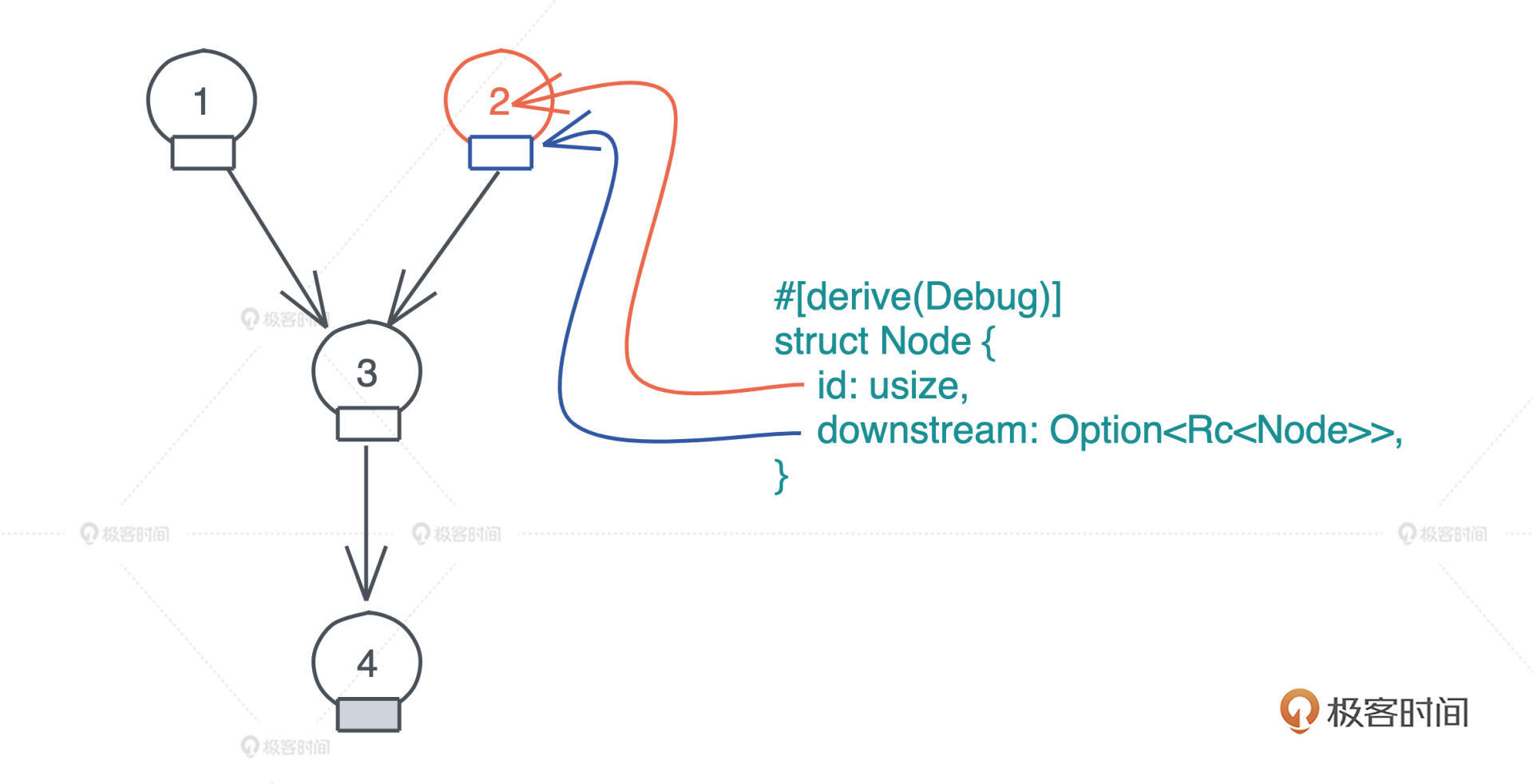
不可修改版本
use std::rc::Rc; #[allow(dead_code)] #[derive(Debug)] struct Node { id: usize, downstream: Option<Rc<Node>>, } impl Node { pub fn new(id: usize) -> Self { Self { id, downstream: None, } } pub fn update_downstream(&mut self, downstream: Rc<Node>) { self.downstream = Some(downstream); } pub fn get_downstream(&self) -> Option<Rc<Node>> { self.downstream.as_ref().cloned() } } fn main() { let mut node1 = Node::new(1); let mut node2 = Node::new(2); let mut node3 = Node::new(3); let node4 = Node::new(4); node3.update_downstream(Rc::new(node4)); node1.update_downstream(Rc::new(node3)); node2.update_downstream(node1.get_downstream().unwrap()); println!("node1: {:?}, node2: {:?}", node1, node2); // 无法编译通过: cannot borrow as mutable // let node5 = Node::new(5); // let node3 = node1.get_downstream().unwrap(); // node3.update_downstream(Rc::new(node5)); // println!("node1: {:?}, node2: {:?}", node1, node2); }
- new():建立一个新的 Node。
- update_downstream():设置 Node 的 downstream。
- get_downstream():clone 一份 Node 里的 downstream。
RefCell: 提供内部可变性,可变引用计数
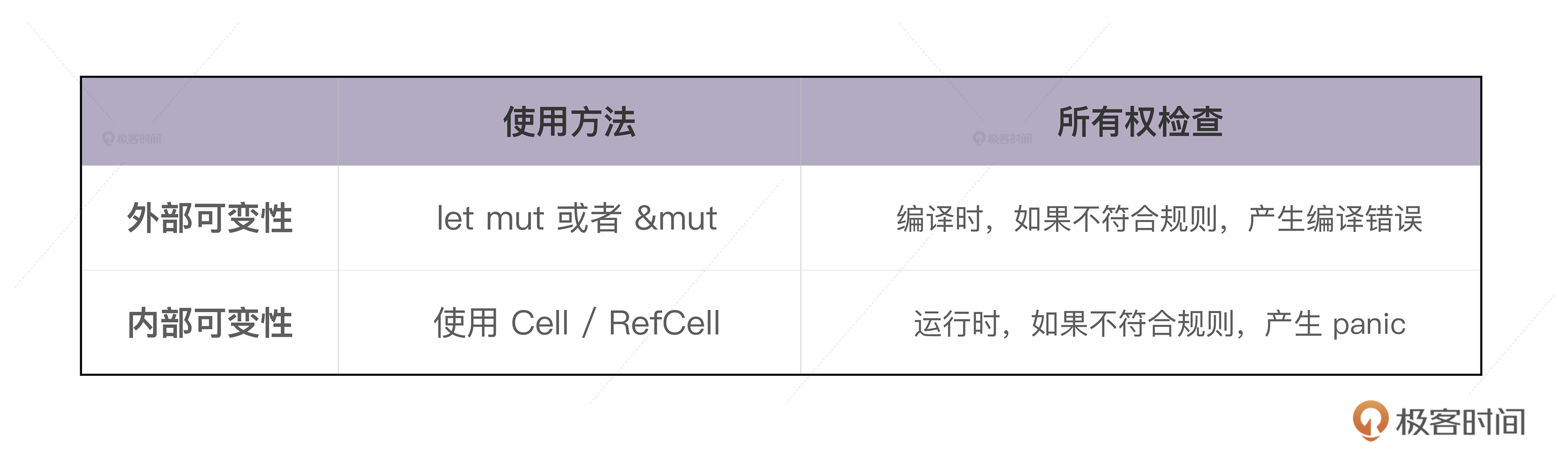
外部可变性与内部可变性
RefCell简单使用
获得 RefCell 内部数据的可变借用
use std::cell::RefCell; fn main() { let data = RefCell::new(1); { // 获得 RefCell 内部数据的可变借用 let mut v = data.borrow_mut(); *v += 1; } println!("data: {:?}", data.borrow()); }
使用RefCell实现可修改版本DAG
use std::cell::RefCell; use std::rc::Rc; #[allow(dead_code)] #[derive(Debug)] struct Node { id: usize, // 使用 Rc<RefCell<T>> 让节点可以被修改 downstream: Option<Rc<RefCell<Node>>>, } impl Node { pub fn new(id: usize) -> Self { Self { id, downstream: None, } } pub fn update_downstream(&mut self, downstream: Rc<RefCell<Node>>) { self.downstream = Some(downstream); } pub fn get_downstream(&self) -> Option<Rc<RefCell<Node>>> { self.downstream.as_ref().cloned() } } fn main() { let mut node1 = Node::new(1); let mut node2 = Node::new(2); let mut node3 = Node::new(3); let node4 = Node::new(4); node3.update_downstream(Rc::new(RefCell::new(node4))); node1.update_downstream(Rc::new(RefCell::new(node3))); node2.update_downstream(node1.get_downstream().unwrap()); println!("node1: {:?}, node2: {:?}", node1, node2); let node5 = Node::new(5); let node3 = node1.get_downstream().unwrap(); // 获得可变引用,来修改 downstream node3.borrow_mut().downstream = Some(Rc::new(RefCell::new(node5))); println!("node1: {:?}, node2: {:?}", node1, node2); }
- 首先数据结构的 downstream 需要 Rc 内部嵌套一个 RefCell
- 这样,就可以利用 RefCell 的内部可变性,来获得数据的可变借用
- 同时 Rc 还允许值有多个所有者。
线程安全版本计数器:Arc(Rc)、Mutex/RwLock(RefCell)
Rust实现两套不同的引用计数数据结构
Arc 内部的引用计数使用了 Atomic Usize ,而非普通的 usize。 从名称上也可以感觉出来,Atomic Usize 是 usize 的原子类型,它使用了 CPU 的特殊指令,来保证多线程下的安全。 如果你对原子类型感兴趣,可以看 std::sync::atomic 的文档。
Rust 实现两套不同的引用计数数据结构,完全是为了性能考虑,从这里我们也可以感受到 Rust 对性能的极致渴求:
- 如果不用跨线程访问,可以用效率非常高的 Rc; 如果要跨线程访问,那么必须用 Arc。
- 同样的,RefCell 也不是线程安全的,如果我们要在多线程中,使用内部可变性,Rust 提供了 Mutex 和 RwLock。
Mutex/RwLock其实是并发的两个方案
这两个数据结构你应该都不陌生:
- Mutex 是互斥量,获得互斥量的线程对数据独占访问.
- RwLock 是读写锁,获得写锁的线程对数据独占访问,但当没有写锁的时候,允许有多个读锁。
- 读写锁的规则和 Rust 的借用规则非常类似,我们可以类比着学。
- Mutex 和 RwLock 都用在多线程环境下,对共享数据访问的保护上。
- 前面构建的 DAG 如果要用在多线程环境下,需要把 Rc> 替换为 Arc> 或者 Arc>。
二、生命周期
动态还是静态?
动态/静态生命周期定义与表示方式
- 静态生命周期: ’static str
- 如果一个值的生命周期贯穿整个进程的生命周期,那么我们就称这种生命周期为静态生命周期。
- 当值拥有静态生命周期,其引用也具有静态生命周期。
- 我们在表述这种引用的时候,可以用 ’static 来表示。比如: &’static str 代表这是一个具有静态生命周期的字符串引用。
- 一般来说,全局变量、静态变量、字符串字面量(string literal (字面) )等,都拥有静态生命周期。
- 堆内存,如果使用了 Box::leak 后,也具有静态生命周期。
- 动态生命周期: ’a 、’b 或者 ’hello 这样的小写字符或者字符串来表述
- 如果一个值是在某个作用域中定义的,也就是说它被创建在栈上或者堆上,那么其生命周期是动态的。
- 当这个值的作用域结束时,值的生命周期也随之结束。
- 对于动态生命周期,我们约定用 ’a 、’b 或者 ’hello 这样的小写字符或者字符串来表述。
- ’ 后面具体是什么名字不重要,它代表某一段动态的生命周期
- 其中, &’a str 和 &’b str 表示这两个字符串引用的生命周期可能不一致。
动静态生命周期示意图
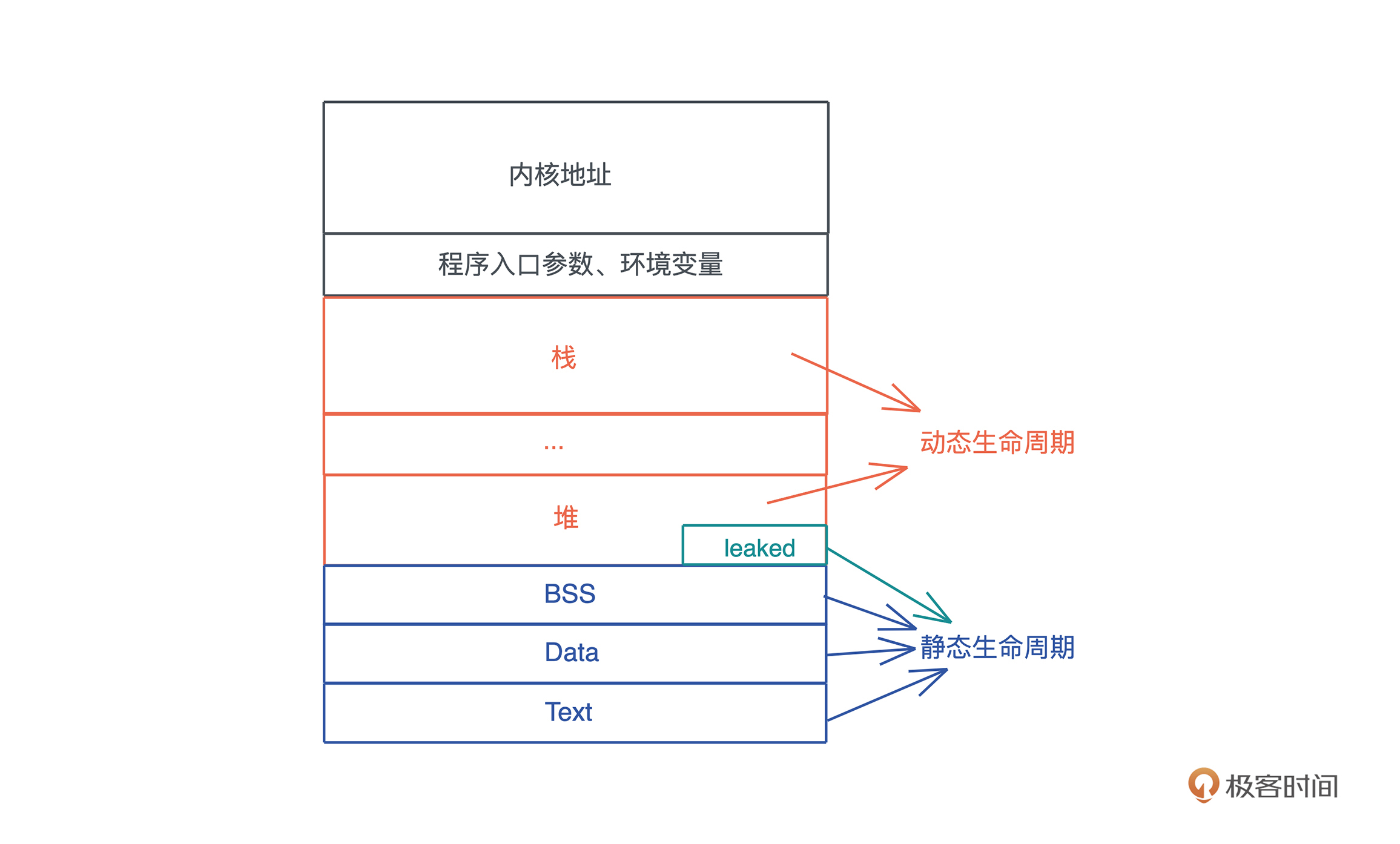
- 分配在堆和栈上的内存有其各自的作用域,它们的生命周期是动态的。
- 全局变量、静态变量、字符串字面量、代码等内容,在编译时,会被编译到可执行文件中的 BSS/Data/RoData/Text 段,然后在加载时,装入内存。
- 因而,它们的生命周期和进程的生命周期一致,所以是静态的。
- 所以,函数指针的生命周期也是静态的,因为函数在 Text 段中,只要进程活着,其内存一直存在。
如何识别生命周期
其实生命周期参数主要用于帮助编译器识别引用的生命周期范围,对于明显不符合生命周期参数的变量,哪怕加了生命周期参数也不会通过。
只有传址的参数,且多于一个,才可能需要生命周期标注
两个小例子
两个小例子
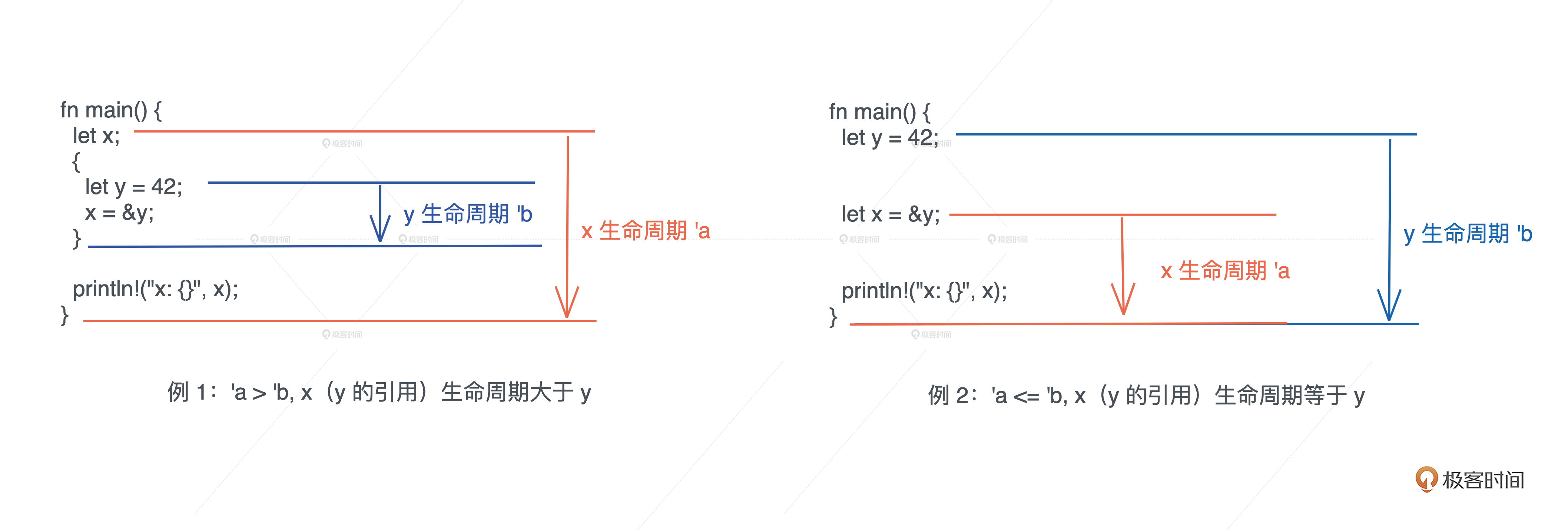
- x 引用了在内层作用域中创建出来的变量 y。由于,变量从开始定义到其作用域结束的这段时间,是它的生命周期,所以 x 的生命周期 ’a 大于 y 的生命周期 ’b,当 x 引用 y 时,编译器报错。
- y 和 x 处在同一个作用域下, x 引用了 y,我们可以看到 x 的生命周期 ’a 和 y 的生命周期 ’b 几乎同时结束,或者说 ’a 小于等于 ’b,所以,x 引用 y 是可行的。
编译器其实会自动进行生命周期标注
编译器希望尽可能减轻开发者的负担,其实所有使用了引用的函数,都需要生命周期的标注,只不过编译器会自动做这件事,省却了开发者的麻烦
编译器自动进行生命周期标注
- 无标注版本
fn main() { let s1 = "Hello world"; println!("first word of s1: {}", first(s1)); } // 如果你用 clippy,多余的 lifetime 会提醒你不需要 // fn first<'a>(s: &'a str) -> &'a str { fn first(s: &str) -> &str { let trimmed = s.trim(); match trimmed.find(' ') { None => "", Some(pos) => &trimmed[..pos], } }
- 自动标注
fn main() { let s1 = "Lindsey"; let s2 = String::from("Rosie"); let result = max(s1, &s2); println!("bigger one: {}", result); } fn max<'a>(s1: &'a str, s2: &'a str) -> &'a str { if s1 > s2 { s1 } else { s2 } }
返回值如何标注?是 ’a 还是’b 呢?这里的冲突,编译器无能为力。
自动标注规则
- 所有引用类型的参数都有独立的生命周期 ’a 、’b 等。
- 如果只有一个引用型输入,它的生命周期会赋给所有输出。
- 如果有多个引用类型的参数,其中一个是 self,那么它的生命周期会赋给所有输出。
需要生命周期标注的情况
missing lifetime specifier
fn main() { let s1 = String::from("Lindsey"); let s2 = String::from("Rosie"); let result = max(&s1, &s2); println!("bigger one: {}", result); let result = get_max(s1); println!("bigger one: {}", result); } fn get_max(s1: &str) -> &str { // 字符串字面量的生命周期是静态的,而 s1 是动态的,它们的生命周期显然不一致 max(s1, "Cynthia") } // 这段代码无法编译通过 fn max(s1: &str, s2: &str) -> &str { if s1 > s2 { s1 } else { s2 } }
- 编译器在编译 max() 函数时,无法判断 s1、s2 和返回值的生命周期。
- 函数本身携带的信息,就是编译器在编译时使用的全部信息。
- 这里函数本身提供的信息就告诉编译期,生命周期不一致
添加生命周期标注即可编译通过
fn main() { let s1 = String::from("Lindsey"); let s2 = String::from("Rosie"); let result = max(&s1, &s2); println!("bigger one: {}", result); let result = get_max(&s1); println!("bigger one: {}", result); } fn get_max(s1: &str) -> &str { max(s1, "Cynthia") } fn max<'a>(s1: &'a str, s2: &'a str) -> &'a str { if s1 > s2 { s1 } else { s2 } }
生命周期标注练习
标注练习题
pub fn strtok(s: &mut &str, delimiter: char) -> &str { if let Some(i) = s.find(delimiter) { let prefix = &s[..i]; // 由于 delimiter 可以是 utf8,所以我们需要获得其 utf8 长度, // 直接使用 len 返回的是字节长度,会有问题 let suffix = &s[(i + delimiter.len_utf8())..]; *s = suffix; prefix } else { // 如果没找到,返回整个字符串,把原字符串指针 s 指向空串 let prefix = *s; *s = ""; prefix } } fn main() { let s = "hello world".to_owned(); let mut s1 = s.as_str(); let hello = strtok(&mut s1, ' '); println!("hello is: {}, s1: {}, s: {}", hello, s1, s); }
- 按照编译器的规则, &mut &str 添加生命周期后变成 &’b mut &’a str
- 这将导致返回的 ’&str 无法选择一个合适的生命周期。
标注练习题参考
pub fn strtok<'a>(s: &mut &'a str, delimiter: char) -> &'a str { if let Some(i) = s.find(delimiter) { let prefix = &s[..i]; let suffix = &s[(i + delimiter.len_utf8())..]; *s = suffix; prefix } else { let prefix = *s; *s = ""; prefix } } fn main() { let s = "hello world".to_owned(); let mut s1 = s.as_str(); let hello = strtok(&mut s1, ' '); println!("hello is: {}, s1: {}, s: {}", hello, s1, s); }
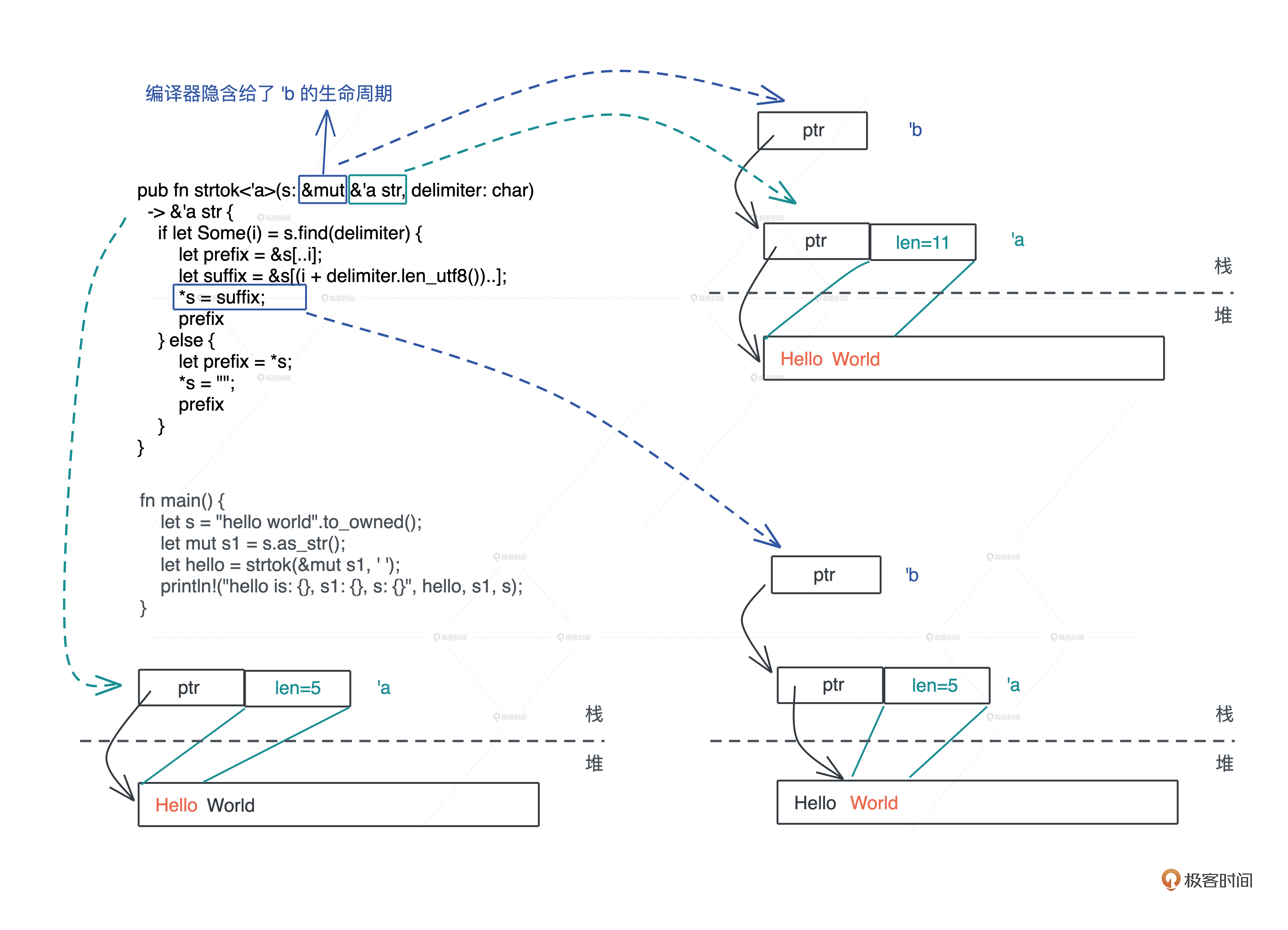
生命周期标注的目的
生命周期标注的目的是,在参数和返回值之间建立联系或者约束
生命周期标注的目的是,在参数和返回值之间建立联系或者约束:
- 调用函数时,传入的参数的生命周期需要大于等于标注的生命周期。
- 当每个函数都添加好生命周期标注后,编译器,就可以从函数调用的上下文中分析出,在传参时,引用的生命周期,是否和函数签名中要求的生命周期匹配。
- 如果不匹配,就违背了“引用的生命周期不能超出值的生命周期”,编译器就会报错。
三、融会贯通,从创建到消亡
创建
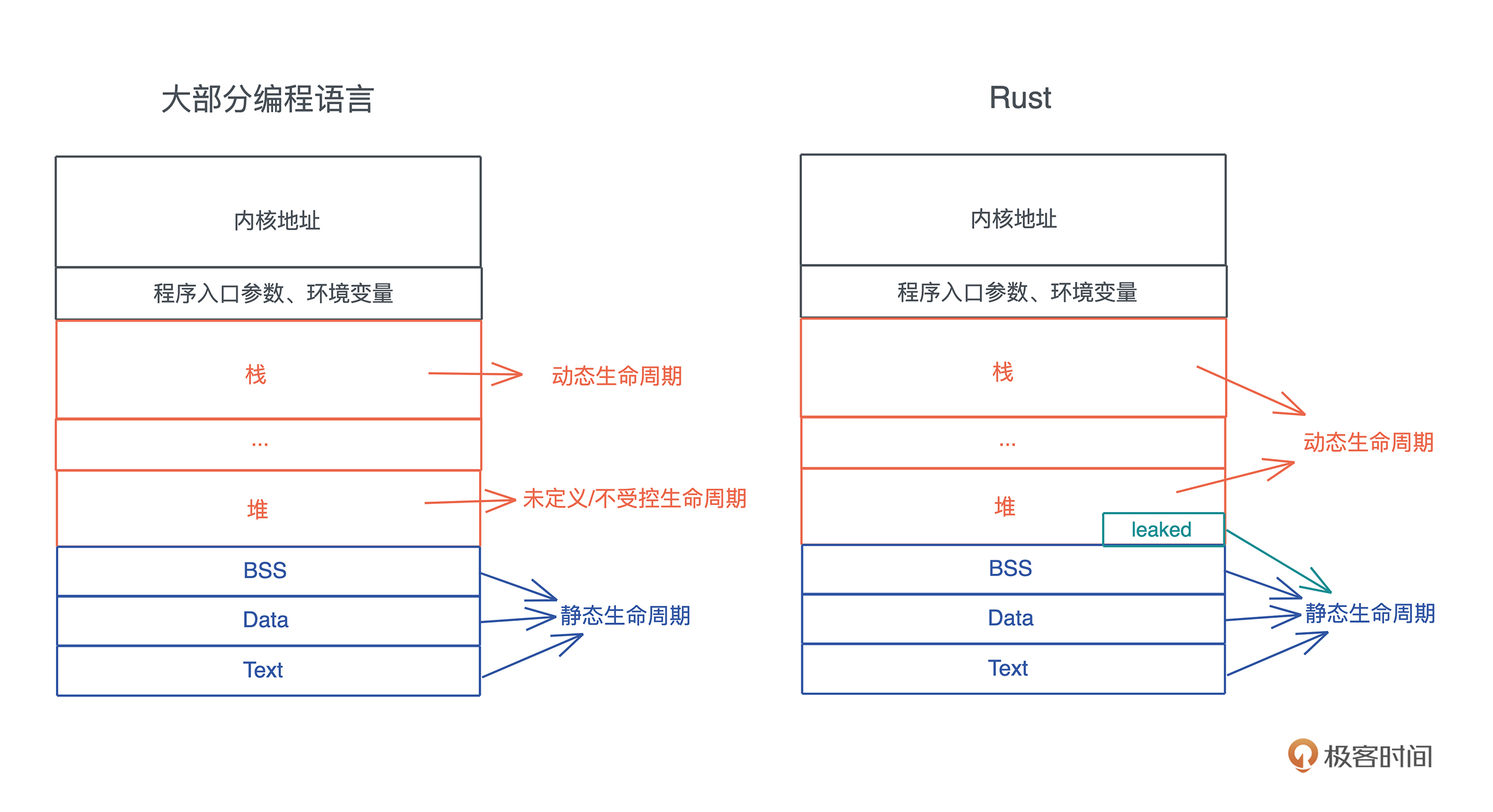
堆内存生命周期管理发展史

堆内存管理需求:动态大小 or 生命周期
Rust 的创造者们,重新审视了堆内存的生命周期,发现:
- 大部分堆内存的需求在于动态大小
- 小部分需求是更长的生命周期。
所以它默认将堆内存的生命周期和使用它的栈内存的生命周期绑在一起,并留了个小口子 leaked 机制,让堆内存在需要的时候,可以有超出帧存活期的生命周期。
struct/enum/vec/String创建时的内存布局
内存布局优化什么意思?
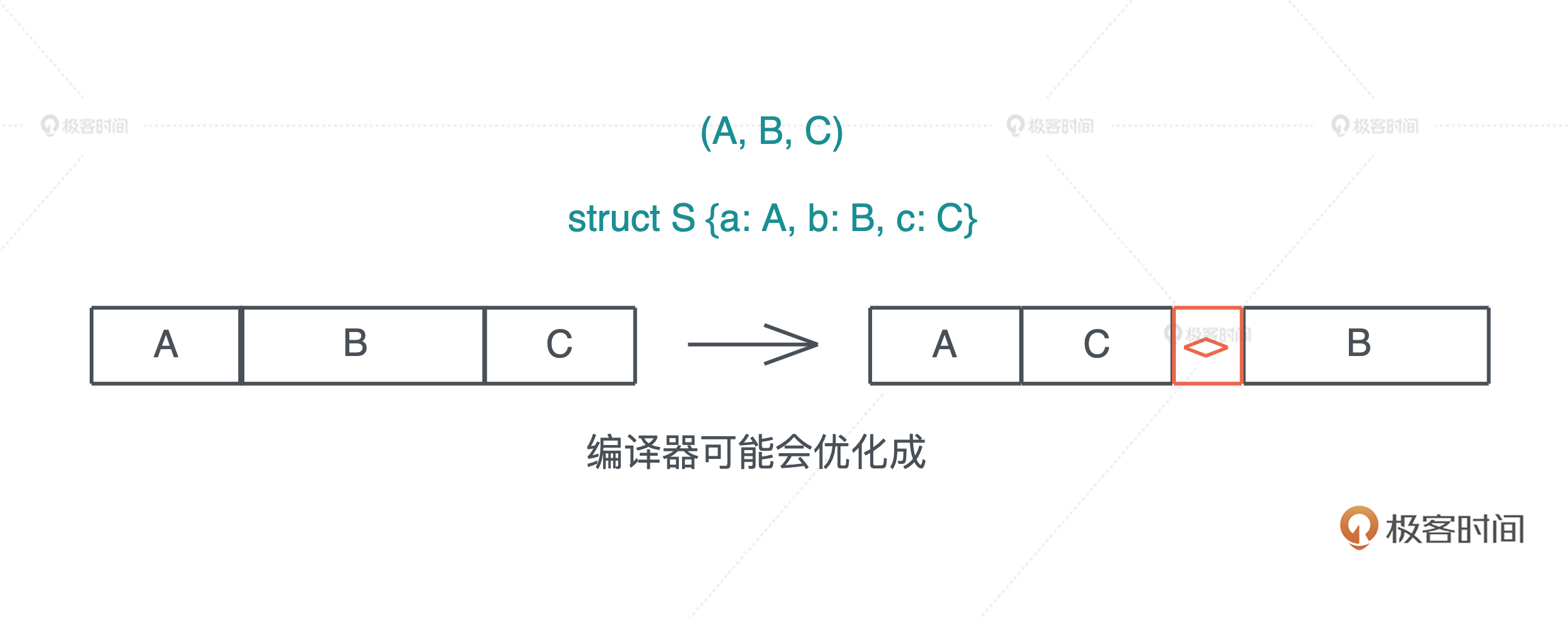
struct

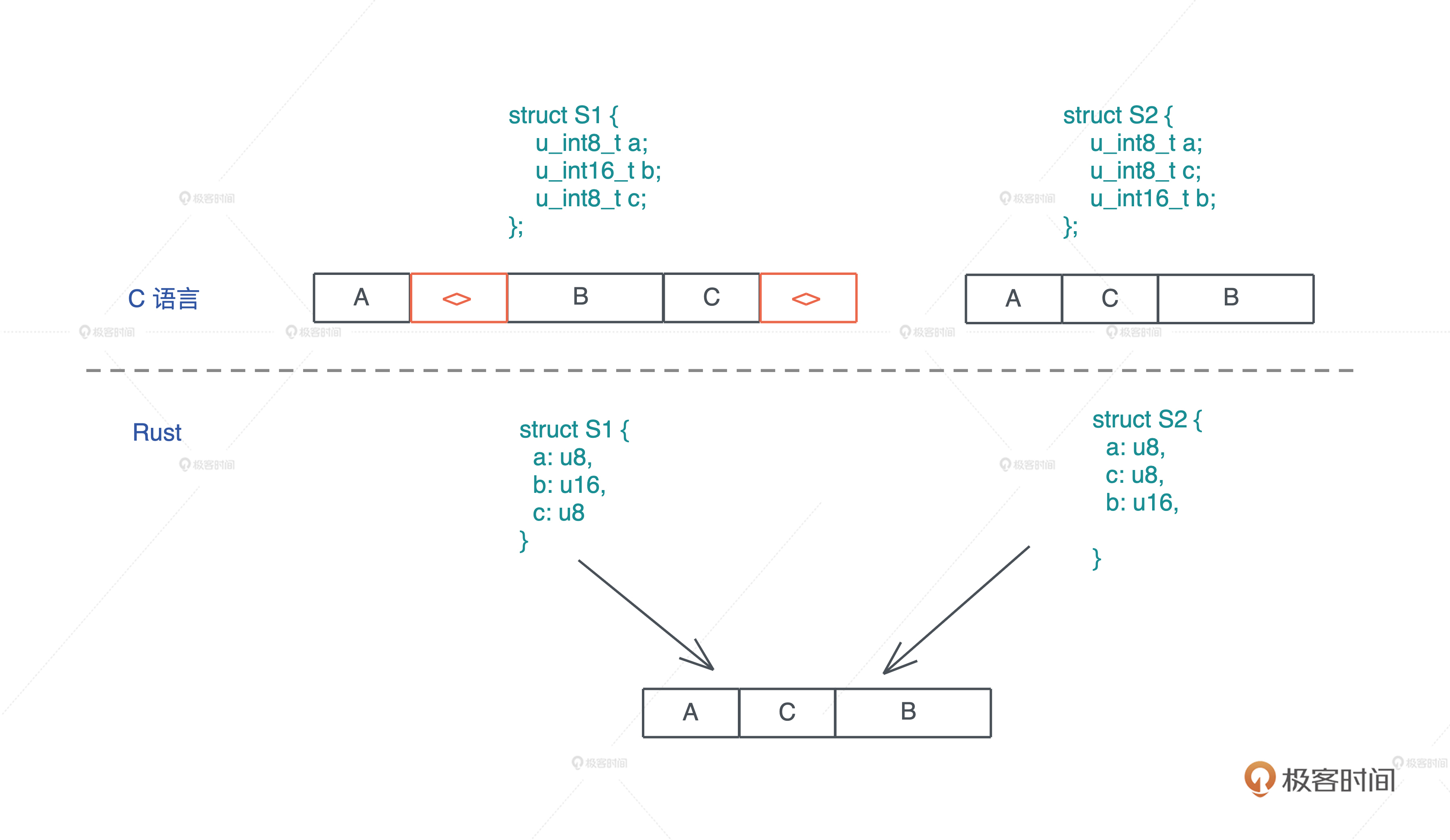
代码对比rust和clang的内存布局优化
#include <stdio.h>
struct S1 {
u_int8_t a;
u_int16_t b;
u_int8_t c;
};
struct S2 {
u_int8_t a;
u_int8_t c;
u_int16_t b;
};
void main() {
printf("size of S1: %d, S2: %d", sizeof(struct S1), sizeof(struct S2));
}
use std::mem::{align_of, size_of}; #[allow(dead_code)] struct S1 { a: u8, b: u16, c: u8, } #[allow(dead_code)] struct S2 { a: u8, c: u8, b: u16, } fn main() { println!("sizeof S1: {}, S2: {}", size_of::<S1>(), size_of::<S2>()); println!("alignof S1: {}, S2: {}", align_of::<S1>(), align_of::<S2>()); }
enum
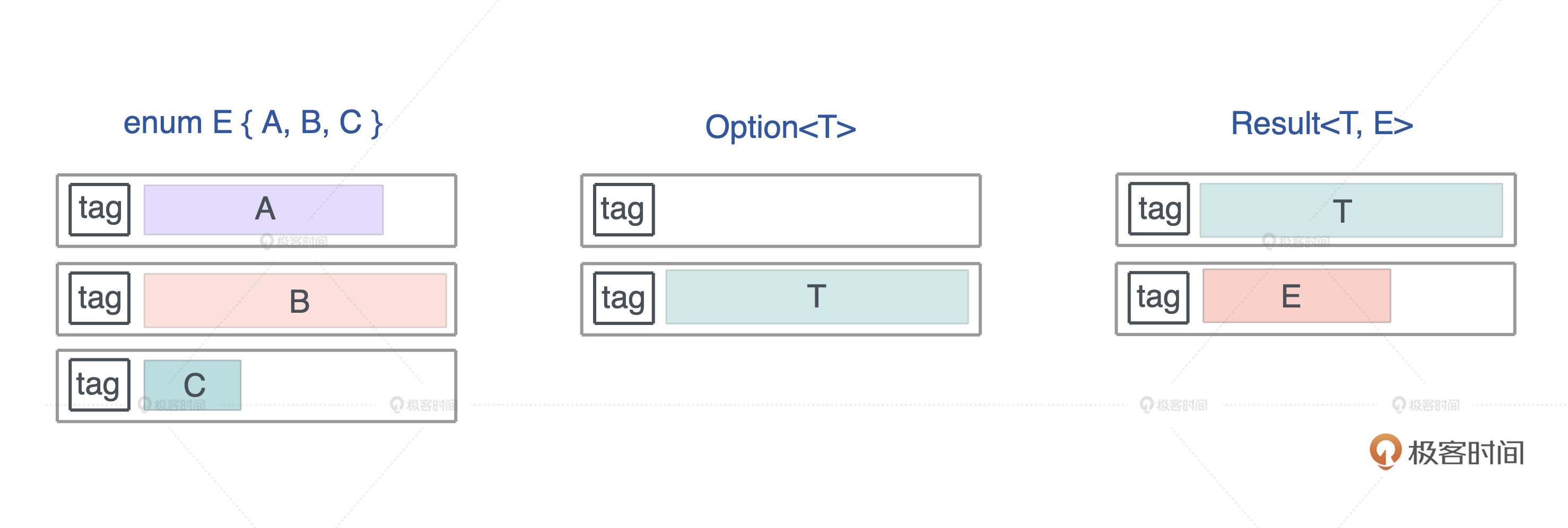
Rust 编译器会对 enum 做一些额外的优化,让某些常用结构的内存布局更紧凑。
use std::collections::HashMap; use std::mem::size_of; #[allow(dead_code)] enum E { A(f64), B(HashMap<String, String>), C(Result<Vec<u8>, String>), } macro_rules! show_size { (header) => { println!( "{:<24} {:>4} {} {}", "Type", "T", "Option<T>", "Result<T, io::Error>" ); println!("{}", "-".repeat(64)); }; ($t:ty) => { println!( "{:<24} {:4} {:8} {:12}", stringify!($t), size_of::<$t>(), size_of::<Option<$t>>(), size_of::<Result<$t, std::io::Error>>(), ) }; } fn main() { show_size!(header); show_size!(u8); show_size!(f64); show_size!(&u8); show_size!(Box<u8>); show_size!(&[u8]); show_size!(String); show_size!(Vec<u8>); show_size!(HashMap<String, String>); show_size!(E); }
你会发现,Option 配合带有引用类型的数据结构,比如 &u8、Box、Vec、HashMap ,没有额外占用空间,这就很有意思了
Type T Option<T> Result<T, io::Error>
----------------------------------------------------------------
u8 1 2 24
f64 8 16 24
&u8 8 8 24
Box<u8> 8 8 24
&[u8] 16 16 24
String 24 24 32
Vec<u8> 24 24 32
HashMap<String, String> 48 48 56
E 56 56 64
Rust 是这么处理的:
- 我们知道,引用类型的第一个域是个指针,而指针是不可能等于 0 的,
- 但是我们可以复用这个指针:当其为 0 时,表示 None,否则是 Some,减少了内存占用,这是个非常巧妙的优化
vec和String
String其实就是Vec
String 和 Vec 占用相同的大小,都是 24 个字节。其实,如果你打开 String 结构的源码,可以看到,它内部就是一个 Vec
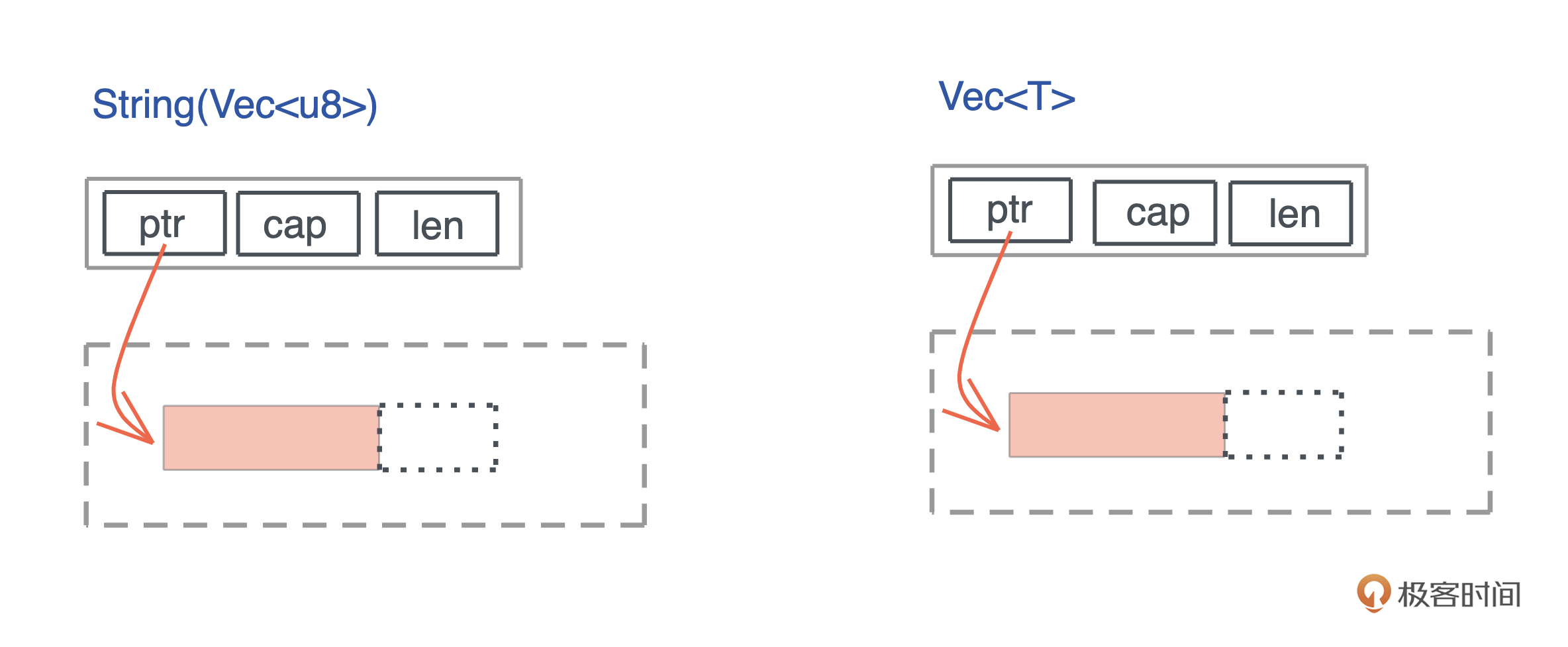
引用类型的内存布局
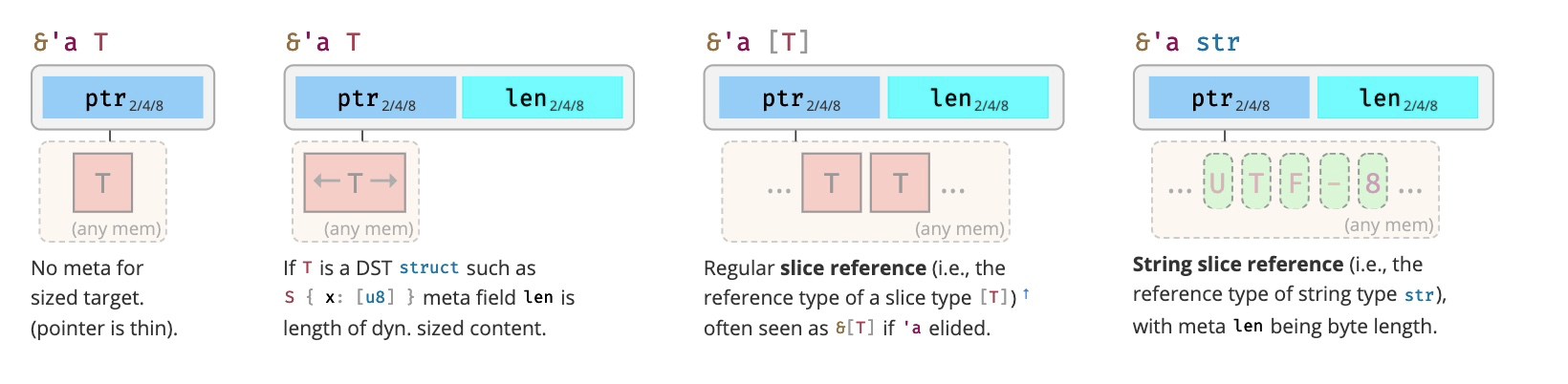
更多可见cheats.rs
使用
copy和move
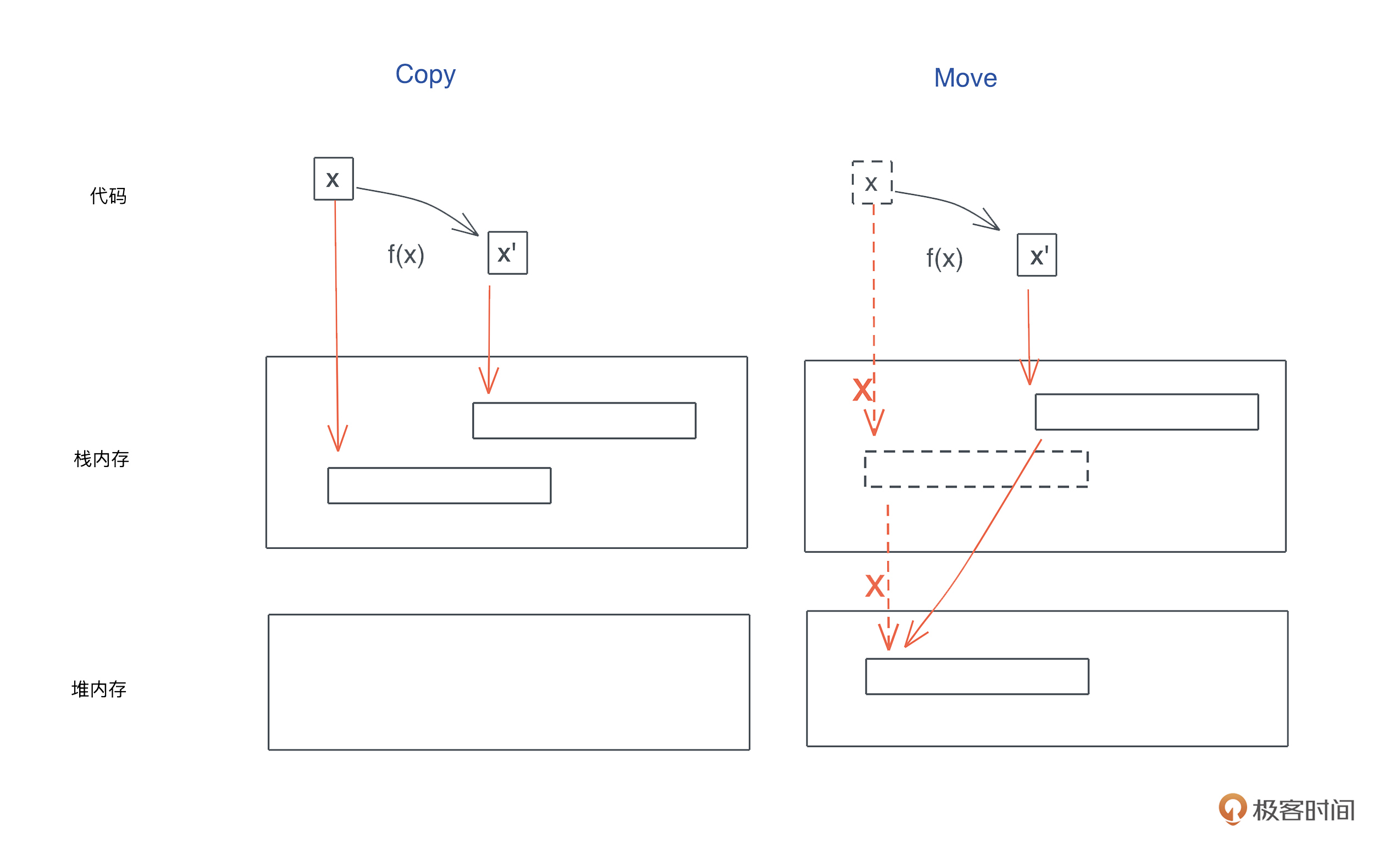
销毁
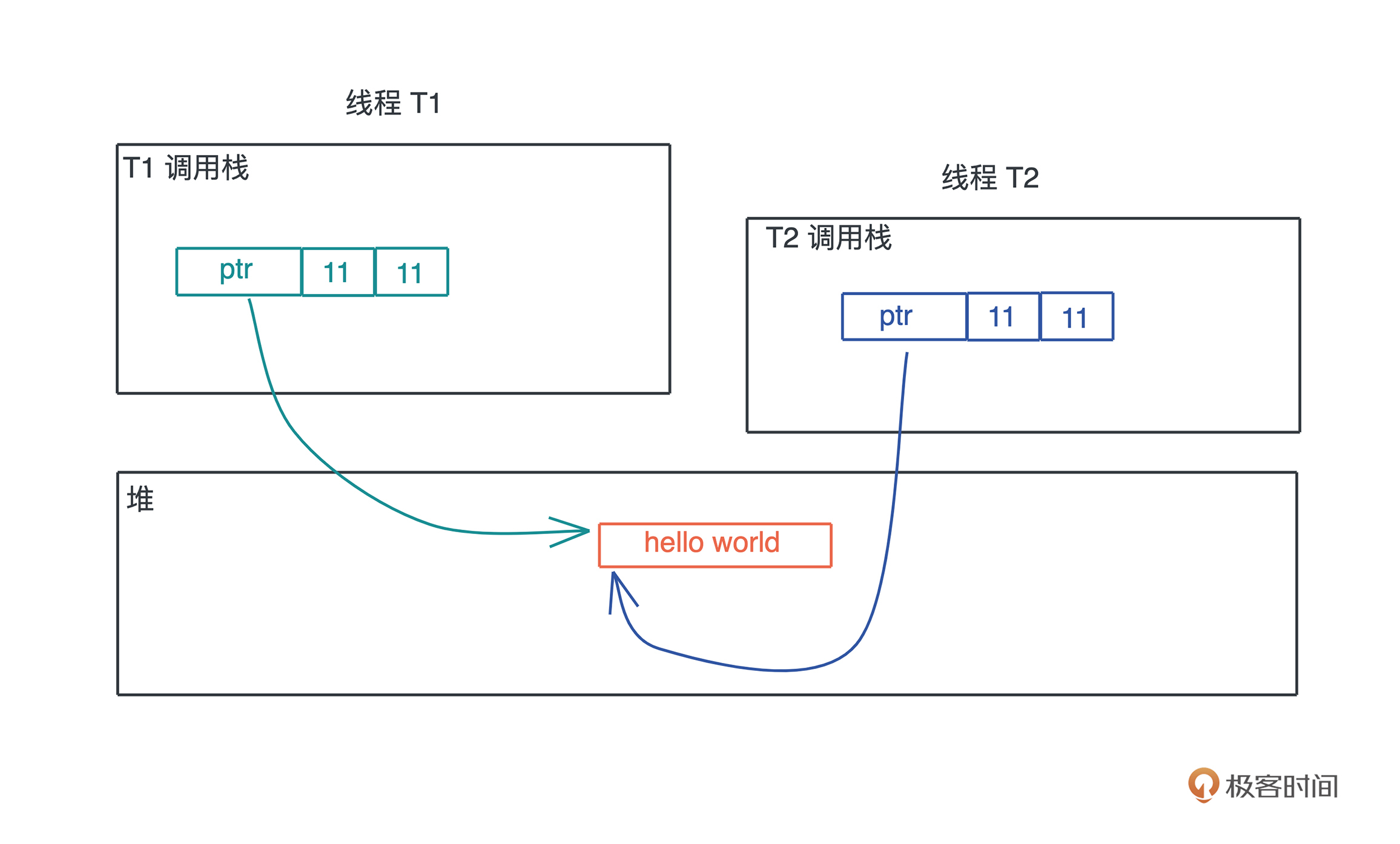
drop释放堆内存
当一个值被释放,其实就是调用它的drop方法
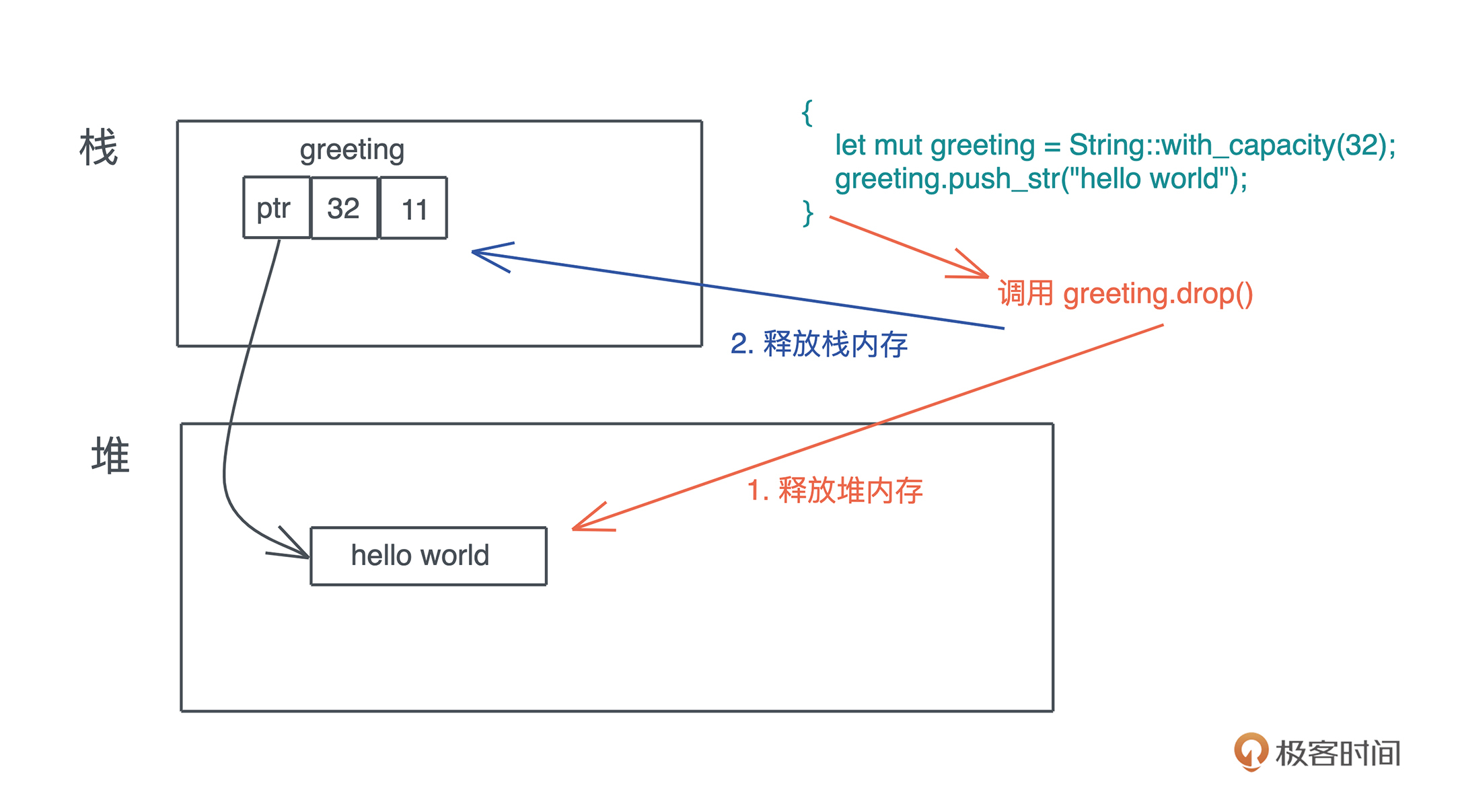
- 变量 greeting 是一个字符串,在退出作用域时,其 drop() 函数被自动调用
- 释放堆上包含 “hello world” 的内存
- 然后再释放栈上的内存
复杂结构递归调用drop
如果要释放的值是一个复杂的数据结构,比如一个结构体,那么:
- 这个结构体在调用 drop() 时,会依次调用每一个域的 drop() 函数
- 如果域又是一个复杂的结构或者集合类型,就会递归下去
- 直到每一个域都释放干净。
- student 变量是一个结构体,有 name、age、scores。
- 其中 name 是 String,scores 是 HashMap,它们本身需要额外 drop()。
- 又因为 HashMap 的 key 是 String,所以还需要进一步调用这些 key 的 drop()。
整个释放顺序从内到外是:先释放 HashMap 下的 key,然后释放 HashMap 堆上的表结构,最后释放栈上的内存
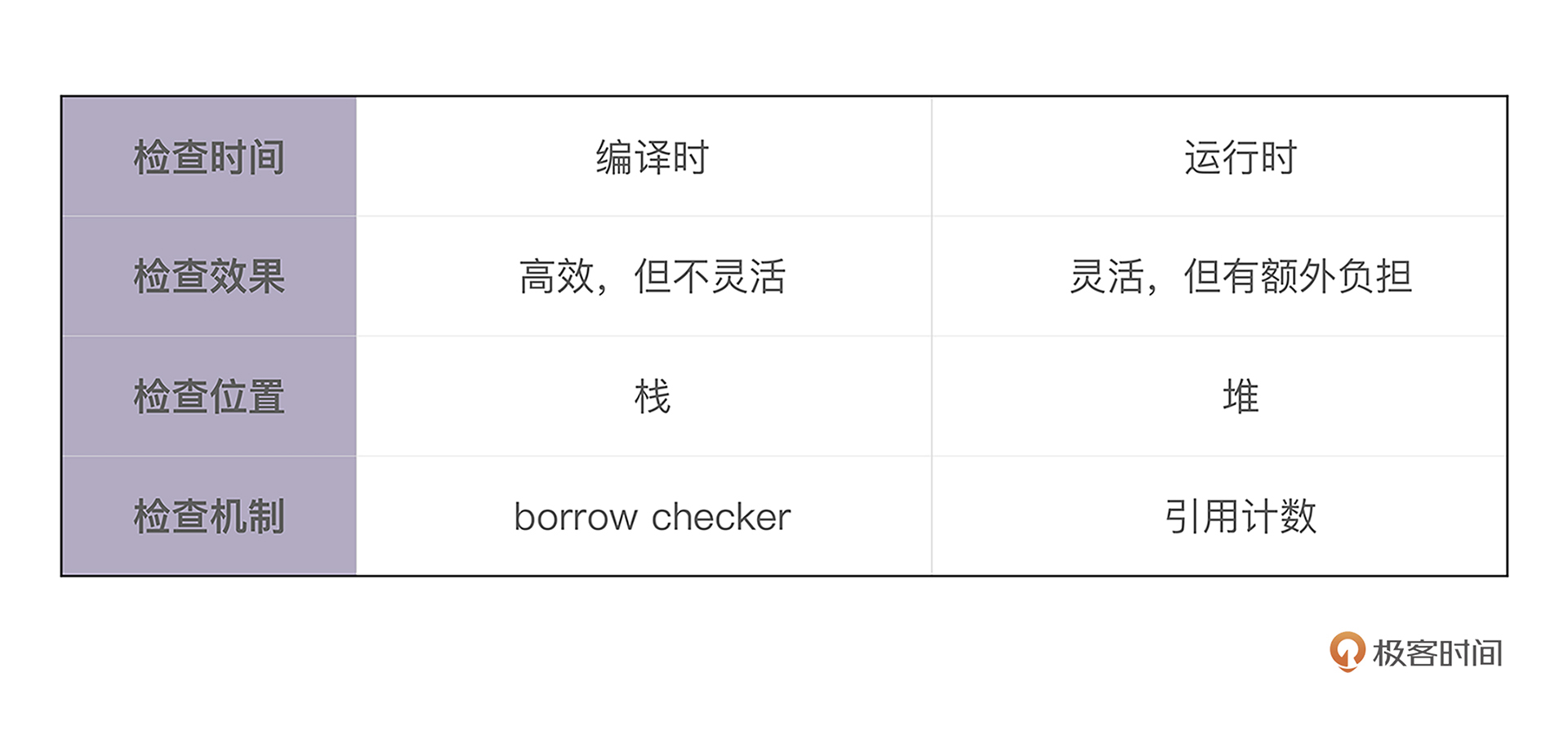
RAII释放其他资源
Rust基于RAII释放文件资源
use std::fs::File; use std::io::prelude::*; fn main() -> std::io::Result<()> { let mut file = File::create("foo.txt")?; file.write_all(b"Hello, world!")?; Ok(()) }
II. 类型系统
类型系统
Rust类型系统特点
三个标准
- 隐式转换
- 检查时机
- 多态支持
类型分类
原生类型
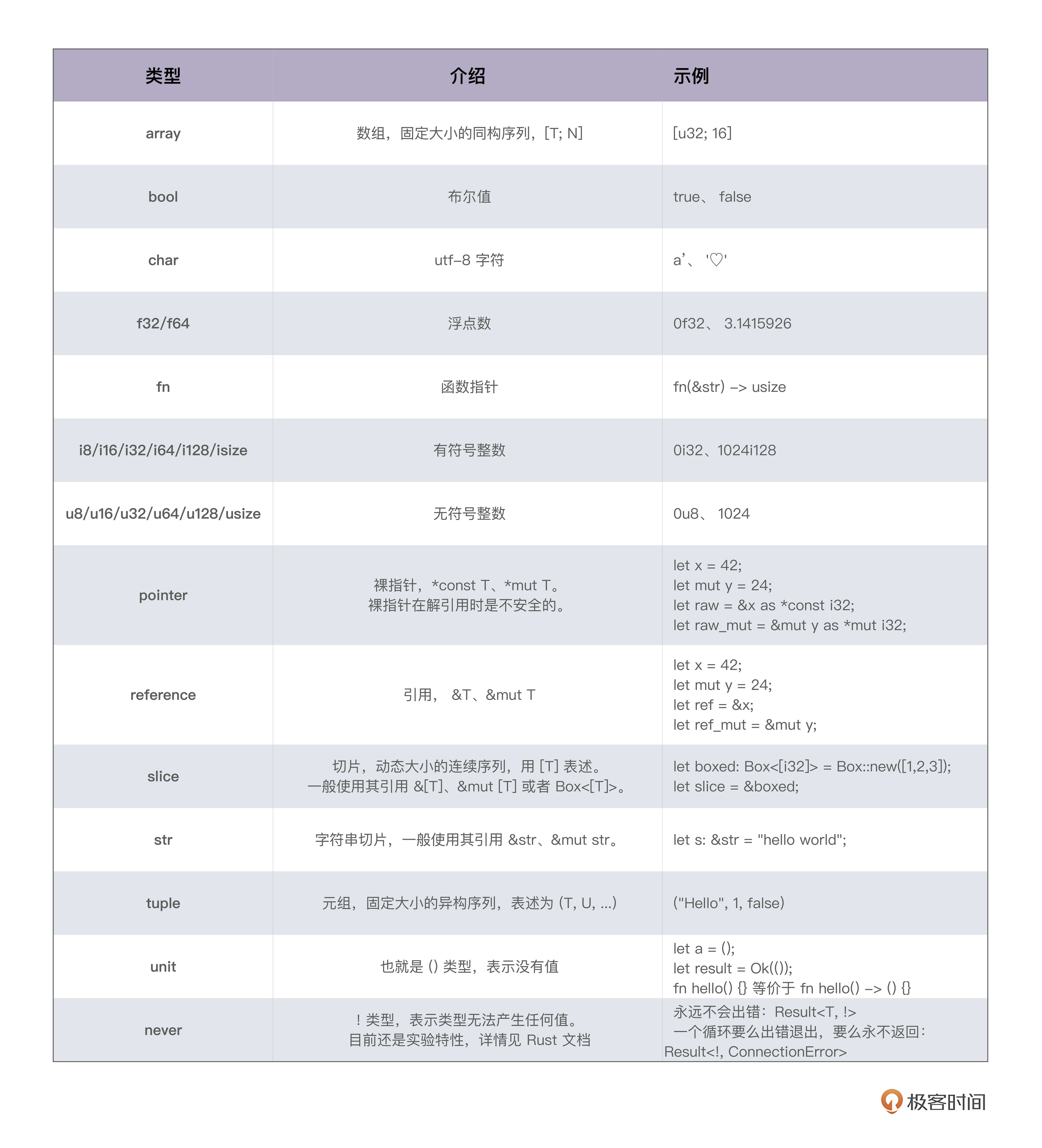
组合类型
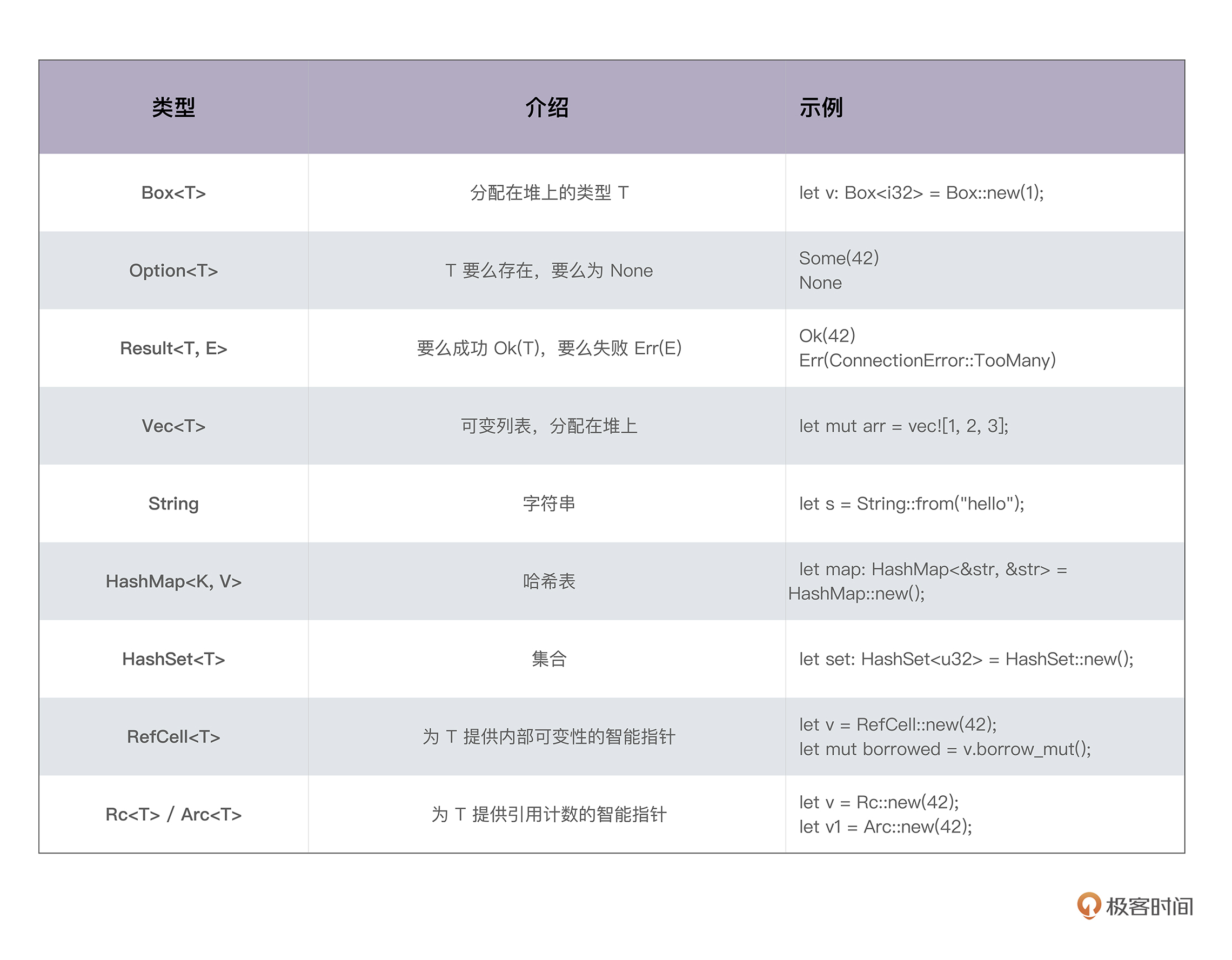
自定义组合类型
小例子
常量
常量定义使用
const PI: f64 = std::f64::consts::PI; static E: f32 = std::f32::consts::E; fn main() { const V: u32 = 10; static V1: &str = "hello"; println!("PI: {}, E: {}, V {}, V1: {}", PI, E, V, V1); }
类型推导
Rust编译器可以从上下文自动推导类型
use std::collections::BTreeMap; fn main() { let mut map = BTreeMap::new(); // 没有这一行就缺少自动推导信息 // map.insert("hello", "world"); println!("map: {:?}", map); }
把第 5 行这个作用域内的 insert 语句注释去掉,Rust 编译器就会报错:“cannot infer type for type parameter K”。
Rust编译器不能获取足够上下文信息时,就需要明确类型
- 无法自动推导collect返回什么类型
fn main() { let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let even_numbers = numbers .into_iter() .filter(|n| n % 2 == 0) .collect(); println!("{:?}", even_numbers); }
- 给even_numbers添加类型声明即可
fn main() { let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let even_numbers: Vec<_> = numbers .into_iter() .filter(|n| n % 2 == 0) .collect(); println!("{:?}", even_numbers); }
这里编译器只是无法推断出集合类型,但集合类型内部元素的类型,还是可以根据上下文得出,所以我们可以简写成 Vec<_>
- 也可以让 collect 返回一个明确的类型
fn main() { let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let even_numbers = numbers .into_iter() .filter(|n| n % 2 == 0) .collect::<Vec<_>>(); println!("{:?}", even_numbers); }
这里在泛型函数后使用 :: 来强制使用类型 T,这种写法被称为 turbofish
Turbofish
一个对 IP 地址和端口转换的例子
use std::net::SocketAddr; fn main() { let addr = "127.0.0.1:8080".parse::<SocketAddr>().unwrap(); println!("addr: {:?}, port: {:?}", addr.ip(), addr.port()); }
如果类型在上下文无法被推导出来,又没有 turbofish 的写法,我们就不得不先给一个局部变量赋值时声明类型,然后再返回,这样代码就变得冗余
#![allow(unused)] fn main() { match data { Some(s) => v.parse::<User>()?, _ => return Err(...), } }
泛型概览
泛型实现方式
阅读这张图的内容,可以理出不少设计。
比如trait object和trait bound其实从一开始就是不同路线的解决方案
泛型就像定义函数
Trait概览

接口抽象 or 特设多态
接口抽象:对不同类型统一实现 + trait将各种接口定义场景考虑进去
trait 作为对不同数据结构中相同行为的一种抽象。
- 延迟实现: 除了基本 trait 之外,当行为和具体的数据关联时,比如字符串解析时定义的 Parse trait,我们引入了带有关联类型的 trait,把和行为有关的数据类型的定义,进一步延迟到 trait 实现的时候。
- 对于同一个类型的同一个 trait 行为,可以有不同的实现,比如我们之前大量使用的 From,此时可以用泛型 trait。可以说 Rust 的 trait 就像一把瑞士军刀,把需要定义接口的各种场景都考虑进去了。
对不同类型的不同实现: 特设多态
特设多态是同一种行为的不同实现。所以其实,通过定义 trait 以及为不同的类型实现这个 trait,我们就已经实现了特设多态。
- Add trait 就是一个典型的特设多态,同样是加法操作,根据操作数据的不同进行不同的处理。
- Service trait 是一个不那么明显的特设多态,同样是 Web 请求,对于不同的 URL,我们使用不同的代码去处理。
孤儿规则
定义或实现,至少有一个
trait 和实现 trait 的数据类型,至少有一个是在当前 crate 中定义的,也就是说,你不能为第三方的类型实现第三方的 trait,当你尝试这么做时,Rust 编译器会报错。
三种多态形式
通俗来讲,只要是为不同类型的数据或操作提供了相同的名字就可以叫多态。
参数多态:
- 操作与类型无关
又叫编译时多态,Rust主要使用泛型来实现
对不同类型,调用相同方法,执行相同逻辑
参数化多态(Parametric polymorphism)是指一段代码适用于不同的类型,把类型作为参数,在实际需要的时候根据类型进行实例化,所有的实例有相同的行为
特设多态:
- 重写继承过来的指定方法, 就是实现接口方法
又叫ad-hoc,Rust主要使用Trait Impl实现。
ad-hoc是一个拉丁词,意思为特定,临时
Ad hoc是一个拉丁文常用短语。
这个短语的意思是“特设的、特定目的的(地)、即席的、临时的、将就的、专案的”。
这个短语通常用来形容一些特殊的、不能用于其它方面的,为一个特定的问题、任务而专门设定的解决方案。
称其为特设是因为这种多态并不像全称量化一样适用于所有类型,而是手动为某些特定类型提供不同的实现(这也就是trait impl过程)。
子类型多态
又叫运行时多态,Rust主要使用Trait Object实现
三种多态两两对比
参数多态 vs 特设多态
可以与参数多态对比一下:
- 相同点:对不同类型,调用相同方法
- 不同点:
- ad-hoc: 但是执行不同逻辑
- 参数多态:执行相同逻辑
参数多态 vs 子类型多态
- 在编程语言中,参数多态的主要实现方式有很多,Rust选择了泛型作为实现方式。
- 泛型的实现方式主要有擦除类型和单态化,前者是运行时操作,后者是编译时操作;
- Rust的泛型使用单态化实现,因此对应的参数多态也是发生在编译时,所以又被称为编译时多态;
- 而Trait Object的实现方式是运行时擦除类型 ,所以它其实是类似于泛型的另一种实现方式。
- java使用运行时擦除类型,其实就是在编译时替换为Object,进而保证类型安全。
- Rust使用运行时擦除类型,其实就是采用C++的方式,编译时替换为一个胖指针。
- 与C++不同的是,C++将虚函数表放在实例里,而Rust的胖指针指向实例和虚函数表
特设多态 vs 子类型多态
- 特设多态的实现很明确:特定实现,发生在编译期
- 子类型多态:胖指针实现,发生在运行期
具体再对比一下rust的两种多态实现方式:
trait impl(特设多态)vs trait object(子类型多态)
trait object(动态分发):
- 前提:trait里面的每个方法都要有&slef参数。
- 优势:使用指针,对参数的要求更灵活,二进制文件小。
- 劣势:运行时动态分发,造成性能不如静态分发。
- 特点:传指针或者引用。
trait bound(静态分发):
- 前提: 只要程序代码中并没初始化类型,那么针对这个类型的trait中的方法也没有生成。
- 执行:编译期分析代码,为每个实现了trait的类型执行单态化(必须满足前提)。
- 优势:编译期决定为类型分发trait实现,不影响运行时,性能高。
- 劣势:编译器为每个实现过trait的类型编译一份方法实现,二进制文件大。
- 特点:传值
具体到self和&self
#[warn(dead_code)] trait Animal { // trait object的方法都要带&self参数 fn hello(&self){println!("hello");} } struct Good{} struct Hello{} impl Animal for Good{}//默认实现 impl Animal for Hello{}//默认实现 //动态分发体现在传递引用&dyn fn test_dyn(x: &dyn Animal) { x.hello(); } //静态分发体现在传递值impl Animal fn test(x: impl Animal){ x.hello(); } fn main() { { let good = Good{}; test_dyn(&good); // let hello = Hello{}; // test_dyn(&hello); } }
- trait object的方法都要带&self参数
- 动态分发体现在参数传递引用&dyn
- 静态分发体现在参数传递值impl Animal
Generics: 参数多态, 编译期单态化
生命周期标注
其实在 Rust 里,生命周期标注也是泛型的一部分,一个生命周期 ’a 代表任意的生命周期,和 T 代表任意类型是一样的。
泛型结构:struct/enum定义中
Generic Vec
泛型结构Vec例子
pub struct Vec<T, A: Allocator = Global> { buf: RawVec<T, A>, len: usize, } pub struct RawVec<T, A: Allocator = Global> { ptr: Unique<T>, cap: usize, alloc: A, }
为什么上面的例子中,Vec 虽然有两个参数,使用时都只需要用 T ?
Vec有两个参数:
- 一个是 T,是列表里的每个数据的类型
- 另一个是 A,它有进一步的限制 A: Allocator
- 也就是说 A 需要满足 Allocator trait。
- A 这个参数有默认值 Global,它是 Rust 默认的全局分配器, 它不需要用到T
- 这也是为什么 Vec 虽然有两个参数,使用时都只需要用 T。
Generic Cow
Cow就像Option
Cow(Clone-on-Write)是 Rust 中一个很有意思且很重要的数据结构。 它就像 Option 一样,在返回数据的时候,提供了一种可能:
- 要么返回一个借用的数据(只读)
- 要么返回一个拥有所有权的数据(可写)。
枚举类型Cow例子
pub enum Cow<'a, B: ?Sized + 'a> where B: ToOwned, { // 借用的数据 Borrowed(&'a B), // 拥有的数据 Owned(<B as ToOwned>::Owned), }
这里对 B 的三个约束分别是:
- 生命周期 ’a
告诉编译器,Cow的生命周期也是’a
- 这里 B 的生命周期是 ’a,所以 B 需要满足 ’a,这里和泛型约束一样,也是用 B: ’a 来表示。
- 当 Cow 内部的类型 B 生命周期为 ’a 时,Cow 自己的生命周期也是 ’a。
- 长度可变 ?Sized
?Sized代表可变大小
?Sized 是一种特殊的约束写法:
- ? 代表可以放松问号之后的约束
- 由于 Rust 默认的泛型参数都需要是 Sized,也就是固定大小的类型,所以这里 ?Sized 代表用可变大小的类型。
- where B: ToOwned
-
符合 ToOwned trait
-
这里把ToOwned放在where字句中,其实行内泛型约束的写法本身就是where子句的一个语法糖,简写。
where子句与行内泛型约束有什么区别呢?
ToOwned: 可以把借用的数据克隆出一个拥有所有权的数据
ToOwned 是一个 trait,它可以把借用的数据克隆出一个拥有所有权的数据。
- ::Owned
::Owned
- 它对 B 做了一个强制类型转换,转成 ToOwned trait
- 然后访问 ToOwned trait 内部的 Owned 类型
因为在 Rust 里,子类型可以强制转换成父类型,B 可以用 ToOwned 约束,所以它是 ToOwned trait 的子类型,因而 B 可以安全地强制转换成 ToOwned。这里 B as ToOwned 是成立的。
trait impl: 在不同的实现下逐步添加约束
逐步约束:把决策交给使用者
use std::fs::File; use std::io::{BufReader, Read, Result}; struct MyReader<R> { reader: R, buf: String, } impl<R> MyReader<R> { pub fn new(reader: R) -> Self { Self { reader, buf: String::with_capacity(1024), } } } impl<R> MyReader<R> where R: Read, { pub fn process(&mut self) -> Result<usize> { self.reader.read_to_string(&mut self.buf) } } fn main() { let f = File::open("/etc/hosts").unwrap(); let mut reader = MyReader::new(BufReader::new(f)); let size = reader.process().unwrap(); println!("total size read: {}", size); }
逐步添加约束,可以让约束只出现在它不得不出现的地方,这样代码的灵活性最大。
泛型参数:三种使用场景
延迟绑定
使用泛型参数延迟数据结构的绑定;
额外类型
使用泛型参数和 PhantomData,声明数据结构中不直接使用,但在实现过程中需要用到的类型;
在定义数据结构时,对于额外的、暂时不需要的泛型参数,用 PhantomData 来“拥有”它们,这样可以规避编译器的报错。
use std::marker::PhantomData; #[derive(Debug, Default, PartialEq, Eq)] pub struct Identifier<T> { inner: u64, _tag: PhantomData<T>, } #[derive(Debug, Default, PartialEq, Eq)] pub struct User { id: Identifier<Self>, } #[derive(Debug, Default, PartialEq, Eq)] pub struct Product { id: Identifier<Self>, } #[cfg(test)] mod tests { use super::*; #[test] fn id_should_not_be_the_same() { let user = User::default(); let product = Product::default(); // 两个 id 不能比较,因为他们属于不同的类型 // assert_ne!(user.id, product.id); assert_eq!(user.id.inner, product.id.inner); } }
加深对PhantomData的理解
use std::{ marker::PhantomData, sync::atomic::{AtomicU64, Ordering}, }; static NEXT_ID: AtomicU64 = AtomicU64::new(1); pub struct Customer<T> { id: u64, name: String, _type: PhantomData<T>, } pub trait Free { fn feature1(&self); fn feature2(&self); } pub trait Personal: Free { fn advance_feature(&self); } impl<T> Free for Customer<T> { fn feature1(&self) { println!("feature 1 for {}", self.name); } fn feature2(&self) { println!("feature 2 for {}", self.name); } } impl Personal for Customer<PersonalPlan> { fn advance_feature(&self) { println!( "Dear {}(as our valuable customer {}), enjoy this advanced feature!", self.name, self.id ); } } pub struct FreePlan; pub struct PersonalPlan(f32); impl<T> Customer<T> { pub fn new(name: String) -> Self { Self { id: NEXT_ID.fetch_add(1, Ordering::Relaxed), name, _type: PhantomData::default(), } } } impl From<Customer<FreePlan>> for Customer<PersonalPlan> { fn from(c: Customer<FreePlan>) -> Self { Self::new(c.name) } } /// 订阅成为付费用户 pub fn subscribe(customer: Customer<FreePlan>, payment: f32) -> Customer<PersonalPlan> { let _plan = PersonalPlan(payment); // 存储 plan 到 DB // ... customer.into() } #[cfg(test)] mod tests { use super::*; #[test] fn test_customer() { // 一开始是个免费用户 let customer = Customer::<FreePlan>::new("Tyr".into()); // 使用免费 feature customer.feature1(); customer.feature2(); // 用着用着觉得产品不错愿意付费 let customer = subscribe(customer, 6.99); customer.feature1(); customer.feature1(); // 付费用户解锁了新技能 customer.advance_feature(); } }
在这个例子里,Customer 有个额外的类型 T:
- 通过类型 T,我们可以将用户分成不同的等级
-
比如免费用户是 Customer
-
付费用户是 Customer
-
免费用户可以转化成付费用户,解锁更多权益
- 使用 PhantomData 处理这样的状态,可以在编译期做状态的检测,避免运行期检测的负担和潜在的错误。
多个实现
使用泛型参数让同一个数据结构对同一个 trait 可以拥有不同的实现。
简单实现
有时候,对于同一个 trait,我们想要有不同的实现,该怎么办?
use std::marker::PhantomData; #[derive(Debug, Default)] pub struct Equation<IterMethod> { current: u32, _method: PhantomData<IterMethod>, } // 线性增长 #[derive(Debug, Default)] pub struct Linear; // 二次增长 #[derive(Debug, Default)] pub struct Quadratic; impl Iterator for Equation<Linear> { type Item = u32; fn next(&mut self) -> Option<Self::Item> { self.current += 1; if self.current >= u32::MAX { return None; } Some(self.current) } } impl Iterator for Equation<Quadratic> { type Item = u32; fn next(&mut self) -> Option<Self::Item> { self.current += 1; if self.current >= u16::MAX as u32 { return None; } Some(self.current * self.current) } } #[cfg(test)] mod tests { use super::*; #[test] fn test_linear() { let mut equation = Equation::<Linear>::default(); assert_eq!(Some(1), equation.next()); assert_eq!(Some(2), equation.next()); assert_eq!(Some(3), equation.next()); } #[test] fn test_quadratic() { let mut equation = Equation::<Quadratic>::default(); assert_eq!(Some(1), equation.next()); assert_eq!(Some(4), equation.next()); assert_eq!(Some(9), equation.next()); } }
AsyncProstReader综合例子
来看一个真实存在的例子AsyncProstReader,它来自KV server 里用过的 async-prost 库
/// A marker that indicates that the wrapping type is compatible with `AsyncProstReader` with Prost support. #[derive(Debug)] pub struct AsyncDestination; /// a marker that indicates that the wrapper type is compatible with `AsyncProstReader` with Framed support. #[derive(Debug)] pub struct AsyncFrameDestination; /// A wrapper around an async reader that produces an asynchronous stream of prost-decoded values #[derive(Debug)] pub struct AsyncProstReader<R, T, D> { reader: R, pub(crate) buffer: BytesMut, into: PhantomData<T>, dest: PhantomData<D>, }
- 这个数据结构使用了三个泛型参数,R,T,D.
- 其实数据结构中真正用到的只有一个 R,它可以是一个实现了 AsyncRead 的数据结构(稍后会看到)。
- 另外两个泛型参数 T 和 D,在数据结构定义的时候其实并不需要,只是在数据结构的实现过程中,才需要用到它们的约束。
- 其中,T 是从 R 中读取出的数据反序列化出来的类型,在实现时用 prost::Message 约束。
- D 是一个类型占位符,它会根据需要被具体化为 AsyncDestination 或者 AsyncFrameDestination。
- 类型参数 D 如何使用,我们可以先想像一下:
- 实现 AsyncProstReader 的时候,我们希望在使用 AsyncDestination 时,提供一种实现
- 而在使用 AsyncFrameDestination 时,提供另一种实现
也就是说,这里的类型参数 D,在 impl 的时候,会被具体化成某个类型。
拿着这个想法,来看 AsyncProstReader 在实现 Stream 时,D 是如何具体化的
这里你不用关心 Stream 具体是什么以及如何实现。
impl<R, T> Stream for AsyncProstReader<R, T, AsyncDestination> where T: Message + Default, R: AsyncRead + Unpin, { type Item = Result<T, io::Error>; fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { ... } }
再看对另外一个对 D 的具体实现:
impl<R, T> Stream for AsyncProstReader<R, T, AsyncFrameDestination> where R: AsyncRead + Unpin, T: Framed + Default, { type Item = Result<T, io::Error>; fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { ... } }
在这个例子里,除了 Stream 的实现不同外,AsyncProstReader 的其它实现都是共享的。
所以我们有必要为其增加一个泛型参数 D,使其可以根据不同的 D 的类型,来提供不同的 Stream 实现。
AsyncProstReader: 综合使用了泛型的三种用法,感兴趣的话你可以看源代码
泛型函数
使用泛型结构作为参数或返回值
在声明一个函数的时候,我们还可以不指定具体的参数或返回值的类型,而是由泛型参数来代替
fn id<T>(x: T) -> T { return x; } fn main() { let int = id(10); let string = id("Tyr"); println!("{}, {}", int, string); }
泛型函数编译时进行单态化
编译时展开泛型参数单态化
对于泛型函数,Rust 会进行单态化(Monomorphization)处理,也就是在编译时,把所有用到的泛型函数的泛型参数展开,生成若干个函数。 所以,下方的 id() 编译后会得到 一个处理后的多个版本
fn id<T>(x: T) -> T { x } fn main() { let int = id(42); let string = id("Tyr"); println!("{}, {}", int, string); }
单态化的优劣
- 单态化的好处是:
- 泛型函数的调用是静态分派(static dispatch) 在编译时就一一对应
- 既保有多态的灵活性,又没有任何效率的损失,和普通函数调用一样高效。
- 坏处:编译慢、文件大、丢失泛型信息。这反过来又是动态分派的好处
- 但是对比刚才编译会展开的代码也能很清楚看出来,单态化有很明显的坏处
- 就是编译速度很慢,一个泛型函数,编译器需要找到所有用到的不同类型,一个个编译
- 所以 Rust 编译代码的速度总被人吐槽,这和单态化脱不开干系(另一个重要因素是宏)。
- 同时,这样编出来的二进制会比较大,因为泛型函数的二进制代码实际存在 N 份。
- 还有一个可能你不怎么注意的问题:因为单态化,代码以二进制分发会损失泛型的信息。
- 如果我写了一个库,提供了如上的 id() 函数,使用这个库的开发者如果拿到的是二进制
- 那么这个二进制中必须带有原始的泛型函数,才能正确调用。但单态化之后,原本的泛型信息就被丢弃了。
返回值携带泛型参数: 选择trait object而不是trait impl
例子:使用trait object的迭代函数
pub trait Storage { ... /// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; }
对于 get_iter() 方法,并不关心返回值是一个什么样的 Iterator,只要它能够允许我们不断调用 next() 方法,获得一个 Kvpair 的结构,就可以了。在实现里,使用了 trait object。
上面的例子不能使用trait impl,因为rust还不允许
// 目前 trait 还不支持 fn get_iter(&self, table: &str) -> Result<impl Iterator<Item = Kvpair>, KvError>;
pub trait ImplTrait { // 允许 fn impl_in_args(s: impl Into<String>) -> String { s.into() } // 不允许 fn impl_as_return(s: String) -> impl Into<String> { s } }
使用impl泛型参数做返回值,很难构造成功
// 目前 trait 还不支持 fn get_iter(&self, table: &str) -> Result<impl Iterator<Item = Kvpair>, KvError>; // 可以正确编译 pub fn generics_as_return_working(i: u32) -> impl Iterator<Item = u32> { std::iter::once(i) } // 期待泛型类型,却返回一个具体类型 pub fn generics_as_return_not_working<T: Iterator<Item = u32>>(i: u32) -> T { std::iter::once(i) }
可以返回 trait object,它消除了类型的差异,把所有不同的实现 Iterator 的类型都统一到一个相同的 trait object 下
// 返回 trait object pub fn trait_object_as_return_working(i: u32) -> Box<dyn Iterator<Item = u32>> { Box::new(std::iter::once(i)) }
使用 trait object 是有额外的代价的,首先这里有一次额外的堆分配,其次动态分派会带来一定的性能损失。
复杂泛型参数处理:一步步分解
一个复杂泛型参数示例
pub fn comsume_iterator<F, Iter, T>(mut f: F) where F: FnMut(i32) -> Iter, Iter: Iterator<Item = T>, T: std::fmt::Debug, { // 根据 F 的类型,f(10) 返回 iterator,所以可以用 for 循环 for item in f(10) { println!("{:?}", item); // item 实现了 Debug trait,所以可以用 {:?} 打印 } }
一步步分解,其实并不难理解其实质:
- F: FnMut(i32) -> Iter: 参数 F 是一个闭包,接受 i32,返回 Iter 类型;
- Iter: Iterator<Item = T>: 参数 Iter 是一个 Iterator,Item 是 T 类型;
- T: std::fmt::Debug: 参数 T 是一个实现了 Debug trait 的类型。
Trait Impl/Bound: 特设多态,编译期单态化
Trait impl的两面派
其实从两个相对的角色🎭来看,就可以理解为何trait impl有两种叫法。
具体实现
当一个开发者想给类型添加方法的时候,需要先定义trait,再为类型实现trait指定方法。
设计约束
当一个设计者设计好完整流程后,为了让使用者能够保留一定空间自由度去自定义实现,就可以要求这个类型需要满足某个trait,这就是trait约束
基本练习: 使用self参数
支持泛型
版本一:支持数字相加
use std::ops::Add; #[derive(Debug)] struct Complex { real: f64, imagine: f64, } impl Complex { pub fn new(real: f64, imagine: f64) -> Self { Self { real, imagine } } } // 对 Complex 类型的实现 impl Add for Complex { type Output = Self; // 注意 add 第一个参数是 self,会移动所有权 fn add(self, rhs: Self) -> Self::Output { let real = self.real + rhs.real; let imagine = self.imagine + rhs.imagine; Self::new(real, imagine) } } fn main() { let c1 = Complex::new(1.0, 1f64); let c2 = Complex::new(2 as f64, 3.0); println!("{:?}", c1 + c2); // c1, c2 已经被移动,所以下面这句无法编译 // println!("{:?}", c1 + c2); }
支持继承
trait B:A
在 Rust 中,一个 trait 可以“继承”另一个 trait 的关联类型和关联函数。比如 trait B: A ,是说任何类型 T,如果实现了 trait B,它也必须实现 trait A,换句话说,trait B 在定义时可以使用 trait A 中的关联类型和方法。
impl<T: ?Sized> StreamExt for T where T: Stream {}
如果你实现了 Stream trait,就可以直接使用 StreamExt 里的方法了
Self和self
类比python:Self对应Cls, self两边一样。
在闭包中还要结合考虑是否转移所有权:
- self转移
- Self不转移
Self和self区别使用, Self其实就是类方法
use std::fmt; use std::io::Write; struct BufBuilder { buf: Vec<u8>, } impl BufBuilder { pub fn new() -> Self { Self { buf: Vec::with_capacity(1024), } } } impl fmt::Debug for BufBuilder { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "{}", String::from_utf8_lossy(self.buf.as_ref())) } } impl Write for BufBuilder { fn write(&mut self, buf: &[u8]) -> std::io::Result<usize> { self.buf.extend_from_slice(buf); Ok(buf.len()) } fn flush(&mut self) -> std::io::Result<()> { Ok(()) } } fn main() { let mut buf = BufBuilder::new(); buf.write_all(b"Hello world!").unwrap(); println!("{:?}", buf); }
self: Self, 实例来自于类型
- Self 代表当前的类型,比如 File 类型实现了 Write,那么实现过程中使用到的 Self 就指代 File。
- self 在用作方法的第一个参数时,实际上是 self: Self 的简写,所以 &self 是 self: &Self, 而 &mut self 是 self: &mut Self。
递进练习trait使用场景
基础使用:具体类型实现
定义Parse trait并实现使用
use regex::Regex; pub trait Parse { fn parse(s: &str) -> Self; } impl Parse for u8 { fn parse(s: &str) -> Self { let re: Regex = Regex::new(r"^[0-9]+").unwrap(); if let Some(captures) = re.captures(s) { captures .get(0) .map_or(0, |s| s.as_str().parse().unwrap_or(0)) } else { 0 } } } #[test] fn parse_should_work() { assert_eq!(u8::parse("123abcd"), 123); assert_eq!(u8::parse("1234abcd"), 0); assert_eq!(u8::parse("abcd"), 0); } fn main() { println!("result: {}", u8::parse("255 hello world")); }
- 这里的Parse Trait里面的parse方法没有传入self/Self参数,所以调用的时候使用::而不是.
- 这种基础用法中,被实现的是具体类型
进阶使用
- 这也是分离定义与实现的用处
- 下方的常用trait实现也是基于进阶使用整理出来提供的工具。
泛型实现+trait约束
impl Parse for T
use std::str::FromStr; use regex::Regex; pub trait Parse { fn parse(s: &str) -> Self; } impl<T> Parse for T where T: FromStr + Default, { fn parse(s: &str) -> Self { let re: Regex = Regex::new(r"^[0-9]+(\.[0-9]+)?").unwrap(); let d = || Default::default(); if let Some(captures) = re.captures(s) { captures .get(0) .map_or(d(), |s| s.as_str().parse().unwrap_or_else(|_| d())) } else { d() } } } #[test] fn parse_should_work() { assert_eq!(u32::parse("123abcd"), 123); assert_eq!(u32::parse("123.45abcd"), 0); assert_eq!(f64::parse("123.45abcd").to_string(), "123.45"); assert_eq!(f64::parse("abcd").to_string(), "0"); } fn main() { println!("result: {}", u8::parse("255 hello world")); }
- 对比上一个例子,这里被实现的是泛型,对于上一种用法进一步抽象
- 这样就把被实现类型从一个具体类型,扩展为一类实现了具体trait的类型,不需要重复去实现trait
这个抽象点多体会一下:从抓类型到抓实现特定trait的泛型
trait带有泛型参数+trait约束
使用一个思考题来加深印象
泛型参数impl报错
use std::io::{BufWriter, Write}; use std::net::TcpStream; #[derive(Debug)] struct MyWriter<W> { writer: W, } impl<W: Write> MyWriter<W> { pub fn new(addr: &str) -> Self { let stream = TcpStream::connect("127.0.0.1:8080").unwrap(); Self { writer: BufWriter::new(stream), } } pub fn write(&mut self, buf: &str) -> std::io::Result<()> { self.writer.write_all(buf.as_bytes()) } } fn main() { let writer = MyWriter::new("127.0.0.1:8080"); writer.write("hello world!"); }
主要原因是,实现 new 方法时,对泛型的约束要求要满足 W: Write,而 new 的声明返回值是 Self,也就是说 self.wirter 必须是 W: Write 类型(泛型),但实际返回值是一个确定的类型 BufWriter
- 修改new方法返回值
use std::io::{BufWriter, Write}; use std::net::TcpStream; #[derive(Debug)] struct MyWriter<W> { writer: W, } impl<W: Write> MyWriter<W> { pub fn new(writer: W) -> Self { Self { writer } } pub fn write(&mut self, buf: &str) -> std::io::Result<()> { self.writer.write_all(buf.as_bytes()) } } fn main() { let stream = TcpStream::connect("127.0.0.1:8080").unwrap(); let mut writer = MyWriter::new(BufWriter::new(stream)); writer.write("hello world!").unwrap(); }
- 针对实现new方法
impl MyWriter<BufWriter<TcpStream>> { pub fn new(addr: &str) -> Self { let stream = TcpStream::connect(addr).unwrap(); Self { writer: BufWriter::new(stream), } } } fn main() { let mut writer = MyWriter::new("127.0.0.1:8080"); writer.write("hello world!"); }
- 使用依赖注入修改new方法实现
impl<W: Write> MyWriter<W> { pub fn new(writer: W) -> Self { Self { writer, } } } fn main() { let stream = TcpStream::connect("127.0.0.1:8080").unwrap(); let mut writer = MyWriter::new(BufWriter::new(stream)); writer.write("hello world!"); }
补充使用:使用关联类型+添加Result<T, E>
关联类型自定义Error
use std::str::FromStr; use regex::Regex; pub trait Parse { type Error; fn parse(s: &str) -> Result<Self, Self::Error> where Self: Sized; } impl<T> Parse for T where T: FromStr + Default, { // 定义关联类型 Error 为 String type Error = String; fn parse(s: &str) -> Result<Self, Self::Error> { let re: Regex = Regex::new(r"^[0-9]+(\.[0-9]+)?").unwrap(); if let Some(captures) = re.captures(s) { // 当出错时我们返回 Err(String) captures .get(0) .map_or(Err("failed to capture".to_string()), |s| { s.as_str() .parse() .map_err(|_err| "failed to parse captured string".to_string()) }) } else { Err("failed to parse string".to_string()) } } } #[test] fn parse_should_work() { assert_eq!(u32::parse("123abcd"), Ok(123)); assert_eq!( u32::parse("123.45abcd"), Err("failed to parse captured string".into()) ); assert_eq!(f64::parse("123.45abcd"), Ok(123.45)); assert!(f64::parse("abcd").is_err()); } fn main() { println!("result: {:?}", u8::parse("255 hello world")); }
#![allow(unused)] fn main() { type Error = String; fn parse(s: &str) -> Result<Self, Self::Error> }
Trait Object: 子类型多态,运行时通过vtable动态分发
子类型多态: 动态分派
在运行期决定, 第一个参数是&self
pub trait Formatter { fn format(&self, input: &mut String) -> bool; } struct MarkdownFormatter; impl Formatter for MarkdownFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with Markdown formatter"); true } } struct RustFormatter; impl Formatter for RustFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with Rust formatter"); true } } struct HtmlFormatter; impl Formatter for HtmlFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with HTML formatter"); true } } pub fn format(input: &mut String, formatters: Vec<&dyn Formatter>) { for formatter in formatters { formatter.format(input); } } fn main() { let mut text = "Hello world!".to_string(); let html: &dyn Formatter = &HtmlFormatter; let rust: &dyn Formatter = &RustFormatter; let formatters = vec![html, rust]; format(&mut text, formatters); println!("text: {}", text); }
要有一种手段,告诉编译器,此处需要并且仅需要任何实现了 Formatter 接口的数据类型。
在 Rust 里,这种类型叫 Trait Object,表现为 &dyn Trait 或者 Box。
- 这里结构体只是声明了一下,并不关注其包含什么字段
实现机理:ptr+vtable
Trait Object的底层逻辑就是胖指针
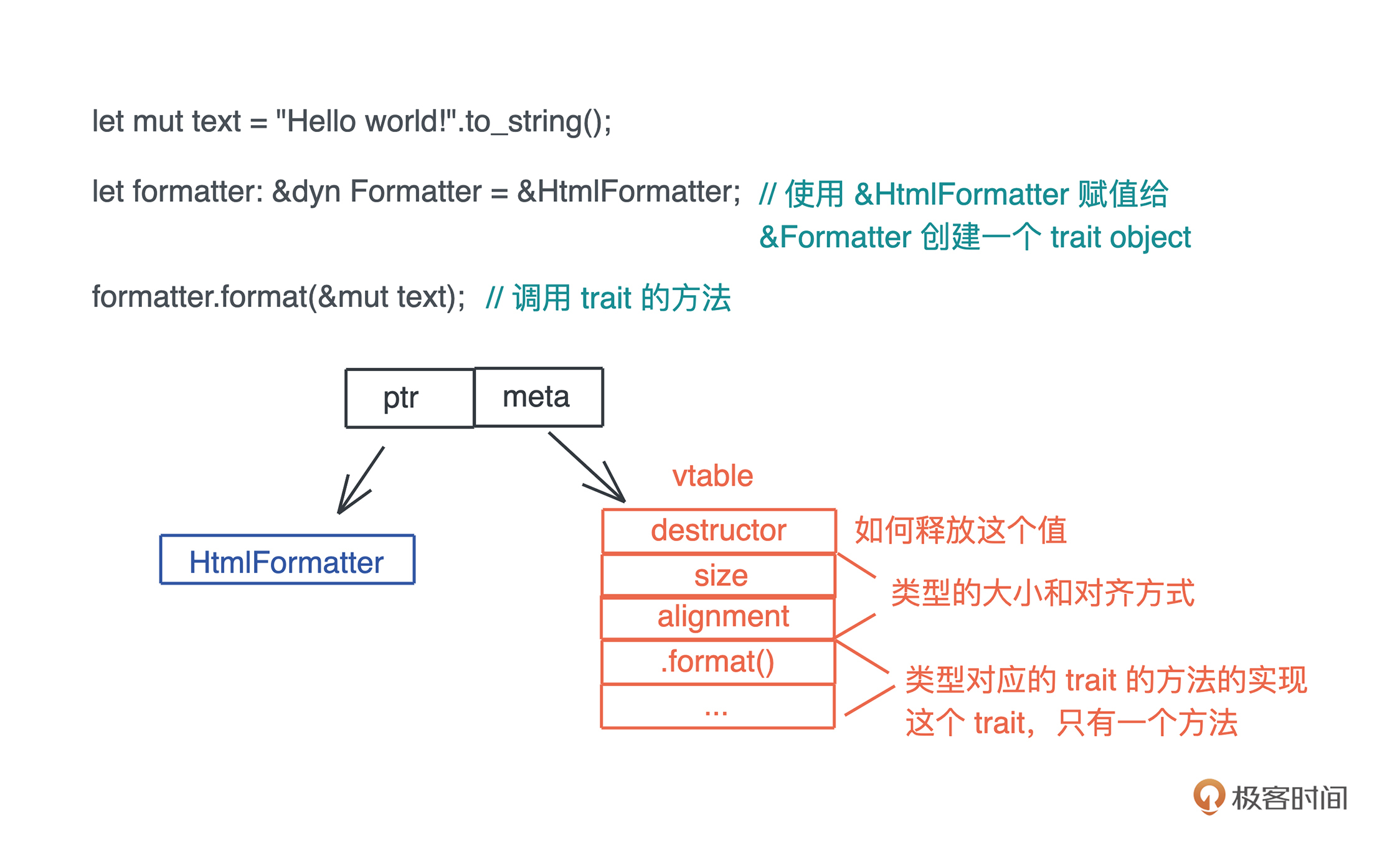
HtmlFormatter 的引用赋值给 Formatter 后,会生成一个 Trait Object,在上图中可以看到,Trait Object 的底层逻辑就是胖指针。
其中,一个指针指向数据本身,另一个则指向虚函数表(vtable)。
vtable是一张静态表
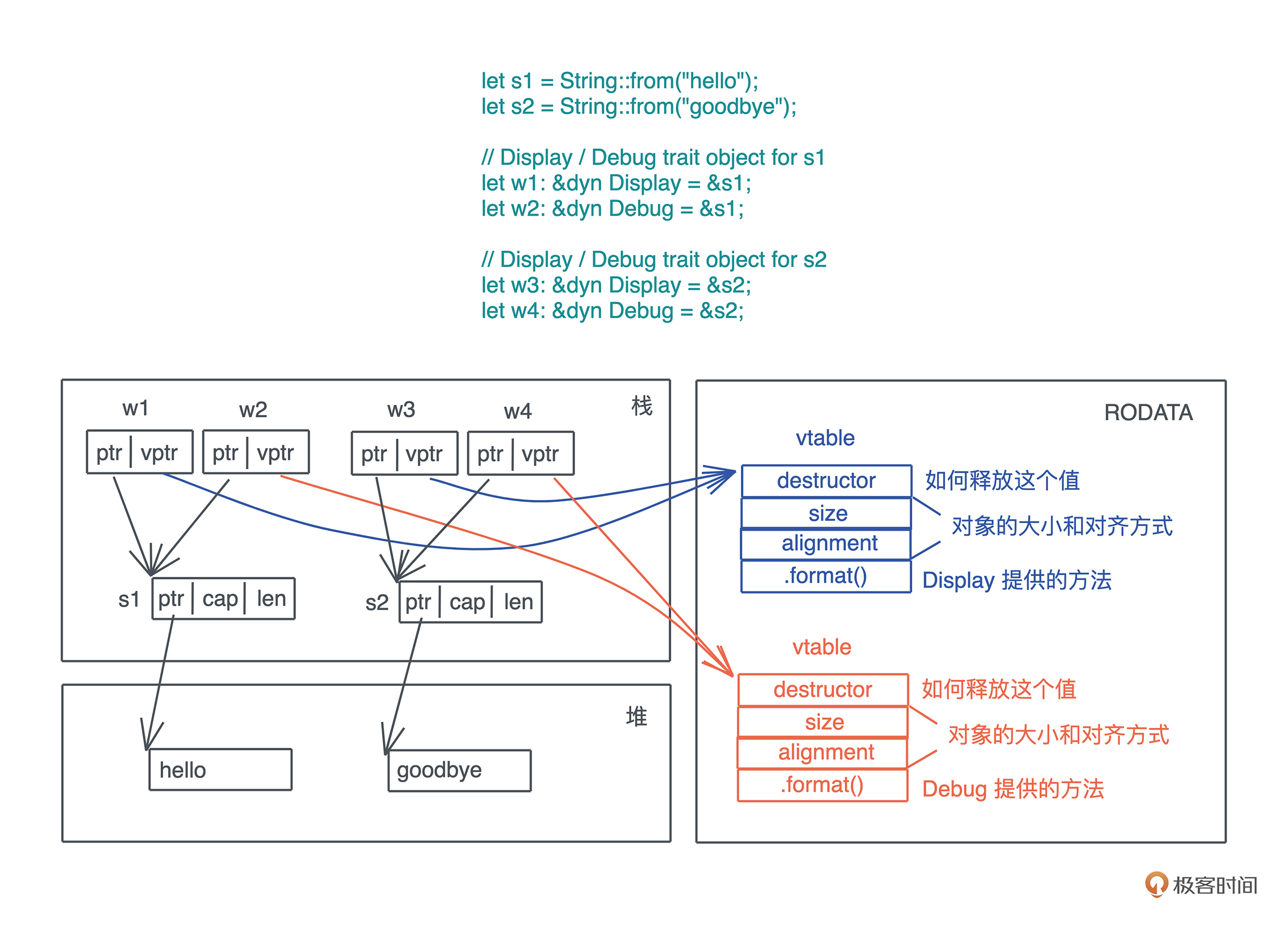
- vtable 是一张静态的表,Rust 在编译时会为使用了 trait object 的类型的 trait 实现生成一张表,放在可执行文件中(一般在 TEXT 或 RODATA 段)
在这张表里,包含具体类型的一些信息,如 size、aligment 以及一系列函数指针 这个接口支持的所有的方法,比如 format() ;具体类型的 drop trait,当 Trait object 被释放,它用来释放其使用的所有资源。这样,当在运行时执行 formatter.format() 时,formatter 就可以从 vtable 里找到对应的函数指针,执行具体的操作。
vtable会为每个类型的每个trait实现一张表
use std::fmt::{Debug, Display}; use std::mem::transmute; fn main() { let s = String::from("hello world!"); let s1 = String::from("goodbye world!"); // Display / Debug trait object for s let w1: &dyn Display = &s; let w2: &dyn Debug = &s; // Display / Debug trait object for s1 let w3: &dyn Display = &s1; let w4: &dyn Debug = &s1; // 强行把 triat object 转换成两个地址 (usize, usize) // 这是不安全的,所以是 unsafe let (addr1, vtable1): (usize, usize) = unsafe { transmute(w1) }; let (addr2, vtable2): (usize, usize) = unsafe { transmute(w2) }; let (addr3, vtable3): (usize, usize) = unsafe { transmute(w3) }; let (addr4, vtable4): (usize, usize) = unsafe { transmute(w4) }; // s 和 s1 在栈上的地址,以及 main 在 TEXT 段的地址 println!( "s: {:p}, s1: {:p}, main(): {:p}", &s, &s1, main as *const () ); // trait object(s / Display) 的 ptr 地址和 vtable 地址 println!("addr1: 0x{:x}, vtable1: 0x{:x}", addr1, vtable1); // trait object(s / Debug) 的 ptr 地址和 vtable 地址 println!("addr2: 0x{:x}, vtable2: 0x{:x}", addr2, vtable2); // trait object(s1 / Display) 的 ptr 地址和 vtable 地址 println!("addr3: 0x{:x}, vtable3: 0x{:x}", addr3, vtable3); // trait object(s1 / Display) 的 ptr 地址和 vtable 地址 println!("addr4: 0x{:x}, vtable4: 0x{:x}", addr4, vtable4); // 指向同一个数据的 trait object 其 ptr 地址相同 assert_eq!(addr1, addr2); assert_eq!(addr3, addr4); // 指向同一种类型的同一个 trait 的 vtable 地址相同 // 这里都是 String + Display assert_eq!(vtable1, vtable3); // 这里都是 String + Debug assert_eq!(vtable2, vtable4); }
对象安全
那什么样的 trait 不是对象安全的呢?
- 如果 trait 所有的方法,返回值是 Self 或者携带泛型参数,那么这个 trait 就不能产生 trait object。
- 不允许返回 Self,是因为 trait object 在产生时,原来的类型会被抹去,所以 Self 究竟是谁不知道。
- 比如 Clone trait 只有一个方法 clone(),返回 Self,所以它就不能产生 trait object。
- 不允许携带泛型参数,是因为 Rust 里带泛型的类型在编译时会做单态化,而 trait object 是运行时的产物,两者不能兼容。
- 比如 Fromtrait,因为整个 trait 带了泛型,每个方法也自然包含泛型,就不能产生 trait object。如果一个 trait 只有部分方法返回 Self 或者使用了泛型参数,那么这部分方法在 trait object 中不能调用。
使用场景
在函数中使用
在函数返回值中使用
在数据结构中使用
复杂多态实例
从编程角度理解多态的意义
理解多态:
- 首先在于和编译器“心有灵犀“:你可以在设计功能时更加自如挥洒,这也是通向高手的必经之路。
- 其次是在看源码的时候,可以和其他高手互相印证。
实例一:参数多态+特设多态(substrate/frame/executive/src/lib.rs)
这个例子是substrate的基础执行库,主要用到泛型结构体(参数多态) + 泛型约束(trait impl: 特设多态)
一个更加复杂的例子:来自substrate的lib.rs
#![allow(unused)] fn main() { /// Main entry point for certain runtime actions as e.g. `execute_block`. /// /// Generic parameters: /// - `System`: Something that implements `frame_system::Config` /// - `Block`: The block type of the runtime /// - `Context`: The context that is used when checking an extrinsic. /// - `UnsignedValidator`: The unsigned transaction validator of the runtime. /// - `AllPalletsWithSystem`: Tuple that contains all pallets including frame system pallet. Will be /// used to call hooks e.g. `on_initialize`. /// - `OnRuntimeUpgrade`: Custom logic that should be called after a runtime upgrade. Modules are /// already called by `AllPalletsWithSystem`. It will be called before all modules will be called. pub struct Executive< System, Block, Context, UnsignedValidator, AllPalletsWithSystem, OnRuntimeUpgrade = (), >( PhantomData<( System, Block, Context, UnsignedValidator, AllPalletsWithSystem, OnRuntimeUpgrade, )>, ); impl< System: frame_system::Config + EnsureInherentsAreFirst<Block>, Block: traits::Block<Header = System::Header, Hash = System::Hash>, Context: Default, UnsignedValidator, AllPalletsWithSystem: OnRuntimeUpgrade + OnInitialize<System::BlockNumber> + OnIdle<System::BlockNumber> + OnFinalize<System::BlockNumber> + OffchainWorker<System::BlockNumber>, COnRuntimeUpgrade: OnRuntimeUpgrade, > ExecuteBlock<Block> for Executive<System, Block, Context, UnsignedValidator, AllPalletsWithSystem, COnRuntimeUpgrade> where Block::Extrinsic: Checkable<Context> + Codec, CheckedOf<Block::Extrinsic, Context>: Applyable + GetDispatchInfo, CallOf<Block::Extrinsic, Context>: Dispatchable<Info = DispatchInfo, PostInfo = PostDispatchInfo>, OriginOf<Block::Extrinsic, Context>: From<Option<System::AccountId>>, UnsignedValidator: ValidateUnsigned<Call = CallOf<Block::Extrinsic, Context>>, { fn execute_block(block: Block) { Executive::< System, Block, Context, UnsignedValidator, AllPalletsWithSystem, COnRuntimeUpgrade, >::execute_block(block); } } impl< System: frame_system::Config + EnsureInherentsAreFirst<Block>, Block: traits::Block<Header = System::Header, Hash = System::Hash>, Context: Default, UnsignedValidator, AllPalletsWithSystem: OnRuntimeUpgrade + OnInitialize<System::BlockNumber> + OnIdle<System::BlockNumber> + OnFinalize<System::BlockNumber> + OffchainWorker<System::BlockNumber>, COnRuntimeUpgrade: OnRuntimeUpgrade, > Executive<System, Block, Context, UnsignedValidator, AllPalletsWithSystem, COnRuntimeUpgrade> where Block::Extrinsic: Checkable<Context> + Codec, CheckedOf<Block::Extrinsic, Context>: Applyable + GetDispatchInfo, CallOf<Block::Extrinsic, Context>: Dispatchable<Info = DispatchInfo, PostInfo = PostDispatchInfo>, OriginOf<Block::Extrinsic, Context>: From<Option<System::AccountId>>, UnsignedValidator: ValidateUnsigned<Call = CallOf<Block::Extrinsic, Context>>, { ... } }
常用trait

内存相关
Clone使用示例
pub trait Clone { fn clone(&self) -> Self; fn clone_from(&mut self, source: &Self) { *self = source.clone() } }
clone()与clone_from()
Clone trait 有两个方法, clone() 和 clone_from() ,后者有缺省实现,所以平时我们只需要实现 clone() 方法即可。你也许会疑惑,这个 clone_from() 有什么作用呢?因为看起来 a.clone_from(&b) ,和 a = b.clone() 是等价的。其实不是,如果 a 已经存在,在 clone 过程中会分配内存,那么用 a.clone_from(&b) 可以避免内存分配,提高效率。b.clone() 是等价的。其实不是,如果 a 已经存在,在 clone 过程中会分配内存,那么用 a.clone_from(&b) 可以避免内存分配,提高效率。
Clone trait 可以通过派生宏直接实现,这样能简化不少代码
#[derive(Clone, Debug)] struct Developer { name: String, age: u8, lang: Language } #[allow(dead_code)] #[derive(Clone, Debug)] enum Language { Rust, TypeScript, Elixir, Haskell } fn main() { let dev = Developer { name: "Tyr".to_string(), age: 18, lang: Language::Rust }; let dev1 = dev.clone(); println!("dev: {:?}, addr of dev name: {:p}", dev, dev.name.as_str()); println!("dev1: {:?}, addr of dev1 name: {:p}", dev1, dev1.name.as_str()) }
如果没有为 Language 实现 Clone 的话,Developer 的派生宏 Clone 将会编译出错。运行这段代码可以看到,对于 name,也就是 String 类型的 Clone,其堆上的内存也被 Clone 了一份,所以 Clone 是深度拷贝,栈内存和堆内存一起拷贝。
clone 方法的接口是 &self
值得注意的是,clone 方法的接口是 &self,这在绝大多数场合下都是适用的,我们在 clone 一个数据时只需要有已有数据的只读引用。但对 Rc 这样在 clone() 时维护引用计数的数据结构,clone() 过程中会改变自己,所以要用 Cell 这样提供内部可变性的结构来进行改变,如果你也有类似的需求,可以参考
Copy
不可变引用实现了 Copy,而可变引用 &mut T 没有实现 Copy
不可变引用实现了 Copy,而可变引用 &mut T 没有实现 Copy。为什么是这样?因为如果可变引用实现了 Copy trait,那么生成一个可变引用然后把它赋值给另一个变量时,就会违背所有权规则: 同一个作用域下只能有一个可变引用。可见,Rust 标准库在哪些结构可以 Copy、哪些不可以 Copy 上,有着仔细的考量。
Drop
有两种情况你可能需要手工实现 Drop
大部分场景无需为数据结构提供 Drop trait,系统默认会依次对数据结构的每个域做 drop。但有两种情况你可能需要手工实现 Drop。
- 第一种是希望在数据结束生命周期的时候做一些事情,比如记日志。
- 第二种是需要对资源回收的场景。编译器并不知道你额外使用了哪些资源,也就无法帮助你 drop 它们。比如说锁资源的释放,
- 在 MutexGuard 中实现了 Drop 来释放锁资源:
impl<T: ?Sized> Drop for MutexGuard<'_, T> { #[inline] fn drop(&mut self) { unsafe { self.lock.poison.done(&self.poison); self.lock.inner.raw_unlock(); } } }
Copy与Drop互斥
需要注意的是,Copy trait 和 Drop trait 是互斥的,两者不能共存,当你尝试为同一种数据类型实现 Copy 时,也实现 Drop,编译器就会报错。
这其实很好理解:
- Copy 是按位做浅拷贝,那么它会默认拷贝的数据没有需要释放的资源;
- 而 Drop 恰恰是为了释放额外的资源而生的。
辅助理解,在代码中,强行用 Box::into_raw 获得堆内存的指针,放入 RawBuffer 结构中,这样就接管了这块堆内存的释放。 虽然 RawBuffer 可以实现 Copy trait,但这样一来就无法实现 Drop trait。 如果程序非要这么写,会导致内存泄漏,因为该释放的堆内存没有释放。
use std::{fmt, slice}; // 注意这里,我们实现了 Copy,这是因为 *mut u8/usize 都支持 Copy #[derive(Clone, Copy)] struct RawBuffer { // 裸指针用 *const / *mut 来表述,这和引用的 & 不同 ptr: *mut u8, len: usize, } impl From<Vec<u8>> for RawBuffer { fn from(vec: Vec<u8>) -> Self { let slice = vec.into_boxed_slice(); Self { len: slice.len(), // into_raw 之后,Box 就不管这块内存的释放了,RawBuffer 需要处理释放 ptr: Box::into_raw(slice) as *mut u8, } } } // 如果 RawBuffer 实现了 Drop trait,就可以在所有者退出时释放堆内存 // 然后,Drop trait 会跟 Copy trait 冲突,要么不实现 Copy,要么不实现 Drop // 如果不实现 Drop,那么就会导致内存泄漏,但它不会对正确性有任何破坏 // 比如不会出现 use after free 这样的问题。 // 你可以试着把下面注释去掉,看看会出什么问题 // impl Drop for RawBuffer { // #[inline] // fn drop(&mut self) { // let data = unsafe { Box::from_raw(slice::from_raw_parts_mut(self.ptr, self.len)) }; // drop(data) // } // } impl fmt::Debug for RawBuffer { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { let data = self.as_ref(); write!(f, "{:p}: {:?}", self.ptr, data) } } impl AsRef<[u8]> for RawBuffer { fn as_ref(&self) -> &[u8] { unsafe { slice::from_raw_parts(self.ptr, self.len) } } } fn main() { let data = vec![1, 2, 3, 4]; let buf: RawBuffer = data.into(); // 因为 buf 允许 Copy,所以这里 Copy 了一份 use_buffer(buf); // buf 还能用 println!("buf: {:?}", buf); } fn use_buffer(buf: RawBuffer) { println!("buf to die: {:?}", buf); // 这里不用特意 drop,写出来只是为了说明 Copy 出来的 buf 被 Drop 了 drop(buf) }
但是这个操作不会破坏 Rust 的正确性保证:即便你 Copy 了 N 份 RawBuffer,由于无法实现 Drop trait,RawBuffer 指向的那同一块堆内存不会释放,所以不会出现 use after free 的内存安全问题
对于代码安全来说,内存泄漏危害大?还是 use after free 危害大呢?
对于代码安全来说,内存泄漏危害大?还是 use after free 危害大呢?
肯定是后者。
- Rust 的底线是内存安全,所以两害相权取其轻。
- 实际上,任何编程语言都无法保证不发生人为的内存泄漏
- 比如程序在运行时,开发者疏忽了,对哈希表只添加不删除,就会造成内存泄漏。
- 但 Rust 会保证即使开发者疏忽了,也不会出现内存安全问题。
标签trait
Sized
Size: Data 和处理 Data 的函数 process_data
struct Data<T> { inner: T, } fn process_data<T>(data: Data<T>) { todo!(); }
等价于:
struct Data<T: Sized> { inner: T, } fn process_data<T: Sized>(data: Data<T>) { todo!(); }
大部分时候,我们都希望能自动添加这样的约束,因为这样定义出的泛型结构,在编译期,大小是固定的,可以作为参数传递给函数。如果没有这个约束,T 是大小不固定的类型, process_data 函数会无法编译。
?Sized: 在少数情况下,需要 T 是可变类型的
pub enum Cow<'a, B: ?Sized + 'a> where B: ToOwned, { // 借用的数据 Borrowed(&'a B), // 拥有的数据 Owned(<B as ToOwned>::Owned), }
这样 B 就可以是 [T] 或者 str 类型,大小都是不固定的。要注意 Borrowed(&’a B) 大小是固定的,因为它内部是对 B 的一个引用,而引用的大小是固定的
Send/Sync
这两个 trait 都是 unsafe auto trait
这两个 trait 都是 unsafe auto trait:
- auto 意味着编译器会在合适的场合,自动为数据结构添加它们的实现
- 而 unsafe 代表实现的这个 trait 可能会违背 Rust 的内存安全准则
- 如果开发者手工实现这两个 trait ,要自己为它们的安全性负责。
Send/Sync 是 Rust 并发安全的基础
Send/Sync 是 Rust 并发安全的基础:
- 如果一个类型 T 实现了 Send trait,意味着 T 可以安全地从一个线程移动到另一个线程,也就是说所有权可以在线程间移动。
- 如果一个类型 T 实现了 Sync trait,则意味着 &T 可以安全地在多个线程中共享。一个类型 T 满足 Sync trait,当且仅当 &T 满足 Send trait。
Send/Sync 在线程安全中的作用
对于 Send/Sync 在线程安全中的作用,可以这么看:
- 如果一个类型 T: Send,那么 T 在某个线程中的独占访问是线程安全的;
- 如果一个类型 T: Sync,那么 T 在线程间的只读共享是安全的。
绝大多数自定义的数据结构都是满足 Send / Sync 的。标准库中,不支持 Send / Sync 的数据结构主要有
- 裸指针 *const T / *mut T。 它们是不安全的,所以既不是 Send 也不是 Sync。
- UnsafeCell 不支持 Sync。 也就是说,任何使用了 Cell 或者 RefCell 的数据结构不支持 Sync。
- 引用计数 Rc 不支持 Send 也不支持 Sync。所以 Rc 无法跨线程。
尝试跨线程使用 Rc / RefCell,会发生什么
use std::{ cell::RefCell, rc::Rc, sync::{Arc, Mutex}, thread, }; // Rc 既不是 Send,也不是 Sync #[allow(dead_code, unused_variables)] fn rc_is_not_send_and_sync() { let a = Rc::new(1); let b = a.clone(); let c = a.clone(); println!("{:?} {:?} {:?}", a, b, c); // 无法编译通过 // thread::spawn(move || { // println!("c= {:?}", c); // }); } #[allow(dead_code)] fn refcell_is_send() { let a = RefCell::new(1); thread::spawn(move || { println!("a= {:?}", a); }); } // RefCell 现在有多个 Arc 持有它,虽然 Arc 是 Send/Sync,但 RefCell 不是 Sync #[allow(dead_code, unused_variables)] fn refcell_is_not_sync() { let a = Arc::new(RefCell::new(1)); let b = a.clone(); let c = a.clone(); println!("{:?} {:?} {:?}", a, b, c); // 无法编译通过 // thread::spawn(move || { // println!("c= {:?}", c); // }); } // Arc<Mutext<T>> 可以多线程共享且修改数据 #[allow(dead_code)] fn arc_mutext_is_send_sync() { let a = Arc::new(Mutex::new(1)); let b = a.clone(); let c = a.clone(); let handle = thread::spawn(move || { let mut g = c.lock().unwrap(); *g += 1; }); { let mut g = b.lock().unwrap(); *g += 1; } handle.join().unwrap(); println!("a= {:?}", a); } // 无法编译通过 // fn mutex_guard_is_not_send() { // let mutex = Mutex::new(1); // let guard = mutex.lock().unwrap(); // thread::spawn(|| { // println!("data= {:?}", guard); // }); // thread::spawn(move || { // println!("data= {:?}", guard); // }); // } fn main() {}
用到的std::thread::spawn
pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static,
它的参数是一个闭包,这个闭包需要 Send + ’static:
- ’static 意思是闭包捕获的自由变量必须是一个拥有所有权的类型,或者是一个拥有静态生命周期的引用;
- Send 意思是,这些被捕获自由变量的所有权可以从一个线程移动到另一个线程。
从这个接口上,可以得出结论:如果在线程间传递 Rc,是无法编译通过的
Rc不支持Send和Sync
// Rc 既不是 Send,也不是 Sync fn rc_is_not_send_and_sync() { let a = Rc::new(1); let b = a.clone(); let c = a.clone(); thread::spawn(move || { println!("c= {:?}", c); }); }
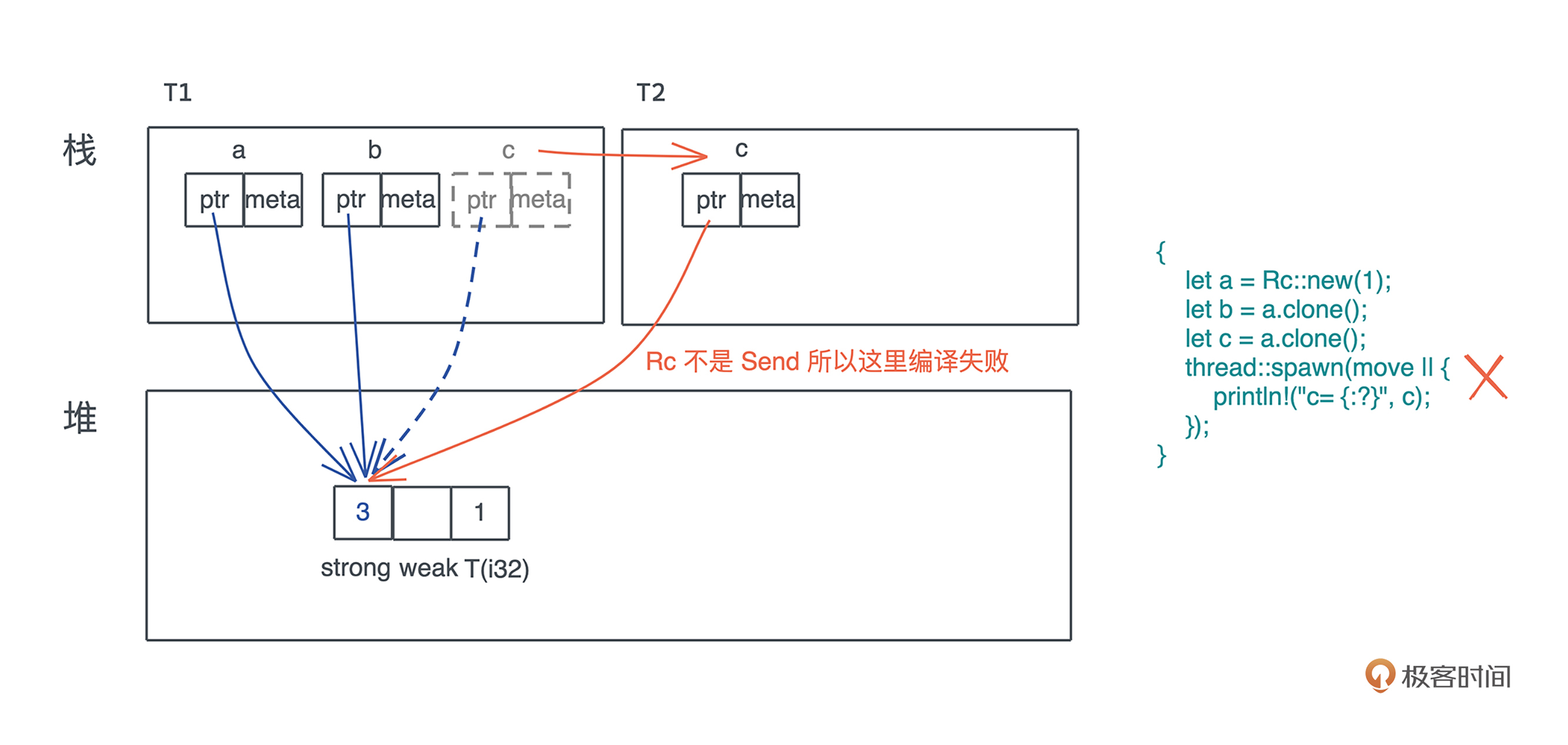
RefCell 可以在线程间转移所有权么?
fn refcell_is_send() { let a = RefCell::new(1); thread::spawn(move || { println!("a= {:?}", a); }); }
Arc支持Send/Sync
// RefCell 现在有多个 Arc 持有它,虽然 Arc 是 Send/Sync,但 RefCell 不是 Sync fn refcell_is_not_sync() { let a = Arc::new(RefCell::new(1)); let b = a.clone(); let c = a.clone(); thread::spawn(move || { println!("c= {:?}", c); }); }
因为 Arc 内部的数据是共享的,需要支持 Sync 的数据结构,但是 RefCell 不是 Sync,编译失败。
在多线程情况下,我们只能使用支持 Send/Sync 的 Arc ,和 Mutex 一起,构造一个可以在多线程间共享且可以修改的类型
use std::{ sync::{Arc, Mutex}, thread, }; // Arc<Mutex<T>> 可以多线程共享且修改数据 fn arc_mutext_is_send_sync() { let a = Arc::new(Mutex::new(1)); let b = a.clone(); let c = a.clone(); let handle = thread::spawn(move || { let mut g = c.lock().unwrap(); *g += 1; }); { let mut g = b.lock().unwrap(); *g += 1; } handle.join().unwrap(); println!("a= {:?}", a); } fn main() { arc_mutext_is_send_sync(); }
最后一个标记 trait Unpin,是用于自引用类型的,属于Future trait。
类型转换
对比两种转化方式
// 第一种方法,为每一种转换提供一个方法 // 把字符串 s 转换成 Path let v = s.to_path(); // 把字符串 s 转换成 u64 let v = s.to_u64(); // 第二种方法,为 s 和要转换的类型之间实现一个 Into<T> trait // v 的类型根据上下文得出 let v = s.into(); // 或者也可以显式地标注 v 的类型 let v: u64 = s.into();
显然,第二种方法要更好,因为它符合软件开发的开闭原则(Open-Close Principle),
“软件中的对象(类、模块、函数等等)对扩展是开放的,但是对修改是封闭的”。
- 在第一种方式下,未来每次要添加对新类型的转换,都要重新修改类型 T 的实现
- 而第二种方式,我们只需要添加一个对于数据转换 trait 的新实现即可。
From/Into: 值到值
这两种方式是等价的,怎么选呢?
let s = String::from("Hello world!"); let s: String = "Hello world!".into();
这两种方式是等价的,怎么选呢?
- From 可以根据上下文做类型推导,使用场景更多;
- 而且因为实现了 From 会自动实现 Into,反之不会。
- 所以需要的时候,不要去实现 Into,只要实现 From 就好了。
From 和 Into 还是自反的
把类型 T 的值转换成类型 T,会直接返回。这是因为标准库有如下的实现:
// From(以及 Into)是自反的 impl<T> From<T> for T { fn from(t: T) -> T { t } }
有了 From 和 Into,很多函数的接口就可以变得灵活
use std::net::{IpAddr, Ipv4Addr, Ipv6Addr}; fn print(v: impl Into<IpAddr>) { println!("{:?}", v.into()); } fn main() { let v4: Ipv4Addr = "2.2.2.2".parse().unwrap(); let v6: Ipv6Addr = "::1".parse().unwrap(); // IPAddr 实现了 From<[u8; 4],转换 IPv4 地址 print([1, 1, 1, 1]); // IPAddr 实现了 From<[u16; 8],转换 IPv6 地址 print([0xfe80, 0, 0, 0, 0xaede, 0x48ff, 0xfe00, 0x1122]); // IPAddr 实现了 From<Ipv4Addr> print(v4); // IPAddr 实现了 From<Ipv6Addr> print(v6); }
函数如果接受一个 IpAddr 为参数,我们可以使用 Into 让更多的类型可以被这个函数使用 所以,合理地使用 From / Into,可以让代码变得简洁,符合 Rust 可读性强的风格,更符合开闭原则。
TryFrom/TryInto: 值到值,可能出现错误
注意,如果你的数据类型在转换过程中有可能出现错误,可以使用 TryFrom 和 TryInto. 它们的用法和 From / Into 一样,只是 trait 内多了一个关联类型 Error,且返回的结果是 Result。
AsRef/AsMut: 引用到引用
AsRef/AsMut定义
pub trait AsRef<T> where T: ?Sized { fn as_ref(&self) -> &T; } pub trait AsMut<T> where T: ?Sized { fn as_mut(&mut self) -> &mut T; }
在 trait 的定义上,都允许 T 使用大小可变的类型,如 str、[u8] 等。 AsMut 除了使用可变引用生成可变引用外,其它都和 AsRef 一样,所以我们重点看 AsRef
体验一下 AsRef 的使用和实现
#[allow(dead_code)] enum Language { Rust, TypeScript, Elixir, Haskell, } impl AsRef<str> for Language { fn as_ref(&self) -> &str { match self { Language::Rust => "Rust", Language::TypeScript => "TypeScript", Language::Elixir => "Elixir", Language::Haskell => "Haskell", } } } fn print_ref(v: impl AsRef<str>) { println!("{}", v.as_ref()); } fn main() { let lang = Language::Rust; // &str 实现了 AsRef<str> print_ref("Hello world!"); // String 实现了 AsRef<str> print_ref("Hello world!".to_string()); // 我们自己定义的 enum 也实现了 AsRef<str> print_ref(lang); }
v.as_ref().clone()
额外说明一下的是: 如果代码出现 v.as_ref().clone() 这样的语句,也就是说你要对 v 进行引用转换,然后又得到了拥有所有权的值,那么应该实现 From,然后做 v.into()。
操作符相关: Deref/DerefMut
Deref/DerefMut定义及说明
pub trait Deref { // 解引用出来的结果类型 type Target: ?Sized; fn deref(&self) -> &Self::Target; } pub trait DerefMut: Deref { fn deref_mut(&mut self) -> &mut Self::Target; }
可以看到,DerefMut “继承”了 Deref,只是它额外提供了一个 deref_mut 方法,用来获取可变的解引用。所以这里重点学习 Deref。
对于普通的引用,解引用很直观
对于普通的引用,解引用很直观,因为它只有一个指向值的地址,从这个地址可以获取到所需要的值
let mut x = 42; let y = &mut x; // 解引用,内部调用 DerefMut(其实现就是 *self) *y += 1;
智能指针来说,拿什么域来解引用就不那么直观, 看看Rc如何实现Deref
impl<T: ?Sized> Deref for Rc<T> { type Target = T; fn deref(&self) -> &T { &self.inner().value } }
可以看到:
- 它最终指向了堆上的 RcBox 内部的 value 的地址
- 然后如果对其解引用的话,得到了 value 对应的值。
- 以下图为例,最终打印出 v = 1。
- 从图中还可以看到,Deref 和 DerefMut 是自动调用的,*b 会被展开为 *(b.deref())。
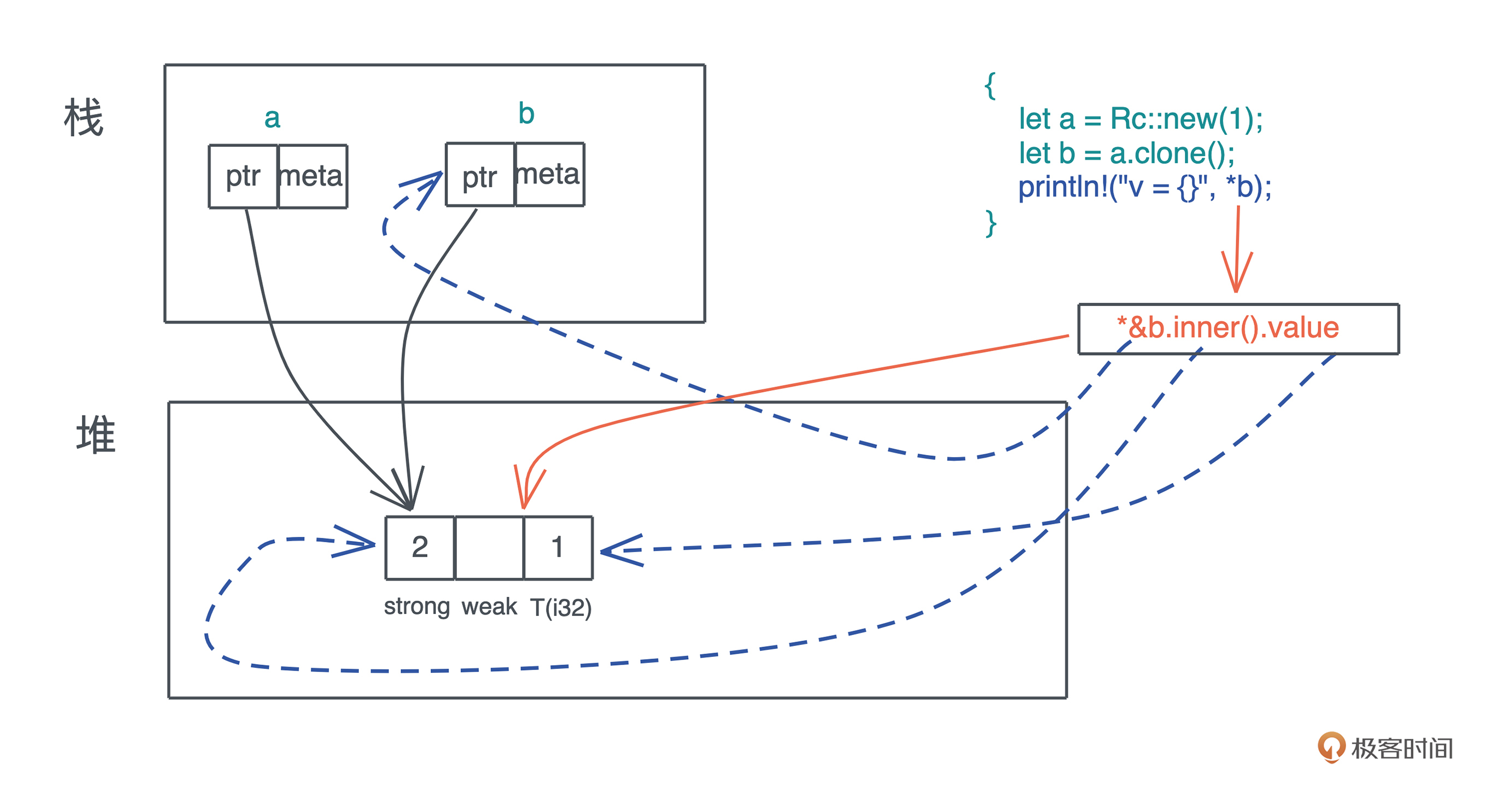
在 Rust 里,绝大多数智能指针都实现了 Deref,我们也可以为自己的数据结构实现 Deref
use std::ops::{Deref, DerefMut}; #[derive(Debug)] struct Buffer<T>(Vec<T>); impl<T> Buffer<T> { pub fn new(v: impl Into<Vec<T>>) -> Self { Self(v.into()) } } impl<T> Deref for Buffer<T> { type Target = [T]; fn deref(&self) -> &Self::Target { &self.0 } } impl<T> DerefMut for Buffer<T> { fn deref_mut(&mut self) -> &mut Self::Target { &mut self.0 } } fn main() { let mut buf = Buffer::new([1, 3, 2, 4]); // 因为实现了 Deref 和 DerefMut,这里 buf 可以直接访问 Vec<T> 的方法 // 下面这句相当于:(&mut buf).deref_mut().sort(),也就是 (&mut buf.0).sort() buf.sort(); println!("buf: {:?}", buf); }
但是在这个例子里,数据结构 Buffer 包裹住了 Vec,但这样一来,原本 Vec 实现了的很多方法,现在使用起来就很不方便,需要用 buf.0 来访问。怎么办? 可以实现 Deref 和 DerefMut,这样在解引用的时候,直接访问到 buf.0,省去了代码的啰嗦和数据结构内部字段的隐藏。
编译器默认强制做解引用
在上面代码里,还有一个值得注意的地方: 写 buf.sort() 的时候,并没有做解引用的操作,为什么会相当于访问了 buf.0.sort() 呢? 这是因为 sort() 方法第一个参数是 &mut self,此时 Rust 编译器会强制做 Deref/DerefMut 的解引用,所以这相当于 (*(&mut buf)).sort()。
其他:Debug/Display/Default
Debug/Display/Defalut定义
pub trait Debug { fn fmt(&self, f: &mut Formatter<'_>) -> Result<(), Error>; } pub trait Display { fn fmt(&self, f: &mut Formatter<'_>) -> Result<(), Error>; }
可以看到,Debug 和 Display 两个 trait 的签名一样,都接受一个 &self 和一个 &mut Formatter。
那为什么要有两个一样的 trait 呢?
这是因为:
- Debug 是为开发者调试打印数据结构所设计的
- 而 Display 是给用户显示数据结构所设计的
- 这也是为什么 Debug trait 的实现可以通过派生宏直接生成,而 Display 必须手工实现(手工决定,自定义如何展现给用户)。
- 在使用的时候,Debug 用 {:?} 来打印,Display 用 {} 打印。
pub trait Default { fn default() -> Self; }
Default trait 用于为类型提供缺省值:
- 它也可以通过 derive 宏 #[derive(Default)] 来生成实现,前提是类型中的每个字段都实现了 Default trait
- 在初始化一个数据结构时,我们可以部分初始化,然后剩余的部分使用 Default::default()。
Debug/Display/Default统一使用例子
use std::fmt; // struct 可以 derive Default,但我们需要所有字段都实现了 Default #[derive(Clone, Debug, Default)] struct Developer { name: String, age: u8, lang: Language, } // enum 不能 derive Default #[allow(dead_code)] #[derive(Clone, Debug)] enum Language { Rust, TypeScript, Elixir, Haskell, } // 手工实现 Default impl Default for Language { fn default() -> Self { Language::Rust } } impl Developer { pub fn new(name: &str) -> Self { // 用 ..Default::default() 为剩余字段使用缺省值 Self { name: name.to_owned(), ..Default::default() } } } impl fmt::Display for Developer { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!( f, "{}({} years old): {:?} developer", self.name, self.age, self.lang ) } } fn main() { // 使用 T::default() let dev1 = Developer::default(); // 使用 Default::default(),但此时类型无法通过上下文推断,需要提供类型 let dev2: Developer = Default::default(); // 使用 T::new let dev3 = Developer::new("Tyr"); println!("dev1: {}\\ndev2: {}\\ndev3: {:?}", dev1, dev2, dev3); }
设计架构
顺手自然
桥接
控制反转
SOLID原则
III. 数据结构
数据结构快速一览
用40分钟的时间,总结了Rust的主要数据结构的内 存布局。它能厘清“数据是如何在堆和栈上存储“的思路,在这里也推荐给你。 Visualizing memory layout of Rust’s data types - YouTube
分类图
数据结构可以看作对于类型系统的进一步整理,结构化。这其实是进一步抽象,从类型中提取出日常常用的工具并分类。
一、智能指针
指针还是引用
引用是特殊的指针
- 指针是一个持有内存地址的值,可以通过解引用来访问它指向的内存地址,理论上可以解引用到任意数据类型;
- 引用是一个特殊 的指针,它的解引用访问是受限的,只能解引用到它引用数据的类型,不能用作它用。
智能指针不仅是指针
智能指针=胖指针+所有权
- 智能指针一定是一个胖指针,但胖指针不一定是一个 智能指针。
- 比如 &str 就只是一个胖指针,它有指向堆内存字符串的指针,同时还有关于字 符串长度的元数据。
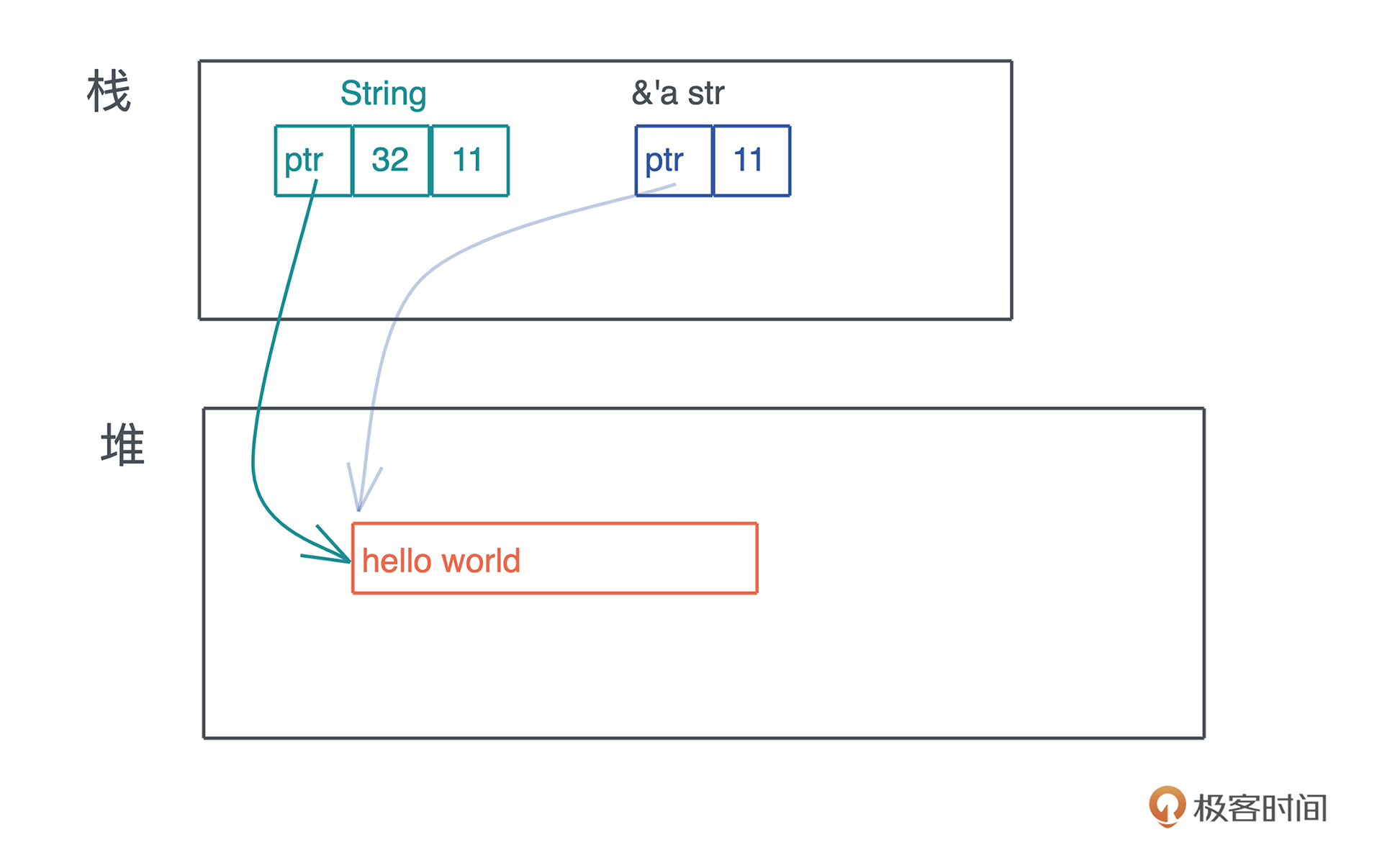
- String 除了多一个 capacity 字段,似乎也没有什么特殊。
- 但 String 对 堆上的值有所有权,而 &str 是没有所有权的
- 这是 Rust 中智能指针和普通胖指针的区 别。
智能指针和结构体有什么区别
- String用结构体定义,其实就是Vec
#![allow(unused)] fn main() { pub struct String { vec: Vec<u8>, } }
- 和普通的结构体不同的是,String 实现了 Deref 和 DerefMut,这使得它在解引用的时 候,会得到 &str
#![allow(unused)] fn main() { impl ops::Deref for String { type Target = str; fn deref(&self) -> &str { unsafe { str::from_utf8_unchecked(&self.vec) } } } impl ops::DerefMut for String { fn deref_mut(&mut self) -> &mut str { unsafe { str::from_utf8_unchecked_mut(&mut *self.vec) } } } }
- 另外,由于在堆上分配了数据,String 还需要为其分配的资源做相应的回收。而 String 内部使用了 Vec,所以它可以依赖 Vec 的能力来释放堆内存
#![allow(unused)] fn main() { unsafe impl<#[may_dangle] T, A: Allocator> Drop for Vec<T, A> { fn drop(&mut self) { unsafe { // use drop for [T] // use a raw slice to refer to the elements of the vector as weakest necessary type; // could avoid questions of validity in certain cases ptr::drop_in_place(ptr::slice_from_raw_parts_mut(self.as_mut_ptr(), self.len)) } // RawVec handles deallocation } } }
在 Rust 中,凡是需要做资源回收的数据结构,且实现了 Deref/DerefMut/Drop,都是智能指针。
按照这个定义,除了 String,还有很多智能指针,比如:
-
用于在堆上 分配内存的 Box
和 Vec -
用于引用计数的 Rc
和 Arc -
很多其他数据结 构,如 PathBuf、Cow<’a, B>、MutexGuard
、RwLockReadGuard 和 RwLockWriteGuard 等也是智能指针。
自定义智能指针
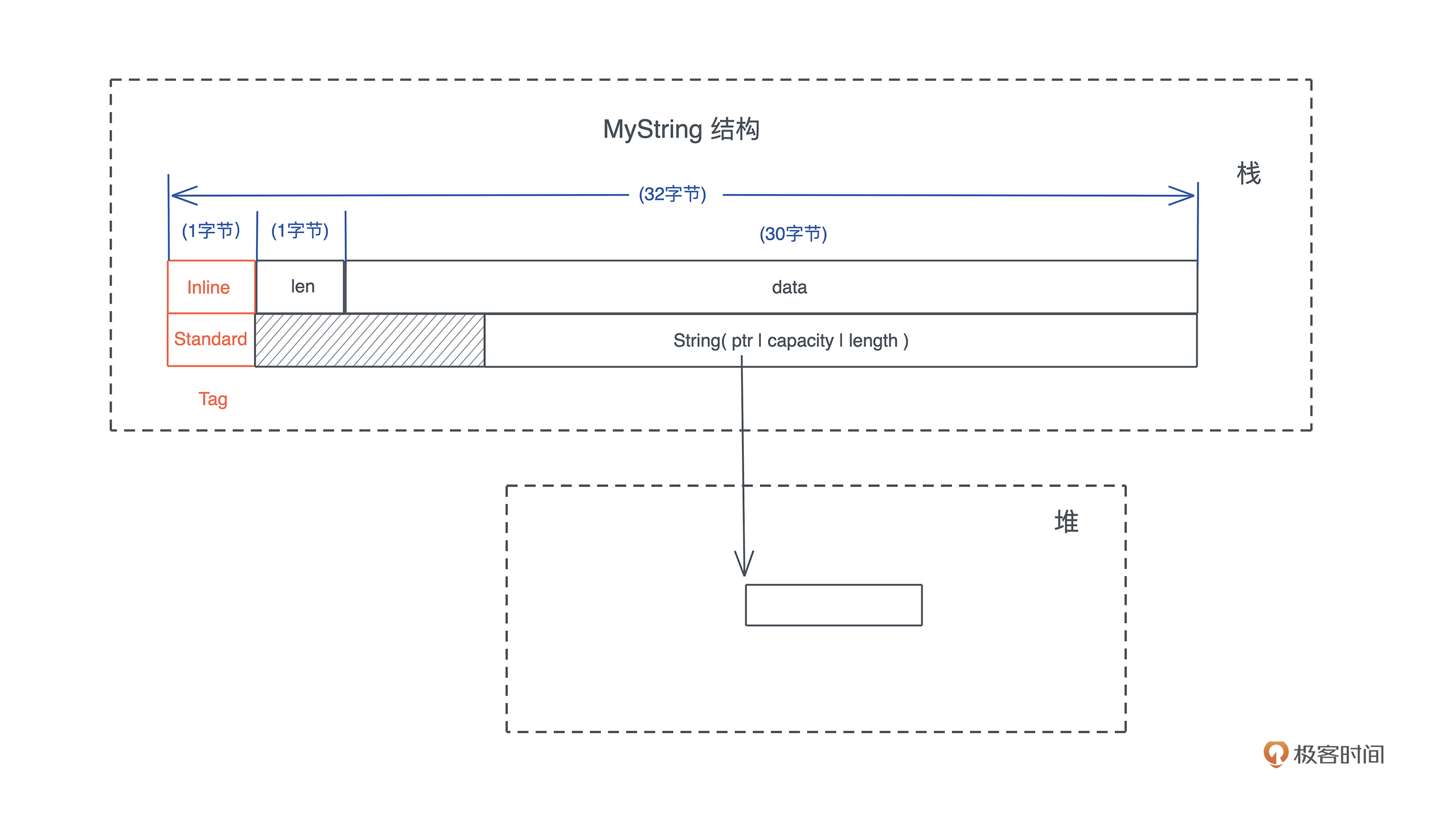
MyString实现代码
use std::{fmt, ops::Deref, str}; const MINI_STRING_MAX_LEN: usize = 30; // MyString 里,String 有 3 个 word,供 24 字节,所以它以 8 字节对齐 // 所以 enum 的 tag + padding 最少 8 字节,整个结构占 32 字节。 // MiniString 可以最多有 30 字节(再加上 1 字节长度和 1字节 tag),就是 32 字节. struct MiniString { len: u8, data: [u8; MINI_STRING_MAX_LEN], } impl MiniString { // 这里 new 接口不暴露出去,保证传入的 v 的字节长度小于等于 30 fn new(v: impl AsRef<str>) -> Self { let bytes = v.as_ref().as_bytes(); // 我们在拷贝内容时一定要要使用字符串的字节长度 let len = bytes.len(); let mut data = [0u8; MINI_STRING_MAX_LEN]; data[..len].copy_from_slice(bytes); Self { len: len as u8, data, } } } impl Deref for MiniString { type Target = str; fn deref(&self) -> &Self::Target { // 由于生成 MiniString 的接口是隐藏的,它只能来自字符串,所以下面这行是安全的 str::from_utf8(&self.data[..self.len as usize]).unwrap() // 也可以直接用 unsafe 版本 // unsafe { str::from_utf8_unchecked(&self.data[..self.len as usize]) } } } impl fmt::Debug for MiniString { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { // 这里由于实现了 Deref trait,可以直接得到一个 &str 输出 write!(f, "{}", self.deref()) } } #[derive(Debug)] enum MyString { Inline(MiniString), Standard(String), } // 实现 Deref 接口对两种不同的场景统一得到 &str impl Deref for MyString { type Target = str; fn deref(&self) -> &Self::Target { match *self { MyString::Inline(ref v) => v.deref(), MyString::Standard(ref v) => v.deref(), } } } // impl From<&str> for MyString { // fn from(s: &str) -> Self { // match s.len() > MINI_STRING_MAX_LEN { // true => Self::Standard(s.to_owned()), // _ => Self::Inline(MiniString::new(s)), // } // } // } // impl From<String> for MyString { // fn from(s: String) -> Self { // match s.len() > MINI_STRING_MAX_LEN { // true => Self::Standard(s), // _ => Self::Inline(MiniString::new(s)), // } // } // } impl<T> From<T> for MyString where T: AsRef<str>, { fn from(s: T) -> Self { match s.as_ref().len() > MINI_STRING_MAX_LEN { true => Self::Standard(s.as_ref().to_owned()), _ => Self::Inline(MiniString::new(s)), } } } impl fmt::Display for MyString { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", self.deref()) } } impl MyString { pub fn push_str(&mut self, s: &str) { match *self { MyString::Inline(ref mut v) => { let len = v.len as usize; let len1 = s.len(); if len + len1 > MINI_STRING_MAX_LEN { let mut owned = v.deref().to_string(); owned.push_str(s); *self = MyString::Standard(owned); } else { let total = len + len1; v.data[len..len + len1].copy_from_slice(s.as_bytes()); v.len = total as u8; } } MyString::Standard(ref mut v) => v.push_str(s), } } } fn main() { let len1 = std::mem::size_of::<MyString>(); let len2 = std::mem::size_of::<MiniString>(); println!("Len: MyString {}, MiniString {}", len1, len2); let s1: MyString = "hello world".into(); let s2: MyString = "这是一个超过了三十个字节的很长很长的字符串".into(); // debug 输出 println!("s1: {:?}, s2: {:?}", s1, s2); // display 输出 println!( "s1: {}({} bytes, {} chars), s2: {}({} bytes, {} chars)", s1, s1.len(), s1.chars().count(), s2, s2.len(), s2.chars().count() ); // MyString 可以使用一切 &str 接口,感谢 Rust 的自动 Deref assert!(s1.ends_with("world")); assert!(s2.starts_with('这')); let s = String::from("这是一个超过了三十个字节的很长很长的字符串"); println!("s: {:p}", &*s); // From<T: AsRef<str>> 的实现会导致额外的复制 let s3: MyString = s.into(); println!("s3: {:p}", &*s3); let mut s4: MyString = "Hello Tyr! ".into(); println!("s4: {:?}", s4); s4.push_str("这是一个超过了三十个字节的很长很长的字符串"); println!("s4: {:?}", s4); }
为了让 MyString 表现行为和 &str 一致:
- 我们可以通过实现 Deref trait 让 MyString 可以被解引用成 &str。
- 除此之外,还可以实现 Debug/Display 和 From
trait,让 MyString 使用起来更方便。 - 这个简单实现的 MyString,不管它内部的数据是纯栈上的 MiniString 版本,还是包含堆 上内存的 String 版本,使用的体验和 &str 都一致,仅仅牺牲了一点点效率和内存,就可 以让小容量的字符串,可以高效地存储在栈上并且自如地使用。
- smartstring 的第三方库实现类似功能,还做了优化。
Box: 在堆上分配内存
从c/c++得到Box灵感
我们先看 Box
为什么有 Box
-
C 需要使用 malloc/calloc/realloc/free 来处理内存的分配,很多时候,被分配出来的内存 在函数调用中来来回回使用,导致谁应该负责释放这件事情很难确定,给开发者造成了极 大的心智负担。
-
C++ 在此基础上改进了一下,提供了一个智能指针 unique_ptr,可以在指针退出作用 域的时候释放堆内存,这样保证了堆内存的单一所有权。这个 unique_ptr 就是 Rust 的 Box
的前身。
Box
#![allow(unused)] fn main() { pub struct Unique<T: ?Sized> { pointer: *const T, // NOTE: this marker has no consequences for variance, but is necessary // for dropck to understand that we logically own a `T`. // // For details, see: // https://github.com/rust-lang/rfcs/blob/master/text/0769-sound-generic-drop.md#phantom-data _marker: PhantomData<T>, } }
堆上分配内存的 Box 其实有一个缺省的泛型参数 A
设计内存分配器的目的除了保证正确性之外,就是为了有效地利用剩余内存,并控制内存 在分配和释放过程中产生的碎片的数量。
在多核环境下,它还要能够高效地处理并发请 求。(如果你对通用内存分配器感兴趣,可以看参考资料) 堆上分配内存的 Box
其实有一个缺省的泛型参数 A,就需要满足 Allocator trait, 并且默认是 Global:
#![allow(unused)] fn main() { pub struct Box<T: ?Sized, A: Allocator = Global>(Unique<T>, A); }
Allocator trait 提供很多方法:
-
allocate 是主要方法,用于分配内存,对应 C 的 malloc/calloc;
-
deallocate,用于释放内存,对应 C 的 free;
-
还有 grow / shrink,用来扩大或缩小堆上已分配的内存,对应 C 的 realloc。
替换默认的内存分配器
如果你想替换默认的内存分配器,可以使用 #[global_allocator] 标记宏,定义你自己的全局分配器。下面的代码展示了如何在 Rust 下使用jemalloc:
use jemallocator::Jemalloc; #[global_allocator] static GLOBAL: Jemalloc = Jemalloc; fn main() {}
实现内存分配器
内存分配器
use std::alloc::{GlobalAlloc, Layout, System}; struct MyAllocator; unsafe impl GlobalAlloc for MyAllocator { unsafe fn alloc(&self, layout: Layout) -> *mut u8 { let data = System.alloc(layout); eprintln!("ALLOC: {:p}, size {}", data, layout.size()); data } unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) { System.dealloc(ptr, layout); eprintln!("FREE: {:p}, size {}", ptr, layout.size()); } } #[global_allocator] static GLOBAL: MyAllocator = MyAllocator; #[allow(dead_code)] struct Matrix { // 使用不规则的数字如 505 可以让 dbg! 的打印很容易分辨出来 data: [u8; 505], } impl Default for Matrix { fn default() -> Self { Self { data: [0; 505] } } } fn main() { // 在这句执行之前已经有一些内存分配和释放 let data = Box::new(Matrix::default()); println!( "!!! allocated memory: {:p}, len: {}", &*data, std::mem::size_of::<Matrix>() ); // data 在这里 drop,可以在打印中看到 FREE // 之后还有很多其它内存被释放 }
- 这里 MyAllocator 就用 System allocator,然后加 eprintln!(),和我 们常用的 println!() 不同的是,eprintln!() 将数据打印到 stderr
- 注意这里不能使用 println!() 。因为 stdout 会打印到一个由 Mutex 互斥锁保护的共享全 局 buffer 中,这个过程中会涉及内存的分配,分配的内存又会触发 println!(),最终造成 程序崩溃。而 eprintln! 直接打印到 stderr,不会 buffer。
- 在使用 Box 分配堆内存的时候要注意,Box::new() 是一个函数,所以传入它的数据会出现 在栈上,再移动到堆上。所以,如果我们的 Matrix 结构不是 505 个字节,是一个非常大 的结构,就有可能出问题。
// #![feature(dropck_eyepatch)] // struct MyBox<T>(Box<T>); // unsafe impl<#[may_dangle] T> Drop for MyBox<T> { // fn drop(&mut self) { // todo!(); // } // } fn main() { // 在堆上分配 16M 内存,但它会现在栈上出现,再移动到堆上 let boxed = Box::new([0u8; 1 << 24]); println!("len: {}", boxed.len()); }
cargo run --bin box或者在 playground 里运行,直接栈溢出 stack overflow- 本地使用 “cargo run –bin box —release” 编译成 release 代码运行,会正常执行!
这是因为 “cargo run” 或者在 playground 下运行,默认是 debug build,它不会做任 何 inline 的优化,而 Box::new() 的实现就一行代码,并注明了要 inline,在 release 模式 下,这个函数调用会被优化掉, 本质是编译器自动调用下列方式:
#![allow(unused)] fn main() { #[cfg(not(no_global_oom_handling))] #[inline(always)] #[doc(alias = "alloc")] #[doc(alias = "malloc")] #[stable(feature = "rust1", since = "1.0.0")] pub fn new(x: T) -> Self { box x } }
这里的关键字 box是 Rust 内部的关键字,用户代码无法调用,它只出现在 Rust 代码中,用于分配堆内存,box 关键字在编译时,会使用内存分配器 分配内存。
内存如何释放
Box默认实现的Drop trait
#![allow(unused)] fn main() { #[stable(feature = "rust1", since = "1.0.0")] unsafe impl<#[may_dangle] T: ?Sized, A: Allocator> Drop for Box<T, A> { fn drop(&mut self) { // FIXME: Do nothing, drop is currently performed by compiler. } } }
先稳定接口,再迭代稳定实现
目前 drop trait 什么都没有做,编译器会自动插入 deallocate 的代码。这是 Rust 语 言的一种策略:在具体实现还没有稳定下来之前,我先把接口稳定,实现随着之后的迭代 慢慢稳定。
Cow<’a, B>: 写时拷贝
写时复制(Copy-on-write)有异曲同工之妙
Cow 是 Rust 下用于提供写时克隆(Clone-on-Write)的一个智能指针,它跟虚拟内存管 理的写时复制(Copy-on-write)有异曲同工之妙:
包裹一个只读借用,但如果调用者需 要所有权或者需要修改内容,那么它会 clone 借用的数据
定义
Cow定义
#![allow(unused)] fn main() { pub enum Cow<'a, B> where B: 'a + ToOwned + ?Sized { Borrowed(&'a B), Owned(<B as ToOwned>::Owned), } }
它是一个 enum,可以包含一个对类型 B 的只读引用,或者包含对类型 B 的拥有所有权的 数据。
具体约束说明见泛型数据结构示例
Cow定义用到ToOwned、Borrowed、Owned、ToOwned梳理
从ToOwned定义开始
想要理解 Cow trait,ToOwned trait 是一道坎: ToOwned定义 -> 关联类型用到Borrow -> Borrow是一个用到Borrowed的trait object
#![allow(unused)] fn main() { pub trait ToOwned { type Owned: Borrow<Self>; #[must_use = "cloning is often expensive and is not expected to have side effects"] fn to_owned(&self) -> Self::Owned; fn clone_into(&self, target: &mut Self::Owned) { ... } } pub trait Borrow<Borrowed> where Borrowed: ?Sized { fn borrow(&self) -> &Borrowed; } }
- 首先,type Owned: Borrow
是一个带有关联类型的 trait - 这里 Owned 是关联类型,需要使用者定义
- 这里 Owned 不能是任意类型,它必须满足 Borrow
trait。
关联类型Owned的理解
type Owned: Borrow: 参考str对ToOwned trait的实现
#![allow(unused)] fn main() { impl ToOwned for str { type Owned = String; #[inline] fn to_owned(&self) -> String { unsafe { String::from_utf8_unchecked(self.as_bytes().to_owned()) } } fn clone_into(&self, target: &mut String) { let mut b = mem::take(target).into_bytes(); self.as_bytes().clone_into(&mut b); *target = unsafe { String::from_utf8_unchecked(b) } } } }
对上面例子的type Owned 为 String如何理解?
-
ToOwned 要求关联类型Owned实现Borrow
, 而此刻实现 ToOwned 的主体是 str,所以 Borrow 是 Borrow -
Owned被定义为String,也就是说 String 要实现 Borrow
#![allow(unused)] fn main() { impl Borrow<str> for String { #[inline] fn borrow(&self) -> &str { &self[..] } } }
Borrow Trait理解: 匹配分发
为何 Borrow 要定义成一个泛型 trait 呢?
例子1:String不同借用方式
use std::borrow::Borrow; fn main() { let s = "hello world!".to_owned(); // 这里必须声明类型,因为 String 有多个 Borrow<T> 实现 // 借用为 &String let r1: &String = s.borrow(); // 借用为 &str let r2: &str = s.borrow(); println!("r1: {:p}, r2: {:p}", r1, r2); }
String 可以被借用为 &String,也可以被借用为 &str
例子2:Cow不同解引用方式
#![allow(unused)] fn main() { impl<B: ?Sized + ToOwned> Deref for Cow<'_, B> { type Target = B; fn deref(&self) -> &B { match *self { Borrowed(borrowed) => borrowed, Owned(ref owned) => owned.borrow(), } } } }
实现的原理很简单,根据 self 是 Borrowed 还是 Owned,我们分别取其内容,生成引用:
- 对于 Borrowed,直接就是引用;
- 对于 Owned,调用其 borrow() 方法,获得引用。
匹配分发
匹配分发:使用match匹配实现静态、动态分发之外的第三种分发
虽然 Cow 是一个 enum,但是通过 Deref 的实现,我们可以获得统一的 体验.
比如 Cow
关系图整理
Cow在需要时才进行内存分配拷贝
场景1:写时拷贝
写时拷贝
那么 Cow 有什么用呢?
- 显然,它可以在需要的时候才进行内存的分配和拷贝,在很多应用 场合,它可以大大提升系统的效率。
- 如果 Cow<’a, B> 中的 Owned 数据类型是一个需要 在堆上分配内存的类型,如 String、Vec
等,还能减少堆内存分配的次数。 - 相对于栈内存的分配释放来说,堆内存的分配和释放效率要低很多,其内部还 涉及系统调用和锁,减少不必要的堆内存分配是提升系统效率的关键手段。
- 而 Rust 的 Cow<’a, B>,在帮助你达成这个效果的同时,使用体验还非常简单舒服。
场景2:URL解析
举例使用Cow进行URL解析
use std::borrow::Cow; use url::Url; fn main() { let url = Url::parse("https://tyr.com/rust?page=1024&sort=desc&extra=hello%20world").unwrap(); let mut pairs = url.query_pairs(); assert_eq!(pairs.count(), 3); let (mut k, v) = pairs.next().unwrap(); // 因为 k, v 都是 Cow<str> 他们用起来感觉和 &str 或者 String 一样 // 此刻,他们都是 Borrowed println!("key: {}, v: {}", k, v); // 当修改发生时,k 变成 Owned k.to_mut().push_str("_lala"); print_pairs((k, v)); print_pairs(pairs.next().unwrap()); print_pairs(pairs.next().unwrap()); } fn print_pairs(pair: (Cow<str>, Cow<str>)) { println!("key: {}, value: {}", show_cow(pair.0), show_cow(pair.1)); } fn show_cow(cow: Cow<str>) -> String { match cow { Cow::Borrowed(v) => format!("Borrowed {}", v), Cow::Owned(v) => format!("Owned {}", v), } }
在解析 URL 的时候,我们经常需要将 querystring 中的参数,提取成 KV pair 来进一步使 用。 绝大多数语言中,提取出来的 KV 都是新的字符串,在每秒钟处理几十 k 甚至上百 k 请求的系统中,你可以想象这会带来多少次堆内存的分配。 但在 Rust 中,我们可以用 Cow 类型轻松高效处理它,在读取 URL 的过程中:
- 每解析出一个 key 或者 value,我们可以用一个 &str 指向 URL 中相应的位置,然后用 Cow 封装它
- 而当解析出来的内容不能直接使用,需要 decode 时,比如 “hello%20world”,我们 可以生成一个解析后的 String,同样用 Cow 封装它。
场景3:序列化/反序列化
举例serde使用Cow进行序列化/反序列化
use serde::Deserialize; use std::borrow::Cow; #[allow(dead_code)] #[derive(Debug, Deserialize)] struct User<'input> { #[serde(borrow)] name: Cow<'input, str>, age: u8, } fn main() { let input = r#"{ "name": "Tyr", "age": 18 }"#; let user: User = serde_json::from_str(input).unwrap(); match user.name { Cow::Borrowed(x) => println!("borrowed {}", x), Cow::Owned(x) => println!("owned {}", x), } }
MutexGuard: 数据加锁
MutexGuard与String、Box、Cow<’a, B>的对比
Deref+Drop
String、Box
- 它不但通过 Deref 提供良好的用户体验
- 还通过 Drop trait 来确保,使用到的内存以外的资源在退出 时进行释放。
使用Mutex::lock获取
MutexGuard这个结构是在调用 Mutex::lock 时生成的
pub fn lock(&self) -> LockResult<MutexGuard<'_, T>> { unsafe { self.inner.raw_lock(); MutexGuard::new(self) } }
- 首先,它会取得锁资源,如果拿不到,会在这里等待;
- 如果拿到了,会把 Mutex 结构的引 用传递给 MutexGuard。
定义与Deref、Drop trait实现
MutexGuard 的定义以及它的 Deref 和 Drop 的实现
// 这里用 must_use,当你得到了却不使用 MutexGuard 时会报警 #[must_use = "if unused the Mutex will immediately unlock"] pub struct MutexGuard<'a, T: ?Sized + 'a> { lock: &'a Mutex<T>, poison: poison::Guard, } impl<T: ?Sized> Deref for MutexGuard<'_, T> { type Target = T; fn deref(&self) -> &T { unsafe { &*self.lock.data.get() } } } impl<T: ?Sized> DerefMut for MutexGuard<'_, T> { fn deref_mut(&mut self) -> &mut T { unsafe { &mut *self.lock.data.get() } } } impl<T: ?Sized> Drop for MutexGuard<'_, T> { #[inline] fn drop(&mut self) { unsafe { self.lock.poison.done(&self.poison); self.lock.inner.raw_unlock(); } } }
从代码中可以看到:
- 当 MutexGuard 结束时,Mutex 会做 unlock
- 这样用户在使用 Mutex 时,可以不必关心何时释放这个互斥锁。
- 因为无论你在调用栈上怎样传递 MutexGuard ,哪怕在错误处理流程上提前退出,Rust 有所有权机制,可以确保只要 MutexGuard 离开作用域,锁就会被释放
使用Mutex_MutexGuard的例子
Mutex & MutexGuard example
use lazy_static::lazy_static; use std::borrow::Cow; use std::collections::HashMap; use std::sync::{Arc, Mutex}; use std::thread; use std::time::Duration; // lazy_static 宏可以生成复杂的 static 对象 lazy_static! { // 一般情况下 Mutex 和 Arc 一起在多线程环境下提供对共享内存的使用 // 如果你把 Mutex 声明成 static,其生命周期是静态的,不需要 Arc static ref METRICS: Mutex<HashMap<Cow<'static, str>, usize>> = Mutex::new(HashMap::new()); } fn main() { // 用 Arc 来提供并发环境下的共享所有权(使用引用计数) let metrics: Arc<Mutex<HashMap<Cow<'static, str>, usize>>> = Arc::new(Mutex::new(HashMap::new())); for _ in 0..32 { let m = metrics.clone(); thread::spawn(move || { let mut g = m.lock().unwrap(); // 此时只有拿到 MutexGuard 的线程可以访问 HashMap let data = &mut *g; // Cow 实现了很多数据结构的 From trait,所以我们可以用 "hello".into() 生成 Cow let entry = data.entry("hello".into()).or_insert(0); *entry += 1; // MutexGuard 被 Drop,锁被释放 }); } thread::sleep(Duration::from_millis(100)); println!("metrics: {:?}", metrics.lock().unwrap()); }
在解析 URL 的时候,我们经常需要将 querystring 中的参数,提取成 KV pair 来进一步使 用。 绝大多数语言中,提取出来的 KV 都是新的字符串,在每秒钟处理几十 k 甚至上百 k 请求的系统中,你可以想象这会带来多少次堆内存的分配。 但在 Rust 中,我们可以用 Cow 类型轻松高效处理它,在读取 URL 的过程中:
- 每解析出一个 key 或者 value,我们可以用一个 &str 指向 URL 中相应的位置,然后用 Cow 封装它
- 而当解析出来的内容不能直接使用,需要 decode 时,比如 “hello%20world”,我们 可以生成一个解析后的 String,同样用 Cow 封装它。
你可以把 MutexGuard 的引用传给另一个线程使用,但你无法把 MutexGuard 整个移动到另一个线程
use std::sync::Mutex; fn main() { // let m = Mutex::new(Mutex::new(1)); let g = m.lock().unwrap(); { rayon::join( || { let mut g1 = g.lock().unwrap(); *g1 += 1; println!("Thread 1: {:?}", *g1); }, || { let mut g1 = g.lock().unwrap(); *g1 += 1; println!("Thread 1: {:?}", *g1); }, ); } }
MutexGuard 的智能指针有很多用途
- r2d2类似实现一个数据库连接池:源码
#![allow(unused)] fn main() { impl<M> Drop for PooledConnection<M> where M: ManageConnection, { fn drop(&mut self) { self.pool.put_back(self.checkout, self.conn.take().unwrap()); } } impl<M> Deref for PooledConnection<M> where M: ManageConnection, { type Target = M::Connection; fn deref(&self) -> &M::Connection { &self.conn.as_ref().unwrap().conn } } impl<M> DerefMut for PooledConnection<M> where M: ManageConnection, { fn deref_mut(&mut self) -> &mut M::Connection { &mut self.conn.as_mut().unwrap().conn } } }
- 类似 MutexGuard 的智能指针有很多用途。比如要创建一个连接池,你可以在 Drop trait 中,回收 checkout 出来的连接,将其再放回连接池。
二、集合容器
对容器进行定义
容器数据结构如何理解
提到容器,很可能你首先会想到的就是数组、列表这些可以遍历的容器,但其实只要把某 种特定的数据封装在某个数据结构中,这个数据结构就是一个容器。比如 Option
对集合容器进行定义
把拥有相同类型对数据放在一起,统一处理
集合容器,顾名思义,就是把一系列拥有相同类型的数据放在一起,统一处理,比如:
-
我们熟悉的字符串 String、数组 [T; n]、列表 Vec
和哈希表 HashMap<K, V> 等; -
虽然到处在使用,但还并不熟悉的切片 slice;
-
在其他语言中使用过,但在 Rust 中还没有用过的循环缓冲区 VecDeque
、双向列 表 LinkedList 等。
这些集合容器有很多共性,比如可以被遍历、可以进行 map-reduce 操作、可以从一种类 型转换成另一种类型等等。
切片
- 切片
- 切片到底是什么
- array vs vector
- [Vec<T> 和 &[T]](#vect-和-t)
- 解引用:转为切片类型
- 切片和迭代器 Iterator
- 特殊的切片:&str
- [Box<[T]>](#boxt)
切片到底是什么
切片的三个特点
- 同一类型、长度不确定的、在内存中连续存放的数据结构
在 Rust 里,切片是描述一组属于同一类型、长度不确定的、在内存中连续存放的数据结 构,用 [T] 来表述。因为长度不确定,所以切片是个 DST(Dynamically Sized Type)。
切片的三种访问方式
- 切片不能直接访问,需要通过引用访问。有三种访问方式:
切片一般只出现在数据结构的定义中,不能直接访问,在使用中主要用以下形式:
-
&[T]:表示一个只读的切片引用。
-
&mut [T]:表示一个可写的切片引用。
-
Box<[T]>:一个在堆上分配的切片。
切片与数据的关系
怎么理解切片呢?我打个比方,切片之于具体的数据结构,就像数据库中的视图之于表。 你可以把它看成一种工具,让我们可以统一访问行为相同、结构类似但有些许差异的类 型。
- 举例切片与数据的关系
fn main() { let arr = [1, 2, 3, 4, 5]; let vec = vec![1, 2, 3, 4, 5]; let s1 = &arr[1..3]; let s2 = &vec[1..3]; println!("s1: {:?}, s2: {:?}", s1, s2); // &[T] 和 &[T] 是否相等取决于长度和内容是否相等 assert_eq!(s1, s2); // &[T] 可以和 Vec<T>/[T;n] 比较,也会看长度和内容 assert_eq!(&arr[..], vec); assert_eq!(&vec[..], arr); }
- 对于 array 和 vector,虽然是不同的数据结构,一个放在栈上,一个放在堆上,但它们的 切片是类似的;
- 而且对于相同内容数据的相同切片,比如 &arr[1…3] 和 &vec[1…3],这 两者是等价的。
- 除此之外,切片和对应的数据结构也可以直接比较,这是因为它们之间实 现了 PartialEq trait
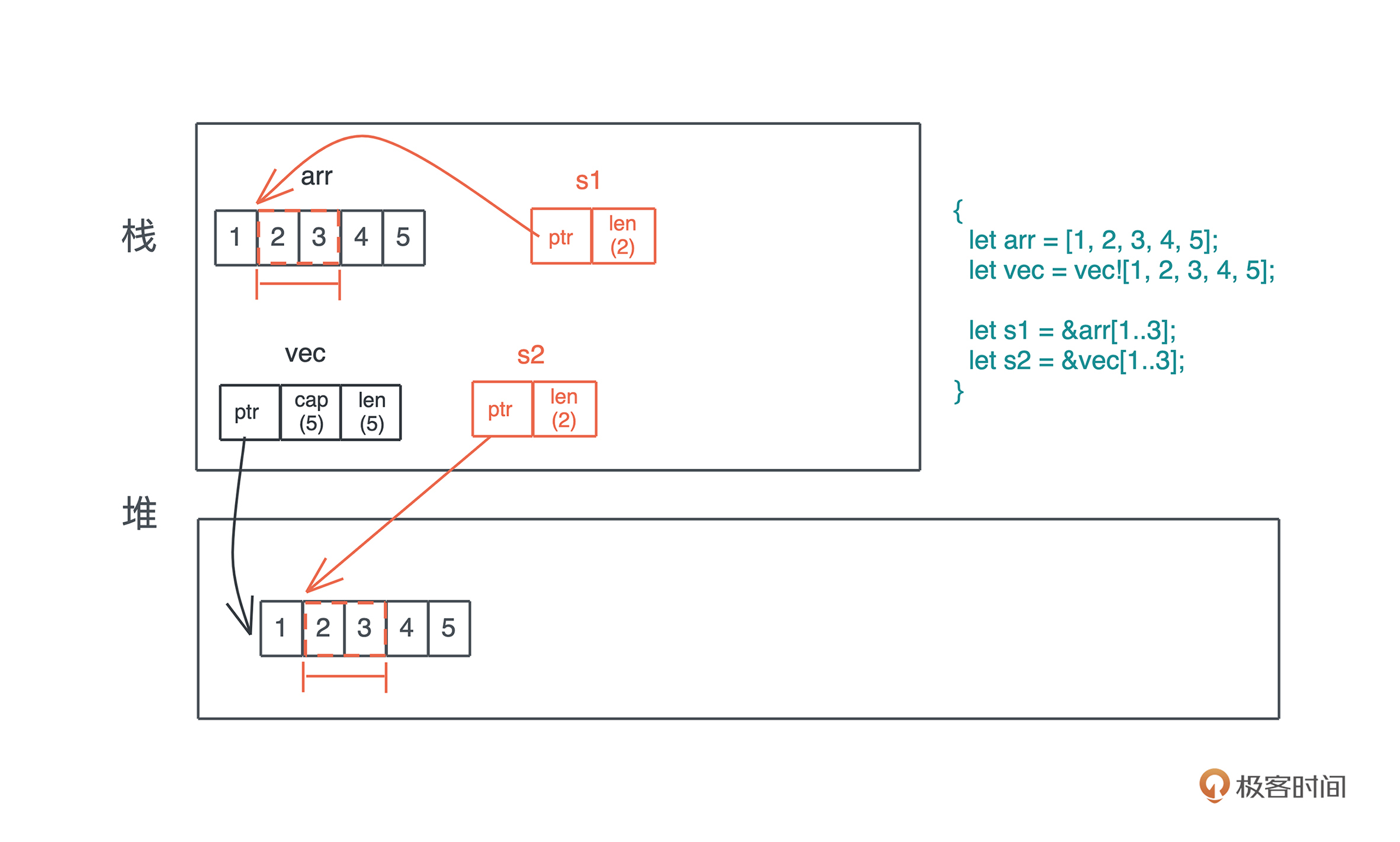
常用切片对比图
下图描述了切片和数组 [T;n]、列表 Vec
建议花些时间理解这张图,也可以用相同的方式去总结学到的其他有关联的数据结构。
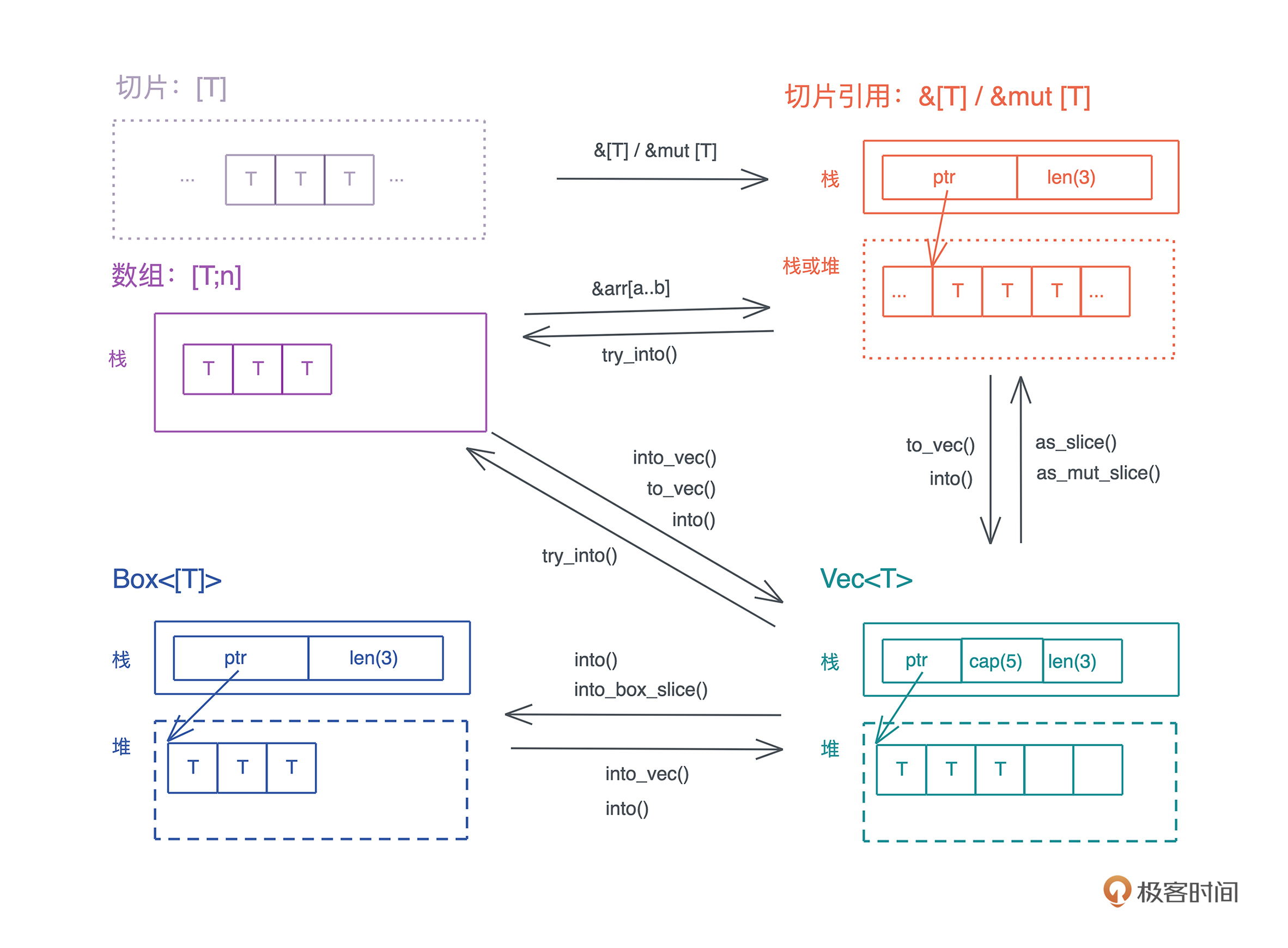
array vs vector
接前面的例子,再次说明array和vector的区别与联系
对于 array 和 vector,虽然是不同的数据结构:
- 一个放在栈上
- 一个放在堆上
但它们的切片是类似的, 而且对于相同内容数据的相同切片
- 比如 &arr[1…3] 和 &vec[1…3],这两者是等价的。
- 除此之外,切片和对应的数据结构也可以直接比较,这是因为它们之间实现了 PartialEq trait(源码参考资料)。
下图比较清晰地呈现了切片和数据之间的关系:
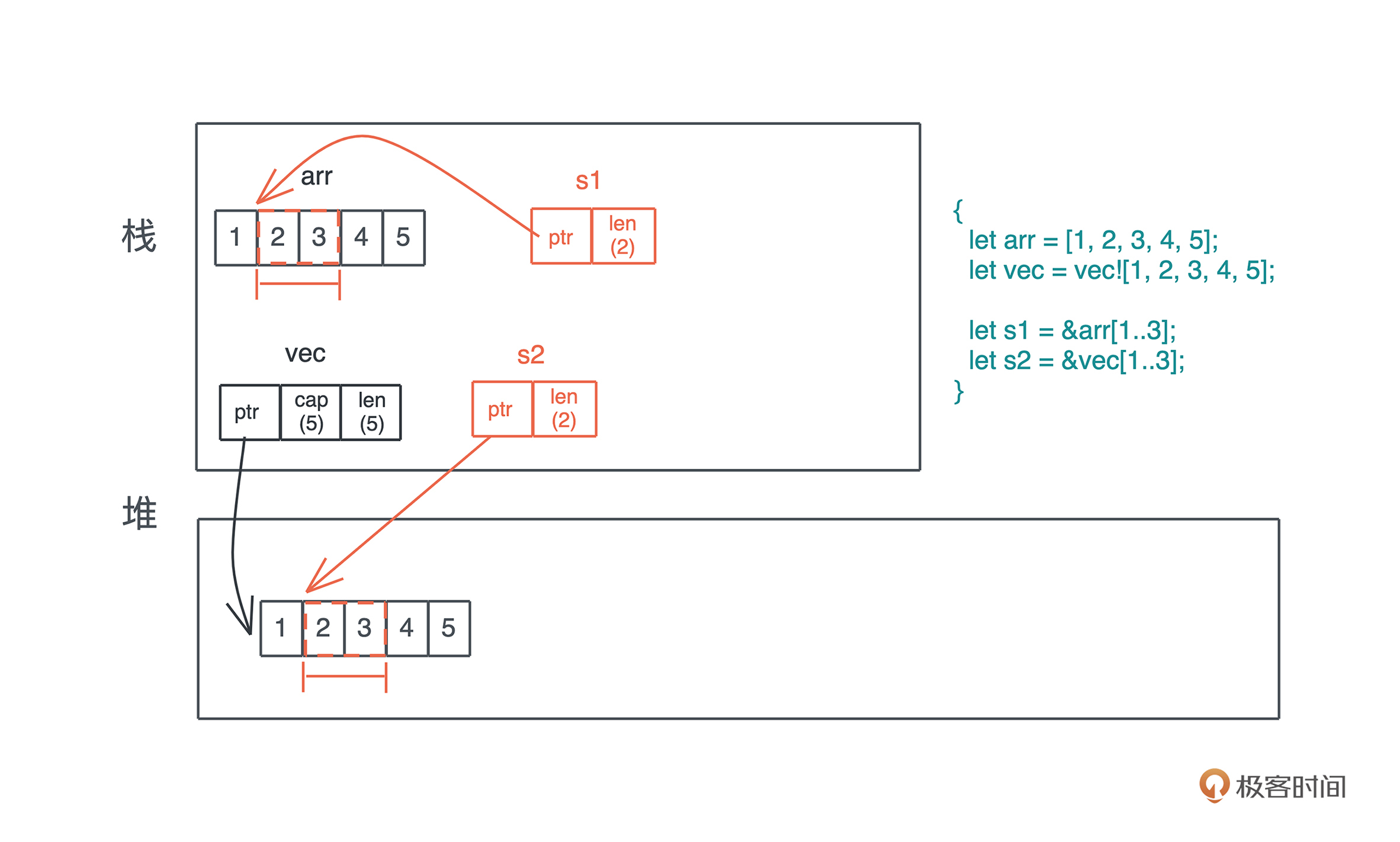
Vec<T> 和 &[T]
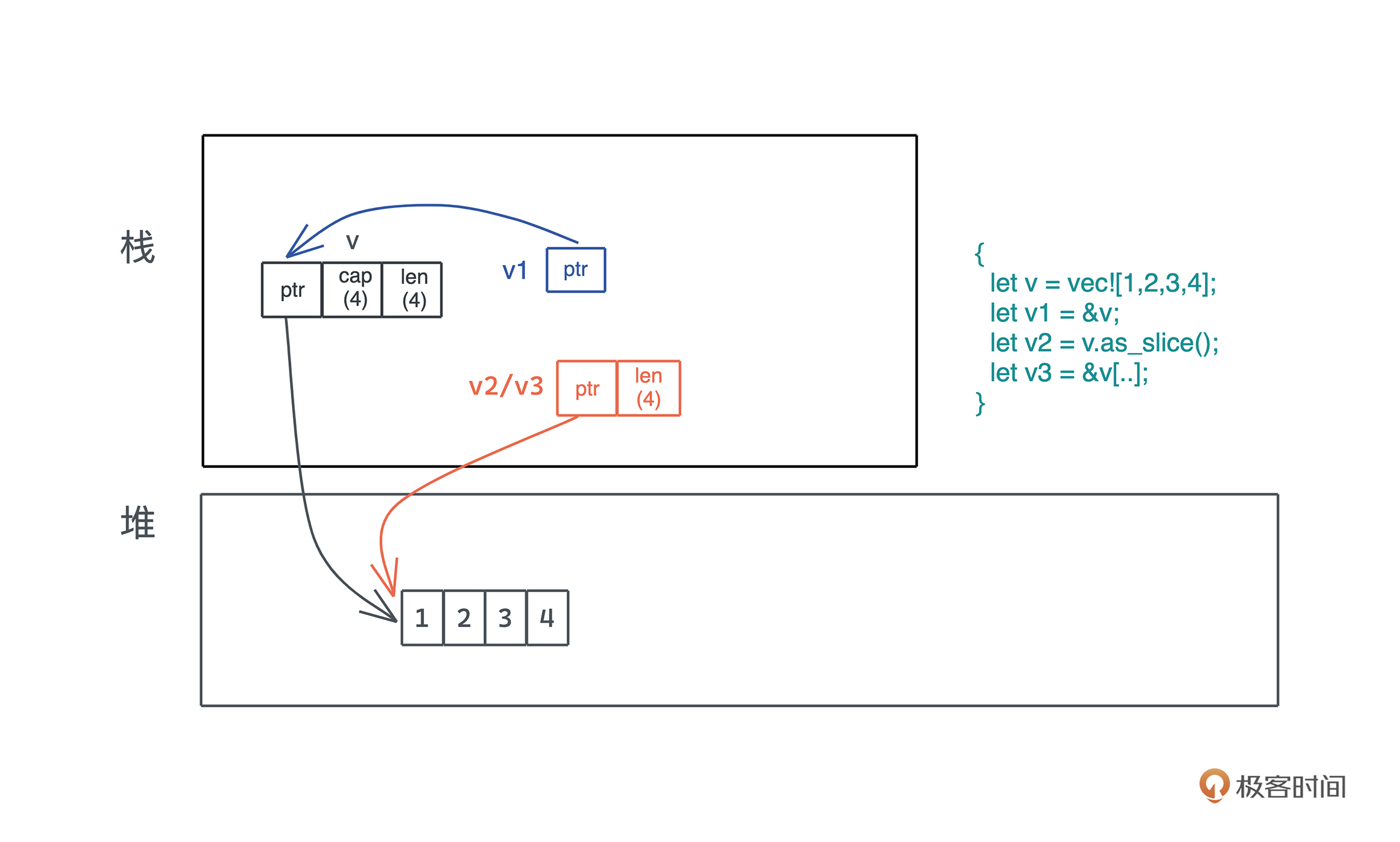
解引用:转为切片类型
在使用的时候,支持切片的具体数据类型,你可以根据需要,解引用转换成切片类型。
- 比如 Vec
和 [T; n] 会转化成为 &[T],这是因为 Vec 实现了 Deref trait,而 array 内建了到 &[T] 的解引用。
Deref、&、AsRef:我们可以写一段代码验证这一行为(代码)
use std::fmt; fn main() { let v = vec![1, 2, 3, 4]; // Vec 实现了 Deref,&Vec<T> 会被自动解引用为 &[T],符合接口定义 print_slice(&v); // 直接是 &[T],符合接口定义 print_slice(&v[..]); // &Vec<T> 支持 AsRef<[T]> print_slice1(&v); // &[T] 支持 AsRef<[T]> print_slice1(&v[..]); // Vec<T> 也支持 AsRef<[T]> print_slice1(v); let arr = [1, 2, 3, 4]; // 数组虽没有实现 Deref,但它的解引用就是 &[T] print_slice(&arr); print_slice(&arr[..]); print_slice1(&arr); print_slice1(&arr[..]); print_slice1(arr); } // 注意下面的泛型函数的使用 fn print_slice<T: fmt::Debug>(s: &[T]) { println!("{:?}", s); } fn print_slice1<T, U>(s: T) where T: AsRef<[U]>, U: fmt::Debug, { println!("{:?}", s.as_ref()); }
这也就意味着,通过解引用,这几个和切片有关的数据结构都会获得切片的所有能力,包括下列丰富的功能:
- binary_search
- chunks
- concat
- contains
- start_with
- end_with
- group_by
- iter
- join
- sort
- split
- swap
切片和迭代器 Iterator
Iterator trait 有大量的方法,但绝大多数情况下,只需要定义它的关联类型 Item 和 next() 方法。
- Item 定义了每次我们从迭代器中取出的数据类型;
- next() 是从迭代器里取下一个值的方法。当一个迭代器的 next() 方法返回 None 时,表明迭代器中没有数据了。
#![allow(unused)] fn main() { #[must_use = "iterators are lazy and do nothing unless consumed"] pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // 大量缺省的方法,包括 size_hint, count, chain, zip, map, // filter, for_each, skip, take_while, flat_map, flatten // collect, partition 等 ... } }
一个例子:对切片类型Vec 使用 iter() 方法,并进行各种 map / filter / take 操作
在函数式编程语言中,这样的写法很常见,代码的可读性很强。Rust 也支持这种写法(代码):
fn main() { // 这里 Vec<T> 在调用 iter() 时被解引用成 &[T],所以可以访问 iter() let result = vec![1, 2, 3, 4] .iter() .map(|v| v * v) .filter(|v| *v < 16) .take(1) .collect::<Vec<_>>(); println!("{:?}", result); }
Rust的迭代器是个懒接口,这是如何实现的?
需要注意的是 Rust 下的迭代器是个懒接口(lazy interface):
- 也就是说这段代码直到运行到 collect 时才真正开始执行
- 之前的部分不过是在不断地生成新的结构,来累积处理逻辑而已。
你可能好奇,这是怎么做到的呢?
原来,Iterator 大部分方法都返回一个实现了 Iterator 的数据结构,所以可以这样一路链式下去.
在 Rust 标准库中,这些数据结构被称为 Iterator Adapter。
比如上面的 map 方法,它返回 Map 结构,而 Map 结构实现了 Iterator(源码)。
整个过程是这样的(链接均为源码资料):
- 在 collect() 执行的时候,它实际试图使用 FromIterator 从迭代器中构建一个集合类型,这会不断调用 next() 获取下一个数据;
- 此时的 Iterator 是 Take,Take 调自己的 next(),也就是它会调用 Filter 的 next();
- Filter 的 next() 实际上调用自己内部的 iter 的 find(),此时内部的 iter 是 Map,find() 会使用 try_fold(),它会继续调用 next(),也就是 Map 的 next();
- Map 的 next() 会调用其内部的 iter 取 next() 然后执行 map 函数。而此时内部的 iter 来自 Vec
。
所以,只有在 collect() 时,才触发代码一层层调用下去,并且调用会根据需要随时结束。这段代码中我们使用了 take(1),整个调用链循环一次,就能满足 take(1) 以及所有中间过程的要求,所以它只会循环一次。
Rust的函数式编程写法性能如何?
你可能会有疑惑:这种函数式编程的写法,代码是漂亮了,然而这么多无谓的函数调用,性能肯定很差吧?毕竟,函数式编程语言的一大恶名就是性能差。
这个你完全不用担心, Rust 大量使用了 inline 等优化技巧,这样非常清晰友好的表达方式,性能和 C 语言的 for 循环差别不大。
与Python类似,Rust的iterator除了标准库,还有itertools提供更多功能
如果标准库中的功能还不能满足你的需求,你可以看看 itertools,它是和 Python 下 itertools 同名且功能类似的工具,提供了大量额外的 adapter。可以看一个简单的例子(代码):
use itertools::Itertools; fn main() { let err_str = "bad happened"; let input = vec![Ok(21), Err(err_str), Ok(7)]; let it = input .into_iter() .filter_map_ok(|i| if i > 10 { Some(i * 2) } else { None }); // 结果应该是:vec![Ok(42), Err(err_str)] println!("{:?}", it.collect::<Vec<_>>()); }
在实际开发中,我们可能从一组 Future 中汇聚出一组结果,里面有成功执行的结果,也有失败的错误信息。
如果想对成功的结果进一步做 filter/map,那么标准库就无法帮忙了,就需要用 itertools 里的 filter_map_ok()。
特殊的切片:&str
String、&String和&str的区别与联系
我们来看一种特殊的切片:&str。之前讲过,String 是一个特殊的 Vec
对于 String、&String、&str,很多人也经常分不清它们的区别.
在&str。对于 &String 和 &str,如果你理解了上文中 &Vec

String在解引用时会转换成&str
可以用下面的代码验证(代码):
use std::fmt; fn main() { let s = String::from("hello"); // &String 会被解引用成 &str print_slice(&s); // &s[..] 和 s.as_str() 一样,都会得到 &str print_slice(&s[..]); // String 支持 AsRef<str> print_slice1(&s); print_slice1(&s[..]); print_slice1(s.clone()); // String 也实现了 AsRef<[u8]>,所以下面的代码成立 // 打印出来是 [104, 101, 108, 108, 111] print_slice2(&s); print_slice2(&s[..]); print_slice2(s); } fn print_slice(s: &str) { println!("{:?}", s); } fn print_slice1<T: AsRef<str>>(s: T) { println!("{:?}", s.as_ref()); } fn print_slice2<T, U>(s: T) where T: AsRef<[U]>, U: fmt::Debug, { println!("{:?}", s.as_ref()); }
字符的列表array和字符串String有什么关系和区别
我们直接写一段代码来看看:
use std::iter::FromIterator; fn main() { let arr = ['h', 'e', 'l', 'l', 'o']; let vec = vec!['h', 'e', 'l', 'l', 'o']; let s = String::from("hello"); let s1 = &arr[1..3]; let s2 = &vec[1..3]; // &str 本身就是一个特殊的 slice let s3 = &s[1..3]; println!("s1: {:?}, s2: {:?}, s3: {:?}", s1, s2, s3); // &[char] 和 &[char] 是否相等取决于长度和内容是否相等 assert_eq!(s1, s2); // &[char] 和 &str 不能直接对比,我们把 s3 变成 Vec<char> assert_eq!(s2, s3.chars().collect::<Vec<_>>()); // &[char] 可以通过迭代器转换成 String,String 和 &str 可以直接对比 assert_eq!(String::from_iter(s2), s3); }
可以看到,字符列表可以通过迭代器转换成 String,String 也可以通过 chars() 函数转换成字符列表,如果不转换,二者不能比较。
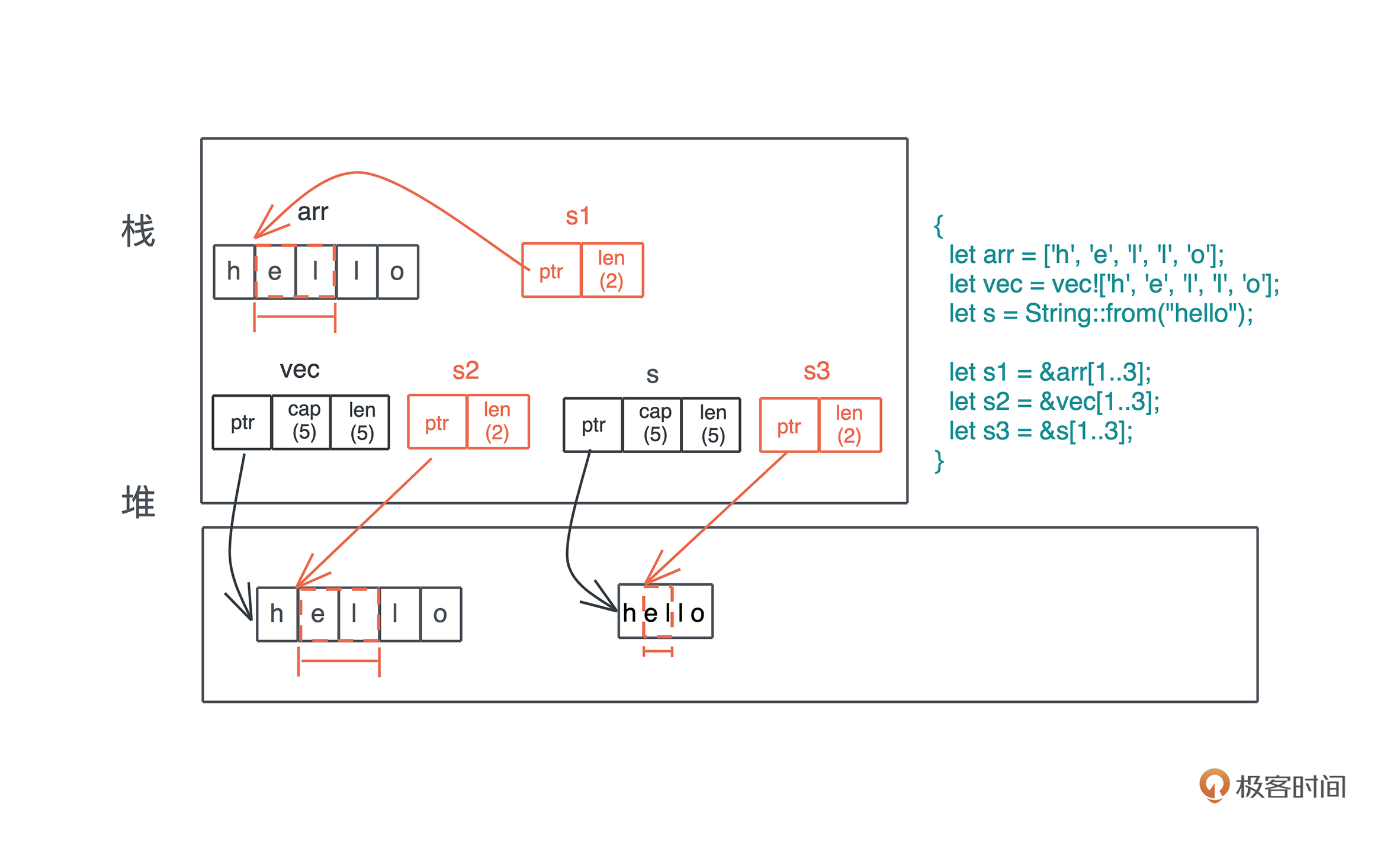
Box<[T]>
Box<[T]>和Vec&[T]对比
切片主要有三种使用方式:
- 切片的只读引用 &[T]
- 切片的可变引用 &mut [T]: 和&[T]类似
- Box<[T]>
现在我们来看看 Box<[T]>。
Box<[T]> 是一个比较有意思的存在,它和 Vec
- Vec
有额外的 capacity,可以增长; - 而 Box<[T]> 一旦生成就固定下来,没有 capacity,也无法增长。
Box<[T]> 和切片的引用 &[T] 也很类似:
- 它们都是在栈上有一个包含长度的胖指针,指向存储数据的内存位置。
- 区别是:Box<[T]> 只会指向堆,&[T] 指向的位置可以是栈也可以是堆;
- 此外,Box<[T]> 对数据具有所有权,而 &[T] 只是一个借用。
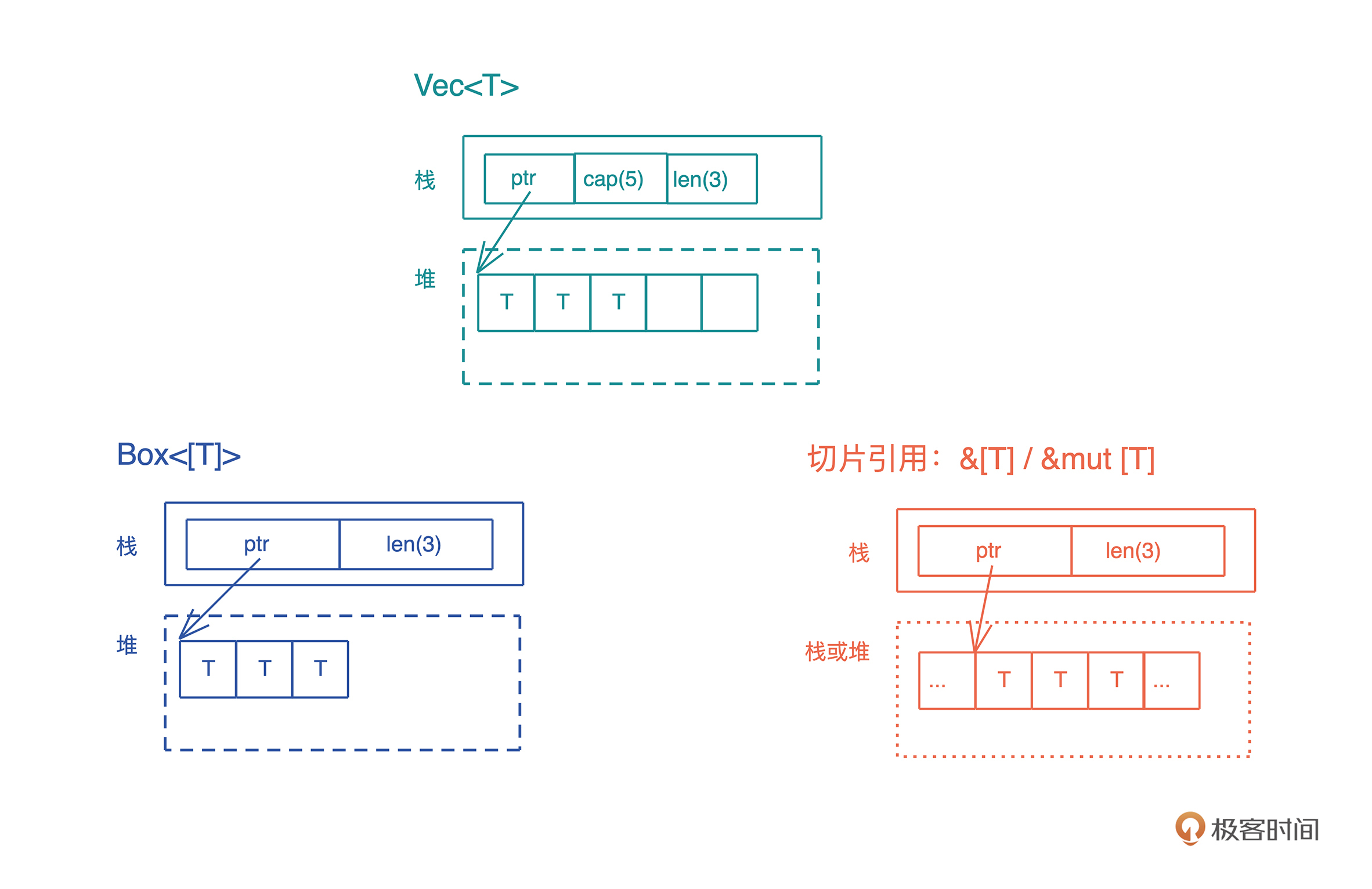
那么如何产生 Box<[T]> 呢?
目前可用的接口就只有一个:从已有的 Vec
中转换。
我们看代码:
use std::ops::Deref; fn main() { let mut v1 = vec![1, 2, 3, 4]; v1.push(5); println!("cap should be 8: {}", v1.capacity()); // 从 Vec<T> 转换成 Box<[T]>,此时会丢弃多余的 capacity let b1 = v1.into_boxed_slice(); let mut b2 = b1.clone(); let v2 = b1.into_vec(); println!("cap should be exactly 5: {}", v2.capacity()); assert!(b2.deref() == v2); // Box<[T]> 可以更改其内部数据,但无法 push b2[0] = 2; // b2.push(6); println!("b2: {:?}", b2); // 注意 Box<[T]> 和 Box<[T; n]> 并不相同 let b3 = Box::new([2, 2, 3, 4, 5]); println!("b3: {:?}", b3); // b2 和 b3 相等,但 b3.deref() 和 v2 无法比较 assert!(b2 == b3); // assert!(b3.deref() == v2); }
运行代码可以看到:
- Vec
可以通过 into_boxed_slice() 转换成 Box<[T]> - Box<[T]> 也可以通过 into_vec() 转换回 Vec
。
这两个转换都是很轻量的转换,只是变换一下结构,不涉及数据的拷贝。
区别是:
- 当 Vec
转换成 Box<[T]> 时,没有使用到的容量就会被丢弃,所以整体占用的内存可能会降低。 - 而且 Box<[T]> 有一个很好的特性是,不像 Box<[T;n]> 那样在编译时就要确定大小,它可以在运行期生成,以后大小不会再改变。
所以,当我们需要在堆上创建固定大小的集合数据,且不希望自动增长,那么,可以先创建 Vec
tokio 在提供 broadcast channel 时,就使用了 Box<[T]> 这个特性,你感兴趣的话,可以自己看看源码。
哈希表
哈希表还是列表
我们知道,哈希表和列表类似,都用于处理需要随机访问的数据结构, 但还有不同选择:
- 如果数据结构的输入和输出能一一对应,那么可以使用列表,
- 如果无法一一对应,那么就需要使用哈希表。
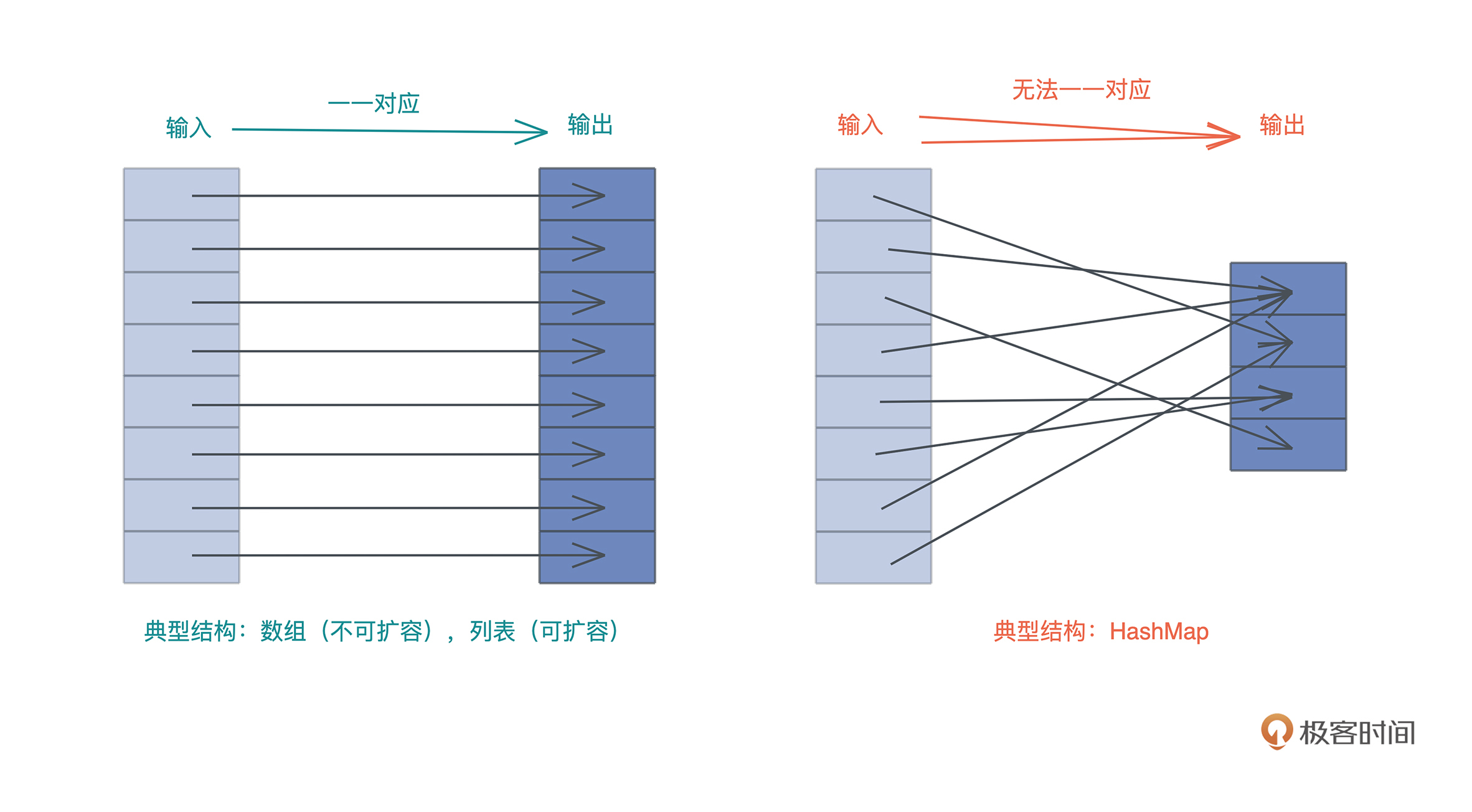
Rust 的哈希表
哈希表核心冲突
哈希表的核心特点与解决
哈希表最核心的特点就是:巨量的可能输入和有限的哈希表容量。
这就会引发哈希冲突,也就是两个或者多个输入的哈希被映射到了同一个位置,所以我们要能够处理哈希冲突。
要解决冲突,首先可以通过更好的、分布更均匀的哈希函数,以及使用更大的哈希表来缓解冲突,但无法完全解决,所以我们还需要使用冲突解决机制。
理论上,主要的冲突解决机制有链地址法(chaining)和开放寻址法(open addressing)。
解决冲突的方法
- 链地址法⛓️
就是把落在同一个哈希上的数据用单链表或者双链表连接起来。
这样在查找的时候:
- 先找到对应的哈希桶(hash bucket),
- 然后再在冲突链上挨个比较,直到找到匹配的项。
冲突链处理哈希冲突非常直观,很容易理解和撰写代码,但缺点是哈希表和冲突链使用了不同的内存,对缓存不友好。
- 开放寻址法
开放寻址法把整个哈希表看做一个大数组,不引入额外的内存,当冲突产生时,按照一定的规则把数据插入到其它空闲的位置。
- 线性探寻(linear probing)在出现哈希冲突时,不断往后探寻,直到找到空闲的位置插入。
- 而二次探查,理论上是在冲突发生时,不断探寻哈希位置加减 n 的二次方,找到空闲的位置插入.
我们看图,更容易理解:
图中示意是理论上的处理方法,实际为了性能会有很多不同的处理。
HashMap数据结构
深入Rust哈希表的数据结构:HashMap->hashbrown->RawTable
- HashMap数据结构
我们来看看 Rust 哈希表的数据结构是什么样子的,打开标准库的 源代码:
use hashbrown::hash_map as base; #[derive(Clone)] pub struct RandomState { k0: u64, k1: u64, } pub struct HashMap<K, V, S = RandomState> { base: base::HashMap<K, V, S>, }
可以看到,HashMap 有三个泛型参数:
- K 和 V 代表 key / value 的类型
- S 是哈希算法的状态,它默认是 RandomState,占两个 u64。
RandomState 使用 SipHash 作为缺省的哈希算法,它是一个加密安全的哈希函数(cryptographically secure hashing)。
- 从定义中还能看到,Rust 的 HashMap 复用了 hashbrown 的 HashMap:
hashbrown 是 Rust 下对 Google Swiss Table 的一个改进版实现,我们打开 hashbrown 的代码,看它的结构:
pub struct HashMap<K, V, S = DefaultHashBuilder, A: Allocator + Clone = Global> { pub(crate) hash_builder: S, pub(crate) table: RawTable<(K, V), A>, }
可以看到,HashMap 里有两个域:
- 一个是 hash_builder,类型是刚才我们提到的标准库使用的 RandomState
- 还有一个是具体的 RawTable:
- hashbrown的HashMap用到的RawTable
pub struct RawTable<T, A: Allocator + Clone = Global> { table: RawTableInner<A>, // Tell dropck that we own instances of T. marker: PhantomData<T>, } struct RawTableInner<A> { // Mask to get an index from a hash value. The value is one less than the // number of buckets in the table. bucket_mask: usize, // [Padding], T1, T2, ..., Tlast, C1, C2, ... // ^ points here ctrl: NonNull<u8>, // Number of elements that can be inserted before we need to grow the table growth_left: usize, // Number of elements in the table, only really used by len() items: usize, alloc: A, }
- RawTable 中,实际上有意义的数据结构是 RawTableInner:
前四个字段很重要:
- usize 的 bucket_mask,是哈希表中哈希桶的数量减一;
- 名字叫 ctrl 的指针,它指向哈希表堆内存末端的 ctrl 区;
这一点在介绍hashmap的内存结构时还会详细说明
- usize 的字段 growth_left,指哈希表在下次自动增长前还能存储多少数据;
- Usize 的 items,表明哈希表现在有多少数据。
这里最后的 alloc 字段,和 RawTable 的 marker 一样,只是一个用来占位的类型,它用来分配在堆上的内存。
HashMap 的基本使用方法
数据结构搞清楚,我们再看具体使用方法。
HashMap基本使用方法
Rust 哈希表的使用很简单,它提供了一系列很方便的方法,使用起来和其它语言非常类似,你只要看看文档,就很容易理解。
我们来写段代码,尝试一下(代码):
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); explain("empty", &map); map.insert('a', 1); explain("added 1", &map); map.insert('b', 2); map.insert('c', 3); explain("added 3", &map); map.insert('d', 4); explain("added 4", &map); // get 时需要使用引用,并且也返回引用 assert_eq!(map.get(&'a'), Some(&1)); assert_eq!(map.get_key_value(&'b'), Some((&'b', &2))); map.remove(&'a'); // 删除后就找不到了 assert_eq!(map.contains_key(&'a'), false); assert_eq!(map.get(&'a'), None); explain("removed", &map); // shrink 后哈希表变小 map.shrink_to_fit(); explain("shrinked", &map); } fn explain<K, V>(name: &str, map: &HashMap<K, V>) { println!("{}: len: {}, cap: {}", name, map.len(), map.capacity()); }
- 可以看到,当 HashMap::new() 时,它并没有分配空间,容量为零
- 随着哈希表不断插入数据,它会以 2 的幂减一的方式增长,最小是 3。
- 当删除表中的数据时,原有的表大小不变,只有显式地调用 shrink_to_fit,才会让哈希表变小。
HashMap 的内存布局
通过 HashMap 的公开接口无法看到 HashMap 在内存中是如何布局,还是需要借助 std::mem::transmute 方法,来把数据结构打出来。
ctrl表的变化:借助std::mem::transmute查看内存布局
我们把刚才的代码改一改(代码):
use std::collections::HashMap; fn main() { let map = HashMap::new(); let mut map = explain("empty", map); map.insert('a', 1); let mut map = explain("added 1", map); map.insert('b', 2); map.insert('c', 3); let mut map = explain("added 3", map); map.insert('d', 4); let mut map = explain("added 4", map); map.remove(&'a'); explain("final", map); } // HashMap 结构有两个 u64 的 RandomState,然后是四个 usize, // 分别是 bucket_mask, ctrl, growth_left 和 items // 我们 transmute 打印之后,再 transmute 回去 fn explain<K, V>(name: &str, map: HashMap<K, V>) -> HashMap<K, V> { let arr: [usize; 6] = unsafe { std::mem::transmute(map) }; println!( "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}", name, arr[2], arr[3], arr[4], arr[5] ); unsafe { std::mem::transmute(arr) } }
运行之后,可以看到:
empty: bucket_mask 0x0, ctrl 0x1056df820, growth_left: 0, items: 0
added 1: bucket_mask 0x3, ctrl 0x7fa0d1405e30, growth_left: 2, items: 1
added 3: bucket_mask 0x3, ctrl 0x7fa0d1405e30, growth_left: 0, items: 3
added 4: bucket_mask 0x7, ctrl 0x7fa0d1405e90, growth_left: 3, items: 4
final: bucket_mask 0x7, ctrl 0x7fa0d1405e90, growth_left: 4, items: 3
发现在运行的过程中,ctrl 对应的堆地址发生了改变。
- 在我的 OS X 下,一开始哈希表为空,ctrl 地址看上去是一个 TEXT/RODATA 段的地址,应该是指向了一个默认的空表地址;
- 插入第一个数据后,哈希表分配了 4 个 bucket,ctrl 地址发生改变;
- 在插入三个数据后,growth_left 为零
- 再插入时,哈希表重新分配,ctrl 地址继续改变。
在探索 HashMap 数据结构时,说过 ctrl 是一个指向哈希表堆地址末端 ctrl 区的地址,所以我们可以通过这个地址,计算出哈希表堆地址的起始地址。
- 因为哈希表有 8 个 bucket(0x7 + 1)
- 每个 bucket 大小是 key(char) + value(i32) 的大小,也就是 8 个字节,
- 所以一共是 64 个字节。
- 对于这个例子,通过 ctrl 地址减去 64,就可以得到哈希表的堆内存起始地址。
然后,我们可以用 rust-gdb / rust-lldb 来打印这个内存。
可以用 Linux 下的 rust-gdb 设置断点,依次查看哈希表有一个、三个、四个值,以及删除一个值的状态:
❯ rust-gdb ~/.target/debug/hashmap2
GNU gdb (Ubuntu 9.2-0ubuntu2) 9.2
...
(gdb) b hashmap2.rs:32
Breakpoint 1 at 0xa43e: file src/hashmap2.rs, line 32.
(gdb) r
Starting program: /home/tchen/.target/debug/hashmap2
...
# 最初的状态,哈希表为空
empty: bucket_mask 0x0, ctrl 0x555555597be0, growth_left: 0, items: 0
Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32
32 unsafe { std::mem::transmute(arr) }
(gdb) c
Continuing.
# 插入了一个元素后,bucket 有 4 个(0x3+1),堆地址起始位置 0x5555555a7af0 - 4*8(0x20)
added 1: bucket_mask 0x3, ctrl 0x5555555a7af0, growth_left: 2, items: 1
Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32
32 unsafe { std::mem::transmute(arr) }
(gdb) x /12x 0x5555555a7ad0
0x5555555a7ad0: 0x00000061 0x00000001 0x00000000 0x00000000
0x5555555a7ae0: 0x00000000 0x00000000 0x00000000 0x00000000
0x5555555a7af0: 0x0affffff 0xffffffff 0xffffffff 0xffffffff
(gdb) c
Continuing.
# 插入了三个元素后,哈希表没有剩余空间,堆地址起始位置不变 0x5555555a7af0 - 4*8(0x20)
added 3: bucket_mask 0x3, ctrl 0x5555555a7af0, growth_left: 0, items: 3
Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32
32 unsafe { std::mem::transmute(arr) }
(gdb) x /12x 0x5555555a7ad0
0x5555555a7ad0: 0x00000061 0x00000001 0x00000062 0x00000002
0x5555555a7ae0: 0x00000000 0x00000000 0x00000063 0x00000003
0x5555555a7af0: 0x0a72ff02 0xffffffff 0xffffffff 0xffffffff
(gdb) c
Continuing.
# 插入第四个元素后,哈希表扩容,堆地址起始位置变为 0x5555555a7b50 - 8*8(0x40)
added 4: bucket_mask 0x7, ctrl 0x5555555a7b50, growth_left: 3, items: 4
Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32
32 unsafe { std::mem::transmute(arr) }
(gdb) x /20x 0x5555555a7b10
0x5555555a7b10: 0x00000061 0x00000001 0x00000000 0x00000000
0x5555555a7b20: 0x00000064 0x00000004 0x00000063 0x00000003
0x5555555a7b30: 0x00000000 0x00000000 0x00000062 0x00000002
0x5555555a7b40: 0x00000000 0x00000000 0x00000000 0x00000000
0x5555555a7b50: 0xff72ffff 0x0aff6502 0xffffffff 0xffffffff
(gdb) c
Continuing.
# 删除 a 后,剩余 4 个位置。注意 ctrl bit 的变化,以及 0x61 0x1 并没有被清除
final: bucket_mask 0x7, ctrl 0x5555555a7b50, growth_left: 4, items: 3
Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32
32 unsafe { std::mem::transmute(arr) }
(gdb) x /20x 0x5555555a7b10
0x5555555a7b10: 0x00000061 0x00000001 0x00000000 0x00000000
0x5555555a7b20: 0x00000064 0x00000004 0x00000063 0x00000003
0x5555555a7b30: 0x00000000 0x00000000 0x00000062 0x00000002
0x5555555a7b40: 0x00000000 0x00000000 0x00000000 0x00000000
0x5555555a7b50: 0xff72ffff 0xffff6502 0xffffffff 0xffffffff
这段输出蕴藏了很多信息,结合示意图来仔细梳理。
- 首先,插入第一个元素 ‘a’: 1 后,哈希表的内存布局如下:
- key ‘a’ 的 hash 和 bucket_mask 0x3 运算后得到第 0 个位置插入。
- 同时,这个 hash 的头 7 位取出来,在 ctrl 表中对应的位置,也就是第 0 个字节,把这个值写入。
要理解这个步骤,关键就是要搞清楚这个 ctrl 表是什么。
ctrl 表
主要目的与设计
ctrl表的主要目的是什么?它如何设计实现这个目的?
ctrl 表的主要目的是快速查找。它的设计非常优雅,值得我们学习。
一张 ctrl 表里:
- 有若干个 128bit 或者说 16 个字节的分组(group)
- group 里的每个字节叫 ctrl byte,对应一个 bucket,那么一个 group 对应 16 个 bucket。
- 如果一个 bucket 对应的 ctrl byte 首位不为 1,就表示这个 ctrl byte 被使用;
- 如果所有位都是 1,或者说这个字节是 0xff,那么它是空闲的。
SIMD查表:
一组 control byte 的整个 128 bit 的数据,可以通过一条指令被加载进来,然后和某个值进行 mask,找到它所在的位置。这就是HashMap的 SIMD 查表。
查询效率高:
我们知道,现代 CPU 都支持单指令多数据集的操作,而 Rust 充分利用了 CPU 这种能力,一条指令可以让多个相关的数据载入到缓存中处理,大大加快查表的速度。所以,Rust 的哈希表查询的效率非常高。
通过ctrl表查询
具体怎么操作,我们来看 HashMap 是如何通过 ctrl 表来进行数据查询的。
假设这张表里已经添加了一些数据,我们现在要查找 key 为 ‘c’ 的数据:
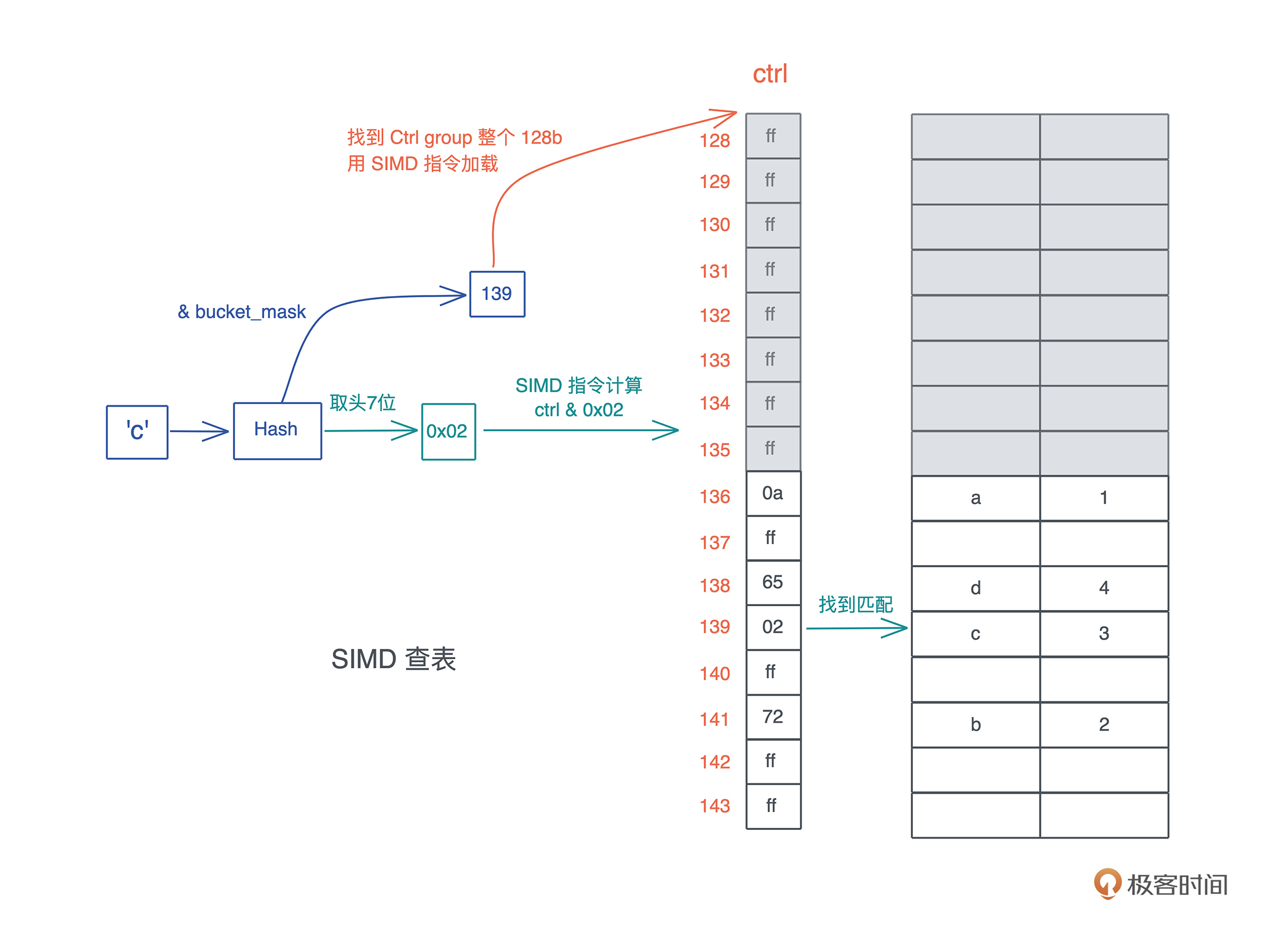
- 把 h 跟 bucket_mask 做与,得到一个值,图中是 139;
- 拿着这个 139,找到对应的 ctrl group 的起始位置,因为 ctrl group 以 16 为一组,所以这里找到 128;
- 用 SIMD 指令加载从 128 对应地址开始的 16 个字节;
- 对 hash 取头 7 个 bit,然后和刚刚取出的 16 个字节一起做与,找到对应的匹配,如果找到了,它(们)很大概率是要找的值;
- 如果不是,那么以二次探查(以 16 的倍数不断累积)的方式往后查找,直到找到为止。
所以,当 HashMap 插入和删除数据,以及因此导致重新分配的时候,主要工作就是在维护这张 ctrl 表和数据的对应。
为何HashMap的结构中,堆内存指针直接指向ctrl表?
因为 ctrl 表是所有操作最先触及的内存,所以,在 HashMap 的结构中,堆内存的指针直接指向 ctrl 表,而不是指向堆内存的起始位置,这样可以减少一次内存的访问。
通过ctrl表新增:重新分配与增长
插入三个元素后没有剩余空间的哈希表,在加入 ‘d’: 4 时,hash map是如何增长的
在插入第一条数据后,哈希表只有 4 个 bucket,所以只有头 4 个字节的 ctrl 表有用。
随着哈希表的增长,bucket 不够,就会导致重新分配。由于 bucket_mask 永远比 bucket 数量少 1,所以插入三个元素后就会重新分配。
根据 rust-gdb 中得到的信息,我们看插入三个元素后没有剩余空间的哈希表,在加入 ‘d’: 4 时,是如何增长的:
- 首先,哈希表会按幂扩容,从 4 个 bucket 扩展到 8 个 bucket。
这会导致分配新的堆内存,然后原来的 ctrl table 和对应的 kv 数据会被移动到新的内存中。
- 这个例子里因为 char 和 i32 实现了 Copy trait,所以是拷贝;
- 如果 key 的类型是 String,那么只有 String 的 24 个字节 (ptr|cap|len) 的结构被移动,String 的实际内存不需要变动。
- 在移动的过程中,会涉及哈希的重分配。
- 从下图可以看到,‘a’ / ‘c’ 的相对位置和它们的 ctrl byte 没有变化,但重新做 hash 后,‘b’ 的 ctrl byte 和位置都发生了变化:
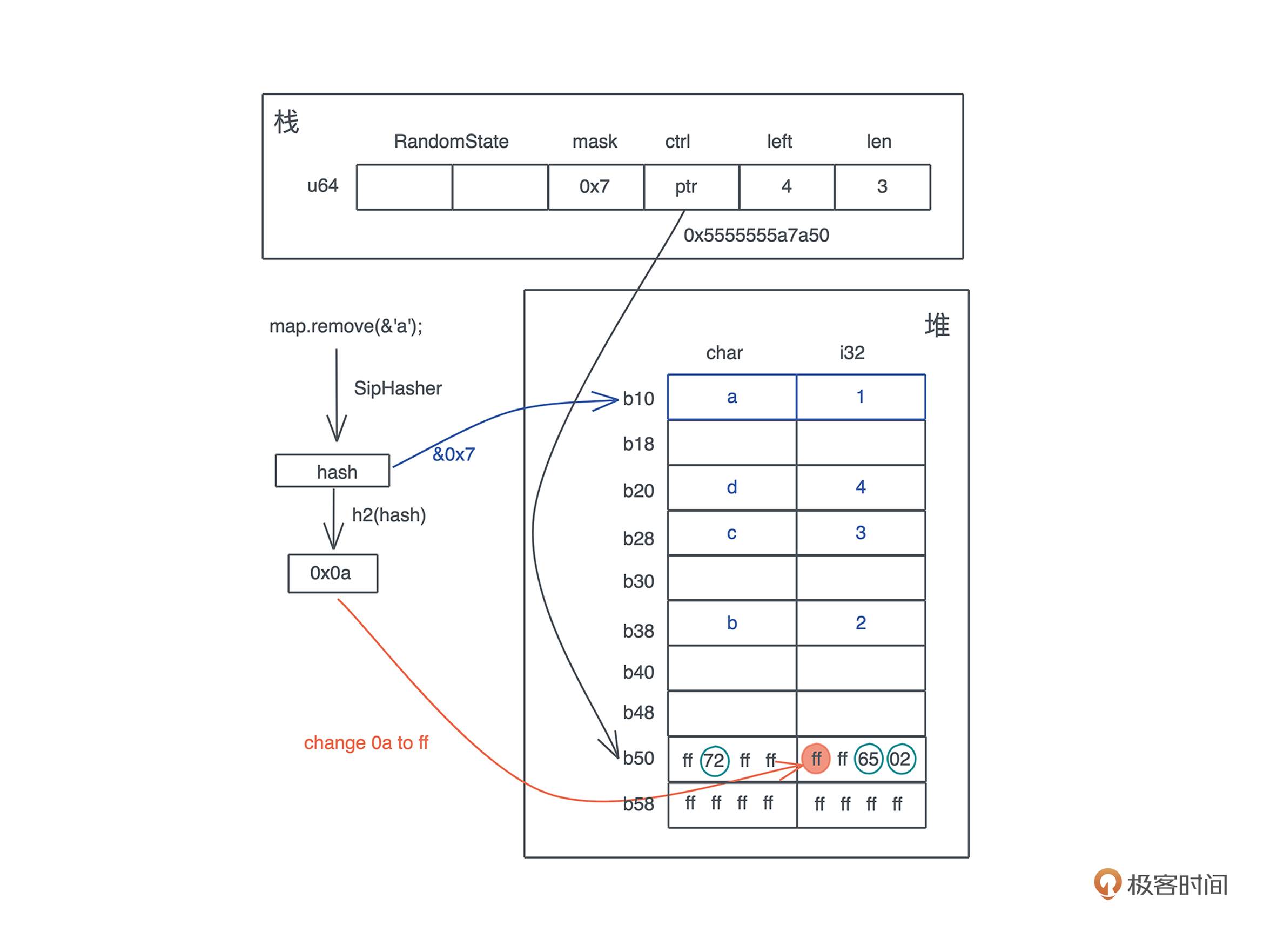
通过ctrl表删除一个值
哈希表删除时内存如何释放?
明白了哈希表是如何增长的,我们再来看删除的时候会发生什么。
当要在哈希表中删除一个值时,整个过程和查找类似:
- 先要找到要被删除的 key 所在的位置。
- 在找到具体位置后,并不需要实际清除内存,只需要将它的 ctrl byte 设回 0xff(或者标记成删除状态)。这样,这个 bucket 就可以被再次使用了
这里有一个问题,当 key/value 有额外的内存时,比如 String,它的内存不会立即回收,只有在下一次对应的 bucket 被使用时,让 HashMap 不再拥有这个 String 的所有权之后,这个 String 的内存才被回收。我们看下面的示意图:
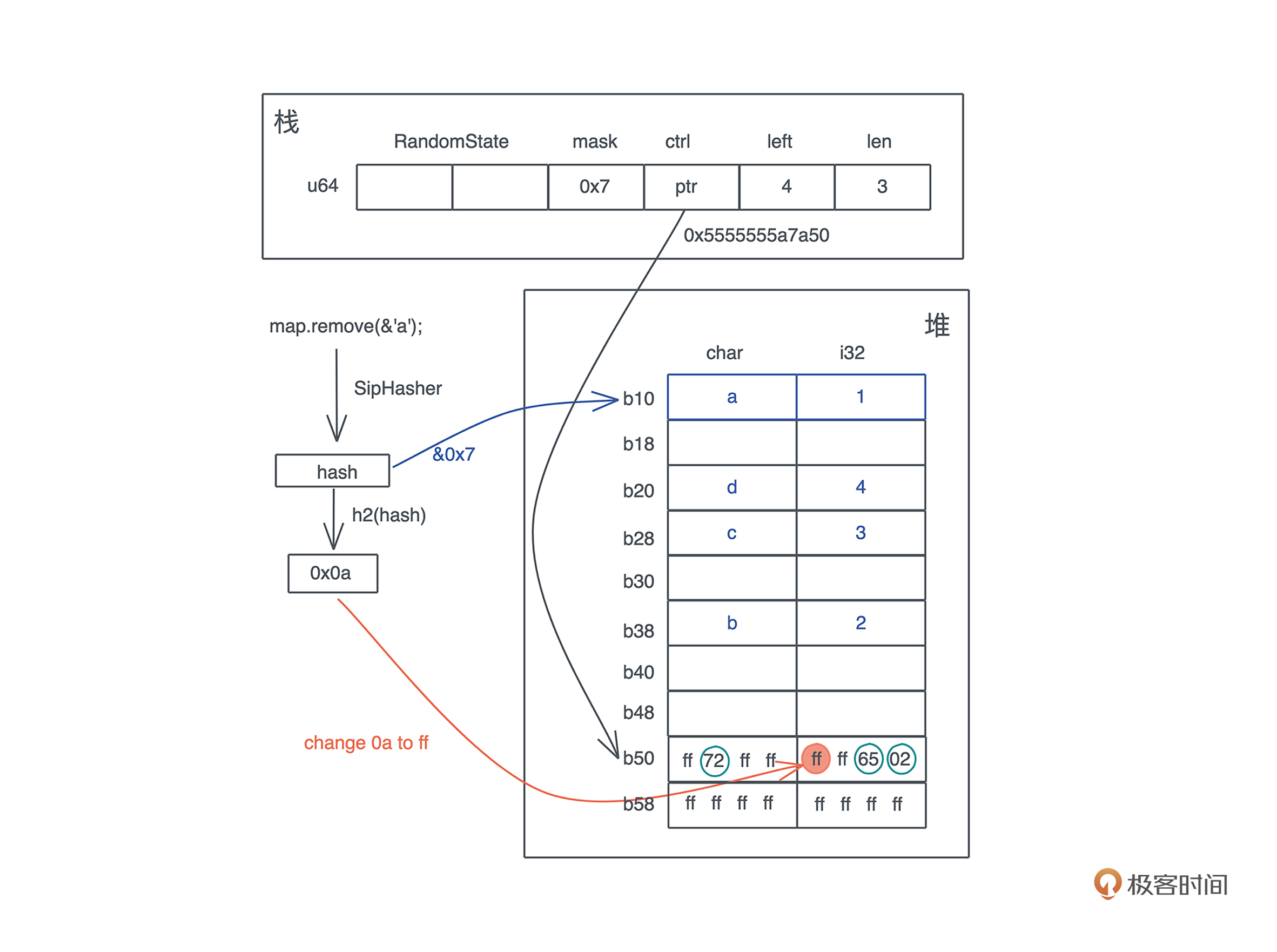
一般来说,这并不会带来什么问题,顶多是内存占用率稍高一些。但某些极端情况下,比如在哈希表中添加大量内容,又删除大量内容后运行,这时你可以通过 shrink_to_fit / shrink_to 释放掉不需要的内存。
让自定义的数据结构做 Hash key
有时候,我们需要让自定义的数据结构成为 HashMap 的 key。此时,要使用到三个 trait:
不过这三个 trait 都可以通过派生宏自动生成。
自定义数据结构需要实现Hash、PartialEq、Eq这三个trait, 它们分别有什么用?
- 实现了 Hash ,可以让数据结构计算哈希;
- 实现了 PartialEq/Eq,可以让数据结构进行相等和不相等的比较:
- Eq 实现了比较的自反性(a == a)、对称性(a == b 则 b == a)以及传递性(a == b,b == c,则 a == c)
- PartialEq 没有实现自反性。
写个例子,看看自定义数据结构如何支持 HashMap:
use std::{ collections::{hash_map::DefaultHasher, HashMap}, hash::{Hash, Hasher}, }; // 如果要支持 Hash,可以用 #[derive(Hash)],前提是每个字段都实现了 Hash // 如果要能作为 HashMap 的 key,还需要 PartialEq 和 Eq #[derive(Debug, Hash, PartialEq, Eq)] struct Student<'a> { name: &'a str, age: u8, } impl<'a> Student<'a> { pub fn new(name: &'a str, age: u8) -> Self { Self { name, age } } } fn main() { let mut hasher = DefaultHasher::new(); let student = Student::new("Tyr", 18); // 实现了 Hash 的数据结构可以直接调用 hash 方法 student.hash(&mut hasher); let mut map = HashMap::new(); // 实现了 Hash / PartialEq / Eq 的数据结构可以作为 HashMap 的 key map.insert(student, vec!["Math", "Writing"]); println!("hash: 0x{:x}, map: {:?}", hasher.finish(), map); }
HashSet / BTreeMap / BTreeSet
HashSet只用于确认存在,存放无序集合
有时我们只需要简单确认元素是否在集合中,如果用 HashMap 就有些浪费空间了。
这时可以用 HashSet,它就是简化的 HashMap,可以用来存放无序的集合,定义直接是 HashMap<K, ()>:
use hashbrown::hash_set as base; pub struct HashSet<T, S = RandomState> { base: base::HashSet<T, S>, } pub struct HashSet<T, S = DefaultHashBuilder, A: Allocator + Clone = Global> { pub(crate) map: HashMap<T, (), S, A>, }
使用 HashSet 查看一个元素是否属于集合的效率非常高。
BTreeMap 是内部使用 B-tree 来组织哈希表的数据结构。
另外 BTreeSet 和 HashSet 类似,是 BTreeMap 的简化版,可以用来存放有序集合。
重点看下 BTreeMap
它的数据结构如下:
pub struct BTreeMap<K, V> { root: Option<Root<K, V>>, length: usize, } pub type Root<K, V> = NodeRef<marker::Owned, K, V, marker::LeafOrInternal>; pub struct NodeRef<BorrowType, K, V, Type> { height: usize, node: NonNull<LeafNode<K, V>>, _marker: PhantomData<(BorrowType, Type)>, } struct LeafNode<K, V> { parent: Option<NonNull<InternalNode<K, V>>>, parent_idx: MaybeUninit<u16>, len: u16, keys: [MaybeUninit<K>; CAPACITY], vals: [MaybeUninit<V>; CAPACITY], } struct InternalNode<K, V> { data: LeafNode<K, V>, edges: [MaybeUninit<BoxedNode<K, V>>; 2 * B], }
和 HashMap 不同的是,BTreeMap 是有序的。
我们看个例子(代码):
use std::collections::BTreeMap; fn main() { let map = BTreeMap::new(); let mut map = explain("empty", map); for i in 0..16usize { map.insert(format!("Tyr {}", i), i); } let mut map = explain("added", map); map.remove("Tyr 1"); let map = explain("remove 1", map); for item in map.iter() { println!("{:?}", item); } } // BTreeMap 结构有 height,node 和 length // 我们 transmute 打印之后,再 transmute 回去 fn explain<K, V>(name: &str, map: BTreeMap<K, V>) -> BTreeMap<K, V> { let arr: [usize; 3] = unsafe { std::mem::transmute(map) }; println!( "{}: height: {}, root node: 0x{:x}, len: 0x{:x}", name, arr[0], arr[1], arr[2] ); unsafe { std::mem::transmute(arr) } }
可以看到,在遍历时,BTreeMap 会按照 key 的顺序把值打印出来。如果你想让自定义的数据结构可以作为 BTreeMap 的 key,那么需要实现 PartialOrd 和 Ord,这两者的关系和 PartialEq / Eq 类似,PartialOrd 也没有实现自反性。同样的,PartialOrd 和 Ord 也可以通过派生宏来实现。
为什么 Rust 的 HashMap 要默认采用加密安全的哈希算法?
为了防备DoS攻击
我们知道哈希表在软件系统中的重要地位,但哈希表在最坏情况下,如果绝大多数 key 的 hash 都碰撞在一起,性能会到 O(n),这会极大拖累系统的效率。
比如 1M 大小的 session 表,正常情况下查表速度是 O(1),但极端情况下,需要比较 1M 个数据后才能找到,这样的系统就容易被 DoS 攻击。 所以如果不是加密安全的哈希函数,只要黑客知道哈希算法,就可以构造出大量的 key 产生足够多的哈希碰撞,造成目标系统 DoS。
SipHash 就是为了回应 DoS 攻击而创建的哈希算法
虽然和 sha2 这样的加密哈希不同(不要将 SipHash 用于加密!),但它可以提供类似等级的安全性。 把 SipHash 作为 HashMap 的缺省的哈希算法,Rust 可以避免开发者在不知情的情况下被 DoS,就像曾经在 Web 世界发生的那样。
当然,这一切的代价是性能损耗,虽然 SipHash 非常快,但它比 hashbrown 缺省使用的 Ahash 慢了不少。
如果你确定使用的 HashMap 不需要 DoS 防护(比如一个完全内部使用的 HashMap),那么可以用 Ahash 来替换。
你只需要使用 Ahash 提供的 RandomState 即可:
use ahash::{AHasher, RandomState}; use std::collections::HashMap; let mut map: HashMap<char, i32, RandomState> = HashMap::default(); map.insert('a', 1);
三、错误处理
配合阅读
错误处理主要内容和主流方法
错误处理包含这么几部分
在一门编程语言中,控制流程是语言的核心流程,而错误处理又是控制流程的重要组成部分。
语言优秀的错误处理能力,会大大减少错误处理对整体流程的破坏,让我们写代码更行云流水,读起来心智负担也更小。
错误处理包含这么几部分
对我们开发者来说,错误处理包含这么几部分:
- 错误捕获后,可以立刻处理
- 也可以延迟到不得不处理的地方再处理,这就涉及到错误的传播(propagate)。
- 最后,根据不同的错误类型,给用户返回合适的、帮助他们理解问题所在的错误消息。
作为一门极其注重用户体验的编程语言,Rust 从其它优秀的语言中,尤其是 Haskell ,吸收了错误处理的精髓,并以自己独到的方式展现出来。
错误处理的主流方法
1. 使用返回值(错误码)
使用返回值来表征错误,是最古老也是最实用的一种方式.
它的使用范围很广:
- 从函数返回值
- 到操作系统的系统调用的错误码 errno
- 进程退出的错误码 retval
- 甚至 HTTP API 的状态码
- 都能看到这种方法的身影。
举个例子,在 C 语言中,如果 fopen(filename) 无法打开文件,会返回 NULL,调用者通过判断返回值是否为 NULL,来进行相应的错误处理。
我们再看个例子:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)
单看这个接口,我们很难直观了解,当读文件出错时,错误是如何返回的:
- 从文档中,我们得知,如果返回的 size_t 和传入的 size_t 不一致
- 那么要么发生了错误,要么是读到文件尾(EOF)
- 调用者要进一步通过 ferror 才能得到更详细的错误。
像 C 这样,通过返回值携带错误信息,有很多局限:
- 返回值有它原本的语义,强行把错误类型嵌入到返回值原本的语义中,需要全面且实时更新的文档,来确保开发者能正确区别对待,正常返回和错误返回。
Golang 对其做了扩展,在函数返回的时候,可以专门携带一个错误对象, 区分开错误返回和正常返回
所以 Golang 对其做了扩展,在函数返回的时候,可以专门携带一个错误对象。比如上文的 fread,在 Golang 下可以这么定义:
func Fread(file *File, b []byte) (n int, err error)
Golang 这样,区分开错误返回和正常返回,相对 C 来说进了一大步。
但是使用返回值的方式,始终有个致命的问题
但是使用返回值的方式,始终有个致命的问题:
在调用者调用时,错误就必须得到处理或者显式的传播。
如果函数 A 调用了函数 B,在 A 返回错误的时候,就要把 B 的错误转换成 A 的错误,显示出来。如下图所示:
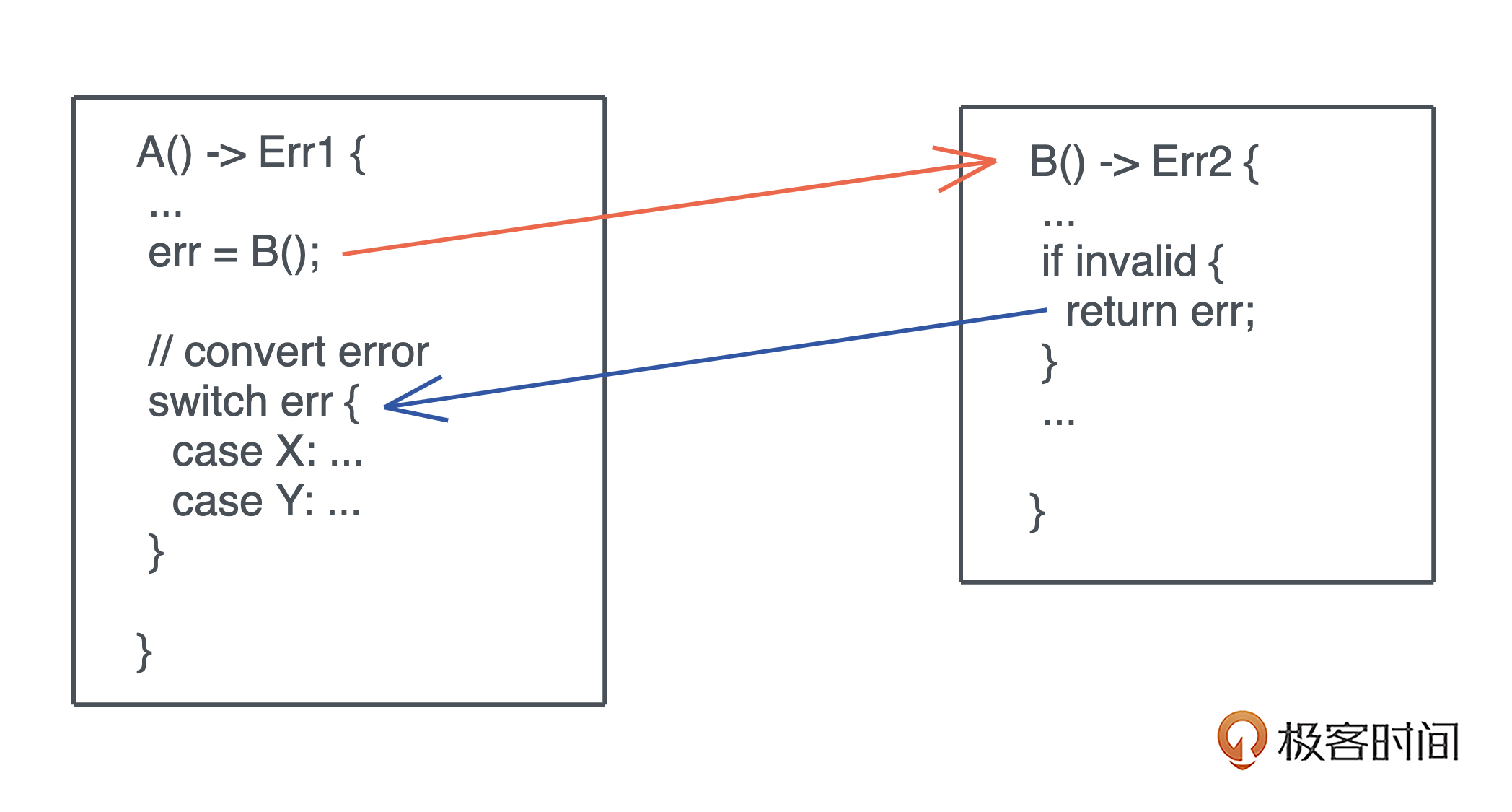
这样写出来的代码会非常冗长,对我们开发者的用户体验不太好。如果不处理,又会丢掉这个错误信息,造成隐患。
另外,大部分生产环境下的错误是嵌套的:
- 一个 SQL 执行过程中抛出的错误,可能是服务器出错,而更深层次的错误可能是,连接数据库服务器的 TLS session 状态异常。
- 其实知道服务器出错之外,我们更需要清楚服务器出错的内在原因。
因为服务器出错这个表层错误会提供给最终用户,而出错的深层原因要提供给我们自己,服务的维护者。 但是这样的嵌套错误在 C / Golang 都是很难完美表述的。
2. 使用异常: 抛出异常+捕获异常
因为返回值不利于错误的传播,有诸多限制,Java 等很多语言使用异常来处理错误。
关注点分离
你可以把异常看成一种关注点分离(Separation of Concerns):
- 错误的产生和错误的处理完全被分隔开
- 调用者不必关心错误,而被调者也不强求调用者关心错误。
- 程序中任何可能出错的地方,都可以抛出异常;
- 而异常可以通过栈回溯(stack unwind)被一层层自动传递,直到遇到捕获异常的地方,
- 如果回溯到 main 函数还无人捕获,程序就会崩溃。如下图所示:
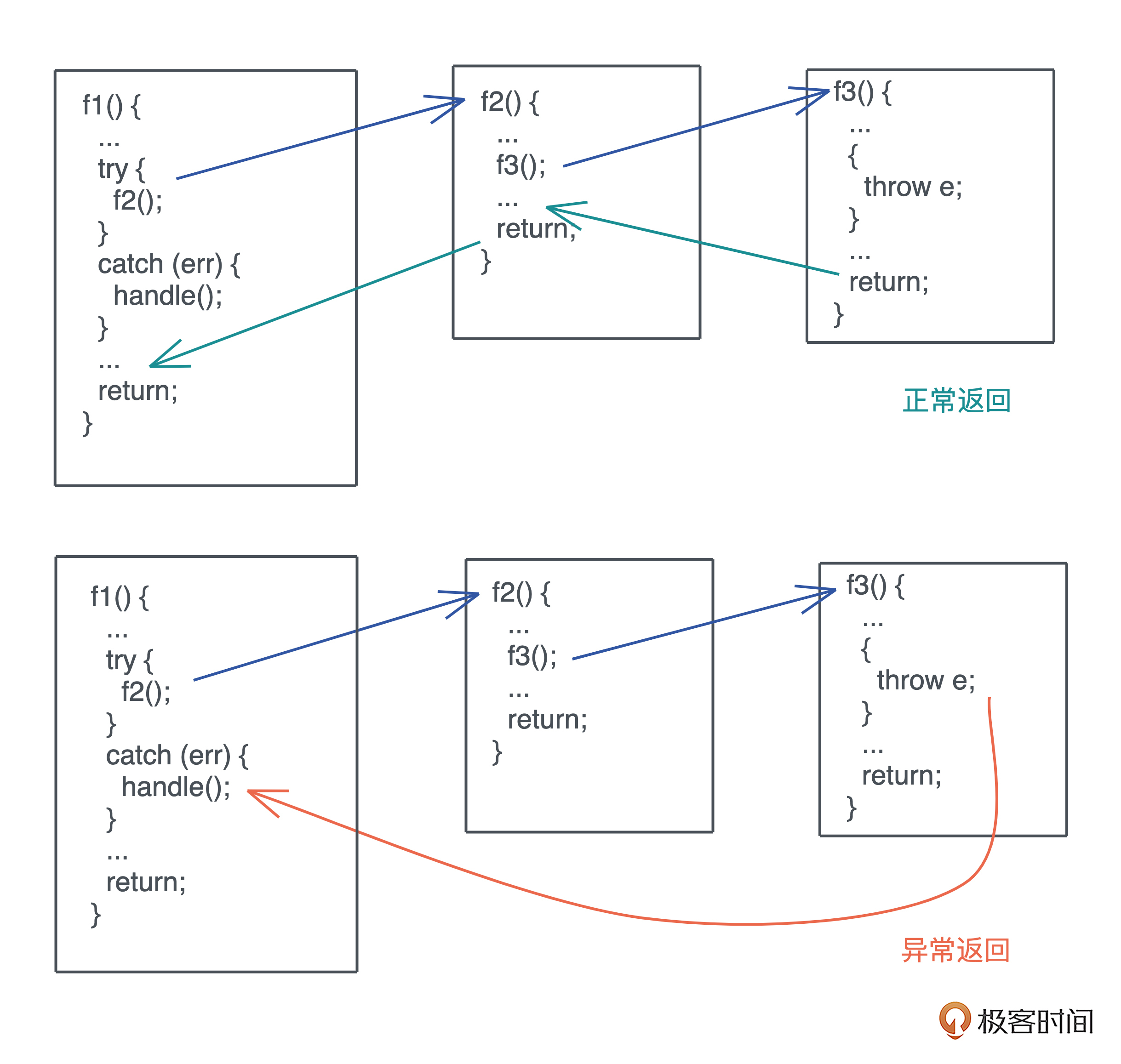
使用异常来返回错误可以极大地简化错误处理的流程,它解决了返回值的传播问题。
然而,上图中异常返回的过程看上去很直观,就像数据库中的事务(transaction)在出错时会被整体撤销(rollback)一样。
但实际上,这个过程远比你想象的复杂,而且需要额外操心异常安全(exception safety)。 我们看下面用来切换背景图片的(伪)代码:
void transition(...) {
lock(&mutex);
delete background;
++changed;
background = new Background(...);
unlock(&mutex);
}
试想, 如果在创建新的背景时失败,抛出异常,会跳过后续的处理流程,一路栈回溯到 try catch 的代码,那么,这里锁住的 mutex 无法得到释放,而已有的背景被清空,新的背景没有创建,程序进入到一个奇怪的状态。
异常的限制:异常安全+异常滥用
确实在大多数情况下,用异常更容易写代码,但当异常安全无法保证时,程序的正确性会受到很大的挑战。因此,你在使用异常处理时,需要特别注意异常安全,尤其是在并发环境下。
异常处理另外一个比较严重的问题是:开发者会滥用异常。只要有错误,不论是否严重、是否可恢复,都一股脑抛个异常。到了需要的地方,捕获一下了之。殊不知,异常处理的开销要比处理返回值大得多,滥用会有很多额外的开销。
3. 使用类型系统
第三种错误处理的方法就是使用类型系统。其实,在使用返回值处理错误的时候,我们已经看到了类型系统的雏形。
错误信息既然可以通过已有的类型携带,或者通过多返回值的方式提供,那么通过类型来表征错误,使用一个内部包含正常返回类型和错误返回类型的复合类型,通过类型系统来强制错误的处理和传递,是不是可以达到更好的效果呢?
Haskell 的 Maybe 和 Either 类型
的确如此。这种方式被大量使用在有强大类型系统支持的函数式编程语言中,如 Haskell/Scala/Swift。其中最典型的包含了错误类型的复合类型是 Haskell 的 Maybe 和 Either 类型。
-
Maybe 类型允许数据包含一个值(Just)或者没有值(Nothing),这对简单的不需要类型的错误很有用。还是以打开文件为例,如果我们只关心成功打开文件的句柄,那么 Maybe 就足够了。
-
当我们需要更为复杂的错误处理时,我们可以使用 Either 类型。它允许数据是 Left a 或者 Right b 。其中,a 是运行出错的数据类型,b 可以是成功的数据类型。
我们可以看到,这种方法依旧是通过返回值返回错误,但是错误被包裹在一个完整的、必须处理的类型中,比 Golang 的方法更安全。
比起返回错误,类型系统有什么好处?
我们前面提到,使用返回值返回错误的一大缺点是,错误需要被调用者立即处理或者显式传递。
但是使用 Maybe / Either 这样的类型来处理错误的好处是,我们可以用函数式编程的方法简化错误的处理,比如 map、fold等函数,让代码相对不那么冗余。
需要注意的是:
很多不可恢复的错误,如“磁盘写满,无法写入”的错误,使用异常处理可以避免一层层传递错误,让代码简洁高效,所以大多数使用类型系统来处理错误的语言,会同时使用异常处理作为补充。
Rust 的错误处理: 使用类型系统来构建
1. 可恢复错误:Option/Result错误类型处理
由于诞生的年代比较晚,Rust 有机会从已有的语言中学习到各种错误处理的优劣。对于 Rust 来说,目前的几种方式相比而言,最佳的方法是,使用类型系统来构建主要的错误处理流程。
Option
Result
Result 是一个更加复杂的 enum,其定义如下:
#[must_use = "this `Result` may be an `Err` variant, which should be handled"] pub enum Result<T, E> { Ok(T), Err(E), }
当函数出错时,可以返回 Err(E),否则 Ok(T)。
Result 类型声明时还有个 must_use 的标注
我们看到,Result 类型声明时还有个 must_use 的标注
编译器会对有 must_use 标注的所有类型做特殊处理:
如果该类型对应的值没有被显式使用,则会告警。这样,保证错误被妥善处理。
如下图所示:

这里,如果我们调用 read_file 函数时,直接丢弃返回值,由于 #[must_use] 的标注,Rust 编译器报警,要求我们使用其返回值。
2. 抛出异常:panic! 和 catch_unwind
panic!抛出异常: 不可/不想恢复
使用 Option 和 Result 是 Rust 中处理错误的首选,绝大多数时候我们也应该使用,但 Rust 也提供了特殊的异常处理能力。
在 Rust 看来,一旦你需要抛出异常,那抛出的一定是严重的错误。
所以,Rust 跟 Golang 一样,使用了诸如 panic! 这样的字眼警示开发者:想清楚了再使用我。
一般而言,panic! 是不可恢复或者不想恢复的错误,我们希望在此刻,程序终止运行并得到崩溃信息。
unwrap/expect语法糖
unwrap() 或者 expect()就是准备panic!
在使用 Option 和 Result 类型时,开发者也可以对其 unwrap() 或者 expect(),强制把 Option
比如下面的代码,它解析 noise protocol的协议变量:
let params: NoiseParams = "Noise_XX_25519_AESGCM_SHA256".parse().unwrap();
如果开发者不小心把协议变量写错了,最佳的方式是立刻 panic! 出来,让错误立刻暴露,以便解决这个问题。
catch_uwind捕获异常:崩溃后恢复上下文
catch_unwind(): 有些场景下,我们也希望能够像异常处理那样能够栈回溯,把环境恢复到捕获异常的上下文。
Rust 标准库下提供了 catch_unwind() ,把调用栈回溯到 catch_unwind 这一刻,作用和其它语言的 try {…} catch {…} 一样。见如下代码:
use std::panic; fn main() { let result = panic::catch_unwind(|| { println!("hello!"); }); assert!(result.is_ok()); let result = panic::catch_unwind(|| { panic!("oh no!"); }); assert!(result.is_err()); println!("panic captured: {:#?}", result); }
当然,和异常处理一样,并不意味着你可以滥用这一特性. 我想这也是 Rust 把抛出异常称作 panic! ,而捕获异常称作 catch_unwind 的原因:让初学者望而生畏,不敢轻易使用。这也是一个不错的用户体验。
catch_unwind 在哪些场景下非常有用:
catch_unwind 在某些场景下非常有用:
-
比如你在使用 Rust 为 erlang VM 撰写 NIF,你不希望 Rust 代码中的任何 panic! 导致 erlang VM 崩溃。 因为崩溃是一个非常不好的体验,它违背了 erlang 的设计原则:process 可以 let it crash,但错误代码不该导致 VM 崩溃。
-
此刻,你就可以把 Rust 代码整个封装在 catch_unwind() 函数所需要传入的闭包中。 这样,一旦任何代码中,包括第三方 crates 的代码,含有能够导致 panic! 的代码,都会被捕获,并被转换为一个 Result。
3. 自定义异常类型
3.1 使用Error trait
我们可以定义我们自己的数据类型,然后为其实现 Error trait。
使用Error trait自定义错误类型
上文中,我们讲到 Result<T, E> 里 E 是一个代表错误的数据类型。为了规范这个代表错误的数据类型的行为,Rust 定义了 Error trait:
pub trait Error: Debug + Display { fn source(&self) -> Option<&(dyn Error + 'static)> { ... } fn backtrace(&self) -> Option<&Backtrace> { ... } fn description(&self) -> &str { ... } fn cause(&self) -> Option<&dyn Error> { ... } }
3.2 使用thiserror简化
不过,这样的工作已经有人替我们简化了:我们可以使用 thiserror和 anyhow来简化这个步骤。
thiserror 提供了一个派生宏(derive macro)来简化错误类型的定义
use thiserror::Error; #[derive(Error, Debug)] #[non_exhaustive] pub enum DataStoreError { #[error("data store disconnected")] Disconnect(#[from] io::Error), #[error("the data for key `{0}` is not available")] Redaction(String), #[error("invalid header (expected {expected:?}, found {found:?})")] InvalidHeader { expected: String, found: String, }, #[error("unknown data store error")] Unknown, }
如果你在撰写一个 Rust 库,那么 thiserror 可以很好地协助你对这个库里所有可能发生的错误进行建模。
3.3 使用anyhow扩展 ?操作符
- anyhow 实现了 anyhow::Error 和任意符合 Error trait 的错误类型之间的转换,让你可以使用 ? 操作符,不必再手工转换错误类型。
- anyhow 还可以让你很容易地抛出一些临时的错误,而不必费力定义错误类型,当然,我们不提倡滥用这个能力。
3.4 让错误无所遁形
作为一名严肃的开发者,我非常建议你在开发前:
- 先用类似 thiserror 的库定义好你项目中主要的错误类型
- 并随着项目的深入,不断增加新的错误类型,让系统中所有的潜在错误都无所遁形。
4. 捕获异常
4.1 ? 操作符
由来
? 操作符的由来
这虽然可以极大避免遗忘错误的显示处理,但如果我们并不关心错误,只需要传递错误,还是会写出像 C 或者 Golang 一样比较冗余的代码。怎么办?
好在 Rust 除了有强大的类型系统外,还具备元编程的能力:
- 早期 Rust 提供了 try! 宏来简化错误的显式处理
- 后来为了进一步提升用户体验,try! 被进化成 ? 操作符。
用于传播📣
如果你只想传播错误,不想就地处理,可以用 ? 操作符
所以在 Rust 代码中,如果你只想传播错误,不想就地处理,可以用 ? 操作符,比如(代码):
use std::fs::File; use std::io::Read; fn read_file(name: &str) -> Result<String, std::io::Error> { let mut f = File::open(name)?; let mut contents = String::new(); f.read_to_string(&mut contents)?; Ok(contents) }
通过 ? 操作符,Rust 让错误传播的代价和异常处理不相上下,同时又避免了异常处理的诸多问题。
?操作符展开
? 操作符内部被展开成类似这样的代码:
match result { Ok(v) => v, Err(e) => return Err(e.into()) }
所以,我们可以方便地写出类似这样的代码,简洁易懂,可读性很强:
fut .await? .process()? .next() .await?;
整个代码的执行流程如下:
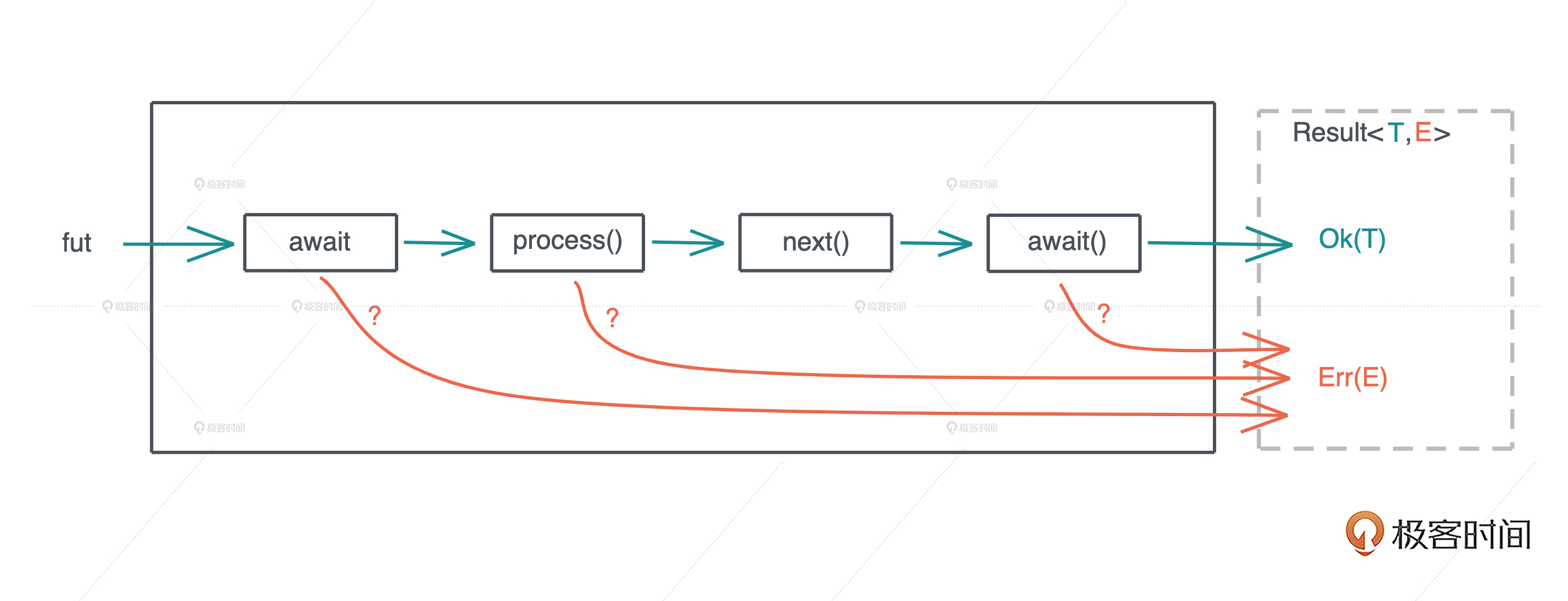
虽然 ? 操作符使用起来非常方便,但你要注意在不同的错误类型之间是无法直接使用的,需要实现 From trait 在二者之间建立起转换的桥梁,这会带来额外的麻烦。
4.2 函数式错误处理: map/map_err/and_then
Rust 还为 Option 和 Result 提供了大量的辅助函数,如 map / map_err / and_then,你可以很方便地处理数据结构中部分情况。
map / map_err / and_then: 使用函数式错误处理
如下图所示:
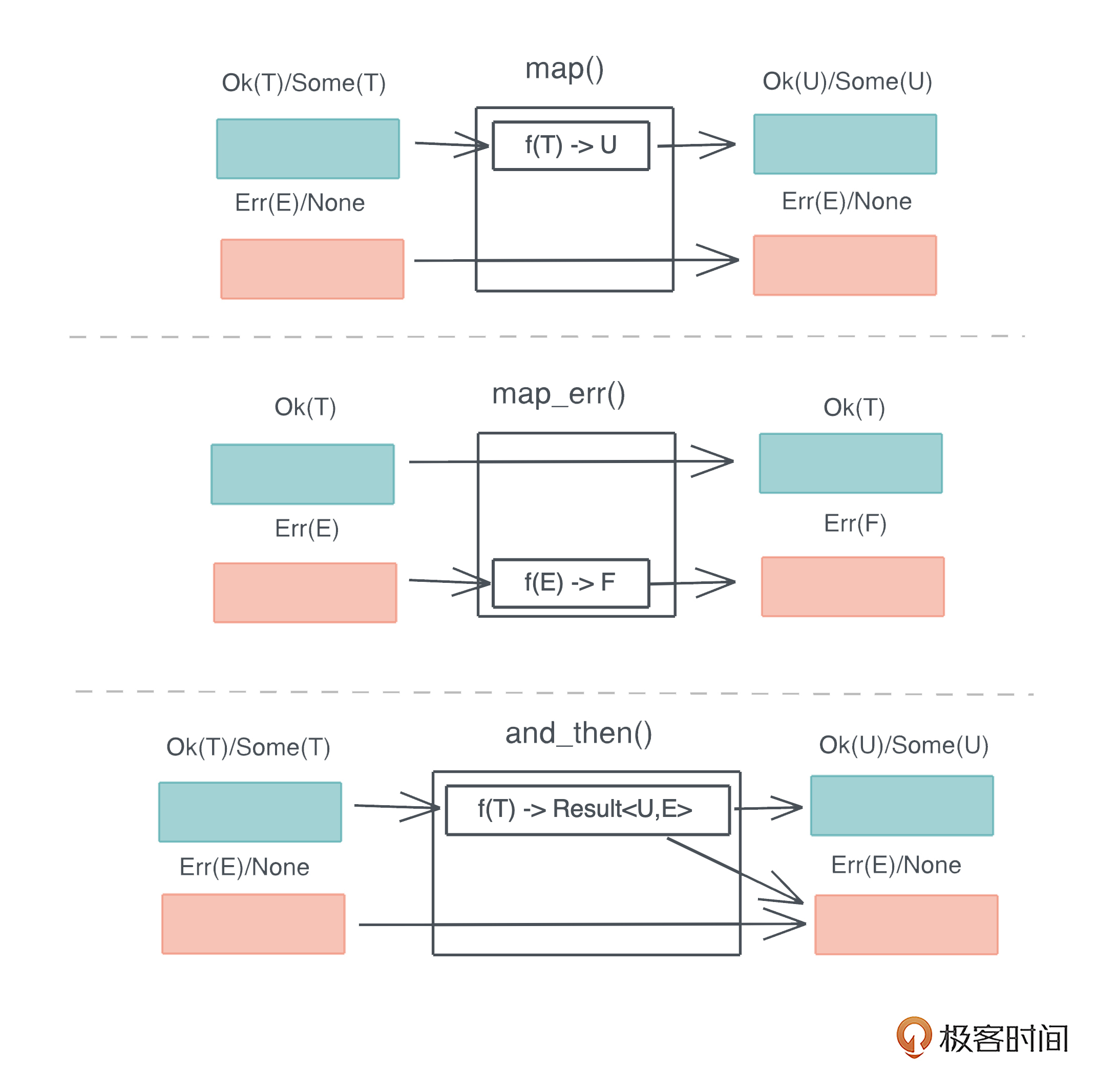
通过这些函数,你可以很方便地对错误处理引入 Railroad oriented programming 范式。
比如用户注册的流程,你需要校验用户输入,对数据进行处理,转换,然后存入数据库中。你可以这么撰写这个流程:
Ok(data) .and_then(validate) .and_then(process) .map(transform) .and_then(store) .map_error(...)
执行流程如下图所示:
此外,Option 和 Result 的互相转换也很方换,这也得益于 Rust 构建的强大的函数式编程的能力。
我们可以看到,无论是通过 ? 操作符,还是函数式编程进行错误处理,Rust 都力求让错误处理灵活高效,让开发者使用起来简单直观。
四、闭包结构
闭包的定义
闭包的基本概念
闭包的基本概念:
- 闭包是将函数,或者说代码和其环境一起存储的一种数据结构。
- 闭包引用的上下文中的自由变量,会被捕获到闭包的结构中,成为闭包类型的一部分
- 闭包会根据内部的使用情况,捕获环境中的自由变量。
Rust中闭包捕获自由变量的两个方法
在 Rust 里,闭包可以用 |args| {code} 来表述,图中闭包 c 捕获了上下文中的 a 和 b,并通过引用来使用这两个自由变量:
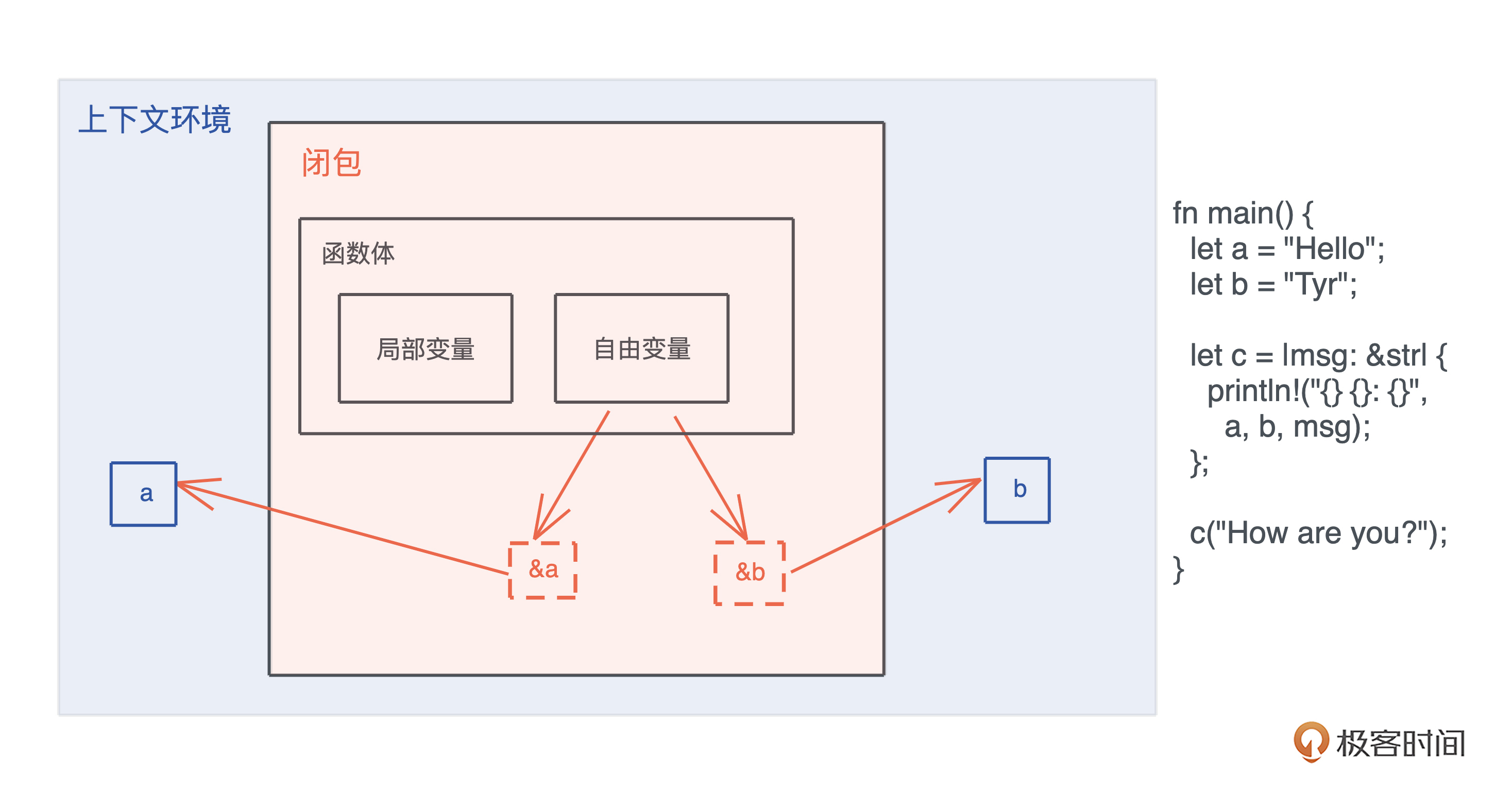
除了用引用来捕获自由变量之外,还有另外一个方法使用 move 关键字 move |args| {code} 。
thread::spawn的参数是一个闭包,使用move关键字
比如创建新线程的 thread::spawn,它的参数就是一个闭包:
pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static,
仔细看这个接口:
- F: FnOnce() → T,表明 F 是一个接受 0 个参数、返回 T 的闭包。FnOnce 我们稍后再说。
- F: Send + ’static,说明闭包 F 这个数据结构,需要静态生命周期或者拥有所有权,并且它还能被发送给另一个线程。a
- T: Send + ’static,说明闭包 F 返回的数据结构 T,需要静态生命周期或者拥有所有权,并且它还能被发送给另一个线程。
1 和 3 都很好理解,2 就有些费解了。一个闭包,它不就是一段代码 + 被捕获的变量么?需要静态生命周期或者拥有所有权是什么意思?
拆开看:
- 代码自然是静态生命周期
- 那么是不是意味着被捕获的变量,需要静态生命周期或者拥有所有权?
的确如此。在使用 thread::spawn 时,我们需要使用 move 关键字,把变量的所有权从当前作用域移动到闭包的作用域,让 thread::spawn 可以正常编译通过:
use std::thread; fn main() { let s = String::from("hello world"); let handle = thread::spawn(move || { println!("moved: {:?}", s); }); handle.join().unwrap(); }
但你有没有好奇过,加 move 和不加 move,这两种闭包有什么本质上的不同?闭包究竟是一种什么样的数据类型,让编译器可以判断它是否满足 Send + ’static 呢?我们从闭包的本质下手来尝试回答这两个问题。
闭包本质上是什么?
匿名结构体: 默认借用,move转移
- 闭包本质上是一个匿名结构体,长度与捕获的自由变量一致
- 默认捕获引用,此时编译器进行借用规则检查
- move转移所有权,此时编译器根据所有权规则检查
闭包的本质是匿名结构体,move会转移自由变量的所有权
在官方的 Rust reference 中,有这样的定义:
A closure expression produces a closure value with a unique, anonymous type that cannot be written out. A closure type is approximately equivalent to a struct which contains the captured variables.
闭包是一种匿名类型,一旦声明,就会产生一个新的类型,但这个类型无法被其它地方使用。这个类型就像一个结构体,会包含所有捕获的变量。
所以闭包类似一个特殊的结构体?
为了搞明白这一点,我们得写段代码探索一下,建议你跟着敲一遍认真思考(代码):
use std::{collections::HashMap, mem::size_of_val}; fn main() { // 长度为 0 let c1 = || println!("hello world!"); // 和参数无关,长度也为 0 let c2 = |i: i32| println!("hello: {}", i); let name = String::from("tyr"); let name1 = name.clone(); let mut table = HashMap::new(); table.insert("hello", "world"); // 如果捕获一个引用,长度为 8 let c3 = || println!("hello: {}", name); // 捕获移动的数据 name1(长度 24) + table(长度 48),closure 长度 72 let c4 = move || println!("hello: {}, {:?}", name1, table); let name2 = name.clone(); // 和局部变量无关,捕获了一个 String name2,closure 长度 24 let c5 = move || { let x = 1; let name3 = String::from("lindsey"); println!("hello: {}, {:?}, {:?}", x, name2, name3); }; println!( "c1: {}, c2: {}, c3: {}, c4: {}, c5: {}, main: {}", size_of_val(&c1), size_of_val(&c2), size_of_val(&c3), size_of_val(&c4), size_of_val(&c5), size_of_val(&main), ) }
查看上面代码的5个闭包得出结论
分别生成了 5 个闭包:
- c1 没有参数,也没捕获任何变量,从代码输出可以看到,c1 长度为 0;
- c2 有一个 i32 作为参数,没有捕获任何变量,长度也为 0,可以看出参数跟闭包的大小无关;
- c3 捕获了一个对变量 name 的引用,这个引用是 &String,长度为 8。而 c3 的长度也是 8;
- c4 捕获了变量 name1 和 table,由于用了 move,它们的所有权移动到了 c4 中。c4 长度是 72,恰好等于 String 的 24 字节,加上 HashMap 的 48 字节。
- c5 捕获了 name2,name2 的所有权移动到了 c5,虽然 c5 有局部变量,但它的大小和局部变量也无关,c5 的大小等于 String 的 24 字节。
可以看到:
- 不带 move 时,闭包捕获的是对应自由变量的引用;
- 带 move 时,对应自由变量的所有权会被移动到闭包结构中。
闭包大小只跟捕获的变量有关
继续分析这段代码的运行结果。
闭包大小只跟捕获的变量有关
还知道了,闭包的大小跟参数、局部变量都无关,只跟捕获的变量有关:
因为它们是在调用的时刻才在栈上产生的内存分配,说到底和闭包类型本身是无关的,所以闭包的大小跟它们自然无关。
use std::{collections::HashMap, mem::size_of_val}; fn main() { // 长度为 0 let c1 = || println!("hello world!"); // 和参数无关,长度也为 0 let c2 = |i: i32| println!("hello: {}", i); let name = String::from("tyr"); let name1 = name.clone(); let mut table = HashMap::new(); table.insert("hello", "world"); // 如果捕获一个引用,长度为 8 let c3 = || println!("hello: {}", name); // 捕获移动的数据 name1(长度 24) + table(长度 48),closure 长度 72 let c4 = move || println!("hello: {}, {:?}", name1, table); let name2 = name.clone(); // 和局部变量无关,捕获了一个 String name2,closure 长度 24 let c5 = move || { let x = 1; let name3 = String::from("lindsey"); println!("hello: {}, {:?}, {:?}", x, name2, name3); }; println!( "c1: {}, c2: {}, c3: {}, c4: {}, c5: {}, main: {}", size_of_val(&c1), size_of_val(&c2), size_of_val(&c3), size_of_val(&c4), size_of_val(&c5), size_of_val(&main), ) }
内存布局
既然闭包是匿名结构体,那么它的内存布局与结构体有什么区别?
闭包的内存布局与结构体有什么区别?
那一个闭包类型在内存中究竟是如何排布的,和结构体有什么区别?
我们要再次结合 rust-gdb 探索,看看上面的代码在运行结束前,几个长度不为 0 闭包内存里都放了什么:

可以看到:
- c3 的确是一个引用,把它指向的内存地址的 24 个字节打出来,是 (ptr | cap | len) 的标准结构。如果打印 ptr 对应的堆内存的 3 个字节,是 ‘t’ ‘y’ ‘r’。
- 而 c4 捕获的 name 和 table,内存结构和下面的结构体一模一样:
struct Closure4 { name: String, // (ptr|cap|len)=24字节 table: HashMap<&str, &str> // (RandomState(16)|mask|ctrl|left|len)=48字节 }
不过,对于 closure 类型来说,编译器知道像函数一样调用闭包 c4() 是合法的,并且知道执行 c4() 时,代码应该跳转到什么地址来执行。 在执行过程中,如果遇到 name、table,可以从自己的数据结构中获取。
那么多想一步,闭包捕获变量的顺序,和其内存结构的顺序是一致的么?
的确如此,如果我们调整闭包里使用 name1 和 table 的顺序:
let c4 = move || println!("hello: {:?}, {}", table, name1);
其数据的位置是相反的,类似于:
struct Closure4 { table: HashMap<&str, &str> // (RandomState(16)|mask|ctrl|left|len)=48字节 name: String, // (ptr|cap|len)=24字节 }
从 gdb 中也可以看到同样的结果:

不过这只是逻辑上的位置,Rust 编译器会重排内存,让数据能够以最小的代价对齐,所以有些情况下,内存中数据的顺序可能和 struct 定义不一致。
所以回到刚才闭包和结构体的比较:
- 在 Rust 里,闭包产生的匿名数据类型,格式和 struct 是一样的。
- 看图中 gdb 的输出,闭包是存储在栈上,并且除了捕获的数据外,闭包本身不包含任何额外函数指针指向闭包的代码。
- 如果你理解了 c3 / c4 这两个闭包,c5 是如何构造的就很好理解了。
现在,你是不是可以回答为什么 thread::spawn 对传入的闭包约束是 Send + ’static 了?究竟什么样的闭包满足它呢?
很明显,使用了 move 且 move 到闭包内的数据结构满足 Send,因为此时,闭包的数据结构拥有所有数据的所有权,它的生命周期是 ’static。
看完 Rust 闭包的内存结构,你是不是想说“就这”,没啥独特之处吧?但是对比其他语言,结合接下来我的解释,你再仔细想想就会有一种“这怎么可能”的惊讶。
不同语言的闭包设计
其他语言闭包设计有什么问题?
闭包最大的问题是变量的多重引用导致生命周期不明确,所以你先想,其它支持闭包的语言(lambda 也是闭包),它们的闭包会放在哪里?
栈上么?是,又好像不是。
因为闭包这玩意,从当前上下文中捕获了些变量,变得有点不伦不类,不像函数那样清楚,尤其是这些被捕获的变量,它们的归属和生命周期处理起来很麻烦。所以,大部分编程语言的闭包很多时候无法放在栈上,需要额外的堆分配。你可以看这个 Golang 的例子。
不光 Golang,Java / Swift / Python / JavaScript 等语言都是如此,这也是为什么大多数编程语言闭包的性能要远低于函数调用。
因为使用闭包就意味着:
- 额外的堆内存分配
- 潜在的动态分派(很多语言会把闭包处理成函数指针)
- 额外的内存回收。
在性能上,唯有 C++ 的 lambda 和 Rust 闭包类似,不过 C++ 的闭包还有一些场景会触发堆内存分配。
Rust / Swift / Kotlin iterator 函数式编程的性能测试:
- Kotlin 运行超时
- Swift 很慢
- Rust 的性能却和使用命令式编程的 C 几乎一样,除了编译器优化的效果,也因为 Rust 闭包的性能和函数差不多。
Rust的设计如何保证闭包性能
为何Rust可以保证闭包的性能与函数差不多: 匿名结构体、借用 or 转移所有权
为什么 Rust 可以做到这样呢?
这又跟 Rust 从根本上使用所有权和借用,解决了内存归属问题有关。
在其他语言中,闭包变量因为多重引用导致生命周期不明确,但 Rust 从一开始就消灭了这个问题:
- 如果不使用 move 转移所有权:
闭包会引用上下文中的变量,这个引用受借用规则的约束,所以只要编译通过,那么闭包对变量的引用就不会超过变量的生命周期,没有内存安全问题。
- 如果使用 move 转移所有权:
上下文中的变量在转移后就无法访问,闭包完全接管这些变量,它们的生命周期和闭包一致,所以也不会有内存安全问题。
- 匿名结构体的好处:
而 Rust 为每个闭包生成一个新的类型,又使得调用闭包时可以直接和代码对应,省去了使用函数指针再转一道手的额外消耗。
所以还是那句话,当回归到最初的本原,你解决的不是单个问题,而是由此引发的所有问题:
我们不必为堆内存管理设计 GC、不必为其它资源的回收提供 defer 关键字、不必为并发安全进行诸多限制、也不必为闭包挖空心思搞优化。
从Rust 的闭包类型开始思考🤔
现在我们搞明白了闭包究竟是个什么东西,在内存中怎么表示,接下来我们看看 FnOnce / FnMut / Fn 这三种闭包类型有什么区别。
既然闭包是一个匿名结构体类型,就可以有三个思考:
- 可以作为函数的参数或返回
- 可以对其添加trait实现;
- 可以用在trait约束;事实上,rust已经做了这件事,提供Fn/FnMut/FnOnce这三个
- 在声明闭包的时候,我们并不需要指定闭包要满足的约束
- 但是当闭包作为函数的参数或者数据结构的一个域时,我们需要告诉调用者,对闭包的约束。
下面👇一一说明
作为函数的参数
在函数的参数中使用闭包
thread::spawn 自不必说,我们熟悉的 Iterator trait 里面大部分函数都接受一个闭包,比如 map:
fn map<B, F>(self, f: F) -> Map<Self, F> where Self: Sized, F: FnMut(Self::Item) -> B, { Map::new(self, f) }
- 可以看到,Iterator 的 map() 方法接受一个 FnMut
- 它的参数是 Self::Item
- 返回值是没有约束的泛型参数 B。
- Self::Item 是 Iterator::next() 方法吐出来的数据,被 map 之后,可以得到另一个结果。
所以在函数的参数中使用闭包,是闭包一种非常典型的用法。
作为函数的返回
在函数的返回值中使用闭包
另外闭包也可以作为函数的返回值,举个简单的例子(代码):
use std::ops::Mul; fn main() { let c1 = curry(5); println!("5 multiply 2 is: {}", c1(2)); let adder2 = curry(3.14); println!("pi multiply 4^2 is: {}", adder2(4. * 4.)); } fn curry<T>(x: T) -> impl Fn(T) -> T where T: Mul<Output = T> + Copy, { move |y| x * y }
为闭包实现trait
为闭包实现某个 trait,使其也能表现出其他行为,而不仅仅是作为函数被调用。
闭包还有一种并不少见,但可能不太容易理解的用法:
为它实现某个 trait,使其也能表现出其他行为,而不仅仅是作为函数被调用。
比如说有些接口既可以传入一个结构体,又可以传入一个函数或者闭包。
我们看一个 tonic(Rust 下的 gRPC 库)的例子
pub trait Interceptor { /// Intercept a request before it is sent, optionally cancelling it. fn call(&mut self, request: crate::Request<()>) -> Result<crate::Request<()>, Status>; } impl<F> Interceptor for F where F: FnMut(crate::Request<()>) -> Result<crate::Request<()>, Status>, { fn call(&mut self, request: crate::Request<()>) -> Result<crate::Request<()>, Status> { self(request) } }
在这个例子里,Interceptor 有一个 call 方法,它可以让 gRPC Request 被发送出去之前被修改,一般是添加各种头,比如 Authorization 头。
我们可以创建一个结构体,为它实现 Interceptor,不过大部分时候 Interceptor 可以直接通过一个闭包函数完成。为了让传入的闭包也能通过 Interceptor::call() 来统一调用,可以为符合某个接口的闭包实现 Interceptor trait。掌握了这种用法,我们就可以通过某些 trait 把特定的结构体和闭包统一起来调用,是不是很神奇。
闭包根据不同trait约束表现不同行为
还以 thread::spawn 为例,它要求传入的闭包满足 FnOnce trait。
FnOnce
FnOnce定义->例子解析
先来看 FnOnce。它的定义如下:
pub trait FnOnce<Args> { type Output; extern "rust-call" fn call_once(self, args: Args) -> Self::Output; }
- FnOnce 有一个关联类型 Output,显然,它是闭包返回值的类型;
- 还有一个方法 call_once,要注意的是 call_once 第一个参数是 self,它会转移 self 的所有权到 call_once 函数中。
这也是为什么 FnOnce 被称作 Once :它只能被调用一次。再次调用,编译器就会报变量已经被 move 这样的常见所有权错误了。
至于 FnOnce 的参数,是一个叫 Args 的泛型参数,它并没有任何约束。
看一个隐式的 FnOnce 的例子:
fn main() { let name = String::from("Tyr"); // 这个闭包啥也不干,只是把捕获的参数返回去 let c = move |greeting: String| (greeting, name); let result = c("hello".to_string()); println!("result: {:?}", result); // 无法再次调用 let result = c("hi".to_string()); }
- 这个闭包 c,啥也没做,只是把捕获的参数返回。
- 就像一个结构体里,某个字段被转移走之后,就不能再访问一样,闭包内部的数据一旦被转移,这个闭包就不完整了,也就无法再次使用,所以它是一个 FnOnce 的闭包。
如果一个闭包并不转移自己的内部数据,那么它就不是 FnOnce,然而,一旦它被当做 FnOnce 调用,自己会被转移到 call_once 函数的作用域中,之后就无法再次调用了,我们看个例子(代码):
fn main() { let name = String::from("Tyr"); // 这个闭包会 clone 内部的数据返回,所以它不是 FnOnce let c = move |greeting: String| (greeting, name.clone()); // 所以 c1 可以被调用多次 println!("c1 call once: {:?}", c("qiao".into())); println!("c1 call twice: {:?}", c("bonjour".into())); // 然而一旦它被当成 FnOnce 被调用,就无法被再次调用 println!("result: {:?}", call_once("hi".into(), c)); // 无法再次调用 // let result = c("hi".to_string()); // Fn 也可以被当成 FnOnce 调用,只要接口一致就可以 println!("result: {:?}", call_once("hola".into(), not_closure)); } fn call_once(arg: String, c: impl FnOnce(String) -> (String, String)) -> (String, String) { c(arg) } fn not_closure(arg: String) -> (String, String) { (arg, "Rosie".into()) }
怎么理解 FnOnce 的 Args 泛型参数呢?
怎么理解 FnOnce 的 Args 泛型参数呢?
Args 又是怎么和 FnOnce 的约束,比如 FnOnce(String) 这样的参数匹配呢?感兴趣的同学可以看下面的例子,它(不完全)模拟了 FnOnce 中闭包的使用(代码):
struct ClosureOnce<Captured, Args, Output> { // 捕获的数据 captured: Captured, // closure 的执行代码 func: fn(Args, Captured) -> Output, } impl<Captured, Args, Output> ClosureOnce<Captured, Args, Output> { // 模拟 FnOnce 的 call_once,直接消耗 self fn call_once(self, greeting: Args) -> Output { (self.func)(greeting, self.captured) } } // 类似 greeting 闭包的函数体 fn greeting_code1(args: (String,), captured: (String,)) -> (String, String) { (args.0, captured.0) } fn greeting_code2(args: (String, String), captured: (String, u8)) -> (String, String, String, u8) { (args.0, args.1, captured.0, captured.1) } fn main() { let name = "Tyr".into(); // 模拟变量捕捉 let c = ClosureOnce { captured: (name,), func: greeting_code1, }; // 模拟闭包调用,这里和 FnOnce 不完全一样,传入的是一个 tuple 来匹配 Args 参数 println!("{:?}", c.call_once(("hola".into(),))); // 调用一次后无法继续调用 // println!("{:?}", clo.call_once("hola".into())); // 更复杂一些的复杂的闭包 let c1 = ClosureOnce { captured: ("Tyr".into(), 18), func: greeting_code2, }; println!("{:?}", c1.call_once(("hola".into(), "hallo".into()))); }
FnMut
FnMut的定义与例子
理解了 FnOnce,我们再来看 FnMut,它的定义如下:
pub trait FnMut<Args>: FnOnce<Args> { extern "rust-call" fn call_mut( &mut self, args: Args ) -> Self::Output; }
- 首先,FnMut “继承”了 FnOnce,或者说 FnOnce 是 FnMut 的 super trait。
- 所以 FnMut 也拥有 Output 这个关联类型和 call_once 这个方法。
- 此外,它还有一个 call_mut() 方法。
- 注意 call_mut() 传入 &mut self,它不移动 self,所以 FnMut 可以被多次调用。
因为 FnOnce 是 FnMut 的 super trait,所以,一个 FnMut 闭包,可以被传给一个需要 FnOnce 的上下文,此时调用闭包相当于调用了 call_once()。
如果你理解了前面讲的闭包的内存组织结构,那么 FnMut 就不难理解,就像结构体如果想改变数据需要用 let mut 声明一样,如果你想改变闭包捕获的数据结构,那么就需要 FnMut。
我们看个例子(代码):
fn main() { let mut name = String::from("hello"); let mut name1 = String::from("hola"); // 捕获 &mut name let mut c = || { name.push_str(" Tyr"); println!("c: {}", name); }; // 捕获 mut name1,注意 name1 需要声明成 mut let mut c1 = move || { name1.push_str("!"); println!("c1: {}", name1); }; c(); c1(); call_mut(&mut c); call_mut(&mut c1); call_once(c); call_once(c1); } // 在作为参数时,FnMut 也要显式地使用 mut,或者 &mut fn call_mut(c: &mut impl FnMut()) { c(); } // 想想看,为啥 call_once 不需要 mut? fn call_once(c: impl FnOnce()) { c(); }
- 在声明的闭包 c 和 c1 里,我们修改了捕获的 name 和 name1。
- 不同的是 name 使用了引用,而 name1 移动了所有权,这两种情况和其它代码一样,也需要遵循所有权和借用有关的规则。
- 所以,如果在闭包 c 里借用了 name,你就不能把 name 移动给另一个闭包 c1。
这里也展示了,c 和 c1 这两个符合 FnMut 的闭包,能作为 FnOnce 来调用。我们在代码中也确认了,FnMut 可以被多次调用,这是因为 call_mut() 使用的是 &mut self,不移动所有权。
Fn
Fn的定义与例子
最后我们来看看 Fn trait。它的定义如下:
pub trait Fn<Args>: FnMut<Args> { extern "rust-call" fn call(&self, args: Args) -> Self::Output; }
- 可以看到,它“继承”了 FnMut,或者说 FnMut 是 Fn 的 super trait。
- 这也就意味着任何需要 FnOnce 或者 FnMut 的场合,都可以传入满足 Fn 的闭包。
我们继续看例子(代码):
fn main() { let v = vec![0u8; 1024]; let v1 = vec![0u8; 1023]; // Fn,不移动所有权 let mut c = |x: u64| v.len() as u64 * x; // Fn,移动所有权 let mut c1 = move |x: u64| v1.len() as u64 * x; println!("direct call: {}", c(2)); println!("direct call: {}", c1(2)); println!("call: {}", call(3, &c)); println!("call: {}", call(3, &c1)); println!("call_mut: {}", call_mut(4, &mut c)); println!("call_mut: {}", call_mut(4, &mut c1)); println!("call_once: {}", call_once(5, c)); println!("call_once: {}", call_once(5, c1)); } fn call(arg: u64, c: &impl Fn(u64) -> u64) -> u64 { c(arg) } fn call_mut(arg: u64, c: &mut impl FnMut(u64) -> u64) -> u64 { c(arg) } fn call_once(arg: u64, c: impl FnOnce(u64) -> u64) -> u64 { c(arg) }
总结一下三种trait闭包使用的情况以及它们之间的关系
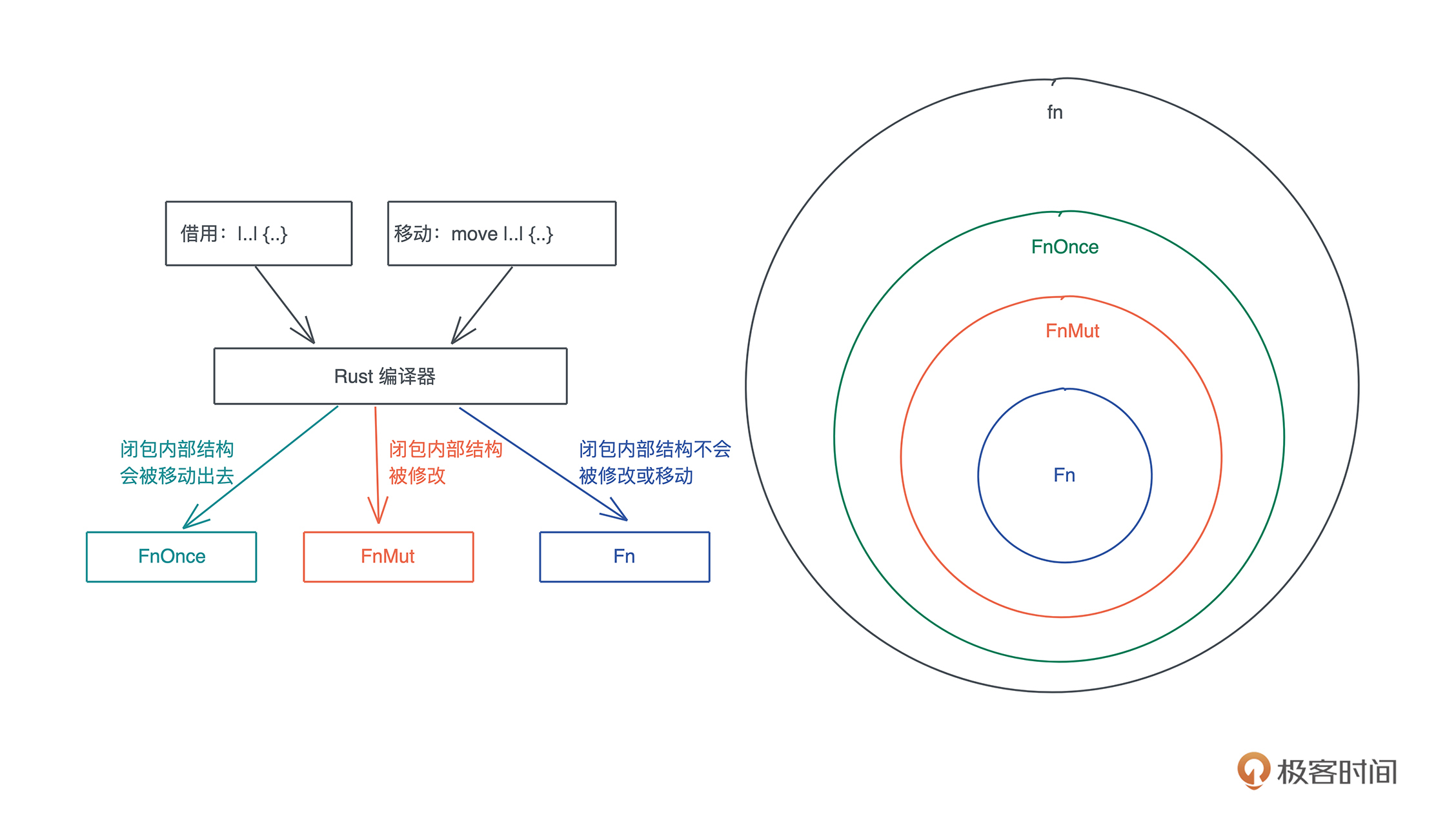
IV 宏编程
资料
宏的分类
使用泳道图
表格
声明宏(declarative macros): macro_rules!(bang)
对代码模版做简单替换 声明宏可以用 macro_rules! 来描述, 如果重复性的代码无法用函数来封装,那么声明宏就是一个好的选择
声明宏的缺陷,而后有了过程宏
为什么过程宏和声明宏那么像
过程宏的缺陷
- 缺乏对宏自动完成和扩展的支持
- 调试声明性宏很困难
- 修改能力有限
- 较大的二进制文件
- 更长的编译时间(这适用于声明性宏和过程宏)
过程宏是语法树级别的转换 过程宏是宏的更高级版本。过程宏允许你扩展现有的 Rust 语法。它接受任意输入并返回有效的 Rust 代码。 过程宏是将 TokenStream 作为输入并返回另一个 Token Stream 的函数。过程宏操作输入 TokenStream 以产生输出流。
过程宏:深度定制与生成代码
陈天B站视频另外提供详细演示
主要以如何使用 function-like macro 在不依赖于 syn / quote 的情况下,把 Json Schema 在编译期转换成 Rust struct。主要目的是让大家熟悉基本的处理 TokenStream 的思路
主要通过一个 derive Builder 宏,来展示使用 syn/quote 如何开发过程宏。
做个收尾,对上一讲的 derive macro 支持 attributes。 我们可以直接解析 attributes 相关的 TokenStream,也可以使用 darling 这个很方便的库,直接把 attributes 像 Clap/Structopts 那样收集到一个数据结构中,然后再进一步处理。
总结
这三讲的内容虽然简单,但足以应付大家绝大多数宏编程的需求。 其实我们现在对 syn 库的使用还只是一个皮毛,我们还没有深入 去撰写自己的数据结构去实现 Parse trait,像 DeriveInput 那样可以直接把 TokenStream 转换成我们想要的东西。
大家感兴趣的话,可以自行去看 syn 库的文档。
1. 函数宏
看起来像函数的宏,但在编译期进行处理.
sqlx 用函数宏来处理SQL query、tokio使用属性宏 #[tokio::main] 来引入 runtime。 它们可以帮助目标代码的实现逻辑变得更加简单, 但一般除非特别必要,否则并不推荐写。 并没有特定的使用场景
2. 属性宏
可以在其他代码块上添加属性,为代码块提供更多功能。
3. 派生宏
为 derive属性添加新的功能。这是我们平时使用最多的宏,比如 #[derive(Debug)].
如果你定义的 trait 别人实现起来有固定的模式可循,那么可以考虑为其构建派生宏
声明宏
Rust常用声明宏
println!
println!使用示例
#![allow(unused)] fn main() { #[macro_export] #[stable(feature = "rust1", since = "1.0.0")] #[allow_internal_unstable(print_internals, format_args_nl)] macro_rules! println { () => ($crate::print!("\n")); ($($arg:tt)*) => ({ $crate::io::_print($crate::format_args_nl!($($arg)*)); }) } }
writeln!
可以将内容输入到指定文件
cargo run --example raw_command > examples/raw_command_output.txt
eprintln!
示例
声明宏示意图
macro_rules!定义与使用
macro_rules!定义示例
#[macro_export] macro_rules! my_vec { // 没带任何参数的 my_vec,我们创建一个空的 vec // 注意,由于宏要在调用的地方展开,我们无法预测调用 // 者的环境是否已经 做了相关的 use,所以我们使用的 // 代码最好带着完整的命名空间。 () => { std::vec::Vec::new() }; // 处理 my_vec![1, 2, 3, 4] ($($el:expr),*) => ({ let mut v = std::vec::Vec::new(); $(v.push($el);)* v }); // 处理 my_vec![0; 10] ($el:expr; $n:expr) => { std::vec::from_elem($el, $n) } }
$($el:expr), *)
- 在声明宏中,条件捕获的参数使用 $ 开头的标识符来声明。
- 每个参数都需要提供类型,这里
expr代表表达式,所以 $el:expr 是说把匹配到的表达式命名为 $el。 - $(…),* 告诉编译器可以匹配任意多个以逗号分隔的表达式,然后捕获到的每一个表达式可以用 $el 来访问。
- 由于匹配的时候匹配到一个 $(…)* (我们可以不管分隔符),在执行的代码块中,我们也要相应地使用 $(…)* 展开。
- 所以这句 $(v.push($el);)* 相当于匹配出多少个 $el就展开多少句 push 语句。
macro_rules!使用示例
fn main() { let mut v = my_vec![]; v.push(1); // 调用时可以使用 [], (), {} let _v = my_vec!(1, 2, 3, 4); let _v = my_vec![1, 2, 3, 4]; let v = my_vec! {1, 2, 3, 4}; println!("{:?}", v); println!("{:?}", v); // let v = my_vec![1; 10]; println!("{:?}", v); }
声明宏用到的参数类型
类型列表
- item,比如一个函数、结构体、模块等。
- block,代码块。比如一系列由花括号包裹的表达式和语句。
- stmt,语句。比如一个赋值语句。
- pat,模式。
- expr,表达式。刚才的例子使用过了。
- ty,类型。比如 Vec。
- ident,标识符。比如一个变量名。
- path,路径。比如:foo、::std::mem::replace、transmute::<_, int>。
- meta,元数据。一般是在 #[…] 和 #![…] 属性内部的数据。
- tt,单个的 token 树。
- vis,可能为空的一个 Visibility 修饰符。比如 pub、pub(crate)
过程宏
- 过程宏
- 手工定义图
- Cargo.toml添加proc-macro声明
- 函数宏
- 派生宏:
- 常用派生宏
- [#[derive(Debug)]](#derivedebug)
- 手工实现builder模式
- 自动实现:使用syn/quote可以不用自己定义模版
- 常用派生宏
- 过程属性宏: proc_macro_derive(macro_name, attributes(attr_name))
手工定义图
过程宏要比声明宏要复杂很多,不过无论是哪一种过程宏,本质都是一样的,都涉及要把
输入的 TokenStream处理成输出的 TokenStream。
Cargo.toml添加proc-macro声明
这样,编译器才允许你使用 #[proc_macro] 相关的宏。
[lib]
proc-macro = true
函数宏
- #[proc_macro]
和macro_rules! 功能类似,但更为强大。
src/lib.rs:定义过程函数宏示例:可以看到,都是处理TokenStream
mod builder; mod builder_with_attr; mod raw_builder; use proc_macro::TokenStream; use raw_builder::BuilderContext; use syn::{parse_macro_input, DeriveInput}; #[proc_macro] pub fn query(input: TokenStream) -> TokenStream { // 只有修改代码之后再次编译才会执行 println!("{:#?}", input); "fn hello() { println!(\"Hello world!\"); }" .parse() .unwrap() } #[proc_macro_derive(RawBuilder)] pub fn derive_raw_builder(input: TokenStream) -> TokenStream { // 只有修改代码之后再次编译才会执行 println!("{:#?}", input); BuilderContext::render(input).unwrap().parse().unwrap() } #[proc_macro_derive(Builder)] pub fn derive_builder(input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); println!("{:#?}", input); builder::BuilderContext::from(input).render().into() } #[proc_macro_derive(BuilderWithAttr, attributes(builder))] pub fn derive_builder_with_attr(input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); println!("{:#?}", input); builder_with_attr::BuilderContext::from(input) .render() .into() }
TokenStream
使用者可以通过 query!(…) 来调用。我们打印传入的 TokenStream, 然后把一段包含在字符串中的代码解析成 TokenStream 返回。
这里可以非常方便地用字符串的 parse() 方法来获得 TokenStream, 是因为 TokenStream 实现了 FromStr trait。
examples/query.rs使用过冲示例
use macros::query; fn main() { // query!(SELECT * FROM users WHERE age > 10); query!(SELECT * FROM users u JOIN (SELECT * from profiles p) WHERE u.id = p.id); hello() }
- .parse().unwrap(): 字符串自动转为TokenStream类型
cargo run --example query > examples/query_output.txt
运行结果示例:可以看到打印出来的TokenStream
TokenStream [
Ident {
ident: "SELECT",
span: #0 bytes(94..100),
},
Punct {
ch: '*',
spacing: Alone,
span: #0 bytes(101..102),
},
Ident {
ident: "FROM",
span: #0 bytes(103..107),
},
Ident {
ident: "users",
span: #0 bytes(108..113),
},
Ident {
ident: "u",
span: #0 bytes(114..115),
},
Ident {
ident: "JOIN",
span: #0 bytes(116..120),
},
Group {
delimiter: Parenthesis,
stream: TokenStream [
Ident {
ident: "SELECT",
span: #0 bytes(122..128),
},
Punct {
ch: '*',
spacing: Alone,
span: #0 bytes(129..130),
},
Ident {
ident: "from",
span: #0 bytes(131..135),
},
Ident {
ident: "profiles",
span: #0 bytes(136..144),
},
Ident {
ident: "p",
span: #0 bytes(145..146),
},
],
span: #0 bytes(121..147),
},
Ident {
ident: "WHERE",
span: #0 bytes(148..153),
},
Ident {
ident: "u",
span: #0 bytes(154..155),
},
Punct {
ch: '.',
spacing: Alone,
span: #0 bytes(155..156),
},
Ident {
ident: "id",
span: #0 bytes(156..158),
},
Punct {
ch: '=',
spacing: Alone,
span: #0 bytes(159..160),
},
Ident {
ident: "p",
span: #0 bytes(161..162),
},
Punct {
ch: '.',
spacing: Alone,
span: #0 bytes(162..163),
},
Ident {
ident: "id",
span: #0 bytes(163..165),
},
]
Hello world!
TokenStream是一个Iterator,里面包含一系列的TokenTree
#![allow(unused)] fn main() { pub enum TokenTree { // 组,如果代码中包含括号,比如{} [] <> () ,那么内部的内容会被分析成一个Group(组) Group(Group), // 标识符 Ident(Ident), // 标点符号 Punct(Punct), // 字面量 Literal(Literal), } }
Group Example
use macros::query; fn main() { // query!(SELECT * FROM users WHERE age > 10); query!(SELECT * FROM users u JOIN (SELECT * from profiles p) WHERE u.id = p.id); hello() }
派生宏:
#[proc_macro_devive(DeriveMacroName)]
用于结构体(struct)、枚举(enum)、联合(union)类型,可为其实现函数或特征(Trait)
常用派生宏
#[derive(Debug)]
手工实现builder模式
实现效果:链式调用
想到达到链式调用的效果
fn main() { let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .build() .unwrap(); assert!(command.current_dir.is_none()); let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .current_dir("..".to_owned()) .build() .unwrap(); assert!(command.current_dir.is_some()); println!("{:?}", command); }
可以这样定义
/// 这是command.rs的派生宏实现的代码样子 #[allow(dead_code)] #[derive(Debug)] pub struct Command { executable: String, args: Vec<String>, env: Vec<String>, current_dir: Option<String>, } #[derive(Debug, Default)] pub struct CommandBuilder { executable: Option<String>, args: Option<Vec<String>>, env: Option<Vec<String>>, current_dir: Option<String>, } impl Command { pub fn builder() -> CommandBuilder { Default::default() } } impl CommandBuilder { pub fn executable(mut self, v: String) -> Self { self.executable = Some(v.to_owned()); self } pub fn args(mut self, v: Vec<String>) -> Self { self.args = Some(v.to_owned()); self } pub fn env(mut self, v: Vec<String>) -> Self { self.env = Some(v.to_owned()); self } pub fn current_dir(mut self, v: String) -> Self { self.current_dir = Some(v.to_owned()); self } pub fn build(mut self) -> Result<Command, &'static str> { Ok(Command { executable: self.executable.take().ok_or("executable must be set")?, args: self.args.take().ok_or("args must be set")?, env: self.env.take().ok_or("env must be set")?, current_dir: self.current_dir.take(), }) }
但是有点繁琐,可以使用派生宏派生出这些代码
派生宏思路
要生成的代码模版: 把输入的 TokenStream 抽取出来,也就是把在 struct 的定义内部,每个域的名字及其类型都抽出来,然后生成对应的方法代码。
impl {{ name }} { pub fn builder() -> {{ builder_name }} { Default::default() } } #[derive(Debug, Default)] pub struct {{ builder_name }} { {% for field in fields %} {{ field.name }}: Option<{{ field.ty }}>, {% endfor %} } impl {{ builder_name }} { {% for field in fields %} pub fn {{ field.name }}(mut self, v: impl Into<{{ field.ty }}>) -> {{ builder_name }} { self.{{ field.name }} = Some(v.into()); self } {% endfor %} pub fn build(self) -> Result<{{ name }}, &'static str> { Ok({{ name }} { {% for field in fields %} {% if field.optional %} {{ field.name }}: self.{{ field.name }}, {% else %} {{ field.name }}: self.{{ field.name }}.ok_or("Build failed: missing {{ field.name }}")?, {% endif %} {% endfor %} }) } }
- 7-12: 这里的 fileds / builder_name 是我们要传入的参数,每个 field 还需要 name 和 ty 两个 属性,分别对应 field 的名字和类型
- 25-26: 对于原本是 Option
类型的域,要避免生成 Option
构建对应数据结构
/// 处理 jinja 模板的数据结构,在模板中我们使用了 name / builder_name / fields #[derive(Template)] #[template(path = "builder.j2", escape = "none")] pub struct BuilderContext { name: String, builder_name: String, fields: Vec<Fd>, }
src/lib.rs: 使用派生宏从TokenStream抽取出想要的信息
对于 derive macro,要使用 proce_macro_derive 这个宏。我们把这个 derive macro 命名为 Builder。
#[proc_macro_derive(RawBuilder)] pub fn derive_raw_builder(input: TokenStream) -> TokenStream { // 只有修改代码之后再次编译才会执行 println!("{:#?}", input); BuilderContext::render(input).unwrap().parse().unwrap() }
examples/raw_command.rs: 使用这个派生宏抽取
use macros::RawBuilder; #[allow(dead_code)] #[derive(Debug, RawBuilder)] pub struct Command { executable: String, args: Vec<String>, env: Vec<String>, current_dir: Option<String>, } fn main() { let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .build() .unwrap(); assert!(command.current_dir.is_none()); let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .current_dir("..".to_owned()) .build() .unwrap(); assert!(command.current_dir.is_some()); println!("{:?}", command); }
运行,查看获取的TokenStream
cargo run --example raw_command > examples/raw_command_output.txt
TokenStream [
Punct {
ch: '#',
spacing: Alone,
span: #0 bytes(25..26),
},
Group {
delimiter: Bracket,
stream: TokenStream [
Ident {
ident: "allow",
span: #0 bytes(27..32),
},
Group {
delimiter: Parenthesis,
stream: TokenStream [
Ident {
ident: "dead_code",
span: #0 bytes(33..42),
},
],
span: #0 bytes(32..43),
},
],
span: #0 bytes(26..44),
},
Ident {
ident: "pub",
span: #0 bytes(74..77),
},
Ident {
ident: "struct",
span: #0 bytes(78..84),
},
Ident {
ident: "Command",
span: #0 bytes(85..92),
},
Group {
delimiter: Brace,
stream: TokenStream [
Ident {
ident: "executable",
span: #0 bytes(99..109),
},
Punct {
ch: ':',
spacing: Alone,
span: #0 bytes(109..110),
},
Ident {
ident: "String",
span: #0 bytes(111..117),
},
Punct {
ch: ',',
spacing: Alone,
span: #0 bytes(117..118),
},
Ident {
ident: "args",
span: #0 bytes(123..127),
},
Punct {
ch: ':',
spacing: Alone,
span: #0 bytes(127..128),
},
Ident {
ident: "Vec",
span: #0 bytes(129..132),
},
Punct {
ch: '<',
spacing: Alone,
span: #0 bytes(132..133),
},
Ident {
ident: "String",
span: #0 bytes(133..139),
},
Punct {
ch: '>',
spacing: Joint,
span: #0 bytes(139..140),
},
Punct {
ch: ',',
spacing: Alone,
span: #0 bytes(140..141),
},
Ident {
ident: "env",
span: #0 bytes(146..149),
},
Punct {
ch: ':',
spacing: Alone,
span: #0 bytes(149..150),
},
Ident {
ident: "Vec",
span: #0 bytes(151..154),
},
Punct {
ch: '<',
spacing: Alone,
span: #0 bytes(154..155),
},
Ident {
ident: "String",
span: #0 bytes(155..161),
},
Punct {
ch: '>',
spacing: Joint,
span: #0 bytes(161..162),
},
Punct {
ch: ',',
spacing: Alone,
span: #0 bytes(162..163),
},
Ident {
ident: "current_dir",
span: #0 bytes(168..179),
},
Punct {
ch: ':',
spacing: Alone,
span: #0 bytes(179..180),
},
Ident {
ident: "Option",
span: #0 bytes(181..187),
},
Punct {
ch: '<',
spacing: Alone,
span: #0 bytes(187..188),
},
Ident {
ident: "String",
span: #0 bytes(188..194),
},
Punct {
ch: '>',
spacing: Joint,
span: #0 bytes(194..195),
},
Punct {
ch: ',',
spacing: Alone,
span: #0 bytes(195..196),
},
],
span: #0 bytes(93..198),
},
]
Command { executable: "cargo", args: ["build", "--release"], env: [], current_dir: Some("..") }
打印信息说明
-
首先有一个 Group,包含了 #[allow(dead_code)] 属性的信息。因为我们现在拿到 的 derive 下的信息,所以所有不属于 #[derive(…)] 的属性,都会被放入 TokenStream 中。
-
之后是 pub / struct / Command 三个 ident。
-
随后又是一个 Group,包含了每个 field 的信息。我们看到,field 之间用逗号这个 Punct 分隔,field 的名字和类型又是通过冒号这个 Punct 分隔。而类型,可能是一个 Ident,如 String,或者一系列 Ident / Punct,如 Vec / < / String / >。
src/raw_builder.rs: 使用anyhow与askama抽取TokenStream中的信息
我们要做的就是,把这个 TokenStream 中的 struct 名字,以及每个 field 的名字和类型拿出来。 如果类型是 Option
,那么把 T 拿出来,把 optional 设置为 true。
use anyhow::Result; use askama::Template; use proc_macro::{Ident, TokenStream, TokenTree}; use std::collections::VecDeque; /// 处理 jinja 模板的数据结构,在模板中我们使用了 name / builder_name / fields #[derive(Template)] #[template(path = "builder.j2", escape = "none")] pub struct BuilderContext { name: String, builder_name: String, fields: Vec<Fd>, } /// 描述 struct 的每个 field #[derive(Debug, Default)] struct Fd { name: String, ty: String, optional: bool, }
templates/builder.j2: 上面askama用到的jinja2模版
impl {{ name }} { pub fn builder() -> {{ builder_name }} { Default::default() } } #[derive(Debug, Default)] pub struct {{ builder_name }} { {% for field in fields %} {{ field.name }}: Option<{{ field.ty }}>, {% endfor %} } impl {{ builder_name }} { {% for field in fields %} pub fn {{ field.name }}(mut self, v: impl Into<{{ field.ty }}>) -> {{ builder_name }} { self.{{ field.name }} = Some(v.into()); self } {% endfor %} pub fn build(self) -> Result<{{ name }}, &'static str> { Ok({{ name }} { {% for field in fields %} {% if field.optional %} {{ field.name }}: self.{{ field.name }}, {% else %} {{ field.name }}: self.{{ field.name }}.ok_or("Build failed: missing {{ field.name }}")?, {% endif %} {% endfor %} }) } }
src/raw_builder.rs: 实现对应抽取方法
impl Fd { /// name 和 field 都是通过冒号 Punct 切分出来的 TokenTree 切片 pub fn new(name: &[TokenTree], ty: &[TokenTree]) -> Self { // 把类似 Ident("Option"), Punct('<'), Ident("String"), Punct('>) 的 ty // 收集成一个 String 列表,如 vec!["Option", "<", "String", ">"] let ty = ty .iter() .map(|v| match v { TokenTree::Ident(n) => n.to_string(), TokenTree::Punct(p) => p.as_char().to_string(), e => panic!("Expect ident, got {:?}", e), }) .collect::<Vec<_>>(); // 冒号前最后一个 TokenTree 是 field 的名字 // 比如:executable: String, // 注意这里不应该用 name[0],因为有可能是 pub executable: String // 甚至,带 attributes 的 field, // 比如:#[builder(hello = world)] pub executable: String match name.last() { Some(TokenTree::Ident(name)) => { // 如果 ty 第 0 项是 Option,那么从第二项取到倒数第一项 // 取完后上面的例子中的 ty 会变成 ["String"],optiona = true let (ty, optional) = if ty[0].as_str() == "Option" { (&ty[2..ty.len() - 1], true) } else { (&ty[..], false) }; Self { name: name.to_string(), ty: ty.join(""), // 把 ty join 成字符串 optional, } } e => panic!("Expect ident, got {:?}", e), } } } impl BuilderContext { /// 从 TokenStream 中提取信息,构建 BuilderContext fn new(input: TokenStream) -> Self { let (name, input) = split(input); let fields = get_struct_fields(input); Self { builder_name: format!("{}Builder", name), name: name.to_string(), fields, } } /// 把模板渲染成字符串代码 pub fn render(input: TokenStream) -> Result<String> { let template = Self::new(input); Ok(template.render()?) } } /// 把 TokenStream 分出 struct 的名字,和包含 fields 的 TokenStream fn split(input: TokenStream) -> (Ident, TokenStream) { let mut input = input.into_iter().collect::<VecDeque<_>>(); // 一直往后找,找到 struct 停下来 while let Some(item) = input.pop_front() { if let TokenTree::Ident(v) = item { if v.to_string() == "struct" { break; } } } // struct 后面,应该是 struct name let ident; if let Some(TokenTree::Ident(v)) = input.pop_front() { ident = v; } else { panic!("Didn't find struct name"); } // struct 后面可能还有若干 TokenTree,我们不管,一路找到第一个 Group let mut group = None; for item in input { if let TokenTree::Group(g) = item { group = Some(g); break; } } (ident, group.expect("Didn't find field group").stream()) } /// 从包含 fields 的 TokenStream 中切出来一个个 Fd fn get_struct_fields(input: TokenStream) -> Vec<Fd> { let input = input.into_iter().collect::<Vec<_>>(); input .split(|v| match v { // 先用 ',' 切出来一个个包含 field 所有信息的 &[TokenTree] TokenTree::Punct(p) => p.as_char() == ',', _ => false, }) .map(|tokens| { tokens .split(|v| match v { // 再用 ':' 把 &[TokenTree] 切成 [&[TokenTree], &[TokenTree]] // 它们分别对应名字和类型 TokenTree::Punct(p) => p.as_char() == ':', _ => false, }) .collect::<Vec<_>>() }) // 正常情况下,应该得到 [&[TokenTree], &[TokenTree]],对于切出来长度不为 2 的统统过滤掉 .filter(|tokens| tokens.len() == 2) // 使用 Fd::new 创建出每个 Fd .map(|tokens| Fd::new(tokens[0], tokens[1])) .collect() }
提示:类比理解
可以对着打印出来的 TokenStream 和刚才的分析进行理解。 核心的就是 get_struct_fields() 方法,如果觉得难懂, 可以想想如果要把一个 a=1,b=2 的字符串切成 [[a, 1], [b, 2]] 该怎么做,就很容易理解了。
自动实现:使用syn/quote可以不用自己定义模版
详见上方对比图
过程属性宏: proc_macro_derive(macro_name, attributes(attr_name))
用于属性宏, 用在结构体、字段、函数等地方,为其指定属性等功能, 类似python的计算属性
定义结构体时在某个字段上方使用对应attr_name
#![allow(unused)] fn main() { #[allow(dead_code)] #[derive(Debug, BuilderWithAttr)] pub struct Command { executable: String, #[builder(each = "arg")] args: Vec<String>, #[builder(each = "env", default = "vec![]")] env: Vec<String>, current_dir: Option<String>, } }
使用syn/quote定义属性宏
详见上方对比图
V 并发与异步
区分并发与并行
再次区分并发与并行
很多人分不清并发和并行的概念,Rob Pike,Golang 的创始人之一,对此有很精辟很直观的解释:
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
- 并发是一种同时处理很多事情的能力
- 并行是一种同时执行很多事情的手段。
我们把要做的事情放在多个线程中,或者多个异步任务中处理,这是并发的能力。在多核多 CPU 的机器上同时运行这些线程或者异步任务,是并行的手段。可以说,并发是为并行赋能。当我们具备了并发的能力,并行就是水到渠成的事情。
并发原语与异步的关系
区别并发原语与Future
- 并发原语是并发任务之间同步的手段
- Future 以及在更高层次上处理 Future 的 async/await,是产生和运行并发任务的手段。
不过产生和运行并发任务的手段有很多,async/await 只是其中之一。
- 在一个分布式系统中,并发任务可以运行在系统的某个节点上;
- 在某个节点上,并发任务又可以运行在多个进程中;
- 而在某个进程中,并发任务可以运行在多个线程中;
- 在某个(些)线程上,并发任务可以运行在多个 Promise / Future / Goroutine / Erlang process 这样的协程上。
它们的粒度从大到小如图所示:
并发原语
Summarize made by cursor
本文主要介绍了 Rust 中的并发原语:
- 包括自由竞争模式、map/reduce 模式和 DAG 模式。
- 在自由竞争模式下,我们需要用互斥锁来保护某个临界区,使进入临界区的任务拥有独占访问的权限。
- 在 map/reduce 模式下,我们需要用原子锁来保证任务的同步。
- 在 DAG 模式下,我们需要用条件变量来保证任务的同步。
- 本文还介绍了 Rust 中的几种并发原语,包括 Atomic、Mutex、Condvar、Channel 和 Actor model。最后,本文还介绍了如何用 Rust 实现一个基本的 MPSC Channel。
- Rust中的并发原语有哪些?
- Rust中的自由竞争模式下需要用什么来保护某个临界区?
- Rust中的map/reduce模式下需要用什么来保证任务的同步?
- Rust中的DAG模式下需要用什么来保证任务的同步?
- Rust中的几种并发原语有哪些?
- Rust中如何用实现一个基本的MPSC Channel?
Answers made by cursor
- Rust中的并发原语有哪些? Atomic、Mutex、Condvar、Channel 和 Actor model。
- Rust中的自由竞争模式下需要用什么来保护某个临界区? 互斥锁 Mutex。
- Rust中的map/reduce模式下需要用什么来保证任务的同步? 原子锁 Atomic。
- Rust中的DAG模式下需要用什么来保证任务的同步? 条件变量 Condvar。
- Rust中的几种并发原语有哪些? Atomic、Mutex、Condvar、Channel 和 Actor model。
- Rust中如何用实现一个基本的MPSC Channel? 可以使用 std::sync::mpsc::channel 函数来创建一个 MPSC Channel,也可以自己实现一个基本的 MPSC Channel。
- 并发原语
- 并发的难点、工作模式和核心
- 常见并发模型梳理,也就是并发原语
- 工作模式一、自由竞争: Atomic & Mutex
- 工作模式二、限制顺序并发: map/reduce
- 工作模式三、限制依赖并发:DAG 模式
- 至于async/await,又是另一个故事
- 自己实现一个基本的MPSC Channel
- 小结一下各种并发原语的使用场景
并发的难点、工作模式和核心
处理并发的难点在哪里?
其实有很多和并发相关的内容。比如用 std::thread 来创建线程、用 std::sync 下的并发原语(Mutex)来处理并发过程中的同步问题、用 Send/Sync trait 来保证并发的安全等等。
在处理并发的过程中,难点并不在于如何创建多个线程来分配工作,在于如何在这些并发的任务中进行同步。
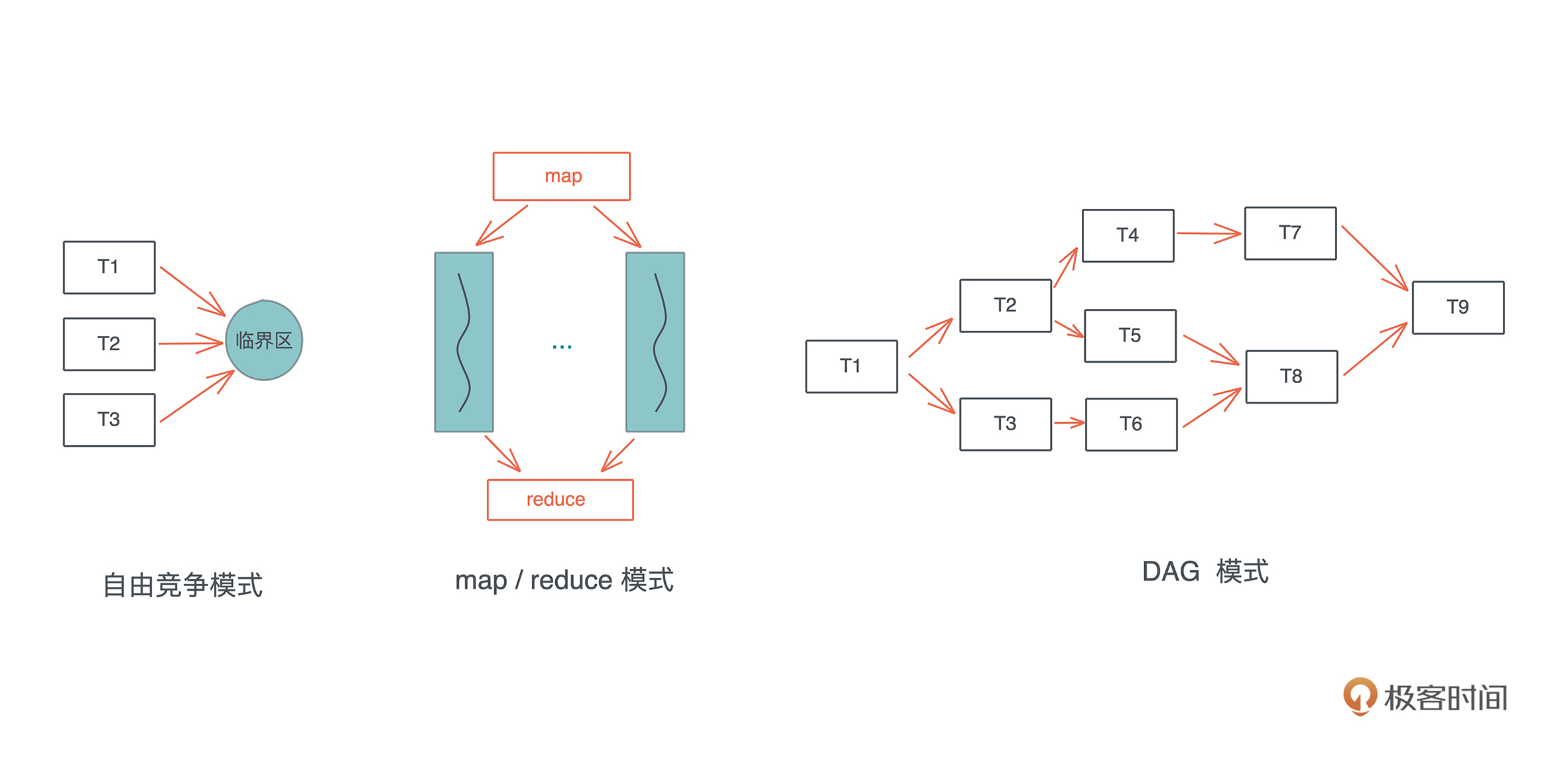
- 自由竞争: Atomic & Mutex
在自由竞争模式下,多个并发任务会竞争同一个临界区的访问权。
任务之间在何时、以何种方式去访问临界区,是不确定的,或者说是最为灵活的,只要在进入临界区时获得独占访问即可。
在自由竞争的基础上,我们可以限制并发的同步模式,典型的有 map/reduce 模式和 DAG 模式:
这些工作模式的核心是什么?
这三种基本模式组合起来,可以处理非常复杂的并发场景。 所以,当我们处理复杂问题的时候:
- 应该先厘清其脉络
- 用分治的思想把问题拆解成正交的子问题
- 然后组合合适的并发模式来处理这些子问题。
常见并发模型梳理,也就是并发原语
在这些并发模式背后,都有哪些并发原语可以为我们所用呢
在这些并发模式背后,都有哪些并发原语可以为我们所用呢:
- Atomic:原子锁
- Mutex:互斥锁
- Condvar:条件变量
- 条件变量表示阻塞线程的能力,使其在等待事件发生时不消耗 CPU 时间。
- 条件变量通常与布尔谓词(条件)和互斥锁相关联。
- 在确定线程必须阻塞之前,始终在互斥锁内部验证谓词。
- Channel
- Actor model
工作模式一、自由竞争: Atomic & Mutex
Atomic解决独占问题
Atomic 是所有并发原语的基础,它为并发任务的同步奠定了坚实的基础。
谈到同步,相信你首先会想到锁 所以在具体介绍 atomic 之前,我们从最基本的锁该如何实现讲起。 自由竞争模式下,我们需要用互斥锁来保护某个临界区,使进入临界区的任务拥有独占访问的权限。
互斥锁代码示例: 这段代码模拟了 Mutex 的实现,它的核心部分是 lock() 方法。
为了简便起见,在获取这把锁的时候,如果获取不到,就一直死循环,直到拿到锁为止(代码):
use std::{cell::RefCell, fmt, sync::Arc, thread}; struct Lock<T> { locked: RefCell<bool>, data: RefCell<T>, } impl<T> fmt::Debug for Lock<T> where T: fmt::Debug, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "Lock<{:?}>", self.data.borrow()) } } // SAFETY: 我们确信 Lock<T> 很安全,可以在多个线程中共享 unsafe impl<T> Sync for Lock<T> {} impl<T> Lock<T> { pub fn new(data: T) -> Self { Self { data: RefCell::new(data), locked: RefCell::new(false), } } pub fn lock(&self, op: impl FnOnce(&mut T)) { // 如果没拿到锁,就一直 spin while *self.locked.borrow() != false {} // **1 // 拿到,赶紧加锁 *self.locked.borrow_mut() = true; // **2 // 开始干活 op(&mut self.data.borrow_mut()); // **3 // 解锁 *self.locked.borrow_mut() = false; // **4 } } fn main() { let data = Arc::new(Lock::new(0)); let data1 = data.clone(); let t1 = thread::spawn(move || { data1.lock(|v| *v += 10); }); let data2 = data.clone(); let t2 = thread::spawn(move || { data2.lock(|v| *v *= 10); }); t1.join().unwrap(); t2.join().unwrap(); println!("data: {:?}", data); }
我们之前说过,Mutex 在调用 lock() 后,会得到一个 MutexGuard 的 RAII 结构. 这里为了简便起见,要求调用者传入一个闭包,来处理加锁后的事务。
在 lock() 方法里:
- 拿不到锁的并发任务会一直 spin
- 拿到锁的任务可以干活
- 干完活后会解锁
- 这样之前 spin 的任务会竞争到锁,进入临界区。
工作模式二、限制顺序并发: map/reduce
Atomic还存在2个问题
这样的实现看上去似乎问题不大,但是你细想,它有两个问题:
- 可能同时拿到锁
-
在多核情况下,**1 和 **2 之间,有可能其它线程也碰巧 spin 结束,把 locked 修改为 true。这样,存在多个线程拿到这把锁,破坏了任何线程都有独占访问的保证。
-
即便在单核情况下,**1 和 **2 之间,也可能因为操作系统的可抢占式调度,导致问题 1 发生。
- CPU乱序执行可能破坏锁
-
如今的编译器会最大程度优化生成的指令,如果操作之间没有依赖关系,可能会生成乱序的机器码,比如**3 被优化放在 **1 之前,从而破坏了这个 lock 的保证。
-
即便编译器不做乱序处理,CPU 也会最大程度做指令的乱序执行,让流水线的效率最高。同样会发生 3 的问题。
所以,我们实现这个锁的行为是未定义的。可能大部分时间如我们所愿,但会随机出现奇奇怪怪的行为。
一旦这样的事情发生,bug 可能会以各种不同的面貌出现在系统的各个角落。 而且,这样的 bug 几乎是无解的,因为它很难稳定复现,表现行为很不一致,甚至,只在某个 CPU 下出现。
这里再强调一下 unsafe 代码需要足够严谨,需要非常有经验的工程师去审查. 这段代码之所以破坏了并发安全性,是因为我们错误地认为:为 Lock
实现 Sync,是安全的。
为了解决上面这段代码的问题,我们必须在 CPU 层面做一些保证,让某些操作成为原子操作。
用CAS操作+Ordering解决两个问题
因为 CAS 和 ordering 都是系统级的操作,所以这里描述的 Ordering 的用途在各种语言中都大同小异。 对于 Rust 来说,它的 atomic 原语继承于 C++。 如果读 Rust 的文档你感觉云里雾里,那么 C++ 关于 ordering 的文档要清晰得多。
CAS操作解决问题1
CAS是什么?
可以通过一条指令读取某个内存地址,判断其值是否等于某个前置值,如果相等,将其修改为新的值。
这就是 Compare-and-swap 操作,简称CAS。
它是操作系统的几乎所有并发原语的基石,使得我们能实现一个可以正常工作的锁。
Rust专门为std::sync::atomic中的数据结构提供了CAS操作方法compare_exhange
Ordering解决问题2:CAS需要Ordering参数说明操作的内存顺序
Ordering枚举体说明: 对锁的5个操作
这就是这个函数里额外的两个和 Ordering 有关的奇怪参数。
pub enum Ordering { Relaxed, Release, Acquire, AcqRel, SeqCst, }
文档里解释了几种 Ordering 的用途,稍稍扩展一下。
-
第一个 Relaxed,这是最宽松的规则,它对编译器和 CPU 不做任何限制,可以乱序执行。
-
Release,当我们写入数据(比如上面代码里的 store)的时候,如果用了 Release order,那么:
- 对于当前线程,任何读取或写入操作都不能被乱序排在这个 store 之后。
- 也就是说,在下面的例子里,CPU 或者编译器不能把 **3 挪到 **4 之后执行。
- 对于其它线程,如果使用了 Acquire 来读取这个 atomic 的数据, 那么它们看到的是修改后的结果。
- 下面代码我们在 compare_exchange 里使用了 Acquire 来读取,所以能保证读到最新的值。
- 而 Acquire 是当我们读取数据的时候,如果用了 Acquire order,那么:
- 对于当前线程,任何读取或者写入操作都不能被乱序排在这个读取之前。在下面的例子里,CPU 或者编译器不能把 **3 挪到 **1 之前执行。
- 对于其它线程,如果使用了 Release 来修改数据,那么,修改的值对当前线程可见。
- 第四个 AcqRel 是 Acquire 和 Release 的结合,同时拥有 Acquire 和 Release 的保证。
- 这个一般用在 fetch_xxx 上,比如你要对一个 atomic 自增 1,你希望这个操作之前和之后的读取或写入操作不会被乱序,并且操作的结果对其它线程可见。
- 最后的 SeqCst 是最严格的 ordering,除了 AcqRel 的保证外,它还保证所有线程看到的所有 SeqCst 操作的顺序是一致的。
解决过程
所以,刚才的代码,我们可以把一开始的循环改成:
Atomic+CAS+ordering: 确保原子操作顺序
while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() {}
这句的意思是:
- 如果 locked 当前的值是 false,就将其改成 true。
- 这整个操作在一条指令里完成,不会被其它线程打断或者修改;
- 如果 locked 的当前值不是 false,那么就会返回错误,我们会在此不停 spin,直到前置条件得到满足。
- 这里,compare_exchange 是 Rust 提供的 CAS 操作,它会被编译成 CPU 的对应 CAS 指令。
当这句执行成功后,locked 必然会被改变为 true,我们成功拿到了锁,而任何其他线程都会在这句话上 spin。
同样在释放锁的时候,相应地需要使用 atomic 的版本,而非直接赋值成 false:
self.locked.store(false, Ordering::Release);
当然,为了配合这样的改动,我们还需要把 locked 从 bool 改成 AtomicBool。
在 Rust 里,std::sync::atomic 有大量的 atomic 数据结构,对应各种基础结构。
AtomicBool+compare_exchange+Ordering参数:我们看使用了 AtomicBool 的新实现(代码):
use std::{ cell::RefCell, fmt, sync::{ atomic::{AtomicBool, Ordering}, Arc, }, thread, }; struct Lock<T> { locked: AtomicBool, data: RefCell<T>, } impl<T> fmt::Debug for Lock<T> where T: fmt::Debug, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "Lock<{:?}>", self.data.borrow()) } } // SAFETY: 我们确信 Lock<T> 很安全,可以在多个线程中共享 unsafe impl<T> Sync for Lock<T> {} impl<T> Lock<T> { pub fn new(data: T) -> Self { Self { data: RefCell::new(data), locked: AtomicBool::new(false), } } pub fn lock(&self, op: impl FnOnce(&mut T)) { // 如果没拿到锁,就一直 spin while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() {} // **1 // 已经拿到并加锁,开始干活 op(&mut self.data.borrow_mut()); // **3 // 解锁 self.locked.store(false, Ordering::Release); } } fn main() { let data = Arc::new(Lock::new(0)); let data1 = data.clone(); let t1 = thread::spawn(move || { data1.lock(|v| *v += 10); }); let data2 = data.clone(); let t2 = thread::spawn(move || { data2.lock(|v| *v *= 10); }); t1.join().unwrap(); t2.join().unwrap(); println!("data: {:?}", data); }
可以看到:
通过使用 compare_exchange+Ordering ,规避了同时拿到锁和CPU乱序这两个问题
- 之前:
#![allow(unused)] fn main() { // 如果没拿到锁,就一直 spin while *self.locked.borrow() != false {} // **1 }
- 使用compare_exchange
#![allow(unused)] fn main() { // 如果没拿到锁,就一直 spin while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() {} // **1 }
临界区优化
其实上面获取锁的 spin 过程性能不够好,更好的方式是这样处理一下:
while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() { // 性能优化:compare_exchange 需要独占访问,当拿不到锁时,我们 // 先不停检测 locked 的状态,直到其 unlocked 后,再尝试拿锁 while self.locked.load(Ordering::Relaxed) == true {} }
注意,我们在 while loop 里,又嵌入了一个 loop。
- 这是因为 CAS 是个代价比较高的操作,它需要获得对应内存的独占访问(exclusive access)
- 我们希望失败的时候只是简单读取 atomic 的状态,只有符合条件的时候再去做独占访问,进行 CAS。
- 所以,看上去多做了一层循环,实际代码的效率更高。
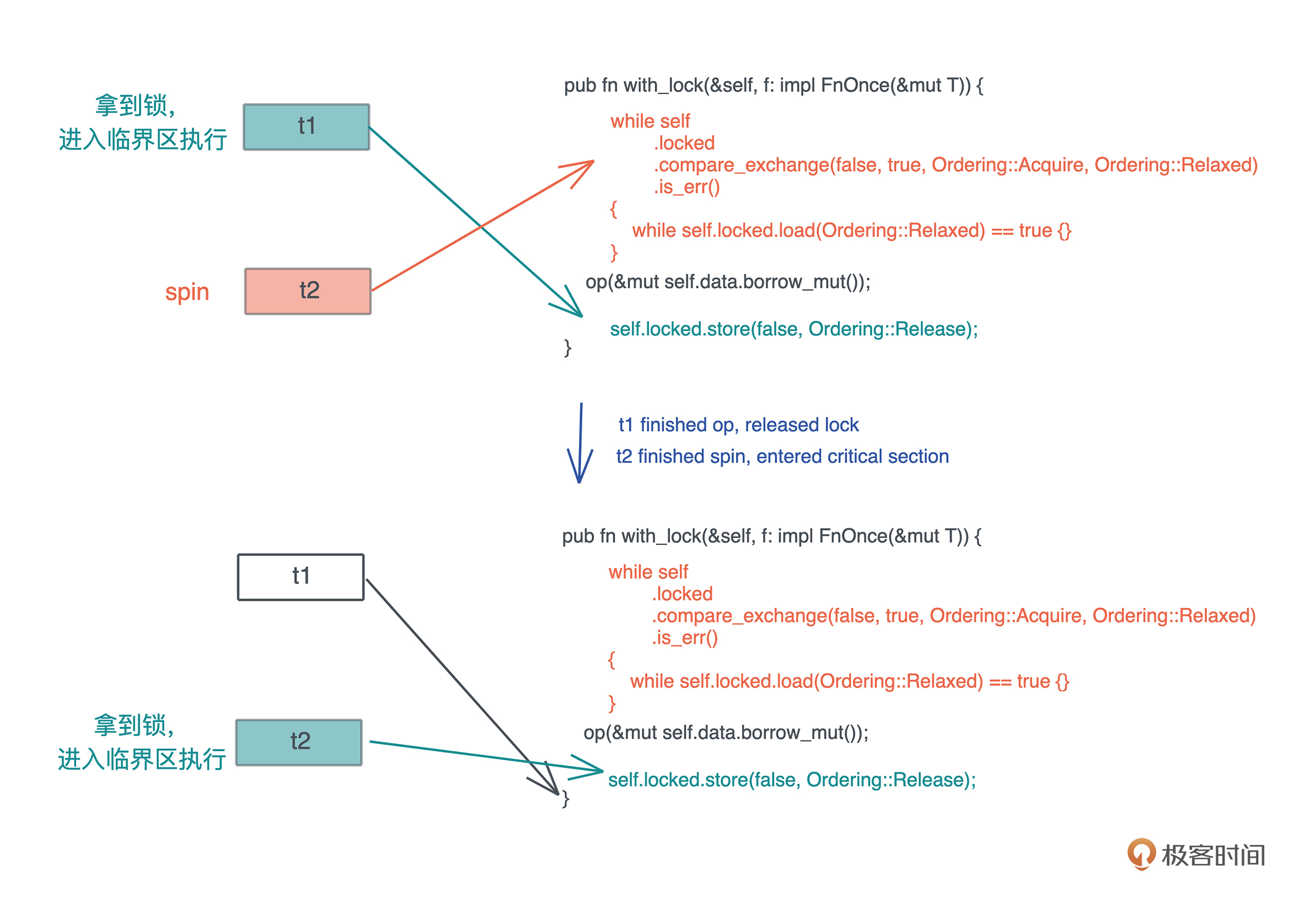
讲到这里,相信你对 atomic 以及其背后的 CAS 有初步的了解了。
Atomic还有什么用
- 全局ID生成器
那么,atomic 除了做其它并发原语,还有什么作用?
我个人用的最多的是做各种 lock-free 的数据结构。比如,需要一个全局的 ID 生成器。当然可以使用 UUID 这样的模块来生成唯一的 ID,但如果我们同时需要这个 ID 是有序的,那么 AtomicUsize 就是最好的选择。
你可以用 fetch_add 来增加这个 ID,而 fetch_add 返回的结果就可以用于当前的 ID。这样,不需要加锁,就得到了一个可以在多线程中安全使用的 ID 生成器。
- 记录系统的各种 metrics
另外,atomic 还可以用于记录系统的各种 metrics。比如一个简单的 in-memory Metrics 模块:
use std::{ collections::HashMap, sync::atomic::{AtomicUsize, Ordering}, }; // server statistics pub struct Metrics(HashMap<&'static str, AtomicUsize>); impl Metrics { pub fn new(names: &[&'static str]) -> Self { let mut metrics: HashMap<&'static str, AtomicUsize> = HashMap::new(); for name in names.iter() { metrics.insert(name, AtomicUsize::new(0)); } Self(metrics) } pub fn inc(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_add(1, Ordering::Relaxed); } } pub fn add(&self, name: &'static str, val: usize) { if let Some(m) = self.0.get(name) { m.fetch_add(val, Ordering::Relaxed); } } pub fn dec(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_sub(1, Ordering::Relaxed); } } pub fn snapshot(&self) -> Vec<(&'static str, usize)> { self.0 .iter() .map(|(k, v)| (*k, v.load(Ordering::Relaxed))) .collect() } }
它允许你初始化一个全局的 metrics 表,然后在程序的任何地方,无锁地操作相应的 metrics:
use lazy_static::lazy_static; use std::{ collections::HashMap, sync::atomic::{AtomicUsize, Ordering}, }; lazy_static! { pub(crate) static ref METRICS: Metrics = Metrics::new(&[ "topics", "clients", "peers", "broadcasts", "servers", "states", "subscribers" ]); } // server statistics pub struct Metrics(HashMap<&'static str, AtomicUsize>); impl Metrics { pub fn new(names: &[&'static str]) -> Self { let mut metrics: HashMap<&'static str, AtomicUsize> = HashMap::new(); for name in names.iter() { metrics.insert(name, AtomicUsize::new(0)); } Self(metrics) } pub fn inc(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_add(1, Ordering::Relaxed); } } pub fn add(&self, name: &'static str, val: usize) { if let Some(m) = self.0.get(name) { m.fetch_add(val, Ordering::Relaxed); } } pub fn dec(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_sub(1, Ordering::Relaxed); } } pub fn snapshot(&self) -> Vec<(&'static str, usize)> { self.0 .iter() .map(|(k, v)| (*k, v.load(Ordering::Relaxed))) .collect() } } fn main() { METRICS.inc("topics"); METRICS.inc("subscribers"); println!("{:?}", METRICS.snapshot()); }
更高层面的Atomic: Mutex(Mutual Exclusive)
Atomic 虽然可以处理自由竞争模式下加锁的需求,但毕竟用起来不那么方便.
我们需要更高层的并发原语,来保证软件系统控制多个线程对同一个共享资源的访问:
使得每个线程在访问共享资源的时候,可以独占或者说互斥访问(mutual exclusive access)。
Atomic有什么限制,Mutex又如何解决?
我们知道:
- 对于一个共享资源,如果所有线程只做读操作,那么无需互斥,大家随时可以访问
- 很多 immutable language(如 Erlang / Elixir)做了语言层面的只读保证,确保了并发环境下的无锁操作。
- 这牺牲了一些效率(常见的 list/hashmap 需要使用 persistent data structure),额外做了不少内存拷贝,换来了并发控制下的简单轻灵。
- 然而,一旦有任何一个或多个线程要修改共享资源,不但写者之间要互斥,读写之间也需要互斥。
- 毕竟如果读写之间不互斥的话,读者轻则读到脏数据,重则会读到已经被破坏的数据,导致 crash。
- 比如读者读到链表里的一个节点,而写者恰巧把这个节点的内存释放掉了,如果不做互斥访问,系统一定会崩溃。
所以操作系统提供了用来解决这种读写互斥问题的基本工具:Mutex(RwLock 我们放下不表)。
其实上文中,为了展示如何使用 atomic,我们制作了一个非常粗糙简单的 SpinLock,就可以看做是一个广义的 Mutex。SpinLock,顾名思义,就是线程通过 CPU 空转(spin,就像前面的 while loop)忙等(busy wait),来等待某个临界区可用的一种锁。
然而,这种通过 SpinLock 做互斥的实现方式有使用场景的限制:如果受保护的临界区太大,那么整体的性能会急剧下降, CPU 忙等,浪费资源还不干实事,不适合作为一种通用的处理方法。
更通用的解决方案是:
- 当多个线程竞争同一个 Mutex 时,获得锁的线程得到临界区的访问,其它线程被挂起,放入该 Mutex 上的一个等待队列里
- 当获得锁的线程完成工作,退出临界区时,Mutex 会给等待队列发一个信号,把队列中第一个线程唤醒,于是这个线程可以进行后续的访问。整个过程如下:
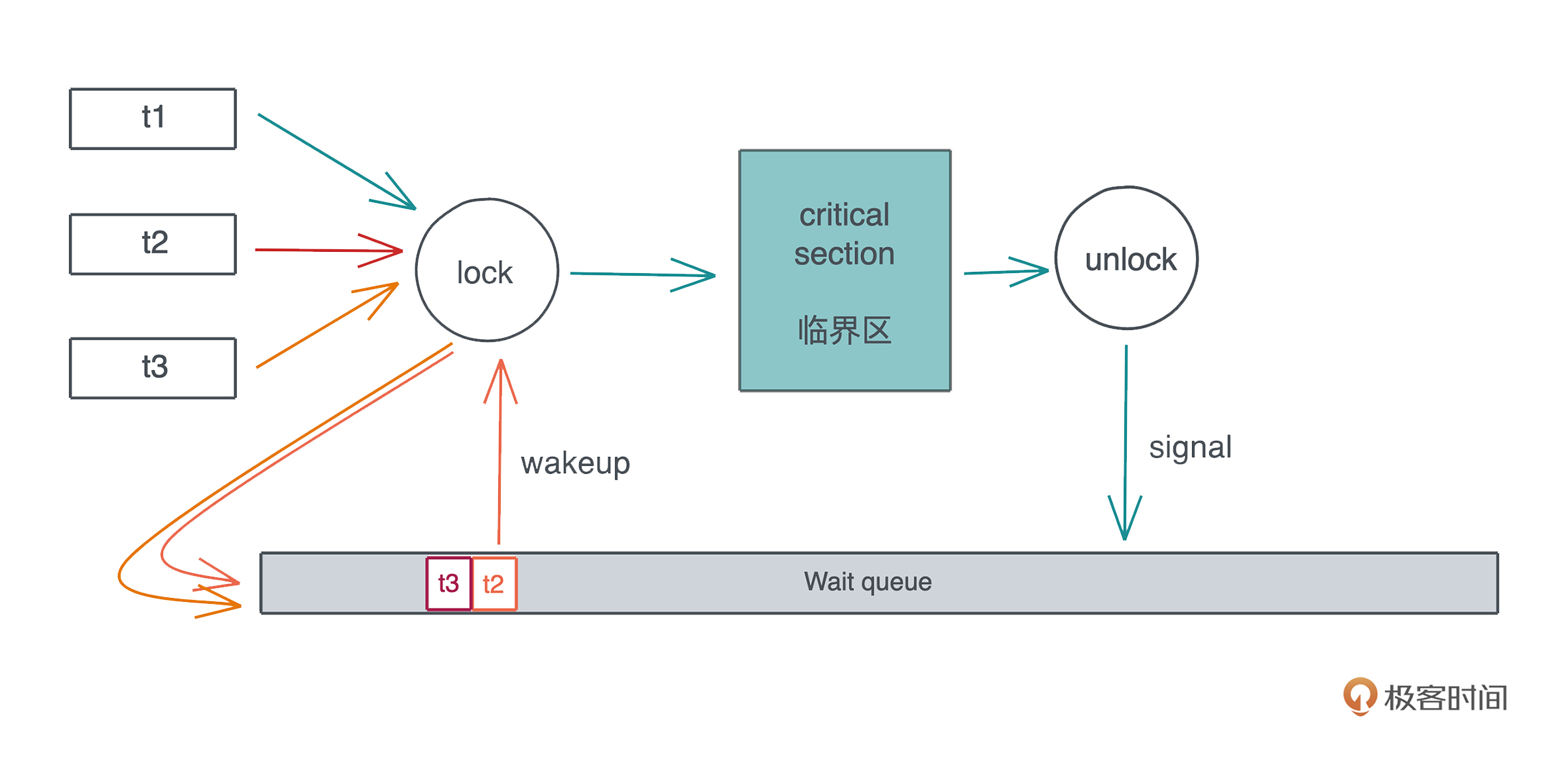
Atomic和Mutex的联系
Atomic、Mutex、semaphore的联系
我们前面也讲过,线程的上下文切换代价很大,所以频繁将线程挂起再唤醒,会降低整个系统的效率。
所以很多 Mutex 具体的实现会将 SpinLock(确切地说是 spin wait)和线程挂起结合使用: 线程的 lock 请求如果拿不到会先尝试 spin 一会,然后再挂起添加到等待队列。
Rust 下的 parking_lot 就是这样实现的。
当然,这样实现会带来公平性的问题:
- 如果新来的线程恰巧在 spin 过程中拿到了锁
- 而当前等待队列中还有其它线程在等待锁
- 那么等待的线程只能继续等待下去
- 这不符合 FIFO,不适合那些需要严格按先来后到排队的使用场景。
- 为此,parking_lot 提供了 fair mutex。
Mutex 的实现依赖于 CPU 提供的 atomic。
你可以把 Mutex 想象成一个粒度更大的 atomic,只不过这个 atomic 无法由 CPU 保证,而是通过软件算法来实现。
两个基本的并发原语 Atomic 和 Mutex:
- Atomic 是一切并发同步的基础
- 通过 CPU 提供特殊的 CAS 指令,操作系统和应用软件可以构建更加高层的并发原语,比如 SpinLock 和 Mutex。
SpinLock 和 Mutex 最大的不同是:
- 使用 SpinLock,线程在忙等(busy wait)
- 而使用 Mutex lock,线程在等待锁的时候会被调度出去,等锁可用时再被调度回来。
听上去 SpinLock 似乎效率很低,其实不是,这要具体看锁的临界区大小。
- 如果临界区要执行的代码很少,那么和 Mutex lock 带来的上下文切换(context switch)相比,SpinLock 是值得的。
- 在 Linux Kernel 中,很多时候我们只能使用 SpinLock。
至于操作系统里另一个重要的概念信号量(semaphore),你可以认为是 Mutex 更通用的表现形式。
比如在新冠疫情下,图书馆要控制同时在馆内的人数,如果满了,其他人就必须排队,出来一个才能再进一个。 这里,如果总人数限制为 1,就是 Mutex,如果 > 1,就是 semaphore。
工作模式三、限制依赖并发:DAG 模式
Atomic和Mutex不能解决DAG模式, 所以有Condvar
Atomic和Mutex主要用于哪种工作模式?基于什么需求提出Condvar原语?
对于并发状态下这三种常见的工作模式:
- 自由竞争模式
- map/reduce 模式
- DAG 模式
我们的难点是如何在这些并发的任务中进行同步:
- atomic / Mutex 解决了自由竞争模式下并发任务的同步问题
- 也能够很好地解决 map/reduce 模式下的同步问题,因为此时同步只发生在 map 和 reduce 两个阶段。
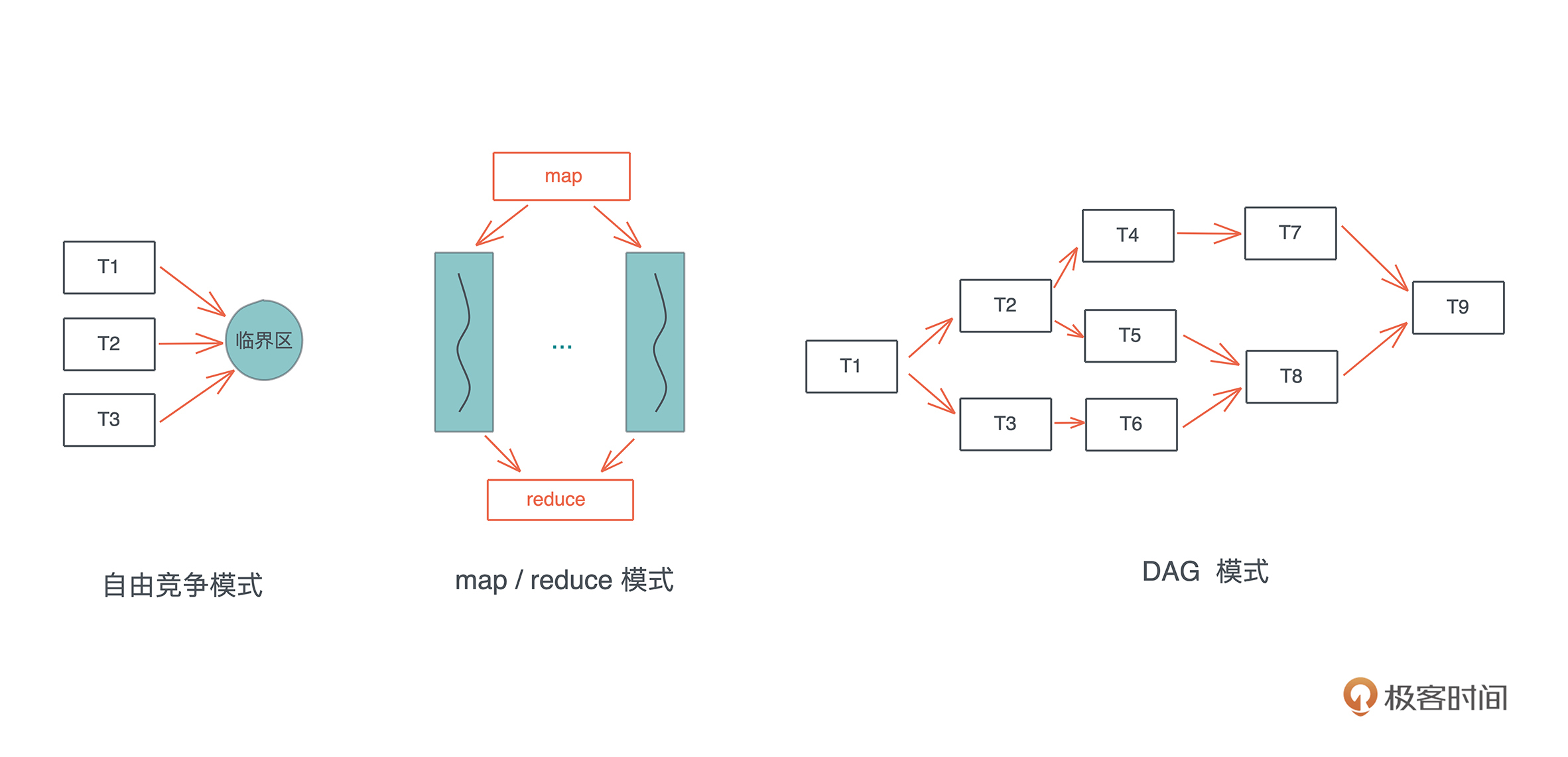
然而,它们没有解决一个更高层次的问题,也就是 DAG 模式:如果这种访问需要按照一定顺序进行或者前后有依赖关系,该怎么做?
这个问题的典型场景是生产者 - 消费者模式:
- 生产者生产出来内容后,需要有机制通知消费者可以消费。
- 比如 socket 上有数据了,通知处理线程来处理数据,处理完成之后,再通知 socket 收发的线程发送数据。
所以,操作系统还提供了 Condvar。
condvar介绍与使用
Condvar介绍与使用
Condvar 有两种状态:
- 等待(wait):线程在队列中等待,直到满足某个条件。
- 通知(notify):当 condvar 的条件满足时,当前线程通知其他等待的线程可以被唤醒。通知可以是单个通知,也可以是多个通知,甚至广播(通知所有人)。
在实践中,Condvar 往往和 Mutex 一起使用:
- Mutex 用于保证条件在读写时互斥
- Condvar 用于控制线程的等待和唤醒。
我们来看一个例子:
use std::sync::{Arc, Condvar, Mutex}; use std::thread; use std::time::Duration; fn main() { let pair = Arc::new((Mutex::new(false), Condvar::new())); let pair2 = Arc::clone(&pair); thread::spawn(move || { let (lock, cvar) = &*pair2; let mut started = lock.lock().unwrap(); *started = true; eprintln!("I'm a happy worker!"); // 通知主线程 cvar.notify_one(); loop { thread::sleep(Duration::from_secs(1)); println!("working..."); } }); let (lock, cvar) = &*pair; // 使用互斥锁作为变量 let mut started = lock.lock().unwrap(); while !*started { // 等待工作线程的通知 started = cvar.wait(started).unwrap(); } eprintln!("Worker started!"); }
-
这段代码通过 condvar,我们实现了 worker 线程在执行到一定阶段后通知主线程,然后主线程再做一些事情。
-
这里,我们使用了一个 Mutex 作为互斥条件,然后在 cvar.wait() 中传入这个 Mutex。
这个接口需要一个 MutexGuard,以便于知道需要唤醒哪个 Mutex 下等待的线程:
pub fn wait<'a, T>( &self, guard: MutexGuard<'a, T> ) -> LockResult<MutexGuard<'a, T>>
复杂DAG模式:Channel or Actor
Channel
Mutex和Condvar的局限性在哪?Channel如何解决的?
但是用 Mutex 和 Condvar 来处理复杂的 DAG 并发模式会比较吃力。所以,Rust 还提供了各种各样的 Channel 用于处理并发任务之间的通讯。
由于 Golang 不遗余力地推广,Channel 可能是最广为人知的并发手段。相对于 Mutex,Channel 的抽象程度最高,接口最为直观,使用起来的心理负担也没那么大。使用 Mutex 时,你需要很小心地避免死锁,控制临界区的大小,防止一切可能发生的意外。
虽然在 Rust 里,我们可以“无畏并发”(Fearless concurrency)—— 当代码编译通过,绝大多数并发问题都可以规避,但性能上的问题、逻辑上的死锁还需要开发者照料。
Channel 把锁封装在了队列写入和读取的小块区域内,然后把读者和写者完全分离,使得读者读取数据和写者写入数据,对开发者而言,除了潜在的上下文切换外,完全和锁无关,就像访问一个本地队列一样。所以,对于大部分并发问题,我们都可以用 Channel 或者类似的思想来处理(比如 actor model)。
Channel分类
Channel根据使用场景如何分类?
Channel 在具体实现的时候,根据不同的使用场景,会选择不同的工具。Rust 提供了以下四种 Channel:
- oneshot:这可能是最简单的 Channel,写者就只发一次数据,而读者也只读一次。
这种一次性的、多个线程间的同步可以用 oneshot channel 完成。由于 oneshot 特殊的用途,实现的时候可以直接用 atomic swap 来完成。
- rendezvous:很多时候,我们只需要通过 Channel 来控制线程间的同步,并不需要发送数据。
rendezvous channel 是 channel size 为 0 的一种特殊情况。
这种情况下,我们用 Mutex + Condvar 实现就足够了,在具体实现中,rendezvous channel 其实也就是 Mutex + Condvar 的一个包装。
- bounded:bounded channel 有一个队列,但队列有上限。
一旦队列被写满了,写者也需要被挂起等待。当阻塞发生后,读者一旦读取数据,channel 内部就会使用 Condvar 的 notify_one 通知写者,唤醒某个写者使其能够继续写入。
因此,实现中,一般会用到 Mutex + Condvar + VecDeque 来实现;如果不用 Condvar,可以直接使用 thread::park + thread::notify 来完成(flume 的做法);如果不用 VecDeque,也可以使用双向链表或者其它的 ring buffer 的实现。
- unbounded:queue 没有上限,如果写满了,就自动扩容。 我们知道,Rust 的很多数据结构如 Vec 、VecDeque 都是自动扩容的。unbounded 和 bounded 相比,除了不阻塞写者,其它实现都很类似。
所有这些 channel 类型,同步和异步的实现思路大同小异,主要的区别在于挂起 / 唤醒的对象:
- 在同步的世界里,挂起 / 唤醒的对象是线程;
- 而异步的世界里,是粒度很小的 task。
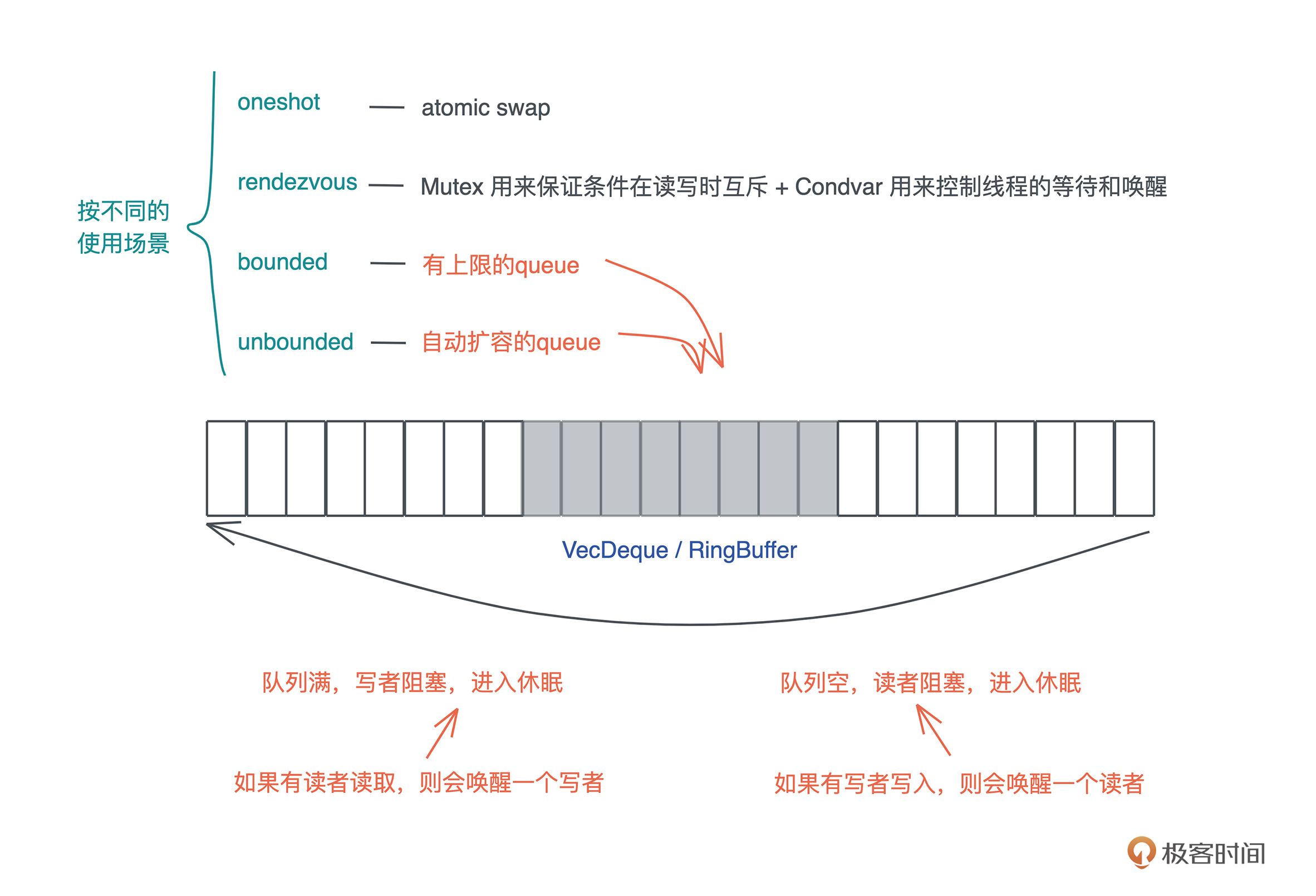
Channel根据读写者数量分别如何分类?
根据 Channel 读者和写者的数量,Channel 又可以分为:
-
SPSC:Single-Producer Single-Consumer 单生产者,单消费者。最简单,可以不依赖于 Mutex,只用 atomics 就可以实现。
-
SPMC:Single-Producer Multi-Consumer 单生产者,多消费者。需要在消费者这侧读取时加锁。
-
MPSC:Multi-Producer Single-Consumer 多生产者,单消费者。需要在生产者这侧写入时加锁。
-
MPMC:Multi-Producer Multi-Consumer 多生产者,多消费者。需要在生产者写入或者消费者读取时加锁。
在众多 Channel 类型中,使用最广的是 MPSC channel, 因为往往我们希望通过单消费者来保证,用于处理消息的数据结构有独占的写访问。
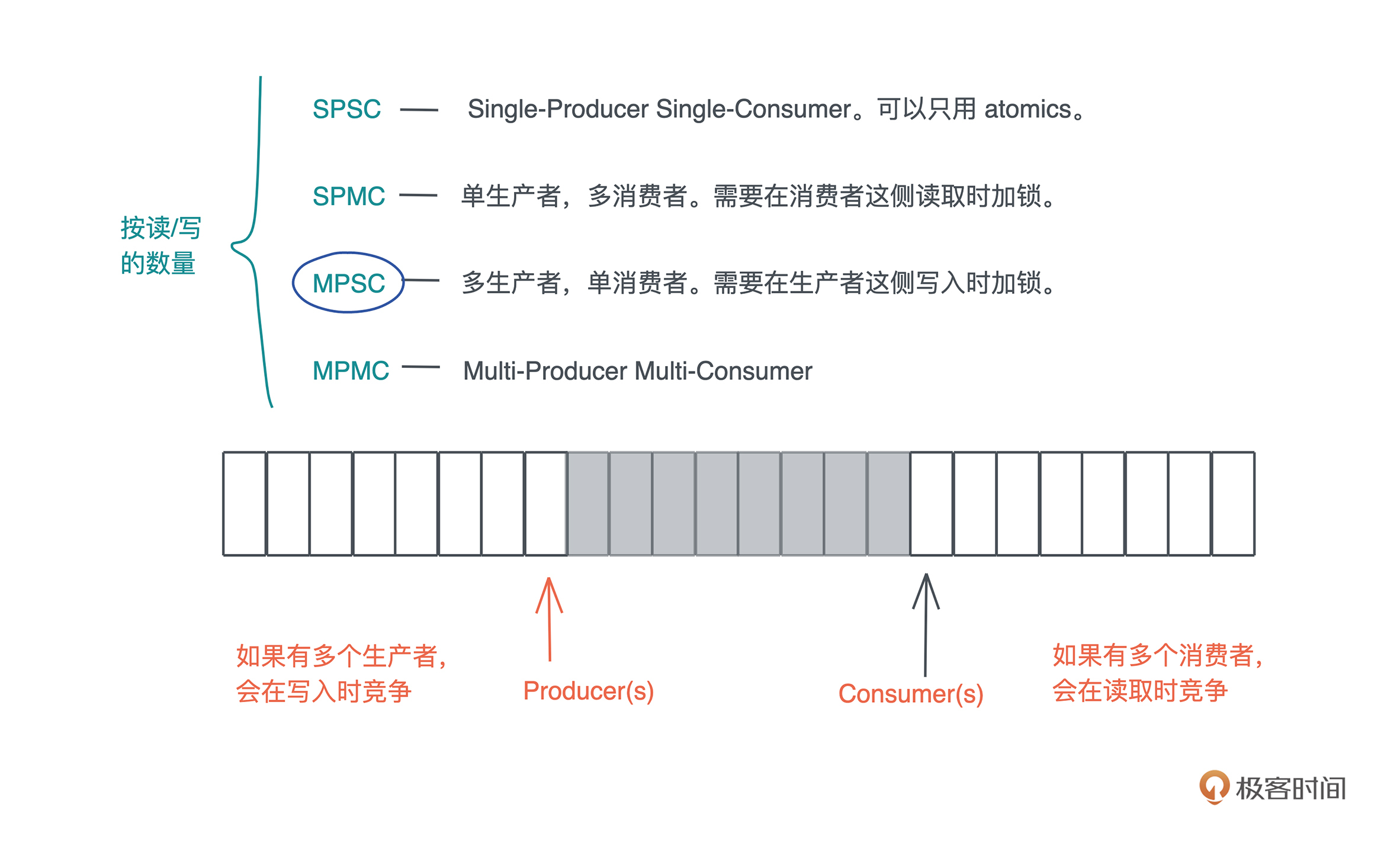
比如,在 xunmi 的实现中:
- index writer 内部是一个多线程的实现
- 但在使用时,我们需要用到它的可写引用。
如果要能够在各种上下文中使用 index writer,我们就不得不将其用 Arc<Mutex
但这样在索引大量数据时效率太低
MPSC channel使用示例:index writer
所以我们可以用 MPSC channel,让各种上下文都把数据发送给单一的线程,使用 index writer 索引,这样就避免了锁:
pub struct IndexInner { index: Index, reader: IndexReader, config: IndexConfig, updater: Sender<Input>, } pub struct IndexUpdater { sender: Sender<Input>, t2s: bool, schema: Schema, } impl Indexer { // 打开或者创建一个 index pub fn open_or_create(config: IndexConfig) -> Result<Self> { let schema = config.schema.clone(); let index = if let Some(dir) = &config.path { fs::create_dir_all(dir)?; let dir = MmapDirectory::open(dir)?; Index::open_or_create(dir, schema.clone())? } else { Index::create_in_ram(schema.clone()) }; Self::set_tokenizer(&index, &config); let mut writer = index.writer(config.writer_memory)?; // 创建一个 unbounded MPSC channel let (s, r) = unbounded::<Input>(); // 启动一个线程,从 channel 的 reader 中读取数据 thread::spawn(move || { for input in r { // 然后用 index writer 处理这个 input if let Err(e) = input.process(&mut writer, &schema) { warn!("Failed to process input. Error: {:?}", e); } } }); // 把 channel 的 sender 部分存入 IndexInner 结构 Self::new(index, config, s) } pub fn get_updater(&self) -> IndexUpdater { let t2s = TextLanguage::Chinese(true) == self.config.text_lang; // IndexUpdater 内部包含 channel 的 sender 部分 // 由于是 MPSC channel,所以这里可以简单 clone 一下 sender // 这也意味着,我们可以创建任意多个 IndexUpdater 在不同上下文发送数据 // 而数据最终都会通过 channel 给到上面创建的线程,由 index writer 处理 IndexUpdater::new(self.updater.clone(), self.index.schema(), t2s) } }
Actor
简单介绍Actor,并举例
最后我们简单介绍一下 actor model,它在业界主要的使用者是 Erlang VM 以及 akka。actor 是一种有栈协程:
- 每个 actor,有自己的一个独立的、轻量级的调用栈
- 以及一个用来接受消息的消息队列(mailbox 或者 message queue)
- 外界跟 actor 打交道的唯一手段就是,给它发送消息。
Rust 标准库没有 actor 的实现,但是社区里有比较成熟的 actix(大名鼎鼎的 actix-web 就是基于 actix 实现的),以及 bastion。
下面的代码用 actix 实现了一个简单的 DummyActor,它可以接收一个 InMsg,返回一个 OutMsg:
use actix::prelude::*; use anyhow::Result; // actor 可以处理的消息 #[derive(Message, Debug, Clone, PartialEq)] #[rtype(result = "OutMsg")] enum InMsg { Add((usize, usize)), Concat((String, String)), } #[derive(MessageResponse, Debug, Clone, PartialEq)] enum OutMsg { Num(usize), Str(String), } // Actor struct DummyActor; impl Actor for DummyActor { type Context = Context<Self>; } // 实现处理 InMsg 的 Handler trait impl Handler<InMsg> for DummyActor { type Result = OutMsg; // <- 返回的消息 fn handle(&mut self, msg: InMsg, _ctx: &mut Self::Context) -> Self::Result { match msg { InMsg::Add((a, b)) => OutMsg::Num(a + b), InMsg::Concat((mut s1, s2)) => { s1.push_str(&s2); OutMsg::Str(s1) } } } } #[actix::main] async fn main() -> Result<()> { let addr = DummyActor.start(); let res = addr.send(InMsg::Add((21, 21))).await?; let res1 = addr .send(InMsg::Concat(("hello, ".into(), "world".into()))) .await?; println!("res: {:?}, res1: {:?}", res, res1); Ok(()) }
可以看到,对 DummyActor,我们只需要实现 Actor trait 和 Handler
trait 。
Channel/Actor对比与联系
- Mixing Metaphors: Actors as Channels and Channels as Actorsdt链接
- What’s the difference between the Actor Model of Concurrency and Communicating Sequential Processes - Theoretical Computer Science Stack Exchange
- Rust的异步编程主要使用async模型: Why Async? - Asynchronous Programming in Rust
至于async/await,又是另一个故事
自己实现一个基本的MPSC Channel
之前我们谈论了如何在搜索引擎的 Index writer 上使用 MPSC channel:
- 要更新 index 的上下文有很多(可以是线程也可以是异步任务)
- 而 IndexWriter 只能是唯一的。
- 为了避免在访问 IndexWriter 时加锁,我们可以使用 MPSC channel
- 在多个上下文中给 channel 发消息,然后在唯一拥有 IndexWriter 的线程中读取这些消息,非常高效。
好,来看看今天要实现的 MPSC channel 的基本功能。为了简便起见,我们只关心 unbounded MPSC channel。也就是说,当队列容量不够时,会自动扩容,所以,任何时候生产者写入数据都不会被阻塞,但是当队列中没有数据时,消费者会被阻塞:
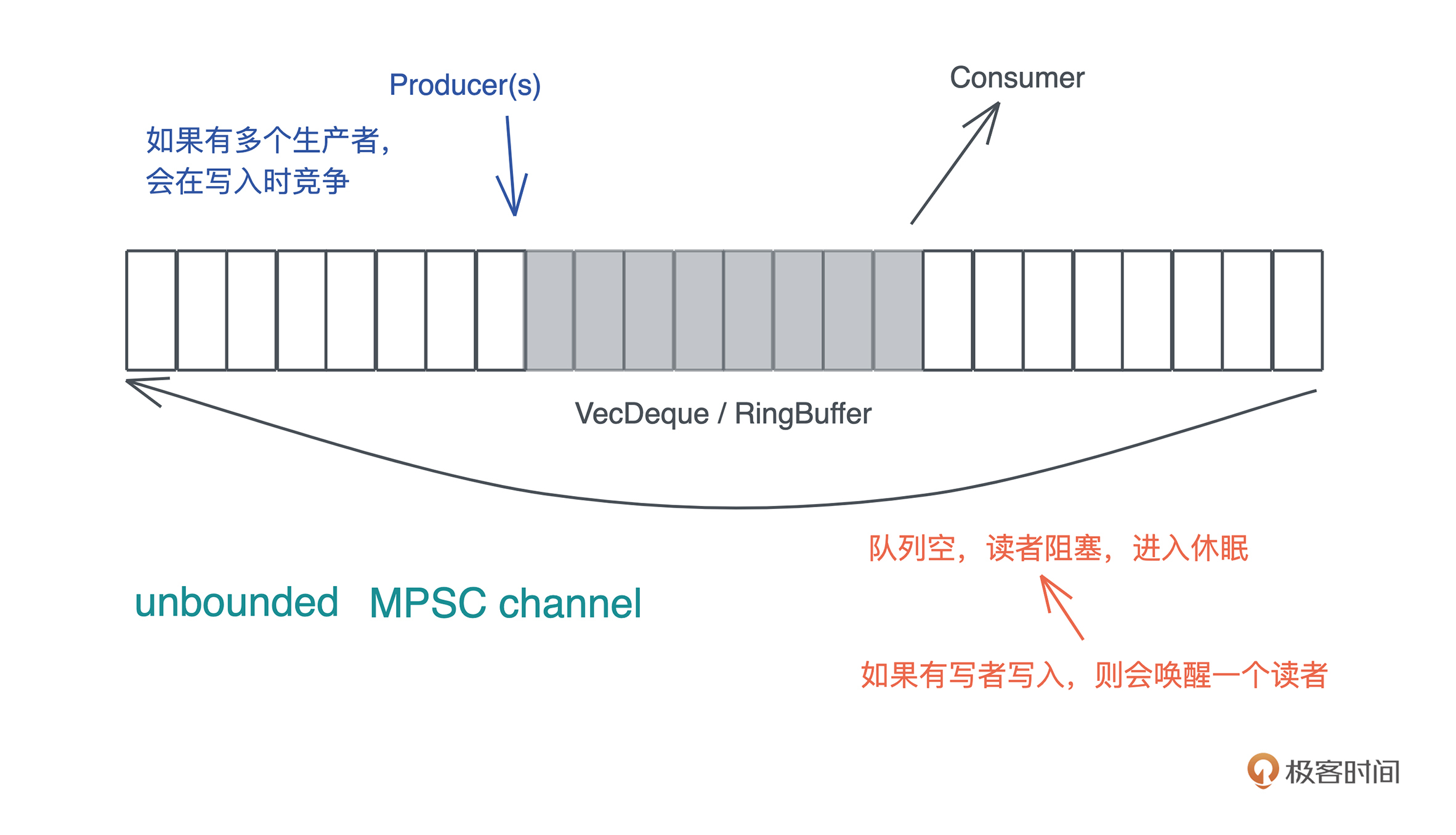
测试驱动的设计
之前我们会从需求的角度来设计接口和数据结构,今天我们就换种方式,完全站在使用者的角度,用使用实例(测试)来驱动接口和数据结构的设计。
需求1: 基本的 send/recv
要实现刚才说的 MPSC channel,都有什么需求呢?首先,生产者可以产生数据,消费者能够消费产生出来的数据,也就是基本的 send/recv,我们以下面这个单元测试 1 来描述这个需求:
#[test] fn channel_should_work() { let (mut s, mut r) = unbounded(); s.send("hello world!".to_string()).unwrap(); let msg = r.recv().unwrap(); assert_eq!(msg, "hello world!"); }
- 这里,通过 unbounded() 方法, 可以创建一个 sender 和一个 receiver
- sender 有 send() 方法,可以发送数据
- receiver 有 recv() 方法,可以接受数据。
- 整体的接口,我们设计和 std::sync::mpsc 保持一致,避免使用者使用上的心智负担。
为了实现这样一个接口,需要什么样的数据结构呢?
- 首先,生产者和消费者之间会共享一个队列,可以用 VecDeque。
- 显然,这个队列在插入和取出数据时需要互斥,所以需要用 Mutex 来保护它。
struct Shared<T> { queue: Mutex<VecDeque<T>>, } pub struct Sender<T> { shared: Arc<Shared<T>>, } pub struct Receiver<T> { shared: Arc<Shared<T>>, }
这样的数据结构应该可以满足单元测试 1。
需求2: 允许多个 sender 往 channel 里发送数据
由于需要的是 MPSC,所以,我们允许多个 sender 往 channel 里发送数据,用单元测试 2 来描述这个需求:
#[test] fn multiple_senders_should_work() { let (mut s, mut r) = unbounded(); let mut s1 = s.clone(); let mut s2 = s.clone(); let t = thread::spawn(move || { s.send(1).unwrap(); }); let t1 = thread::spawn(move || { s1.send(2).unwrap(); }); let t2 = thread::spawn(move || { s2.send(3).unwrap(); }); for handle in [t, t1, t2] { handle.join().unwrap(); } let mut result = [r.recv().unwrap(), r.recv().unwrap(), r.recv().unwrap()]; // 在这个测试里,数据到达的顺序是不确定的,所以我们排个序再 assert result.sort(); assert_eq!(result, [1, 2, 3]); }
这个需求,刚才的数据结构就可以满足,只是 Sender 需要实现 Clone trait。不过我们在写这个测试的时候稍微有些别扭,因为这一行有不断重复的代码:
let mut result = [r.recv().unwrap(), r.recv().unwrap(), r.recv().unwrap()];
注意,测试代码的 DRY 也很重要,我们之前强调过。所以,当写下这个测试的时候,也许会想,我们可否提供 Iterator 的实现?恩这个想法先暂存下来。
需求3: 当队列空的时候,receiver 所在的线程会被阻塞
接下来考虑当队列空的时候,receiver 所在的线程会被阻塞这个需求。那么,如何对这个需求进行测试呢?这并不简单,我们没有比较直观的方式来检测线程的状态。
不过,我们可以通过检测“线程是否退出”来间接判断线程是否被阻塞。
理由很简单:
- 如果线程没有继续工作,又没有退出,那么一定被阻塞住了。
- 阻塞住之后,我们继续发送数据,消费者所在的线程会被唤醒,继续工作
- 所以最终队列长度应该为 0。我们看单元测试 3:
#[test] fn receiver_should_be_blocked_when_nothing_to_read() { let (mut s, r) = unbounded(); let mut s1 = s.clone(); thread::spawn(move || { for (idx, i) in r.into_iter().enumerate() { // 如果读到数据,确保它和发送的数据一致 assert_eq!(idx, i); } // 读不到应该休眠,所以不会执行到这一句,执行到这一句说明逻辑出错 assert!(false); }); thread::spawn(move || { for i in 0..100usize { s.send(i).unwrap(); } }); // 1ms 足够让生产者发完 100 个消息,消费者消费完 100 个消息并阻塞 thread::sleep(Duration::from_millis(1)); // 再次发送数据,唤醒消费者 for i in 100..200usize { s1.send(i).unwrap(); } // 留点时间让 receiver 处理 thread::sleep(Duration::from_millis(1)); // 如果 receiver 被正常唤醒处理,那么队列里的数据会都被读完 assert_eq!(s1.total_queued_items(), 0); }
这个测试代码中:
- 我们假定 receiver 实现了 Iterator
- 还假定 sender 提供了一个方法 total_queued_items()。这些可以在实现的时候再处理。
你可以花些时间仔细看看这段代码,想想其中的处理逻辑。虽然代码很简单,不难理解,但是把一个完整的需求转化成合适的测试代码,还是要颇费些心思的。
好,如果要能支持队列为空时阻塞,我们需要使用 Condvar。
所以 Shared
struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, }
这样当实现 Receiver 的 recv() 方法后,我们可以在读不到数据时阻塞线程:
// 拿到锁 let mut inner = self.shared.queue.lock().unwrap(); // ... 假设读不到数据 // 使用 condvar 和 MutexGuard 阻塞当前线程 self.shared.available.wait(inner)
需求4: Receiver没有数据可读
顺着刚才的多个 sender 想,如果现在所有 Sender 都退出作用域,Receiver 继续接收,到没有数据可读了,该怎么处理?是不是应该产生一个错误,让调用者知道,现在 channel 的另一侧已经没有生产者了,再读也读不出数据了?
我们来写单元测试 4:
#[test] fn last_sender_drop_should_error_when_receive() { let (s, mut r) = unbounded(); let s1 = s.clone(); let senders = [s, s1]; let total = senders.len(); // sender 即用即抛 for mut sender in senders { thread::spawn(move || { sender.send("hello").unwrap(); // sender 在此被丢弃 }) .join() .unwrap(); } // 虽然没有 sender 了,接收者依然可以接受已经在队列里的数据 for _ in 0..total { r.recv().unwrap(); } // 然而,读取更多数据时会出错 assert!(r.recv().is_err()); }
这个测试依旧很简单。你可以想象一下,使用什么样的数据结构可以达到这样的目的:
- 首先,每次 Clone 时,要增加 Sender 的计数;
- 在 Sender Drop 时,减少这个计数;
- 然后,我们为 Receiver 提供一个方法 total_senders(),来读取 Sender 的计数
- 当计数为 0,且队列中没有数据可读时,recv() 方法就报错。
有了这个思路,你想一想,这个计数器用什么数据结构呢?用锁保护么?
哈,你一定想到了可以使用 atomics。对,我们可以用 AtomicUsize。所以,Shared 数据结构需要更新一下:
struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, }
需求5: 没有Receiver处理数据
既然没有 Sender 了要报错,那么如果没有 Receiver 了,Sender 发送时是不是也应该错误返回?这个需求和上面类似,就不赘述了。看构造的单元测试 5:
#[test] fn receiver_drop_should_error_when_send() { let (mut s1, mut s2) = { let (s, _) = unbounded(); let s1 = s.clone(); let s2 = s.clone(); (s1, s2) }; assert!(s1.send(1).is_err()); assert!(s2.send(1).is_err()); }
这里,我们创建一个 channel,产生两个 Sender 后便立即丢弃 Receiver。两个 Sender 在发送时都会出错。
同样的,Shared 数据结构要更新一下:
struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, receivers: AtomicUsize, }
实现 MPSC channel
现在写了五个单元测试,我们已经把需求摸透了,并且有了基本的接口和数据结构的设计。接下来,我们来写实现的代码。
创建一个新的项目
cargo new con_utils --lib
- 在 cargo.toml 中添加 anyhow 作为依赖。
- 在 lib.rs 里,我们就写入一句:pub mod channel , 然后创建 src/channel.rs
- 把刚才设计时使用的 test case、设计的数据结构,以及 test case 里使用到的接口,用代码全部放进来:
use anyhow::Result; use std::{ collections::VecDeque, sync::{atomic::AtomicUsize, Arc, Condvar, Mutex}, }; /// 发送者 pub struct Sender<T> { shared: Arc<Shared<T>>, } /// 接收者 pub struct Receiver<T> { shared: Arc<Shared<T>>, } /// 发送者和接收者之间共享一个 VecDeque,用 Mutex 互斥,用 Condvar 通知 /// 同时,我们记录有多少个 senders 和 receivers struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, receivers: AtomicUsize, } impl<T> Sender<T> { /// 生产者写入一个数据 pub fn send(&mut self, t: T) -> Result<()> { todo!() } pub fn total_receivers(&self) -> usize { todo!() } pub fn total_queued_items(&self) -> usize { todo!() } } impl<T> Receiver<T> { pub fn recv(&mut self) -> Result<T> { todo!() } pub fn total_senders(&self) -> usize { todo!() } } impl<T> Iterator for Receiver<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { todo!() } } /// 克隆 sender impl<T> Clone for Sender<T> { fn clone(&self) -> Self { todo!() } } /// Drop sender impl<T> Drop for Sender<T> { fn drop(&mut self) { todo!() } } impl<T> Drop for Receiver<T> { fn drop(&mut self) { todo!() } } /// 创建一个 unbounded channel pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { todo!() } #[cfg(test)] mod tests { use std::{thread, time::Duration}; use super::*; // 此处省略所有 test case }
实现单元测试相关功能
目前这个代码虽然能够编译通过,但因为没有任何实现,所以 cargo test 全部出错。接下来,我们就来一点点实现功能。
- 创建 unbounded channel
pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { let shared = Shared::default(); let shared = Arc::new(shared); ( Sender { shared: shared.clone(), }, Receiver { shared }, ) } const INITIAL_SIZE: usize = 32; impl<T> Default for Shared<T> { fn default() -> Self { Self { queue: Mutex::new(VecDeque::with_capacity(INITIAL_SIZE)), available: Condvar::new(), senders: AtomicUsize::new(1), receivers: AtomicUsize::new(1), } } }
因为这里使用 default() 创建了 Shared
- 实现消费者
对于消费者,我们主要需要实现 recv 方法。
在 recv 中:
- 如果队列中有数据,那么直接返回;
- 如果没数据,且所有生产者都离开了,我们就返回错误;
- 如果没数据,但还有生产者,我们就阻塞消费者的线程:
impl<T> Receiver<T> { pub fn recv(&mut self) -> Result<T> { // 拿到队列的锁 let mut inner = self.shared.queue.lock().unwrap(); loop { match inner.pop_front() { // 读到数据返回,锁被释放 Some(t) => { return Ok(t); } // 读不到数据,并且生产者都退出了,释放锁并返回错误 None if self.total_senders() == 0 => return Err(anyhow!("no sender left")), // 读不到数据,把锁提交给 available Condvar,它会释放锁并挂起线程,等待 notify None => { // 当 Condvar 被唤醒后会返回 MutexGuard,我们可以 loop 回去拿数据 // 这是为什么 Condvar 要在 loop 里使用 inner = self .shared .available .wait(inner) .map_err(|_| anyhow!("lock poisoned"))?; } } } } pub fn total_senders(&self) -> usize { self.shared.senders.load(Ordering::SeqCst) } }
注意看这里 Condvar 的使用。
- 在 wait() 方法里,它接收一个 MutexGuard,然后释放这个 Mutex,挂起线程。
- 等得到通知后,它会再获取锁,得到一个 MutexGuard,返回。所以这里是:
inner = self.shared.available.wait(inner).map_err(|_| anyhow!("lock poisoned"))?;
因为 recv() 会返回一个值,所以阻塞回来之后,我们应该循环回去拿数据。这是为什么这段逻辑要被 loop {} 包裹。我们前面在设计时考虑过:当发送者发送数据时,应该通知被阻塞的消费者。所以,在实现 Sender 的 send() 时,需要做相应的 notify 处理。
记得还要处理消费者的 drop:
impl<T> Drop for Receiver<T> { fn drop(&mut self) { self.shared.receivers.fetch_sub(1, Ordering::AcqRel); } }
很简单,消费者离开时,将 receivers 减一。
实现生产者功能
接下来我们看生产者的功能怎么实现。
- 首先,在没有消费者的情况下,应该报错。
- 正常应该使用 thiserror 定义自己的错误,不过这里为了简化代码,就使用 anyhow! 宏产生一个 adhoc 的错误。
- 如果消费者还在,那么我们获取 VecDeque 的锁,把数据压入:
impl<T> Sender<T> { /// 生产者写入一个数据 pub fn send(&mut self, t: T) -> Result<()> { // 如果没有消费者了,写入时出错 if self.total_receivers() == 0 { return Err(anyhow!("no receiver left")); } // 加锁,访问 VecDeque,压入数据,然后立刻释放锁 let was_empty = { let mut inner = self.shared.queue.lock().unwrap(); let empty = inner.is_empty(); inner.push_back(t); empty }; // 通知任意一个被挂起等待的消费者有数据 if was_empty { self.shared.available.notify_one(); } Ok(()) } pub fn total_receivers(&self) -> usize { self.shared.receivers.load(Ordering::SeqCst) } pub fn total_queued_items(&self) -> usize { let queue = self.shared.queue.lock().unwrap(); queue.len() } }
这里,获取 total_receivers 时,我们使用了 Ordering::SeqCst,保证所有线程看到同样顺序的对 receivers 的操作。这个值是最新的值。
在压入数据时,需要判断一下之前是队列是否为空,因为队列为空的时候,我们需要用 notify_one() 来唤醒消费者。这个非常重要,如果没处理的话,会导致消费者阻塞后无法复原接收数据。
由于我们可以有多个生产者,所以要允许它 clone:
impl<T> Clone for Sender<T> { fn clone(&self) -> Self { self.shared.senders.fetch_add(1, Ordering::AcqRel); Self { shared: Arc::clone(&self.shared), } } }
实现 Clone trait 的方法很简单,但记得要把 shared.senders 加 1,使其保持和当前的 senders 的数量一致。
当然,在 drop 的时候我们也要维护 shared.senders 使其减 1:
impl<T> Drop for Sender<T> { fn drop(&mut self) { self.shared.senders.fetch_sub(1, Ordering::AcqRel); } }
其他功能实现
目前还缺乏 Receiver 的 Iterator 的实现,这个很简单,就是在 next() 里调用 recv() 方法,Rust 提供了支持在 Option / Result 之间很方便转换的函数,所以这里我们可以直接通过 ok() 来将 Result 转换成 Option:
impl<T> Iterator for Receiver<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { self.recv().ok() } }
好,目前所有需要实现的代码都实现完毕, cargo test 测试一下。wow!测试一次性通过!这也太顺利了吧!
最后来仔细审视一下代码。很快,我们发现 Sender 的 Drop 实现似乎有点问题。如果 Receiver 被阻塞,而此刻所有 Sender 都走了,那么 Receiver 就没有人唤醒,会带来资源的泄露。这是一个很边边角角的问题,所以之前的测试没有覆盖到。
我们来设计一个场景让这个问题暴露:
#[test] fn receiver_shall_be_notified_when_all_senders_exit() { let (s, mut r) = unbounded::<usize>(); // 用于两个线程同步 let (mut sender, mut receiver) = unbounded::<usize>(); let t1 = thread::spawn(move || { // 保证 r.recv() 先于 t2 的 drop 执行 sender.send(0).unwrap(); assert!(r.recv().is_err()); }); thread::spawn(move || { receiver.recv().unwrap(); drop(s); }); t1.join().unwrap(); }
在我进一步解释之前,你可以停下来想想:
- 为什么这个测试可以保证暴露这个问题?
- 它是怎么暴露的?
- 如果想不到,再 cargo test 看看会出现什么问题。
来一起分析分析,这里,我们创建了两个线程 t1 和 t2,分别让它们处理消费者和生产者。t1 读取数据,此时没有数据,所以会阻塞,而 t2 直接把生产者 drop 掉。所以,此刻如果没有人唤醒 t1,那么 t1.join() 就会一直等待,因为 t1 一直没有退出。
所以,为了保证一定是 t1 r.recv()先执行导致阻塞、t2 再 drop(s),我们(eat your own dog food)用另一个 channel 来控制两个线程的执行顺序。这是一种很通用的做法,你可以好好琢磨一下。
运行 cargo test 后,测试被阻塞。这是因为,t1 没有机会得到唤醒,所以这个测试就停在那里不动了。
要修复这个问题,我们需要妥善处理 Sender 的 Drop:
impl<T> Drop for Sender<T> { fn drop(&mut self) { let old = self.shared.senders.fetch_sub(1, Ordering::AcqRel); // sender 走光了,唤醒 receiver 读取数据(如果队列中还有的话),读不到就出错 if old <= 1 { // 因为我们实现的是 MPSC,receiver 只有一个,所以 notify_all 实际等价 notify_one self.shared.available.notify_all(); } } }
这里,如果减一之前,旧的 senders 的数量小于等于 1,意味着现在是最后一个 Sender 要离开了,不管怎样我们都要唤醒 Receiver ,所以这里使用了 notify_all()。如果 Receiver 之前已经被阻塞,此刻就能被唤醒。修改完成,cargo test 一切正常。
对锁进行性能优化
从功能上来说,目前我们的 MPSC unbounded channel 没有太多的问题,可以应用在任何需要 MPSC channel 的场景。然而,每次读写都需要获取锁,虽然锁的粒度很小,但还是让整体的性能打了个折扣。有没有可能优化锁呢?
之前我们讲到,优化锁的手段无非是减小临界区的大小,让每次加锁的时间很短,这样冲突的几率就变小。另外,就是降低加锁的频率,对于消费者来说,如果我们能够一次性把队列中的所有数据都读完缓存起来,以后在需要的时候从缓存中读取,这样就可以大大减少消费者加锁的频次。
顺着这个思路,我们可以在 Receiver 的结构中放一个 cache:
pub struct Receiver<T> { shared: Arc<Shared<T>>, cache: VecDeque<T>, }
如果你之前有 C 语言开发的经验,也许会想,到了这一步,何必把 queue 中的数据全部读出来,存入 Receiver 的 cache 呢?这样效率太低,如果能够直接 swap 两个结构内部的指针,这样,即便队列中有再多的数据,也是一个 O(1) 的操作。
Rust 有类似的 std::mem::swap 方法。比如
use std::mem; fn main() { let mut x = "hello world".to_string(); let mut y = "goodbye world".to_string(); mem::swap(&mut x, &mut y); assert_eq!("goodbye world", x); assert_eq!("hello world", y); }
好,了解了 swap 方法,我们看看如何修改 Receiver 的 recv() 方法来提升性能:
pub fn recv(&mut self) -> Result<T> { // 无锁 fast path if let Some(v) = self.cache.pop_front() { return Ok(v); } // 拿到队列的锁 let mut inner = self.shared.queue.lock().unwrap(); loop { match inner.pop_front() { // 读到数据返回,锁被释放 Some(t) => { // 如果当前队列中还有数据,那么就把消费者自身缓存的队列(空)和共享队列 swap 一下 // 这样之后再读取,就可以从 self.queue 中无锁读取 if !inner.is_empty() { std::mem::swap(&mut self.cache, &mut inner); } return Ok(t); } // 读不到数据,并且生产者都退出了,释放锁并返回错误 None if self.total_senders() == 0 => return Err(anyhow!("no sender left")), // 读不到数据,把锁提交给 available Condvar,它会释放锁并挂起线程,等待 notify None => { // 当 Condvar 被唤醒后会返回 MutexGuard,我们可以 loop 回去拿数据 // 这是为什么 Condvar 要在 loop 里使用 inner = self .shared .available .wait(inner) .map_err(|_| anyhow!("lock poisoned"))?; } } } }
- 当 cache 中有数据时,总是从 cache 中读取;
- 当 cache 中没有,我们拿到队列的锁,读取一个数据
- 然后看看队列是否还有数据,有的话,就 swap cache 和 queue,然后返回之前读取的数据。
好,做完这个重构和优化,我们可以运行 cargo test,看看已有的测试是否正常。如果你遇到报错,应该是 cache 没有初始化,你可以自行解决,也可以参考:
pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { let shared = Shared::default(); let shared = Arc::new(shared); ( Sender { shared: shared.clone(), }, Receiver { shared, cache: VecDeque::with_capacity(INITIAL_SIZE), }, ) }
虽然现有的测试全数通过,但我们并没有为这个优化写测试,这里补个测试:
#[test] fn channel_fast_path_should_work() { let (mut s, mut r) = unbounded(); for i in 0..10usize { s.send(i).unwrap(); } assert!(r.cache.is_empty()); // 读取一个数据,此时应该会导致 swap,cache 中有数据 assert_eq!(0, r.recv().unwrap()); // 还有 9 个数据在 cache 中 assert_eq!(r.cache.len(), 9); // 在 queue 里没有数据了 assert_eq!(s.total_queued_items(), 0); // 从 cache 里读取剩下的数据 for (idx, i) in r.into_iter().take(9).enumerate() { assert_eq!(idx + 1, i); } }
这个测试很简单,详细注释也都写上了。
完整代码
use anyhow::{anyhow, Result}; use std::{ collections::VecDeque, sync::{ atomic::{AtomicUsize, Ordering}, Arc, Condvar, Mutex, }, }; /// 发送者 pub struct Sender<T> { shared: Arc<Shared<T>>, } /// 接收者 pub struct Receiver<T> { shared: Arc<Shared<T>>, cache: VecDeque<T>, } /// 发送者和接收者之间共享一个 VecDeque,用 Mutex 互斥,用 Condvar 通知 /// 同时,我们记录有多少个 senders 和 receivers struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, receivers: AtomicUsize, } const INITIAL_SIZE: usize = 32; impl<T> Default for Shared<T> { fn default() -> Self { Self { queue: Mutex::new(VecDeque::with_capacity(INITIAL_SIZE)), available: Condvar::new(), senders: AtomicUsize::new(1), receivers: AtomicUsize::new(1), } } } impl<T> Sender<T> { /// 生产者写入一个数据 pub fn send(&mut self, t: T) -> Result<()> { // 如果没有消费者了,写入时出错 if self.total_receivers() == 0 { return Err(anyhow!("no receiver left")); } // 加锁,访问 VecDeque,压入数据,然后立刻释放锁 let was_empty = { let mut inner = self.shared.queue.lock().unwrap(); let empty = inner.is_empty(); inner.push_back(t); empty }; // 通知任意一个被挂起等待的消费者有数据 if was_empty { self.shared.available.notify_one(); } Ok(()) } pub fn total_receivers(&self) -> usize { self.shared.receivers.load(Ordering::SeqCst) } pub fn total_queued_items(&self) -> usize { let queue = self.shared.queue.lock().unwrap(); queue.len() } } /// 克隆 sender impl<T> Clone for Sender<T> { fn clone(&self) -> Self { self.shared.senders.fetch_add(1, Ordering::AcqRel); Self { shared: Arc::clone(&self.shared), } } } /// Drop sender impl<T> Drop for Sender<T> { fn drop(&mut self) { let old = self.shared.senders.fetch_sub(1, Ordering::AcqRel); // sender 走光了,唤醒 receiver 读取数据(如果队列中还有的话),读不到就出错 if old <= 1 { // 因为我们实现的是 MPSC,receiver 只有一个,所以 notify_all 实际等价 notify_one self.shared.available.notify_all(); } } } impl<T> Receiver<T> { pub fn recv(&mut self) -> Result<T> { // 无锁 fast path if let Some(v) = self.cache.pop_front() { return Ok(v); } // 拿到队列的锁 let mut inner = self.shared.queue.lock().unwrap(); loop { match inner.pop_front() { // 读到数据返回,锁被释放 Some(t) => { // 如果当前队列中还有数据,那么就把消费者自身缓存的队列(空)和共享队列 swap 一下 // 这样之后再读取,就可以从 self.queue 中无锁读取 if !inner.is_empty() { std::mem::swap(&mut self.cache, &mut inner); } return Ok(t); } // 读不到数据,并且生产者都退出了,释放锁并返回错误 None if self.total_senders() == 0 => return Err(anyhow!("no sender left")), // 读不到数据,把锁提交给 available Condvar,它会释放锁并挂起线程,等待 notify None => { // 当 Condvar 被唤醒后会返回 MutexGuard,我们可以 loop 回去拿数据 // 这是为什么 Condvar 要在 loop 里使用 inner = self .shared .available .wait(inner) .map_err(|_| anyhow!("lock poisoned"))?; } } } } pub fn total_senders(&self) -> usize { self.shared.senders.load(Ordering::SeqCst) } } impl<T> Iterator for Receiver<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { self.recv().ok() } } impl<T> Drop for Receiver<T> { fn drop(&mut self) { self.shared.receivers.fetch_sub(1, Ordering::AcqRel); // 因为 sender 不会阻塞,所以 receiver 离开不需要唤醒 sender } } /// 创建一个 unbounded channel pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { let shared = Shared::default(); let shared = Arc::new(shared); ( Sender { shared: shared.clone(), }, Receiver { shared, cache: VecDeque::with_capacity(INITIAL_SIZE), }, ) } #[cfg(test)] mod tests { use std::{thread, time::Duration}; use super::*; #[test] fn channel_should_work() { let (mut s, mut r) = unbounded(); s.send("hello world!".to_string()).unwrap(); let msg = r.recv().unwrap(); assert_eq!(msg, "hello world!"); } #[test] fn multiple_senders_should_work() { let (mut s, mut r) = unbounded(); let mut s1 = s.clone(); let mut s2 = s.clone(); let t = thread::spawn(move || { s.send(1).unwrap(); }); let t1 = thread::spawn(move || { s1.send(2).unwrap(); }); let t2 = thread::spawn(move || { s2.send(3).unwrap(); }); for handle in [t, t1, t2] { handle.join().unwrap(); } let mut result = [r.recv().unwrap(), r.recv().unwrap(), r.recv().unwrap()]; // 在这个测试里,数据到达的顺序是不确定的,所以我们排个序再 assert result.sort_unstable(); assert_eq!(result, [1, 2, 3]); } #[test] #[allow(clippy::all)] fn receiver_should_be_blocked_when_nothing_to_read() { let (mut s, r) = unbounded(); let mut s1 = s.clone(); thread::spawn(move || { for (idx, i) in r.into_iter().enumerate() { // 如果读到数据,确保它和发送的数据一致 assert_eq!(idx, i); } // 读不到应该休眠,所以不会执行到这一句,执行到这一句说明逻辑出错 assert!(false); }); thread::spawn(move || { for i in 0..100usize { s.send(i).unwrap(); } // 防止所有 sender 都离开 loop {} }); // 1ms 足够让生产者发完 100 个消息,消费者消费完 100 个消息并阻塞 thread::sleep(Duration::from_millis(1)); // 再次发送数据,唤醒消费者 for i in 100..200usize { s1.send(i).unwrap(); } // 留点时间让 receiver 处理 thread::sleep(Duration::from_millis(1)); // 如果 receiver 被正常唤醒处理,那么队列里的数据会都被读完 assert_eq!(s1.total_queued_items(), 0); } #[test] fn last_sender_drop_should_error_when_receive() { let (s, mut r) = unbounded(); let s1 = s.clone(); let senders = [s, s1]; let total = senders.len(); // sender 即用即抛 for mut sender in senders { thread::spawn(move || { sender.send("hello").unwrap(); // sender 在此被丢弃 }) .join() .unwrap(); } // 虽然没有 sender 了,接收者依然可以接受已经在队列里的数据 for _ in 0..total { r.recv().unwrap(); } // 然而,读取更多数据时会出错 assert!(r.recv().is_err()); } #[test] fn receiver_drop_should_error_when_send() { let (mut s1, mut s2) = { let (s, _) = unbounded(); let s1 = s.clone(); (s1, s) }; assert!(s1.send(1).is_err()); assert!(s2.send(1).is_err()); } #[test] fn receiver_shall_be_notified_when_all_senders_exit() { let (s, mut r) = unbounded::<usize>(); // 用于两个线程同步 let (mut sender, mut receiver) = unbounded::<usize>(); let t1 = thread::spawn(move || { // 保证 r.recv() 先于 t2 的 drop 执行 sender.send(0).unwrap(); assert!(r.recv().is_err()); }); thread::spawn(move || { receiver.recv().unwrap(); drop(s); }); t1.join().unwrap(); } #[test] fn channel_fast_path_should_work() { let (mut s, mut r) = unbounded(); for i in 0..10usize { s.send(i).unwrap(); } assert!(r.cache.is_empty()); // 读取一个数据,此时应该会导致 swap,cache 中有数据 assert_eq!(0, r.recv().unwrap()); // 还有 9 个数据在 cache 中 assert_eq!(r.cache.len(), 9); // 在 queue 里没有数据了 assert_eq!(s.total_queued_items(), 0); // 从 cache 里读取剩下的数据 for (idx, i) in r.into_iter().take(9).enumerate() { assert_eq!(idx + 1, i); } } }
回顾测试驱动开发
回顾测试驱动开发
这里完全顺着需求写测试,然后在写测试的过程中进行数据结构和接口的设计。和普通的 TDD 不同的是,先一口气把主要需求涉及的行为用测试来表述,然后通过这个表述,构建合适的接口,以及能够运行这个接口的数据结构。
在开发产品的时候,这也是一种非常有效的手段,可以让我们通过测试完善设计,最终得到一个能够让测试编译通过的、完全没有实现代码、只有接口的版本。之后,我们再一个接口一个接口实现,全部实现完成之后,运行测试,看看是否出问题。
在这里你可以多多关注构建测试用例的技巧。之前的课程中,我反复强调过单元测试的重要性,也以身作则在几个重要的实操中都有详尽地测试。不过相比之前写的测试,这一讲中的测试要更难写一些,尤其是在并发场景下那些边边角角的功能测试。
不要小看测试代码,有时候构造测试代码比撰写功能代码还要烧脑。但是,当你有了扎实的单元测试覆盖后,再做重构,比如最后我们做和性能相关的重构,就变得轻松很多,因为只要cargo test通过,起码这个重构没有引起任何回归问题(regression bug)。
当然,重构没有引入回归问题,并不意味着重构完全没有问题,我们还需要考虑撰写新的测试,覆盖重构带来的改动。
小结一下各种并发原语的使用场景
如何根据使用场景选择使用Atomic、Mutex、RwLock、Semaphore、Condvar、Channel、Actor
Atomic、Mutex、RwLock、Semaphore、Condvar、Channel、Actor。
- Atomic 在处理简单的原生类型时非常有用,如果你可以通过 AtomicXXX 结构进行同步,那么它们是最好的选择。
- 当你的数据结构无法简单通过 AtomicXXX 进行同步,但你又的确需要在多个线程中共享数据,那么 Mutex / RwLock 可以是一种选择。不过,你需要考虑锁的粒度,粒度太大的 Mutex / RwLock 效率很低。
- 如果你有 N 份资源可以供多个并发任务竞争使用,那么,Semaphore 是一个很好的选择。比如你要做一个 DB 连接池。
- 当你需要在并发任务中通知、协作时,Condvar 提供了最基本的通知机制,而 Channel 把这个通知机制进一步广泛扩展开,于是你可以用 Condvar 进行点对点的同步,用 Channel 做一对多、多对一、多对多的同步。
所以,当我们做大部分复杂的系统设计时,Channel 往往是最有力的武器,除了可以让数据穿梭于各个线程、各个异步任务间,它的接口还可以很优雅地跟 stream 适配。
如果说在做整个后端的系统架构时,我们着眼的是:有哪些服务、服务和服务之间如何通讯、数据如何流动、服务和服务间如何同步; 那么在做某一个服务的架构时,着眼的是有哪些功能性的线程(异步任务)、它们之间的接口是什么样子、数据如何流动、如何同步。
在这里,Channel 兼具接口、同步和数据流三种功能,所以我说是最有力的武器。
然而它不该是唯一的武器。我们面临的真实世界的并发问题是多样的,解决方案也应该是多样的,计算机科学家们在过去的几十年里不断探索,构建了一系列的并发原语,也说明了很难有一种银弹解决所有问题。
就连 Mutex 本身,在实现中,还会根据不同的场景做不同的妥协(比如做 faireness 的妥协),因为这个世界就是这样,鱼与熊掌不可兼得,没有完美的解决方案,只有妥协出来的解决方案。所以 Channel 不是银弹,actor model 不是银弹,lock 不是银弹。
一门好的编程语言,可以提供大部分场景下的最佳实践(如 Erlang/Golang),但不该营造一种气氛,只有某个最佳实践才是唯一方案。我很喜欢 Erlang 的 actor model 和 Golang 的 Channel,但很可惜,它们过分依赖特定的、唯一的并发方案,使得开发者拿着榔头,看什么都是钉子。
相反,Rust 提供几乎你需要的所有解决方案,并且并不鼓吹它们的优劣,完全交由你按需选择。我在用 Rust 撰写多线程应用时,Channel 仍然是第一选择,但我还是会在合适的时候使用 Mutex、RwLock、Semaphore、Condvar、Atomic 等工具,而不是试图笨拙地用 Channel 叠加 Channel 来应对所有的场景。
Future
Summarize made by chatGPT
- Rust的Future和JavaScript的Promise、Python的Future非常相似,都代表了在未来的某个时刻才能得到的结果的值。
- async/await是Future的语法糖,async定义了一个可以并发执行的任务,而await则触发这个任务并发执行。
- Future的出现是为了解决CPU算力和IO速度之间的矛盾,而async/await则是为了更好地利用CPU资源。
- 在使用async/await时,需要注意不能把代码写成单独await的形式,需要使用try_join!来轮询多个Future。
- Future和线程的区别在于,Future是无栈协程,线程是有栈协程。
- Future的本质是Reactor Pattern,async/await是Future的语法糖,它们使用状态机将Promise/Future这样的结构包装起来进行处理。
- Rust 的 Future 机制允许我们编写非阻塞的异步代码,从而避免了在等待 I/O 操作时线程的阻塞。
- Rust 中的 Async 和 Await 关键字可以帮助我们编写基于 Future 的异步代码,使其更易于阅读和编写。 通过 Futures-rs 库和 Tokio 运行时库,我们可以更方便地创建和管理 Future。
- Tokio 运行时库是一个用于异步 I/O 操作的高效运行时系统。
- Rust 的异步编程模型是基于回调的,通过定义 Future 的回调函数,我们可以实现异步代码的执行。
- Async 和 Await 关键字的底层实现是基于 Future 和生成器的,通过使用生成器,我们可以更方便地编写异步代码
Questions made by chatGPT
- Rust中的Future机制的作用是什么?
- Async和Await关键字的作用是什么?
- Futures-rs库和Tokio运行时库的作用分别是什么?
- Rust的异步编程模型基于什么原理?
- Async和Await关键字的底层实现基于什么技术?
- Rust中的异步编程模型相比于同步编程模型有哪些优势?
- Rust中如何通过Future实现非阻塞异步代码?
- 什么是Tokio运行时库,它的主要作用是什么?
- Rust中的生成器是什么?它如何与Async和Await关键字相关联?
- 在Rust中,通过什么机制可以实现异步任务之间的协作?
- 在Rust中,如何处理异步操作的错误?
- 在Rust中,如何同时处理多个异步任务?
- Rust中的异步编程模型与其他语言中的异步编程模型有何异同?
- 在Rust中,如何控制异步任务的执行顺序?
- 什么是Futures combinators?在Rust的异步编程中如何使用它们?
- 在Rust中,如何处理长时间运行的异步任务?
- Rust中的异步编程是否支持并发和并行处理?
- 如何在Rust中实现异步文件操作?
- Rust中的异步编程是否适用于网络编程?如何处理网络编程中的异步操作?
- 在Rust中,如何实现跨线程的异步通信?
Answers made by chatGPT
Rust中的Future机制的作用是什么? 答:Rust中的Future机制允许我们编写非阻塞的异步代码,从而避免了在等待I/O操作时线程的阻塞。
Async和Await关键字的作用是什么? 答:Async和Await关键字可以帮助我们编写基于Future的异步代码,使其更易于阅读和编写。
Futures-rs库和Tokio运行时库的作用分别是什么? 答:Futures-rs库和Tokio运行时库可以帮助我们更方便地创建和管理Future,Tokio运行时库是一个用于异步I/O操作的高效运行时系统。
Rust的异步编程模型基于什么原理? 答:Rust的异步编程模型基于回调的,通过定义Future的回调函数,我们可以实现异步代码的执行。
Async和Await关键字的底层实现基于什么技术? 答:Async和Await关键字的底层实现基于Future和生成器的。
Rust中的异步编程模型相比于同步编程模型有哪些优势? 答:Rust的异步编程模型相比于同步编程模型具有更高的效率和更好的性能。
Rust中如何通过Future实现非阻塞异步代码? 答:我们可以使用Future的回调函数,通过定义异步代码的执行流程来实现非阻塞异步代码。
什么是Tokio运行时库,它的主要作用是什么? 答:Tokio运行时库是一个用于异步I/O操作的高效运行时系统,它的主要作用是提供异步I/O操作的支持,并管理异步任务的执行。
Rust中的生成器是什么?它如何与Async和Await关键字相关联? 答:生成器是一种特殊的函数,它可以挂起并恢复执行,异步编程中的Async和Await关键字可以利用生成器的特性来实现非阻塞异步代码。
在Rust中,通过什么机制可以实现异步任务之间的协作? 答:Rust中可以使用Future的组合器(Futures combinators)来实现异步任务之间的协作。
在Rust中,如何处理异步操作的错误? 答:可以使用Future的Error trait来处理异步操作的错误,它提供了一种标准的错误处理方式。
在Rust中,如何同时处理多个异步任务? 答:可以使用Future的join或race方法来同时处理多个异步任务。
Rust中的异步编程模型与其他语言中的异步编程模型有何异同?
Rust中的Async和Await关键字与JavaScript中的Async和Await关键字有何异同? 答:Rust中的Async和Await关键字与JavaScript中的Async和Await关键字有相似之处,但是实现方式不同,Rust是基于Future和生成器的,而JavaScript是基于Promise和生成器的。
Rust中的异步编程模型是否适合所有场景? 答:Rust的异步编程模型适用于大部分需要异步编程的场景,但是对于一些对性能要求非常高的场景,可能需要使用更底层的异步编程模型。
Rust中的Future和Tokio与Java中的Future和CompletableFuture有何异同? 答:Rust中的Future和Tokio与Java中的Future和CompletableFuture有相似之处,但是实现方式不同,Rust是基于回调函数的,而Java是基于Promise的。
Rust中的异步编程模型是否可以在Web开发中使用? 答:Rust的异步编程模型可以在Web开发中使用,尤其是在高并发场景下,可以通过异步编程提高性能。
Rust中的Tokio与Go语言中的Goroutines和Channels有何异同? 答:Rust中的Tokio与Go语言中的Goroutines和Channels有相似之处,都是基于协程的,但是实现方式不同,Tokio是基于回调函数的,而Go是基于Channel的。
Rust中的异步编程模型与C++中的异步编程模型有何异同? 答:Rust中的异步编程模型与C++中的异步编程模型有相似之处,但是实现方式不同,Rust是基于Future和生成器的,而C++是基于协程的。
Rust中的异步编程模型是否需要特殊的编程技巧? 答:Rust中的异步编程模型需要一些特殊的编程技巧,例如使用Future的组合器来处理异步任务之间的协作,以及使用Error trait来处理异步操作的错误。
actor是有栈协程,Future是无栈协程
Rust的Future
Rust 的 Future 跟 JavaScript 的 Promise、Python的Future非常相似
其实 Rust 的 Future 跟 JavaScript 的 Promise 非常类似。
如果你熟悉 JavaScript,应该熟悉 Promise 的概念,它代表了在未来的某个时刻才能得到的结果的值,Promise 一般存在三个状态;
- 等待(pending)状态
- Promise 已运行,但还未结束;
- 结束状态,Promise 成功解析出一个值,或者执行失败。
只不过 JavaScript 的 Promise 和线程类似,一旦创建就开始执行,对 Promise await 只是为了“等待”并获取解析出来的值;而 Rust 的 Future,只有在主动 await 后才开始执行。
Future和async/await
二者是什么关系?
一般而言,async/await和Future是什么关系
讲到这里估计你也看出来了,谈 Future 的时候,我们总会谈到 async/await。
一般而言:
- async 定义了一个可以并发执行的任务
- 而 await 则触发这个任务并发执行。
- 大多数语言,包括 Rust,async/await 都是一个语法糖(syntactic sugar)
- 它们使用状态机将 Promise/Future 这样的结构包装起来进行处理。
为什么需要Future,那不用async/await有什么问题?
CPU的算力不能尽情施展
在 Future 出现之前,我们的 Rust 代码都是同步的。也就是说:
- 当你执行一个函数,CPU 处理完函数中的每一个指令才会返回。
- 如果这个函数里有 IO 的操作,实际上,操作系统会把函数对应的线程挂起,放在一个等待队列中
- 直到 IO 操作完成,才恢复这个线程,并从挂起的位置继续执行下去。
这个模型非常简单直观,代码是一行一行执行的,开发者并不需要考虑哪些操作会阻塞,哪些不会,只关心他的业务逻辑就好。
然而,随着 CPU 技术的不断发展,情况大有不同:
- 新世纪应用软件的主要矛盾不再是 CPU 算力不足,而是过于充沛的 CPU 算力和提升缓慢的 IO 速度之间的矛盾。
- 如果有大量的 IO 操作,你的程序大部分时间并没有在运算,而是在不断地等待 IO。
- 同步版本读写多个文件
use anyhow::Result; use serde_yaml::Value; use std::fs; fn main() -> Result<()> { // 读取 Cargo.toml,IO 操作 1 let content1 = fs::read_to_string("./Cargo.toml")?; // 读取 Cargo.lock,IO 操作 2 let content2 = fs::read_to_string("./Cargo.lock")?; // 计算 let yaml1 = toml2yaml(&content1)?; let yaml2 = toml2yaml(&content2)?; // 写入 /tmp/Cargo.yml,IO 操作 3 fs::write("/tmp/Cargo.yml", &yaml1)?; // 写入 /tmp/Cargo.lock,IO 操作 4 fs::write("/tmp/Cargo.lock", &yaml2)?; // 打印 println!("{}", yaml1); println!("{}", yaml2); Ok(()) } fn toml2yaml(content: &str) -> Result<String> { let value: Value = toml::from_str(&content)?; Ok(serde_yaml::to_string(&value)?) }
这段代码读取 Cargo.toml 和 Cargo.lock 将其转换成 yaml,再分别写入到 /tmp 下。
虽然说这段代码的逻辑并没有问题,但性能有很大的问题:
- 在读 Cargo.toml 时,整个主线程被阻塞,直到 Cargo.toml 读完,才能继续读下一个待处理的文件。
- 整个主线程,只有在运行 toml2yaml 的时间片内,才真正在执行计算任务,之前的读取文件以及之后的写入文件,CPU 都在闲置。
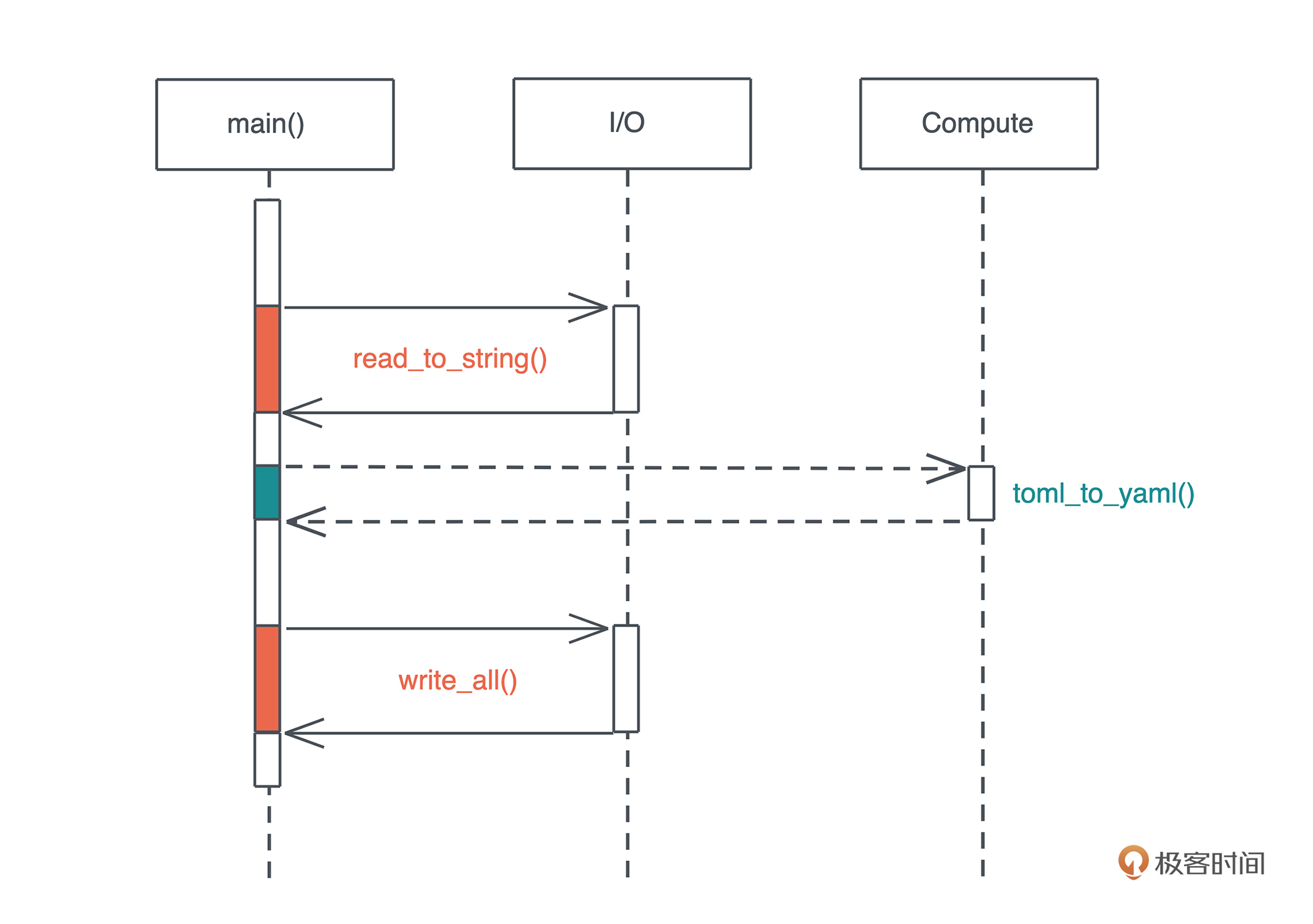
当然,你会辩解,在读文件的过程中,我们不得不等待,因为 toml2yaml 函数的执行有赖于读取文件的结果。
这里还有很大的 CPU 浪费: 我们读完第一个文件才开始读第二个文件,有没有可能两个文件同时读取呢?这样总共等待的时间是 max(time_for_file1, time_for_file2),而非 time_for_file1 + time_for_file2 。
- 多线程版本读写文件,类似await
这并不难,我们可以把文件读取和写入的操作放入单独的线程中执行,比如(代码):
use anyhow::{anyhow, Result}; use serde_yaml::Value; use std::{ fs, thread::{self, JoinHandle}, }; /// 包装一下 JoinHandle,这样可以提供额外的方法 struct MyJoinHandle<T>(JoinHandle<Result<T>>); impl<T> MyJoinHandle<T> { /// 等待 thread 执行完(类似 await) pub fn thread_await(self) -> Result<T> { self.0.join().map_err(|_| anyhow!("failed"))? } } fn main() -> Result<()> { // 读取 Cargo.toml,IO 操作 1 let t1 = thread_read("./Cargo.toml"); // 读取 Cargo.lock,IO 操作 2 let t2 = thread_read("./Cargo.lock"); let content1 = t1.thread_await()?; let content2 = t2.thread_await()?; // 计算 let yaml1 = toml2yaml(&content1)?; let yaml2 = toml2yaml(&content2)?; // 写入 /tmp/Cargo.yml,IO 操作 3 let t3 = thread_write("/tmp/Cargo.yml", yaml1); // 写入 /tmp/Cargo.lock,IO 操作 4 let t4 = thread_write("/tmp/Cargo.lock", yaml2); let yaml1 = t3.thread_await()?; let yaml2 = t4.thread_await()?; fs::write("/tmp/Cargo.yml", &yaml1)?; fs::write("/tmp/Cargo.lock", &yaml2)?; // 打印 println!("{}", yaml1); println!("{}", yaml2); Ok(()) } fn thread_read(filename: &'static str) -> MyJoinHandle<String> { let handle = thread::spawn(move || { let s = fs::read_to_string(filename)?; Ok::<_, anyhow::Error>(s) }); MyJoinHandle(handle) } fn thread_write(filename: &'static str, content: String) -> MyJoinHandle<String> { let handle = thread::spawn(move || { fs::write(filename, &content)?; Ok::<_, anyhow::Error>(content) }); MyJoinHandle(handle) } fn toml2yaml(content: &str) -> Result<String> { let value: Value = toml::from_str(&content)?; Ok(serde_yaml::to_string(&value)?) }
这样,读取或者写入多个文件的过程并发执行,使等待的时间大大缩短。
多线程版本读写文件会存在很大的资源调度浪费, 所以需要async/await
- 但是,如果要同时读取 100 个文件呢?
- 显然,创建 100 个线程来做这样的事情不是一个好主意。
- 在操作系统中,线程的数量是有限的,创建 / 阻塞 / 唤醒 / 销毁线程,都涉及不少的动作
- 每个线程也都会被分配一个不小的调用栈
- 所以从 CPU 和内存的角度来看,创建过多的线程会大大增加系统的开销。
- 其实,绝大多数操作系统对 I/O 操作提供了非阻塞接口,也就是说:
- 你可以发起一个读取的指令
- 自己处理类似 EWOULDBLOCK这样的错误码
- 来更好地在同一个线程中处理多个文件的 IO
- 而不是依赖操作系统通过调度帮你完成这件事。
- 不过这样就意味着,你需要:
- 定义合适的数据结构来追踪每个文件的读取
- 在用户态进行相应的调度
- 阻塞等待 IO 的数据结构的运行
- 让没有等待 IO 的数据结构得到机会使用 CPU
- 以及当 IO 操作结束后,恢复等待 IO 的数据结构的运行等等。
这样的操作粒度更小,可以最大程度利用 CPU 资源。 这就是类似 Future 这样的并发结构的主要用途。
- 然而,如果这么处理,我们需要在用户态做很多事情,包括:
- 处理 IO 任务的事件通知
- 创建 Future
- 合理地调度 Future
这些事情,统统交给开发者做显然是不合理的。所以,Rust 提供了相应处理手段 async/await :
- async 来方便地生成 Future
- await 来触发 Future 的调度和执行。
- async/await版本更高效读写文件
我们看看,同样的任务,如何用 async/await 更高效地处理(代码):
use anyhow::Result; use serde_yaml::Value; use tokio::{fs, try_join}; #[tokio::main] async fn main() -> Result<()> { // 读取 Cargo.toml,IO 操作 1 let f1 = fs::read_to_string("./Cargo.toml"); // 读取 Cargo.lock,IO 操作 2 let f2 = fs::read_to_string("./Cargo.lock"); let (content1, content2) = try_join!(f1, f2)?; // 计算 let yaml1 = toml2yaml(&content1)?; let yaml2 = toml2yaml(&content2)?; // 写入 /tmp/Cargo.yml,IO 操作 3 let f3 = fs::write("/tmp/Cargo.yml", &yaml1); // 写入 /tmp/Cargo.lock,IO 操作 4 let f4 = fs::write("/tmp/Cargo.lock", &yaml2); try_join!(f3, f4)?; // 打印 println!("{}", yaml1); println!("{}", yaml2); Ok(()) } fn toml2yaml(content: &str) -> Result<String> { let value: Value = toml::from_str(&content)?; Ok(serde_yaml::to_string(&value)?) }
在这段代码里:
- 我们使用了 tokio::fs,而不是 std::fs
- tokio::fs 的文件操作都会返回一个 Future,然后可以 join 这些 Future,得到它们运行后的结果。
- join / try_join 是用来轮询多个 Future 的宏:
- 它会依次处理每个 Future
- 遇到阻塞就处理下一个
- 直到所有 Future 产生结果。
整个等待文件读取的时间是 max(time_for_file1, time_for_file2),性能和使用线程的版本几乎一致,但是消耗的资源(主要是线程)要少很多。
建议你好好对比这三个版本的代码,写一写,运行一下,感受它们的处理逻辑。
3.1 注意在最后的 async/await 的版本中,我们不能把代码写成这样:
- try_join!轮询,加入事件循环才有上下文切换:
// 读取 Cargo.toml,IO 操作 1 let f1 = fs::read_to_string("./Cargo.toml"); // 读取 Cargo.lock,IO 操作 2 let f2 = fs::read_to_string("./Cargo.lock"); let (content1, content2) = try_join!(f1, f2)?;
- 单独await,还是要等待,这与多线程版本效果一样:
// 读取 Cargo.toml,IO 操作 1 let content1 = fs::read_to_string("./Cargo.toml").await?; // 读取 Cargo.lock,IO 操作 2 let content1 = fs::read_to_string("./Cargo.lock").await?;
这样写的话,和第一版同步的版本没有区别:
- 因为 await 会运行 Future 直到 Future 执行结束,所以依旧是先读取 Cargo.toml,再读取 Cargo.lock,并没有达到并发的效果。
从async fn深入了解Reactor Pattern
好,了解了 Future 在软件开发中的必要性,来深入研究一下 Future/async/await。
首先看看Future的定义
Future Trait: Output + fn poll
来看 Future 的定义:
pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } pub enum Poll<T> { Ready(T), Pending, }
- 除了 Output 外,它还有一个 poll() 方法,这个方法返回 PollSelf::Output。
- 而 Poll
是个 enum,包含 Ready 和 Pending 两个状态。 - 显然,当 Future 返回 Pending 状态时,活还没干完,但干不下去了,需要阻塞一阵子,等某个事件将其唤醒;
- 当 Future 返回 Ready 状态时,Future 对应的值已经得到,此时可以返回了。
你看,这样一个简单的数据结构,就托起了庞大的 Rust 异步 async/await 处理的生态。
然后看看async fn这个语法糖
从async fn了解到future的思路
- 拆解 async fn 有点奇怪的返回值结构
- 我们学习了 Reactor pattern
- 大致了解了 tokio 如何通过 executor 和 reactor 共同作用,完成 Future 的调度、执行、阻塞,以及唤醒。
- 这是一个完整的循环,直到 Future 返回 Poll::Ready(T)。
异步函数(async fn)其实是语法糖,它有等价函数写法: async fn ‘封装’ 生命周期标注+返回值约束
在前面代码撰写过程中,不知道你有没有发现,异步函数(async fn)的返回值是一个奇怪的 impl Future

我们知道:
- 一般会用 impl 关键字为数据结构实现 trait,也就是说接在 impl 关键字后面的东西是一个 trait
- 所以,显然 Future 是一个 trait,并且还有一个关联类型 Output。
- 也就是说,这里已经知道f1、f2是一个实现了Future的类型
那么如果我们给一个普通的函数返回 impl Future
来写个简单的实验(代码):
use futures::executor::block_on; use std::future::Future; #[tokio::main] async fn main() { let name1 = "Tyr".to_string(); let name2 = "Lindsey".to_string(); say_hello1(&name1).await; say_hello2(&name2).await; // Future 除了可以用 await 来执行外,还可以直接用 executor 执行 block_on(say_hello1(&name1)); block_on(say_hello2(&name2)); } async fn say_hello1(name: &str) -> usize { println!("Hello {}", name); 42 } // async fn 关键字相当于一个返回 impl Future<Output> 的语法糖 fn say_hello2<'fut>(name: &'fut str) -> impl Future<Output = usize> + 'fut { async move { println!("Hello {}", name); 42 } }
运行这段代码你会发现:
- say_hello1 和 say_hello2 是等价的, 区别有两个:
- say_hello1使用async fn语法糖
- say_hello2就是它对应的繁琐写法:生命周期标注+返回值约束
- 二者都可以使用 await 来执行, 也可以将其提供给一个 executor 来执行。
异步的本质其实就是 executor
- executor是什么
这里我们见到了一个新的名词:executor。
什么是 executor?
- 你可以把 executor 大致想象成一个 Future 的调度器。
- 对于线程来说,操作系统负责调度;
- 但操作系统不会去调度用户态的协程(比如 Future),所以任何使用了协程来处理并发的程序,都需要有一个 executor 来负责协程的调度。
很多在语言层面支持协程的编程语言,比如 Golang / Erlang,都自带一个用户态的调度器。
- Rust如何支持?
Rust 虽然也提供 Future 这样的协程,但它在语言层面并不提供 executor,把要不要使用 executor 和使用什么样的 executor 的自主权交给了开发者。
- 好处是,当我的代码中不需要使用协程时,不需要引入任何运行时;
- 而需要使用协程时,可以在生态系统中选择最合适我应用的 executor。
- Rust常用的executor有哪些
常见的 executor 有:
- futures 库自带的很简单的 executor,上面的代码就使用了它的 block_on 函数;
- tokio 提供的 executor,当使用 #[tokio::main] 时,就隐含引入了 tokio 的 executor;
- async-std 提供的 executor,和 tokio 类似;
- smol 提供的 async-executor,主要提供了 block_on。
注意,上面的代码我们混用了 #[tokio::main] 和 futures:executor::block_on, 这只是为了展示 Future 使用的不同方式,在正式代码里,不建议混用不同的 executor,会降低程序的性能,还可能引发奇怪的问题。
executor和reactor都是reactor pattern(事件循环)的组成部分
Reactor Pattern如何组成?
当我们谈到 executor 时,就不得不提 reactor,它俩都是 Reactor Pattern 的组成部分。
作为构建高性能事件驱动系统的一个很典型模式,Reactor pattern 它包含三部分:
- task,待处理的任务
任务可以被打断,并且把控制权交给 executor,等待之后的调度;
- executor,一个调度器。
维护等待运行的任务(ready queue),以及被阻塞的任务(wait queue);
- reactor,维护事件队列
当事件来临时,通知 executor 唤醒某个任务等待运行。
Reactor Pattern如何运行
- executor 会调度执行待处理的任务,当任务无法继续进行却又没有完成时,它会挂起任务,并设置好合适的唤醒条件。
- 之后,如果 reactor 得到了满足条件的事件,它会唤醒之前挂起的任务,然后 executor 就有机会继续执行这个任务。
- 这样一直循环下去,直到任务执行完毕。
executor 和 reactor 是怎么联动最终让 Future 得到了一个结果?
Rust如何基于Reactor pattern使用Future做异步处理
理解了 Reactor pattern 后,Rust 使用 Future 做异步处理的整个结构就清晰了,我们以 tokio 为例:
- async/await 提供语法层面的支持
- Future 是异步任务的数据结构
- 当 fut.await 时,executor 就会调度并执行它。
- tokio 的调度器(executor)会运行在多个线程上,运行线程自己的 ready queue 上的任务(Future)
- 如果没有,就去别的线程的调度器上“偷”一些过来运行。
- 当某个任务无法再继续取得进展,此时 Future 运行的结果是 Poll::Pending,那么调度器会挂起任务,并设置好合适的唤醒条件(Waker),等待被 reactor 唤醒。
- 而 reactor 会利用操作系统提供的异步 I/O,比如 epoll / kqueue / IOCP,来监听操作系统提供的 IO 事件,当遇到满足条件的事件时,就会调用 Waker.wake() 唤醒被挂起的 Future。这个 Future 会回到 ready queue 等待执行。
整个流程如下:
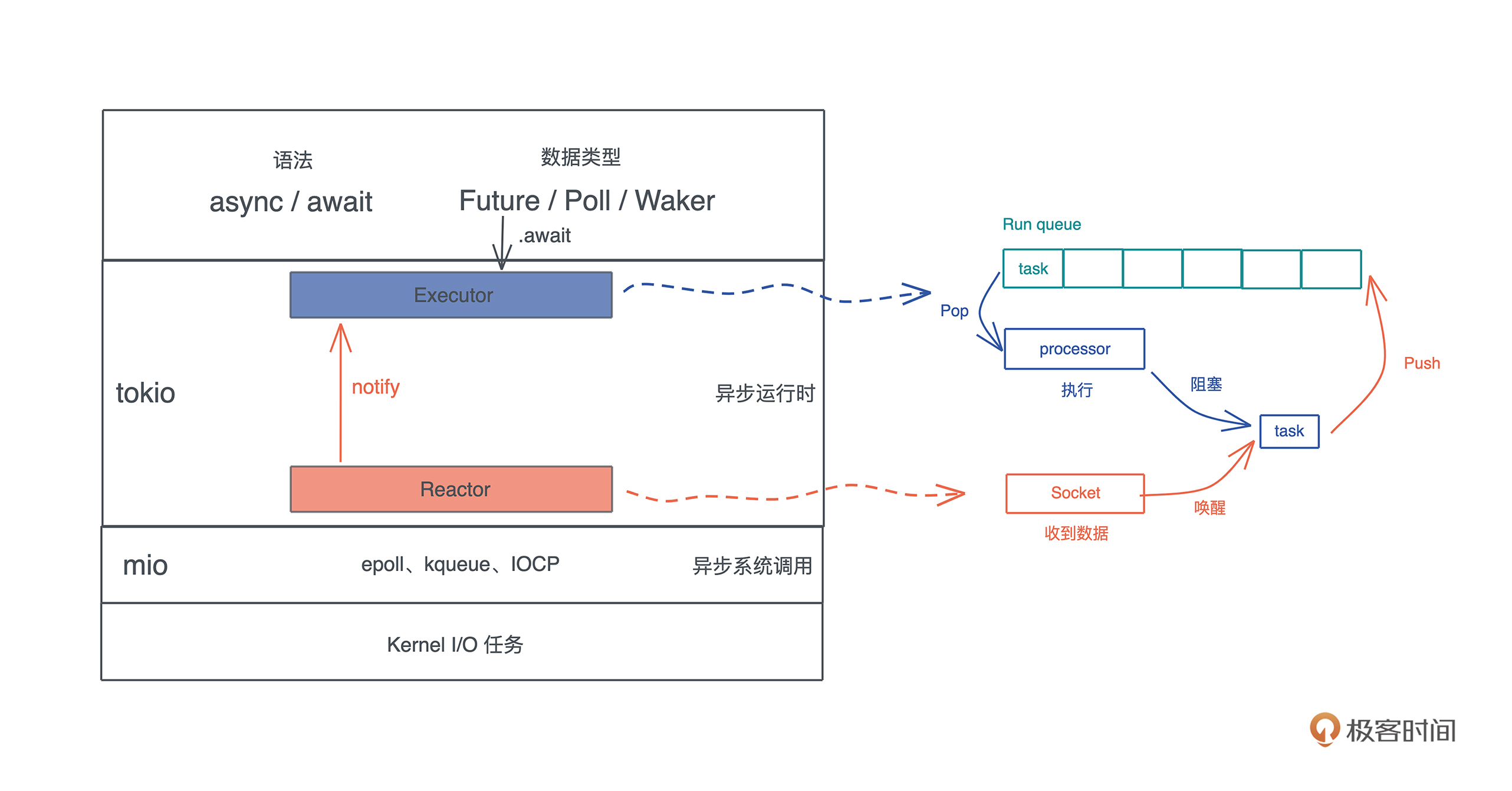
我们以一个具体的代码示例来进一步理解这个过程(代码):
use anyhow::Result; use futures::{SinkExt, StreamExt}; use tokio::net::TcpListener; use tokio_util::codec::{Framed, LinesCodec}; #[tokio::main] async fn main() -> Result<()> { let addr = "0.0.0.0:8080"; let listener = TcpListener::bind(addr).await?; println!("listen to: {}", addr); loop { let (stream, addr) = listener.accept().await?; println!("Accepted: {:?}", addr); tokio::spawn(async move { // 使用 LinesCodec 把 TCP 数据切成一行行字符串处理 let framed = Framed::new(stream, LinesCodec::new()); // split 成 writer 和 reader let (mut w, mut r) = framed.split(); for line in r.next().await { // 每读到一行就加个前缀发回 w.send(format!("I got: {}", line?)).await?; } Ok::<_, anyhow::Error>(()) }); } }
这是一个简单的 TCP 服务器:
- 服务器每收到一个客户端的请求,就会用 tokio::spawn 创建一个异步任务,放入 executor 中执行。
- 这个异步任务接受客户端发来的按行分隔(分隔符是 “\r\n”)的数据帧,服务器每收到一行,就加个前缀把内容也按行发回给客户端。
- 你可以用 telnet 和这个服务器交互:
❯ telnet localhost 8080
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
hello
I got: hello
Connection closed by foreign host.
- 假设我们在客户端输入了很大的一行数据,服务器在做 r.next().await 在执行的时候,收不完一行的数据,因而这个 Future 返回 Poll::Pending,此时它被挂起。
- 当后续客户端的数据到达时,reactor 会知道这个 socket 上又有数据了,于是找到 socket 对应的 Future,将其唤醒,继续接收数据。
- 这样反复下去,最终 r.next().await 得到 Poll::Ready(Ok(line)),于是它返回 Ok(line),程序继续往下走,进入到 w.send() 的阶段。
从这段代码中你可以看到,在 Rust 下使用异步处理是一件非常简单的事情
- 除了几个你可能不太熟悉的概念:
- 比如用于创建 Future 的 async 关键字
- 用于执行和等待 Future 执行完毕的 await 关键字
- 以及用于调度 Future 执行的运行时 #[tokio:main]
- 整体的代码和使用线程处理的代码完全一致。所以,它的上手难度非常低,很容易使用。
使用 Future 的注意事项
目前我们已经基本明白 Future 运行的基本原理了,也可以在程序的不同部分自如地使用 Future/async/await 来进行异步处理。
但是要注意,不是所有的应用场景都适合用 async/await,在使用的时候,有一些不容易注意到的坑需要我们妥善考虑。
- 处理计算密集型任务时
当你要处理的任务是 CPU 密集型,而非 IO 密集型,更适合使用线程,而非 Future。
这是因为 Future 的调度是协作式多任务(Cooperative Multitasking),也就是说,除非 Future 主动放弃 CPU,不然它就会一直被执行,直到运行结束。我们看一个例子(代码):
use anyhow::Result; use std::time::Duration; // 强制 tokio 只使用一个工作线程,这样 task 2 不会跑到其它线程执行 #[tokio::main(worker_threads = 1)] async fn main() -> Result<()> { // 先开始执行 task 1 的话会阻塞,让 task 2 没有机会运行 tokio::spawn(async move { eprintln!("task 1"); // 试试把这句注释掉看看会产生什么结果 // tokio::time::sleep(Duration::from_millis(1)).await; loop {} }); tokio::spawn(async move { eprintln!("task 2"); }); tokio::time::sleep(Duration::from_millis(1)).await; Ok(()) }
task 1 里有一个死循环,你可以把它想象成是执行时间很长又不包括 IO 处理的代码。运行这段代码,你会发现,task 2 没有机会得到执行。这是因为 task 1 不执行结束,或者不让出 CPU,task 2 没有机会被调度。
- 异步代码中使用 Mutex 时
大部分时候,标准库的 Mutex 可以用在异步代码中,而且,这是推荐的用法。
然而,标准库的 MutexGuard 不能安全地跨越 await,所以,当我们需要获得锁之后执行异步操作,必须使用 tokio 自带的 Mutex,看下面的例子(代码):
use anyhow::Result; use std::{sync::Arc, time::Duration}; use tokio::sync::Mutex; struct DB; impl DB { // 假装在 commit 数据 async fn commit(&mut self) -> Result<usize> { Ok(42) } } #[tokio::main] async fn main() -> Result<()> { let db1 = Arc::new(Mutex::new(DB)); let db2 = Arc::clone(&db1); tokio::spawn(async move { let mut db = db1.lock().await; // 因为拿到的 MutexGuard 要跨越 await,所以不能用 std::sync::Mutex // 只能用 tokio::sync::Mutex let affected = db.commit().await?; println!("db1: Total affected rows: {}", affected); Ok::<_, anyhow::Error>(()) }); tokio::spawn(async move { let mut db = db2.lock().await; let affected = db.commit().await?; println!("db2: Total affected rows: {}", affected); Ok::<_, anyhow::Error>(()) }); // 让两个 task 有机会执行完 tokio::time::sleep(Duration::from_millis(1)).await; Ok(()) }
这个例子模拟了一个数据库的异步 commit() 操作
- 如果我们需要在多个 tokio task 中使用这个 DB,需要使用 Arc<Mutext
>。 - 然而,db1.lock() 拿到锁后,我们需要运行 db.commit().await,这是一个异步操作。
- 前面讲过,因为 tokio 实现了 work-stealing 调度,Future 有可能在不同的线程中执行,普通的 MutexGuard 编译直接就会出错,所以需要使用 tokio 的 Mutex。更多信息可以看文档。
在这个例子里,我们又见识到了 Rust 编译器的伟大之处:如果一件事,它觉得你不能做,会通过编译器错误阻止你,而不是任由编译通过,然后让程序在运行过程中听天由命,让你无休止地和捉摸不定的并发 bug 斗争。
想想看,为什么标准库的 Mutex 不能跨越 await?
你可以把文中使用 tokio::sync::Mutex 的代码改成使用 std::sync::Mutex,并对使用的接口做相应的改动(把 lock().await 改成 lock().unwrap()),看看编译器会报什么错。
对着错误提示,你明白为什么了么?
- 在线程和异步任务间做同步时
在一个复杂的应用程序中,会兼有计算密集和 IO 密集的任务。
前面说了,要避免在 tokio 这样的异步运行时中运行大量计算密集型的任务,一来效率不高,二来还容易饿死其它任务。
所以,一般的做法是我们使用 channel 来在线程和 future 两者之间做同步。看一个例子:
use std::thread; use anyhow::Result; use blake3::Hasher; use futures::{SinkExt, StreamExt}; use rayon::prelude::*; use tokio::{ net::TcpListener, sync::{mpsc, oneshot}, }; use tokio_util::codec::{Framed, LinesCodec}; pub const PREFIX_ZERO: &[u8] = &[0, 0, 0]; #[tokio::main] async fn main() -> Result<()> { let addr = "0.0.0.0:8080"; let listener = TcpListener::bind(addr).await?; println!("listen to: {}", addr); // 创建 tokio task 和 thread 之间的 channel let (sender, mut receiver) = mpsc::unbounded_channel::<(String, oneshot::Sender<String>)>(); // 使用 thread 处理计算密集型任务 thread::spawn(move || { // 读取从 tokio task 过来的 msg,注意这里用的是 blocking_recv,而非 await while let Some((line, reply)) = receiver.blocking_recv() { // 计算 pow let result = match pow(&line) { Some((hash, nonce)) => format!("hash: {}, once: {}", hash, nonce), None => "Not found".to_string(), }; // 把计算结果从 oneshot channel 里发回 if let Err(e) = reply.send(result) { println!("Failed to send: {}", e); } } }); // 使用 tokio task 处理 IO 密集型任务 loop { let (stream, addr) = listener.accept().await?; println!("Accepted: {:?}", addr); let sender1 = sender.clone(); tokio::spawn(async move { // 使用 LinesCodec 把 TCP 数据切成一行行字符串处理 let framed = Framed::new(stream, LinesCodec::new()); // split 成 writer 和 reader let (mut w, mut r) = framed.split(); for line in r.next().await { // 为每个消息创建一个 oneshot channel,用于发送回复 let (reply, reply_receiver) = oneshot::channel(); sender1.send((line?, reply))?; // 接收 pow 计算完成后的 hash 和 nonce if let Ok(v) = reply_receiver.await { w.send(format!("Pow calculated: {}", v)).await?; } } Ok::<_, anyhow::Error>(()) }); } } // 使用 rayon 并发计算 u32 空间下所有 nonce,直到找到有头 N 个 0 的哈希 pub fn pow(s: &str) -> Option<(String, u32)> { let hasher = blake3_base_hash(s.as_bytes()); let nonce = (0..u32::MAX).into_par_iter().find_any(|n| { let hash = blake3_hash(hasher.clone(), n).as_bytes().to_vec(); &hash[..PREFIX_ZERO.len()] == PREFIX_ZERO }); nonce.map(|n| { let hash = blake3_hash(hasher, &n).to_hex().to_string(); (hash, n) }) } // 计算携带 nonce 后的哈希 fn blake3_hash(mut hasher: blake3::Hasher, nonce: &u32) -> blake3::Hash { hasher.update(&nonce.to_be_bytes()[..]); hasher.finalize() } // 计算数据的哈希 fn blake3_base_hash(data: &[u8]) -> Hasher { let mut hasher = Hasher::new(); hasher.update(data); hasher }
在这个例子里:
- 我们使用了之前撰写的 TCP server
- 只不过这次,客户端输入过来的一行文字,会被计算出一个 POW(Proof of Work)的哈希
- 调整 nonce,不断计算哈希,直到哈希的头三个字节全是零为止。
- 服务器要返回计算好的哈希和获得该哈希的 nonce。
- 这是一个典型的计算密集型任务,所以我们需要使用线程来处理它。
- 而在 tokio task 和 thread 间使用 channel 进行同步。我们使用了一个 ubounded MPSC channel 从 tokio task 侧往 thread 侧发送消息,每条消息都附带一个 oneshot channel 用于 thread 侧往 tokio task 侧发送数据。
建议你仔细读读这段代码,最好自己写一遍,感受一下使用 channel 在计算密集型和 IO 密集型任务同步的方式。
如果你用 telnet 连接,发送 “hello world!”,会得到不同的哈希和 nonce,它们都是正确的结果:
❯ telnet localhost 8080
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
hello world!
Pow calculated: hash: 0000006e6e9370d0f60f06bdc288efafa203fd99b9af0480d040b2cc89c44df0, once: 403407307
Connection closed by foreign host.
❯ telnet localhost 8080
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
hello world!
Pow calculated: hash: 000000e23f0e9b7aeba9060a17ac676f3341284800a2db843e2f0e85f77f52dd, once: 36169623
Connection closed by foreign host.
对比线程学习Future
对比线程来学习future
在学习 Future 的使用时,估计你也发现了,我们可以对比线程来学习,可以看到,下列代码的结构多么相似:
fn thread_async() -> JoinHandle<usize> { thread::spawn(move || { println!("hello thread!"); 42 }) } fn task_async() -> impl Future<Output = usize> { async move { println!("hello async!"); 42 } }
async/await内部是怎么实现的?
Summarize made by chatGPT
- Asynchronous programming is a way of writing code that can perform multiple tasks concurrently, without blocking the main thread.
- Rust provides a number of abstractions for working with asynchronous code, including futures, async functions, and tokio.
- The
async/awaitsyntax is a convenient way of writing asynchronous code in Rust, allowing developers to write code that looks similar to synchronous code. - To use
async/await, developers must mark functions asasyncand use theawaitkeyword to await the completion of asynchronous tasks. async/awaitcan be used with a number of Rust libraries, including tokio and async-std.
Q&A made by chatGPT
- What is asynchronous programming?
Answer: Asynchronous programming is a way of writing code that can perform multiple tasks concurrently, without blocking the main thread. In an asynchronous program, tasks are executed independently of each other, allowing the program to make progress even if some tasks take longer to complete than others.
- What is a future in Rust?
Answer: A future is a placeholder object that represents a value that may not be available yet. In Rust, futures are used to represent asynchronous tasks that may complete at some point in the future. Futures allow developers to write code that can execute multiple tasks concurrently, without blocking the main thread.
Here is an example code for a future in Rust:
#![allow(unused)] fn main() { async fn hello() -> String { "Hello, world!".to_string() } let future = hello(); }
In this code, the hello function returns a future that will eventually resolve to a string. The future is stored in the future variable.
- What is an async function in Rust?
Answer: An async function is a function that can be executed asynchronously using the async/await syntax in Rust. An async function is marked with the async keyword, and it can use the await keyword to wait for the completion of asynchronous tasks.
Here is an example code for an async function in Rust:
#![allow(unused)] fn main() { async fn get_data() -> String { let response = reqwest::get("https://example.com/data").await.unwrap(); response.text().await.unwrap() } }
In this code, the get_data function makes an HTTP request to https://example.com/data using the reqwest library. The await keyword is used to wait for the completion of the request and the response, which are both asynchronous tasks.
- What is the
async/awaitsyntax in Rust?
Answer: The async/await syntax is a convenient way of writing asynchronous code in Rust. With this syntax, developers can write code that looks similar to synchronous code, while still taking advantage of asynchronous programming.
Here is an example code for the async/await syntax in Rust:
#![allow(unused)] fn main() { async fn get_data() -> String { let response = reqwest::get("https://example.com/data").await.unwrap(); response.text().await.unwrap() } }
In this code, the get_data function is marked as async, and the await keyword is used to wait for the completion of two asynchronous tasks: the HTTP request and the response.
- What is tokio in Rust?
Answer: Tokio is a runtime for writing asynchronous Rust applications. Tokio provides a number of abstractions for working with asynchronous code, including futures, tasks, and streams. Tokio is built on top of Rust’s async/await syntax, and it is widely used in the Rust community for writing high-performance, concurrent applications.
- How do you create a task in Tokio?
Answer: To create a task in Tokio, you can use the tokio::spawn function. The spawn function takes a closure that returns a future, and it returns a handle to the spawned task.
Here is an example code for creating a task in Tokio:
#![allow(unused)] fn main() { let handle = tokio::spawn(async { // Do some async work here }); // Wait for the task to complete let result = handle.await.unwrap(); }
In this code, the tokio::spawn function is used to create a new task that performs some async work. The handle.await call is used to wait for the task to complete, and the result of the task is stored in the `
- async/await内部是怎么实现的?
- Future、Async/Await的联动理解
- 问题一:async 产生的 Future 究竟是什么类型?
- 问题二:Future 是怎么被 executor 处理的
- 回顾整理Future的Context、Pin/Unpin,以及async/await
Future、Async/Await的联动理解
对 Future 和 async/await 的基本概念有一个比较扎实的理解:
然而:
- 我们并不清楚为什么 async fn 或者 async block 就能够产生 Future
- 也并不明白 Future 是怎么被 executor 处理的。
继续深入下去,看看 async/await 这两个关键词究竟施了什么样的魔法,能够让一切如此简单又如此自然地运转起来。
问题一:async 产生的 Future 究竟是什么类型?
Rust中Future是一个trait,async返回的是一个实现了Future的GenFuture类型
现在,我们对 Future 的接口有了一个完整的认识,也知道 async 关键字的背后都发生了什么事情:
pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; }
那么,当你写一个 async fn 或者使用了一个 async block 时,究竟得到了一个什么类型的数据呢?比如:
let fut = async { 42 };
你肯定能拍着胸脯说,这个我知道,不就是 impl Future<Output = i32> 么?
对,但是 impl Future 不是一个具体的类型啊,我们讲过,它相当于 T: Future,那么这个 T 究竟是什么呢?
我们来写段代码探索一下(代码):
fn main() { let fut = async { 42 }; println!("type of fut is: {}", get_type_name(&fut)); } fn get_type_name<T>(_: &T) -> &'static str { std::any::type_name::<T>() }
它的输出如下:
type of fut is: core::future::from_generator::GenFuture<xxx::main::{{closure}}>
实现 Future trait 的是一个叫 GenFuture 的结构,它内部有一个闭包。猜测这个闭包是 async { 42 } 产生的?
GenFuture: 这里颇似python的yield如何变成协程的过程。
我们看 GenFuture 的定义(感兴趣可以在 Rust 源码中搜 from_generator),可以看到它是一个泛型结构,内部数据 T 要满足 Generator trait:
struct GenFuture<T: Generator<ResumeTy, Yield = ()>>(T); pub trait Generator<R = ()> { type Yield; type Return; fn resume( self: Pin<&mut Self>, arg: R ) -> GeneratorState<Self::Yield, Self::Return>; }
Generator 是 Rust nightly 的一个 trait,还没有进入到标准库。大致看看官网展示的例子,它是怎么用的:
#![feature(generators, generator_trait)] use std::ops::{Generator, GeneratorState}; use std::pin::Pin; fn main() { let mut generator = || { yield 1; return "foo" }; match Pin::new(&mut generator).resume(()) { GeneratorState::Yielded(1) => {} _ => panic!("unexpected return from resume"), } match Pin::new(&mut generator).resume(()) { GeneratorState::Complete("foo") => {} _ => panic!("unexpected return from resume"), } }
- 可以看到,如果你创建一个闭包,里面有 yield 关键字,就会得到一个 Generator。
- 如果你在 Python 中使用过 yield,二者其实非常类似。
- 因为 Generator 是一个还没进入到稳定版的功能,大致了解一下就行,以后等它的 API 稳定后再仔细研究。
问题二:Future 是怎么被 executor 处理的
再度深入Future Trait: Context、Pin
从Future定义中的Pin和Context开始
提前说明一下,我们会继续围绕着 Future 这个简约却又并不简单的接口,来探讨一些原理性的东西,主要是 Context 和 Pin 这两个结构:
pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; }
Context::waker: Waker 的调用机制
Context包含Waker
Context 就是 Waker 的一个封装
先来看这个接口的 Context 是个什么东西。
- executor 通过调用 poll 方法来让 Future 继续往下执行
- 如果 poll 方法返回 Poll::Pending,就阻塞 Future
- 直到 reactor 收到了某个事件,然后调用 Waker.wake() 把 Future 唤醒。
- 这个 Waker 是哪来的呢?
其实,它隐含在 Context 中:
pub struct Context<'a> { waker: &'a Waker, _marker: PhantomData<fn(&'a ()) -> &'a ()>, }
所以,Context 就是 Waker 的一个封装。
Waker包含Vtable记录回调
RawWakerVTable
如果你去看 Waker 的定义和相关的代码,会发现它非常抽象,内部使用了一个 vtable 来允许各种各样的 waker 的行为:
pub struct RawWakerVTable { clone: unsafe fn(*const ()) -> RawWaker, wake: unsafe fn(*const ()), wake_by_ref: unsafe fn(*const ()), drop: unsafe fn(*const ()), }
- 这种手工生成 vtable 的做法,可以最大程度兼顾效率和灵活性。
- Rust 自身并不提供异步运行时,它只在标准库里规定了一些基本的接口,至于怎么实现,可以由各个运行时(如 tokio)自行决定。
- 所以在标准库中,你只会看到这些接口的定义,以及“高层”接口的实现,比如 Waker 下的 wake 方法,只是调用了 vtable 里的 wake() 而已:
impl Waker { /// Wake up the task associated with this `Waker`. #[inline] pub fn wake(self) { // The actual wakeup call is delegated through a virtual function call // to the implementation which is defined by the executor. let wake = self.waker.vtable.wake; let data = self.waker.data; // Don't call `drop` -- the waker will be consumed by `wake`. crate::mem::forget(self); // SAFETY: This is safe because `Waker::from_raw` is the only way // to initialize `wake` and `data` requiring the user to acknowledge // that the contract of `RawWaker` is upheld. unsafe { (wake)(data) }; } ... }
如果你想顺藤摸瓜找到 vtable 是怎么设置的,却发现一切线索都悄无声息地中断了,那是因为,具体的实现并不在标准库中,而是在第三方的异步运行时里,比如 tokio。
不过,虽然我们开发时会使用 tokio,但阅读、理解代码时,我建议看 futures 库,比如 waker vtable 的定义。futures 库还有一个简单的 executor,也非常适合进一步通过代码理解 executor 的原理。
Future 是怎么被 executor 处理的
不断pool
不断poll,匹配状态执行不同逻辑
为了讲明白 Pin,我们得往前追踪一步,看看产生 Future 的一个 async block/fn 内部究竟生成了什么样的代码?来看下面这个简单的 async 函数:
async fn write_hello_file_async(name: &str) -> anyhow::Result<()> { let mut file = fs::File::create(name).await?; // 这里其实就类似python的yield from file.write_all(b"hello world!").await?; Ok(()) }
- 首先它创建一个文件,然后往这个文件里写入 “hello world!”。
- 这个函数有两个 await,创建文件的时候会异步创建,写入文件的时候会异步写入。
- 最终,整个函数对外返回一个 Future。
其它人可以这样调用:
write_hello_file_async("/tmp/hello").await?;
我们知道,executor 处理 Future 时,会不断地调用它的 poll() 方法,于是,上面那句实际上相当于:
match write_hello_file_async.poll(cx) { Poll::Ready(result) => return result, Poll::Pending => return Poll::Pending }
这是单个 await 的处理方法,那更加复杂的,一个函数中有若干个 await,该怎么处理呢?
实现Future trait匹配不同逻辑
匹配的不同操作逻辑,需要在Future trait里面实现
以前面write_hello_file_async 函数的内部实现为例,显然,我们只有在处理完 create(),才能处理 write_all(),所以,应该是类似这样的代码:
let fut = fs::File::create(name); match fut.poll(cx) { Poll::Ready(Ok(file)) => { let fut = file.write_all(b"hello world!"); match fut.poll(cx) { Poll::Ready(result) => return result, Poll::Pending => return Poll::Pending, } } Poll::Pending => return Poll::Pending, }
但是,前面说过,async 函数返回的是一个 Future,所以,还需要把这样的代码封装在一个 Future 的实现里,对外提供出去。
因此,我们需要实现一个数据结构,把内部的状态保存起来,并为这个数据结构实现 Future。比如:
enum WriteHelloFile { // 初始阶段,用户提供文件名 Init(String), // 等待文件创建,此时需要保存 Future 以便多次调用 // 这是伪代码,impl Future 不能用在这里 AwaitingCreate(impl Future<Output = Result<fs::File, std::io::Error>>), // 等待文件写入,此时需要保存 Future 以便多次调用 AwaitingWrite(impl Future<Output = Result<(), std::io::Error>>), // Future 处理完毕 Done, } impl WriteHelloFile { pub fn new(name: impl Into<String>) -> Self { Self::Init(name.into()) } } impl Future for WriteHelloFile { type Output = Result<(), std::io::Error>; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { todo!() } } fn write_hello_file_async(name: &str) -> WriteHelloFile { WriteHelloFile::new(name) }
这样,我们就把刚才的 write_hello_file_async 异步函数,转化成了一个返回 WriteHelloFile Future 的函数。
实现过程其实是一个状态机
来看这个 Future 如何实现(详细注释了):状态机
impl Future for WriteHelloFile { type Output = Result<(), std::io::Error>; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let this = self.get_mut(); loop { match this { // 如果状态是 Init,那么就生成 create Future,把状态切换到 AwaitingCreate WriteHelloFile::Init(name) => { let fut = fs::File::create(name); *self = WriteHelloFile::AwaitingCreate(fut); } // 如果状态是 AwaitingCreate,那么 poll create Future // 如果返回 Poll::Ready(Ok(_)),那么创建 write Future // 并把状态切换到 Awaiting WriteHelloFile::AwaitingCreate(fut) => match fut.poll(cx) { Poll::Ready(Ok(file)) => { let fut = file.write_all(b"hello world!"); *self = WriteHelloFile::AwaitingWrite(fut); } Poll::Ready(Err(e)) => return Poll::Ready(Err(e)), Poll::Pending => return Poll::Pending, }, // 如果状态是 AwaitingWrite,那么 poll write Future // 如果返回 Poll::Ready(_),那么状态切换到 Done,整个 Future 执行成功 WriteHelloFile::AwaitingWrite(fut) => match fut.poll(cx) { Poll::Ready(result) => { *self = WriteHelloFile::Done; return Poll::Ready(result); } Poll::Pending => return Poll::Pending, }, // 整个 Future 已经执行完毕 WriteHelloFile::Done => return Poll::Ready(Ok(())), } } } }
这个 Future 完整实现的内部结构 ,其实就是一个状态机的迁移。
这个 Future 完整实现的内部结构 ,其实就是一个状态机的迁移。
这段(伪)代码和之前异步函数是等价的:
async fn write_hello_file_async(name: &str) -> anyhow::Result<()> { let mut file = fs::File::create(name).await?; file.write_all(b"hello world!").await?; Ok(()) }
Rust 在编译 async fn 或者 async block 时,就会生成类似的状态机的实现。你可以看到,看似简单的异步处理,内部隐藏了一套并不难理解、但是写起来很生硬很啰嗦的状态机管理代码。
为什么需要 Pin?
我们接下来看 Pin。这是一个奇怪的数据结构,正常数据结构的方法都是直接使用 self / &self / &mut self,可是 poll() 却使用了 Pin<&mut self>,为什么? 好搞明白这个问题,回到 pin 。刚才我们手写状态机代码的过程,能帮你理解为什么会需要 Pin 这个问题。
异步代码会出现自引用结构
什么场景下会出现自引用数据结构?
在上面实现 Future 的状态机中,我们引用了 file 这样一个局部变量:
WriteHelloFile::AwaitingCreate(fut) => match fut.poll(cx) { Poll::Ready(Ok(file)) => { let fut = file.write_all(b"hello world!"); *self = WriteHelloFile::AwaitingWrite(fut); } Poll::Ready(Err(e)) => return Poll::Ready(Err(e)), Poll::Pending => return Poll::Pending, }
这个代码是有问题的,file 被 fut 引用,但 file 会在这个作用域被丢弃。
所以,我们需要把它保存在数据结构中:
enum WriteHelloFile { // 初始阶段,用户提供文件名 Init(String), // 等待文件创建,此时需要保存 Future 以便多次调用 AwaitingCreate(impl Future<Output = Result<fs::File, std::io::Error>>), // 等待文件写入,此时需要保存 Future 以便多次调用 AwaitingWrite(AwaitingWriteData), // Future 处理完毕 Done, } struct AwaitingWriteData { fut: impl Future<Output = Result<(), std::io::Error>>, file: fs::File, }
- 可以生成一个 AwaitingWriteData 数据结构,把 file 和 fut 都放进去
- 然后在 WriteHelloFile 中引用它。
- 此时,在同一个数据结构内部,fut 指向了对 file 的引用,这样的数据结构,叫自引用结构(Self-Referential Structure)。
可以说,异步代码这种状态机情况下,容易出现自引用结构
当然,自引用数据结构并非只在异步代码里出现,只不过异步代码在内部生成用状态机表述的 Future 时,很容易产生自引用结构。
我们看一个和 Future 无关的例子(代码):
#[derive(Debug)] struct SelfReference { name: String, // 在初始化后指向 name name_ptr: *const String, } impl SelfReference { pub fn new(name: impl Into<String>) -> Self { SelfReference { name: name.into(), name_ptr: std::ptr::null(), } } pub fn init(&mut self) { self.name_ptr = &self.name as *const String; } pub fn print_name(&self) { println!( "struct {:p}: (name: {:p} name_ptr: {:p}), name: {}, name_ref: {}", self, &self.name, self.name_ptr, self.name, // 在使用 ptr 是需要 unsafe // SAFETY: 这里 name_ptr 潜在不安全,会指向旧的位置 unsafe { &*self.name_ptr }, ); } } fn main() { let data = move_creates_issue(); println!("data: {:?}", data); // 如果把下面这句注释掉,程序运行会直接 segment error // data.print_name(); print!("\\n"); mem_swap_creates_issue(); } fn move_creates_issue() -> SelfReference { let mut data = SelfReference::new("Tyr"); data.init(); // 不 move,一切正常 data.print_name(); let data = move_it(data); // move 之后,name_ref 指向的位置是已经失效的地址 // 只不过现在 move 前的地址还没被回收挪作它用 data.print_name(); data } fn mem_swap_creates_issue() { let mut data1 = SelfReference::new("Tyr"); data1.init(); let mut data2 = SelfReference::new("Lindsey"); data2.init(); data1.print_name(); data2.print_name(); std::mem::swap(&mut data1, &mut data2); data1.print_name(); data2.print_name(); } fn move_it(data: SelfReference) -> SelfReference { data }
- 我们创建了一个自引用结构 SelfReference,它里面的 name_ref 指向了 name。
- 正常使用它时,没有任何问题
- 但一旦对这个结构做 move 操作,name_ref 指向的位置还会是 move 前 name 的地址,这就引发了问题。看下图:
同样的,如果我们使用 std::mem:swap,也会出现类似的问题,一旦 swap,两个数据的内容交换,然而,由于 name_ref 指向的地址还是旧的,所以整个指针体系都混乱了:
看代码的输出,辅助你理解:
struct 0x7ffeea91d6e8: (name: 0x7ffeea91d6e8 name_ptr: 0x7ffeea91d6e8), name: Tyr, name_ref: Tyr
struct 0x7ffeea91d760: (name: 0x7ffeea91d760 name_ptr: 0x7ffeea91d6e8), name: Tyr, name_ref: Tyr
data: SelfReference { name: "Tyr", name_ptr: 0x7ffeea91d6e8 }
struct 0x7ffeea91d6f0: (name: 0x7ffeea91d6f0 name_ptr: 0x7ffeea91d6f0), name: Tyr, name_ref: Tyr
struct 0x7ffeea91d710: (name: 0x7ffeea91d710 name_ptr: 0x7ffeea91d710), name: Lindsey, name_ref: Lindsey
struct 0x7ffeea91d6f0: (name: 0x7ffeea91d6f0 name_ptr: 0x7ffeea91d710), name: Lindsey, name_ref: Tyr
struct 0x7ffeea91d710: (name: 0x7ffeea91d710 name_ptr: 0x7ffeea91d6f0), name: Tyr, name_ref: Lindsey
可以看到,swap 之后,name_ref 指向的内容确实和 name 不一样了。这就是自引用结构带来的问题。
你也许会奇怪,不是说 move 也会出问题么?为什么第二行打印 name_ref 还是指向了 “Tyr”?
这是因为 move 后,之前的内存失效,但是内存地址还没有被挪作它用,所以还能正常显示 “Tyr”。但这样的内存访问是不安全的,如果你把 main 中这句代码注释掉,程序就会 crash:
fn main() { let data = move_creates_issue(); println!("data: {:?}", data); // 如果把下面这句注释掉,程序运行会直接 segment error // data.print_name(); print!("\\n"); mem_swap_creates_issue(); }
现在你应该了解到在 Rust 下,自引用类型带来的潜在危害了吧。
自引用结构的问题
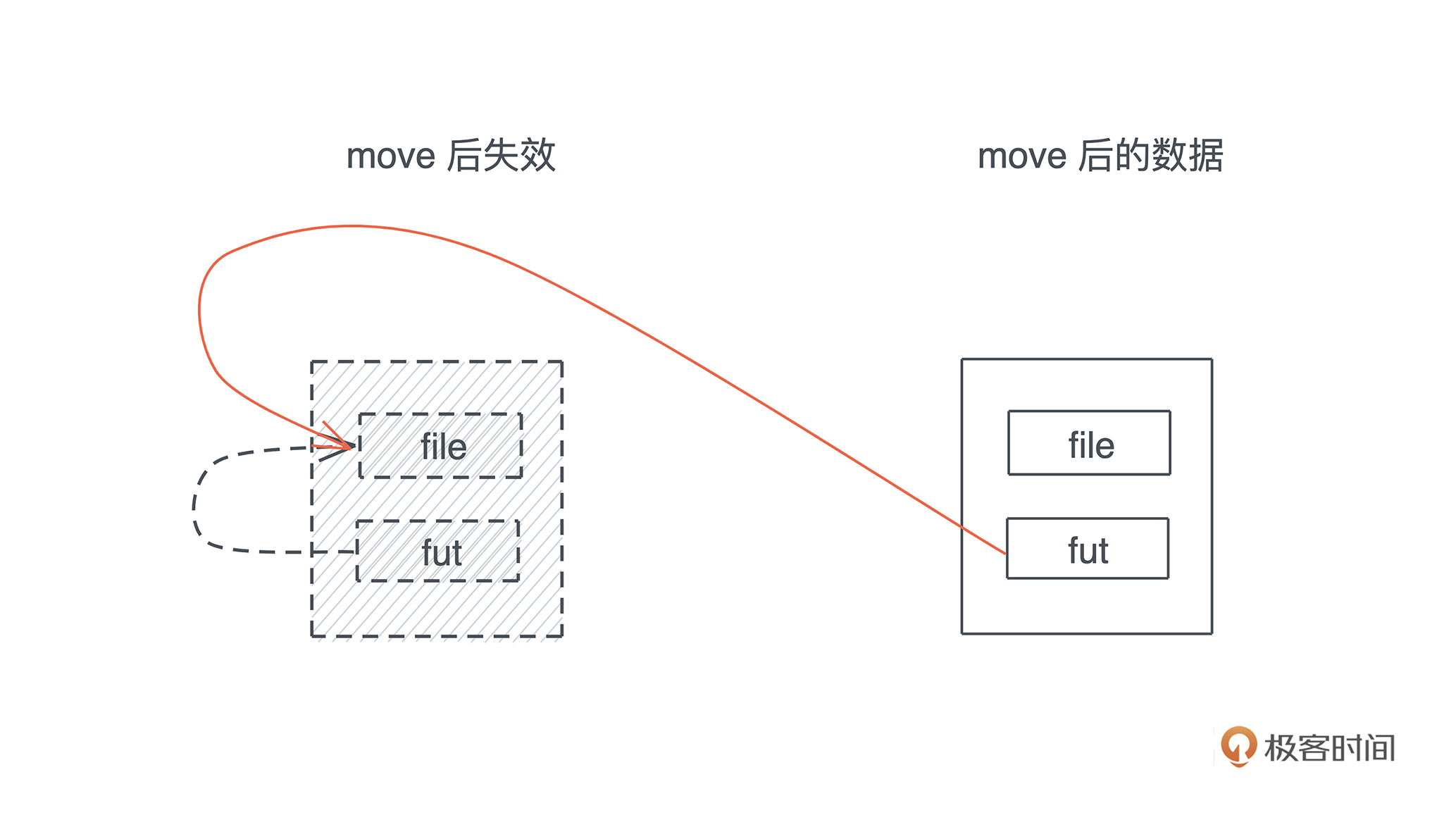
所以需要有某种机制来保证这种情况不会发生。
Pin就是为了解决这个问题
Pin定义就是解决这个问题?
Pin 就是为这个目的而设计的一个数据结构: 我们可以 Pin 住指向一个 Future 的指针
看文稿中 Pin 的声明:
pub struct Pin<P> { pointer: P, } impl<P: Deref> Deref for Pin<P> { type Target = P::Target; fn deref(&self) -> &P::Target { Pin::get_ref(Pin::as_ref(self)) } } impl<P: DerefMut<Target: Unpin>> DerefMut for Pin<P> { fn deref_mut(&mut self) -> &mut P::Target { Pin::get_mut(Pin::as_mut(self)) } }
- Pin 拿住的是一个可以解引用成 T 的指针类型 P,而不是直接拿原本的类型 T。
- 所以,对于 Pin 而言,你看到的都是 Pin<Box
>、Pin<&mut T>,但不会是 Pin 。 - 因为 Pin 的目的是,把 T 的内存位置锁住,从而避免移动后自引用类型带来的引用失效问题。
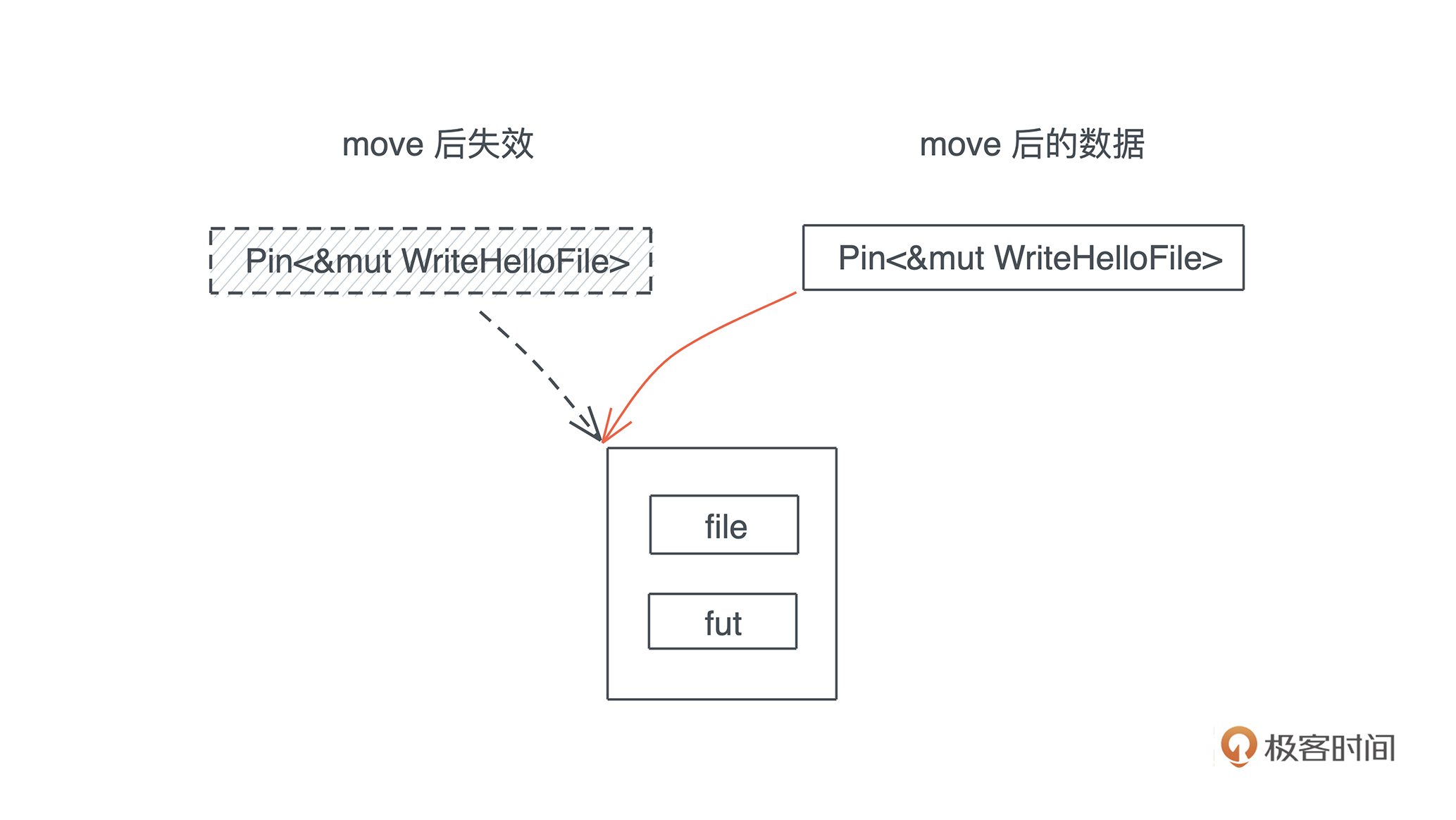
这样数据结构可以正常访问,但是你无法直接拿到原来的数据结构进而移动它。
所以,Pin 的出现,对解决这类问题很关键,如果你试图移动被 Pin 住的数据结构:
- 要么,编译器会通过编译错误阻止你;
- 要么,你强行使用 unsafe Rust,自己负责其安全性。
使用pin之后如何解决问题
我们来看使用 Pin 后如何避免移动带来的问题:
use std::{marker::PhantomPinned, pin::Pin}; #[derive(Debug)] struct SelfReference { name: String, // 在初始化后指向 name name_ptr: *const String, // PhantomPinned 占位符 _marker: PhantomPinned, } impl SelfReference { pub fn new(name: impl Into<String>) -> Self { SelfReference { name: name.into(), name_ptr: std::ptr::null(), _marker: PhantomPinned, } } pub fn init(self: Pin<&mut Self>) { let name_ptr = &self.name as *const String; // SAFETY: 这里并不会把任何数据从 &mut SelfReference 中移走 let this = unsafe { self.get_unchecked_mut() }; this.name_ptr = name_ptr; } pub fn print_name(self: Pin<&Self>) { println!( "struct {:p}: (name: {:p} name_ptr: {:p}), name: {}, name_ref: {}", self, &self.name, self.name_ptr, self.name, // 在使用 ptr 是需要 unsafe // SAFETY: 因为数据不会移动,所以这里 name_ptr 是安全的 unsafe { &*self.name_ptr }, ); } } fn main() { move_creates_issue(); } fn move_creates_issue() { let mut data = SelfReference::new("Tyr"); let mut data = unsafe { Pin::new_unchecked(&mut data) }; SelfReference::init(data.as_mut()); // 不 move,一切正常 data.as_ref().print_name(); // 现在只能拿到 pinned 后的数据,所以 move 不了之前 move_pinned(data.as_mut()); println!("{:?} ({:p})", data, &data); // 你无法拿回 Pin 之前的 SelfReference 结构,所以调用不了 move_it // move_it(data); } fn move_pinned(data: Pin<&mut SelfReference>) { println!("{:?} ({:p})", data, &data); } #[allow(dead_code)] fn move_it(data: SelfReference) { println!("{:?} ({:p})", data, &data); }
由于数据结构被包裹在 Pin 内部,所以在函数间传递时,变化的只是指向 data 的 Pin:
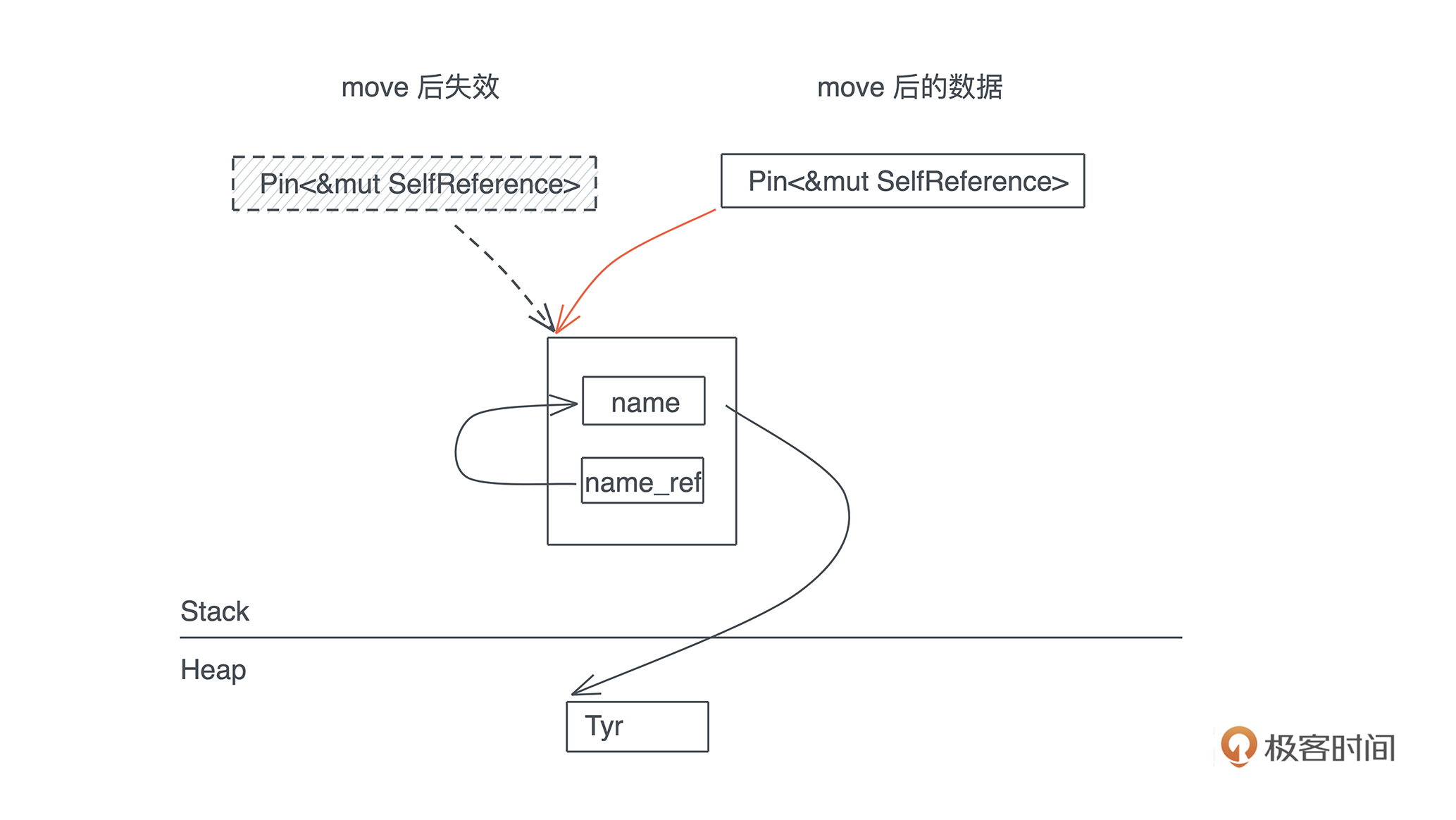
联想Unpin
学习了 Pin,不知道你有没有想起 Unpin 。
那么,Unpin 是做什么的?
Unpin声明可以移动
了解pin的作用后,Unpin有什么用?
Pin 是为了让某个数据结构无法合法地移动,而 Unpin 则相当于声明数据结构是可以移动的.
它的作用类似于 Send / Sync,通过类型约束来告诉编译器哪些行为是合法的、哪些不是。
在 Rust 中,绝大多数数据结构都是可以移动的,所以它们都自动实现了 Unpin。
声明Unpin的结构即使被 Pin 包裹,它们依旧可以进行移动,比如:
use std::mem; use std::pin::Pin; let mut string = "this".to_string(); let mut pinned_string = Pin::new(&mut string); // We need a mutable reference to call `mem::replace`. // We can obtain such a reference by (implicitly) invoking `Pin::deref_mut`, // but that is only possible because `String` implements `Unpin`. mem::replace(&mut *pinned_string, "other".to_string());
!Unpin
当我们不希望一个数据结构被移动,可以使用 !Unpin。
在 Rust 里,实现了 !Unpin 的,除了内部结构(比如 Future),主要就是 PhantomPinned:
pub struct PhantomPinned; impl !Unpin for PhantomPinned {}
所以,如果你希望你的数据结构不能被移动,可以为其添加 PhantomPinned 字段来隐式声明 !Unpin。
Unpin与Pin的关系
当数据结构满足 Unpin 时,创建 Pin 以及使用 Pin(主要是 DerefMut)都可以使用安全接口,否则,需要使用 unsafe 接口:
// 如果实现了 Unpin,可以通过安全接口创建和进行 DerefMut impl<P: Deref<Target: Unpin>> Pin<P> { pub const fn new(pointer: P) -> Pin<P> { // SAFETY: the value pointed to is `Unpin`, and so has no requirements // around pinning. unsafe { Pin::new_unchecked(pointer) } } pub const fn into_inner(pin: Pin<P>) -> P { pin.pointer } } impl<P: DerefMut<Target: Unpin>> DerefMut for Pin<P> { fn deref_mut(&mut self) -> &mut P::Target { Pin::get_mut(Pin::as_mut(self)) } } // 如果没有实现 Unpin,只能通过 unsafe 接口创建,不能使用 DerefMut impl<P: Deref> Pin<P> { pub const unsafe fn new_unchecked(pointer: P) -> Pin<P> { Pin { pointer } } pub const unsafe fn into_inner_unchecked(pin: Pin<P>) -> P { pin.pointer } }
Box<T>的Unpin思考
回顾整理Future的Context、Pin/Unpin,以及async/await
回顾整理Future的Context、Pin/Unpin,以及async/await
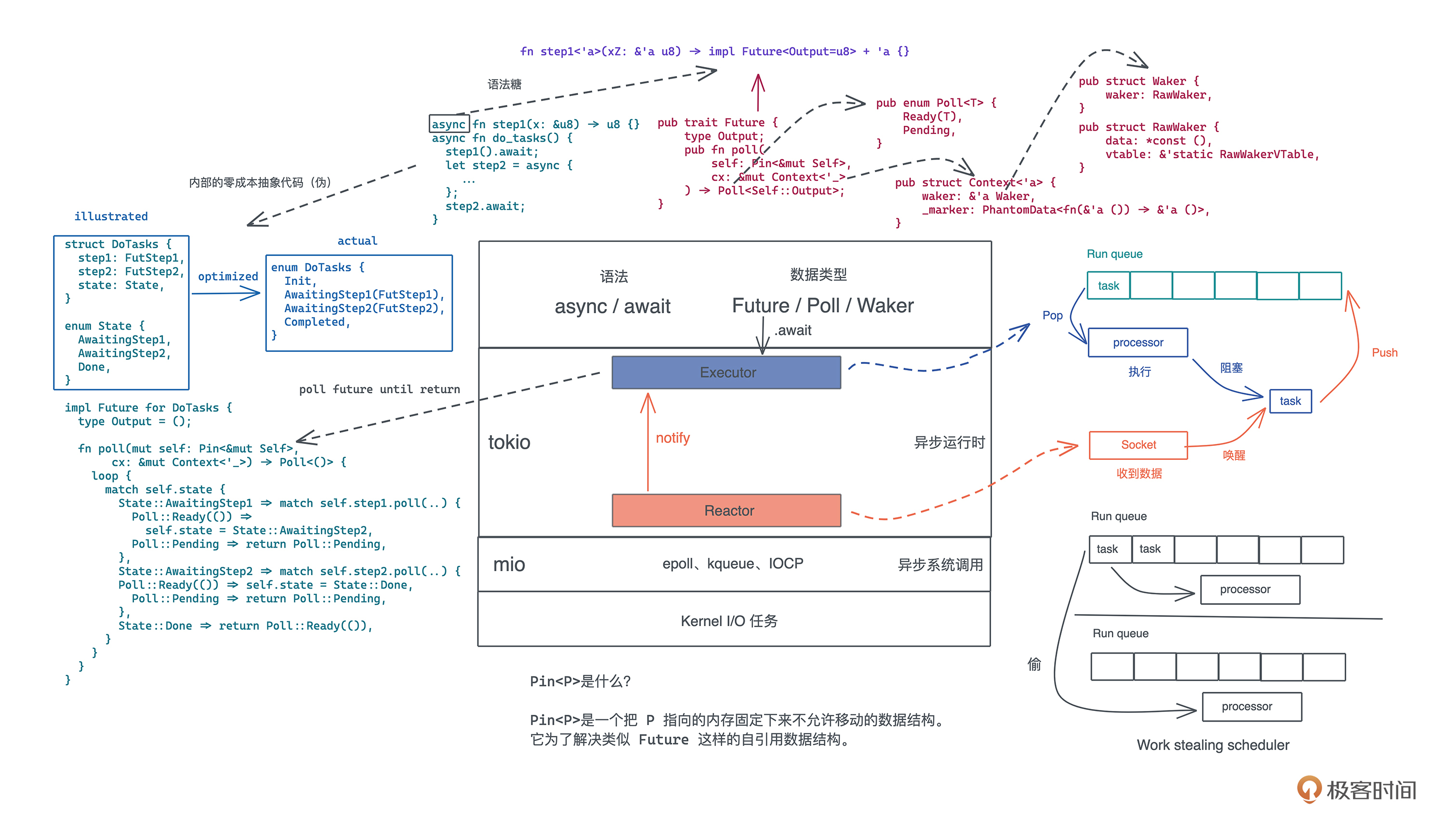
并发任务运行在 Future 这样的协程上时,async/await 是产生和运行并发任务的手段,async 定义一个可以并发执行的 Future 任务,await 触发这个任务并发执行。具体来说:
- 当我们使用 async 关键字时,它会产生一个 impl Future 的结果。
- 对于一个 async block 或者 async fn 来说,内部的每个 await 都会被编译器捕捉,并成为返回的 Future 的 poll() 方法的内部状态机的一个状态。
- Rust 的 Future 需要异步运行时来运行 Future
- 以 tokio 为例,它的 executor 会从 run queue 中取出 Future 进行 poll()
- 当 poll() 返回 Pending 时,这个 Future 会被挂起
- 直到 reactor 得到了某个事件,唤醒这个 Future,将其添加回 run queue 等待下次执行。
- tokio 一般会在每个物理线程(或者 CPU core)下运行一个线程
- 每个线程有自己的 run queue 来处理 Future。
- 为了提供最大的吞吐量,tokio 实现了 work stealing scheduler,这样,当某个线程下没有可执行的 Future,它会从其它线程的 run queue 中“偷”一个执行。
VI 混合编程
网络开发
基于网络协议
在互联网时代,谈到网络开发,我们想到的首先是 Web 开发以及涉及的部分 HTTP 协议和 WebSocket 协议。
为什么说部分?
所以对于网络开发,这个非常宏大的议题,当然是不可能、也没有必要覆盖全部内容的,这里按照如下顺序进行:
- 先简单聊聊网络开发的大全景图
- 然后重点学习如何使用 Rust 标准库以及生态系统中的库来做网络处理,包括网络连接、网络数据处理的一些方法
- 最后也会介绍几种典型的网络通讯模型的使用。
回顾网络协议
先来简单回顾一下 ISO/OSI 七层模型以及对应的协议
物理层主要跟 **PHY 芯片**有关,就不多提了:
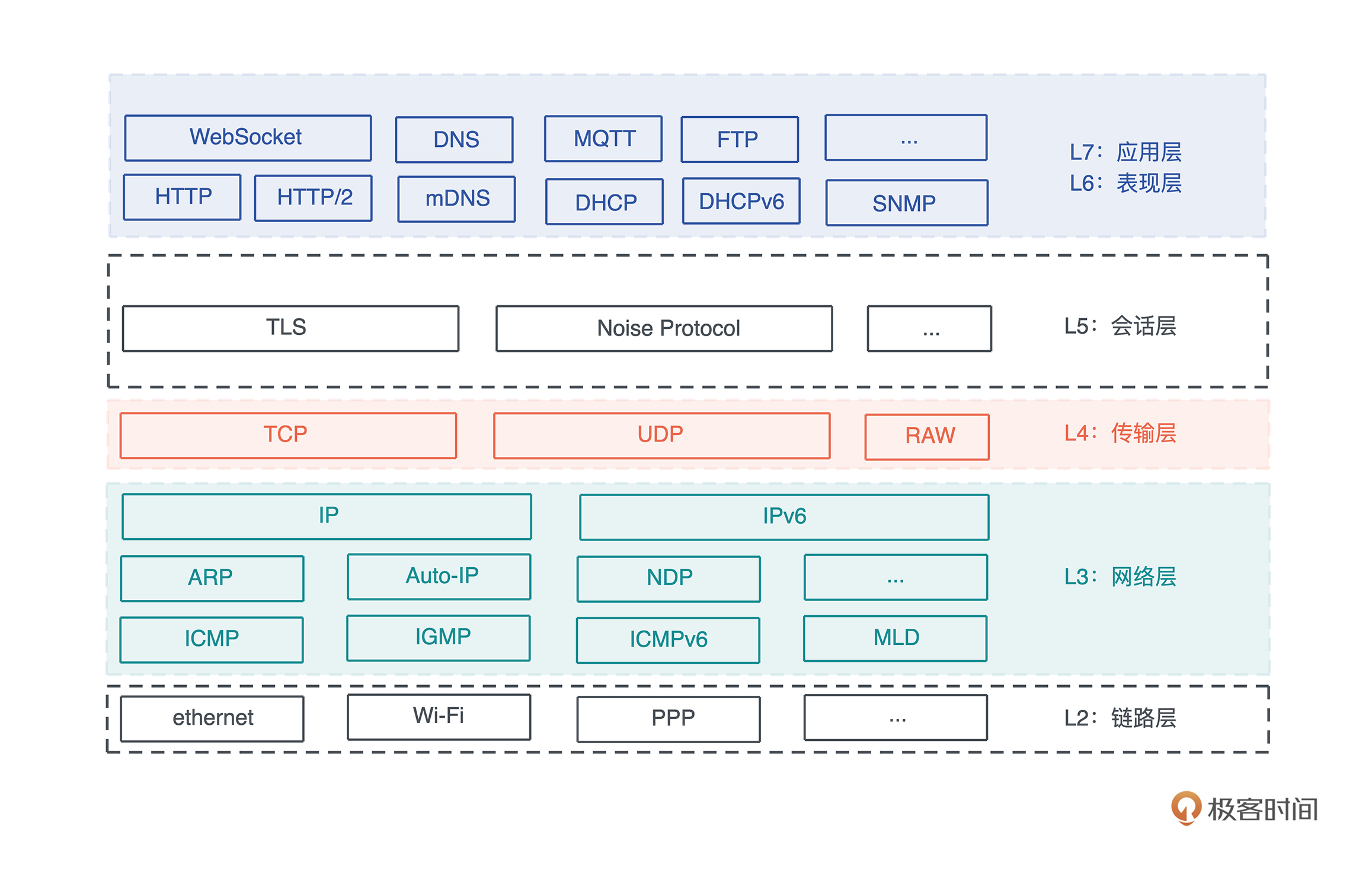
七层模型中:
- 链路层和网络层一般构建在操作系统之中,我们并不需要直接触及
- 而表现层和应用层关系紧密
- 所以在实现过程中,大部分应用程序只关心网络层、传输层和应用层:
只关心网络层、传输层和应用层
- 网络层目前 IPv4 和 IPv6 分庭抗礼,IPv6 还未完全对 IPv4 取而代之;
- 传输层除了对延迟非常敏感的应用(比如游戏),绝大多数应用都使用 TCP;
- 而在应用层,对用户友好,且对防火墙友好的 HTTP 协议家族:HTTP、WebSocket、HTTP/2,以及尚处在草案之中的 HTTP/3,在漫长的进化中,脱颖而出,成为应用程序主流的选择。
Rust生态对网络协议的支持
笔记:从std::net到tokio
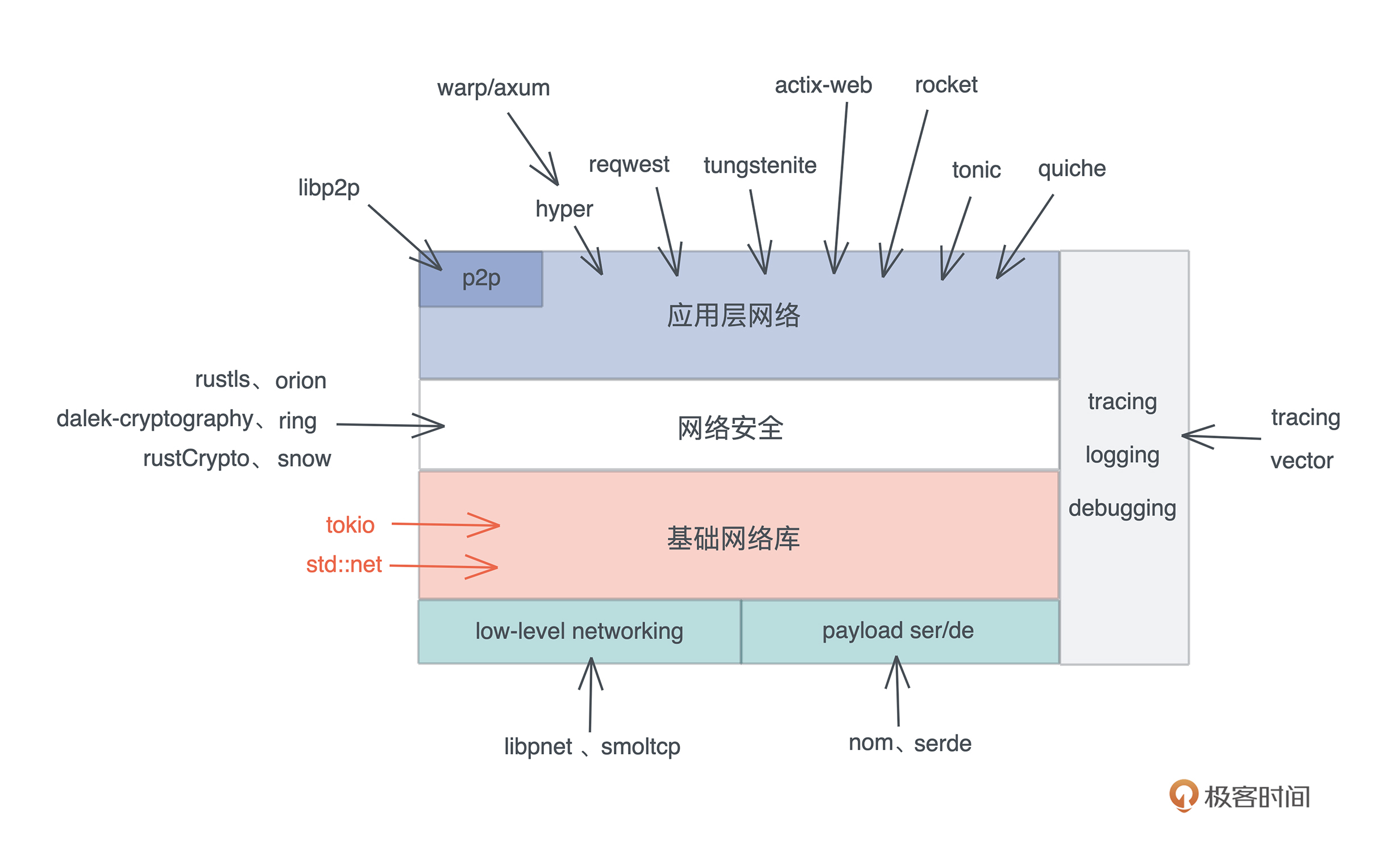
- Rust 标准库提供了 std::net,为整个 TCP/IP 协议栈的使用提供了封装。
- 然而 std::net 是同步的,所以,如果你要构建一个高性能的异步网络,可以使用 tokio。
tokio::net 提供了和 std::net 几乎一致的封装,一旦你熟悉了 std::net,tokio::net 里的功能对你来说都并不陌生。所以先从 std::net 开始了解。
std::net
std::net 下提供了处理 TCP / UDP 的数据结构,以及一些辅助结构:
-
TCP:TcpListener / TcpStream,处理服务器的监听以及客户端的连接
-
UDP:UdpSocket,处理 UDP socket
-
其它:IpAddr 是 IPv4 和 IPv6 地址的封装;SocketAddr,表示 IP 地址 + 端口的数据结构
这里就主要介绍一下 TCP 的处理(TcpListener/TcpStream),顺带会使用到 IpAddr / SocketAddr。
服务端:TcpListener
如果要创建一个 TCP server,我们可以:
- 绑定监听:使用 TcpListener 绑定某个端口
- 循环处理♻️:用 loop 循环处理接收到的客户端请求
- 接收到请求后,会得到一个 TcpStream
- 它实现了 Read / Write trait,可以像读写文件一样,进行 socket 的读写:
例子: 使用std::net 创建一个 TCP server (github)
use std::{ io::{Read, Write}, net::TcpListener, thread, }; fn main() { let listener = TcpListener::bind("0.0.0.0:9527").unwrap(); loop { // unwrap(): let (mut stream, addr) = listener.accept().unwrap(); println!("Accepted a new connection: {}", addr); thread::spawn(move || { let mut buf = [0u8; 12]; stream.read_exact(&mut buf).unwrap(); println!("data: {:?}", String::from_utf8_lossy(&buf)); // 一共写了 17 个字节 stream.write_all(b"glad to meet you!").unwrap(); }); } }
客户端:TcpStream
对于客户端,我们可以用 TcpStream::connect() 得到一个 TcpStream。
一旦客户端的请求被服务器接受,就可以发送或者接收数据:
例子: 客户端使用TcpStream::connect() (github)
use std::{ io::{Read, Write}, net::TcpStream, }; fn main() { let mut stream = TcpStream::connect("127.0.0.1:9527").unwrap(); // 一共写了 12 个字节 stream.write_all(b"hello world!").unwrap(); let mut buf = [0u8; 17]; stream.read_exact(&mut buf).unwrap(); println!("data: {:?}", String::from_utf8_lossy(&buf)); }
在这个例子中:
- 客户端在连接成功后,会发送 12 个字节的 “hello world!“给服务器
- 服务器读取并回复后,客户端会尝试接收完整的、来自服务器的 17 个字节的 “glad to meet you!”。
但是,目前客户端和服务器都需要硬编码要接收数据的大小,这样不够灵活,后续我们会看到如何通过使用消息帧(frame)更好地处理。
为什么上方的客户端代码无需显式关闭TcpStream?
从客户端的代码中可以看到,我们无需显式地关闭 TcpStream:
-
因为 TcpStream 的内部实现也处理了 Drop trait,使得其离开作用域时会被关闭。
-
但如果你去看 TcpStream 的文档,会发现它并没有实现 Drop。
这是因为:
- TcpStream 内部包装了 sys_common::net::TcpStream
- 然后它又包装了 Socket
- 而 Socket 是一个平台相关的结构
- 比如,在 Unix 下的实现是 FileDesc
- 然后它内部是一个 OwnedFd
- 最终会调用 libc::close(self.fd) 来关闭 fd,也就关闭了 TcpStream。
处理网络连接的一般方法
如果你使用某个 Web Framework 处理 Web 流量,那么无需关心网络连接,框架会帮你打点好一切,你只需要关心某个路由或者某个 RPC 的处理逻辑就可以了。
但如果你要在 TCP 之上构建自己的协议,那么你需要认真考虑如何妥善处理网络连接。
之前的 listener 代码有什么问题?
我们在之前的 listener 代码中也看到了,在网络处理的主循环中,会不断 accept() 一个新的连接:
fn main() { ... loop { let (mut stream, addr) = listener.accept().unwrap(); println!("Accepted a new connection: {}", addr); thread::spawn(move || { ... }); } }
但是,处理连接的过程,需要放在另一个线程或者另一个异步任务中进行,而不要在主循环中直接处理。 因为这样会阻塞主循环,使其在处理完当前的连接前,无法 accept() 新的连接。
换成loop+spawn可以吗?
所以,loop + spawn 是处理网络连接的基本方式:
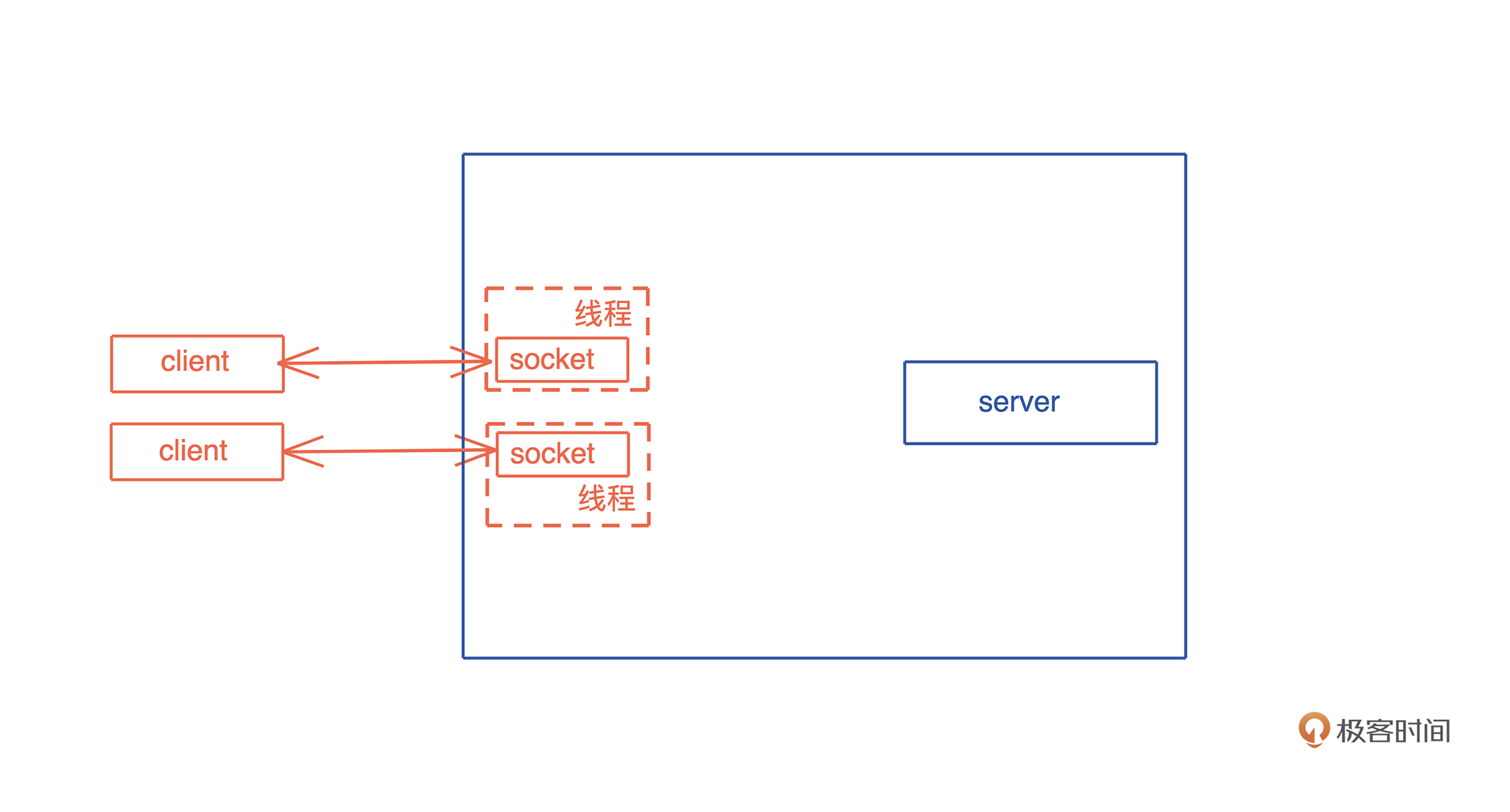
但是使用线程处理频繁连接和退出的网络连接会有如下问题:
-
一来会有效率上的问题
-
二来线程间如何共享公共的数据也让人头疼
我们来详细看看。
问题一:如何处理大量连接?
为什么使用线程处理大量连接的网络服务不是一个好的方式?
- 从资源的角度,如果不断创建线程,那么当连接数一高,就容易把系统中可用的线程资源吃光。
过多的线程占用过多的内存:
- Rust 缺省的栈大小是 2M
- 10k 连接就会占用 20G 内存(当然缺省栈大小也可以**根据需要修改**)
- 从算力的角度,太多线程在连接数据到达时,会来来回回切换线程,导致 CPU 过分忙碌,无法处理更多的连接请求。
所以如果使用线程,那么,在遭遇到 C10K 的瓶颈,也就是连接数到万这个级别,系统就会遭遇到资源和算力的双重瓶颈。
- 从算力的角度:因为线程的调度是操作系统完成的,每次调度都要经历一个**复杂的、不那么高效的 save and load 的上下文切换过程**
所以,对于潜在的有大量连接的网络服务,使用线程不是一个好的方式。
如果要突破 C10K 的瓶颈,达到 C10M,该如何处理?
如果要突破 C10K 的瓶颈,达到 C10M,我们就只能使用在用户态的协程来处理:
- 要么是类似 Erlang/Golang 那样的有栈协程(stackful coroutine)
- 要么是类似 Rust 异步处理这样的无栈协程(stackless coroutine)。
所以,在 Rust 下大部分处理网络相关的代码中,你会看到,很少直接有用 std::net 进行处理的,大部分都是用某个异步网络运行时,比如 tokio。
问题二:如何处理共享信息?
服务器的一些共享的状态,比如数据库连接该如何共享?
在构建服务器时,我们总会有一些共享的状态供所有的连接使用,比如数据库连接。
对于这样的场景,如果共享数据不需要修改,我们可以考虑使用 Arc<T>,如果需要修改,可以使用 Arc<RwLock<T>>。
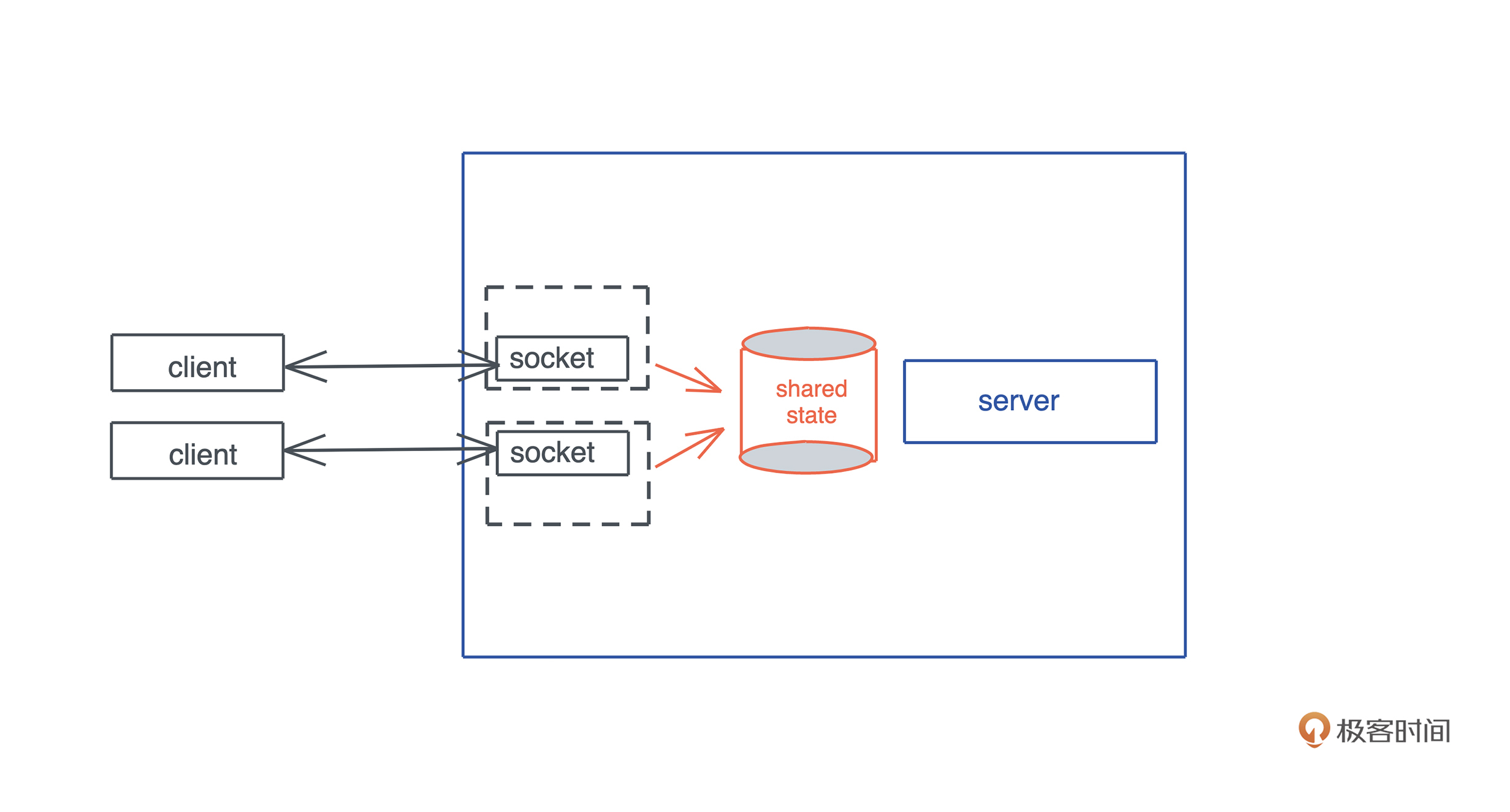
但使用锁,就意味着一旦在关键路径上需要访问被锁住的资源,整个系统的吞吐量都会受到很大的影响。
笔记: 降低粒度
一种思路是,我们把锁的粒度降低,这样冲突就会减少。
比如在 kv server 中,我们把 key 哈希一下模 N,将不同的 key 分摊到 N 个 memory store 中。这样,锁的粒度就降低到之前的 1/N 了:

笔记:特定访问
另一种思路是我们改变共享资源的访问方式,使其只被一个特定的线程访问;
其它线程或者协程只能通过给其发消息的方式与之交互。
如果你用 Erlang / Golang,这种方式你应该不陌生,在 Rust 下,可以使用 channel 数据结构。
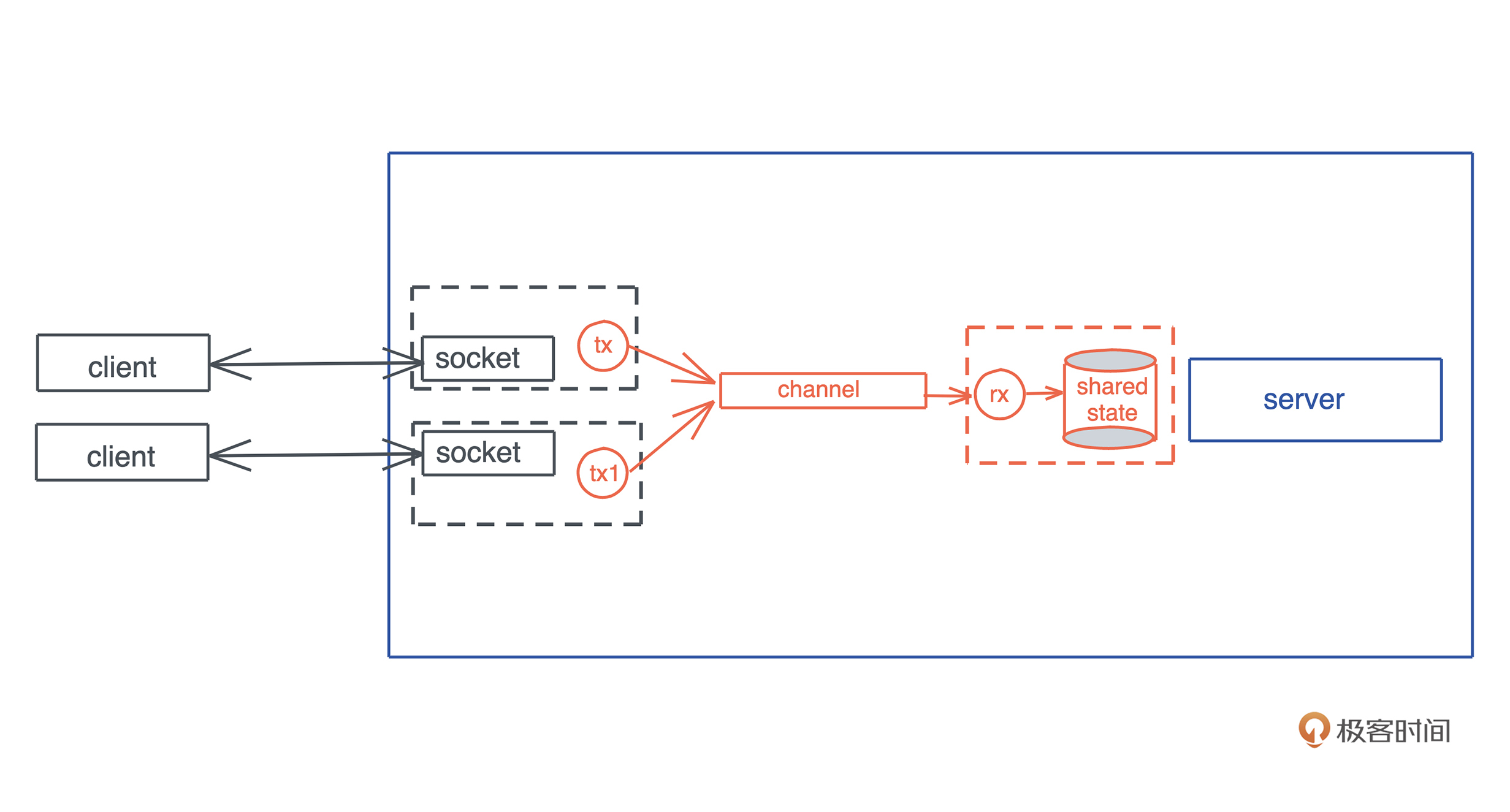
Rust 下 channel,无论是标准库,还是第三方库,都有非常棒的的实现:
- 同步 channel 的有**标准库的 mpsc:channel** 和第三方的 crossbeam_channel
- 异步 channel 有 tokio 下的 mpsc:channel,以及 flume
处理网络数据的一般方法
我们再来看看如何处理网络数据。
大部分时候,我们可以使用已有的应用层协议来处理网络数据,比如 HTTP。
JSON序列化
在 HTTP 协议下,基本上使用 JSON 构建 REST API / JSON API 是业界的共识,客户端和服务器也有足够好的生态系统来支持这样的处理。
你只需要使用 serde 让你定义的 Rust 数据结构具备 Serialize/Deserialize 的能力,然后用 serde_json 生成序列化后的 JSON 数据。
Rocket 是 Rust 的一个全功能的 Web 框架,类似于 Python 的 Django。
下面是一个使用 rocket 来处理 JSON 数据的例子。
然后在 main.rs 里添加代码:(github)
#[macro_use] extern crate rocket; use rocket::serde::json::Json; use rocket::serde::{Deserialize, Serialize}; #[derive(Serialize, Deserialize)] #[serde(crate = "rocket::serde")] struct Hello { name: String, } #[get("/", format = "json")] fn hello() -> Json<Hello> { Json(Hello { name: "Tyr".into() }) } #[launch] fn rocket() -> _ { rocket::build().mount("/", routes![hello]) }
可以看到,使用 rocket,10 多行代码,我们就可以运行起一个 Web Server。
如果你出于性能或者其他原因,可能需要定义自己的客户端 / 服务器间的协议。那么,可以使用传统的 TLV(Type-Length-Value)来描述协议数据,或者使用更加高效简洁的 protobuf。
使用 protobuf 自定义协议
protobuf 是一种非常方便的定义向后兼容协议的工具,它不仅能使用在构建 gRPC 服务的场景,还能用在其它网络服务中。
在之前的小项目中,无论是 thumbor 的实现,还是 kv server 的实现,都用到了 protobuf。
kv server 的实现在 TCP 之上构建了基于 protobuf 的协议,支持一系列 HXXX 命令。
不过,使用 protobuf 构建协议消息的时候需要注意,因为 protobuf 生成的是不定长消息,所以需要在客户端和服务器之间约定好:
如何界定一个消息帧(frame)
常用的界定消息帧的方法有哪些?
常用的界定消息帧的方法有:
- 在消息尾添加 “\r\n”以及
消息尾添加 “\r\n” 一般用于基于文本的协议,比如 HTTP 头 / POP3 / Redis 的 RESP 协议等。但对于二进制协议,更好的方式是在消息前面添加固定的长度,比如对于 protobuf 这样的二进制而言,消息中的数据可能正好出现连续的“\r\n“,如果使用 “\r\n” 作为消息的边界,就会发生紊乱,所以不可取。
- 在消息头添加长度
不过两种方式也可以混用
比如 HTTP 协议,本身使用 “\r\n” 界定头部,但它的 body 会使用长度界定,只不过这个长度在 HTTP 头中的 Content-Length 来声明。
前面说到 gRPC 使用 protobuf,那么 gRPC 是怎么界定消息帧呢?
-
gRPC 使用了**五个字节的 Length-Prefixed-Message**,其中包含一个字节的压缩标志和四个字节的消息长度。
-
这样,在处理 gRPC 消息时,我们先读取 5 个字节,取出其中的长度 N,再读取 N 个字节就得到一个完整的消息了。
因为这种处理方式很常见,所以 tokio 提供了 length_delimited codec,来处理用长度隔离的消息帧,它可以和 **tokio的Framed 结构**配合使用。如果你看它的文档,会发现它除了简单支持在消息前加长度外,还支持各种各样复杂的场景。
如何采用这样的方法来处理使用 protobuf 自定义的协议?
比如消息有一个固定的消息头,其中包含 3 字节长度,5 字节其它内容,LengthDelimitedCodec 处理完后,会把完整的数据给你。你也可以通过 num_skip(3) 把长度丢弃,总之非常灵活:

tokio/tokio_util
下面是使用 tokio / tokio_util 撰写的服务器和客户端,你可以看到,服务器和客户端都使用了 LengthDelimitedCodec 来处理消息帧。
例子: 服务器的代码 (github)
use anyhow::Result; use bytes::Bytes; use futures::{SinkExt, StreamExt}; use tokio::net::TcpListener; use tokio_util::codec::{Framed, LengthDelimitedCodec}; #[tokio::main] async fn main() -> Result<()> { let listener = TcpListener::bind("127.0.0.1:9527").await?; loop { let (stream, addr) = listener.accept().await?; println!("accepted: {:?}", addr); // LengthDelimitedCodec 默认 4 字节长度 let mut stream = Framed::new(stream, LengthDelimitedCodec::new()); tokio::spawn(async move { // 接收到的消息会只包含消息主体(不包含长度) while let Some(Ok(data)) = stream.next().await { println!("Got: {:?}", String::from_utf8_lossy(&data)); // 发送的消息也脏需要发送消息主体,不需要提供长度 // Framed/LengthDelimitedCodec 会自动计算并添加 stream.send(Bytes::from("goodbye world!")).await.unwrap(); } }); } }
例子: 客户端代码 (github)
use anyhow::Result; use bytes::Bytes; use futures::{SinkExt, StreamExt}; use tokio::net::TcpStream; use tokio_util::codec::{Framed, LengthDelimitedCodec}; #[tokio::main] async fn main() -> Result<()> { let stream = TcpStream::connect("127.0.0.1:9527").await?; let mut stream = Framed::new(stream, LengthDelimitedCodec::new()); stream.send(Bytes::from("hello world")).await?; // 接收从服务器返回的数据 if let Some(Ok(data)) = stream.next().await { println!("Got: {:?}", String::from_utf8_lossy(&data)); } Ok(()) }
和前面std::net的 TcpListener / TcpStream 代码相比:
双方都不需要知道对方发送的数据的长度,就可以通过 StreamExt trait 的 next() 接口 得到下一个消息;
- 在发送时,只需要调用 SinkExt trait 的 send() 接口 发送,相应的长度就会被自动计算并添加到要发送的消息帧的开头。
当然啦,如果你想自己运行这两段代码,
记得在 Cargo.toml 里添加:
#![allow(unused)] fn main() { [dependencies] anyhow = "1" bytes = "1" futures = "0.3" tokio = { version = "1", features = ["full"] } tokio-util = { version = "0.6", features = ["codec"] } }
这里为了代码的简便,并没有直接使用 protobuf。你可以把发送和接收到的 Bytes 里的内容视作 protobuf 序列化成的二进制(如果你想看 protobuf 的处理,可以看thumbor 和 kv server 的源代码)。
我们可以看到,使用 LengthDelimitedCodec,构建一个自定义协议,变得非常简单。短短二十行代码就完成了非常繁杂的工作。
Tokio
绝大多数情况下,我们应该使用支持异步的网络开发,所以你会在各种网络相关的代码中,看到 tokio 的身影。作为 Rust 下主要的异步网络运行时,你可以多花点时间了解它的功能。
尝试改写
在kv server 的 examples 里,使用过async_prost,
可以尝试使用使用 tokio_util 下的 LengthDelimitedCodec 来改写下方的example:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv1::{CommandRequest, CommandResponse, Service, ServiceInner, SledDb}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let service: Service<SledDb> = ServiceInner::new(SledDb::new("/tmp/kvserver")) .fn_before_send(|res| match res.message.as_ref() { "" => res.message = "altered. Original message is empty.".into(), s => res.message = format!("altered: {}", s), }) .into(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); stream.send(res).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
总结:如何用 Rust 做基于 TCP 的网络开发
- 通过 TcpListener 监听,使用 TcpStream 连接。
- 在 *nix 操作系统层面,一个 TcpStream 背后就是一个文件描述符。
- 值得注意的是,当我们在处理网络应用的时候,
有些问题一定要正视
- 网络是不可靠的
可以使用 TCP 以及构建在 TCP 之上的协议应对网络的不可靠;
- 网络的延迟可能会非常大
我们使用队列和超时来应对网络的延时;
- 带宽是有限的
使用精简的二进制结构、压缩算法以及某些技巧(比如 HTTP 的 304)来减少带宽的使用,以及不必要的网络传输;
- 网络是非常不安全的
需要使用 TLS 或者 noise protocol 这样的安全协议来保护传输中的数据。
基于通讯模型
通讯模型
双向通讯
笔记:前面TCP 服务器的例子里,所做的都是双向通讯。这是最典型的一种通讯方式:
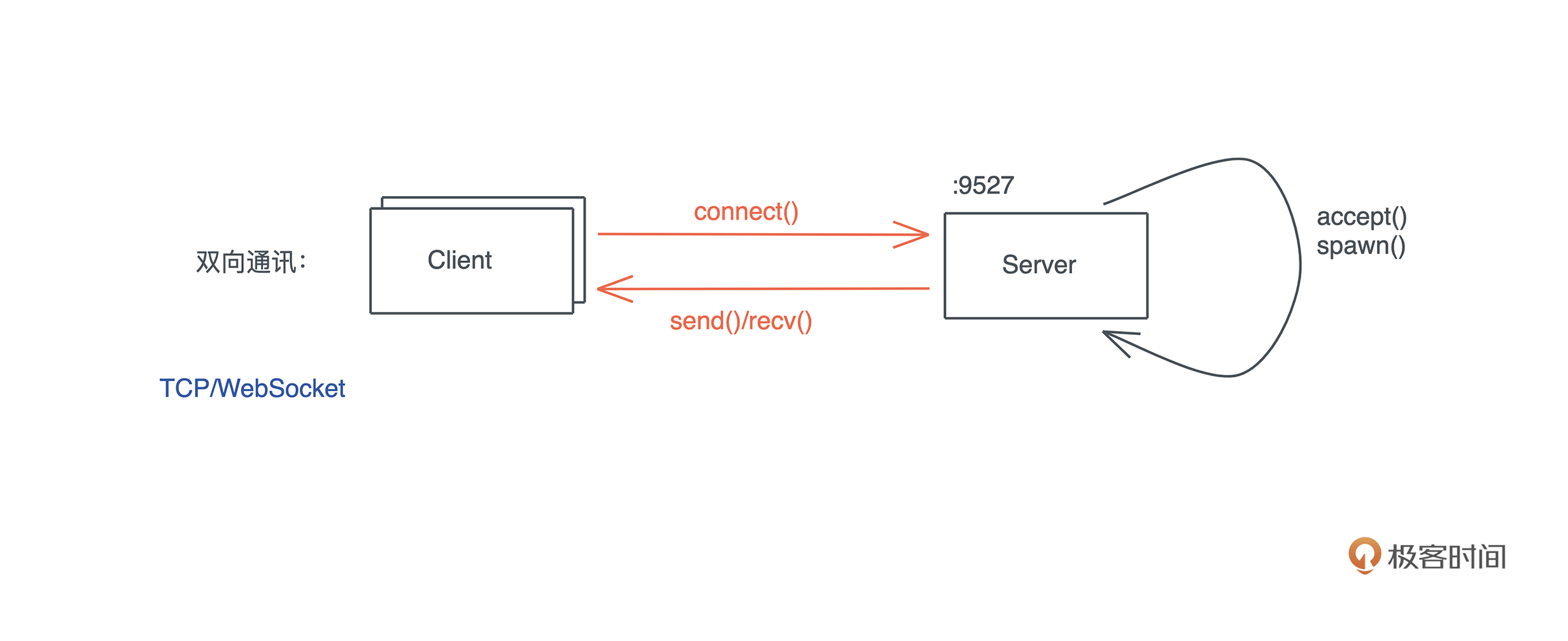
- 服务端监听9527端口
- 客户端连接9527端口
- 一旦连接建立,服务器和客户端都可以根据需要主动向对方发起传输。
- 服务器收到消息后就spawn一个线程处理
- 整个网络运行在全双工模式下(full duplex)
我们熟悉的 TCP / WebSocket 就运行在这种模型下。
双向通讯的好处是:数据的流向是没有限制的,一端不必等待另一端才能发送数据,网络可以进行比较实时地处理。
请求响应
笔记:在 Web 开发的世界里,请求 - 响应模型是我们最熟悉的模型。
客户端发送请求,服务器根据请求返回响应。
整个网络处在半双工模式下(half duplex)。HTTP/1.x 就运行在这种模式下。
- 一般而言,请求响应模式下,在客户端没有发起请求时,服务器不会也无法主动向客户端发送数据。
- 除此之外,请求发送的顺序和响应返回的顺序是一一对应的,不会也不能乱序,这种处理方式会导致**应用层的队头阻塞(Head-Of-Line blocking)**。
请求响应模型处理起来很简单,由于 HTTP 协议的流行,尽管有很多限制,请求响应模型还是得到了非常广泛的应用。
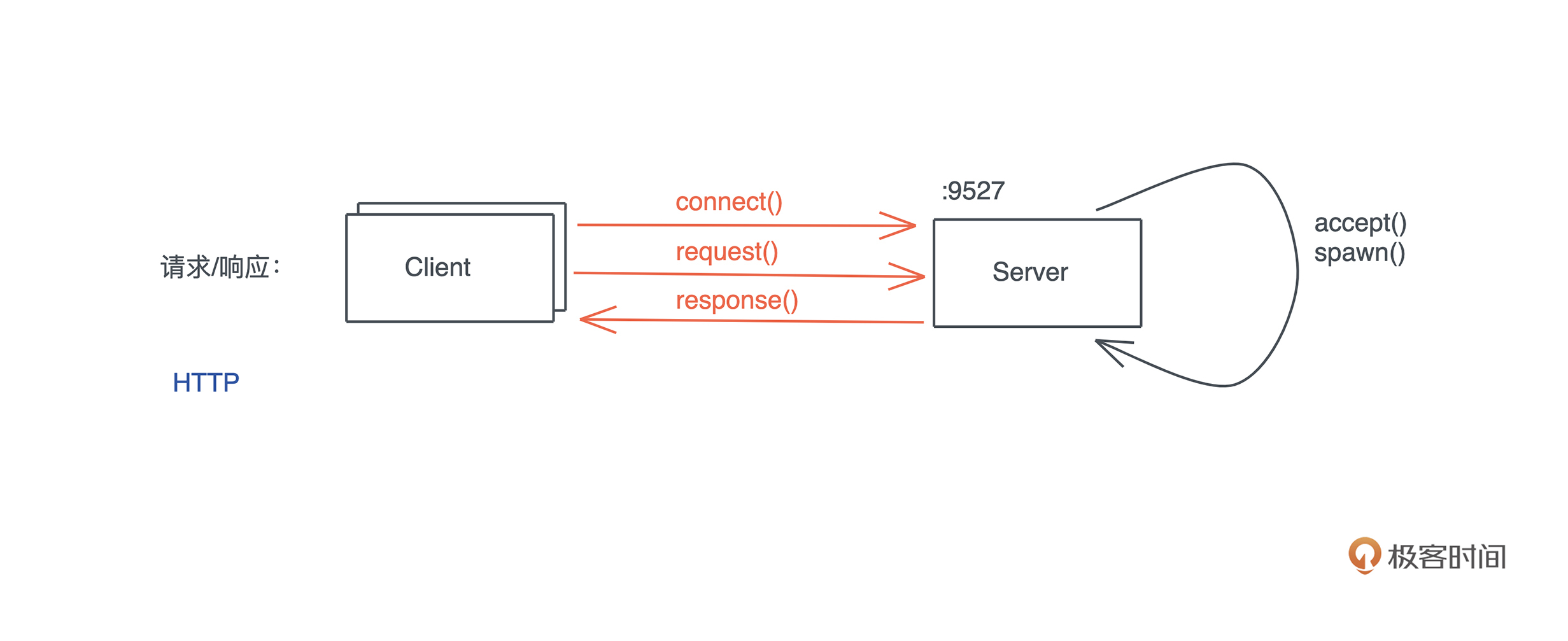
笔记:基于请求-响应 和 双向通讯的组合模型
基础模型只有
请求-响应模型和双向通讯模型两个, 其他的组合模型是在这两个基础模型的基础上进行了不同方式的组合和扩展。
一、基础模型
- 请求-响应模型
- 双向通讯模型
二、组合模型
-
请求-回调模型 1.1 客户端发送请求,服务器异步处理请求并回调客户端。 1.2 整个网络处于异步通信状态。 1.3 Rust相关开源项目:actix-web、Rocket等。
-
请求-流式处理模型 2.1 客户端发送请求,服务器以流的形式异步处理请求。 2.2 整个网络处于异步通信状态。 2.3 Rust相关开源项目:tokio、async-std等。
-
请求-队列模型 3.1 客户端发送请求,服务器将请求放入队列中异步处理。 3.2 整个网络处于异步通信状态。 3.3 Rust相关开源项目:RabbitMQ、Kafka等。
-
请求-推送模型 4.1 客户端发送请求,服务器将处理结果主动推送给客户端。 4.2 整个网络处于异步通信状态。 4.3 Rust相关开源项目:actix-web、Rocket等。
-
异步通知模型 5.1 客户端发送请求,服务器在之后通过Webhooks等技术进行异步通知。 5.2 整个网络处于异步通信状态。 5.3 Rust相关开源项目:actix-web、Rocket等。
-
请求-响应-异步通知模型 6.1 客户端发送请求,服务器根据请求返回响应,并在之后异步通知客户端相关数据更新。 6.2 整个网络处于异步通信状态。 6.3 Rust相关开源项目:actix-web、Rocket等。
-
请求-流式处理-异步通知模型 7.1 客户端发送请求,服务器将请求以流的形式异步处理,并在之后异步通知客户端相关数据更新。 7.2 整个网络处于异步通信状态。 7.3 Rust相关开源项目:tokio、async-std等。
-
请求-队列-回调模型 8.1 客户端发送请求,服务器将请求放入队列中异步处理,并在完成后回调客户端。 8.2 整个网络处于异步通信状态。 8.3 Rust相关开源项目:RabbitMQ、Kafka等。
-
请求-队列-推送模型 9.1 客户端发送请求,服务器将请求放入队列中异步处理,并将处理结果主动推送给客户端。 9.2 整个网络处于异步通信状态。 9.3 Rust相关开源项目:RabbitMQ、Kafka等。
-
请求-回调-推送模型 10.1 客户端发送请求,服务器异步处理请求并回调客户端,同时将处理结果主动推送给客户端。 10.2 整个网络处于异步通信状态。 10.3 Rust相关开源项目:actix-web、Rocket等。
-
请求-响应-流式处理模型 11.1 客户端发送请求,服务器根据请求返回响应,并以流的形式异步处理相关数据并返回给客户端。 11.2 整个网络处于异步通信状态。 11.3 Rust相关开源项目:tokio、async-std等。
-
请求-响应-队列模型 12.1 客户端发送请求,服务器根据请求返回响应,并将请求放入队列中异步处理。 12.2 整个网络处于异步通信状态。 12.3 Rust相关开源项目:RabbitMQ、Kafka等。
-
请求-响应-推送模型 13.1 客户端发送请求,服务器根据请求返回响应,并将处理结果主动推送给客户端。 13.2 整个网络处于异步通信状态。 13.3 Rust相关开源项目:actix-web、Rocket等。
-
请求-响应-异步通知模型 14.1 客户端发送请求,服务器根据请求返回响应,并在之后通过Webhooks等技术进行异步通知。 14.2 整个网络处于异步通信状态。 14.3 Rust相关开源项目:actix-web、Rocket等。
-
请求-流式处理-队列模型 15.1 客户端发送请求,服务器以流的形式异步处理请求,并将请求放入队列中异步处理相关数据并返回给客户端。 15.2 整个网络处于异步通信状态。 15.3 Rust相关开源项目:tokio、async-std、RabbitMQ、Kafka等。
-
请求-流式处理-推送模型 16.1 客户端发送请求,服务器以流的形式异步处理请求,并将处理结果主动推送给客户端。 16.2 整个网络处于异步通信状态。 16.3 Rust相关开源项目:tokio、async-std、actix-web、Rocket等。
-
请求-队列-回调-推送模型 17.1 客户端发送请求,服务器将请求放入队列中异步处理,并在完成后回调客户端并将处理结果主动推送给客户端。 17.2 整个网络处于异步通信状态。 17.3 Rust相关开源项目:RabbitMQ、Kafka、actix-web、Rocket等。
-
请求-回调-异步通知模型 18.1 客户端发送请求,服务器异步处理请求并回调客户端,在之后通过Webhooks等技术进行异步通知。 18.2 整个网络处于异步通信状态。 18.3 Rust相关开源项目:actix-web、Rocket等。
-
请求-响应-流式处理-异步通知模型 19.1 客户端发送请求,服务器根据请求返回响应,并以流的形式异步处理相关数据并返回给客户端,在之后通过Webhooks等技术进行异步通知。 19.2 整个网络处于异步通信状态。 19.3 Rust相关开源项目:tokio、async-std、actix-web、Rocket等。
-
请求-队列-流式处理模型 20.1 客户端发送请求,服务器将请求放入队列中异步处理,并以流的形式异步处理相关数据并返回给客户端。 20.2 整个网络处于异步通信状态。 20.3 Rust相关开源项目:RabbitMQ、Kafka、tokio、async-std等。
-
请求-队列-推送-异步通知模型 21.1 客户端发送请求,服务器将请求放入队列中异步处理,并将处理结果主动推送给客户端,在之后通过Webhooks等技术进行异步通知。 21.2 整个网络处于异步通信状态。 21.3 Rust相关开源项目:RabbitMQ、Kafka、actix-web、Rocket等。
-
请求-回调-推送-异步通知模型 22.1 客户端发送请求,服务器异步处理请求并回调客户端,同时将处理结果主动推送给客户端,在之后通过Webhooks等技术进行异步通知。 22.2 整个网络处于异步通信状态。 22.3 Rust相关开源项目:actix-web、Rocket等。
控制平面 / 数据平面分离
但有时候,服务器和客户端之间会进行复杂的通讯,这些通讯包含控制信令和数据流。
因为 TCP 有天然的网络层的队头阻塞,所以当控制信令和数据交杂在同一个连接中时,过大的数据流会阻塞控制信令,使其延迟加大,无法及时响应一些重要的命令。
以 FTP 为例:
- 如果用户在传输一个 1G 的文件后,再进行 ls 命令
- 如果文件传输和 ls 命令都在同一个连接中进行,那么,只有文件传输结束,用户才会看到 ls 命令的结果,这样显然对用户非常不友好。
所以,我们会采用控制平面和数据平面分离的方式,进行网络处理:
所以,我们会采用控制平面和数据平面分离的方式,进行网络处理:
-
connect()/ctrl_send/ctrl_recv:
客户端会首先连接服务器,建立控制连接。控制连接是一个长连接,会一直存在,直到交互终止。
-
connect/data_send/data_recv:
然后,二者会根据需要额外创建新的临时的数据连接,用于传输大容量的数据,数据连接在完成相应的工作后,会自动关闭。
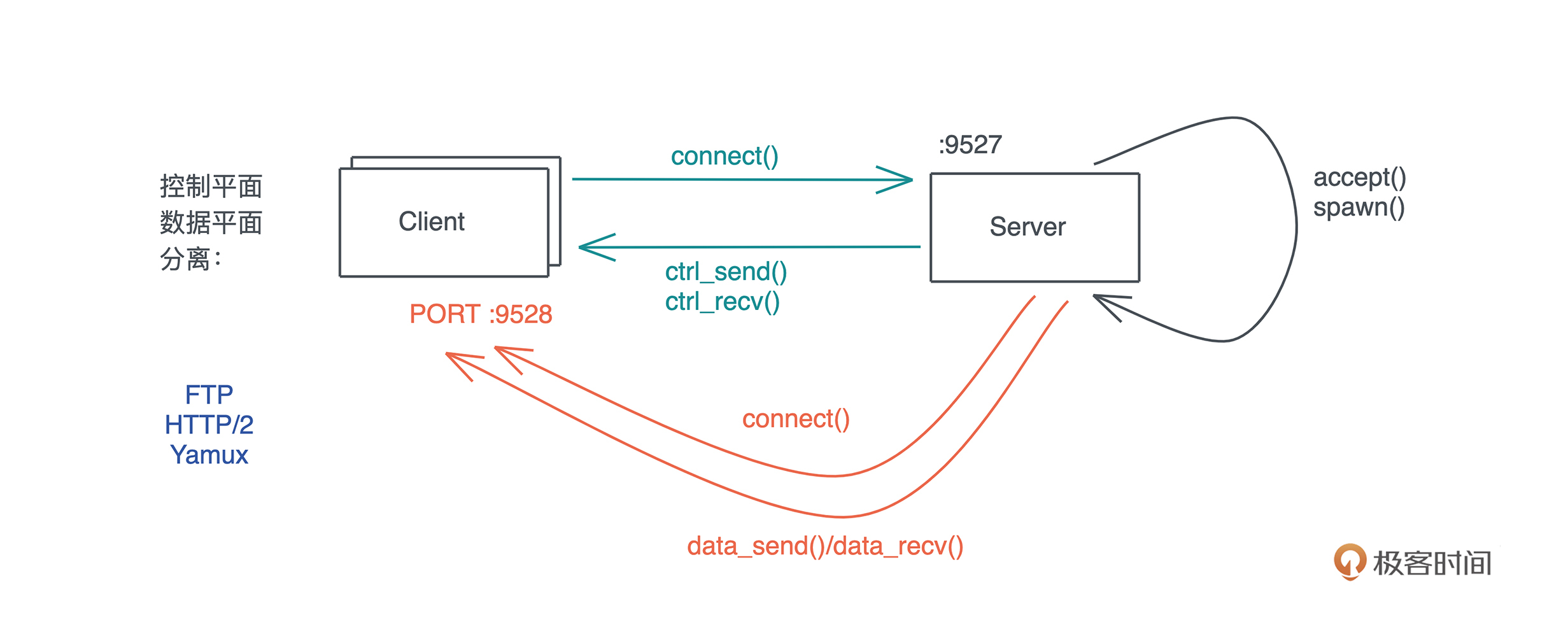
除 FTP 外,还有很多协议都是类似的处理方式:
-
比如**多媒体通讯协议SIP 协议**。
-
HTTP/2 和借鉴了 HTTP/2 的用于多路复用的 Yamux 协议,虽然运行在同一个 TCP 连接之上,它们在应用层也构建了类似的控制平面和数据平面。
以 HTTP/2 为例
-
控制平面(ctrl stream)可以创建很多新的 stream,用于并行处理多个应用层的请求
-
比如使用 HTTP/2 的 gRPC,各个请求可以并行处理
-
不同 stream 之间的数据可以乱序返回,而不必受请求响应模型的限制
虽然 HTTP/2 依旧受困于 TCP 层的队头阻塞,但它解决了应用层的队头阻塞。
P2P 网络
前面我们谈论的网络通讯模型,都是传统的客户端 / 服务器交互模型(C/S 或 B/S):
客户端和服务器在网络中的作用是不对等的,客户端永远是连接的发起方,而服务器是连接的处理方。
不对等的网络模型有很多好处
比如客户端不需要公网地址,可以隐藏在网络地址转换(NAT)设备(比如 NAT 网关、防火墙)之后,只要服务器拥有公网地址,这个网络就可以连通。
所以,客户端 / 服务器模型是天然中心化的,所有连接都需要经过服务器这个中间人,即便是两个客户端的数据交互也不例外。
这种模型随着互联网的大规模使用成为了网络世界的主流。
然而,很多应用场景需要通讯的两端可以直接交互,而无需一个中间人代为中转。
比如 A 和 B 分享一个 1G 的文件,如果通过服务器中转,数据相当于传输了两次,效率很低。
P2P 模型打破了这种不对等的关系,使得任意两个节点在理论上可以直接连接,每个节点既是客户端,又是服务器。
如何构建 P2P 网络
可是由于历史上 IPv4 地址的缺乏,以及对隐私和网络安全的担忧,互联网的运营商在接入端,大量使用了 NAT 设备,使得普通的网络用户,缺乏直接可以访问的公网 IP。
因而,构建一个 P2P 网络首先需要解决网络的连通性。
解决网络连通
笔记:主流的解决方法
-
探索
P2P 网络的每个节点,都会首先会通过 STUN 服务器探索自己的公网 IP/port
-
注册
然后在 bootstrap/signaling server 上注册自己的公网 IP/port,让别人能发现自己,从而和潜在的“邻居”建立连接。
在一个大型的 P2P 网络中,一个节点常常会拥有几十个邻居,通过这些邻居以及邻居掌握的网络信息,每个节点都能构建一张如何找到某个节点(某个数据)的路由表。
在此之上,节点还可以加入某个或者某些 topic,然后通过某些协议(比如 gossip)在整个 topic 下扩散消息:
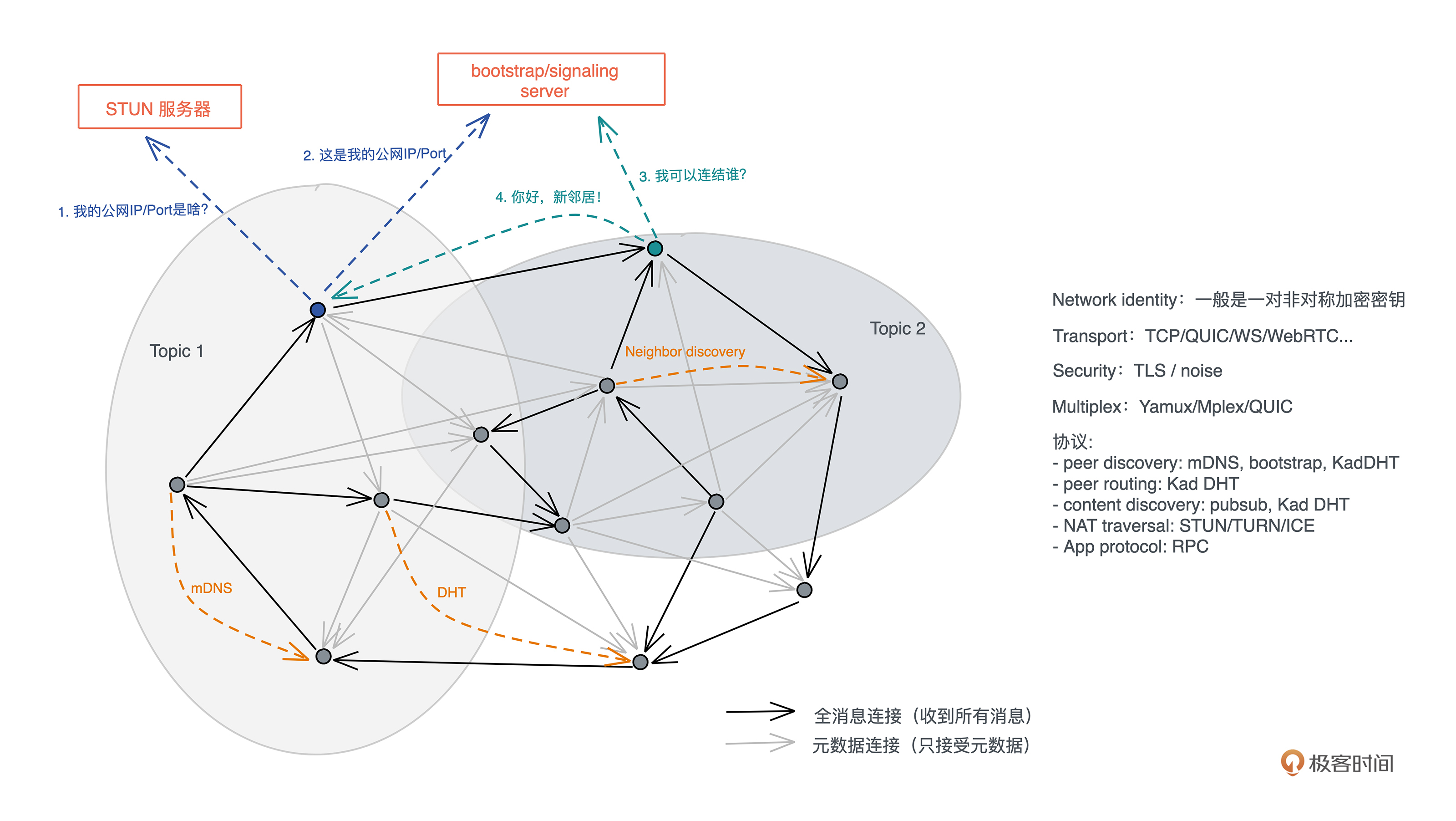
承载多个协议
P2P 网络的构建,一般要比客户端 / 服务器网络复杂,因为节点间的连接要承载很多协议:
-
节点发现(mDNS、bootstrap、Kad DHT)
-
节点路由(Kad DHT)
-
内容发现(pubsub、Kad DHT)
-
应用层协议
同时,连接的安全性受到的挑战也和之前不同。

网络安全解决
在网络安全方面,TLS 虽然能很好地保护客户端 / 服务器模型,然而证书的创建、发放以及信任对 P2P 网络是个问题
所以 P2P 网络倾向于使用自己的安全协议,或者使用 noise protocol,来构建安全等级可以媲美 TLS 1.3 的安全协议。
Rust 如何处理 P2P 网络
在 Rust 下,有 **libp2p 这个比较成熟的库**来处理 P2P 网络。
P2P聊天应用
例子: 下面是一个简单的 P2P 聊天应用:在本地网络中通过 MDNS 做节点发现,使用 floodpub 做消息传播。 (github)
在关键位置都写了注释:
use anyhow::Result; use futures::StreamExt; use libp2p::{ core::upgrade, floodsub::{self, Floodsub, FloodsubEvent, Topic}, identity, mdns::{Mdns, MdnsEvent}, noise, swarm::{NetworkBehaviourEventProcess, SwarmBuilder, SwarmEvent}, tcp::TokioTcpConfig, yamux, NetworkBehaviour, PeerId, Swarm, Transport, }; use std::borrow::Cow; use tokio::io::{stdin, AsyncBufReadExt, BufReader}; /// 处理 p2p 网络的 behavior 数据结构 /// 里面的每个域需要实现 NetworkBehaviour,或者使用 #[behaviour(ignore)] #[derive(NetworkBehaviour)] #[behaviour(event_process = true)] struct ChatBehavior { /// flood subscription,比较浪费带宽,gossipsub 是更好的选择 floodsub: Floodsub, /// 本地节点发现机制 mdns: Mdns, // 在 behavior 结构中,你也可以放其它数据,但需要 ignore // #[behaviour(ignore)] // _useless: String, } impl ChatBehavior { /// 创建一个新的 ChatBehavior pub async fn new(id: PeerId) -> Result<Self> { Ok(Self { mdns: Mdns::new(Default::default()).await?, floodsub: Floodsub::new(id), }) } } impl NetworkBehaviourEventProcess<FloodsubEvent> for ChatBehavior { // 处理 floodsub 产生的消息 fn inject_event(&mut self, event: FloodsubEvent) { if let FloodsubEvent::Message(msg) = event { let text = String::from_utf8_lossy(&msg.data); println!("{:?}: {:?}", msg.source, text); } } } impl NetworkBehaviourEventProcess<MdnsEvent> for ChatBehavior { fn inject_event(&mut self, event: MdnsEvent) { match event { MdnsEvent::Discovered(list) => { // 把 mdns 发现的新的 peer 加入到 floodsub 的 view 中 for (id, addr) in list { println!("Got peer: {} with addr {}", &id, &addr); self.floodsub.add_node_to_partial_view(id); } } MdnsEvent::Expired(list) => { // 把 mdns 发现的离开的 peer 加入到 floodsub 的 view 中 for (id, addr) in list { println!("Removed peer: {} with addr {}", &id, &addr); self.floodsub.remove_node_from_partial_view(&id); } } } } } #[tokio::main] async fn main() -> Result<()> { // 如果带参数,当成一个 topic let name = match std::env::args().nth(1) { Some(arg) => Cow::Owned(arg), None => Cow::Borrowed("lobby"), }; // 创建 floodsub topic let topic = floodsub::Topic::new(name); // 创建 swarm let mut swarm = create_swarm(topic.clone()).await?; swarm.listen_on("/ip4/127.0.0.1/tcp/0".parse()?)?; // 获取 stdin 的每一行 let mut stdin = BufReader::new(stdin()).lines(); // main loop loop { tokio::select! { line = stdin.next_line() => { let line = line?.expect("stdin closed"); swarm.behaviour_mut().floodsub.publish(topic.clone(), line.as_bytes()); } event = swarm.select_next_some() => { if let SwarmEvent::NewListenAddr { address, .. } = event { println!("Listening on {:?}", address); } } } } } async fn create_swarm(topic: Topic) -> Result<Swarm<ChatBehavior>> { // 创建 identity(密钥对) let id_keys = identity::Keypair::generate_ed25519(); let peer_id = PeerId::from(id_keys.public()); println!("Local peer id: {:?}", peer_id); // 使用 noise protocol 来处理加密和认证 let noise_keys = noise::Keypair::<noise::X25519Spec>::new().into_authentic(&id_keys)?; // 创建传输层 let transport = TokioTcpConfig::new() .nodelay(true) .upgrade(upgrade::Version::V1) .authenticate(noise::NoiseConfig::xx(noise_keys).into_authenticated()) .multiplex(yamux::YamuxConfig::default()) .boxed(); // 创建 chat behavior let mut behavior = ChatBehavior::new(peer_id).await?; // 订阅某个主题 behavior.floodsub.subscribe(topic.clone()); // 创建 swarm let swarm = SwarmBuilder::new(transport, behavior, peer_id) .executor(Box::new(|fut| { tokio::spawn(fut); })) .build(); Ok(swarm) }
要运行这段代码,你需要在 Cargo.toml 中使用 futures 和 libp2p:
futures = "0.3"
libp2p = { version = "0.39", features = ["tcp-tokio"] }
演示
例子: 开一个窗口 A 运行:
❯ cargo run --example p2p_chat --quiet
Local peer id: PeerId("12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg")
Listening on "/ip4/127.0.0.1/tcp/51654"
// 下面的内容在新节点加入时逐渐出现
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/192.168.86.23/tcp/51656
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/127.0.0.1/tcp/51656
Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/192.168.86.23/tcp/51661
Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/127.0.0.1/tcp/51661
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/192.168.86.23/tcp/51670
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/127.0.0.1/tcp/51670
例子: 窗口 B
#![allow(unused)] fn main() { ❯ cargo run --example p2p_chat --quiet Local peer id: PeerId("12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA") Listening on "/ip4/127.0.0.1/tcp/51656" Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/192.168.86.23/tcp/51654 Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/127.0.0.1/tcp/51654 // 下面的内容在新节点加入时逐渐出现 Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/192.168.86.23/tcp/51661 Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/127.0.0.1/tcp/51661 Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/192.168.86.23/tcp/51670 Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/127.0.0.1/tcp/51670 }
例子: 窗口C
❯ cargo run --example p2p_chat --quiet
Local peer id: PeerId("12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT")
Listening on "/ip4/127.0.0.1/tcp/51661"
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/192.168.86.23/tcp/51656
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/127.0.0.1/tcp/51656
Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/192.168.86.23/tcp/51654
Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/127.0.0.1/tcp/51654
// 下面的内容在新节点加入时逐渐出现
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/192.168.86.23/tcp/51670
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/127.0.0.1/tcp/51670
例子: 窗口 D 使用 topic 参数,让它和其它的 topic 不同
#![allow(unused)] fn main() { ❯ cargo run --example p2p_chat --quiet -- hello Local peer id: PeerId("12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh") Listening on "/ip4/127.0.0.1/tcp/51670" Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/192.168.86.23/tcp/51661 Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/127.0.0.1/tcp/51661 Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/192.168.86.23/tcp/51656 Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/127.0.0.1/tcp/51656 Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/192.168.86.23/tcp/51654 Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/127.0.0.1/tcp/51654 }
你会看到,每个节点运行时,都会通过 MDNS 广播,来发现本地已有的 P2P 节点。
现在 A/B/C/D 组成了一个 P2P 网络,其中 A/B/C 都订阅了 lobby,而 D 订阅了 hello。
例子: 我们在 A/B/C/D 四个窗口中分别输入 “Hello from X”,可以看到
- 窗口 A:
hello from A
PeerId("12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA"): "hello from B"
PeerId("12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT"): "hello from C"
- 窗口 B:
PeerId("12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg"): "hello from A"
hello from B
PeerId("12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT"): "hello from C"
- 窗口 C:
#![allow(unused)] fn main() { PeerId("12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg"): "hello from A" PeerId("12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA"): "hello from B" hello from C }
- 窗口 D:
#![allow(unused)] fn main() { hello from D }
可以看到,在 lobby 下的 A/B/C 都收到了各自的消息。
这个使用 libp2p 的聊天代码,如果你读不懂,没关系。
P2P 有大量的新的概念和协议需要预先掌握,所以如果你对这些概念和协议感兴趣,可以自行阅读 * libp2p 的文档* ,以及它的**示例代码**。
通讯模型练习题
- 看一看 libp2p 的文档和示例代码,把 libp2p clone 到本地,运行每个示例代码。
- 阅读 libp2p 的 NetworkBehaviour trait ,以及 floodsub 对应的实现。
- 尝试把P2P聊天应用例子中的 floodsub 替换成**更高效更节省带宽的 gossipsub**。
KV Server设计与实现
整体回顾
我们的 KV server 之旅就到此为止了。在整整 7 堂课里,我们一点点从零构造了一个完整的 KV server,包括注释在内,撰写了近三千行代码:
使用tokei检查代码行数
❯ tokei .
-------------------------------------------------------------------------------
Language Files Lines Code Comments Blanks
-------------------------------------------------------------------------------
Makefile 1 24 16 1 7
Markdown 1 7 7 0 0
Protocol Buffers 1 119 79 23 17
Rust 25 3366 2730 145 491
TOML 2 268 107 142 19
-------------------------------------------------------------------------------
Total 30 3784 2939 311 534
-------------------------------------------------------------------------------
在这个系列里:
- 我们大量使用 trait 和泛型,构建了很多复杂的数据结构;
- 还为自己的类型实现了 AsyncRead / AsyncWrite / Stream / Sink 这些比较高阶的 trait
- 通过良好的设计,我们把网络层和业务层划分地非常清晰,网络层的变化不会影响到业务层,反之亦然:
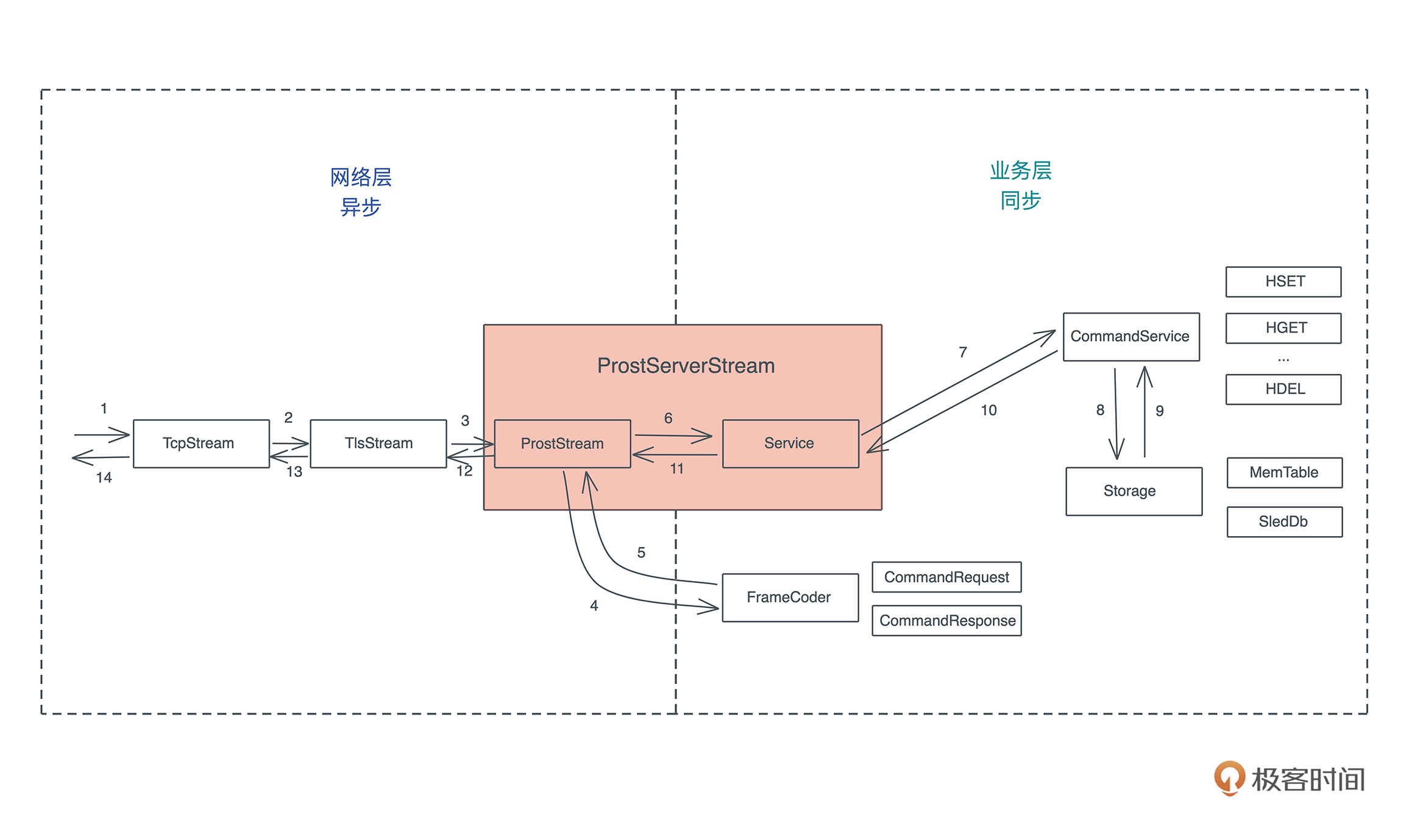
-
我们还模拟了比较真实的开发场景,通过大的需求变更,引发了一次不小的代码重构。
-
最终,通过性能测试,发现了一个客户端实现的小 bug。在处理这个 bug 的时候,我们欣喜地看到,Rust 有着非常强大的测试工具链,除了我们使用的单元测试、集成测试、性能测试,Rust 还支持模糊测试(fuzzy testing)和基于特性的测试(property testing)。
-
对于测试过程中发现的问题,Rust 有着非常完善的 tracing 工具链,可以和整个 opentelemetry 生态系统(包括 jaeger、prometheus 等工具)打通。我们就是通过使用 jaeger 找到并解决了问题。除此之外,Rust tracing 工具链还支持生成 flamegraph,篇幅关系,没有演示,你感兴趣的话可以试试。
希望通过这个系列,你对如何使用 Rust 的特性来构造应用程序有了深度的认识。
我相信,如果你能够跟得上这个系列的节奏,另外如果遇到新的库,用阅读代码的方式快速掌握,那么,大部分 Rust 开发中的挑战,对你而言都不是难事。
考虑提供日志配置
我们目前并未对日志做任何配置。一般来说,怎么做日志,会有相应的开关以及日志级别,如果希望能通过如下的配置记录日志,该怎么做?试试看:
[log]
enable_log_file = true
enable_jaeger = false
log_level = 'info'
path = '/tmp/kv-log'
rotation = 'Daily'
一、基本流程
Summarize
本文主要介绍了如何设计一个 KV server,从需求分析、基本流程、架构和设计等方面进行了讲解。
- 文章首先介绍了 KV server 的需求,然后通过一个简单的实现来说明过程式代码的缺点。
- 接着,文章提出了好的实现应该:
- 从系统的主流程开始,搞清楚从客户端的请求到最终客户端收到响应,都会经过哪些主要的步骤
- 然后根据这些步骤,思考哪些东西需要延迟绑定,构建主要的接口和 trait。
- 最后,文章介绍了客户端和服务器之间的协议、服务器和命令处理流程的接口、服务器和存储的接口等几个重要的接口,并使用 protobuf 定义了第一版支持的客户端命令。
为什么选 KV server 来实操呢?
因为它是一个足够简单又足够复杂的服务。
基础需求梳理
参考工作中用到的 Redis / Memcached 等服务,来梳理它的需求:
-
最核心的功能是根据不同的命令进行诸如数据存贮、读取、监听等操作;
-
而客户端要能通过网络访问 KV server,发送包含命令的请求,得到结果;
-
数据要能根据需要,存储在内存中或者持久化到磁盘上。
先来一个短平糙的实现
如果是为了完成任务构建 KV server,其实最初的版本两三百行代码就可以搞定,但是这样的代码以后维护起来就是灾难。
例子: 一个过程式的意大利版本
我们看一个省却了不少细节的意大利面条式的版本,你可以随着我的注释重点看流程:
use anyhow::Result; use async_prost::AsyncProstStream; use dashmap::DashMap; use futures::prelude::*; use kv::{ command_request::RequestData, CommandRequest, CommandResponse, Hset, KvError, Kvpair, Value, }; use std::sync::Arc; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { // 初始化日志 tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); // 使用 DashMap 创建放在内存中的 kv store let table: Arc<DashMap<String, Value>> = Arc::new(DashMap::new()); loop { // 得到一个客户端请求 let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); // 复制 db,让它在 tokio 任务中可以使用 let db = table.clone(); // 创建一个 tokio 任务处理这个客户端 tokio::spawn(async move { // 使用 AsyncProstStream 来处理 TCP Frame // Frame: 两字节 frame 长度,后面是 protobuf 二进制 let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); // 从 stream 里取下一个消息(拿出来后已经自动 decode 了) while let Some(Ok(msg)) = stream.next().await { info!("Got a new command: {:?}", msg); let resp: CommandResponse = match msg.request_data { // 为演示我们就处理 HSET Some(RequestData::Hset(cmd)) => hset(cmd, &db), // 其它暂不处理 _ => unimplemented!(), }; info!("Got response: {:?}", resp); // 把 CommandResponse 发送给客户端 stream.send(resp).await.unwrap(); } }); } } // 处理 hset 命令 fn hset(cmd: Hset, db: &DashMap<String, Value>) -> CommandResponse { match cmd.pair { Some(Kvpair { key, value: Some(v), }) => { // 往 db 里写入 let old = db.insert(key, v).unwrap_or_default(); // 把 value 转换成 CommandResponse old.into() } v => KvError::InvalidCommand(format!("hset: {:?}", v)).into(), } }
这段代码非常地平铺直叙,从输入到输出,一蹴而就,如果这样写,任务确实能很快完成,但是它有种“完成之后,哪管洪水滔天”的感觉。
你复制代码后,打开两个窗口,分别运行
cargo run --example naive_server
和
cargo run --example client
就可以看到运行 server 的窗口有如下打印:
Sep 19 22:25:34.016 INFO naive_server: Start listening on 127.0.0.1:9527
Sep 19 22:25:38.401 INFO naive_server: Client 127.0.0.1:51650 connected
Sep 19 22:25:38.401 INFO naive_server: Got a new command: CommandRequest { request_data: Some(Hset(Hset { table: "table1", pair: Some(Kvpair { key: "hello", value: Some(Value { value: Some(String("world")) }) }) })) }
Sep 19 22:25:38.401 INFO naive_server: Got response: CommandResponse { status: 200, message: "", values: [Value { value: None }], pairs: [] }
警告⚠️: 耦合严重
虽然整体功能算是搞定了,不过以后想继续为这个 KV server 增加新的功能,就需要来来回回改这段代码。
此外,也不好做单元测试,因为所有的逻辑都被压缩在一起了,没有“单元”可言。虽然未来可以逐步把不同的逻辑分离到不同的函数,使主流程尽可能简单一些。但是,它们依旧是耦合在一起的,如果不做大的重构,还是解决不了实质的问题。
所以不管用什么语言开发,这样的代码都是我们要极力避免的,不光自己不要这么写,code review 遇到别人这么写也要严格地揪出来。
架构和设计
那么,怎样才算是好的实现呢?
好的实现应该是:
- 在分析完需求后,首先从系统的主流程开始,搞清楚从客户端的请求到最终客户端收到响应,都会经过哪些主要的步骤;
- 然后根据这些步骤,思考哪些东西需要延迟绑定,构建主要的接口和 trait;
- 等这些东西深思熟虑之后,最后再考虑实现。也就是所谓的“谋定而后动”。
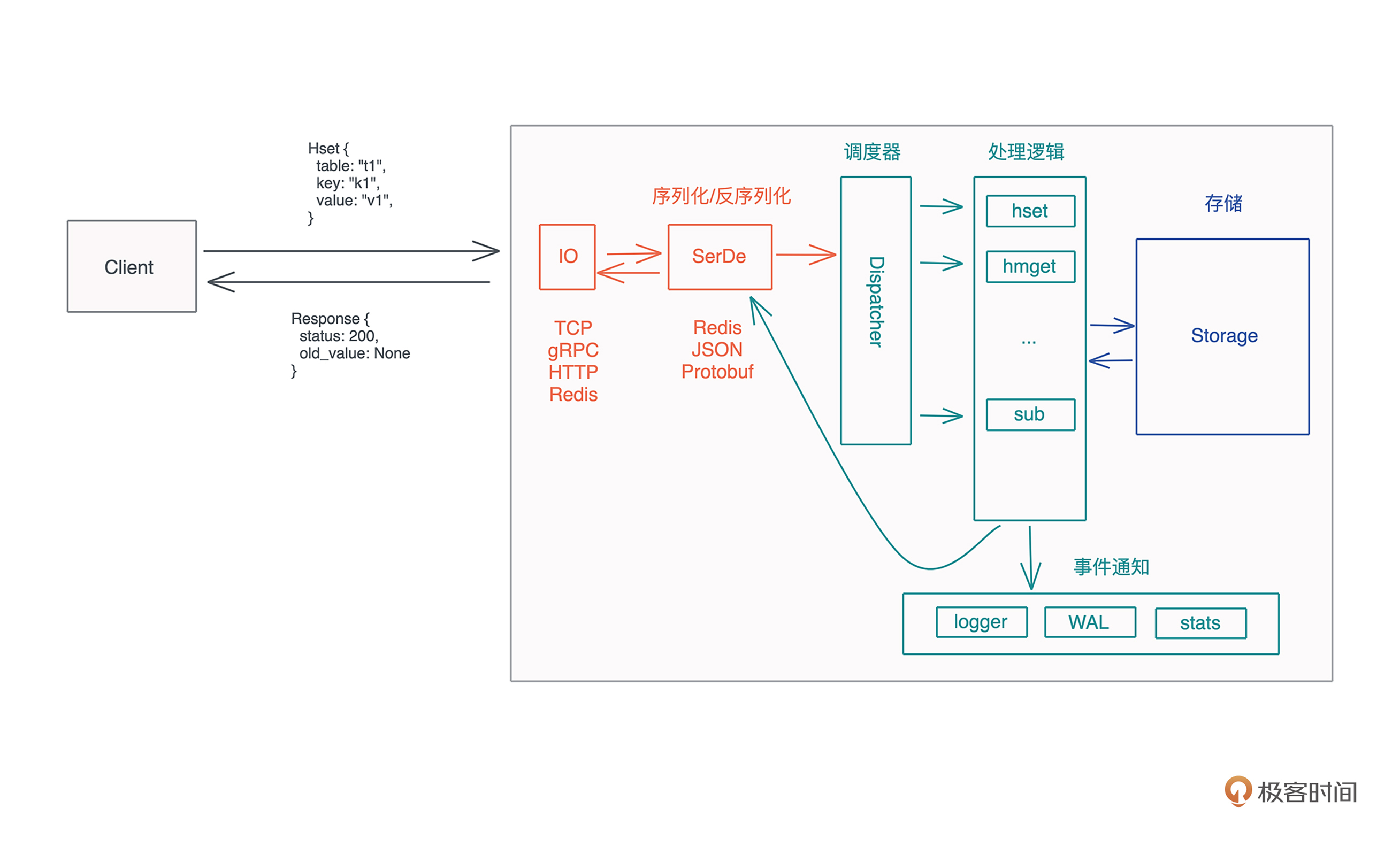
笔记:这个流程中有一些关键问题需要进一步探索
- 客户端和服务器用什么协议通信?TCP?gRPC?HTTP?支持一种还是多种?
- 客户端和服务器之间交互的应用层协议如何定义?怎么做序列化 / 反序列化?是用 Protobuf、JSON 还是 Redis RESP?或者也可以支持多种?
- 具体的处理逻辑中,需不需要加 hook,在处理过程中发布一些事件,让其他流程可以得到通知,进行额外的处理?这些 hook 可不可以提前终止整个流程的处理?
- 对于存储,要支持不同的存储引擎么?比如 MemDB(内存)、RocksDB(磁盘)、SledDB(磁盘)等。对于 MemDB,我们考虑支持 WAL(Write-Ahead Log) 和 snapshot 么?
- 整个系统可以配置么?比如服务使用哪个端口、哪个存储引擎?
如果你想做好架构,那么,问出这些问题,并且找到这些问题的答案就很重要。值得注意的是,这里面很多问题产品经理并不能帮你回答,或者 TA 的回答会将你带入歧路。作为一个架构师,我们需要对系统未来如何应对变化负责。
下面是我的思考,你可以参考:
-
像 KV server 这样需要高性能的场景,通信应该优先考虑 TCP 协议。所以我们暂时只支持 TCP,未来可以根据需要支持更多的协议,如 HTTP2/gRPC。还有,未来可能对安全性有额外的要求,所以我们要保证 TLS 这样的安全协议可以即插即用。总之,网络层需要灵活。
-
应用层协议我们可以用 protobuf 定义。protobuf 直接解决了协议的定义以及如何序列化和反序列化。Redis 的 RESP 固然不错,但它的短板也显而易见,命令需要额外的解析,而且大量的 \r\n 来分隔命令或者数据,也有些浪费带宽。使用 JSON 的话更加浪费带宽,且 JSON 的解析效率不高,尤其是数据量很大的时候。
protobuf 就很适合 KV server 这样的场景,灵活、可向后兼容式升级、解析效率很高、生成的二进制非常省带宽,唯一的缺点是需要额外的工具 protoc 来编译成不同的语言。虽然 protobuf 是首选,但也许未来为了和 Redis 客户端互通,还是要支持 RESP。
-
服务器支持的命令我们可以参考Redis 的命令集。第一版先来支持 HXXX 命令,比如 HSET、HMSET、HGET、HMGET 等。从命令到命令的响应,可以做个 trait 来抽象。
-
处理流程中计划加这些 hook:收到客户端的命令后 OnRequestReceived、处理完客户端的命令后 OnRequestExecuted、发送响应之前 BeforeResponseSend、发送响应之后 AfterResponseSend。这样,处理过程中的主要步骤都有事件暴露出去,让我们的 KV server 可以非常灵活,方便调用者在初始化服务的时候注入额外的处理逻辑。
-
存储必然需要足够灵活。可以对存储做个 trait 来抽象其基本的行为,一开始可以就只做 MemDB,未来肯定需要有支持持久化的存储。
-
需要支持配置,但优先级不高。等基本流程搞定,使用过程中发现足够的痛点,就可以考虑配置文件如何处理了。
当这些问题都敲定下来,系统的基本思路就有了。
主体交互接口
我们可以先把几个重要的接口定义出来,然后仔细审视这些接口。
客户端和服务器间的协议
首先是客户端和服务器之间的协议。
来试着用 protobuf 定义一下我们第一版支持的客户端命令:
syntax = "proto3";
package abi;
// 来自客户端的命令请求
message CommandRequest {
oneof request_data {
Hget hget = 1;
Hgetall hgetall = 2;
Hmget hmget = 3;
Hset hset = 4;
Hmset hmset = 5;
Hdel hdel = 6;
Hmdel hmdel = 7;
Hexist hexist = 8;
Hmexist hmexist = 9;
}
}
// 服务器的响应
message CommandResponse {
// 状态码;复用 HTTP 2xx/4xx/5xx 状态码
uint32 status = 1;
// 如果不是 2xx,message 里包含详细的信息
string message = 2;
// 成功返回的 values
repeated Value values = 3;
// 成功返回的 kv pairs
repeated Kvpair pairs = 4;
}
// 从 table 中获取一个 key,返回 value
message Hget {
string table = 1;
string key = 2;
}
// 从 table 中获取所有的 Kvpair
message Hgetall { string table = 1; }
// 从 table 中获取一组 key,返回它们的 value
message Hmget {
string table = 1;
repeated string keys = 2;
}
// 返回的值
message Value {
oneof value {
string string = 1;
bytes binary = 2;
int64 integer = 3;
double float = 4;
bool bool = 5;
}
}
// 返回的 kvpair
message Kvpair {
string key = 1;
Value value = 2;
}
// 往 table 里存一个 kvpair,
// 如果 table 不存在就创建这个 table
message Hset {
string table = 1;
Kvpair pair = 2;
}
// 往 table 中存一组 kvpair,
// 如果 table 不存在就创建这个 table
message Hmset {
string table = 1;
repeated Kvpair pairs = 2;
}
// 从 table 中删除一个 key,返回它之前的值
message Hdel {
string table = 1;
string key = 2;
}
// 从 table 中删除一组 key,返回它们之前的值
message Hmdel {
string table = 1;
repeated string keys = 2;
}
// 查看 key 是否存在
message Hexist {
string table = 1;
string key = 2;
}
// 查看一组 key 是否存在
message Hmexist {
string table = 1;
repeated string keys = 2;
}
通过 prost,这个 protobuf 文件可以被编译成 Rust 代码(主要是 struct 和 enum),供我们使用。你应该还记得,thumbor 的开发时,已经见识到了 prost 处理 protobuf 的方式了。
CommandService trait
客户端和服务器间的协议敲定之后,就要思考如何处理请求的命令,返回响应。
-
我们目前打算支持 9 种命令,未来可能支持更多命令。所以最好定义一个 trait 来统一处理所有的命令,返回处理结果。
-
在处理命令的时候,需要和存储发生关系,这样才能根据请求中携带的参数读取数据,或者把请求中的数据存入存储系统中。
- 所以,这个 trait 可以这么定义:
/// 对 Command 的处理的抽象 pub trait CommandService { /// 处理 Command,返回 Response fn execute(self, store: &impl Storage) -> CommandResponse; }
有了这个 trait,并且每一个命令都实现了这个 trait 后,dispatch 方法就可以是类似这样的代码:
// 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { match cmd.request_data { Some(RequestData::Hget(param)) => param.execute(store), Some(RequestData::Hgetall(param)) => param.execute(store), Some(RequestData::Hset(param)) => param.execute(store), None => KvError::InvalidCommand("Request has no data".into()).into(), _ => KvError::Internal("Not implemented".into()).into(), } }
Storage trait
再来看为不同的存储而设计的 Storage trait,它提供 KV store 的主要接口
/// 对存储的抽象,我们不关心数据存在哪儿,但需要定义外界如何和存储打交道 pub trait Storage { /// 从一个 HashTable 里获取一个 key 的 value fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; /// 从一个 HashTable 里设置一个 key 的 value,返回旧的 value fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError>; /// 查看 HashTable 中是否有 key fn contains(&self, table: &str, key: &str) -> Result<bool, KvError>; /// 从 HashTable 中删除一个 key fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; /// 遍历 HashTable,返回所有 kv pair(这个接口不好) fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError>; /// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; }
trait的好处
在 CommandService trait 中已经看到,在处理客户端请求的时候,与之打交道的是 Storage trait,而非具体的某个 store。
这样做的好处是,未来根据业务的需要,在不同的场景下添加不同的 store,只需要为其实现 Storage trait 即可,不必修改 CommandService 有关的代码。
比如在 HGET 命令的实现时,我们使用 Storage::get 方法,从 table 中获取数据,它跟某个具体的存储方案无关
比如在 HGET 命令的实现时,我们使用 Storage::get 方法,从 table 中获取数据,它跟某个具体的存储方案无关
impl CommandService for Hget { fn execute(self, store: &impl Storage) -> CommandResponse { match store.get(&self.table, &self.key) { Ok(Some(v)) => v.into(), Ok(None) => KvError::NotFound(self.table, self.key).into(), Err(e) => e.into(), } } }
为什么get_iter返回Box?
/// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>;
Storage trait 里面的绝大多数方法相信你可以定义出来,但 get_iter() 这个接口可能你会比较困惑,因为它返回了一个 Box
这是一个 trait object。
这里我们想返回一个 iterator:
- 调用者不关心它具体是什么类型,只要可以不停地调用 next() 方法取到下一个值就可以了。
- 不同的实现,可能返回不同的 iterator,如果要用同一个接口承载,我们需要使用 trait object。
- 在使用 trait object 时,因为 Iterator 是个带有关联类型的 trait,所以这里需要指明关联类型 Item 是什么类型,这样调用者才好拿到这个类型进行处理。
你也许会有疑问,set / del 明显是个会导致 self 修改的方法,为什么它的接口依旧使用的是 &self 呢?
KV Server使用HashMap数据结构
我们思考一下它的用法。对于 Storage trait,最简单的实现是 in-memory 的 HashMap。
由于我们支持的是 HSET / HGET 这样的命令,它们可以从不同的表中读取数据,所以需要嵌套的 HashMap,类似 HashMap<String, HashMap<String, Value>>。
另外,由于要在多线程 / 异步环境下读取和更新内存中的 HashMap,所以我们需要类似这样的结构:
Arc<RwLock<HashMap<String, Arc<RwLock<HashMap<String, Value>>>>>>
这个结构是一个多线程环境下具有内部可变性的数据结构,所以 get / set 的接口是 &self 就足够了。
为什么返回值都用Result<T, E>?
想一想,对于 Storage trait,为什么返回值都用了 Result<T, E>?在实现 MemTable 的时候,似乎所有返回都是 Ok(T) 啊?
Storage作为trait,需要关注IO操作失败的错误情况,而MemTable实现,都是内存操作,几乎不会失败,所以返回Ok(T)就可以了
二、实现并验证协议层
Summarize
本篇文章主要讲解了如何实现并验证协议层和Storage trait。
- 在实现协议层时,需要创建项目并添加依赖
- 处理protobuf,实现Storage trait和CommandService trait
- 最后实现Service结构。
- 在实现Storage trait时,需要定义外界如何和存储打交道,包括get、set、contains、del、get_all和get_iter等接口。
- 在实现过程中,使用了dashmap创建MemTable结构。
- 还提供了测试代码,帮助读者理解和实践。
还是按照上一讲定义接口的顺序来一个一个测试:首先我们来构建协议层。
创建项目,添加依赖
笔记:
- 先创建一个项目:cargo new kv –lib
- 进入到项目目录,在 Cargo.toml 中添加依赖:
[package]
name = "kv"
version = "0.1.0"
edition = "2018"
[dependencies]
bytes = "1" # 高效处理网络 buffer 的库
prost = "0.8" # 处理 protobuf 的代码
tracing = "0.1" # 日志处理
[dev-dependencies]
anyhow = "1" # 错误处理
async-prost = "0.2.1" # 支持把 protobuf 封装成 TCP frame
futures = "0.3" # 提供 Stream trait
tokio = { version = "1", features = ["rt", "rt-multi-thread", "io-util", "macros", "net" ] } # 异步网络库
tracing-subscriber = "0.2" # 日志处理
[build-dependencies]
prost-build = "0.8" # 编译 protobuf
protobuf处理
然后在项目根目录下创建 abi.proto,把上文中 protobuf 的代码放进去。
在根目录下,再创建 build.rs
fn main() { let mut config = prost_build::Config::new(); config.bytes(&["."]); config.type_attribute(".", "#[derive(PartialOrd)]"); config .out_dir("src/pb") .compile_protos(&["abi.proto"], &["."]) .unwrap(); }
- 这里我们为编译出来的代码额外添加了一些属性。比如为 protobuf 的 bytes 类型生成 Bytes 而非缺省的 Vec
,为所有类型加入 PartialOrd 派生宏。 - 关于 prost-build 的扩展,你可以看文档。
记得创建 src/pb 目录,否则编不过。
现在,在项目根目录下做 cargo build 会生成 src/pb/abi.rs 文件,里面包含所有 protobuf 定义的消息的 Rust 数据结构。
我们创建 src/pb/mod.rs,引入 abi.rs,并做一些基本的类型转换
pub mod abi; use abi::{command_request::RequestData, *}; impl CommandRequest { /// 创建 HSET 命令 pub fn new_hset(table: impl Into<String>, key: impl Into<String>, value: Value) -> Self { Self { request_data: Some(RequestData::Hset(Hset { table: table.into(), pair: Some(Kvpair::new(key, value)), })), } } } impl Kvpair { /// 创建一个新的 kv pair pub fn new(key: impl Into<String>, value: Value) -> Self { Self { key: key.into(), value: Some(value), } } } /// 从 String 转换成 Value impl From<String> for Value { fn from(s: String) -> Self { Self { value: Some(value::Value::String(s)), } } } /// 从 &str 转换成 Value impl From<&str> for Value { fn from(s: &str) -> Self { Self { value: Some(value::Value::String(s.into())), } } }
这样,我们就有了能把 KV server 最基本的 protobuf 接口运转起来的代码。
使用示例:examples
在根目录下创建 examples,这样可以写一些代码测试客户端和服务器之间的协议。
- 我们可以先创建一个 examples/client.rs 文件,写入如下代码:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv::{CommandRequest, CommandResponse}; use tokio::net::TcpStream; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; // 连接服务器 let stream = TcpStream::connect(addr).await?; // 使用 AsyncProstStream 来处理 TCP Frame let mut client = AsyncProstStream::<_, CommandResponse, CommandRequest, _>::from(stream).for_async(); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".into()); // 发送 HSET 命令 client.send(cmd).await?; if let Some(Ok(data)) = client.next().await { info!("Got response {:?}", data); } Ok(()) }
这段代码连接服务器的 9527 端口,发送一个 HSET 命令出去,然后等待服务器的响应。
- 同样的,我们创建一个 examples/dummy_server.rs 文件,写入代码:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv::{CommandRequest, CommandResponse}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); tokio::spawn(async move { let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); while let Some(Ok(msg)) = stream.next().await { info!("Got a new command: {:?}", msg); // 创建一个 404 response 返回给客户端 let mut resp = CommandResponse::default(); resp.status = 404; resp.message = "Not found".to_string(); stream.send(resp).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
在这段代码里,服务器监听 9527 端口,对任何客户端的请求,一律返回 status = 404,message 是 “Not found” 的响应。
如果你对这两段代码中的异步和网络处理半懂不懂,没关系,你先把代码抄下来运行。今天的内容跟网络无关,你重点看处理流程就行。未来会讲到网络和异步处理的。
运行测试
我们可以打开一个命令行窗口,运行:
RUST_LOG=info cargo run --example dummy_server --quiet。
然后在另一个命令行窗口,运行:
RUST_LOG=info cargo run --example client --quiet
此时,服务器和客户端都收到了彼此的请求和响应,协议层看上去运作良好。一旦验证通过,就你可以进入下一步,因为协议层的其它代码都只是工作量而已,在之后需要的时候可以慢慢实现。
实现并验证 Storage trait
接下来构建 Storage trait。
我们上一讲谈到了如何使用嵌套的支持并发的 im-memory HashMap 来实现 storage trait。由于 Arc<RwLock<HashMap<K, V>>> 这样的支持并发的 HashMap 是一个刚需,Rust 生态有很多相关的 crate 支持,这里我们可以使用 dashmap 创建一个 MemTable 结构,来实现 Storage trait。
实现
- 先创建 src/storage 目录
- 然后创建 src/storage/mod.rs,把刚才讨论的 trait 代码放进去后
- 在 src/lib.rs 中引入 “mod storage”。此时会发现一个错误:并未定义 KvError。
- 创建 src/error.rs,使用thiserror的派生宏自定义错误类型,然后填入:
use crate::Value; use thiserror::Error; #[derive(Error, Debug, PartialEq)] pub enum KvError { #[error("Not found for table: {0}, key: {1}")] NotFound(String, String), #[error("Cannot parse command: `{0}`")] InvalidCommand(String), #[error("Cannot convert value {:0} to {1}")] ConvertError(Value, &'static str), #[error("Cannot process command {0} with table: {1}, key: {2}. Error: {}")] StorageError(&'static str, String, String, String), #[error("Failed to encode protobuf message")] EncodeError(#[from] prost::EncodeError), #[error("Failed to decode protobuf message")] DecodeError(#[from] prost::DecodeError), #[error("Internal error: {0}")] Internal(String), }
这些 error 的定义其实是在实现过程中逐步添加的,但为了讲解方便,先一次性添加。对于 Storage 的实现,我们只关心 StorageError,其它的 error 定义未来会用到。
- 同样,在 src/lib.rs 下引入 mod error,现在 src/lib.rs 是这个样子的:
mod error; mod pb; mod storage; pub use error::KvError; pub use pb::abi::*; pub use storage::*;
src/storage/mod.rs 是这个样子的:
use crate::{KvError, Kvpair, Value}; /// 对存储的抽象,我们不关心数据存在哪儿,但需要定义外界如何和存储打交道 pub trait Storage { /// 从一个 HashTable 里获取一个 key 的 value fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; /// 从一个 HashTable 里设置一个 key 的 value,返回旧的 value fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError>; /// 查看 HashTable 中是否有 key fn contains(&self, table: &str, key: &str) -> Result<bool, KvError>; /// 从 HashTable 中删除一个 key fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; /// 遍历 HashTable,返回所有 kv pair(这个接口不好) fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError>; /// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; }
成功: 通过 Storage trait 已经大概知道 MemTable 怎么用,所以可以先写段测试体验一下
代码目前没有编译错误,可以在这个文件末尾添加测试代码,尝试使用这些接口了,当然,我们还没有构建 MemTable,但通过 Storage trait 已经大概知道 MemTable 怎么用,所以可以先写段测试体验一下:
#[cfg(test)] mod tests { use super::*; #[test] fn memtable_basic_interface_should_work() { let store = MemTable::new(); test_basi_interface(store); } #[test] fn memtable_get_all_should_work() { let store = MemTable::new(); test_get_all(store); } fn test_basi_interface(store: impl Storage) { // 第一次 set 会创建 table,插入 key 并返回 None(之前没值) let v = store.set("t1", "hello".into(), "world".into()); assert!(v.unwrap().is_none()); // 再次 set 同样的 key 会更新,并返回之前的值 let v1 = store.set("t1", "hello".into(), "world1".into()); assert_eq!(v1, Ok(Some("world".into()))); // get 存在的 key 会得到最新的值 let v = store.get("t1", "hello"); assert_eq!(v, Ok(Some("world1".into()))); // get 不存在的 key 或者 table 会得到 None assert_eq!(Ok(None), store.get("t1", "hello1")); assert!(store.get("t2", "hello1").unwrap().is_none()); // contains 纯在的 key 返回 true,否则 false assert_eq!(store.contains("t1", "hello"), Ok(true)); assert_eq!(store.contains("t1", "hello1"), Ok(false)); assert_eq!(store.contains("t2", "hello"), Ok(false)); // del 存在的 key 返回之前的值 let v = store.del("t1", "hello"); assert_eq!(v, Ok(Some("world1".into()))); // del 不存在的 key 或 table 返回 None assert_eq!(Ok(None), store.del("t1", "hello1")); assert_eq!(Ok(None), store.del("t2", "hello")); } fn test_get_all(store: impl Storage) { store.set("t2", "k1".into(), "v1".into()).unwrap(); store.set("t2", "k2".into(), "v2".into()).unwrap(); let mut data = store.get_all("t2").unwrap(); data.sort_by(|a, b| a.partial_cmp(b).unwrap()); assert_eq!( data, vec![ Kvpair::new("k1", "v1".into()), Kvpair::new("k2", "v2".into()) ] ) } fn test_get_iter(store: impl Storage) { store.set("t2", "k1".into(), "v1".into()).unwrap(); store.set("t2", "k2".into(), "v2".into()).unwrap(); let mut data: Vec<_> = store.get_iter("t2").unwrap().collect(); data.sort_by(|a, b| a.partial_cmp(b).unwrap()); assert_eq!( data, vec![ Kvpair::new("k1", "v1".into()), Kvpair::new("k2", "v2".into()) ] ) } }
这种在写实现之前写单元测试,是标准的 TDD(Test-Driven Development)方式。
这种在写实现之前写单元测试,是标准的 TDD(Test-Driven Development)方式。
我个人不是 TDD 的狂热粉丝,但会在构建完 trait 后,为这个 trait 撰写测试代码,因为写测试代码是个很好的验证接口是否好用的时机。毕竟我们不希望实现 trait 之后,才发现 trait 的定义有瑕疵,需要修改,这个时候改动的代价就比较大了。
所以,当 trait 推敲完毕,就可以开始写使用 trait 的测试代码了。在使用过程中仔细感受,如果写测试用例时用得不舒服,或者为了使用它需要做很多繁琐的操作,那么可以重新审视 trait 的设计。
你如果仔细看单元测试的代码,就会发现我始终秉持测试 trait 接口的思想。尽管在测试中需要一个实际的数据结构进行 trait 方法的测试,但核心的测试代码都用的泛型函数,让这些代码只跟 trait 相关。
这样:
- 一来可以避免某个具体 trait 实现的干扰
- 二来在之后想加入更多 trait 实现时,可以共享测试代码。
- 比如未来想支持 DiskTable,那么只消加几个测试例,调用已有的泛型函数即可。
好,搞定测试,确认 trait 设计没有什么问题之后,我们来写具体实现。
构建MemTable
可以创建 src/storage/memory.rs 来构建 MemTable:
use crate::{KvError, Kvpair, Storage, Value}; use dashmap::{mapref::one::Ref, DashMap}; /// 使用 DashMap 构建的 MemTable,实现了 Storage trait #[derive(Clone, Debug, Default)] pub struct MemTable { tables: DashMap<String, DashMap<String, Value>>, } impl MemTable { /// 创建一个缺省的 MemTable pub fn new() -> Self { Self::default() } /// 如果名为 name 的 hash table 不存在,则创建,否则返回 fn get_or_create_table(&self, name: &str) -> Ref<String, DashMap<String, Value>> { match self.tables.get(name) { Some(table) => table, None => { let entry = self.tables.entry(name.into()).or_default(); entry.downgrade() } } } } impl Storage for MemTable { fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> { let table = self.get_or_create_table(table); Ok(table.get(key).map(|v| v.value().clone())) } fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError> { let table = self.get_or_create_table(table); Ok(table.insert(key, value)) } fn contains(&self, table: &str, key: &str) -> Result<bool, KvError> { let table = self.get_or_create_table(table); Ok(table.contains_key(key)) } fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> { let table = self.get_or_create_table(table); Ok(table.remove(key).map(|(_k, v)| v)) } fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError> { let table = self.get_or_create_table(table); Ok(table .iter() .map(|v| Kvpair::new(v.key(), v.value().clone())) .collect()) } fn get_iter(&self, _table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { todo!() } }
-
除了 get_iter() 外,这个实现代码非常简单,相信你看一下 dashmap 的文档,也能很快写出来。
-
get_iter() 写起来稍微有些难度,我们先放下不表,后面讲。
-
如果你对此感兴趣,想挑战一下,欢迎尝试。
实现完成之后,我们可以测试它是否符合预期。
警告⚠️: 要在 src/storage/mod.rs 开头添加代码
注意现在 src/storage/memory.rs 还没有被添加,所以 cargo 并不会编译它。要在 src/storage/mod.rs 开头添加代码:
mod memory; pub use memory::MemTable;
这样代码就可以编译通过了。因为还没有实现 get_iter 方法,所以这个测试需要被注释掉:
// #[test] // fn memtable_iter_should_work() { // let store = MemTable::new(); // test_get_iter(store); // }
测试
如果你运行 cargo test ,可以看到测试都通过了:
\> cargo test
Compiling kv v0.1.0 (/Users/tchen/projects/mycode/rust/geek-time-rust-resources/21/kv)
Finished test [unoptimized + debuginfo] target(s) in 1.95s
Running unittests (/Users/tchen/.target/debug/deps/kv-8d746b0f387a5271)
running 2 tests
test storage::tests::memtable_basic_interface_should_work ... ok
test storage::tests::memtable_get_all_should_work ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in0.00s
Doc-tests kv
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in0.00s
实现并验证 CommandService trait
笔记: Storage trait 我们就算基本验证通过了,现在再来验证 CommandService
Storage trait 我们就算基本验证通过了,现在再来验证 CommandService。
- 我们创建 src/service 目录
- 以及 src/service/mod.rs
- 和 src/service/command_service.rs 文件
- 并在 src/service/mod.rs 写入:
use crate::*; mod command_service; /// 对 Command 的处理的抽象 pub trait CommandService { /// 处理 Command,返回 Response fn execute(self, store: &impl Storage) -> CommandResponse; }
-
然后,在 src/service/command_service.rs 中,我们可以先写一些测试
为了简单起见,就列 HSET、HGET、HGETALL 三个命令:
use crate::*; #[cfg(test)] mod tests { use super::*; use crate::command_request::RequestData; #[test] fn hset_should_work() { let store = MemTable::new(); let cmd = CommandRequest::new_hset("t1", "hello", "world".into()); let res = dispatch(cmd.clone(), &store); assert_res_ok(res, &[Value::default()], &[]); let res = dispatch(cmd, &store); assert_res_ok(res, &["world".into()], &[]); } #[test] fn hget_should_work() { let store = MemTable::new(); let cmd = CommandRequest::new_hset("score", "u1", 10.into()); dispatch(cmd, &store); let cmd = CommandRequest::new_hget("score", "u1"); let res = dispatch(cmd, &store); assert_res_ok(res, &[10.into()], &[]); } #[test] fn hget_with_non_exist_key_should_return_404() { let store = MemTable::new(); let cmd = CommandRequest::new_hget("score", "u1"); let res = dispatch(cmd, &store); assert_res_error(res, 404, "Not found"); } #[test] fn hgetall_should_work() { let store = MemTable::new(); let cmds = vec![ CommandRequest::new_hset("score", "u1", 10.into()), CommandRequest::new_hset("score", "u2", 8.into()), CommandRequest::new_hset("score", "u3", 11.into()), CommandRequest::new_hset("score", "u1", 6.into()), ]; for cmd in cmds { dispatch(cmd, &store); } let cmd = CommandRequest::new_hgetall("score"); let res = dispatch(cmd, &store); let pairs = &[ Kvpair::new("u1", 6.into()), Kvpair::new("u2", 8.into()), Kvpair::new("u3", 11.into()), ]; assert_res_ok(res, &[], pairs); } // 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { match cmd.request_data.unwrap() { RequestData::Hget(v) => v.execute(store), RequestData::Hgetall(v) => v.execute(store), RequestData::Hset(v) => v.execute(store), _ => todo!(), } } // 测试成功返回的结果 fn assert_res_ok(mut res: CommandResponse, values: &[Value], pairs: &[Kvpair]) { res.pairs.sort_by(|a, b| a.partial_cmp(b).unwrap()); assert_eq!(res.status, 200); assert_eq!(res.message, ""); assert_eq!(res.values, values); assert_eq!(res.pairs, pairs); } // 测试失败返回的结果 fn assert_res_error(res: CommandResponse, code: u32, msg: &str) { assert_eq!(res.status, code); assert!(res.message.contains(msg)); assert_eq!(res.values, &[]); assert_eq!(res.pairs, &[]); } }
这些测试的作用就是验证产品需求,比如
这些测试的作用就是验证产品需求,比如:
-
HSET 成功返回上一次的值(这和 Redis 略有不同,Redis 返回表示多少 key 受影响的一个整数)
-
HGET 返回 Value
-
HGETALL 返回一组无序的 Kvpair
目前这些测试是无法编译通过的,因为里面使用了一些未定义的方法
目前这些测试是无法编译通过的,因为里面使用了一些未定义的方法,比如
- 10.into():想把整数 10 转换成一个 Value
- CommandRequest::new_hgetall(“score”):想生成一个 HGETALL 命令。
为什么要这么写?
因为如果是 CommandService 接口的使用者,自然希望使用这个接口的时候,调用的整体感觉非常简单明了
因为如果是 CommandService 接口的使用者,自然希望使用这个接口的时候,调用的整体感觉非常简单明了。
如果接口期待一个 Value,但在上下文中拿到的是 10、“hello” 这样的值,那我们作为设计者就要考虑为 Value 实现 From
到现在为止我们写了两轮测试了,相信你对测试代码的作用有大概理解。我们来总结一下:
- 验证并帮助接口迭代
- 验证产品需求
- 通过使用核心逻辑,帮助我们更好地思考外围逻辑并反推其实现
前两点是最基本的,也是很多人对 TDD 的理解,其实还有更重要的也就是第三点。除了前面的辅助函数外,我们在测试代码中还看到了 dispatch 函数,它目前用来辅助测试。但紧接着你会发现,这样的辅助函数,可以合并到核心代码中。这才是“测试驱动开发”的实质。
在 src/pb/mod.rs 中添加相关的外围逻辑
笔记:好,根据测试,我们需要在 src/pb/mod.rs 中添加相关的外围逻辑
- 首先是 CommandRequest 的一些方法,之前写了 new_hset,现在再加入 new_hget 和 new_hgetall:
impl CommandRequest { /// 创建 HGET 命令 pub fn new_hget(table: impl Into<String>, key: impl Into<String>) -> Self { Self { request_data: Some(RequestData::Hget(Hget { table: table.into(), key: key.into(), })), } } /// 创建 HGETALL 命令 pub fn new_hgetall(table: impl Into<String>) -> Self { Self { request_data: Some(RequestData::Hgetall(Hgetall { table: table.into(), })), } } /// 创建 HSET 命令 pub fn new_hset(table: impl Into<String>, key: impl Into<String>, value: Value) -> Self { Self { request_data: Some(RequestData::Hset(Hset { table: table.into(), pair: Some(Kvpair::new(key, value)), })), } } }
- 然后写对 Value 的 From
的实现:
/// 从 i64转换成 Value impl From<i64> for Value { fn from(i: i64) -> Self { Self { value: Some(value::Value::Integer(i)), } } }
- 测试代码目前就可以编译通过了,然而测试显然会失败,因为还没有做具体的实现。我们在 src/service/command_service.rs 下添加 trait 的实现代码:
impl CommandService for Hget { fn execute(self, store: &impl Storage) -> CommandResponse { match store.get(&self.table, &self.key) { Ok(Some(v)) => v.into(), Ok(None) => KvError::NotFound(self.table, self.key).into(), Err(e) => e.into(), } } } impl CommandService for Hgetall { fn execute(self, store: &impl Storage) -> CommandResponse { match store.get_all(&self.table) { Ok(v) => v.into(), Err(e) => e.into(), } } } impl CommandService for Hset { fn execute(self, store: &impl Storage) -> CommandResponse { match self.pair { Some(v) => match store.set(&self.table, v.key, v.value.unwrap_or_default()) { Ok(Some(v)) => v.into(), Ok(None) => Value::default().into(), Err(e) => e.into(), }, None => Value::default().into(), } } }
这自然会引发更多的编译错误,因为我们很多地方都是用了 into() 方法,却没有实现相应的转换,比如,Value 到 CommandResponse 的转换、KvError 到 CommandResponse 的转换、Vec
到 CommandResponse 的转换等等。
- 所以在 src/pb/mod.rs 里继续补上相应的外围逻辑:
/// 从 Value 转换成 CommandResponse impl From<Value> for CommandResponse { fn from(v: Value) -> Self { Self { status: StatusCode::OK.as_u16() as _, values: vec![v], ..Default::default() } } } /// 从 Vec<Kvpair> 转换成 CommandResponse impl From<Vec<Kvpair>> for CommandResponse { fn from(v: Vec<Kvpair>) -> Self { Self { status: StatusCode::OK.as_u16() as _, pairs: v, ..Default::default() } } } /// 从 KvError 转换成 CommandResponse impl From<KvError> for CommandResponse { fn from(e: KvError) -> Self { let mut result = Self { status: StatusCode::INTERNAL_SERVER_ERROR.as_u16() as _, message: e.to_string(), values: vec![], pairs: vec![], }; match e { KvError::NotFound(_, _) => result.status = StatusCode::NOT_FOUND.as_u16() as _, KvError::InvalidCommand(_) => result.status = StatusCode::BAD_REQUEST.as_u16() as _, _ => {} } result } }
into()和struct绕过孤儿原则
从前面写接口到这里具体实现,不知道你是否感受到了这样一种模式:
- 在 Rust 下,但凡出现两个数据结构 v1 到 v2 的转换,你都可以先以 v1.into() 来表示这个逻辑,继续往下写代码
- 之后再去补 From
的实现 - 如果 v1 和 v2 都不是你定义的数据结构,那么你需要把其中之一用 struct 包装一下,来绕过之前提到的孤儿规则。
现在代码应该可以编译通过并测试通过了,你可以 cargo test 测试一下。
最后的拼图:Service 结构的实现
好,所有的接口,包括客户端 / 服务器的协议接口、Storage trait 和 CommandService trait 都验证好了,接下来就是考虑如何用一个数据结构把所有这些东西串联起来。
笔记: 依旧从使用者的角度来看如何调用它。为此,我们在 src/service/mod.rs 里添加如下的测试代码:
#[cfg(test)] mod tests { use super::*; use crate::{MemTable, Value}; #[test] fn service_should_works() { // 我们需要一个 service 结构至少包含 Storage let service = Service::new(MemTable::default()); // service 可以运行在多线程环境下,它的 clone 应该是轻量级的 let cloned = service.clone(); // 创建一个线程,在 table t1 中写入 k1, v1 let handle = thread::spawn(move || { let res = cloned.execute(CommandRequest::new_hset("t1", "k1", "v1".into())); assert_res_ok(res, &[Value::default()], &[]); }); handle.join().unwrap(); // 在当前线程下读取 table t1 的 k1,应该返回 v1 let res = service.execute(CommandRequest::new_hget("t1", "k1")); assert_res_ok(res, &["v1".into()], &[]); } } #[cfg(test)] use crate::{Kvpair, Value}; // 测试成功返回的结果 #[cfg(test)] pub fn assert_res_ok(mut res: CommandResponse, values: &[Value], pairs: &[Kvpair]) { res.pairs.sort_by(|a, b| a.partial_cmp(b).unwrap()); assert_eq!(res.status, 200); assert_eq!(res.message, ""); assert_eq!(res.values, values); assert_eq!(res.pairs, pairs); } // 测试失败返回的结果 #[cfg(test)] pub fn assert_res_error(res: CommandResponse, code: u32, msg: &str) { assert_eq!(res.status, code); assert!(res.message.contains(msg)); assert_eq!(res.values, &[]); assert_eq!(res.pairs, &[]); }
注意,这里的 assert_res_ok() 和 assert_res_error() 是从 src/service/command_service.rs 中挪过来的。在开发的过程中,不光产品代码需要不断重构,测试代码也需要重构来贯彻 DRY 思想。
围绕接口测试
提示:那什么样的测试代码是稳定的?测试接口的代码是稳定的。
我见过很多生产环境的代码,产品功能部分还说得过去,但测试代码像是个粪坑,经年累月地 copy/paste 使其臭气熏天,每个开发者在添加新功能的时候,都掩着鼻子往里扔一坨走人,使得维护难度越来越高,每次需求变动,都涉及一大坨测试代码的变动,这样非常不好。
测试代码的质量也要和产品代码的质量同等要求。好的开发者写的测试代码的可读性也是非常强的。你可以对比上面写的三段测试代码多多感受。
在撰写测试的时候,我们要特别注意:测试代码要围绕着系统稳定的部分,也就是接口,来测试,而尽可能少地测试实现。这是我对这么多年工作中血淋淋的教训的深刻总结。
因为产品代码和测试代码,两者总需要一个是相对稳定的,既然产品代码会不断地根据需求变动,测试代码就必然需要稳定一些。
那什么样的测试代码是稳定的?测试接口的代码是稳定的。只要接口不变,无论具体实现如何变化,哪怕今天引入一个新的算法,明天重写实现,测试代码依旧能够凛然不动,做好产品质量的看门狗。
继续写代码
好,我们回来写代码。在这段测试中,已经敲定了 Service 这个数据结构的使用蓝图,它可以跨线程,可以调用 execute 来执行某个 CommandRequest 命令,返回 CommandResponse。
根据这些想法,在 src/service/mod.rs 里添加 Service 的声明和实现:
/// Service 数据结构 pub struct Service<Store = MemTable> { inner: Arc<ServiceInner<Store>>, } impl<Store> Clone for Service<Store> { fn clone(&self) -> Self { Self { inner: Arc::clone(&self.inner), } } } /// Service 内部数据结构 pub struct ServiceInner<Store> { store: Store, } impl<Store: Storage> Service<Store> { pub fn new(store: Store) -> Self { Self { inner: Arc::new(ServiceInner { store }), } } pub fn execute(&self, cmd: CommandRequest) -> CommandResponse { debug!("Got request: {:?}", cmd); // TODO: 发送 on_received 事件 let res = dispatch(cmd, &self.inner.store); debug!("Executed response: {:?}", res); // TODO: 发送 on_executed 事件 res } } // 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { match cmd.request_data { Some(RequestData::Hget(param)) => param.execute(store), Some(RequestData::Hgetall(param)) => param.execute(store), Some(RequestData::Hset(param)) => param.execute(store), None => KvError::InvalidCommand("Request has no data".into()).into(), _ => KvError::Internal("Not implemented".into()).into(), } }
这段代码有几个地方值得注意:
-
首先 Service 结构内部有一个 ServiceInner 存放实际的数据结构,Service 只是用 Arc 包裹了 ServiceInner。这也是 Rust 的一个惯例,把需要在多线程下 clone 的主体和其内部结构分开,这样代码逻辑更加清晰。
-
execute() 方法目前就是调用了 dispatch,但它未来潜在可以做一些事件分发。这样处理体现了 SRP(Single Responsibility Principle)原则。
-
dispatch 其实就是把测试代码的 dispatch 逻辑移动过来改动了一下。
再一次,我们重构了测试代码,把它的辅助函数变成了产品代码的一部分。现在,你可以运行 cargo test 测试一下,如果代码无法编译,可能是缺一些 use 代码,比如:
use crate::{ command_request::RequestData, CommandRequest, CommandResponse, KvError, MemTable, Storage, }; use std::sync::Arc; use tracing::debug;
新的 server
现在处理逻辑已经都完成了,可以写个新的 example 测试服务器代码。
- 把之前的 examples/dummy_server.rs 复制一份,成为 examples/server.rs,然后引入 Service,主要的改动就三句:
// main 函数开头,初始化 service let service: Service = Service::new(MemTable::new()); // tokio::spawn 之前,复制一份 service let svc = service.clone(); // while loop 中,使用 svc 来执行 cmd let res = svc.execute(cmd);
- 你可以试着自己修改。完整的代码如下:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv::{CommandRequest, CommandResponse, MemTable, Service}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let service: Service = Service::new(MemTable::new()); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); while let Some(Ok(cmd)) = stream.next().await { let res = svc.execute(cmd); stream.send(res).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
运行
使用两个窗口分别模拟服务端与客户端
完成之后,打开一个命令行窗口,运行:
RUST_LOG=info cargo run --example server --quiet
然后在另一个命令行窗口,运行:
RUST_LOG=info cargo run --example server --quiet
此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。
我们的 KV server 第一版的基本功能就完工了!当然,目前还只处理了 3 个命令,剩下 6 个需要你自己完成。
初步感受Rust撰写代码最佳实践
有两点我们一定要认真领会
KV server 并不是一个很难的项目,但想要把它写好,并不简单。如果你跟着讲解一步步走下来,可以感受到一个有潜在生产环境质量的 Rust 项目应该如何开发。在这两讲内容中,有两点我们一定要认真领会。
-
你要对需求有一个清晰的把握,找出其中不稳定的部分(variant)和比较稳定的部分(invariant)。在 KV server 中,不稳定的部分是,对各种新的命令的支持,以及对不同的 storage 的支持。所以需要构建接口来消弭不稳定的因素,让不稳定的部分可以用一种稳定的方式来管理。
-
代码和测试可以围绕着接口螺旋前进,使用 TDD 可以帮助我们进行这种螺旋式的迭代。在一个设计良好的系统中:接口是稳定的,测试接口的代码是稳定的,实现可以是不稳定的。在迭代开发的过程中,我们要不断地重构,让测试代码和产品代码都往最优的方向发展。
纵观我们写的 KV server,包括测试在内,你很难发现有函数或者方法超过 50 行,代码可读性非常强,几乎不需要注释,就可以理解。另外因为都是用接口做的交互,未来维护和添加新的功能,也基本上满足 OCP 原则,除了 dispatch 函数需要很小的修改外,其它新的代码都是在实现一些接口而已。
相信你能初步感受到在 Rust 下撰写代码的最佳实践。如果你之前用其他语言,已经采用了类似的最佳实践,那么可以感受一下同样的实践在 Rust 下使用的那种优雅;如果你之前由于种种原因,写的是类似之前意大利面条似的代码,那在开发 Rust 程序时,你可以试着接纳这种更优雅的开发方式。
毕竟,现在我们手中有了更先进的武器,就可以用更先进的打法。
为剩下6个命令构建测试并实现
为剩下 6 个命令 HMGET、HMSET、HDEL、HMDEL、HEXIST、HMEXIST 构建测试,并实现它们。在测试和实现过程中,你也许需要添加更多的
From
考虑用线程池处理并发
虽然我们的 KV server 使用了 concurrent hashmap 来处理并发,但这并不一定是最好的选择。
我们也可以创建一个线程池,每个线程有自己的 HashMap。当 HGET/HSET 等命令来临时,可以对 key 做个哈希,然后分派到 “拥有” 那个 key 的线程,这样,可以避免在处理的时候加锁,提高系统的吞吐。你可以想想如果用这种方式处理,该怎么做。
三、高级trait技巧
Summarize made by cursor
本篇文章主要介绍了 Rust 中高级 trait 技巧:
- 包括处理 Iterator
- 支持事件通知
- 为持久化数据库实现 Storage trait
- 构建新的 KV server
- 进一步认识 trait 的威力以及泛型结构和生命周期标注
- 更多用于阅读源码等内容。
- 其中,处理 Iterator 主要是介绍了如何使用 Rust 标准库中的 IntoIterator trait,将数据结构的所有权转移到 Iterator 中;
- 支持事件通知则是通过构造者模式,为 ServiceInner 注册相应的事件处理函数,并提供了 Notify 和 NotifyMut 两个 trait,用于事件通知。
- 为持久化数据库实现 Storage trait 主要是介绍了如何为 sled 实现 Storage trait,并测试通过。
- 构建新的 KV server 主要是介绍了如何使用 Service 和 ServiceInner 两个数据结构,以及如何使用 Builder Pattern 构建 Service。
- 进一步认识 trait 的威力则是介绍了 trait 的多态性和动态分发的特性,以及如何使用 trait 对代码进行抽象。
- 泛型结构和生命周期标注更多用于阅读源码则是介绍了如何阅读 Rust 源码中的泛型结构和生命周期标注。
前面已经完成了 KV store 的基本功能,但留了两个小尾巴:
-
Storage trait 的 get_iter() 方法没有实现;
-
Service 的 execute() 方法里面还有一些 TODO,需要处理事件的通知。
我们一个个来解决。先看 get_iter() 方法。
处理 Iterator
- 在开始撰写代码之前,先把之前在 src/storage/mod.rs 里注掉的测试,加回来:
#[test] fn memtable_iter_should_work() { let store = MemTable::new(); test_get_iter(store); }
- 然后在 src/storge/memory.rs 里尝试实现它。
impl Storage for MemTable { ... fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { // 使用 clone() 来获取 table 的 snapshot let table = self.get_or_create_table(table).clone(); let iter = table .iter() .map(|v| Kvpair::new(v.key(), v.value().clone())); Ok(Box::new(iter)) // <-- 编译出错 } }
很不幸的,编译器提示我们 Box::new(iter) 不行,“cannot return value referencing local variable table” 。
这让人很不爽,究其原因,table.iter() 使用了 table 的引用,我们返回 iter,但 iter 引用了作为局部变量的 table,所以无法编译通过。
- 此刻,我们需要有一个能够完全占有 table 的迭代器。
- Rust 标准库里提供了一个 trait IntoIterator,它可以把数据结构的所有权转移到 Iterator 中,看它的声明(代码):
pub trait IntoIterator { type Item; type IntoIter: Iterator<Item = Self::Item>; fn into_iter(self) -> Self::IntoIter; }
- 绝大多数的集合类数据结构都实现了它。
- DashMap 也实现了它,所以我们可以用 table.into_iter() 把 table 的所有权转移给 iter:
impl Storage for MemTable { ... fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { // 使用 clone() 来获取 table 的 snapshot let table = self.get_or_create_table(table).clone(); let iter = table.into_iter().map(|data| data.into()); Ok(Box::new(iter)) } }
- 这里又遇到了数据转换: 从 DashMap 中 iterate 出来的值 (String, Value) 需要转换成 Kvpair,我们依旧用 into() 来完成这件事。
为此,需要为 Kvpair 实现这个简单的 Fromtrait:
为此,需要为 Kvpair 实现这个简单的 Fromtrait:
impl From<(String, Value)> for Kvpair { fn from(data: (String, Value)) -> Self { Kvpair::new(data.0, data.1) } }
这两段代码都放在 src/storage/memory.rs 下。
Bingo!这个代码可以编译通过。现在如果运行 cargo test 进行测试的话,对 get_iter() 接口的测试也能通过。
- 对get_iter()进行抽象
虽然这个代码可以通过测试,并且本身也非常精简,我们还是有必要思考一下,如果以后想为更多的 data store 实现 Storage trait,都会怎样处理 get_iter() 方法?
我们会:
- 拿到一个关于某个 table 下的拥有所有权的 Iterator
- 对 Iterator 做 map
- 将 map 出来的每个 item 转换成 Kvpair
这里的第 2 步对于每个 Storage trait 的 get_iter() 方法的实现来说,都是相同的。
有没有可能把它封装起来呢?使得 Storage trait 的实现者只需要提供它们自己的拥有所有权的 Iterator,并对 Iterator 里的 Item
类型提供 Into
笔记: 这样,我们在 src/storage/memory.rs 里对 get_iter() 的实现,就可以直接使用 StorageIter
来尝试一下,在 src/storage/mod.rs 中,构建一个 StorageIter,并实现 Iterator trait:
/// 提供 Storage iterator,这样 trait 的实现者只需要 /// 把它们的 iterator 提供给 StorageIter,然后它们保证 /// next() 传出的类型实现了 Into<Kvpair> 即可 pub struct StorageIter<T> { data: T, } impl<T> StorageIter<T> { pub fn new(data: T) -> Self { Self { data } } } impl<T> Iterator for StorageIter<T> where T: Iterator, T::Item: Into<Kvpair>, { type Item = Kvpair; fn next(&mut self) -> Option<Self::Item> { self.data.next().map(|v| v.into()) } }
这样,我们在 src/storage/memory.rs 里对 get_iter() 的实现,就可以直接使用 StorageIter 了。
- 不过,还要为 DashMap 的 Iterator 每次调用 next() 得到的值 (String, Value) ,做个到 Kvpair 的转换:
impl Storage for MemTable { ... fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { // 使用 clone() 来获取 table 的 snapshot let table = self.get_or_create_table(table).clone(); let iter = StorageIter::new(table.into_iter()); // 这行改掉了 Ok(Box::new(iter)) } }
我们可以再次使用 cargo test 测试,同样通过!
辛辛苦苦又写了 20 行代码,创建了一个新的数据结构,就是为了 get_iter() 方法里的一行代码改得更漂亮?何苦呢?
如果回顾刚才撰写的代码,你可能会哑然一笑:我辛辛苦苦又写了 20 行代码,创建了一个新的数据结构,就是为了 get_iter() 方法里的一行代码改得更漂亮?何苦呢?
的确,在这个 KV server 的例子里,这样的抽象收益不大。
但是,如果刚才那个步骤不是 3 步,而是 5 步 /10 步,其中大量的步骤都是相同的,也就是说,我们每实现一个新的 store,就要撰写相同的代码逻辑,那么,这个抽象就非常有必要了。
支持事件通知
好,我们再来看事件通知。
在 src/service/mod.rs 中(以下代码,如无特殊声明,都是在 src/service/mod.rs 中),目前的 execute() 方法还有很多 TODO 需要解决:
pub fn execute(&self, cmd: CommandRequest) -> CommandResponse { debug!("Got request: {:?}", cmd); // TODO: 发送 on_received 事件 let res = dispatch(cmd, &self.inner.store); debug!("Executed response: {:?}", res); // TODO: 发送 on_executed 事件 res }
先看事件处理函数如何注册。
思路
如果想要能够注册,那么倒推也就是,Service/ServiceInner 数据结构就需要有地方能够承载事件注册函数。
可以尝试着把它加在 ServiceInner 结构里:
/// Service 内部数据结构 pub struct ServiceInner<Store> { store: Store, on_received: Vec<fn(&CommandRequest)>, on_executed: Vec<fn(&CommandResponse)>, on_before_send: Vec<fn(&mut CommandResponse)>, on_after_send: Vec<fn()>, }
按照 前面的设计,我们提供了四个事件:
- on_received:
当服务器收到 CommandRequest 时触发;
- on_executed:
当服务器处理完 CommandRequest 得到 CommandResponse 时触发;
- on_before_send:
在服务器发送 CommandResponse 之前触发。注意这个接口提供的是 &mut CommandResponse,这样事件的处理者可以根据需要,在发送前,修改 CommandResponse。
- on_after_send
在服务器发送完 CommandResponse 后触发。
先写测试
在撰写事件注册的代码之前,还是先写个测试,从使用者的角度,考虑如何进行注册:
#[test] fn event_registration_should_work() { fn b(cmd: &CommandRequest) { info!("Got {:?}", cmd); } fn c(res: &CommandResponse) { info!("{:?}", res); } fn d(res: &mut CommandResponse) { res.status = StatusCode::CREATED.as_u16() as _; } fn e() { info!("Data is sent"); } let service: Service = ServiceInner::new(MemTable::default()) .fn_received(|_: &CommandRequest| {}) .fn_received(b) .fn_executed(c) .fn_before_send(d) .fn_after_send(e) .into(); let res = service.execute(CommandRequest::new_hset("t1", "k1", "v1".into())); assert_eq!(res.status, StatusCode::CREATED.as_u16() as _); assert_eq!(res.message, ""); assert_eq!(res.values, vec![Value::default()]); }
从测试代码中可以看到:
- 我们希望通过 ServiceInner 结构,不断调用 fn_xxx 方法,为 ServiceInner 注册相应的事件处理函数;
- 添加完毕后,通过 into() 方法,我们再把 ServiceInner 转换成 Service。
- 这是一个经典的构造者模式(Builder Pattern),在很多 Rust 代码中,都能看到它的身影。
fn_received的链式调用
所以,我们继续添加如下代码:
impl<Store: Storage> ServiceInner<Store> { pub fn new(store: Store) -> Self { Self { store, on_received: Vec::new(), on_executed: Vec::new(), on_before_send: Vec::new(), on_after_send: Vec::new(), } } pub fn fn_received(mut self, f: fn(&CommandRequest)) -> Self { self.on_received.push(f); self } pub fn fn_executed(mut self, f: fn(&CommandResponse)) -> Self { self.on_executed.push(f); self } pub fn fn_before_send(mut self, f: fn(&mut CommandResponse)) -> Self { self.on_before_send.push(f); self } pub fn fn_after_send(mut self, f: fn()) -> Self { self.on_after_send.push(f); self } }
这样处理之后呢,Service 之前的 new() 方法就没有必要存在了,可以把它删除。
同时,我们需要为 Service 类型提供一个 From 的实现:
impl<Store: Storage> From<ServiceInner<Store>> for Service<Store> { fn from(inner: ServiceInner<Store>) -> Self { Self { inner: Arc::new(inner), } } }
目前,代码中几处使用了 Service::new() 的地方需要改成使用 ServiceInner::new(),比如:
impl<Store: Storage> From<ServiceInner<Store>> for Service<Store> { fn from(inner: ServiceInner<Store>) -> Self { Self { inner: Arc::new(inner), } } }
全部改动完成后,代码可以编译通过。
然而,如果运行 cargo test,新加的测试会失败:
test service::tests::event_registration_should_work ... FAILED
- 这是因为,我们虽然完成了事件处理函数的注册,但现在还没有发事件通知。
- 另外因为我们的事件包括不可变事件(比如 on_received)和可变事件(比如 on_before_send),所以事件通知需要把二者分开。
来定义两个 trait:Notify 和 NotifyMut:
/// 事件通知(不可变事件) pub trait Notify<Arg> { fn notify(&self, arg: &Arg); } /// 事件通知(可变事件) pub trait NotifyMut<Arg> { fn notify(&self, arg: &mut Arg); }
这两个 trait 是泛型 trait,其中的 Arg 参数,对应事件注册函数里的 arg,比如:
fn(&CommandRequest);
由此,我们可以特地为 Vec<fn(&Arg)> 和 Vec<fn(&mut Arg)> 实现事件处理,它们涵盖了目前支持的几种事件:
impl<Arg> Notify<Arg> for Vec<fn(&Arg)> { #[inline] fn notify(&self, arg: &Arg) { for f in self { f(arg) } } } impl<Arg> NotifyMut<Arg> for Vec<fn(&mut Arg)> { #[inline] fn notify(&self, arg: &mut Arg) { for f in self { f(arg) } } }
Notify / NotifyMut trait 实现好之后,我们就可以修改 execute() 方法了:
impl<Store: Storage> Service<Store> { pub fn execute(&self, cmd: CommandRequest) -> CommandResponse { debug!("Got request: {:?}", cmd); self.inner.on_received.notify(&cmd); let mut res = dispatch(cmd, &self.inner.store); debug!("Executed response: {:?}", res); self.inner.on_executed.notify(&res); self.inner.on_before_send.notify(&mut res); if !self.inner.on_before_send.is_empty() { debug!("Modified response: {:?}", res); } res } }
现在,相应的事件就可以被通知到相应的处理函数中了。
这个通知机制目前还是同步的函数调用,未来如果需要,我们可以将其改成消息传递,进行异步处理。
好,现在测试应该可以工作了,cargo test 所有的测试都通过。
为持久化数据库实现 Storage trait
方案选择
持久化的两个方案, 选择 为 sled 实现 Storage trait,让它能够适配我们的 KV server
到目前为止,我们的 KV store 还都是一个在内存中的 KV store。一旦终止应用程序,用户存储的所有 key / value 都会消失。我们希望存储能够持久化。
- 一个方案是为 MemTable 添加 WAL 和 disk snapshot 支持,让用户发送的所有涉及更新的命令都按顺序存储在磁盘上,同时定期做 snapshot,便于数据的快速恢复;
- 另一个方案是使用已有的 KV store,比如 RocksDB,或者 sled。
- RocksDB 是 Facebook 在 Google 的 levelDB 基础上开发的嵌入式 KV store,用 C++ 编写
- 而 sled 是 Rust 社区里涌现的优秀的 KV store,对标 RocksDB。
- 二者功能很类似,从演示的角度,sled 使用起来更简单,更加适合今天的内容
- 如果在生产环境中使用,RocksDB 更加合适,因为它在各种复杂的生产环境中经历了千锤百炼。
所以,我们今天就尝试为 sled 实现 Storage trait,让它能够适配我们的 KV server。
为sled实现Storage trait,并测试通过
为sled实现Storage trait,并测试通过
- 首先在 Cargo.toml 里引入 sled:
sled = "0.34" # sled db
- 然后创建 src/storage/sleddb.rs,并添加如下代码:
use sled::{Db, IVec}; use std::{convert::TryInto, path::Path, str}; use crate::{KvError, Kvpair, Storage, StorageIter, Value}; #[derive(Debug)] pub struct SledDb(Db); impl SledDb { pub fn new(path: impl AsRef<Path>) -> Self { Self(sled::open(path).unwrap()) } // 在 sleddb 里,因为它可以 scan_prefix,我们用 prefix // 来模拟一个 table。当然,还可以用其它方案。 fn get_full_key(table: &str, key: &str) -> String { format!("{}:{}", table, key) } // 遍历 table 的 key 时,我们直接把 prefix: 当成 table fn get_table_prefix(table: &str) -> String { format!("{}:", table) } } /// 把 Option<Result<T, E>> flip 成 Result<Option<T>, E> /// 从这个函数里,你可以看到函数式编程的优雅 fn flip<T, E>(x: Option<Result<T, E>>) -> Result<Option<T>, E> { x.map_or(Ok(None), |v| v.map(Some)) } impl Storage for SledDb { fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> { let name = SledDb::get_full_key(table, key); let result = self.0.get(name.as_bytes())?.map(|v| v.as_ref().try_into()); flip(result) } fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError> { let name = SledDb::get_full_key(table, &key); let data: Vec<u8> = value.try_into()?; let result = self.0.insert(name, data)?.map(|v| v.as_ref().try_into()); flip(result) } fn contains(&self, table: &str, key: &str) -> Result<bool, KvError> { let name = SledDb::get_full_key(table, &key); Ok(self.0.contains_key(name)?) } fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> { let name = SledDb::get_full_key(table, &key); let result = self.0.remove(name)?.map(|v| v.as_ref().try_into()); flip(result) } fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError> { let prefix = SledDb::get_table_prefix(table); let result = self.0.scan_prefix(prefix).map(|v| v.into()).collect(); Ok(result) } fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { let prefix = SledDb::get_table_prefix(table); let iter = StorageIter::new(self.0.scan_prefix(prefix)); Ok(Box::new(iter)) } } impl From<Result<(IVec, IVec), sled::Error>> for Kvpair { fn from(v: Result<(IVec, IVec), sled::Error>) -> Self { match v { Ok((k, v)) => match v.as_ref().try_into() { Ok(v) => Kvpair::new(ivec_to_key(k.as_ref()), v), Err(_) => Kvpair::default(), }, _ => Kvpair::default(), } } } fn ivec_to_key(ivec: &[u8]) -> &str { let s = str::from_utf8(ivec).unwrap(); let mut iter = s.split(":"); iter.next(); iter.next().unwrap() }
这段代码主要就是在实现 Storage trait。每个方法都很简单,就是在 sled 提供的功能上增加了一次封装。如果你对代码中某个调用有疑虑,可以参考 sled 的文档。
- 在 src/storage/mod.rs 里引入 sleddb,我们就可以加上相关的测试,测试新的 Storage 实现啦:
mod sleddb; pub use sleddb::SledDb; #[cfg(test)] mod tests { use tempfile::tempdir; use super::*; ... #[test] fn sleddb_basic_interface_should_work() { let dir = tempdir().unwrap(); let store = SledDb::new(dir); test_basi_interface(store); } #[test] fn sleddb_get_all_should_work() { let dir = tempdir().unwrap(); let store = SledDb::new(dir); test_get_all(store); } #[test] fn sleddb_iter_should_work() { let dir = tempdir().unwrap(); let store = SledDb::new(dir); test_get_iter(store); } }
- 因为 SledDb 创建时需要指定一个目录,所以要在测试中使用 tempfile 库,它能让文件资源在测试结束时被回收。
我们在 Cargo.toml 中引入它:
[dev-dependencies]
...
Tempfile = "3" # 处理临时目录和临时文件
...
代码目前就可以编译通过了。如果你运行 cargo test 测试,会发现所有测试都正常通过!
构建新的 KV server
完成 SledDb 和事件通知相关的实现之后,我们可以尝试构建支持事件通知,并且使用 SledDb 的 KV server。
把 examples/server.rs 拷贝出 examples/server_with_sled.rs,然后修改 let service 那一行:
// let service: Service = ServiceInner::new(MemTable::new()).into(); let service: Service<SledDb> = ServiceInner::new(SledDb::new("/tmp/kvserver")) .fn_before_send(|res| match res.message.as_ref() { "" => res.message = "altered. Original message is empty.".into(), s => res.message = format!("altered: {}", s), }) .into();
当然,需要引入 SledDb 让编译通过。
你看,只需要在创建 KV server 时使用 SledDb,就可以实现 data store 的切换,未来还可以进一步通过配置文件,来选择使用什么样的 store。非常方便。
新的 examples/server_with_sled.rs 的完整的代码:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv1::{CommandRequest, CommandResponse, Service, ServiceInner, SledDb}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let service: Service<SledDb> = ServiceInner::new(SledDb::new("/tmp/kvserver")) .fn_before_send(|res| match res.message.as_ref() { "" => res.message = "altered. Original message is empty.".into(), s => res.message = format!("altered: {}", s), }) .into(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); stream.send(res).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
它和之前的 server 几乎一样,只有 11 行生成 service 的代码应用了新的 storage,并且引入了事件通知。
测试
- 完成之后,我们可以打开一个命令行窗口,运行:
RUST_LOG=info cargo run --example server_with_sled --quiet
- 然后在另一个命令行窗口,运行:
RUST_LOG=info cargo run --example client --quiet。
-
此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。
-
如果你停掉服务器,再次运行,然后再运行客户端,会发现,客户端在尝试 HSET 时得到了服务器旧的值,我们的新版 KV server 可以对数据进行持久化了。
-
此外,如果你注意看 client 的日志,会发现原本应该是空字符串的 messag 包含了 “altered. Original message is empty.”:
❯ RUST_LOG=info cargo run --example client --quiet
Sep 23 22:09:12.215 INFO client: Got response CommandResponse { status: 200, message: "altered. Original message is empty.", values: [Value { value: Some(String("world")) }], pairs: [] }
这是因为,我们的服务器注册了 fn_before_send 的事件通知,对返回的数据做了修改。
未来我们可以用这些事件做很多事情,比如监控数据的发送,甚至写 WAL。
进一步认识trait的威力
前面我们进一步认识到了 trait 的威力:
前面我们进一步认识到了 trait 的威力:
当为系统设计了合理的 trait ,整个系统的可扩展性就大大增强,之后在添加新的功能的时候,并不需要改动多少已有的代码。
在使用 trait 做抽象时,我们要衡量:
- 这么做的好处是什么
- 它未来可以为实现者带来什么帮助
- 就像我们撰写的 StorageIter,它实现了 Iterator trait,并封装了 map 的处理逻辑,让这个公共的步骤可以在 Storage trait 中复用。
进一步熟悉如何为带泛型参数的数据结构实现 trait
除此之外,也进一步熟悉如何为带泛型参数的数据结构实现 trait:
我们不仅可以为具体的数据结构实现 trait,也可以为更笼统的泛型参数实现 trait。
除了文中这个例子:
impl<Arg> Notify<Arg> for Vec<fn(&Arg)> { #[inline] fn notify(&self, arg: &Arg) { for f in self { f(arg) } } }
其实之前还见到过:
impl<T, U> Into<U> for T where U: From<T>, { fn into(self) -> U { U::from(self) } }
也是一样的道理。
泛型结构和生命周期标注更多用于阅读源码
我们目前完成了一个功能比较完整的 KV server 的核心逻辑,但是,整体的代码似乎没有太多复杂的生命周期标注,或者太过抽象的泛型结构。
是的,别看我们在介绍 Rust 的基础知识时,扎的比较深,但是大多数写代码的时候,并不会用到那么深的知识。 Rust 编译器会尽最大的努力,让你的代码简单。如果你用 clippy 这样的 linter 的话,它还会进一步给你提一些建议,让你的代码更加简单。
那么,为什么我们还要讲那么深入呢?
这是因为我们在写代码的时候不可避免地要引入第三方库,你也看到了,在写这个项目的时候用了不少依赖。 当你使用这些库的时候,又不可避免地要阅读一些它们的源码,而这些源码,可能有各种各样复杂的写法。 这也是为什么在开头我会说,现阶段能看懂包含泛型的代码就可以了。
深入地了解 Rust 的基础知识:
- 可以帮我们更快更清晰地阅读源码
- 而更快更清晰地读懂别人的源码,又可以更快地帮助我们用好别人的库,从而写好我们的代码。
四、网络处理
Summarize made by cursor
本篇文章主要介绍了 Rust 中的网络处理:
- 包括如何定义协议的 Frame
- 如何撰写处理 Frame 的代码
- 以及如何让网络层可以像 AsyncProst 那样方便使用。
- 文章中详细介绍了 async-prost 库的使用,以及如何自己处理封包和解包的逻辑。
- 同时,还介绍了如何使用 tokio-util 库来处理和 frame 相关的封包解包的主要需求,包括 LinesDelimited 和 LengthDelimited。
- 最后,文章还介绍了如何为 CommandRequest / CommandResponse 提供缺省实现,以便做 frame 级别的处理。
async-prost
之前一直在使用一个神秘的 async-prost 库,我们神奇地完成了 TCP frame 的封包和解包。
是怎么完成的呢?
async-prost 是仿照 Jonhoo 的 async-bincode 做的一个处理 protobuf frame 的库,它可以和各种网络协议适配,包括 TCP / WebSocket / HTTP2 等。
由于考虑通用性,它的抽象级别比较高,用了大量的泛型参数
主流程如下图所示:
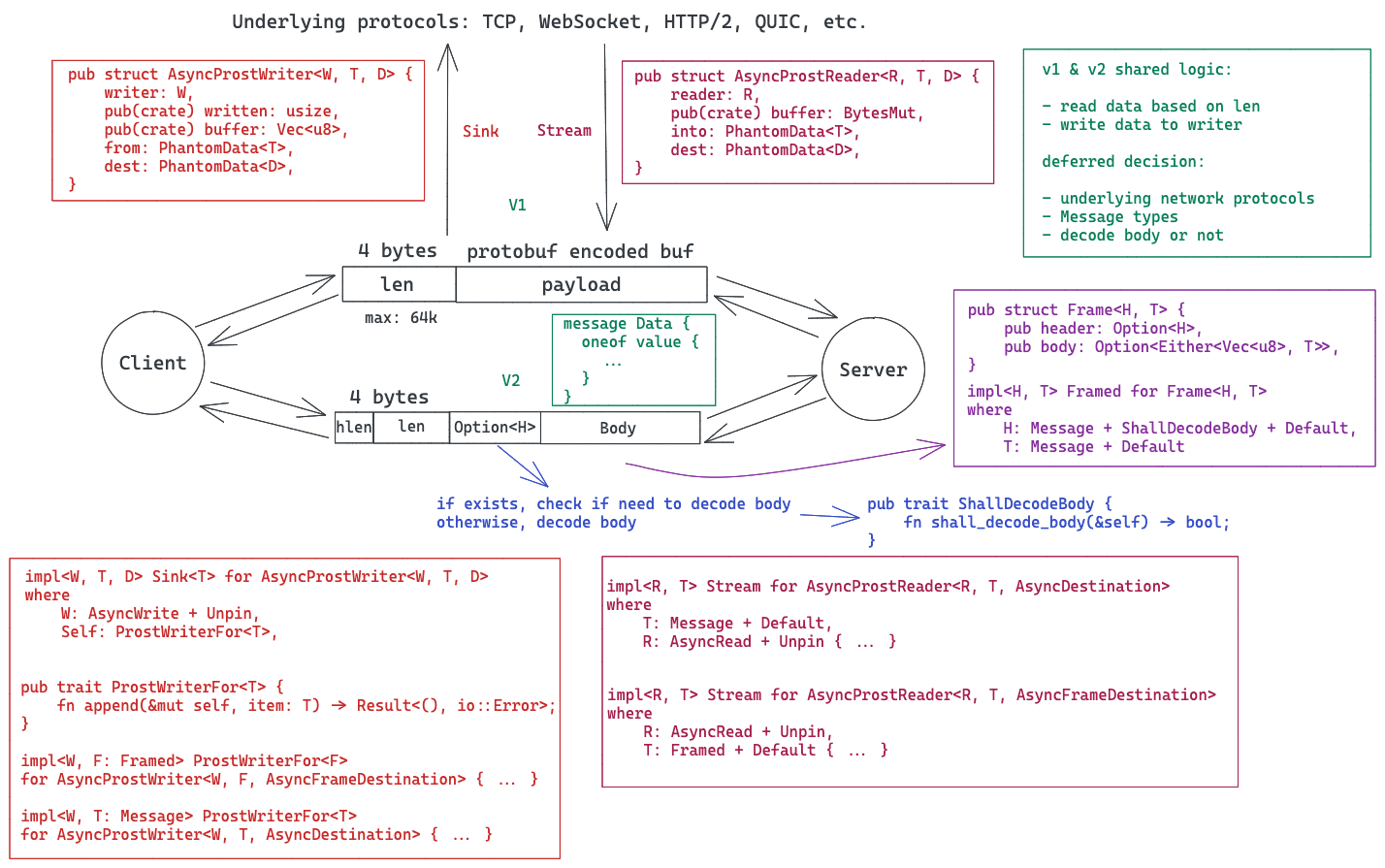
主要的思路:
- 在序列化数据的时候,添加一个头部来提供 frame 的长度
- 反序列化的时候,先读出头部,获得长度,再读取相应的数据。
这里试着不依赖 async-prost,自己处理封包和解包的逻辑。 如果你掌握了这个能力,配合 protobuf,就可以设计出任何可以承载实际业务的协议了。
如何定义协议的 Frame?
protobuf 帮我们解决了协议消息如何定义的问题,然而一个消息和另一个消息之间如何区分,是个伤脑筋的事情。
我们需要定义合适的分隔符。
分隔符 + 消息数据,就是一个 Frame。
- 很多基于 TCP 的协议会使用 \r\n 做分隔符,比如 FTP;
- 也有使用消息长度做分隔符的,比如 gRPC;
- 还有混用两者的,比如 Redis 的 RESP;
- 更复杂的如 HTTP,header 之间使用 \r\n 分隔,header / body 之间使用 \r\n\r\n,header 中会提供 body 的长度等等。
- “\r\n” 这样的分隔符,适合协议报文是 ASCII 数据;
- 而通过长度进行分隔,适合协议报文是二进制数据
- 我们的 KV Server 承载的 protobuf 是二进制,所以就在 payload 之前放一个长度,来作为 frame 的分隔。
这个长度取什么大小呢?
- 如果使用 2 个字节,那么 payload 最大是 64k;
- 如果使用 4 个字节,payload 可以到 4G。
- 一般的应用取 4 个字节就足够了。
- 如果你想要更灵活些,也可以使用 varint。
tokio 有个 tokio-util 库,已经帮我们处理了和 frame 相关的封包解包的主要需求,包括 LinesDelimited(处理 \r\n 分隔符)和 LengthDelimited(处理长度分隔符)。
我们可以使用它的 LengthDelimitedCodec 尝试一下。
- 首先在 Cargo.toml 里添加依赖:
[dev-dependencies]
...
tokio-util = { version = "0.6", features = ["codec"]}
...
- 然后创建 examples/server_with_codec.rs 文件,添入如下代码:
use anyhow::Result; use futures::prelude::*; use kv2::{CommandRequest, MemTable, Service, ServiceInner}; use prost::Message; use tokio::net::TcpListener; use tokio_util::codec::{Framed, LengthDelimitedCodec}; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let service: Service = ServiceInner::new(MemTable::new()).into(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let mut stream = Framed::new(stream, LengthDelimitedCodec::new()); while let Some(Ok(mut buf)) = stream.next().await { let cmd = CommandRequest::decode(&buf[..]).unwrap(); info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); buf.clear(); res.encode(&mut buf).unwrap(); stream.send(buf.freeze()).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
你可以对比一下它和之前的 examples/server.rs 的差别,主要改动了这一行:
// let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); let mut stream = Framed::new(stream, LengthDelimitedCodec::new());
测试
- 完成之后,我们打开一个命令行窗口,运行:
RUST_LOG=info cargo run --example server_with_codec --quiet
- 然后在另一个命令行窗口,运行:
RUST_LOG=info cargo run --example client --quiet
- 此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常
如何撰写处理 Frame 的代码?
按照前面分析,我们在 protobuf payload 前加一个 4 字节的长度。
这样对端读取数据时,可以先读 4 字节,然后根据读到的长度,进一步读取满足这个长度的数据,之后就可以用相应的数据结构解包了。
为了更贴近实际,我们把 4 字节长度的最高位拿出来作为是否压缩的信号. 如果设置了,代表后续的 payload 是 gzip 压缩过的 protobuf,否则直接是 protobuf:

实现处理 Frame 的代码: CommandRequest / CommandResponse 做 frame 级别的处理
- 按照惯例,还是先来定义处理这个逻辑的 trait:
pub trait FrameCoder where Self: Message + Sized + Default, { /// 把一个 Message encode 成一个 frame fn encode_frame(&self, buf: &mut BytesMut) -> Result<(), KvError>; /// 把一个完整的 frame decode 成一个 Message fn decode_frame(buf: &mut BytesMut) -> Result<Self, KvError>; }
定义了两个方法:
-
encode_frame() 可以把诸如 CommandRequest 这样的消息封装成一个 frame,写入传进来的 BytesMut;
-
decode_frame() 可以把收到的一个完整的、放在 BytesMut 中的数据,解封装成诸如 CommandRequest 这样的消息。
-
如果要实现这个 trait,Self 需要实现了 prost::Message,大小是固定的,并且实现了 Default(prost 的需求)。
- 好,我们再写实现代码。
-
首先创建 src/network 目录,并在其下添加两个文件mod.rs和 frame.rs。
-
然后在 src/network/mod.rs 里引入 src/network/frame.rs:
mod frame; pub use frame::FrameCoder;
- 同时在 lib.rs 里引入 network:
mod network; pub use network::*;
-
因为要处理 gzip 压缩,还需要在 Cargo.toml 中引入 flate2
-
同时,因为今天这一讲引入了网络相关的操作和数据结构,我们需要把 tokio 从 dev-dependencies 移到 dependencies 里,为简单起见,就用 full features:
[dependencies] ... flate2 = "1" # gzip 压缩 ... tokio = { version = "1", features = ["full"] } # 异步网络库 ...
- 然后,在 src/network/frame.rs 里添加 trait 和实现 trait 的代码:
use std::io::{Read, Write}; use crate::{CommandRequest, CommandResponse, KvError}; use bytes::{Buf, BufMut, BytesMut}; use flate2::{read::GzDecoder, write::GzEncoder, Compression}; use prost::Message; use tokio::io::{AsyncRead, AsyncReadExt}; use tracing::debug; /// 长度整个占用 4 个字节 pub const LEN_LEN: usize = 4; /// 长度占 31 bit,所以最大的 frame 是 2G const MAX_FRAME: usize = 2 * 1024 * 1024 * 1024; /// 如果 payload 超过了 1436 字节,就做压缩 const COMPRESSION_LIMIT: usize = 1436; /// 代表压缩的 bit(整个长度 4 字节的最高位) const COMPRESSION_BIT: usize = 1 << 31; /// 处理 Frame 的 encode/decode pub trait FrameCoder where Self: Message + Sized + Default, { /// 把一个 Message encode 成一个 frame fn encode_frame(&self, buf: &mut BytesMut) -> Result<(), KvError> { let size = self.encoded_len(); if size >= MAX_FRAME { return Err(KvError::FrameError); } // 我们先写入长度,如果需要压缩,再重写压缩后的长度 buf.put_u32(size as _); if size > COMPRESSION_LIMIT { let mut buf1 = Vec::with_capacity(size); self.encode(&mut buf1)?; // BytesMut 支持逻辑上的 split(之后还能 unsplit) // 所以我们先把长度这 4 字节拿走,清除 let payload = buf.split_off(LEN_LEN); buf.clear(); // 处理 gzip 压缩,具体可以参考 flate2 文档 let mut encoder = GzEncoder::new(payload.writer(), Compression::default()); encoder.write_all(&buf1[..])?; // 压缩完成后,从 gzip encoder 中把 BytesMut 再拿回来 let payload = encoder.finish()?.into_inner(); debug!("Encode a frame: size {}({})", size, payload.len()); // 写入压缩后的长度 buf.put_u32((payload.len() | COMPRESSION_BIT) as _); // 把 BytesMut 再合并回来 buf.unsplit(payload); Ok(()) } else { self.encode(buf)?; Ok(()) } } /// 把一个完整的 frame decode 成一个 Message fn decode_frame(buf: &mut BytesMut) -> Result<Self, KvError> { // 先取 4 字节,从中拿出长度和 compression bit let header = buf.get_u32() as usize; let (len, compressed) = decode_header(header); debug!("Got a frame: msg len {}, compressed {}", len, compressed); if compressed { // 解压缩 let mut decoder = GzDecoder::new(&buf[..len]); let mut buf1 = Vec::with_capacity(len * 2); decoder.read_to_end(&mut buf1)?; buf.advance(len); // decode 成相应的消息 Ok(Self::decode(&buf1[..buf1.len()])?) } else { let msg = Self::decode(&buf[..len])?; buf.advance(len); Ok(msg) } } } impl FrameCoder for CommandRequest {} impl FrameCoder for CommandResponse {} fn decode_header(header: usize) -> (usize, bool) { let len = header & !COMPRESSION_BIT; let compressed = header & COMPRESSION_BIT == COMPRESSION_BIT; (len, compressed) }
这段代码本身并不难理解。
- 我们直接为 FrameCoder 提供了缺省实现
- 然后 CommandRequest / CommandResponse 做了空实现
- 其中使用了之前介绍过的 bytes 库里的 BytesMut,以及新引入的 GzEncoder / GzDecoder。
- 你可以按照阅读源码的方式,了解这几个数据类型的用法。
- 最后还写了个辅助函数 decode_header(),让 decode_frame() 的代码更直观一些。
为什么 COMPRESSION_LIMIT 设成 1436?
- 这是因为以太网的 MTU 是 1500,除去 IP 头 20 字节、TCP 头 20 字节,还剩 1460;
- 一般 TCP 包会包含一些 Option(比如 timestamp),IP 包也可能包含,所以我们预留 20 字节;
- 再减去 4 字节的长度,就是 1436,不用分片的最大消息长度。
- 如果大于这个,很可能会导致分片,我们就干脆压缩一下。
现在,CommandRequest / CommandResponse 就可以做 frame 级别的处理了,我们写一些测试验证是否工作。
成功:测试代码,涉及From和Into
还是在 src/network/frame.rs 里,添加测试代码:
#[cfg(test)] mod tests { use super::*; use crate::Value; use bytes::Bytes; #[test] fn command_request_encode_decode_should_work() { let mut buf = BytesMut::new(); let cmd = CommandRequest::new_hdel("t1", "k1"); cmd.encode_frame(&mut buf).unwrap(); // 最高位没设置 assert_eq!(is_compressed(&buf), false); let cmd1 = CommandRequest::decode_frame(&mut buf).unwrap(); assert_eq!(cmd, cmd1); } #[test] fn command_response_encode_decode_should_work() { let mut buf = BytesMut::new(); let values: Vec<Value> = vec![1.into(), "hello".into(), b"data".into()]; let res: CommandResponse = values.into(); res.encode_frame(&mut buf).unwrap(); // 最高位没设置 assert_eq!(is_compressed(&buf), false); let res1 = CommandResponse::decode_frame(&mut buf).unwrap(); assert_eq!(res, res1); } #[test] fn command_response_compressed_encode_decode_should_work() { let mut buf = BytesMut::new(); let value: Value = Bytes::from(vec![0u8; COMPRESSION_LIMIT + 1]).into(); let res: CommandResponse = value.into(); res.encode_frame(&mut buf).unwrap(); // 最高位设置了 assert_eq!(is_compressed(&buf), true); let res1 = CommandResponse::decode_frame(&mut buf).unwrap(); assert_eq!(res, res1); } fn is_compressed(data: &[u8]) -> bool { if let &[v] = &data[..1] { v >> 7 == 1 } else { false } } }
这个测试代码里面有从 [u8; N] 到 Value(b“data“.into()) 以及从 Bytes 到 Value 的转换
- 所以我们需要在 src/pb/mod.rs 里添加 From trait 的相应实现:
impl<const N: usize> From<&[u8; N]> for Value { fn from(buf: &[u8; N]) -> Self { Bytes::copy_from_slice(&buf[..]).into() } } impl From<Bytes> for Value { fn from(buf: Bytes) -> Self { Self { value: Some(value::Value::Binary(buf)), } } }
运行 cargo test ,所有测试都可以通过。
到这里,我们就完成了 Frame 的序列化(encode_frame)和反序列化(decode_frame),并且用测试确保它的正确性。
做网络开发的时候,要尽可能把实现逻辑和 IO 分离,这样有助于可测性以及应对未来 IO 层的变更。
目前,这个代码没有触及任何和 socket IO 相关的内容,只是纯逻辑,接下来我们要将它和我们用于处理服务器客户端的 TcpStream 联系起来。
在进一步写网络相关的代码前,还有一个问题需要解决:
decode_frame() 函数使用的 BytesMut,是如何从 socket 里拿出来的?
显然,先读 4 个字节,取出长度 N,然后再读 N 个字节。
这个细节和 frame 关系很大,所以还需要在 src/network/frame.rs 里写个辅助函数 read_frame():
/// 从 stream 中读取一个完整的 frame pub async fn read_frame<S>(stream: &mut S, buf: &mut BytesMut) -> Result<(), KvError> where S: AsyncRead + Unpin + Send, { let header = stream.read_u32().await? as usize; let (len, _compressed) = decode_header(header); // 如果没有这么大的内存,就分配至少一个 frame 的内存,保证它可用 buf.reserve(LEN_LEN + len); buf.put_u32(header as _); // advance_mut 是 unsafe 的原因是,从当前位置 pos 到 pos + len, // 这段内存目前没有初始化。我们就是为了 reserve 这段内存,然后从 stream // 里读取,读取完,它就是初始化的。所以,我们这么用是安全的 unsafe { buf.advance_mut(len) }; stream.read_exact(&mut buf[LEN_LEN..]).await?; Ok(()) }
- 在写 read_frame() 时,我们不希望它只能被用于 TcpStream,这样太不灵活,所以用了泛型参数 S
- 要求传入的 S 必须满足 AsyncRead + Unpin + Send。
要求传入的 S 必须满足 AsyncRead + Unpin + Send, 我们来看看这 3 个约束:
- AsyncRead 是 tokio 下的一个 trait,用于做异步读取,它有一个方法 poll_read():
pub trait AsyncRead { fn poll_read( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &mut ReadBuf<'_> ) -> Poll<Result<()>>; }
一旦某个数据结构实现了 AsyncRead,它就可以使用 AsyncReadExt 提供的多达 29 个辅助方法。这是因为任何实现了 AsyncRead 的数据结构,都自动实现了 AsyncReadExt:
impl<R: AsyncRead + ?Sized> AsyncReadExt for R {}
我们虽然还没有正式学怎么做异步处理,但是之前已经看到了很多 async/await 的代码。
异步处理,目前你可以把它想象成一个内部有个状态机的数据结构:
- 异步运行时根据需要不断地对其做 poll 操作,直到它返回 Poll::Ready,说明得到了处理结果;
- 如果它返回 Poll::Pending,说明目前还无法继续,异步运行时会将其挂起,等下次某个事件将这个任务唤醒。
对于 Socket 来说,读取 socket 就是一个不断 poll_read() 的过程,直到读到了满足 ReadBuf 需要的内容。
-
至于 Send 约束,很好理解, 需要能在不同线程间移动所有权。
-
对于 Unpin 约束
如果编译器抱怨一个泛型参数 “cannot be unpinned” ,一般来说,这个泛型参数需要加 Unpin 的约束。你可以试着把 Unpin 去掉,看看编译器的报错。
好,既然又写了一些代码,自然需为其撰写相应的测试。
但是,要测 read_frame() 函数,需要一个支持 AsyncRead 的数据结构,虽然 TcpStream 支持它,但是我们不应该在单元测试中引入太过复杂的行为。
为了测试 read_frame() 而建立 TCP 连接,显然没有必要。怎么办?
我们聊过测试代码和产品代码同等的重要性,所以,在开发中,也要为测试代码创建合适的生态环境,让测试简洁、可读性强。
那这里,我们就创建一个简单的数据结构,使其实现 AsyncRead,这样就可以“单元”测试 read_frame() 了。
在 src/network/frame.rs 里的 mod tests 下加入:
#[cfg(test)] mod tests { struct DummyStream { buf: BytesMut, } impl AsyncRead for DummyStream { fn poll_read( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, buf: &mut tokio::io::ReadBuf<'_>, ) -> std::task::Poll<std::io::Result<()>> { // 看看 ReadBuf 需要多大的数据 let len = buf.capacity(); // split 出这么大的数据 let data = self.get_mut().buf.split_to(len); // 拷贝给 ReadBuf buf.put_slice(&data); // 直接完工 std::task::Poll::Ready(Ok(())) } } }
因为只需要保证 AsyncRead 接口的正确性,所以不需要太复杂的逻辑. 我们就放一个 buffer,poll_read() 需要读多大的数据,我们就给多大的数据。
有了这个 DummyStream,就可以测试 read_frame() 了:
#[tokio::test] async fn read_frame_should_work() { let mut buf = BytesMut::new(); let cmd = CommandRequest::new_hdel("t1", "k1"); cmd.encode_frame(&mut buf).unwrap(); let mut stream = DummyStream { buf }; let mut data = BytesMut::new(); read_frame(&mut stream, &mut data).await.unwrap(); let cmd1 = CommandRequest::decode_frame(&mut data).unwrap(); assert_eq!(cmd, cmd1); }
运行 “cargo test”,测试通过。
如果你的代码无法编译,可以看看编译错误,是不是缺了一些 use 语句来把某些数据结构和 trait 引入。
让网络层可以像 AsyncProst 那样方便使用
现在,我们的 frame 已经可以正常工作了。
接下来要构思一下,服务端和客户端该如何封装。
- 对于服务器,我们期望可以对 accept 下来的 TcpStream 提供一个 process() 方法,处理协议的细节:
#[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; let service: Service = ServiceInner::new(MemTable::new()).into(); let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let stream = ProstServerStream::new(stream, service.clone()); tokio::spawn(async move { stream.process().await }); } }
这个 process() 方法,实际上就是对 examples/server.rs 中 tokio::spawn 里的 while loop 的封装:
while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); stream.send(res).await.unwrap(); }
- 对客户端,我们也希望可以直接 execute() 一个命令,就能得到结果:
#[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; // 连接服务器 let stream = TcpStream::connect(addr).await?; let mut client = ProstClientStream::new(stream); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".to_string().into()); // 发送 HSET 命令 let data = client.execute(cmd).await?; info!("Got response {:?}", data); Ok(()) }
这个 execute(),实际上就是对 examples/client.rs 中发送和接收代码的封装:
client.send(cmd).await?; if let Some(Ok(data)) = client.next().await { info!("Got response {:?}", data); }
这样的代码,看起来很简洁,维护起来也很方便。
- 好,先看服务器处理一个 TcpStream 的数据结构,它需要包含 TcpStream,还有我们之前创建的用于处理客户端命令的 Service。
所以,让服务器处理 TcpStream 的结构包含这两部分:
pub struct ProstServerStream<S> { inner: S, service: Service, }
- 这里,依旧使用了泛型参数 S。
- 未来,如果要支持 WebSocket,或者在 TCP 之上支持 TLS,它都可以让我们无需改变这一层的代码。
- 接下来就是具体的实现。
有了 frame 的封装,服务器的 process() 方法和客户端的 execute() 方法都很容易实现。
我们直接在 src/network/mod.rs 里添加完整代码:
mod frame; use bytes::BytesMut; pub use frame::{read_frame, FrameCoder}; use tokio::io::{AsyncRead, AsyncWrite, AsyncWriteExt}; use tracing::info; use crate::{CommandRequest, CommandResponse, KvError, Service}; /// 处理服务器端的某个 accept 下来的 socket 的读写 pub struct ProstServerStream<S> { inner: S, service: Service, } /// 处理客户端 socket 的读写 pub struct ProstClientStream<S> { inner: S, } impl<S> ProstServerStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { pub fn new(stream: S, service: Service) -> Self { Self { inner: stream, service, } } pub async fn process(mut self) -> Result<(), KvError> { while let Ok(cmd) = self.recv().await { info!("Got a new command: {:?}", cmd); let res = self.service.execute(cmd); self.send(res).await?; } // info!("Client {:?} disconnected", self.addr); Ok(()) } async fn send(&mut self, msg: CommandResponse) -> Result<(), KvError> { let mut buf = BytesMut::new(); msg.encode_frame(&mut buf)?; let encoded = buf.freeze(); self.inner.write_all(&encoded[..]).await?; Ok(()) } async fn recv(&mut self) -> Result<CommandRequest, KvError> { let mut buf = BytesMut::new(); let stream = &mut self.inner; read_frame(stream, &mut buf).await?; CommandRequest::decode_frame(&mut buf) } } impl<S> ProstClientStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { pub fn new(stream: S) -> Self { Self { inner: stream } } pub async fn execute(&mut self, cmd: CommandRequest) -> Result<CommandResponse, KvError> { self.send(cmd).await?; Ok(self.recv().await?) } async fn send(&mut self, msg: CommandRequest) -> Result<(), KvError> { let mut buf = BytesMut::new(); msg.encode_frame(&mut buf)?; let encoded = buf.freeze(); self.inner.write_all(&encoded[..]).await?; Ok(()) } async fn recv(&mut self) -> Result<CommandResponse, KvError> { let mut buf = BytesMut::new(); let stream = &mut self.inner; read_frame(stream, &mut buf).await?; CommandResponse::decode_frame(&mut buf) } }
这段代码不难阅读,基本上和 frame 的测试代码大同小异。
- 当然了,我们还是需要写段代码来测试客户端和服务器交互的整个流程:
#[cfg(test)] mod tests { use anyhow::Result; use bytes::Bytes; use std::net::SocketAddr; use tokio::net::{TcpListener, TcpStream}; use crate::{assert_res_ok, MemTable, ServiceInner, Value}; use super::*; #[tokio::test] async fn client_server_basic_communication_should_work() -> anyhow::Result<()> { let addr = start_server().await?; let stream = TcpStream::connect(addr).await?; let mut client = ProstClientStream::new(stream); // 发送 HSET,等待回应 let cmd = CommandRequest::new_hset("t1", "k1", "v1".into()); let res = client.execute(cmd).await.unwrap(); // 第一次 HSET 服务器应该返回 None assert_res_ok(res, &[Value::default()], &[]); // 再发一个 HSET let cmd = CommandRequest::new_hget("t1", "k1"); let res = client.execute(cmd).await?; // 服务器应该返回上一次的结果 assert_res_ok(res, &["v1".into()], &[]); Ok(()) } #[tokio::test] async fn client_server_compression_should_work() -> anyhow::Result<()> { let addr = start_server().await?; let stream = TcpStream::connect(addr).await?; let mut client = ProstClientStream::new(stream); let v: Value = Bytes::from(vec![0u8; 16384]).into(); let cmd = CommandRequest::new_hset("t2", "k2", v.clone().into()); let res = client.execute(cmd).await?; assert_res_ok(res, &[Value::default()], &[]); let cmd = CommandRequest::new_hget("t2", "k2"); let res = client.execute(cmd).await?; assert_res_ok(res, &[v.into()], &[]); Ok(()) } async fn start_server() -> Result<SocketAddr> { let listener = TcpListener::bind("127.0.0.1:0").await.unwrap(); let addr = listener.local_addr().unwrap(); tokio::spawn(async move { loop { let (stream, _) = listener.accept().await.unwrap(); let service: Service = ServiceInner::new(MemTable::new()).into(); let server = ProstServerStream::new(stream, service); tokio::spawn(server.process()); } }); Ok(addr) } }
正式创建 kv-server 和 kv-client
我们之前写了很多代码,真正可运行的 server/client 都是 examples 下的代码。
现在我们终于要正式创建 kv-server / kv-client 了。
- 首先在 Cargo.toml 中,加入两个可执行文件:kvs(kv-server)和 kvc(kv-client)。还需要把一些依赖移动到 dependencies 下。
- 修改之后,Cargo.toml 长这个样子:
[package]
name = "kv2"
version = "0.1.0"
edition = "2018"
[[bin]]
name = "kvs"
path = "src/server.rs"
[[bin]]
name = "kvc"
path = "src/client.rs"
[dependencies]
anyhow = "1" # 错误处理
bytes = "1" # 高效处理网络 buffer 的库
dashmap = "4" # 并发 HashMap
flate2 = "1" # gzip 压缩
http = "0.2" # 我们使用 HTTP status code 所以引入这个类型库
prost = "0.8" # 处理 protobuf 的代码
sled = "0.34" # sled db
thiserror = "1" # 错误定义和处理
tokio = { version = "1", features = ["full" ] } # 异步网络库
tracing = "0.1" # 日志处理
tracing-subscriber = "0.2" # 日志处理
[dev-dependencies]
async-prost = "0.2.1" # 支持把 protobuf 封装成 TCP frame
futures = "0.3" # 提供 Stream trait
tempfile = "3" # 处理临时目录和临时文件
tokio-util = { version = "0.6", features = ["codec"]}
[build-dependencies]
prost-build = "0.8" # 编译 protobuf
- 然后,创建 src/client.rs 和 src/server.rs,分别写入下面的代码。
src/client.rs:
use anyhow::Result; use kv2::{CommandRequest, ProstClientStream}; use tokio::net::TcpStream; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; // 连接服务器 let stream = TcpStream::connect(addr).await?; let mut client = ProstClientStream::new(stream); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".to_string().into()); // 发送 HSET 命令 let data = client.execute(cmd).await?; info!("Got response {:?}", data); Ok(()) }
这和之前的 client / server 的代码几乎一致,不同的是,我们使用了自己撰写的 frame 处理方法。
测试成功:
- 完成之后,我们可以打开一个命令行窗口,运行:
RUST_LOG=info cargo run --bin kvs --quiet
- 然后在另一个命令行窗口,运行:
RUST_LOG=info cargo run --bin kvc --quiet
- 此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。现在,我们的 KV server 越来越像回事了!
回顾网络开发
网络开发是 Rust 下一个很重要的应用场景。tokio 为我们提供了很棒的异步网络开发的支持。
网络开发的提示:1. frame如何封装;2. 自定义测试数据结构;3. 单元测试覆盖率
在开发网络协议时,你要确定你的 frame 如何封装:
- 一般来说,长度 + protobuf 足以应付绝大多数复杂的协议需求。
- 我们虽然详细介绍了自己该如何处理用长度封装 frame 的方法,其实 tokio-util 提供了 LengthDelimitedCodec,可以完成今天关于 frame 部分的处理。如果你自己撰写网络程序,可以直接使用它。
在网络开发的时候,如何做单元测试是一大痛点,我们可以根据其实现的接口,围绕着接口来构建测试数据结构,比如 TcpStream 实现了 AsycnRead / AsyncWrite。
考虑简洁和可读,为了测试 read_frame() ,我们构建了 DummyStream 来协助测试。你也可以用类似的方式处理你所做项目的测试需求。
结构良好架构清晰的代码,一定是容易测试的代码,纵观整个项目,从 CommandService trait 和 Storage trait 的测试,一路到现在网络层的测试。如果使用 tarpaulin 来看测试覆盖率,你会发现,这个项目目前已经有 89% 了,如果不算 src/server.rs 和 src/client.rs 的话,有接近 92% 的测试覆盖率。即便在生产环境的代码里,这也算是很高质量的测试覆盖率了。
INFO cargo_tarpaulin::report: Coverage Results:
|| Tested/Total Lines:
|| src/client.rs: 0/9 +0.00%
|| src/network/frame.rs: 80/82 +0.00%
|| src/network/mod.rs: 65/66 +4.66%
|| src/pb/mod.rs: 54/75 +0.00%
|| src/server.rs: 0/11 +0.00%
|| src/service/command_service.rs: 120/129 +0.00%
|| src/service/mod.rs: 79/84 +0.00%
|| src/storage/memory.rs: 34/37 +0.00%
|| src/storage/mod.rs: 58/58 +0.00%
|| src/storage/sleddb.rs: 40/43 +0.00%
||
89.23% coverage, 530/594 lines covered
考虑支持gzip、lz4和zstd
在设计 frame 的时候,如果我们的压缩方法不止 gzip 一种,而是服务器或客户端都会根据各自的情况,在需要的时候做某种算法的压缩。假设服务器和客户端都支持 gzip、lz4 和 zstd 这三种压缩算法。那么 frame 该如何设计呢?需要用几个 bit 来存放压缩算法的信息?
目前我们的 client 只适合测试,你可以将其修改成一个完整的命令行程序么?小提示,可以使用 clap 或 structopt,用户可以输入不同的命令;或者做一个交互式的命令行,使用 shellfish 或 rustyline,就像 redis-cli 那样。
试着使用 LengthDelimitedCodec 来重写 frame 这一层。
关于tarpaulin
arpaulin 是 Rust 下做测试覆盖率的工具。因为使用了操作系统和 CPU 的特殊指令追踪代码的执行,所以它目前只支持 x86_64 / Linux。测试覆盖率一般在 CI 中使用,所以有 Linux 的支持也足够了。
一般来说,我们在生产环境中运行的代码,都要求至少有 80% 以上的测试覆盖率。为项目构建足够好的测试覆盖率并不容易,因为这首先意味着写出来的代码要容易测试。所以,对于新的项目,最好一开始就在 CI 中为测试覆盖率设置一个门槛,这样可以倒逼着大家保证单元测试的数量。同时,单元测试又会倒逼代码要有良好的结构和良好的接口,否则不容易测试。
五、网络安全:生成 x509 证书
Summarize made by cursor
本篇文章主要介绍了如何使用 TLS 来保证客户端和服务器间的安全性。
- 文章首先介绍了 TLS 的作用和 TLS 的数据封装
- 然后详细讲解了如何使用 tokio-rustls 库来实现 TLS
- 文章提供了两个数据结构 TlsServerAcceptor / TlsClientConnector,分别用于存放 TLS ServerConfig 和 TLS ClientConfig
- 并提供了 accept() 和 connect() 方法,用于把底层的协议转换成 TLS stream。
- 最后,文章提供了一个测试用例,演示了如何使用 TLS 客户端和服务器之间进行通信。
那么,当我们的应用架构在 TCP 上时,如何使用 TLS 来保证客户端和服务器间的安全性呢?
想要使用 TLS,我们首先需要 x509 证书。TLS 需要 x509 证书让客户端验证服务器是否是一个受信的服务器,甚至服务器验证客户端,确认对方是一个受信的客户端。
为了测试方便,我们要有能力生成自己的 CA 证书、服务端证书,甚至客户端证书。证书生成的细节今天就不详细介绍了,我之前做了一个叫 certify 的库,可以用来生成各种证书。
使用与测试:生成证书
- 我们可以在 Cargo.toml 里加入这个库:
[dev-dependencies]
...
certify = "0.3"
...
- 然后在根目录下创建 fixtures 目录存放证书
- 再创建 examples/gen_cert.rs 文件,添入如下代码:
use anyhow::Result; use certify::{generate_ca, generate_cert, load_ca, CertType, CA}; use tokio::fs; struct CertPem { cert_type: CertType, cert: String, key: String, } #[tokio::main] async fn main() -> Result<()> { let pem = create_ca()?; gen_files(&pem).await?; let ca = load_ca(&pem.cert, &pem.key)?; let pem = create_cert(&ca, &["kvserver.acme.inc"], "Acme KV server", false)?; gen_files(&pem).await?; let pem = create_cert(&ca, &[], "awesome-device-id", true)?; gen_files(&pem).await?; Ok(()) } fn create_ca() -> Result<CertPem> { let (cert, key) = generate_ca( &["acme.inc"], "CN", "Acme Inc.", "Acme CA", None, Some(10 * 365), )?; Ok(CertPem { cert_type: CertType::CA, cert, key, }) } fn create_cert(ca: &CA, domains: &[&str], cn: &str, is_client: bool) -> Result<CertPem> { let (days, cert_type) = if is_client { (Some(365), CertType::Client) } else { (Some(5 * 365), CertType::Server) }; let (cert, key) = generate_cert(ca, domains, "CN", "Acme Inc.", cn, None, is_client, days)?; Ok(CertPem { cert_type, cert, key, }) } async fn gen_files(pem: &CertPem) -> Result<()> { let name = match pem.cert_type { CertType::Client => "client", CertType::Server => "server", CertType::CA => "ca", }; fs::write(format!("fixtures/{}.cert", name), pem.cert.as_bytes()).await?; fs::write(format!("fixtures/{}.key", name), pem.key.as_bytes()).await?; Ok(()) }
这个代码很简单:
- 它先生成了一个 CA 证书
- 然后再生成服务器和客户端证书,全部存入刚创建的 fixtures 目录下。
- 你需要
cargo run --examples gen_cert运行一下这个命令,待会我们会在测试中用到这些证书和密钥。
在 KV server 中使用 TLS
TLS 是目前最主要的应用层安全协议
TLS 是目前最主要的应用层安全协议,被广泛用于保护架构在 TCP 之上的,比如 MySQL、HTTP 等各种协议。一个网络应用,即便是在内网使用,如果没有安全协议来保护,都是很危险的。
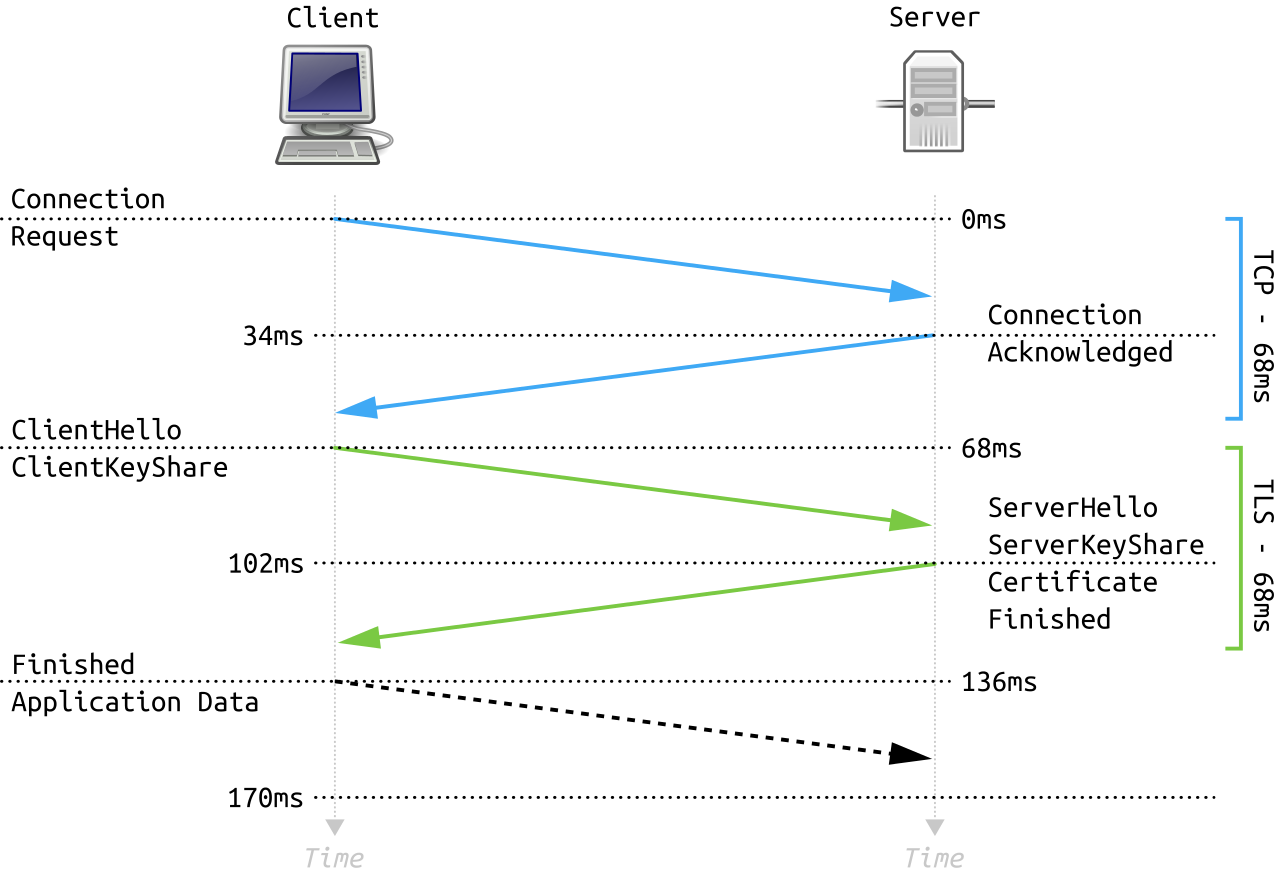
对于 KV server 来说,使用 TLS 之后,整个协议的数据封装如下图所示:

所以今天要做的就是在上一讲的网络处理的基础上,添加 TLS 支持,使得 KV server 的客户端服务器之间的通讯被严格保护起来,确保最大程度的安全,免遭第三方的偷窥、篡改以及仿造。
实现TLS
好,接下来我们看看 TLS 怎么实现。
估计很多人一听 TLS 或者 SSL,就头皮发麻,因为之前跟 openssl 打交道有过很多不好的经历。openssl 的代码库太庞杂,API 不友好,编译链接都很费劲。
不过,在 Rust 下使用 TLS 的体验还是很不错的:
- Rust 对 openssl 有很不错的封装: rust-openssl
- 也有不依赖 openssl 用 Rust 撰写的 rustls
- tokio 进一步提供了符合 tokio 生态圈的 tls 支持,有 openssl 版本和 rustls 版本可选。
我们今天就用 tokio-rustls 来撰写 TLS 的支持。
相信你在实现过程中可以看到,在应用程序中加入 TLS 协议来保护网络层,是多么轻松的一件事情。
- 然后创建 src/network/tls.rs,撰写如下代码, 记得在 src/network/mod.rs 中引入这个文件
use std::io::Cursor; use std::sync::Arc; use tokio::io::{AsyncRead, AsyncWrite}; use tokio_rustls::rustls::{internal::pemfile, Certificate, ClientConfig, ServerConfig}; use tokio_rustls::rustls::{AllowAnyAuthenticatedClient, NoClientAuth, PrivateKey, RootCertStore}; use tokio_rustls::webpki::DNSNameRef; use tokio_rustls::TlsConnector; use tokio_rustls::{ client::TlsStream as ClientTlsStream, server::TlsStream as ServerTlsStream, TlsAcceptor, }; use crate::KvError; /// KV Server 自己的 ALPN (Application-Layer Protocol Negotiation) const ALPN_KV: &str = "kv"; /// 存放 TLS ServerConfig 并提供方法 accept 把底层的协议转换成 TLS #[derive(Clone)] pub struct TlsServerAcceptor { inner: Arc<ServerConfig>, } /// 存放 TLS Client 并提供方法 connect 把底层的协议转换成 TLS #[derive(Clone)] pub struct TlsClientConnector { pub config: Arc<ClientConfig>, pub domain: Arc<String>, } impl TlsClientConnector { /// 加载 client cert / CA cert,生成 ClientConfig pub fn new( domain: impl Into<String>, identity: Option<(&str, &str)>, server_ca: Option<&str>, ) -> Result<Self, KvError> { let mut config = ClientConfig::new(); // 如果有客户端证书,加载之 if let Some((cert, key)) = identity { let certs = load_certs(cert)?; let key = load_key(key)?; config.set_single_client_cert(certs, key)?; } // 加载本地信任的根证书链 config.root_store = match rustls_native_certs::load_native_certs() { Ok(store) | Err((Some(store), _)) => store, Err((None, error)) => return Err(error.into()), }; // 如果有签署服务器的 CA 证书,则加载它,这样服务器证书不在根证书链 // 但是这个 CA 证书能验证它,也可以 if let Some(cert) = server_ca { let mut buf = Cursor::new(cert); config.root_store.add_pem_file(&mut buf).unwrap(); } Ok(Self { config: Arc::new(config), domain: Arc::new(domain.into()), }) } /// 触发 TLS 协议,把底层的 stream 转换成 TLS stream pub async fn connect<S>(&self, stream: S) -> Result<ClientTlsStream<S>, KvError> where S: AsyncRead + AsyncWrite + Unpin + Send, { let dns = DNSNameRef::try_from_ascii_str(self.domain.as_str()) .map_err(|_| KvError::Internal("Invalid DNS name".into()))?; let stream = TlsConnector::from(self.config.clone()) .connect(dns, stream) .await?; Ok(stream) } } impl TlsServerAcceptor { /// 加载 server cert / CA cert,生成 ServerConfig pub fn new(cert: &str, key: &str, client_ca: Option<&str>) -> Result<Self, KvError> { let certs = load_certs(cert)?; let key = load_key(key)?; let mut config = match client_ca { None => ServerConfig::new(NoClientAuth::new()), Some(cert) => { // 如果客户端证书是某个 CA 证书签发的,则把这个 CA 证书加载到信任链中 let mut cert = Cursor::new(cert); let mut client_root_cert_store = RootCertStore::empty(); client_root_cert_store .add_pem_file(&mut cert) .map_err(|_| KvError::CertifcateParseError("CA", "cert"))?; let client_auth = AllowAnyAuthenticatedClient::new(client_root_cert_store); ServerConfig::new(client_auth) } }; // 加载服务器证书 config .set_single_cert(certs, key) .map_err(|_| KvError::CertifcateParseError("server", "cert"))?; config.set_protocols(&[Vec::from(&ALPN_KV[..])]); Ok(Self { inner: Arc::new(config), }) } /// 触发 TLS 协议,把底层的 stream 转换成 TLS stream pub async fn accept<S>(&self, stream: S) -> Result<ServerTlsStream<S>, KvError> where S: AsyncRead + AsyncWrite + Unpin + Send, { let acceptor = TlsAcceptor::from(self.inner.clone()); Ok(acceptor.accept(stream).await?) } } fn load_certs(cert: &str) -> Result<Vec<Certificate>, KvError> { let mut cert = Cursor::new(cert); pemfile::certs(&mut cert).map_err(|_| KvError::CertifcateParseError("server", "cert")) } fn load_key(key: &str) -> Result<PrivateKey, KvError> { let mut cursor = Cursor::new(key); // 先尝试用 PKCS8 加载私钥 if let Ok(mut keys) = pemfile::pkcs8_private_keys(&mut cursor) { if !keys.is_empty() { return Ok(keys.remove(0)); } } // 再尝试加载 RSA key cursor.set_position(0); if let Ok(mut keys) = pemfile::rsa_private_keys(&mut cursor) { if !keys.is_empty() { return Ok(keys.remove(0)); } } // 不支持的私钥类型 Err(KvError::CertifcateParseError("private", "key")) }
- 这个代码创建了两个数据结构 TlsServerAcceptor / TlsClientConnector。
- 虽然它有 100 多行,但主要的工作其实就是根据提供的证书,来生成 tokio-tls 需要的 ServerConfig / ClientConfig。
- 因为 TLS 需要验证证书的 CA,所以还需要加载 CA 证书。虽然平时在做 Web 开发时,我们都只使用服务器证书,但其实 TLS 支持双向验证,服务器也可以验证客户端的证书是否是它认识的 CA 签发的。
处理完 config 后,这段代码的核心逻辑其实就是客户端的 connect() 方法和服务器的 accept() 方法,它们都接受一个满足 AsyncRead + AsyncWrite + Unpin + Send 的 stream。
- 考虑到通用性,我们不希望 TLS 代码只能接受 TcpStream,所以这里提供了一个泛型参数 S:
/// 触发 TLS 协议,把底层的 stream 转换成 TLS stream pub async fn connect<S>(&self, stream: S) -> Result<ClientTlsStream<S>, KvError> where S: AsyncRead + AsyncWrite + Unpin + Send, { let dns = DNSNameRef::try_from_ascii_str(self.domain.as_str()) .map_err(|_| KvError::Internal("Invalid DNS name".into()))?; let stream = TlsConnector::from(self.config.clone()) .connect(dns, stream) .await?; Ok(stream) } /// 触发 TLS 协议,把底层的 stream 转换成 TLS stream pub async fn accept<S>(&self, stream: S) -> Result<ServerTlsStream<S>, KvError> where S: AsyncRead + AsyncWrite + Unpin + Send, { let acceptor = TlsAcceptor::from(self.inner.clone()); Ok(acceptor.accept(stream).await?) }
- 在使用 TlsConnector 或者 TlsAcceptor 处理完 connect/accept 后,我们得到了一个 TlsStream
- 它也满足 AsyncRead + AsyncWrite + Unpin + Send
- 后续的操作就可以在其上完成了。
- 百来行代码就搞定了 TLS,是不是很轻松?
- 我们来顺着往下写段测试:
#[cfg(test)] mod tests { use std::net::SocketAddr; use super::*; use anyhow::Result; use tokio::{ io::{AsyncReadExt, AsyncWriteExt}, net::{TcpListener, TcpStream}, }; const CA_CERT: &str = include_str!("../../fixtures/ca.cert"); const CLIENT_CERT: &str = include_str!("../../fixtures/client.cert"); const CLIENT_KEY: &str = include_str!("../../fixtures/client.key"); const SERVER_CERT: &str = include_str!("../../fixtures/server.cert"); const SERVER_KEY: &str = include_str!("../../fixtures/server.key"); #[tokio::test] async fn tls_should_work() -> Result<()> { let ca = Some(CA_CERT); let addr = start_server(None).await?; let connector = TlsClientConnector::new("kvserver.acme.inc", None, ca)?; let stream = TcpStream::connect(addr).await?; let mut stream = connector.connect(stream).await?; stream.write_all(b"hello world!").await?; let mut buf = [0; 12]; stream.read_exact(&mut buf).await?; assert_eq!(&buf, b"hello world!"); Ok(()) } #[tokio::test] async fn tls_with_client_cert_should_work() -> Result<()> { let client_identity = Some((CLIENT_CERT, CLIENT_KEY)); let ca = Some(CA_CERT); let addr = start_server(ca.clone()).await?; let connector = TlsClientConnector::new("kvserver.acme.inc", client_identity, ca)?; let stream = TcpStream::connect(addr).await?; let mut stream = connector.connect(stream).await?; stream.write_all(b"hello world!").await?; let mut buf = [0; 12]; stream.read_exact(&mut buf).await?; assert_eq!(&buf, b"hello world!"); Ok(()) } #[tokio::test] async fn tls_with_bad_domain_should_not_work() -> Result<()> { let addr = start_server(None).await?; let connector = TlsClientConnector::new("kvserver1.acme.inc", None, Some(CA_CERT))?; let stream = TcpStream::connect(addr).await?; let result = connector.connect(stream).await; assert!(result.is_err()); Ok(()) } async fn start_server(ca: Option<&str>) -> Result<SocketAddr> { let acceptor = TlsServerAcceptor::new(SERVER_CERT, SERVER_KEY, ca)?; let echo = TcpListener::bind("127.0.0.1:0").await.unwrap(); let addr = echo.local_addr().unwrap(); tokio::spawn(async move { let (stream, _) = echo.accept().await.unwrap(); let mut stream = acceptor.accept(stream).await.unwrap(); let mut buf = [0; 12]; stream.read_exact(&mut buf).await.unwrap(); stream.write_all(&buf).await.unwrap(); }); Ok(addr) } }
- 这段测试代码使用了 include_str! 宏,在编译期把文件加载成字符串放在 RODATA 段。
- 我们测试了三种情况:标准的 TLS 连接、带有客户端证书的 TLS 连接,以及客户端提供了错的域名的情况。
- 运行 cargo test ,所有测试都能通过。
让 KV client/server 支持 TLS
在 TLS 的测试都通过后,就可以添加 kvs 和 kvc 对 TLS 的支持了。
由于我们一路以来良好的接口设计,尤其是 ProstClientStream / ProstServerStream 都接受泛型参数,使得 TLS 的代码可以无缝嵌入。
和上一版项目相比,更新后的客户端和服务器代码,各自仅仅多了一行,就把 TcpStream 封装成了 TlsStream。
- 比如客户端:
// 新加的代码 let connector = TlsClientConnector::new("kvserver.acme.inc", None, Some(ca_cert))?; let stream = TcpStream::connect(addr).await?; // 新加的代码 let stream = connector.connect(stream).await?; let mut client = ProstClientStream::new(stream);
仅仅需要把传给 ProstClientStream 的 stream,从 TcpStream 换成生成的 TlsStream,就无缝支持了 TLS。
- 我们看完整的代码,src/server.rs:
use anyhow::Result; use kv3::{MemTable, ProstServerStream, Service, ServiceInner, TlsServerAcceptor}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; // 以后从配置文件取 let server_cert = include_str!("../fixtures/server.cert"); let server_key = include_str!("../fixtures/server.key"); let acceptor = TlsServerAcceptor::new(server_cert, server_key, None)?; let service: Service = ServiceInner::new(MemTable::new()).into(); let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let tls = acceptor.clone(); let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let stream = tls.accept(stream).await?; let stream = ProstServerStream::new(stream, service.clone()); tokio::spawn(async move { stream.process().await }); } }
- src/client.rs:
use anyhow::Result; use kv3::{CommandRequest, ProstClientStream, TlsClientConnector}; use tokio::net::TcpStream; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); // 以后用配置替换 let ca_cert = include_str!("../fixtures/ca.cert"); let addr = "127.0.0.1:9527"; // 连接服务器 let connector = TlsClientConnector::new("kvserver.acme.inc", None, Some(ca_cert))?; let stream = TcpStream::connect(addr).await?; let stream = connector.connect(stream).await?; let mut client = ProstClientStream::new(stream); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".to_string().into()); // 发送 HSET 命令 let data = client.execute(cmd).await?; info!("Got response {:?}", data); Ok(()) }
这就是使用 trait 做面向接口编程的巨大威力,系统的各个组件可以来自不同的 crates,但只要其接口一致(或者我们创建 adapter 使其接口一致),就可以无缝插入。
测试通过
- 完成之后,打开一个命令行窗口,运行:
RUST_LOG=info cargo run --bin kvs --quiet
- 然后在另一个命令行窗口,运行:
RUST_LOG=info cargo run --bin kvc --quie
此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。
现在,我们的 KV server 已经具备足够的安全性了!
以后,等我们使用配置文件,就可以根据配置文件读取证书和私钥。这样可以在部署的时候,才从 vault 中获取私钥,既保证灵活性,又能保证系统自身的安全。
网络安全开发回顾
网络安全是开发网络相关的应用程序中非常重要的一个环节。虽然 KV Server 这样的服务基本上会运行在云端受控的网络环境中,不会对 internet 提供服务,然而云端内部的安全性也不容忽视。你不希望数据在流动的过程中被篡改。
TLS 很好地解决了安全性的问题,可以保证整个传输过程中数据的机密性和完整性。如果使用客户端证书的话,还可以做一定程度的客户端合法性的验证。比如你可以在云端为所有有权访问 KV server 的客户端签发客户端证书,这样,只要客户端的私钥不泄露,就只有拥有证书的客户端才能访问 KV server。
不知道你现在有没有觉得,在 Rust 下使用 TLS 是非常方便的一件事情。并且,我们构建的 ProstServerStream / ProstClientStream,因为有足够好的抽象,可以在 TcpStream 和 TlsStream 之间游刃有余地切换。当你构建好相关的代码,只需要把 TcpStream 换成 TlsStream,KV server 就可以无缝切换到一个安全的网络协议栈。
考虑双向验证
目前我们的 kvc / kvs 只做了单向的验证,如果服务器要验证客户端的证书,该怎么做?如果你没有头绪,可以再仔细看看测试 TLS 的代码,然后改动 kvc/kvs 使得双向验证也能通过吧。
除了 TLS,另外一个被广泛使用的处理应用层安全的协议是 noise protocol 。你可以阅读陈天的这篇文章了解 noise protocol。Rust 下有 snow 这个很优秀的库处理 noise protocol。对于有余力的同学,你们可以看看它的文档,尝试着写段类似reqwest的 tls.rs 的代码 ,让我们的 kvs / kvc 可以使用 noise protocol。
六、异步处理
Summarize made by cursor
本篇文章主要介绍了 Rust 异步处理的相关知识。
- 首先回顾了构建 KV server 的过程,然后介绍了异步重构的必要性。
- 接着,详细讲解了如何创建 ProstStream 结构,让它实现 Stream 和 Sink 这两个 trait
- 然后让 ProstServerStream 和 ProstClientStream 使用它。
- 最后,分别实现了 Stream 和 Sink 的 poll_next()、poll_ready()、start_send()、poll_flush() 和 poll_close() 方法。
回顾构建过程
之前已经完成了一个相对完善的 KV server。
还记得是怎么一步步构建这个服务的么?
- 搭好 KV server 的基础功能:
- 构造了客户端和服务器间交互的 protobuf
- 然后设计CommandService trait 和 Storage trait,分别处理客户端命令和存储。
- 进一步构造了 Service 数据结构:
- 接收 CommandRequest
- 根据其类型调用相应的 CommandService 处理
- 并做合适的事件通知
- 最后返回 CommandResponse。
但所有这一切都发生在同步的世界:不管数据是怎么获得的,数据已经在那里,我们需要做的就是把一种数据类型转换成另一种数据类型的运算而已。
- 之后涉足网络的世界。
- 为 KV server 构造了自己的 frame:一个包含长度和是否压缩的信息的 4 字节的头,以及实际的 payload;
- 还设计了一个 FrameCoder 来对 frame 进行封包和拆包,这为接下来构造网络接口打下了坚实的基础。
-
考虑到网络安全,提供了 TLS 的支持。
-
在构建 ProstStream 的时候开始处理异步
- ProstStream 内部的 stream 需要支持 AsyncRead + AsyncWrite,这可以让 ProstStream 适配包括 TcpStream 和 TlsStream 在内的一切实现了 AsyncRead 和 AsyncWrite 的异步网络接口。
至此,我们打通了:
- 从远端得到一个命令
- 历经 TCP、TLS
- 然后被 FrameCoder 解出来一个 CommandRequest
- 交由 Service 来处理的过程
- 把同步世界和异步世界连接起来的,就是 ProstServerStream 这个结构。
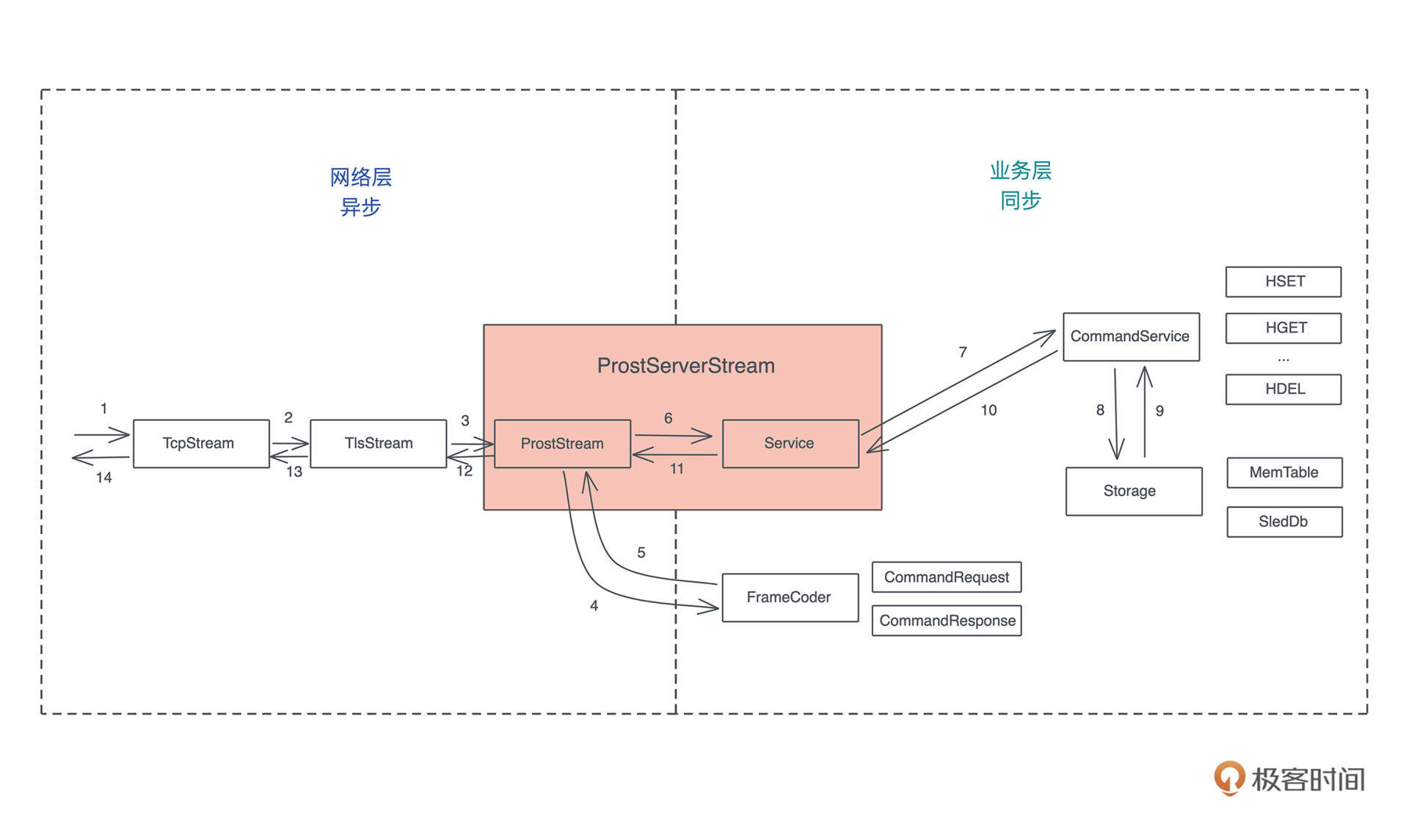
开始做异步重构
虽然我们很早就已经撰写了不少异步或者和异步有关的代码。但是最能体现 Rust 异步本质的 poll()、poll_read()、poll_next() 这样的处理函数还没有怎么写过,之前测试异步的 read_frame() 写过一个 DummyStream,算是体验了一下底层的异步处理函数的复杂接口。
不过在 DummyStream 里,并没有做任何复杂的动作:
struct DummyStream { buf: BytesMut, } impl AsyncRead for DummyStream { fn poll_read( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, buf: &mut tokio::io::ReadBuf<'_>, ) -> std::task::Poll<std::io::Result<()>> { // 看看 ReadBuf 需要多大的数据 let len = buf.capacity(); // split 出这么大的数据 let data = self.get_mut().buf.split_to(len); // 拷贝给 ReadBuf buf.put_slice(&data); // 直接完工 std::task::Poll::Ready(Ok(())) } }
这里对现有的代码做些重构,让核心的 ProstStream 更符合 Rust 的异步 IO 接口逻辑。
具体要做点什么呢?
看之前写的 ProstServerStream 的 process() 函数,比较一下它和 async_prost 库的 AsyncProst 的调用逻辑:
// process() 函数的内在逻辑 while let Ok(cmd) = self.recv().await { info!("Got a new command: {:?}", cmd); let res = self.service.execute(cmd); self.send(res).await?; } // async_prost 库的 AsyncProst 的调用逻辑 while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); stream.send(res).await.unwrap(); }
可以看到:
- 由于 AsyncProst 实现了 Stream 和 Sink
- 能更加自然地调用 StreamExt trait 的 next() 方法和 SinkExt trait 的 send() 方法,来处理数据的收发
- 而 ProstServerStream 则自己额外实现了函数 recv() 和 send()。
虽然从代码对比的角度,这两段代码几乎一样,但未来的可扩展性,和整个异步生态的融洽性上,AsyncProst 还是更胜一筹。
所以这里就构造一个 ProstStream 结构,让它实现 Stream 和 Sink 这两个 trait,然后让 ProstServerStream 和 ProstClientStream 使用它。
创建 ProstStream
在开始重构之前,先来简单复习一下 Stream trait 和 Sink trait:
// 可以类比 Iterator pub trait Stream { // 从 Stream 中读取到的数据类型 type Item; // 从 stream 里读取下一个数据 fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; } // pub trait Sink<Item> { type Error; fn poll_ready( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; fn start_send(self: Pin<&mut Self>, item: Item) -> Result<(), Self::Error>; fn poll_flush( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; fn poll_close( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; }
那么 ProstStream 具体需要包含什么类型呢?
那么 ProstStream 具体需要包含什么类型呢?
-
因为它的主要职责是从底下的 stream 中读取或者发送数据,所以一个支持 AsyncRead 和 AsyncWrite 的泛型参数 S 是必然需要的。
-
另外 Stream trait 和 Sink 都各需要一个 Item 类型,对于我们的系统来说,Item 是 CommandRequest 或者 CommandResponse,但为了灵活性,我们可以用 In 和 Out 这两个泛型参数来表示。
-
当然,在处理 Stream 和 Sink 时还需要 read buffer 和 write buffer。
综上所述,我们的 ProstStream 结构看上去是这样子的:
pub struct ProstStream<S, In, Out> { // innner stream stream: S, // 写缓存 wbuf: BytesMut, // 读缓存 rbuf: BytesMut, }
然而,Rust 不允许数据结构有超出需要的泛型参数。怎么办?
别急,可以用 PhantomData,它是一个零字节大小的占位符,可以让我们的数据结构携带未使用的泛型参数。
好,现在有足够的思路了,我们创建 src/network/stream.rs,添加如下代码(记得在 src/network/mod.rs 添加对 stream.rs 的引用):
这段代码包含了为 ProstStream 实现 Stream 和 Sink 的骨架代码。
use bytes::BytesMut; use futures::{Sink, Stream}; use std::{ marker::PhantomData, pin::Pin, task::{Context, Poll}, }; use tokio::io::{AsyncRead, AsyncWrite}; use crate::{FrameCoder, KvError}; /// 处理 KV server prost frame 的 stream pub struct ProstStream<S, In, Out> where { // innner stream stream: S, // 写缓存 wbuf: BytesMut, // 读缓存 rbuf: BytesMut, // 类型占位符 _in: PhantomData<In>, _out: PhantomData<Out>, } impl<S, In, Out> Stream for ProstStream<S, In, Out> where S: AsyncRead + AsyncWrite + Unpin + Send, In: Unpin + Send + FrameCoder, Out: Unpin + Send, { /// 当调用 next() 时,得到 Result<In, KvError> type Item = Result<In, KvError>; fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { todo!() } } /// 当调用 send() 时,会把 Out 发出去 impl<S, In, Out> Sink<Out> for ProstStream<S, In, Out> where S: AsyncRead + AsyncWrite + Unpin, In: Unpin + Send, Out: Unpin + Send + FrameCoder, { /// 如果发送出错,会返回 KvError type Error = KvError; fn poll_ready(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { todo!() } fn start_send(self: Pin<&mut Self>, item: Out) -> Result<(), Self::Error> { todo!() } fn poll_flush(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { todo!() } fn poll_close(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { todo!() } }
接下来我们就一个个处理。
注意对于 In 和 Out 参数,还为其约束了 FrameCoder,这样,在实现里我们可以使用 decode_frame() 和 encode_frame() 来获取一个 Item 或者 encode 一个 Item。
- Stream 的实现, 主要是Stream 的 poll_next() 方法。
poll_next() 可以直接调用之前写好的 read_frame(),然后再用 decode_frame() 来解包:
fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { // 上一次调用结束后 rbuf 应该为空 assert!(self.rbuf.len() == 0); // 从 rbuf 中分离出 rest(摆脱对 self 的引用) let mut rest = self.rbuf.split_off(0); // 使用 read_frame 来获取数据 let fut = read_frame(&mut self.stream, &mut rest); ready!(Box::pin(fut).poll_unpin(cx))?; // 拿到一个 frame 的数据,把 buffer 合并回去 self.rbuf.unsplit(rest); // 调用 decode_frame 获取解包后的数据 Poll::Ready(Some(In::decode_frame(&mut self.rbuf))) }
这个不难理解,但中间这段需要稍微解释一下:
// 使用 read_frame 来获取数据 let fut = read_frame(&mut self.stream, &mut rest); ready!(Box::pin(fut).poll_unpin(cx))?;
- 因为 poll_xxx() 方法已经是 async/await 的底层 API 实现,所以我们在 poll_xxx() 方法中,是不能直接使用异步函数的,需要把它看作一个 future,然后调用 future 的 poll 函数。
- 因为 future 是一个 trait,所以需要 Box 将其处理成一个在堆上的 trait object,这样就可以调用 FutureExt 的 poll_unpin() 方法。Box::pin 会生成 Pin
。 - 至于 ready! 宏,它会在 Pending 时直接 return Pending,而在 Ready 时,返回 Ready 的值:
macro_rules! ready { ($e:expr $(,)?) => { match $e { $crate::task::Poll::Ready(t) => t, $crate::task::Poll::Pending => return $crate::task::Poll::Pending, } }; }
Stream 我们就实现好了,是不是也没有那么复杂?
- Sink的实现:主要是四个方法
再写 Sink,看上去要实现好几个方法,其实也不算复杂的四个方法 :
- poll_ready
- start_send()
- poll_flush
- poll_close
我们再回顾一下:
- poll_ready() 是做背压的
你可以根据负载来决定要不要返回 Poll::Ready。对于我们的网络层来说,可以先不关心背压,依靠操作系统的 TCP 协议栈提供背压处理即可,所以这里直接返回 Poll::Ready(Ok(())),也就是说,上层想写数据,可以随时写。
fn poll_ready(self: Pin<&mut Self>, _cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { Poll::Ready(Ok(())) }
- 当 poll_ready() 返回 Ready 后,Sink 就走到 start_send()。我们在 start_send() 里就把必要的数据准备好。这里把 item 封包成字节流,存入 wbuf 中:
fn start_send(self: Pin<&mut Self>, item: Out) -> Result<(), Self::Error> { let this = self.get_mut(); item.encode_frame(&mut this.wbuf)?; Ok(()) }
- 然后在 poll_flush() 中,我们开始写数据。这里需要记录当前写到哪里,所以需要在 ProstStream 里加一个字段 written,记录写入了多少字节:
/// 处理 KV server prost frame 的 stream pub struct ProstStream<S, In, Out> { // innner stream stream: S, // 写缓存 wbuf: BytesMut, // 写入了多少字节 written: usize, // 读缓存 rbuf: BytesMut, // 类型占位符 _in: PhantomData<In>, _out: PhantomData<Out>, }
有了这个 written 字段, 就可以循环写入:
fn poll_flush(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { let this = self.get_mut(); // 循环写入 stream 中 while this.written != this.wbuf.len() { let n = ready!(Pin::new(&mut this.stream).poll_write(cx, &this.wbuf[this.written..]))?; this.written += n; } // 清除 wbuf this.wbuf.clear(); this.written = 0; // 调用 stream 的 poll_flush 确保写入 ready!(Pin::new(&mut this.stream).poll_flush(cx)?); Poll::Ready(Ok(())) }
- 最后是 poll_close(),我们只需要调用 stream 的 flush 和 shutdown 方法,确保数据写完并且 stream 关闭:
fn poll_close(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { // 调用 stream 的 poll_flush 确保写入 ready!(self.as_mut().poll_flush(cx))?; // 调用 stream 的 poll_shutdown 确保 stream 关闭 ready!(Pin::new(&mut self.stream).poll_shutdown(cx))?; Poll::Ready(Ok(())) }
- 我们的 ProstStream 目前已经实现了 Stream 和 Sink,为了方便使用,再构建一些辅助方法,比如 new():
impl<S, In, Out> ProstStream<S, In, Out> where S: AsyncRead + AsyncWrite + Send + Unpin, { /// 创建一个 ProstStream pub fn new(stream: S) -> Self { Self { stream, written: 0, wbuf: BytesMut::new(), rbuf: BytesMut::new(), _in: PhantomData::default(), _out: PhantomData::default(), } } } // 一般来说,如果我们的 Stream 是 Unpin,最好实现一下 impl<S, Req, Res> Unpin for ProstStream<S, Req, Res> where S: Unpin {}
此外,我们还为其实现 Unpin trait,这会给别人在使用你的代码时带来很多方便。
一般来说,为异步操作而创建的数据结构,如果使用了泛型参数,那么只要内部没有自引用数据,就应该实现 Unpin。
测试!
又到了重要的测试环节。我们需要写点测试来确保 ProstStream 能正常工作。因为之前在 src/network/frame.rs 中写了个 DummyStream,实现了 AsyncRead,我们只需要扩展它,让它再实现 AsyncWrite。
- 为了让它可以被复用,我们将其从 frame.rs 中移出来,放在 src/network/mod.rs 中,并修改成下面的样子(记得在 frame.rs 的测试里 use 新的 DummyStream):
#[cfg(test)] pub mod utils { use bytes::{BufMut, BytesMut}; use std::task::Poll; use tokio::io::{AsyncRead, AsyncWrite}; pub struct DummyStream { pub buf: BytesMut, } impl AsyncRead for DummyStream { fn poll_read( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, buf: &mut tokio::io::ReadBuf<'_>, ) -> Poll<std::io::Result<()>> { let len = buf.capacity(); let data = self.get_mut().buf.split_to(len); buf.put_slice(&data); Poll::Ready(Ok(())) } } impl AsyncWrite for DummyStream { fn poll_write( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, buf: &[u8], ) -> Poll<Result<usize, std::io::Error>> { self.get_mut().buf.put_slice(buf); Poll::Ready(Ok(buf.len())) } fn poll_flush( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, ) -> Poll<Result<(), std::io::Error>> { Poll::Ready(Ok(())) } fn poll_shutdown( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, ) -> Poll<Result<(), std::io::Error>> { Poll::Ready(Ok(())) } } }
- 好,这样我们就可以在 src/network/stream.rs 下写个测试了:
#[cfg(test)] mod tests { use super::*; use crate::{utils::DummyStream, CommandRequest}; use anyhow::Result; use futures::prelude::*; #[tokio::test] async fn prost_stream_should_work() -> Result<()> { let buf = BytesMut::new(); let stream = DummyStream { buf }; let mut stream = ProstStream::<_, CommandRequest, CommandRequest>::new(stream); let cmd = CommandRequest::new_hdel("t1", "k1"); stream.send(cmd.clone()).await?; if let Some(Ok(s)) = stream.next().await { assert_eq!(s, cmd); } else { assert!(false); } Ok(()) } }
- 运行 cargo test ,一切测试通过!(如果你编译错误,可能缺少 use 的问题,可以自行修改,或者参考 GitHub 上的完整代码)。
使用 ProstStream
接下来,我们可以让 ProstServerStream 和 ProstClientStream 使用新定义的 ProstStream 了,你可以参考下面的对比,看看二者的区别:
// 旧的接口 // pub struct ProstServerStream<S> { // inner: S, // service: Service, // } pub struct ProstServerStream<S> { inner: ProstStream<S, CommandRequest, CommandResponse>, service: Service, } // 旧的接口 // pub struct ProstClientStream<S> { // inner: S, // } pub struct ProstClientStream<S> { inner: ProstStream<S, CommandResponse, CommandRequest>, }
然后删除 send() / recv() 函数,并修改 process() / execute() 函数使其使用 next() 方法和 send() 方法。主要的改动如下:
/// 处理服务器端的某个 accept 下来的 socket 的读写 pub struct ProstServerStream<S> { inner: ProstStream<S, CommandRequest, CommandResponse>, service: Service, } /// 处理客户端 socket 的读写 pub struct ProstClientStream<S> { inner: ProstStream<S, CommandResponse, CommandRequest>, } impl<S> ProstServerStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { pub fn new(stream: S, service: Service) -> Self { Self { inner: ProstStream::new(stream), service, } } pub async fn process(mut self) -> Result<(), KvError> { let stream = &mut self.inner; while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = self.service.execute(cmd); stream.send(res).await.unwrap(); } Ok(()) } } impl<S> ProstClientStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { pub fn new(stream: S) -> Self { Self { inner: ProstStream::new(stream), } } pub async fn execute(&mut self, cmd: CommandRequest) -> Result<CommandResponse, KvError> { let stream = &mut self.inner; stream.send(cmd).await?; match stream.next().await { Some(v) => v, None => Err(KvError::Internal("Didn't get any response".into())), } } }
测试
再次运行 cargo test ,所有的测试应该都能通过。同样如果有编译错误,可能是缺少了引用。
我们也可以打开一个命令行窗口,运行:
RUST_LOG=info cargo run --bin kvs --quiet
然后在另一个命令行窗口,运行:
RUST_LOG=info cargo run --bin kvc --quiet
此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常!
我们重构了 ProstServerStream 和 ProstClientStream 的代码,使其内部使用更符合 futures 库里 Stream / Sink trait 的用法,整体代码改动不小,但是内部实现的变更并不影响系统的其它部分!这简直太棒了!
异步处理回顾:单元测试的重要性
在实际开发中,进行重构来改善既有代码的质量是必不可少的。之前在开发 KV server 的过程中,我们在不断地进行一些小的重构。
本节我们做了个稍微大一些的重构,为已有的代码提供更加符合异步 IO 接口的功能。
从对外使用的角度来说,它并没有提供或者满足任何额外的需求,但是从代码结构和质量的角度,它使得我们的 ProstStream 可以更方便和更直观地被其它接口调用,也更容易跟整个 Rust 的现有生态结合起来。
你可能会好奇,为什么可以这么自然地进行代码重构?这是因为我们有足够的单元测试覆盖来打底。
就像生物的进化一样,好的代码是在良性的重构中不断演进出来的,而良性的重构,是在优秀的单元测试的监管下,使代码朝着正确方向迈出的步伐。在这里,单元测试扮演着生物进化中自然环境的角色,把重构过程中的错误一一扼杀。
思考题
为什么在创建 ProstStream 时,要在数据结构中放 wbuf / rbuf 和 written 字段?为什么不能用局部变量?
七、如何做大的重构?
Summarize made by cursor
本篇文章主要介绍了如何在 Rust 中进行大规模重构,以支持 Pub/Sub。
- 首先,文章分析了现有架构的问题,即同步处理和 head of line blocking 问题。
- 然后,文章介绍了如何使用 yamux 做多路复用,以解决 head of line blocking 问题。
- 接着,文章讲解了如何支持 Pub/Sub,包括设计思路和数据结构。
- 最后,文章提供了完整的代码实现和测试。
现有架构分析
先简单回顾一下 Redis 对 Pub/Sub 的支持
- 客户端可以随时发起 SUBSCRIBE、PUBLISH 和 UNSUBSCRIBE。
- 如果客户端 A 和 B SUBSCRIBE 了一个叫 lobby 的主题,客户端 C 往 lobby 里发了 “hello”,A 和 B 都将立即收到这个信息。
- 使用起来是这个样子的:
A: SUBSCRIBE "lobby"
A: SUBSCRIBE "王者荣耀"
B: SUBSCRIBE "lobby"
C: PUBLISH "lobby" "hello"
// A/B 都收到 "hello"
B: UNSUBSCRIBE "lobby"
B: SUBSCRIBE "王者荣耀"
D: PUBLISH "lobby" "goodbye"
// 只有 A 收到 "goodbye"
C: PUBLISH "王者荣耀" "good game"
// A/B 都收到 "good game"
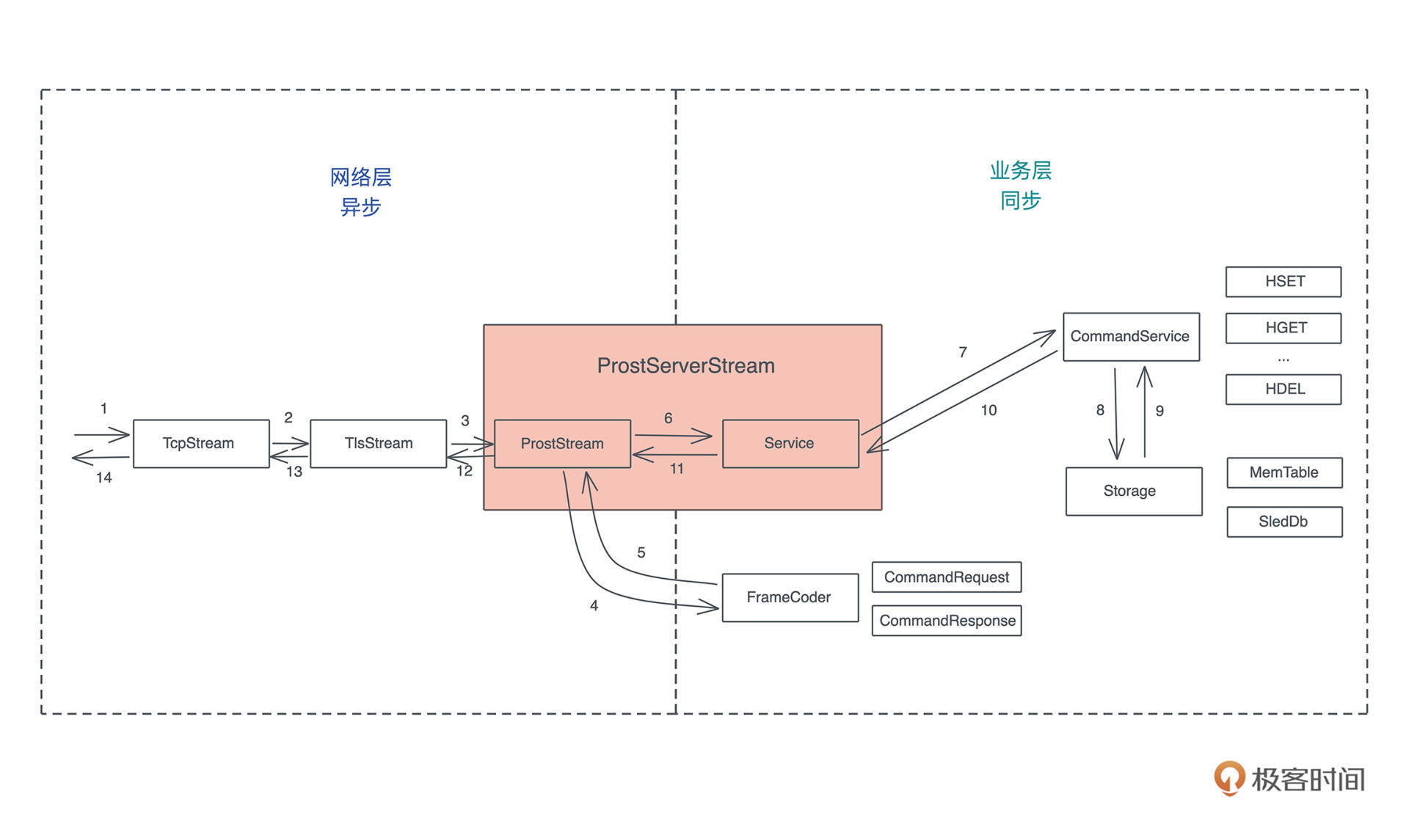
要支持 Pub/Sub,现有架构有两个很大的问题。
- CommandService是同步处理
首先,CommandService 是一个同步的处理,来一个命令,立刻就能计算出一个值返回。但现在来一个 SUBSCRIBE 命令,它期待的不是一个值,而是未来可能产生的若干个值。而 Stream 代表未来可能产生的一系列值,所以这里需要返回一个异步的 Stream。
因此,这里有两个思路:
- 要么需要牺牲 CommandService 这个 trait 来适应新的需求
- 要么构建一个新的、和 CommandService trait 并列的 trait,来处理和 Pub/Sub 有关的命令。
其次,如果直接在 TCP/TLS 之上构建 Pub/Sub 的支持,我们需要在 Request 和 Response 之间建立“流”的概念,为什么呢?
之前我们的协议运行模式是同步的,一来一回:
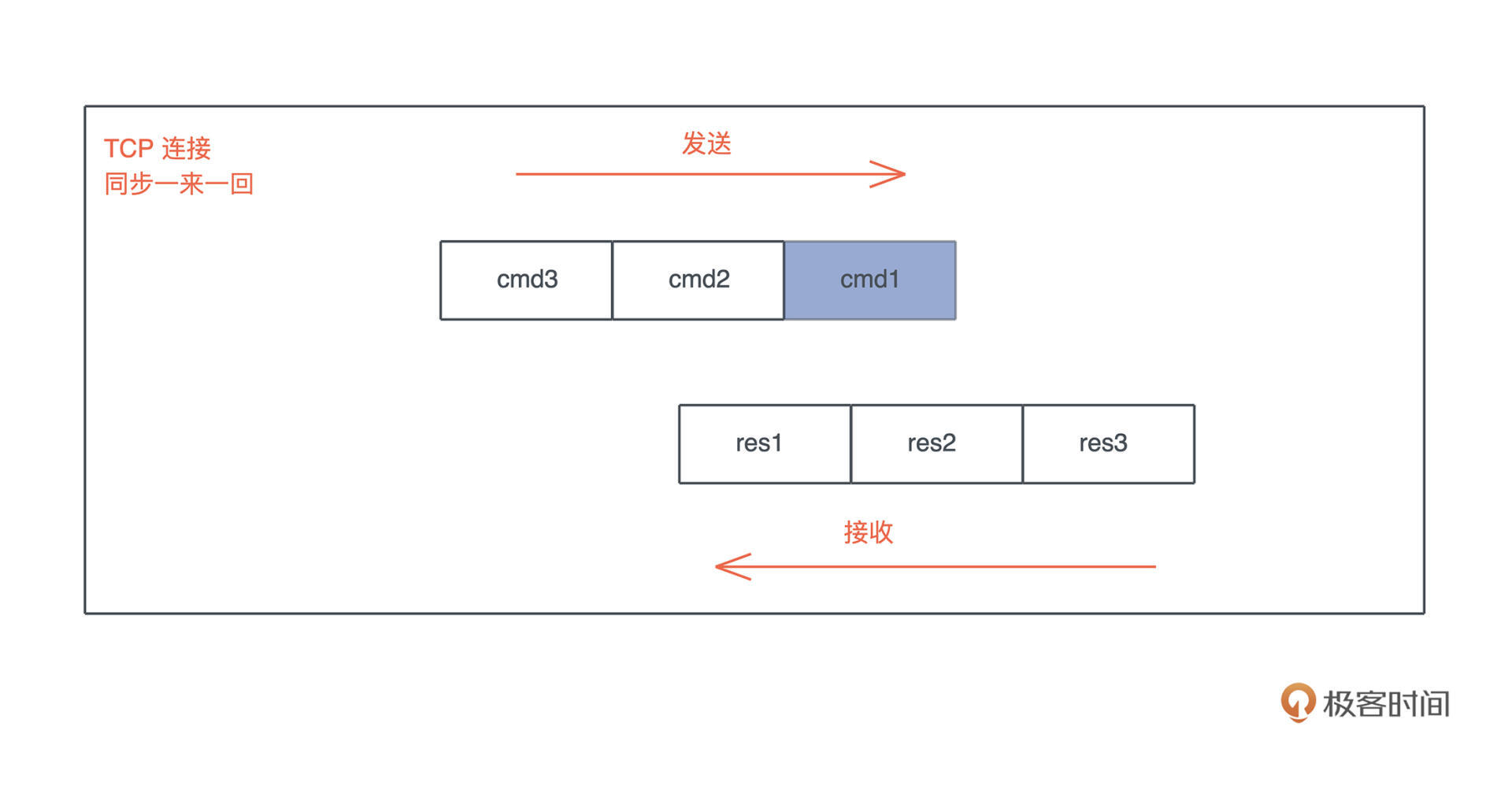
但是,如果继续采用这样的方式,就会有应用层的 head of line blocking(队头阻塞)问题:
-
一个 SUBSCRIBE 命令,因为其返回结果不知道什么时候才结束,会阻塞后续的所有命令。
-
所以,我们需要在一个连接里,划分出很多彼此独立的“流”,让它们的收发不受影响:
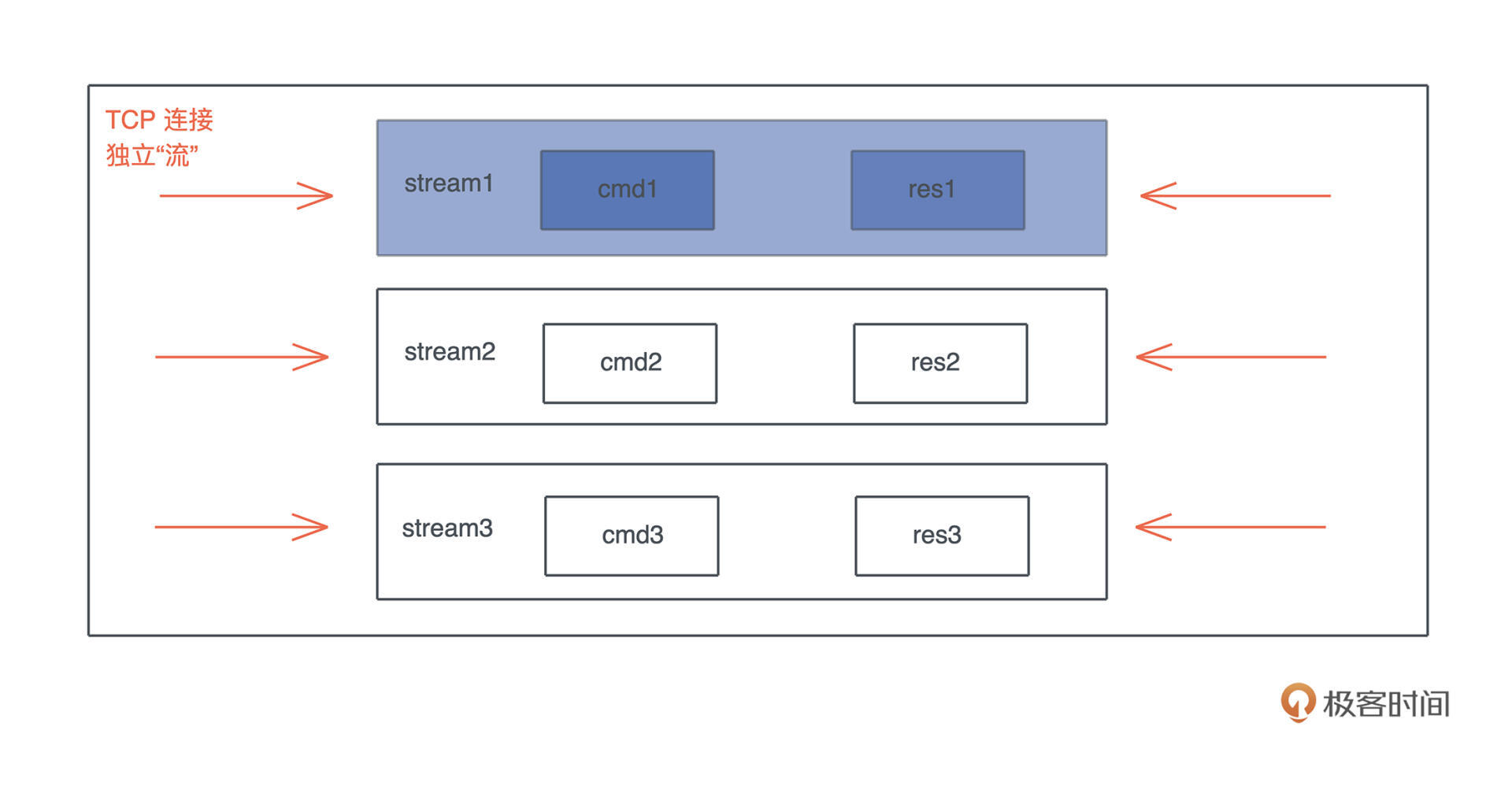
流式处理的的典型协议使用了多路复用的HTTP/2,有两个方案选择
这种流式处理的典型协议是使用了多路复用(multiplex)的 HTTP/2。所以:
-
一种方案是我们可以把 KV server 构建在使用 HTTP/2 的 gRPC 上。不过,HTTP 是个太过庞杂的协议,对于 KV server 这种性能非常重要的服务来说,不必要的额外开销太多,所以它不太适合。
-
另一种方式是使用 Yamux 协议,它是一个简单的、和 HTTP/2 内部多路复用机制非常类似的协议。如果使用它,整个协议的交互看上去是这个样子的:
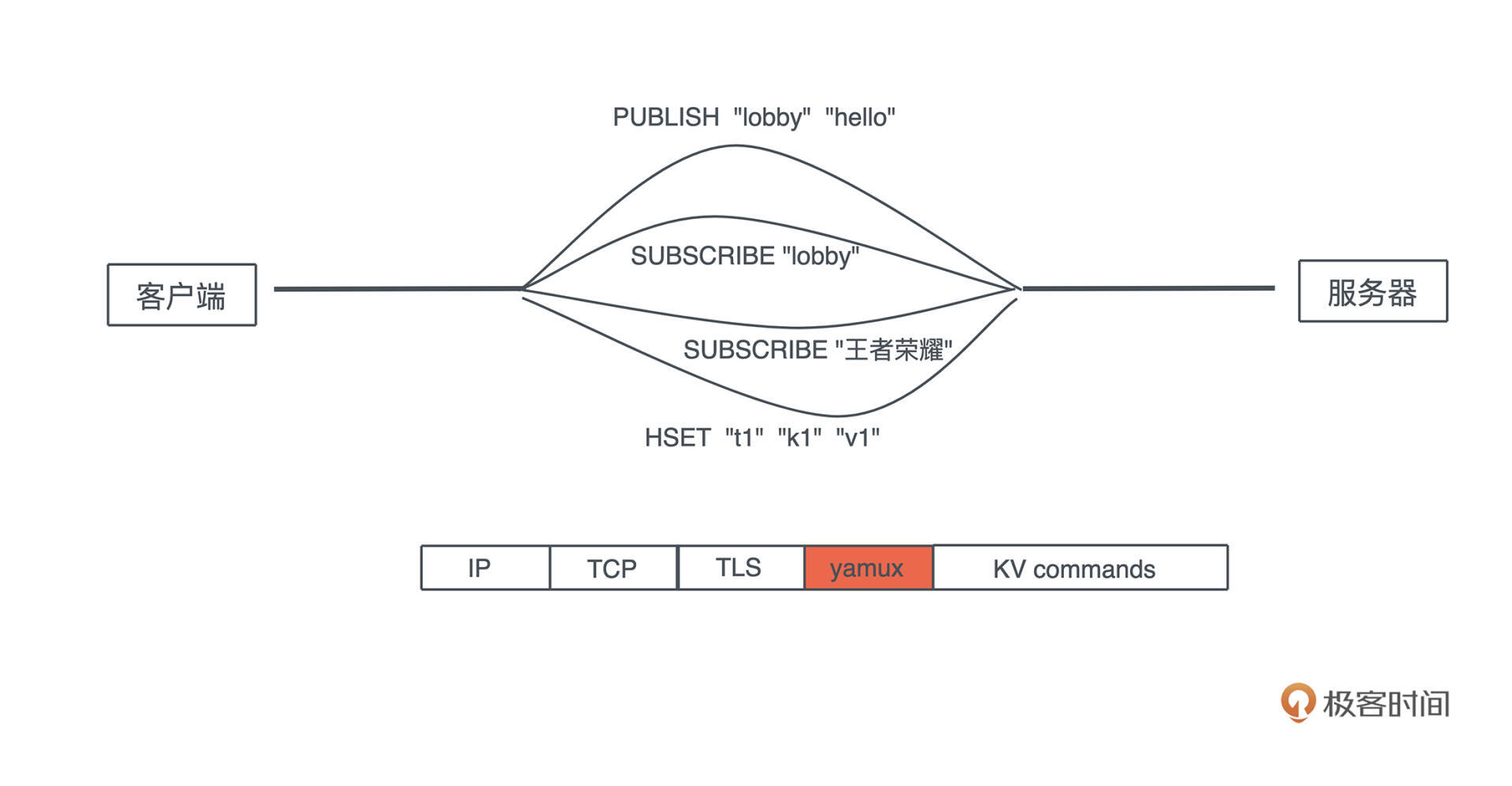
Yamux 适合不希望引入 HTTP 的繁文缛节(大量的头信息),在 TCP 层做多路复用的场景,这里就用它来支持我们所要实现的 Pub/Sub。
使用 yamux 做多路复用
Rust 下有lip2p出品的 rust-yamux 这个库,来支持 yamux。
除此之外,我们还需要 tokio-util,它提供了 tokio 下的 trait 和 futures 下的 trait 的兼容能力。
- 在 Cargo.toml 中引入它们:
[dependencies]
...
tokio-util = { version = "0.6", features = ["compat"]} # tokio 和 futures 的兼容性库
...
yamux = "0.9" # yamux 多路复用支持
...
- 然后创建 src/network/multiplex.rs(记得在 mod.rs 里引用),添入如下代码:
use futures::{future, Future, TryStreamExt}; use std::marker::PhantomData; use tokio::io::{AsyncRead, AsyncWrite}; use tokio_util::compat::{Compat, FuturesAsyncReadCompatExt, TokioAsyncReadCompatExt}; use yamux::{Config, Connection, ConnectionError, Control, Mode, WindowUpdateMode}; /// Yamux 控制结构 pub struct YamuxCtrl<S> { /// yamux control,用于创建新的 stream ctrl: Control, _conn: PhantomData<S>, } impl<S> YamuxCtrl<S> where S: AsyncRead + AsyncWrite + Unpin + Send + 'static, { /// 创建 yamux 客户端 pub fn new_client(stream: S, config: Option<Config>) -> Self { Self::new(stream, config, true, |_stream| future::ready(Ok(()))) } /// 创建 yamux 服务端,服务端我们需要具体处理 stream pub fn new_server<F, Fut>(stream: S, config: Option<Config>, f: F) -> Self where F: FnMut(yamux::Stream) -> Fut, F: Send + 'static, Fut: Future<Output = Result<(), ConnectionError>> + Send + 'static, { Self::new(stream, config, false, f) } // 创建 YamuxCtrl fn new<F, Fut>(stream: S, config: Option<Config>, is_client: bool, f: F) -> Self where F: FnMut(yamux::Stream) -> Fut, F: Send + 'static, Fut: Future<Output = Result<(), ConnectionError>> + Send + 'static, { let mode = if is_client { Mode::Client } else { Mode::Server }; // 创建 config let mut config = config.unwrap_or_default(); config.set_window_update_mode(WindowUpdateMode::OnRead); // 创建 config,yamux::Stream 使用的是 futures 的 trait 所以需要 compat() 到 tokio 的 trait let conn = Connection::new(stream.compat(), config, mode); // 创建 yamux ctrl let ctrl = conn.control(); // pull 所有 stream 下的数据 tokio::spawn(yamux::into_stream(conn).try_for_each_concurrent(None, f)); Self { ctrl, _conn: PhantomData::default(), } } /// 打开一个新的 stream pub async fn open_stream(&mut self) -> Result<Compat<yamux::Stream>, ConnectionError> { let stream = self.ctrl.open_stream().await?; Ok(stream.compat()) } }
这段代码提供了 Yamux 的基本处理。如果有些地方你看不明白,比如 WindowUpdateMode,yamux::into_stream() 等,很正常,需要看看 yamux crate 的文档和例子(由于这个库没有发布,所以只能clone本地运行cargo doc查看)。
这里有一个复杂的接口,我们稍微解释一下:
这里有一个复杂的接口,我们稍微解释一下:
pub fn new_server<F, Fut>(stream: S, config: Option<Config>, f: F) -> Self where F: FnMut(yamux::Stream) -> Fut, F: Send + 'static, Fut: Future<Output = Result<(), ConnectionError>> + Send + 'static, { Self::new(stream, config, false, f) }
它的意思是:
- 参数 f 是一个 FnMut 闭包
- 接受一个 yamux::Stream 参数
- 返回 Future
这样的结构我们之前见过,之所以接口这么复杂,是因为 Rust 还没有把 async 闭包稳定下来。所以,如果要想写一个 async || {},这是最佳的方式。
测试通过
还是写一段测试测一下(篇幅关系,完整的代码就不放了,你可以到 GitHub repo 下对照 diff_yamux 看修改):
#[tokio::test] async fn yamux_ctrl_client_server_should_work() -> Result<()> { // 创建使用了 TLS 的 yamux server let acceptor = tls_acceptor(false)?; let addr = start_yamux_server("127.0.0.1:0", acceptor, MemTable::new()).await?; let connector = tls_connector(false)?; let stream = TcpStream::connect(addr).await?; let stream = connector.connect(stream).await?; // 创建使用了 TLS 的 yamux client let mut ctrl = YamuxCtrl::new_client(stream, None); // 从 client ctrl 中打开一个新的 yamux stream let stream = ctrl.open_stream().await?; // 封装成 ProstClientStream let mut client = ProstClientStream::new(stream); let cmd = CommandRequest::new_hset("t1", "k1", "v1".into()); client.execute(cmd).await.unwrap(); let cmd = CommandRequest::new_hget("t1", "k1"); let res = client.execute(cmd).await.unwrap(); assert_res_ok(res, &["v1".into()], &[]); Ok(()) }
可以看到:
- 经过简单的封装,yamux 就很自然地融入到我们现有的架构中
- 因为 open_stream() 得到的是符合 tokio AsyncRead / AsyncWrite 的 stream,所以它可以直接配合 ProstClientStream 使用。
- 也就是说,我们网络层又改动了一下,但后面逻辑依然不用变。
运行 cargo test ,所有测试都能通过。
支持 pub/sub
好,现在网络层已经支持了 yamux,为多路复用打下了基础。我们来看 pub/sub 具体怎么实现。
首先修改 abi.proto,加入新的几个命令:
// 来自客户端的命令请求 message CommandRequest { oneof request_data { ... Subscribe subscribe = 10; Unsubscribe unsubscribe = 11; Publish publish = 12; } } // subscribe 到某个主题,任何发布到这个主题的数据都会被收到 // 成功后,第一个返回的 CommandResponse,我们返回一个唯一的 subscription id message Subscribe { string topic = 1; } // 取消对某个主题的订阅 message Unsubscribe { string topic = 1; uint32 id = 2; } // 发布数据到某个主题 message Publish { string topic = 1; repeated Value data = 2; }
命令的响应我们不用改变。当客户端 Subscribe 时,返回的 stream 里的第一个值包含订阅 ID,这是一个全局唯一的 ID,这样,客户端后续可以用 Unsubscribe 取消。
Pub/Sub 如何设计?
那么,Pub/Sub 该如何实现呢?
我们可以用两张表:
- 一张 Topic Table,存放主题和对应的订阅列表;
- 一张 Subscription Table,存放订阅 ID 和 channel 的发送端。
- 当 SUBSCRIBE 时,我们获取一个订阅 ID,插入到 Topic Table
- 然后再创建一个 MPSC channel,把 channel 的发送端和订阅 ID 存入 subscription table。
这样:
- 当有人 PUBLISH 时,可以从 Topic table 中找到对应的订阅 ID 的列表
- 然后循环从 subscription table 中找到对应的 Sender,往里面写入数据。
- 此时,channel 的 Receiver 端会得到数据,这个数据会被 yamux stream poll 到,然后发给客户端。
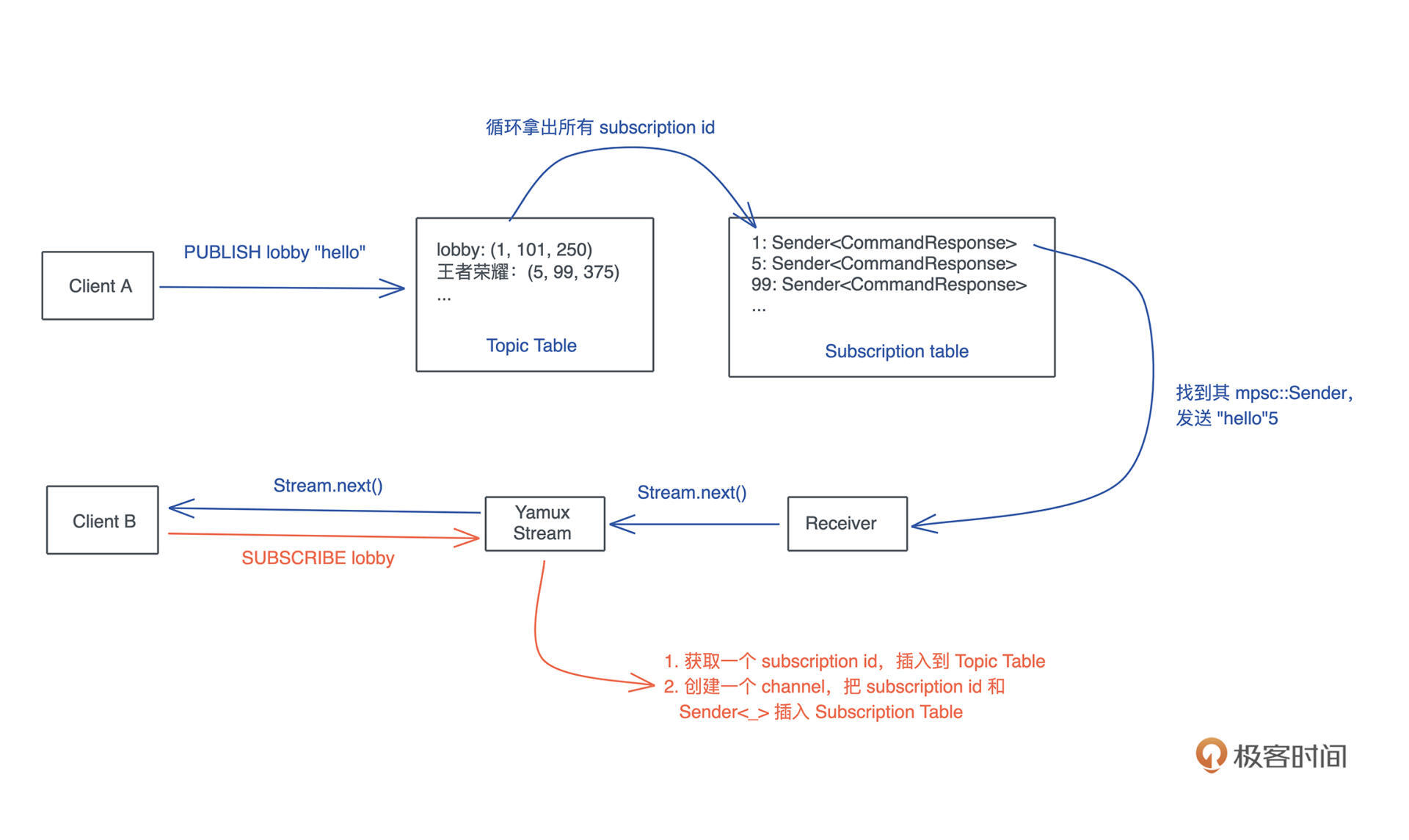
有了这个基本设计,我们可以着手接口和数据结构的构建了:
/// 下一个 subscription id static NEXT_ID: AtomicU32 = AtomicU32::new(1); /// 获取下一个 subscription id fn get_next_subscription_id() -> u32 { NEXT_ID.fetch_add(1, Ordering::Relaxed) } pub trait Topic: Send + Sync + 'static { /// 订阅某个主题 fn subscribe(self, name: String) -> mpsc::Receiver<Arc<CommandResponse>>; /// 取消对主题的订阅 fn unsubscribe(self, name: String, id: u32); /// 往主题里发布一个数据 fn publish(self, name: String, value: Arc<CommandResponse>); } /// 用于主题发布和订阅的数据结构 #[derive(Default)] pub struct Broadcaster { /// 所有的主题列表 topics: DashMap<String, DashSet<u32>>, /// 所有的订阅列表 subscriptions: DashMap<u32, mpsc::Sender<Arc<CommandResponse>>>, }
这里,subscription_id 我们用一个 AtomicU32 来表述。
- 对于这样一个全局唯一的 ID,很多同学喜欢用 UUID4 来表述。
- 注意使用 UUID 的话,存储时一定不要存它的字符串表现形式,太浪费内存且每次都有额外的堆分配,应该用它 u128 的表现形式。
- 不过即便 u128,也比 u32 浪费很多空间
假设某个主题 M 下有一万个订阅,要往这个 M 里发送一条消息,就意味着整个 DashSet
- 另外,我们把 CommandResponse 封装进了一个 Arc。
如果一条消息要发送给一万个客户端,那么我们不希望这条消息被复制后,再被发送,而是直接发送同一份数据。
这里对 Pub/Sub 的接口,构建了一个 Topic trait。虽然目前我们只有 Broadcaster 会实现 Topic trait,但未来也许会换不同的实现方式,所以,抽象出 Topic trait 很有意义。
Pub/Sub 的实现
创建 src/service/topic.rs(记得在 mod.rs 里引用),并添入:
use dashmap::{DashMap, DashSet}; use std::sync::{ atomic::{AtomicU32, Ordering}, Arc, }; use tokio::sync::mpsc; use tracing::{debug, info, warn}; use crate::{CommandResponse, Value}; /// topic 里最大存放的数据 const BROADCAST_CAPACITY: usize = 128; /// 下一个 subscription id static NEXT_ID: AtomicU32 = AtomicU32::new(1); /// 获取下一个 subscription id fn get_next_subscription_id() -> u32 { NEXT_ID.fetch_add(1, Ordering::Relaxed) } pub trait Topic: Send + Sync + 'static { /// 订阅某个主题 fn subscribe(self, name: String) -> mpsc::Receiver<Arc<CommandResponse>>; /// 取消对主题的订阅 fn unsubscribe(self, name: String, id: u32); /// 往主题里发布一个数据 fn publish(self, name: String, value: Arc<CommandResponse>); } /// 用于主题发布和订阅的数据结构 #[derive(Default)] pub struct Broadcaster { /// 所有的主题列表 topics: DashMap<String, DashSet<u32>>, /// 所有的订阅列表 subscriptions: DashMap<u32, mpsc::Sender<Arc<CommandResponse>>>, } impl Topic for Arc<Broadcaster> { fn subscribe(self, name: String) -> mpsc::Receiver<Arc<CommandResponse>> { let id = { let entry = self.topics.entry(name).or_default(); let id = get_next_subscription_id(); entry.value().insert(id); id }; // 生成一个 mpsc channel let (tx, rx) = mpsc::channel(BROADCAST_CAPACITY); let v: Value = (id as i64).into(); // 立刻发送 subscription id 到 rx let tx1 = tx.clone(); tokio::spawn(async move { if let Err(e) = tx1.send(Arc::new(v.into())).await { // TODO: 这个很小概率发生,但目前我们没有善后 warn!("Failed to send subscription id: {}. Error: {:?}", id, e); } }); // 把 tx 存入 subscription table self.subscriptions.insert(id, tx); debug!("Subscription {} is added", id); // 返回 rx 给网络处理的上下文 rx } fn unsubscribe(self, name: String, id: u32) { if let Some(v) = self.topics.get_mut(&name) { // 在 topics 表里找到 topic 的 subscription id,删除 v.remove(&id); // 如果这个 topic 为空,则也删除 topic if v.is_empty() { info!("Topic: {:?} is deleted", &name); drop(v); self.topics.remove(&name); } } debug!("Subscription {} is removed!", id); // 在 subscription 表中同样删除 self.subscriptions.remove(&id); } fn publish(self, name: String, value: Arc<CommandResponse>) { tokio::spawn(async move { match self.topics.get(&name) { Some(chan) => { // 复制整个 topic 下所有的 subscription id // 这里我们每个 id 是 u32,如果一个 topic 下有 10k 订阅,复制的成本 // 也就是 40k 堆内存(外加一些控制结构),所以效率不算差 // 这也是为什么我们用 NEXT_ID 来控制 subscription id 的生成 let chan = chan.value().clone(); // 循环发送 for id in chan.into_iter() { if let Some(tx) = self.subscriptions.get(&id) { if let Err(e) = tx.send(value.clone()).await { warn!("Publish to {} failed! error: {:?}", id, e); } } } } None => {} } }); } }
这段代码就是 Pub/Sub 的核心功能了。你可以对照着上面的设计图和代码中的详细注释去理解。
我们来写一个测试确保它正常工作:
#[cfg(test)] mod tests { use std::convert::TryInto; use crate::assert_res_ok; use super::*; #[tokio::test] async fn pub_sub_should_work() { let b = Arc::new(Broadcaster::default()); let lobby = "lobby".to_string(); // subscribe let mut stream1 = b.clone().subscribe(lobby.clone()); let mut stream2 = b.clone().subscribe(lobby.clone()); // publish let v: Value = "hello".into(); b.clone().publish(lobby.clone(), Arc::new(v.clone().into())); // subscribers 应该能收到 publish 的数据 let id1: i64 = stream1.recv().await.unwrap().as_ref().try_into().unwrap(); let id2: i64 = stream2.recv().await.unwrap().as_ref().try_into().unwrap(); assert!(id1 != id2); let res1 = stream1.recv().await.unwrap(); let res2 = stream2.recv().await.unwrap(); assert_eq!(res1, res2); assert_res_ok(&res1, &[v.clone()], &[]); // 如果 subscriber 取消订阅,则收不到新数据 b.clone().unsubscribe(lobby.clone(), id1 as _); // publish let v: Value = "world".into(); b.clone().publish(lobby.clone(), Arc::new(v.clone().into())); assert!(stream1.recv().await.is_none()); let res2 = stream2.recv().await.unwrap(); assert_res_ok(&res2, &[v.clone()], &[]); } }
这个测试需要一系列新的改动,比如 assert_res_ok() 的接口变化了,我们需要在 src/pb/mod.rs 里添加新的 TryFrom 支持等等,详细代码你可以看 repo 里的 diff_topic。
在处理流程中引入 Pub/Sub
好,再来看它和用户传入的 CommandRequest 如何发生关系。
我们之前设计了 CommandService trait,它虽然可以处理其它命令,但对 Pub/Sub 相关的几个新命令无法处理,因为接口没有任何和 Topic 有关的参数:
/// 对 Command 的处理的抽象 pub trait CommandService { /// 处理 Command,返回 Response fn execute(self, store: &impl Storage) -> CommandResponse; }
但是如果直接修改这个接口,对已有的代码就非常不友好。所以我们还是对比着创建一个新的 trait:
pub type StreamingResponse = Pin<Box<dyn Stream<Item = Arc<CommandResponse>> + Send>>; pub trait TopicService { /// 处理 Command,返回 Response fn execute<T>(self, chan: impl Topic) -> StreamingResponse; }
因为 Stream 是一个 trait,在 trait 的方法里我们无法返回一个 impl Stream,所以用 trait object:Pin<Box<dyn Stream>>。
实现它很简单,我们创建 src/service/topic_service.rs(记得在 mod.rs 引用),然后添加:
use futures::{stream, Stream}; use std::{pin::Pin, sync::Arc}; use tokio_stream::wrappers::ReceiverStream; use crate::{CommandResponse, Publish, Subscribe, Topic, Unsubscribe}; pub type StreamingResponse = Pin<Box<dyn Stream<Item = Arc<CommandResponse>> + Send>>; pub trait TopicService { /// 处理 Command,返回 Response fn execute<T, S>(self, topic: impl Topic) -> StreamingResponse; } impl TopicService for Subscribe { fn execute<T, S>(self, topic: impl Topic) -> StreamingResponse { let rx = topic.subscribe(self.topic); Box::pin(ReceiverStream::new(rx)) } } impl TopicService for Unsubscribe { fn execute<T, S>(self, topic: impl Topic) -> StreamingResponse { topic.unsubscribe(self.topic, self.id); Box::pin(stream::once(async { Arc::new(CommandResponse::ok()) })) } } impl TopicService for Publish { fn execute<T, S>(self, topic: impl Topic) -> StreamingResponse { topic.publish(self.topic, Arc::new(self.data.into())); Box::pin(stream::once(async { Arc::new(CommandResponse::ok()) })) } }
- 我们使用了 tokio-stream 的 wrapper 把一个 mpsc::Receiver 转换成 ReceiverStream, 这样 Subscribe 的处理就能返回一个 Stream。
- 对于 Unsubscribe 和 Publish,它们都返回单个值,我们使用 stream::once 将其统一起来。
同样地,要在 src/pb/mod.rs 里添加一些新的方法,比如 CommandResponse::ok(),它返回一个状态码是 OK 的 response:
impl CommandResponse { pub fn ok() -> Self { let mut result = CommandResponse::default(); result.status = StatusCode::OK.as_u16() as _; result } }
好,接下来看 src/service/mod.rs,我们可以对应着原来的 dispatch 做一个 dispatch_stream。
同样地,已有的接口应该少动,我们平行添加一个新的:
/// 从 Request 中得到 Response,目前处理所有 HGET/HSET/HDEL/HEXIST pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { match cmd.request_data { Some(RequestData::Hget(param)) => param.execute(store), Some(RequestData::Hgetall(param)) => param.execute(store), Some(RequestData::Hmget(param)) => param.execute(store), Some(RequestData::Hset(param)) => param.execute(store), Some(RequestData::Hmset(param)) => param.execute(store), Some(RequestData::Hdel(param)) => param.execute(store), Some(RequestData::Hmdel(param)) => param.execute(store), Some(RequestData::Hexist(param)) => param.execute(store), Some(RequestData::Hmexist(param)) => param.execute(store), None => KvError::InvalidCommand("Request has no data".into()).into(), // 处理不了的返回一个啥都不包括的 Response,这样后续可以用 dispatch_stream 处理 _ => CommandResponse::default(), } } /// 从 Request 中得到 Response,目前处理所有 PUBLISH/SUBSCRIBE/UNSUBSCRIBE pub fn dispatch_stream(cmd: CommandRequest, topic: impl Topic) -> StreamingResponse { match cmd.request_data { Some(RequestData::Publish(param)) => param.execute(topic), Some(RequestData::Subscribe(param)) => param.execute(topic), Some(RequestData::Unsubscribe(param)) => param.execute(topic), // 如果走到这里,就是代码逻辑的问题,直接 crash 出来 _ => unreachable!(), } }
为了使用这个新的接口,Service 结构也需要相应改动:
/// Service 数据结构 pub struct Service<Store = MemTable> { inner: Arc<ServiceInner<Store>>, broadcaster: Arc<Broadcaster>, } impl<Store> Clone for Service<Store> { fn clone(&self) -> Self { Self { inner: Arc::clone(&self.inner), broadcaster: Arc::clone(&self.broadcaster), } } } impl<Store: Storage> From<ServiceInner<Store>> for Service<Store> { fn from(inner: ServiceInner<Store>) -> Self { Self { inner: Arc::new(inner), broadcaster: Default::default(), } } } impl<Store: Storage> Service<Store> { pub fn execute(&self, cmd: CommandRequest) -> StreamingResponse { debug!("Got request: {:?}", cmd); self.inner.on_received.notify(&cmd); let mut res = dispatch(cmd, &self.inner.store); if res == CommandResponse::default() { dispatch_stream(cmd, Arc::clone(&self.broadcaster)) } else { debug!("Executed response: {:?}", res); self.inner.on_executed.notify(&res); self.inner.on_before_send.notify(&mut res); if !self.inner.on_before_send.is_empty() { debug!("Modified response: {:?}", res); } Box::pin(stream::once(async { Arc::new(res) })) } } }
这里,为了处理 Pub/Sub,我们引入了一个破坏性的更新:
- execute() 方法的返回值变成了 StreamingResponse
- 这就意味着所有围绕着这个方法的调用,包括测试,都需要相应更新。
- 这是迫不得已的,不过通过构建和 CommandService / dispatch 平行的 TopicService / dispatch_stream,我们已经让这个破坏性更新尽可能地在比较高层,否则,改动会更大。
目前,代码无法编译通过,这是因为如下的代码,res 现在是个 stream,
我们需要处理一下:
impl<S> ProstServerStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send + 'static, { ... pub async fn process(mut self) -> Result<(), KvError> { let stream = &mut self.inner; while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let mut res = self.service.execute(cmd); while let Some(data) = res.next().await { // 目前 data 是 Arc<CommandResponse>, // 所以我们 send 最好用 &CommandResponse stream.send(&data).await.unwrap(); } } // info!("Client {:?} disconnected", self.addr); Ok(()) } }
当然,这样的改动也意味着,原本的函数需要变成 async。
如果是个 test,需要使用 #[tokio::test]。你可以自己试着把所有相关的代码都改一下。
当你改到 src/network/mod.rs 里 ProstServerStream 的 process 方法里面的stream.send(data) 时,我们目前的 data 是 Arc:
impl<S> ProstServerStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send + 'static, { ... pub async fn process(mut self) -> Result<(), KvError> { let stream = &mut self.inner; while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let mut res = self.service.execute(cmd); while let Some(data) = res.next().await { // 目前 data 是 Arc<CommandResponse>, // 所以我们 send 最好用 &CommandResponse stream.send(&data).await.unwrap(); } } // info!("Client {:?} disconnected", self.addr); Ok(()) } }
所以我们还需要稍微改动一下 src/network/stream.rs:
// impl<S, In, Out> Sink<Out> for ProstStream<S, In, Out> impl<S, In, Out> Sink<&Out> for ProstStream<S, In, Out>
这会引发一系列的变动,你可以试着自己改一下。
如果你把所有编译错误都改正,cargo test 会全部通过。你也可以看 repo 里的 diff_service,看看所有改动的代码。
继续重构:弥补设计上的小问题
现在看上去大功告成,但你有没有注意,我们在撰写 src/service/topic_service.rs 时,没有写测试。你也许会说:这段代码如此简单,还有必要测试么?
还是那句话,测试是体验和感受接口完备性的一种手段。测试并不是为了测试实现本身,而是看接口是否好用,是否遗漏了某些产品需求。
测试
当开始写测试的时候,我们就会思考:
- unsubscribe 接口如果遇到不存在的 subscription,要不要返回一个 404?
- publish 的时候遇到错误,是不是意味着客户端非正常退出了?
- 我们要不要把它从 subscription 中移除掉?
#[cfg(test)] mod tests { use super::*; use crate::{assert_res_error, assert_res_ok, dispatch_stream, Broadcaster, CommandRequest}; use futures::StreamExt; use std::{convert::TryInto, time::Duration}; use tokio::time; #[tokio::test] async fn dispatch_publish_should_work() { let topic = Arc::new(Broadcaster::default()); let cmd = CommandRequest::new_publish("lobby", vec!["hello".into()]); let mut res = dispatch_stream(cmd, topic); let data = res.next().await.unwrap(); assert_res_ok(&data, &[], &[]); } #[tokio::test] async fn dispatch_subscribe_should_work() { let topic = Arc::new(Broadcaster::default()); let cmd = CommandRequest::new_subscribe("lobby"); let mut res = dispatch_stream(cmd, topic); let id: i64 = res.next().await.unwrap().as_ref().try_into().unwrap(); assert!(id > 0); } #[tokio::test] async fn dispatch_subscribe_abnormal_quit_should_be_removed_on_next_publish() { let topic = Arc::new(Broadcaster::default()); let id = { let cmd = CommandRequest::new_subscribe("lobby"); let mut res = dispatch_stream(cmd, topic.clone()); let id: i64 = res.next().await.unwrap().as_ref().try_into().unwrap(); drop(res); id as u32 }; // publish 时,这个 subscription 已经失效,所以会被删除 let cmd = CommandRequest::new_publish("lobby", vec!["hello".into()]); dispatch_stream(cmd, topic.clone()); time::sleep(Duration::from_millis(10)).await; // 如果再尝试删除,应该返回 KvError let result = topic.unsubscribe("lobby".into(), id); assert!(result.is_err()); } #[tokio::test] async fn dispatch_unsubscribe_should_work() { let topic = Arc::new(Broadcaster::default()); let cmd = CommandRequest::new_subscribe("lobby"); let mut res = dispatch_stream(cmd, topic.clone()); let id: i64 = res.next().await.unwrap().as_ref().try_into().unwrap(); let cmd = CommandRequest::new_unsubscribe("lobby", id as _); let mut res = dispatch_stream(cmd, topic); let data = res.next().await.unwrap(); assert_res_ok(&data, &[], &[]); } #[tokio::test] async fn dispatch_unsubscribe_random_id_should_error() { let topic = Arc::new(Broadcaster::default()); let cmd = CommandRequest::new_unsubscribe("lobby", 9527); let mut res = dispatch_stream(cmd, topic); let data = res.next().await.unwrap(); assert_res_error(&data, 404, "Not found: subscription 9527"); } }
在撰写这些测试,并试图使测试通过的过程中,我们又进一步重构了代码。具体的代码变更,你可以参考 repo 里的 diff_refactor。
让客户端能更好地使用新的接口
目前,我们 ProstClientStream 还是一个统一的 execute() 方法:
impl<S> ProstClientStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { ... pub async fn execute(&mut self, cmd: CommandRequest) -> Result<CommandResponse, KvError> { let stream = &mut self.inner; stream.send(&cmd).await?; match stream.next().await { Some(v) => v, None => Err(KvError::Internal("Didn't get any response".into())), } } }
它并没有妥善处理 SUBSCRIBE。
为了支持 SUBSCRIBE,我们需要两个接口:
- execute_unary
- execute_streaming。
在 src/network/mod.rs 修改这个代码:
impl<S> ProstClientStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send + 'static, { ... pub async fn execute_unary( &mut self, cmd: &CommandRequest, ) -> Result<CommandResponse, KvError> { let stream = &mut self.inner; stream.send(cmd).await?; match stream.next().await { Some(v) => v, None => Err(KvError::Internal("Didn't get any response".into())), } } pub async fn execute_streaming(self, cmd: &CommandRequest) -> Result<StreamResult, KvError> { let mut stream = self.inner; stream.send(cmd).await?; stream.close().await?; StreamResult::new(stream).await } }
注意:
- 因为 execute_streaming 里返回 Box:pin(stream)
- 我们需要对 ProstClientStream 的 S 限制是 ’static,否则编译器会抱怨
- 这个改动会导致使用 execute() 方法的测试都无法编译,你可以试着修改掉它们。
此外我们还创建了一个新的文件 src/network/stream_result.rs,用来帮助客户端更好地使用 execute_streaming() 接口。所有改动的具体代码可以看 repo 中的 diff_client。
测试
现在,代码一切就绪:
- 打开一个命令行窗口,运行:
RUST_LOG=info cargo run --bin kvs --quiet
- 然后在另一个命令行窗口,运行:
RUST_LOG=info cargo run --bin kvc --quiet
此时,服务器和客户端都收到了彼此的请求和响应,即便混合 HSET/HGET 和 PUBLISH/SUBSCRIBE 命令,一切都依旧处理正常!今天我们做了一个比较大的重构,但比预想中对原有代码的改动要小,这简直太棒了!
你可以仔细阅读这一节中的代码,好好品味这些接口的设计。
你可以仔细阅读这一节中的代码,好好品味这些接口的设计。
当一个项目越来越复杂,且新加的功能并不能很好地融入已有的系统时,大的重构是不可避免的。在重构的时候,我们一定要首先要弄清楚现有的流程和架构,然后再思考如何重构,这样对系统的侵入才是最小的。
重构一般会带来对现有测试的破坏,在修复被破坏的测试时,我们要注意不要变动原有测试的逻辑。在做因为新功能添加导致的重构时,如果伴随着大量测试的删除和大量新测试的添加,那么,说明要么原来的测试写得很有问题,要么重构对原有系统的侵入性太强。我们要尽量避免这种事情发生。
在架构和设计都相对不错的情况下,撰写代码的终极目标是对使用者友好的抽象。所谓对使用者友好的抽象,是指让别人调用我们写的接口时,不用想太多,接口本身就是自解释的。
如果你仔细阅读 diff_client,可以看到类似 StreamResult 这样的抽象。它避免了调用者需要了解如何手工从 Stream 中取第一个值作为 subscription_id 这样的实现细节,直接替调用者完成了这个工作,并以一个优雅的 ID 暴露给调用者。
你可以仔细阅读这一节中的代码,好好品味这些接口的设计。它们并非完美,世上没有完美的代码,只有不断完善的代码。如果把一行行代码比作一段段文字,起码它们都需要努力地推敲和不断地迭代。
一些相关考虑
思考用GC处理客户端意外终止
现在我们的系统对 Pub/Sub 已经有比较完整的支持,但你有没有注意到,有一个潜在的内存泄漏的 bug。如果客户端 A subscribe 了 Topic M,但客户端意外终止,且随后也没有任何人往 Topic M publish 消息。这样,A 的 subscription 就一直放在表中。你能做一个 GC 来处理这种情况么?
Redis 还支持 PSUBSCRIBE,也就是说除了可以 subscribe “chat” 这样固定的 topic,还可以是 “chat.*”,一并订阅所有 “chat”、“chat.rust”、“chat.elixir” 。想想看,如果要支持 PSUBSCRIBE,你该怎么设计 Broadcaster 里的两张表?
tokio 本身不就是 支持了多路复用吗?用 yamux来整合多路复用的意义是什么?
yamux 是一个具体的网络协议,它在 TCP 之上可以运行多个互不干扰的 stream(就像 HTTP/2);tokio 是一个异步运行时,可以在 N 个线程上跑 M 个 tokio task。我们利用 tokio 的异步能力来承载 Yamux 协议。
非rust写的客户端可否进行通信?
yamux 是个协议,比如你可以用 nodejs client, python client 访问。你当然需要使用支持 yamux 协议的库,比如 yamux-js。这就跟你要访问 http server,需要符合协议规范的 http client 一样。
八、配置/测试/监控/CI/CD
Summarize made by cursor
本篇文章主要介绍了 Rust 语言下的 KV server 项目的配置、测试、监控、CI/CD 等方面。
- 首先介绍了如何使用 serde 和 toml 处理配置文件
- 然后讲解了如何编写集成测试和性能测试
- 接着,介绍了如何使用 jaeger 和 opentelemetry 进行测量和监控
- 最后讲解了如何使用 GitHub Actions 实现 CI/CD。
虽然这是一个“简单”的 KV server:
- 它没有复杂的性能优化:只用了一句 unsafe;
- 也没有复杂的生命周期处理:只有零星 ’static 标注;
- 更没有支持集群的处理。
然而,如果你能够理解到目前为止的代码,甚至能独立写出这样的代码,那么,你已经具备足够的、能在一线大厂开发的实力了,国内我不是特别清楚,但在北美这边,保守一些地说,300k+ USD 的 package 应该可以轻松拿到。
今天我们就给 KV server 项目收个尾,结合之前梳理的实战中 Rust 项目应该考虑的问题,来聊聊和生产环境有关的一些处理,按开发流程,主要讲五个方面:
- 配置
- 集成测试
- 性能测试
- 测量和监控
- CI/CD
配置
- 使用 toml 做配置文件
- serde 用来处理配置的序列化和反序列化
Cargo.toml
[dependencies]
...
serde = { version = "1", features = ["derive"] } # 序列化/反序列化
...
toml = "0.5" # toml 支持
...
- 然后来创建一个 src/config.rs,构建 KV server 的配置:
use crate::KvError; use serde::{Deserialize, Serialize}; use std::fs; #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ServerConfig { pub general: GeneralConfig, pub storage: StorageConfig, pub tls: ServerTlsConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ClientConfig { pub general: GeneralConfig, pub tls: ClientTlsConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct GeneralConfig { pub addr: String, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] #[serde(tag = "type", content = "args")] pub enum StorageConfig { MemTable, SledDb(String), } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ServerTlsConfig { pub cert: String, pub key: String, pub ca: Option<String>, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ClientTlsConfig { pub domain: String, pub identity: Option<(String, String)>, pub ca: Option<String>, } impl ServerConfig { pub fn load(path: &str) -> Result<Self, KvError> { let config = fs::read_to_string(path)?; let config: Self = toml::from_str(&config)?; Ok(config) } } impl ClientConfig { pub fn load(path: &str) -> Result<Self, KvError> { let config = fs::read_to_string(path)?; let config: Self = toml::from_str(&config)?; Ok(config) } } #[cfg(test)] mod tests { use super::*; #[test] fn server_config_should_be_loaded() { let result: Result<ServerConfig, toml::de::Error> = toml::from_str(include_str!("../fixtures/server.conf")); assert!(result.is_ok()); } #[test] fn client_config_should_be_loaded() { let result: Result<ClientConfig, toml::de::Error> = toml::from_str(include_str!("../fixtures/client.conf")); assert!(result.is_ok()); } }
你可以看到:
- 在 Rust 下,有了 serde 的帮助,处理任何已知格式的配置文件,是多么容易的一件事情。
- 我们只需要定义数据结构,并为数据结构使用 Serialize/Deserialize 派生宏,就可以处理任何支持 serde 的数据结构。
- examples/gen_config.rs, 用来生成toml配置文件
use crate::KvError; use serde::{Deserialize, Serialize}; use std::fs; #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ServerConfig { pub general: GeneralConfig, pub storage: StorageConfig, pub tls: ServerTlsConfig, pub log: LogConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ClientConfig { pub general: GeneralConfig, pub tls: ClientTlsConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct GeneralConfig { pub addr: String, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct LogConfig { pub path: String, pub rotation: RotationConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub enum RotationConfig { Hourly, Daily, Never, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] #[serde(tag = "type", content = "args")] pub enum StorageConfig { MemTable, SledDb(String), } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ServerTlsConfig { pub cert: String, pub key: String, pub ca: Option<String>, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ClientTlsConfig { pub domain: String, pub identity: Option<(String, String)>, pub ca: Option<String>, } impl ServerConfig { pub fn load(path: &str) -> Result<Self, KvError> { let config = fs::read_to_string(path)?; let config: Self = toml::from_str(&config)?; Ok(config) } } impl ClientConfig { pub fn load(path: &str) -> Result<Self, KvError> { let config = fs::read_to_string(path)?; let config: Self = toml::from_str(&config)?; Ok(config) } } #[cfg(test)] mod tests { use super::*; #[test] fn server_config_should_be_loaded() { let result: Result<ServerConfig, toml::de::Error> = toml::from_str(include_str!("../fixtures/server.conf")); assert!(result.is_ok()); } #[test] fn client_config_should_be_loaded() { let result: Result<ClientConfig, toml::de::Error> = toml::from_str(include_str!("../fixtures/client.conf")); assert!(result.is_ok()); } }
下面是生成的服务端的配置:
[general]
addr = '127.0.0.1:9527'
[storage]
type = 'SledDb'
args = '/tmp/kv_server'
[tls]
cert = """
-----BEGIN CERTIFICATE-----\r
MIIBdzCCASmgAwIBAgIICpy02U2yuPowBQYDK2VwMDMxCzAJBgNVBAYMAkNOMRIw\r
EAYDVQQKDAlBY21lIEluYy4xEDAOBgNVBAMMB0FjbWUgQ0EwHhcNMjEwOTI2MDEy\r
NTU5WhcNMjYwOTI1MDEyNTU5WjA6MQswCQYDVQQGDAJDTjESMBAGA1UECgwJQWNt\r
ZSBJbmMuMRcwFQYDVQQDDA5BY21lIEtWIHNlcnZlcjAqMAUGAytlcAMhAK2Z2AjF\r
A0uiltNuCvl6EVFl6tpaS/wJYB5IdWT2IISdo1QwUjAcBgNVHREEFTATghFrdnNl\r
cnZlci5hY21lLmluYzATBgNVHSUEDDAKBggrBgEFBQcDATAMBgNVHRMEBTADAQEA\r
MA8GA1UdDwEB/wQFAwMH4AAwBQYDK2VwA0EASGOmOWFPjbGhXNOmYNCa3lInbgRy\r
iTNtB/5kElnbKkhKhRU7yQ8HTHWWkyU5WGWbOOIXEtYp+5ERUJC+mzP9Bw==\r
-----END CERTIFICATE-----\r
"""
key = """
-----BEGIN PRIVATE KEY-----\r
MFMCAQEwBQYDK2VwBCIEIPMyINaewhXwuTPUufFO2mMt/MvQMHrGDGxgdgfy/kUu\r
oSMDIQCtmdgIxQNLopbTbgr5ehFRZeraWkv8CWAeSHVk9iCEnQ==\r
-----END PRIVATE KEY-----\r
"""
有了配置文件的支持,就可以在 lib.rs 下写一些辅助函数,让我们创建服务端和客户端更加简单:
examples/gen_config.rs
mod config; mod error; mod network; mod pb; mod service; mod storage; pub use config::*; pub use error::KvError; pub use network::*; pub use pb::abi::*; pub use service::*; pub use storage::*; use anyhow::Result; use tokio::net::{TcpListener, TcpStream}; use tokio_rustls::client; use tokio_util::compat::FuturesAsyncReadCompatExt; use tracing::{info, instrument, span}; /// 通过配置创建 KV 服务器 #[instrument(skip_all)] pub async fn start_server_with_config(config: &ServerConfig) -> Result<()> { let acceptor = TlsServerAcceptor::new(&config.tls.cert, &config.tls.key, config.tls.ca.as_deref())?; let addr = &config.general.addr; match &config.storage { StorageConfig::MemTable => start_tls_server(addr, MemTable::new(), acceptor).await?, StorageConfig::SledDb(path) => start_tls_server(addr, SledDb::new(path), acceptor).await?, }; Ok(()) } /// 通过配置创建 KV 客户端 #[instrument(skip_all)] pub async fn start_client_with_config( config: &ClientConfig, ) -> Result<YamuxCtrl<client::TlsStream<TcpStream>>> { let addr = &config.general.addr; let tls = &config.tls; let identity = tls.identity.as_ref().map(|(c, k)| (c.as_str(), k.as_str())); let connector = TlsClientConnector::new(&tls.domain, identity, tls.ca.as_deref())?; let stream = TcpStream::connect(addr).await?; let stream = connector.connect(stream).await?; // 打开一个 stream Ok(YamuxCtrl::new_client(stream, None)) } async fn start_tls_server<Store: Storage>( addr: &str, store: Store, acceptor: TlsServerAcceptor, ) -> Result<()> { let service: Service<Store> = ServiceInner::new(store).into(); let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let root = span!(tracing::Level::INFO, "server_process"); let _enter = root.enter(); let tls = acceptor.clone(); let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let stream = tls.accept(stream).await.unwrap(); YamuxCtrl::new_server(stream, None, move |stream| { let svc1 = svc.clone(); async move { let stream = ProstServerStream::new(stream.compat(), svc1.clone()); stream.process().await.unwrap(); Ok(()) } }); }); } }
有了 start_server_with_config 和 start_client_with_config 这两个辅助函数,我们就可以简化 src/server.rs 和 src/client.rs 了。
下面是 src/server.rs 的新代码:
use anyhow::Result; use kv6::{start_server_with_config, ServerConfig}; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let config: ServerConfig = toml::from_str(include_str!("../fixtures/server.conf"))?; start_server_with_config(&config).await?; Ok(()) }
examples/gen_config.rs
use std::env; use anyhow::Result; use kv6::{start_server_with_config, RotationConfig, ServerConfig}; use tokio::fs; use tracing::span; use tracing_subscriber::{ fmt::{self, format}, layer::SubscriberExt, prelude::*, EnvFilter, }; #[tokio::main] async fn main() -> Result<()> { let config = match env::var("KV_SERVER_CONFIG") { Ok(path) => fs::read_to_string(&path).await?, Err(_) => include_str!("../fixtures/server.conf").to_string(), }; let config: ServerConfig = toml::from_str(&config)?; let tracer = opentelemetry_jaeger::new_pipeline() .with_service_name("kv-server") .install_simple()?; let opentelemetry = tracing_opentelemetry::layer().with_tracer(tracer); // 添加 let log = &config.log; let file_appender = match log.rotation { RotationConfig::Hourly => tracing_appender::rolling::hourly(&log.path, "server.log"), RotationConfig::Daily => tracing_appender::rolling::daily(&log.path, "server.log"), RotationConfig::Never => tracing_appender::rolling::never(&log.path, "server.log"), }; let (non_blocking, _guard1) = tracing_appender::non_blocking(file_appender); let fmt_layer = fmt::layer() .event_format(format().compact()) .with_writer(non_blocking); tracing_subscriber::registry() .with(EnvFilter::from_default_env()) .with(fmt_layer) .with(opentelemetry) .init(); let root = span!(tracing::Level::INFO, "app_start", work_units = 2); let _enter = root.enter(); start_server_with_config(&config).await?; Ok(()) }
可以看到,整个代码简洁了很多。在这个重构的过程中,还有一些其它改动,你可以看 GitHub repo 下 45 讲的 diff_config。
集成测试
之前我们写了很多单元测试,但还没有写过一行集成测试。今天就来写一个简单的集成测试,确保客户端和服务器完整的交互工作正常。
之前提到在 Rust 里,集成测试放在 tests 目录下,每个测试编成单独的二进制。
- 所以首先,我们创建和 src 平行的 tests 目录。
- 然后再创建 tests/server.rs,填入以下代码:
examples/gen_config.rs
use anyhow::Result; use kv6::{ start_client_with_config, start_server_with_config, ClientConfig, CommandRequest, ServerConfig, StorageConfig, }; use std::time::Duration; use tokio::time; #[tokio::test] async fn yamux_server_client_full_tests() -> Result<()> { let addr = "127.0.0.1:10086"; let mut config: ServerConfig = toml::from_str(include_str!("../fixtures/server.conf"))?; config.general.addr = addr.into(); config.storage = StorageConfig::MemTable; // 启动服务器 tokio::spawn(async move { start_server_with_config(&config).await.unwrap(); }); time::sleep(Duration::from_millis(10)).await; let mut config: ClientConfig = toml::from_str(include_str!("../fixtures/client.conf"))?; config.general.addr = addr.into(); let mut ctrl = start_client_with_config(&config).await.unwrap(); let mut stream = ctrl.open_stream().await?; // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".to_string().into()); stream.execute_unary(&cmd).await?; // 生成一个 HGET 命令 let cmd = CommandRequest::new_hget("table1", "hello"); let data = stream.execute_unary(&cmd).await?; assert_eq!(data.status, 200); assert_eq!(data.values, &["world".into()]); Ok(()) }
可以看到,集成测试的写法和单元测试其实很类似,只不过我们不需要再使用 #[cfg(test)] 来做条件编译。
1. 在 tests 下 cargo new 出一个项目
2. 然后在那个项目里撰写辅助代码和测试代码
3. 如果你对此感兴趣,可以看[ tonic 的集成测试](https://github.com/hyperium/tonic/tree/master/tests)。
4. 不过注意了,集成测试和你的 crate 用同样的条件编译,所以在集成测试里,无法使用单元测试中构建的辅助代码。
</div>
</details>
## 性能测试
在之前不断完善 KV server 的过程中,你一定会好奇:我们的 KV server 性能究竟如何呢?那来写一个关于 Pub/Sub 的性能测试吧。
基本的想法是我们连上 100 个 subscriber 作为背景,然后看 publisher publish 的速度。
因为 BROADCAST_CAPACITY 有限,是 128,当 publisher 速度太快,而导致 server 不能及时往 subscriber 发送时,server 接收 client
数据的速度就会降下来,无法接收新的
client,整体的 publish 的速度也会降下来,所以这个测试能够了解 server 处理 publish 的速度。
<details id="admonition-为了确认这一点我们在-start_tls_server-函数中在-process-之前再加个-100ms-的延时人为减缓系统的处理速度" class="admonition note">
<summary class="admonition-title">
为了确认这一点,我们在 start_tls_server() 函数中,在 process() 之前,再加个 100ms 的延时,人为减缓系统的处理速度:
<a class="admonition-anchor-link" href="#admonition-为了确认这一点我们在-start_tls_server-函数中在-process-之前再加个-100ms-的延时人为减缓系统的处理速度"></a>
</summary>
<div>
```rust, editable
async move {
let stream = ProstServerStream::new(stream.compat(), svc1.clone());
// 延迟 100ms 处理
time::sleep(Duration::from_millis(100)).await;
stream.process().await.unwrap();
Ok(())
}
```
</div>
</details>
好,现在可以写性能测试了。
<details id="admonition-在-rust-下我们可以用-criterion-库httpsgithubcombheislercriterionrs它可以处理基本的性能测试并生成漂亮的报告" class="admonition note">
<summary class="admonition-title">
在 Rust 下,我们可以用 [criterion 库](https://github.com/bheisler/criterion.rs)。它可以处理基本的性能测试,并生成漂亮的报告
<a class="admonition-anchor-link" href="#admonition-在-rust-下我们可以用-criterion-库httpsgithubcombheislercriterionrs它可以处理基本的性能测试并生成漂亮的报告"></a>
</summary>
<div>
所以在 Cargo.toml 中加入:
```toml
[dev-dependencies]
...
criterion = { version = "0.3", features = ["async_futures", "async_tokio", "html_reports"] } # benchmark
...
rand = "0.8" # 随机数处理
...
[[bench]]
name = "pubsub"
harness = false
```
> 最后这个 bench section,描述了性能测试的名字,它对应 benches 目录下的同名文件。
我们创建和 src 平级的 benches,然后再创建 benches/pubsub.rs,添入如下代码:
~~~admonish info title="examples/gen_config.rs" collapsible=true
```rust, editable
use anyhow::Result;
use criterion::{criterion_group, criterion_main, Criterion};
use futures::StreamExt;
use kv6::{
start_client_with_config, start_server_with_config, ClientConfig, CommandRequest, ServerConfig,
StorageConfig, YamuxCtrl,
};
use rand::prelude::SliceRandom;
use std::time::Duration;
use tokio::net::TcpStream;
use tokio::runtime::Builder;
use tokio::time;
use tokio_rustls::client::TlsStream;
use tracing::{info, span};
use tracing_subscriber::{layer::SubscriberExt, prelude::*, EnvFilter};
async fn start_server() -> Result<()> {
let addr = "127.0.0.1:9999";
let mut config: ServerConfig = toml::from_str(include_str!("../fixtures/server.conf"))?;
config.general.addr = addr.into();
config.storage = StorageConfig::MemTable;
tokio::spawn(async move {
start_server_with_config(&config).await.unwrap();
});
Ok(())
}
async fn connect() -> Result<YamuxCtrl<TlsStream<TcpStream>>> {
let addr = "127.0.0.1:9999";
let mut config: ClientConfig = toml::from_str(include_str!("../fixtures/client.conf"))?;
config.general.addr = addr.into();
Ok(start_client_with_config(&config).await?)
}
async fn start_subscribers(topic: &'static str) -> Result<()> {
let mut ctrl = connect().await?;
let stream = ctrl.open_stream().await?;
info!("C(subscriber): stream opened");
let cmd = CommandRequest::new_subscribe(topic.to_string());
tokio::spawn(async move {
let mut stream = stream.execute_streaming(&cmd).await.unwrap();
while let Some(Ok(data)) = stream.next().await {
drop(data);
}
});
Ok(())
}
async fn start_publishers(topic: &'static str, values: &'static [&'static str]) -> Result<()> {
let mut rng = rand::thread_rng();
let v = values.choose(&mut rng).unwrap();
let mut ctrl = connect().await.unwrap();
let mut stream = ctrl.open_stream().await.unwrap();
info!("C(publisher): stream opened");
let cmd = CommandRequest::new_publish(topic.to_string(), vec![(*v).into()]);
stream.execute_unary(&cmd).await.unwrap();
Ok(())
}
fn pubsub(c: &mut Criterion) {
let tracer = opentelemetry_jaeger::new_pipeline()
.with_service_name("kv-bench")
.install_simple()
.unwrap();
let opentelemetry = tracing_opentelemetry::layer().with_tracer(tracer);
tracing_subscriber::registry()
.with(EnvFilter::from_default_env())
.with(opentelemetry)
.init();
let root = span!(tracing::Level::INFO, "app_start", work_units = 2);
let _enter = root.enter();
// 创建 Tokio runtime
let runtime = Builder::new_multi_thread()
.worker_threads(4)
.thread_name("pubsub")
.enable_all()
.build()
.unwrap();
let base_str = include_str!("../fixtures/server.conf"); // 891 bytes
let values: &'static [&'static str] = Box::leak(
vec![
&base_str[..64],
&base_str[..128],
&base_str[..256],
&base_str[..512],
]
.into_boxed_slice(),
);
let topic = "lobby";
// 运行服务器和 100 个 subscriber,为测试准备
runtime.block_on(async {
eprint!("preparing server and subscribers");
start_server().await.unwrap();
time::sleep(Duration::from_millis(50)).await;
for _ in 0..1000 {
start_subscribers(topic).await.unwrap();
eprint!(".");
}
eprintln!("Done!");
});
// 进行 benchmark
c.bench_function("publishing", move |b| {
b.to_async(&runtime)
.iter(|| async { start_publishers(topic, values).await })
});
}
criterion_group! {
name = benches;
config = Criterion::default().sample_size(10);
targets = pubsub
}
criterion_main!(benches);
```
</div>
</details>
大部分的代码都很好理解,就是创建服务器和客户端,为测试做准备。
说一下这里面核心的 benchmark 代码:
```rust, editable
c.bench_function("publishing", move |b| {
b.to_async(&runtime)
.iter(|| async { start_publishers(topic, values).await })
});
```
对于要测试的代码,我们可以封装成一个函数进行测试。
- 这里因为要做 async 函数的测试,需要使用 runtime。
- 普通的函数不需要调用 to_async。对于更多有关 criterion 的用法,可以参考它的文档。
````admonish success title="运行 cargo bench 后,会见到如下打印(如果你的代码无法通过,可以参考 repo 里的 diff_benchmark,我顺便做了一点小重构): " collapsible=true
preparing server and subscribers....................................................................................................Done!
publishing time: [419.73 ms 426.84 ms 434.20 ms]
change: [-1.6712% +1.0499% +3.6586%] (p = 0.48 > 0.05)
No change in performance detected.
可以看到,单个 publish 的处理速度要 426ms,好慢!我们把之前在 start_tls_server() 里加的延迟去掉,再次测试:
preparing server and subscribers....................................................................................................Done!
publishing time: [318.61 ms 324.48 ms 329.81 ms]
change: [-25.854% -23.980% -22.144%] (p = 0.00 < 0.05)
Performance has improved.
>
> 嗯,这下 324ms,正好是减去刚才加的 100ms。可是这个速度依旧不合理,凭直觉我们感觉一下这个速度,是 Python 这样的语言还正常,如果是
> Rust 也太慢了吧?
## 测量和监控
>
> 工业界有句名言:如果你无法测量,那你就无法改进(If you can’t measure it, you can’t improve it)。
现在知道了 KV server 性能有问题,但并不知道问题出在哪里。我们需要使用合适的测量方式。
目前,比较好的端对端的性能监控和测量工具是 jaeger,我们可以在 KV server/client 侧收集监控信息,发送给 jaeger
来查看在服务器和客户端的整个处理流程中,时间都花费到哪里去了。
之前我们在 KV server 里使用的日志工具是
tracing,不过日志只是它的诸多功能之一,它还能做[ instrument](https://docs.rs/tracing/0.1.28/tracing/attr.instrument.html)
,然后配合 [opentelemetry 库](https://github.com/open-telemetry/opentelemetry-rust),我们就可以把 instrument 的结果发送给
jaeger 了。
<details id="admonition-1-加入jaeger" class="admonition note">
<summary class="admonition-title">
1. 加入jaeger
<a class="admonition-anchor-link" href="#admonition-1-加入jaeger"></a>
</summary>
<div>
好,在 Cargo.toml 里添加新的依赖:
````toml
[dependencies]
...
opentelemetry-jaeger = "0.15" # opentelemetry jaeger 支持
...
tracing-appender = "0.1" # 文件日志
tracing-opentelemetry = "0.15" # opentelemetry 支持
tracing-subscriber = { version = "0.2", features = ["json", "chrono"] } # 日志处理
有了这些依赖后,在 benches/pubsub.rs 里,我们可以在初始化 tracing_subscriber 时,使用 jaeger 和 opentelemetry tracer:
fn pubsub(c: &mut Criterion) { let tracer = opentelemetry_jaeger::new_pipeline() .with_service_name("kv-bench") .install_simple() .unwrap(); let opentelemetry = tracing_opentelemetry::layer().with_tracer(tracer); tracing_subscriber::registry() .with(EnvFilter::from_default_env()) .with(opentelemetry) .init(); let root = span!(tracing::Level::INFO, "app_start", work_units = 2); let _enter = root.enter(); // 创建 Tokio runtime ... }
设置好 tracing 后,就在系统的主流程上添加相应的 instrument:
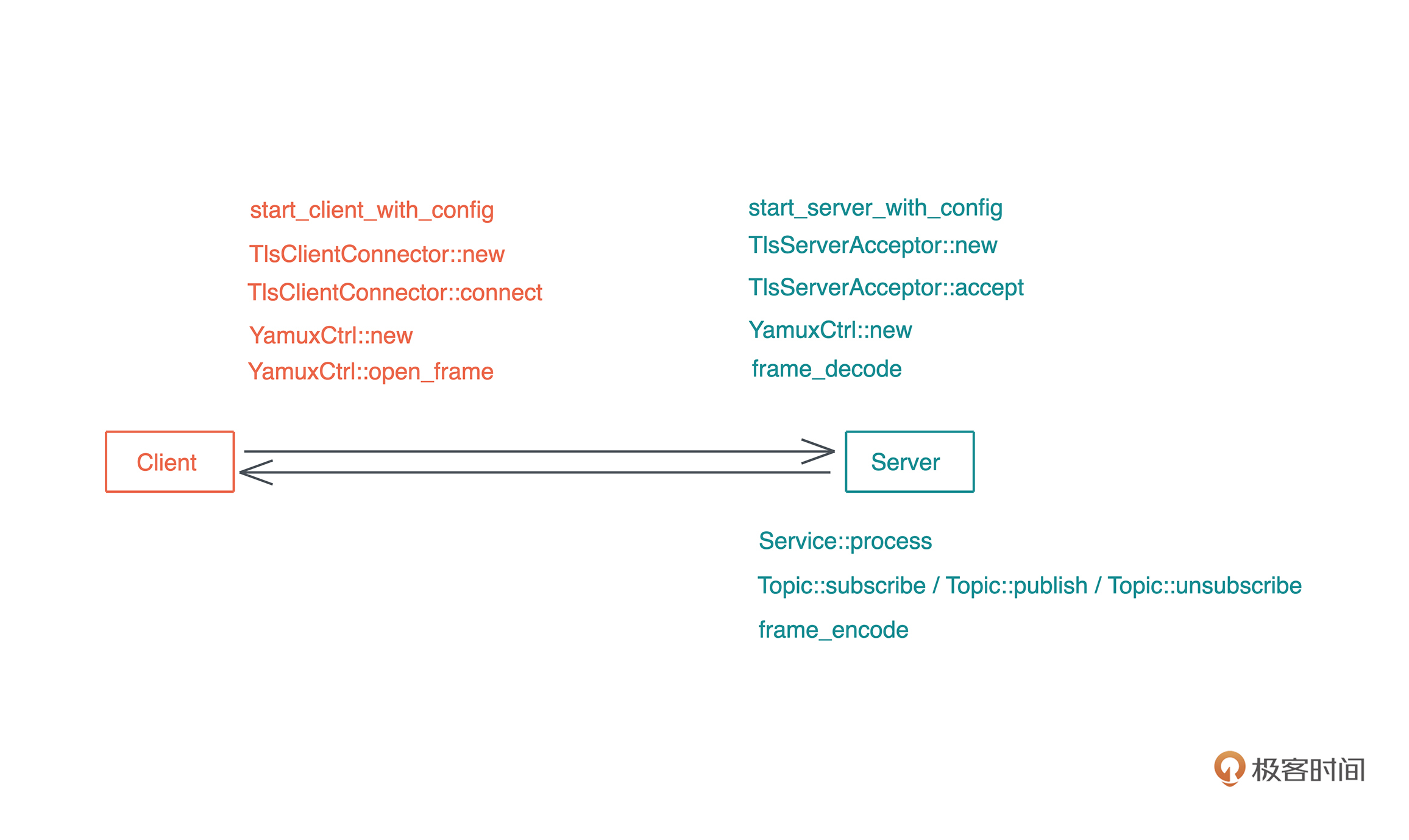
新添加的代码你可以看 repo 中的 diff_telemetry。
注意 instrument 可以用不同的名称:
比如,对于 TlsConnector::new() 函数,可以用 #[instrument(name = “tls_connector_new”)],这样它的名字辨识度高一些。
- 运行jaeger
为主流程中的函数添加完 instrument 后,你需要先打开一个窗口,运行 jaeger(需要 docker):
docker run -d -p6831:6831/udp -p6832:6832/udp -p16686:16686 -p14268:14268 jaegertracing/all-in-one:latest
然后带着 RUST_LOG=info 运行 benchmark:
RUST_LOG=info cargo bench
preparing server and subscribers....................................................................................................Done!
publishing time: [1.7464 ms 1.9556 ms 2.2343 ms]
Found 2 outliers among 10 measurements (20.00%)
1 (10.00%) high mild
1 (10.00%) high severe
并没有做任何事情,似乎只是换了个系统,性能就提升了很多,这给我们一个 tip:也许问题出在 OS X 和 Linux 系统相关的部分。
不管怎样,已经发送了不少数据给 jaeger,我们到 jaeger 上看看问题出在哪里。
第一次检查
- 打开 http://localhost:16686/
- service 选 kv-bench
- Operation 选 app_start
- 点击 “Find Traces”
- 我们可以看到捕获的 trace。因为运行了两次 benchmark,所以有两个 app_start 的查询结果:
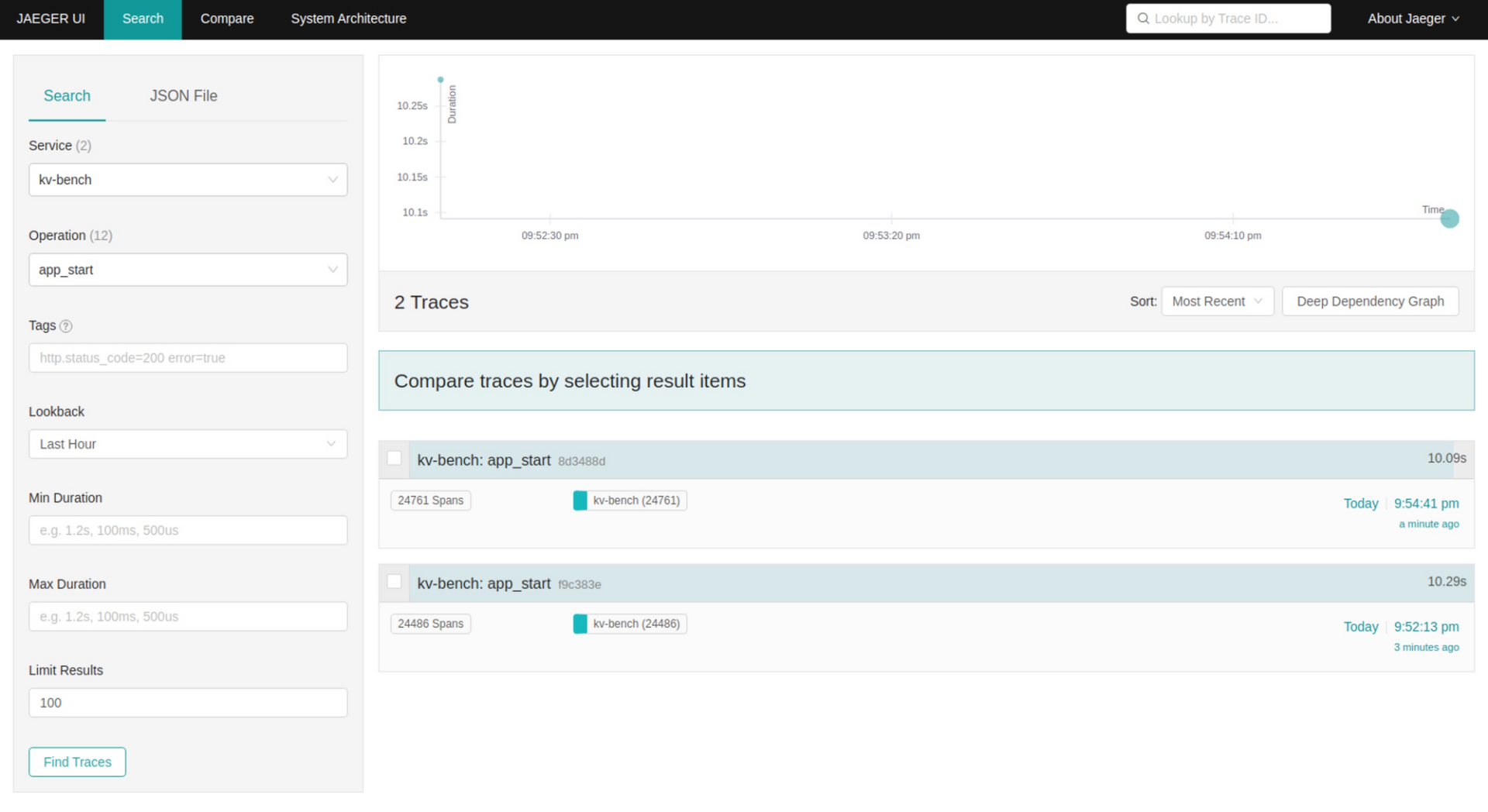
可以看到,每次 start_client_with_config 都要花 1.6-2.5ms,其中有差不多一小半时间花在了 TlsClientConnector::new() 上:
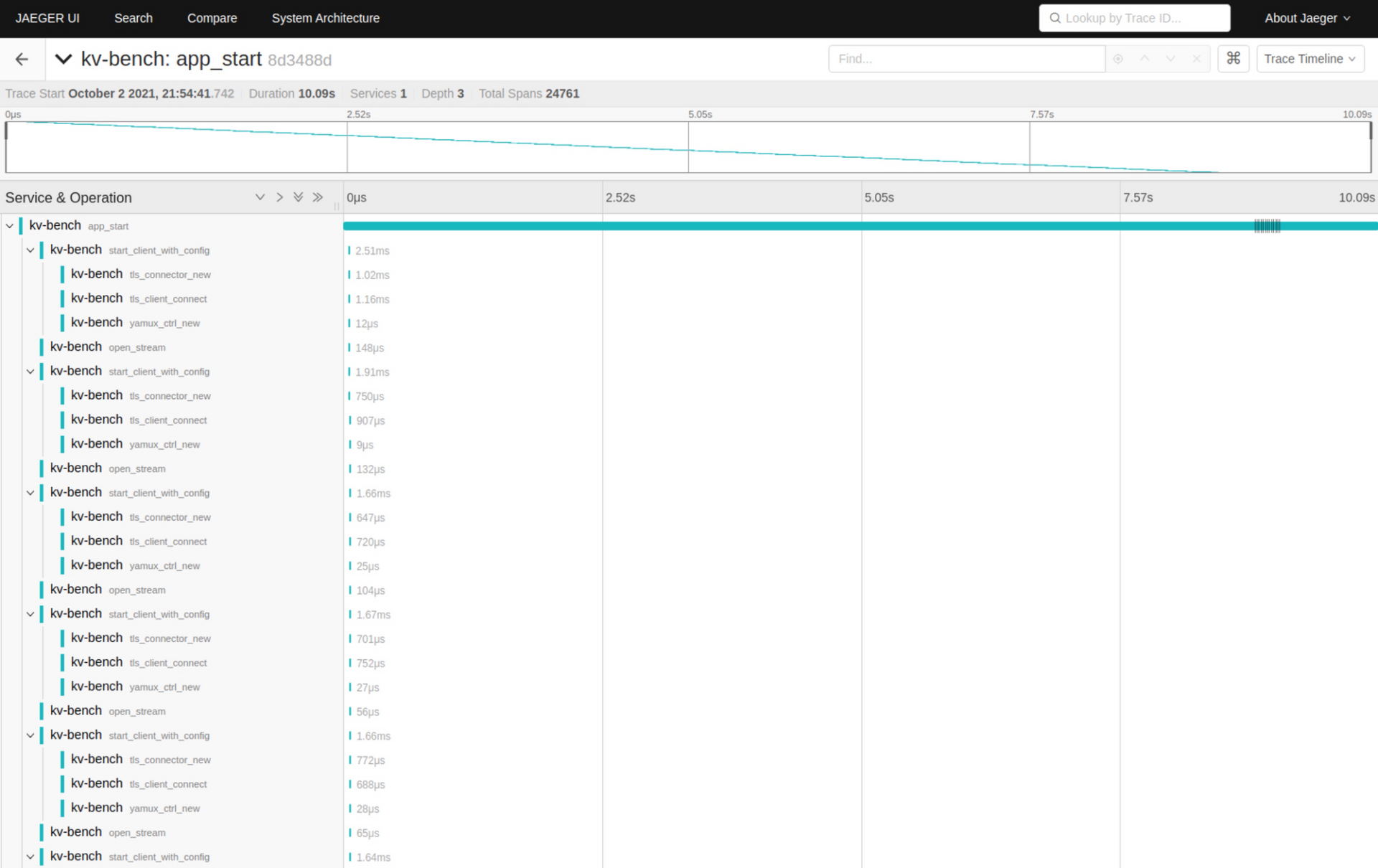
第一次修改
如果说 TlsClientConnector::connect() 花不少时间还情有可原,因为这是整个 TLS 协议的握手过程,涉及到网络调用、包的加解密等。
但 TlsClientConnector::new() 就是加载一些证书、创建 TlsConnector 这个数据结构而已,为何这么慢?
仔细阅读 TlsClientConnector::new() 的代码,你可以对照注释看:
#[instrument(name = "tls_connector_new", skip_all)] pub fn new( domain: impl Into<String> + std::fmt::Debug, identity: Option<(&str, &str)>, server_ca: Option<&str>, ) -> Result<Self, KvError> { let mut config = ClientConfig::new(); // 如果有客户端证书,加载之 if let Some((cert, key)) = identity { let certs = load_certs(cert)?; let key = load_key(key)?; config.set_single_client_cert(certs, key)?; } // 加载本地信任的根证书链 config.root_store = match rustls_native_certs::load_native_certs() { Ok(store) | Err((Some(store), _)) => store, Err((None, error)) => return Err(error.into()), }; // 如果有签署服务器的 CA 证书,则加载它,这样服务器证书不在根证书链 // 但是这个 CA 证书能验证它,也可以 if let Some(cert) = server_ca { let mut buf = Cursor::new(cert); config.root_store.add_pem_file(&mut buf).unwrap(); } Ok(Self { config: Arc::new(config), domain: Arc::new(domain.into()), }) }
可以发现,它的代码唯一可能影响性能的就是加载本地信任的根证书链的部分。这个代码会和操作系统交互,获取信任的根证书链。也许,这就是影响性能的原因之一?
那我们将其简单重构一下。因为根证书链,只有在客户端没有提供用于验证服务器证书的 CA 证书时,才需要,所以可以在没有 CA 证书时,才加载本地的根证书链:
#[instrument(name = "tls_connector_new", skip_all)] pub fn new( domain: impl Into<String> + std::fmt::Debug, identity: Option<(&str, &str)>, server_ca: Option<&str>, ) -> Result<Self, KvError> { let mut config = ClientConfig::new(); // 如果有客户端证书,加载之 if let Some((cert, key)) = identity { let certs = load_certs(cert)?; let key = load_key(key)?; config.set_single_client_cert(certs, key)?; } // 如果有签署服务器的 CA 证书,则加载它,这样服务器证书不在根证书链 // 但是这个 CA 证书能验证它,也可以 if let Some(cert) = server_ca { let mut buf = Cursor::new(cert); config.root_store.add_pem_file(&mut buf).unwrap(); } else { // 加载本地信任的根证书链 config.root_store = match rustls_native_certs::load_native_certs() { Ok(store) | Err((Some(store), _)) => store, Err((None, error)) => return Err(error.into()), }; } Ok(Self { config: Arc::new(config), domain: Arc::new(domain.into()), }) }
完成这个修改后,我们再运行 RUST_LOG=info cargo bench,现在的性能达到了 1.64ms,相比之前的 1.95ms,提升了 16%。
第二次检查
打开 jaeger,看最新的 app_start 结果,发现 TlsClientConnector::new() 所花时间降到了 ~12us 左右。嗯,虽然没有抓到服务器本身的 bug,但客户端的 bug 倒是解决了一个。

至于服务器,如果我们看 Service::execute 的主流程,执行速度在 40-60us,问题不大:
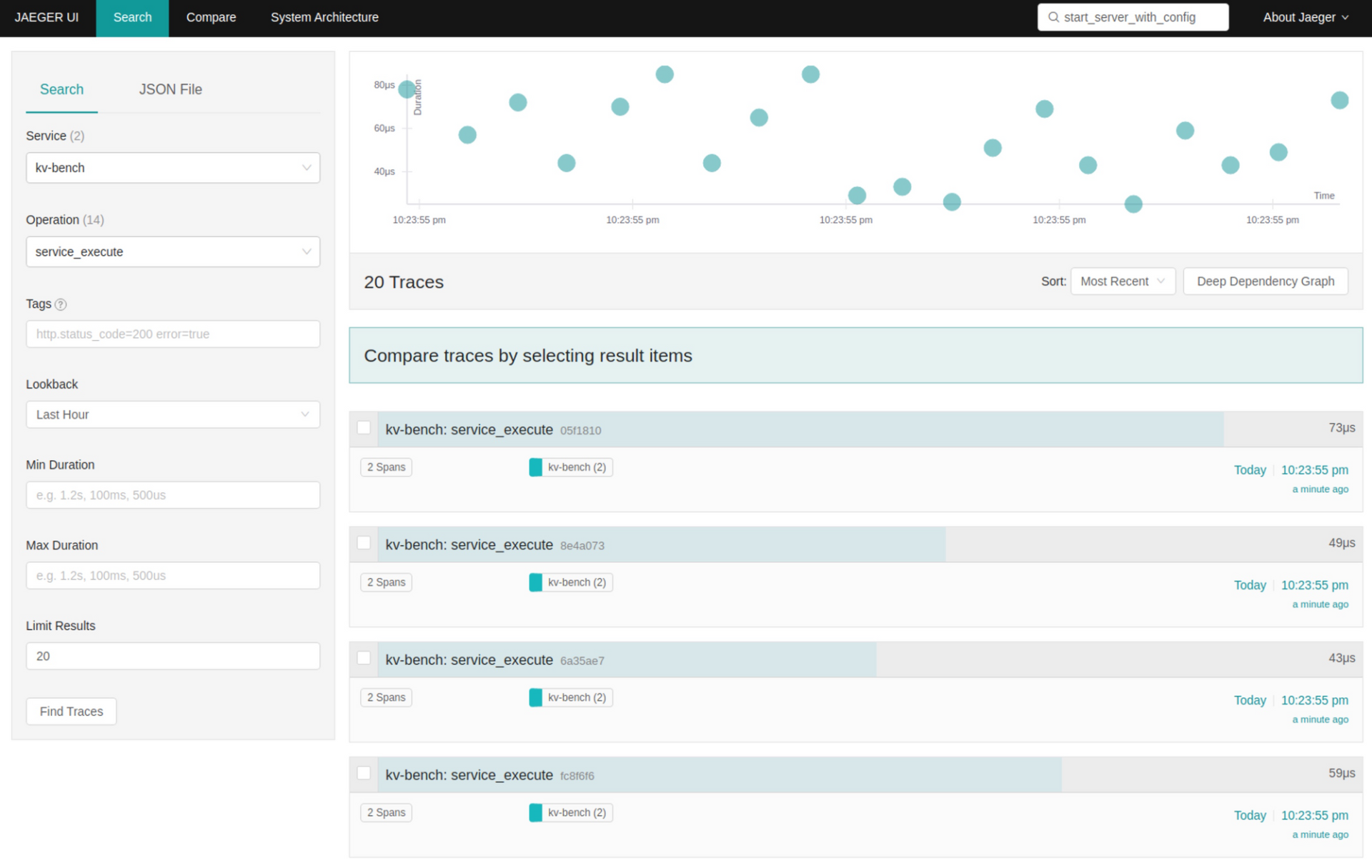
再看服务器的主流程 server_process:
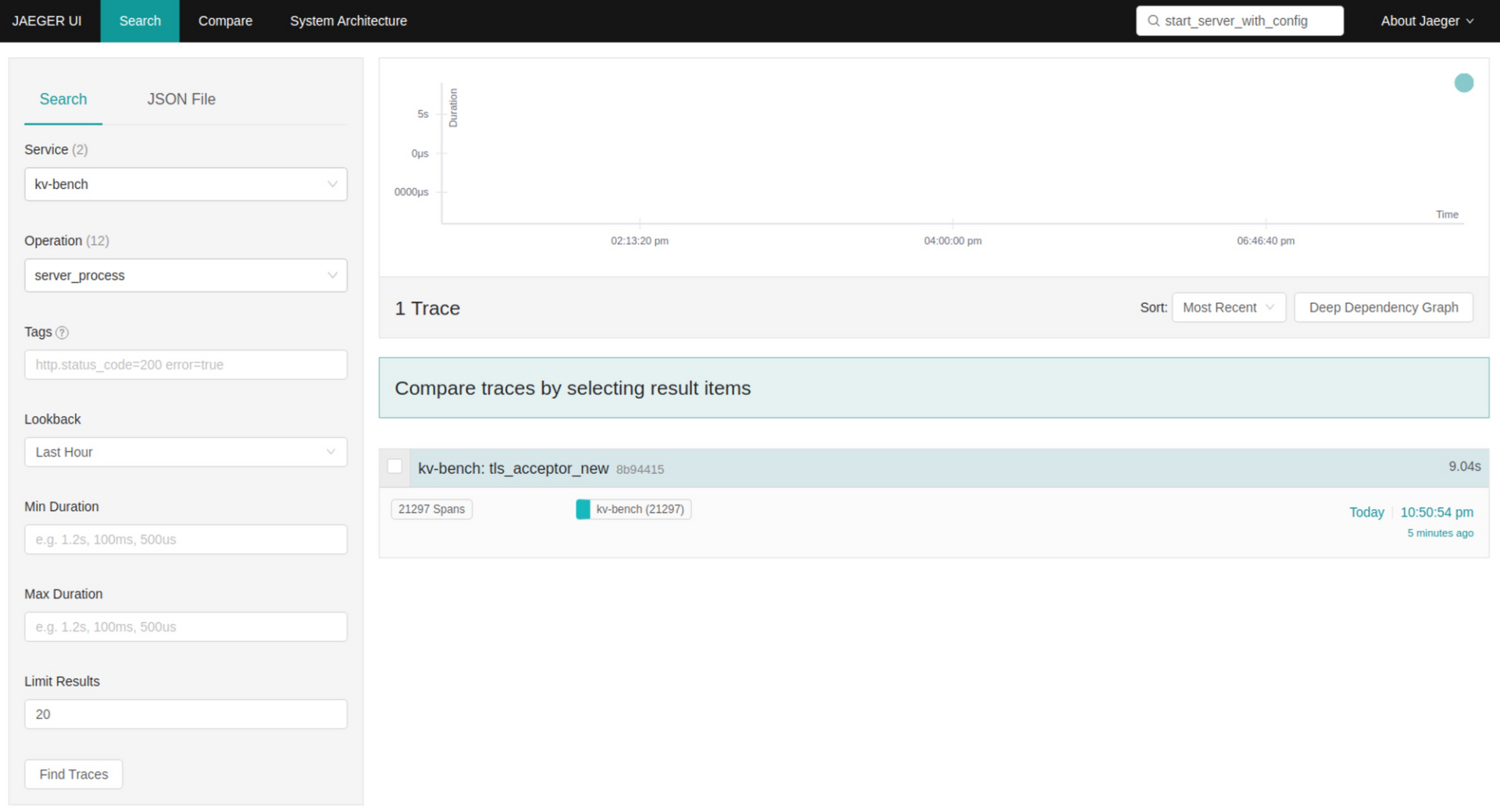
这是我们在 start_tls_server() 里额外添加的 tracing span:
loop { let root = span!(tracing::Level::INFO, "server_process"); let _enter = root.enter(); ... }
把右上角的 trace timeline 改成 trace graph,然后点右侧的 time:
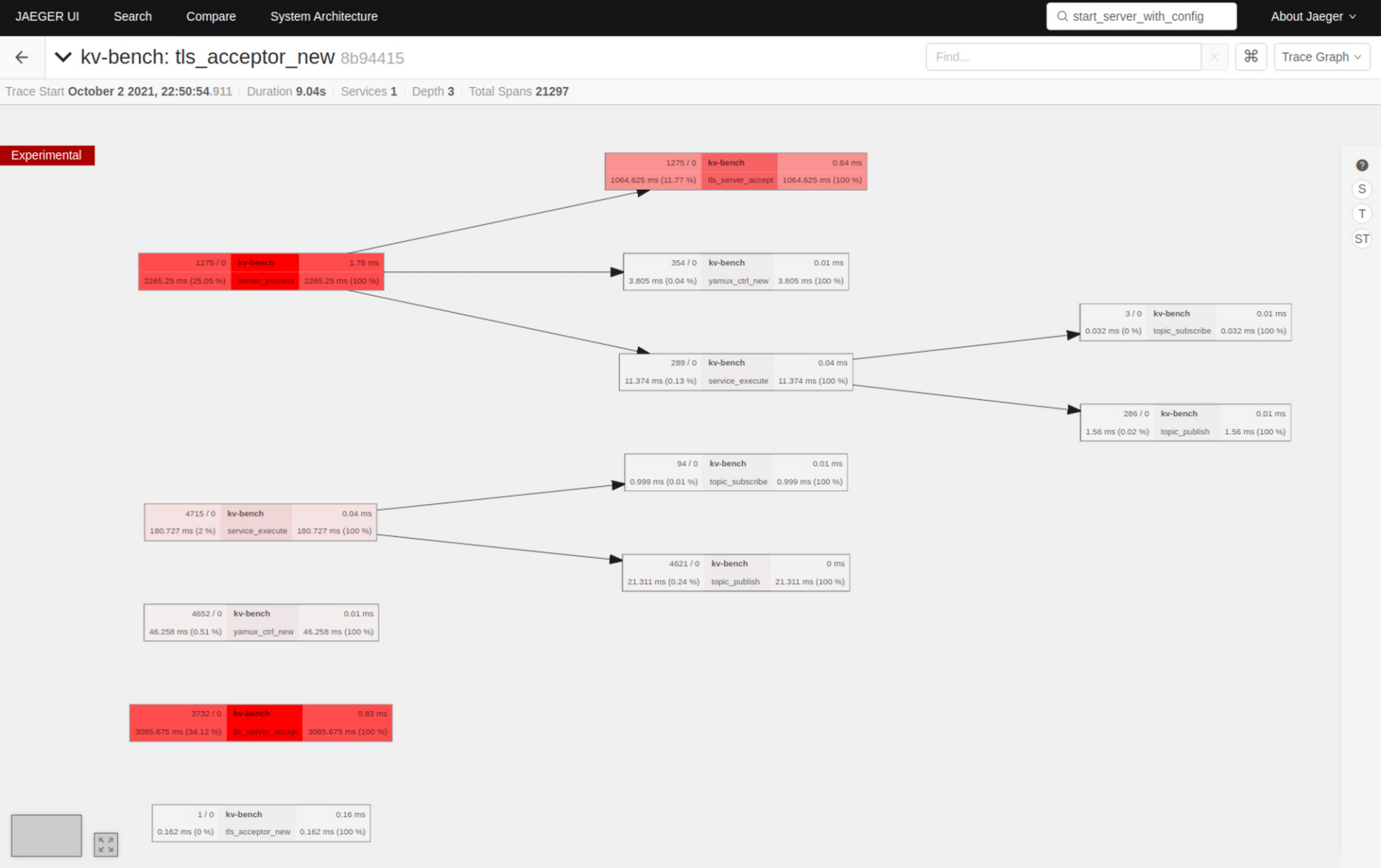
可以看到,主要的服务器时间都花在了 TLS accept 上,所以,目前服务器没有太多值得优化的地方。
由于 tracing 本身也占用不少 CPU,所以我们直接 cargo bench 看看目前的结果:
preparing server and subscribers....................................................................................................Done!
publishing time: [1.3986 ms 1.4140 ms 1.4474 ms]
change: [-26.647% -19.977% -10.798%] (p = 0.00 < 0.05)
Performance has improved.
Found 2 outliers among 10 measurements (20.00%)
2 (20.00%) high severe
不加 RUST_LOG=info 后,整体性能到了 1.4ms。这是我在 Ubuntu 虚拟机下的结果。
我们再回到 OS X 下测试,看看 TlsClientConnector::new() 的修改,对 OS X 是否有效:
preparing server and subscribers....................................................................................................Done!
publishing time: [1.4086 ms 1.4229 ms 1.4315 ms]
change: [-99.570% -99.563% -99.554%] (p = 0.00 < 0.05)
Performance has improved.
嗯,在我的 OS X 下,现在整体性能也到了 1.4ms 的水平。这也意味着,在有 100 个 subscribers 的情况下,我们的 KV server 每秒钟可以处理 714k publish 请求;而在 1000 个 subscribers 的情况下,性能在 11.1ms 的水平,也就是每秒可以处理 90k publish 请求:
publishing time: [11.007 ms 11.095 ms 11.253 ms]
change: [-96.618% -96.556% -96.486%] (p = 0.00 < 0.05)
Performance has improved.
你也许会觉得目前 publish 的 value 太小,那换一些更加贴近实际的字符串大小:
// let values = &["Hello", "Tyr", "Goodbye", "World"];
let base_str = include_str!("../fixtures/server.conf"); // 891 bytes
let values: &'static [&'static str] = Box::leak(
vec![
&base_str[..64],
&base_str[..128],
&base_str[..256],
&base_str[..512],
]
.into_boxed_slice(),
);
测试结果差不太多:
publishing time: [10.917 ms 11.098 ms 11.428 ms]
change: [-0.4822% +2.3311% +4.9631%] (p = 0.12 > 0.05)
No change in performance detected.
criterion 还会生成漂亮的 report
你可以用浏览器打开 ./target/criterion/publishing/report/index.html 查看(名字是 publishing ,因为 benchmark ID 是 publishing):
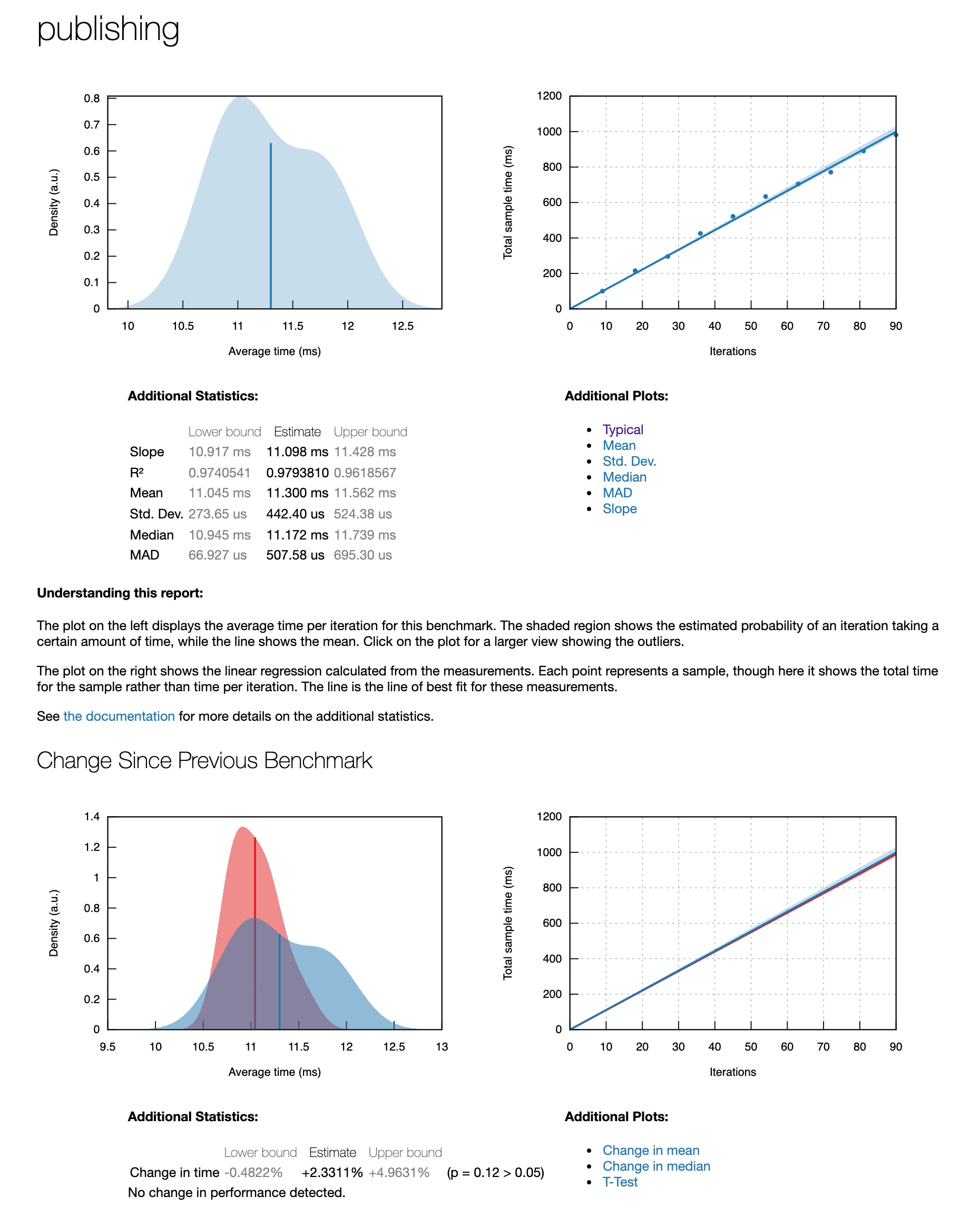
好,处理完性能相关的问题,我们来为 server 添加日志和性能监测的支持:
use std::env; use anyhow::Result; use kv6::{start_server_with_config, RotationConfig, ServerConfig}; use tokio::fs; use tracing::span; use tracing_subscriber::{ fmt::{self, format}, layer::SubscriberExt, prelude::*, EnvFilter, }; #[tokio::main] async fn main() -> Result<()> { // 如果有环境变量,使用环境变量中的 config let config = match env::var("KV_SERVER_CONFIG") { Ok(path) => fs::read_to_string(&path).await?, Err(_) => include_str!("../fixtures/server.conf").to_string(), }; let config: ServerConfig = toml::from_str(&config)?; let tracer = opentelemetry_jaeger::new_pipeline() .with_service_name("kv-server") .install_simple()?; let opentelemetry = tracing_opentelemetry::layer().with_tracer(tracer); // 添加 let log = &config.log; let file_appender = match log.rotation { RotationConfig::Hourly => tracing_appender::rolling::hourly(&log.path, "server.log"), RotationConfig::Daily => tracing_appender::rolling::daily(&log.path, "server.log"), RotationConfig::Never => tracing_appender::rolling::never(&log.path, "server.log"), }; let (non_blocking, _guard1) = tracing_appender::non_blocking(file_appender); let fmt_layer = fmt::layer() .event_format(format().compact()) .with_writer(non_blocking); tracing_subscriber::registry() .with(EnvFilter::from_default_env()) .with(fmt_layer) .with(opentelemetry) .init(); let root = span!(tracing::Level::INFO, "app_start", work_units = 2); let _enter = root.enter(); start_server_with_config(&config).await?; Ok(()) }
为了让日志能在配置文件中配置,需要更新一下 src/config.rs:
#[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ServerConfig { pub general: GeneralConfig, pub storage: StorageConfig, pub tls: ServerTlsConfig, pub log: LogConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct LogConfig { pub path: String, pub rotation: RotationConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub enum RotationConfig { Hourly, Daily, Never, }
你还需要更新 examples/gen_config.rs。相关的改变可以看 repo 下的 diff_logging。
CI/CD
为了讲述方便,我把 CI/CD 放在最后,但 CI/CD 应该是在一开始的时候就妥善设置的。
使用github action实现CI
先说 CI 吧, repo tyrchen/geektime-rust 在一开始就设置了 github action,每次 commit 都会运行:
-
代码格式检查:cargo fmt
-
依赖 license 检查:cargo deny
-
linting:cargo check 和 cargo clippy
-
单元测试和集成测试:cargo test
-
生成文档:cargo doc
github action 配置如下,供你参考:
name: build
on:
push:
branches:
- master
pull_request:
branches:
- master
jobs:
build-rust:
strategy:
matrix:
platform: [ubuntu-latest, windows-latest]
runs-on: ${{ matrix.platform }}
steps:
- uses: actions/checkout@v2
- name: Cache cargo registry
uses: actions/cache@v1
with:
path: ~/.cargo/registry
key: ${{ runner.os }}-cargo-registry
- name: Cache cargo index
uses: actions/cache@v1
with:
path: ~/.cargo/git
key: ${{ runner.os }}-cargo-index
- name: Cache cargo build
uses: actions/cache@v1
with:
path: target
key: ${{ runner.os }}-cargo-build-target
- name: Install stable
uses: actions-rs/toolchain@v1
with:
profile: minimal
toolchain: stable
override: true
- name: Check code format
run: cargo fmt -- --check
- name: Check the package for errors
run: cargo check --all
- name: Lint rust sources
run: cargo clippy --all-targets --all-features --tests --benches -- -D warnings
- name: Run tests
run: cargo test --all-features -- --test-threads=1 --nocapture
- name: Generate docs
run: cargo doc --all-features --no-deps
- name: Deploy docs to gh-page
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./target/doc
除此之外,我们还可以在每次 push tag 时做 release:
name: release
on:
push:
tags:
- "v*" # Push events to matching v*, i.e. v1.0, v20.15.10
jobs:
build:
name: Upload Release Asset
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest]
steps:
- name: Cache cargo registry
uses: actions/cache@v1
with:
path: ~/.cargo/registry
key: ${{ runner.os }}-cargo-registry
- name: Cache cargo index
uses: actions/cache@v1
with:
path: ~/.cargo/git
key: ${{ runner.os }}-cargo-index
- name: Cache cargo build
uses: actions/cache@v1
with:
path: target
key: ${{ runner.os }}-cargo-build-target
- name: Checkout code
uses: actions/checkout@v2
with:
token: ${{ secrets.GH_TOKEN }}
submodules: recursive
- name: Build project
run: |
make build-release
- name: Create Release
id: create_release
uses: actions/create-release@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
tag_name: ${{ github.ref }}
release_name: Release ${{ github.ref }}
draft: false
prerelease: false
- name: Upload asset
id: upload-kv-asset
uses: actions/upload-release-asset@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
upload_url: ${{ steps.create_release.outputs.upload_url }}
asset_path: ./target/release/kvs
asset_name: kvs
asset_content_type: application/octet-stream
- name: Set env
run: echo "RELEASE_VERSION=${GITHUB_REF#refs/*/}" >> $GITHUB_ENV
- name: Deploy docs to gh-page
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./target/doc/simple_kv
destination_dir: ${{ env.RELEASE_VERSION }}
这样,每次 push tag 时,都可以打包出来 Linux 的 kvs 版本:
如果你不希望直接使用编译出来的二进制,也可以打包成 docker,在 Kubernetes 下使用。
在做 CI 的过程中,我们也可以触发 CD,比如:
在做 CI 的过程中,我们也可以触发 CD,比如:
-
PR merge 到 master,在 build 完成后,触发 dev 服务器的部署,团队内部可以尝试;
-
如果 release tag 包含 alpha,在 build 完成后,触发 staging 服务器的部署,公司内部可以使用;
-
如果 release tag 包含 beta,在 build 完成后,触发 beta 服务器的部署,beta 用户可以使用;
-
正式的 release tag 会触发生产环境的滚动升级,升级覆盖到的用户可以使用。
一般来说,每家企业都有自己的 CI/CD 的工具链,这里为了展示方便,我们演示了如何使用 github action 对 Rust 代码做 CI,你可以按照自己的需要来处理。
在刚才的 action 代码中,还编译并上传了文档,所以我们可以通过 github pages 很方便地访问文档:
