并发原语
Summarize made by cursor
本文主要介绍了 Rust 中的并发原语:
- 包括自由竞争模式、map/reduce 模式和 DAG 模式。
- 在自由竞争模式下,我们需要用互斥锁来保护某个临界区,使进入临界区的任务拥有独占访问的权限。
- 在 map/reduce 模式下,我们需要用原子锁来保证任务的同步。
- 在 DAG 模式下,我们需要用条件变量来保证任务的同步。
- 本文还介绍了 Rust 中的几种并发原语,包括 Atomic、Mutex、Condvar、Channel 和 Actor model。最后,本文还介绍了如何用 Rust 实现一个基本的 MPSC Channel。
- Rust中的并发原语有哪些?
- Rust中的自由竞争模式下需要用什么来保护某个临界区?
- Rust中的map/reduce模式下需要用什么来保证任务的同步?
- Rust中的DAG模式下需要用什么来保证任务的同步?
- Rust中的几种并发原语有哪些?
- Rust中如何用实现一个基本的MPSC Channel?
Answers made by cursor
- Rust中的并发原语有哪些? Atomic、Mutex、Condvar、Channel 和 Actor model。
- Rust中的自由竞争模式下需要用什么来保护某个临界区? 互斥锁 Mutex。
- Rust中的map/reduce模式下需要用什么来保证任务的同步? 原子锁 Atomic。
- Rust中的DAG模式下需要用什么来保证任务的同步? 条件变量 Condvar。
- Rust中的几种并发原语有哪些? Atomic、Mutex、Condvar、Channel 和 Actor model。
- Rust中如何用实现一个基本的MPSC Channel? 可以使用 std::sync::mpsc::channel 函数来创建一个 MPSC Channel,也可以自己实现一个基本的 MPSC Channel。
- 并发原语
- 并发的难点、工作模式和核心
- 常见并发模型梳理,也就是并发原语
- 工作模式一、自由竞争: Atomic & Mutex
- 工作模式二、限制顺序并发: map/reduce
- 工作模式三、限制依赖并发:DAG 模式
- 至于async/await,又是另一个故事
- 自己实现一个基本的MPSC Channel
- 小结一下各种并发原语的使用场景
并发的难点、工作模式和核心
处理并发的难点在哪里?
其实有很多和并发相关的内容。比如用 std::thread 来创建线程、用 std::sync 下的并发原语(Mutex)来处理并发过程中的同步问题、用 Send/Sync trait 来保证并发的安全等等。
在处理并发的过程中,难点并不在于如何创建多个线程来分配工作,在于如何在这些并发的任务中进行同步。
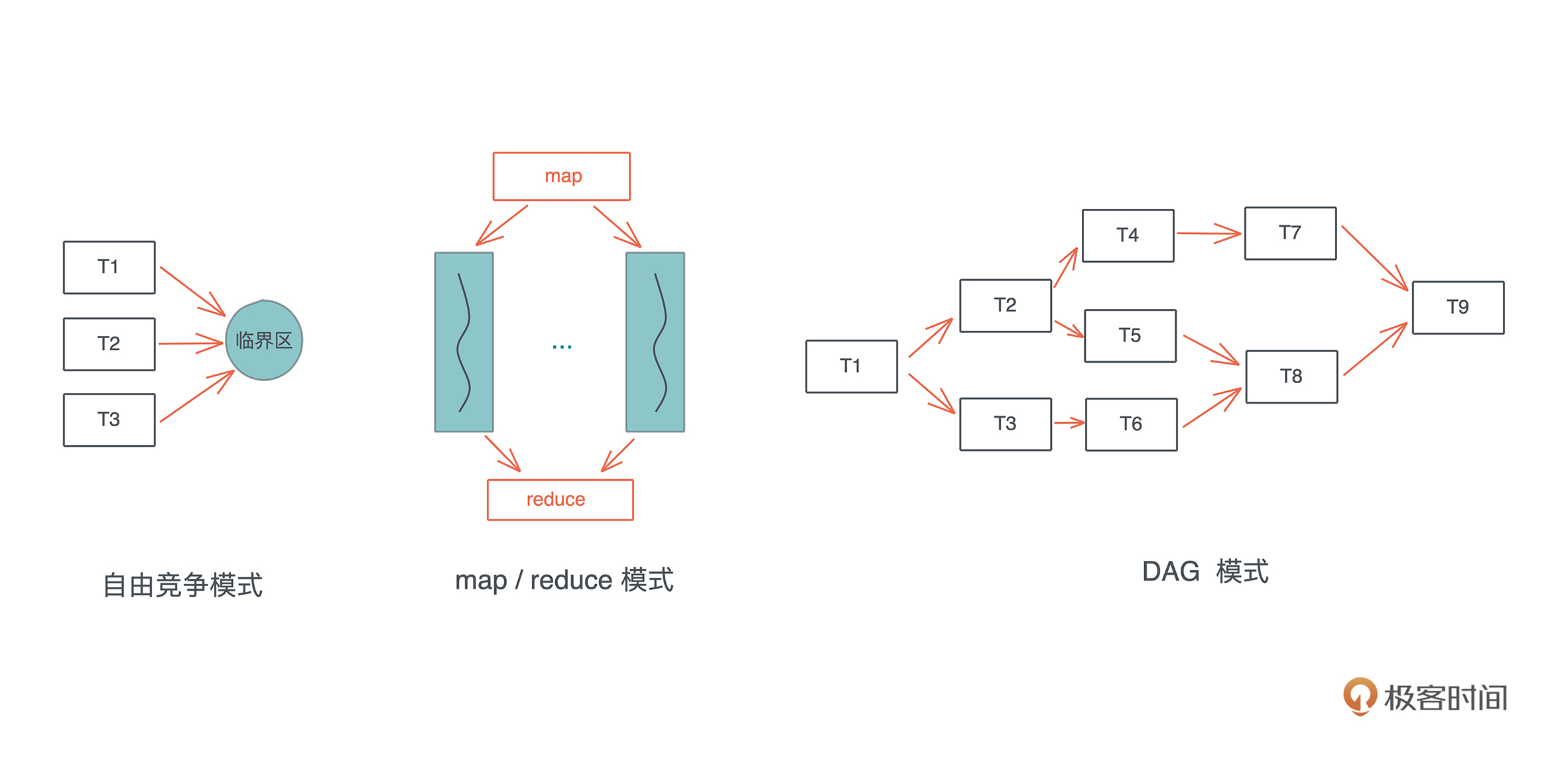
- 自由竞争: Atomic & Mutex
在自由竞争模式下,多个并发任务会竞争同一个临界区的访问权。
任务之间在何时、以何种方式去访问临界区,是不确定的,或者说是最为灵活的,只要在进入临界区时获得独占访问即可。
在自由竞争的基础上,我们可以限制并发的同步模式,典型的有 map/reduce 模式和 DAG 模式:
这些工作模式的核心是什么?
这三种基本模式组合起来,可以处理非常复杂的并发场景。 所以,当我们处理复杂问题的时候:
- 应该先厘清其脉络
- 用分治的思想把问题拆解成正交的子问题
- 然后组合合适的并发模式来处理这些子问题。
常见并发模型梳理,也就是并发原语
在这些并发模式背后,都有哪些并发原语可以为我们所用呢
在这些并发模式背后,都有哪些并发原语可以为我们所用呢:
- Atomic:原子锁
- Mutex:互斥锁
- Condvar:条件变量
- 条件变量表示阻塞线程的能力,使其在等待事件发生时不消耗 CPU 时间。
- 条件变量通常与布尔谓词(条件)和互斥锁相关联。
- 在确定线程必须阻塞之前,始终在互斥锁内部验证谓词。
- Channel
- Actor model
工作模式一、自由竞争: Atomic & Mutex
Atomic解决独占问题
Atomic 是所有并发原语的基础,它为并发任务的同步奠定了坚实的基础。
谈到同步,相信你首先会想到锁 所以在具体介绍 atomic 之前,我们从最基本的锁该如何实现讲起。 自由竞争模式下,我们需要用互斥锁来保护某个临界区,使进入临界区的任务拥有独占访问的权限。
互斥锁代码示例: 这段代码模拟了 Mutex 的实现,它的核心部分是 lock() 方法。
为了简便起见,在获取这把锁的时候,如果获取不到,就一直死循环,直到拿到锁为止(代码):
use std::{cell::RefCell, fmt, sync::Arc, thread}; struct Lock<T> { locked: RefCell<bool>, data: RefCell<T>, } impl<T> fmt::Debug for Lock<T> where T: fmt::Debug, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "Lock<{:?}>", self.data.borrow()) } } // SAFETY: 我们确信 Lock<T> 很安全,可以在多个线程中共享 unsafe impl<T> Sync for Lock<T> {} impl<T> Lock<T> { pub fn new(data: T) -> Self { Self { data: RefCell::new(data), locked: RefCell::new(false), } } pub fn lock(&self, op: impl FnOnce(&mut T)) { // 如果没拿到锁,就一直 spin while *self.locked.borrow() != false {} // **1 // 拿到,赶紧加锁 *self.locked.borrow_mut() = true; // **2 // 开始干活 op(&mut self.data.borrow_mut()); // **3 // 解锁 *self.locked.borrow_mut() = false; // **4 } } fn main() { let data = Arc::new(Lock::new(0)); let data1 = data.clone(); let t1 = thread::spawn(move || { data1.lock(|v| *v += 10); }); let data2 = data.clone(); let t2 = thread::spawn(move || { data2.lock(|v| *v *= 10); }); t1.join().unwrap(); t2.join().unwrap(); println!("data: {:?}", data); }
我们之前说过,Mutex 在调用 lock() 后,会得到一个 MutexGuard 的 RAII 结构. 这里为了简便起见,要求调用者传入一个闭包,来处理加锁后的事务。
在 lock() 方法里:
- 拿不到锁的并发任务会一直 spin
- 拿到锁的任务可以干活
- 干完活后会解锁
- 这样之前 spin 的任务会竞争到锁,进入临界区。
工作模式二、限制顺序并发: map/reduce
Atomic还存在2个问题
这样的实现看上去似乎问题不大,但是你细想,它有两个问题:
- 可能同时拿到锁
-
在多核情况下,**1 和 **2 之间,有可能其它线程也碰巧 spin 结束,把 locked 修改为 true。这样,存在多个线程拿到这把锁,破坏了任何线程都有独占访问的保证。
-
即便在单核情况下,**1 和 **2 之间,也可能因为操作系统的可抢占式调度,导致问题 1 发生。
- CPU乱序执行可能破坏锁
-
如今的编译器会最大程度优化生成的指令,如果操作之间没有依赖关系,可能会生成乱序的机器码,比如**3 被优化放在 **1 之前,从而破坏了这个 lock 的保证。
-
即便编译器不做乱序处理,CPU 也会最大程度做指令的乱序执行,让流水线的效率最高。同样会发生 3 的问题。
所以,我们实现这个锁的行为是未定义的。可能大部分时间如我们所愿,但会随机出现奇奇怪怪的行为。
一旦这样的事情发生,bug 可能会以各种不同的面貌出现在系统的各个角落。 而且,这样的 bug 几乎是无解的,因为它很难稳定复现,表现行为很不一致,甚至,只在某个 CPU 下出现。
这里再强调一下 unsafe 代码需要足够严谨,需要非常有经验的工程师去审查. 这段代码之所以破坏了并发安全性,是因为我们错误地认为:为 Lock
实现 Sync,是安全的。
为了解决上面这段代码的问题,我们必须在 CPU 层面做一些保证,让某些操作成为原子操作。
用CAS操作+Ordering解决两个问题
因为 CAS 和 ordering 都是系统级的操作,所以这里描述的 Ordering 的用途在各种语言中都大同小异。 对于 Rust 来说,它的 atomic 原语继承于 C++。 如果读 Rust 的文档你感觉云里雾里,那么 C++ 关于 ordering 的文档要清晰得多。
CAS操作解决问题1
CAS是什么?
可以通过一条指令读取某个内存地址,判断其值是否等于某个前置值,如果相等,将其修改为新的值。
这就是 Compare-and-swap 操作,简称CAS。
它是操作系统的几乎所有并发原语的基石,使得我们能实现一个可以正常工作的锁。
Rust专门为std::sync::atomic中的数据结构提供了CAS操作方法compare_exhange
Ordering解决问题2:CAS需要Ordering参数说明操作的内存顺序
Ordering枚举体说明: 对锁的5个操作
这就是这个函数里额外的两个和 Ordering 有关的奇怪参数。
pub enum Ordering { Relaxed, Release, Acquire, AcqRel, SeqCst, }
文档里解释了几种 Ordering 的用途,稍稍扩展一下。
-
第一个 Relaxed,这是最宽松的规则,它对编译器和 CPU 不做任何限制,可以乱序执行。
-
Release,当我们写入数据(比如上面代码里的 store)的时候,如果用了 Release order,那么:
- 对于当前线程,任何读取或写入操作都不能被乱序排在这个 store 之后。
- 也就是说,在下面的例子里,CPU 或者编译器不能把 **3 挪到 **4 之后执行。
- 对于其它线程,如果使用了 Acquire 来读取这个 atomic 的数据, 那么它们看到的是修改后的结果。
- 下面代码我们在 compare_exchange 里使用了 Acquire 来读取,所以能保证读到最新的值。
- 而 Acquire 是当我们读取数据的时候,如果用了 Acquire order,那么:
- 对于当前线程,任何读取或者写入操作都不能被乱序排在这个读取之前。在下面的例子里,CPU 或者编译器不能把 **3 挪到 **1 之前执行。
- 对于其它线程,如果使用了 Release 来修改数据,那么,修改的值对当前线程可见。
- 第四个 AcqRel 是 Acquire 和 Release 的结合,同时拥有 Acquire 和 Release 的保证。
- 这个一般用在 fetch_xxx 上,比如你要对一个 atomic 自增 1,你希望这个操作之前和之后的读取或写入操作不会被乱序,并且操作的结果对其它线程可见。
- 最后的 SeqCst 是最严格的 ordering,除了 AcqRel 的保证外,它还保证所有线程看到的所有 SeqCst 操作的顺序是一致的。
解决过程
所以,刚才的代码,我们可以把一开始的循环改成:
Atomic+CAS+ordering: 确保原子操作顺序
while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() {}
这句的意思是:
- 如果 locked 当前的值是 false,就将其改成 true。
- 这整个操作在一条指令里完成,不会被其它线程打断或者修改;
- 如果 locked 的当前值不是 false,那么就会返回错误,我们会在此不停 spin,直到前置条件得到满足。
- 这里,compare_exchange 是 Rust 提供的 CAS 操作,它会被编译成 CPU 的对应 CAS 指令。
当这句执行成功后,locked 必然会被改变为 true,我们成功拿到了锁,而任何其他线程都会在这句话上 spin。
同样在释放锁的时候,相应地需要使用 atomic 的版本,而非直接赋值成 false:
self.locked.store(false, Ordering::Release);
当然,为了配合这样的改动,我们还需要把 locked 从 bool 改成 AtomicBool。
在 Rust 里,std::sync::atomic 有大量的 atomic 数据结构,对应各种基础结构。
AtomicBool+compare_exchange+Ordering参数:我们看使用了 AtomicBool 的新实现(代码):
use std::{ cell::RefCell, fmt, sync::{ atomic::{AtomicBool, Ordering}, Arc, }, thread, }; struct Lock<T> { locked: AtomicBool, data: RefCell<T>, } impl<T> fmt::Debug for Lock<T> where T: fmt::Debug, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "Lock<{:?}>", self.data.borrow()) } } // SAFETY: 我们确信 Lock<T> 很安全,可以在多个线程中共享 unsafe impl<T> Sync for Lock<T> {} impl<T> Lock<T> { pub fn new(data: T) -> Self { Self { data: RefCell::new(data), locked: AtomicBool::new(false), } } pub fn lock(&self, op: impl FnOnce(&mut T)) { // 如果没拿到锁,就一直 spin while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() {} // **1 // 已经拿到并加锁,开始干活 op(&mut self.data.borrow_mut()); // **3 // 解锁 self.locked.store(false, Ordering::Release); } } fn main() { let data = Arc::new(Lock::new(0)); let data1 = data.clone(); let t1 = thread::spawn(move || { data1.lock(|v| *v += 10); }); let data2 = data.clone(); let t2 = thread::spawn(move || { data2.lock(|v| *v *= 10); }); t1.join().unwrap(); t2.join().unwrap(); println!("data: {:?}", data); }
可以看到:
通过使用 compare_exchange+Ordering ,规避了同时拿到锁和CPU乱序这两个问题
- 之前:
#![allow(unused)] fn main() { // 如果没拿到锁,就一直 spin while *self.locked.borrow() != false {} // **1 }
- 使用compare_exchange
#![allow(unused)] fn main() { // 如果没拿到锁,就一直 spin while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() {} // **1 }
临界区优化
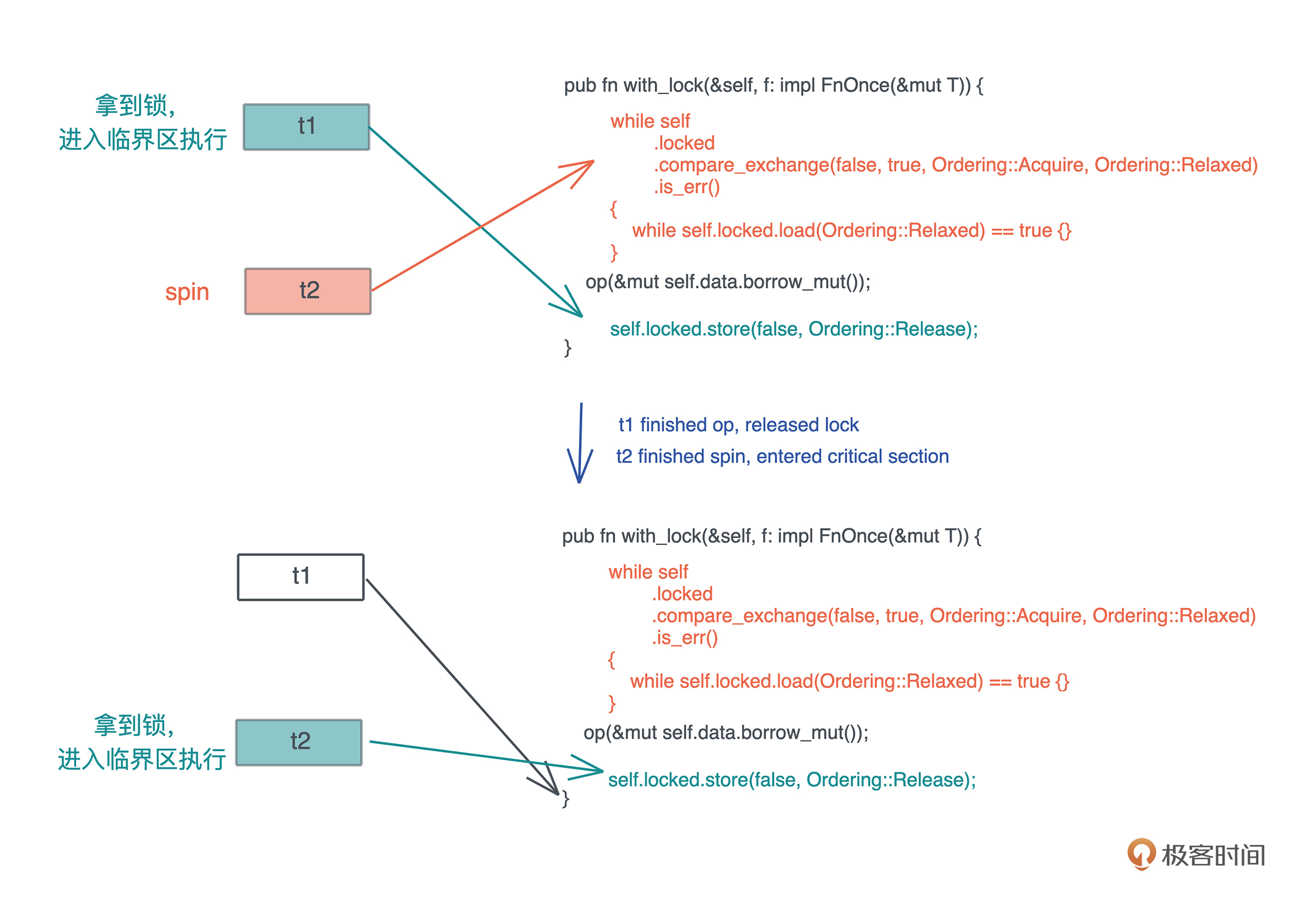
其实上面获取锁的 spin 过程性能不够好,更好的方式是这样处理一下:
while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() { // 性能优化:compare_exchange 需要独占访问,当拿不到锁时,我们 // 先不停检测 locked 的状态,直到其 unlocked 后,再尝试拿锁 while self.locked.load(Ordering::Relaxed) == true {} }
注意,我们在 while loop 里,又嵌入了一个 loop。
- 这是因为 CAS 是个代价比较高的操作,它需要获得对应内存的独占访问(exclusive access)
- 我们希望失败的时候只是简单读取 atomic 的状态,只有符合条件的时候再去做独占访问,进行 CAS。
- 所以,看上去多做了一层循环,实际代码的效率更高。
讲到这里,相信你对 atomic 以及其背后的 CAS 有初步的了解了。
Atomic还有什么用
- 全局ID生成器
那么,atomic 除了做其它并发原语,还有什么作用?
我个人用的最多的是做各种 lock-free 的数据结构。比如,需要一个全局的 ID 生成器。当然可以使用 UUID 这样的模块来生成唯一的 ID,但如果我们同时需要这个 ID 是有序的,那么 AtomicUsize 就是最好的选择。
你可以用 fetch_add 来增加这个 ID,而 fetch_add 返回的结果就可以用于当前的 ID。这样,不需要加锁,就得到了一个可以在多线程中安全使用的 ID 生成器。
- 记录系统的各种 metrics
另外,atomic 还可以用于记录系统的各种 metrics。比如一个简单的 in-memory Metrics 模块:
use std::{ collections::HashMap, sync::atomic::{AtomicUsize, Ordering}, }; // server statistics pub struct Metrics(HashMap<&'static str, AtomicUsize>); impl Metrics { pub fn new(names: &[&'static str]) -> Self { let mut metrics: HashMap<&'static str, AtomicUsize> = HashMap::new(); for name in names.iter() { metrics.insert(name, AtomicUsize::new(0)); } Self(metrics) } pub fn inc(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_add(1, Ordering::Relaxed); } } pub fn add(&self, name: &'static str, val: usize) { if let Some(m) = self.0.get(name) { m.fetch_add(val, Ordering::Relaxed); } } pub fn dec(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_sub(1, Ordering::Relaxed); } } pub fn snapshot(&self) -> Vec<(&'static str, usize)> { self.0 .iter() .map(|(k, v)| (*k, v.load(Ordering::Relaxed))) .collect() } }
它允许你初始化一个全局的 metrics 表,然后在程序的任何地方,无锁地操作相应的 metrics:
use lazy_static::lazy_static; use std::{ collections::HashMap, sync::atomic::{AtomicUsize, Ordering}, }; lazy_static! { pub(crate) static ref METRICS: Metrics = Metrics::new(&[ "topics", "clients", "peers", "broadcasts", "servers", "states", "subscribers" ]); } // server statistics pub struct Metrics(HashMap<&'static str, AtomicUsize>); impl Metrics { pub fn new(names: &[&'static str]) -> Self { let mut metrics: HashMap<&'static str, AtomicUsize> = HashMap::new(); for name in names.iter() { metrics.insert(name, AtomicUsize::new(0)); } Self(metrics) } pub fn inc(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_add(1, Ordering::Relaxed); } } pub fn add(&self, name: &'static str, val: usize) { if let Some(m) = self.0.get(name) { m.fetch_add(val, Ordering::Relaxed); } } pub fn dec(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_sub(1, Ordering::Relaxed); } } pub fn snapshot(&self) -> Vec<(&'static str, usize)> { self.0 .iter() .map(|(k, v)| (*k, v.load(Ordering::Relaxed))) .collect() } } fn main() { METRICS.inc("topics"); METRICS.inc("subscribers"); println!("{:?}", METRICS.snapshot()); }
更高层面的Atomic: Mutex(Mutual Exclusive)
Atomic 虽然可以处理自由竞争模式下加锁的需求,但毕竟用起来不那么方便.
我们需要更高层的并发原语,来保证软件系统控制多个线程对同一个共享资源的访问:
使得每个线程在访问共享资源的时候,可以独占或者说互斥访问(mutual exclusive access)。
Atomic有什么限制,Mutex又如何解决?
我们知道:
- 对于一个共享资源,如果所有线程只做读操作,那么无需互斥,大家随时可以访问
- 很多 immutable language(如 Erlang / Elixir)做了语言层面的只读保证,确保了并发环境下的无锁操作。
- 这牺牲了一些效率(常见的 list/hashmap 需要使用 persistent data structure),额外做了不少内存拷贝,换来了并发控制下的简单轻灵。
- 然而,一旦有任何一个或多个线程要修改共享资源,不但写者之间要互斥,读写之间也需要互斥。
- 毕竟如果读写之间不互斥的话,读者轻则读到脏数据,重则会读到已经被破坏的数据,导致 crash。
- 比如读者读到链表里的一个节点,而写者恰巧把这个节点的内存释放掉了,如果不做互斥访问,系统一定会崩溃。
所以操作系统提供了用来解决这种读写互斥问题的基本工具:Mutex(RwLock 我们放下不表)。
其实上文中,为了展示如何使用 atomic,我们制作了一个非常粗糙简单的 SpinLock,就可以看做是一个广义的 Mutex。SpinLock,顾名思义,就是线程通过 CPU 空转(spin,就像前面的 while loop)忙等(busy wait),来等待某个临界区可用的一种锁。
然而,这种通过 SpinLock 做互斥的实现方式有使用场景的限制:如果受保护的临界区太大,那么整体的性能会急剧下降, CPU 忙等,浪费资源还不干实事,不适合作为一种通用的处理方法。
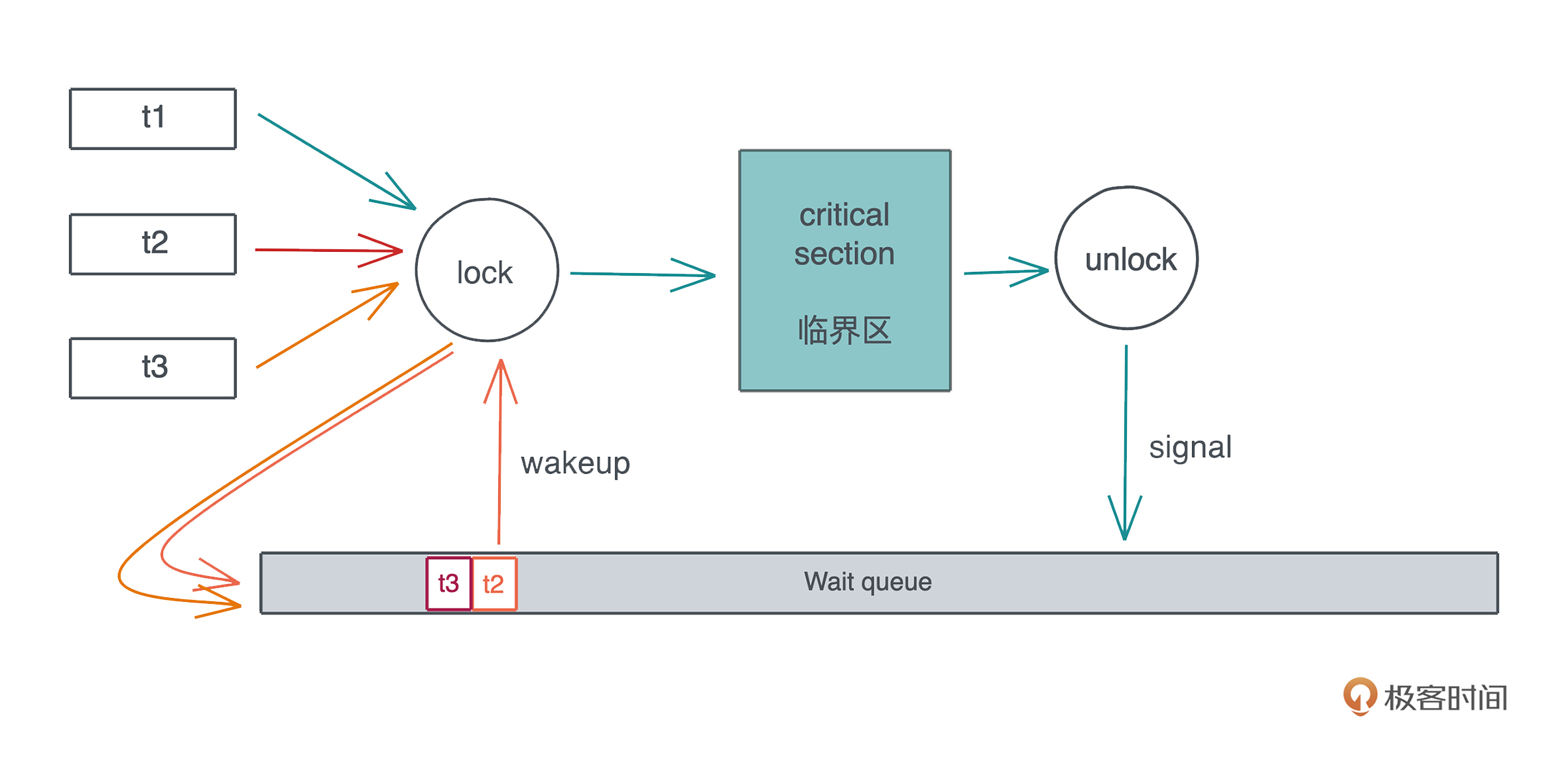
更通用的解决方案是:
- 当多个线程竞争同一个 Mutex 时,获得锁的线程得到临界区的访问,其它线程被挂起,放入该 Mutex 上的一个等待队列里
- 当获得锁的线程完成工作,退出临界区时,Mutex 会给等待队列发一个信号,把队列中第一个线程唤醒,于是这个线程可以进行后续的访问。整个过程如下:
Atomic和Mutex的联系
Atomic、Mutex、semaphore的联系
我们前面也讲过,线程的上下文切换代价很大,所以频繁将线程挂起再唤醒,会降低整个系统的效率。
所以很多 Mutex 具体的实现会将 SpinLock(确切地说是 spin wait)和线程挂起结合使用: 线程的 lock 请求如果拿不到会先尝试 spin 一会,然后再挂起添加到等待队列。
Rust 下的 parking_lot 就是这样实现的。
当然,这样实现会带来公平性的问题:
- 如果新来的线程恰巧在 spin 过程中拿到了锁
- 而当前等待队列中还有其它线程在等待锁
- 那么等待的线程只能继续等待下去
- 这不符合 FIFO,不适合那些需要严格按先来后到排队的使用场景。
- 为此,parking_lot 提供了 fair mutex。
Mutex 的实现依赖于 CPU 提供的 atomic。
你可以把 Mutex 想象成一个粒度更大的 atomic,只不过这个 atomic 无法由 CPU 保证,而是通过软件算法来实现。
两个基本的并发原语 Atomic 和 Mutex:
- Atomic 是一切并发同步的基础
- 通过 CPU 提供特殊的 CAS 指令,操作系统和应用软件可以构建更加高层的并发原语,比如 SpinLock 和 Mutex。
SpinLock 和 Mutex 最大的不同是:
- 使用 SpinLock,线程在忙等(busy wait)
- 而使用 Mutex lock,线程在等待锁的时候会被调度出去,等锁可用时再被调度回来。
听上去 SpinLock 似乎效率很低,其实不是,这要具体看锁的临界区大小。
- 如果临界区要执行的代码很少,那么和 Mutex lock 带来的上下文切换(context switch)相比,SpinLock 是值得的。
- 在 Linux Kernel 中,很多时候我们只能使用 SpinLock。
至于操作系统里另一个重要的概念信号量(semaphore),你可以认为是 Mutex 更通用的表现形式。
比如在新冠疫情下,图书馆要控制同时在馆内的人数,如果满了,其他人就必须排队,出来一个才能再进一个。 这里,如果总人数限制为 1,就是 Mutex,如果 > 1,就是 semaphore。
工作模式三、限制依赖并发:DAG 模式
Atomic和Mutex不能解决DAG模式, 所以有Condvar
Atomic和Mutex主要用于哪种工作模式?基于什么需求提出Condvar原语?
对于并发状态下这三种常见的工作模式:
- 自由竞争模式
- map/reduce 模式
- DAG 模式
我们的难点是如何在这些并发的任务中进行同步:
- atomic / Mutex 解决了自由竞争模式下并发任务的同步问题
- 也能够很好地解决 map/reduce 模式下的同步问题,因为此时同步只发生在 map 和 reduce 两个阶段。
然而,它们没有解决一个更高层次的问题,也就是 DAG 模式:如果这种访问需要按照一定顺序进行或者前后有依赖关系,该怎么做?
这个问题的典型场景是生产者 - 消费者模式:
- 生产者生产出来内容后,需要有机制通知消费者可以消费。
- 比如 socket 上有数据了,通知处理线程来处理数据,处理完成之后,再通知 socket 收发的线程发送数据。
所以,操作系统还提供了 Condvar。
condvar介绍与使用
Condvar介绍与使用
Condvar 有两种状态:
- 等待(wait):线程在队列中等待,直到满足某个条件。
- 通知(notify):当 condvar 的条件满足时,当前线程通知其他等待的线程可以被唤醒。通知可以是单个通知,也可以是多个通知,甚至广播(通知所有人)。
在实践中,Condvar 往往和 Mutex 一起使用:
- Mutex 用于保证条件在读写时互斥
- Condvar 用于控制线程的等待和唤醒。
我们来看一个例子:
use std::sync::{Arc, Condvar, Mutex}; use std::thread; use std::time::Duration; fn main() { let pair = Arc::new((Mutex::new(false), Condvar::new())); let pair2 = Arc::clone(&pair); thread::spawn(move || { let (lock, cvar) = &*pair2; let mut started = lock.lock().unwrap(); *started = true; eprintln!("I'm a happy worker!"); // 通知主线程 cvar.notify_one(); loop { thread::sleep(Duration::from_secs(1)); println!("working..."); } }); let (lock, cvar) = &*pair; // 使用互斥锁作为变量 let mut started = lock.lock().unwrap(); while !*started { // 等待工作线程的通知 started = cvar.wait(started).unwrap(); } eprintln!("Worker started!"); }
-
这段代码通过 condvar,我们实现了 worker 线程在执行到一定阶段后通知主线程,然后主线程再做一些事情。
-
这里,我们使用了一个 Mutex 作为互斥条件,然后在 cvar.wait() 中传入这个 Mutex。
这个接口需要一个 MutexGuard,以便于知道需要唤醒哪个 Mutex 下等待的线程:
pub fn wait<'a, T>( &self, guard: MutexGuard<'a, T> ) -> LockResult<MutexGuard<'a, T>>
复杂DAG模式:Channel or Actor
Channel
Mutex和Condvar的局限性在哪?Channel如何解决的?
但是用 Mutex 和 Condvar 来处理复杂的 DAG 并发模式会比较吃力。所以,Rust 还提供了各种各样的 Channel 用于处理并发任务之间的通讯。
由于 Golang 不遗余力地推广,Channel 可能是最广为人知的并发手段。相对于 Mutex,Channel 的抽象程度最高,接口最为直观,使用起来的心理负担也没那么大。使用 Mutex 时,你需要很小心地避免死锁,控制临界区的大小,防止一切可能发生的意外。
虽然在 Rust 里,我们可以“无畏并发”(Fearless concurrency)—— 当代码编译通过,绝大多数并发问题都可以规避,但性能上的问题、逻辑上的死锁还需要开发者照料。
Channel 把锁封装在了队列写入和读取的小块区域内,然后把读者和写者完全分离,使得读者读取数据和写者写入数据,对开发者而言,除了潜在的上下文切换外,完全和锁无关,就像访问一个本地队列一样。所以,对于大部分并发问题,我们都可以用 Channel 或者类似的思想来处理(比如 actor model)。
Channel分类
Channel根据使用场景如何分类?
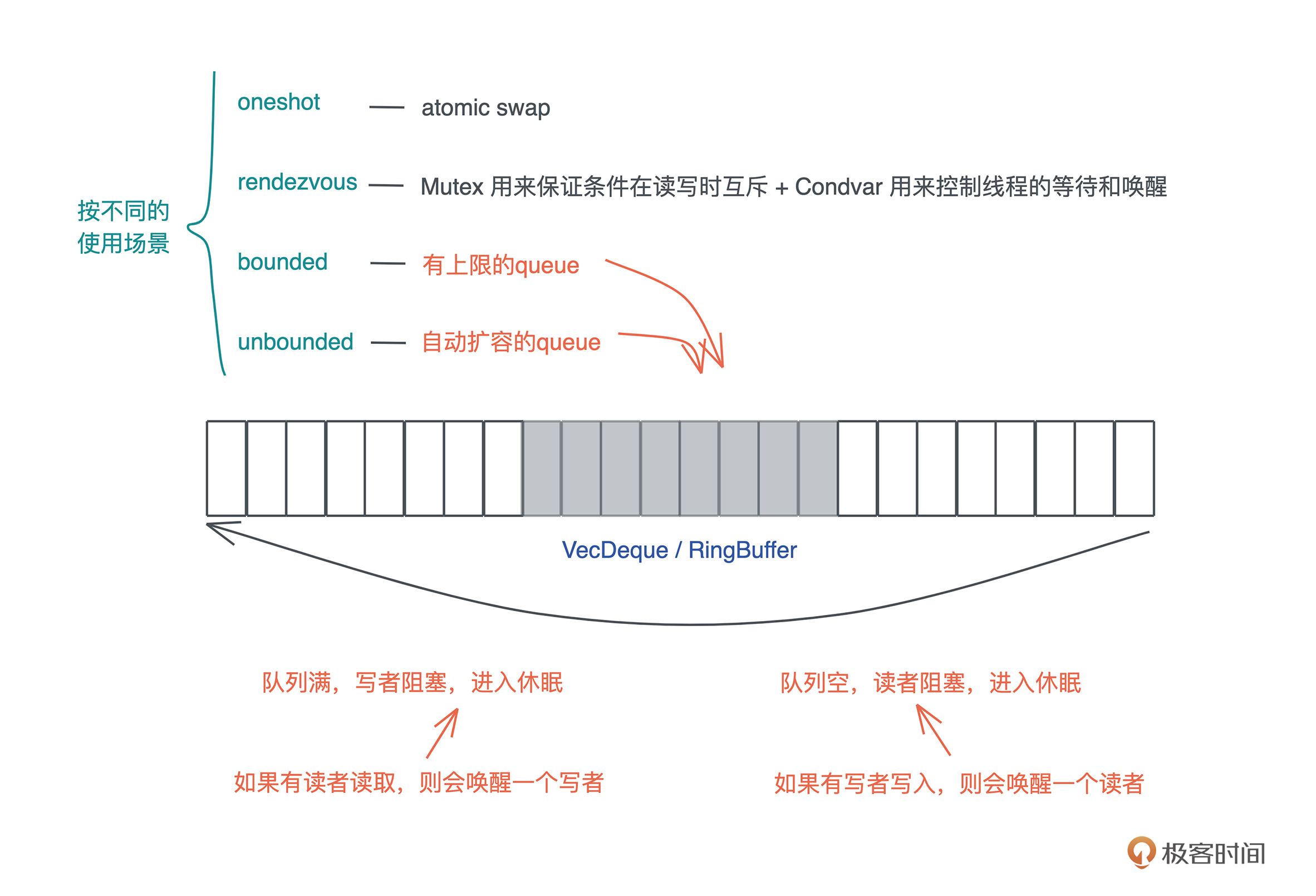
Channel 在具体实现的时候,根据不同的使用场景,会选择不同的工具。Rust 提供了以下四种 Channel:
- oneshot:这可能是最简单的 Channel,写者就只发一次数据,而读者也只读一次。
这种一次性的、多个线程间的同步可以用 oneshot channel 完成。由于 oneshot 特殊的用途,实现的时候可以直接用 atomic swap 来完成。
- rendezvous:很多时候,我们只需要通过 Channel 来控制线程间的同步,并不需要发送数据。
rendezvous channel 是 channel size 为 0 的一种特殊情况。
这种情况下,我们用 Mutex + Condvar 实现就足够了,在具体实现中,rendezvous channel 其实也就是 Mutex + Condvar 的一个包装。
- bounded:bounded channel 有一个队列,但队列有上限。
一旦队列被写满了,写者也需要被挂起等待。当阻塞发生后,读者一旦读取数据,channel 内部就会使用 Condvar 的 notify_one 通知写者,唤醒某个写者使其能够继续写入。
因此,实现中,一般会用到 Mutex + Condvar + VecDeque 来实现;如果不用 Condvar,可以直接使用 thread::park + thread::notify 来完成(flume 的做法);如果不用 VecDeque,也可以使用双向链表或者其它的 ring buffer 的实现。
- unbounded:queue 没有上限,如果写满了,就自动扩容。 我们知道,Rust 的很多数据结构如 Vec 、VecDeque 都是自动扩容的。unbounded 和 bounded 相比,除了不阻塞写者,其它实现都很类似。
所有这些 channel 类型,同步和异步的实现思路大同小异,主要的区别在于挂起 / 唤醒的对象:
- 在同步的世界里,挂起 / 唤醒的对象是线程;
- 而异步的世界里,是粒度很小的 task。
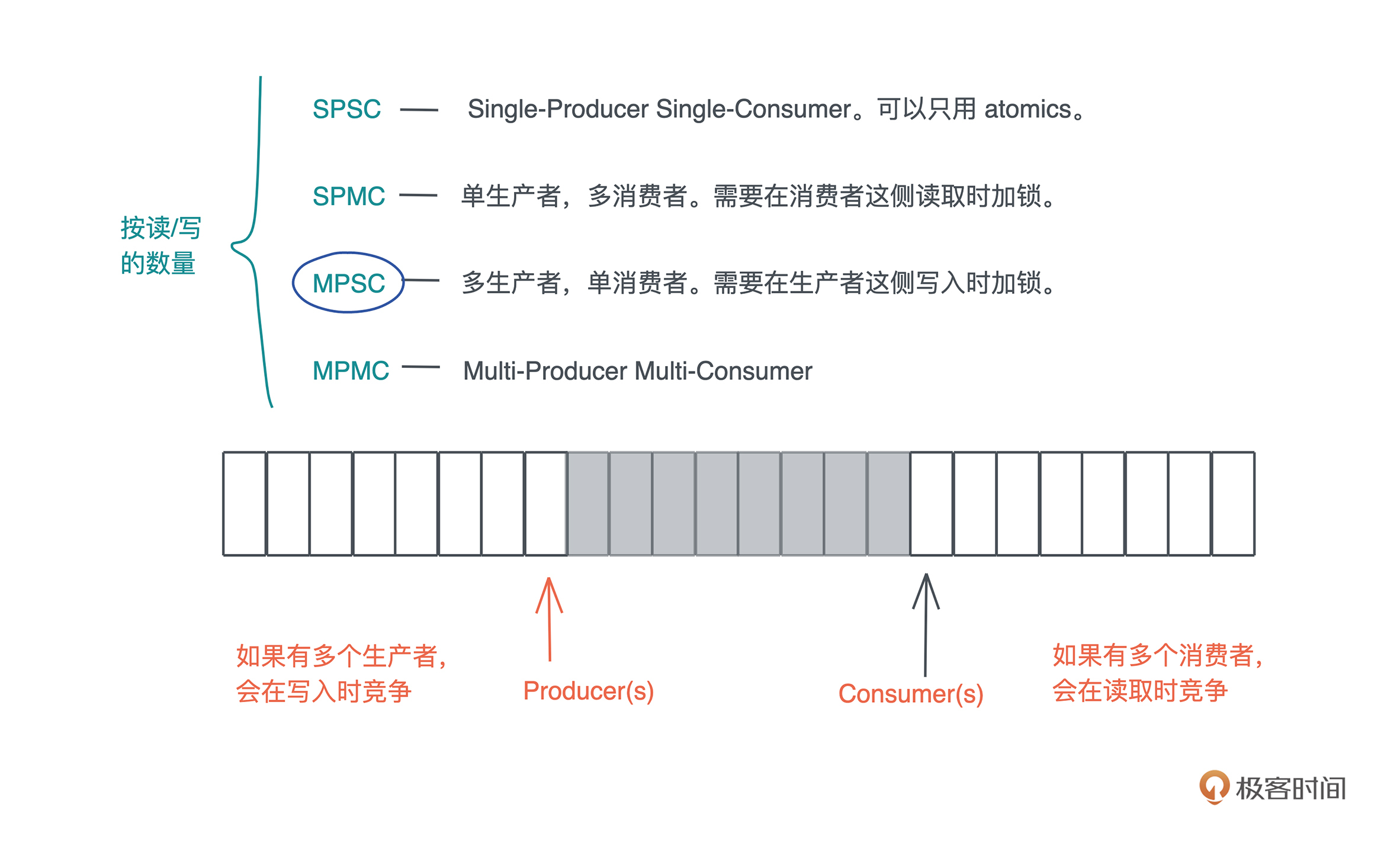
Channel根据读写者数量分别如何分类?
根据 Channel 读者和写者的数量,Channel 又可以分为:
-
SPSC:Single-Producer Single-Consumer 单生产者,单消费者。最简单,可以不依赖于 Mutex,只用 atomics 就可以实现。
-
SPMC:Single-Producer Multi-Consumer 单生产者,多消费者。需要在消费者这侧读取时加锁。
-
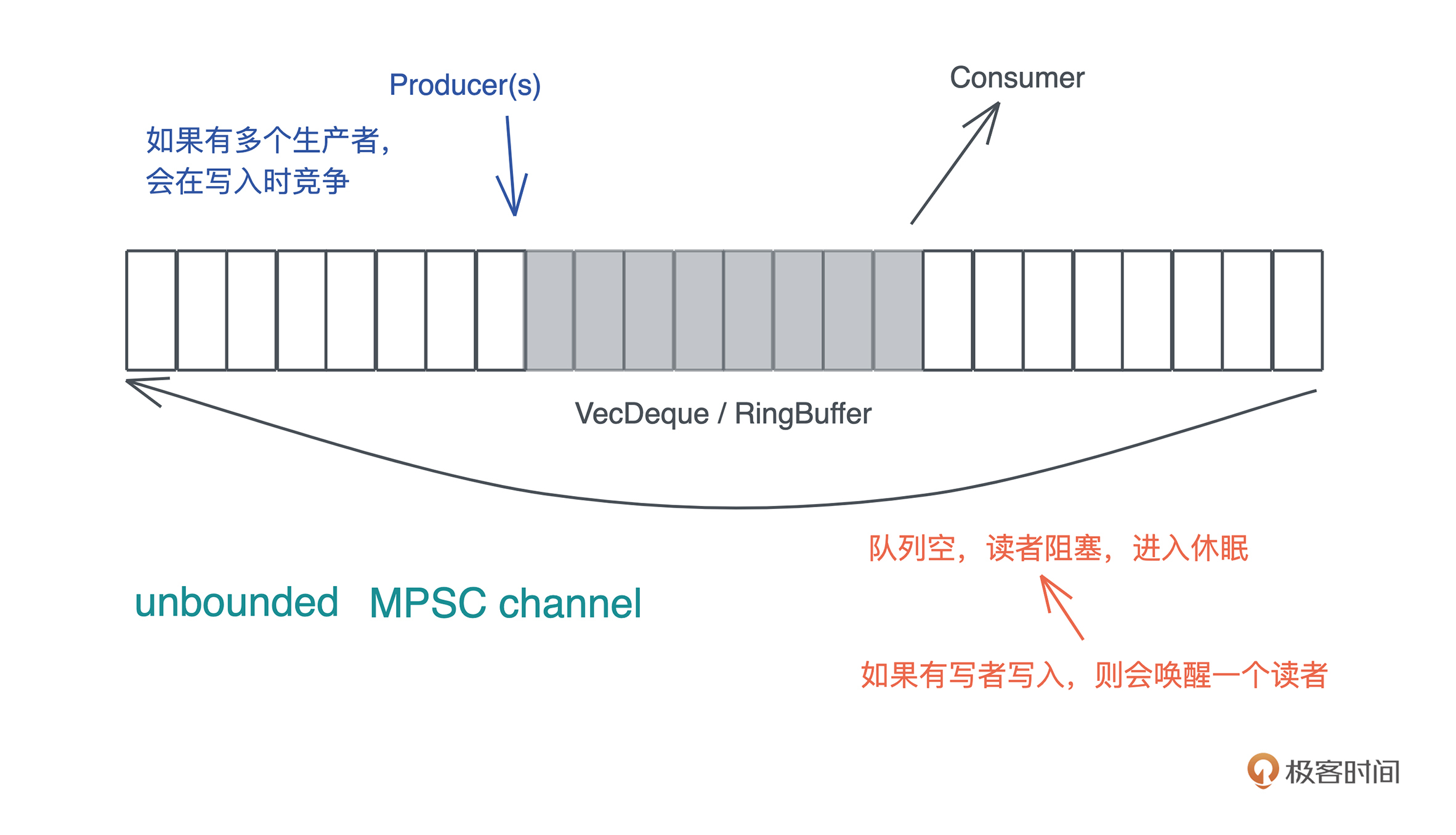
MPSC:Multi-Producer Single-Consumer 多生产者,单消费者。需要在生产者这侧写入时加锁。
-
MPMC:Multi-Producer Multi-Consumer 多生产者,多消费者。需要在生产者写入或者消费者读取时加锁。
在众多 Channel 类型中,使用最广的是 MPSC channel, 因为往往我们希望通过单消费者来保证,用于处理消息的数据结构有独占的写访问。
比如,在 xunmi 的实现中:
- index writer 内部是一个多线程的实现
- 但在使用时,我们需要用到它的可写引用。
如果要能够在各种上下文中使用 index writer,我们就不得不将其用 Arc<Mutex
但这样在索引大量数据时效率太低
MPSC channel使用示例:index writer
所以我们可以用 MPSC channel,让各种上下文都把数据发送给单一的线程,使用 index writer 索引,这样就避免了锁:
pub struct IndexInner { index: Index, reader: IndexReader, config: IndexConfig, updater: Sender<Input>, } pub struct IndexUpdater { sender: Sender<Input>, t2s: bool, schema: Schema, } impl Indexer { // 打开或者创建一个 index pub fn open_or_create(config: IndexConfig) -> Result<Self> { let schema = config.schema.clone(); let index = if let Some(dir) = &config.path { fs::create_dir_all(dir)?; let dir = MmapDirectory::open(dir)?; Index::open_or_create(dir, schema.clone())? } else { Index::create_in_ram(schema.clone()) }; Self::set_tokenizer(&index, &config); let mut writer = index.writer(config.writer_memory)?; // 创建一个 unbounded MPSC channel let (s, r) = unbounded::<Input>(); // 启动一个线程,从 channel 的 reader 中读取数据 thread::spawn(move || { for input in r { // 然后用 index writer 处理这个 input if let Err(e) = input.process(&mut writer, &schema) { warn!("Failed to process input. Error: {:?}", e); } } }); // 把 channel 的 sender 部分存入 IndexInner 结构 Self::new(index, config, s) } pub fn get_updater(&self) -> IndexUpdater { let t2s = TextLanguage::Chinese(true) == self.config.text_lang; // IndexUpdater 内部包含 channel 的 sender 部分 // 由于是 MPSC channel,所以这里可以简单 clone 一下 sender // 这也意味着,我们可以创建任意多个 IndexUpdater 在不同上下文发送数据 // 而数据最终都会通过 channel 给到上面创建的线程,由 index writer 处理 IndexUpdater::new(self.updater.clone(), self.index.schema(), t2s) } }
Actor
简单介绍Actor,并举例
最后我们简单介绍一下 actor model,它在业界主要的使用者是 Erlang VM 以及 akka。actor 是一种有栈协程:
- 每个 actor,有自己的一个独立的、轻量级的调用栈
- 以及一个用来接受消息的消息队列(mailbox 或者 message queue)
- 外界跟 actor 打交道的唯一手段就是,给它发送消息。
Rust 标准库没有 actor 的实现,但是社区里有比较成熟的 actix(大名鼎鼎的 actix-web 就是基于 actix 实现的),以及 bastion。
下面的代码用 actix 实现了一个简单的 DummyActor,它可以接收一个 InMsg,返回一个 OutMsg:
use actix::prelude::*; use anyhow::Result; // actor 可以处理的消息 #[derive(Message, Debug, Clone, PartialEq)] #[rtype(result = "OutMsg")] enum InMsg { Add((usize, usize)), Concat((String, String)), } #[derive(MessageResponse, Debug, Clone, PartialEq)] enum OutMsg { Num(usize), Str(String), } // Actor struct DummyActor; impl Actor for DummyActor { type Context = Context<Self>; } // 实现处理 InMsg 的 Handler trait impl Handler<InMsg> for DummyActor { type Result = OutMsg; // <- 返回的消息 fn handle(&mut self, msg: InMsg, _ctx: &mut Self::Context) -> Self::Result { match msg { InMsg::Add((a, b)) => OutMsg::Num(a + b), InMsg::Concat((mut s1, s2)) => { s1.push_str(&s2); OutMsg::Str(s1) } } } } #[actix::main] async fn main() -> Result<()> { let addr = DummyActor.start(); let res = addr.send(InMsg::Add((21, 21))).await?; let res1 = addr .send(InMsg::Concat(("hello, ".into(), "world".into()))) .await?; println!("res: {:?}, res1: {:?}", res, res1); Ok(()) }
可以看到,对 DummyActor,我们只需要实现 Actor trait 和 Handler
trait 。
Channel/Actor对比与联系
- Mixing Metaphors: Actors as Channels and Channels as Actorsdt链接
- What’s the difference between the Actor Model of Concurrency and Communicating Sequential Processes - Theoretical Computer Science Stack Exchange
- Rust的异步编程主要使用async模型: Why Async? - Asynchronous Programming in Rust
至于async/await,又是另一个故事
自己实现一个基本的MPSC Channel
之前我们谈论了如何在搜索引擎的 Index writer 上使用 MPSC channel:
- 要更新 index 的上下文有很多(可以是线程也可以是异步任务)
- 而 IndexWriter 只能是唯一的。
- 为了避免在访问 IndexWriter 时加锁,我们可以使用 MPSC channel
- 在多个上下文中给 channel 发消息,然后在唯一拥有 IndexWriter 的线程中读取这些消息,非常高效。
好,来看看今天要实现的 MPSC channel 的基本功能。为了简便起见,我们只关心 unbounded MPSC channel。也就是说,当队列容量不够时,会自动扩容,所以,任何时候生产者写入数据都不会被阻塞,但是当队列中没有数据时,消费者会被阻塞:
测试驱动的设计
之前我们会从需求的角度来设计接口和数据结构,今天我们就换种方式,完全站在使用者的角度,用使用实例(测试)来驱动接口和数据结构的设计。
需求1: 基本的 send/recv
要实现刚才说的 MPSC channel,都有什么需求呢?首先,生产者可以产生数据,消费者能够消费产生出来的数据,也就是基本的 send/recv,我们以下面这个单元测试 1 来描述这个需求:
#[test] fn channel_should_work() { let (mut s, mut r) = unbounded(); s.send("hello world!".to_string()).unwrap(); let msg = r.recv().unwrap(); assert_eq!(msg, "hello world!"); }
- 这里,通过 unbounded() 方法, 可以创建一个 sender 和一个 receiver
- sender 有 send() 方法,可以发送数据
- receiver 有 recv() 方法,可以接受数据。
- 整体的接口,我们设计和 std::sync::mpsc 保持一致,避免使用者使用上的心智负担。
为了实现这样一个接口,需要什么样的数据结构呢?
- 首先,生产者和消费者之间会共享一个队列,可以用 VecDeque。
- 显然,这个队列在插入和取出数据时需要互斥,所以需要用 Mutex 来保护它。
struct Shared<T> { queue: Mutex<VecDeque<T>>, } pub struct Sender<T> { shared: Arc<Shared<T>>, } pub struct Receiver<T> { shared: Arc<Shared<T>>, }
这样的数据结构应该可以满足单元测试 1。
需求2: 允许多个 sender 往 channel 里发送数据
由于需要的是 MPSC,所以,我们允许多个 sender 往 channel 里发送数据,用单元测试 2 来描述这个需求:
#[test] fn multiple_senders_should_work() { let (mut s, mut r) = unbounded(); let mut s1 = s.clone(); let mut s2 = s.clone(); let t = thread::spawn(move || { s.send(1).unwrap(); }); let t1 = thread::spawn(move || { s1.send(2).unwrap(); }); let t2 = thread::spawn(move || { s2.send(3).unwrap(); }); for handle in [t, t1, t2] { handle.join().unwrap(); } let mut result = [r.recv().unwrap(), r.recv().unwrap(), r.recv().unwrap()]; // 在这个测试里,数据到达的顺序是不确定的,所以我们排个序再 assert result.sort(); assert_eq!(result, [1, 2, 3]); }
这个需求,刚才的数据结构就可以满足,只是 Sender 需要实现 Clone trait。不过我们在写这个测试的时候稍微有些别扭,因为这一行有不断重复的代码:
let mut result = [r.recv().unwrap(), r.recv().unwrap(), r.recv().unwrap()];
注意,测试代码的 DRY 也很重要,我们之前强调过。所以,当写下这个测试的时候,也许会想,我们可否提供 Iterator 的实现?恩这个想法先暂存下来。
需求3: 当队列空的时候,receiver 所在的线程会被阻塞
接下来考虑当队列空的时候,receiver 所在的线程会被阻塞这个需求。那么,如何对这个需求进行测试呢?这并不简单,我们没有比较直观的方式来检测线程的状态。
不过,我们可以通过检测“线程是否退出”来间接判断线程是否被阻塞。
理由很简单:
- 如果线程没有继续工作,又没有退出,那么一定被阻塞住了。
- 阻塞住之后,我们继续发送数据,消费者所在的线程会被唤醒,继续工作
- 所以最终队列长度应该为 0。我们看单元测试 3:
#[test] fn receiver_should_be_blocked_when_nothing_to_read() { let (mut s, r) = unbounded(); let mut s1 = s.clone(); thread::spawn(move || { for (idx, i) in r.into_iter().enumerate() { // 如果读到数据,确保它和发送的数据一致 assert_eq!(idx, i); } // 读不到应该休眠,所以不会执行到这一句,执行到这一句说明逻辑出错 assert!(false); }); thread::spawn(move || { for i in 0..100usize { s.send(i).unwrap(); } }); // 1ms 足够让生产者发完 100 个消息,消费者消费完 100 个消息并阻塞 thread::sleep(Duration::from_millis(1)); // 再次发送数据,唤醒消费者 for i in 100..200usize { s1.send(i).unwrap(); } // 留点时间让 receiver 处理 thread::sleep(Duration::from_millis(1)); // 如果 receiver 被正常唤醒处理,那么队列里的数据会都被读完 assert_eq!(s1.total_queued_items(), 0); }
这个测试代码中:
- 我们假定 receiver 实现了 Iterator
- 还假定 sender 提供了一个方法 total_queued_items()。这些可以在实现的时候再处理。
你可以花些时间仔细看看这段代码,想想其中的处理逻辑。虽然代码很简单,不难理解,但是把一个完整的需求转化成合适的测试代码,还是要颇费些心思的。
好,如果要能支持队列为空时阻塞,我们需要使用 Condvar。
所以 Shared
struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, }
这样当实现 Receiver 的 recv() 方法后,我们可以在读不到数据时阻塞线程:
// 拿到锁 let mut inner = self.shared.queue.lock().unwrap(); // ... 假设读不到数据 // 使用 condvar 和 MutexGuard 阻塞当前线程 self.shared.available.wait(inner)
需求4: Receiver没有数据可读
顺着刚才的多个 sender 想,如果现在所有 Sender 都退出作用域,Receiver 继续接收,到没有数据可读了,该怎么处理?是不是应该产生一个错误,让调用者知道,现在 channel 的另一侧已经没有生产者了,再读也读不出数据了?
我们来写单元测试 4:
#[test] fn last_sender_drop_should_error_when_receive() { let (s, mut r) = unbounded(); let s1 = s.clone(); let senders = [s, s1]; let total = senders.len(); // sender 即用即抛 for mut sender in senders { thread::spawn(move || { sender.send("hello").unwrap(); // sender 在此被丢弃 }) .join() .unwrap(); } // 虽然没有 sender 了,接收者依然可以接受已经在队列里的数据 for _ in 0..total { r.recv().unwrap(); } // 然而,读取更多数据时会出错 assert!(r.recv().is_err()); }
这个测试依旧很简单。你可以想象一下,使用什么样的数据结构可以达到这样的目的:
- 首先,每次 Clone 时,要增加 Sender 的计数;
- 在 Sender Drop 时,减少这个计数;
- 然后,我们为 Receiver 提供一个方法 total_senders(),来读取 Sender 的计数
- 当计数为 0,且队列中没有数据可读时,recv() 方法就报错。
有了这个思路,你想一想,这个计数器用什么数据结构呢?用锁保护么?
哈,你一定想到了可以使用 atomics。对,我们可以用 AtomicUsize。所以,Shared 数据结构需要更新一下:
struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, }
需求5: 没有Receiver处理数据
既然没有 Sender 了要报错,那么如果没有 Receiver 了,Sender 发送时是不是也应该错误返回?这个需求和上面类似,就不赘述了。看构造的单元测试 5:
#[test] fn receiver_drop_should_error_when_send() { let (mut s1, mut s2) = { let (s, _) = unbounded(); let s1 = s.clone(); let s2 = s.clone(); (s1, s2) }; assert!(s1.send(1).is_err()); assert!(s2.send(1).is_err()); }
这里,我们创建一个 channel,产生两个 Sender 后便立即丢弃 Receiver。两个 Sender 在发送时都会出错。
同样的,Shared 数据结构要更新一下:
struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, receivers: AtomicUsize, }
实现 MPSC channel
现在写了五个单元测试,我们已经把需求摸透了,并且有了基本的接口和数据结构的设计。接下来,我们来写实现的代码。
创建一个新的项目
cargo new con_utils --lib
- 在 cargo.toml 中添加 anyhow 作为依赖。
- 在 lib.rs 里,我们就写入一句:pub mod channel , 然后创建 src/channel.rs
- 把刚才设计时使用的 test case、设计的数据结构,以及 test case 里使用到的接口,用代码全部放进来:
use anyhow::Result; use std::{ collections::VecDeque, sync::{atomic::AtomicUsize, Arc, Condvar, Mutex}, }; /// 发送者 pub struct Sender<T> { shared: Arc<Shared<T>>, } /// 接收者 pub struct Receiver<T> { shared: Arc<Shared<T>>, } /// 发送者和接收者之间共享一个 VecDeque,用 Mutex 互斥,用 Condvar 通知 /// 同时,我们记录有多少个 senders 和 receivers struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, receivers: AtomicUsize, } impl<T> Sender<T> { /// 生产者写入一个数据 pub fn send(&mut self, t: T) -> Result<()> { todo!() } pub fn total_receivers(&self) -> usize { todo!() } pub fn total_queued_items(&self) -> usize { todo!() } } impl<T> Receiver<T> { pub fn recv(&mut self) -> Result<T> { todo!() } pub fn total_senders(&self) -> usize { todo!() } } impl<T> Iterator for Receiver<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { todo!() } } /// 克隆 sender impl<T> Clone for Sender<T> { fn clone(&self) -> Self { todo!() } } /// Drop sender impl<T> Drop for Sender<T> { fn drop(&mut self) { todo!() } } impl<T> Drop for Receiver<T> { fn drop(&mut self) { todo!() } } /// 创建一个 unbounded channel pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { todo!() } #[cfg(test)] mod tests { use std::{thread, time::Duration}; use super::*; // 此处省略所有 test case }
实现单元测试相关功能
目前这个代码虽然能够编译通过,但因为没有任何实现,所以 cargo test 全部出错。接下来,我们就来一点点实现功能。
- 创建 unbounded channel
pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { let shared = Shared::default(); let shared = Arc::new(shared); ( Sender { shared: shared.clone(), }, Receiver { shared }, ) } const INITIAL_SIZE: usize = 32; impl<T> Default for Shared<T> { fn default() -> Self { Self { queue: Mutex::new(VecDeque::with_capacity(INITIAL_SIZE)), available: Condvar::new(), senders: AtomicUsize::new(1), receivers: AtomicUsize::new(1), } } }
因为这里使用 default() 创建了 Shared
- 实现消费者
对于消费者,我们主要需要实现 recv 方法。
在 recv 中:
- 如果队列中有数据,那么直接返回;
- 如果没数据,且所有生产者都离开了,我们就返回错误;
- 如果没数据,但还有生产者,我们就阻塞消费者的线程:
impl<T> Receiver<T> { pub fn recv(&mut self) -> Result<T> { // 拿到队列的锁 let mut inner = self.shared.queue.lock().unwrap(); loop { match inner.pop_front() { // 读到数据返回,锁被释放 Some(t) => { return Ok(t); } // 读不到数据,并且生产者都退出了,释放锁并返回错误 None if self.total_senders() == 0 => return Err(anyhow!("no sender left")), // 读不到数据,把锁提交给 available Condvar,它会释放锁并挂起线程,等待 notify None => { // 当 Condvar 被唤醒后会返回 MutexGuard,我们可以 loop 回去拿数据 // 这是为什么 Condvar 要在 loop 里使用 inner = self .shared .available .wait(inner) .map_err(|_| anyhow!("lock poisoned"))?; } } } } pub fn total_senders(&self) -> usize { self.shared.senders.load(Ordering::SeqCst) } }
注意看这里 Condvar 的使用。
- 在 wait() 方法里,它接收一个 MutexGuard,然后释放这个 Mutex,挂起线程。
- 等得到通知后,它会再获取锁,得到一个 MutexGuard,返回。所以这里是:
inner = self.shared.available.wait(inner).map_err(|_| anyhow!("lock poisoned"))?;
因为 recv() 会返回一个值,所以阻塞回来之后,我们应该循环回去拿数据。这是为什么这段逻辑要被 loop {} 包裹。我们前面在设计时考虑过:当发送者发送数据时,应该通知被阻塞的消费者。所以,在实现 Sender 的 send() 时,需要做相应的 notify 处理。
记得还要处理消费者的 drop:
impl<T> Drop for Receiver<T> { fn drop(&mut self) { self.shared.receivers.fetch_sub(1, Ordering::AcqRel); } }
很简单,消费者离开时,将 receivers 减一。
实现生产者功能
接下来我们看生产者的功能怎么实现。
- 首先,在没有消费者的情况下,应该报错。
- 正常应该使用 thiserror 定义自己的错误,不过这里为了简化代码,就使用 anyhow! 宏产生一个 adhoc 的错误。
- 如果消费者还在,那么我们获取 VecDeque 的锁,把数据压入:
impl<T> Sender<T> { /// 生产者写入一个数据 pub fn send(&mut self, t: T) -> Result<()> { // 如果没有消费者了,写入时出错 if self.total_receivers() == 0 { return Err(anyhow!("no receiver left")); } // 加锁,访问 VecDeque,压入数据,然后立刻释放锁 let was_empty = { let mut inner = self.shared.queue.lock().unwrap(); let empty = inner.is_empty(); inner.push_back(t); empty }; // 通知任意一个被挂起等待的消费者有数据 if was_empty { self.shared.available.notify_one(); } Ok(()) } pub fn total_receivers(&self) -> usize { self.shared.receivers.load(Ordering::SeqCst) } pub fn total_queued_items(&self) -> usize { let queue = self.shared.queue.lock().unwrap(); queue.len() } }
这里,获取 total_receivers 时,我们使用了 Ordering::SeqCst,保证所有线程看到同样顺序的对 receivers 的操作。这个值是最新的值。
在压入数据时,需要判断一下之前是队列是否为空,因为队列为空的时候,我们需要用 notify_one() 来唤醒消费者。这个非常重要,如果没处理的话,会导致消费者阻塞后无法复原接收数据。
由于我们可以有多个生产者,所以要允许它 clone:
impl<T> Clone for Sender<T> { fn clone(&self) -> Self { self.shared.senders.fetch_add(1, Ordering::AcqRel); Self { shared: Arc::clone(&self.shared), } } }
实现 Clone trait 的方法很简单,但记得要把 shared.senders 加 1,使其保持和当前的 senders 的数量一致。
当然,在 drop 的时候我们也要维护 shared.senders 使其减 1:
impl<T> Drop for Sender<T> { fn drop(&mut self) { self.shared.senders.fetch_sub(1, Ordering::AcqRel); } }
其他功能实现
目前还缺乏 Receiver 的 Iterator 的实现,这个很简单,就是在 next() 里调用 recv() 方法,Rust 提供了支持在 Option / Result 之间很方便转换的函数,所以这里我们可以直接通过 ok() 来将 Result 转换成 Option:
impl<T> Iterator for Receiver<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { self.recv().ok() } }
好,目前所有需要实现的代码都实现完毕, cargo test 测试一下。wow!测试一次性通过!这也太顺利了吧!
最后来仔细审视一下代码。很快,我们发现 Sender 的 Drop 实现似乎有点问题。如果 Receiver 被阻塞,而此刻所有 Sender 都走了,那么 Receiver 就没有人唤醒,会带来资源的泄露。这是一个很边边角角的问题,所以之前的测试没有覆盖到。
我们来设计一个场景让这个问题暴露:
#[test] fn receiver_shall_be_notified_when_all_senders_exit() { let (s, mut r) = unbounded::<usize>(); // 用于两个线程同步 let (mut sender, mut receiver) = unbounded::<usize>(); let t1 = thread::spawn(move || { // 保证 r.recv() 先于 t2 的 drop 执行 sender.send(0).unwrap(); assert!(r.recv().is_err()); }); thread::spawn(move || { receiver.recv().unwrap(); drop(s); }); t1.join().unwrap(); }
在我进一步解释之前,你可以停下来想想:
- 为什么这个测试可以保证暴露这个问题?
- 它是怎么暴露的?
- 如果想不到,再 cargo test 看看会出现什么问题。
来一起分析分析,这里,我们创建了两个线程 t1 和 t2,分别让它们处理消费者和生产者。t1 读取数据,此时没有数据,所以会阻塞,而 t2 直接把生产者 drop 掉。所以,此刻如果没有人唤醒 t1,那么 t1.join() 就会一直等待,因为 t1 一直没有退出。
所以,为了保证一定是 t1 r.recv()先执行导致阻塞、t2 再 drop(s),我们(eat your own dog food)用另一个 channel 来控制两个线程的执行顺序。这是一种很通用的做法,你可以好好琢磨一下。
运行 cargo test 后,测试被阻塞。这是因为,t1 没有机会得到唤醒,所以这个测试就停在那里不动了。
要修复这个问题,我们需要妥善处理 Sender 的 Drop:
impl<T> Drop for Sender<T> { fn drop(&mut self) { let old = self.shared.senders.fetch_sub(1, Ordering::AcqRel); // sender 走光了,唤醒 receiver 读取数据(如果队列中还有的话),读不到就出错 if old <= 1 { // 因为我们实现的是 MPSC,receiver 只有一个,所以 notify_all 实际等价 notify_one self.shared.available.notify_all(); } } }
这里,如果减一之前,旧的 senders 的数量小于等于 1,意味着现在是最后一个 Sender 要离开了,不管怎样我们都要唤醒 Receiver ,所以这里使用了 notify_all()。如果 Receiver 之前已经被阻塞,此刻就能被唤醒。修改完成,cargo test 一切正常。
对锁进行性能优化
从功能上来说,目前我们的 MPSC unbounded channel 没有太多的问题,可以应用在任何需要 MPSC channel 的场景。然而,每次读写都需要获取锁,虽然锁的粒度很小,但还是让整体的性能打了个折扣。有没有可能优化锁呢?
之前我们讲到,优化锁的手段无非是减小临界区的大小,让每次加锁的时间很短,这样冲突的几率就变小。另外,就是降低加锁的频率,对于消费者来说,如果我们能够一次性把队列中的所有数据都读完缓存起来,以后在需要的时候从缓存中读取,这样就可以大大减少消费者加锁的频次。
顺着这个思路,我们可以在 Receiver 的结构中放一个 cache:
pub struct Receiver<T> { shared: Arc<Shared<T>>, cache: VecDeque<T>, }
如果你之前有 C 语言开发的经验,也许会想,到了这一步,何必把 queue 中的数据全部读出来,存入 Receiver 的 cache 呢?这样效率太低,如果能够直接 swap 两个结构内部的指针,这样,即便队列中有再多的数据,也是一个 O(1) 的操作。
Rust 有类似的 std::mem::swap 方法。比如
use std::mem; fn main() { let mut x = "hello world".to_string(); let mut y = "goodbye world".to_string(); mem::swap(&mut x, &mut y); assert_eq!("goodbye world", x); assert_eq!("hello world", y); }
好,了解了 swap 方法,我们看看如何修改 Receiver 的 recv() 方法来提升性能:
pub fn recv(&mut self) -> Result<T> { // 无锁 fast path if let Some(v) = self.cache.pop_front() { return Ok(v); } // 拿到队列的锁 let mut inner = self.shared.queue.lock().unwrap(); loop { match inner.pop_front() { // 读到数据返回,锁被释放 Some(t) => { // 如果当前队列中还有数据,那么就把消费者自身缓存的队列(空)和共享队列 swap 一下 // 这样之后再读取,就可以从 self.queue 中无锁读取 if !inner.is_empty() { std::mem::swap(&mut self.cache, &mut inner); } return Ok(t); } // 读不到数据,并且生产者都退出了,释放锁并返回错误 None if self.total_senders() == 0 => return Err(anyhow!("no sender left")), // 读不到数据,把锁提交给 available Condvar,它会释放锁并挂起线程,等待 notify None => { // 当 Condvar 被唤醒后会返回 MutexGuard,我们可以 loop 回去拿数据 // 这是为什么 Condvar 要在 loop 里使用 inner = self .shared .available .wait(inner) .map_err(|_| anyhow!("lock poisoned"))?; } } } }
- 当 cache 中有数据时,总是从 cache 中读取;
- 当 cache 中没有,我们拿到队列的锁,读取一个数据
- 然后看看队列是否还有数据,有的话,就 swap cache 和 queue,然后返回之前读取的数据。
好,做完这个重构和优化,我们可以运行 cargo test,看看已有的测试是否正常。如果你遇到报错,应该是 cache 没有初始化,你可以自行解决,也可以参考:
pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { let shared = Shared::default(); let shared = Arc::new(shared); ( Sender { shared: shared.clone(), }, Receiver { shared, cache: VecDeque::with_capacity(INITIAL_SIZE), }, ) }
虽然现有的测试全数通过,但我们并没有为这个优化写测试,这里补个测试:
#[test] fn channel_fast_path_should_work() { let (mut s, mut r) = unbounded(); for i in 0..10usize { s.send(i).unwrap(); } assert!(r.cache.is_empty()); // 读取一个数据,此时应该会导致 swap,cache 中有数据 assert_eq!(0, r.recv().unwrap()); // 还有 9 个数据在 cache 中 assert_eq!(r.cache.len(), 9); // 在 queue 里没有数据了 assert_eq!(s.total_queued_items(), 0); // 从 cache 里读取剩下的数据 for (idx, i) in r.into_iter().take(9).enumerate() { assert_eq!(idx + 1, i); } }
这个测试很简单,详细注释也都写上了。
完整代码
use anyhow::{anyhow, Result}; use std::{ collections::VecDeque, sync::{ atomic::{AtomicUsize, Ordering}, Arc, Condvar, Mutex, }, }; /// 发送者 pub struct Sender<T> { shared: Arc<Shared<T>>, } /// 接收者 pub struct Receiver<T> { shared: Arc<Shared<T>>, cache: VecDeque<T>, } /// 发送者和接收者之间共享一个 VecDeque,用 Mutex 互斥,用 Condvar 通知 /// 同时,我们记录有多少个 senders 和 receivers struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, receivers: AtomicUsize, } const INITIAL_SIZE: usize = 32; impl<T> Default for Shared<T> { fn default() -> Self { Self { queue: Mutex::new(VecDeque::with_capacity(INITIAL_SIZE)), available: Condvar::new(), senders: AtomicUsize::new(1), receivers: AtomicUsize::new(1), } } } impl<T> Sender<T> { /// 生产者写入一个数据 pub fn send(&mut self, t: T) -> Result<()> { // 如果没有消费者了,写入时出错 if self.total_receivers() == 0 { return Err(anyhow!("no receiver left")); } // 加锁,访问 VecDeque,压入数据,然后立刻释放锁 let was_empty = { let mut inner = self.shared.queue.lock().unwrap(); let empty = inner.is_empty(); inner.push_back(t); empty }; // 通知任意一个被挂起等待的消费者有数据 if was_empty { self.shared.available.notify_one(); } Ok(()) } pub fn total_receivers(&self) -> usize { self.shared.receivers.load(Ordering::SeqCst) } pub fn total_queued_items(&self) -> usize { let queue = self.shared.queue.lock().unwrap(); queue.len() } } /// 克隆 sender impl<T> Clone for Sender<T> { fn clone(&self) -> Self { self.shared.senders.fetch_add(1, Ordering::AcqRel); Self { shared: Arc::clone(&self.shared), } } } /// Drop sender impl<T> Drop for Sender<T> { fn drop(&mut self) { let old = self.shared.senders.fetch_sub(1, Ordering::AcqRel); // sender 走光了,唤醒 receiver 读取数据(如果队列中还有的话),读不到就出错 if old <= 1 { // 因为我们实现的是 MPSC,receiver 只有一个,所以 notify_all 实际等价 notify_one self.shared.available.notify_all(); } } } impl<T> Receiver<T> { pub fn recv(&mut self) -> Result<T> { // 无锁 fast path if let Some(v) = self.cache.pop_front() { return Ok(v); } // 拿到队列的锁 let mut inner = self.shared.queue.lock().unwrap(); loop { match inner.pop_front() { // 读到数据返回,锁被释放 Some(t) => { // 如果当前队列中还有数据,那么就把消费者自身缓存的队列(空)和共享队列 swap 一下 // 这样之后再读取,就可以从 self.queue 中无锁读取 if !inner.is_empty() { std::mem::swap(&mut self.cache, &mut inner); } return Ok(t); } // 读不到数据,并且生产者都退出了,释放锁并返回错误 None if self.total_senders() == 0 => return Err(anyhow!("no sender left")), // 读不到数据,把锁提交给 available Condvar,它会释放锁并挂起线程,等待 notify None => { // 当 Condvar 被唤醒后会返回 MutexGuard,我们可以 loop 回去拿数据 // 这是为什么 Condvar 要在 loop 里使用 inner = self .shared .available .wait(inner) .map_err(|_| anyhow!("lock poisoned"))?; } } } } pub fn total_senders(&self) -> usize { self.shared.senders.load(Ordering::SeqCst) } } impl<T> Iterator for Receiver<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { self.recv().ok() } } impl<T> Drop for Receiver<T> { fn drop(&mut self) { self.shared.receivers.fetch_sub(1, Ordering::AcqRel); // 因为 sender 不会阻塞,所以 receiver 离开不需要唤醒 sender } } /// 创建一个 unbounded channel pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { let shared = Shared::default(); let shared = Arc::new(shared); ( Sender { shared: shared.clone(), }, Receiver { shared, cache: VecDeque::with_capacity(INITIAL_SIZE), }, ) } #[cfg(test)] mod tests { use std::{thread, time::Duration}; use super::*; #[test] fn channel_should_work() { let (mut s, mut r) = unbounded(); s.send("hello world!".to_string()).unwrap(); let msg = r.recv().unwrap(); assert_eq!(msg, "hello world!"); } #[test] fn multiple_senders_should_work() { let (mut s, mut r) = unbounded(); let mut s1 = s.clone(); let mut s2 = s.clone(); let t = thread::spawn(move || { s.send(1).unwrap(); }); let t1 = thread::spawn(move || { s1.send(2).unwrap(); }); let t2 = thread::spawn(move || { s2.send(3).unwrap(); }); for handle in [t, t1, t2] { handle.join().unwrap(); } let mut result = [r.recv().unwrap(), r.recv().unwrap(), r.recv().unwrap()]; // 在这个测试里,数据到达的顺序是不确定的,所以我们排个序再 assert result.sort_unstable(); assert_eq!(result, [1, 2, 3]); } #[test] #[allow(clippy::all)] fn receiver_should_be_blocked_when_nothing_to_read() { let (mut s, r) = unbounded(); let mut s1 = s.clone(); thread::spawn(move || { for (idx, i) in r.into_iter().enumerate() { // 如果读到数据,确保它和发送的数据一致 assert_eq!(idx, i); } // 读不到应该休眠,所以不会执行到这一句,执行到这一句说明逻辑出错 assert!(false); }); thread::spawn(move || { for i in 0..100usize { s.send(i).unwrap(); } // 防止所有 sender 都离开 loop {} }); // 1ms 足够让生产者发完 100 个消息,消费者消费完 100 个消息并阻塞 thread::sleep(Duration::from_millis(1)); // 再次发送数据,唤醒消费者 for i in 100..200usize { s1.send(i).unwrap(); } // 留点时间让 receiver 处理 thread::sleep(Duration::from_millis(1)); // 如果 receiver 被正常唤醒处理,那么队列里的数据会都被读完 assert_eq!(s1.total_queued_items(), 0); } #[test] fn last_sender_drop_should_error_when_receive() { let (s, mut r) = unbounded(); let s1 = s.clone(); let senders = [s, s1]; let total = senders.len(); // sender 即用即抛 for mut sender in senders { thread::spawn(move || { sender.send("hello").unwrap(); // sender 在此被丢弃 }) .join() .unwrap(); } // 虽然没有 sender 了,接收者依然可以接受已经在队列里的数据 for _ in 0..total { r.recv().unwrap(); } // 然而,读取更多数据时会出错 assert!(r.recv().is_err()); } #[test] fn receiver_drop_should_error_when_send() { let (mut s1, mut s2) = { let (s, _) = unbounded(); let s1 = s.clone(); (s1, s) }; assert!(s1.send(1).is_err()); assert!(s2.send(1).is_err()); } #[test] fn receiver_shall_be_notified_when_all_senders_exit() { let (s, mut r) = unbounded::<usize>(); // 用于两个线程同步 let (mut sender, mut receiver) = unbounded::<usize>(); let t1 = thread::spawn(move || { // 保证 r.recv() 先于 t2 的 drop 执行 sender.send(0).unwrap(); assert!(r.recv().is_err()); }); thread::spawn(move || { receiver.recv().unwrap(); drop(s); }); t1.join().unwrap(); } #[test] fn channel_fast_path_should_work() { let (mut s, mut r) = unbounded(); for i in 0..10usize { s.send(i).unwrap(); } assert!(r.cache.is_empty()); // 读取一个数据,此时应该会导致 swap,cache 中有数据 assert_eq!(0, r.recv().unwrap()); // 还有 9 个数据在 cache 中 assert_eq!(r.cache.len(), 9); // 在 queue 里没有数据了 assert_eq!(s.total_queued_items(), 0); // 从 cache 里读取剩下的数据 for (idx, i) in r.into_iter().take(9).enumerate() { assert_eq!(idx + 1, i); } } }
回顾测试驱动开发
回顾测试驱动开发
这里完全顺着需求写测试,然后在写测试的过程中进行数据结构和接口的设计。和普通的 TDD 不同的是,先一口气把主要需求涉及的行为用测试来表述,然后通过这个表述,构建合适的接口,以及能够运行这个接口的数据结构。
在开发产品的时候,这也是一种非常有效的手段,可以让我们通过测试完善设计,最终得到一个能够让测试编译通过的、完全没有实现代码、只有接口的版本。之后,我们再一个接口一个接口实现,全部实现完成之后,运行测试,看看是否出问题。
在这里你可以多多关注构建测试用例的技巧。之前的课程中,我反复强调过单元测试的重要性,也以身作则在几个重要的实操中都有详尽地测试。不过相比之前写的测试,这一讲中的测试要更难写一些,尤其是在并发场景下那些边边角角的功能测试。
不要小看测试代码,有时候构造测试代码比撰写功能代码还要烧脑。但是,当你有了扎实的单元测试覆盖后,再做重构,比如最后我们做和性能相关的重构,就变得轻松很多,因为只要cargo test通过,起码这个重构没有引起任何回归问题(regression bug)。
当然,重构没有引入回归问题,并不意味着重构完全没有问题,我们还需要考虑撰写新的测试,覆盖重构带来的改动。
小结一下各种并发原语的使用场景
如何根据使用场景选择使用Atomic、Mutex、RwLock、Semaphore、Condvar、Channel、Actor
Atomic、Mutex、RwLock、Semaphore、Condvar、Channel、Actor。
- Atomic 在处理简单的原生类型时非常有用,如果你可以通过 AtomicXXX 结构进行同步,那么它们是最好的选择。
- 当你的数据结构无法简单通过 AtomicXXX 进行同步,但你又的确需要在多个线程中共享数据,那么 Mutex / RwLock 可以是一种选择。不过,你需要考虑锁的粒度,粒度太大的 Mutex / RwLock 效率很低。
- 如果你有 N 份资源可以供多个并发任务竞争使用,那么,Semaphore 是一个很好的选择。比如你要做一个 DB 连接池。
- 当你需要在并发任务中通知、协作时,Condvar 提供了最基本的通知机制,而 Channel 把这个通知机制进一步广泛扩展开,于是你可以用 Condvar 进行点对点的同步,用 Channel 做一对多、多对一、多对多的同步。
所以,当我们做大部分复杂的系统设计时,Channel 往往是最有力的武器,除了可以让数据穿梭于各个线程、各个异步任务间,它的接口还可以很优雅地跟 stream 适配。
如果说在做整个后端的系统架构时,我们着眼的是:有哪些服务、服务和服务之间如何通讯、数据如何流动、服务和服务间如何同步; 那么在做某一个服务的架构时,着眼的是有哪些功能性的线程(异步任务)、它们之间的接口是什么样子、数据如何流动、如何同步。
在这里,Channel 兼具接口、同步和数据流三种功能,所以我说是最有力的武器。
然而它不该是唯一的武器。我们面临的真实世界的并发问题是多样的,解决方案也应该是多样的,计算机科学家们在过去的几十年里不断探索,构建了一系列的并发原语,也说明了很难有一种银弹解决所有问题。
就连 Mutex 本身,在实现中,还会根据不同的场景做不同的妥协(比如做 faireness 的妥协),因为这个世界就是这样,鱼与熊掌不可兼得,没有完美的解决方案,只有妥协出来的解决方案。所以 Channel 不是银弹,actor model 不是银弹,lock 不是银弹。
一门好的编程语言,可以提供大部分场景下的最佳实践(如 Erlang/Golang),但不该营造一种气氛,只有某个最佳实践才是唯一方案。我很喜欢 Erlang 的 actor model 和 Golang 的 Channel,但很可惜,它们过分依赖特定的、唯一的并发方案,使得开发者拿着榔头,看什么都是钉子。
相反,Rust 提供几乎你需要的所有解决方案,并且并不鼓吹它们的优劣,完全交由你按需选择。我在用 Rust 撰写多线程应用时,Channel 仍然是第一选择,但我还是会在合适的时候使用 Mutex、RwLock、Semaphore、Condvar、Atomic 等工具,而不是试图笨拙地用 Channel 叠加 Channel 来应对所有的场景。